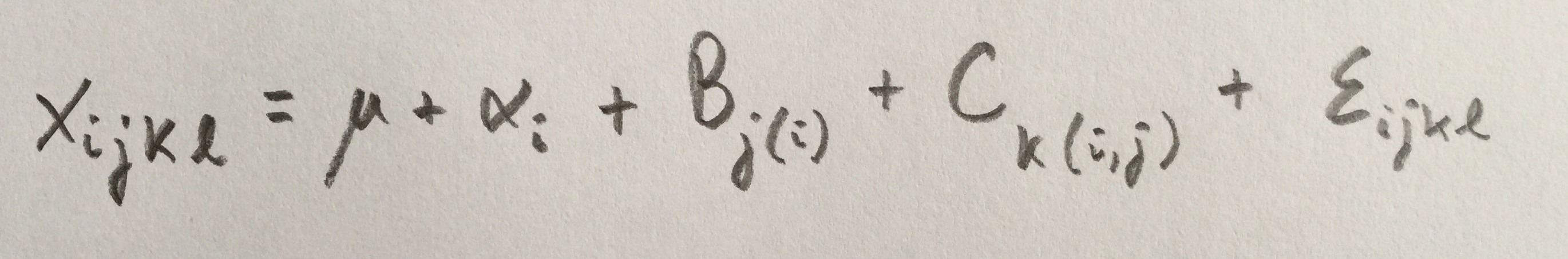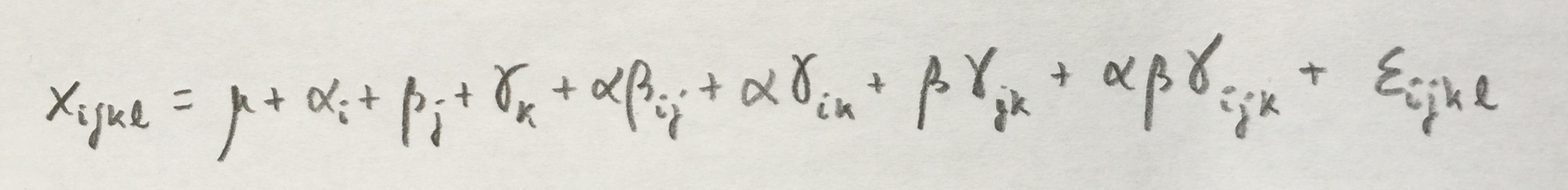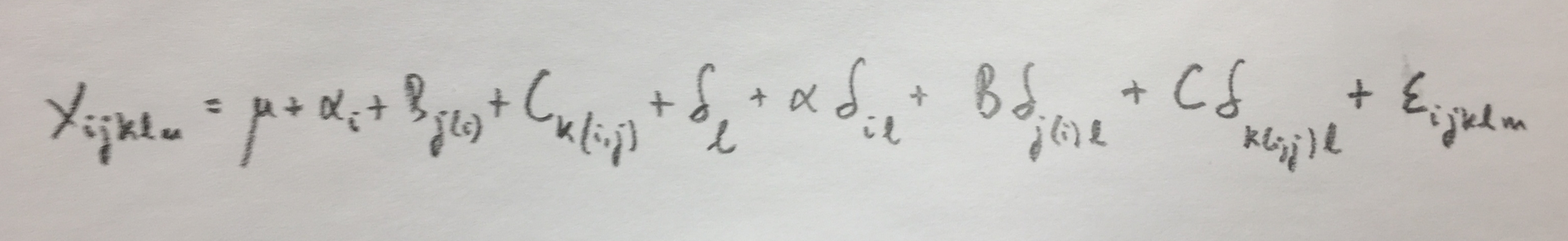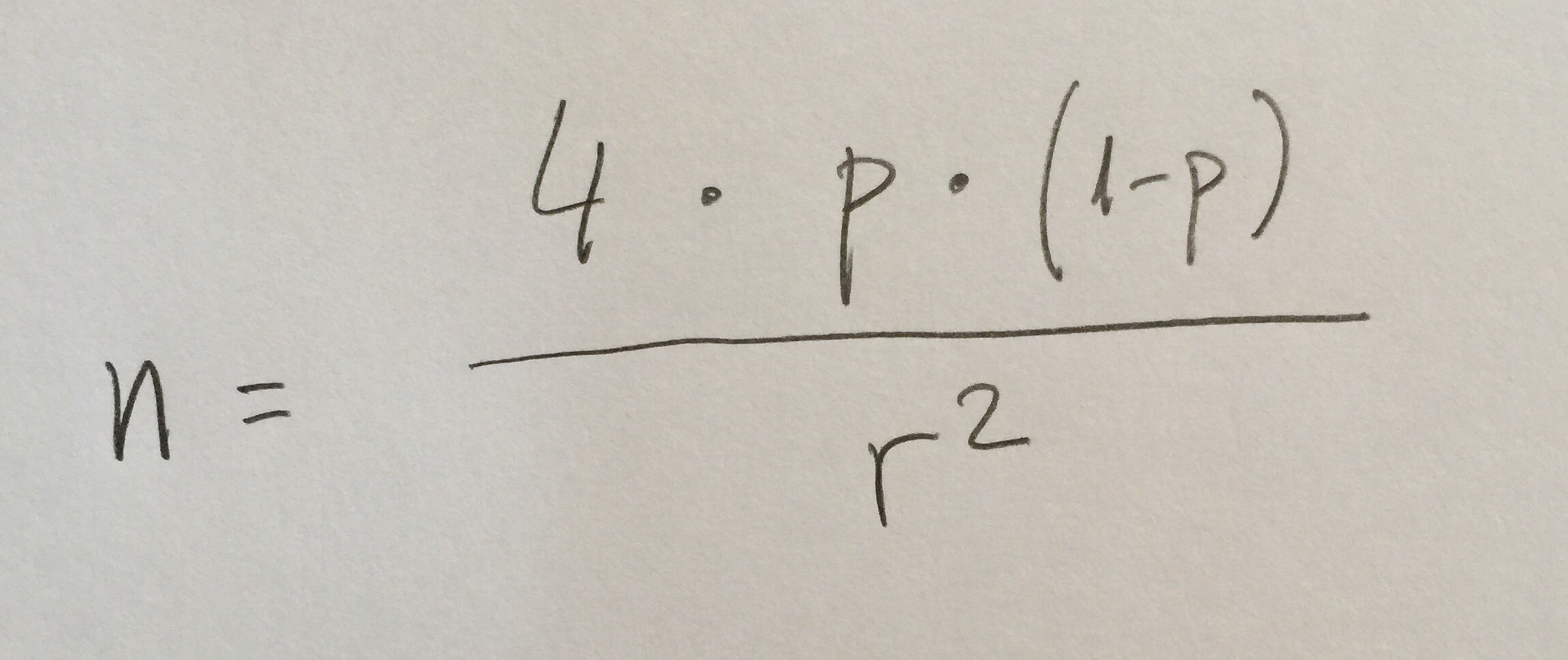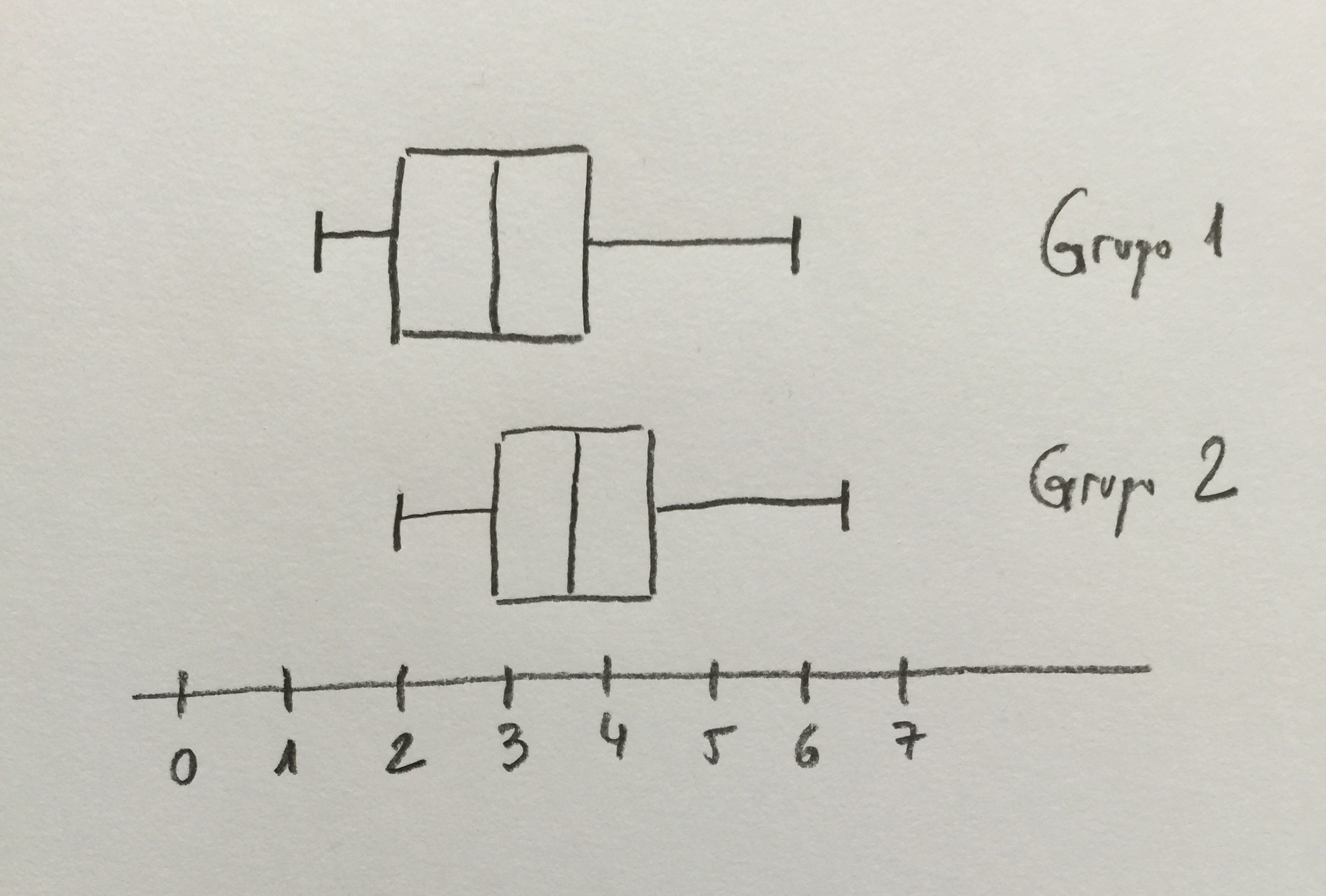1.Se trata de un diseño con tres factores. Zona es un factor fijo, Subzona es un factor aleatorio anidado en el factor Zona. Profundidad es un factor fijo cruzado con los dos factores restantes. El modelo sería el mismo que el visto en la Situación 41.
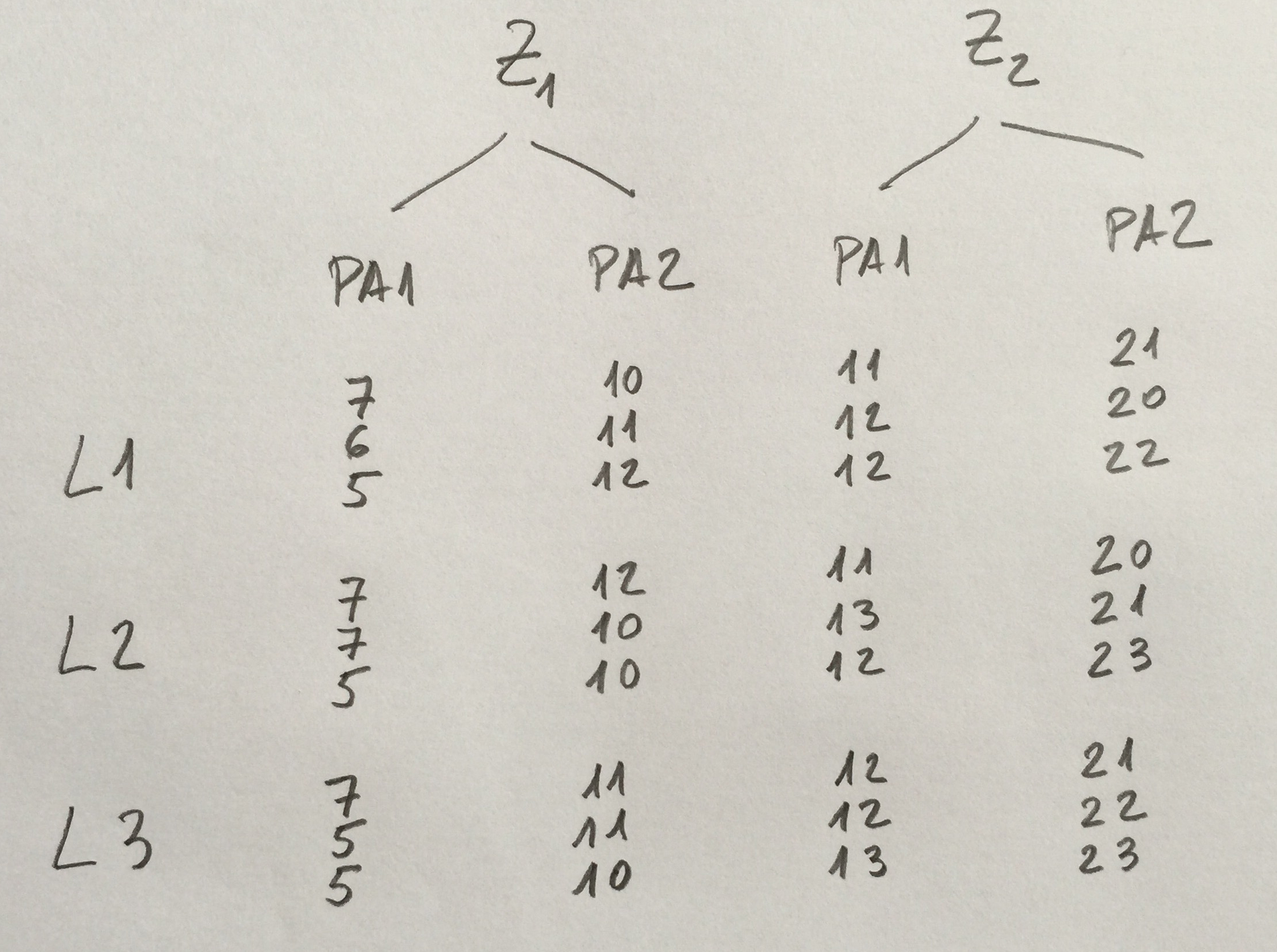
Los factores Profundidad y Subzona parecen, viendo los datos, significativos. El factor zona, no.
2.Se trata de un diseño con tres factores. Zona es un factor fijo, Política ambiental es un factor también fijo y cruzado con el factor Zona. Laboratorio sería un factor aleatorio anidado en la interacción de los otros dos factores. El modelo sería el mismo que el visto en la Situación 45.
Los factores Zona y Política ambiental parecen significativos, viendo los datos. El factor Laboratorio, no.
3. Se trata de un diseño de tres factores. Zona es un factor fijo, Subzona es un factor aleatorio anidado en el factor Zona. Operario es también un factor aleatorio anidado en el factor Subzona. El modelo es el siguiente:
El algoritmo de Bennet-Franklin nos proporciona las esperanzas de los cuadrados medios y n los cocientes que hay que hacer en la tabla ANOVA para encontrar los efectos significativos del modelo:
Los factores Zona y Operario parecen significativos. Pero Subzona, no.
