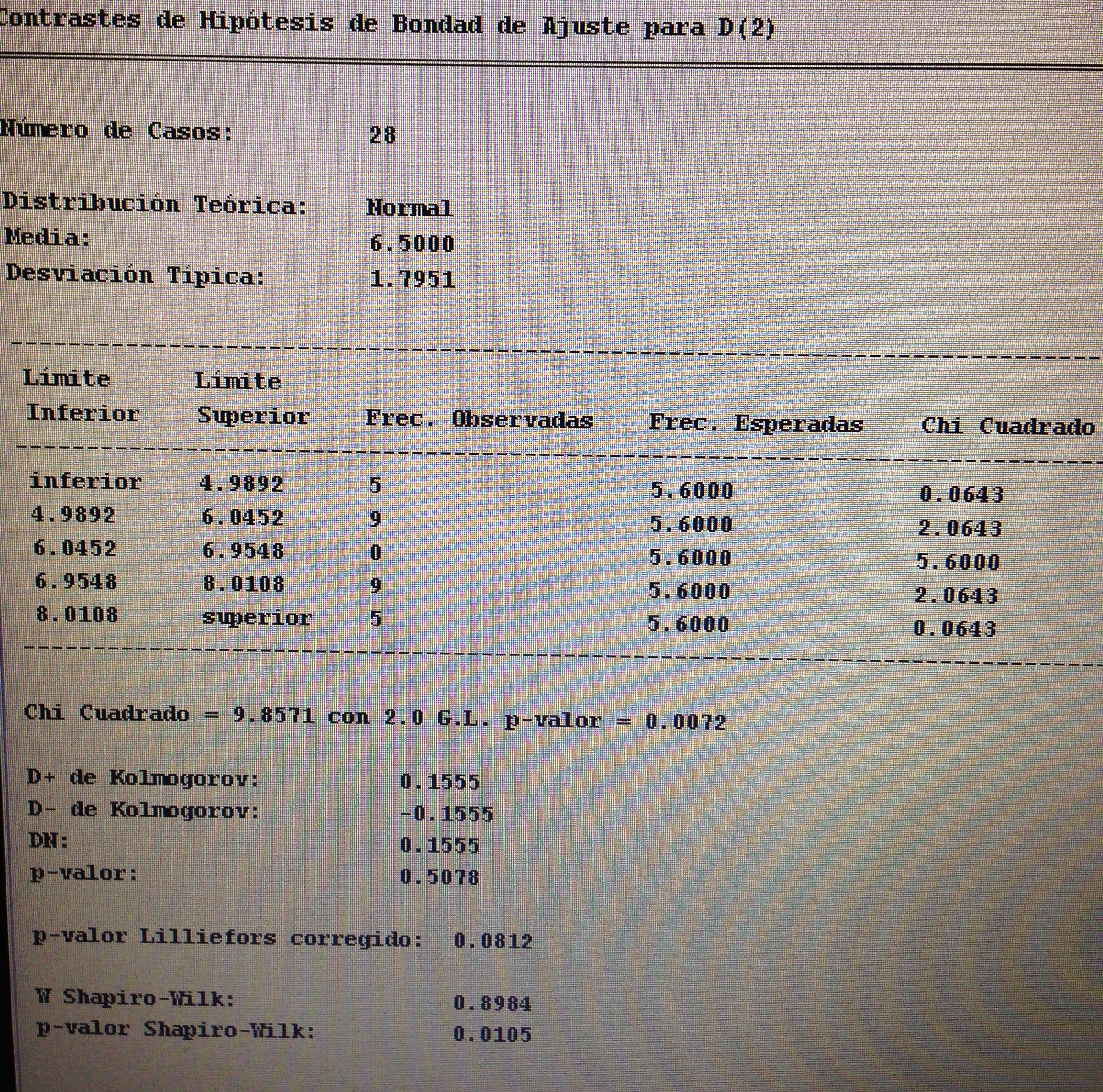
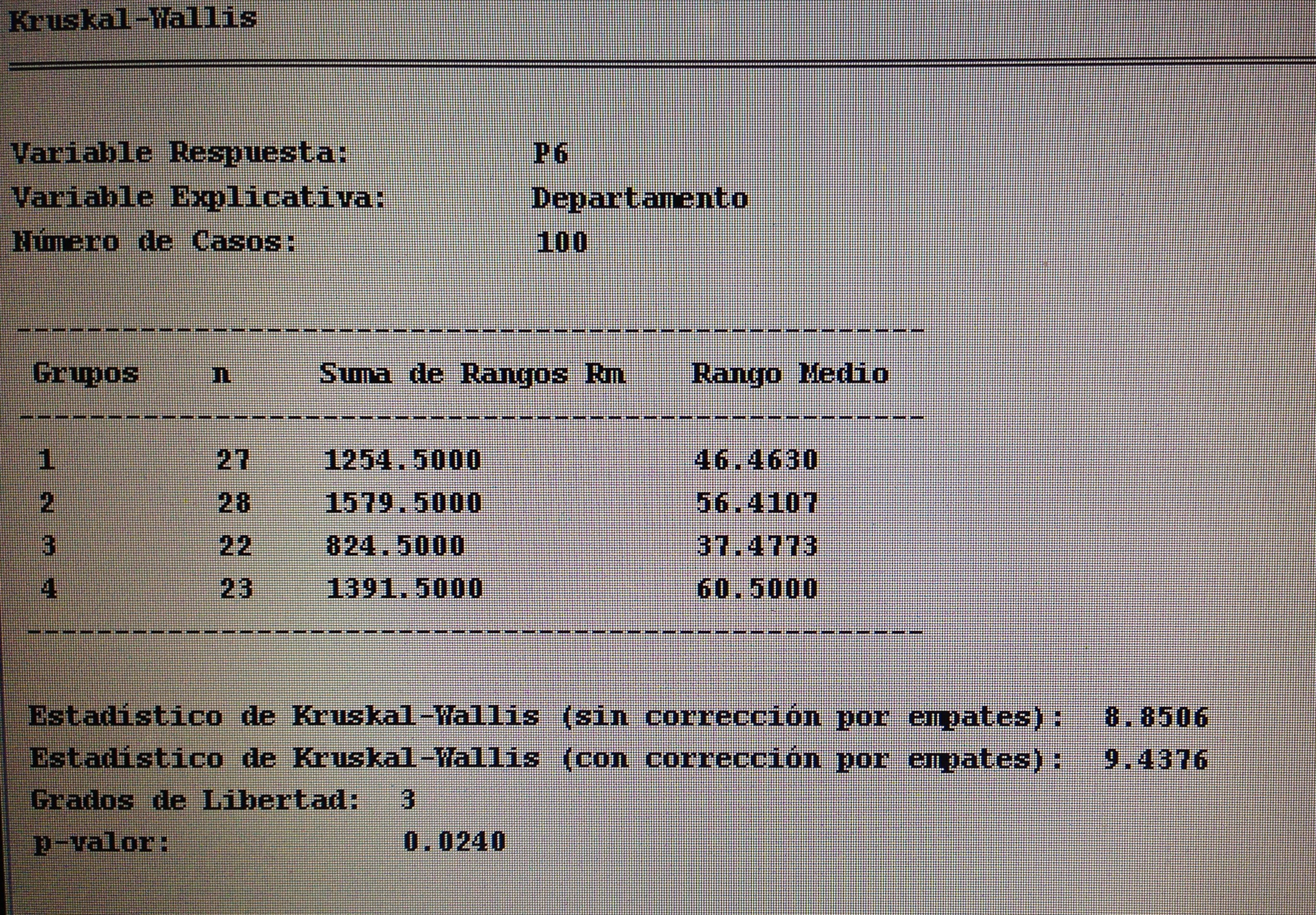
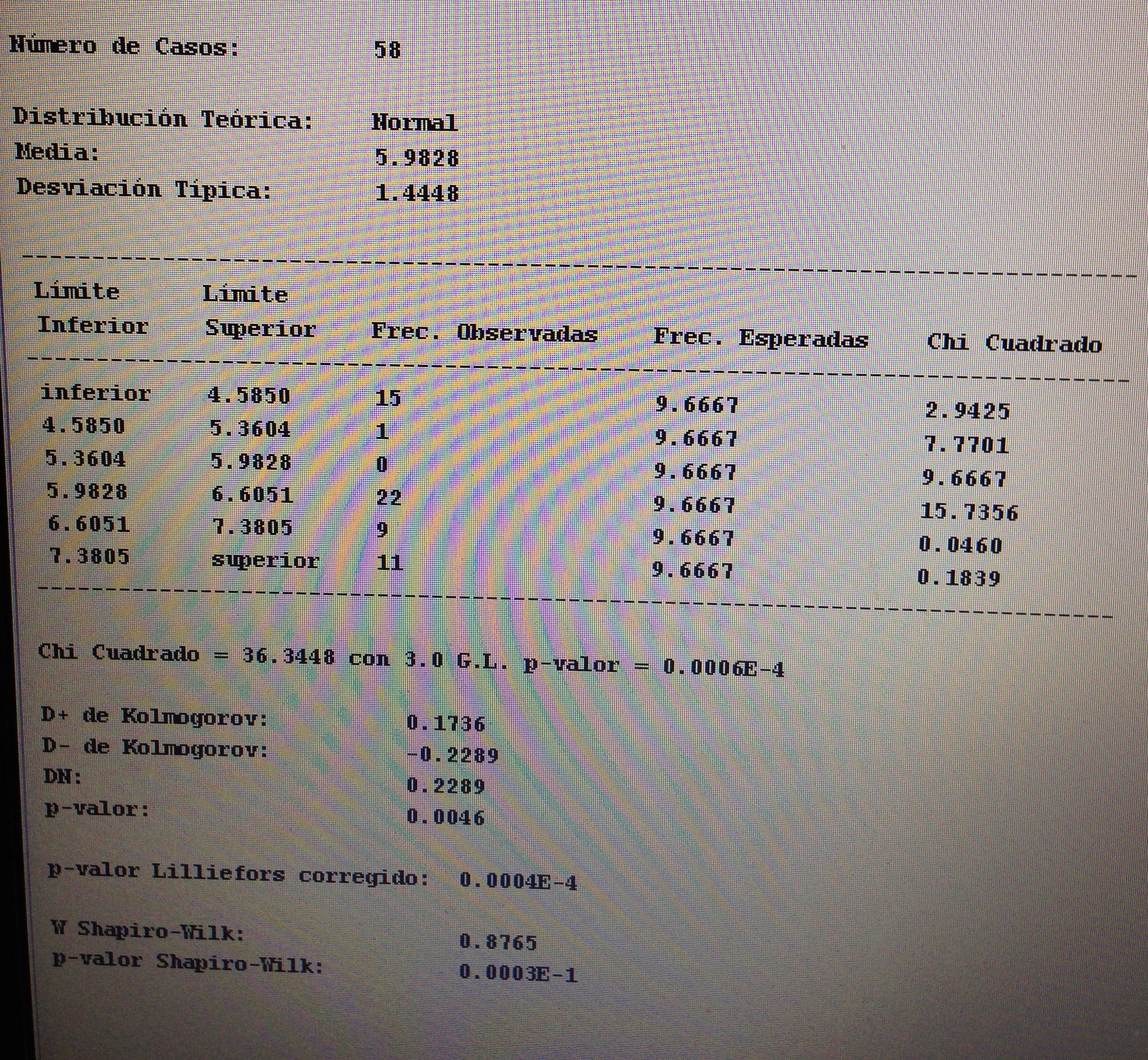
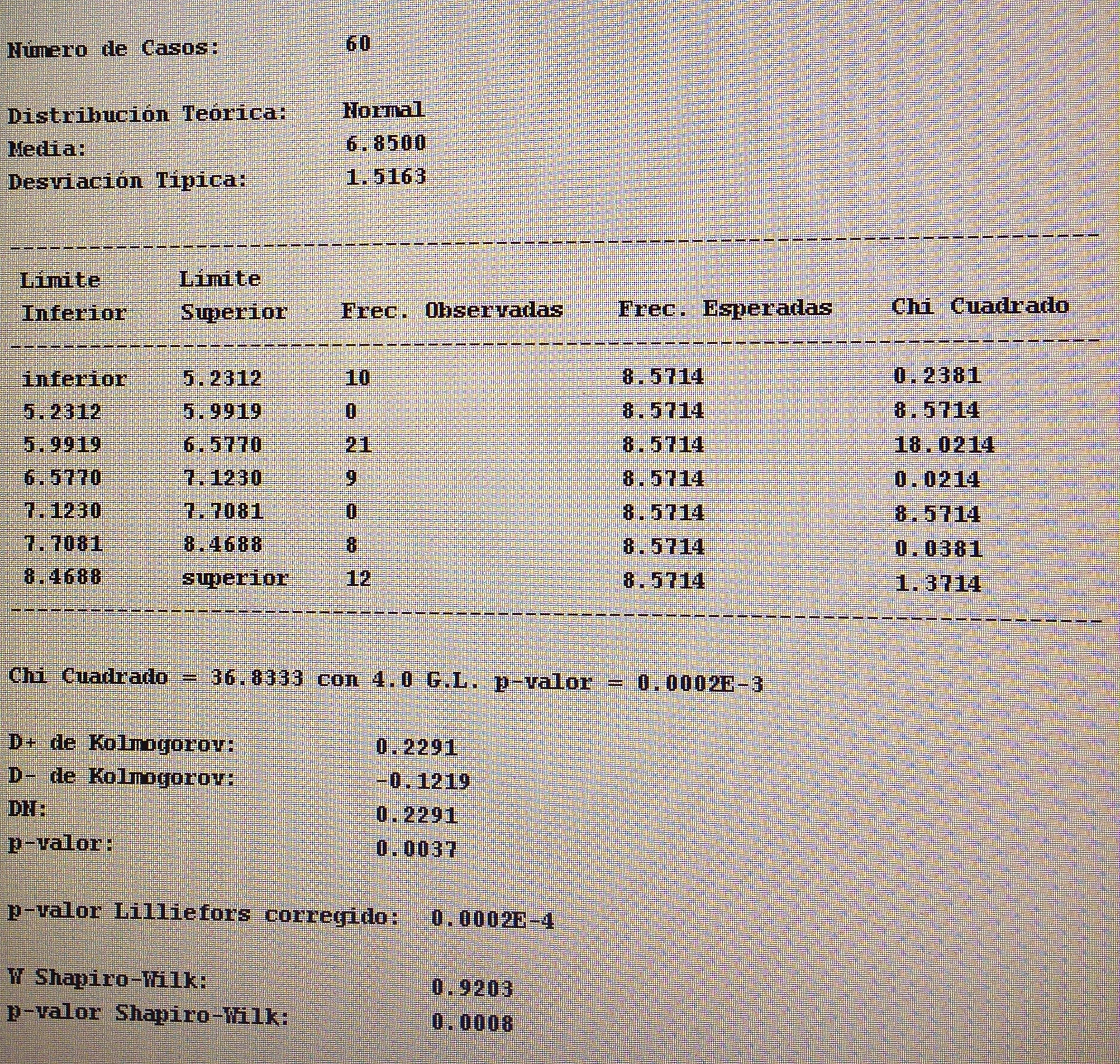
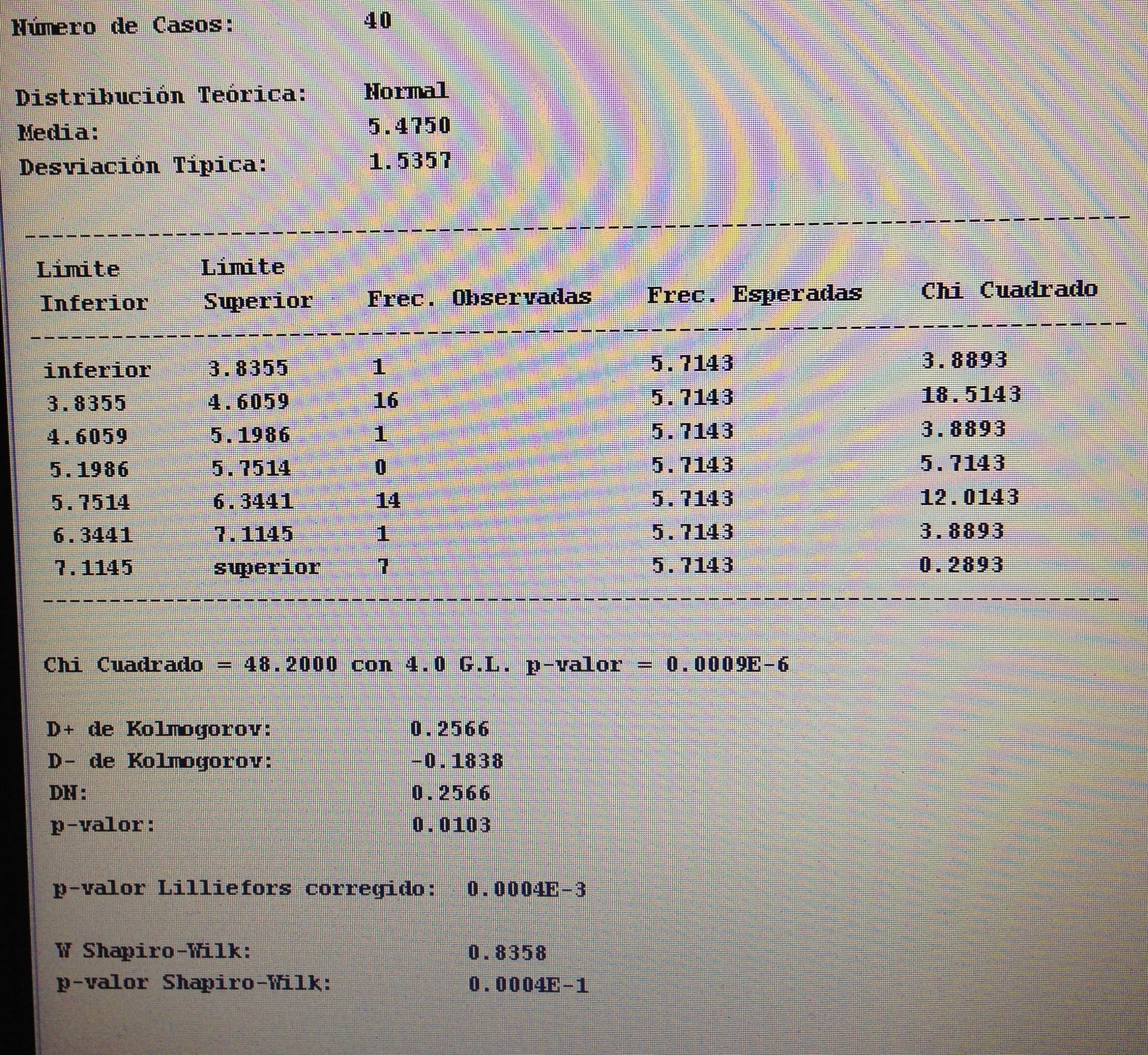
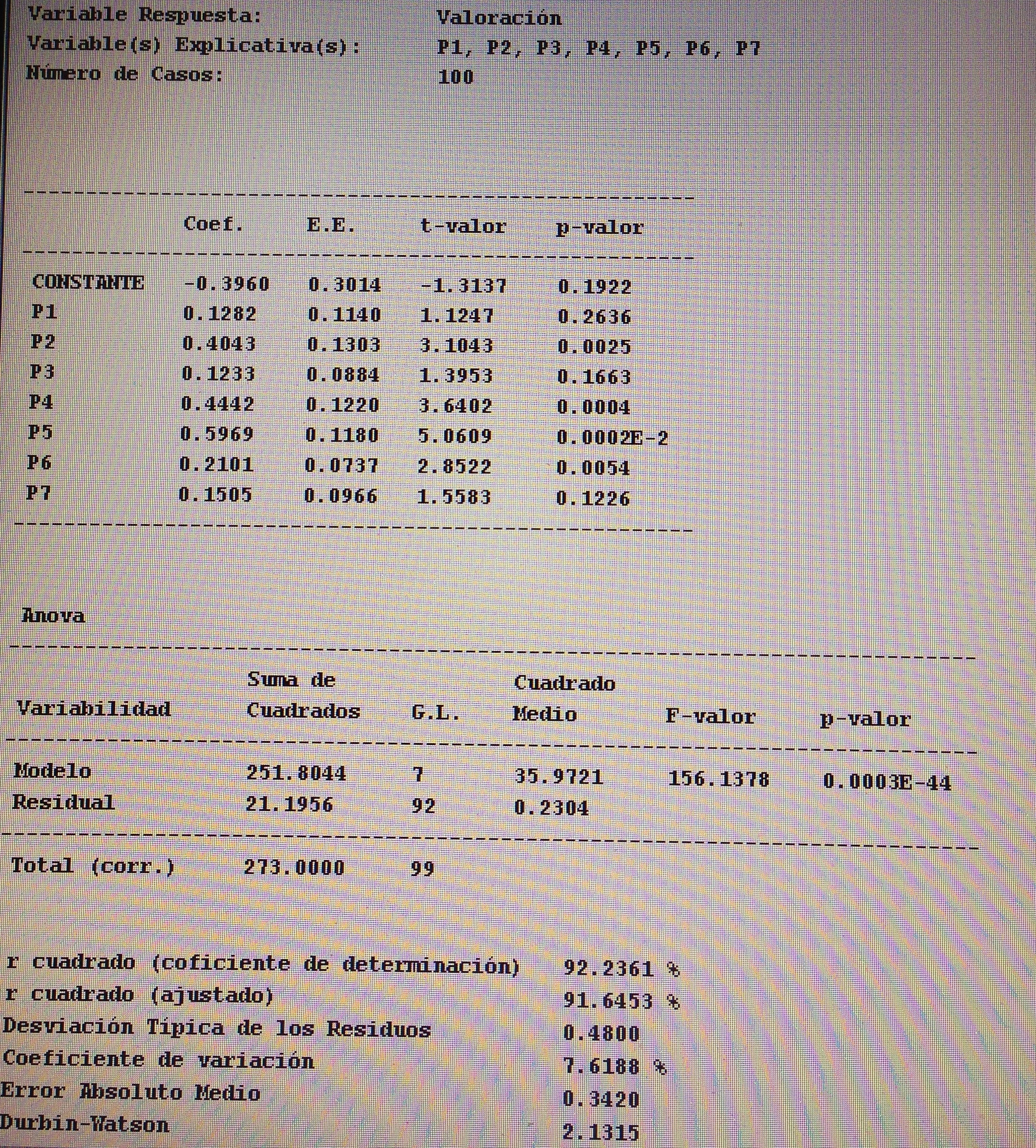
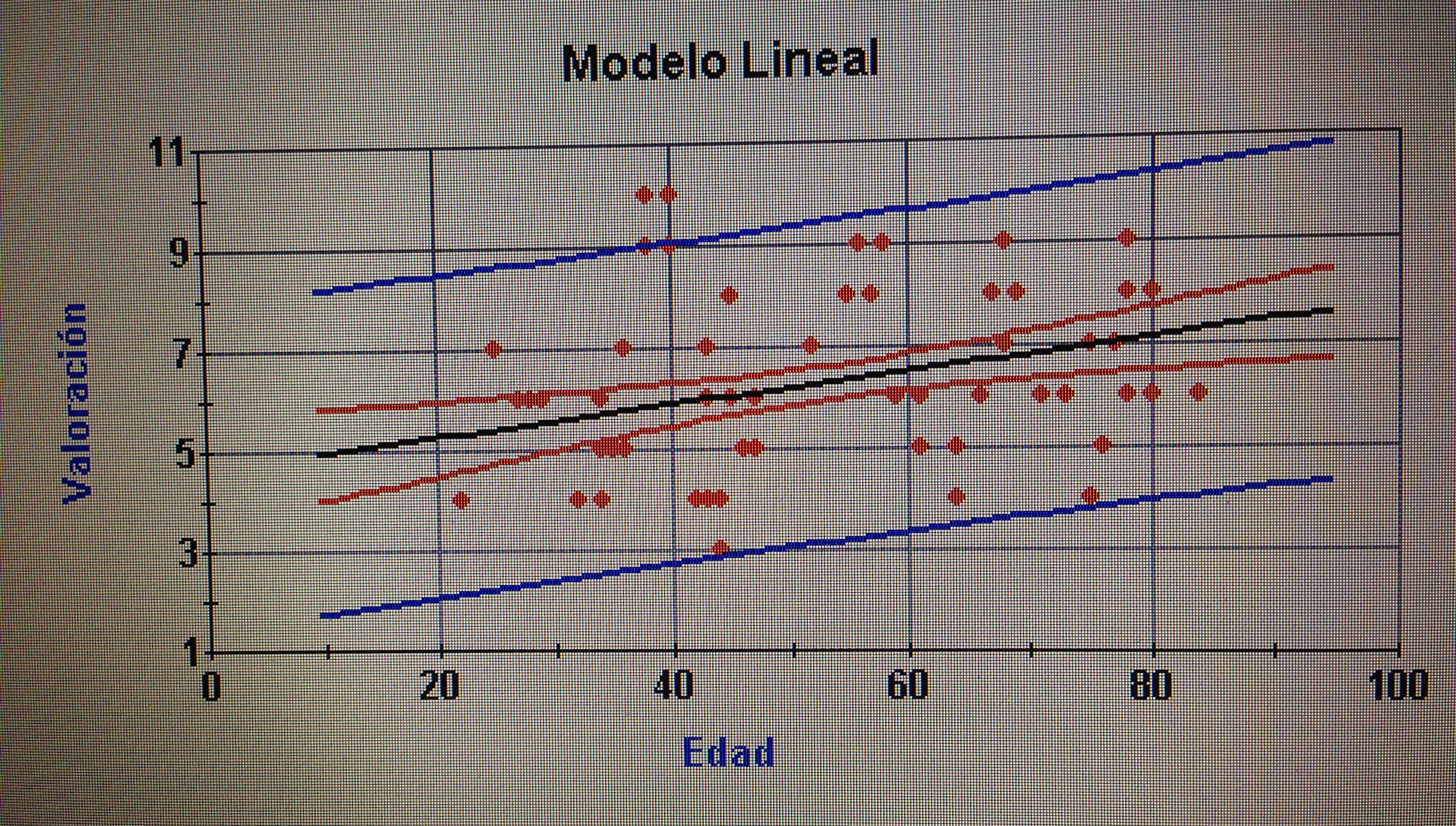
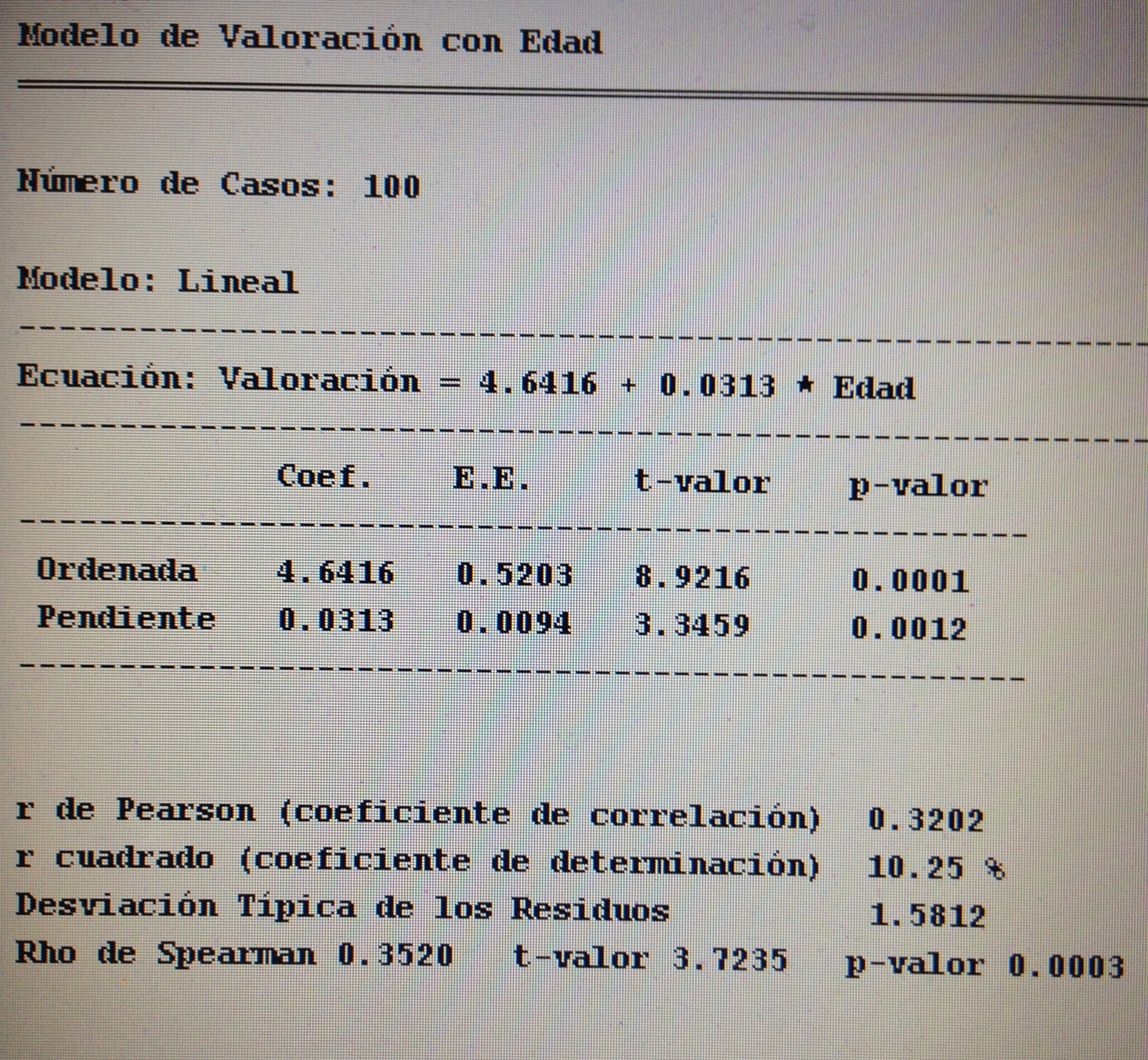
