1c
2d
3c
4b
5c
6c
7c
8b
9a
10a
1c
2d
3c
4b
5c
6c
7c
8b
9a
10a
1. En la muestra (-1, 0, 1, 16), no es cierto:
a. El rango intercuartílico es 17.
b. La mediana es 0.5.
c. La media es 4.
d. El tercer cuartil es 8.5.
2. En una muestra con una variable que se ajusta bien a una distribución normal y que se resume así: 20 ± 3, podemos afirmar:
a. Que el percentil 97.5 es, aproximadamente, 26.
b. Que el 95% de la población, aproximadamente, tiene valores entre 17 y 23.
c. Que el rango intercuartílico es 6.
d. Que el 68.5% de la población, aproximadamente, tiene valores por encima de 17.
3. Si nos dicen que la correlación entre dos variables es 0.75 (p>0.05), podemos afirmar:
a. Que estamos trabajando con una muestra muy grande.
b. Que es una correlación significativa y positiva.
c. Que no tenemos argumentos suficientes para desestimar que la correlación poblacional sea 0.
d. Que no es suficiente saber que el p-valor es mayor que 0.05, que necesitamos saber con precisión el p-valor para tomar una decisión.
4. ¿Qué afirmación, entre las siguientes, es cierta?:
a. Cuanta más dispersión tenemos en dos grupos a comparar menos tamaño de muestra necesitamos para encontrar diferencias significativas.
b. Cuanta menos diferencia haya entre las medias muestrales de dos grupos a comparar menos tamaño de muestra necesitaremos para detectar significación estadística.
c. Una técnica estadística de comparación de dos poblaciones aplicada a dos muestras con medias muestrales iguales nos dará un p-valor de 0, independientemente de la dispersión que tengamos.
d. Hay muestras con simetría en sus valores que no se ajustan bien a una distribución normal.
5. ¿Qué afirmación, entre las siguientes, es cierta?:
a. Si la Odds ratio entre dos variables dicotómicas nos da un intervalo de confianza del 95% (0.9, 1.1) se trata de una relación significativa porque es un intervalo muy estrecho.
b. Una V de Cramer de 0.4 será significativa si el p-valor de la ji-cuadrado es menor que 0.05.
c. Una correlación de Pearson entre dos variables cuantitativas con intervalo de confianza del 95% (0.1, 0.9) no es una correlación significativa porque es un intervalo demasiado amplio.
d. Si dos medias muestrales son distintas con una diferencia superior al 5% esa diferencia ya se considera estadísticamente significativa.
1. En la muestra (1, 1, 2, 16), no es cierto:
a. La media es 5.
b. La mediana es 1.5.
c. El rango intercuartílico es 7.5.
d. El tercer cuartil es 9.
2. En una muestra de una variable que no se ajusta bien a una distribución normal nos dicen que se resume así: 20 ± 3, podemos afirmar:
a. Que el 95% de la muestra, aproximadamente, tiene valores entre 14 y 26.
b. Que el 95% de la población, aproximadamente, tiene valores entre 14 y 26.
c. Que el error estándar es 3.
d. Ninguna de las tres afirmaciones anteriores es cierta.
3. Si nos dicen que la correlación entre dos variables es 0.75 (p>0.05), podemos afirmar:
a. Que es una fuerte correlación.
b. Que es una correlación significativa y bastante fuerte.
c. Que no tenemos argumentos suficientes para desestimar que la correlación poblacional sea 0.
d. Que no es suficiente saber que el p-valor es mayor que 0.05, que necesitamos saber con precisión el p-valor para tomar una decisión.
4. Si la correlación de Pearson entre dos variables es 0.9 (p<0.05) podemos afirmar:
a. La R2 es del 90%.
b. La Regresión lineal que podremos hacer entre estas dos variables tendrá pendiente significativa.
c. La Regresión lineal que podremos hacer entre estas dos variables tendrá pendiente significativa y negativa.
d. La Regresión lineal que podremos hacer entre estas dos variables tendrá pendiente positiva pero no significativa.
5. La V de Cramer entre dos variables cualitativas entre las cuales la ji-cuadrado nos ha dado un p-valor de 0.75.
a. Nos dará 0.
b. Nos dará 1.
c. No tiene mucho sentido calcularla porque no hay relación significativa entre esas variables.
d. En este caso calcularemos una correlación de Pearson.
6. Si queremos comparar la diferencia de medias que hay entre los hipertensos en Barcelona y Nueva York y lo hacemos tomando una muestra de 20 personas adultas en cada una de estas ciudades, donde cada una de ellas se comprueba que no se ajusta bien a una distribución normal, el test estadístico que deberemos aplicar es:
a. El Test exacto de Fisher.
b. El Test de la t de Student de datos apareados.
c. El Test de Mann-Whitney.
d. El Test de la t de Student de muestras independientes y varianzas iguales.
7. Nos dicen que han comparado la media de rentas de dos poblaciones con una muestra de cada población. Ambas muestras siguen bien una distribución normal y una estadística básica de cada una de ellas es: Población A: 15000±4000 y Población B: 13000±4000, podemos afirmar lo siguiente:
a. La diferencia de medias no es significativa porque si hacemos los intervalos de confianza del 95% de la media los intervalos se tocan porque son: (7000, 23000) y (5000, 21000).
b. La diferencia de medias sí que es significativa porque si hacemos los intervalos de confianza del 95% de la media los intervalos no se tocan porque son: (14200, 15800 ) y (12.200, 13800).
c. Para ver la diferencias de medias necesitamos saber el tamaño de las muestras que nos permita calcular el intervalo de confianza de la media de cada población para ver si se tocan o no los intervalos.
d. Estadísticamente lo único que podemos decir es que las medias de las rentas son distintas.
8. Si se quiere hacer un resumen descriptivo de una muestra de la variable cantidad de agua caída en diferentes días del año mediante una muestra como la siguiente:
(0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 3, 3, 4, 5, 5, 7, 8, 25, 250), la forma más coherente sería:
a. Lo haremos con los dos descriptores más habituales: la media y la desviación estándar.
b. Lo haremos con la mediana y el rango intercuartílico expresado con el primer y tercer cuartil.
c. Lo haremos con la mediana y la media.
d. Muestras tan anormales no pueden resumirse.
9. Se quiere comparar la humedad relativa entre dos zonas a partir de muestras de cada una de esas dos zonas. Se ha aplicado el Test de Shapiro-Wilk a las dos muestras y el p-valor en ambas es mayor que 0.05. Para comparar las medias o las medianas de ambas poblaciones el test más adecuado al caso será:
a. Test de la t de Student de varianzas iguales si se comprueba previamente, mediante el test de Fisher, que las varianzas no son distintas significativamente.
b. Test de Mann-Whitney.
c. El Test de proporciones.
d. El Test de la t de Student de datos apareados.
10. Si en una Regresión lineal simple entre dos variables tenemos una r=0.9 (p<0.05) y una R2 del 81% podemos afirmar:
a. Que la pendiente es significativa.
b. Que existe no hay suficiente determinación.
c. Que la pendiente podría ser positiva o negativa.
d. Poco podemos decir si no sabemos, también, el p-valor de la R2.
Vamos a mostras cuáles son las cuatro tablas que obtenemos si valoramos las relaciones entre Fumador e Infarto, entre Colesterol e Infarto, entre Perímetro de cintura e Infarto y entre Deporte e Infarto. Y cuáles son, también las Odds ratio respectivas.
Fumador e Infarto:

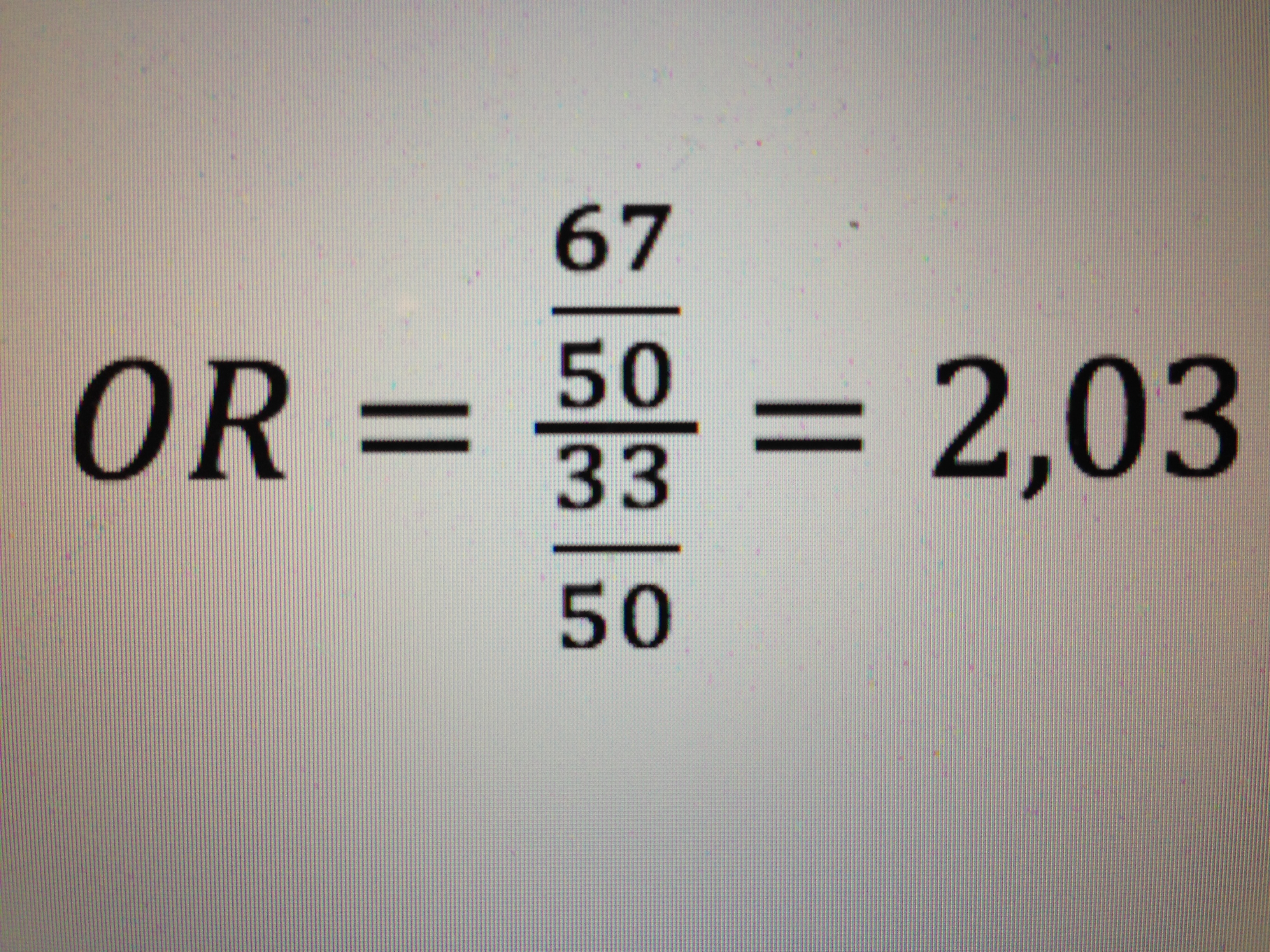
Por lo tanto, fumar, en hombres, al nivel establecido en el estudio, proporciona un riesgo 2,03 veces superior al de no fumar.
