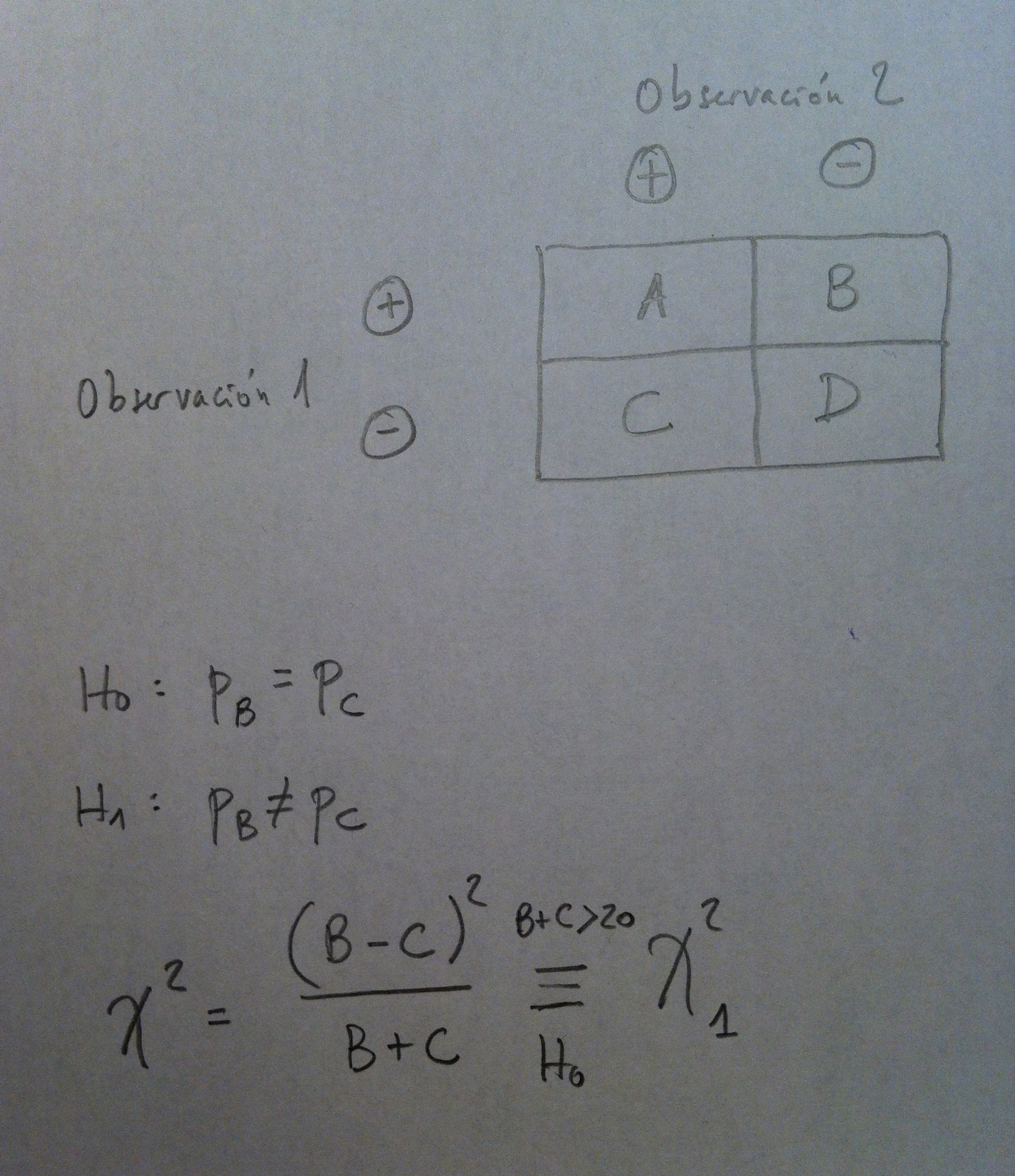
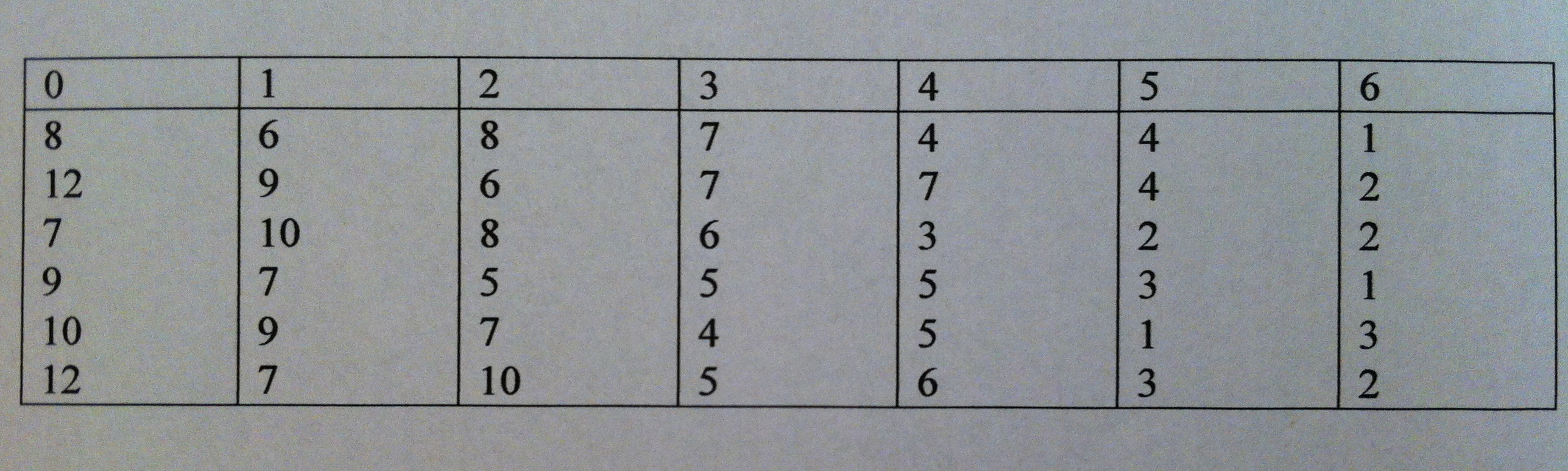
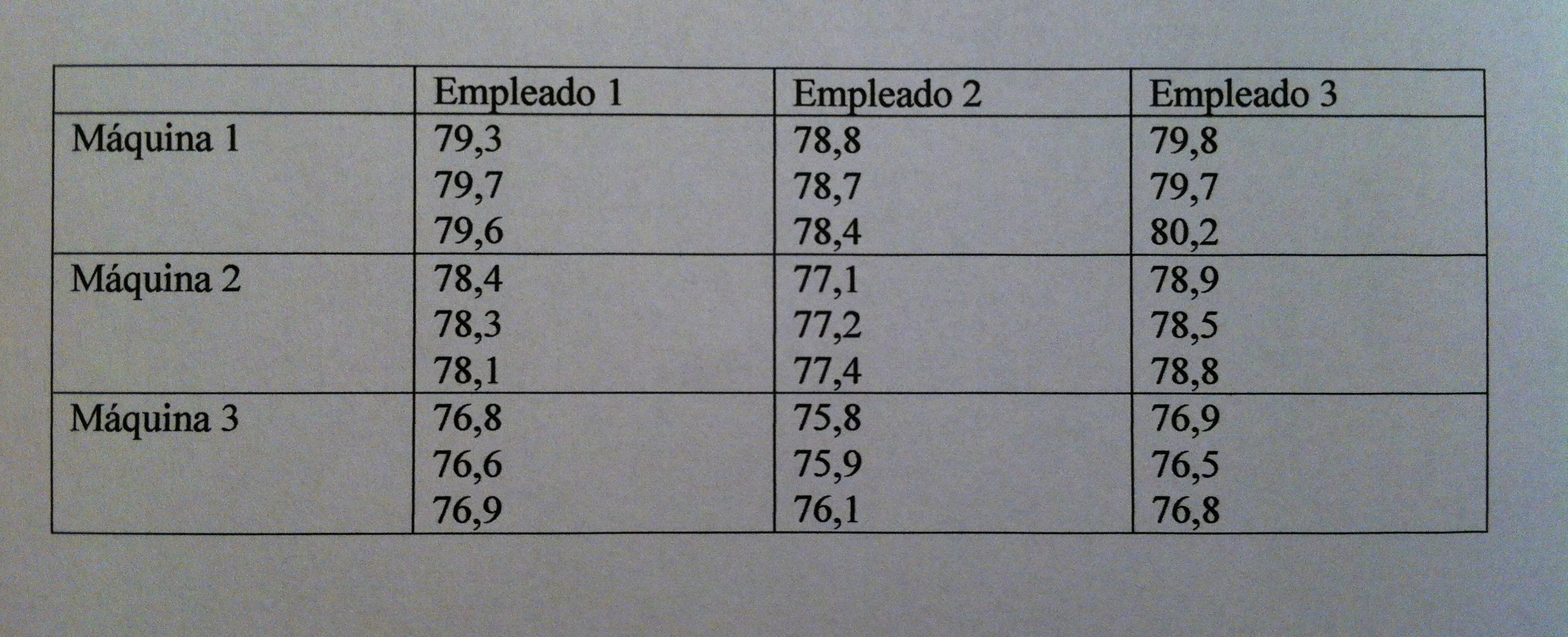
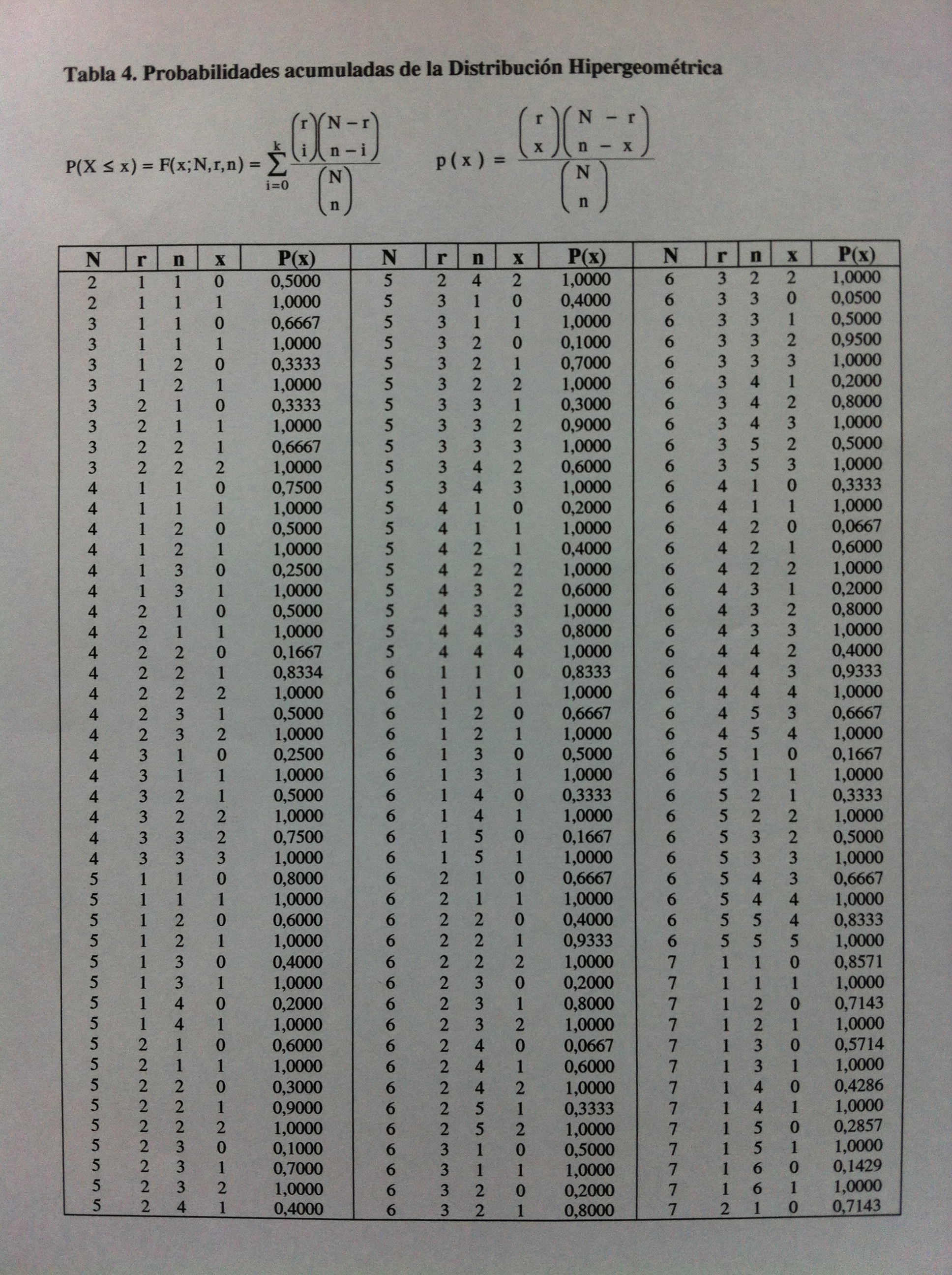
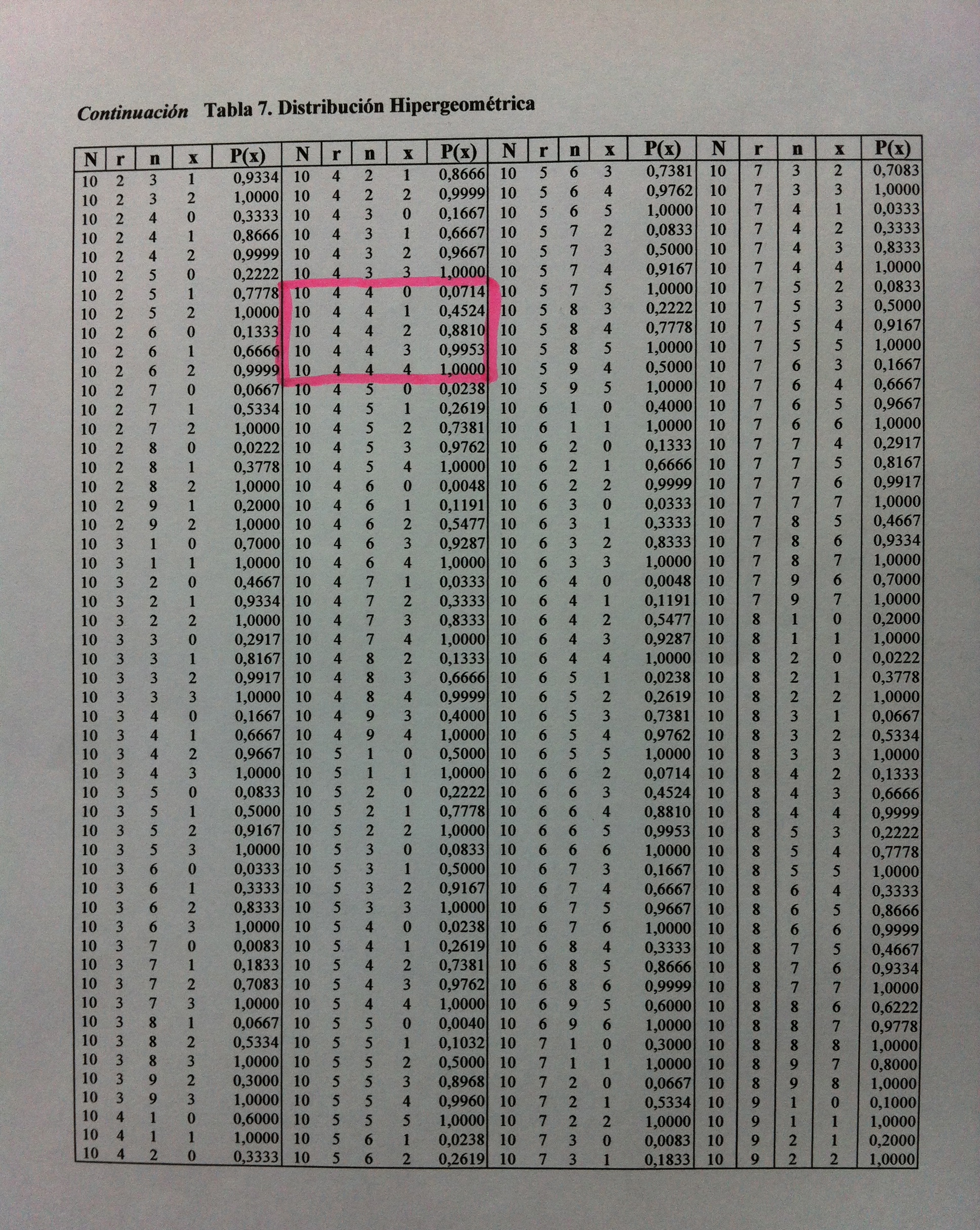
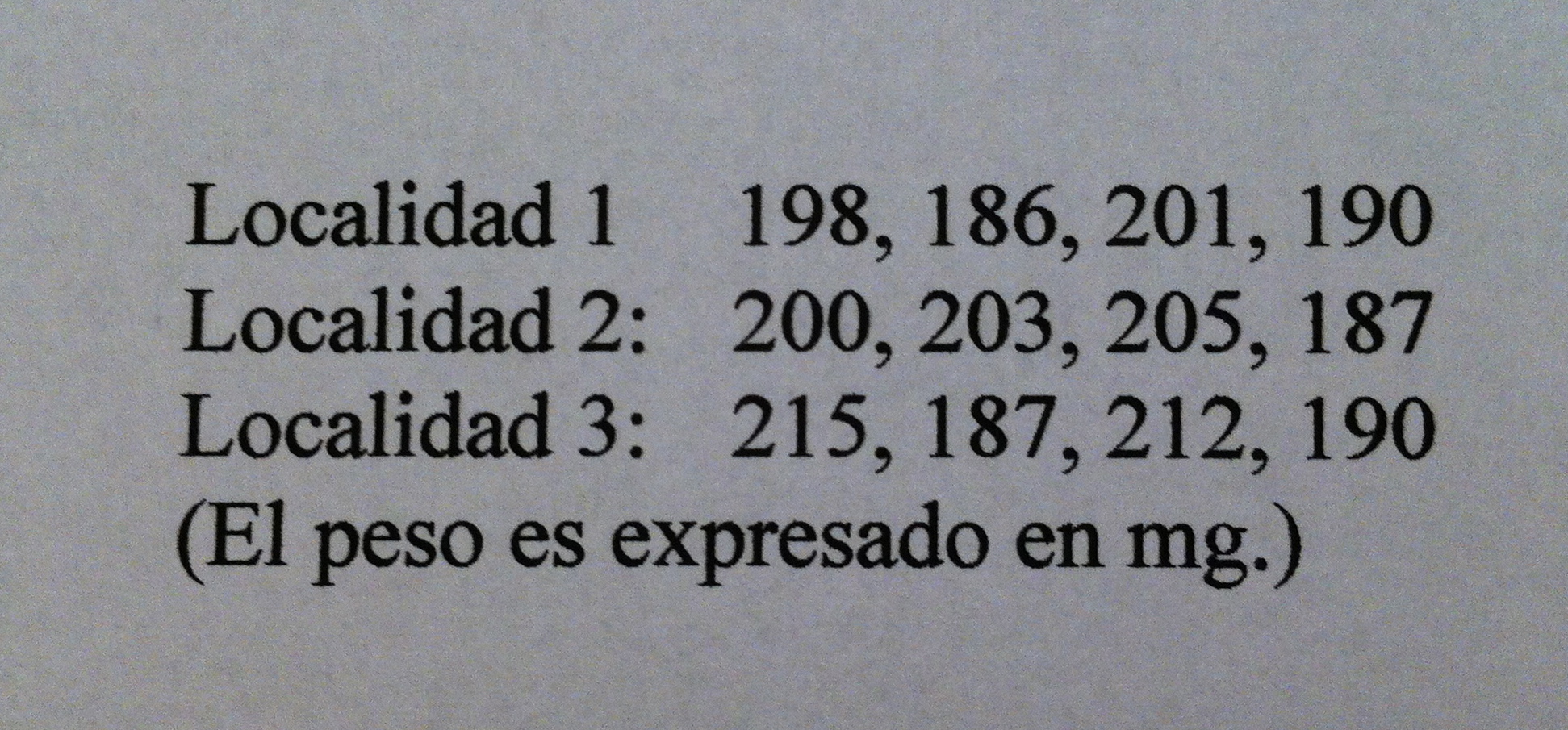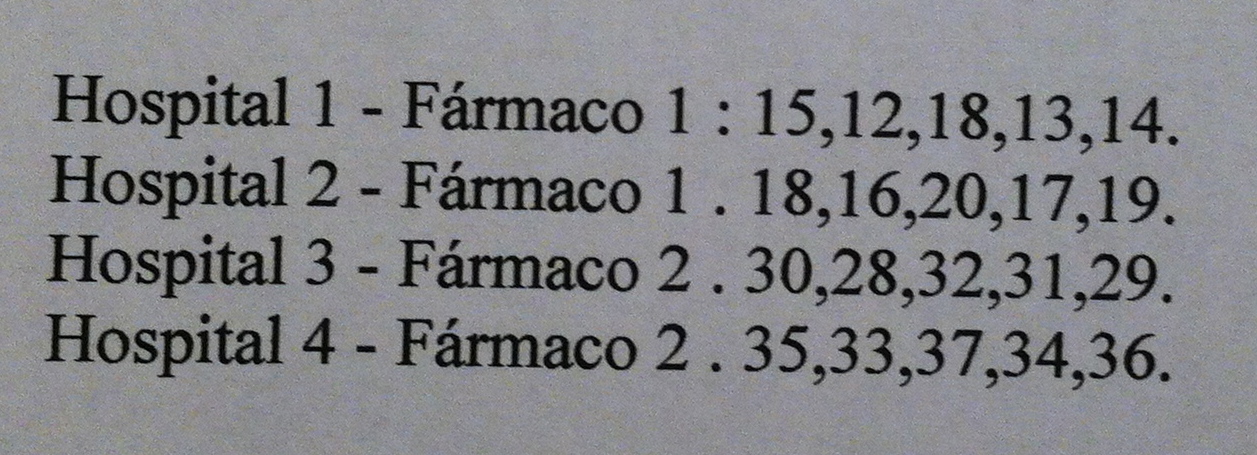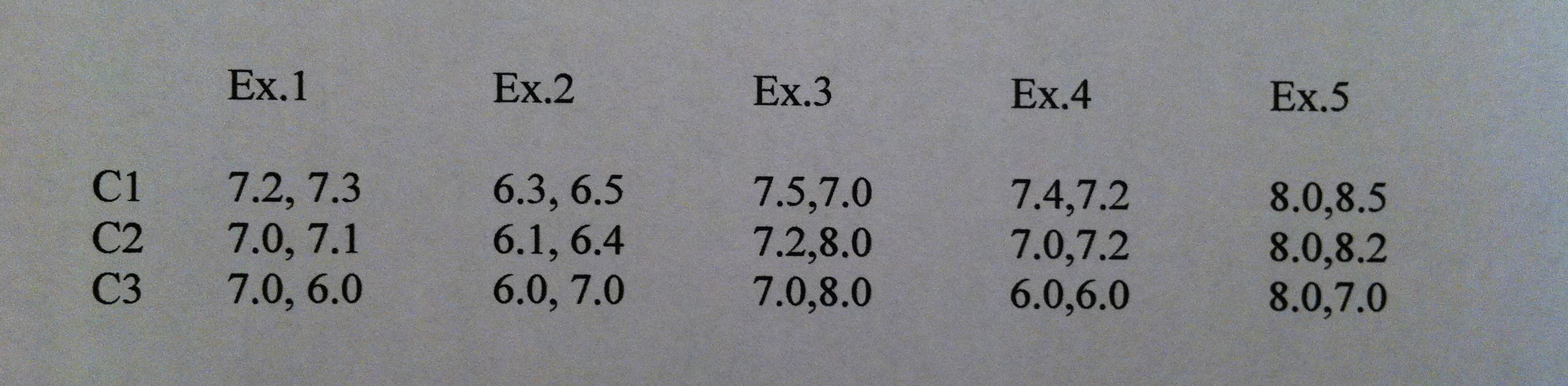Explicaciones:
1. Una correlación incluso tan grande como 0.9 podría no ser significativa si el tamaño de muestra fuera muy pequeño. El Error estándar es