4.Tenemos tres factores fijos y cruzados. El modelo es:
La resolución de este modelo no presenta ninguna dificultad por tratarse de factores fijos y cruzados. Todos los cocientes se realizan respecto del residuo.
Viendo los datos parece que los únicos efectos significativos serán los producidos por el factor Zona y el factor Política ambiental.
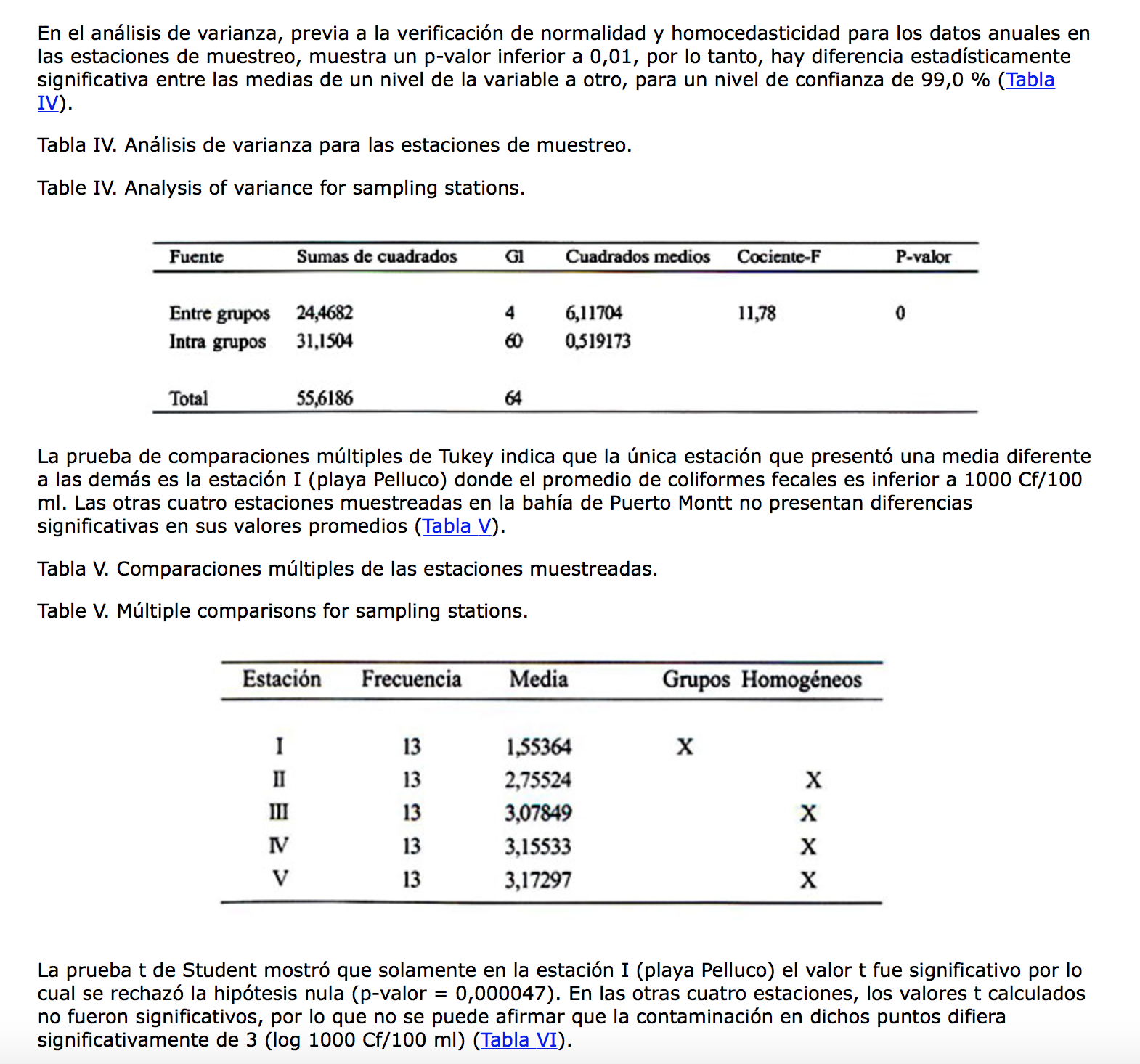
5.Estamos ante un diseño con cuatro factores. El factor zona es fijo. El factor subzona es aleatorio y anidado en el factor zona. El factor operario es también aleatorio y anidado en subzona. El factor técnica es fijo y cruzado con los otros tres factores. El modelo sería:
El algoritmo de Bennet-Franklin nos proporciona las esperanzas de los cuadrados medios y n los cocientes que hay que hacer en la tabla ANOVA para encontrar los efectos significativos del modelo:
Viendo los datos parecen significativos los cuatro factores.
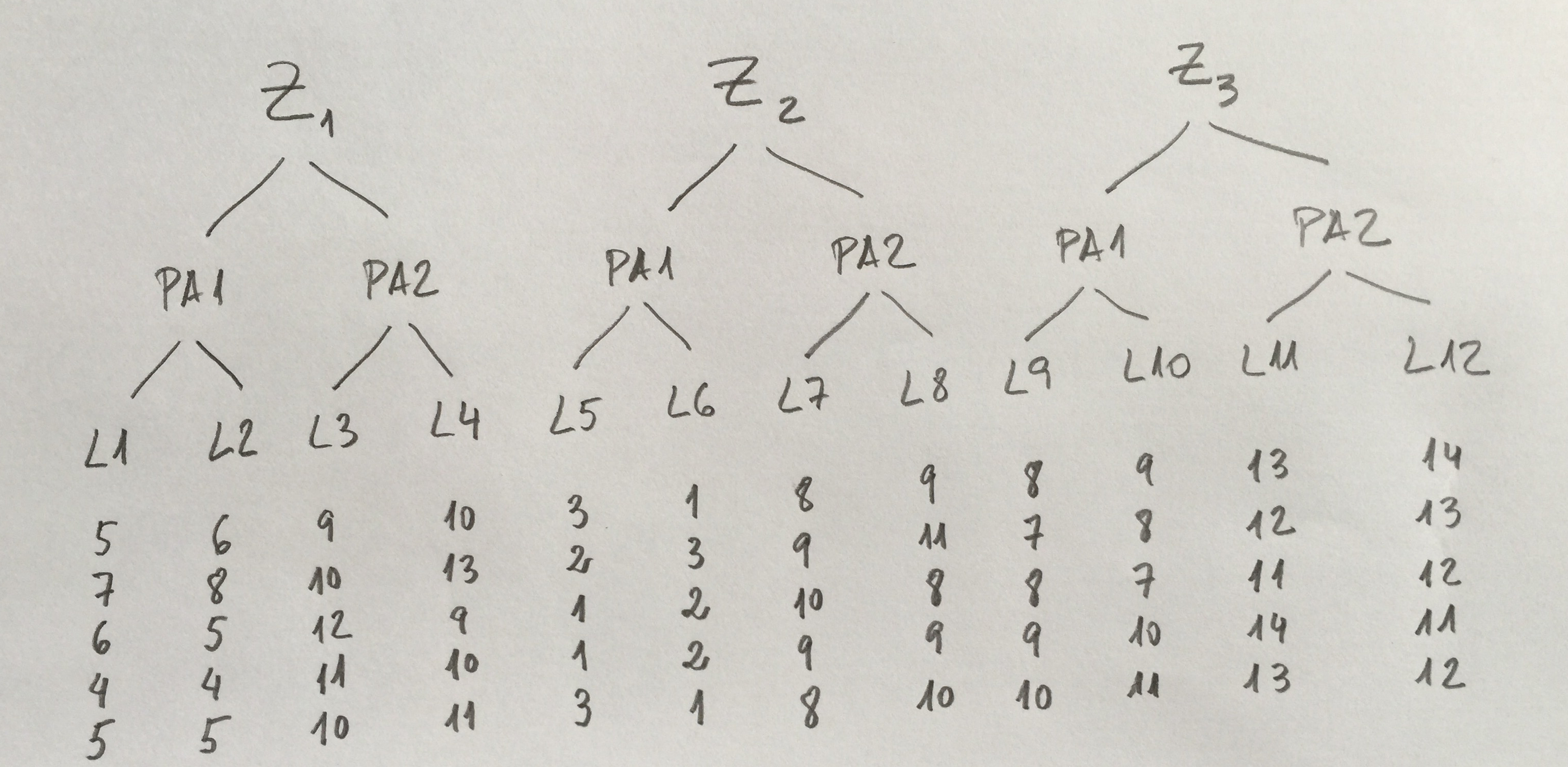
1. Supongamos que hemos estudiado la cantidad de un contaminante en tres zonas del litoral concretos que queremos comparar. En cada uno de ellos hemos elegido al azar dos subzonas porque queremos ver la homogeneidad que hay en cada zona. Hemos estudiado el agua a tres profundidades: 0, 10 y 20 metros. En cada punto hemos efectuado tres réplicas. Los resultados son los siguientes:
¿Cuántos factores tenemos? ¿Son fijos, aleatorios? ¿Cómo están estructurados unos respecto de otros (cruzados, anidados)? ¿Cuál es el modelo? ¿Únicamente visualizando los datos cuáles serán los resultados que obtendremos mediante el ANOVA oportuno?
2. Supongamos que en tres zonas que expresamente queremos comparar hemos aplicado a dos subzonas de cada una de ellas, completamente equivalentes, dos políticas medio-ambientales distintas que pretendemos también comparar. Los resultados los hemos encargado a doce laboratorios elegidos al azar con la finalidad, también, de medir el grado de fiabilidad que nos pueden aportar ellos. Cada laboratorio hace cinco réplicas de la muestra recibida. Los resultados son los siguientes:
¿Cuántos factores tenemos? ¿Son fijos, aleatorios? ¿Cómo están estructurados unos respecto de otros (cruzados, anidados)? ¿Cuál es el modelo? ¿Únicamente visualizando los datos cuáles serán los resultados que obtendremos mediante el ANOVA oportuno?
3. Supongamos que en tres zonas que expresamente queremos comparar hemos elegido dos subzonas al azar con la finalidad de evaluar la homogeneidad que haya dentro de las zonas. Hemos evaluado la concentración de un determinado contaminante. Hemos tomado una muestra de cada subzona y hemos encargado a diferentes estudiantes para que realicen los análisis. Cada alumno, cada operario, realizaba cuatro réplicas de una única muestra. Queríamos ver, también, el grado de dispersión que hay entre los análisis hechos por estudiantes de ciencias ambientales. Los resultados son los siguientes:
¿Cuántos factores tenemos? ¿Son fijos, aleatorios? ¿Cómo están estructurados unos respecto de otros (cruzados, anidados)? ¿Cuál es el modelo? ¿Únicamente visualizando los datos cuáles serán los resultados que obtendremos mediante el ANOVA oportuno?
4. Supongamos que en dos zonas que expresamente queremos comparar hemos aplicado a dos subzonas de cada una de ellas, completamente equivalentes, dos políticas medio-ambientales distintas que pretendemos también comparar. Los resultados los hemos encargado a tres laboratorios que expresamente también queremos comparar. Cada laboratorio realizaba tres réplicas de cada una de las muestras recibidas. Los resultados son los siguientes:
¿Cuántos factores tenemos? ¿Son fijos, aleatorios? ¿Cómo están estructurados unos respecto de otros (cruzados, anidados)? ¿Cuál es el modelo? ¿Únicamente visualizando los datos cuáles serán los resultados que obtendremos mediante el ANOVA oportuno?
5. Supongamos que en dos zonas que expresamente queremos comparar hemos elegido dos subzonas al azar con la finalidad de evaluar la homogeneidad que haya dentro de las zonas. Hemos evaluado la concentración de un determinado contaminante. Hemos tomado una muestra de cada subzona y hemos encargado a diferentes estudiantes para que realicen los análisis. Hemos evaluado, con la finalidad de compararlas, dos técnicas analíticas que existen para evaluar la concentración de ese contaminante. Cada alumno, cada operario, realizaba tres réplicas de una única muestra en cada uno de las dos técnicas. Queríamos ver, pues, también, el grado de dispersión que hay entre los análisis hechos por estudiantes de ciencias ambientales. Los resultados son los siguientes:
¿Cuántos factores tenemos? ¿Son fijos, aleatorios? ¿Cómo están estructurados unos respecto de otros (cruzados, anidados)? ¿Cuál es el modelo? ¿Únicamente visualizando los datos cuáles serán los resultados que obtendremos mediante el ANOVA oportuno?
1c: El primer cuartil es 5 y el tercero es 27, por lo que el rango intercuartílico es 22.
2c: La relación es significativa porque el p-valor es inferior a 0.05, pero la capacidad predictiva es muy mala: es sólo del 4%.
3a: Si aplicamos la fórmula de los intervalos de confianza modificándola para que haya tres errores estándares sumados y restados el intervalo es el a.
4d: Si la tabla observada y la esperada coinciden el valor de la ji-cuadrado es 0 y por lo tanto la V de Crámer es también 0.
5c: Obviamente en este caso c la correlación será de mayor magnitud y, por lo tanto, el coeficiente de determinación será el mayor de los cuatro.
6c: Obviamente estamos usando una técnica inadecuada. La correlación de Pearson es para relacionar variables cuantitativas. Deberíamos usar una ji-cuadrado.
7d: Como no sabemos qué tabla de contingencias tenemos sólo podemos afirmar lo que dice la d, porque el 3.84 es el umbral más pequeño de los que podemos tener.
8c: Cualquier pendiente que no sea 0 potencialmente puede ser estadísticamente significativa. Dependerá del intervalo de confianza del 95% que construyamos o del p-valor que tengamos.
9c: El valor de ji-cuadrado 23.33 está por encima del umbral de nivel de significación del 0.05 (21.02) pero está por debajo del umbral de nivel de significación del 0.01 (26.21).
10d: El error estándar es 1, por lo tanto el intervalos de confianza del 95% de la media es el d.
2.De una correlación r=0.2 (p=0.0001), podemos decir:
a.El tamaño muestral es pequeño porque la correlación es pequeña.
b.Hay una relación significativa entre las variables comparadas porque el coeficiente de determinación es mayor del 5%.
c.No tenemos una buena capacidad predictiva a pesar de que tenemos una correlación significativa.
d.El coeficiente de determinación es del 20%.
3.Estamos interesado en saber en cuántos lugares a lo largo de un río se supera un cierto nivel de un contaminante. Para ello se toman al azar 100 muestras a lo largo del río. En 15 de ellas se supera ese nivel. Un intervalo de confianza del 99.5% del porcentaje de puntos del río donde se supera dicho nivel es:
a.(4.29, 25.71).
b.(7.86, 22.14).
c.(11.43, 18.57).
d.(10.25, 14.75).
4.¿Cuál de las siguientes afirmaciones es cierta?
a.La ji-cuadrado mide bien la cantidad de relación que hay entre dos variables cualitativas.
b.Una correlación de Pearson es significativa si el coeficiente de determinación es superior al 50%.
c.Si la V de Crámer si es negativa indica una relación de tipo inverso entre las variables.
d.Si la tabla de contingencias observada y la tabla de contingencias esperada son iguales entonces la V de Crámer es 0.
5.En cuál de las siguientes regresiones lineales simples podremos hacer mejores predicciones:
a)y=-6x-10; IC del 95% de la correlación (-0.3, -0.1).
b)y=3x+3; IC del 95% de la correlación (0.3, 0.5)
c)y=-x-2; IC del 95% de la correlación (-0.8, -0.7)
d)y= 8x+2; IC del 95% de la correlación (-0.1, 0.9).
