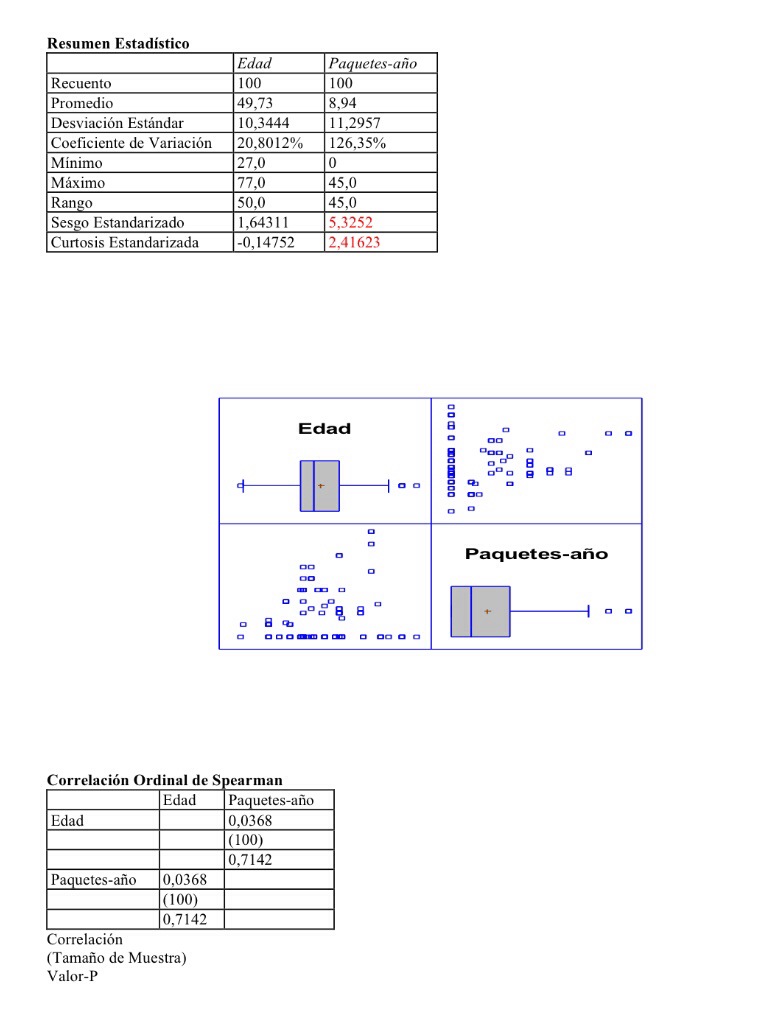
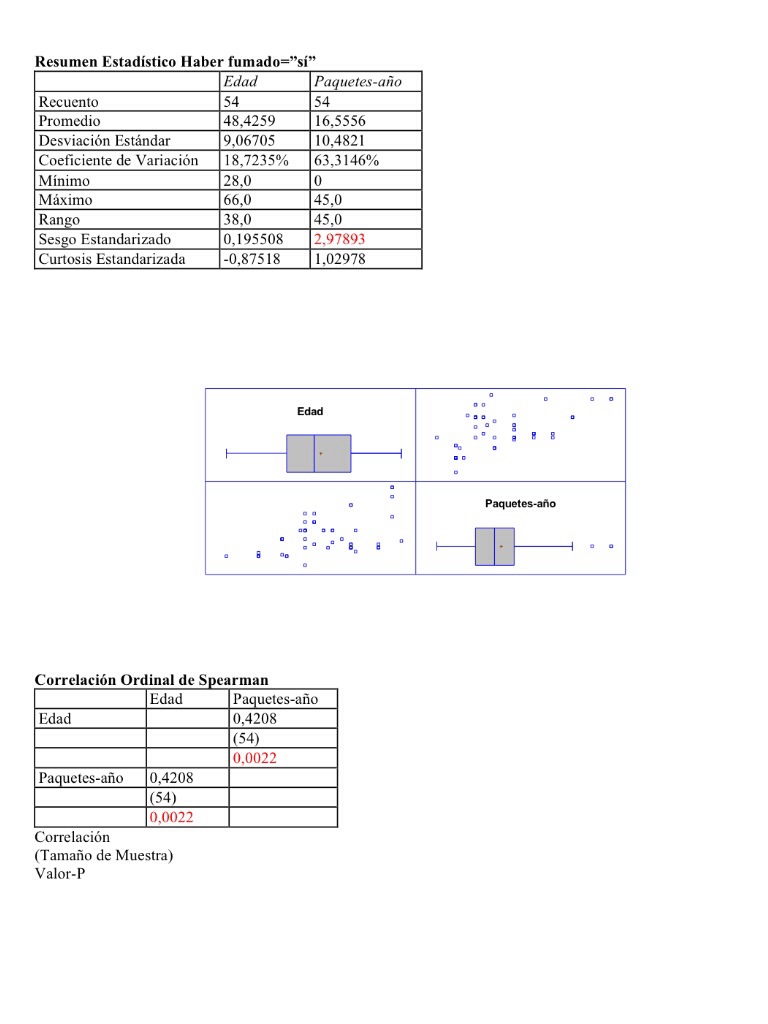
1. Es muy frecuente en estudios estadísticos encontrarnos con las dos situaciones siguientes:
a. Que no se aprecien diferencias estadísticamente significativas entre los grupos comparados o que no se pueda hablar de una asociación, también estadísticamente significativa, entre dos variables, debido a un tamaño de muestra pequeño.