Colesterol e Infarto:

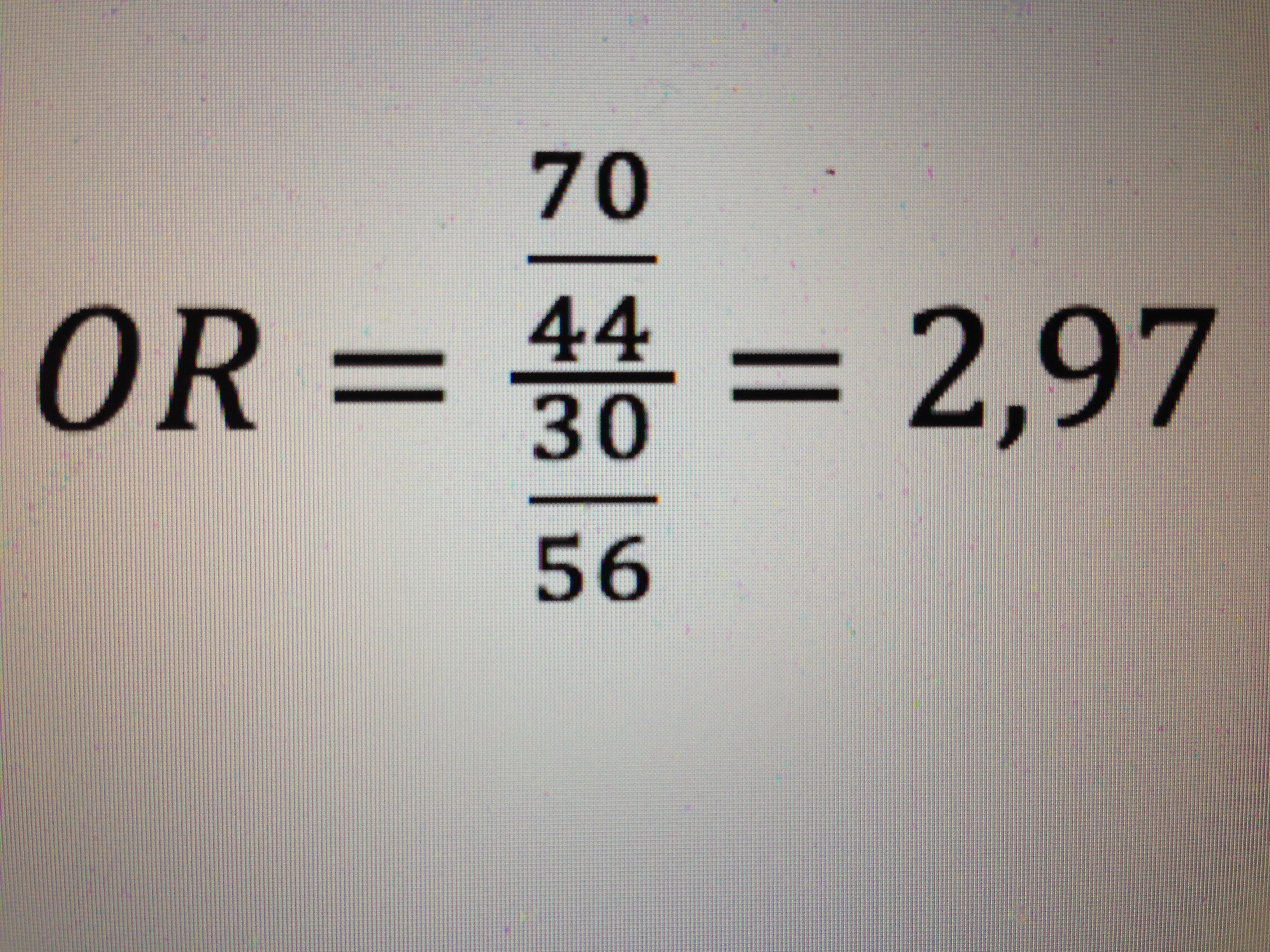
Por lo tanto, el colesterol por encima de 240 mg/dL, en hombres, proporciona un riesgo 2,97 veces superior al tenerlo por debajo.
Perímetro de cintura e Infarto:


Por lo tanto, el perímetro de cintura por encima de 102 cm, en hombres, proporciona un riesgo 5,67 veces superior al tenerlo por debajo.
Deporte e Infarto:

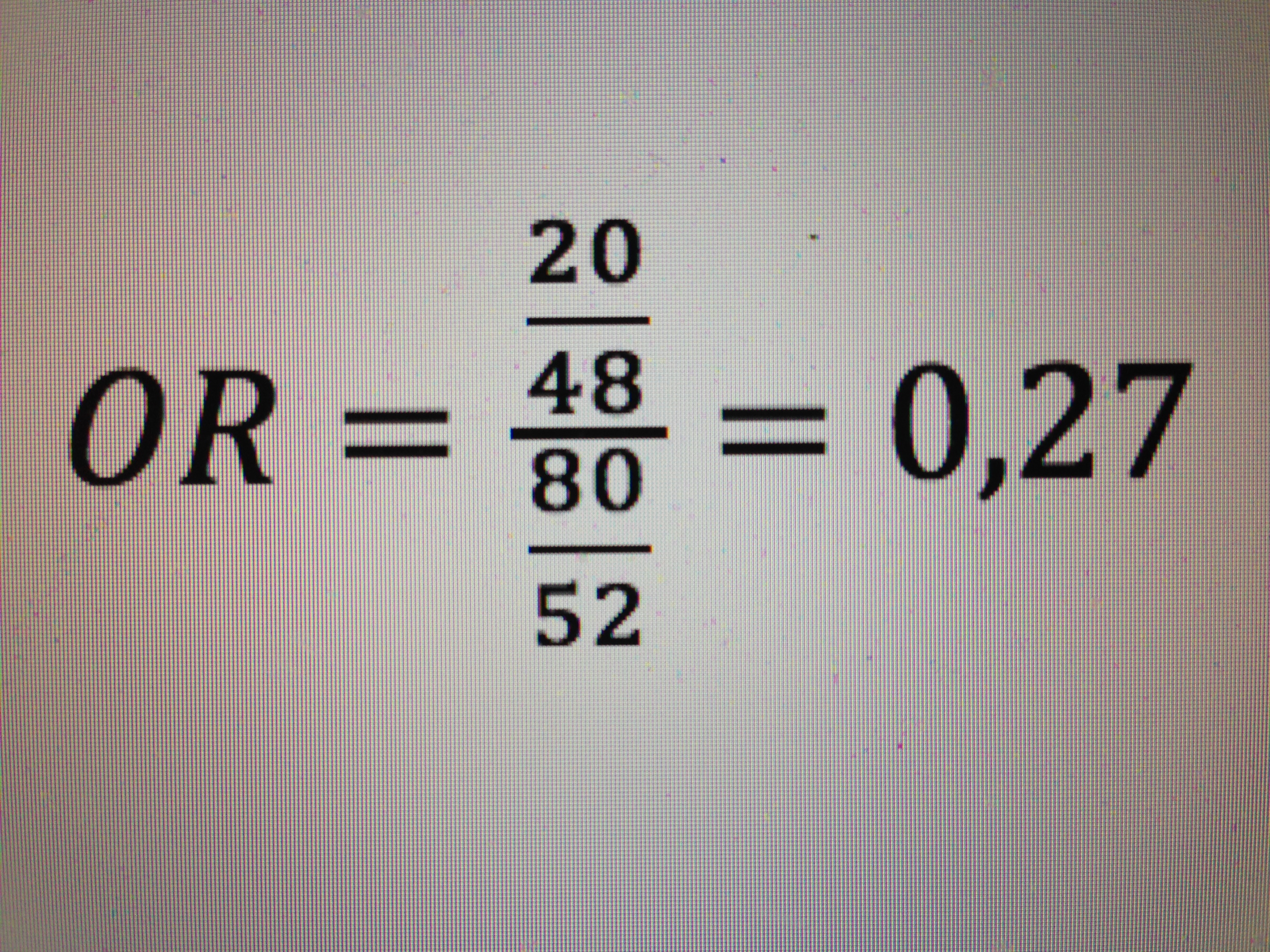
Por lo tanto, según estos datos hacer deporte a ese nivel, en hombres, representa una protección de 3,7 veces superior a no hacerlo. El 3,7 sale de dividir 1 por 0,27, como hemos visto en el planteamiento del problema.
La Odds ratio es una medida del riesgo o de la protección, que supone cierto hábito o cierta situación en la que se encuentra una persona, de tener una determinada enfermedad o un determinado resultado final.
Se trata de un concepto que con los años se ha transformado en una parte esencial del lenguaje médico.
Es importante familiarizarse con esta importante noción. Para ello hemos destinado este artículo (1), en el que planteamos una situación preparada para estudiantes de ESO, y un artículo (2) donde se aporta las soluciones a lo planteado en éste.
A continuación se van a dar los datos de 200 hombres (no mujeres). 100 de ellos han tenido un infarto de miocardio. Los otros 100 no lo han tenido. Hemos elegido hombres por tratarse de una enfermedad más prevalente es este sexo.
En la tabla de datos que adjuntamos se presenta en la primera columna si se trata de un hombre que ha tenido o no un infarto. Se presentan, también, a continuación, los valores de las siguientes variables:
Fumador: El SÍ significa que el paciente ha fumado a lo largo de su vida más de 10 años a razón de 1 ó más paquetes al día.
Colesterol: El SÍ significa, ahora, que su nivel de colesterol está por encima de 240 mg/dL.
Perímetro cintura: El SÍ significa que su perímetro de cintura es superior a 102 cm.
Deporte: El SÍ significa, ahora, que el paciente ha practicado deporte más de 5 horas semanales durante más de 10 años.
La tabla de datos es la siguiente (Esta tabla se puede copiar y pegar en Excel o en un software estadístico):
| Infarto | Fumador | Colesterol | Perímetro cintura | Deporte |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | SI | SI | NO |
| SI | NO | SI | NO | SI |
| SI | SI | SI | SI | NO |
| SI | NO | NO | SI | NO |
| SI | SI | NO | SI | NO |
| SI | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | NO | SI |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | NO | SI |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | NO | SI |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | NO | SI |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | NO | SI |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | NO | SI |
| NO | SI | NO | SI | NO |
| NO | NO | SI | SI | SI |
| NO | SI | SI | NO | NO |
| NO | NO | NO | SI | SI |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
| NO | NO | SI | SI | NO |
| NO | NO | NO | NO | SI |
| NO | SI | NO | NO | NO |
| NO | SI | NO | NO | SI |
| NO | NO | SI | NO | NO |
Para calcular la Odds ratio que hay entre Infarto y alguna de las otras variables, por ejemplo: Fumar, debe rellenarse la información de la siguiente tabla:
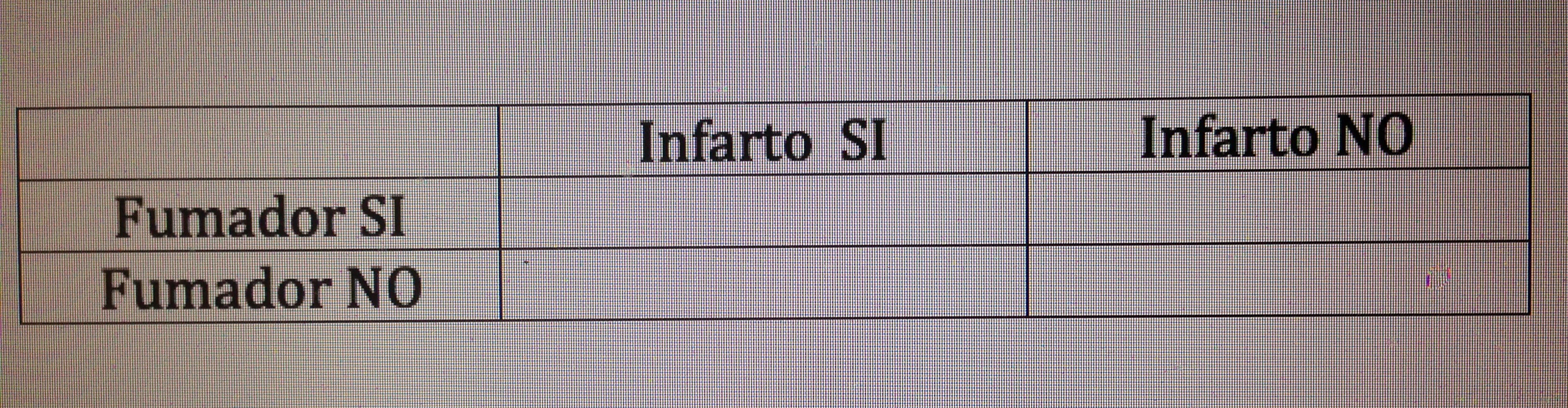
Hay que rellenar el número de pacientes que han sufrido un infarto y fumaban, el número de los que han sufrido un infarto pero no fumaban, el número de los que no han sufrido un infarto pero fumaban y, finalmente, el número de los que no han sufrido un infarto y no fumaban.
