El Test de coincidencia de rectas de regresión contrasta la hipótesis nula de igualdad de rectas. El procedimiento es el siguiente:

El Test de coincidencia de rectas de regresión contrasta la hipótesis nula de igualdad de rectas. El procedimiento es el siguiente:
El Test de paralelismo entre rectas de regresión es un test de igualdad de pendientes de dos rectas. Veamos el procedimiento:
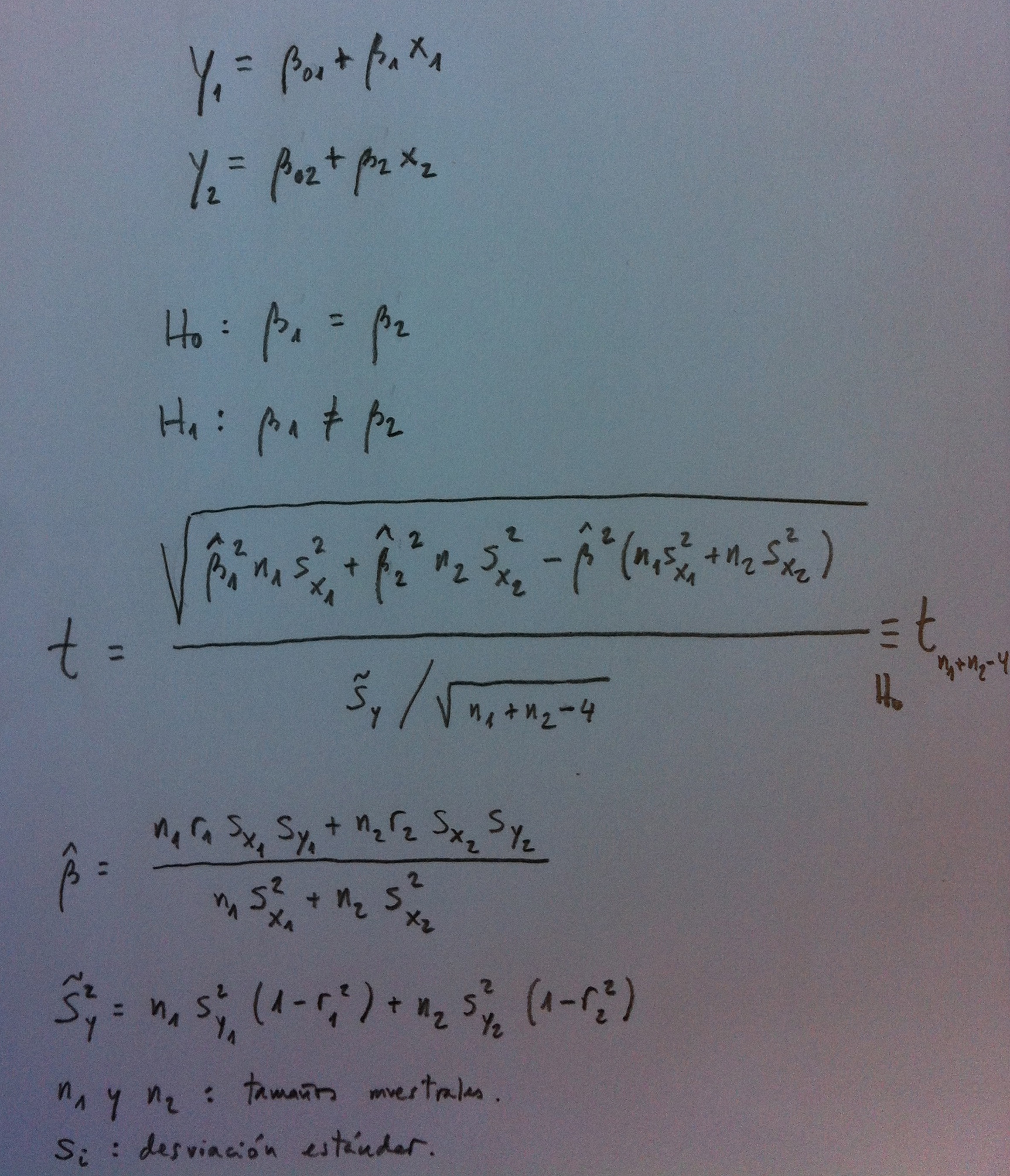