b. Que se hayan hecho muchos estudios relativamente similares y que sea difícil acabar de perfilar una conclusión global por la falta de sintonía entre los diferentes resultados.
2. Para enfrentarse a estas situaciones suele hablarse de dos soluciones posibles: Los estudios multicéntricos o el metaanálisis. En los estudios multicéntricos el objetivo es unificar criterios de diferentes grupos para realizar un estudio conjunto. En los estudios de metaanálisis el objetivo es aprovecharse de la información de diferentes estudios hechos con la misma intención por grupos diferentes buscando una unificación de toda esa información.
3. En los estudios multicéntricos y en los metaanálisis el objetivo es siempre aumentar la mirada, aumentar el tamaño de muestra. Sin embargo, la calidad no es la misma. El grado de unificación es muy superior en los estudios multicéntricos, sin lugar a dudas.
4. En ocasiones no es posible la organización de un estudio multicéntrico y, al mismo tiempor se dispone de muchos estudios, en cierta forma análogos, hechos por diferentes grupos. En estas situaciones es interesante tratar de sintetizar la información que se tiene en esos diferentes estudios. Por esto ha tenido y tiene mucho éxito este tipo de estudios.
5. En muchas ocasiones un metaanálisis ha sido la antesala de un posterior estudio multicéntrico. Es obtener ciertas conclusiones en la particular ampliación del tamaño de muestra que representa un metaanálisis ha llevado en muchas ocasiones a la realización de estudios multicéntricos que han acabado demostrando o no, mediante un estudio de más calidad metedológica, lo que apuntaba el metaanálisis.
6. Lo primero que hay que hacer en un metaanálisis es reunir una serie de estudios que hayan hecho lo mismo. Que hayan estudiado lo mismo. Evidentemente con una muestra distinta tomado en una zona diferente. Puede que con algunos aspectos metodológicos diferentes, pero lo fundamental es que se haya buscado lo mismo: la relación que hay entre la exposición a un riesgo y una determinada enfermedad, la comparación de un tratamiento determinado respecto a un placebo, etc.
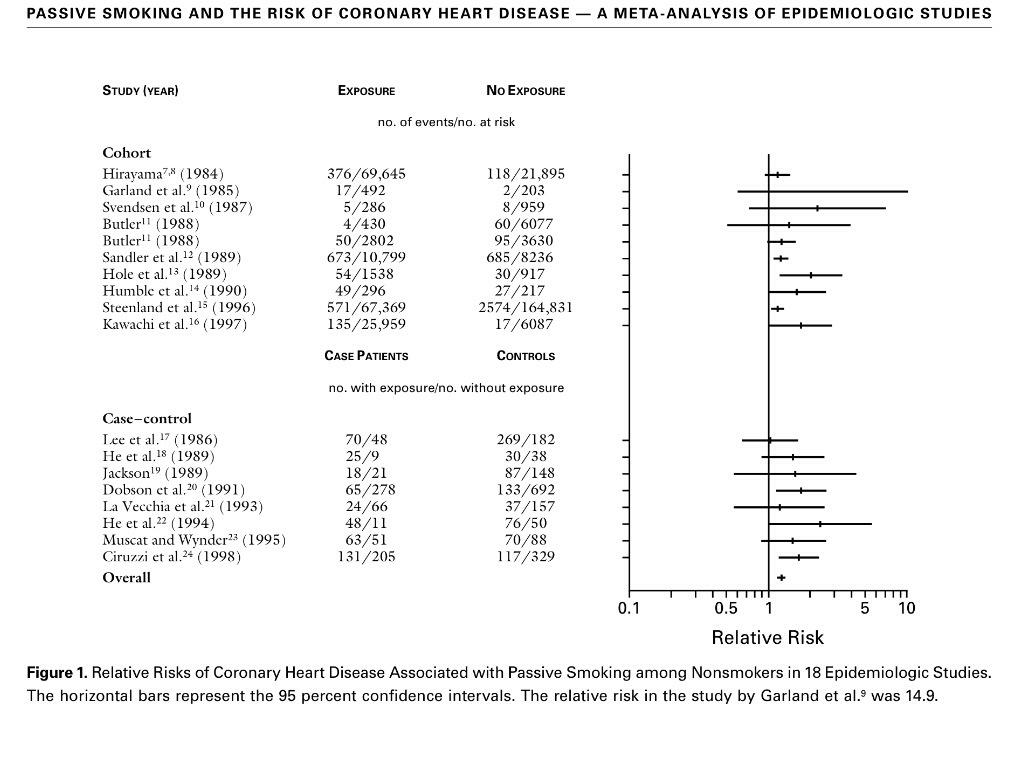
