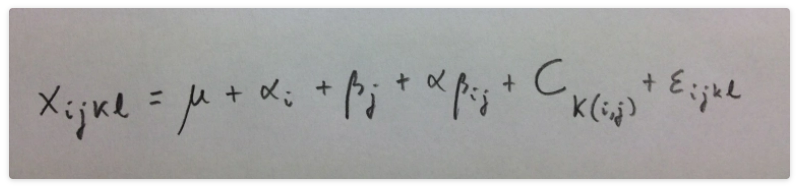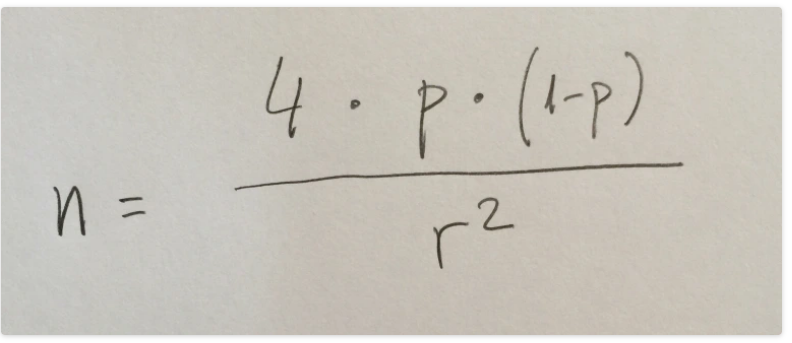a)En la muestra (1, -4, 2, 0, 5) el rango intercuartílico es 4.
b)Una correlación r=0.3 con IC 95% (0.1, 0.5) es compatible con una pendiente con p=0.23.
c)Un intervalo de confianza de la media del 99.5% de (8.1, 8.7) tiene un error estándar de 0.3.
d)La muestra (1, 3, 4, 8) tiene el mismo rango intercuartílico que la muestra (3, 4, 6, 8, 23)
2.Indicar dónde hay una incoherencia:
a)IC 95% de la r: (0.23, 0.56) y p-valor de la pendiente de 0.001
b)IC 95% de la r: (-0.31, 0.12) y p-valor de la pendiente de 0.34
c)IC 95% de la r: (0.23, 0.56) e IC 95% de la pendiente de la recta: (-0.34, -0.12)
d)P-valor de la r de 0.23 y p-valor de la ordenada en el origen de 0.001
3. ¿Qué afirmación entre las siguientes es cierta?
a)El tercer cuartil siempre es mayor que el primer cuartil.
b)La mediana puede ser mayor que el tercer cuartil.
c)La media puede ser inferior al primer cuartil.
d)El rango siempre es mayor que el rango intercuartílico.
4. ¿Qué afirmación es cierta?
a)r=0.9 es una correlación más significativa que una correlación r=0.5.
b)Una r=0.5 con un IC 95%: (0.3, 0.7) es una correlación mayor que r= – 0.6 (p=0.01).
c)Una r=0.4 con un IC 99.5% (-0.05, 0.85) es compatible con una pendiente con p=0.02.
d)Una correlación r=0.5 tiene un coeficiente de determinación del 50%.
5. Tenemos una muestra de tamaño 10000 de una variable que se ajusta bien a una distribución normal. El IC de la media del 99.5% es (49.7, 50.3). La media muestral es 50. ¿Qué afirmación es cierta?
a) Un intervalo de confianza del 95% de la media sería: (30, 70).
b) Un intervalo de confianza del 95% de valores individuales de la variable sería: (40, 60).
c) Un intervalo de confianza del 95% de valores individuales de la variable sería: (20, 80).
d) Un intervalo de confianza del 68.5% de la media sería: (49.9, 50.1).
Tenemos la siguiente base de datos de pacientes que ingresaron por ictus y que fueron sometidos a un ensayo clínico aleatorizado donde se comparaba el tratamiento trombolítico mecánico con el tratamiento trombolítico farmacológico tras ingreso:
P=Paciente
G=Grupo de tratamiento (TM=Trombolisis mecánica; TF=Trombolisis farmacológica)
E=Edad
S=Sexo (0=Varón; 1=Mujer)
Ch=Charlson ajustado a la edad (Cuantificación de las comorbilidades)
1.Comprobar si el reparto aleatorio de los dos grupos ha resultado efectivo: Edad, Sexo, Charlson y nihss en el ingreso.
2.¿Hay diferencia estadísticamente significativa en el descenso en el nihss entre los dos tratamientos del ictus comparados?
3.¿Hay relación estadísticamente significativa entre el tipo de tratamiento del ictus y la mortalidad intrahospitalaria? Calcula la Odds ratio asociada a la trombectomía mecánica respecto a la farmacológica.