El Estimador de Kaplan-Meier es un estimador no paramétrico de la función de supervivencia. Se basa en la fórmula siguiente:
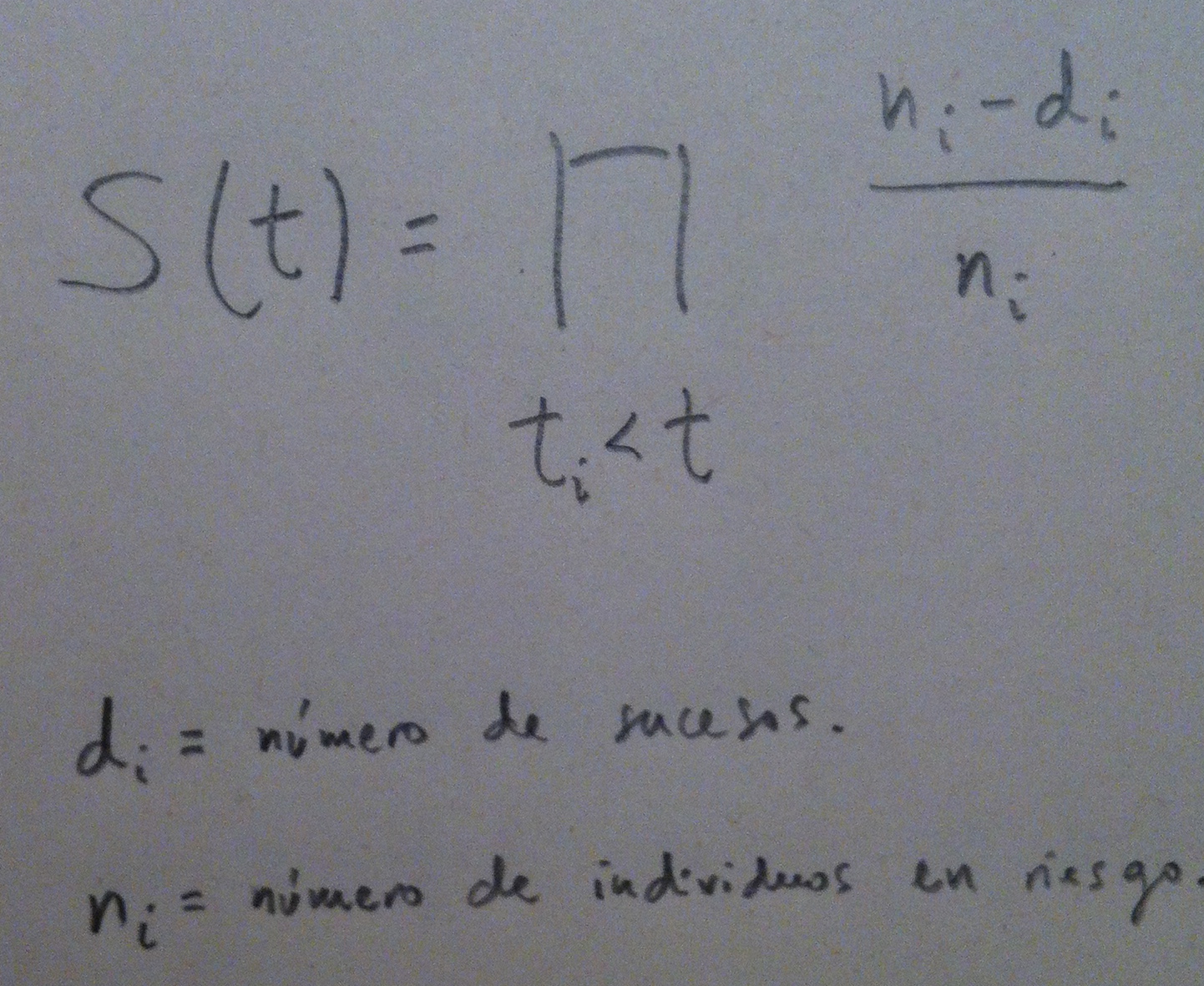
Veamos un ejemplo, basado en la siguiente muestra de valores de supervivencia expresados en unidades de tiempo:
(4, 6, 7c, 8, 10, 10, 10, 15c, 20, 25)
donde la c añadida a un valor indica que el valor es censurado, que significa que o bien ha salido del estudio o que el estudio ha terminado y todavía este individuo no le había sufrido el suceso estudiado.
