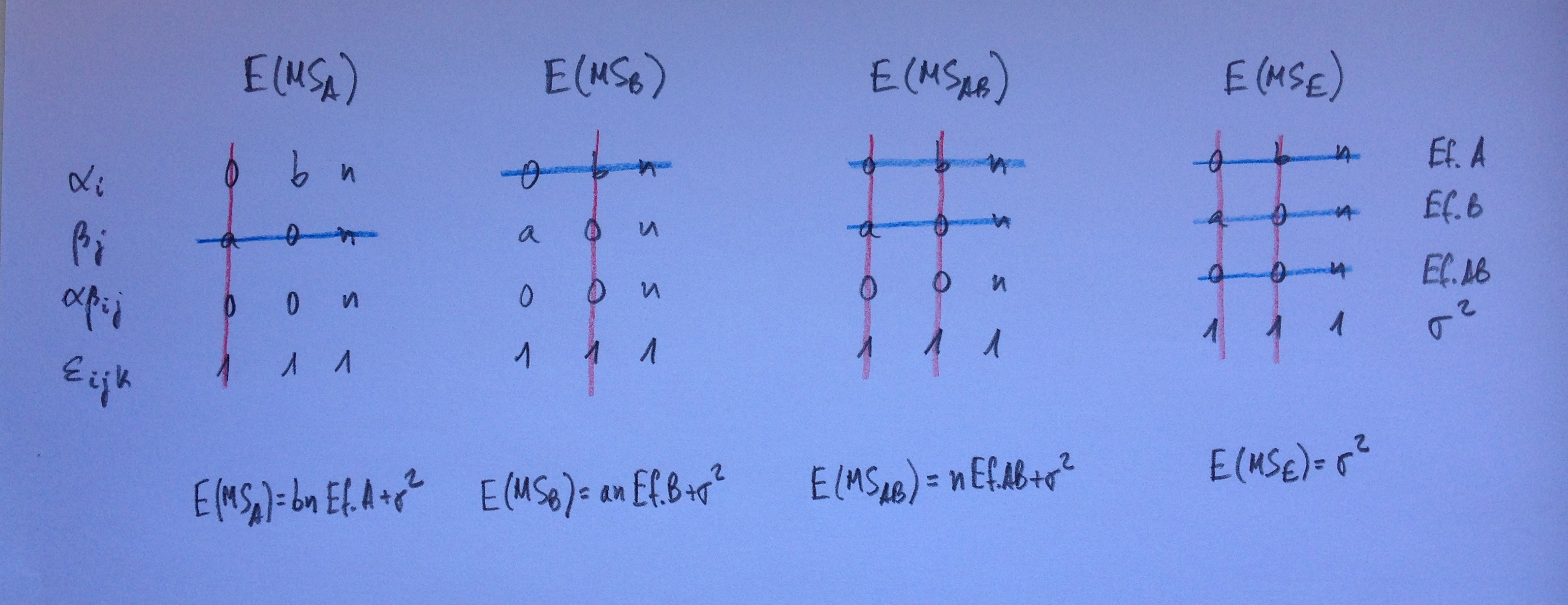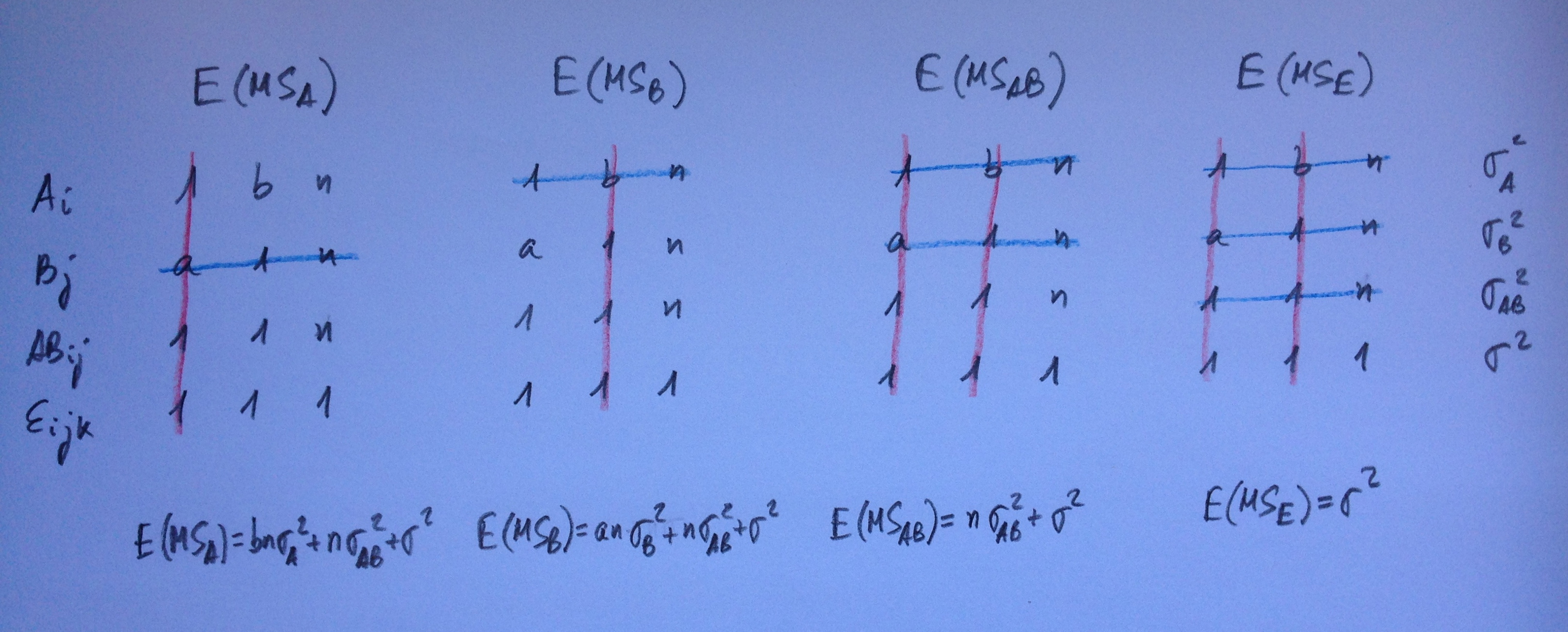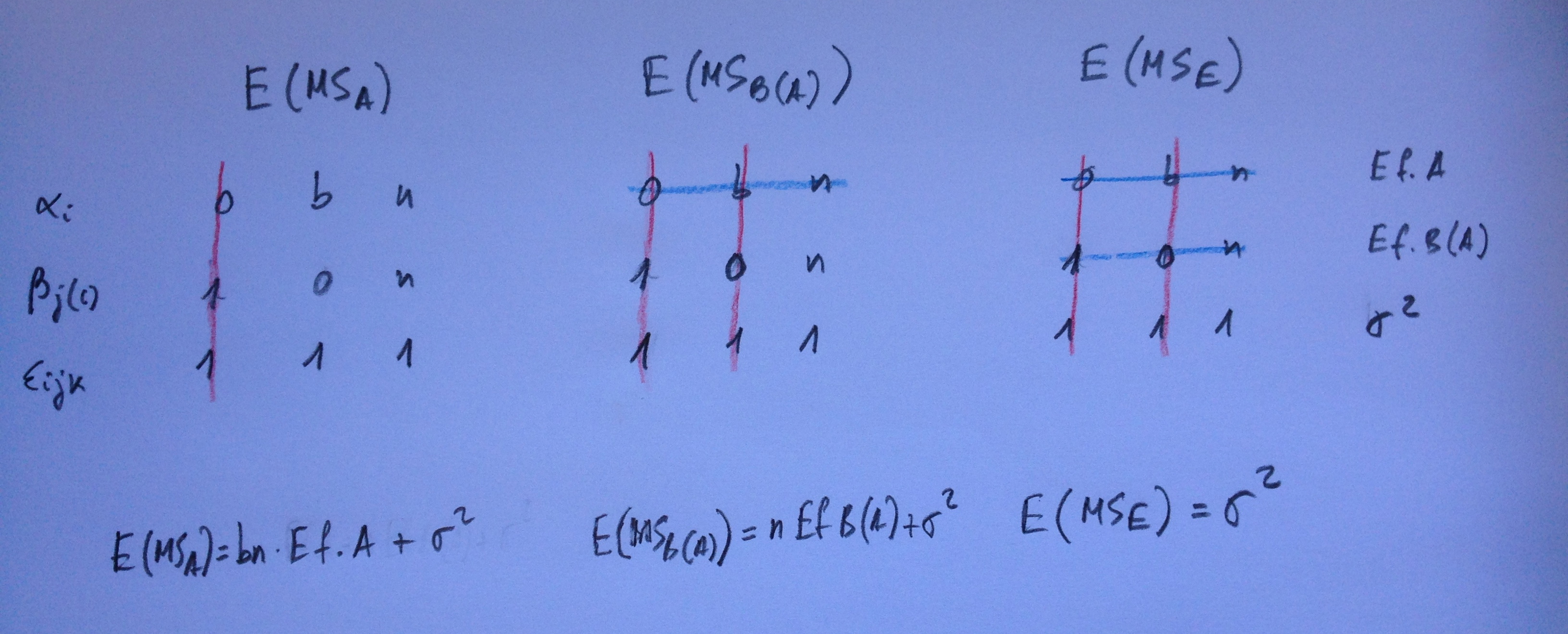