4.¿Al comparar los pacientes que mueren respecto a los que no mueren, dónde hay más diferencias entre ellos, en el nihss en el ingreso o en el descenso del nihss tras tratamiento?
1.Si en una variable cuantitativa tenemos una Asimetría estandarizada de 0.24 y una Curtosis estandarizada de 1.33, la media muestral es 15 y la desviación estándar es 10, ¿cuál de las siguientes afirmaciones es la más coherente?
a.Entre 5 y 25 tenemos el 68.5% de los valores.
b.Entre 5 y 25 tenemos el 95% de los valores.
c.Por debajo de 12 tenemos el mismo porcentaje de valores que por encima de 18.
d.Por debajo de 5 tenemos un 1% de valores.
2.Tenemos en un estudio de relación entre dos variables cualitativas el siguiente valor de estadístico de test: 12.33.
El umbral para decidir si mantener la hipótesis nula o rechazarla en los tres contrastes de hipótesis que se realizan es:
a.24.28
b.4.75
c.0.46
d.No lo podemos saber con la información que se nos da.
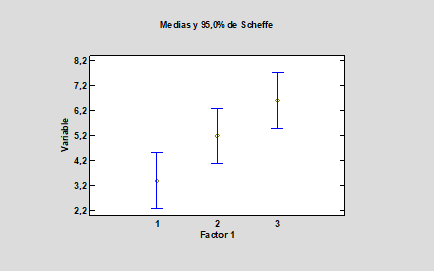
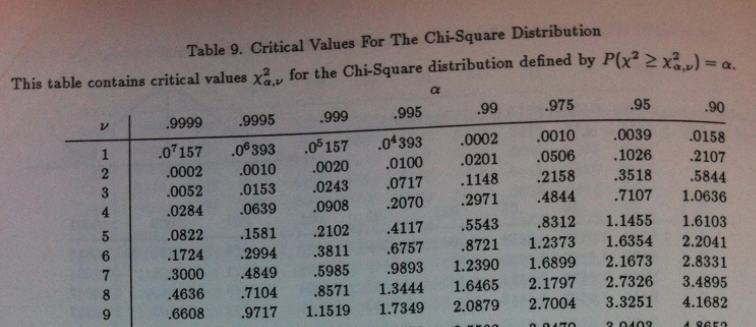
3.En un ANOVA de un factor con estos IC del 95 % de la media:
¿Cuál es la afirmación cierta?
a.El p-valor del ANOVA será p>0.05.
b.Hay tres grupos homogéneos.
c.Hay dos grupos homogéneos.
d.Hay un único grupo homogéneo.
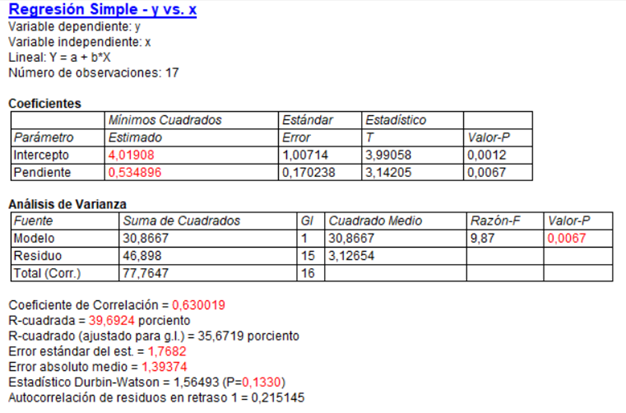
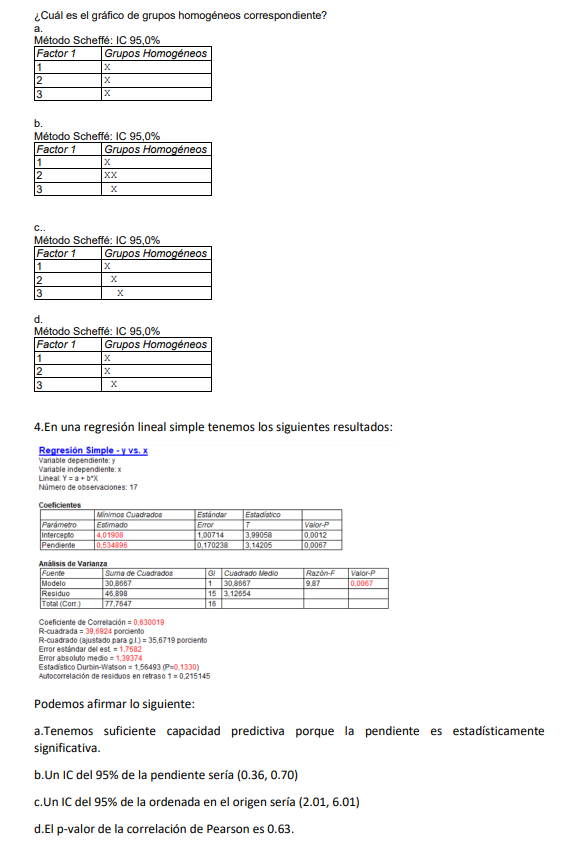
4.En una regresión lineal simple tenemos los siguientes resultados:
Podemos afirmar lo siguiente:
a.Tenemos un coeficiente de determinación del 63%
b.Un IC del 68.5% de la pendiente sería (0.36, 0.70)
c.Un IC del 95% de la ordenada en el origen sería (1.01, 7.01)
d.El p-valor de la correlación de Pearson es mayor que 0.05.