Una vez llena la tabla, la Odds ratio (OR) se calcula de la siguiente forma:

La Odds ratio es, por lo tanto, como se puede ver, una relación de relaciones. Una relación entre la relación de enfermos y no enfermos que hay entre los que cumplen una determinada condición (en nuestro caso, ahora, ser fumador) y la relación de los enfermos y no enfermos que hay entre los que no cumplen esa misma condición (en nuestro caso, ahora, el no ser fumador). Lo veremos más claro en casos concretos.
Supongamos que tuviéramos los siguientes valores en la tabla anterior. El cálculo de la OR sería:

La Odds ratio, en este caso, sería: 2,25. Y esto significa que la relación entre infartos y no infartos que hay entre los fumadores es 2,25 veces mayor que la relación que hay entre los fumadores. Dicho de otra forma: El riesgo de tener un infarto es 2,25 veces mayor fumando que no fumando.
Si en lugar de cruzar Fumador con Infarto, cruzáramos Deporte con Infarto y tuviéramos, supongamos, los valores siguiente, el cálculo sería, entonces:

La Odds ratio es, ahora, 0,44. Y esto significa que la relación entre infartos y no infartos que hay entre los que hacen deporte es 0,44 veces la relación que hay entre los que no practican deporte habitualmente. Dicho de otra forma: El riesgo de tener un infarto haciendo deporte es 0,44 veces no haciéndolo. Si este riesgo es menor que 1 significa que el riesgo es menor. Suele decirse, entonces, que es un factor de protección.
Observemos, además, que los valores con el deporte y los valores con el fumar están invertidos. Está hecho con toda la intención para que se vea el paralelismo. El 2,25 y el 0,44 guardan la siguiente relación: Que 1/0,44=2,25 y que 1/2,25=0,44.
Por eso, cuando una OR es menor que uno para ver cuántas veces te protege aquella actividad basta con dividir 1 por ese valor de OR.
Por lo tanto, en nuestro caso, hablaríamos, pues, de que el Deporte nos protege 2,25 veces de tener un infarto.
Estas dos tablas son valores puestos como ejemplo. Además, puestos con la simetría comentada para entender mejor lo que supone valores de OR por encima y por debajo de 1 y ver, también, como se puede establecer paralelismos entre ellos.
Ahora, como actividad, deberíais ir rellenando tanto la tabla que tenéis entre Fumador e Infarto, como otras nuevas que podéis ir creando donde se relacione Colesterol e Infarto, Perímetro de cintura e Infarto y, finalmente, Deporte e Infarto.
Una vez rellenadas las cuatro tablas se trataría de calcular la Odds ratio de cada una de las cuatro tablas, detectar si es un factor de riesgo o protección y valorar cuántas veces es riesgo o cuántas es protección cada uno de esas cuatro situaciones, para tener un infarto, en base a los datos de nuestra muestra.
A partir de nuestra base de datos adjunta del artículo Explotación de una base de datos 1: Base de datos podemos realizar Análisis factorial. Veamos algunos ejemplos:
1. Hacer un Análisis factorial con las variables P1, P2, P3, P4, P5, P6 y P7. Ver cuánta variabilidad explican los factores.
2. Hacer un giro de los ejes que consiga la máxima capacidad explicativa de los factores.
3. Representar los cien pacientes en ejes formados por los factores encontrados.
4. Proyectar en la representación de los ejes de los factores la variable P8.
5. Proyectar en la representación de los ejes de los factores la variable Cirugía.
6. Proyectar en la representación de los ejes de los factores la variable Sexo.
7. Proyectar en la representación de los ejes de los factores la variable Departamento.
SOLUCIONES
1. Hacer un Análisis factorial con las variables P1, P2, P3, P4, P5, P6 y P7. Ver cuánta variabilidad explican los factores:
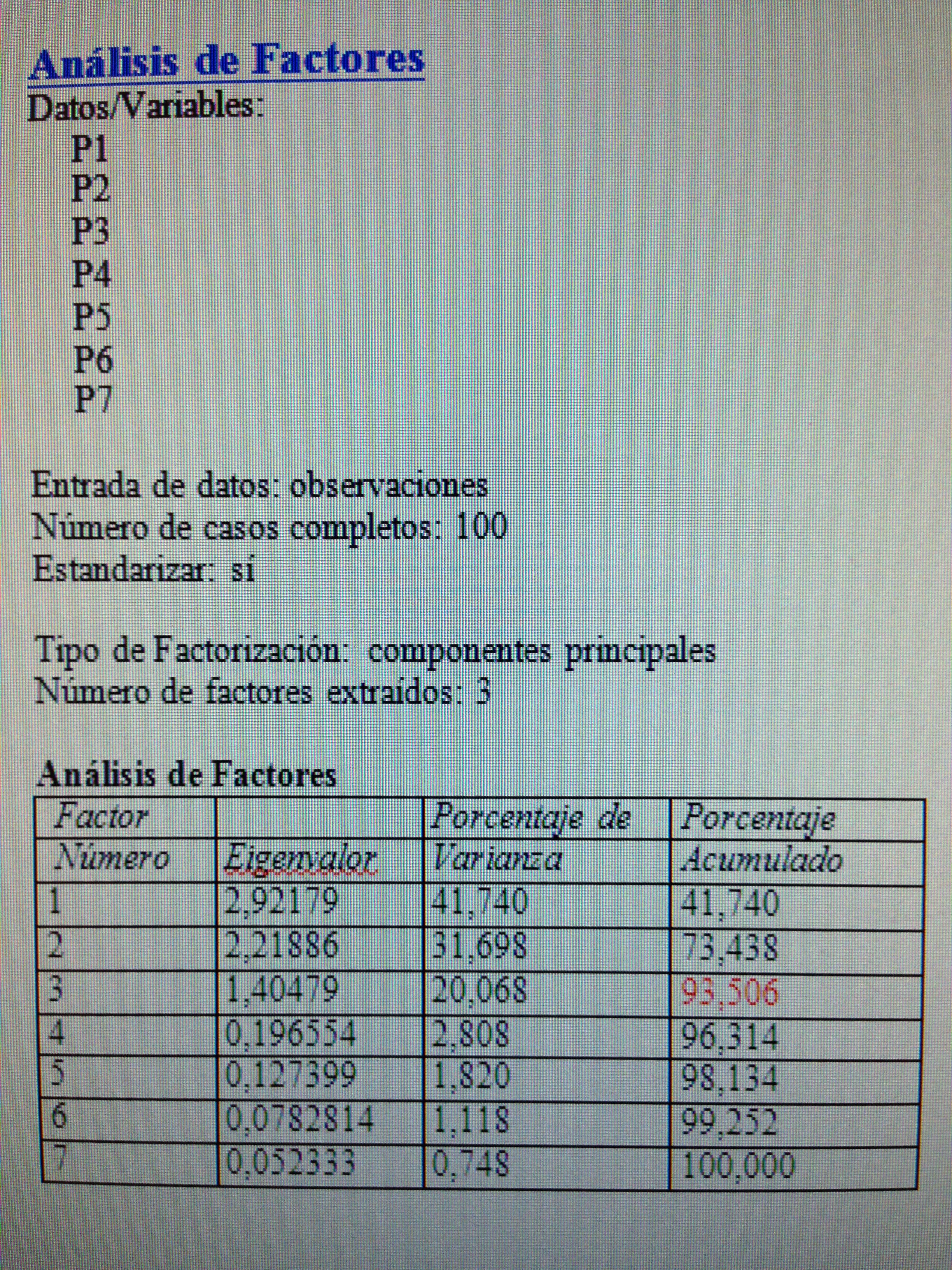
Obsérvese que con tres factores explicamos un 93,5% de la información. Esto es mucho, realmente.
2. Hacer un giro de los ejes que consiga la máxima capacidad explicativa de los factores:
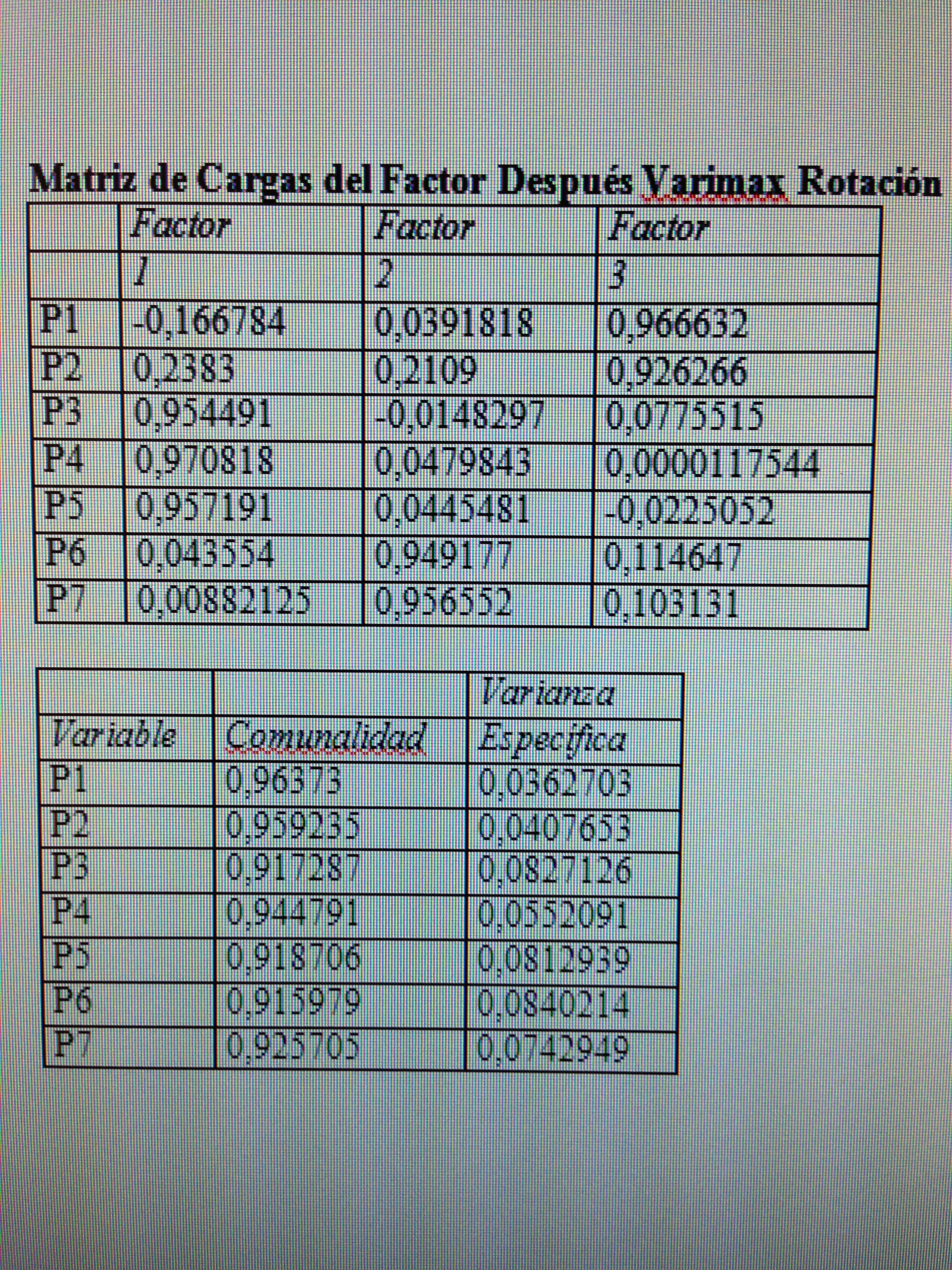
Con la rotación variamax conseguimos realmente tres factores claramente delimitados. Observemos que en el primer factor las variables con peso son la P3, P4 y P5. En el segundo son P6 y P7. En el tercer factor son P1 y P2 las que tienen el protagonismo. Esto cuadra con lo que hemos visto al analizar las correlaciones en el fichero 3 de esta serie.
