Cuando se realiza, en Estadística, un contraste de hipótesis, se formulan dos hipótesis: La Hipótesis nula y la Hipótesis alternativa. En esas hipótesis hay afirmaciones. La intersección entre ellas debe ser vacía; o sea, no pueden tocarse, no pueden decir lo mismo, puesto que debemos decidirnos por una u otra.
La Hipótesis nula parte con ventaja porque, a priori, se toma como cierta. En ésta solemos escribir las afirmaciones de lo que podemos decir antes de hacer nada. Y en la Hipótesis alternativa suele estar escrito lo que debemos demostrar, lo que únicamente se puede decir si hay detrás una buena masa de datos que lo certifica.
Entonces se toma una muestra o varias muestras, según lo que estemos haciendo, y se le calcula o se les calcula lo que se denomina un estadístico de test. Este estadístico tiene una determinada distribución ante una población o unas poblaciones determinadas y ante un tamaño muestral o unos tamaños muestrales determinados. Pero observemos que al final siempre se acaba con la misma expresión:
que significa que la distribución de este estadístico T es F(x) en el caso de ser cierta la Hipótesis nula. Las tres rayitas horizontales significan “distribuido”. Solemos decir “bajo la Hipótesis nula” en lugar de “en el caso de ser cierta la Hipótesis nula”, que significa lo mismo y solemos escribir el H0 debajo de las tres rayitas horizontales.
Las distribuciones F(x) de esos estadísticos de test T pueden ser muchas, dependiendo del caso, pero las más usuales son la Distribución t de Student, F de Fisher, N(0,1), ji-cuadrado.
Y entonces se crean en esa distribución dos zonas bien distintas: la zona donde sería más posible tener valores si fuese cierta la Hipótesis nula y la zona donde sería más posible tener valores si fuese cierta la Hipótesis alternativa y tenemos entonces con distribuciones distintas gráficos como los siguientes:
Observemos que se dibujan esas dos zonas donde es más verosímil una Hipótesis o la otra. En todos los casos se crea una zona amplia, grande, de probabilidad normalmente de 0.95 para la Hipótesis nula y una zona pequeña, restringida, de probabilidad generalmente de 0.05 para la Hipótesis alternativa.
De esta forma se construye un Test cualquiera, un contraste de hipótesis de los cientos o miles diseñados históricamente en Estadística. La estructura es siempre la misma.
Una vez diseñado se hacen las observaciones muestrales y se ve dónde cae lo que vemos. En función del criterio preestablecido decidimos finalmente, a la luz de lo que vemos, si mantenemos la Hipótesis nula o si, por el contrario, la rechazamos y nos pasamos a afirmar lo que dice la Hipótesis alternativa.
Los conceptos de Sensibilidad, Especificidad, Valor predictivo positivo y Valor predictivo negativo son esenciales en Medicina. Se trata de cuatro conceptos realmente nucleares en Medicina. Constituyen, de hecho, el esqueleto abstracto del diagnóstico.
La siguiente fotografía es clave para ir entendiendo los conceptos que iré explicando a continuación:
Puede observarse que cada rectángulo separa dos grupos: uno de personas con la enfermedad diagnosticada (superior) y otro sin ella (inferior). Al mismo tiempo con todos ellos se ensaya una prueba diagnóstica. Los que dan positivo en esta prueba son los del cuadro interior coloreado.
Llamemos E al grupo de los que tienen la patología en estudio, NE al de los que no la tienen y P a los que la prueba da positivo y N a los que la prueba da negativo.
Sensibilidad
La sensibilidad es el cociente: P/E; o sea, la proporción de positivos que tenemos entre los que tienen la patología. En el dibujo anterior es la proporción que ocupa el grupo de los positivos en el interior del grupo de los que tienen la enfermedad.
Como puede verse en los cuatro rectángulos del dibujo, según el método diagnóstico podemos tener sensibilidades muy distintas. Evidentemente interesa un método diagnóstico con alta sensibilidad, que la mayor parte de enfermos con esa patología den positivo.
Especificidad
La especificidad mide la proporción de negativos que hay en el grupo de los que no padecen la enfermedad que estudiamos. La especificidad será, pues, el cociente: N/NE. La especificidad también interesa que sea alta. Interesa que quien no esté enfermo nos dé negativo en la prueba, evidentemente.
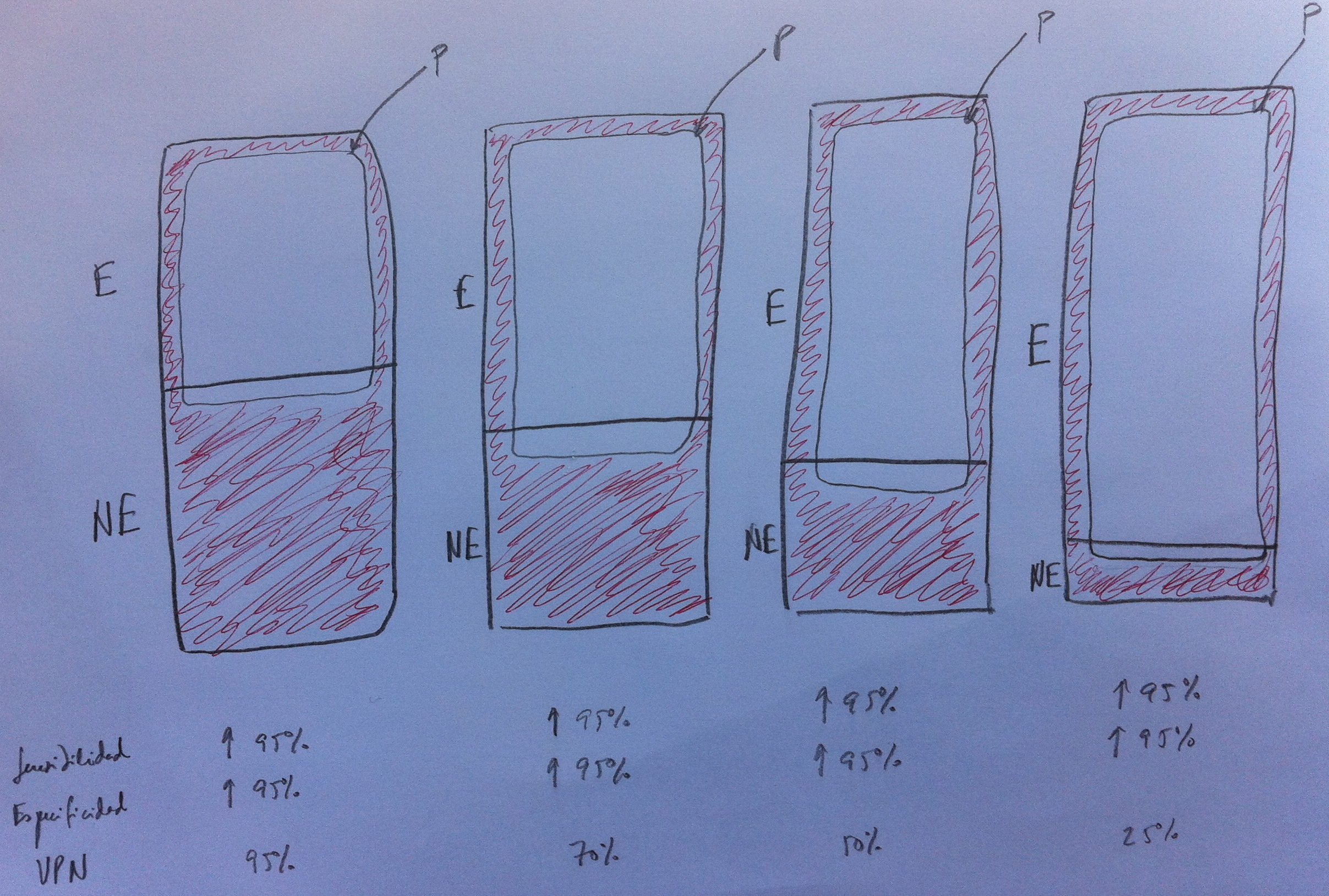
Si volvemos a mirar el dibujo anterior podremos ver distintos posibles métodos diagnósticos y su calidad.