5.Si tenemos un intervalo de confianza del 95% de una proporción de botellas tomadas del mar mediterráneo con valores de un contaminante por encima del umbral tolerado que es (45%, 55%), determinar el tamaño de muestra con el que se ha trabajado:
a.100
b.200
c.300
d.400
6.En una regresión logística donde se pretende relacionar la temperatura del agua y la reproducción o no de una especie de pez criado en una piscifactoría, hemos obtenido una Odds ratio de 1.75 con un IC del 95%: (1.35, 2.88), donde hemos codificado como 1 la reproducción, podemos afirmar:
a.No hay relación entre temperatura y reproducción.
b.A mayor temperatura más probabilidades de reproducción.
c.A menor temperatura más probabilidades de reproducción.
d.Nos falta información para poder afirmar cualquiera de las tres cosas anteriores.
7.Hemos estudiado los cambios temporales de la diversidad de especies del zooplanton en el mediterráneo. Para ello se tomó una muestra de tamaño 50 en distintos puntos, al azar, en 2010 y se volvió a hacer en otra muestra al azar, también de tamaño 50, en 2020. Se midió el índice de Shannon-Weaver como medida de diversidad. Se aplicó en cada muestra el test de Shapiro-Wilk y el p-valor fue, en ambas, superior a 0.05. Se aplicó, también, el test de Fisher-Snedecor obteniendo un p-valor de 0.01. Para realizar la comparación se debió de aplicar:
a.Un test de la Mann-Whitney.
b.Un test de la t de Student de varianzas iguales.
c.Un test de la t de Student de varianzas distintas.
d.Un test de la Chi-cuadrado.
8.En el problema anterior tuvimos una diferencia de medias de 0.5 y un error standard del estadístico de test con un valor de 0.4. ¿Cuál de las siguientes afirmaciones es cierta?
a.El p-valor será menor que 0.05 porque 0.5 es mayor que 0.4.
b.El p-valor será menor que 0.05 porque el intervalo de confianza del 95% de la diferencia de medias poblacionales no contendrá al cero.
c.El p-valor será mayor que 0.05 porque el intervalo de confianza del 95% de la diferencia de medias poblacionales contendrá al cero.
d.El p-valor será mayor que 0.05 porque 0.5 es mayor que 0.4.
9.En la muestra (1, 1, 2, 2, 3, 8, 9, 10), el rango intercuartílico es:
a.7
b.9
c.4
d.6
10.En un estudio donde hemos comparado la salinidad en dos zonas del mediterráneo la salinidad de la zona 1 es de 35.1 con un tamaño de muestra de 200 y una desviación estándar de 1 y de la zona 2 es de 35.4 con un tamaño de muestra de 200 y una desviación estándar de 1. El estadístico de test es -1.96. En una distribución t de Student con valor del parámetro 398 un IC 95% es (-1.96, 1.96). ¿Qué p-valor es razonable en este estudio?
a.0.001.
b.0.5.
c.0.0000001.
d.0.05.
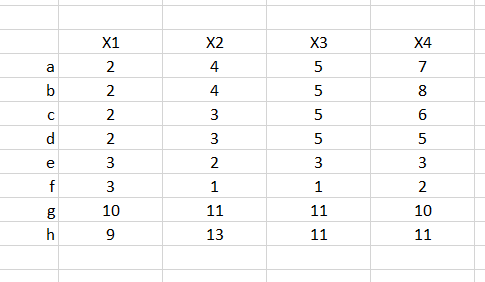
11.¿Cuál de las siguientes afirmaciones es cierta en un análisis de componentes principales cuya primera componente es Y=0.5X1-0.5X2+0.01X3-0.5X4?
a.La variable X3 tiene una fuerte relación con las demás.
b.No hay buena correlación entre las variables.
c.Debemos conocer el p-valor.
d.La variable X3 no tiene ningún peso en la primera componente.