3. Representar los cien pacientes en ejes formados por los factores encontrados:

4. Proyectar en la representación de los ejes de los factores la variable P8:
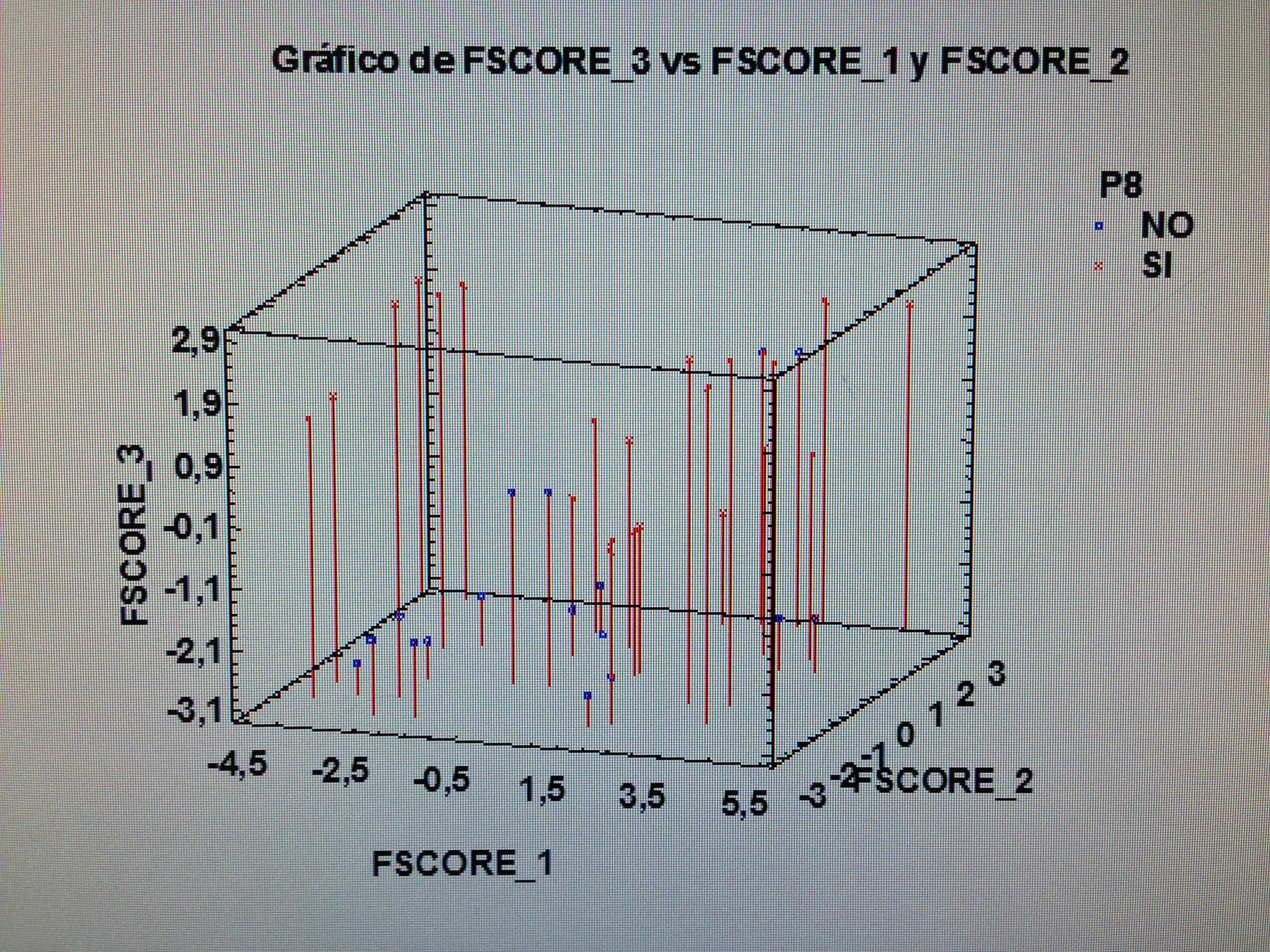
Observemos que los pacientes que consideran su problema resuelto tienen mucho de todos los factores, pero hay un grupo que tienen valor bajo del primer factor, pero nunca de los otros dos. Los que consideran que su problema no ha quedado resuelto estos están mayoritariamente próximo al vértice donde los tres factores tienen valores bajos.
5. Proyectar en la representación de los ejes de los factores la variable Cirugía:
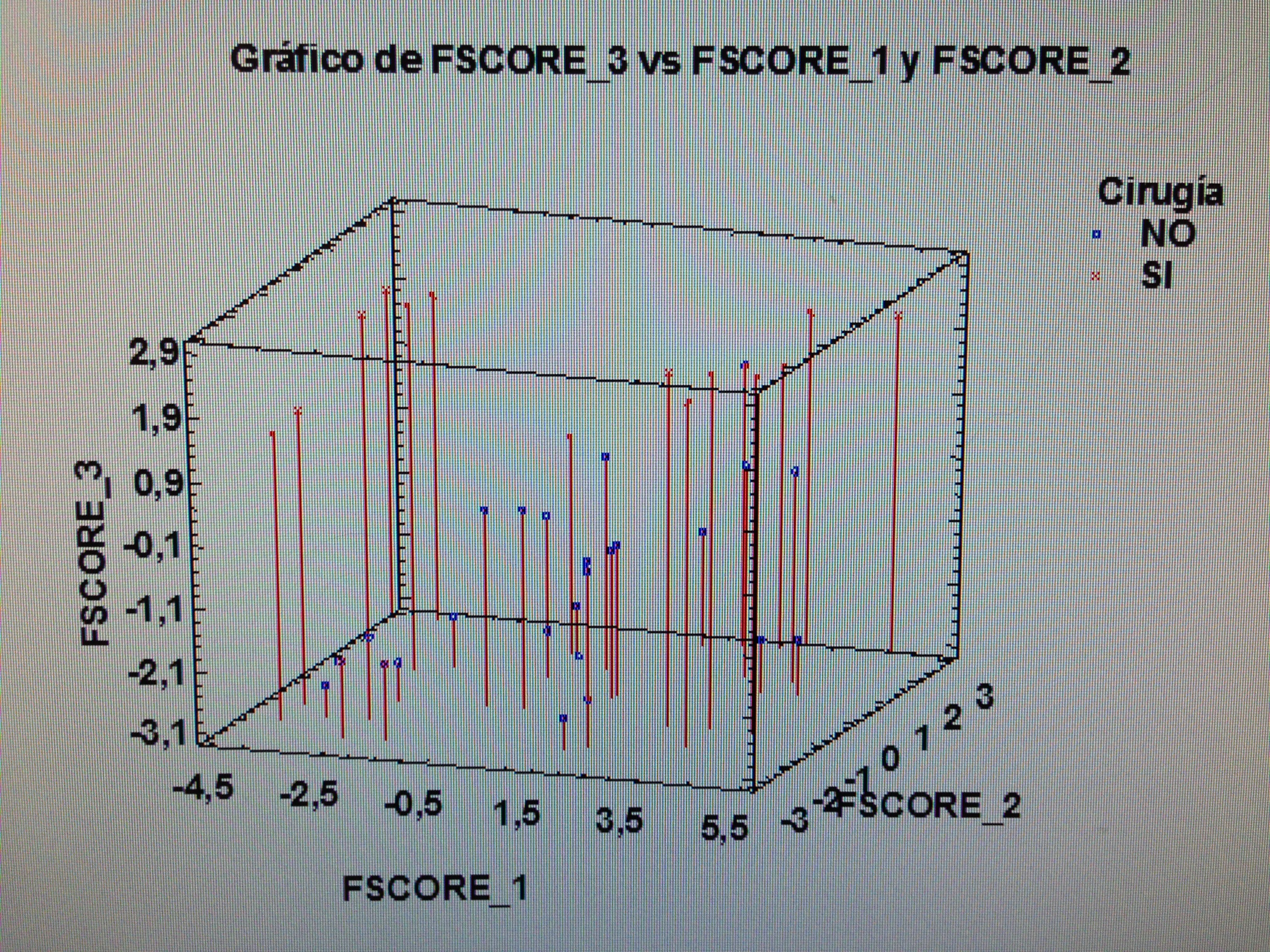
A los que se ha aplicado Cirugía siguen un patrón similar al seguido con la P8.
6. Proyectar en la representación de los ejes de los factores la variable Sexo:
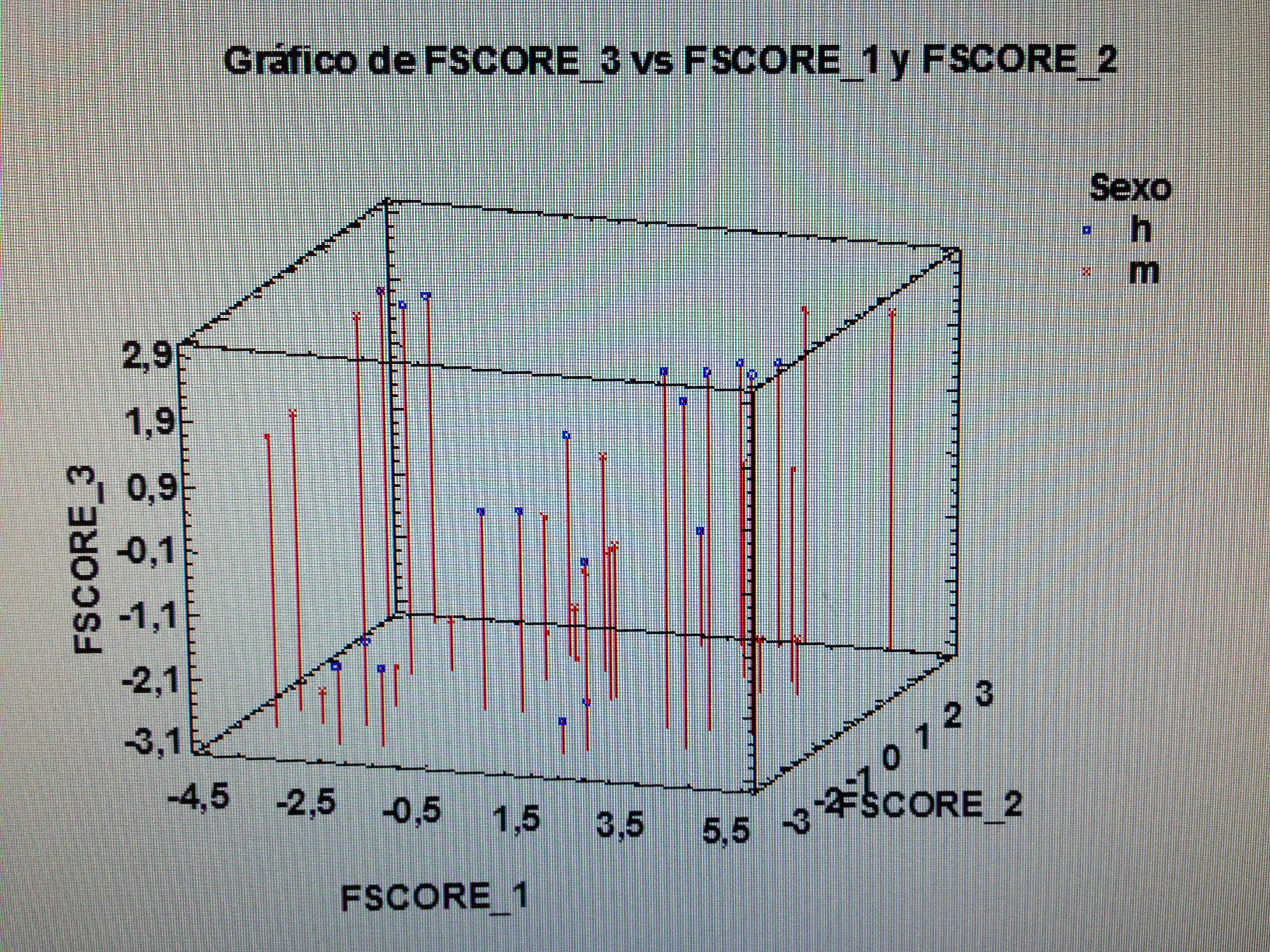
Aquí no parece haber un patrón determinado. Todo está muy disperso.