Veamos a continuación cómo se calcularía con estos valores la información necesaria para construir la función de Kaplan-Meier:

Cuando un valor es censurado se salta, lo que significa que su información se asocia a valores próximos. Por lo tanto, es una información que se utiliza. Lo mismo sucede con valores repetidos, se calculan valores sólo del último. Pero, evidentemente, los demás quedan asociados a este último valor.
A partir de estos valores la curva de supervivencia es la siguiente:

Cuando un valor es censurado se señala en el momento que ha salido del estudio. Si estuviera al final del estudio se marcaría también.
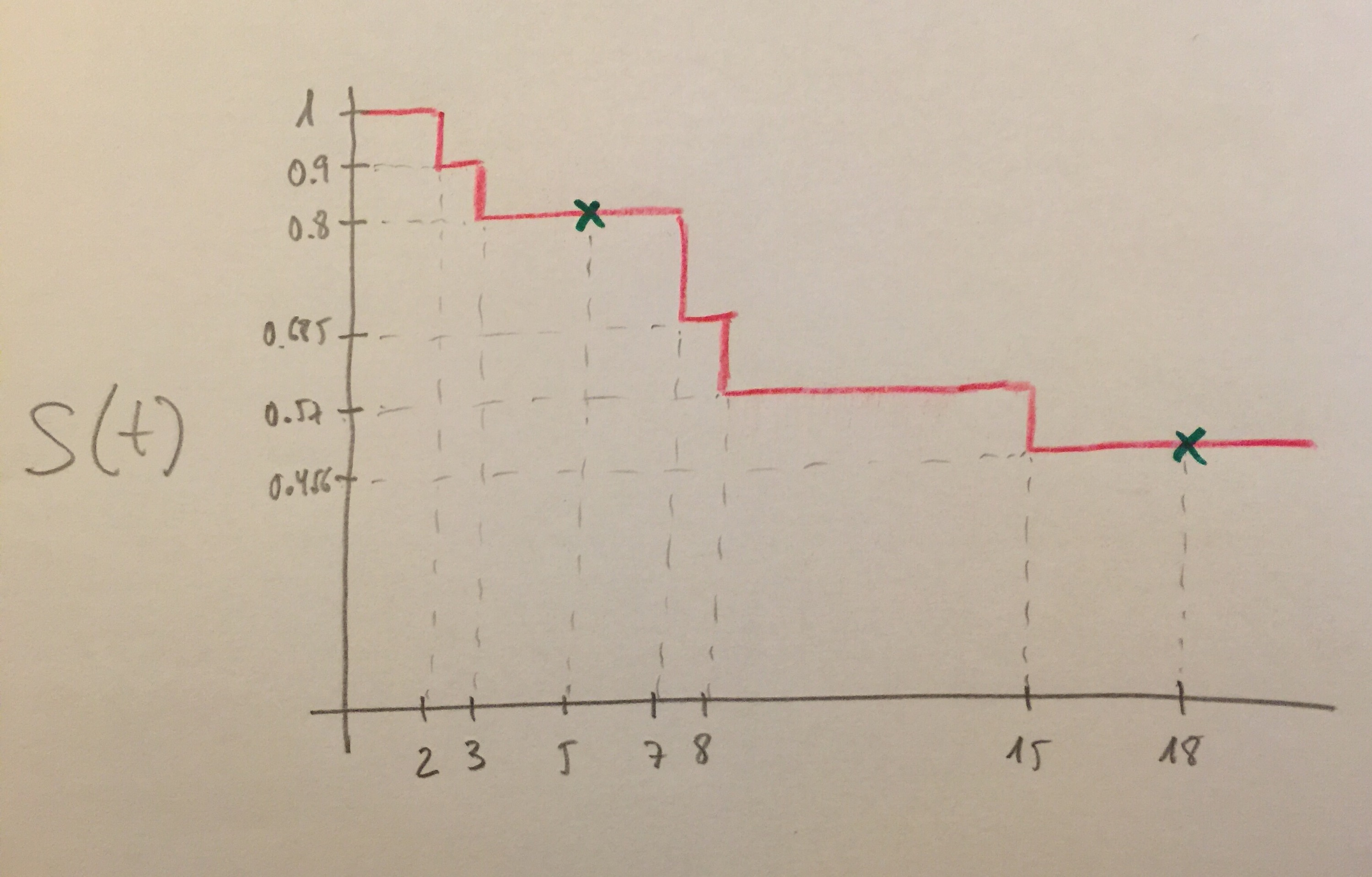
Otro ejemplo. Supongamos ahora la muestra de las siguientes unidades de tiempo:
(2, 3, 5c, 7, 8, 15, 18c, 18c, 18c, 18c)