12.Si un intervalo de confianza del 99.5% de la pendiente en una regresión lineal simple es (2.7, 3.3) el error estándar es:
a.0.5
b.0.05
c.0.1
d.1
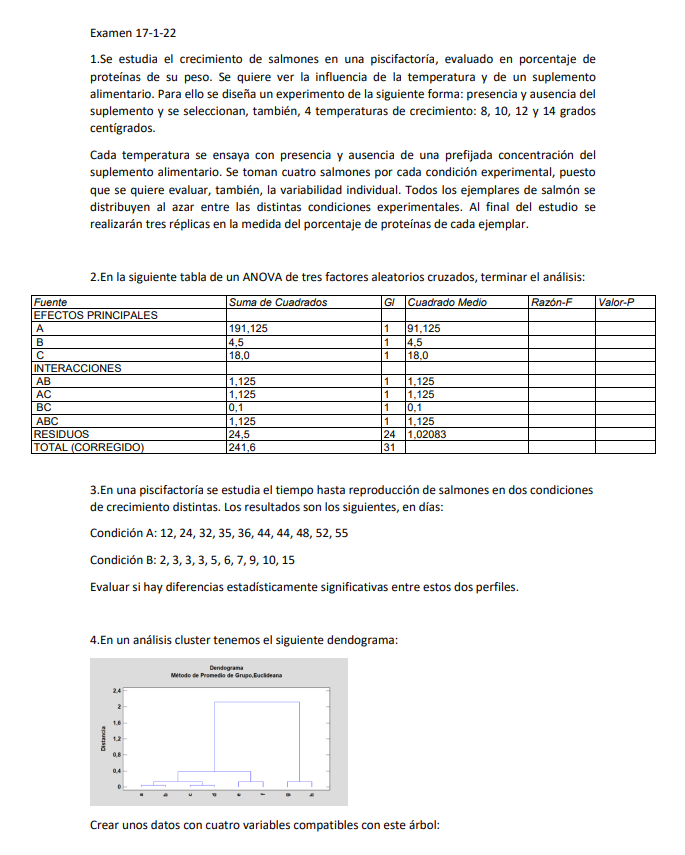
13.Se pretende determinar el tamaño de muestra para un estudio donde se quiere pronosticar en qué porcentaje de puntos del mar mediterráneo se supera el valor de un umbral determinado de concentración de hidrocarburos. Es un estudio que nunca que se ha llevado a cabo en el mundo. Se pretende, además, mucha precisión: se quiere que el intervalo de confianza del 95% tenga un radio del 2%. ¿Qué tamaño de muestra necesitamos?
a.2500
b.1000
c.500
d.250
14.En un proceso de selección de operadores que clasifiquen organismos vivos del plancton marino hemos evaluado el kappa de un operador consigo mismo y resulta ser 0.95. ¿Cuál de las siguientes afirmaciones es cierta?
a.La t de Student que calculemos será significativa.
b.La Chi-cuadrado que calculemos será significativa.
c.La regresión logística que calculemos será significativa.
d.El Análisis de componentes que calculemos será significativo.
15.En un estudio de predicción de la temperatura en una zona marina nos proporcionan un IC de la media del 95% que es (18.4, 18.6). El tamaño muestral con el que se realizó tal predicción es de 100. Un IC del 99.5% descriptivo de la variable temperatura en esta zona sería:
a.(16.5, 20.5)
b.(17.5, 19.5)
c.(17.0, 20.0)
d.(18.0, 19.0)
16.En un estudio de comparación de dos poblaciones el intervalo de confianza del 95% de la diferencia de las dos proporciones poblacionales ha resultado ser (0.13, 0.56). ¿Cuál de las siguientes afirmaciones es cierta?
a.El p-valor es mayor que 0.05.
b.El p-valor es menor que 0.05.
c.El p-valor es 0.05.
d.El p-valor dependerá del tamaño de muestra.