7. Un elemento presente en un metaanálisis es siempre la tabla resumen de los diferentes resultados obtenidos en los diferentes estudios. Veamos un ejemplo de estas tablas resumen en un estudio donde se analiza el riesgo de enfermedad coronaria en fumadores pasivos:
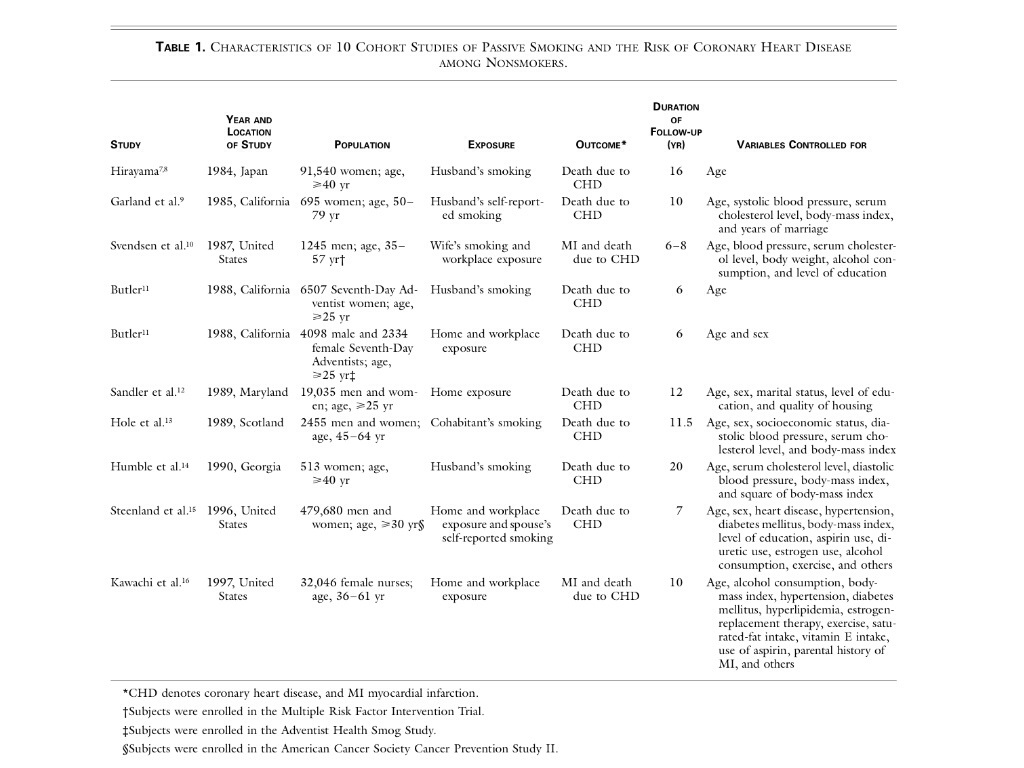
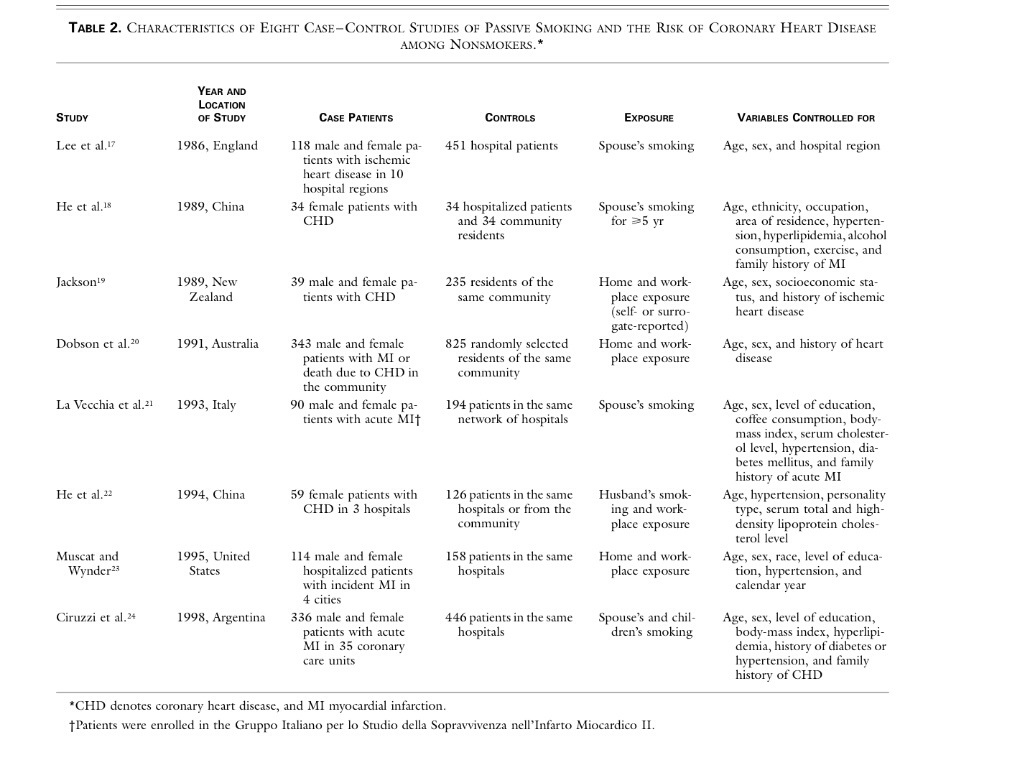
8. Los gráficos son muy importantes en metaanálisis. Se han diseñado muchos tipos de gráficos. Posiblemente los más usados son los siguientes:
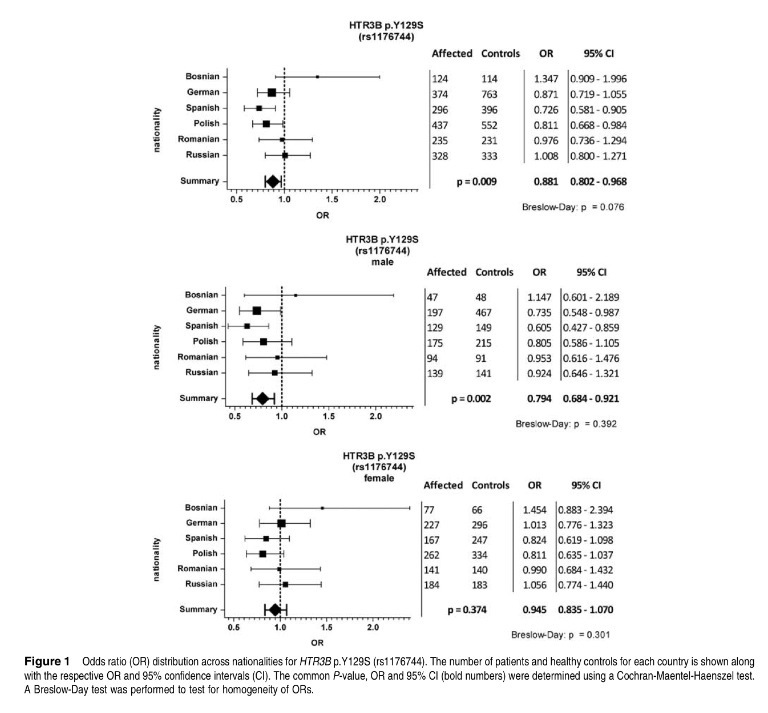
9. El denominado Forest plot, que es el que suele usarse más, resume digamos que sin voluntad de estructuración los diferentes estudios que tenemos. Es un orden incluso alfabético, no hay una ordenación estructurada como la hay en otros tipos de gráficos en metaanálisis. La estructura general es, pues, la siguiente:

10. El Funnel plot resume la información con ya cierta estructuración. Lo hace según el peso estadístico que tiene cada uno de los estudios. Por el tamaño de muestra o por el error estándar. Por ejemplo, veamos cómo quedaría estructurado según el tamaño de muestra:
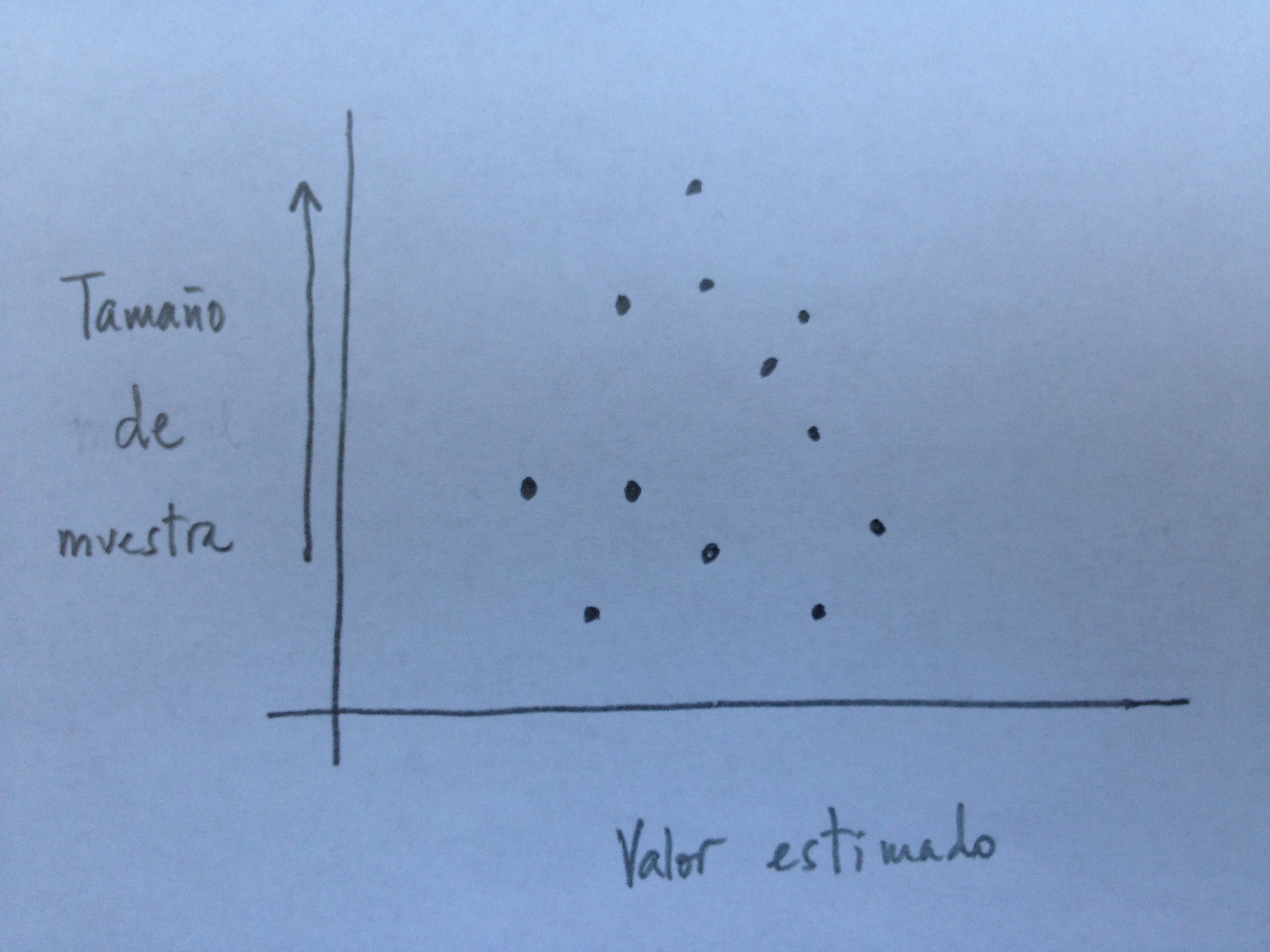
11. Observemos que cada punto hace referencia al valor obtenido en un estudio incluido en el metaanálisis pero ahora están estructurados en función del tamaño muestral del estudio. Es interesante porque, de hecho, el peso del tamaño de muestra por estudio es un elemento muy importante. Suele darse, lógicamente, una estructuración en forma de triángulo isósceles con base en la zona de tamaño muestral reducido y con vértice en la parte de mayor tamaño muestral.
12. El Abbé plot es la creación de dos territorios diferentes: uno donde va mejor un tratamiento y otro donde va mejor el otro. Se trata, entonces, de ver dónde caen mayoritariamente, los diferentes estudios.
13. A la hora de juntar todos los valores buscando por lo tanto la unificación y el aumento del tamaño de muestra es muy importante tener en cuenta la heterogeneidad de los estudios. Este es el gran caballo de batalla del metaanálisis, sin lugar a dudas.
14. Un elemento para evaluar esta heterogeneidad es el llamado Test de heterogeneidad. Es un contraste de hipótesis con la Hipótesis nula: Homogeneidad (igualdad entre los estudios) e Hipótesis alternativa: Heterogeneidad (diferencia significativa entre los estudios). Es un Test de la ji-cuadrado, como veremos después.
