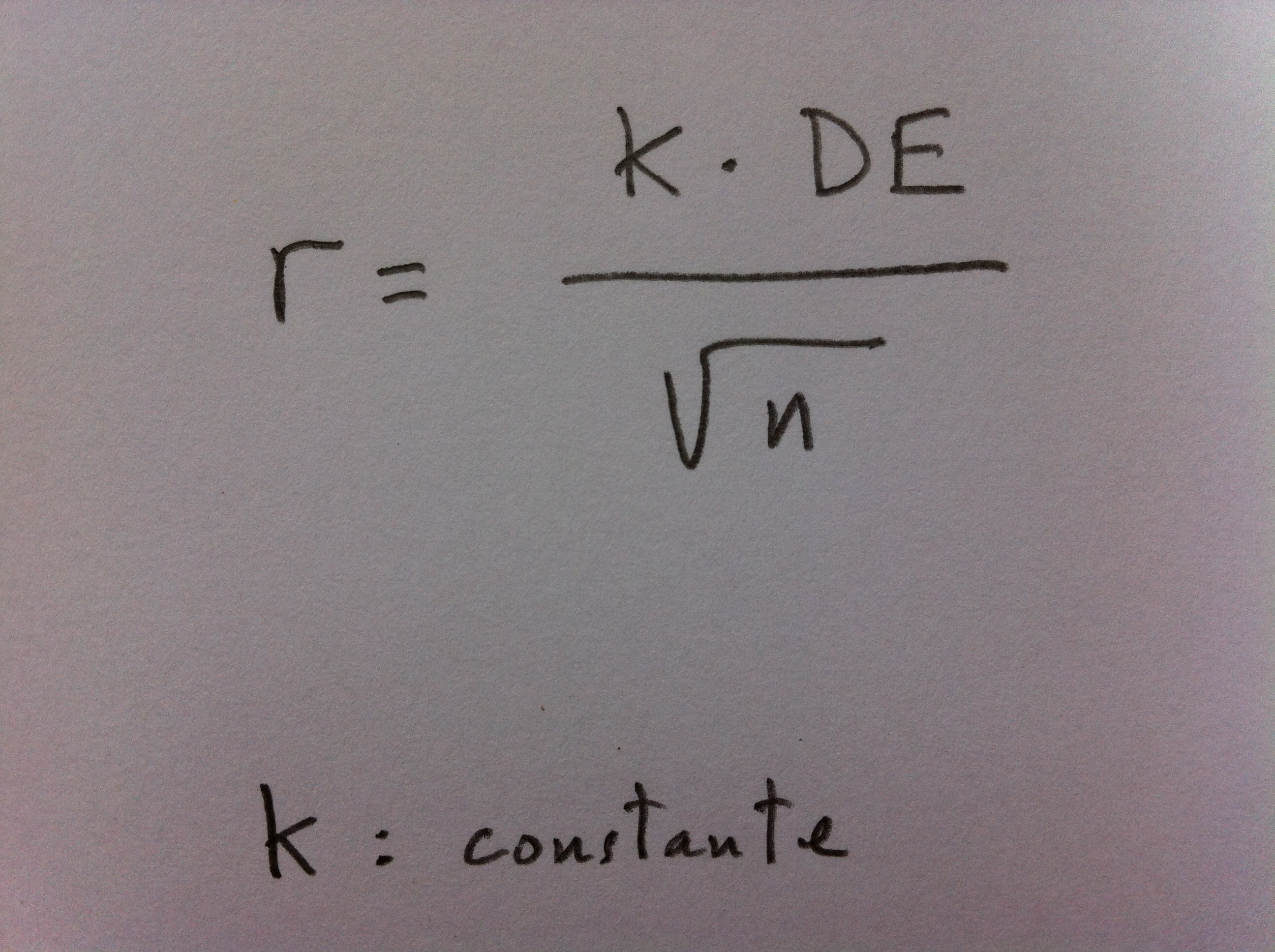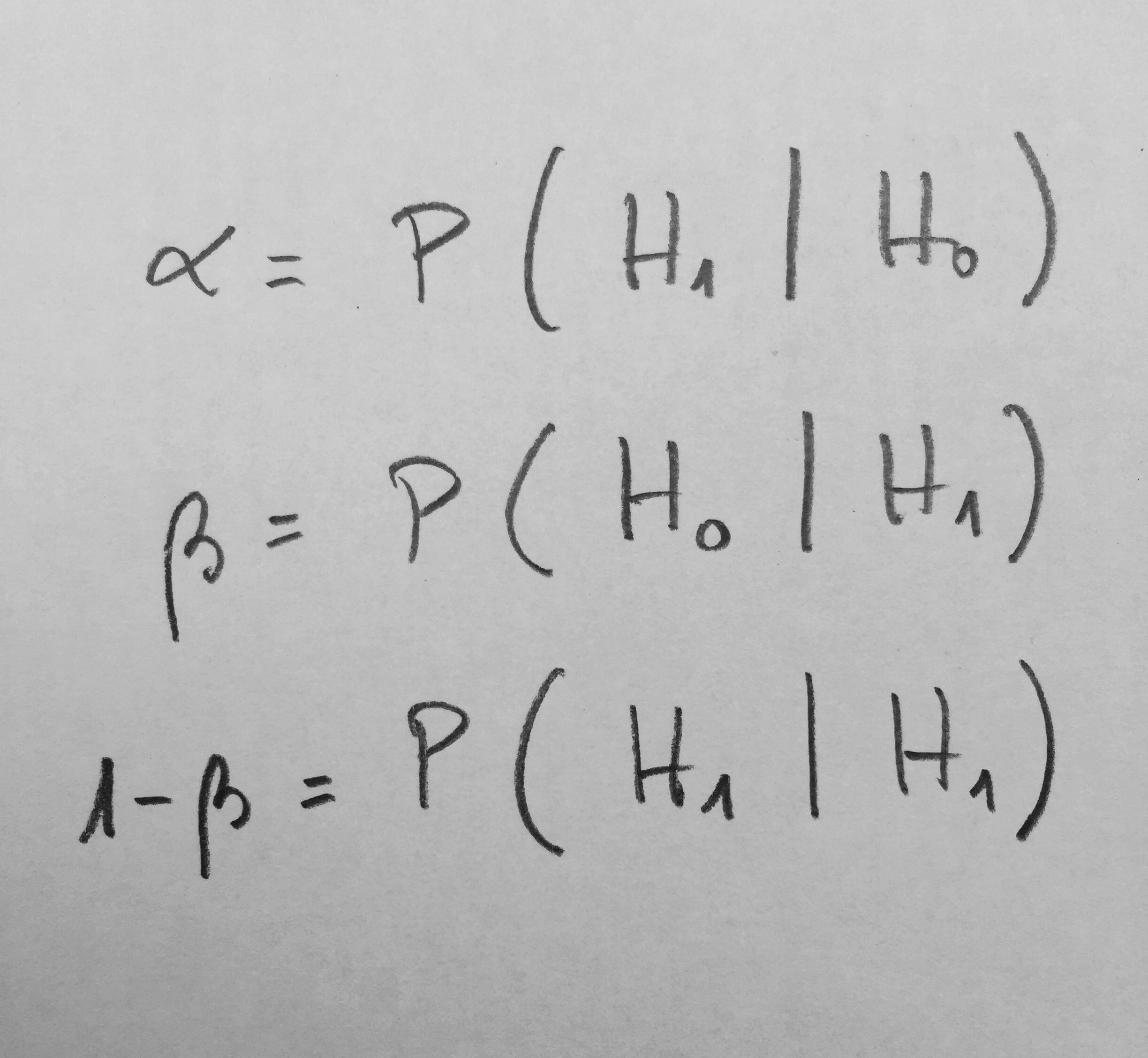Vamos a empezar hoy la clase jugando: Voy a pensarme un número entero del 1 al 100. ¡Ya lo he pensado! Ahora se trata de que vosotros lo adivinéis a base de preguntas que me podéis ir haciendo, y a las que yo puedo contestar únicamente: sí o no.
Seguro que inmediatamente se ha generado en vosotros un estado de duda: «¿Qué número será?» Vamos a intentar representar este estado de duda mediante una función matemática. Sí, digo bien, mediante una función matemática.
Recordemos -pues se trata de un concepto fundamental- que una función, en matemáticas, es una regla mediante la cual a todo elemento de un conjunto, llamado dominio, se le asigna un único elemento de otro conjunto, llamado recorrido o codominio. Algo tan sencillo y a la vez tan complejo como eso. De hecho es lo que empezasteis a estudiar en la primaria. Recordad.
Como vosotros no me conocéis, tampoco debéis de conocer mis preferencias en cuanto a números, por lo tanto, es coherente representar vuestro estado de duda con una función que asigne un valor constante; o sea, que asigne el mismo valor a todos los números que yo puedo haber pensado: 1, 2, 3, … , 100. A los que no pueden ser les asignaremos, también a todos ellos, el mismo valor y distinto al anterior. Además, una función definida en los números reales, que a los números que no puedo haber pensado les asigne el cero y a los que, por el contrario, sí pueda haber pensado, les asigne un valor distinto del cero, parece ciertamente coherente para modelar este estado de duda.
No perdamos de vista lo que en realidad estamos haciendo. Estamos intentando traducir a lenguaje matemático lo que está en vuestra cabeza, vuestro estado de duda. Estamos traduciendo un estado, digamos, cerebral a un lenguaje matemático. Estamos creando una maquinaria construida con piezas matemáticas: conjunto de los números reales, función, etc., para utilizarla como un dibujo de un estado real.
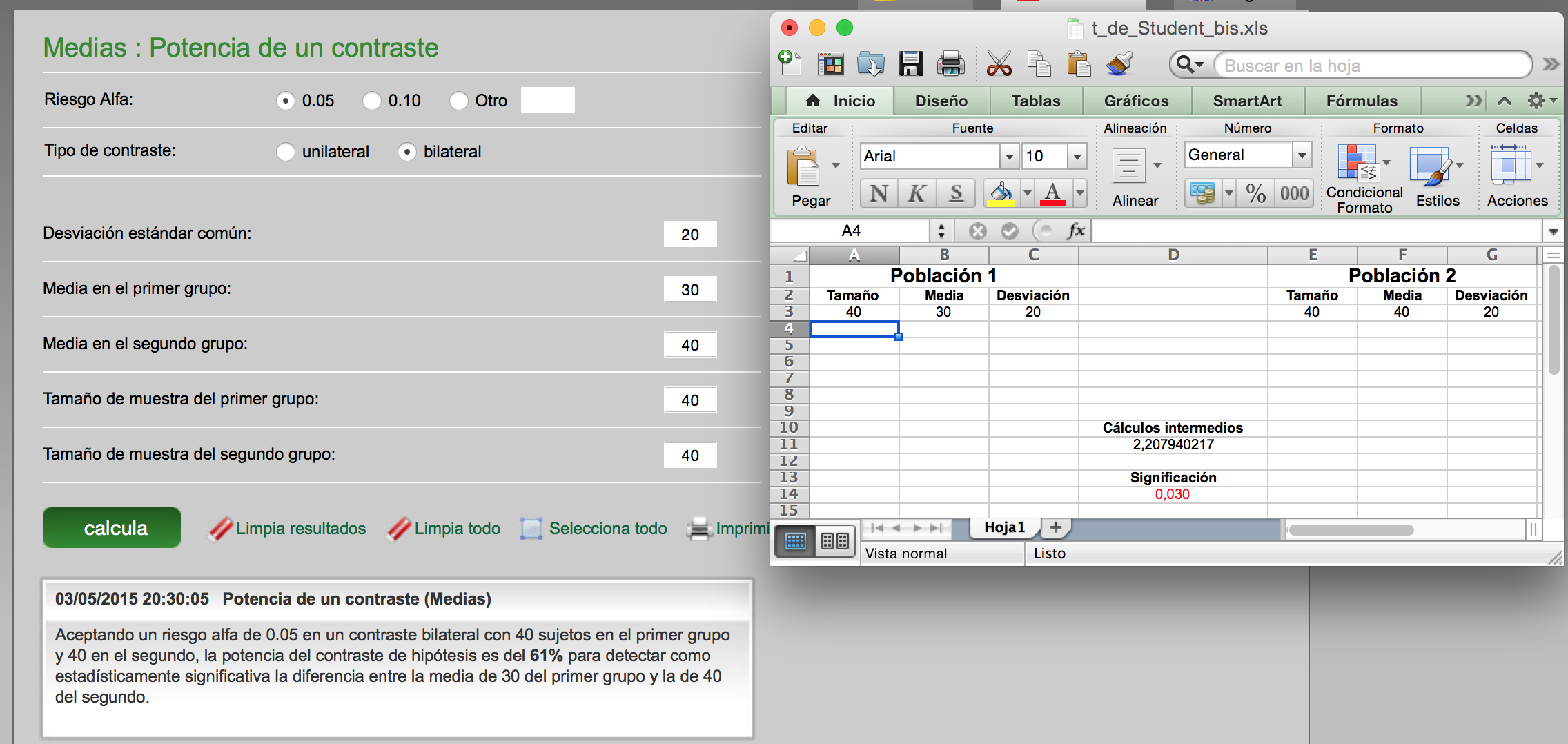
Asignemos el valor que asignemos a los números 1, 2, 3, … , 100, con la condición que sea el mismo para todos y distinto de cero, estaremos reflejando de forma abstracta este estado de duda generado con el juego. Pero por convenio podemos adoptar la siguiente opción: les daremos un valor encaminado a que la suma de todos ellos resulte ser uno. Podríamos adoptar otros convenios, por ejemplo que la suma fuera cien, veintiuno o treinta y dos. Pero para situarnos dentro de una teoría generalmente adoptada, que veremos más adelante, adoptaremos el uno, por lo que la posibilidad, de cada uno de los números factibles, la representaremos en tanto por uno. En nuestro caso, a cada uno de los números posibles le asignaremos el valor 1/100, para que la suma de los cien valores sea uno.
Por lo tanto, la función creada tiene una forma como la que sigue:

Si ahora se me hace alguna pregunta, mi respuesta posiblemente cambie el estado de duda y por consiguiente también la función que lo trata de representar o modelar. A ver, ¿quién me hace una pregunta?
– ¿Es un número par?
Me preguntan si se trata de un número par. Yo respondo: ¡No!.
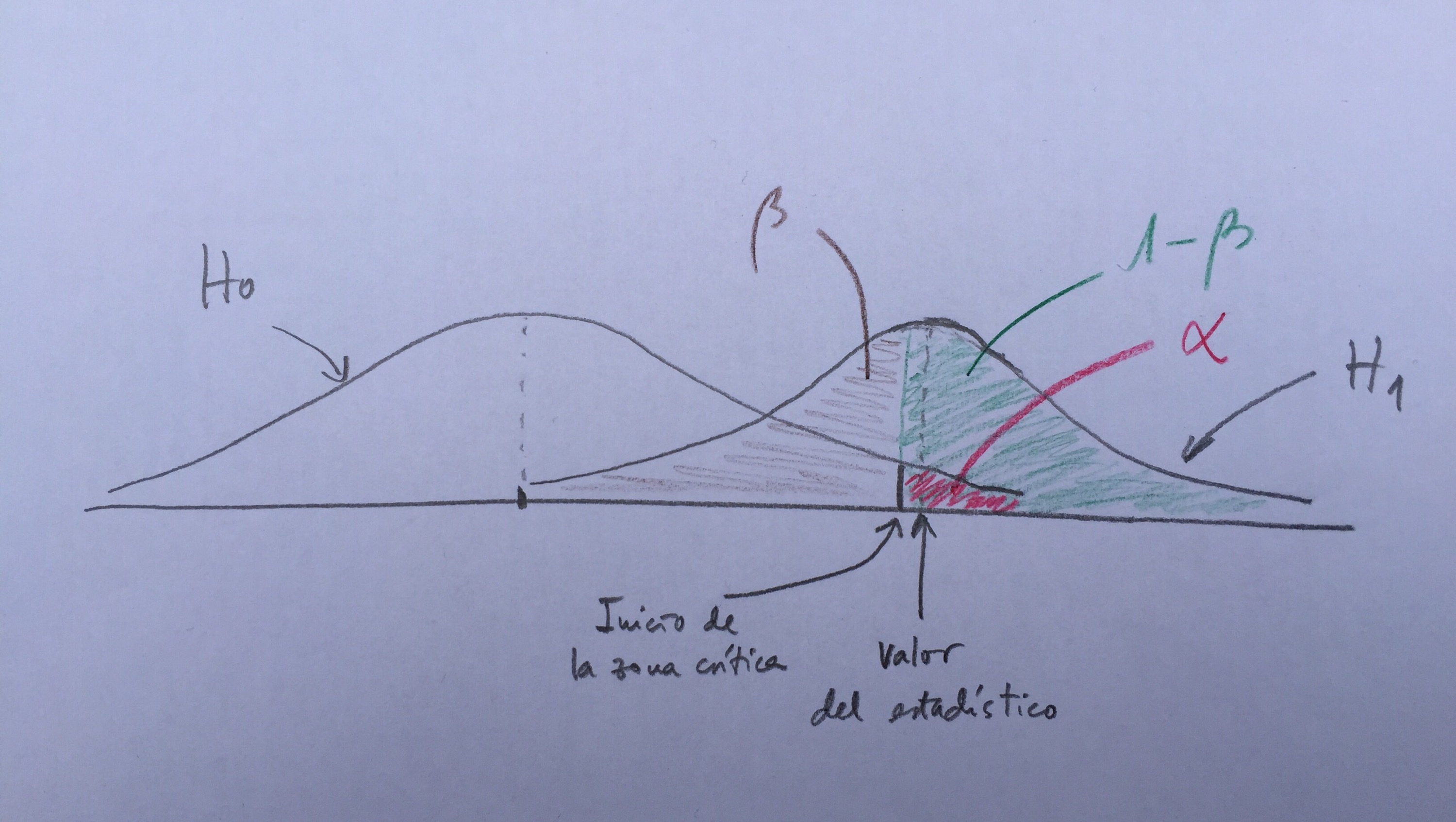
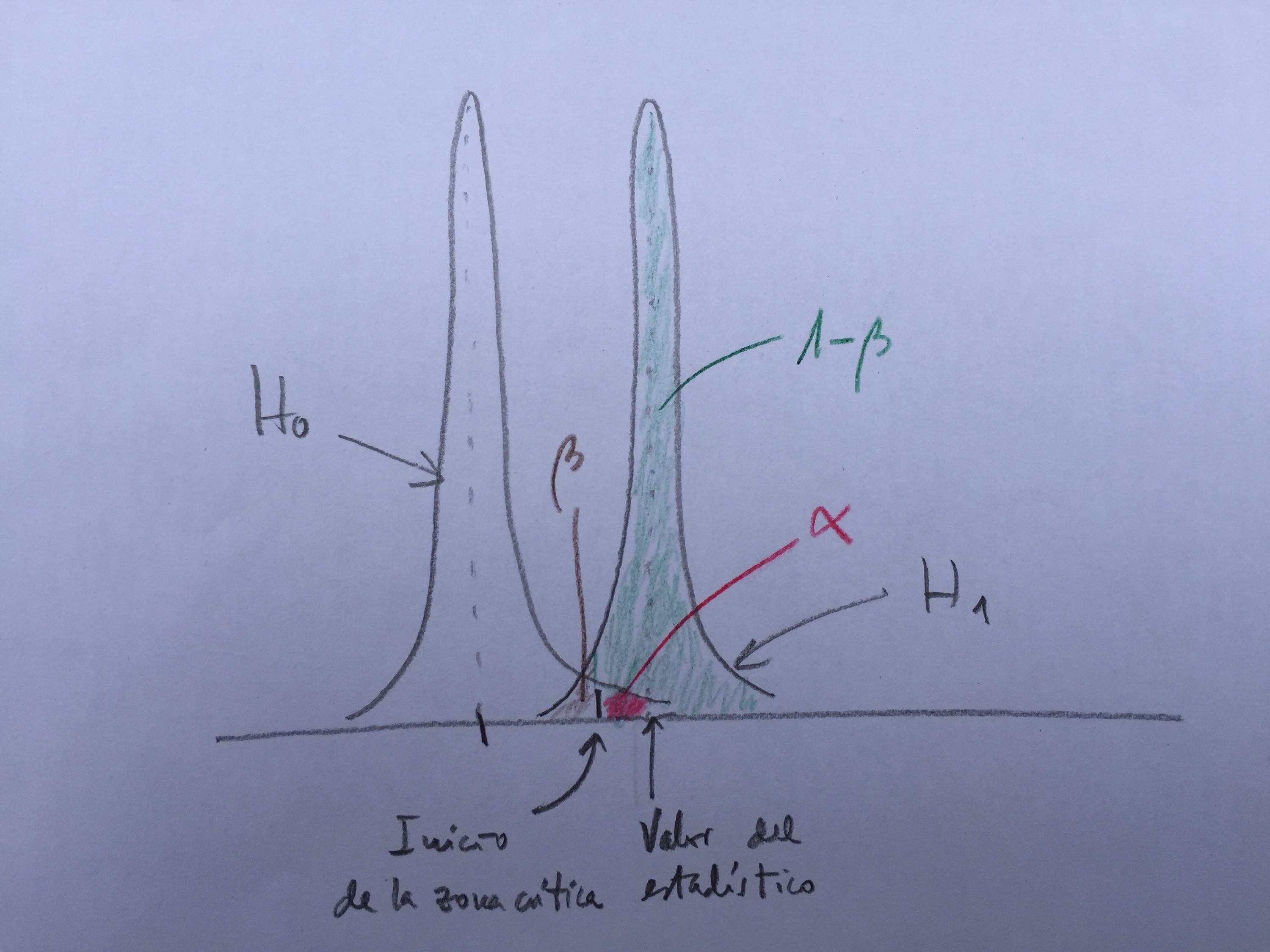
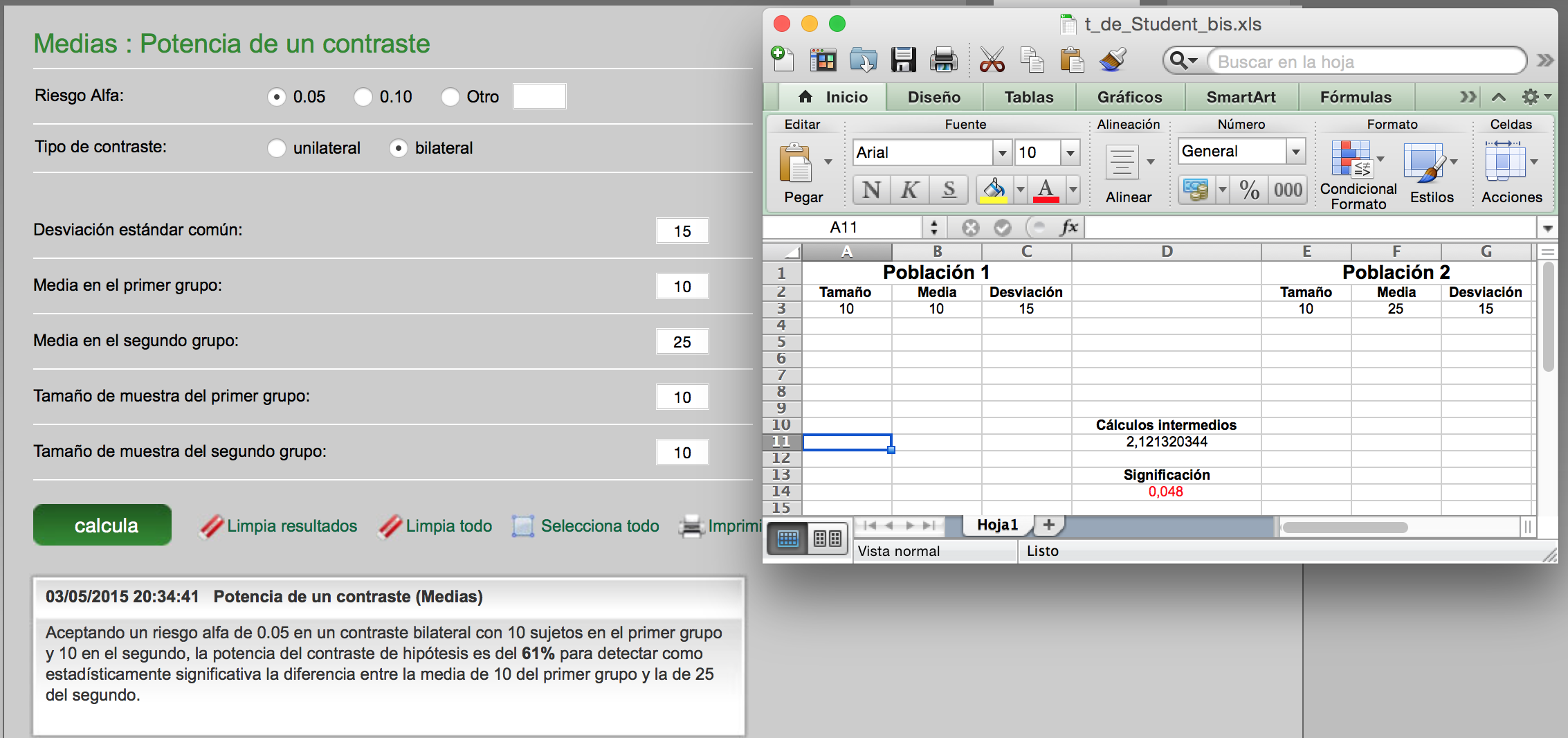
Fijaos: Al responder que no a la pregunta de vuestro compañero, automáticamente se produce un cambio de estado de duda en vosotros. ¿Cómo reflejar esta transformación mediante lenguaje matemático? Es como si, de repente, en la función anteriormente creada, los palos de los números pares se encogieran hasta el cero y los de los números impares ascendieran recogiendo lo que los pares han dejado. Como la altura total debe ser uno, si unos números ceden altura otros la deben de tomar para sí. Tendremos, pues, ahora, una nueva función: los números impares del 1 al 99 tendrán asignado el valor 1/50 y el resto el cero. La función será la siguiente:

Sucesivamente, si se me van preguntando cosas, se irá haciendo cada vez más concreta la función hasta que finalmente la posibilidad esté toda concentrada en un único número, justo el que había pensado inicialmente.
Cada estado de duda tiene su función matemática que lo puede representar. Esto es lo fundamental.
Supongamos que estamos de nuevo en la posición inicial. No me habéis hecho ninguna pregunta todavía. Os pido ahora que me hagáis una pregunta tal que mi respuesta genere en vosotros un estado de duda que, para ser representado matemáticamente, necesite la creación de un modelo, de una función, donde los valores con posibilidad no tengan todos la misma, como sí ha ocurrido en el caso anterior. ¿Me entendéis?
Venga, pues. ¿Quién se atreve?
– ¿Tiene dos cifras el número?
Mira. Fíjate que si yo respondo que sí todos los números que están formados por una única cifra pasan a tener probabilidad cero, pero entre todos los demás no tienes ninguna razón para dar más probabilidad a unos o a otros. ¿Te das cuenta?
Venga, pues. Otra pregunta.
– ¿Es número primo?
Tampoco. Fíjate. Si yo te digo que no, ¿qué ocurre? ¿Cómo modelarías vuestro estado de duda? Todos los números que no fueran el 1, 2, 3, 5, 7, etc, que son los números primos, todos ellos tendrían la misma probabilidad y yo pido, fíjate bien, una pregunta que mi respuesta origine la necesidad de crear un modelo en el que los números posibles no tengan la misma posibilidad.
-¿Es un número próximo al 50?
¡Exacto!.¡Perfecto! Esto es lo que quería. Yo a esta pregunta respondo que sí. Entonces: ¿Cómo dibujar mediante una función vuestro estado de duda actual? Observad bien que ahora todos los números siguen teniendo algo de posibilidad, pero los centrales, los próximos a 50, tienen más posibilidad, porque yo he respuesto que sí a la pregunta de vuestra compañera. El problema es que, según la idea de proximidad que tenga cada uno de los participantes en el juego, la función será distinta. Pero tendrán todas ellas algo en común: la unidad de posibilidad a repartir estará más concentrada en valores centrales y cuanto más nos alejemos del centro más deberá disminuirse la altura o los valores asignados a aquellos números. Una posible función de las muchas posibles sería la siguiente:

¿De acuerdo? ¿Me habéis seguido? ¿Alguna duda?… ¿No?
Cambiemos de juego. Si lanzamos al aire una moneda, la situación es parecida, pero más sencilla de modelar matemáticamente. Estamos de nuevo ante una situación de incertidumbre porque hay variabilidad de valores posibles. Una variabilidad más pequeña que antes, pero lo cierto es que antes de lanzar no sabemos el resultado que vamos a obtener. Fijaos que si a cara le asigno el valor 0 y a cruz el 1, antes de lanzar la moneda parece coherente dibujar el estado de duda, acerca de cuál será el desenlace del juego, mediante una función que asigne un valor de 1/2 al 0, de 1/2 también al 1 y cero al resto de los números reales. Por lo tanto, esta función será una traducción a lenguaje matemático de un estado mental.
Puesto que ahora, después de haber hecho todo lo que hemos hecho, puede que ya os empiece a gustar este inesperado uso de unos conceptos matemáticos que creíamos muy alejados de la realidad, vamos a intentar representar, mediante lenguaje matemático, otra situación. Supongamos que queremos pronosticar la altura que tendrá la primera persona que pase por la calle cuando salgamos. Alturas nos podemos encontrar desde un mínimo si es que pasa un niño, hasta un máximo que lo podemos cifrar en la altura máxima en humanos. Pero las posibilidades sabemos que no son las mismas para esta enorme variedad de alturas con las que en potencia podemos encontrarnos. Fijémonos que la popular campana de Gauss puede reflejar esta situación. Un buen dibujo del estado de duda generado ahora sería una función en forma de campana que tuviera el máximo próximo al número que prevemos que sea la altura media de la población en la que estamos realizando el juego. Y si queremos ser más precisos, la altura media de los que pueden circular por aquella calle y a aquella hora.
Esta situación última es un poco más sofisticada que las anteriores, pero esencialmente la misma. En definitiva, utilizamos estructuras matemáticas para reflejar estados reales, para reflejar la organización de la variabilidad, para dibujar nuestra incertidumbre. Esta perspectiva de la matemática puede sorprender de entrada, pero debemos ver que toda la metodología utilizada en los estudios secundarios es parte de un contexto más general donde existe una serie de estructuras matemáticas que tienen su dimensión aplicada.
La variabilidad la encontramos en todas partes. La longitud de un organismo cualquiera, el peso, cualquier medida que estudiemos en él. El tiempo de vida de un organismo, de una lámpara. El número de coches que irá a una gasolinera en una hora, el número de llamadas telefónicas a un determinado número en un día. Todas éstas son situaciones donde se presenta variabilidad. Mediante funciones como las que hemos visto y como las que iremos viendo a lo largo del curso intentaremos modelar esta variabilidad.
La estadística es el estudio de la variabilidad. Es el estudio de la variabilidad realizado mediante las herramientas aportadas por las matemáticas. Donde hay variabilidad la estadística tiene algo que decir. Las situaciones que hemos planteado anteriormente son situaciones de variabilidad. Variabilidad de números que yo he podido pensar, variabilidad de los resultados posibles en el lanzamiento de una moneda, variabilidad de alturas en una población.
La estadística es, pues, el arte de utilizar estructuras matemáticas para responder a preguntas acerca de la variabilidad que hay en una población, en una población que se nos escapa por enorme o por impredecible. Estas imágenes con las que hemos empezado son una caricatura, pero una caricatura de lo que es en realidad la actividad estadística. Además, estas imágenes recogen bien los rasgos fundamentales sobre los que descansa este esfuerzo de decir cosas de un todo a partir de una pequeña parte de este todo.
Podemos distinguir como mínimo dos mundos: En primer lugar, el de nuestra realidad, de las cosas que nos rodean; o sea, el mundo de los animales, de los vegetales, de las bacterias, de los hombres y de todos nuestros objetos. En segundo lugar, el mundo de los objetos matemáticos; o sea, el mundo de los conjuntos, de las funciones, de las matrices, etc.
El mundo de los objetos matemáticos es un mundo que tiene una realidad al margen del nuestro. Ésta es una distinción que guiará continuamente nuestro recorrido y nos ayudará a comprender la verdadera naturaleza de la actividad estadística. Pensemos que la estadística es una forma de hacer matemáticas, por lo tanto, es importante situar bien qué es en realidad lo que hacemos cuando hacemos matemáticas.
La matemática ha sido siempre básicamente, a lo largo de toda la historia, una diversión útil. Una diversión que ha entretenido a muchos hombres a lo largo de la historia, pero una diversión que ha ido dejando su sedimento, y del que la humanidad ha ido sacando paulatinamente provecho. Este entretenimiento, esta diversión, ha dado lugar, ciertamente, a una de las piezas más extraordinarias del espíritu humano. Si uno se sorprende ante un cuadro de Goya o ante una sinfonía de Mozart, no causan menor sorpresa muchos de los conceptos matemáticos que han sido creados a lo largo de la historia.
Un curso de matemáticas es un viaje a otro mundo. Un viaje es, sin duda -supongo que estaréis de acuerdo conmigo- más atractivo si el camino se realiza tocando lo que se ve. El mundo de la matemática se digiere mejor tocando los objetos que se van viendo por el camino. El mundo de las cosas que nos rodean ha sido creado a base de millones de años, el de la matemática tiene tan sólo unos pocos miles de años, pero tiene una riqueza que impresiona a quien se introduce en él. En este curso viajaremos por el mundo de las matemáticas y tocaremos todo lo que veamos en él. Además, crearemos cosas, añadiremos cosas a este mundo. Crearemos objetos para que habiten en el mundo de las matemáticas.
Las matemáticas pueden verse como un gran museo. Un museo donde se exponen creaciones humanas. Para mirarlas hay que realizar un esfuerzo intelectual considerable. Por ejemplo, ante una función deberemos agudizar nuestra mirada. Ver qué pasa en las proximidades de un punto cualquiera, qué sucede cuando nos alejamos hacia un extremo de la gráfica, etc. Los conjuntos y las funciones son las piezas que descansan en los pedestales, pero hay un enorme repertorio de carteles escritos, como teoremas, que han ido dejando visitantes ilustres, en los cuales constan leyes generales que pueden encontrarse entre toda aquella inmensa masa de fascinantes piezas.
En el museo de las matemáticas algunos objetos son, además, herramientas para entender otros objetos. Se trata de un sistema profundamente interconectado. No son piezas aisladas. El museo está constituido de una red no visible de conexiones que, visitas sucesivas a él, nos van permitiendo desentrañar. Estamos, además, ante un museo que tiene algo ciertamente muy especial, algo que no ocurre en ningún otro museo: es un mundo abierto. Al salir, si hemos agudizado nuestro ingenio y nuestros deseos de crear, podemos dejar, en su interior, nuestras propias creaciones.
La idea de museo nos aportará una dimensión importante para ver de otra forma las matemáticas. Normalmente un estudiante ante una pregunta acerca del límite de una función en un punto, acerca de la derivada de una función o acerca del desarrollo de Taylor de una función suele ver un problema meramente de cálculo. Éste es en gran parte el problema de las matemáticas. Las operaciones, el cálculo, son una fachada que no deja ver lo que hay dentro y que es realmente lo interesante. Hay que descubrir que estos cálculos tienen una finalidad fundamental: conocer unas formas, unas formas, en la mayor parte de los casos, bellas y sorprendentes. Tanto el límite de una función en un punto, como la derivada de una función, como un desarrollo de Taylor y otras muchas técnicas matemáticas, son herramientas para conocer mejor los verdaderos protagonistas de la escena matemática: las funciones. Hay que cambiar el enfoque en la mirada matemática.
El museo de la matemática tiene, finalmente, una característica que lo transforma en un recinto ciertamente especial: sus límites no tienen límite, su ubicación está allí donde una cabeza humana, preparada para imaginar, comience a tocar y a descubrir los entresijos de unas piezas que se mueven mediante la fuerza de una profunda reflexión. El mundo de los objetos matemáticos se expone allí donde alguien esté dispuesto a pensar.
Bueno, hasta el próximo día.