6.Estamos tratando de asociar la presencia o la ausencia de una especie fitoplanctónica con la presencia o ausencia de una especie zooplanctónica en muestras marinas de distintas zonas del mediterráneo. Hemos codificado la ausencia con un 0 y la presencia con un 1. Hemos calculado una correlación de Pearson y tenemos una r=0.35 (p=0.035), podemos decir:
a.Que hay una relación significativa entre esas dos variables.
b.Que relación tiene buena capacidad predictiva porque la relación es significativa.
c.Que estamos usando una técnica estadística no apropiada al caso.
d.Que necesitamos saber el tamaño de muestra para saber si esta relación es estadísticamente significativa.
7.Si se realiza una ji-cuadrado para analizar la relación entre dos variables cualitativas es cierto:
a.Si el valor del cálculo de la ji-cuadrado es mayor que 50 se puede considerar ya una relación estadísticamente significativa.
b.Si el p-valor es menor que 0.05 el valor del cálculo de la ji-cuadrado es menor que 3.84.
c.Si el p-valor es mayor que 0.05 el valor del cálculo de la ji-cuadrado es menor que 3.84.
d.Si el valor del cálculo de la ji-cuadrado es menor que 3.84 el p-valor será mayor que 0.05.
8.En una Regresión lineal simple es cierto:
a.Si la R2 es superior al 50% tenemos una relación estadísticamente significativa entre las variables de la regresión.
b.Si el p-valor de la correlación y de la pendiente es inferior a 0.05 tendremos una aceptable capacidad predictiva.
c.La ecuación de la recta y=0.0001x+20 puede ser estadísticamente significativa.
d.Si la ecuación de la recta es y=2x+3, y sabemos que es significativa, la recta y=20x+3 lo será también de significativa porque la pendiente es aún mayor.
9.Estamos relacionando en cuatro zonas distintas la presencia de cinco especies de peces distintos. Hemos aplicado una ji-cuadrado y el valor es 23.33. Entonces:
a.No podemos decir que hay relación porque 23.33 es mayor que 21.02.
b.No podemos decir que hay relación porque 23.33 es menor que 31.41.
c.Si el nivel de significación fuese 0.05 diríamos que hay relación pero si fuese 0.01 diríamos que no hay relación.
d.Podemos decir que hay relación estadísticamente significativa porque 23.33 es mayor que 3.84.
10.Un intervalo de confianza del 95% de la media en una muestra con media muestral 20, desviación estándar 20 y tamaño muestral de 400 es:
Un viaje amplio por el mundo ANOVA (Análisis de la varianza), como un viaje por una compleja ciudad como Nueva York, París o Londres, merece un previo recorrido global en autobús turístico para conocer, de entrada, cuál es la estructura global, la textura, de lo que nos encontraremos, en días sucesivos.
Vamos a hacerlo introduciendo unos conceptos que constituyen la columna vertebral de la inmensa urbe ANOVA. Se trata de los siguientes conceptos:
Factor
Nivel
Factor fijo/Factor aleatorio
Comparaciones múltiples/Componentes de la varianza
Factores cruzados/Factores anidados
Interacción entre factores
Factor intersujeto/Factor intrasujeto
Variable respuesta/Vector respuesta
Variable/Covariable
Efectos
Vayamos paso a paso con este corto viaje en autobús turístico:
1. Un factor en ANOVA es una variable cualitativa que genera o que contempla una serie de poblaciones a comparar. Por ejemplo, se ensayan tres tipos de fertilizantes en unos campos de cultivo para evaluar la productividad, se ensayan cuatro medicamentos distintos para ver si aumentan los niveles de hemoglobina en pacientes con anemia. En estos casos tenemos, en primer lugar el factor tipo de fertilizante. En el segundo, el factor fármaco.
2. Los niveles de un factor son los grupos o poblaciones que tenemos de un factor. En el primer ejemplo anterior tenemos tres niveles. En el segundo ejemplo tenemos cuatro niveles.
3. Un factor es fijo si los niveles que tenemos de él en el estudio son realmente todos los que nos interesa comparar. Un factor es aleatorio si los niveles que tenemos en nuestro estudio es una muestra de niveles tomados de una población de niveles que son los que, en realidad, queremos comparar. Los dos ejemplos anteriores si los tres fertilizantes o los cuatro fármacos son nuestro objeto de comparación, estamos ante factores fijos. Pero, observemos lo siguiente: si en otro ejemplo, estoy comparando si hay diferencias en la calidad de un producto fabricado por 100 operarios trabajando en una industria y, para hacerlo, elijo al azar a 5 de esos 100 operarios y analizo 3 productos elaborados por cada uno de ellos, pero lo que me interesa es ver si hay diferencias entre los 100, no entre esos 5, estoy ante el factor operario con 5 niveles, pero ese factor es, ahora, no fijo, sino aleatorio.