una desviación estándar. Es la desviación estándar de una predicción. Y la Odds ratio es una medida de la relación entre dos variables cualitativas o entre una cualitativa y una cuantitativa.
2. Una Odds ratio nunca es menor que cero. La pendiente de una recta de regresión puede ser, evidentemente, positiva o negativa. Si el intervalo de confianza del 95% de una Odds ratio contiene al 1 se trata, entonces de una Odds ratio no significativa. Y una Odds ratio de 1 indica una no relación entre la variables que estemos relacionando.
3.El Kappa es un índice para evaluar el grado de concordancia entre dos observadores, no es una media del grado de relación entre variables cuantitativas. Si la r es significativa y positiva va asociada a una pendiente positiva, nunca a una pendiente negativa.Una r singnificativa puede ir asociada tanto a una pendiente positiva como negativa. Si un intervalo de confianza del 95% de la pendiente de una Regresión lineal simple no contiene al 0, como ocurre en el intervalo (0.5, 1.9) indica que la pendiente es significativa y si tenemos una pendiente significativa es porque tenemos una correlación r significativa.
4. El área desde -7 a -1 la podemos desglosar en dos zonas: Desde -7 hasta -3 se trata de la Media más menos 2 DE, que es 68.5. A esto hay que sumar el área que hay desde -3 hasta -1 que es 0.1575-0.025=0.1325, porque a la derecha de -3 el área es 0.1575 pero hay que restarle el área que