Como se puede ver acompañando a la flecha que indica alto o bajo se ponen unos valores porcentuales que son aproximados: 5% ó 95%.
Voy a analizar uno por uno los cuatro casos hipotéticos dibujados. Los ordenaré de izquierda a derecha.
El primero nos marca la situación ideal: alta sensibilidad y alta especificidad. Observemos que casi todos los positivos están en E. Y observemos también que casi todos los de E, los que tienen la patología, dan positivo. Los de E que dan negativo son los llamados falsos negativos. Los de NE positivos son denominados falsos positivos. Los falsos negativos son el complementario, el contrapunto, de la sensibilidad. Los falsos positivos lo son de la especificidad.
El segundo caso es un ejemplo de mala técnica diagnóstica. Da positivo cuando no hay enfermedad y da negativo cuando hay enfermedad. En este caso tenemos baja tanto la sensibilidad como la especificidad. Casi todos son falsos positivos o falsos negativos.
Tampoco es bueno lo que sucede en el tercer caso. Aquí casi siempre da positiva la técnica, haya o no enfermedad. En este caso la sensibilidad es alta pero la especificidad muy baja. Esto tampoco es bueno para una técnica diagnóstica.
En el cuarto caso la técnica casi nunca da positiva. Tenemos baja sensibilidad, aunque, eso sí, alta especificidad. Tampoco es buena esta situación.
Es muy importante entender bien estos cuatro casos paradigmáticos para situar bien qué evaluamos con cada uno de estos dos conceptos.
Valor predictivo positivo
Vamos a definir ahora el Valor predictivo positivo (VPP) y el Valor predictivo negativo (VPN).
El Valor predictivo positivo es el siguiente cálculo: VPP=E/P.
Es interesante comparar la Sensibilidad con el VPP. Observemos que la sensibilidad calcula: sabiendo que es E cuántos serán P, y, sin embargo, el VPP calcula: sabiendo que es P cuántos serán E.
Es muy importante entender bien la relación entre estos dos cálculos. Y es muy importante también entender su papel en la Medicina.
Pensemos en el camino para el cálculo de la Sensibilidad: sabiendo que tiene la patología, probabilidad de que dé positivo el método.
Y pensemos ahora en el camino del cálculo del VPP: sabiendo que es positivo probabilidad de tener la enfermedad.
Se ve claramente que el camino del VPP es un camino que nos lleva al día a día de la práctica médica. Porque lo que tenemos son positivos o negativos de una prueba diagnóstica; o sea, tenemos P o N y debemos aventurarnos a decir nosotros tiene o no tiene la enfermedad; o sea, si E o NE.
Por lo que tanto, un VPP grande es muy importante. Tener alta sensibilidad pero bajo VPP nos lleva a una técnica muy poco útil realmente. Por lo tanto, una gran sensibilidad si no va acompañada de un elevado VPP de poco nos servirá en el día a día de la práctica médica.
Y, ¿de qué depende el VPP? Depende de la sensibilidad, de la especificidad, de la relación entre ambas, pero especialmente depende de la prevalencia de la enfermedad, de lo grande o pequeño que sea el fragmento de E respecto al de NE.
En el siguiente dibujo pueden verse cuatro situaciones con la misma sensibilidad y especificidad pero muy distinto VPP:
En los casos expuestos en el gráfico anterior podemos ver cómo el VPP depende de la prevalencia. Al bajar la prevalencia baja el VPP. Al bajar la prevalencia aunque se mantenga una buena sensibilidad los falsos positivos ganan peso relativo y hacen disminuir el VPP.
Observemos la siguiente información extraída de una diapositiva de un curso de Pediatría:
Vemos en esta diapositiva un ejemplo de cómo un cambio en la prevalencia puede cambiar considerablemente el VPP de una técnica.
Una temperatura superior a 39.5 y una leucocitosis superior a 15000 tenían, antes de la introducción de la vacuna contra el Haemophilus influenzae y de la vacuna antineumocócica, un VPP del 10% para una bacteriemia oculta. Sin embargo, después de instaurar esas vacunas, al bajar la prevalencia de las bacteriemias, el VPP pasó a ser del 2-3%.
Valor predictivo negativo
Vamos a ver, ahora, el Valor predictivo negativo. Se trata del siguiente cálculo: VPN=NE/N.
Es interesante comparar, ahora, la Especificidad con el VPN. Observemos que la especificidad calcula: sabiendo que es NE cuántos serán N, y, sin embargo, el VPN calcula: sabiendo que es N cuántos serán NE.
El Valor Predictivo Negativo (VPN) también puede cambiar en función de la prevalencia. Si la prevalencia de una patología aumenta mucho los falsos negativos pueden provocar una disminución muy considerable del VPN, de la capacidad predictiva que pueda tener el valor negativo de una prueba diagnóstica. Veamos en el siguiente gráfico cómo al aumentar la prevalencia de una enfermedad puede disminuir el VPN:
Observemos que, aunque se mantenga muy alta la sensibilidad, al aumentar mucho el número de enfermos, el número de faltos negativos (los negativos de la técnica diagnóstica que tienen verdaderos enfermos) aumenta mucho relativamente a los verdaderos negativos. Por lo tanto, la información que nos da un negativo, en estas situaciones, va perdiendo capacidad predictiva, lo que se traduce en un bajo VPN.
Observemos que ahora la zona marcada en rojo es la zona en la que tenemos un resultado negativo en la prueba diagnóstica. En la medida que nos vamos hacia la derecha vemos que hay cada vez más zona pintada de rojo en la zona de los enfermos (falsos negativos) respecto a la que hay en la zona de los no enfermos (verdaderos negativos). Por esto el VPN va bajando progresivamente.