7. Proyectar en la representación de los ejes de los factores la variable Departamento:
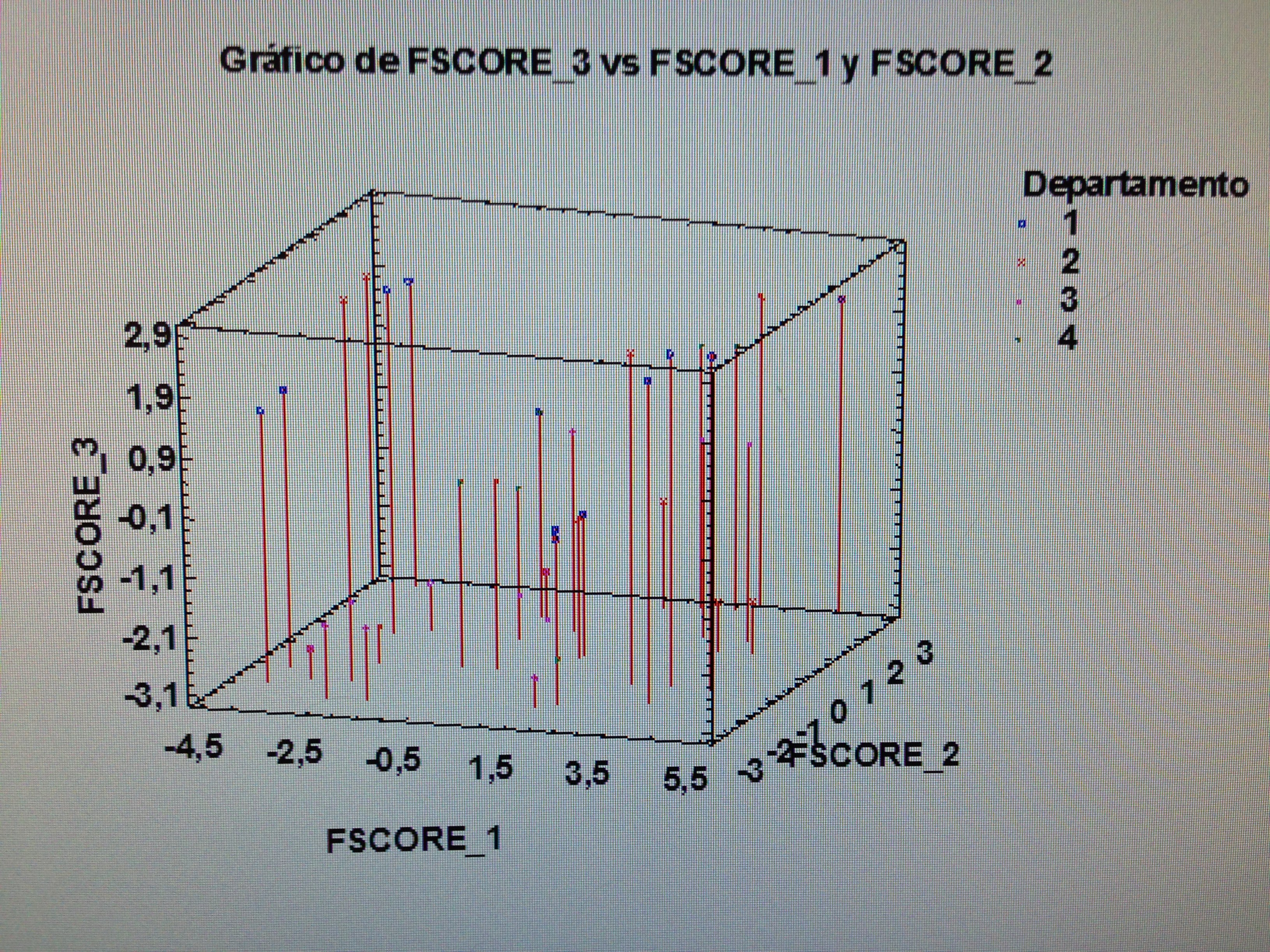
Si se observa con detalle el gráfico puede apreciarse que el departamento 3, que es Urología, es el departamento que tiene valoraciones más bajas. Sus valores están preferentemente en el extremo de los valores bajos de los tres factores.
1a: Variable es dicotómica, son muestras independientes y como el tamaño de muestra es inferior a 30 deberemos aplicar el Test exacto de Fisher.
2b: El error estándar será 400, porque 4000/raiz(100) es 400. Por lo tanto, un intervalo de confianza de la media del 95% de cada una de las dos poblaciones es el que nos da esta opción «b». Como estos intervalos no se tocan la diferencia es significativa.
Los intervalos de la opción «a» son de valores individuales, no de la media.
La «c» no es correcta. Trabajar con intervalos de confianza de la media y valorar si se tocan o no es equivalente a obtener un p-valor. Es otra forma de evaluar, estadísticamente, la significación de las diferencias.
Por lo dicho en el párrafo anterior, la «d» tampoco es correcta.
3b: La distribución de esta variable claramente no sigue la distribución normal, por lo tanto a la hora de describirla hay que hacerlo con la mediana y el rango intercuartílico.
4b: Variable continua, muestras independiente y no normales, porque el p-valor del Shapiro-Wilk es inferior a 0.05. Por lo tanto, hay que aplicar el Test de Mann-Whitney.
5d: Realmente el coeficiente de determinación es algo (80%), pero sin tener el p-valor de la correlación no podemos decir nada sobre la calidad de la Regresión lineal simple que podamos hacer entre esas dos variables.
1. Si queremos comparar la diferencia que hay de hipertensos en Barcelona y Nueva York y lo hacemos tomando una muestra de 20 personas adultas en cada una de estas ciudades, el test estadístico que deberemos aplicar es:
a. El Test exacto de Fisher.
b. El Test de la t de Student de datos apareados.
c. El Test de proporciones.
d. El Test de McNemar.
2. Nos dicen que han comparado la media de rentas de dos poblaciones con una muestra de tamaño 100 en cada población. Ambas muestras siguen bien una distribución normal y una estadística básica de cada una de ellas es: Población A: 15000±4000 y Población B: 13000±4000, podemos afirmar lo siguiente:
a. La diferencia no es significativa porque si hacemos los intervalos de confianza del 95% de la media los intervalos se tocan porque son: (7000, 23000) y (5000, 21000).
b. La diferencia sí que es significativa porque si hacemos los intervalos de confianza del 95% de la media los intervalos no se tocan porque son: (14200, 15800 ) y (12.200, 13800).
c. Necesitamos tener un p-valor para poder afirmar tal cosa. De otra forma no tiene relevancia estadística.
d. Estadísticamente lo único que podemos decir es que las medias de las rentas son distintas.
3. Si se quiere hacer un resumen descriptivo de una muestra de la variable cantidad de agua caída en diferentes días del año mediante una muestra como la siguiente:
(0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 3, 3, 4, 5, 5, 7, 8, 25, 120), la forma más coherente sería:
a. 9.25±26.6, que son la media y la desviación estándar.
b. 2(0, 5), que son la mediana y el rango intercuartílico expresado con el primer y tercer cuartil.
c. N(9.25, 26.6), que es la expresión de la distribución normal con parámetros 9.25 y 26.6.
d. (2, 9.25), que son la mediana y la media.
4. Se quiere comparar la humedad relativa entre dos muestras de dos zonas que se quiere comparar. Se ha aplicado el Test de Shapiro-Wilk a las dos muestras y el p-valor en ambas es menor que 0.05. Para comparar las medias o las medianas de ambas poblaciones el test más adecuado al caso será:
a. Test de la t de Student de varianzas iguales si se comprueba previamente, mediante el test de Fisher, que no son distintas significativamente.
b. Test de Mann-Whitney.
c. El Test de proporciones.
d. El Test de la t de Student de datos apareados.
5. Si en una Regresión lineal simple entre dos variables tenemos una R2 del 80% podemos afirmar:
a. Que la pendiente es significativa.
b. Que existe una buena determinación.
c. Que la correlación es 0.8.
d. Poco podemos decir sin comprobar previamente que la correlación sea significativa.
A nuestra base de datos adjunta en el artículo Explotación de una base de datos 1: Base de datos le podemos aplicar también el ANOVA. Veamos algunos ejemplos:
1. Comparar la variable Valoración general según el Departamento.
2. Comparar la variable P6 según el Departamento.
SOLUCIONES
1. Comparar la variable Valoración general según el Departamento:
Como hay cuatro departamentos en nuestro estudio deberemos aplicar un ANOVA. Para ello vamos a comprobar, en primer lugar, la normalidad de cada uno de los cuatro grupos a comparar.
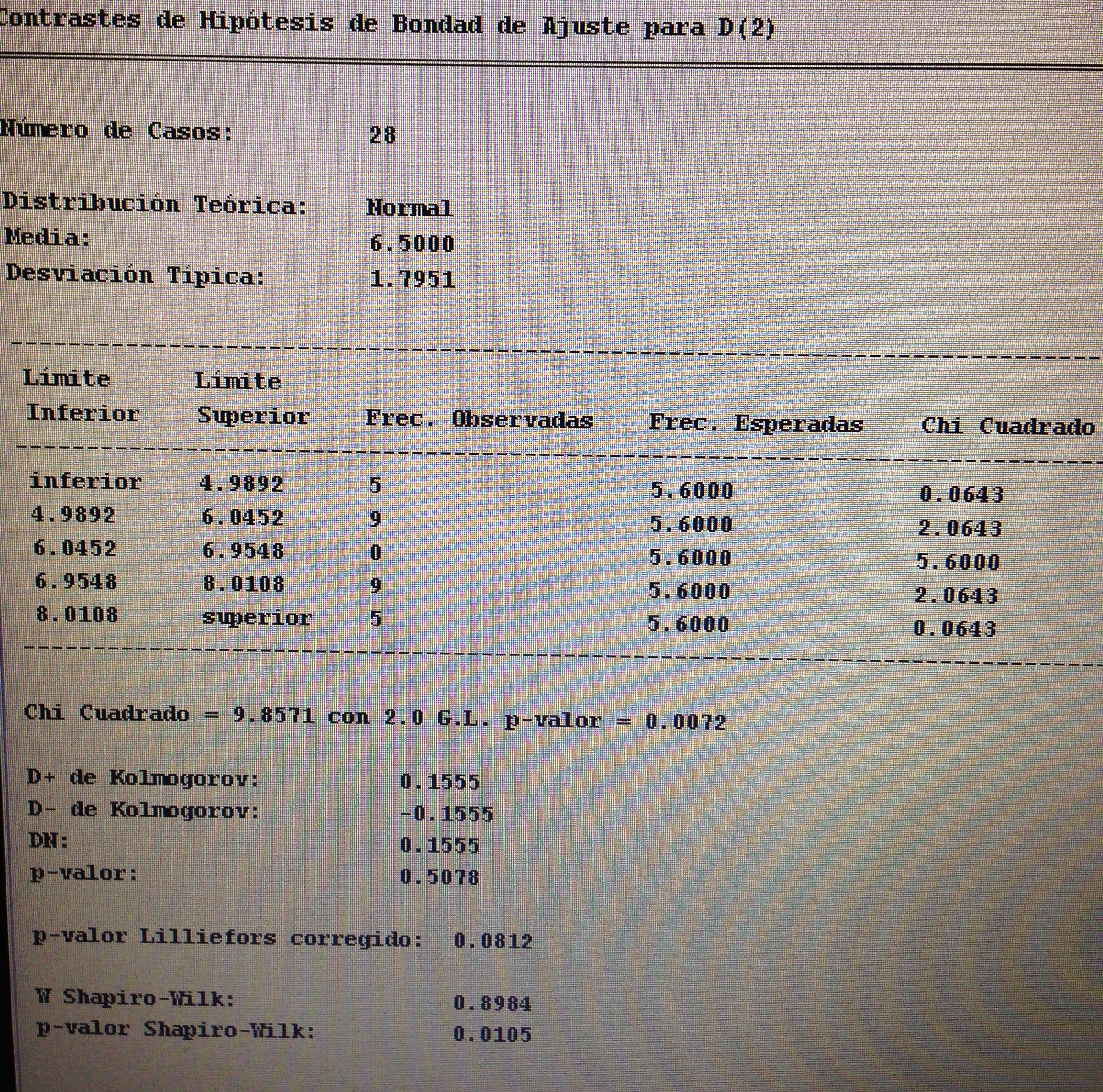


Si observamos el Shapiro-Wilk observamos que ninguno de los cuatro grupos se ajusta a la distribución normal. Por lo tanto, vamos a aplicar el Test de Kruskal-Wallis:
Las comparaciones múltiples (en este caso mediante el método Bonferroni-Dunn):
Por lo tanto, el causante de las diferencias entre los cuatro departamentos es el 3, el departamento de Urología.