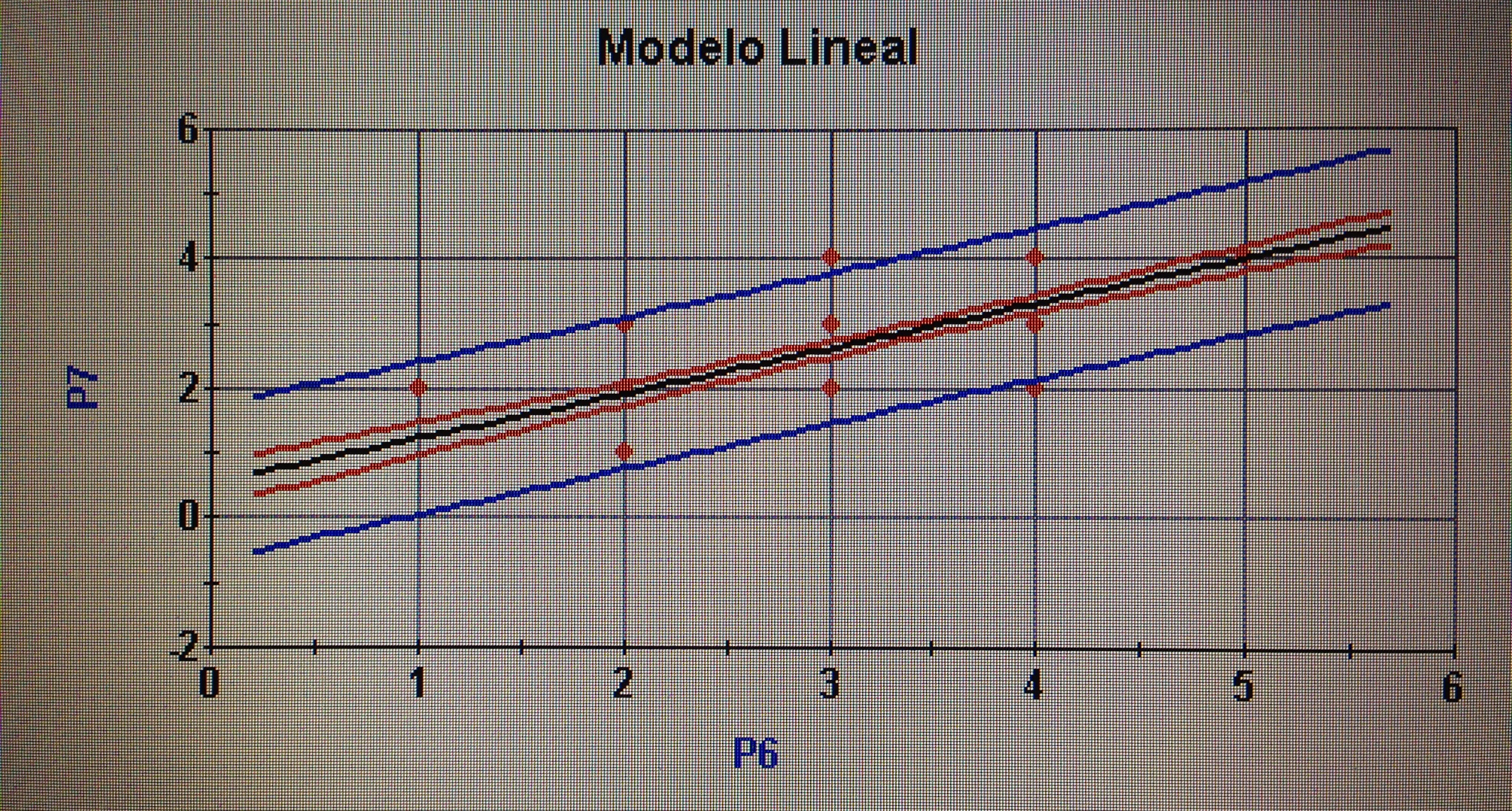
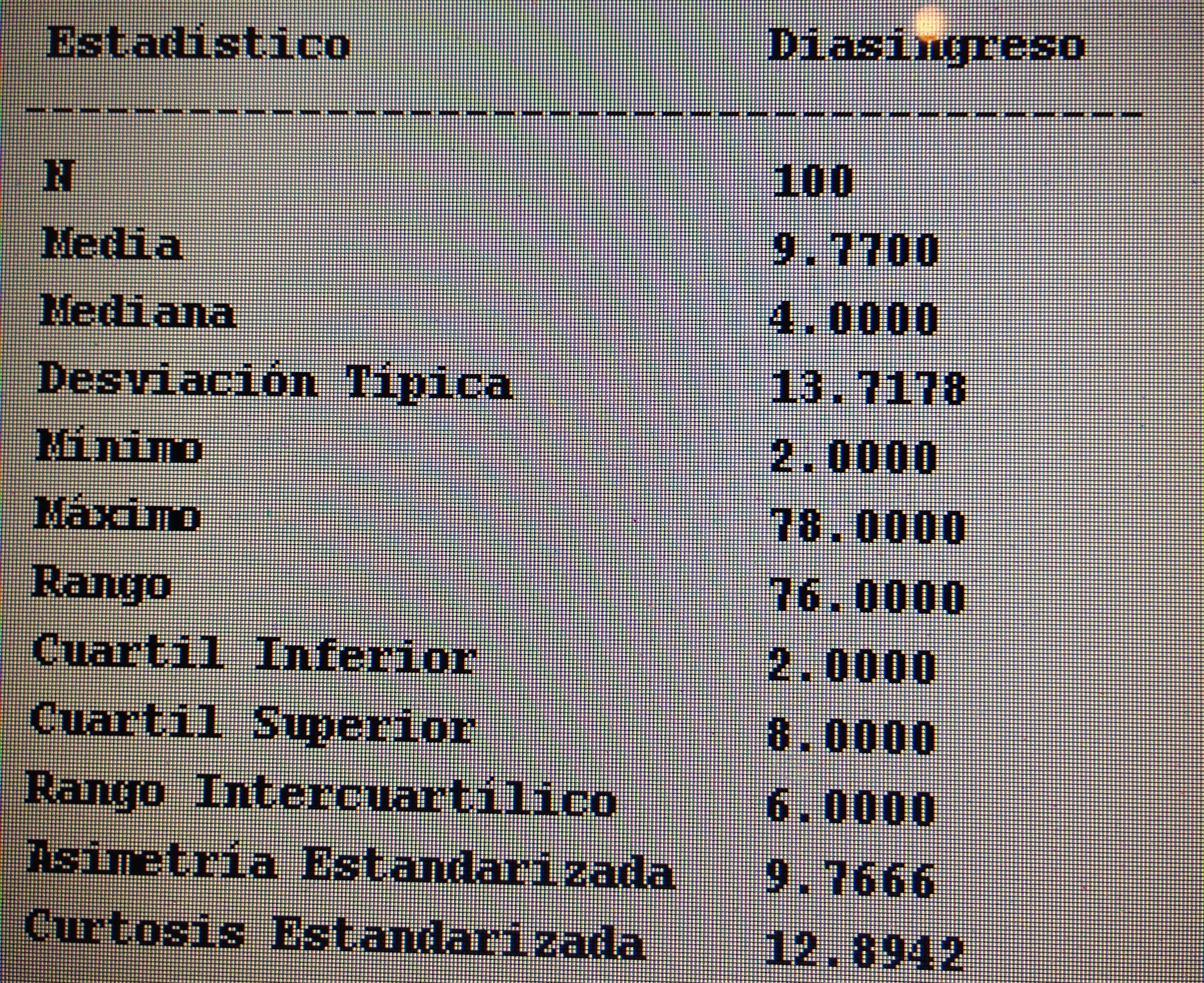
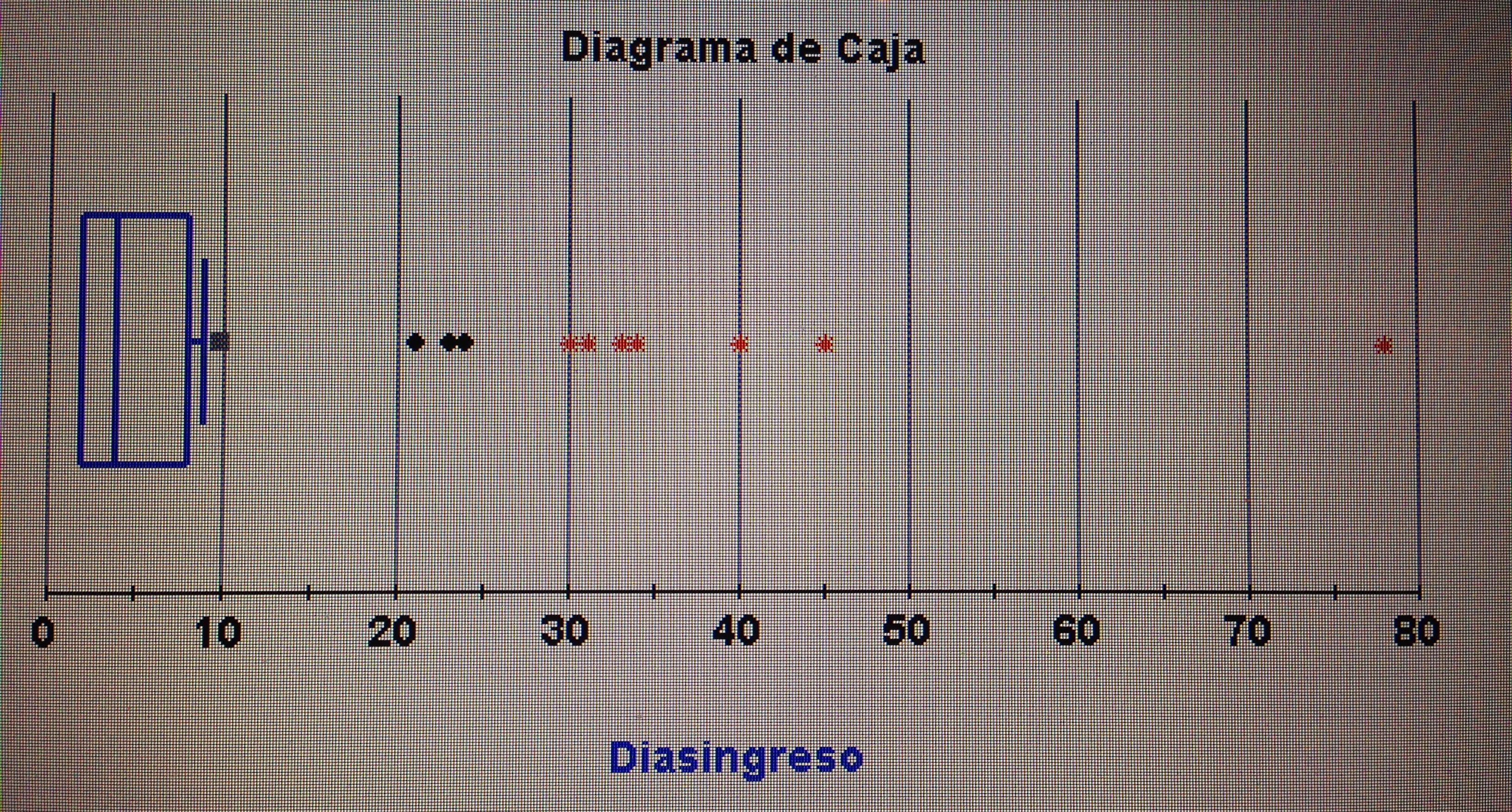
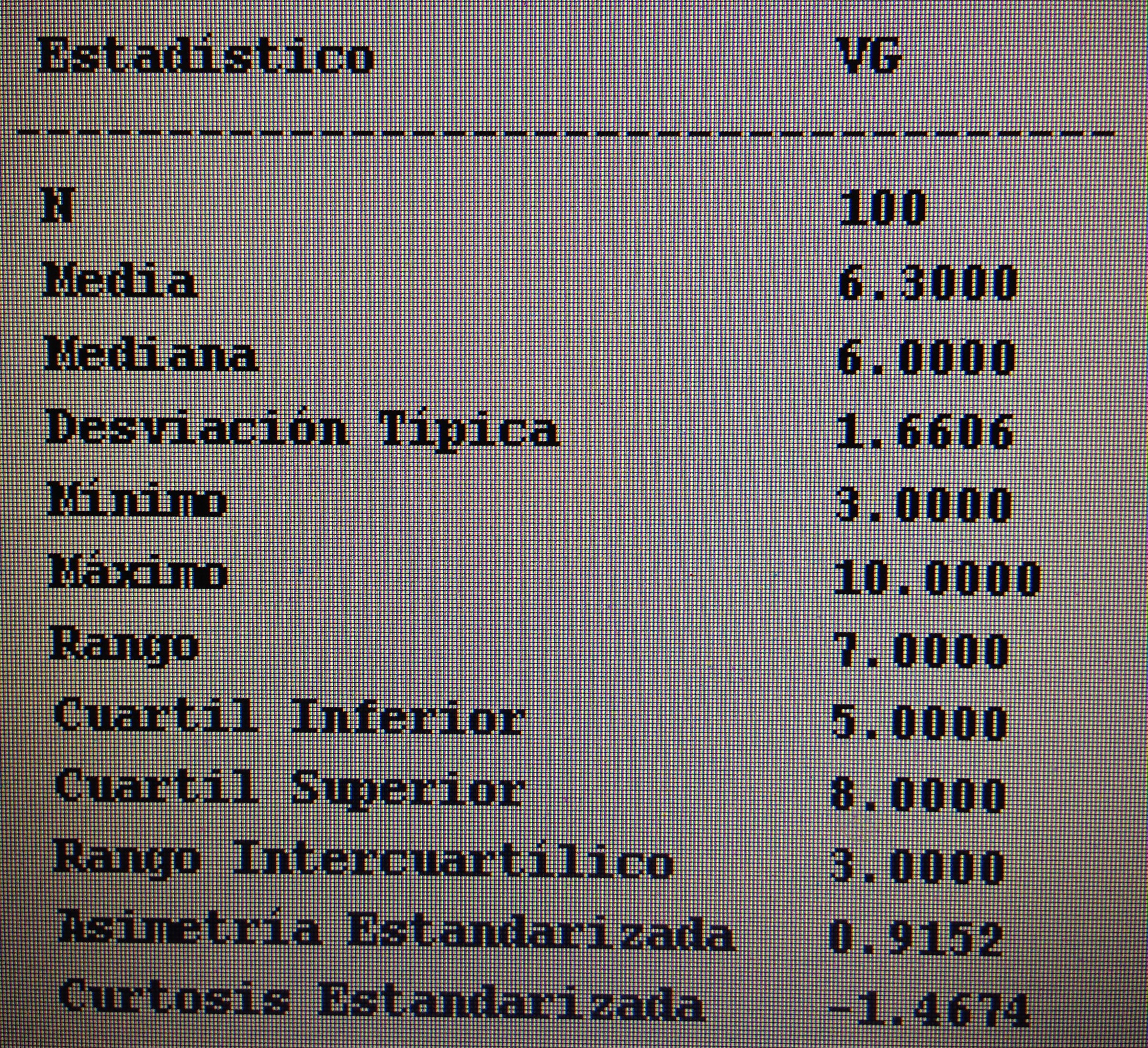
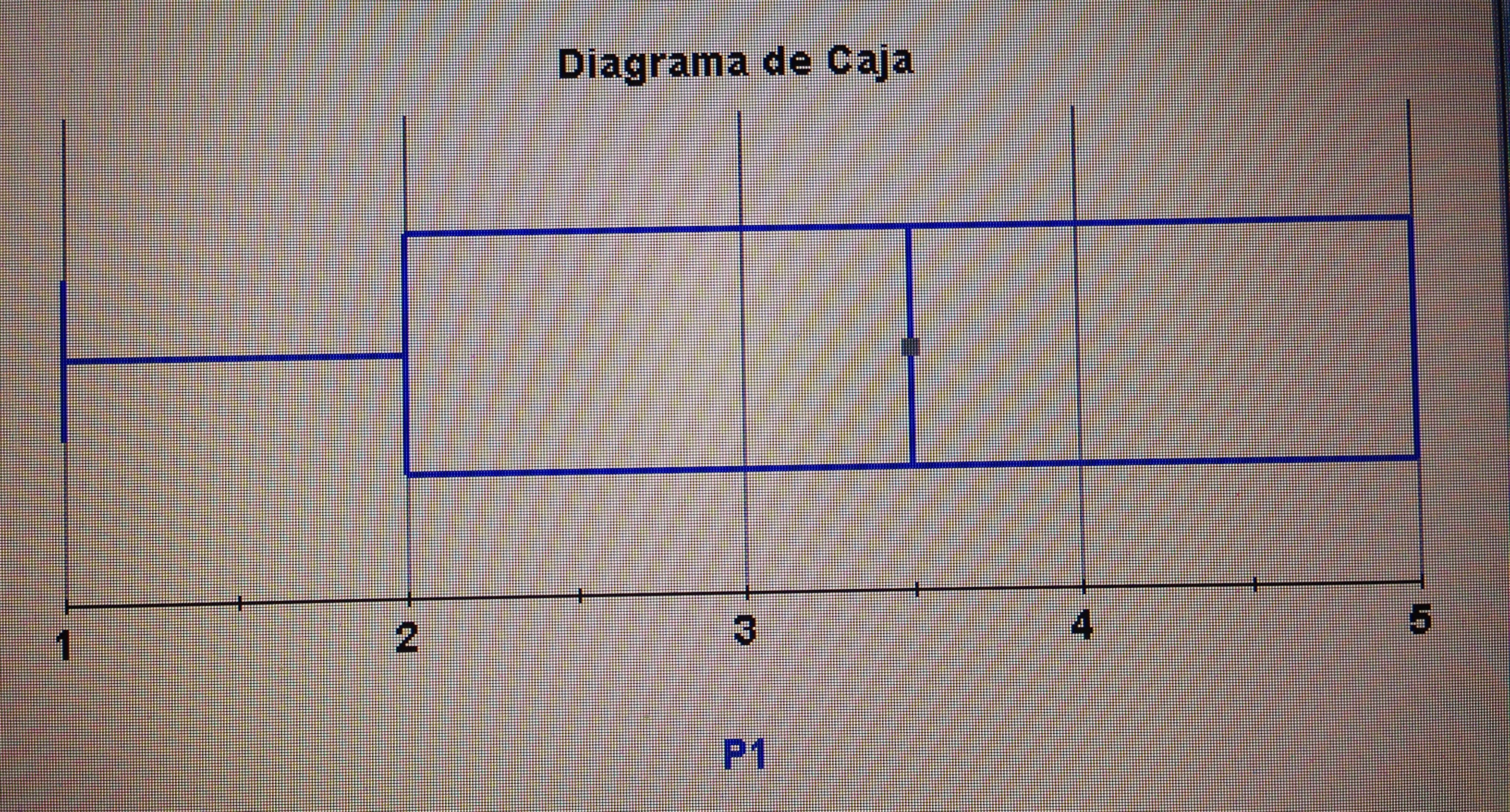
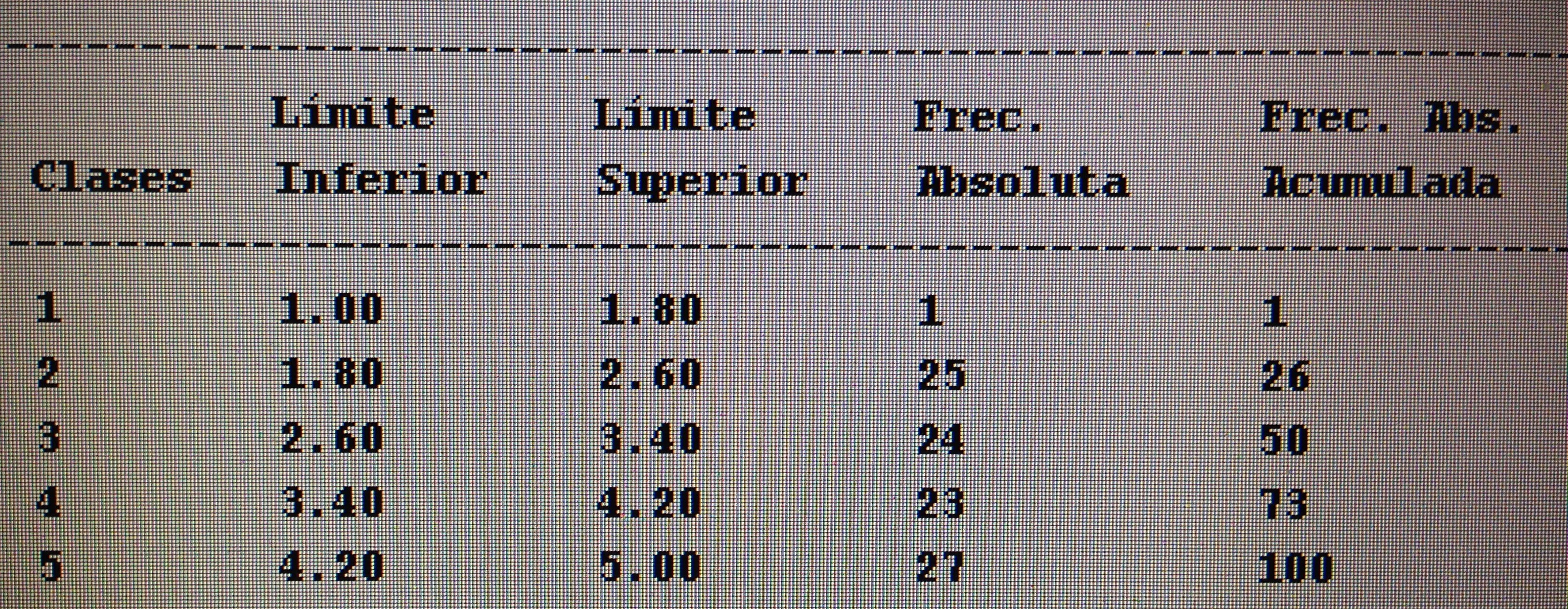
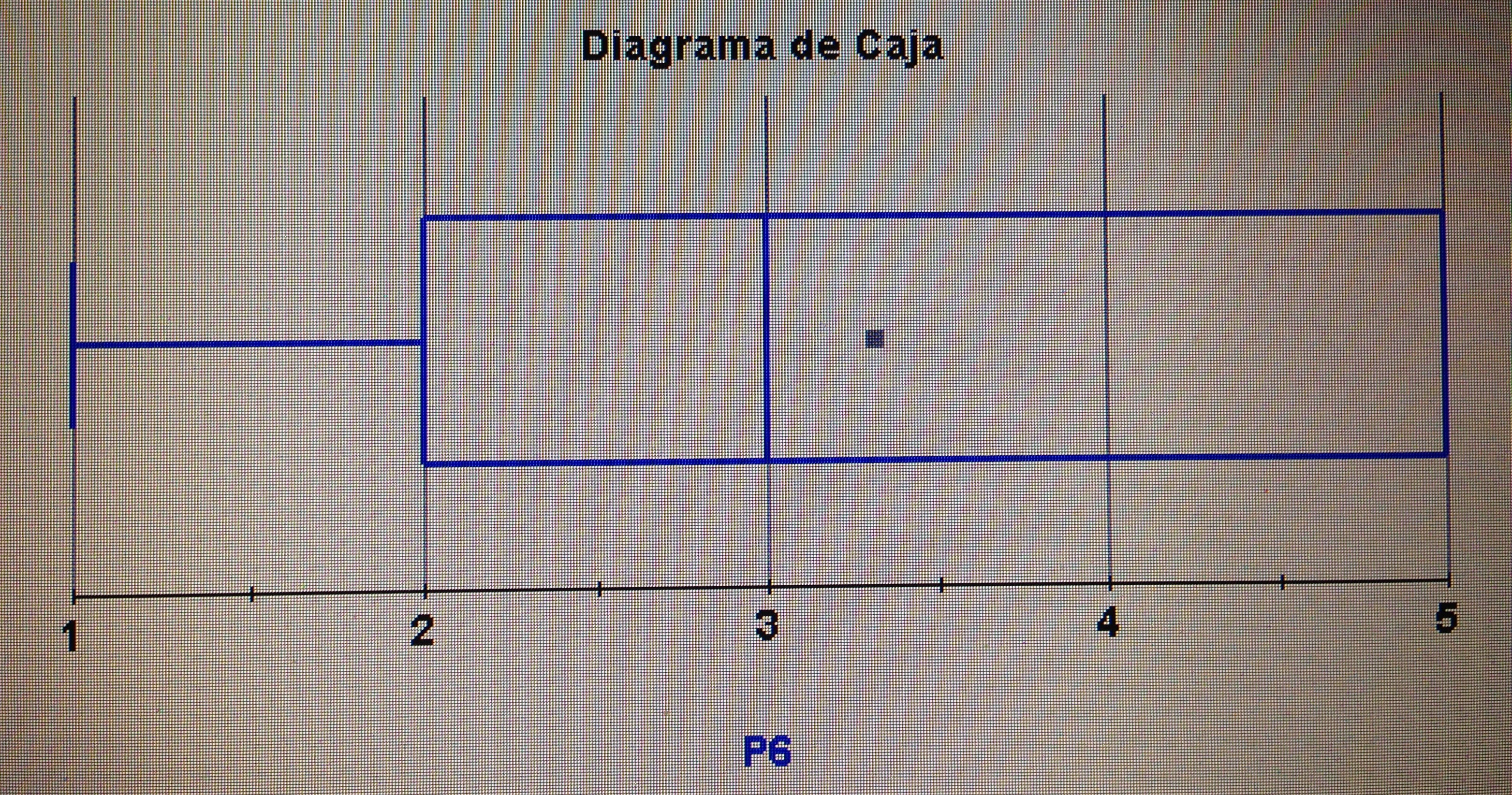
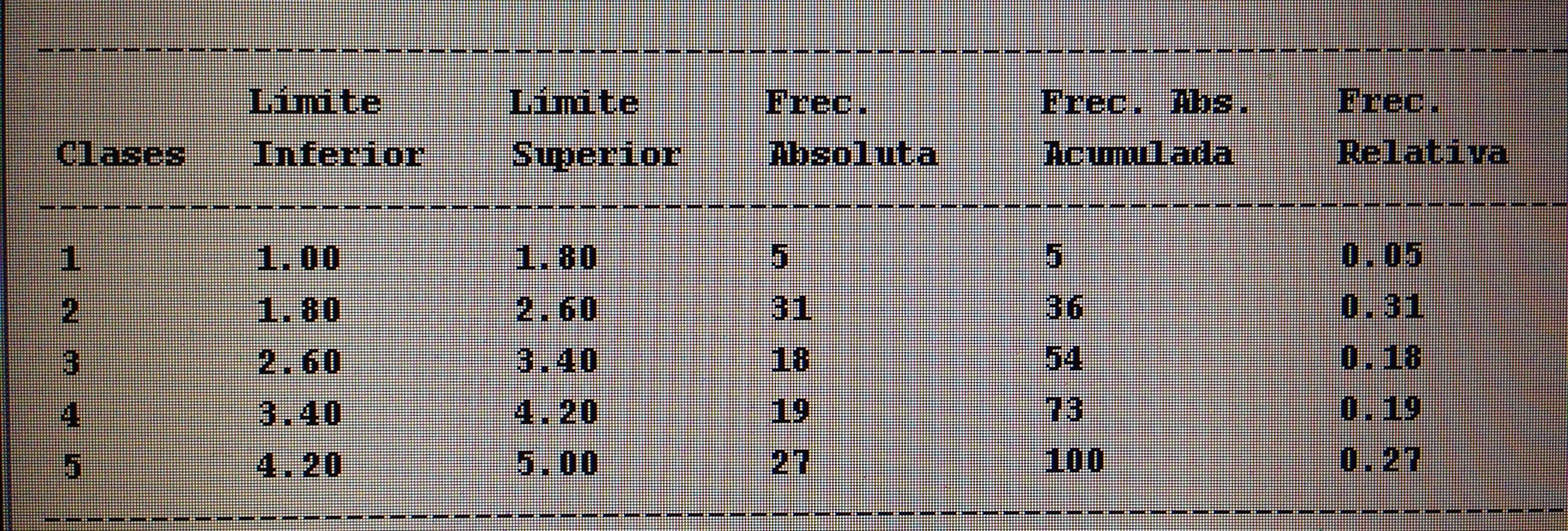