Veamos un ejemplo hipotético y de actualidad que puede ayudarnos a entender mejor todo esto que estamos viendo:
Supongamos que queremos predecir si una persona, tomada al azar en cualquier parte del mundo, es catalana o no. Y queremos hacerlo a partir de una prueba diagnóstica: ser o no aficionado del Barça. Supongamos que en el mundo hay unos 10.000.000.000 de habitantes. La prevalencia de ser catalán es muy baja: 7.000.000 de casos. Supongamos que en el mundo hay (no sé si es correcta la cifra) 500.000.000 de seguidores del Barça y supongamos, también, que de los 7.000.000 de catalanes 6.500.000 son del Barça. Repito: Queremos diagnosticar “Ser catalán” mediante la prueba diagnóstica “Ser del Barça”. Esta prueba diagnóstica tiene mucha Sensibilidad porque en Catalunya hay un porcentaje muy alto de aficionados del Barça. La relación entre los 6.500.000 de seguidores del Barça en Catalunya y los 7.000.000 de catalanes es la Sensibilidad. Estamos, pues, ante un 92,8% de sensibilidad. Si alguien es catalán es muy probable que sea del Barça. La Especificidad de la prueba sería muy buena también. Entre los no catalanes una gran mayoría no son del Barça: el 95%, porque hay 9.499.500.000 no catalanes que no son del Barça y hay 9.993.000.000 no catalanes. El Valor predictivo negativo (VPN) es muy bueno también: Si tomamos a alguien al azar y vemos que no es del Barça esto es un muy buen procedimiento para pronosticar que no es catalán. Este VPN es del 99,99% en los datos que muestro. Por lo tanto, la técnica diagnóstica de ver si es o no seguidor del Barça para pronosticar si alguien es o no catalán tiene elevada sensibilidad, elevada especificidad y elevado Valor predictor negativo (VPN). Vamos, pues, bien. Sin embargo, este método diagnóstico tienen un muy bajo Valor predictivo positivo (VPP). Si sabemos que un ciudadano del mundo es del Barça esto nos sirve muy poco para predecir que es catalán.
Para calcular el VPP, para este caso, hemos de relacionar los 6.500.000 de catalanes del Barça respecto a los 500.000.000 de seguidores en el mundo. El VPP es, así, del 1,3%. Si tomamos a alguien en el mundo y sólo sabemos que es del Barça lo más probable es que no sea catalán. Si el VPP es bajo, como ocurre en este caso, el método diagnóstico es muy deficitario. No nos sirve realmente.
El siguiente gráfico resume toda la información de este ejemplo hipotético. En él se pueden ver los cálculos tanto de la Sensibilidad, de la Especificidad, del Valor predictivo positivo y del Valor predictivo negativo:
También suele usarse, en este ámbito, la Precisión diagnóstica (diagnostic accuracy) que se puede medir de diferentes formas:
Una forma de medir esa precisión es mediante un cociente entre los aciertos conseguidos respecto al total. O sea, se trata de hacer un cociente entre los verdaderos positivos y los verdaderos negativos respecto del total. En realidad, se trata de un promedio entre S y E.
Otros cocientes usados para evaluar la precisión diagnóstica son las llamadas Razones de verosimilitud, la positiva y la negativa:
RV+= S/(1-E)
RV-= (1-S)/E
La RV+ es, en realidad, un cociente entre los verdaderos positivos y los falsos positivos. Y la RV- es un cociente entre los falsos negativos y los verdaderos negativos.
Estos cocientes miden cuánto más probable es un resultado analítico positivo o negativo según la presencia o ausencia de enfermedad.
Observemos que en el caso del ejemplo anterior estos dos cocientes valdrían:
RV+=92.8/5=18.56
RV-=7.2/95=0.07
Lo que indica que entre los aficionados del Barça hay 18.56 veces más posibilidad de encontrar uno de Cataluña que uno del resto del mundo. Y que entre los no aficionados del Barça hay una mucha mayor proporción de no catalanes que de catalanes puesto que la proporción de catalanes respecto a los no catalanes entre los que no son del Barça es de 0.07.
Suele considerarse que una RV+ superior a 10 y una RV- inferior a 0,1 indican una buena precisión diagnóstica. En nuestro caso estaríamos bajo este supuesto porque 18,56>10 y 0,07<0,1.
Es interesante comparar este modelo y el del ANOVA de un factor a efectos fijos. La única diferencias básica es que aparece otro parámetro en el modelo, escrito como Ai y que este parámetro en lugar de sumar cero, como sucedía en el caso de efectos fijos, sigue una distribución normal. Aquí está en esencia la idea de factor aleatorio, puesto que los niveles tomados como muestra sólo son eso, niveles muestra para hablar de la población de niveles. Y esa población de niveles es la que nos interesa. También cambia el contraste. Ahora el contraste de hipótesis esencial es el de que la Desviación estándar al cuadrado en esa población de niveles es igual a cero versus la alternativa que esa dispersión es mayor que cero.
1. La técnica de técnicas denominada Análisis de la varianza (ANOVA), del acrónimo Analysis of variance: ANalysis Of VAriance, tiene como objetivo básico la comparación de las medias de más de dos poblaciones.
2. El nombre de Análisis de la varianza, sin embargo, no es muy afortunado. En el ANOVA se comparan siempre las medias de varias poblaciones y se hace a través de un contraste de hipótesis donde se analiza la varianza, es cierto; pero no sólo eso, porque también se analizan las diferencias de medias que hay entre las muestras, y también, por supuesto, como siempre en Estadística, se analiza el tamaño de muestra.
3. Las técnicas de comparación siempre analizan estos tres elementos: dispersión, diferencias de medias y tamaño muestral. Por lo tanto, ANOVA es, en realidad, una metonimia: se habla del todo a partir de una parte. Porque, en realidad, la técnica que vamos a ver en este tema, se debería denominar: Análisis de la varianza, de la diferencia de medias y del tamaño muestral.
4. En el Tema 13: Introducción a las técnicas de comparación he explicado cómo influyen estos tres elementos (diferencia de medias, dispersión y tamaño de muestra) en las comparaciones de dos poblaciones. Lo visto allí es fácilmente generalizable a la comparación de más de dos poblaciones, porque el mecanismo de fondo usado para comparar más de dos poblaciones es, en realidad, equivalente al usado para comparar dos poblaciones.
5. Para entender bien la complejidad del ANOVA hemos de ver una serie de conceptos básicos que nos permitirán conocer el vocabulario que maneja el lenguaje de esta técnica. Tal vez sería interesante una primera lectura del artículo del apartado de COMPLEMENTOS Viaje en autobús turístico por el mundo ANOVA. En él se dibuja una introducción de cuáles son esos conceptos básicos del mundo ANOVA. En este tema vamos a ver los más importantes de estos conceptos.
