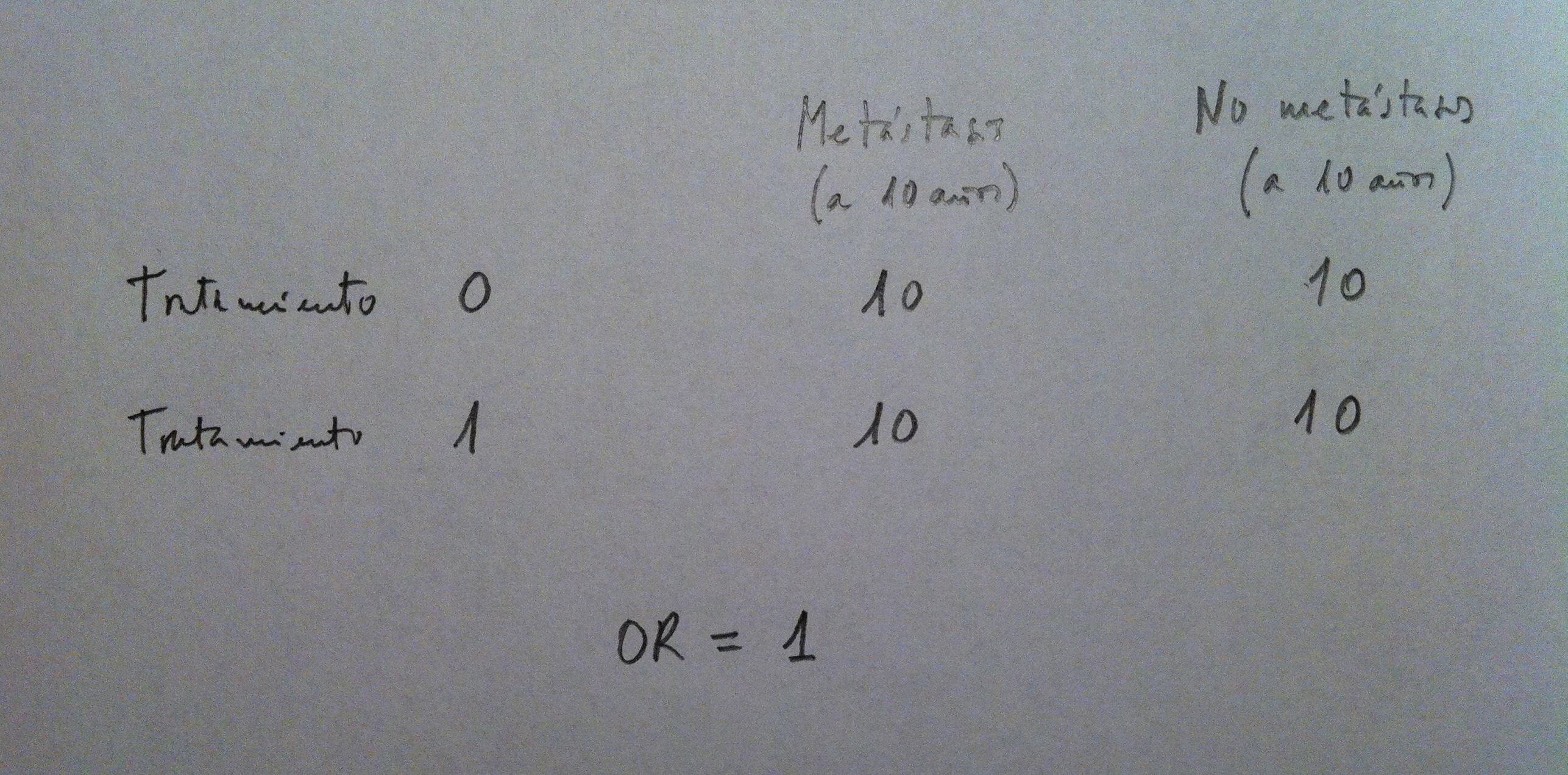Dos conceptos estadísticos muy usuales en el lenguaje de la Medicina son el concepto de Odds ratio (Ver el tema dedicado a las Medidas de la relación entre variables cualitativas) y el concepto de Hazard ratio (Ver los temas dedicados al Análisis de supervivencia y a la Regresión de Cox).
Vamos a delimitar uno y otro a través de un ejemplo que espero que aclare las similaridades y las diferencias entre ellos.