2. Comparar la variable P6 según el Departamento:
Como la variable respuesta ahora, la variable P6, es una variable tipo Likert, podemos ya directamente aplicar un Test de Kruskal-Wallis. Conceptualmente este tipo de variables no se ajusta bien nunca a una distribución normal. Son muy pocos los valores que contempla. Es verdad que tampoco es continua, pero es más oportuno, en este caso, aplicar este Test por la mucha mayor versatilidad que tiene.
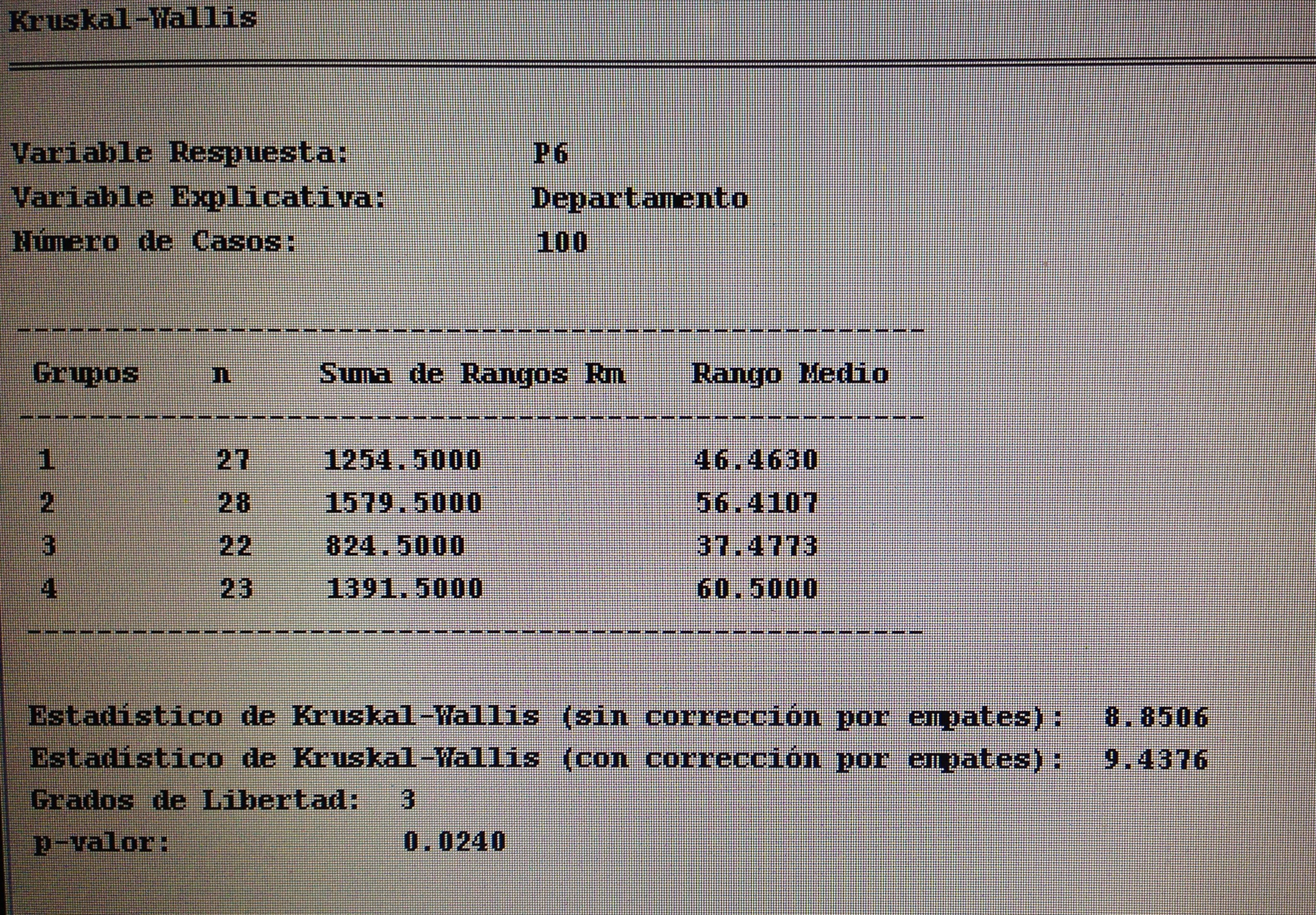
Como rechazamos la Hipótesis nula de igualdad de grupos, debemos aplicar unas comparaciones múltiples:
Como puede verse, la única diferencia apreciable es la que hay entre los departamentos 3 y 4. Las otras comparaciones no muestran diferencias significativas.
A nuestra base de datos adjunta en el artículo Explotación de una base de datos 1: Base de datos le podemos aplicar diferentes comparaciones de dos poblaciones. Veamos algunos ejemplos:
1. Compobar si hay diferencias significativas en cuanto a la Valoración general entre los hombres y mujeres. Calcular la d de Cohen si es que antes se comprueba que la diferencia es estadísticamente significativa.
2. Comparar la Valoración general entre los operados y no operados. Calcular la d de Cohen si es que antes se comprueba que la diferencia es estadísticamente significativa.