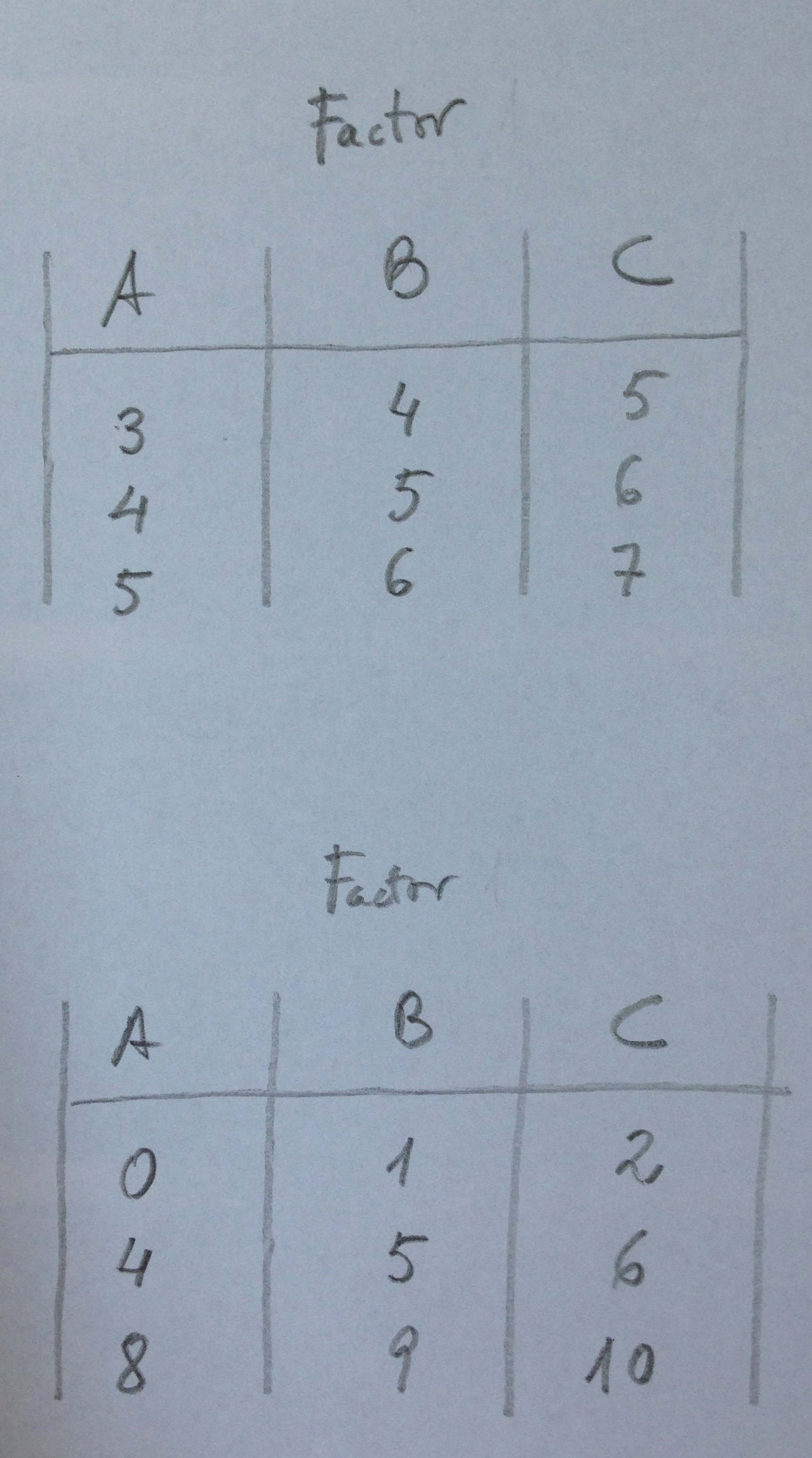
6. El primero de esos conceptos es el de factor. Un factor en ANOVA es una variable cualitativa que genera o que contempla una serie de poblaciones a comparar. A estos grupos o poblaciones que un factor delimita se les denomina «niveles del factor». Pe: Imaginemos que estamos comparando el peso de un tipo de insecto en tres localidades distintas: diríamos que trabajamos con el factor localidad y que ese factor tiene tres niveles: las tres localidades concretas. Veamos unos datos posibles y cómo estarían estructurados:
7. Otro ejemplo: Supongamos que estamos comparando, en un estudio clínico, cuatro fármacos diferentes aplicados a una serie de pacientes diagnosticados de una determinada patología. Ahora tenemos el factor fármaco con cuatro niveles. La estructura que tendríamos ahora sería muy similar a la anterior pero con cuatro columnas en lugar de tres.
8. Otro concepto importante en ANOVA: Un factor puede ser fijo o aleatorio. Fijo es cuando los niveles que se estudian son los únicos niveles que interesan. Aleatorio es cuando los niveles que se estudian es una muestra de niveles. Lo que interesa, realmente, es decir cosas de una población de niveles, no de la muestra de niveles que hemos seleccionado para el estudio.
9. Supongamos el siguiente ejemplo: Estamos estudiando la calidad del producto fabricado por operarios en una empresa. Tenemos 50 operarios trabajando en la manufactura del producto que comercializa nuestra empresa.
10. Supongamos que queremos comparar al operario A, que es de nuestra confianza, es una referencia para nosotros, con los operarios B y C, que son operarios que queremos evaluar expresamente porque creemos que no elaboran el producto con la calidad deseada. Para ello se toma una muestra de cuatro productos fabricados por cada uno de estos tres operarios. Estamos en un caso de un factor fijo (el factor operario), con tres niveles. El ANOVA a utilizar sería, en este caso, un ANOVA de un factor a efectos fijos.
11. Supongamos que ahora lo que queremos es ver si entre los 50 operarios hay diferencias en cuanto a la calidad del producto elaborado y no podemos estudiar producto de los 50 operarios. Entonces seleccionamos tres operarios al azar y tomamos una muestra de cuatro productos fabricados por cada uno de esos tres operarios. Estamos ahora ante un caso de un factor aleatorio (el factor operario), de donde hemos tomado una muestra de tres operarios al azar. El ANOVA a utilizar sería, en este caso, un ANOVA de un factor a efectos aleatorios. Pero aunque detrás tengamos una finalidad diferente, la estructura de los datos será la misma, algo así como lo siguiente:
12. El ANOVA puede tener uno, dos, tres, cuatro, etc., factores. Sin embargo, lo más habitual es tratar con un número reducido de factores. Y cada uno de esos factores puede ser fijo o aleatorio.
13. Otro concepto importante en ANOVA: Cuando tenemos dos o más factores éstos pueden estar, entre sí, dos a dos, cruzados o anidados.
14. Dos factores están cruzados cuando todos los niveles de un factor se cruzan, se combinan, con todos los niveles del otro factor.
15. Supongamos que en un estudio clínico ensayamos dos tipos de antihipertensivos: un IECA y un ARA II. Cada uno es un factor y sus dos niveles son ausencia y presencia. Y se cruzan: o sea, unos pacientes son tratados con placebo (sin nada), otros sólo con IECA, otros sólo con ARA II y, finalmente, un grupo de pacientes es tratado con los dos antihipertensivos al mismo tiempo. Para simplificar supongamos que se trata a una única dosis, por eso los niveles por factor son únicamente dos: ausencia y presencia. Para ver cómo sería la estructura y la disposición de unos datos posibles observemos el siguiente ejemplo:
16. Son dos factores cruzados porque se combinan todos los niveles de un factor con todos los niveles del otro factor, como hemos visto. Observemos que la combinación No con No es el Placebo. Esta combinación unida a las otras tres posibles, según se combinen No con Sí, o Sí con Sí, configuran los cuatro cruces posibles entre dos factores cada uno con dos niveles.
17. Dos factores están anidados (uno dentro de otro) cuando los niveles de uno se combinan, jerárquicamente, entre los niveles del otro.
18. Supongamos, por ejemplo, que queremos ver la influencia que tienen, en los resultados de calidad de un producto, la máquina y el operario. Y tenemos cuatro tipos de máquinas y dos operarios. El primer operario trabaja en las máquinas 1 y 2, el segundo en la 3 y la 4.
19. Tenemos, pues, dos factores: máquina (con cuatro niveles) y operario (con dos niveles). Y están anidados. No están cruzados. Dos máquinas las usa un operario y las otras dos máquinas las usa el otro operario. Observemos cómo sería la estructura de unos datos posibles:
20. Obsérvese que el Operario A trabaja sólo con las Máquinas 1 y 2. Y el Operario B lo hace únicamente con las Máquinas 3 y 4. Esta es la disposición de los datos anidados o jerarquizados.
21. Si este mismo estudio lo hiciéramos con factores cruzados cada operario debería usar las cuatro máquinas y, entonces, los datos tendrían la siguiente estructura:
22. En ANOVA, como técnica de comparación que es, el objetivo es contrastar la Hipótesis nula de igualdad de niveles de un factor versus la Hipótesis alternativa de no igualdad de esos niveles. Esto se hace para cada factor contemplado en el ANOVA.