Supongamos dos tratamientos contra un determinado tipo de cáncer: El tratamiento 0 y el tratamiento 1. Supongamos, también, que a los 10 años se analiza cuántos de los tratados de una forma u otra, en un estudio clínico, han presentado metástasis y cuántos no la han presentado. Supongamos que los datos son los siguientes:

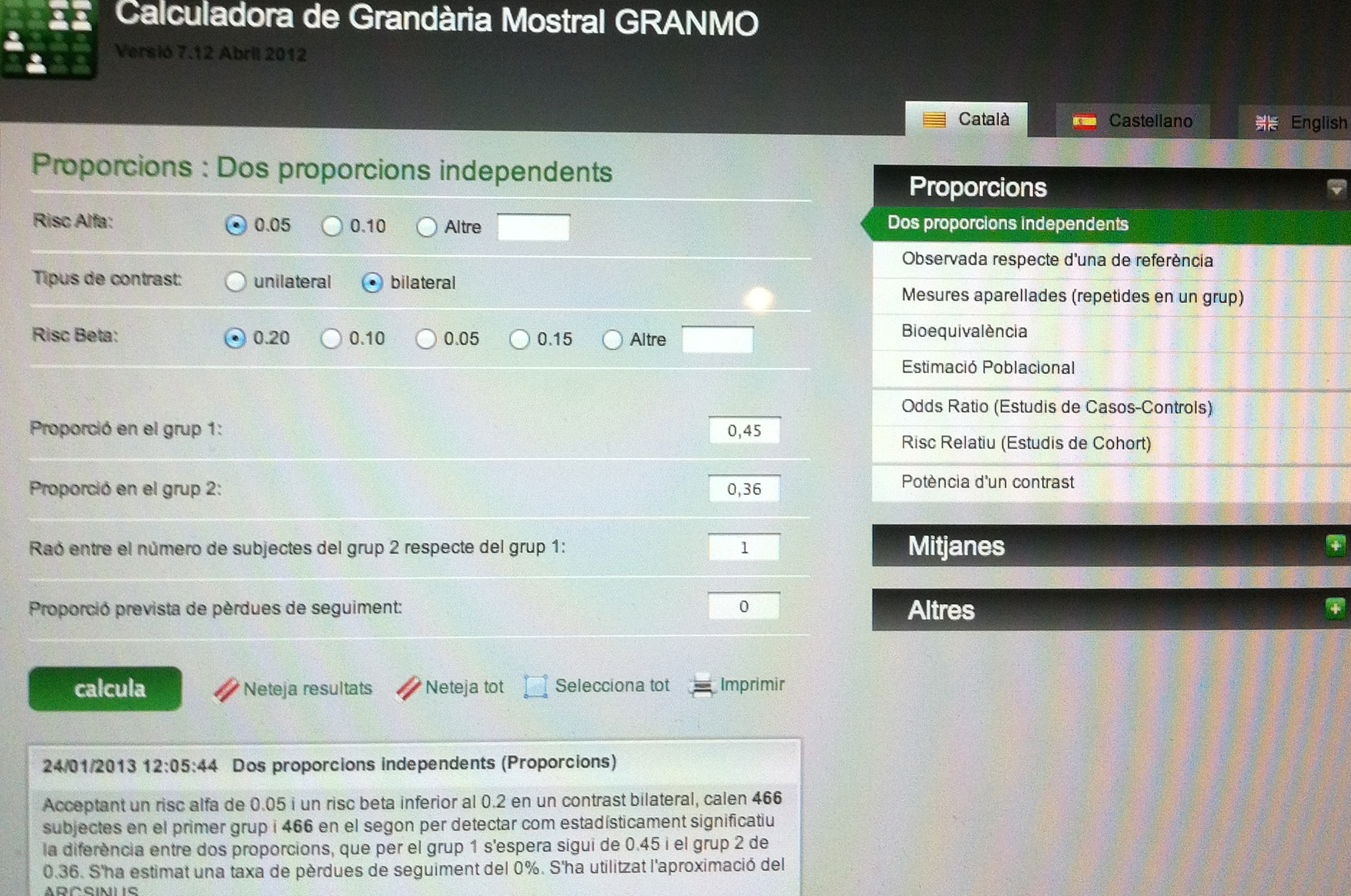
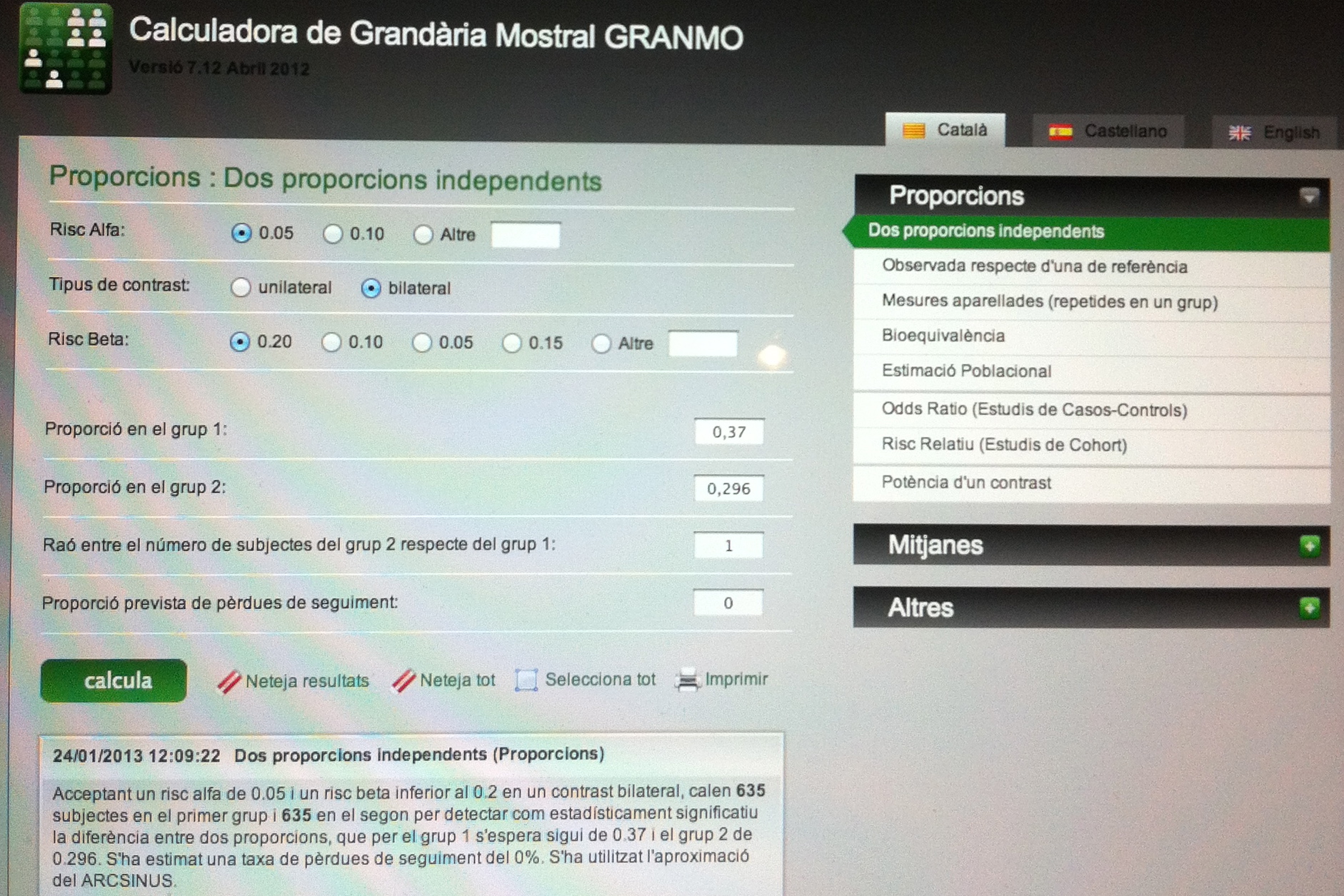
En cada tratamiento, de los 20 tratados, a los 10 años 10 tienen metástasis y 10 no. Esto nos da una Odds ratio (OR) de 1. No hay ventaja de un tratamiento respecto de otro, visto desde los 10 años, y sin más perspectiva temporal que esa, la de los 10 años.
La OR es una mirada a una relación en un momento temporal, prescindiendo de lo que ha pasado en el recorrido hasta llegar allí. Es una mirada estática. La Hazard ratio (HR) es, por el contario, una mirada dinámica, es una mirada al recorrido, es una relación entre recorridos. Diferentes estudios pueden tener una misma OR pero con HR muy diferentes, como vamos a ver en este ejemplo.