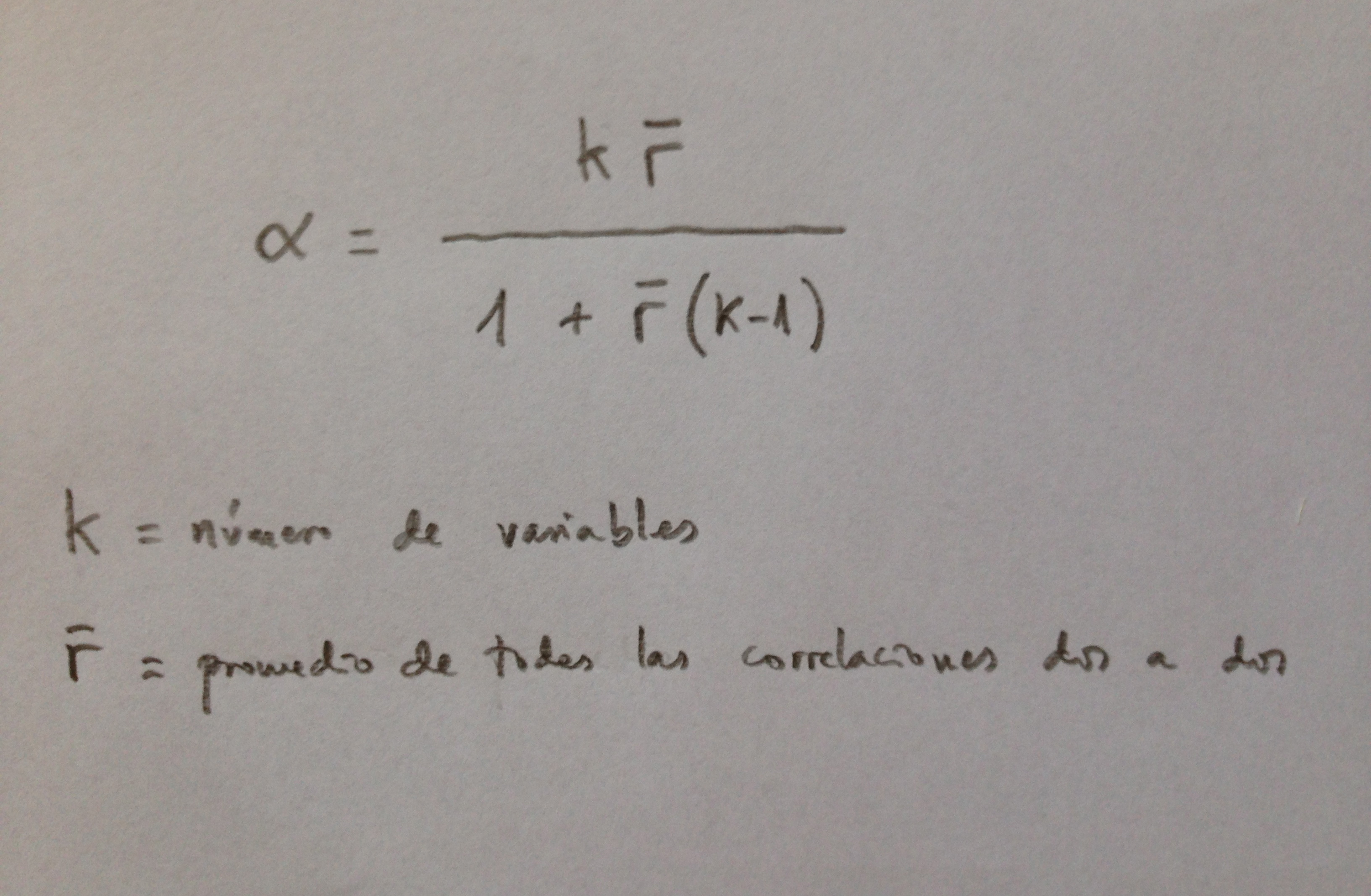A partir de nuestra base de datos adjunta del artículo Explotación de una base de datos 1: Base de datos podemos realizar Análisis factorial. Veamos algunos ejemplos:
1. Hacer un Análisis factorial con las variables P1, P2, P3, P4, P5, P6 y P7. Ver cuánta variabilidad explican los factores.