3. Comparar si los dos grupos formados por la variable P8 tienen valores diferentes, significativamente, en cuanto a la variable Valoración. Calcular la d de Cohen si es que antes se comprueba que la diferencia es estadísticamente significativa.
SOLUCIONES:
1. Compobar si hay diferencias significativas en cuanto a la Valoración general entre los hombres y mujeres. Calcular la d de Cohen si es que antes se comprueba que la diferencia es estadísticamente significativa:
Se trata de variables continuas, muestras independientes, por lo tanto, hace falta comprobar la normalidad de cada una de las dos muestras:
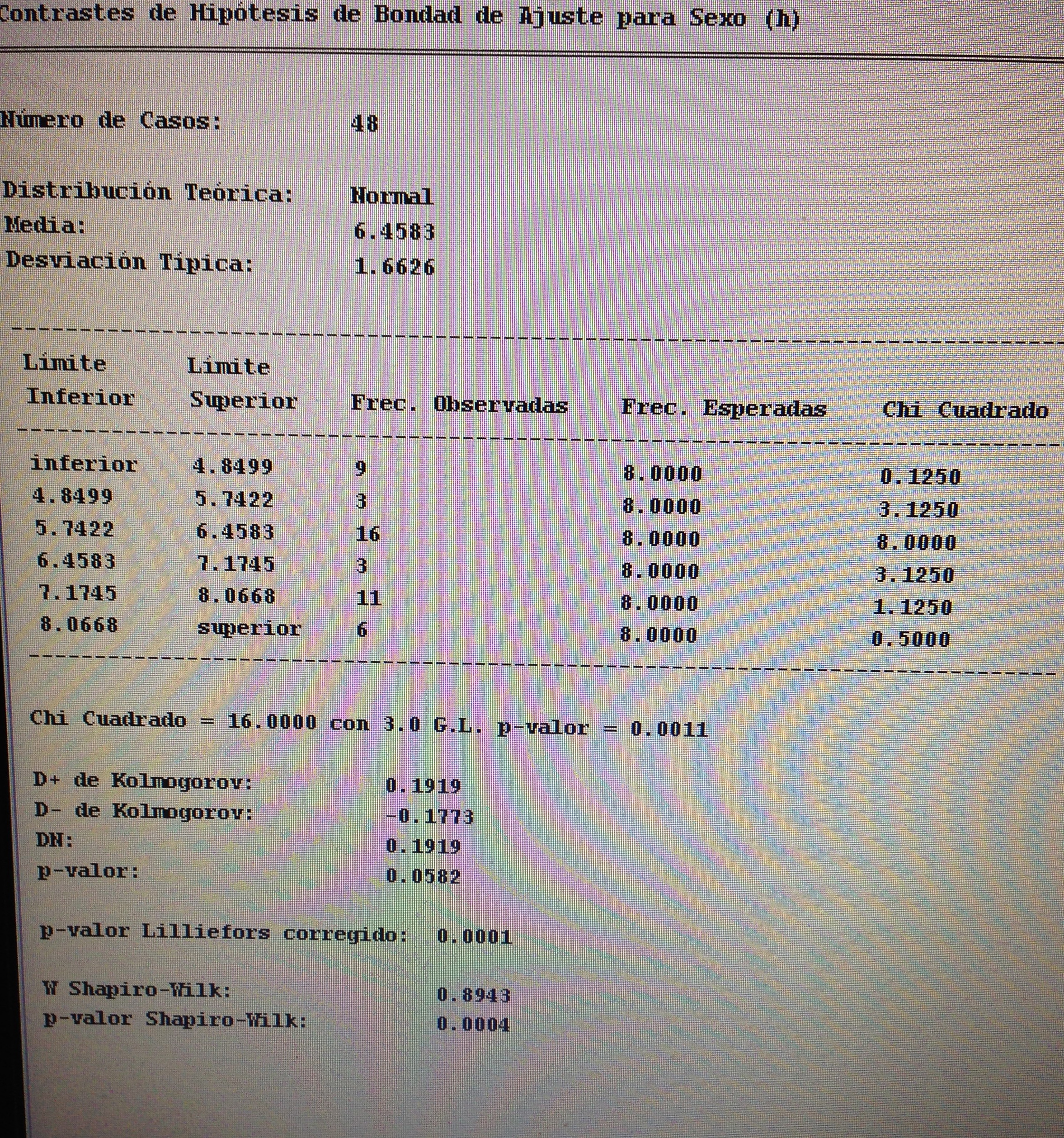
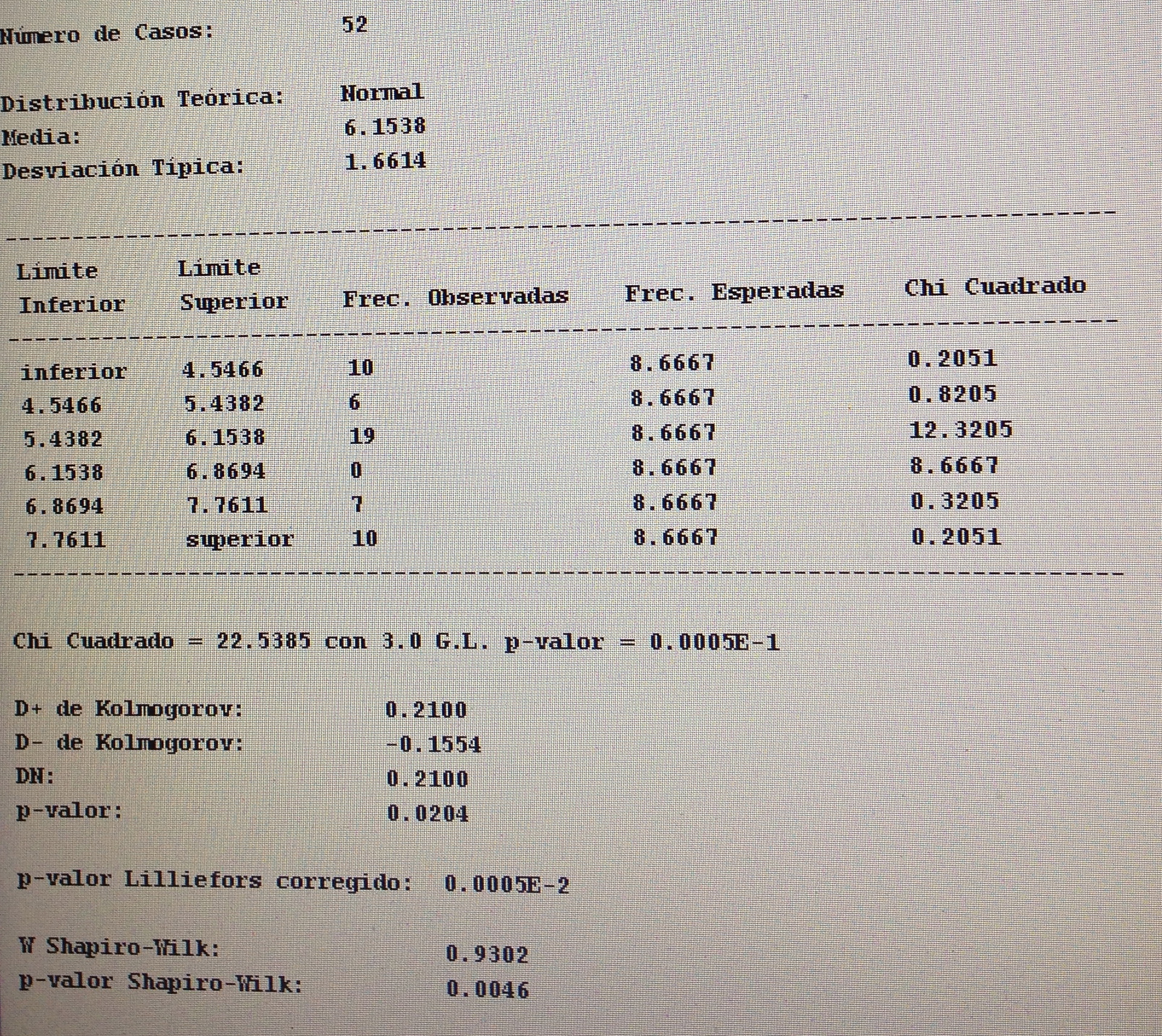
Debemos, pues, aplicar el Test de Mann-Whitney:

No hay diferencias significativas entre los dos sexos, por lo tanto no tiene sentido aplicar aquí la d de Cohen.
2. Comparar la Valoración general entre los operados y no operados. Calcular la d de Cohen si es que antes se comprueba que la diferencia es estadísticamente significativa:
Se trata de variables continuas, muestras independientes y, por lo tanto, hemos de comprobar la normalidad de cada una de las dos muestras:
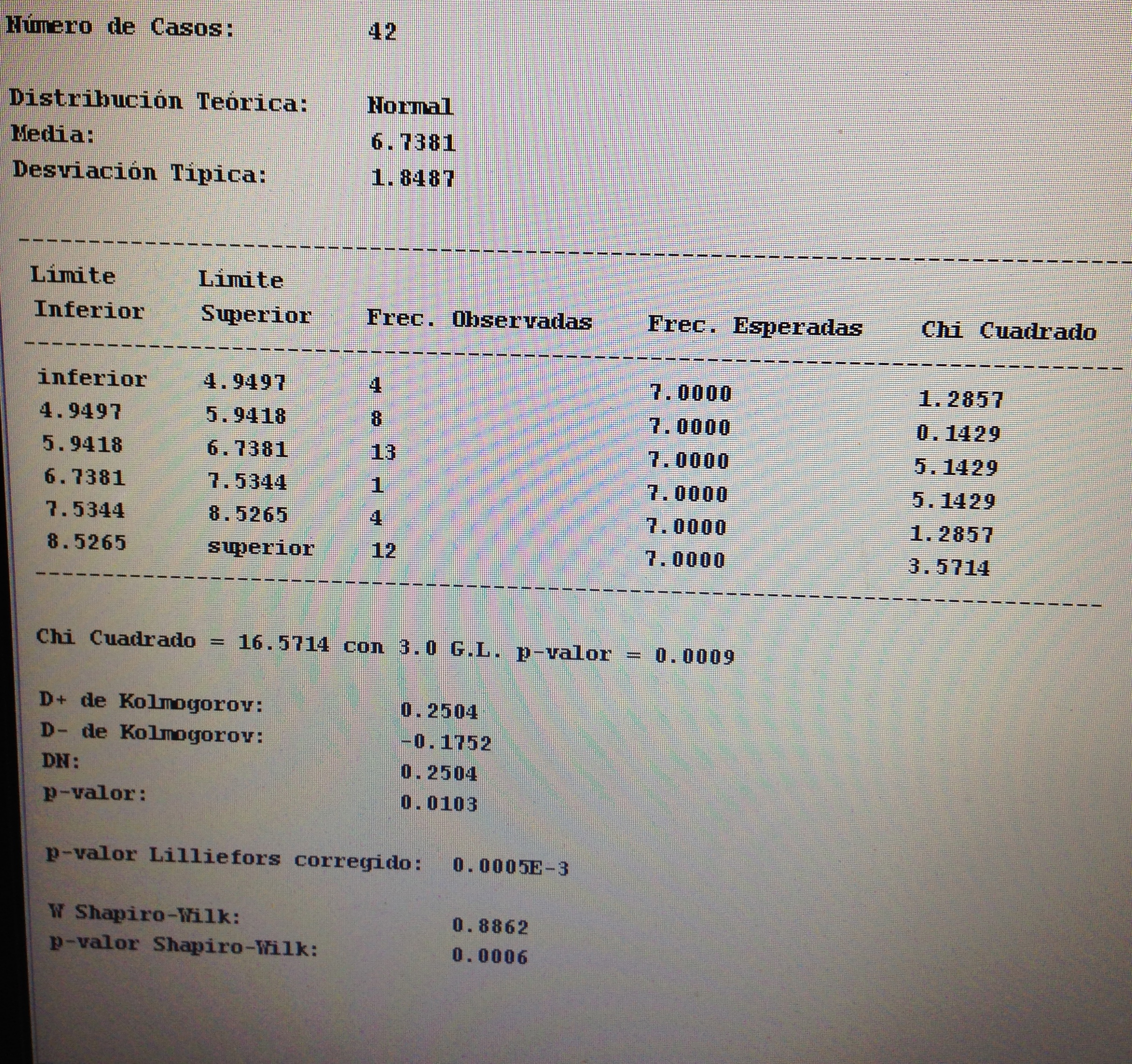
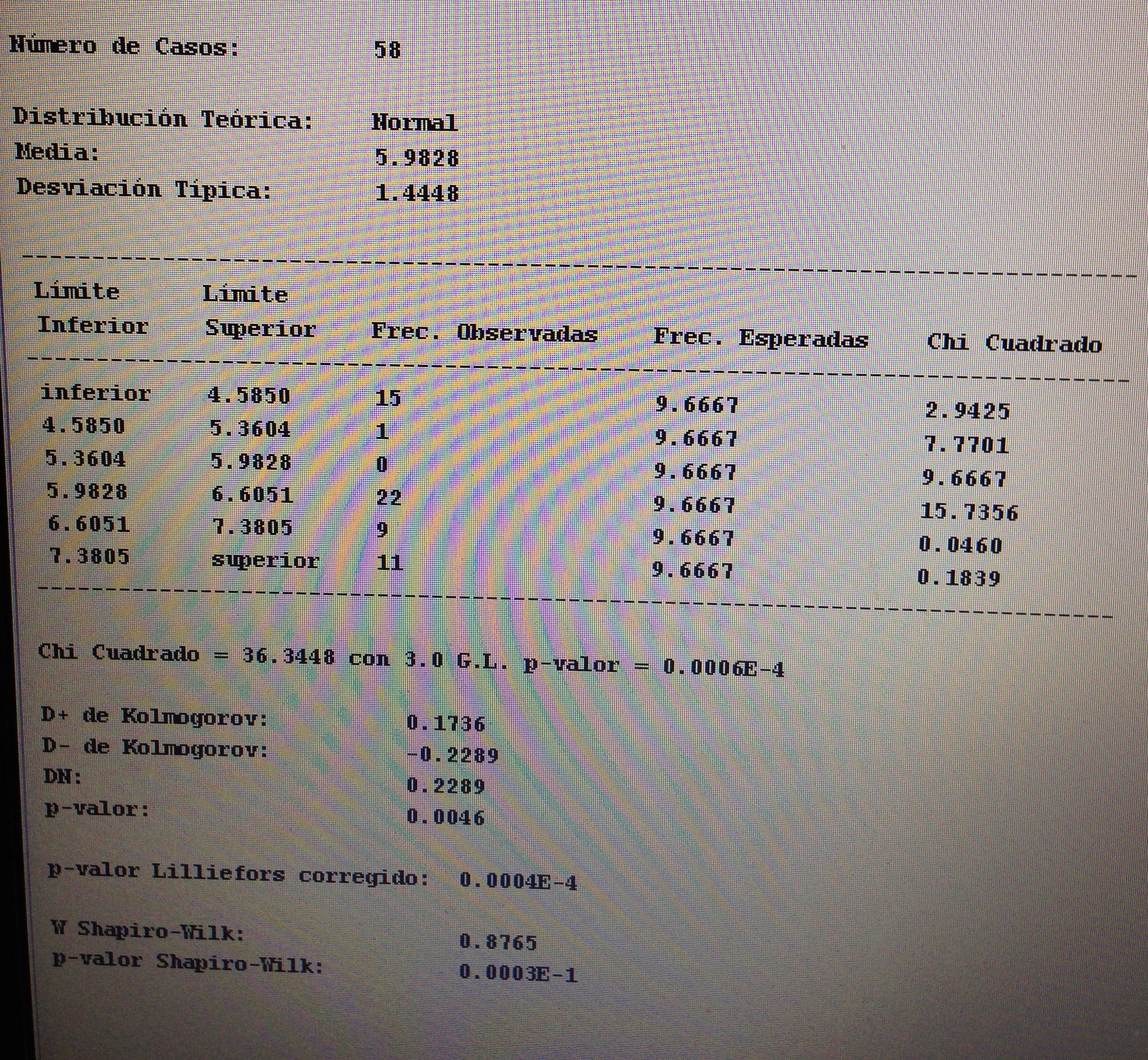
Como no hay normalidad debemos aplicar el Test de Mann-Whitney:

No hay diferencias significativas entre los dos grupos, por lo tanto, no debemos aplicar la d de Cohen.