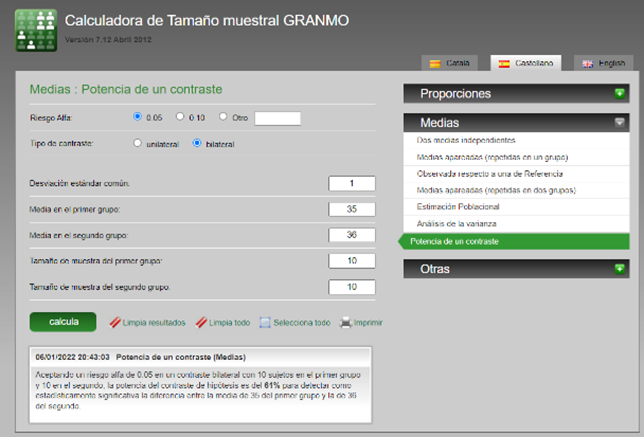
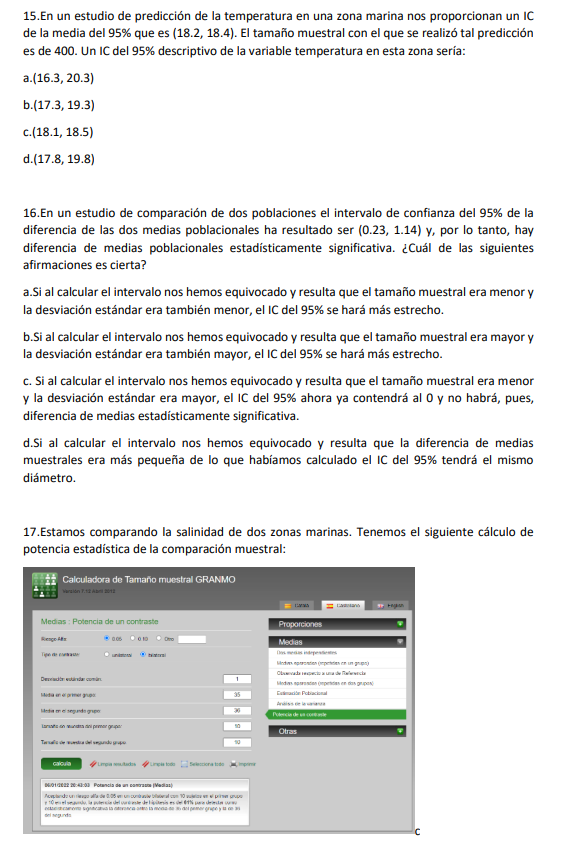
17.Estamos comparando la salinidad de dos zonas marinas. Tenemos el siguiente cálculo de potencia estadística de la comparación muestral:
¿Cuál de las siguientes afirmaciones es cierta?
a.Si pasamos de una desviación estándar de 1 a una de 2 la potencia aumentará.
b.Si la diferencia de medias aumenta la potencia aumentará.
c.Si aumentamos el tamaño de muestra la potencia disminuirá.
d.Si aumentamos el tamaño de muestra y la desviación estándar la potencia aumentará.
18.Hemos estudiado en cinco zonas concretas del mar un metro cúbico de agua y hemos hecho un recuento de cinco especies de zooplanton presentes en cada una de esas muestras. Hemos realizado un test de la Ji-cuadrado. El valor del estadístico de test ha sido 31.99. ¿Cuál de las siguientes respuestas es correcta?
a.p=0.03
b.p=0.01
c.p=0.95
d.p=0.0001
19.¿En cuál de las siguientes afirmaciones hay una incoherencia?
a.IC 95% de la correlación de Pearson: (0.23, 0.35). IC 95% de la pendiente de una regresión lineal simple: (0.47, 2.33).
b.IC 95% de la diferencia de proporciones es (-1.77, 2.18) y el p-valor mayor que 0.05.
c.IC 95% de la correlación de Pearson: (0, 0.12) y el p-valor es 0.05
d.Correlación de Pearson: -0.5. Coeficiente de determinación del 25%.
20.¿Cuál de las siguientes afirmaciones es cierta?
a.Un Análisis clúster es una técnica de comparación entre tres grupos.
b.Una correlación de Pearson entre dos variables cualitativas con una r=0.56 y con una p<0.05 indica una relación estadísticamente significativa.
c.La V de Crámer es una medida de diferencia entre dos poblaciones a comparar.
d.La Chi-cuadrado puede usarse como técnica de relación y como técnica de comparación.
Una forma de introducir un curso de Cálculo de probabilidades y Estadística es relacionándolo con lo que podríamos denominar la columna vertebral de las matemáticas: la noción de función.
Puede resultar, asimismo, conveniente, situar la noción de función en un ámbito ontológico más general. Veámoslo.
Podemos considerar que el mundo, que la realidad, está constituidas de entidades, de unidades diferenciadas de un entorno, y de relaciones entre ellas.