2. Hacer un giro de los ejes que consiga la máxima capacidad explicativa de los factores.
3. Representar los cien pacientes en ejes formados por los factores encontrados.
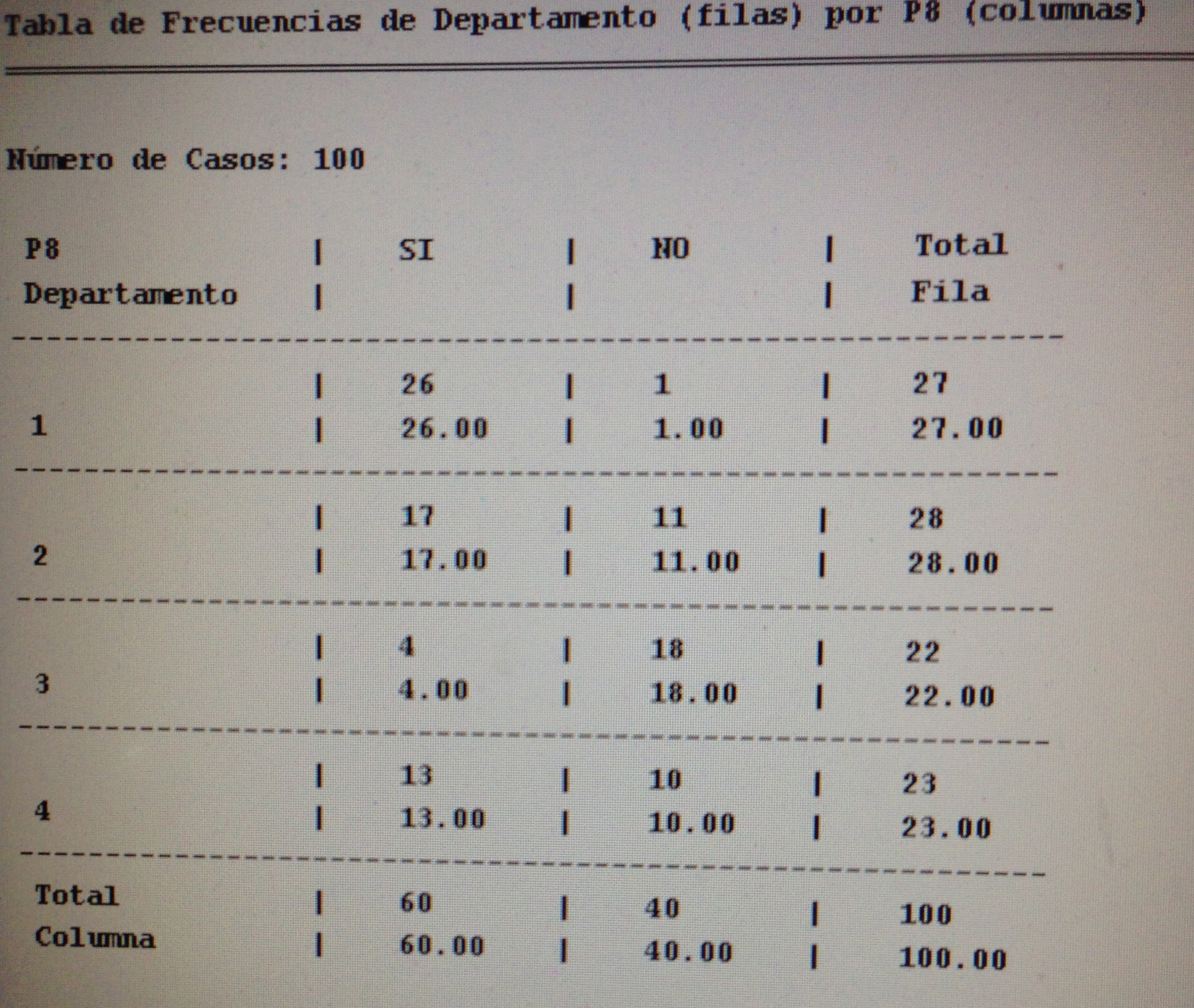
4. Proyectar en la representación de los ejes de los factores la variable P8.
5. Proyectar en la representación de los ejes de los factores la variable Cirugía.
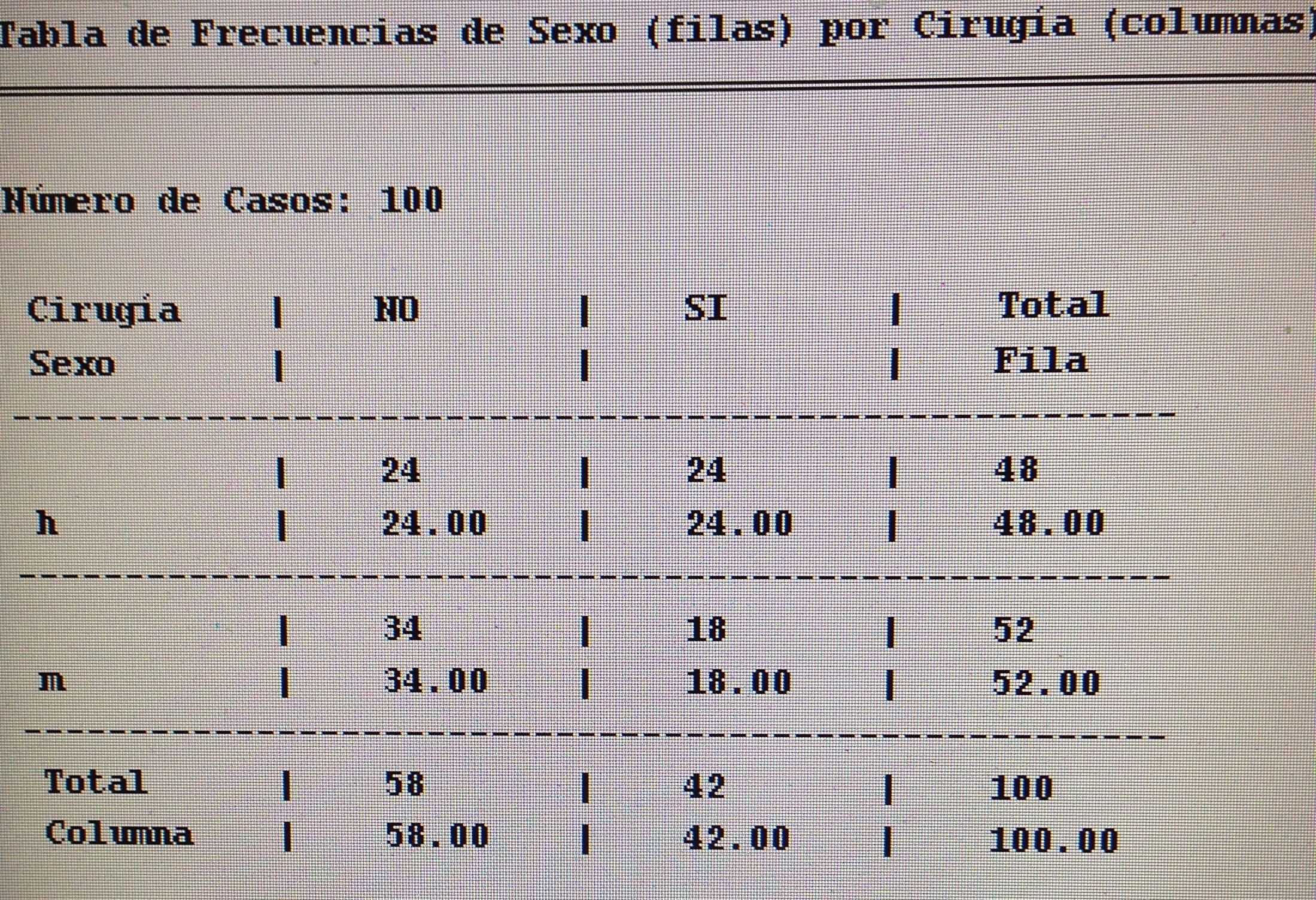
6. Proyectar en la representación de los ejes de los factores la variable Sexo.