Obsérvese que en este caso el valor 18, que podría representar 18 meses de seguimiento, podríamos considerar el final del seguimiento. Por lo tanto, tenemos 4 individuos en los que no ha sucedido el acontecimiento estudiado en las 18 unidades temporales del seguimiento.
El cálculo del Estimador de Kaplan-Meier es el siguiente:

La curva de supervivencia de Kaplan-Meier es, pues, la siguiente:
El Test Log-Rank es un contraste de hipótesis que comparar curvas de supervivencia. Se pueden comparar dos o más de dos.
Para comparar dos curvas de supervivencia el Test es el siguiente:
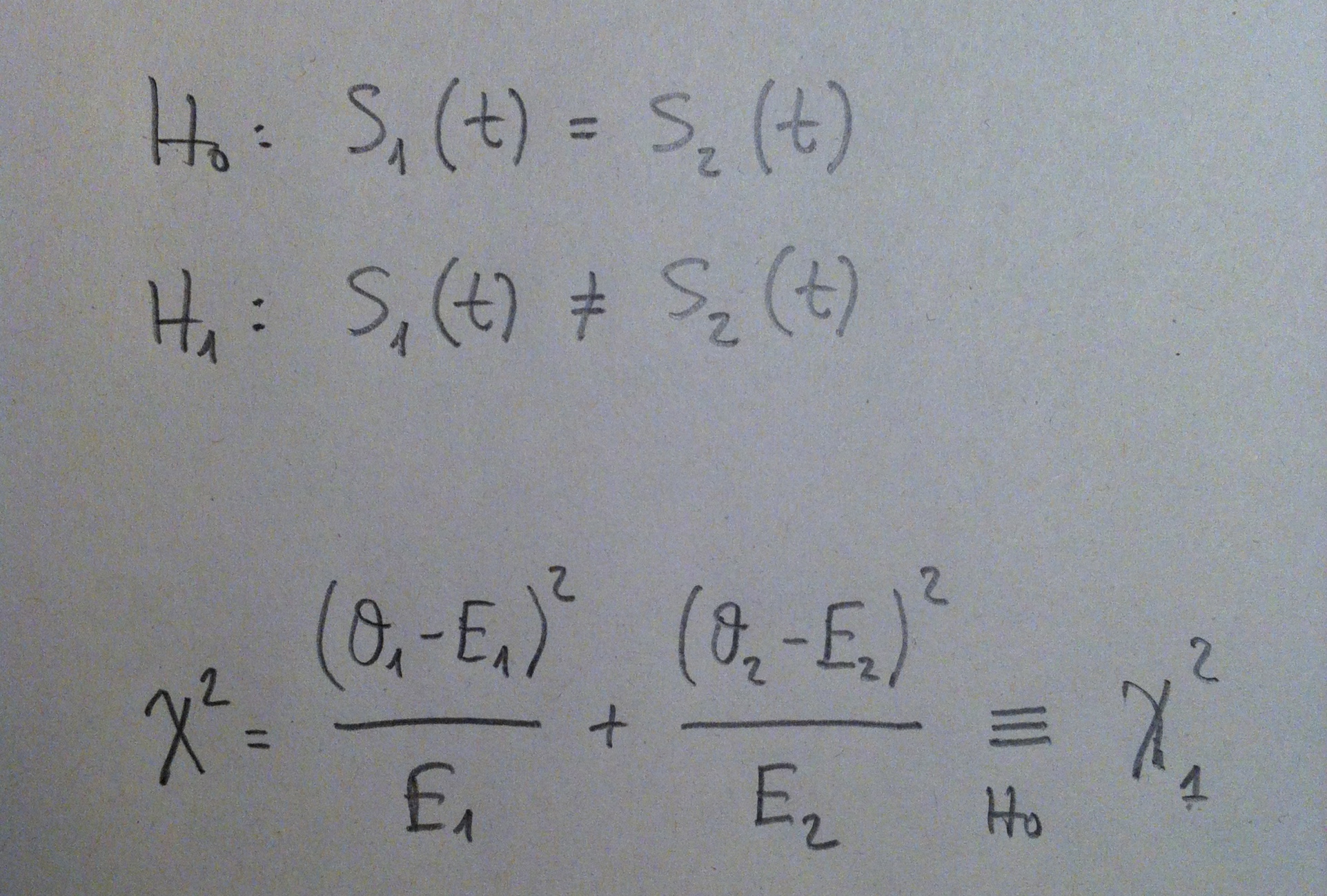
Veámoslo en un ejemplo. Supongamos estos dos grupos, cada uno con su curva de supervivencia que es evidentemente distinta muestralmente. El problema es ver si esta diferencia es estadísticamente significativa. Apliquemos el Test:
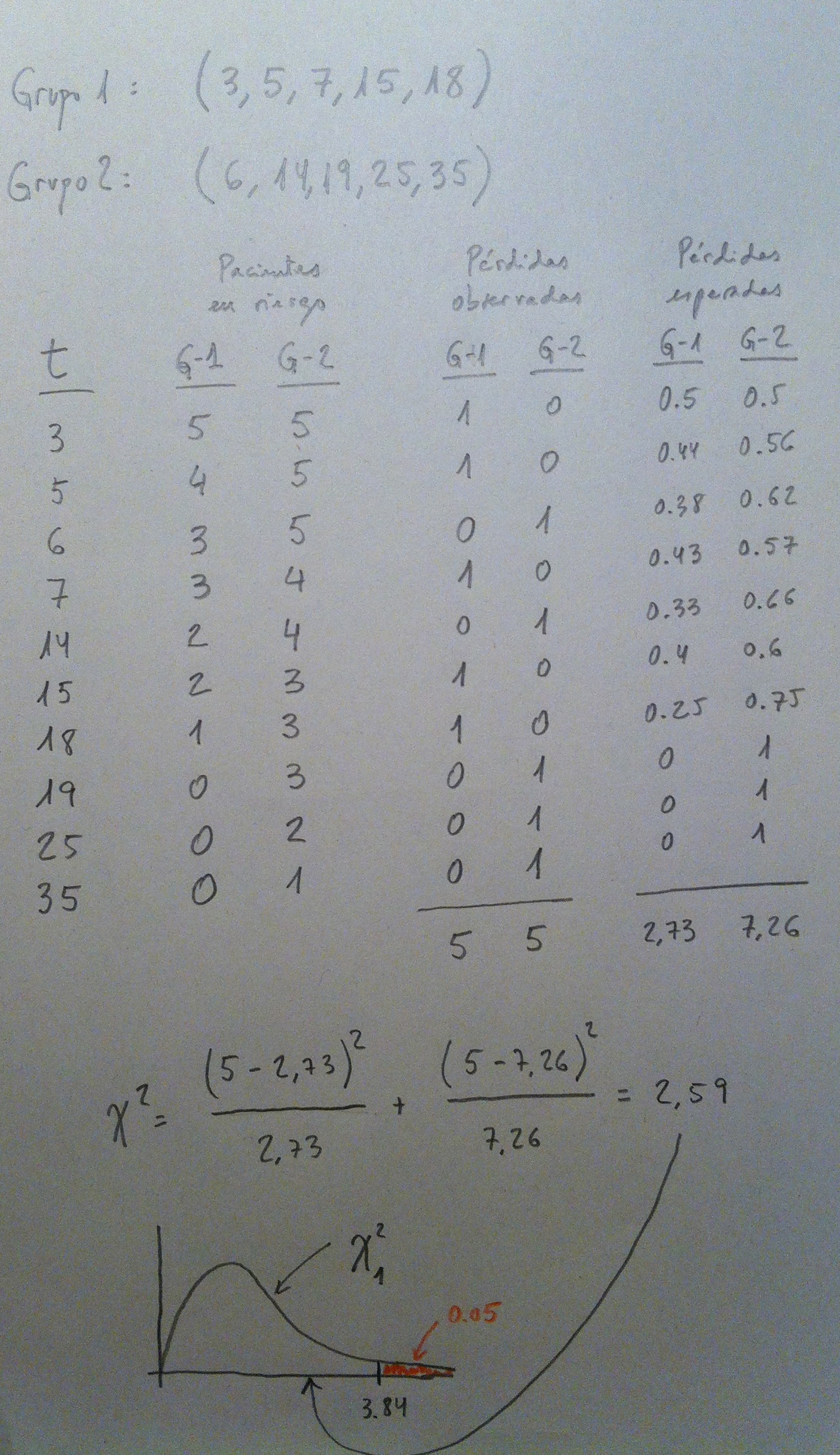