15. Otro elemento que evalúa la heterogeneidad entre estudios incluidos en el metaanálisis es el denominado coeficiente de heterogeneidad que se suele simbolizar con una I2. El cálculo de este coeficiente es el siguiente:
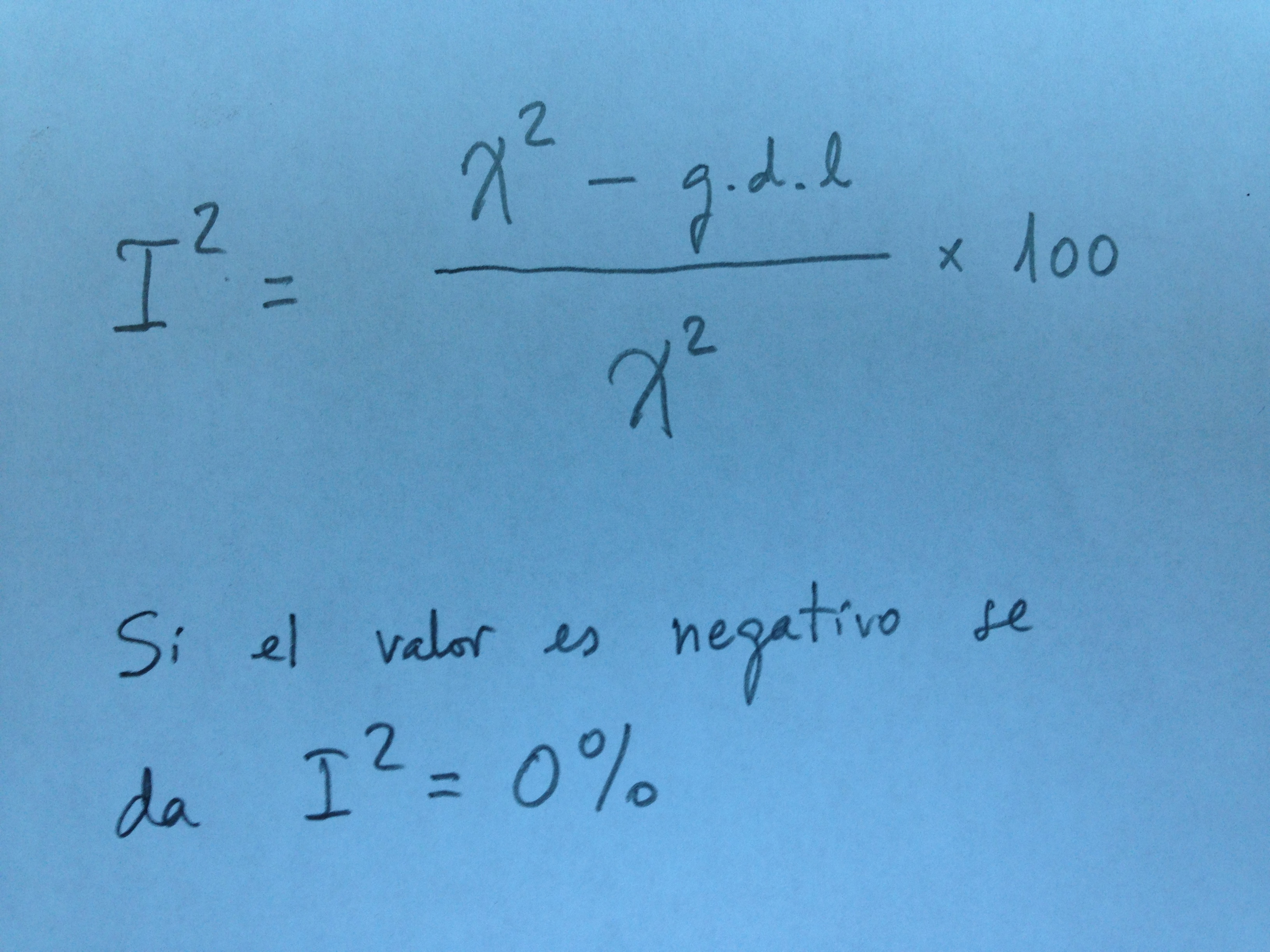
16. El valor, como puede verse, se calcula mediante el valor de la ji-cuadrado y el número de grado de libertad, que será el número de estudios menos 1.
17. Veamos, a continuación, dos ejemplos diferentes donde veremos aplicar tanto el Test de heterogeneidad como el cálculo del coeficiente de heterogeneidad.
18. Vamos a ver el primero paso a paso. Supongamos un metaanálisis en pequeño para entenderlo mejor:

19. Ahora hacemos el total; o sea, sumamos los tres estudios:

20. Ahora tenemos una probabilidad total, con la que construiremos un Test de la ji-cuadrado (Ver el Tema 8: Relación entre variables cualitativas. El test de la ji-cuadrado): o sea, el observado, que es lo que tenemos, y el esperado, que es lo que tendrían los tres estudios si la probabilidad fuera única:

21. A partir de aquí podemos aplicar el Test de la ji-cuadrado y el coeficiente de heterogeneidad para obtener:

22. El coeficiente como es negativo se hace 0% que es el valor más bajo posible.
23. El otro ejemplo, ahora con todos los datos de golpe y donde se puede ver una importante heterogeneidad entre los estudios:

24. El coeficiente de heterogeneidad servirá para rectificar los intervalos de confianza y los contrastes de hipótesis que se realicen con los datos del metaanálisis agrupados. Un coeficiente de heterogeneidad elevado penalizará las decisiones finales, hará que el tamaño de muestra alcanzado sumando estudios no sea tan trascendente.