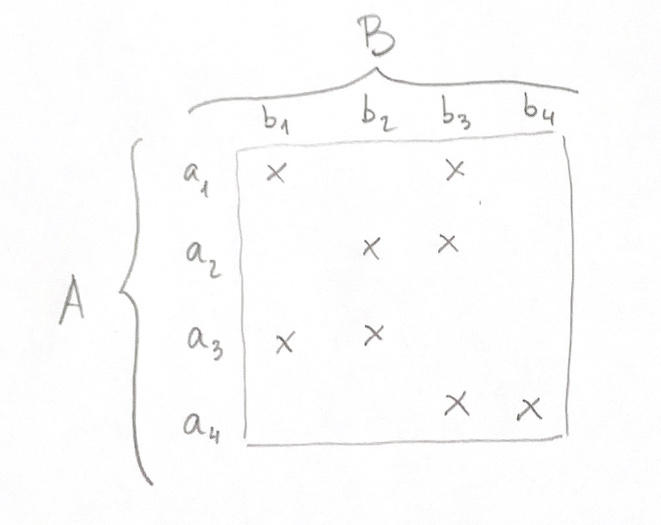
El concepto matemático de relación es el siguiente: Es un subconjunto del producto cartesiano de dos conjuntos:
El producto cartesiano de dos conjuntos es el listado de todas las parejas de valores donde un elemento es de A y el otro de B. Una relación concreta especifica cuáles de estas posibilidades potenciales se realizan. En definitiva, entre dos conjuntos cualesquiera una relación es el listado de conexiones que se establecen entre los elementos de un conjunto y los elementos del otro. Por ejemplo, dos grupos de personas A y B las flechas marcarían cuáles son las relaciones, por ejemplo, de amistad.
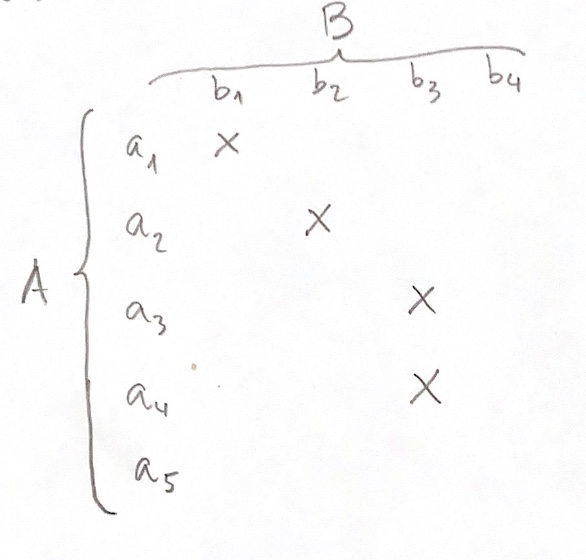
En matemáticas hay un tipo muy especial de relación: la aplicación o función, que es la dibujada asÍ:
Para que una relación sea función debe todo elemento del conjunto denominado dominio (en este caso A) tener relación con uno y sólo un elemento del conjunto denominado codominio (en este caso B).
Vemos que cada elemento a del conjunto A, excepto el quinto elemento, tiene una y sólo una conexión con un elemento b del conjunto B. En este caso, diríamos que el dominio de la función no es todo A, sino el subconjunto formado por los primeros cuatro elementos y que el recorrido de esta función está formada únicamente por los tres primeros elementos del codominio B. La búsqueda del dominio y el recorrido de una función es algo muy habitual en matemáticas.
Esta noción es trascendental, puesto que muchas cosas en la vida real, en nuestra forma de ser, menejamos esta noción. Podríamos decir que esta noción de función forma parte esencial del funcionamiento del mundo.
En todo caso a nosotros esta noción nos va a ser muy útil para trazar una mirada unitaria a todo el mundo del Cálculo de probabilidades y Estadística. De hecho, buena parte de los que se realiza en esta disciplina se puede visualizar bajo el prisma de la noción de función, como iremos viendo.
Una noción más: Vamos a delimitar tres tipos de entidades en el mundo real:
Entidades no matemáticas: ENM.
Entidades matemáticas no numéricas: EMNN.
Entindes matemáticas numéricas: EMN.
El siguiente esquema nos ayuda a ver algunas de las entidades que forman parte de estos tres tipos de conjuntos:
Podemos ver que se trata de tres listados bien distintos. En la primera lista se trata de entidades de la vida real, de nuestro entono. Son las entidades con las que se enfrentan las distintas ciencias, las entidades que constituyen el objetivo de cualquiera de las distintas ciencias. Al final de esta lista vemos una dualidad general, pero muy importante: el enfrentamiento de dos hipótesis a contrastar. Veremos que esto es algo común en los mecanimos estadísticos esenciales de decisión de todas las ciencias.