Como puede verse, a pesar de que las diferencias muestrales son sustanciales esa diferencia no es significativa. Veamos el siguiente cambio. He creados dos grupos que repiten cada uno de los cinco valores anteriores. Por lo tanto, las diferencias entre curvas se mantienen pero ahora con un tamaño muestral mayor. Recordemos que el tamaño muestral es determinante a la hora de detectar diferencias estadísticamente significativas. Veamos cómo van a cambiar las cosas. Calculemos el Test para estos nuevos datos:

Como puede verse ahora sí tenemos un resultado significativo. Ahora las diferencias son estadísticamente significativas. Ahora sí que ya podemos afirmar que las dos curvas de supervivencia poblacionales son distintas.
Por lo tanto, antes el tamaño muestral jugaba en contra de la significación estadística. Ahora el tamaño muestral es lo suficientemente grande como para que podamos decir que las diferencias que antes veíamos no pueden ser atribuibles al azar del muestreo.
En el ANOVA de dos factores a efectos aleatorios tenemos tres contrastes a realizar, uno por cada factor y otro para la interacción. Pensemos que estamos en factores cruzados. En ANOVA si hay más de un factor si no se dice lo contrario los factores están cruzados.
La clave en estos tres contrastes de hipótesis es qué cocientes hay que hacer a la hora de dividir cuadrados medios (MS) en la F-ratio. Por eso pongo las esperanzas de los cuadrados medios. Viendo esas esperanzas y bajo la Hipótesis nula vemos por qué los cocientes son los que son. Se trata de que los cocientes, bajo la Hipótesis nula tengan la misma esperanza. De esta forma valores pequeños de la F-ratio nos permitirán mantener la Hipótesis nula y, por el contrario, valores grandes de la F-ratio nos permitirán rechazarla y pasarnos a la Hipótesis alternativa.

