1. ¿Cuál de las siguientes afirmaciones no es cierta?
a. Una Odds ratio con un intervalo de confianza (0.23, 2.45) no es significativa.
b. Una Odds ratio con un intervalo de confianza (2.33, 3.75) es significativa.
c. Una Odds ratio con un p-valor de 0.67 es compatible con un intervalo de confianza como el siguiente: (1.23, 1.98).
d. Una Odds ratio con un p-valor de 0.34 es compatible con un intervalo de confianza como el siguiente: (0.63, 2.34).
2. ¿Cuál de las siguientes afirmaciones no es cierta?
a. Una correlación de Pearson con un intervalo de confianza (0.23, 0.78) no es significativa.
b. Una correlación de Pearson con un intervalo de confianza (-0.83, -0.15) es significativa.
c. Una correlación de Pearson con un p-valor de 0.37 es compatible con un intervalo de confianza como el siguiente: (-0.23, 0.98).
d. Una correlación de Pearson con un p-valor de 0.02 es compatible con un intervalo de confianza como el siguiente: (0.63, 0.78).
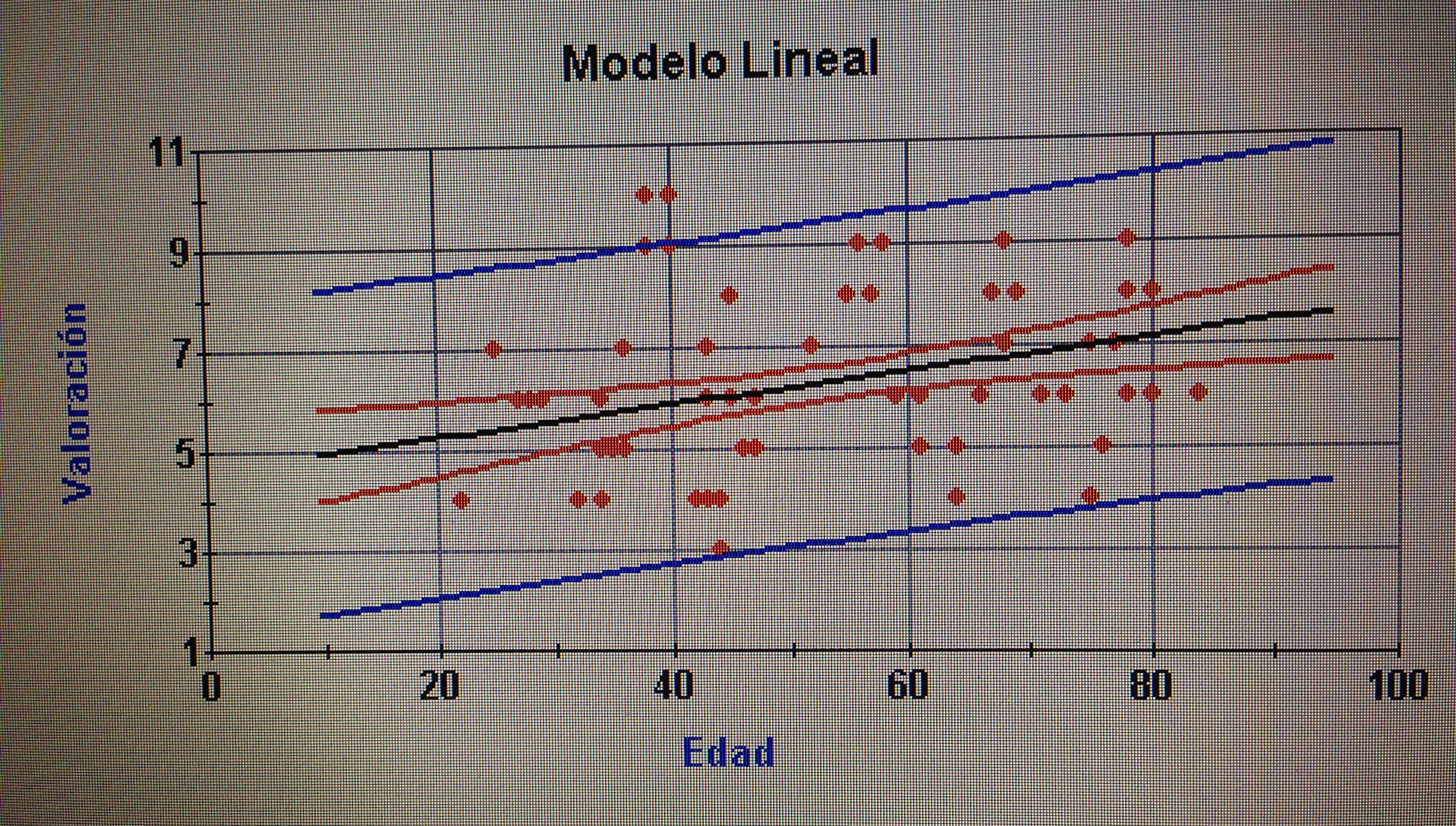
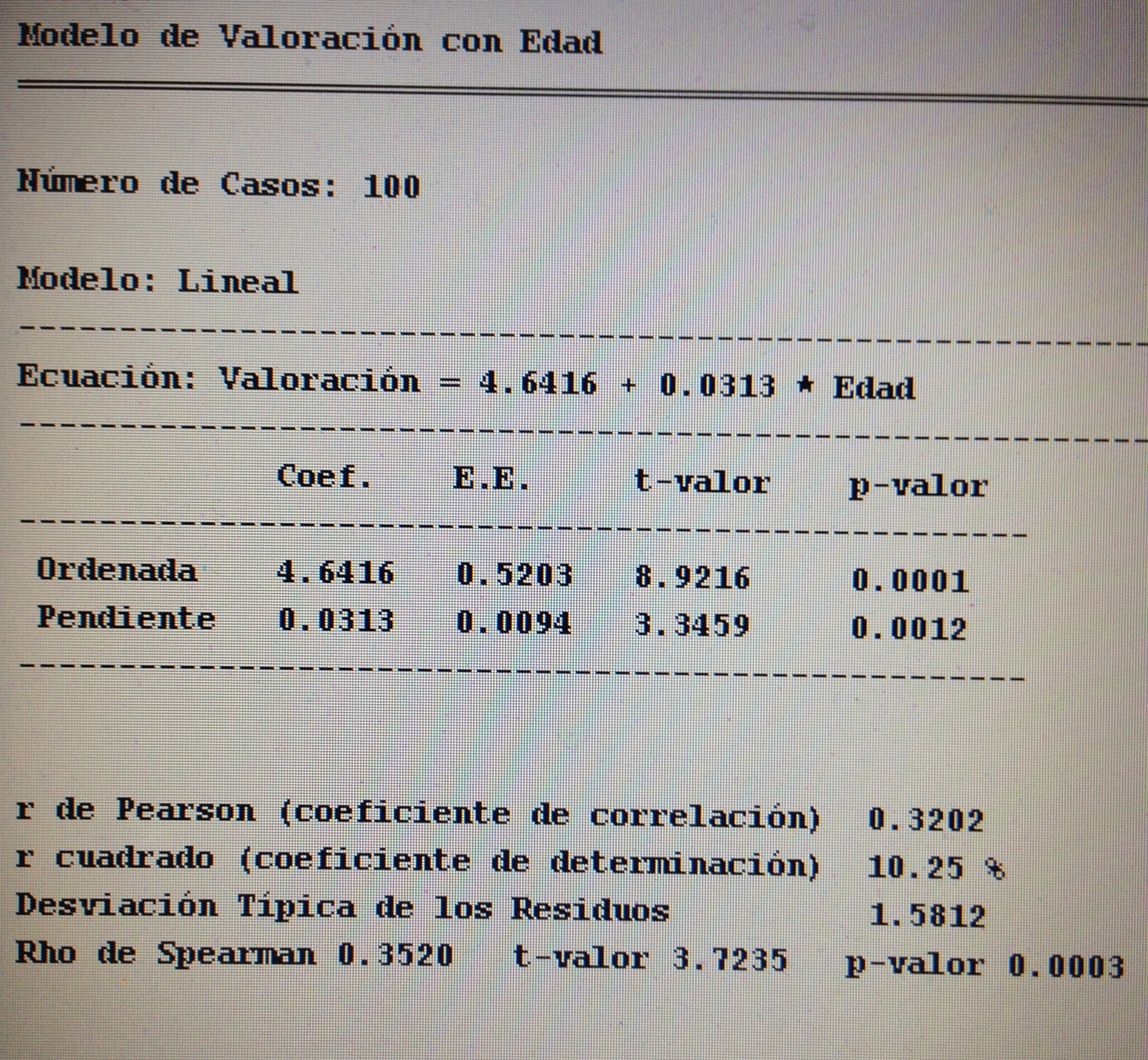
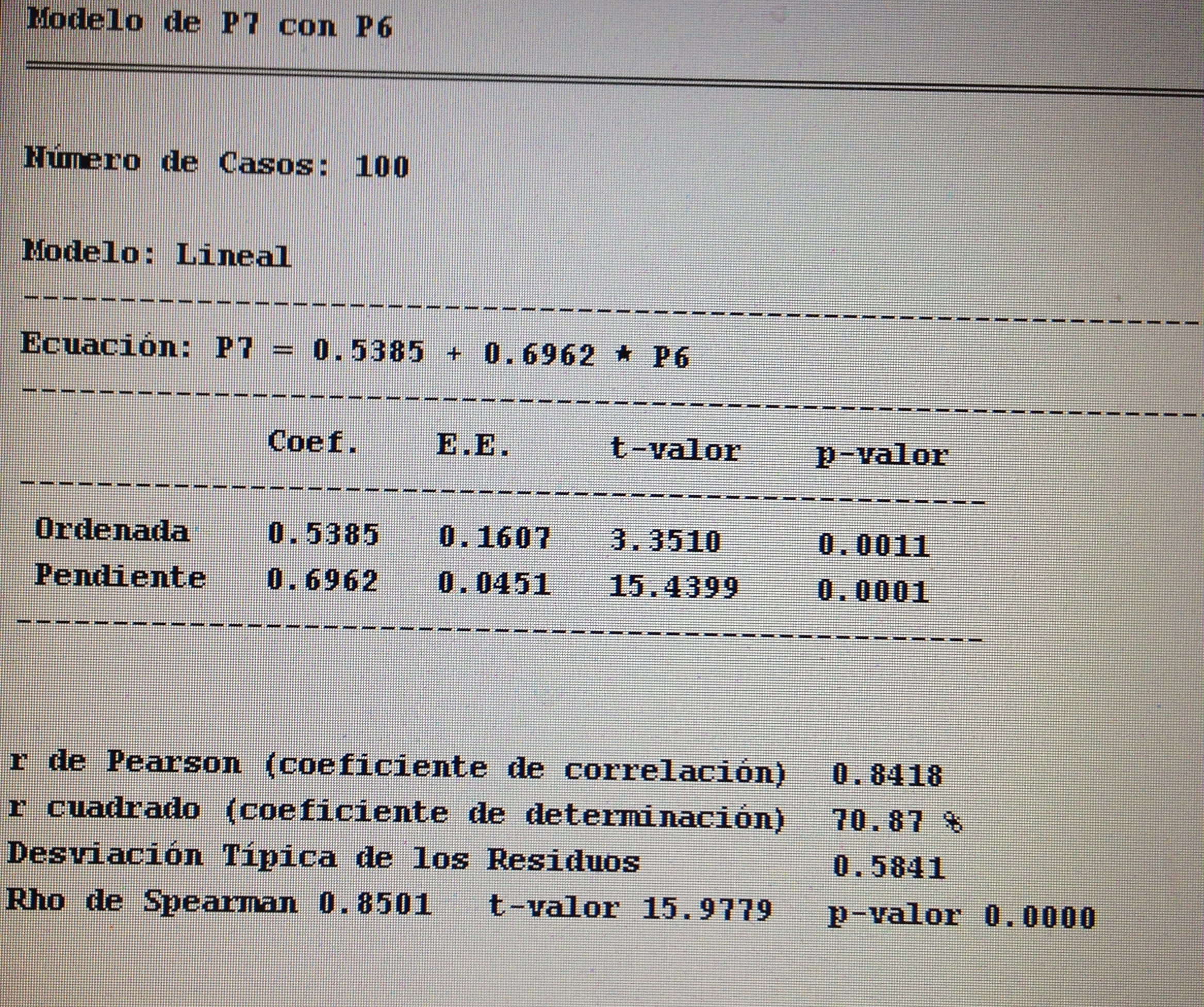
3. En la Regresión lineal simple, no es cierto:
a. Una correlación de Pearson con un intervalo de confianza (0.63, 0.88) irá asociada de una pendiente positiva y significativa.
b. Una correlación de Pearson con un intervalo de confianza (-0.73, -0.55) irá asociada a una pendiente negativa y significativa.
c. Una correlación de Pearson con un intervalo de confianza (-0.23, 0.18) irá asociada a una pendiente no significativa.
d. Una correlación de Pearson con un intervalo de confianza (-0.93, -0.48) irá asociada a una pendiente negativa pero no significativa.
4. ¿Cuál de los siguientes modelos es una Regresión lineal múltiple?:
a. y=2x+7
b. y=3x+5z-3
c. y=7
d. y=x+2x+3x+4x
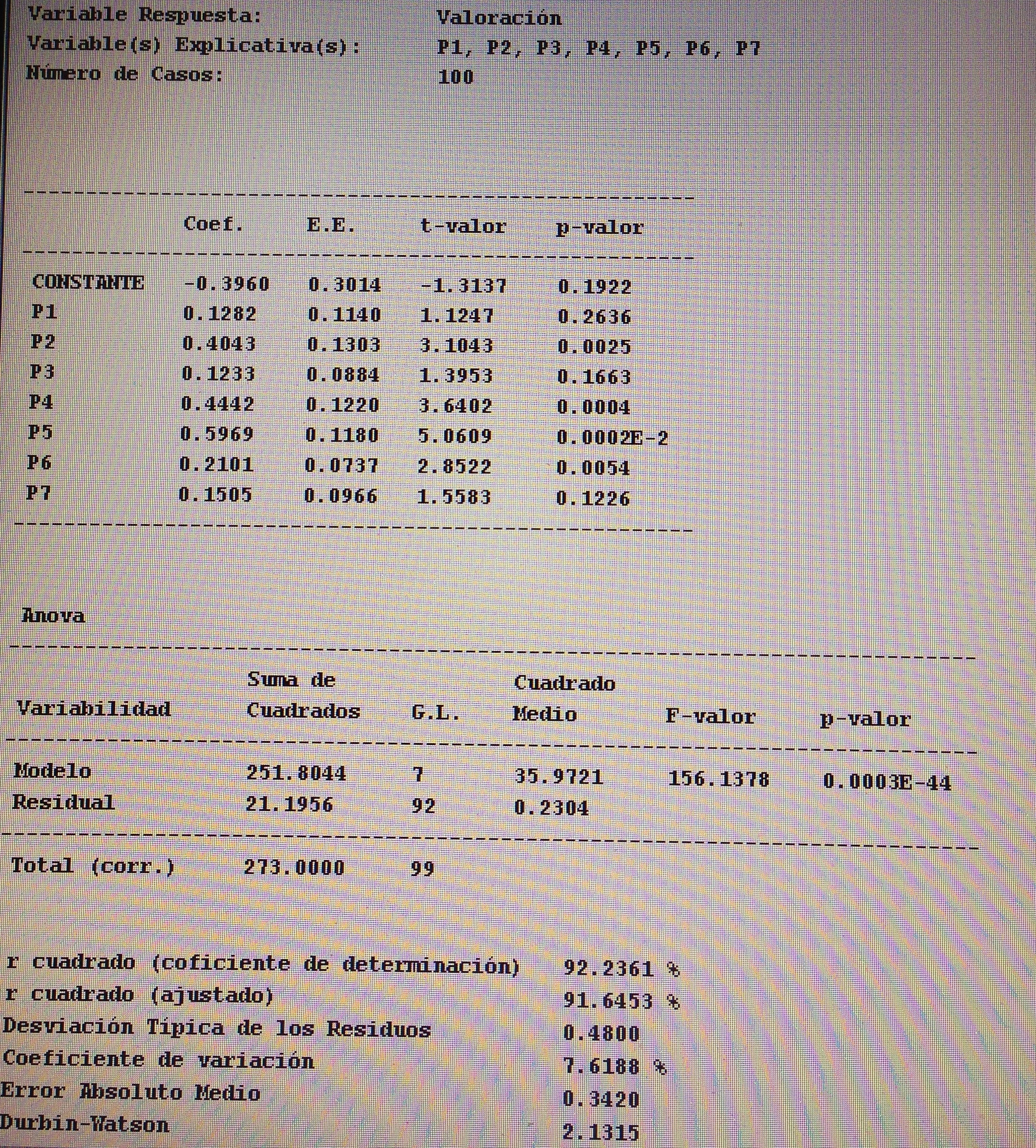
5. La R2 significa:
a. Que tenemos una Regresión lineal simple.
b. Que si el valor es superior al 5% tenemos una Regresión significativa.
c. El grado de determinación que hay entre la variable dependiente y las variables independientes.
d. Que podemos hacer una Regresión logística.
6.En una Regresión logística simple no es cierto:
a. La variable dependiente es dicotómica.
b. Debemos aplicar un Stepwise para seleccionar qué variables independientes son relevantes.
c. La Odds ratio es un elemento muy importante para evaluar su calidad.
d. Una Odds ratio con un intervalo de confianza (1.45, 2.26) indica que se trata de una relación significativa.
7. En una Regresión logística simple es cierto:
a. Un coeficiente que multiplica a la variable independiente con un intervalo de confianza (-0.6, 0.7) es compatible con un intervalo de confianza de la Odds ratio de (1.15, 2.33).
b. Un coeficiente que multiplica a la variable independiente con un intervalo de confianza (0.6, 0.8) es compatible con un intervalo de confianza de la Odds ratio de (1.82, 2.22).
c. Un coeficiente que multiplica a la variable independiente con un intervalo de confianza (-0.6, -0.4) es compatible con un intervalo de confianza de la Odds ratio de (1.45, 3.33).
d. Un coeficiente que multiplica a la variable independiente con un intervalo de confianza (0.8, 0.9) es compatible con un intervalo de confianza de la Odds ratio de (0.15, 0.33).
8. En una Regresión logística simple si tenemos un coeficiente que multiplica a la variable independiente con un intervalo de confianza como el siguiente (0.34, 1.66), podemos afirmar:
a. Que la Odds ratio no será significativa.
b. Que la Odds ratio será significativa y mayor que 1.
c. Que la Odds ratio será significativa y menor que 1.
d. Que la Odds ratio será negativa.
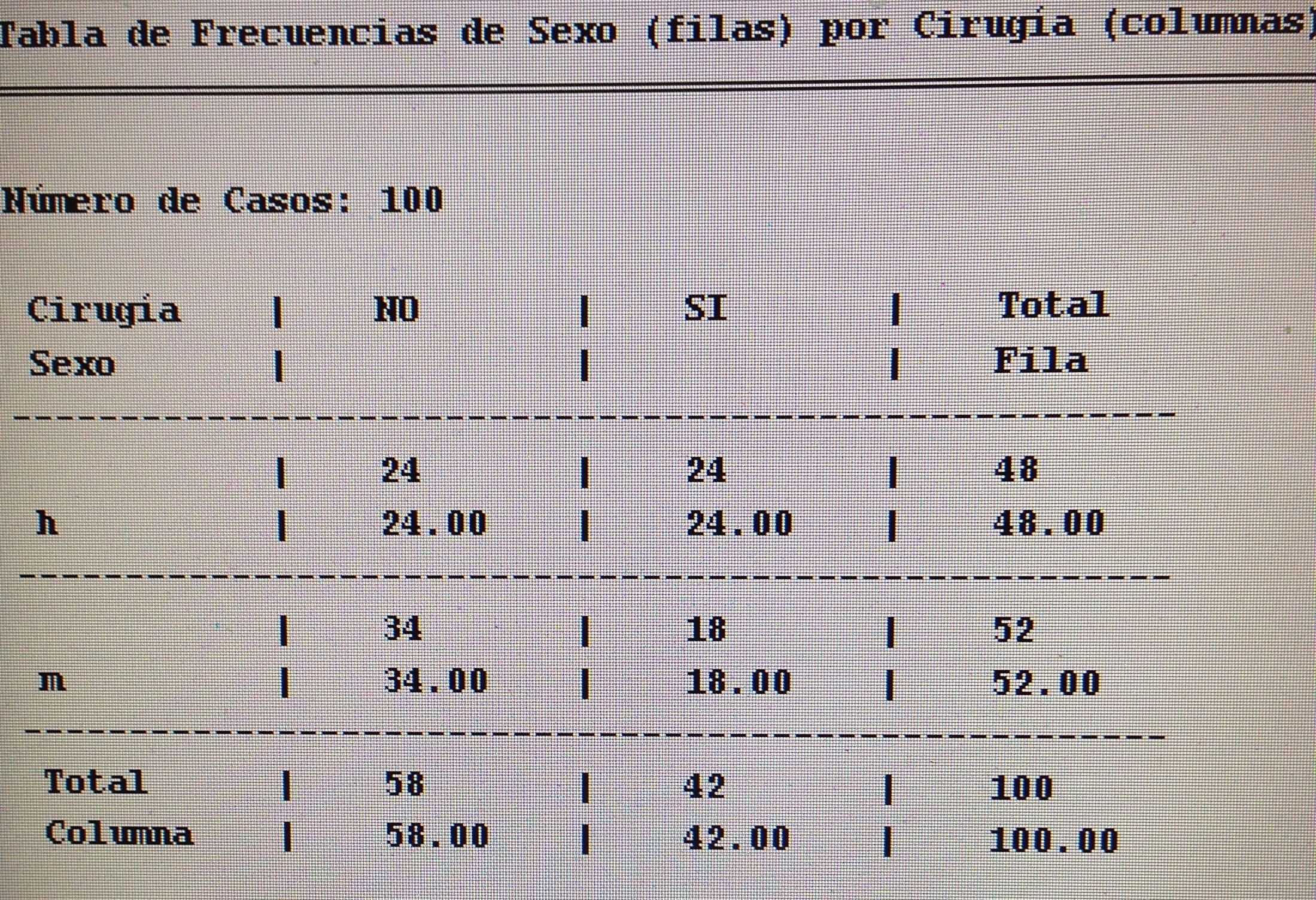
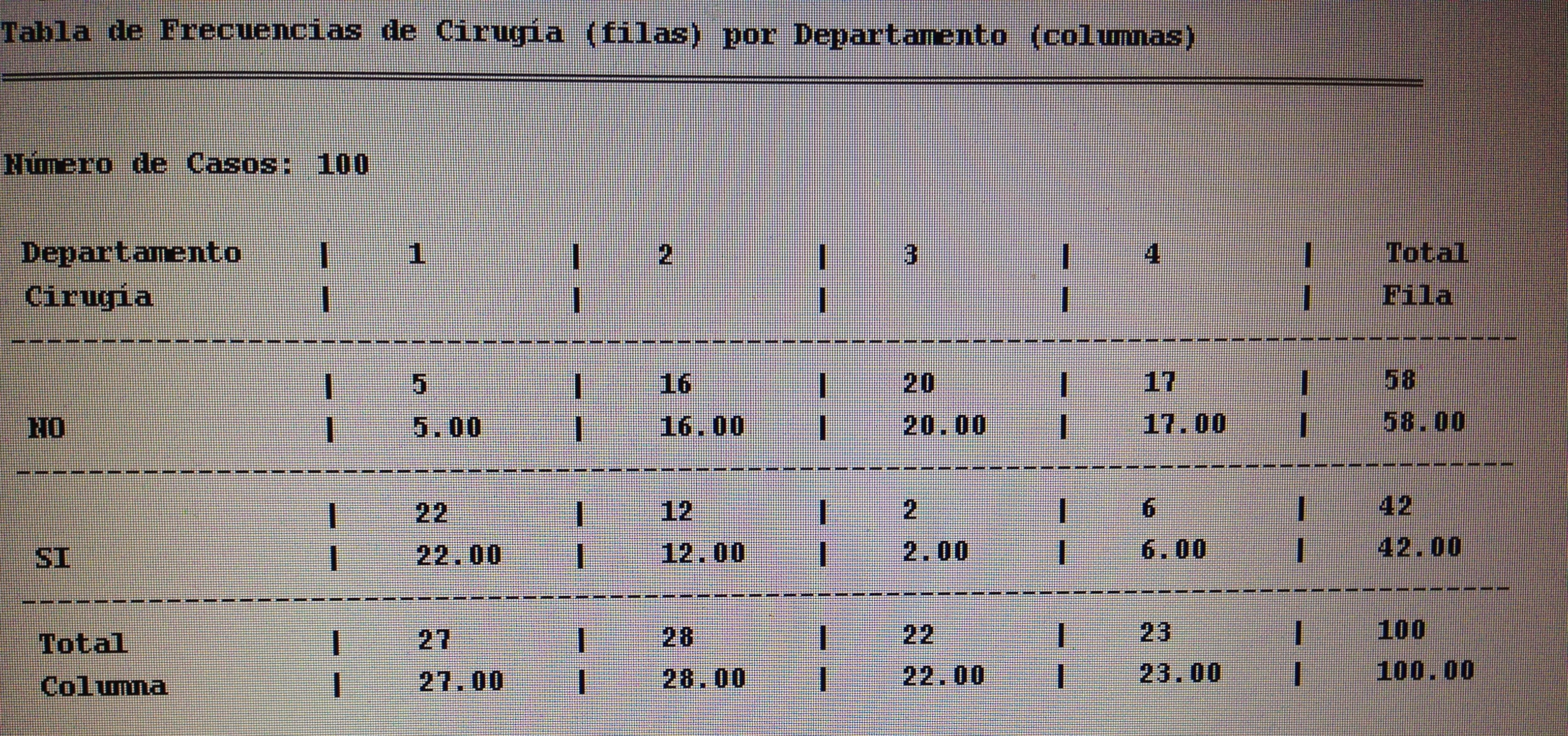
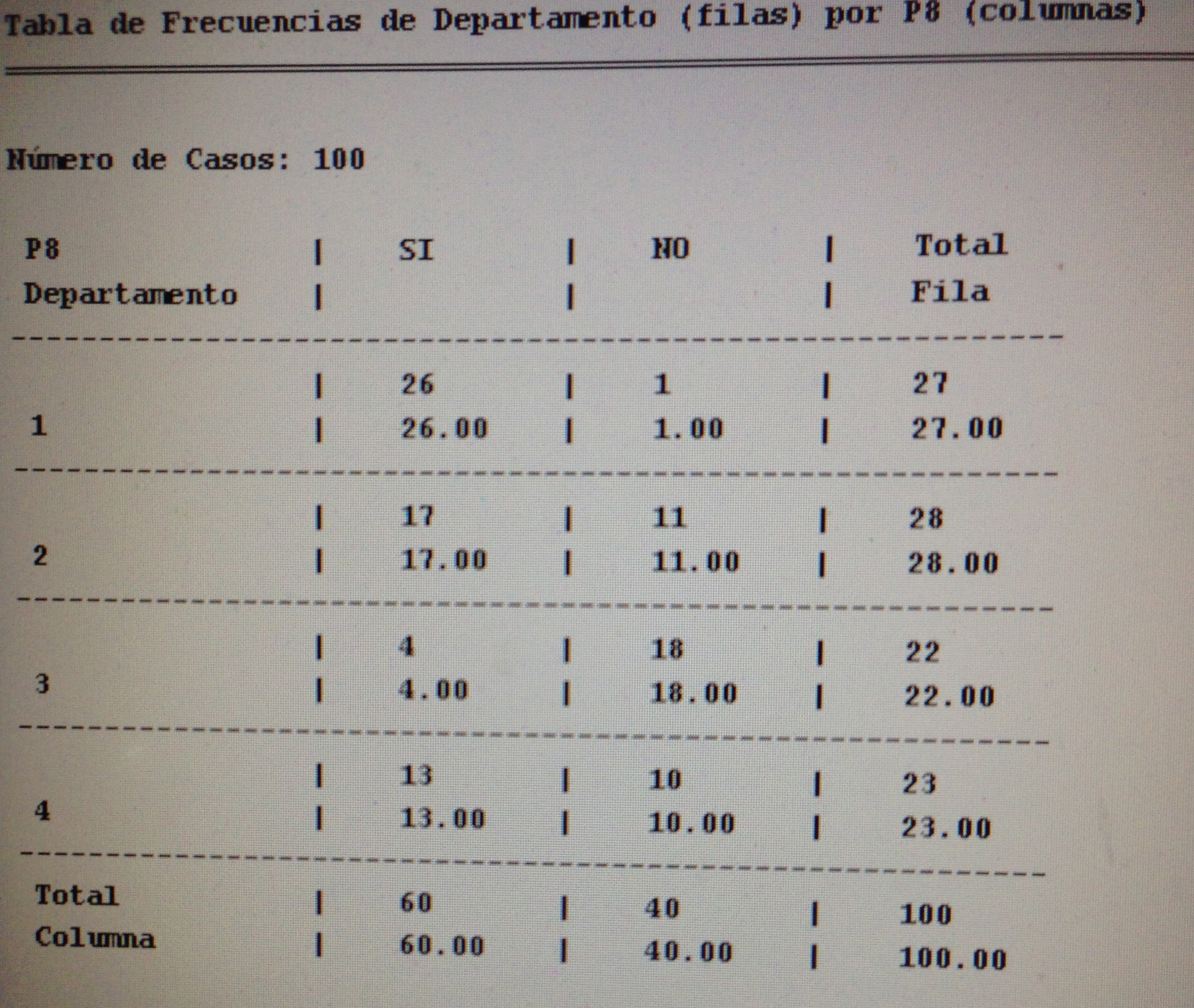
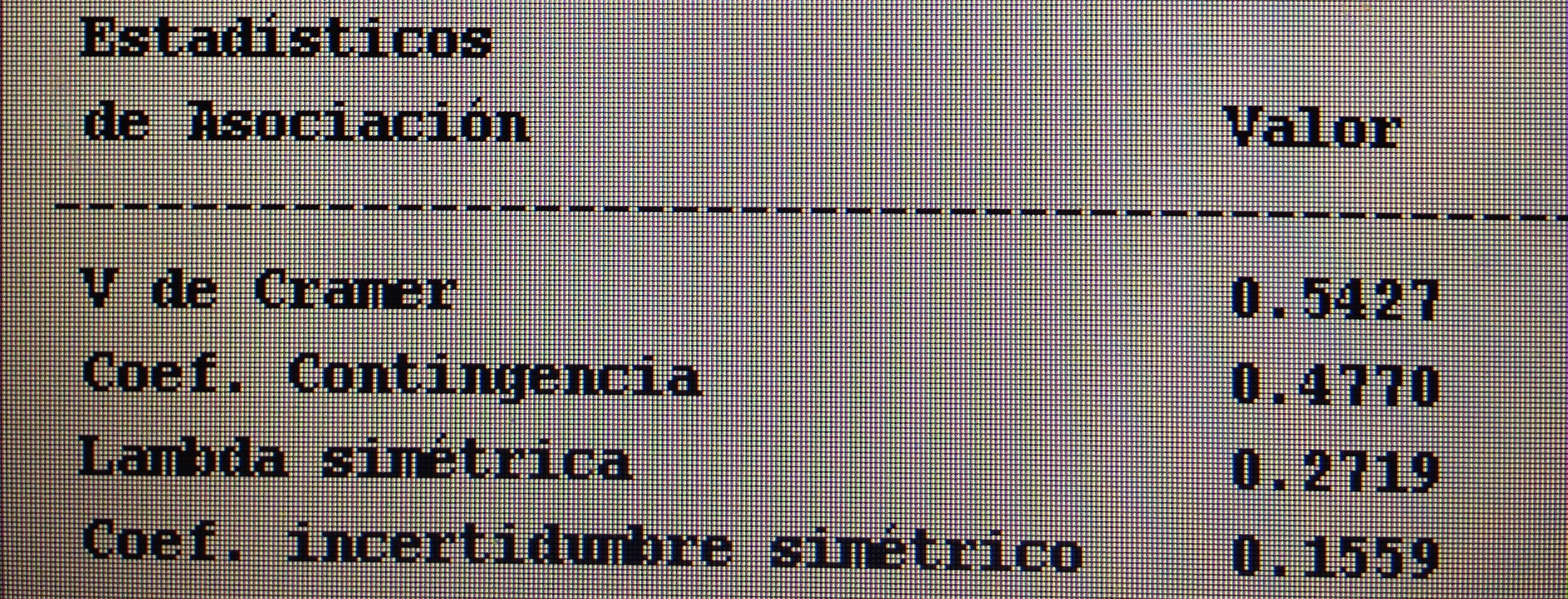
9. En una V de Cramer no es cierto:
a. Es un valor entre el 0 y el 1.
b. Es una medida del grado de relación entre variables cualitativas.
c. Es un valor que será significativo si es menor que 0.05.
d. Cuanto mayor es indica más relación entre las variables cualitativas.
10. En los datos siguientes:
|
y
|
x
|
|
1
|
2
|
|
1
|
3
|
|
1
|
5
|
|
1
|
6
|
|
1
|
8
|
|
0
|
7
|
|
0
|
9
|
|
0
|
11
|
|
0
|
13
|
|
0
|
15
|
Podemos afirmar lo siguiente:
a. La correlación de Pearson será negativa.
b. En una Regresión logística simple el coeficiente que multiplica a la variable independiente será positivo.
c. En una Regresión logística simple la Odds ratio será menor que 1.
d. En una Regresión logística simple la Odds ratio será 0.