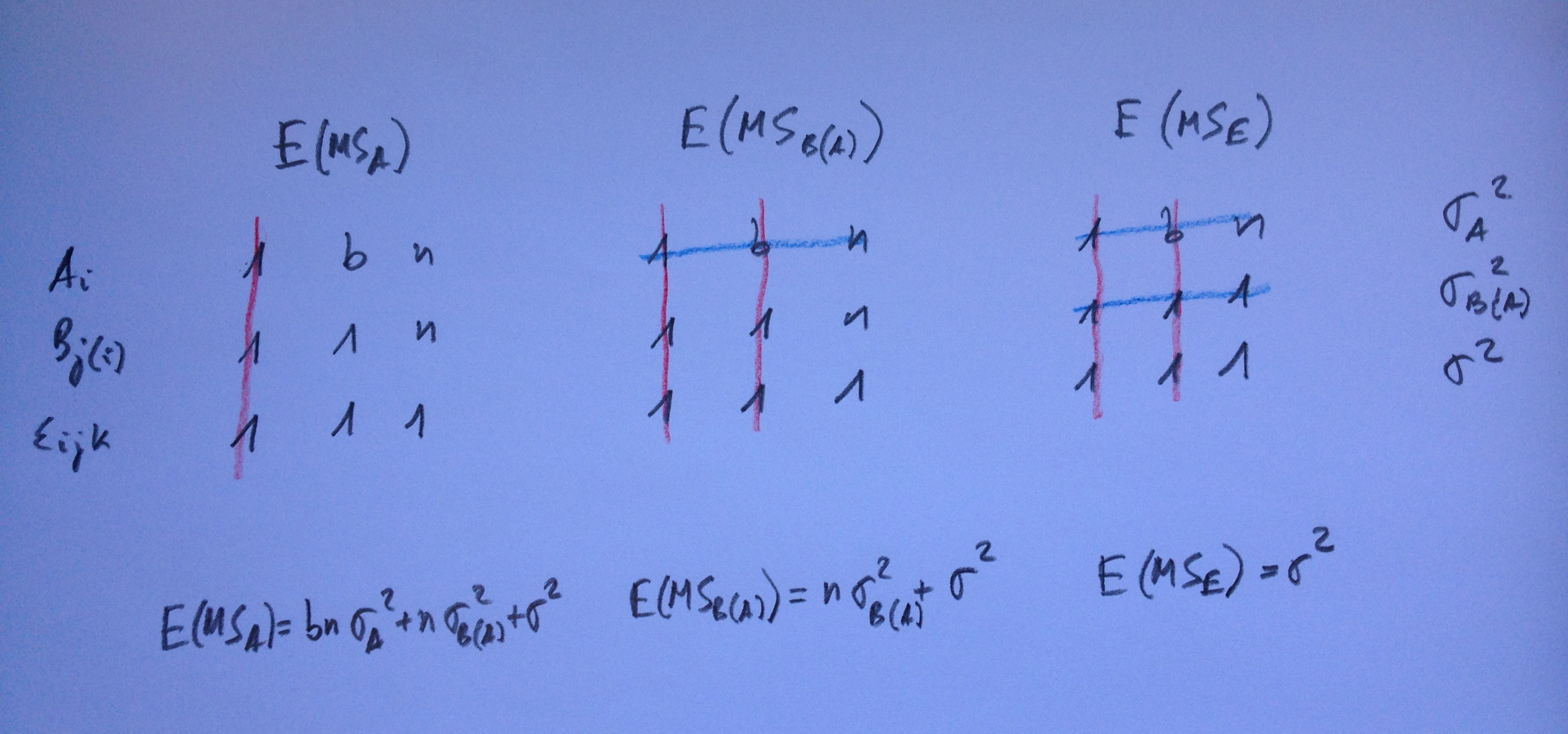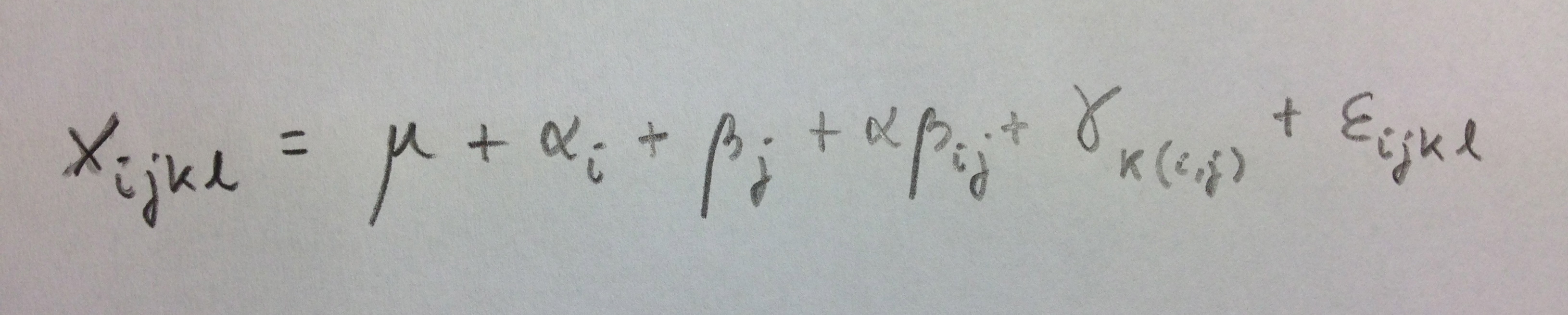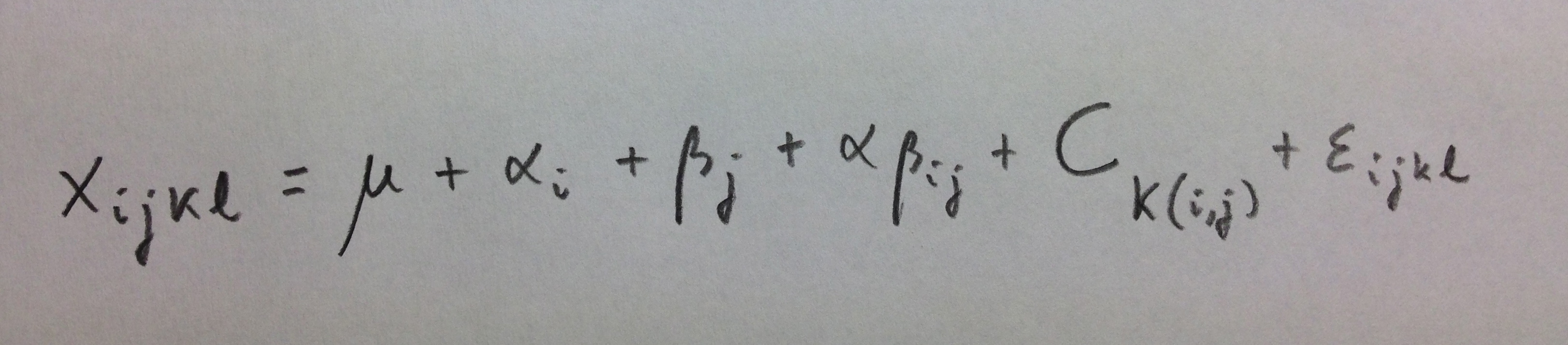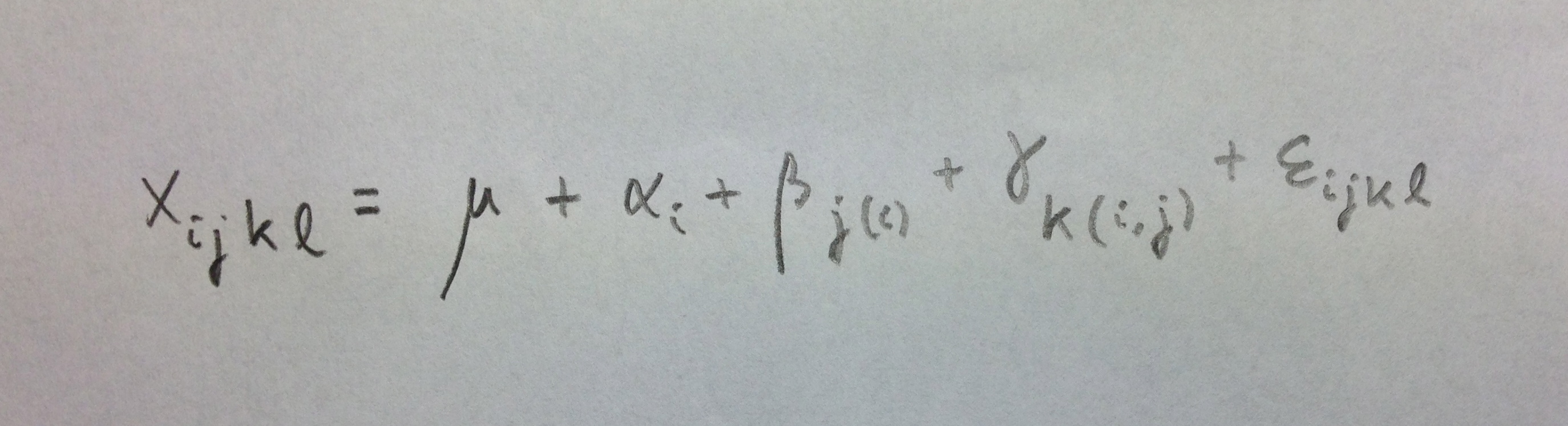