25. La variabilidad en los estudios de metaanálisis debe verse en dos componentes. Una es la variabilidad intraestudio y otra la variabilidad interestudios, que queda evaluada mediante el coeficientes de heterogeneidad o mediante el Test de heterogeneidad. En los intervalos de confianza de un pronóstico o en un contraste de hipótesis siempre está presente la noción de Error estándar que hemos visto en el Tema 3: Intervalos de confianza:

26. La magnitud del coeficiente de heterogeneidad modifica el numerador. Lo amplía. Por lo tanto, un mismo metaanálisis, con un mismo tamaño de muestra total proporcionará intervalos de confianza distintos según el grado de heterogeneidad. Cuanta más heterogeneidad más grande se hace el numerador.
27. Supongamos un nuevo ejemplo sencillo y simplificado que nos ayudará a valorar esto que estamos diciendo. Lo vemos en un tema que trata de estudiar la media de colesterol en una población. Cuatro estudios presentan los siguientes valores:
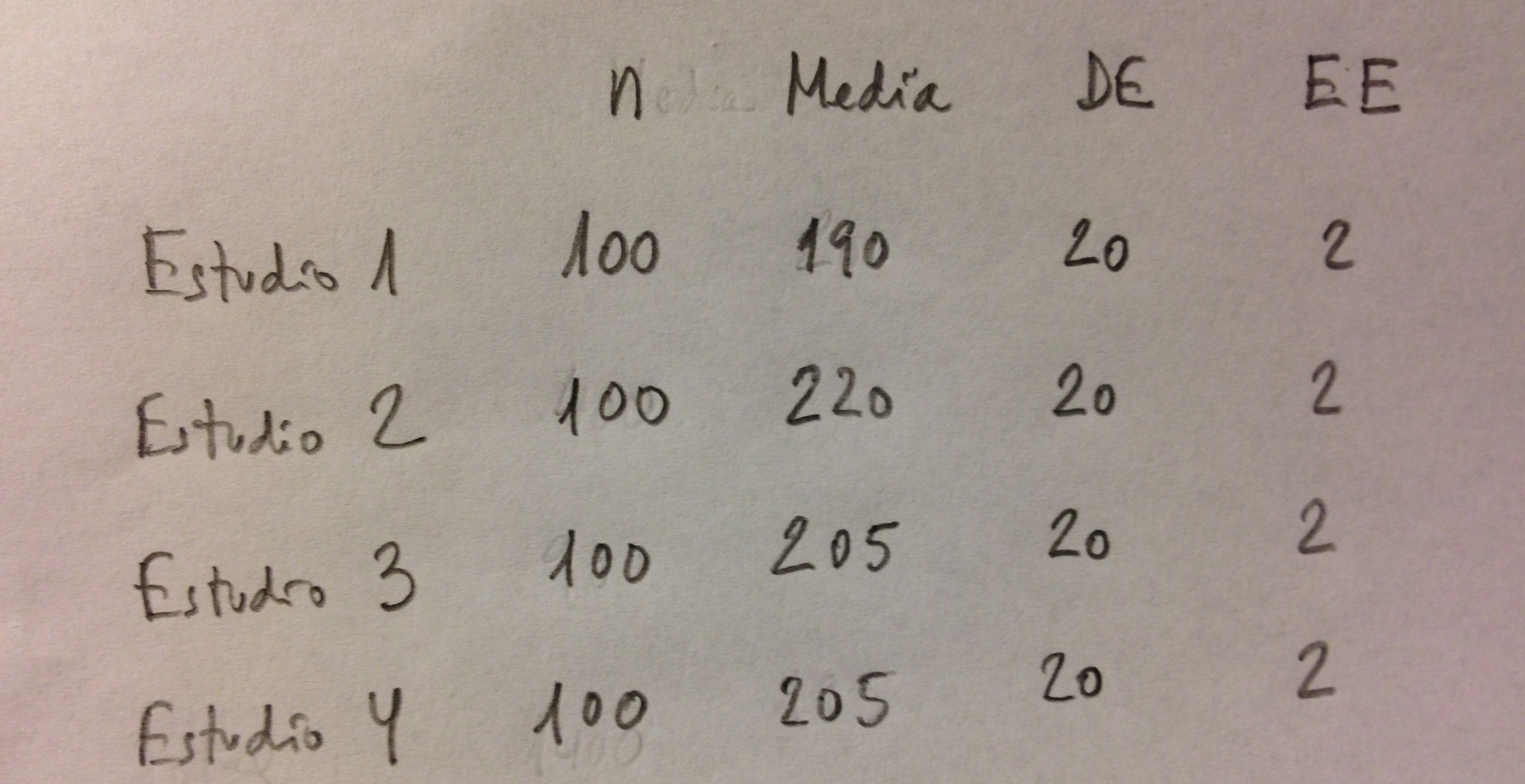
28. Si ahora calculamos la media de los cuatro estudios es 205, pero hay una cierta heterogeneidad que nos debe penalizar a la hora de construir un intervalo de confianza de la media juntando los cuatro estudios.