Veamos, pues, ahora la información no desde los 10 años, sino durante los 10 años. Veamos el recorrido de cada tratamiento durante esos 10 años. Supongamos que las 10 metástasis de cada grupo de tratamiento se producen a lo largo de estos años según uno de los tres patrones distintos A, B y C que se muestran a continuación:

Las cosas, evidentemente, son bien distintas según tengamos un patrón u otro. En A, en B y en C la relación entre los dos tratamientos es completamente distinta. Viendo cuidadosamente los datos ya se puede apreciar perfectamente la diferencia. En A no hay diferencias, en B es mejor el tratamiento 1, porque la metástasis llega más tarde. En C, finalmente, el mejor es el tratamiento 0, porque es ahora en él que las metástasis llegan más tarde. Pero, veámoslos con más detalles.
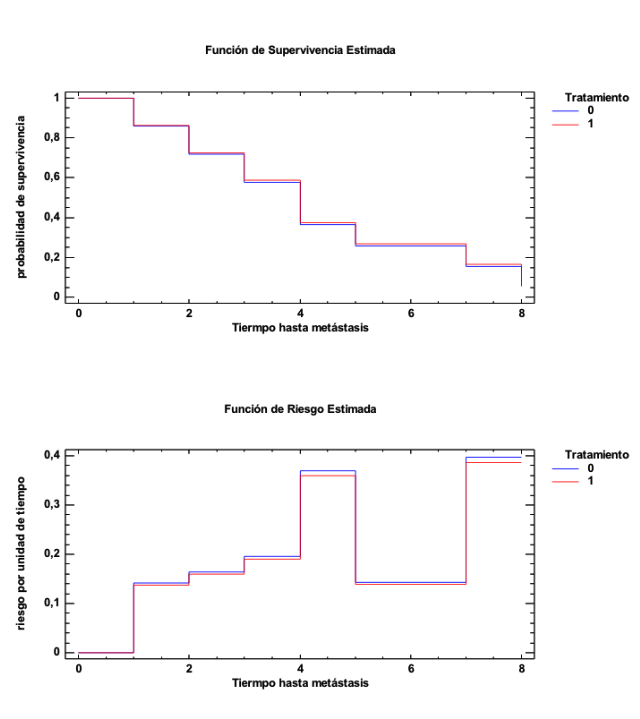
En A el perfil es muy similar en ambos tratamientos, es prácticamente igual. El Hazard ratio (HR) es, entonces, 1. Observemos la curva de supervivencia y la función de riesgo de los dos tratamientos. En ambos casos, la función de un tratamiento y la del otro son prácticamente iguales. El HR lo que hace es establecer una relación entre ambas curvas, entre ambas funciones, y, en este caso, la relación es 1, porque están prácticamente solapadas:

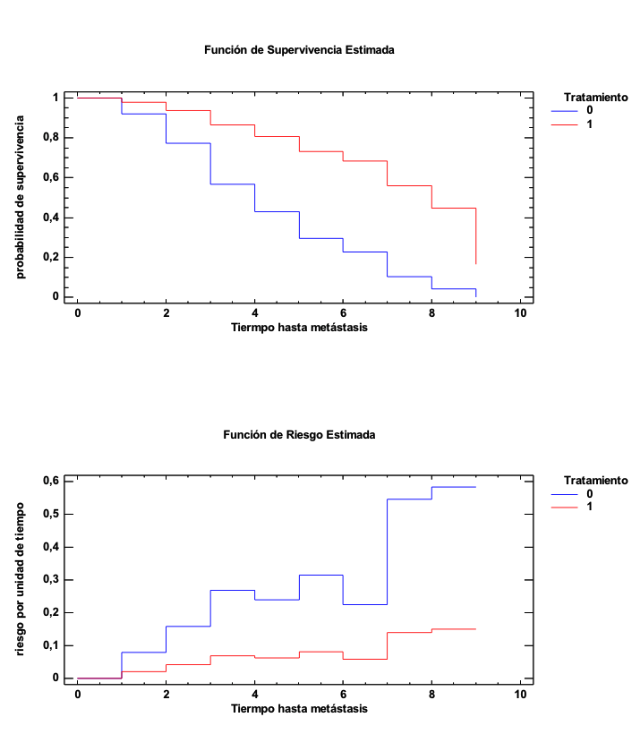
En B los perfiles de un tratamiento y del otro son, ahora, muy distintos. El tratamiento 1 tiene menor riesgo que el tratamiento 0. La función de riesgo del tratamiento 1 va por debajo de la del tratamiento 0. La curva de supervivencia del tratamiento 1 va, entonces, lógicamente por encima. El HR es 0.25. La HR es una relación entre curvas, entre funciones; es una cuantificación de la posición relativa de una función respecto de la otra. En este caso la relación es entre la curva del tratamiento 1 respecto a la del tratamiento 0 y se hace, siempre, respecto a la función de riesgo. Veamos las curvas de supervivencia y las funciones de riesgos de ambos tratamientos, especialmente las funciones de riesgo donde vemos que la del tratamiento 1 está unas cuatro veces, en promedio, por debajo de la del tratamiento 0:

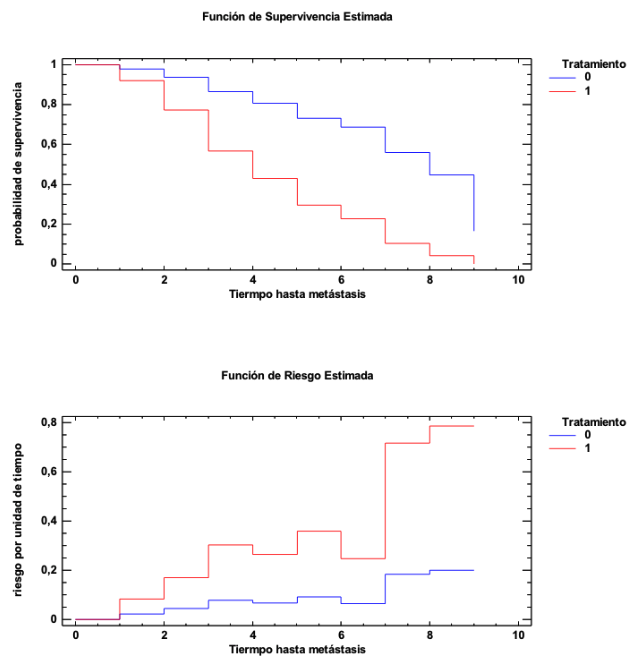
En C los perfiles de los dos tratamientos también son muy distintos. Pero ahora ocurre justo todo lo contrario (porque, observemos, que los datos son los mismos pero cambiados de posición). El tratamiento 1 tiene ahora mayor riesgo que el tratamiento 0. El HR es ahora 4, porque la relación entre la función de riesgo del tratamiento 1 y la función de riesgo del tratamiento 0 es, en promedio, 4. Veamos ahora las curvas de supervivencia y las funciones de riesgos de ambos tratamientos y veamos cómo la función de riesgo del tratamiento 1 va unas cuatro veces por encima de la función de riesgo de la función del tratamiento 0:

La HR, por lo tanto, cuantifica la posición relativa de una función de riesgo respecto de la otra. Es un cociente de funciones. Tiene en cuenta no el final de un recorrido sino la dinámica de ese recorrido. Esto es un elemento claramente diferencial respecto a la OR que mira las cosas en un punto estático. Digamos, pues, que la OR es estática y la HR es dinámica.
Tanto en OR como en HR hay que prestar siempre mucha atención qué está en el numerador del cociente y qué está en el denominador de la relación. Porque que sea la OR o la HR mayor que 1 o menor que 1 cambia completamente el sentido de la relación. En nuestro caso, la HR está dando la relación entre la función de riesgo del tratamiento 1 respecto a la función de riesgo en el tratamiento 0.
En muchos artículos de Medicina donde se exponen OR o HR se acostumbra a informar de qué tratamiento o condición tiene más o menos riesgo a la derecha y a la izquierda del 1, para que no haya dudas en la interpretación.
Observemos, también, un fenómeno también común de la OR y de la HR: la distinta escala a la izquierda y a la derecha del 1 pero con valores paralelos: observemos en nuestro caso que una HR da 0.25 y la otra da 4. Porque son equivalentes (valores intercambiados en el caso B y el C): una hacia la izquierda y la otra hacia la derecha del 1 (1/4 ó 4/1). Cuatro veces menos riesgo de una respecto a la otra o cuatro veces más riesgo de una respecto de la otra.