Esta mirada nos ayudará a delimitar una serie de procedimientos que constituyen la columna vertebral del mundo del Cálculo de probabilidades y de la Estadística. Nos ayudará, también, a situar las distintas acciones implicadas en el conjunto de técnicas manejadas en esta disciplina matemática. De una forma especial, este esquema nos ayudará a ver la conexión entre el nivel teórico y formal de esta materia y su importantísimo nivel aplicado.
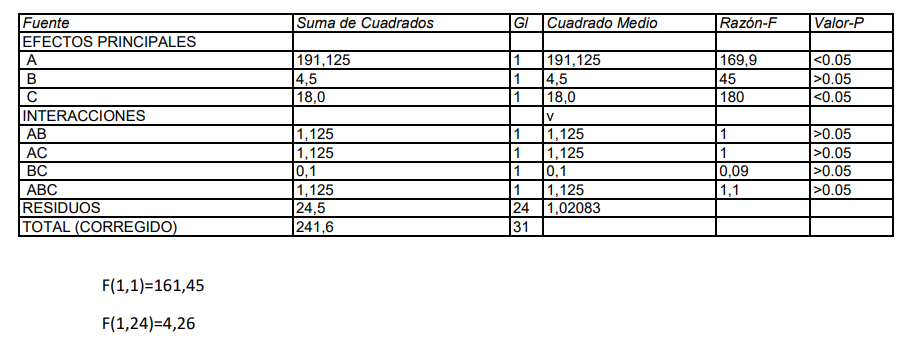
Se trata de una ANOVA de tres factores, dos fijos y un tercero aleatorio anidado en la interacción.
El modelo es:
Hay cuatro efectos y, por lo tanto, cuatro contrastes de hipótesis. Los estadísticos de test se pueden deducir fácilmente de estas esperanzas de los cuadrados medios.
1c. Tenemos simetría pero no ajuste a la normal porque la curtosis supera ampliamente el umbral. No podemos afirmar, pues, ni a, ni b, ni d. Sin embargo, c sí, puesto que requiere únicamente simetría.
2b. Para los tres valores de los estadísticos de test (25.19, 3.86 y 0.43) el valor de 4.75 es el único que es coherente con los p-valores. El 25.19 supera en mucho el umbral puesto que el p-valor es muy pequeño, el 3.86 no lo supera pero está cerca, por eso el p-valor es mayor que 0.05 pero muy cercano a él y el 0.43 está muy lejos de superar el umbral, por eso el p-valor es muy superior a 0.05.
3.b. Es claro que el grupo 1 y el 2 los intervalos se solapan, el 2 y el 3 también, pero el 1 y el 3 no se solapan.
4c. La ordenada en el origen tiene un valor estimado de 4.01 y un error estándar de 1. Si contruimos un IC del 95% debemos sumar y restar a 4.01 dos veces ese error estándar.
5b. La respuesta a no es cierta porque la información que tenemos no nos habla sobre la significación de la pendiente. Si nos fijamos en el IC descriptivo podemos observar que la desviación estándar para un individuo con valor x=5 es aproximadamente 3.88 (10.57-6.99). Como este IC se ha hecho con con desviaciones estándares, si cogemos una desviación estándar será 1.94, que si le sumamos y restamos este valor a 6.69 nos da la respuesta b.
7b. Es una variable continua, son muestras independientes, hay normalidad porque los p-valores de ambas muestras son superiores a 0.05. Hay igualdad de varianzas. Debe aplicarse el test de la t de Student de varianzas iguales.
8c. Al estar comparando dos medias si la diferencia de medias muestral es 0.5 y el error estándar es 0.4, un IC del 95% de la diferencia de medias poblacional será (-0.3, 1.3) porque consiste en sumar y restar dos veces el error estándar a la diferencia de medias obtenida. Por lo que el p-valor será superior a 0.05 puesto que el IC contiene al 0.
9c. Si ordenamos la muestra tenemos (1, 3, 4, 5, 6, 8, 9, 10, 16), como son nueve valores el primer cuartil es 4 y el tercero es 9. El rango intercuartílico es 5.
10a. Estamos ante un contraste de hipótesis que el criterio de rechazo es estar fuera del intervalo (-1.96, 1.96). El valor obtenido del estadístico es 3. Se rechaza la hipótesis nula, por lo tanto. La d, pues, claramente descartada. La b da un p-valor muy próximo a 0.05, el valor del estadístico en este caso debería estar fuera del intervalo pero muy próximo a -1.96 ó a 1.96; por ejemplo, -2.01. La c da un p-valor muy pequeño, debe estar mucho más alejado; por ejemplo, -17. La respuesta a es una respuesta más coherente. Si se observa la tabla de la t de Student se puede deducir este p-valor aproximadamente:
Si se observa la última fila de la tabla se observa que a la derecha de 3.09 el área es 0.001, a la izquierda, pues, de -3.09 también habrá un área de 0.001. Estamos hablando de que el estadístico de test ha dado -3, luego el p-valor es el área que hay a la izquierda de -3 y a la derecha de 3, sumadas. El p-valor exacto calculado con un ordenador es 0.0028. P
11b. La suma de los valores propios debe ser 5, los porcentajes deben sumar 100 y las componentes deben tener un orden de progresiva pérdida de varianza explicada.