23. Además, en el ANOVA de dos o más factores cruzados, podemos valorar algo muy importante: la interacción entre factores.
24. Interacción entre factores significa que la variable estudiada, la variable dependiente, se comporta, ante niveles de un factor, dependiendo de cuáles sean los niveles del otro factor. O sea, que la variable estudiada tiene un valor que es función de la combinación que se dé de niveles. Después, con los ejemplos, se entenderá mejor esta importantísima noción.
25. En la sección HERBARIO DE TÉCNICAS de este Blog podremos ver cómo es cada una de las técnicas de ANOVA más importantes (hay que tener en cuenta que si se tienen dos factores, y no se dice lo contrario, esos factores están cruzados):
26. En todas estas técnicas el objetivo básico será contrastar la hipótesis de igualdad o diferencia entre los distintos niveles en cada factor. Y si hay más de un factor y están cruzados contrastar la existencia de interacción entre esos factores. La importancia de diferenciar entre modelos diferentes es porque, como puede verse en cada uno de ellos, el cálculo de los p-valores para evaluar la significación es diferente según sean factores fijos o aleatorios, cruzado y anidados. Para ampliar todo esto ver el fichero Algoritmo de Bennet-Franklin.
27. Vamos a ver ahora algo muy importante en las técnicas ANOVA. Recordemos que la hipótesis alternativa en el análisis de cada uno de los factores es «la no igualdad de niveles».
28. Pero esta «no igualdad» puede ser por motivos muy diferentes. La igualdad de la H0 es sólo una, pero la desigualdad de la H1 puede tener paisajes muy diferentes. Supongamos, por ejemplo, un factor con cuatro niveles. La aceptación de H1 puede ser porque los cuatro niveles son diferentes o porque dos son iguales, los otros dos también y las diferencias se dan entre esos dos grupos de niveles, etc.
29. Hay, por lo tanto, muchas formas de cumplirse la H1. Si hay dos niveles sólo hay una posible H1, que un nivel sea mayor que el otro; pero si hay más de dos niveles en un factor la H1 contempla muchas alternativas posibles.
30. Pues bien, las técnicas llamadas «Comparaciones múltiples», también llamadas, en ciertos ámbitos, pruebas “Post hoc”, tratan de elegir una de esas muchas posibles afirmaciones que, de hecho, están comprimidas dentro de la Hipótesis alternativa, dentro de H1.
31. Con estas técnicas dibujamos, perfilamos, concretamos, la forma de la H1, lo que específicamente podemos afirmar en ella.
32. Existen diversas técnicas de Comparaciones múltiples: LSD de Fisher, Bonferroni, HSD de Tuckey, Duncan, Newman-Keuls, Scheffé (Ver Herbario de técnicas para ver en qué consisten cada una de ellas). Estas son las más usadas y las más prestigiosas. Todas hacen lo mismo pero con distinto nivel de conservadurismo. Unas ven antes que otras diferencias entre niveles. Sin embargo, cuando las cosas son claras todas esas técnicas trazan el mismo dibujo de la hipótesis alternativa. Sólo cuando hay dudas, cuando las diferencias no son muy claras, pueden aparecer diferencias. Para ver una visión comparativa de todas ellas ver el artículo Comparación entre técnicas de comparaciones múltiples.
33. Lo peculiar de estas técnicas es que, mediante un único contraste de hipótesis, se realizan múltiples comparaciones dos a dos. La idea nuclear de todas ellas es la creación de un umbral. Una diferencia de dos de las medias de los niveles del factor que esté por encima de ese umbral se considerará diferencia significativa y si, por el contrario, esa diferencia está por debajo de ese umbral se considerará una diferencia no significativa. Cada una de esas comparaciones múltiples crea un umbral distinto según un criterio diferente.
34. Es de esta forma cómo cada una de esas técnicas de comparaciones múltiples llega a establecer la posición relativa de un nivel respecto a todos los demás y se puede dibujar, así, con el nivel de información que tenemos, cuál es el mejor perfil concreto a asignar a la Hipótesis alternativa, a H1.
36. De no cumplirse las condiciones hay que utilizar una técnica no paramétrica, como el Test de Kruskal-Wallis cuando tenemos un único factor.
37. Vamos a ver ejemplos de aplicaciones de la técnica ANOVA. Empezaremos con el caso de los primeros datos que hemos mostrado. Se trata de una estudio donde se compara el peso de un tipo de insecto en tres localidades distintas. El factor localidad y tiene tres niveles y se trata de tres localidades concretas, por lo tanto estamos ante un caso de ANOVA de un factor a efectos fijos. Recordemos los datos:
38. Antes de mostrar los resultados obtenidos podemos ver que la media de localidad 3 es la mayor. Es una media de 3.87. La media de la localidad 1 es 3.47. La de la localidad 2 está entre ellas: 3.67. El problema es: ¿Son estas diferencias estadísticamente significativas? El tamaño de muestra juega en contra de la significación. Hay sólo dos datos. Pero la dispersión es pequeña, esto iría a favor de la significación.
39. Si hacemos el análisis nos encontramos que el p-valor del contraste de hipótesis de igualdad de medias es 0.0331. Como es menor que 0.05 rechazamos la Hipótesis nula. Observemos la tabla ANOVA que es el procedimiento técnico para realizar este contraste de hipótesis:
40. Si comprobamos la normalidad de los datos, mediante el Test de Kolmogorov, tenemos un p-valor de 0.96, por lo tanto, como es mayor que 0.05 aceptamos la Hipótesis nula de normalidad (en los tests de bondad de ajuste a la normal la Hipótesis nula es normalidad). Si comprobamos la igualdad de varianzas, aplicando el Test de Bartlett, tenemos un p-valor de 0.66, lo que indica que podemos aceptar la Hipótesis nula de igualdad de varianzas. Con el Test de Durbin-Watson comprobamos que no haya autocorrelación entre los datos y tampoco la hay. Esto nos indica que se cumplen las principales suposiciones: la normalidad, la igualdad de varianzas y la independencia de los datos y que, por lo tanto, el p-valor que hemos calculado en la tabla ANOVA es fiable, está basado en unas suposiciones correctas.
41. Pero ahora debemos aplicar un Test de comparaciones múltiples para tratar de ver el porqué no hay igualdad entre las medias. Si aplicamos el Test LSD vemos que la localidad 1 no es distinta significativamente a la 2, la 2 no lo es tampoco de la 3 pero la 1 y la 3 sí que lo son. O sea, que el motivo del rechazo de la igualdad de medias es porque las localidades 1 y la 3 tienen insectos con peso significativamente distinto. Veamos a continuación un gráfico que ilustra extraordinariamente lo que estoy diciendo:
42. Se trata de un gráfico de los intervalos de confianza del 95% de la media de cada una de las localidades. Puede verse, perfectamente, que, en una mirada horizontal, la localidad 1 y la 2 tienen intervalos que se solapan. Pensemos que son intervalos de la media poblacional, por lo tanto, estamos hablando de que podría ser que la media poblacional de la localidad 2 estuviera por debajo de la media poblacional de la localidad 1, aunque la media muestral de la localidad 2 esté por encima de la media muestral de la localidad 1. Pensemos que estamos infiriendo, que la muestra es un medio, no un fin. Están (como diríamos en política con las horquillas) en empate técnico, cualquiera puede estar, poblacionalmente, por encima. Entre la localidad 2 y 3 sucede lo mismo: se solapan. Pero entre localidad 1 y 3 la separación entre intervalos de la media es clara. Por esto se rechaza la Hipótesis nula de igualdad de media en el ANOVA, por esta diferencia entre la localidad 1 y la localidad 3.