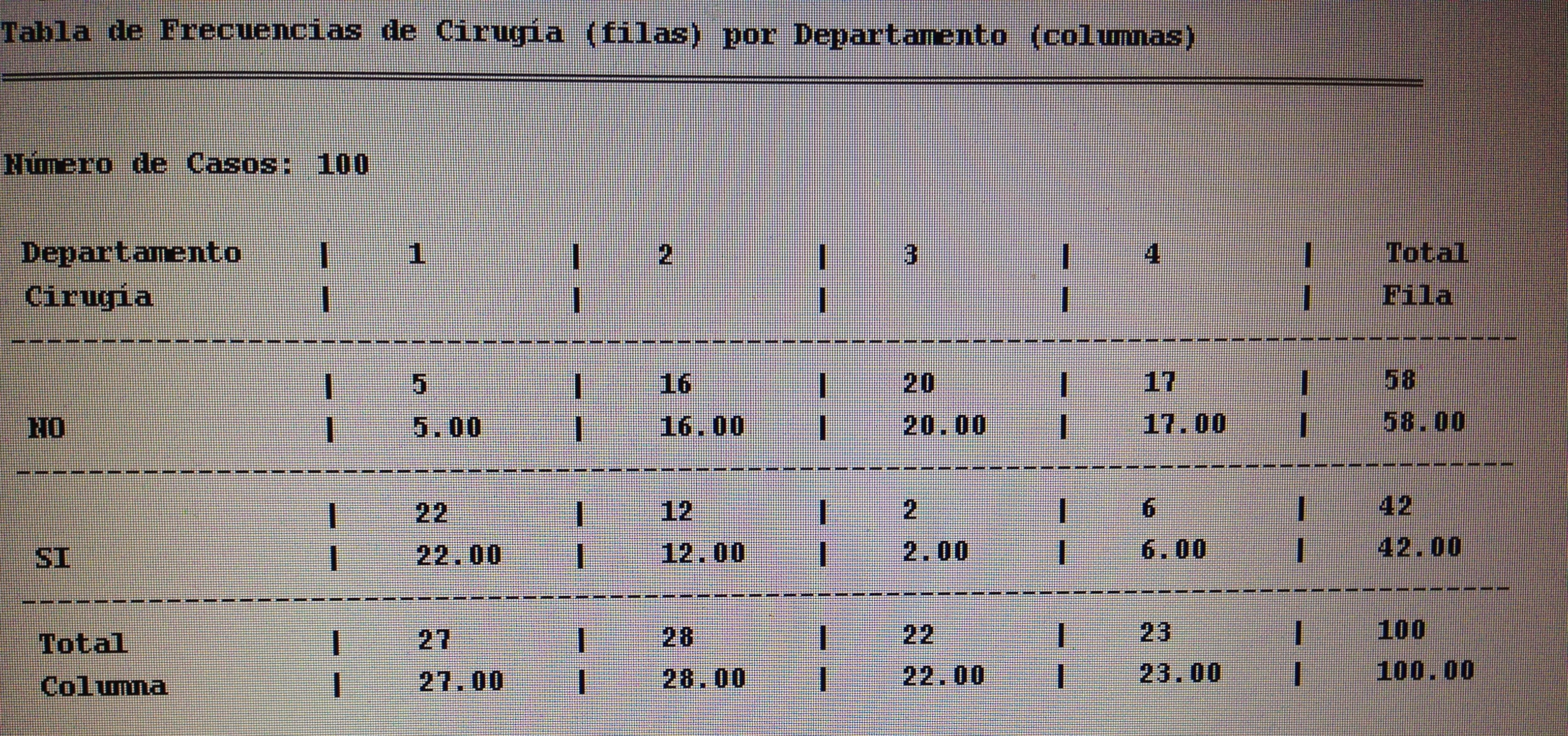
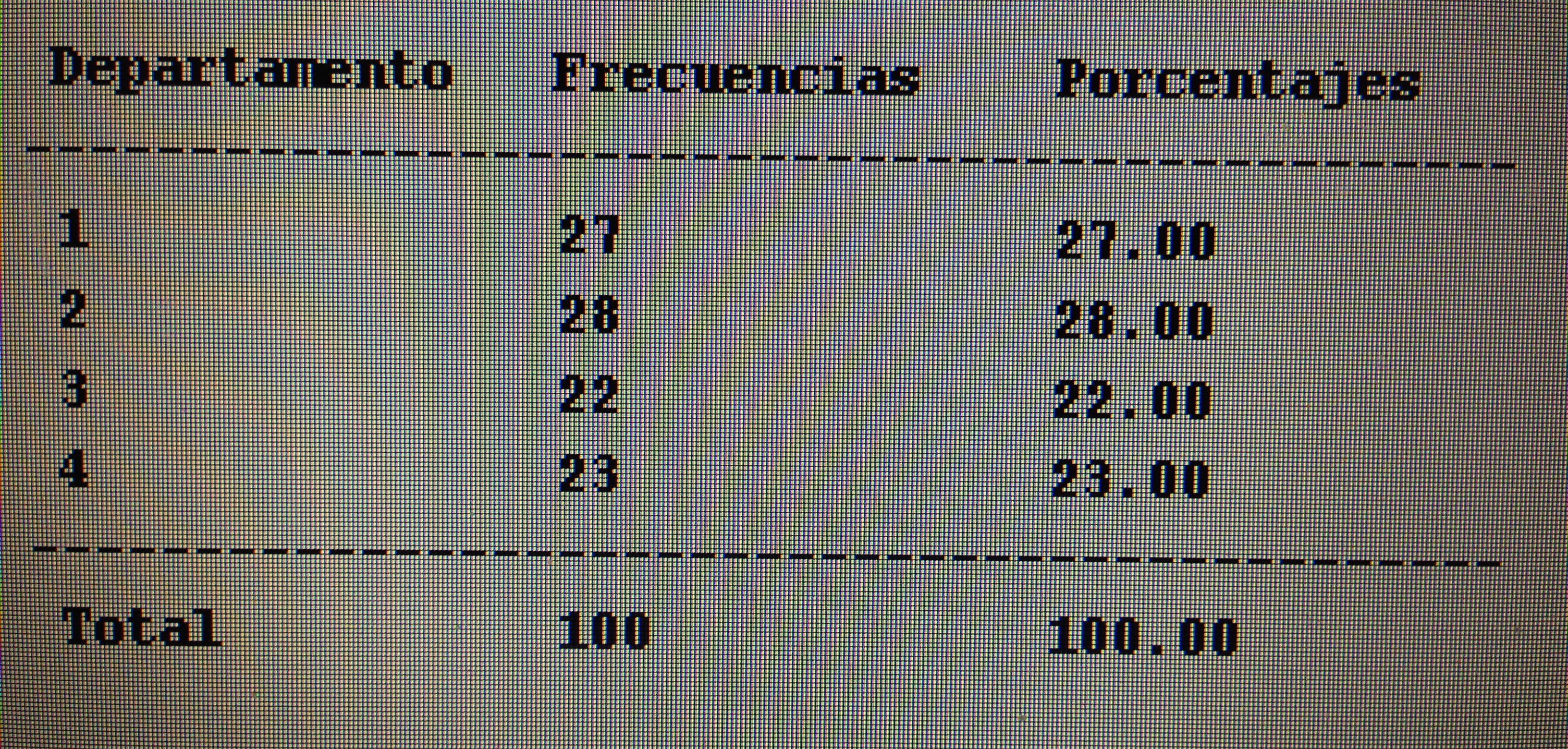
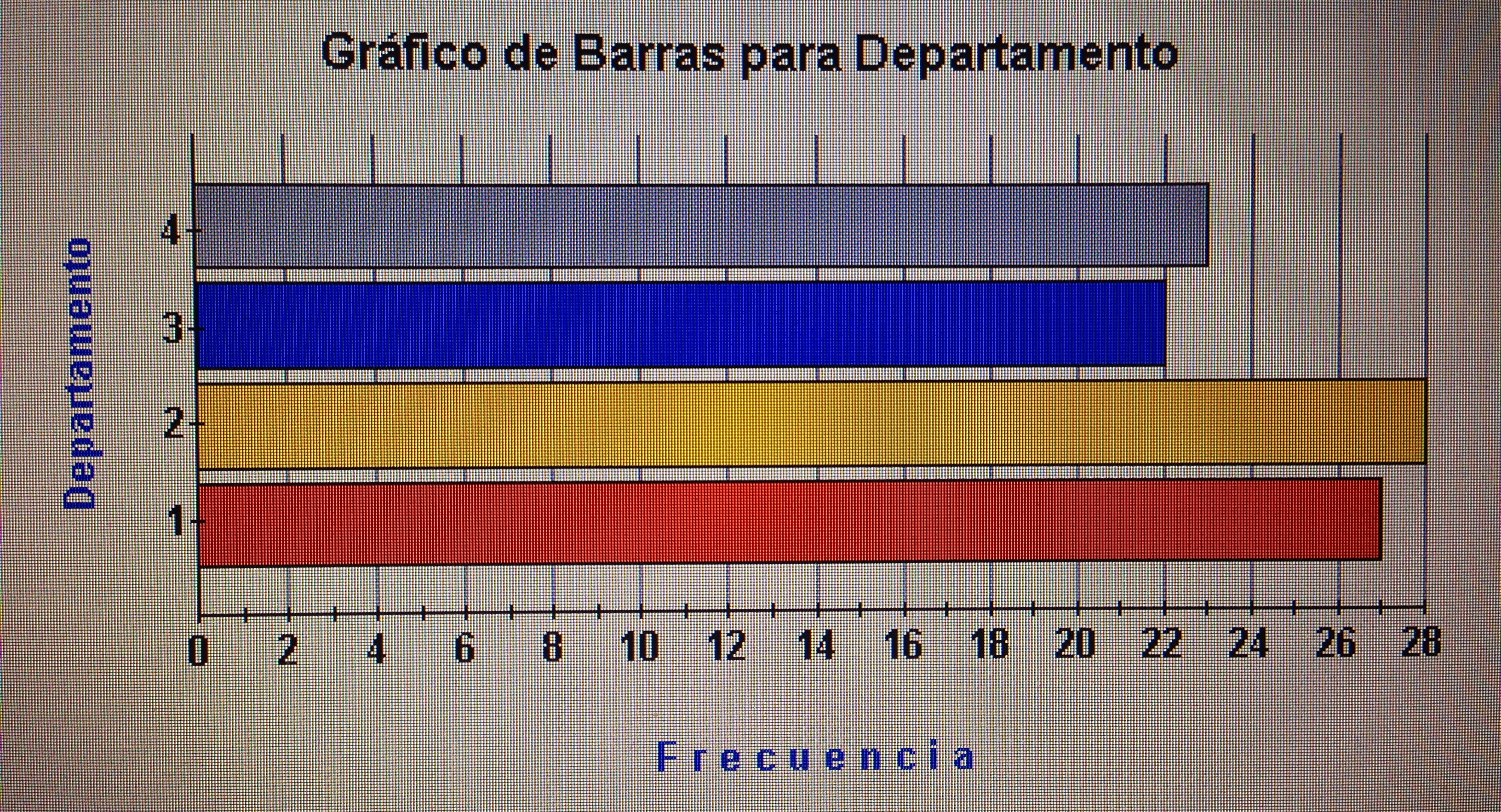
7. Proyectar en la representación de los ejes de los factores la variable Departamento.
SOLUCIONES
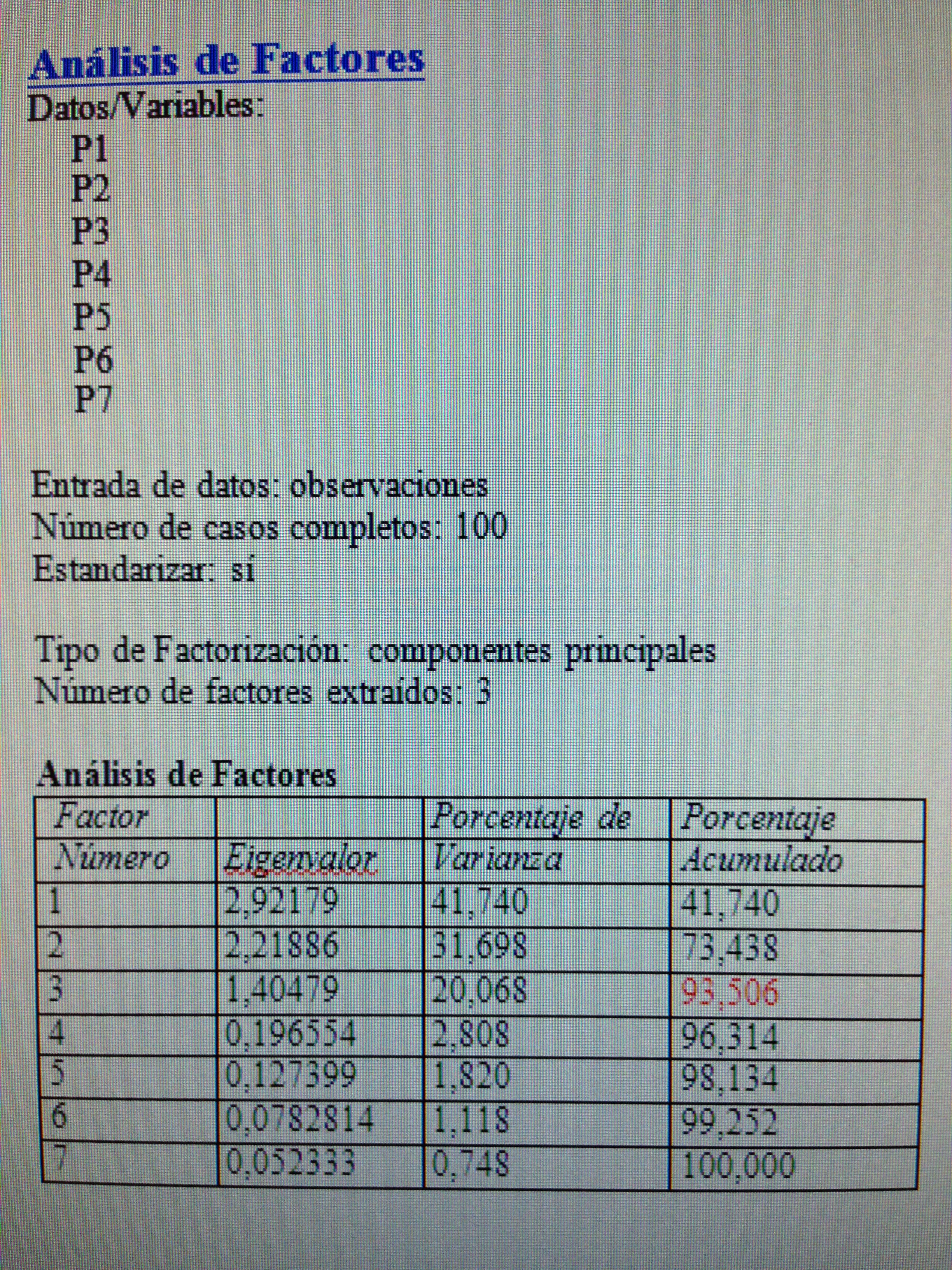
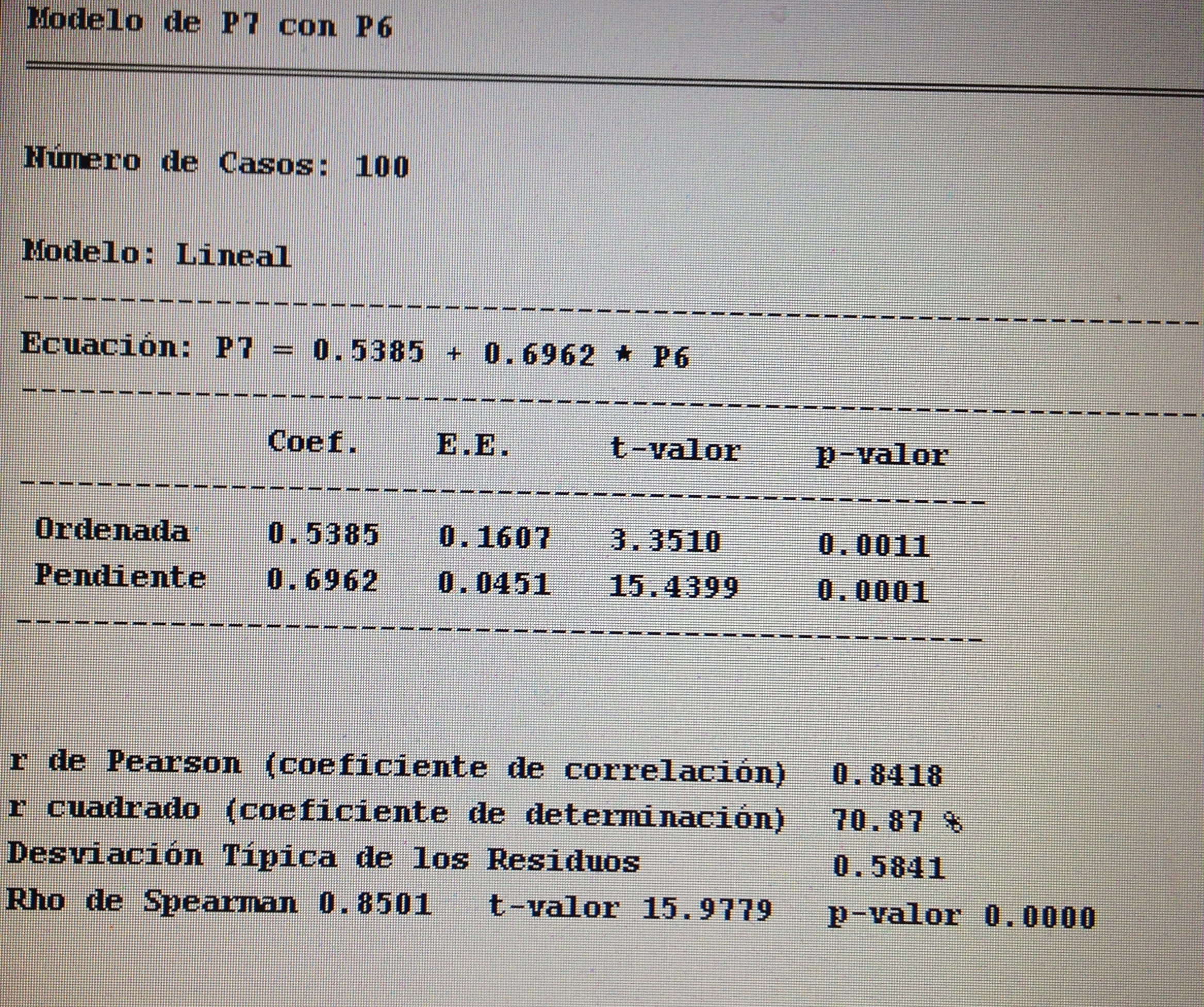
1. Hacer un Análisis factorial con las variables P1, P2, P3, P4, P5, P6 y P7. Ver cuánta variabilidad explican los factores:

Obsérvese que con tres factores explicamos un 93,5% de la información. Esto es mucho, realmente.