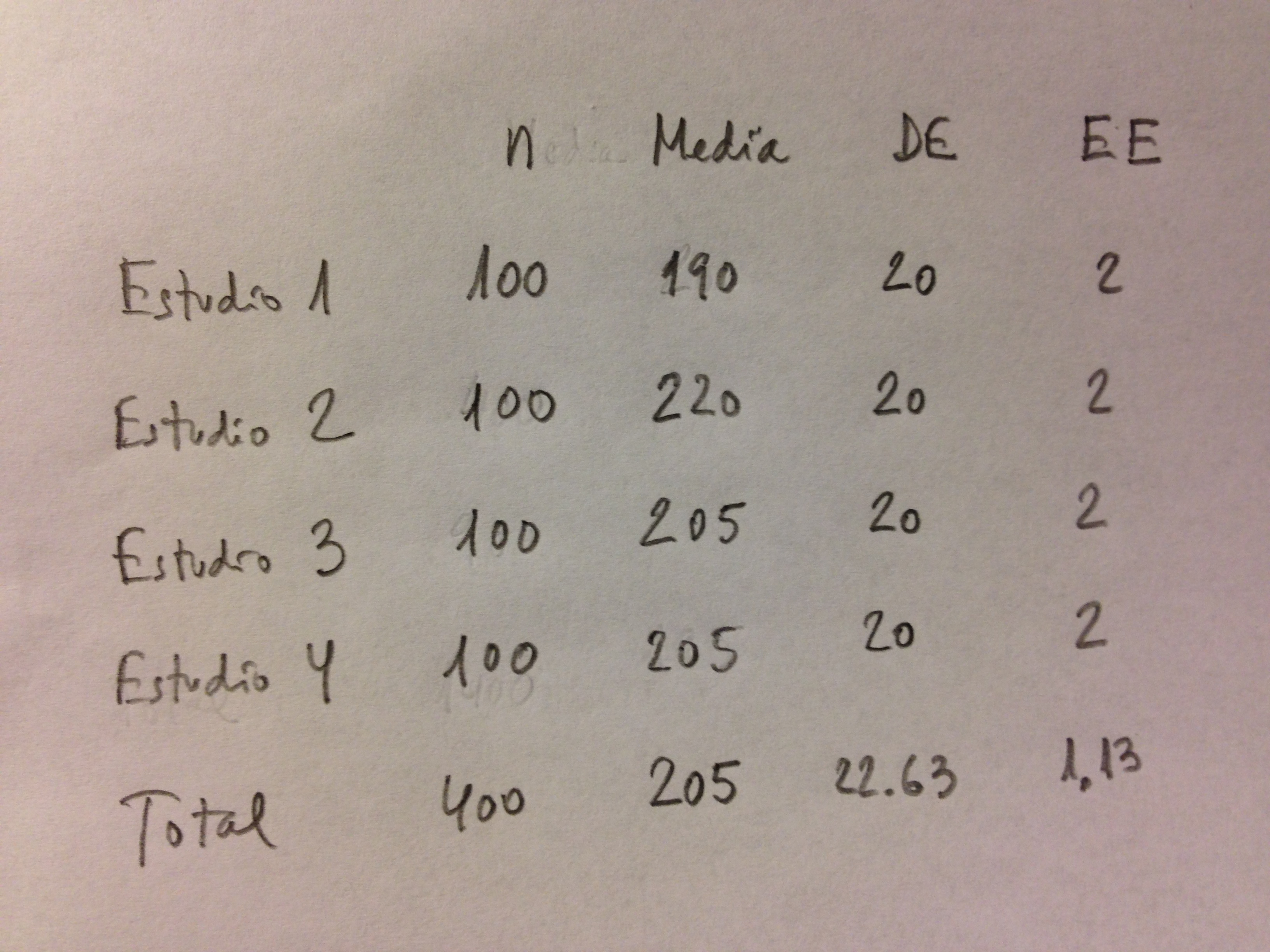
29. Calcularemos la varianza dentro de los estudios, marcada con un subíndice D, y la varianza entre los estudios, marcada con el subíndice E. Vemos también a continuación una alternativa forma de cálculo del coeficiente de heterogeneidad a partir de estas dos varianzas. Y calcularemos también la varianza global y la DE global a partir de la suma de estas dos varianzas:

30. Si ahora incorporamos los valores totales en la tabla anterior y el valor de esta DE global ello nos permite calcular el Error estándar (EE) y ver cómo queda penalizado por la varianza entre estudios o heterogeneidad:
31. Observemos que al final el EE es 1.13 y no 1, como sería sin esta penalización. Si tuviéramos más heterogeneidad tendríamos más penalización.
32. Finalmente una tabla donde se expresan los resultados finales del metaanálisis mostrado anteriormente del estudio del riesgo de enfermedad coronaria en fumadores pasivo: