El objetivo de este artículo es confeccionar una hoja de ruta, un mapa, para moverse entre las principales técnicas estadísticas en Medicina. Con esa hoja de ruta pretendo orientar al usuario de la Estadística a moverse en el complejo bosque de esas técnicas analíticas, especialmente tal como suelen usarse en el ámbito de la Medicina.
El índice básico de esta hoja de ruta es el siguiente:
1. Estadística descriptiva.
2. Técnicas de comparación.
3. Técnicas de relación.
4. Determinación del tamaño de muestra.
En la gran mayoría de investigaciones en Medicina se usan, al mismo tiempo, estos cuatro tipos de técnicas. Veamos cada una de estas familias de técnicas. Veamos lo que analizan, cómo se usan habitualmente y veamos, también, sucesivos enlaces donde encontrar detalles más concretos para quien quiera ampliar información:
1. Estadística descriptiva
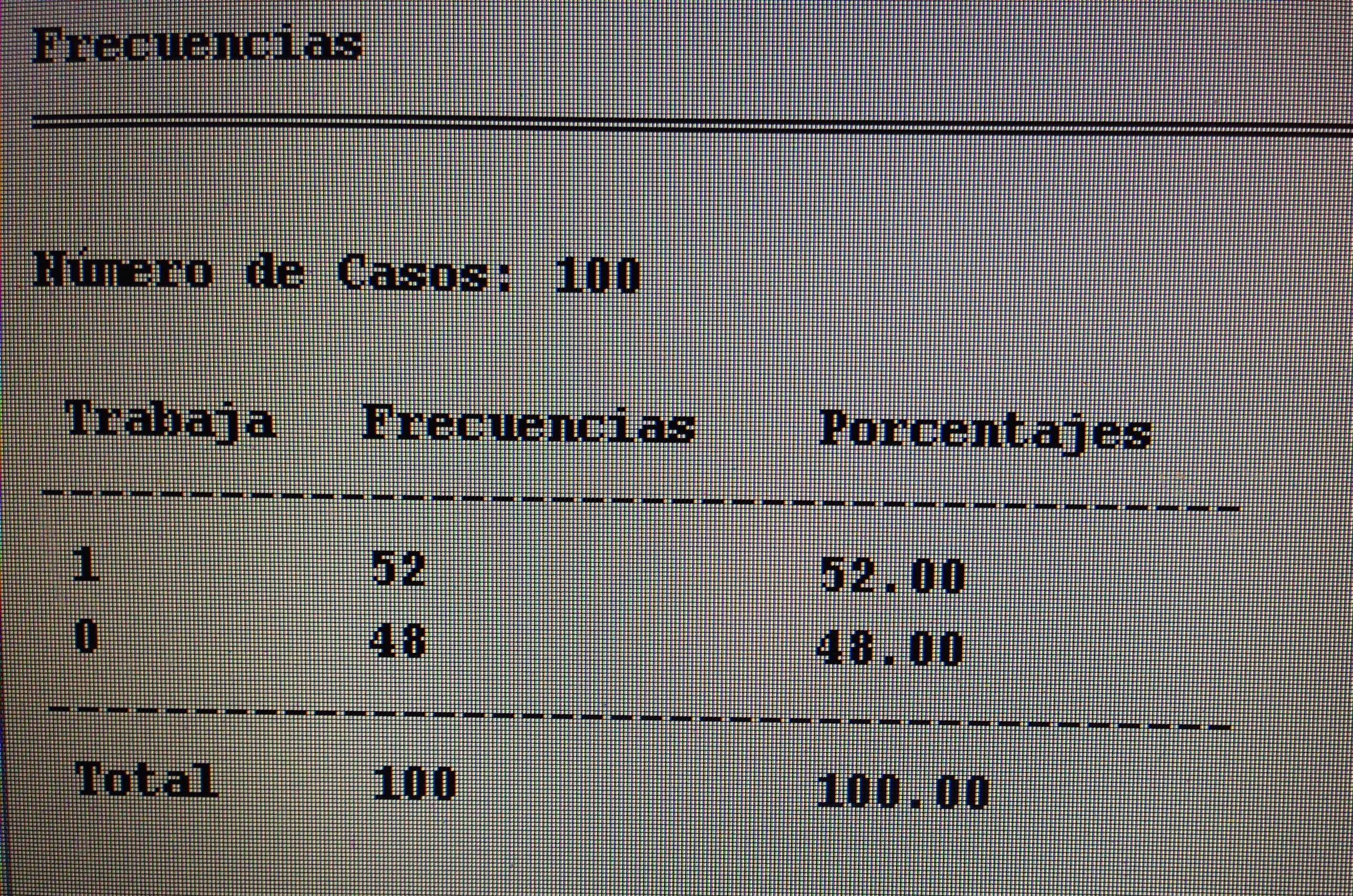
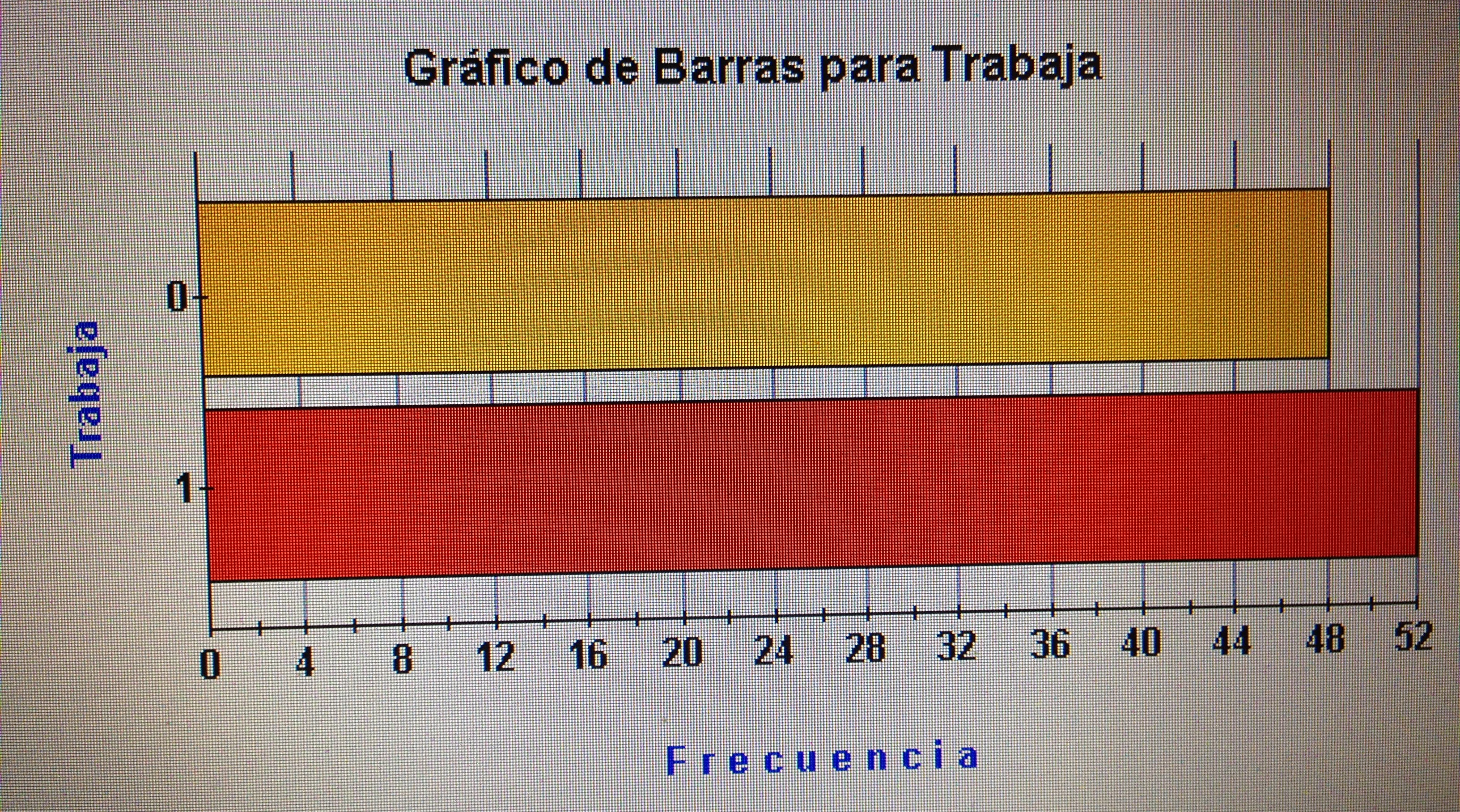
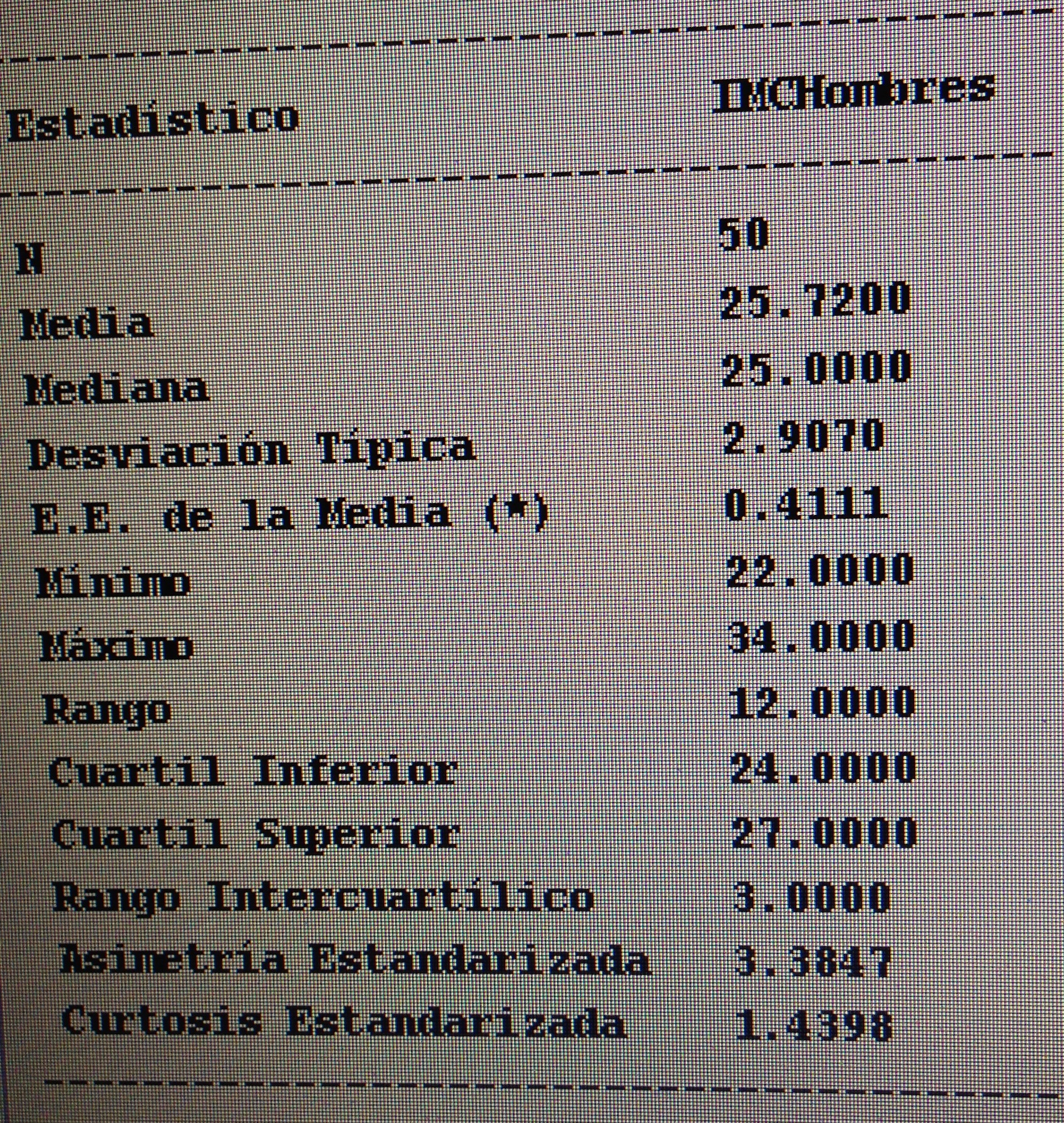
El objetivo fundamental de la Estadística descriptiva es cuantificar ciertas características a las variables con las que hemos trabajado (media, mediana, desviación estándar, rango intercuartílico, etc., en las variables cuantitativas, y frecuencia absoluta y frecuencia relativa en las variables cualitativas).
La decisión de cómo presentar, de cómo resumir, las variables cualitativas y, especialmente, las variables cuantitativas, en un estudio, en absoluto es un tema trivial y suelen cometerse importantes errores a este nivel.
Unas pautas para el resumen básico, según el tipo de variable, son las siguientes:
a. Variables cualitativas: Suelen resumirse sin demasiado problema mediante las frecuencias absolutas y la frecuencias relativas de los diferentes valores que esa variable puede tener.
b. Variables cuantitativas: Con la media y la desviación estándar, si la variable se ajusta a la distribución normal. Con la mediana y el rango intercuartílico, si la variable no se ajusta a la distribución normal.
Para más información consultar los artículos: La Estadística descriptiva en Medicina, para ver cómo suele presentarse la Estadística descriptiva en artículos de Medicina, y Media y desviación estándar o Mediana y rango intercuartílico para la explicación de cuándo resumir una variable cuantitativa mediante Media y desviación estándar o mediante Mediana y rango intercuartílico.
2. Técnicas de comparación
El objetivo de las Técnicas de comparación es comprobar si las diferencias apreciadas en los distintos grupos comparados son diferencias estadísticamente significativas. Esto nos lleva al que seguramente es el elemento nuclear de la Estadística: la noción de «significación». En Estadística «significativo» significa que estamos ante un resultado que es muy poco probable que sea debido al azar, que estamos ante un resultado fiable. Ver los artículos: La Estadística como ciencia de lo significativo o La Estadística es como un partido de baloncesto o Introducción a las técnicas de comparación.
Entre las técnicas de comparación suele distinguirse entre Técnicas de comparación de dos grupos y Técnicas de comparación de más de dos grupos:
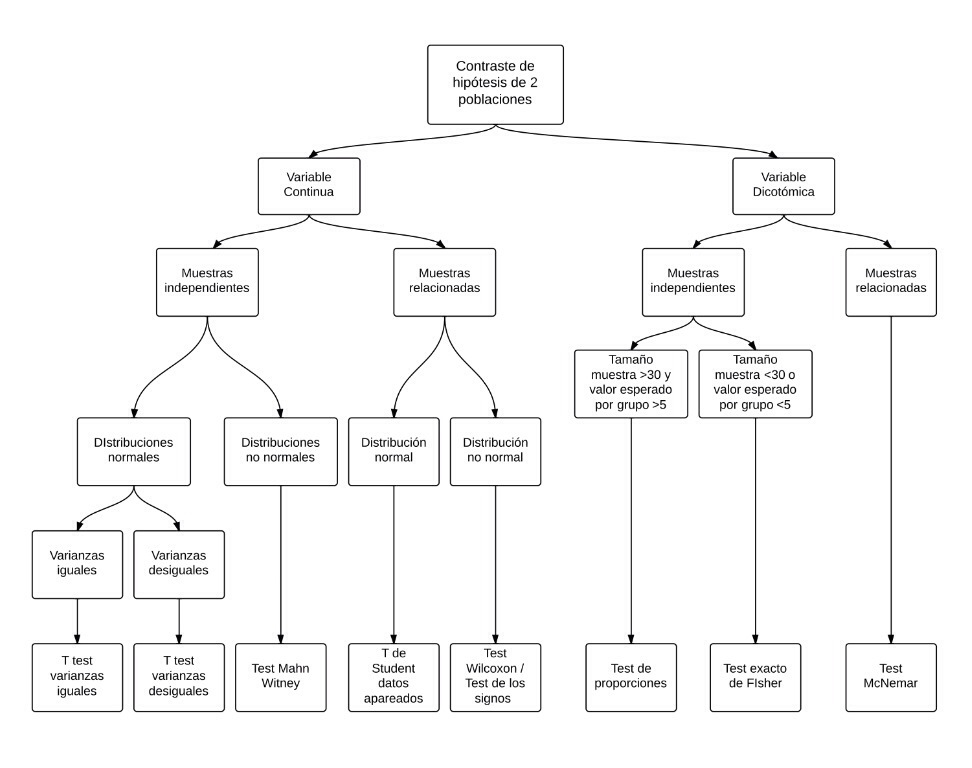
a. Comparación de dos grupos: En el tema dedicado a la Comparación de dos poblaciones se puede seguir el protocolo de decisión de la técnica a aplicar en un caso concreto. Es importante saber que disponemos de técnicas adaptadas a manejar datos que tengan una estructura adecuada. Es importante aplicar, pues, en cada caso, la técnica adecuada al caso. De esta forma optimizamos la decisión. Un resumen, en forma de diagrama de flujo, de los pasos seguidos para la elección de la técnica de comparación de dos poblaciones es el siguiente:

b. Comparación de más de dos grupos: Para la comparación de más de dos grupos debemos introducirnos en el mundo ANOVA.
Es importante distinguir que hay dos momentos diferentes en los que se suele usar cualquiera de las técnicas de comparación en Medicina:
a. Comparación en la búsqueda de igualdad: donde se busca la igualdad de unos grupos, respecto a una serie de variables-descriptoras. Grupos que respecto a un tratamiento o la exposición a un riesgo están en posiciones diferentes.
b. Comparación en la búsqueda de diferencia: donde se buscan diferencias en ciertas variables-resultado entre los grupos sometidos a condiciones diferentes.