4. Si tenemos un factor fijo y detectamos que hay diferencias entre esas poblaciones, nos interesará decir cuáles son esas diferencias concretas. Las comparaciones múltiples hacen esa labor, comparan, dos a dos, de una forma muy especial, todas las poblaciones para dibujar un mapa de las diferencias. Si tenemos un factor aleatorio, el planteamiento es ahora muy diferente: debemos pasar de la muestra de muestras de poblaciones que tenemos a una población de poblaciones y eso lo haremos estimando la varianza, la dispersión que debe haber dentro de esa población de poblaciones.
5. Cuando hay más de un factor en un estudio, los factores, dos a dos, pueden estar cruzados o anidados. Tenemos factores cruzados cuando todos los niveles de un factor están combinados con todos los niveles del otro factor. Tenemos factores anidados cuando los niveles de un factor están jerarquizados entre los niveles del otro factor.
6. Cuando los factores están cruzados podemos estudiar algo muy importante en ANOVA: la interacción entre esos factores. Hay interacción cuando la respuesta, el efecto conseguido con la presencia de un nivel de un factor, depende de con qué nivel del otro factor esté combinado.
7. Un factor es intersujeto cuando cada sujeto pertenece a un único nivel del factor. Un factor es intrasujeto cuando cada sujeto está presente en cada uno de los niveles del factor.
8. Tenemos una variable respuesta, cuando la variable estudiada en la combinación de factores estudiados que tengamos es una variable cuantitativa única. Tenemos un vector respuesta cuando lo que se estudia es un vector de variables; o sea, varias variables al mismo tiempo. Se pretende buscar las diferencias en bloque, no variable a variable.
9. Una variable en ANOVA significa la respuesta en una variable cuantitativa que estamos estudiando. Una covariable es una variable cuantitativa complementaria que puede estar asociada a la variable respuesta estudiada y puede explicar las diferencias que estamos viendo en la variable respuesta estudiada. Viene a ser como un factor pero cuantititivo, no cualitativo.
10. En el lenguaje ANOVA hablamos de efectos cuando vemos diferencias. En este contexto vamos a realizar distintas comparaciones. La hipótesis de partida (la llamada hipótesis nula) es igualdad y la alternativa es diferencia. Si rechazamos la hipótesis nula y nos quedamos la alternativa decimos que estsmos viendo efectos. Por lo tanto, en ANOVA, efectos es sinónimo de diferencias y no efectos sinónimo de igualdad.
Veamos un ejemplo práctico dende ver todos estos conceptos. Se hace el siguiente estudio experimental: Se toma una muestra de 30 alumnos durante toda la ESO. Se dividen en tres clases distintas, en tres líneas distintas. Cada una va a seguir, durante los cuatro años, un plan distinto de enseñanza del inglés. Se sabe el nivel escrito y el nivel oral de esos alumnos al final de la primaria. Se han diferenciado dos niveles dentro de cada grupo, según el promedio de notas globales de esos alumnos ha sido alto o bajo, en el global de las materias. Durante los cuatro cursos de la ESO se ha hecho un seguimiento, alumno por alumno, del nivel de inglés oral de esos alumnos. Los resultados son los siguientes:
Hay dos factores fijos: Grupo y Nivel. Grupo a tres niveles y Nivel a dos niveles. Los dos factores son fijos y están cruzados. Pero hay un tercer factor: el factor ESO, con cuatro niveles fijos. La variable estudiada es el nivel de inglés oral. Los factores Grupo y Nivel son intersujetos. El factor ESO es intrasujetos. Las variables InglésEscrito e InglésOral a finales de primaria podría tratarse como covariable.
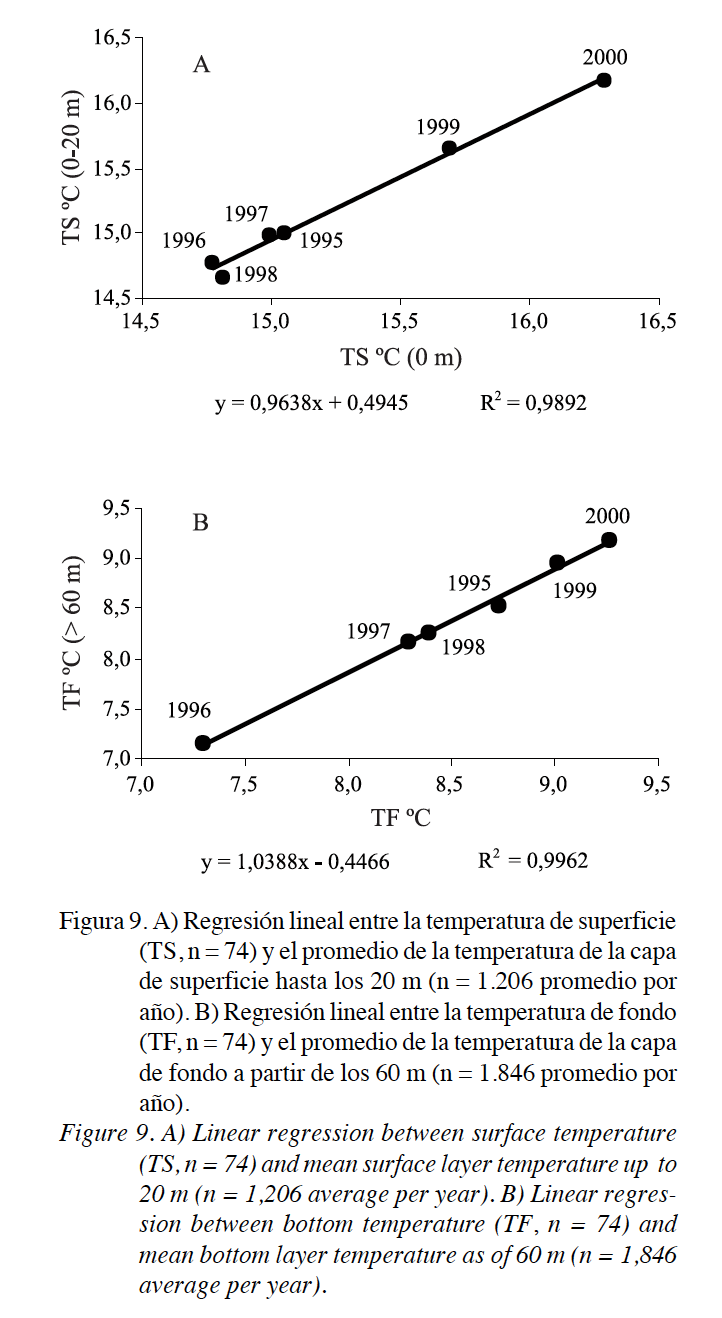
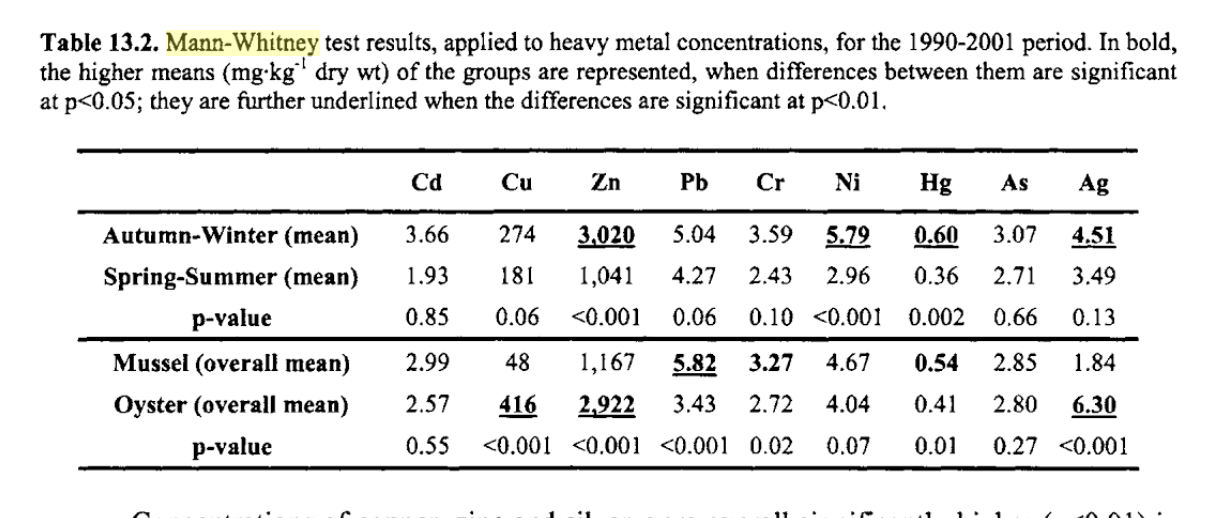
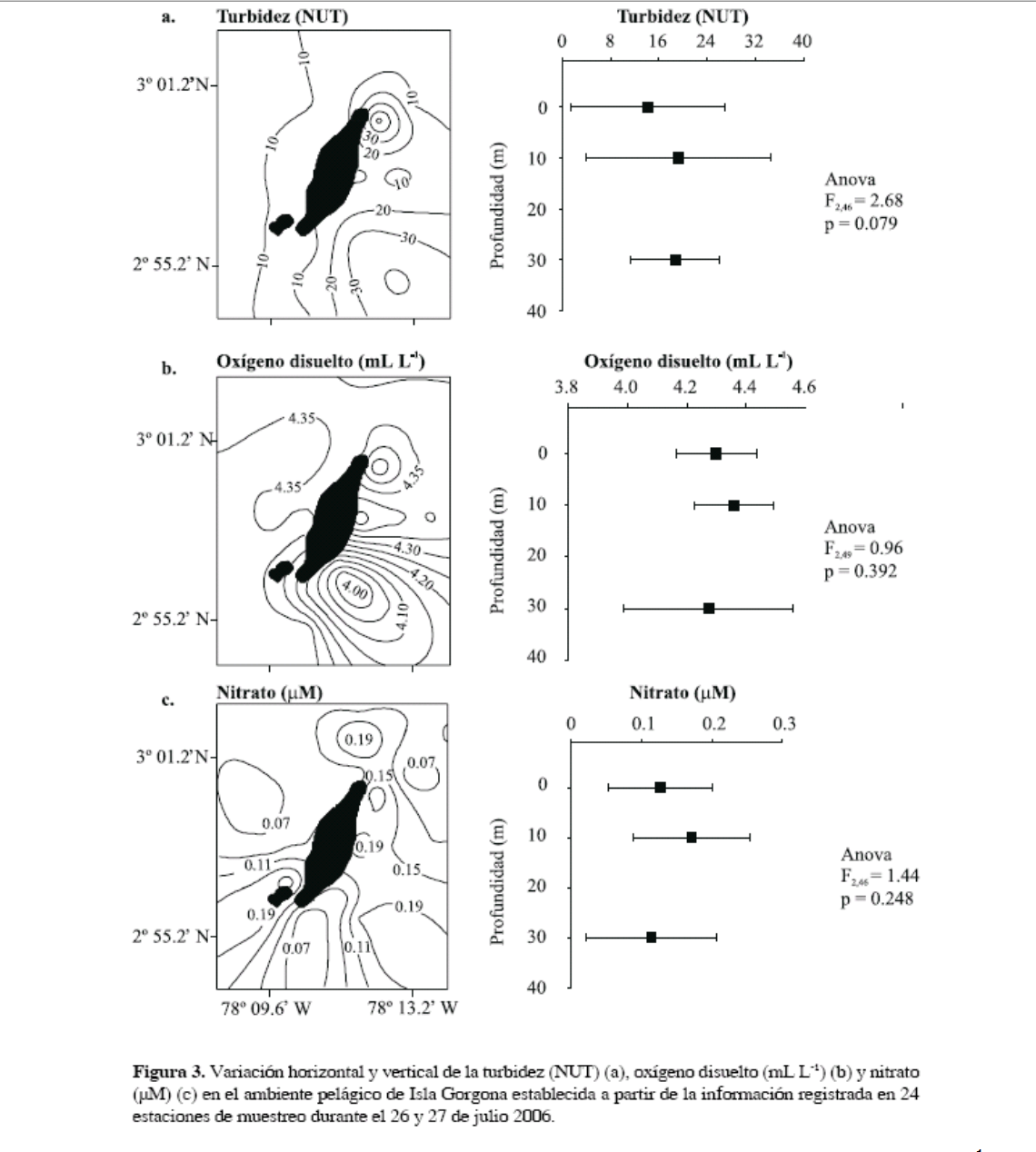
Vamos a ver aquí diferentes tablas y gráficos donde se usa la Estadística en Oceanografía:
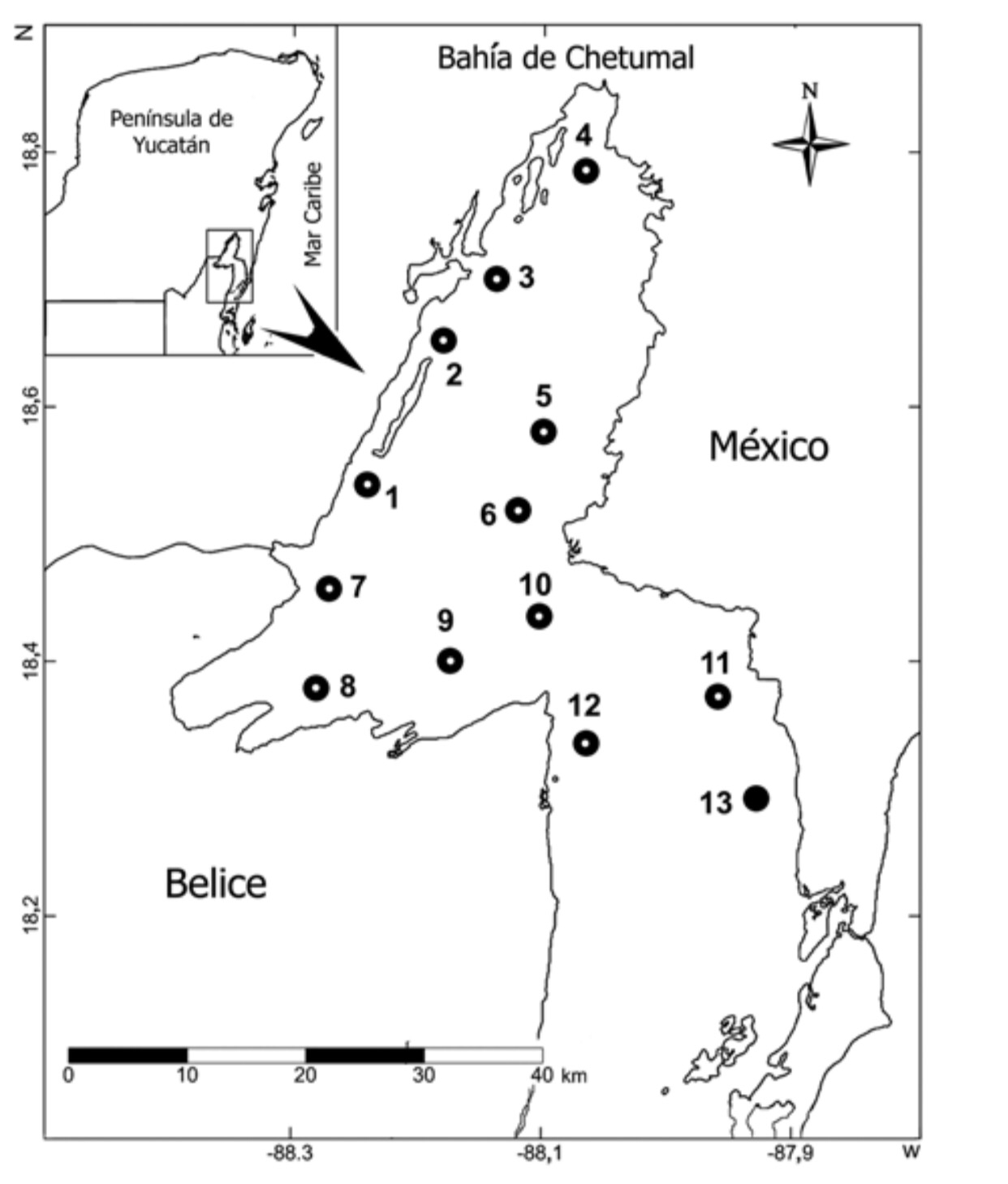
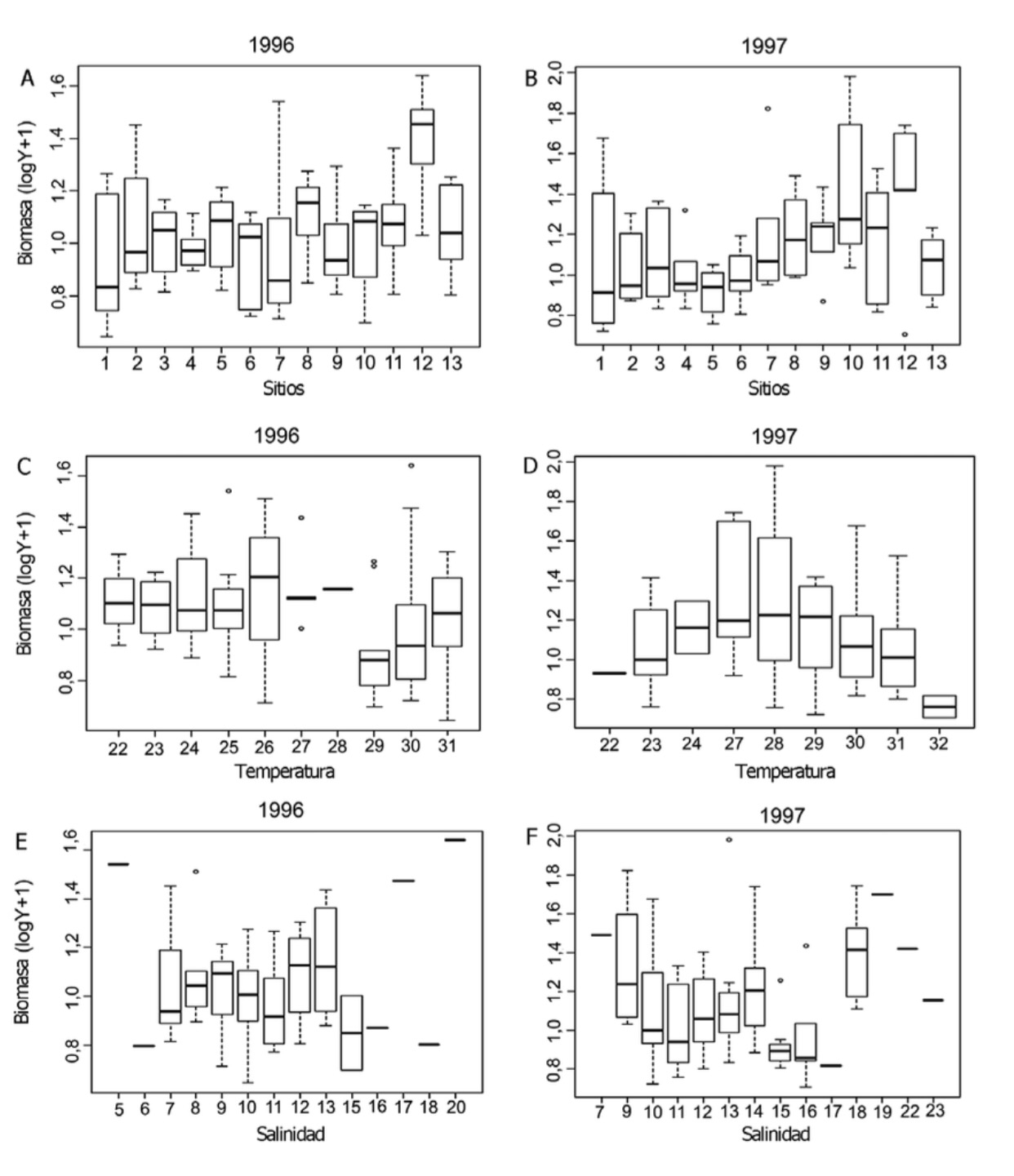
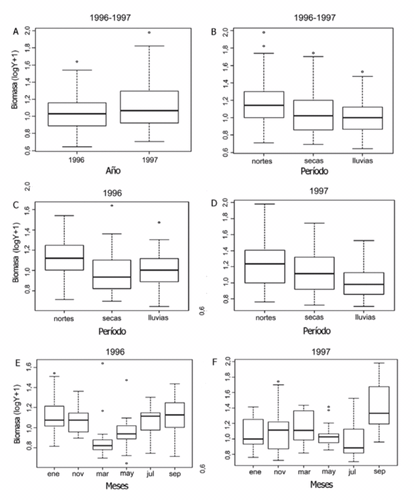
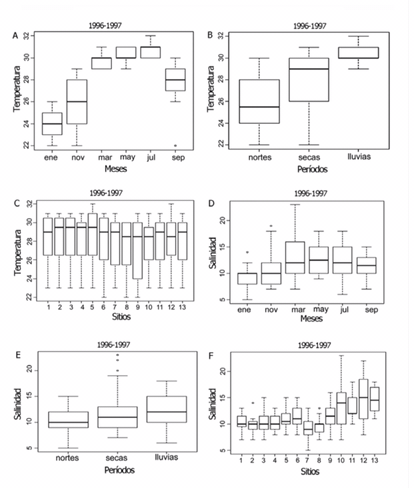
1. Veamos un ejemplo característico de uso del gráfico Box-Plot en oceanografía, donde se eligen una serie de puntos de muestreo y se evalúan en ellos una serie de variables típicas:
2. Veamos a continuación diferentes usos de la media, la desviación típica y el error estándar. El gran problema con el uso de esos dos conceptos (desviación estándar y error estándar) es que, en muchas ocasiones, no queda claro cuál se ha usado y el problema es que el que escribe el artículo tampoco tiene claro cuál le interesa usar en un momento determinado.
A continuación puede verse un redactado de una información descriptiva:
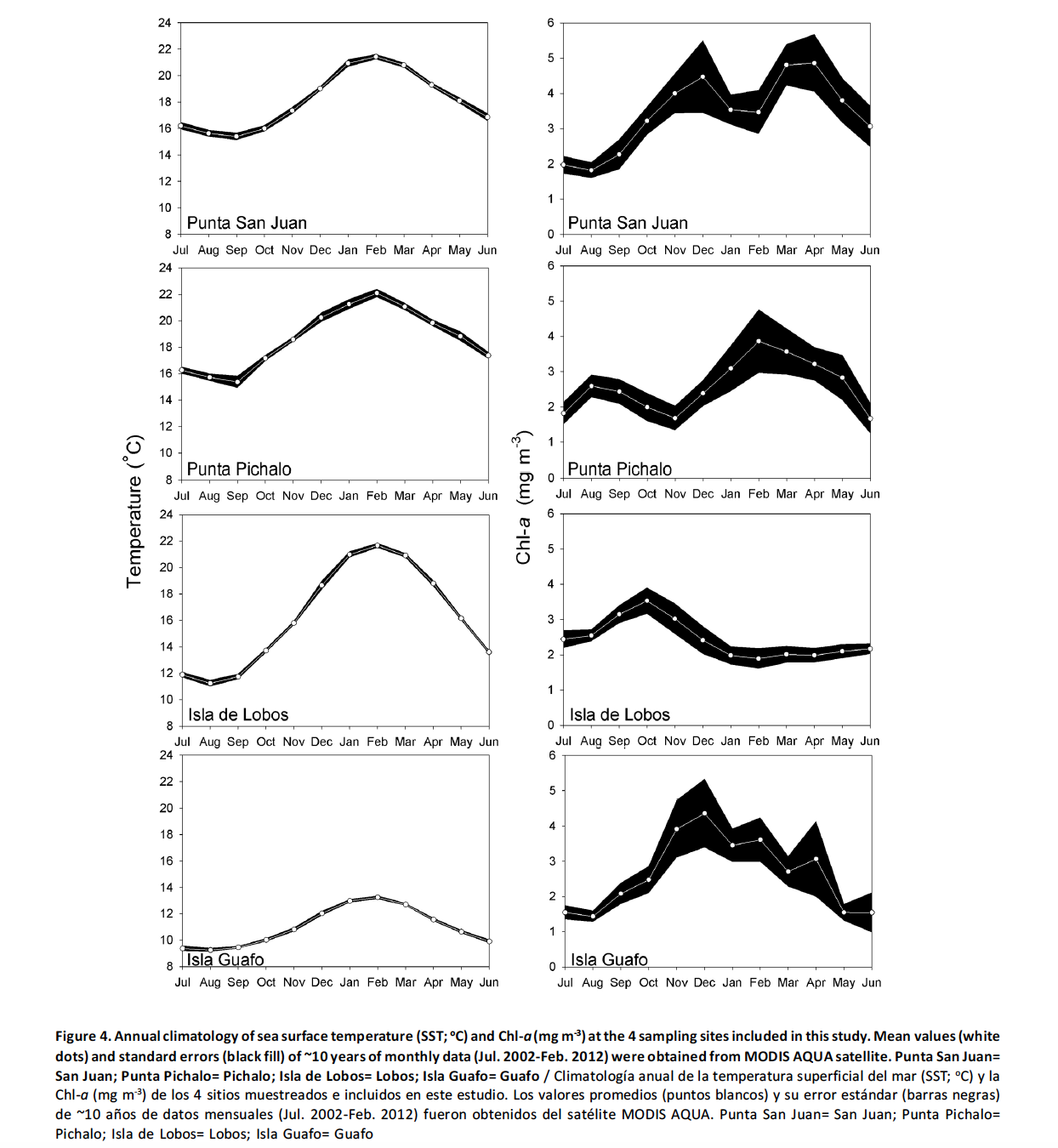
3. Veamos ahora diferentes usos del concepto de correlación:
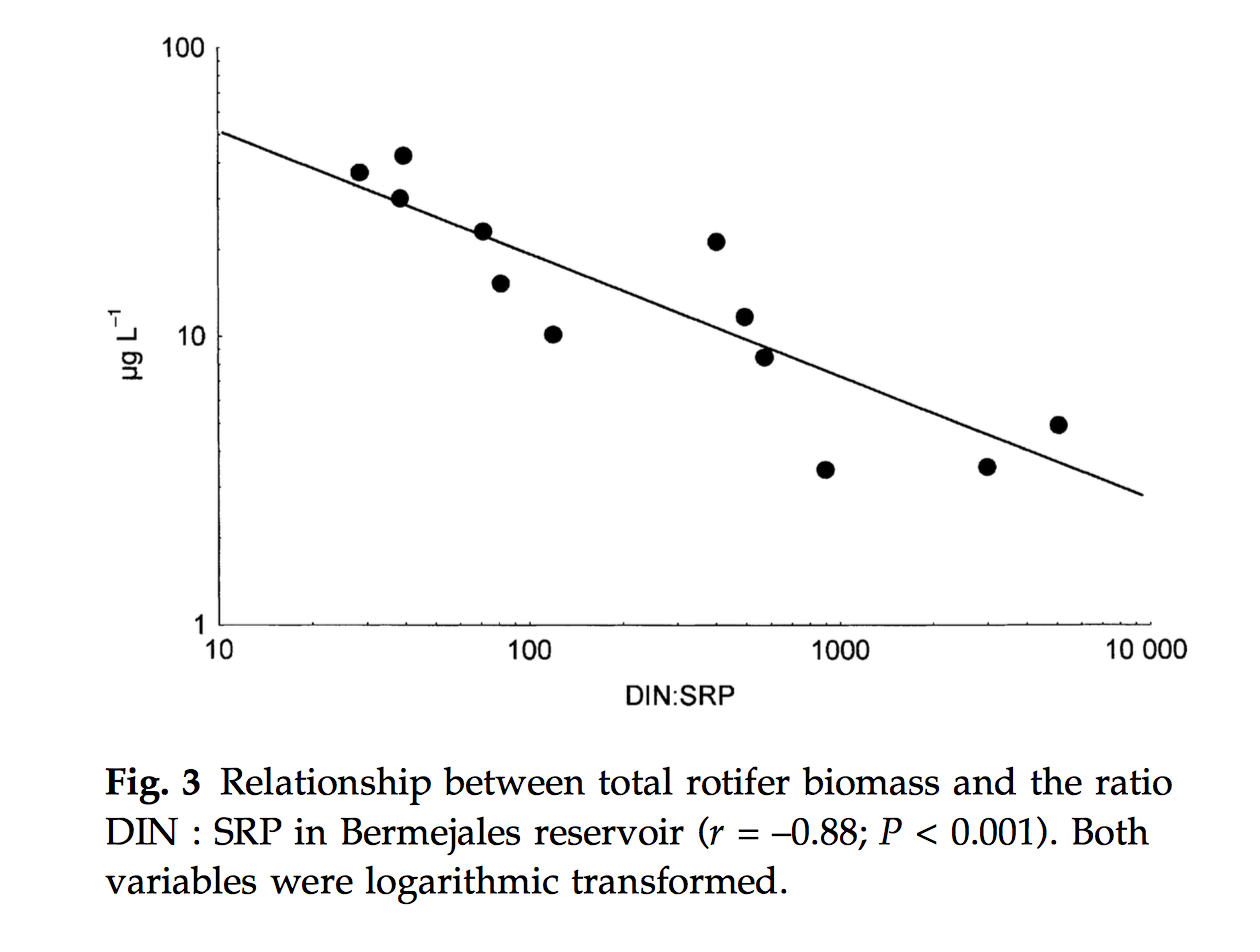
4. Veamos ahora diferentes ejemplos donde aparece la regresión:
Este es un curso de Estadística pensado para preparar para el inicio posterior de un curso universitario de Estadística. Por eso lo llamo «Curso 0». Intenta, mediante un lenguaje sencillo, introducir el lenguaje y los problemas fundamentales que aborda la Estadística.