43. Y con esto habríamos concluido el análisis. Observemos todos los pasos. Observemos bien todo lo que hemos hecho y las conclusiones que al final sacamos.
44. Vamos a ver ahora otra aplicación. Supongamos el siguiente estudio:
45. Este es un caso interesante para visualizar un estudio donde es aplicable un ANOVA de dos factor a efectos fijos. Observemos que la media más baja es la de los tres valores de resistencia de la mucosa de los profesores que tomaron el placebo (No Vitamina A y No Vitamina E). Cuando toman sólo Vitamina A o sólo Vitamina E la resistencia aumenta en torno a una 20 unidades de mayor resistencia. Sin embargo, cuando se combinan ambas vitaminas la resistencia aumenta más que la suma de lo obtenido por una y otra vitaminas. No aumenta 40 sino que aumenta en torno a 60 unidades más. Esto es lo que nos detectará la interacción.
46. Se comprueban las suposiciones y todas se cumplen: normalidad, igualdad de varianzas e independencia. Aquí la tabla ANOVA nos proporcionará tres p-valores: uno para el factor vitamina A, otro para el factor vitamina E y otro para la interacción. Los tres son p-valores inferiores a 0.05, lo que indica que la presencia de cada una de las dos vitaminas aumenta la resistencia de la mucosa y que, además, al darse interacción significativa estamos ante la presencia de una correlación entre ambas vitaminas, que en este caso indica que la presencia de las dos conjuntamente producen una sinergia positiva.
47. Observemos a continuación el gráfico de interacción entre ambos factores:
48. Pueden observarse en este gráfico cuatro asteriscos: son las medias de las cuatro condiciones experimentales del estudio, que podríamos simplificar mediante las categorías: no-no, no-sí, sí-no, sí-sí. Observemos en el eje de las abscisas la no presencia y la presencia de Vitamina A y observemos, también, que los dos colores unen puntos con el mismo nivel de Vitamina E. El no-no es el placebo, es el valor más bajo. El sí-sí es el valor de media superior y observemos que su valor está muy por encima del que esperaríamos si no hubiera interacción. De no haber interacción esperaríamos que las dos rectas del gráfico fueran paralelas.
49. De la misma forma que en este caso vemos sinergia positiva podemos ver, en otros casos, sinergia negativa. Supongamos que en el gráfico anterior la recta roja en lugar de subir hubiera bajado cruzándose con la azul dibujando una X: estaríamos hablando también de interacción, pero la interpretación sería otra: diríamos que ambas vitaminas están en sinergia negativa; o sea, que cada una de ellas hace su efecto pero al combinarlas se pierde todo lo que individualmente hacen.
50. Vamos a ver un ejemplo de dos factores pero anidados:
51. Se trata de dos factores fijos, porque se han tomado cuatro hospitales concretos que quieren estudiarse, y dos fármacos también concretos. Son, además, dos factores que no están cruzados, están anidados. Observemos que el fármaco 1 se ensaya únicamente en los Hospitales 1 y 2 y que el fármaco 2 se ensayo sólo en los Hospitales 3 y 4. Estamos, pues, ante un ANOVA de dos factores anidados a efectos fijos.
52. Supongamos también que hemos ya comprobado la normalidad de los datos, la igualdad de las varianzas y la independencia de los datos. Ahora el ANOVA nos proporcionará dos p-valores sobre dos contrastes de hipótesis. Una hipótesis nula es la igualdad entre hospitales, la otra la igualdad entre fármacos.
53. Observemos los datos. ¿Qué podemos decir si los comparamos con detenimiento? Una cosa importante: se sabe Estadística cuando uno es capaz de saber lo que dará una técnica antes de aplicarla, mirando los datos. Mirémoslos, pues. ¿Qué se observa? Realmente si aprendemos a mirar estos datos aprenderemos las peculiaridades de un ANOVA de factores anidados.
54. Para ayudarnos a sacar conclusiones de nuestros datos, veamos los tres siguientes grupos de datos posibles:
55. Tenemos tres situaciones distintas. En el caso de arriba observemos que la diferencia está centrada entre fármacos. Al pasar del fármaco 1 al 2 es cuando vemos diferencias. Sin embargo, cuando estamos en un fármaco u otro entre hospitales no hay diferencias remarcables. Por lo tanto, hemos de pensar que en este caso habrá diferencia significativa entre fármacos pero no entre hospitales. Como así sucede si aplicamos la técnica ANOVA a estos primeros datos.
56. En el caso del medio observemos que la diferencia está centrada, ahora, entre hospitales. Al pasar del fármaco 1 al 2 no vemos diferencias, el patrón se repite. Sin embargo, cuando estamos en un fármaco u otro entre hospitales sí hay diferencias destacable. Por lo tanto, hemos de pensar que, ahora, en este caso, habrá diferencia significativa entre hospitales pero no entre fármacos. Como así sucede si aplicamos la técnica ANOVA a estos segundos datos.
57. En el caso de abajo observemos que la diferencia ahora es tanto entre fármacos como entre hospitales. Al pasar del fármaco 1 al 2 vemos diferencias, pero cuando estamos en un fármaco o en otro entre hospitales también se aprecian diferencias remarcables. Por lo tanto, hemos de pensar que en este caso habrá diferencias significativas entre fármacos y también entre hospitales. Como así sucede si aplicamos la técnica ANOVA a este tercer grupo de datos.
58. Si ahora volvemos a los datos reales del estudio planteado, observaremos que más bien estamos en un caso como el tercero de los datos ficticios. Parece que la variabilidad total que observamos tanto está canalizada hacia diferencias entre los dos fármacos como hacia diferencias entre los hospitales. Si aplicamos el ANOVA de dos factores anidados fijos a los datos del estudio vemos que tanto el factor Fármaco como el Factor Hospital presentan diferencias significativas, con un p-valor inferior a 0.05.
59. En todos estos ejemplos hemos visto alguna diferencia, sea de un factor, del otro, o de ambos, pero no nos olvidemos que podríamos encontrarnos también con datos como los siguientes:
60. Como puede apreciarse ahora, perfectamente, la variabilidad está centrada en la dispersión que hay dentro de cada uno de los cuatro grupos, no hay diferencias remarcables al cambiar de fármaco o al cambiar de hospital. Ahora todas las diferencias las vemos dentro de cada una de las cuatro situaciones experimentales. Lo que nos llevaría claramente a decir que ni el fármaco ni el hospital introducen ningún tipo de diferencias en la variable estudiada.
61. Hay una noción importante y útil en ANOVA que es necesario explicar: me refiero a la noción de bloque. Esto da lugar a una serie de modelos ANOVA que son muy utilizados.