3. Comparar si los dos grupos formados por la variable P8 tienen valores diferentes, significativamente, en cuanto a la variable Valoración. Calcular la d de Cohen si es que antes se comprueba que la diferencia es estadísticamente significativa:
Se trata de variables continuas, muestras independientes y hace falta, pues, ahora comprobar la normalidad de cada una de las dos muestras:
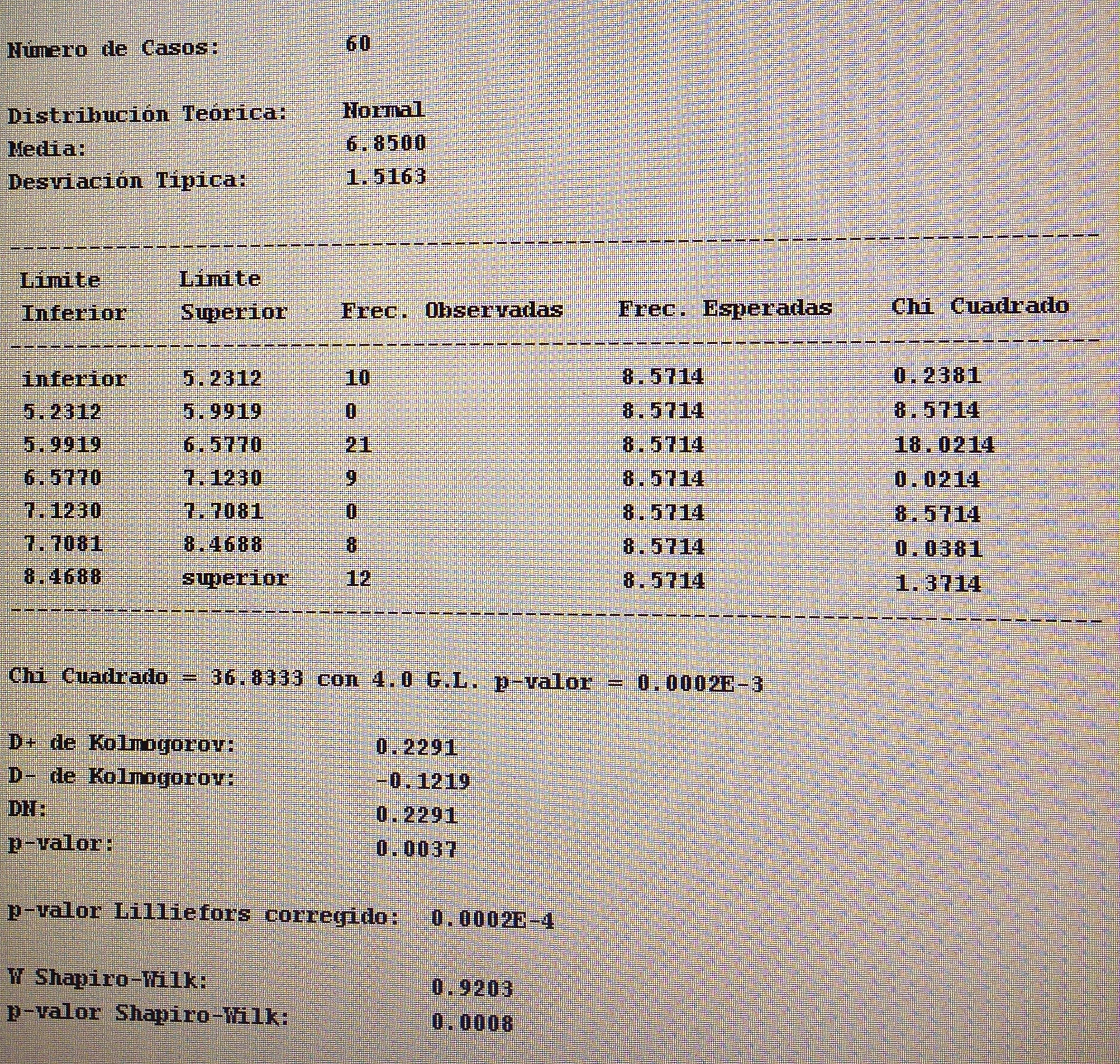
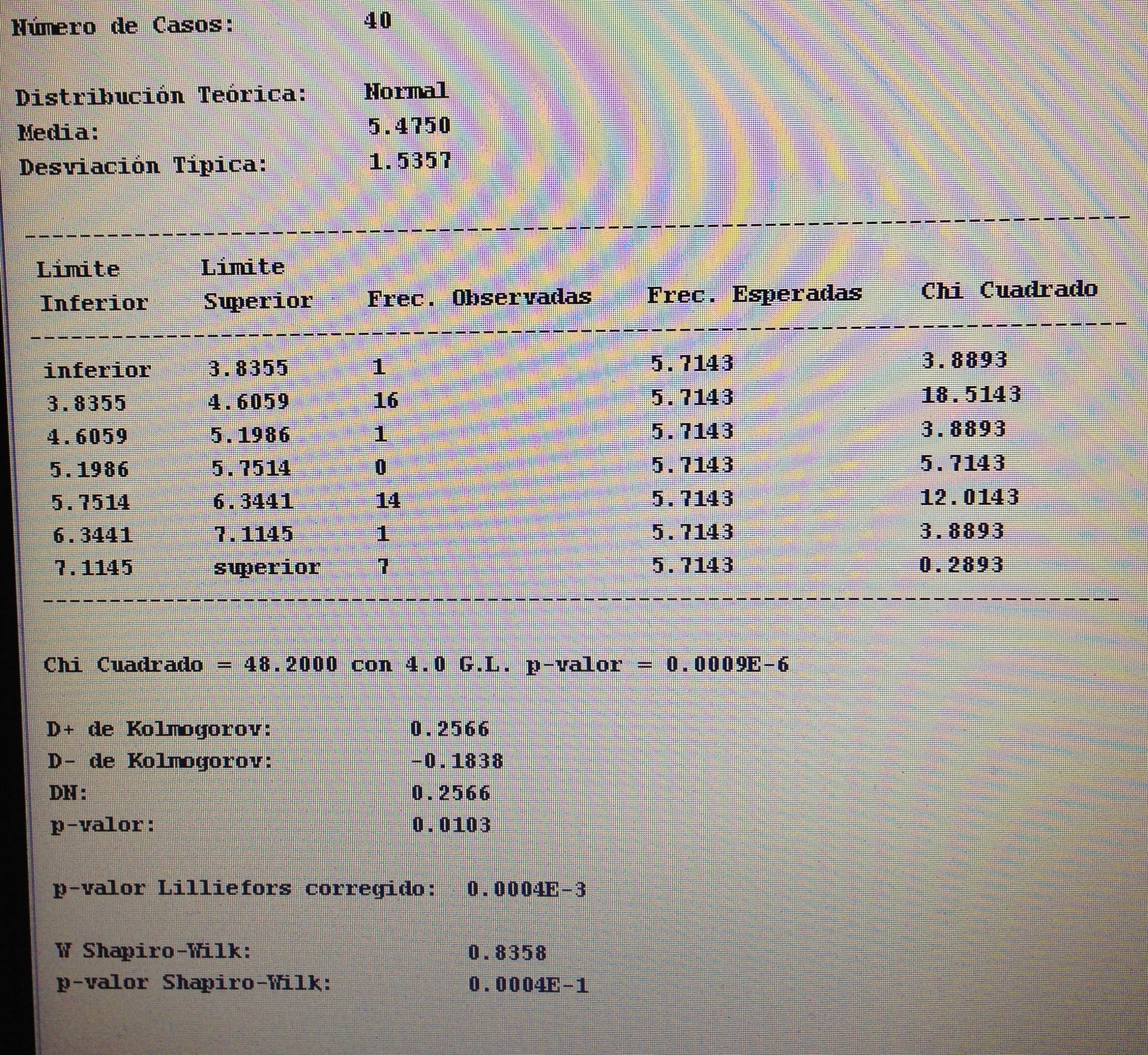
Como no hay normalidad aplicamos el Test de Mann-Whitney:
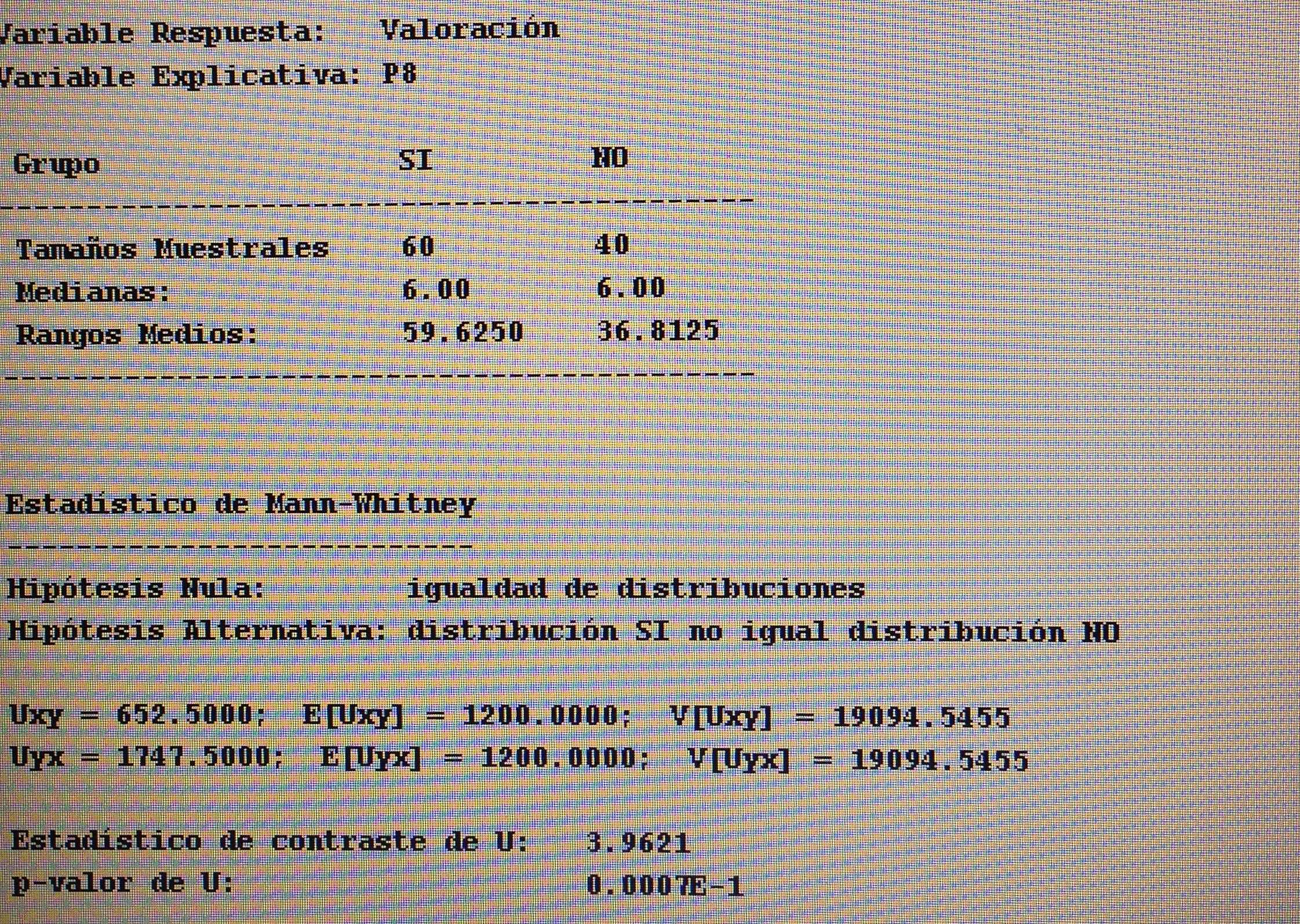
Ahora sí que vemos diferencias significativas entre los dos grupos. Ahora sí tiene sentido aplicar la d de Cohen.
