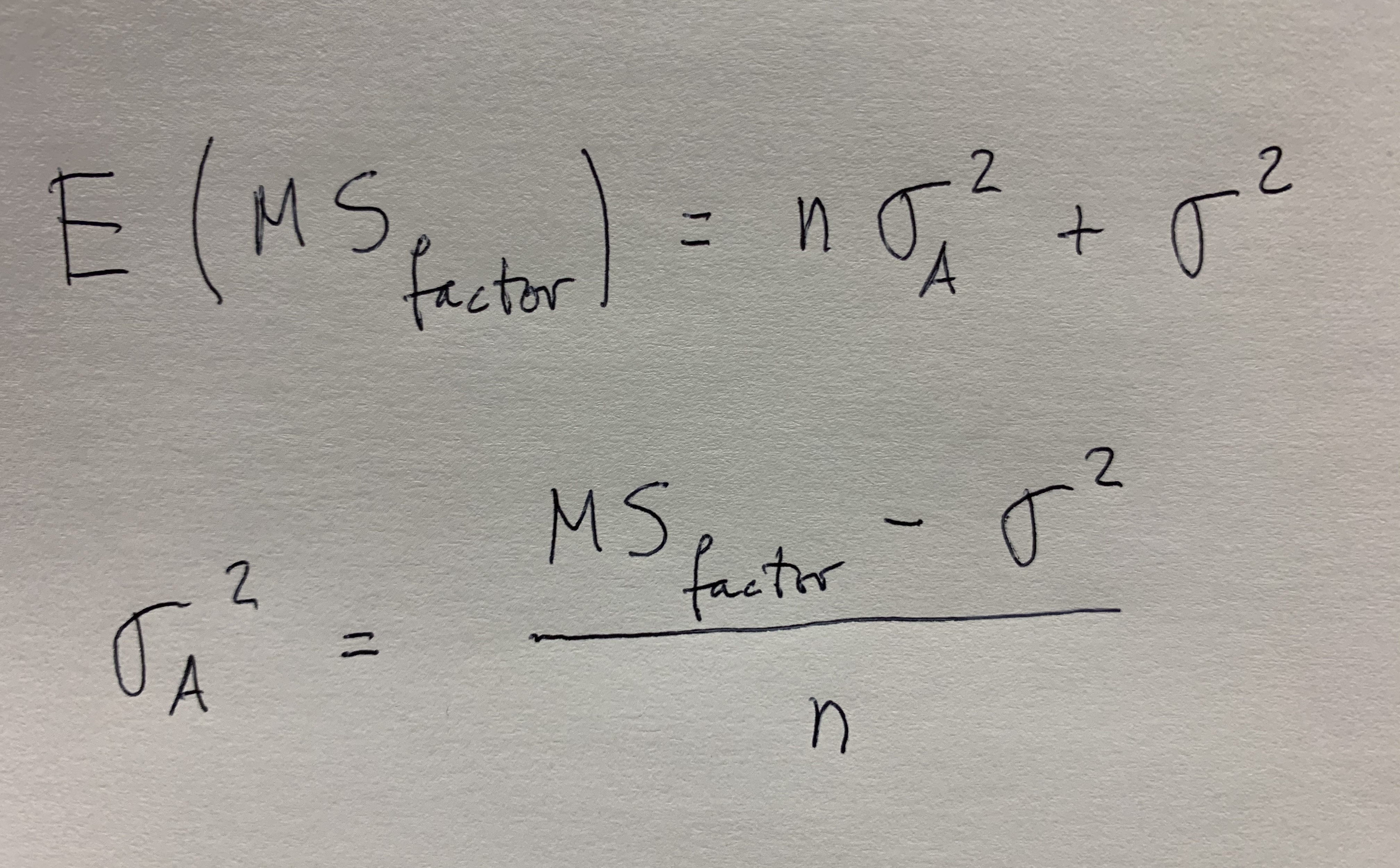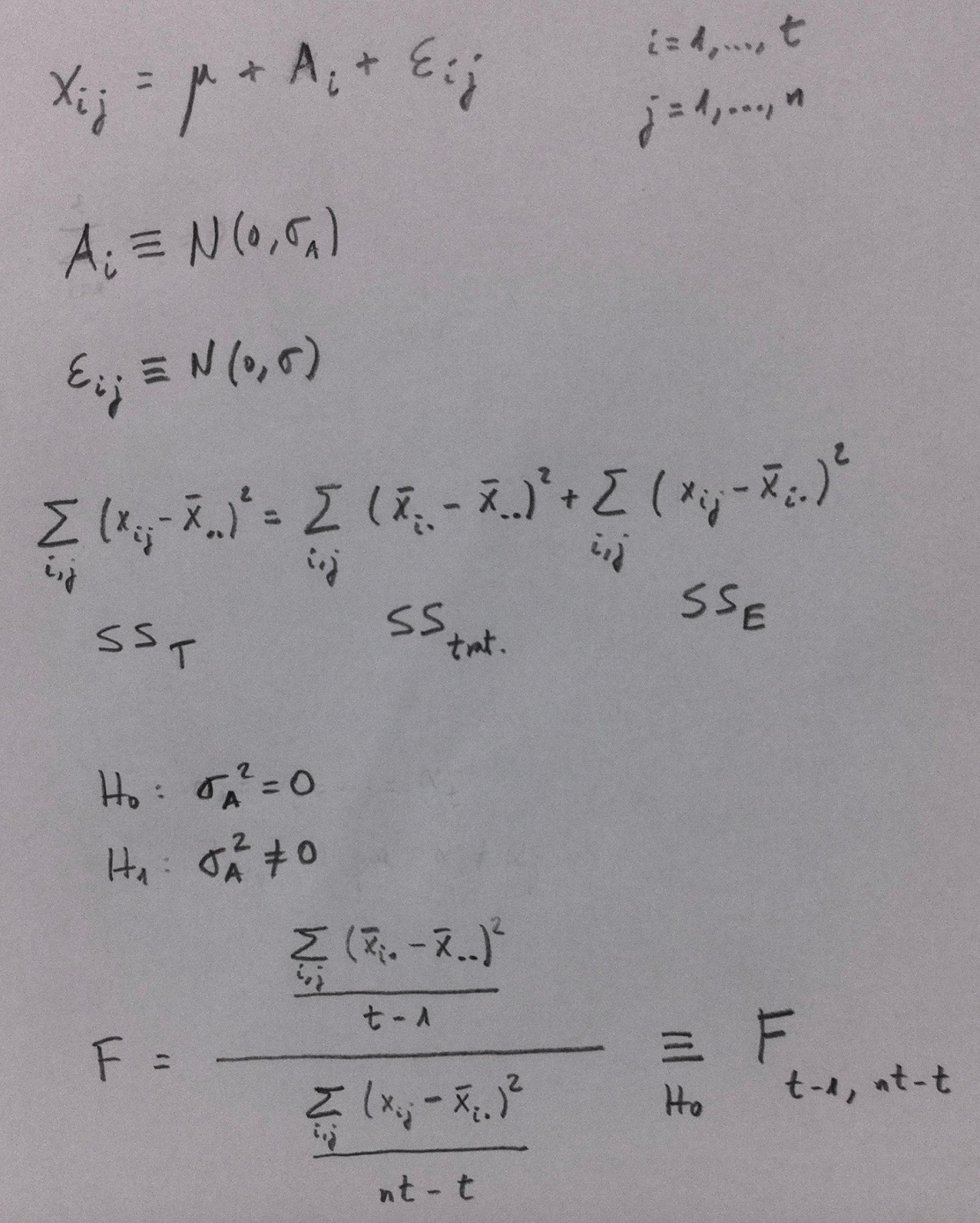El Teorema de las probabilidades totales y el Teorema de Bayes son dos teoremas clásicos en el campo de las Probabilidades que tienen muchas aplicaciones.
Parten ambos de que tenemos una partición definida en un conjunto de individuos. Esto quiere decir que un conjunto de individuos lo tenemos partido en una serie de grupos que no se tocan entre ellos; o sea, en términos matemáticos diríamos que tienen intersección vacía. Nadie, en definitiva, pertenece a más de uno de esos grupos. Y todos pertenecen a uno u otro de esos grupos.
Por ejemplo, la población de personas queda estructura en una partición según el grupo sanguíneo del sistema AB: La partición es A, B, AB y O. Respecto a una determinada patología la población siempre queda partida en un grupo formado por todos los que tienen esa patología y en otro formado por todos los que no la tienen. Esta partición veremos que en Medicina tiene mucha importancia a la hora de abordar unos conceptos esenciales en diagnóstico: la sensibilidad, la especificidad, el valor predictivo positivo y el valor predictivo negativo.
Dentro de esta partición puede definirse un conjunto, que llamaremos A, que está inmerso en ella y que se toca con todos los grupos que define tal partición. Puede darse algún caso en el que se tenga la información de la probabilidad de cada uno de los grupos de la partición y que se sepan, también, todas las probabilidad de que se dé este suceso A condicionadas a que se haya dado cualquiera de los grupos de la partición. En este caso podemos calcular la probabilidad de A mediante el Teorema de las probabilidades totales. Observemos el siguiente gráfico:

Para llegar a la formulación final del Teorema es necesario aplicar la definición de probabilidad condicionada. Es importante tener en cuenta que para poder aplicar este Teorema debemos conocer la probabilidad de cada uno de los elementos de la partición y todas las probabilidades condicionadas que nos muestra el gráfico.