12ac. Hay, por error, dos respuestas de 0.5. Si el IC es del 95, el error estándar debe ser la mitad del radio del intervalo. El radio es 1 (4.5-3.5).
13b. Si calculamos el IC 95% con la fórmula:
Tomaremos p=0.5 porque no tenemos información previa. Y r=0.01.
14c. Es la única opción donde la concordancia es muy elevada.
15a. El error estándar es 0.05. La desviación estándar será, pues, 1.
16d. La amplitud de un intervalo de confianza de la diferencia de dos medias poblacionaes depende sólo del error estándar y éste depende de la relación entre desviación estándar y tamaño de muestra. En el apartado d no ha cambiado ni la desviación estándar ni el tamaño de muestra, por lo tanto, la amplitud (su diámetro) del intervalo no cambiará.
La c no es correcta en general porque es verdad que si el tamaño de muestra es menor y encima la desviación es mayor el intervalo se ampliará, pero esto no implica necesariamente que se amplíe tanto como para que acabe incluyendo al 0 un IC que era de (0.23, 1.14).
17d. Si la desviación estándar baja la potencia aumentará.
18b. Si vamos a la tabla de la chi-cuadrado y miramos la fila de valor 9 (=(4-1)x(4-1)), veremos que la derecha de 4,1682 hay un área de 0.90:
19c. Ya sabemos que lo que le pase a la correlación le pasa a la pendiente. Este caso es muy sutil, pero observemos que en la correlación el IC del 95% es (-0.43, 0.02), con muchísimo peso en la parte negativa y el de la pendiente es (-0.04, 5.13) con muchísimo peso ahora en la parte positiva. Esto tampoco sucede en la realidad. Correlación y pendiente tienen destinos comunes y aquí hay una incoherencia.
20b. La curva de Lorenz y el coeficiente de Gini miden la diversidad del reparto de un total. En la muestra b se puede observar que la zona que tiene más temperatura es casi el doble de la temperatura de la zona más fría. Esto no sucede en las otras muestras. El coeficiente de Gini es el mayor, porque es donde hay más desigualdad en el reparto del total.
Si se observan las Odds ratio de la Regresión logística y entendiendo que hemos codificado con un 1 los ejemplares viables y con un 0 los ejemplares no viables, debemos concluir lo siguiente:
La humedad tiene una OR significativa (no contiene el 1 el intervalo de confianza del 95%). Al ser mayor que 1 significa que al aumentar la humedad aumenta la probabilidad de que se dé viabilidad.
La inclinación del terreno tiene una OR significativa (no contiene el 1 el intervalo de confianza del 95%). Al ser menor que 1 significa que al aumentar la humedad disminuye la probabilidad de que se dé viabilidad.
La temperatura tiene, también, una OR significativa (no contiene el 1 el intervalo de confianza del 95%). Al ser menor que 1 significa que al aumentar la humedad disminuye la probabilidad de que se dé viabilidad.
La densidad del sotobosque no tiene una relación significativa con la viabilidad. El IC del 95% del a OR contiene al 1.
3.
La primera componente tiene un enorme peso (79,1%). Los valores absolutos de los coeficientes altos son los de las variables Crecimiento, Humedad, Inclinación y Temperatura. Sin embargo, en la primer componente no pesa la variable Densidad del sotobosque. Tengamos en cuenta que el crecimiento tiene una relación obvia con la viabilidad. Los ejemplares viables deben tener un crecimiento medio alto y las no viables un crecimiento medio bajo. Los signos de los coeficientes (positivos Crecimiento y Humedad y negativos Inclinación y Temperatura) están en perfecta correspondencia con el hecho visto en la Regresión logística: Humedad alta aumenta la viabilidad e Inclinación y Temperatura alta la disminuye. La Densidad del sotobosque no tiene relación con la viabilidad en la Regresión logística y tampoco pesa en esa primera componente.
Luego, es la primera componente la que realmente nos informa bien sobre la viabilidad. Y los puntos que estarán más a la izquierda del gráfico, los que tienen un valor más bajo de esa primera componente son los que deben ser los ejemplares no viables.