El Test de Mann-Whitney es un test no paramétrico que contrasta la igualdad de medianas de dos poblaciones. A este Test también se le llama, a veces, Test de Mann-Whitney-Wilcoxon o, también, Test de Wilcoxon de la suma de rangos.
Consiste en realizar nxm comparaciones: todos los valores de una muestra se comparan con los de la otra y se cuenta el número de veces que los de una muestra son superiores a los de la otra. El estadístico de test U es ese contador.

El Test de Wilcoxon es similar al Test de los signos pero no sólo tiene en cuenta los signos sino que tiene también en cuenta el valor absoluto de las diferencias de cada valor muestral respecto al valor mo de Mediana poblacional que se quiere contrastar. O sea, tiene en cuenta los rangos, por esto se le conoce, también, como el Test de los rangos con signo de Wilcoxon. No hay que confundirlo con el Test de la suma de rangos de Wilcoxon que es como se llama, a veces, al Test de Mann-Whitney. El Test de los rangos con signo, que es el que estamos viendo ahora, es para muestras relacionadas, apareadas. El Test de la suma de rangos es para muestras independientes.
Se suele utilizar, como el Test de los signos, para contrastar la igualdad de medianas en datos apareados en los que no se cumplen las suposiciones para realizar el Test de la t de Student. En este caso se restan uno a uno los valores apareados de ambas muestras y se contrasta la Hipótesis que la Mediana poblacional es cero.

En el Test de los signos se contrasta si la Mediana poblacional tiene un cierto valor mo. El estadístico de test consiste en contar el número de valores muestrales que están por encima de este valor mo. Por esto se cuenta el número de valores positivos.
Un ámbito donde se suele aplicar este Test es para muestras apareadas donde se quiera contrastar la igualdad de medias y no se cumplen las condiciones para realizar un Test de la t de Student de datos apareados. En este caso se restan los valores muestrales, individuo por individuo, y se realiza este contraste con mo=0.

En el ANOVA de dos factores a efectos fijos tenemos tres contrastes a realizar, uno por cada factor y la interacción. Pensemos que estamos en factores cruzados. En ANOVA si hay más de un factor si no se dice lo contrario los factores están cruzados.
La clave en estos tres contrastes de hipótesis es qué cocientes hay que hacer a la hora de dividir cuadrados medios (MS) en la F-ratio. Por eso pongo las esperanzas de los cuadrados medios. Viendo esas esperanzas y bajo la Hipótesis nula vemos por qué los cocientes son los que son. Se trata de que los cocientes, bajo la Hipótesis nula tengan la misma esperanza. De esta forma valores pequeños de la F-ratio nos permitirán mantener la Hipótesis nula y, por el contrario, valores grandes de la F-ratio nos permitirán rechazarla y pasarnos a la Hipótesis alternativa.

En el ANOVA de dos factores a efectos mixtos, uno fijo y uno aleatorio, tenemos tres contrastes a realizar, uno por cada factor y otro para la interacción. Pensemos que estamos en factores cruzados. En ANOVA si hay más de un factor si no se dice lo contrario los factores están cruzados.
La clave en estos tres contrastes de hipótesis es qué cocientes hay que hacer a la hora de dividir cuadrados medios (MS) en la F-ratio. Por eso pongo las esperanzas de los cuadrados medios. Viendo esas esperanzas y bajo la Hipótesis nula vemos por qué los cocientes son los que son. Se trata de que los cocientes, bajo la Hipótesis nula tengan la misma esperanza. De esta forma valores pequeños de la F-ratio nos permitirán mantener la Hipótesis nula y, por el contrario, valores grandes de la F-ratio nos permitirán rechazarla y pasarnos a la Hipótesis alternativa.