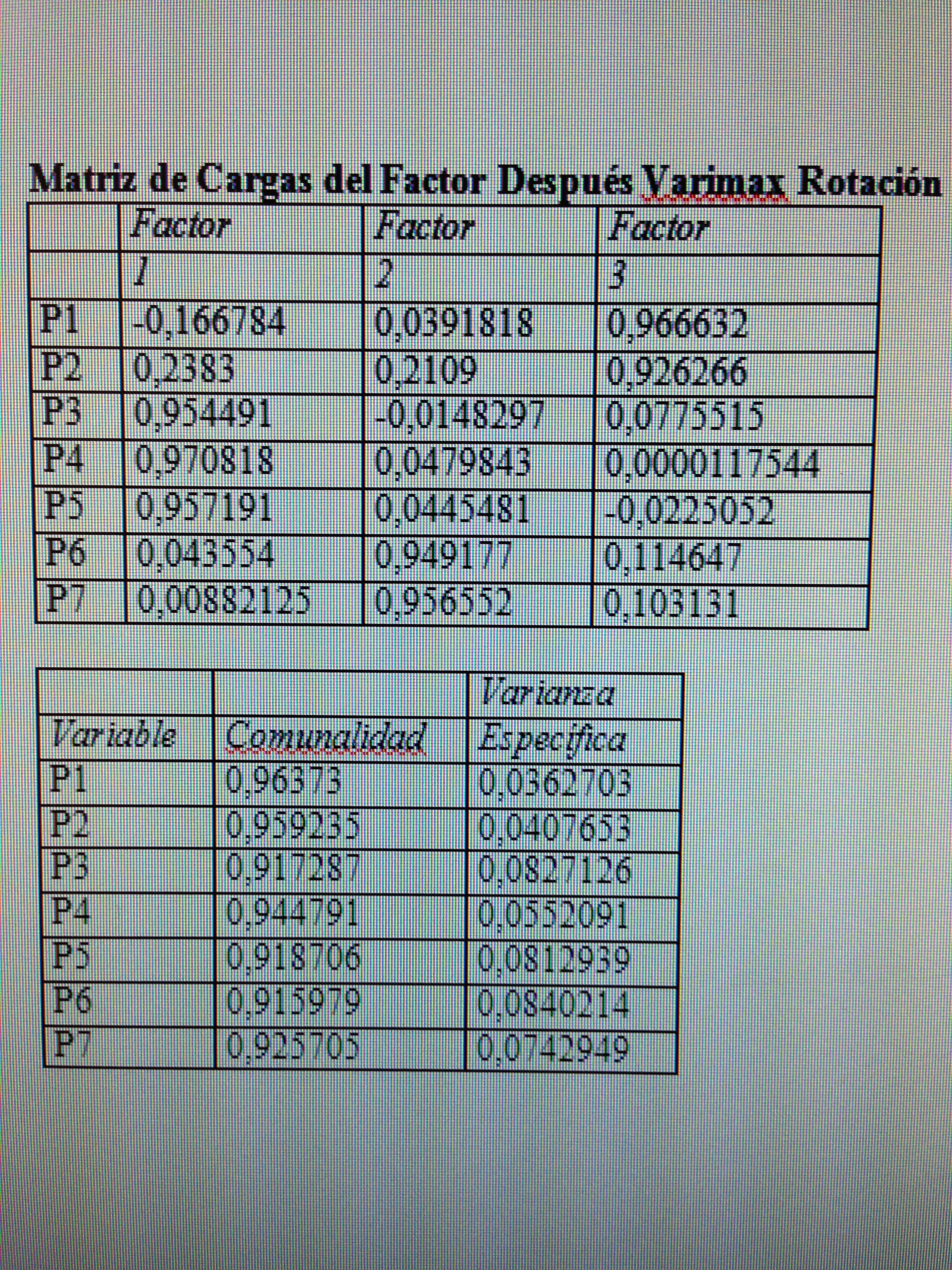
2. Hacer un giro de los ejes que consiga la máxima capacidad explicativa de los factores:

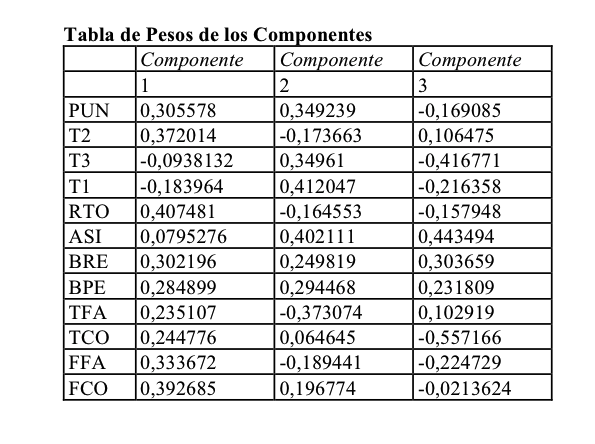
Con la rotación variamax conseguimos realmente tres factores claramente delimitados. Observemos que en el primer factor las variables con peso son la P3, P4 y P5. En el segundo son P6 y P7. En el tercer factor son P1 y P2 las que tienen el protagonismo. Esto cuadra con lo que hemos visto al analizar las correlaciones en el fichero 3 de esta serie.
3. Representar los cien pacientes en ejes formados por los factores encontrados:

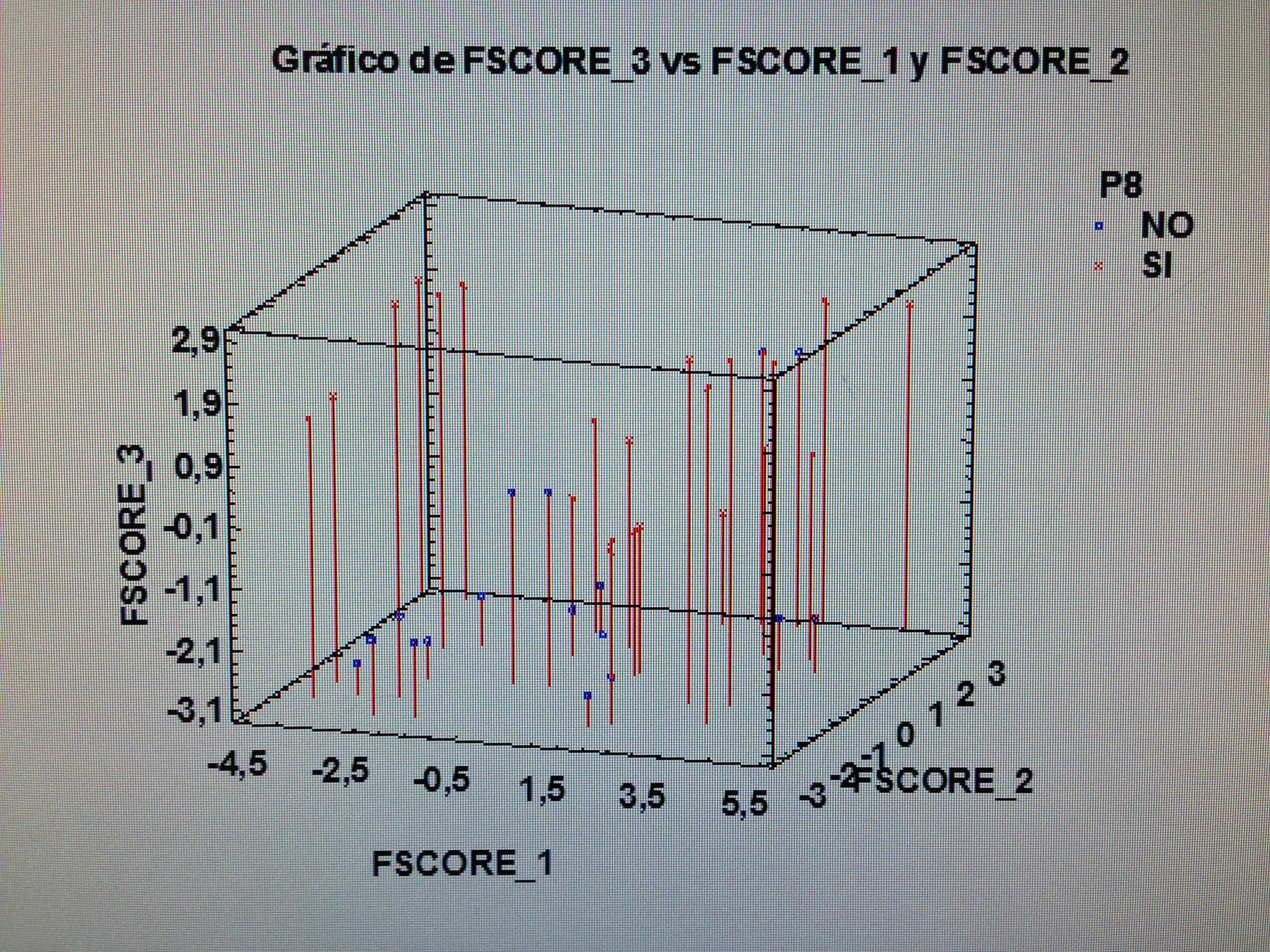
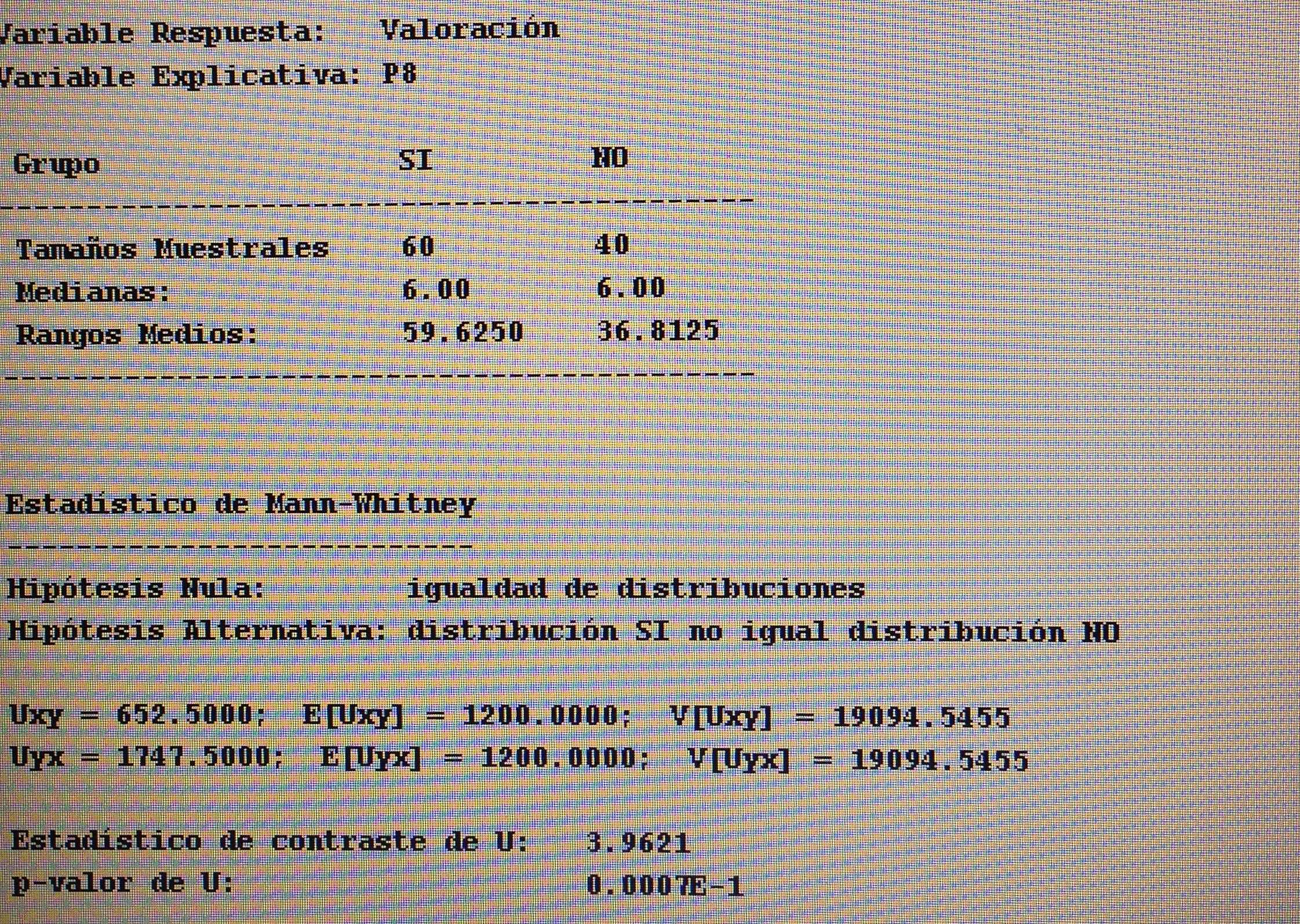
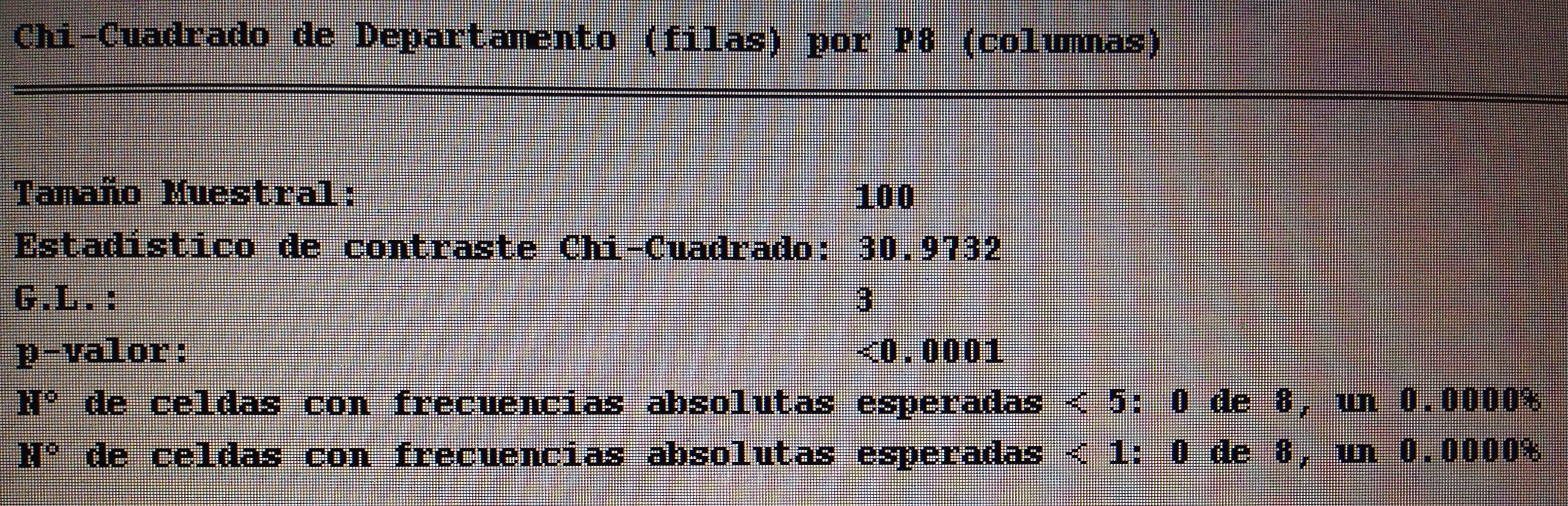
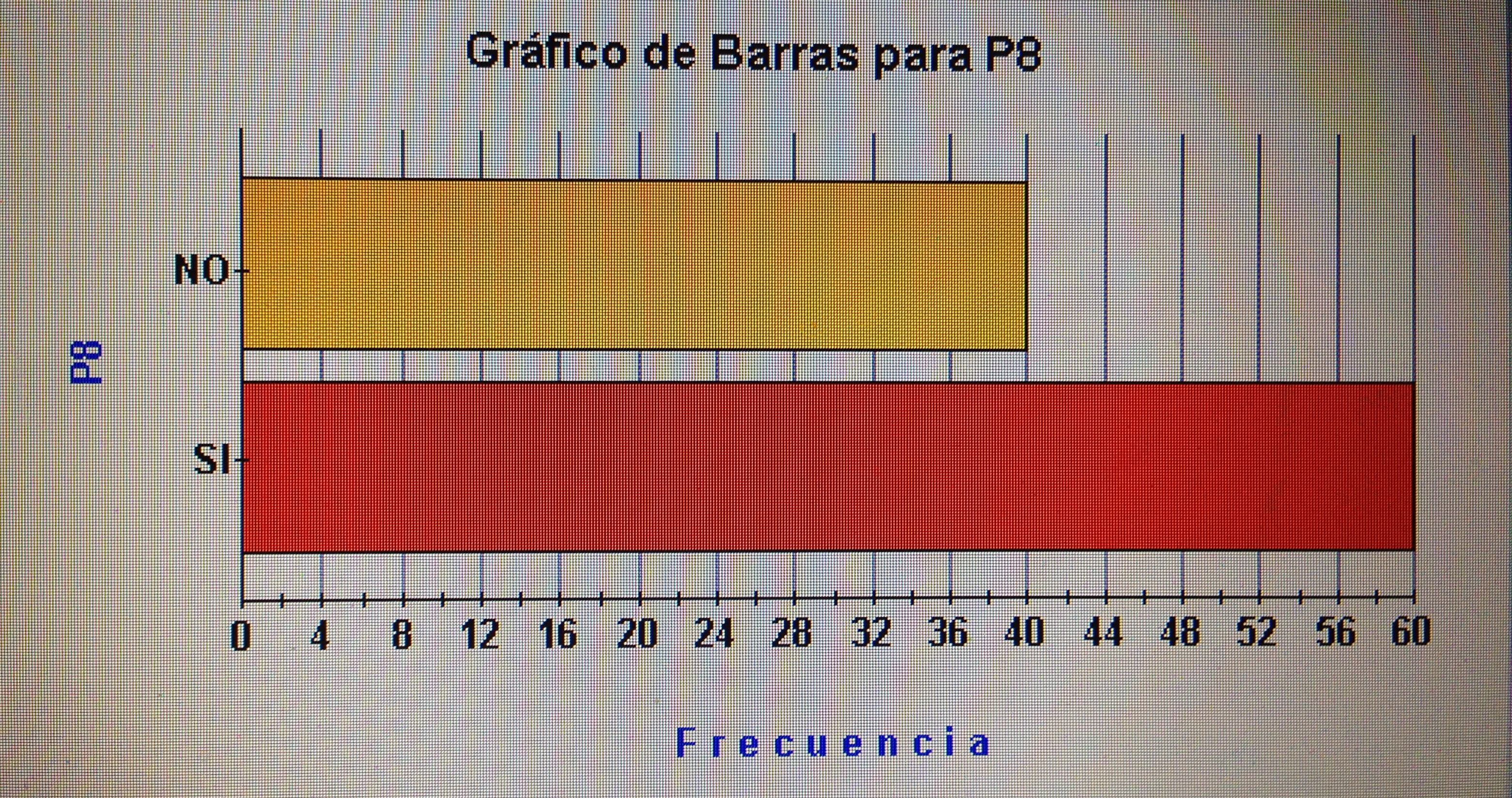
4. Proyectar en la representación de los ejes de los factores la variable P8:

Observemos que los pacientes que consideran su problema resuelto tienen mucho de todos los factores, pero hay un grupo que tienen valor bajo del primer factor, pero nunca de los otros dos. Los que consideran que su problema no ha quedado resuelto estos están mayoritariamente próximo al vértice donde los tres factores tienen valores bajos.