Podéis seguir, también, si queréis, la explicación con los siguientes vídeos:
Empecemos, pues:
La Estadística es una técnica de decisión, una técnica para la toma de decisiones. Una técnica de decisión basada en procedimientos matemáticos. Una técnica que se basa en la utilización de información que tenemos o que podemos obtener.
La Estadística es la ciencia con la que, a partir de MUESTRAS, decimos cosas (tomamos decisiones) sobre POBLACIONES.
Vamos a ver, en primer lugar, pues, qué entendemos por Poblaciones y por Muestras en Estadística.
Una POBLACIÓN es un conjunto, generalmente muy grande, de personas, de seres vivos, de cosas, etc.
Ejemplos:
La población de todos los menores de 14 años en España.
La población de todos los enfermos de Alzheimer de España.
La población de todos los colegios de Barcelona.
La población de todos los estudiantes de sexto de primaria de Cataluña.
La población de todos los pokémons.
La población de todas las ciudades del mundo.
La población de todos los perros de España.
Una MUESTRA es una parte, generalmente pequeña, de una POBLACIÓN.
Ejemplos:
Hemos seleccionado al azar 100 niños menores de 14 años en España.
Hemos seleccionado, también al azar, 50 personas con Alzheimer en España.
Hemos seleccionada al azar 20 colegios de Barcelona.
Hemos seleccionado 70 estudiantes de sexto de primaria de Cataluña.
Hemos seleccionado al azar 20 pokémons.
Hemos seleccionado al azar 1000 ciudades del mundo.
Hemos seleccionado al azar 200 perros de España.
Observa que la estructura de la relación entre POBLACIÓN y MUESTRA es siempre la que se ve en el siguiente dibujo:
Siempre una MUESTRA es una parte de una POBLACIÓN. Y el objetivo de la Estadística es, precisamente, a partir de lo que podremos saber de esta MUESTRA, a base de estudiarla, de calcular cosas con ella, intentar decir cosas de cómo es la POBLACIÓN que no tenemos.
Evidentemente, no toda MUESTRA tiene la misma calidad. Hay muestras más representativas de la POBLACIÓN que otras. A la hora de elegir la muestra se trata de hacerlo con el máximo de coherencia para tratar que la MUESTRA sea lo más parecido a la POBLACIÓN pero en miniatura. De momento, en este curso 0, basta con saber esto, pero, parece claro que la elección de la muestra es un paso fundamental puesto que, como ya hemos dicho, la Estadística pretende decir cosas de las POBLACIONES a partir del estudio de MUESTRAS. Si la elección de ésta es incoherente mala ciencia estaremos haciendo.
Esto es, pues, la Estadística: Intentar saber cómo es un todo (una POBLACIÓN) que no tienes a partir del estudio de una parte (una MUESTRA) que sí que tienes.
Por lo tanto, estos dos conceptos (MUESTRA y POBLACIÓN) están siempre presentes en la Estadística.
A las personas, seres vivos o cosas de las muestras que tenemos las analizamos para obtener de ellos alguna característica. A estas características las llamamos VARIABLES.
Ejemplos (Observa que cada punto está constituido por los elementos de las POBLACIONES y MUESTRAS vistas en la lección anterior):
La presión arterial de niños menores de 14 años.
El valor del Mini-Mental (es una prueba con una serie de preguntas que finalmente da una puntuación que marca el nivel de gravedad de la enfermedad) que tiene un enfermo con Alzheimer.
La cantidad de alumnos matriculados en un colegio.
La nota de matemáticas de estudiantes de sexto de primaria.
La velocidad de un pokémon.
El número de habitantes en una ciudad.
Si un perro lleva o no un chip identificativo.
Observa que hemos definido una VARIABLE en cada caso pero podríamos escoger otras. Para que lo veas puedo tomar una POBLACIÓN de donde podríamos tener una MUESTRA y definir una larga lista de VARIABLES distintas. Un ejemplo, con los alumnos de sexto de primaria:
Nota de sociales.
Días que no han ido al colegio en el curso pasado.
Nota promedio de quinto.
Nota que le pondría él al tutor que ha tenido.
Si prefiere un hombre o una mujer como tutor.
A qué distancia vive de su escuela.
Si ha repetido o no anteriormente un curso.
Deberá o no repetir quinto.
Observemos, pues, que hasta ahora hemos visto tres conceptos en Estadística que son nucleares y que están siempre presentes en cualquier estudio realizado en cualquier ciencia:
POBLACIÓN.
MUESTRA.
VARIABLE.
Es muy importante, siempre, situar bien cada uno de estos tres conceptos cuando se hace un estudio.
Veamos un ejemplo práctico:
Se quiere ver, en personas que tienen una enfermedad, si un nuevo medicamento que se quiere probar consigue más, menos o igual número de curaciones que el medicamento que se utiliza actualmente.
Llamemos al medicamento habitual como A y al nuevo como B.
Tenemos la POBLACIÓN de todos los enfermos de esa patología. Que pueden ser miles y miles.
El medicamento A lo damos a 100 personas con esa enfermedad y a los que seguiremos con detalle para ver si se curan o no. Estas 100 personas son una MUESTRA de la POBLACIÓN de todos los enfermos.
El medicamento B lo damos a otras 100 personas con esa enfermedad. Evidentemente, personas diferentes a las anteriores. Personas que también seguiremos detalladamente para ver si se curan o no con ese tratamiento. Estas 100 personas son una MUESTRA de la misma POBLACIÓN anterior, la POBLACIÓN de todos los enfermos de esa enfermedad.
La VARIABLE en este estudio es si el enfermo se cura o no con el tratamiento.
Veamos todo el planteamiento del estudio con un dibujo:
Unos resultados que podríamos obtener finalmente del estudio podrían ser los siguientes:
Medicamento A:
70 se curan.
30 no se curan.
Medicamento B:
90 se curan.
10 no se curan.
Observa que entre las dos MUESTRAS hay diferencias. Con el medicamento B se curan más personas que con el medicamento A. Es muy claro. De las 100 personas tratadas con el medicamento B se han curado 90. Esto lo expresamos así: un 90 por 100 (lo solemos escribir así: 90%). Sin embargo, con el medicamento A se han curado sólo 70: un 70 por 100 (70%).
Pero, algo muy importante: esto que vemos lo vemos en las MUESTRAS. ¿Pasaría lo mismo si estos tratamientos se aplicaran a la POBLACIÓN entera, a todos los enfermos? Observemos que esto no lo podremos decir hasta que no lo apliquemos. Pero sería interesante predecir si las diferencias que vemos en esas MUESTRAS las veríamos también si cada uno de esos medicamentos se aplicara a toda la POBLACIÓN.
Pues éste es el papel de la Estadística. A eso nos dedicamos los estadísticos y para saber hacer este paso de las MUESTRAS a las POBLACIONES todos los científicos estudian Estadística.
Ya veremos que el gran problema de la Estadística será saber cuándo podemos decir que lo que vemos en las MUESTRAS es lo que veríamos, también, en las POBLACIONES. Cuando decimos, en Estadística, que lo que vemos es ESTADÍSTICAMENTE SIGNIFICATIVO es porque, con muchas posibilidades de no equivocarnos, lo que vemos en las MUESTRAS es lo que veríamos, también, en las POBLACIONES. Pero esto ya lo veremos más adelante. Sigamos, poco a poco.
Veamos ahora un poco más en detalle el tercero de esos tres conceptos que estamos viendo como nucleares en Estadística: el concepto de VARIABLE.
Hay dos tipos básicos de VARIABLES (esas características que medimos o evaluamos a las personas, seres vivos o cosas de una muestra o de una población): las variables cuantitativas y las variables cualitativas.
Las variables cuantitativas son variables que miden una cantidad. Nos dan un número a cada individuo de la muestra que tengamos.
Las variables cualitativas, también llamadas variables nominales, nos valoran una cualidad. Por eso se les llama también nominales, porque los valores de cada individuo son nombres.
Observemos las variables que listábamos antes en referencia a alumnos de sexto de primaria:
Nota de sociales.
Días que no han ido al colegio en el curso pasado.
Nota promedio de quinto.
Nota que le pondría él al tutor que ha tenido.
Si prefiere un hombre o una mujer como tutor.
A qué distancia vive de su escuela.
Si ha repetido o no anteriormente un curso.
Deberá o no repetir quinto.
Las variables 1, 2, 3, 4, 6 son variables cuantitativas. Son o una nota (una nota entre 0 y 10, suponemos) o un número de días o una distancia (en metros o kilómetros). Sin embargo, las variables 5, 7 y 8 son cualitativas. No son una cantidad numérica, sino una cualidad: prefiere un hombre o una mujer como tutor, ha repetido o no anteriormente un curso, debe o no repetir quinto.
Observemos que podríamos definir muchas más variables, tanto de cualitativas como de cuantitativas.
Veamos más ejemplos de variables cualitativas, en esa misma muestra de estudiantes de sexto de primaria:
El sexo del alumno: niño o niña.
El grupo sanguíneo: A, B, AB, O.
Ciudad donde nació.
Tiene o no ordenador en la habitación.
Veamos más ejemplos de variables cuantitativas:
Altura.
Peso.
Metros cuadrados del piso donde vive.
Número de hermanos que tiene.
Ya tenemos los elementos básicos con los que se trabaja, siempre, en Estadística: POBLACIONES, MUESTRAS y VARIABLES.
Ahora vamos a empezar a manejarlos.
La Estadística es una ciencia que actúa manejando Técnica analíticas. Con ellas es como hace este proceso de decir cosas de POBLACIONES a partir de las MUESTRAS.
Existen tres tipos de técnicas en Estadística. Técnicas descriptivas, de relación y de comparación. Vamos a dividir el resto de este curso 0 en tres apartados: uno para cada uno de estos tres tipos de técnicas.
Técnicas descriptivas:
Con las técnicas descriptivas pretendemos resumir nuestras muestras. Hacer una síntesis de la inmensa cantidad de información que hay en ellas.
Lo primero que podemos hacer con una muestra es, siempre, hacer una descripción, un resumen de ella, que es lo que llamamos habitualmente: Estadística descriptiva.
Veamos las principales técnicas descriptivas que se engloban en la llamada Estadística descriptiva.
Con estas técnicas descriptivas conseguiremos una serie de valores que nos proporcionan una serie de rasgos característicos de la MUESTRA que podremos generalizar a la POBLACIÓN, si es que esta MUESTRA es representativa de la POBLACIÓN. Ya sabemos que este es el objetivo de la Estadística como ciencia.
Supongamos que tenemos una muestra de 10 alumnos de sexto de primaria y tenemos los siguientes valores de dos variables: Sexo (niño o niña) y nota de matemáticas:
Alumno
Sexo
Nota
1
h
3
2
m
5
3
m
2
4
m
8
5
h
4
6
h
6
7
h
5
8
m
7
9
m
9
10
h
4
Las técnicas descriptivas que tenemos son distintas según las variables sean cualitativas o cuantitativas.