El Teorema de Bayes parte también del conocimiento de estas mismas probabilidades pero el planteamiento es otro. Sabemos que se ha producido el suceso A y nos planteamos la probabilidad de que se haya dada uno de los elementos de la partición. Veamos el planteamiento:

Un ejemplo aclarará ambos teoremas:
Supongamos que estamos estudiando una enfermedad en una población que sabemos que tiene una prevalencia de 0.3 (o, en porcentaje, del 30%). La población queda partida en dos grupos: Enfermos (E) y No enfermos (NE). La probabilidad de E es 0.3 y la de NE es 0.7. Supongamos también que podemos aplicar una técnica diagnóstica para ver si una persona tiene o no tiene esa enfermedad. Supongamos que sabemos la probabilidad de que la prueba dé positiva (+) si una persona tiene la enfermedad; o sea, la P(+/E) y que también sabemos la probabilidad de que la prueba dé positiva si una persona no tiene la enfermedad; o sea, la P(+/NE). Si quisiéramos sabe la probabilidad de que cogiendo una persona al azar en esa población la prueba diera positiva; o sea, la P(+) deberíamos aplicar el Teorema de las probabilidades totales. Si lo que nos planteáramos fuera saber que sabiendo que ha dado positiva la prueba en una persona calcular la probabilidad de que sea una persona con la enfermedad; o sea, P(E/+) deberíamos aplicar el Teorema de Bayes. Veámoslo:
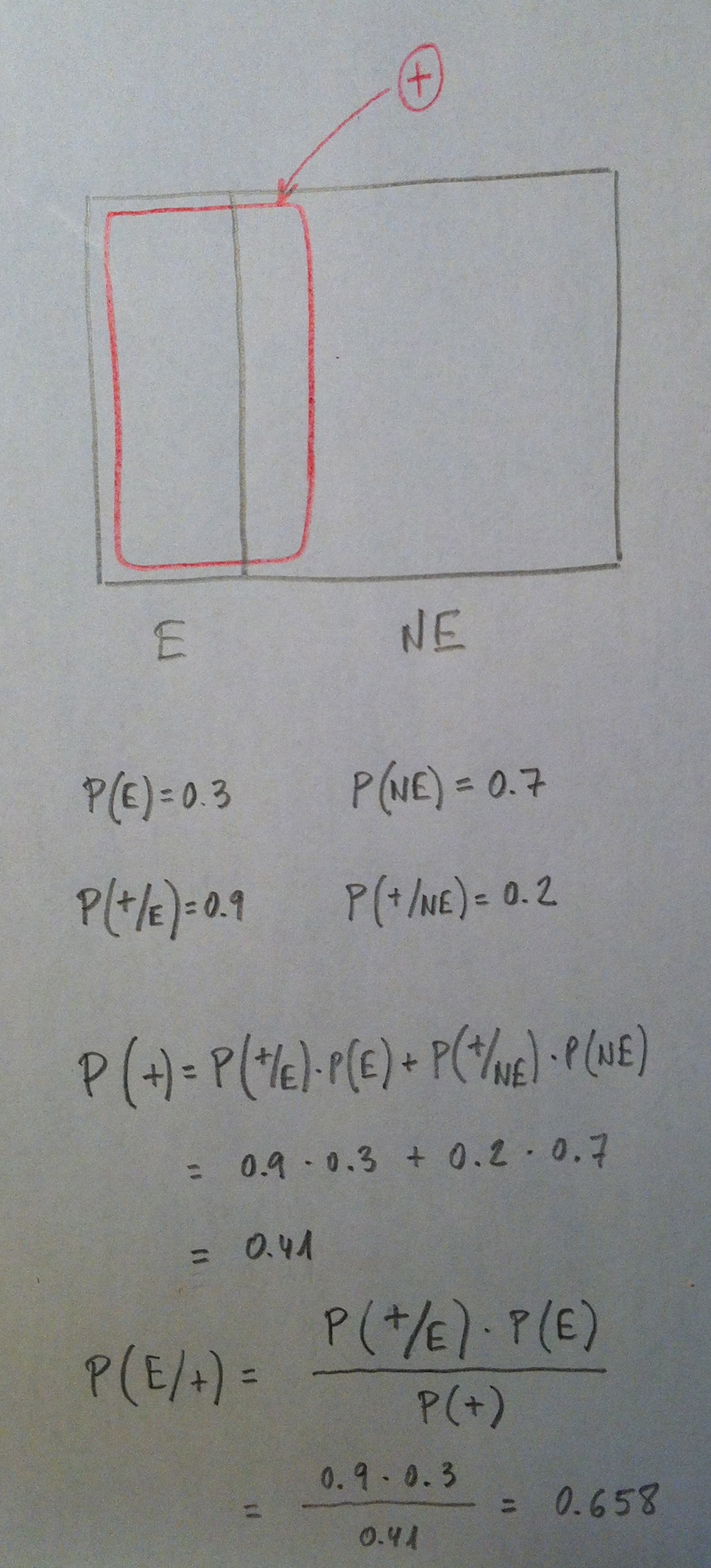
De hecho, aquí, en este ejemplo, aparecen conceptos de una importancia crucial en Medicina. En cualquier procedimiento diagnóstico a la probabilidad P(+/E) se la denomina Sensibilidad, al valor 1-P(+/NE); o sea, a la P(-/NE) se le denomina Especificidad. Y a la probabilidad P(E/+) se le denomina Valor predictivo positivo. Ver el artículo «Sensibilidad, Especificidad, Valor predictivo positivo, Valor predictivo negativo» del apartado de Estadística y Medicina.