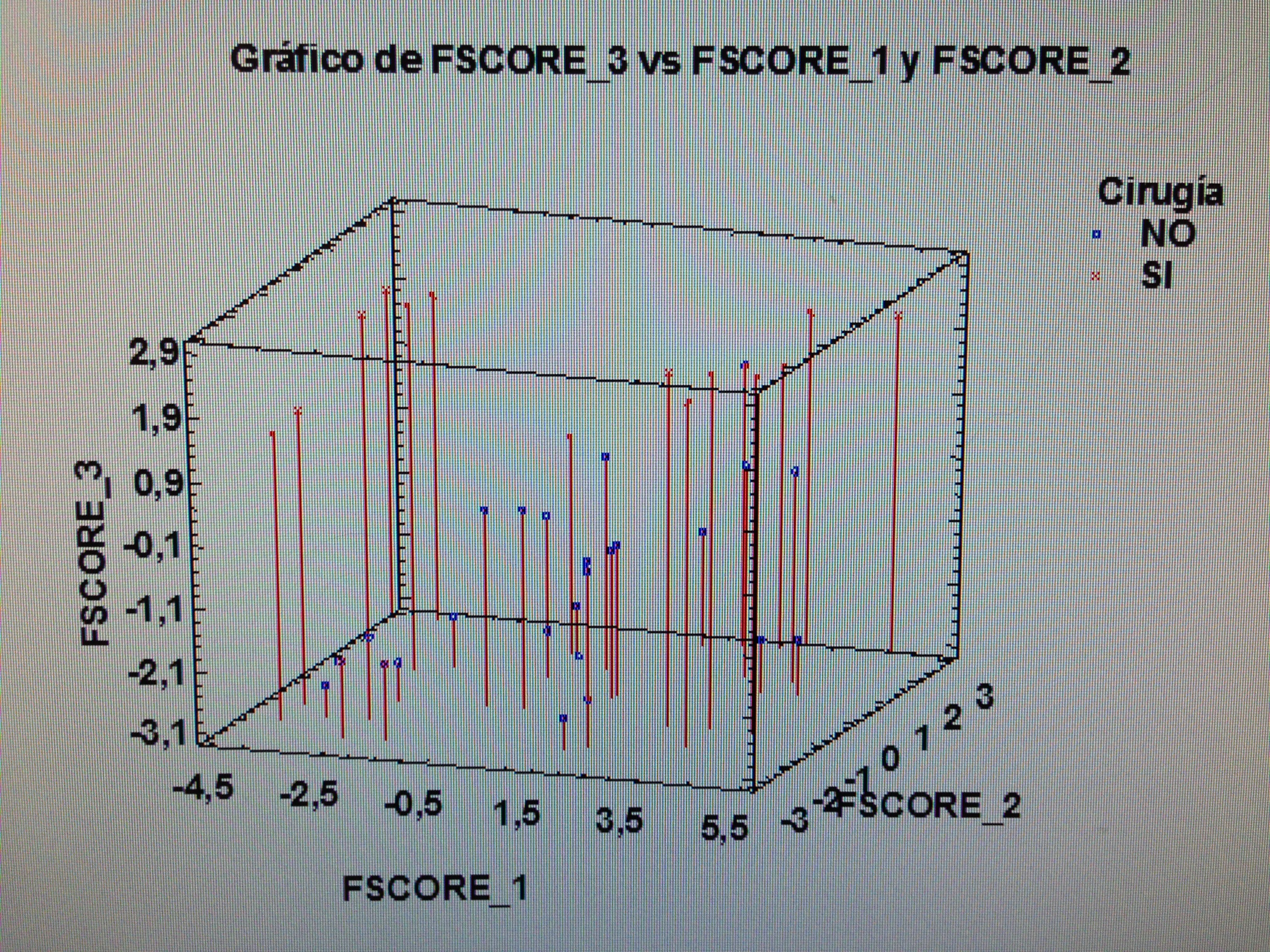
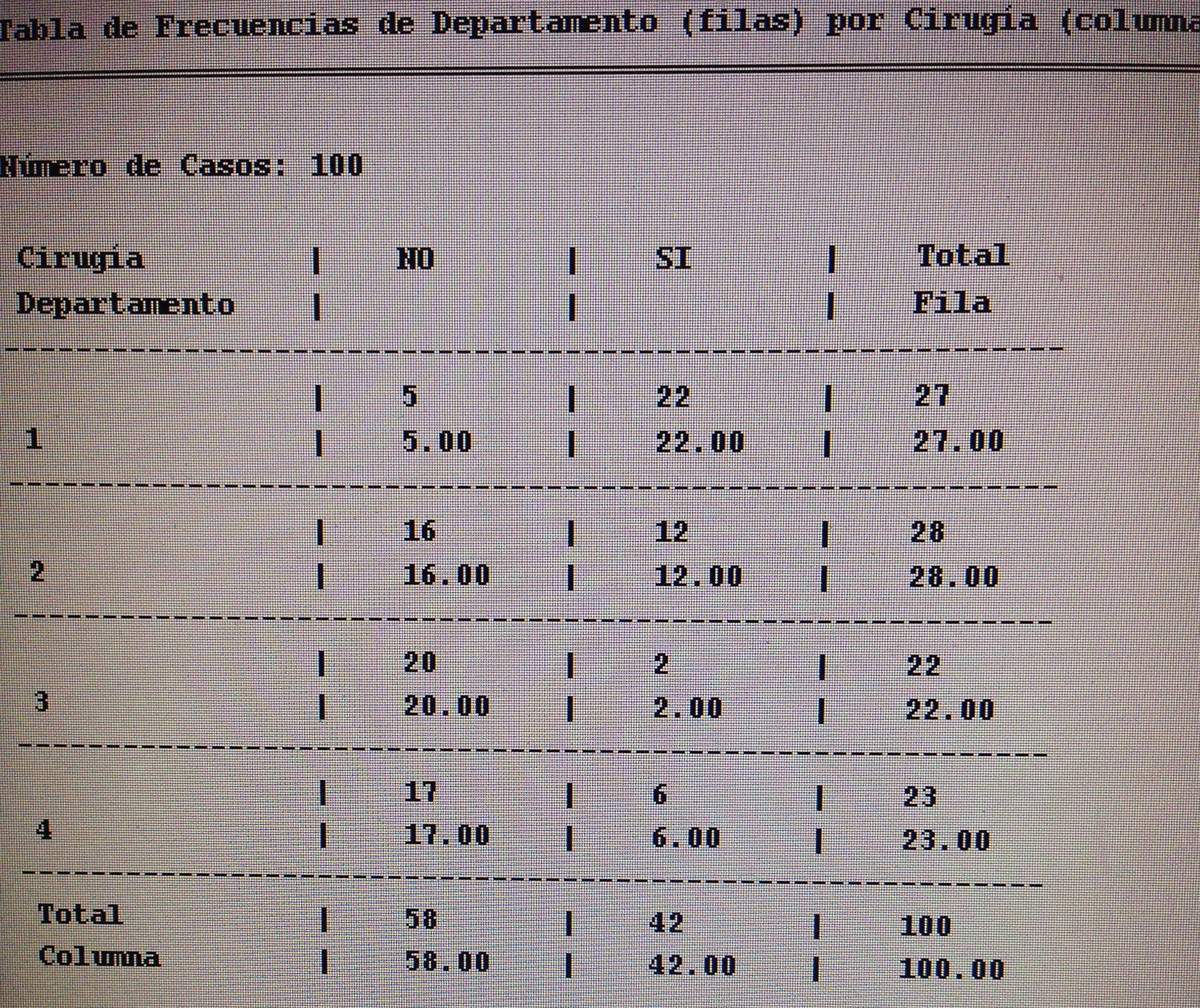
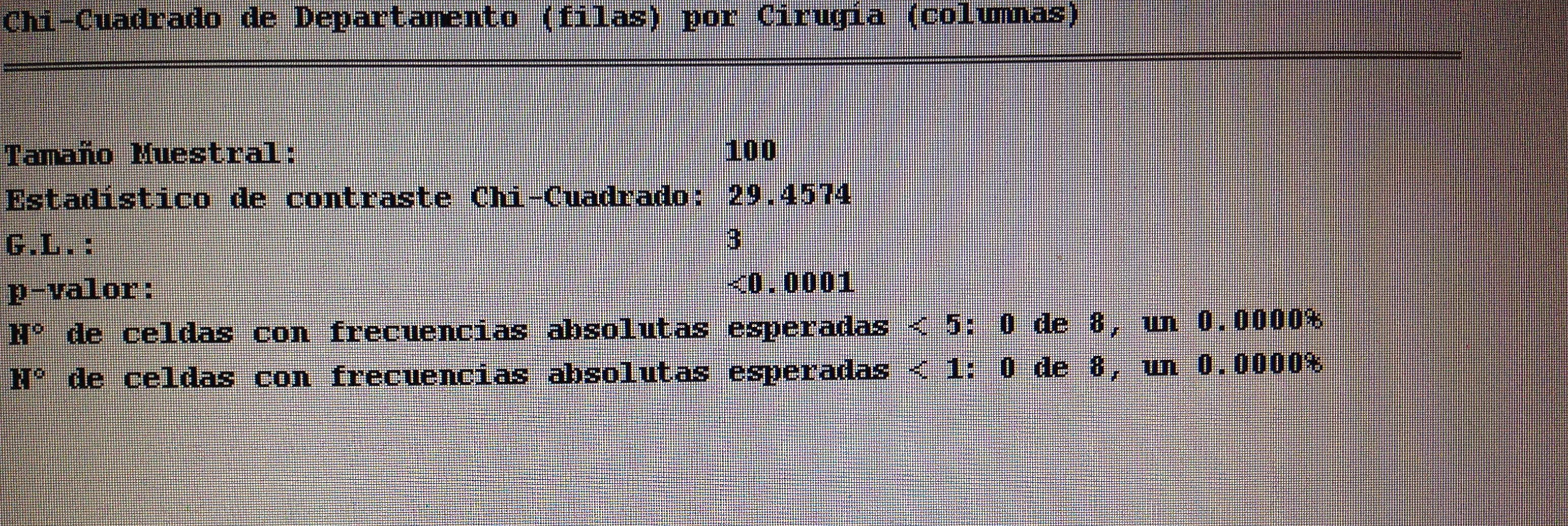
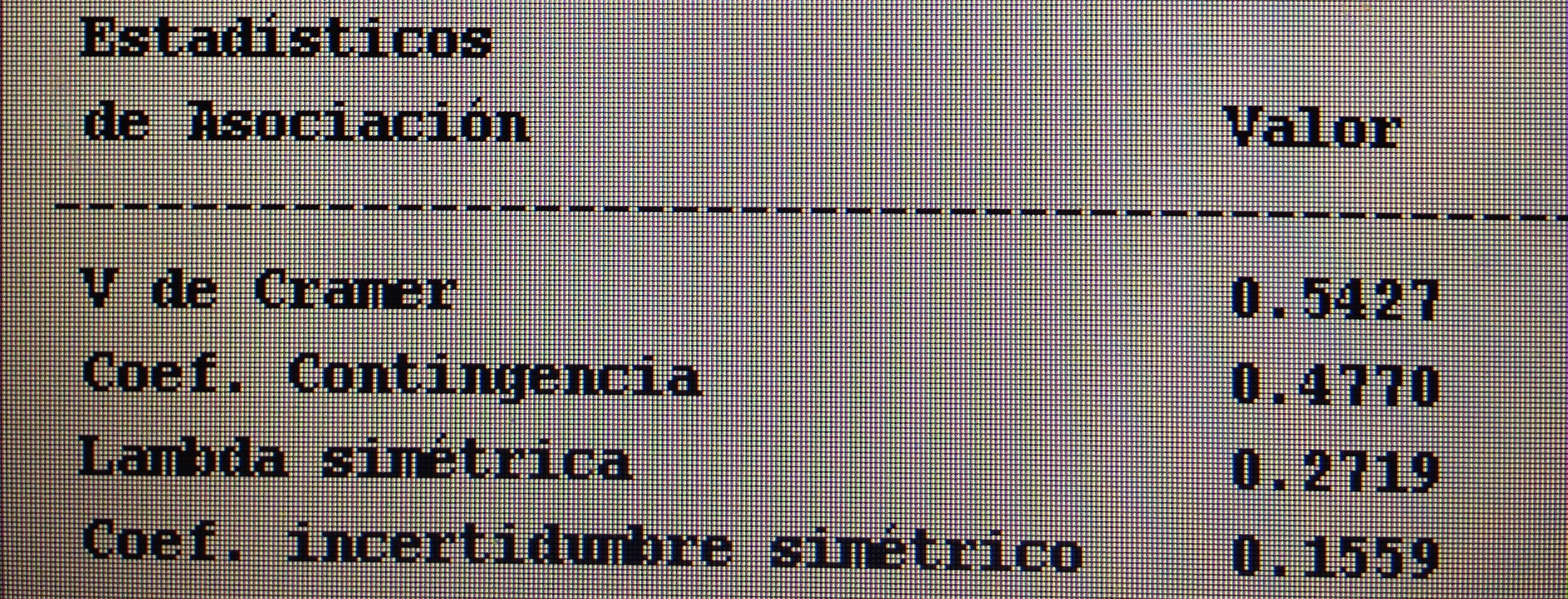
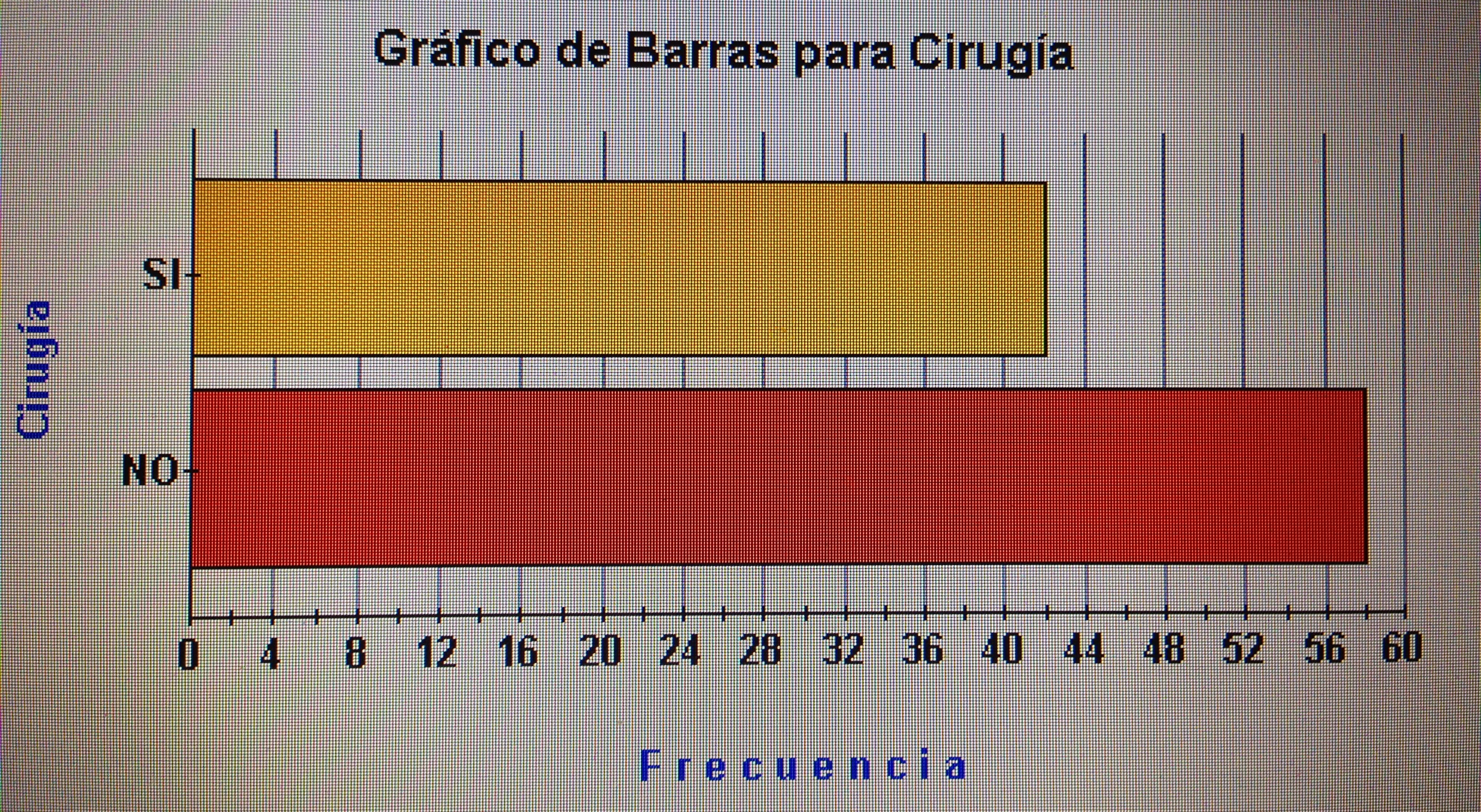
5. Proyectar en la representación de los ejes de los factores la variable Cirugía:

A los que se ha aplicado Cirugía siguen un patrón similar al seguido con la P8.