62. En ocasiones un factor, que es el objeto básico de un estudio, a la hora de experimentar con él, de ensayar sus diferentes niveles, los ámbitos donde se aplica se sabe ciertamente, o se sospecha, que son ámbitos con importantes diferencias. Por ejemplo, supongamos que queremos ensayar tres tipos de abono y lo tenemos que hacer en cuatro terrenos que sabemos que son muy distintos desde el punto de vista químico y geológico. Esos cuatro terrenos actúan de bloques y lo que haremos es ensayar cada uno de los tres niveles del factor abono en cada uno de los cuatro terrenos, distribuyéndolos al azar dentro de ellos. El experimento quedaría así:
63. Este planteamiento da lugar a un modelo que se denomina ANOVA de un factor con bloques aleatorizados. Se trata de un modelo muy usado en diferentes ámbitos. Veamos un caso muy distinto del anterior: Supongamos que a unas personas es posible aplicarles todos los niveles del factor que se pretende estudiar, como podría ser, por ejemplo, que quisiéramos ensayar cuatro condiciones diferentes para ver cómo influye cada una de ellas en el valor de cierta variable (Por ejemplo, andar durante 5 minutos en ambientes con distinto grado de contaminación, el dolor después de la extracción de una pieza dental donde se han usado cuatro procedimientos distintos, valorar cuatro fórmulas distintas de un producto alimentario, etc). Y para ello tomamos a cinco personas a las que les aplicaremos esas cuatro condiciones en momentos diferentes y con un orden aleatorizado. Los resultados podrían ser los reflejados en la tabla siguiente:
64. Este caso, como el de los terrenos, es un caso de ANOVA de un factor con bloques aleatorizados. Ahora es la persona la que hace de bloque. Observemos que realmente cada individuo tiene un perfil característico y que en todos ellos se produce un mismo patrón: valor bajo en C1, sube en C2, sube más en C3 y baja hasta el mínimo en C4. Si no tuviéramos en cuenta a los bloques «personas» no habría diferencia significativa entre las medias de las condiciones por culpa de la enorme variabilidad que tenemos en el estudio. Sin embargo, el ANOVA de un factor con bloques aleatorizados compara las cuatro columnas de valores pero lo hace individuo por individuo. De esta forma capta la regularidad de estos cambios comentados y acabará diciendo que las diferencias muestrales entre las diferentes condiciones son diferencias estadísticamente significativas.
65. El ANOVA de un factor con bloques aleatorizados es un importante ejemplo de control de la dispersión con la finalidad de ver diferencias. Pensemos que la dispersión introduce un ruido que impide ver diferencias. Al introducir los bloques controlamos la dispersión, la explicamos. En el Tema 30: Ampliación de ANOVA veremos cómo a partir de este modelo podemos llegar a modelos un poco más sofisticados de control de la variación como es el ANCOVA o el ANOVA de medidas repetidas.
66. Ver estos ejemplos que hemos visto en este tema nos ayuda a situar lo que hacen las diferentes técnicas ANOVA que tenemos a nuestra disposición para comparar grupos diferentes. Son técnicas que comparan esos grupos en base a cómo está repartida la variación. Por eso se llaman Análisis de la varianza, porque realmente esto es lo llamativo, lo que más se ve, aunque, como ya hemos dicho, las diferencias de las medias entre los grupos y el propio tamaño de muestra los analiza también la técnica para decantarse por la igualdad o la diferencia entre las medias poblacionales de los grupos que compara.
67. En el ámbito del ANOVA se han introducido, también, aspectos de Significación material. Hemos dicho en el tema dedicado a la Significación formal y material que en Estadística el esfuerzo está principalmente dirigido a la Significación formal; o sea, a detectar diferencias entre poblaciones o relaciones entre variables, significativas, sin entrar en la valoración de aspectos de Significación material; o sea, de aspectos de Tamaño del efecto (en inglés “Effect size”), que suelen dejarse habitualmente en manos de los expertos en el campo concreto de aplicación: la medicina, la economía, la sociología, la biología, etc.
69. Veamos la interpretación de estos dos cálculos: En la eta cuadrada se relativiza la suma de cuadrados; o sea, la variabilidad explicada por el factor o por el efecto estudiado, respecto a la suma de cuadrados total. En la eta cuadrada parcial se relativiza respecto a la suma de esa suma de cuadrados más la del error, la residual.
70. Como en todos los cálculos del Tamaño del efecto el tamaño muestral no tiene ninguna influencia, por eso únicamente juega en su cuantificación y valoración las diferencias de medias y las dispersiones y, en cambio, el tamaño de muestra no juega ningún papel.
71. Veamos unos ejemplos de ANOVA de un factor y de ANOVA de dos factores para ver cómo son esos cálculos e interpretar su papel:
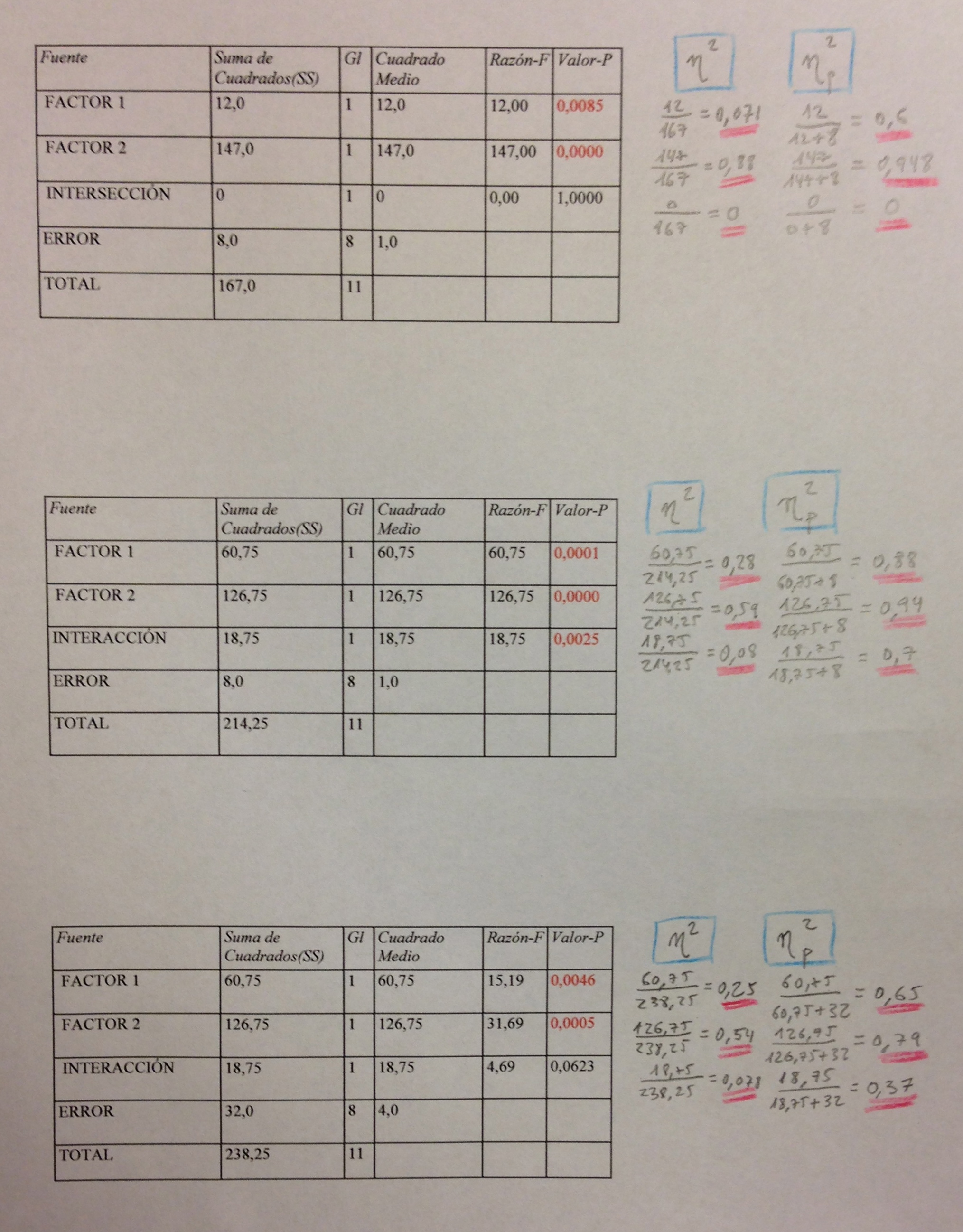
72. Veamos, a continuación, dos casos de ANOVA de un factor:
73. Si hacemos una mirada a esos datos, antes de hacer el análisis estadístico, podemos ver que, en los dos estudios, las medias de los tres grupos, de los tres niveles del factor estudiado, son: 4, 5 y 6. Pero que en el caso de arriba los tres grupos están más separados, están más segregados. En el caso de abajo hay mucha dispersión intragrupo para el nivel de diferencia de medias que tenemos. Esto es lo que evalúa la eta cuadrada. Básicamente es eso.