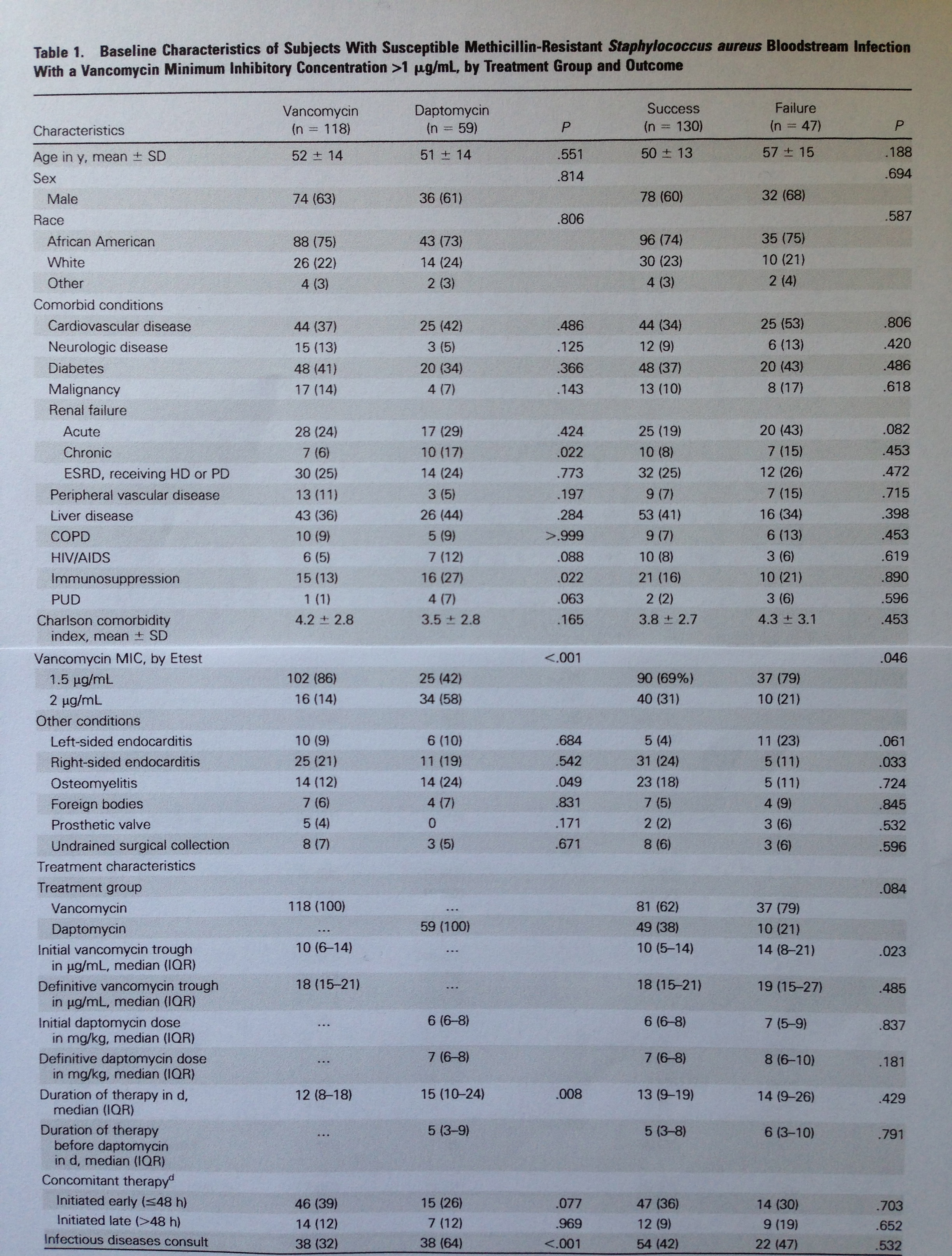
La siguiente tabla nos resume todo lo visto en el apartado 1 y 2:

Observemos que en esta tabla se sintetiza Estadística descriptiva y Técnicas de comparación. Se expresan las variables cualitativas en frecuencia absoluta y frecuencia relativa y las variables cuantitativas mediante la media y desviación estándar o mediante la mediana y el rango intercuartílico. En las dos primeras columnas vemos los dos grupos a comparar en la búsqueda de igualdad, con el p-valor respectivo de esa comparación, con la técnica apropiada, en la tercera columna. En las columnas cuarta y quinta están los dos grupos a comparar en la búsqueda, ahora, de diferencia, con el p-valor respectivo en la sexta columna. Los dos primeros grupos comparados son según el tratamiento, los dos últimos grupos han sido creados según el resultado (éxito/fracaso). Es lógica la búsqueda de igualdad en la primera comparación y la búsqueda de diferencia en la segunda.
3. Técnicas de relación
En las técnicas de relación el objetivo es establecer relaciones entre variables. En el ámbito de las técnicas estadísticas que analizan las relaciones entre variables es habitual diferenciar tres situaciones posibles:
a. Relaciones entre dos variables cuantitativas.
b. Relaciones entre dos variables cualitativas.
c. Relaciones entre una variable cualitativa y una cuantitativa.
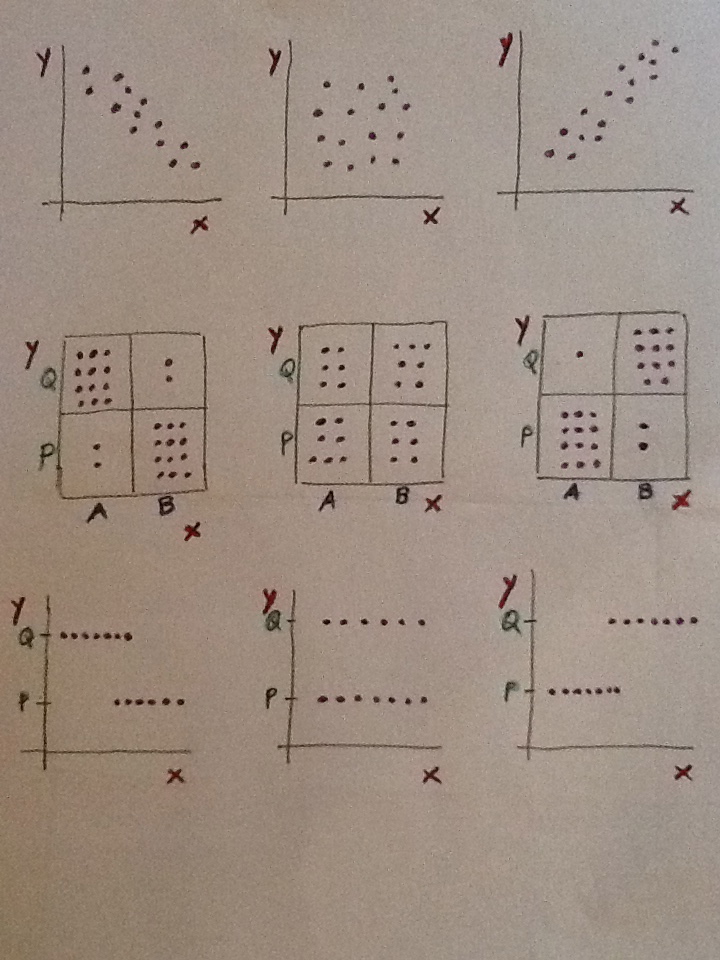
La siguiente figura resume estas tres situaciones posibles:

Observemos que tenemos tres filas y tres columnas. Las tres filas indican los tres posibles tipos de relación entre dos tipos de variables: Dos cuantitativas, dos cualitativas y una cualitativa y una cuantitativa. Las tres columnas indican tres tipos de situaciones en cuanto a la relación. En la columna del medio no hay relación entre las variables. En las columnas de la izquierda y de la derecha hay relación. Y en ambos lados digamos que se trata de una relación de tipo, de signo distinto.
En cada uno de estos tres ámbitos el objetivo será triple:
a. Detectar si hay o no relación estadísticamente significativa.
b. Cuantificar esa relación.
c. Matematizar esa relación, crear una función que exprese, matemáticamente, esa relación.
De todos los conceptos que se manejan en el ámbito de la relación entre variables los que son más frecuentemente usados en el ámbito de la Medicina son los siguientes:
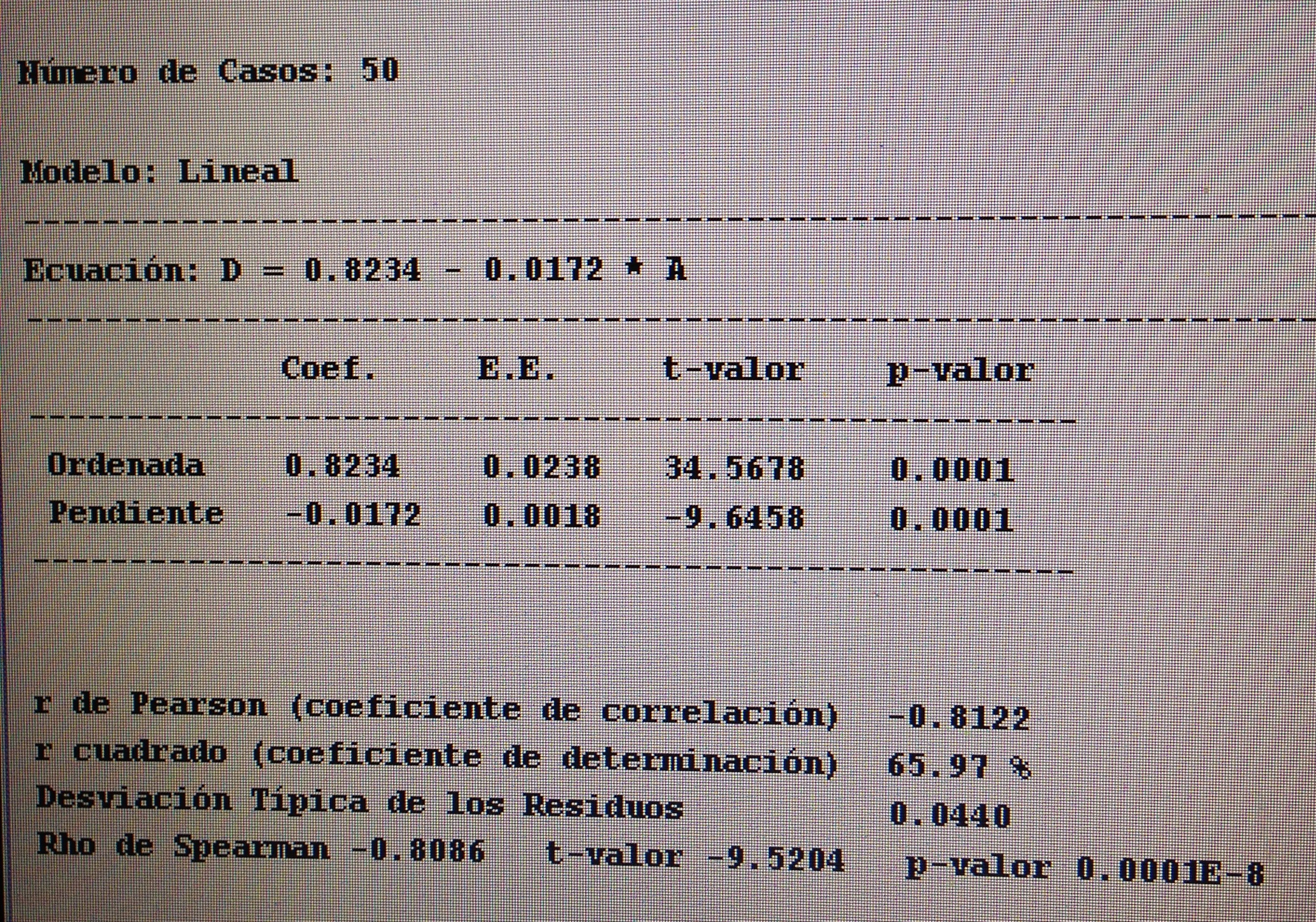
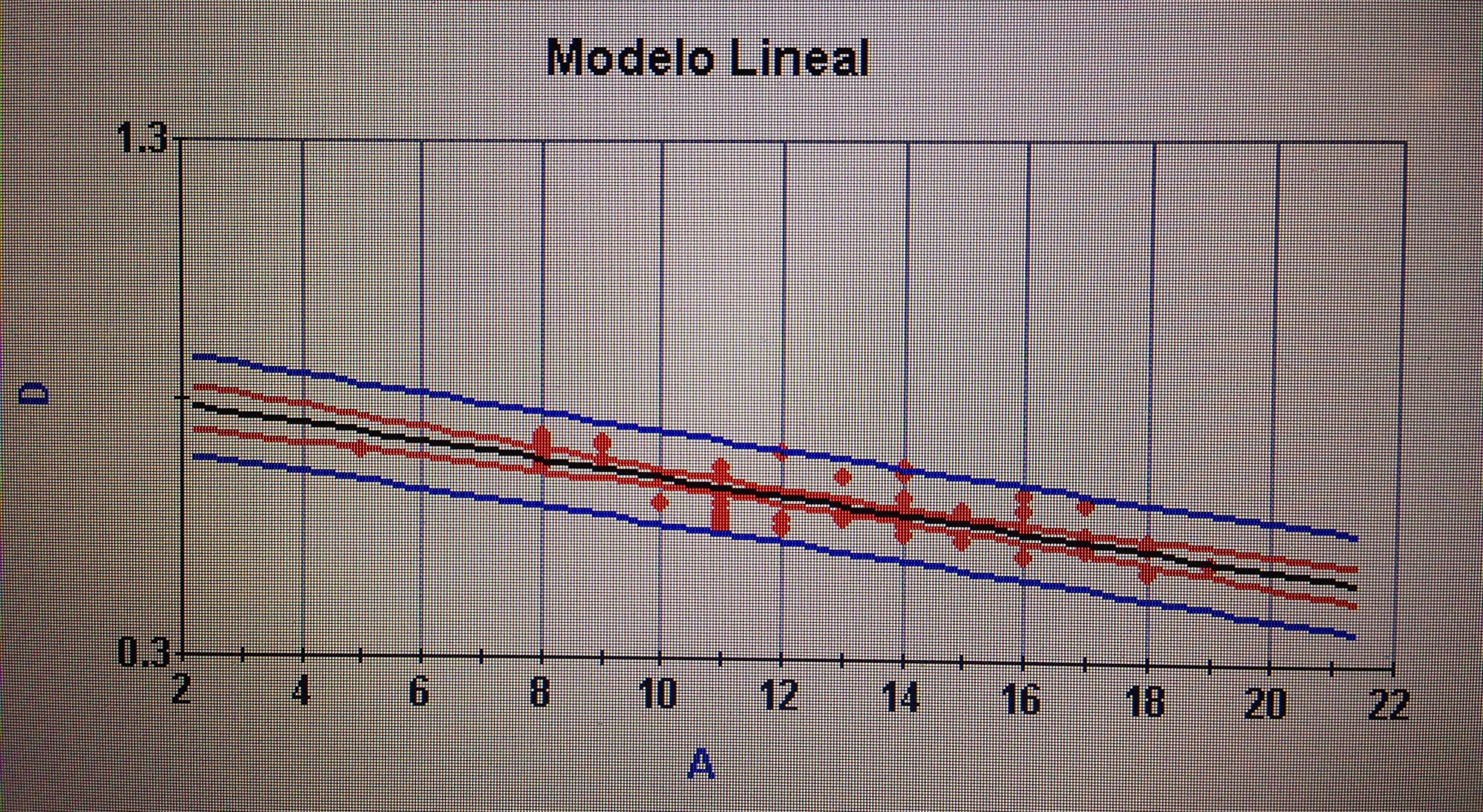
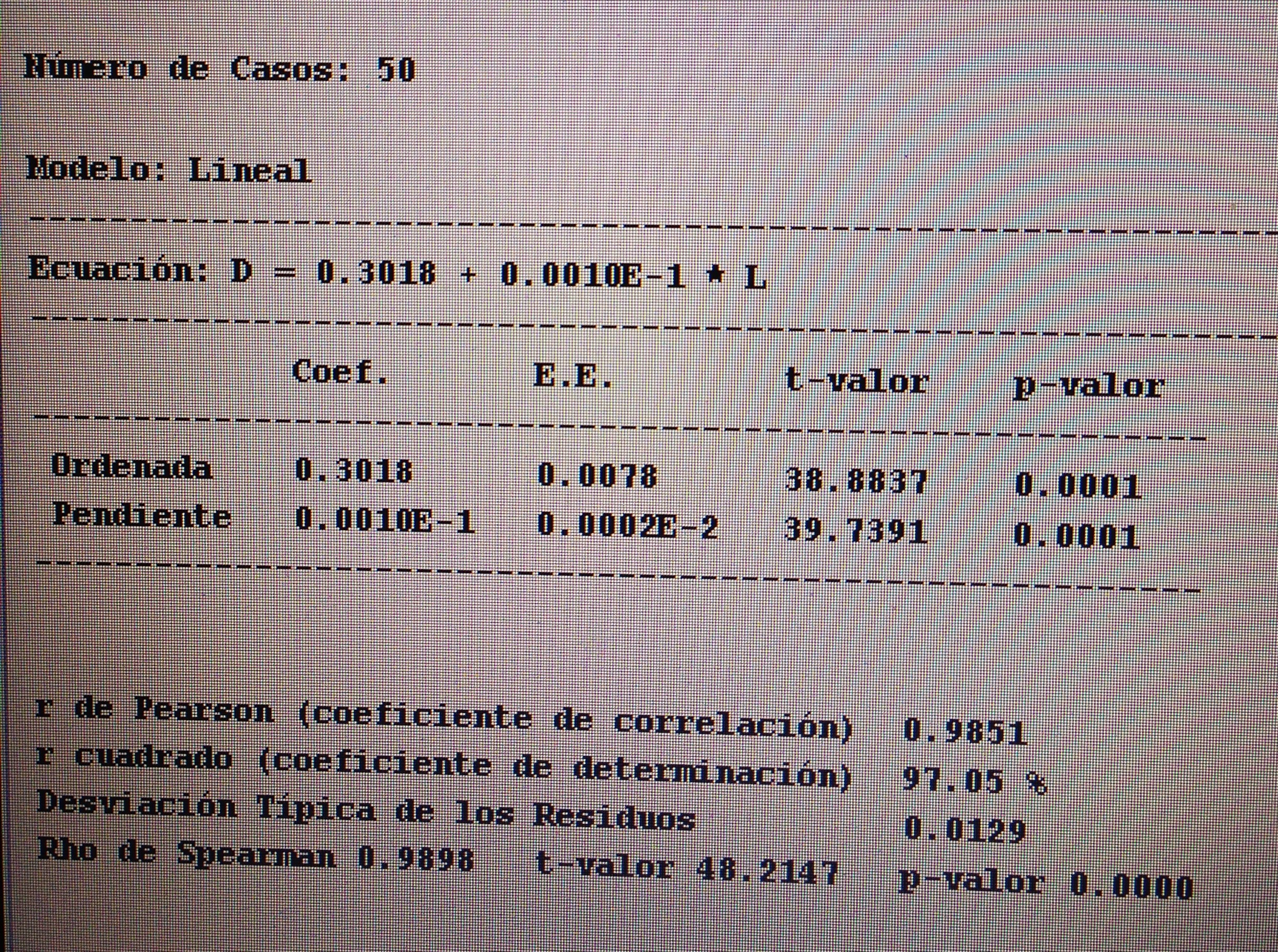
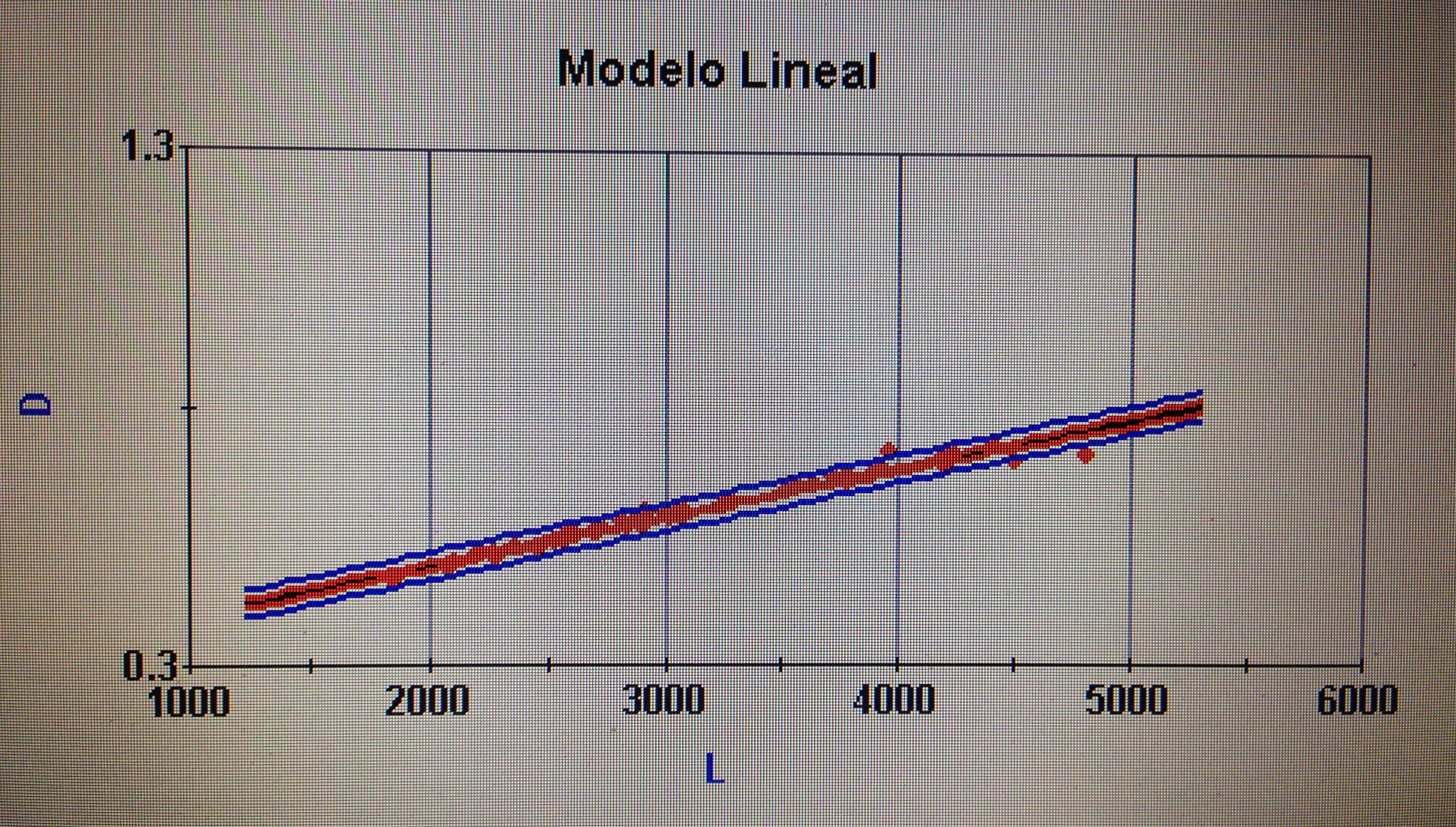
a. Para detectar relación y cuantificarla, entre variables cuantitativas: la correlación, en sus diferentes versiones: Pearson, Spearman y Kendall.
b. Para matematizar la relación entre variables cuantitativas: la Regresión lineal simple. Para más de dos variables: la Regresión múltiple.
c. Para detectar relación entre variables cualitativas: el Test de la ji-cuadrado.
d. Para cuantificar la relación entre variables cualitativas: la Odds ratio.
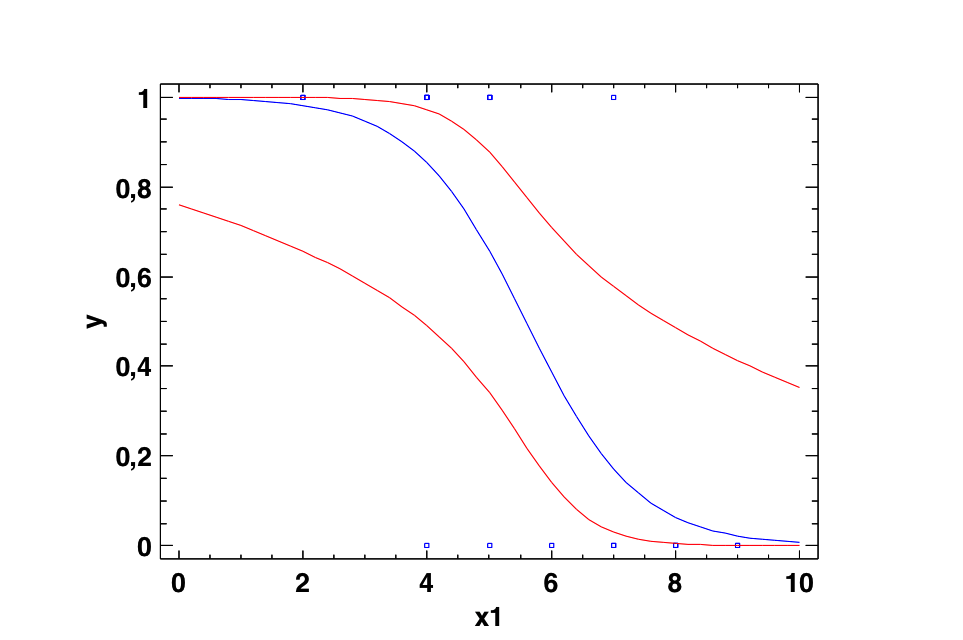
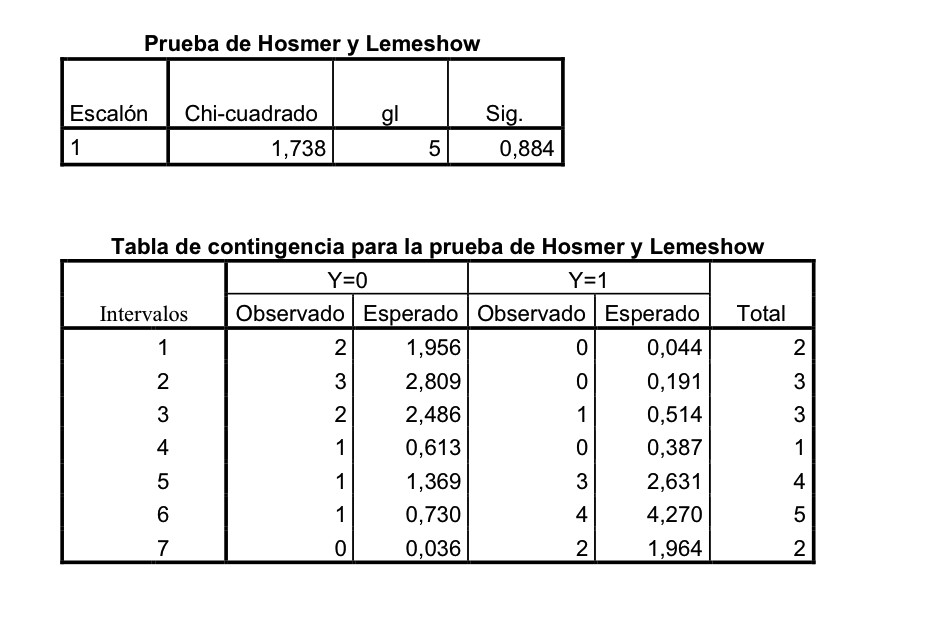
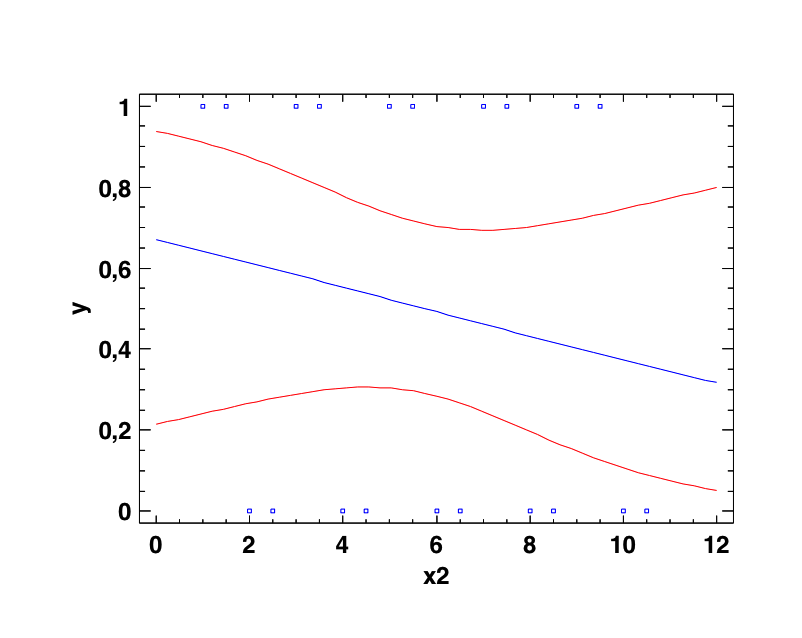
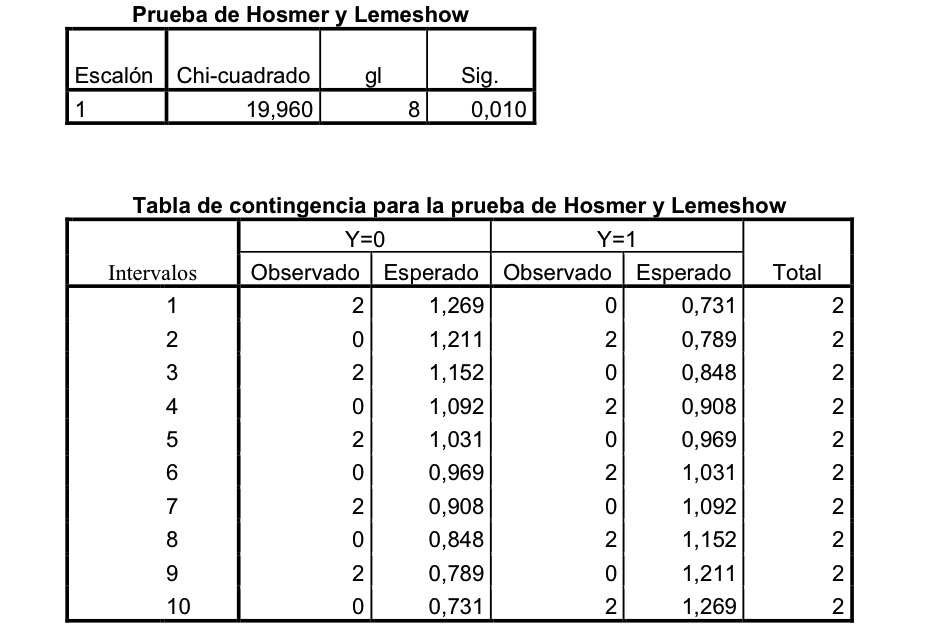
e. Para detectar, cuantificar y matematizar la relación entre variables cualitativas y cuantitativas: la Regresión logística.
f. Cuando una de las variables es el tiempo hasta que sucede un determinado acontecimiento tenemos: el Análisis de supervivencia y cuando esta supervivencia queremos explicarla matemáticamente mediante otra u otras variables tenemos: la Regresión de Cox. En este ámbito aparece una nueva cuantificación de la relación: el Hazard ratio, que, aunque guarde una estrecha relación con la Odds ratio se trata de dos medidas diferentes que es importante saber situar. Para esa distinción ver el artículo: Odds ratio versus Hazard ratio.
4. Determinación del tamaño de muestra
La muestra es el punto de partida del análisis estadístico. Sin embargo, la elección misma de la muestra ya supone un análisis estadístico previo bastante complejo. El tamaño de muestra depende de una serie de factores que es muy importante entender bien:
a. De los errores que se esté dispuesto a cometer (Error de tipo 1 y Error de tipo 2). Al de tipo 1 se le suele denominar Error alfa y al de tipo 2 Error beta. Al valor 1-Error de tipo 2 (1-beta), expresado en porcentaje, es lo que se suele denominar la potencia del test. Como se decide igualdad versus diferencia o no relación versus relación, según lo que estemos trabajando y que, por lo tanto, es una decisión entre dos opciones, podemos cometer dos tipos de errores. Por ejemplo, en el caso de igualdad versus diferencia podemos decir que hay diferencia siendo iguales (Error tipo 1) o podemos decir que hay igualdad siendo diferentes (Error tipo 2). Lo que interesa es que estos dos errores sean pequeños, especialmente el primero. Es habitual, por ejemplo, que el primero se fije en 0.05 i el segundo en 0.2 (lo que supondría una potencia del 80%).
b. De la dispersión de las variables analizadas, usualmente expresada mediante la desviación estándar. El grado de dispersión que es algo que nos viene impuesto por la realidad estudiada influye en el tamaño de muestra necesario para decir cosas en ciencia. A mayor dispersión necesitamos más tamaño muestral para saber cómo es aquella realidad.
c. De la diferencia mínima que queramos detectar o del nivel de relación mínimo que queramos detectar. Esto es importante y complejo de establecer, en muchas ocasiones. Se trata de fijar el mínimo que se entiende como significativo, médicamente. Diferencia por debajo de la cual aunque viéramos una diferencia estadísticamente significativa sería irrelevante clínicamente. Por lo tanto, se pretende encontrar la muestra que necesitamos para que si acabamos viendo aquella diferencia mínima o relación mínima, o más, teniendo la desviación estándar especificada y, con el nivel de error fijado, podamos hablar de que se trata de una diferencia estadísticamente significativa.
Observemos un caso de declaración de muestreo en un artículo:


En este tipo de información donde se especifica el tamaño de muestra usado siempre se acaba concretando que ha sido en función de estos dos tipos de error, de la dispersión que se tiene y de la diferencia mínima o el grado de relación mínimo a detectar. Esto es una constante que conviene entender y saber aplicar.
Tenemos afortunadamente extraordinarios calculadores del tamaño muestral. Todos ellos, evidentemente, nos pedirán estos elementos para determinar la muestra que necesitamos.
Para más información consultar los siguientes artículos: La maquinaria de un contraste de hipótesis, La noción de potencia estadística, Determinación del tamaño de muestra y Un ejemplo de la determinación del tamaño de muestra en Medicina.
Siempre tenemos en una investigación en Medicina si no todos los elementos comentados aquí, sí prácticamente todos. Es muy importante saberlos situar e interpretar. El análisis será mucho más ajustado y preciso si la mirada estadística es la adecuada.
Y, finalmente, ligado, por un lado, a la necesidad de aumentar el tamaño de muestra en Medicina y ligado también a la necesidad de evaluar la coherencia entre diferentes estudios análogos hecho por grupos de investigación distintos se ha desarrollado todo un nuevo repertorio de técnicas: el Metaanálisis.