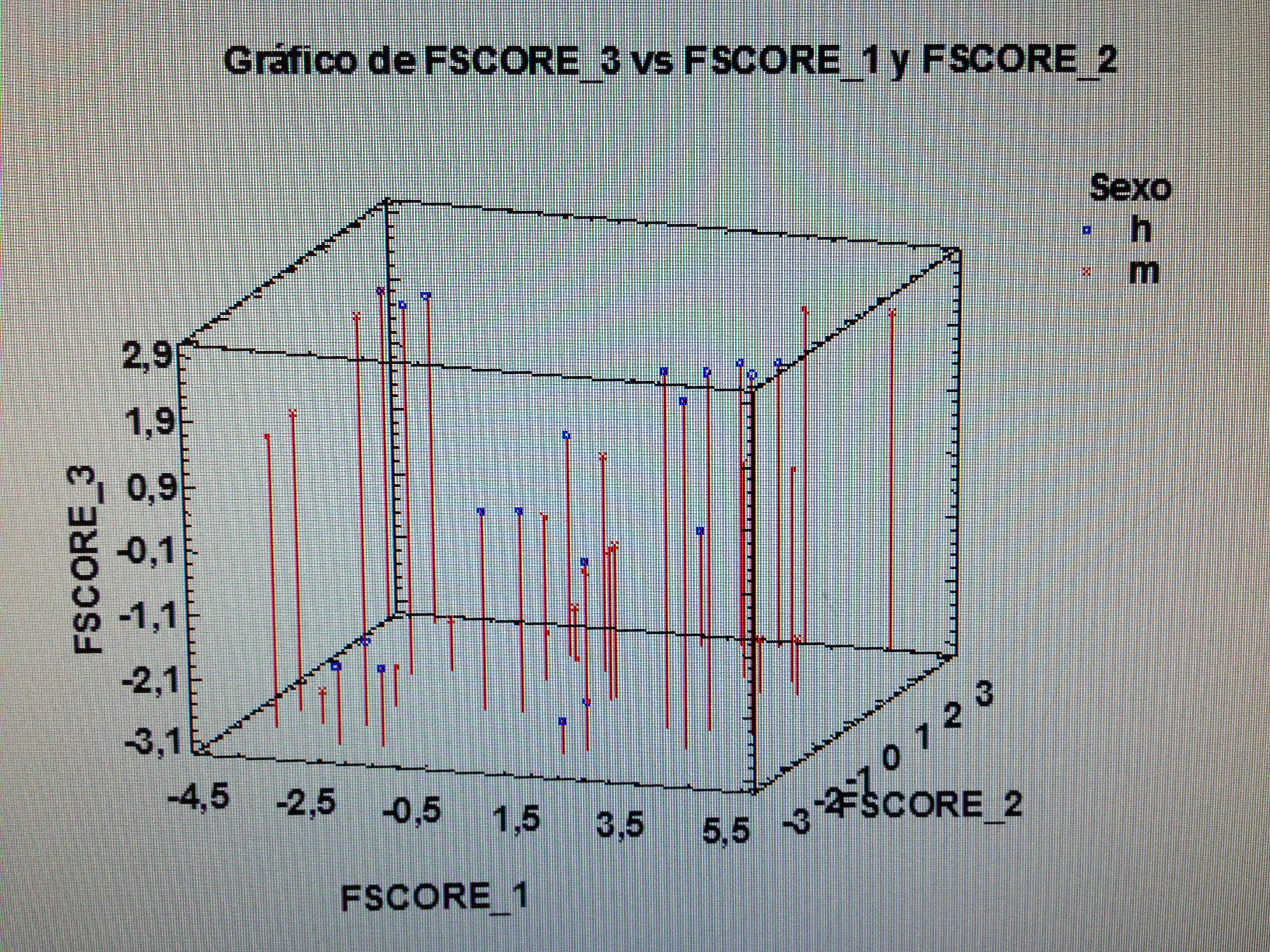
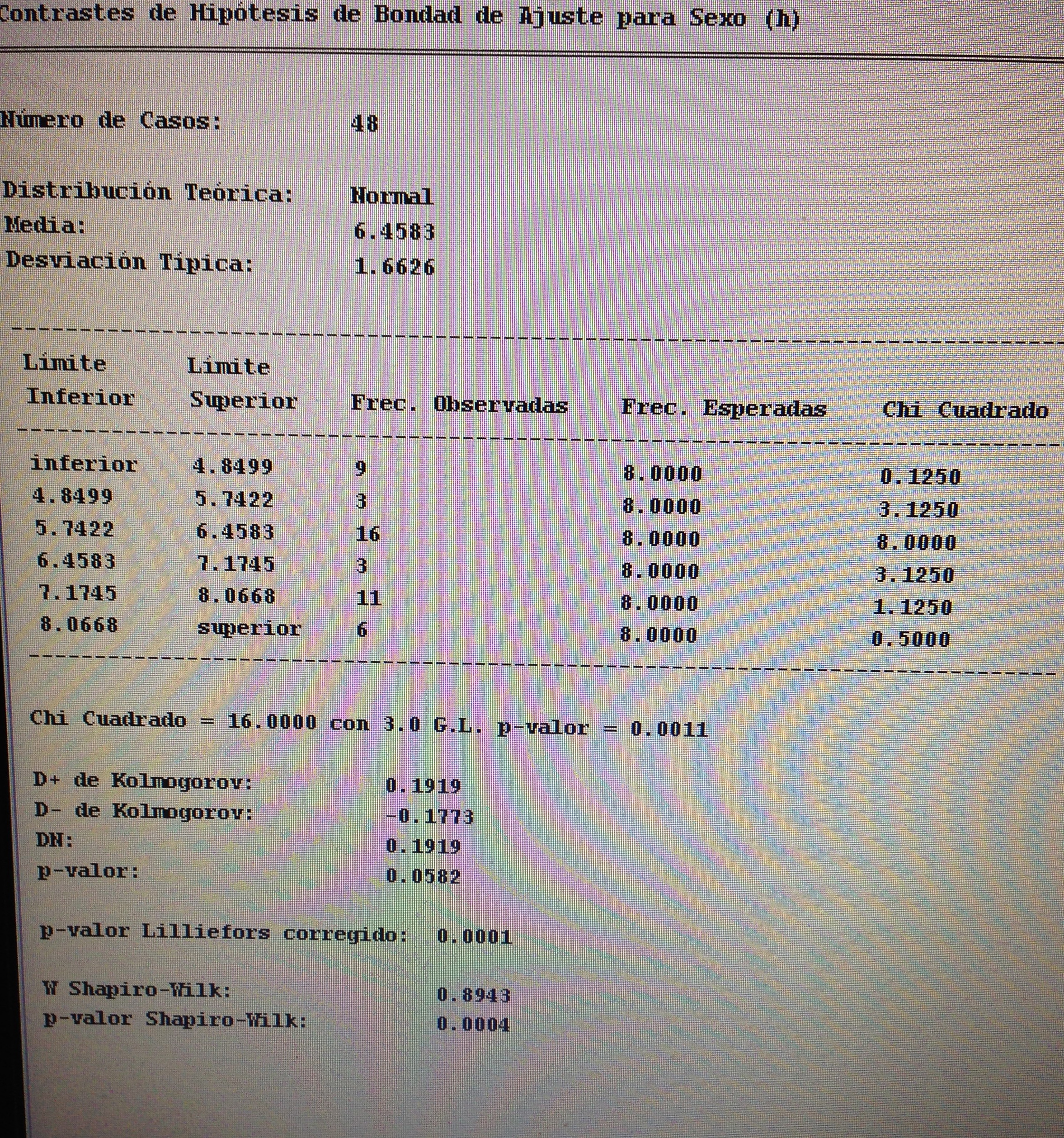
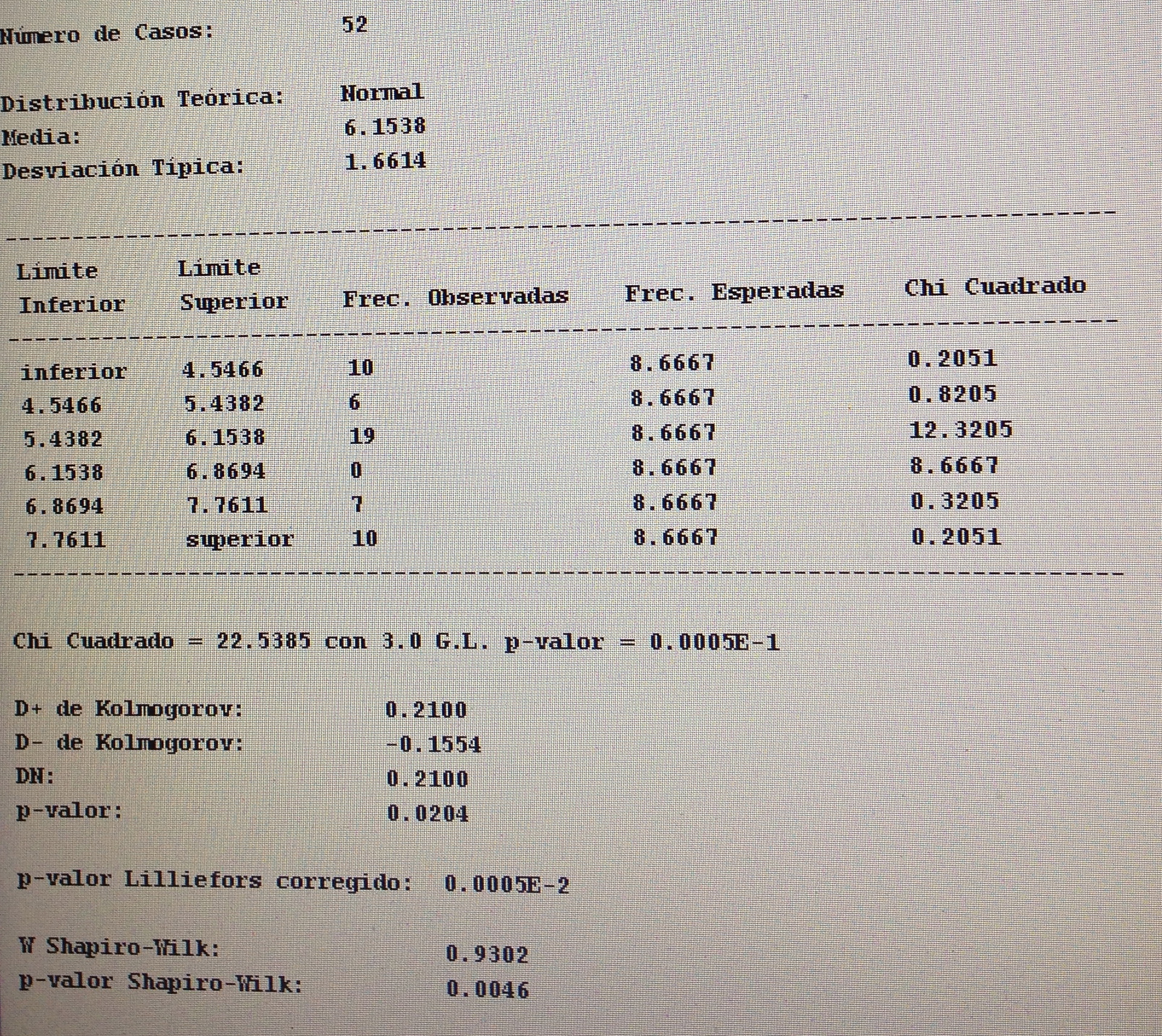
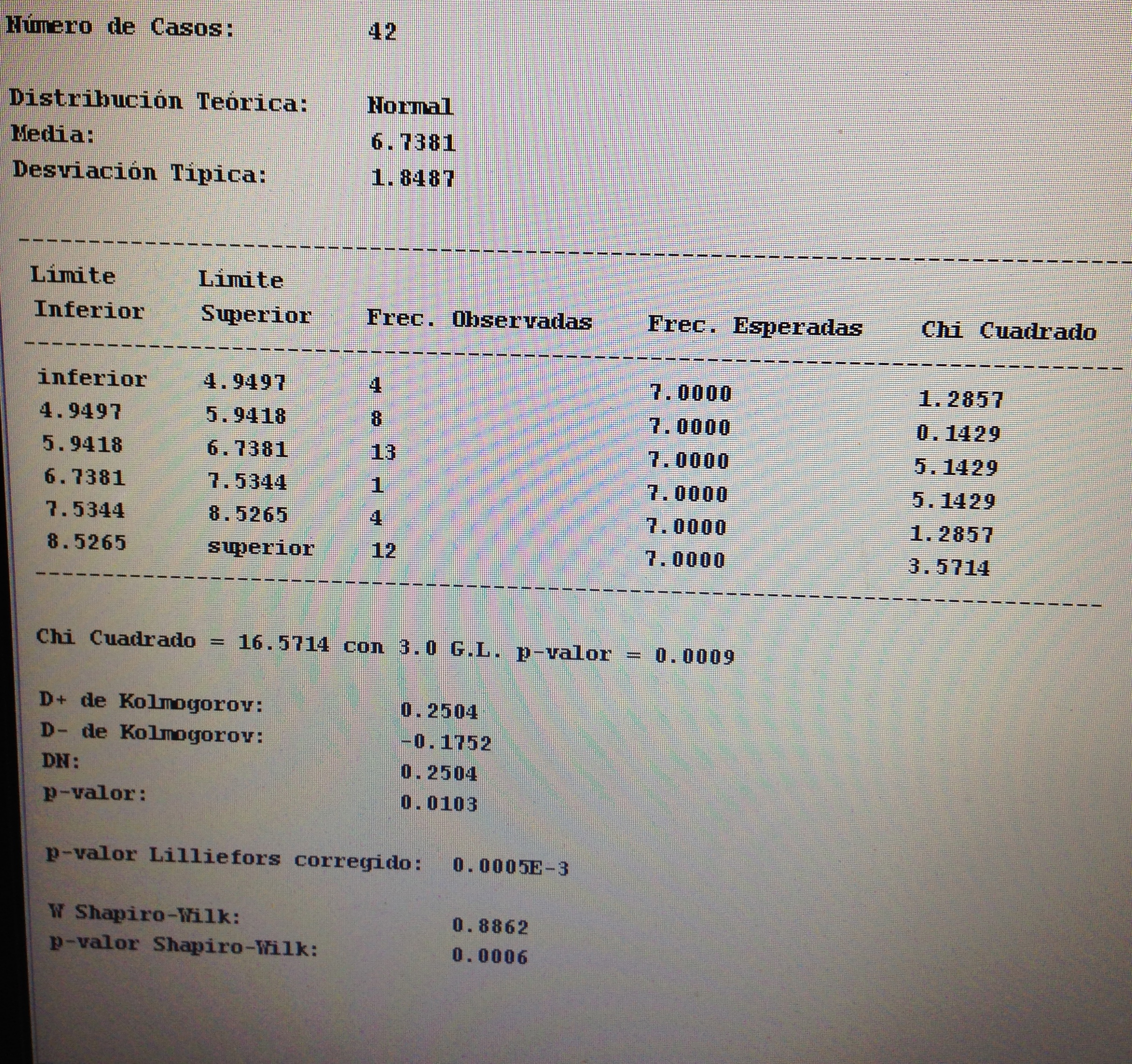
6. Proyectar en la representación de los ejes de los factores la variable Sexo:

Aquí no parece haber un patrón determinado. Todo está muy disperso.
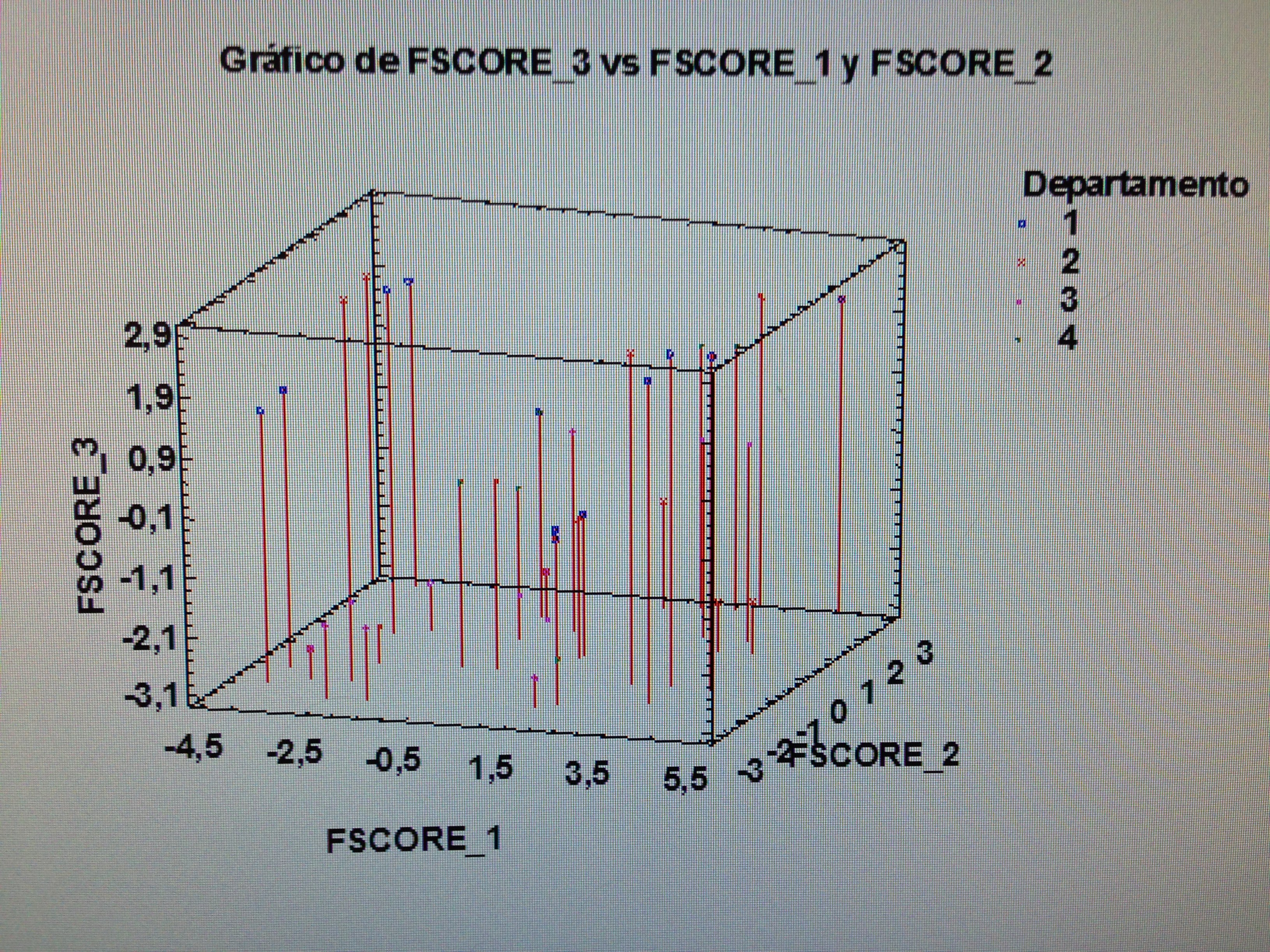
7. Proyectar en la representación de los ejes de los factores la variable Departamento:

Si se observa con detalle el gráfico puede apreciarse que el departamento 3, que es Urología, es el departamento que tiene valoraciones más bajas. Sus valores están preferentemente en el extremo de los valores bajos de los tres factores.