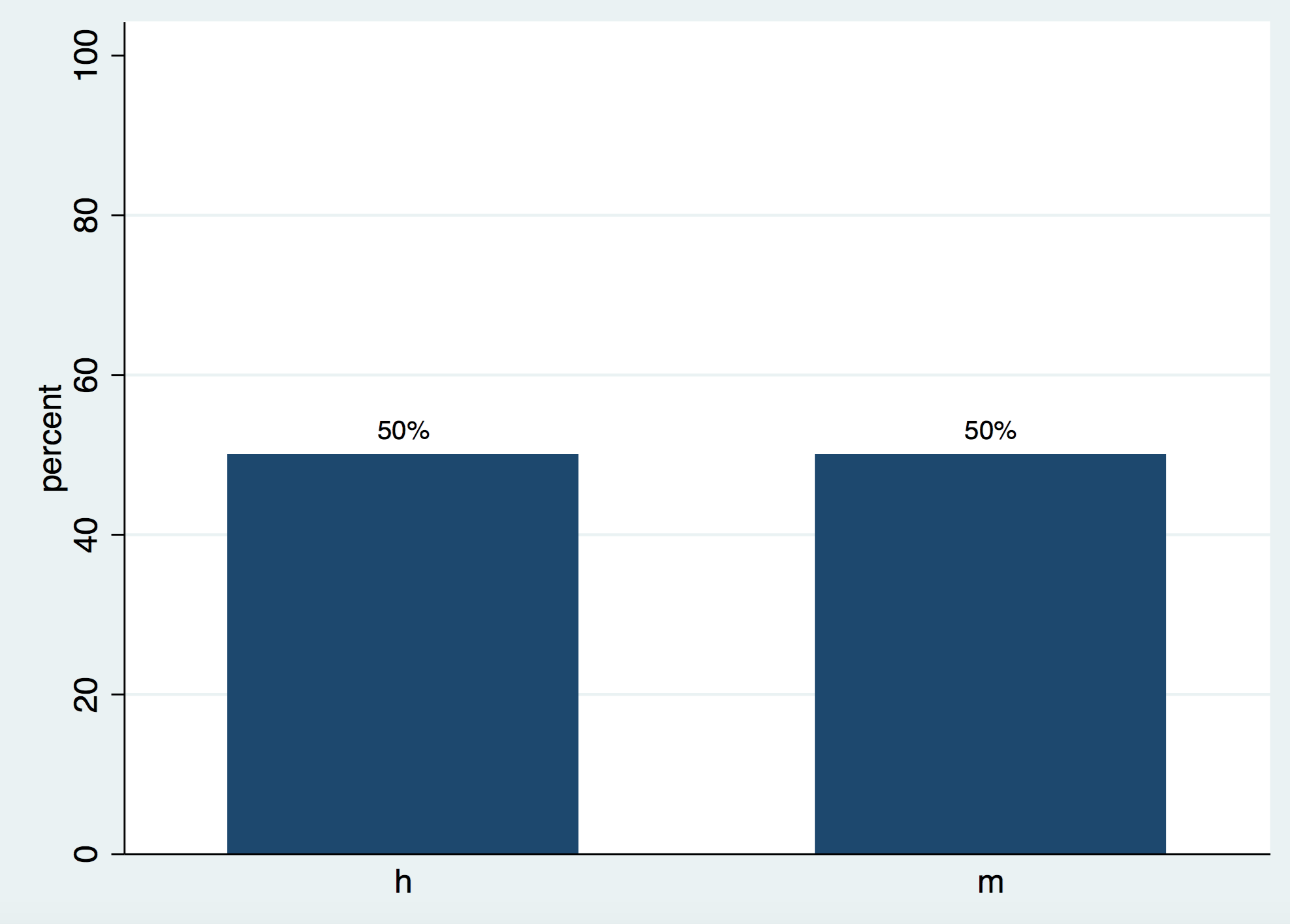
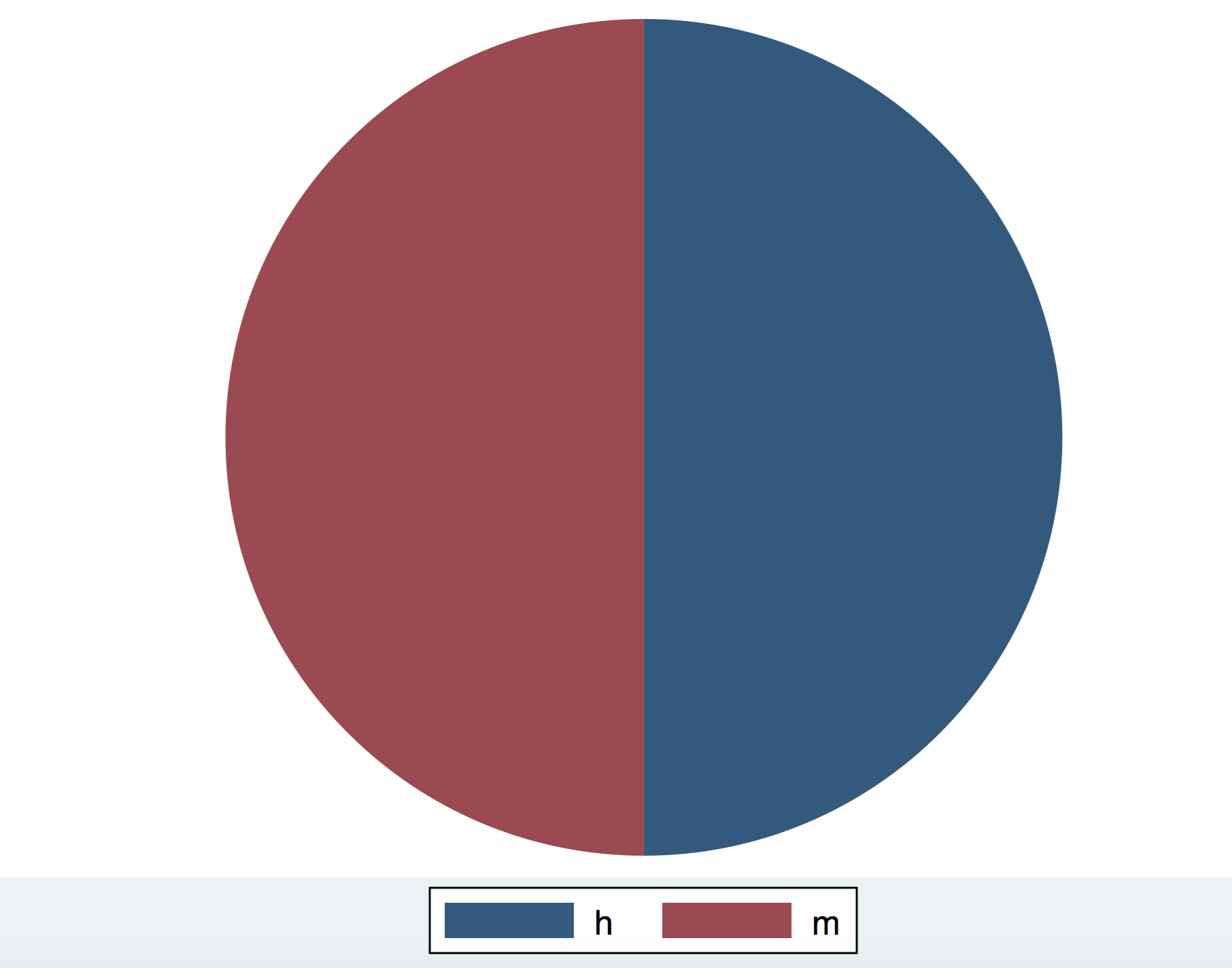
En las cualitativas suele hacerse únicamente un recuento de cada uno de los valores. Consiste, simplemente, en contar cuántos individuos hay de cada una de las diferentes cualidades. En nuestro caso la variable Sexo sólo tiene dos valores posibles: hombres y mujeres. En nuestro caso: 5 hombres y 5 mujeres. Suele también expresarse en porcentaje. En nuestro caso: 50% de hombres y 50% de mujeres. Si se dan los valores sin porcentaje se dice que se dan las frecuencias absolutas, si se dan en porcentaje se dice que se dan las frecuencias relativas.
También se suele acompañar de un gráfico con diagramas de frecuencias o con un diagrama pastel. A continuación veréis cómo quedarían estos gráficos:
Con las variables cuantitativas las posibilidades son mucho mayores. Suelen calcularse diferentes valores que resuman la muestra, respecto a un determinado aspecto. Es muy habitual dar la media y la desviación estándar. En la variable Nota, de nuestro ejemplo, estos dos valores serían:
La media (Mean) y la desviación estándar (Std. Dev.) son las que ahora nos interesan. La media es el centro de gravedad de los valores de la muestra. La desviación estándar es una medida de dispersión de los valores de la muestra. Son dos valores muy importantes que se estudian con mucho detalle en un curso de Estadística. Ahora, de momento, nos basta tener en cuenta que son dos valores que se usan con mucha frecuencia para resumir numéricamente una variable cuantitativa.
Basta saber, de momento, que la media es la suma de todos los valores de la muestra dividido por el tamaño muestral, y que la desviación estándar es un valor que va de 0 hacia arriba y que cuanta más dispersión de valores mayor es su valor.
Por ejemplo, la muestra: (5, 5, 5, 5) tiene desviación estándar 0. Y la muestra (0, 5, 5, 10) tiene mayor desviación estándar que la muestra (4, 5, 5, 6). También es bueno saber que la muestra (10, 11, 11, 12) tiene la misma desviación estándar que esta última y que la siguiente: (105, 106, 106, 107). Es muy importante, de momento, tener muy claro todo esto.
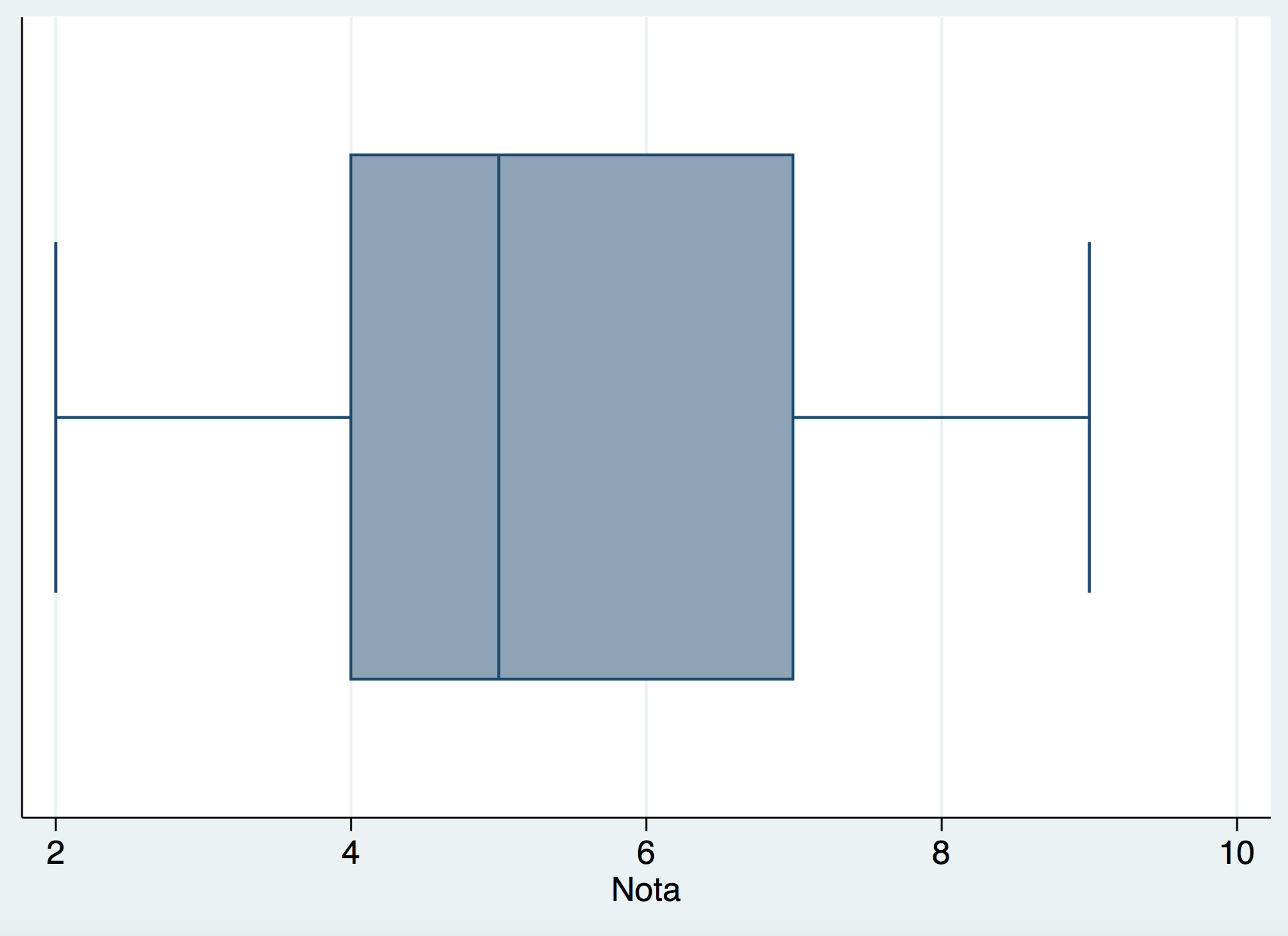
También en las variables cuantitativas es muy importante el denominado Box-Plot. En la variable Nota el Box-Plot es el siguiente:
Este gráfico es muy importante. Pero para entenderlo bien es mejor verlo en otra muestra.
El valor extremo de la izquierda es el valor mínimo de la muestra, el valor extremo de la derecha es el valor máximo. El punto donde empieza la caja es el primer cuartil o percentil 25. Donde acaba la caja es el tercer cuartil o percentil 75. La línea que fragmenta la caja en dos rectángulos es el segundo cuartil, percentil 50 ó Mediana (esta última denominación es la más habitual).
Para ver cómo se calculan esos importantes valores resumen de la muestra, veamos un caso de una muestra un poco más sencilla de manejar.
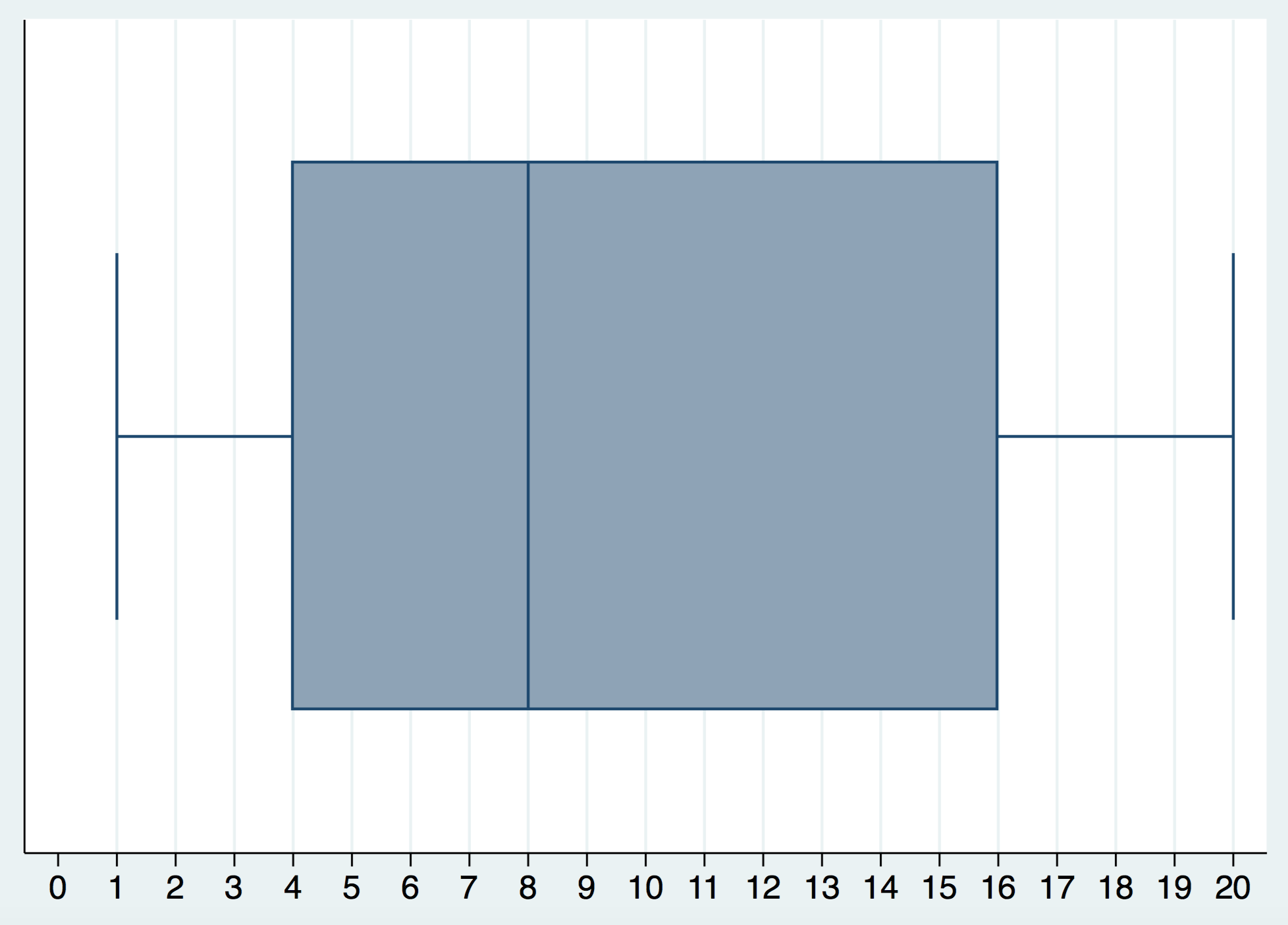
Supongamos la siguiente muestra: (1, 3, 5, 7, 9, 15, 17, 20). El Box-Plot sería el siguiente:
Lo primero que hay que hacer para realizar estos cálculos es ordenar la muestra de menor a mayor. El mínimo y el máximo de la muestra es claro cómo se obtienen. El primer cuartil o percentil 25 es aquel valor que divide la muestra es un 25% de valores a la izquierda y un 75% de valores a la derecha. El tercer cuartil o percentil 75 es aquel valor que divide la muestra es un 75% de valores a la izquierda y un 25% de valores a la derecha. La mediana es aquel valor que divide la muestra es un 50% de valores a la izquierda y un 50% de valores a la derecha.
Veamos el cálculo del primer cuartil: Si nos situamos entre el 3 y el 5 tenemos un 25% de valores a la izquierda y un 75% de valores a la derecha. En este caso se hace el promedio de estos dos valores para tener el primer cuartil, que es 4.
Veamos el cálculo del tercer cuartil: Si nos situamos entre el 15 y el 17 tenemos un 75% de valores a la izquierda y un 25% de valores a la derecha. En este caso se hace el promedio de estos dos valores para tener el tercer cuartil, que es 16.
Veamos el cálculo de la mediana: Si nos situamos entre el 7 y el 9 tenemos un 50% de valores a la izquierda y un 50% de valores a la derecha. En este caso se hace el promedio de estos dos valores para tener la mediana, que es, en este caso: 8.
A veces el primer o tercer cuartil o la mediana no se sitúa entre dos valores sino que es un valor mismo de la muestra. Un ejemplo: En la muestra (2, 5, 7, 9, 20) la mediana es 7. Observemos que a la izquierda de 7 tenemos el 50% de valores y a su derecha tenemos, también, un 50% de valores.
Encontraréis Box-Plots en muchos artículos de cualquier ciencia, pero mirad a continuación un ejemplo muy sorprendente. Raramente veréis un Box-Plots con los valores muestrales superpuestos:
2. Técnicas de relación
Con las técnicas de relación, como dice bien su nombre, tratamos de detectar relación entre diferentes variables de nuestra muestra. Como siempre, el objetivo será ver si las relaciones que detectamos en la MUESTRA son generalizables a la POBLACIÓN. Esto siempre está presente porque, como ya hemos dicho desde el principio, este es el objetivo de la Estadística como ciencia.
Detectar relación entre variables es muy importante en cualquier ciencia. Detectar si hay o no relación y, si la hay, mirar de cuantificarla, mirar de ver su intensidad. Porque hay grados distintos de relación.
Un ejemplo sencillo: la variable altura y peso en humanos tiene relación. Personas altas pesan más y personas bajas pesan menos. Esto indica que hay relación entre esas dos variables. Pero entre altura y número de pie hay mucha más relación. Y entre altura y longitud del fémur aún hay más relación. A esto nos referimos al decir que hay que detectar relación, primero, y, después, ver qué cantidad de relación tenemos.
Las dos técnicas más importantes y más usadas para detectar y cuantificar la relación entre dos variables son: la correlación de Pearson y la Odds ratio.
La correlación de Pearson cuantifica la relación entre dos variables cuantitativas.
La Odds ratio cuantifica la relación entre dos variables cualitativas dicotómicas (una variable dicotómica es una variable con sólo dos valores posibles).
En este curso 0 para introducirnos en el mundo de las técnicas de relación vamos a centrarnos en la Odds ratio, que es una medida extraordinariamente importante, especialmente en el ámbito de las ciencias de la salud.
Lo vamos a hacer viendo una serie de artículos de este blog que están pensados especialmente para introducirnos en esta importante técnica estadística. Los artículos son los siguientes:
Con las técnicas de comparación tratamos de comparar los valores de una variable en diferentes muestras. El objetivo será, evidentemente, como siempre, ver si las diferencias que detectamos en las MUESTRAS son generalizables a las POBLACIONES que hay detrás de ellas. Esto siempre está presente porque, no lo olvidemos, de nuevo, este es el objetivo de la Estadística como ciencia.
Hay que distinguir, a la hora de realizar una comparación estadística, varias situaciones distintas muy importantes:
a. Comparación de dos poblaciones/Comparación de más de dos poblaciones.
b. Comparación de una variable dicotómica/Comparación de una variable cuantitativa.
c. Comparación de muestras independientes/Comparación de muestras relacionadas.
d. Comparación de variables cuantitativas normales/Comparación de variables cuantitativas no normales.
e. Comparación de proporciones/Comparación de medias/Comparación de medianas/Comparación de distribuciones/Comparación de correlaciones/Comparación de Odds ratio.
Y todo esto porque así como en las técnicas de relación hay realmente un listado pequeño de técnicas analíticas (la correlación de Pearson y la Odds ratio son muy mayoritarias), en las técnicas de comparación son muchísimas las técnicas de comparación que se aplicar en la realidad. Y es en función de estos conceptos vistos cómo van delimitándose cuáles son las técnica a aplicar en un momento determinado.
1b:Debe aplicarse la fórmula de la construcción de un intervalo de confianza del 95%. Aquí tenemos las dos fórmulas. La primera para una variable cuantitativa y la segunda para una variable dicotómica. En nuestro caso debemos aplicar la segunda:
El cálculo es:
0,08±2x(Raíz(0,08×0,92))/Raíz(10000))
en tanto por uno, que da este intervalo de (7.46, 8.54), en tanto por ciento.
2a: El error estándar es 0.25 porque el radio del intervalo es 0.5 y como es un intervalo del 95% se ha cogido dos veces ese error estándar al construir el intervalo.
Entonces: 0.25=DE/Raíz(400). Por lo tanto, la DE es 5.
Si ahora construimos un intervalo de valores individuales del 95% debemos coger dos veces esa DE y nos da el intervalo (40, 60).
3b: El primer cuartil es 5 y el tercero es 8. Por lo que el rango intercuartílico es 3.
4b: Es el único caso donde se dice lo mismo sobre la significación de la correlación y de la pendiente.
5d: Es el único caso donde la relación es significativa y, por lo tanto, el único caso donde tiene sentido hacer una predicción y, por lo tanto, será la mejore de las posibles predicciones.
6c:Este es el único caso en el que las dos afirmaciones van en la misma dirección de la respuesta generada. En este caso si disminuimos la diferencia de medias y aumentamos la desviación estándar el p-valor subirá por las dos causas.
7c:Debemos aplicar la fórmula:
pero con una variación: con un 9 en lugar de un 4 porque es un intervalo del 99.5%, lo que implica que hay que construir un intervalo con 3 veces el error estándar. El 9 viene de hacer el cuadrado de 3. Podemos deducirlo de las fórmula del inicio del Tema 16.
Si aplicamos esta fórmula con una p=0.2 y un radio r=0.01 porque se trabaja siempre en tanto por uno, obtenemos n=14400.
8c:El valor de referencia es 12.59 en una tabla 4×3. Como el valor de la ji-cuadrado es mayor que ese valor de referencia el p-valor será menor que 0.05.
9d:Variable dicotómica, muestras relacionadas, la técnica a aplicar es el Test de McNemar.
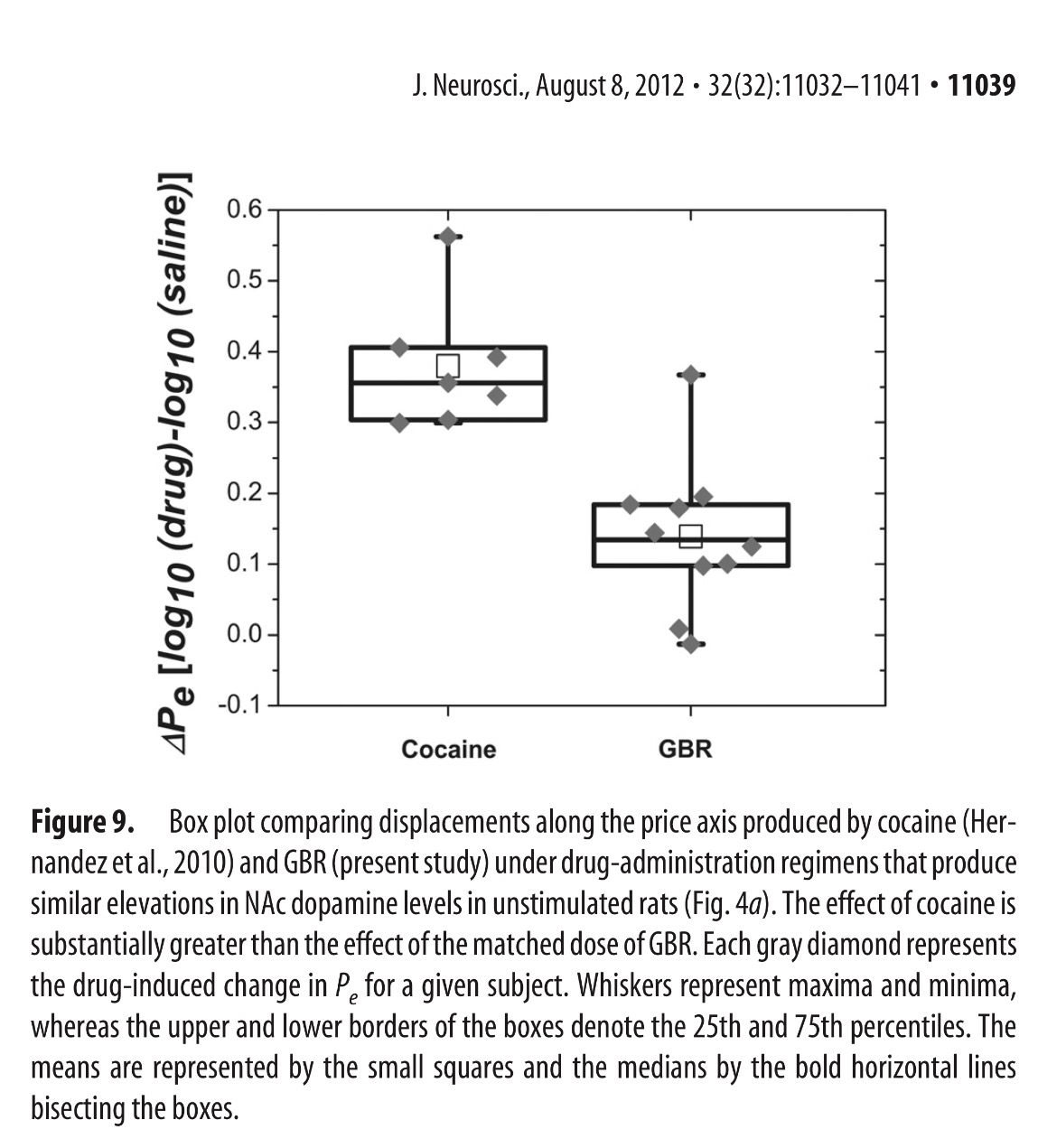
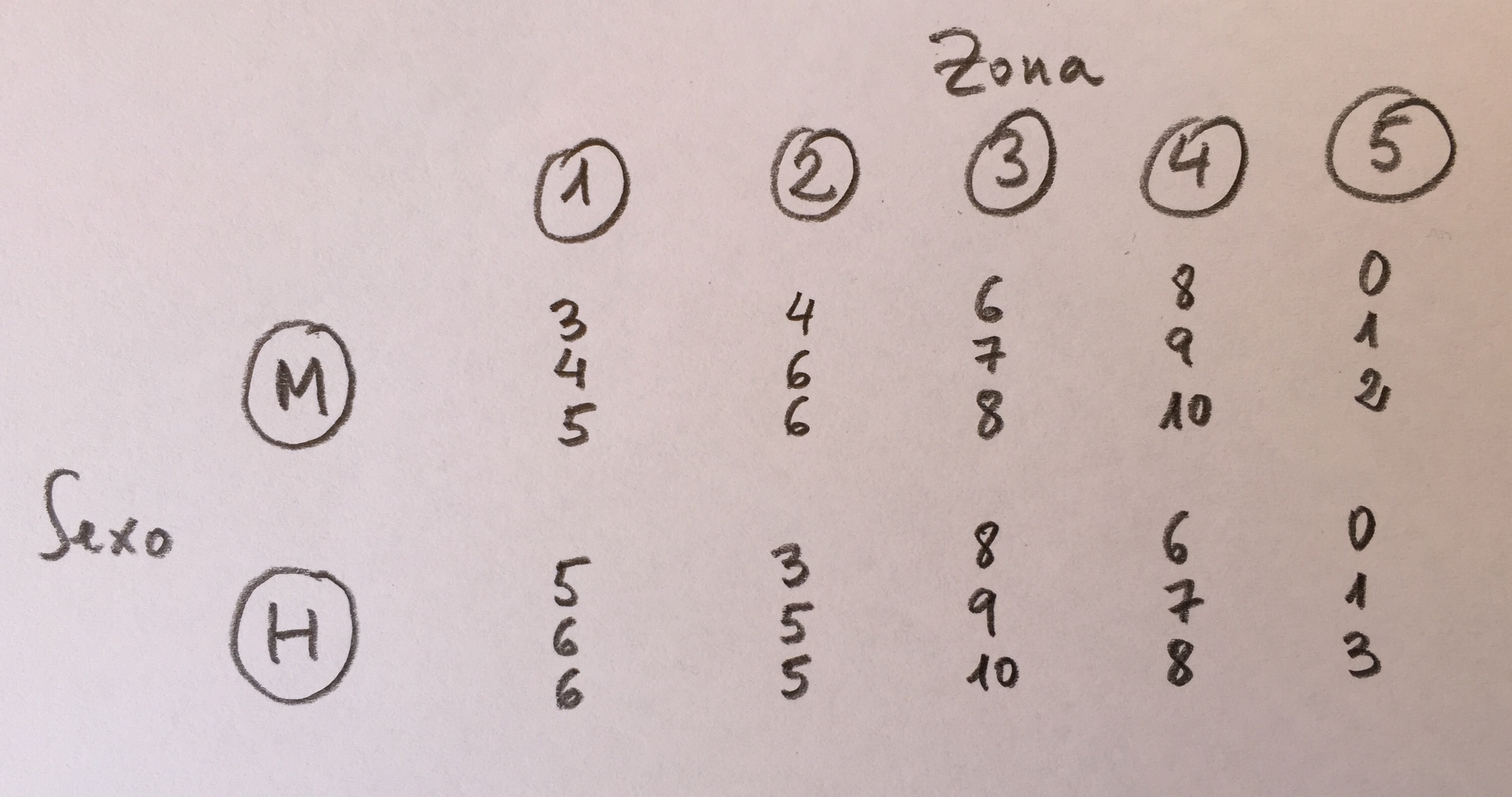
10a: Zona es un factor significativo. Claramente hay tres grupos homogéneos. El sexo no es significativo. Se observa claramente que en promedio no hay diferencias entre ambos sexos. Y hay interacción porque claramente dependiendo de la zona los valores de los sexos cambian.