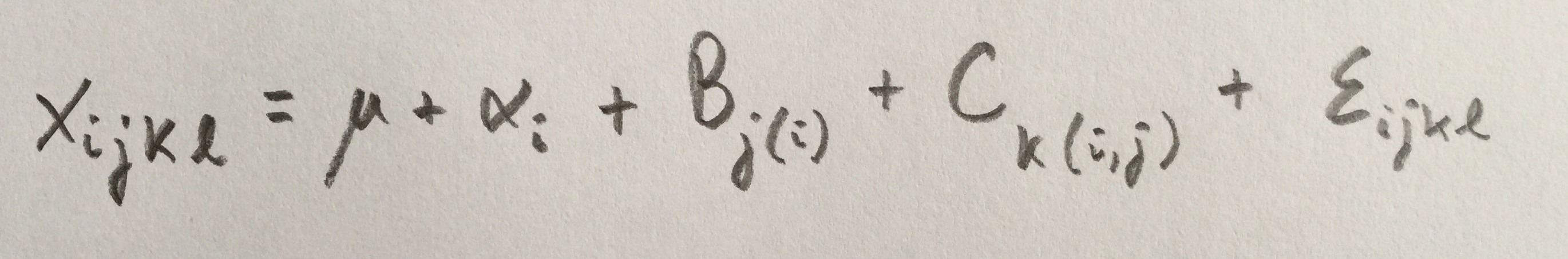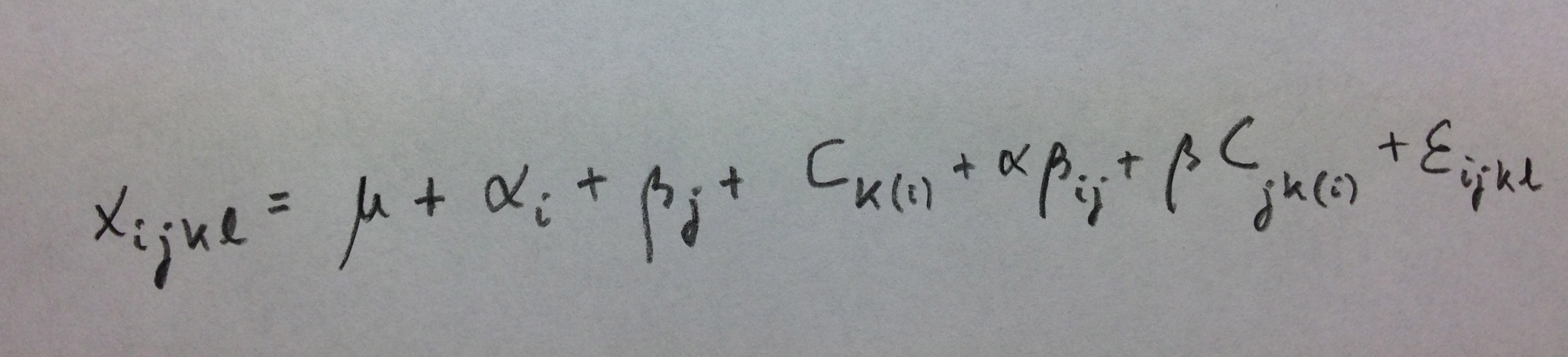Al tratar con tres factores las posibilidades de combinación se multiplican. Los factores pueden estar cruzados, anidados, pueden ser fijos aleatorios, en diferentes combinaciones, como ahora veremos.
Vamos a ver algunos posibles modelos de tres factores y su resolución en los cocientes de cuadrados medios para evaluar los posibles efectos del modelo en los correspondientes contrastes de hipótesis.
El primero es un modelo de tres factores cruzados fijos:

A partir de estas esperanzas de los cuadrados medios obtenidas mediante el Algoritmo de Bennet-Franklin podemos ver que en todos los contrastes de hipótesis de los siete efectos que se pueden evaluar el cociente de cuadrados medios será el del efecto a evaluar dividido por el residuo. Este es el caso más sencillo de todos los que veremos.
Veamos ahora una caso en el que los tres factores están cruzados pero uno es aleatorio y los otros dos fijos:

Ahora los cocientes a realizar, si observamos con atención las esperanzas de los cuadrados medios, son los siguientes:

Veamos ahora que son dos los factores aleatorios que están cruzados:

A la hora de hacer los contrastes de hipótesis no encontramos con un único problema. A la hora de contrastar el efecto del factor C, del fijo, vemos que en el denominador para poder dividir dos términos cuyas esperanzas, si es cierta la hipótesis nula, sean iguales, debemos hacer una combinación de cuadrados medios:

Veamos ahora el caso en que los tres factores cruzados son aleatorios:
 En los contrastes en los efectos individuales de los tres factores debemos buscar combinaciones en el denominador:
En los contrastes en los efectos individuales de los tres factores debemos buscar combinaciones en el denominador:

Veamos ahora casos donde no están los tres cruzados. Veamos primero un caso donde un primer factor está cruzado con el segundo. Ambos fijos. Y un tercer factor aleatorio está anidado en el primero:


Veamos un caso como el anterior pero en el que los dos factores que están anidados, jerarquizados, son, ambos, aleatorios:

Los cocientes son claros: Para el efecto A dividiremos MSA por MSC(A) porque si fuese cierta la hipótesis nula de que no hay Efecto de A entonces estaríamos dividiendo dos cuadrados medios con la misma esperanza. Y aquí está la clave: Se trata siempre de dividir dos cuadrados medios que si es cierta la hipótesis nula apunten en la misma dirección y, por lo tanto, el cociente será un valor pequeño, próximo a 1 y si, por el contrario, el cociente en grande será porque la hipótesis nula de que no hay efecto no es posible mantenerla. Esta es la clave, siempre, a la hora de resolver un modelo ANOVA.
Por lo mismo para el efecto B dividiremos MSB por MSAB, para el efecto C(A) dividiremos MSC(A) por MSE, para el efecto AB dividiremos MSAB por MSBC(A) y, finalmente, para el efecto BC(A) dividiremos MSBC(A) por MSE.
Veamos una versión como esta pero en la que los tres factores son aleatorios:

Los cocientes ahora serán los siguientes:

Observemos especialmente el primer cociente en el que en el denominador debe buscarse una combinación de cuadrados medios cuya esperanza sea la misma que en el numerador si la hipótesis nula fuese cierta.
Veamos ahora un caso de dos factores cruzados fijos y un tercer factor, aleatorio, anidado en los dos primeros, cosa que suele decirse que está anidado en la interacción:


Como puede verse al valorar tanto el efecto de A, como el de B, como el de la interacción AB deberemos dividir por MSC(A,B). El efecto de C(A,B) lo evaluaremos dividiendo por el residuo.
Veamos el mismo caso que el anterior pero en el que el tercer factor anidado es fijo:


Aquí todos los contrastes los realizaremos dividiendo por el residuo MSE.
Veamos el mismo caso que los dos anteriores pero en el que los tres factores fuesen aleatorios:

Par evaluar el efecto de A dividiremos por MSAB, el de B también por MSAB, el efecto de AB por MSC(A,B) y el efecto de C(A,B) dividiremos por el residuo MSE.
Veamos ahora el caso de un factor fijo, uno aleatorio anidado en él y un tercero, también aleatorio, anidado en el segundo y, por lo tanto, también en el primero:


Para evaluar el efecto de A dividiremos por MSB(A), para evaluar el efecto de B(A) dividiremos por MSC(A,B) y para evaluar el efecto de C(A,B) dividiremos por MSE.
Un modelo más de forma rápida: Si en el modelo tenemos que los tres factores son aleatorios, el único cero que hay en la matriz sería un 1, pero se puede comprobar fácilmente que eso no cambiaría para nada las esperanzas de los cuadrados medios ni, por supuesto los cocientes a realizar.