74. Los resultados del ANOVA, en ambos casos, y del cálculo de la eta cuadrada y de la eta cuadrada parcial, seguiendo las fórmula mostradas anteriormente, son los siguientes:
75. Suele considerarse que una eta cuadrada en torno a 0,01 indica poco efecto, que una eta cuadrada en torno a 0,06 indica un efecto medio y que una eta cuadrada superior a 0,14 es ya un efecto grande. Observemos que en los datos de arriba tendríamos un tamaño del efecto grande y abajo un tamaño del efecto pequeño. Observemos que en el caso de un único factor la eta cuadrada y la eta cuadrada parcial coinciden en cantidad.
76. Los datos del caso de arriba muestran grupos más separados, muestran más efecto. Muestran, de hecho, un efecto grande. Sin embargo, no es estadísticamente significativo. Y en Ciencias primero es la Significación formal y luego la Significación material. Como en un juicio: primero hay que decir si el acusado es o no culpable, luego ya valoraremos si lo que ha robado es mucho o poco.
77. Observemos otro caso ahora con dos factores cruzados con interacción:
78. Si hacemos los análisis ANOVA de cada tabla y los cálculos de la eta cuadrada y de la eta cuadrada parcial tenemos el siguiente cuadro:
79. Podemos ver los cálculos de la eta cuadrada y la eta cuadrada parcial, que ahora, con dos factores, no coinciden, y podremos apreciar cosas como las siguientes: El factor 2 siempre presenta un tamaño del efecto grande y mayor que el producido por el factor 1 y por la interacción. Observemos en el cuadro de los valores de los estudios que realmente se produce un mayor salto de valores entre las dos filas que entre las dos columnas. Esto es lo que mide la eta cuadrado: donde se produce más salto y si éste es grande o es pequeño respecto a otras variabilidades que muestran los datos.
80. Estas medidas son muy interesantes, pero, siempre y cuando, previamente, se haya evaluado la Significación formal, que es, sin lugar a dudas, prioritaria. Por muchos millones que, presuntamente, haya robado una persona hasta que el tribuna no dicte culpabilidad, no formalice la culpabilidad, no podemos decir que materialmente se trata de un robo muy voluminoso. Si al final se comprueba la inocencia de aquella persona nos habremos equivocado mucho haciendo valoraciones materiales previas. Es importante, por lo tanto, situar bien estos cálculos que evalúan el tamaño del efecto.
81. El tamaño del efecto es, pues, en ANOVA, una forma de evaluar el peso relativo de la variabilidad, cómo está distribuido el reparto de cambios entre los distintos niveles de los factores estudiados. Y evalúa si estos cambios entre las medias de los diferentes grupos son grandes o pequeños relativizando estas diferencias respecto a la dispersión que hay en general y, más en concreto, dentro de los grupos (el error, o también llamado residuo).
La 1 es incorrecta: En una decisión estadística; o sea, en un contraste de hipótesis siempre hay una probabilidad de error que no es nula.
La 2 también es incorrecta. La Estadística habla de significación estadística no de significación o relevancia clínica. Ver el Tema “Significación formal versus Significación material”.
La 3 no es correcta tampoco y, de hecho, es la más interesante a comentar porque hay en su afirmación un error frecuente del usuario de la Estadística. El p-valor no es una probabilidad de equivocarse o no. El p-valor es un valor de referencia para comprobar si, en un contraste de hipótesis, con la información de la muestra o las muestras que tenemos, estamos por encima o por debajo del nivel de significación, que normalmente es del 0.05 y que se establece a priopi, nunca a posteriori. Saber que el p-valor es 0.001 en este estudio nos dice que es menor que 0.05 i poco más. La probabilidad de equivocarnos diciendo que es diferente la acción de un fármaco respecto a otro; o sea, la probabilidad de rechazar una Hipótesis nula que en realidad no deberíamos rechazar es el nivel de significación que previamente se ha establecido, no es el p-valor. Es 0.05, no 0.001. El p-valor nos sirve, básicamente, para ver si estamos por encima o por debajo de 0.05, o de otro nivel de significación que previamente hubiéramos prefijado.
La 5 es incorrecta también, puesto que estos mecanismos de inferencia sí que aportan elementos a la comparación, especialmente los intervalos de confianza. Ver la Reflexión “Las tres formas de decir cosas en inferencia estadística”.
Hay dos Odds ratio significativas, la de 3.12 y la de 2.5, porque sus intervalos de confianza del 95% no contienen al 1. La OR de 10.2 es la mayor cuantitativamente pero no es significativa, porque su intervalo de confianza del 95% incluye al 1. La OR de 2.5 tiene un intervalo de confianza más estrecho, lo que indica que el tamaño de muestra es mucho mayor, pero al ser las dos Odds ratio significativas, debemos decir que la mayor es la de 3.12 porque el valor de estimación puntual es mayor.
Tenemos que evaluar los resultados de un ensayo clínico que compara un nuevo antihipertensivo respecto a otro considerado desde el punto de vista clínico como un buen estándar, y donde la reducción de la presión arterial diastólica (TAD) se predefinió como la variable principal. Suponemos que tanto el diseño como la ejecución del estudio son correctos. Los resultados indican que el nuevo tratamiento es más efectivo ya que reduce más la TAD, concretamente en media (intervalo confianza al 95% bilateral) reduce 0,5 (0,2 a 0,7) mmHg más que el grupo control, con p=0,001. ¿Cuál de las siguientes afirmaciones es correcta?
1) El valor de p (0,001) encontrado demuestra con una probabilidad nula de equivocarnos que el nuevo tratamiento es mejor.
2) En base al valor observado de p (0,001) se puede concluir que la magnitud de la reducción de TAD del nuevo medicamento en relación al control es de gran relevancia clínica.
3) Si yo acepto que el tratamiento nuevo es el mejor, me equivocaría sólo con una probabilidad de 0,001.
4) La reducción de TAD es mayor con el nuevo tratamiento, pero la mejoría que en promedio ofrece en relación al tratamiento control no sobrepasaría 0,7 mmHg en el mejor de los casos, teniendo en cuenta un error alfa o de tipo I del 5% bilateral.
5) La estimación puntual y los intervalos de confianza no aportan información de la magnitud del efecto de la comparación entre ambos tratamientos.