11d: En un análisis de componentes principales siempre el número de componentes es el mismo que el número de variables originales del estudio.
12a: La Odds ratio estimada siempre debe estar dentro del intervalo de confianza construido.
13c:Es la Odds ratio con mayor relación. Veamos cuál es su equivalente del otro lado: 1/0.6=1.6666, que es mayor que 1.5. Las otras OR no hace falta valorarlas porque no son significativas.
14c: Observemos que intervalo de confianza que nos dan es del 68.5% no del 95%. Además, con lo próximo que está el 0 en este intervalo es evidente que el intervalo del 95% que será bastante mayor contendrá al 0 e indicará que no hay relación.
15c: Observemos que una OR de 5 es equivalente a una de 0.2. Si tener madre anoréxica es un factor de riesgo con OR de 5, obviamente no tenerla es un factor de protección equivalente y, por lo tanto, con OR de 0.2.
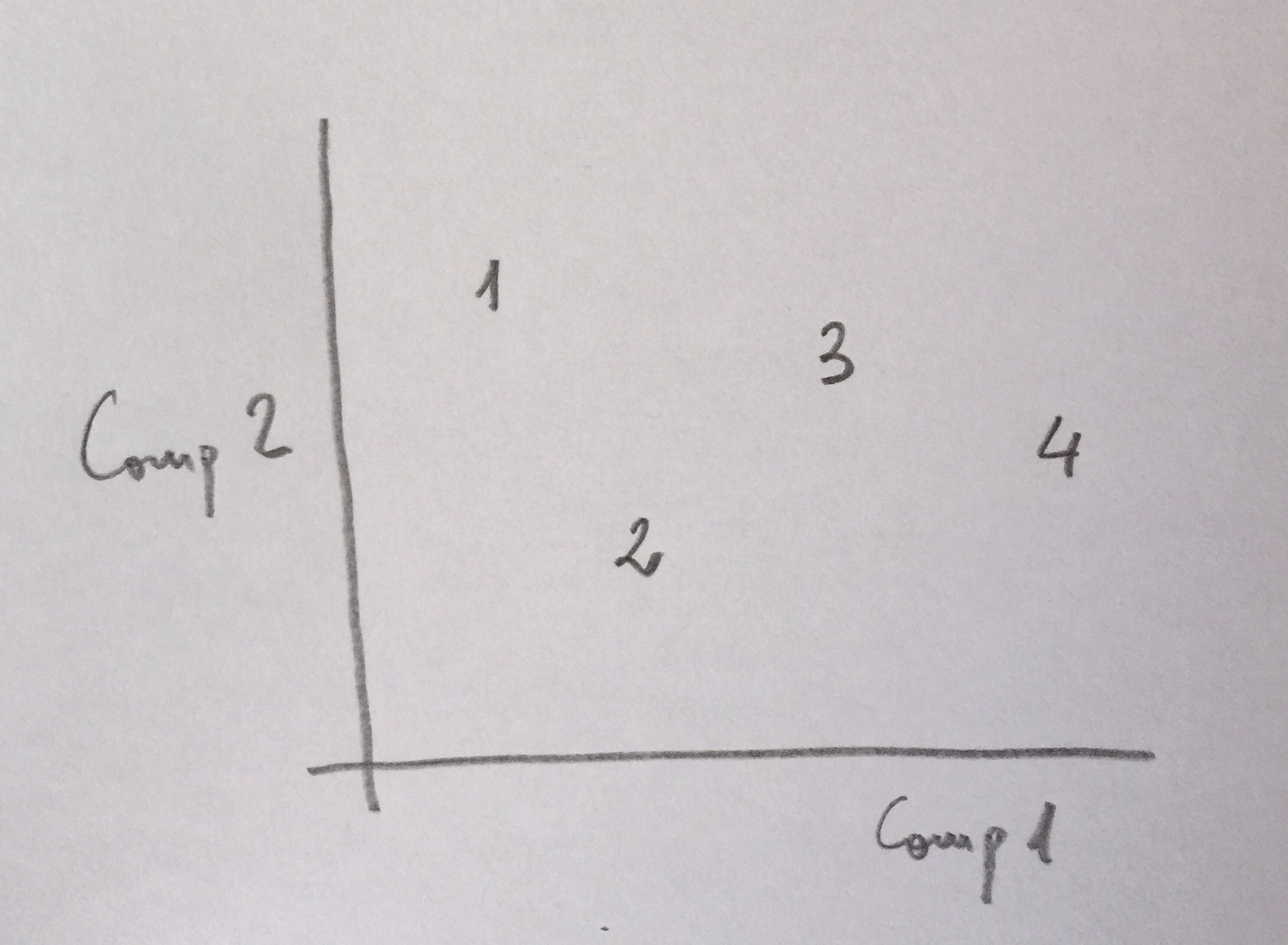
16d: El 2 está a la izquierda para la primera componente y abajo para la segunda. Para estar a la izquierda por la primera componente debe tener valores pequeños de X e Y y grandes de Z. En este caso c y de serían las opciones. Para estar abajo para la segunda componente es necesario que X sea pequeño e Y más grande. Sería el caso, pues, de la opción d.
17c:Es la respuesta incorrecta. Porque claramente no hay relación. Observad que hay un total paralelismo entre las filas. La tabla esperada será exactamente igual que la observada. Por lo tanto, a y b serán ciertas y la d también es cierta: 9.4877 es el valor umbral.
18c: Tenemos dibujados los Box-Plot. Para saber si hay diferencias significativas debemos construir los intervalos de la media y ver si se solapan y, por lo tanto, necesitamos el tamaño de muestra.
19c:La ji-cuadrado no da la significación de una V de Crámer. Como en este caso el p-valor es mayor que 0.05 esta V aunque sea muy grande no es estadísticamente significativa.
20b: En un contraste de hipótesis siempre podemos comenter un error: o el de tipo 1 ó el de tipo 2. Siempre. En este caso, debido al p-valor mantendríamos la Hipótesis nula, por lo que podríamos cometer el error de tipo 2.
1.Si en un estudio sobre la prevalencia de una enfermedad psiquiátrica tenemos una muestra de tamaño 10000 de los cuales 800 tienen esa patología, un intervalo de confianza del 95% del porcentaje poblacional será:
a)(7.20, 8.80)
b)(7.46, 8.54)
c)(7.16, 8.84)
d)(7.50, 8.50)
2.En un estudio vemos que nos dan el siguiente intervalo de confianza del 95% de la media: (49.5, 50.5). Leemos que el tamaño de muestra ha sido 400. ¿Cuál es el intervalo de confianza del 95% descriptivo de la variable o, también denominado, intervalo de valores individuales de esa variable?
a)(40, 60)
b)(35, 65)
c)(30, 70)
d)(45, 55)
3.¿En cuál de las siguientes muestras el rango intercuartílico es 3?
a)(1, 3, 6, 10)
b)(1, 5, 5, 8, 12)
c)(1, 3, 3, 3, 7)
d)(1, 1, 3, 6)
4.De las siguientes afirmaciones cuál es cierta:
a)En una Regresión es compatible una pendiente con p=0.45 con un IC de confianza del 95% de la correlación de (-0.7, -0.1)
b) En una Regresión es compatible un intervalo de confianza del 95% de la pendiente (-2.1, 3.8) con una correlación con p=0.28
c) En una Regresión es compatible una pendiente con un p-valor de 0.01 con una de la correlación con un intervalo de confianza del 95% (-0.2, 0.3)
d) En una Regresión es compatible un intervalo de confianza del 95% de la pendiente (1.7, 3.8) con uno de la correlación de (-0.35, -0.15)
5.En cuál de las siguientes regresiones lineales simples podremos hacer mejores predicciones:
a) y=5x-5; IC del 95% de la pendiente (-1, 11)
b) y=10x-3; IC del 95% de la correlación (-0.2, 0.2)
c) y=x-2; IC del 95% de la pendiente (-1, 2)
d) y= 4x+1; IC del 95% de la correlación (0.1, 0.4)
6.Si en una comparación de dos poblaciones al aplicar el test adecuado al caso el p-valor final es 0.01 es cierto lo siguiente:
a)Si aumentamos el tamaño de muestra y disminuimos la desviación estándar el p-valor subirá.
b)Si aumentamos la desviación estándar y aumentamos la diferencia de medias el p-valor bajará.
c)Si disminuimos la diferencias de medias y aumentamos la desviación estándar el p-valor subirá.
d)Si disminuimos el tamaño de muestra y aumentamos la diferencia de medias el p-valor bajará.
7.Se quiere hacer un pronóstico del porcentaje de consumidores que tendría un producto y se quiere tener una muy buena precisión: que el radio del intervalo sea del 1% en un intervalo del 99.5%. Sabemos que un producto similar en países muy parecidos al nuestro tiene un porcentaje de consumo alrededor del 20%. ¿Cuál es el tamaño de muestra recomendable en base a esta información:
a)6400.
b)11500.
c)14400.
d)8800.
8.Si en una tabla de contingencias 4×3 en la que relacionamos dos variables cualitativas tenemos que el valor de la ji-cuadrado es 14.55 podemos afirmar:
a)Que el p-valor es superior a 0.05 porque 14.55 es menor que el umbral que es 21.02.
b)Que el p-valor es inferior a 0.05 porque 14.55 es mayor que el umbral que es 3.84.
c)Que el p-valor es inferior a 0.05 porque 14.55 es mayor que el umbral que es 12.59.
d)Que el p-valor es superior a 0.05 porque 14.55 es menor que el umbral que es 24.99.
9.Se ensayan dos medicamentos (A y B) en 50 pacientes con Alzhéimer, en dos épocas distintas. Cada paciente recibe, pues, ambos tratamientos en épocas diferentes. El objetivo es evaluar si durante medio año el valor del Mini-Mental ha bajado o no respecto al valor basal. Con el A un 5% no baja y con el B no baja sólo un 2%. Para analizar los datos deberemos aplicar:
a)El Test de proporciones.
b)El Test exacto de Fisher.
c)El Test de Mann-Whitney.
d)El Test de McNemar.
10.Se ha hecho un estudio de valoración de la atención psicológica en pediatría entre el 1 y el 10 en cinco zonas del país y en los dos sexos (padres y madres). Los resultados obtenidos son los siguientes:
a)Zona: p<0.05 con tres grupos homogéneos. Sexo: p>0.05. Interacción: p<0.05.
b)Zona: p<0.05 con tres grupos homogéneos. Sexo: p<0.05. Interacción: p<0.05.
d)Zona: p<0.05 con dos grupos homogéneos. Sexo: p<0.05. Interacción: p>0.05.
¿Cuál de las siguientes afirmaciones es cierta?
a)Un intervalo de confianza de la media del 95% es siempre más amplio que un intervalo de confianza del 99.5% también de la media.
b)En una muestra con Asimetría estandarizada entre -2 y +2 la Curtosis estandarizada también cae entre -2 y +2.
c)En el Análisis clúster la hipótesis nula afirma que hay un único grupo y la hipótesis alternativa afirma, por el contrario, que hay más de un grupo.
d)En un Análisis de componentes principales hecho a diez variables originales obtenemos diez componentes.
12.¿Cuál de estas cuatro informaciones es incoherente?
a) OR=3.1; IC 95% (0.2, 0.45); p=0.001
b) OR=2.5; IC 95% (2.1, 3.2); p=0.0001
c) OR=2.8; IC 95% (1.24, 4.95); p=0.01
d) OR=0.6; IC 95% (0.12, 1.83); p=0.34
13.¿Qué Odds ratio indica una mayor relación?
a)OR=1.5; IC 95% (1.1, 2.45)
b)OR=2; IC 95% (0.91, 5.2)
c)OR=0.6; IC 95% (0.35, 0.87)
d)OR=0.3; IC 95% (0.02, 1.34)
14.En una Regresión lineal simple es cierto:
a)Si la pendiente tiene un intervalo de confianza del 95% de (0.55, 1.5) no es estadísticamente significativa por contener al 1.
b)Si la R2 es inferior al 5% tenemos una relación que no es estadísticamente significativa entre las variables de la regresión.
c)Con una correlación r=0.3 con un intervalo de confianza del 68.5% de (0.03, 0.68) podemos decir que se trata de una correlación que no es estadísticamente significativa.
d)Una pendiente positiva o negativa pero estadísticamente significativa no puede tener una R2 menor del 50%.
15.¿Cuál de las siguientes afirmaciones es cierta?
a)Una correlación r=-0.75 (p<0.05) tendrá una pendiente de regresión negativa pero no necesariamente significativa.
b)Si en una muestra no hay normalidad, con una Asimetría estandarizada que desplaza mayoritariamente los valores hacia el lado izquierdo, por debajo del primer cuartil hay más valores que por encima del tercer cuartil.
c)Si tener madre anoréxica es un factor de riesgo para que una chica sea anoréxica con una OR=5, tener una madre sin anorexia es un factor de protección para la anorexia, con una OR=0.2.
d)El valor del percentil 75 es siempre mayor que el valor del percentil 25.
16.En un Análisis de componentes principales la primera componente principal es V=0.5X+0.5Y-0.5Z y la segunda es W=0.5X-0.5Y+0.01Z ¿Cuál de los siguientes puntos es el que está en la posición del 2?:
a)(1, 0, 1)
b)(1, 2, 1)
c)(2, 1, 5)
d)(0, 2, 5)
17.En la tabla de contingencias siguiente:
¿Cuál de las siguientes afirmaciones no es cierta?
a)El valor de la ji-cuadrado será 0.
b)El p-valor será 1.
c)El p-valor no será 1 porque la tabla de contingencia esperada no coincide con esta tabla observada.
d)El valor umbral a partir del cual rechazaríamos la hipótesis nula es 9.4877.
18.Hemos hecho una comparación de dos tratamientos en dos grupos diferentes. Los valores de la muestra que tenemos quedan representados de la siguiente forma mediante un Box-Plot:
Si queremos hacer una comparación de medias de ambos grupos, ¿cuál de las siguientes afirmaciones es cierta?
a)Estos dos grupos constituyen un único grupo homogéneo puesto que se solapan los intervalos de confianza.
b)Las medias serán significativamente diferentes porque ya se observa que el grupo 2 tiene una media superior a la del grupo 1.
c)Necesitamos saber el tamaño de muestra para construir los intervalos de confianza de la media del 95% de cada grupo y ver si esos intervalos se solapan o no.
d)El test que deberíamos aplicar aquí es el test de proporciones.
19.¿Cuál de las siguientes afirmaciones es cierta?
a)Una Odds ratio de 0.5 con un intervalo de confianza del 95% que no contenga al cero es estadísticamente significativa.
b)Una correlación de Pearson de 0.9 con un intervalo de confianza del 95% que no contenga al uno es estadísticamente significativa.
c)Una V de Crámer de 0.9 con una ji-cuadrado con un p-valor de 0.15 implica que no hay relación significativa entre las variables cualitativas relacionadas.
d)Una R2 superior al 50% implica que la regresión lineal simple es estadísticamente significativa.
20.¿Qué error podríamos estar cometiendo si al comparar dos tratamientos el p-valor que obtenemos es de 0.25?
a)El error de tipo I.
b)El error de tipo II.
c)Ambos errores: El error de tipo I y el error de tipo II.
d)No podemos cometer error en este caso porque aceptaríamos la Hipótesis nula por ser el p-valor superior a 0.05.