hay a la derecha de -1, que es 0.025. Al final si sumamos 0.685 y 0.1325 tenemos un área de 0.8175, que con tres decimales es 0.817.
5.El Error estándar es 5/raiz(25) que es 1. Entonces la media más menos dos Errores estándar da el intervalo (48, 52).
6. Si se revisa el Tema que introduce a las técnicas de comparación queda claro que cuanta mayor dispersión tengamos en un estudio más dificultad tendremos para detectar diferencias. En cambio, con un mayor tamaño y con mayor diferencia entre las medias muestrales más posibilidades tendremos de detectar diferencias.
7. Si nuestro p-valor es igual a 0.0001 rechazamos la Hipótesis nula, no la aceptamos. La pregunta especifica que este p-valor es de un contraste cualquiera, ello no implica que no haya normalidad. Únicamente indicaría eso si el contraste fuera sobre la normalidad, pero no en general. Y ese valor de 0.001 no indica la probabilidad de equivocarnos al aceptar la Hipótesis alternativa. La probabilidad de equivocarnos aceptando la Hipótesis alternativa queda concretada por el nivel de significación elegido, para el contraste, inicialmente, antes de empezar el estudio, por ejemplo: 0.05. El p-valor nos sirve únicamente par ver si estamos por encima o por debajo de ese nivel de significación, no es una probabilidad de error. Si el contraste es sobre la Odds ratio y el p-valor es 0.0001 efectivamente rechazaremos la Hipótesis nula de que la Odds ratio poblacional es 1.
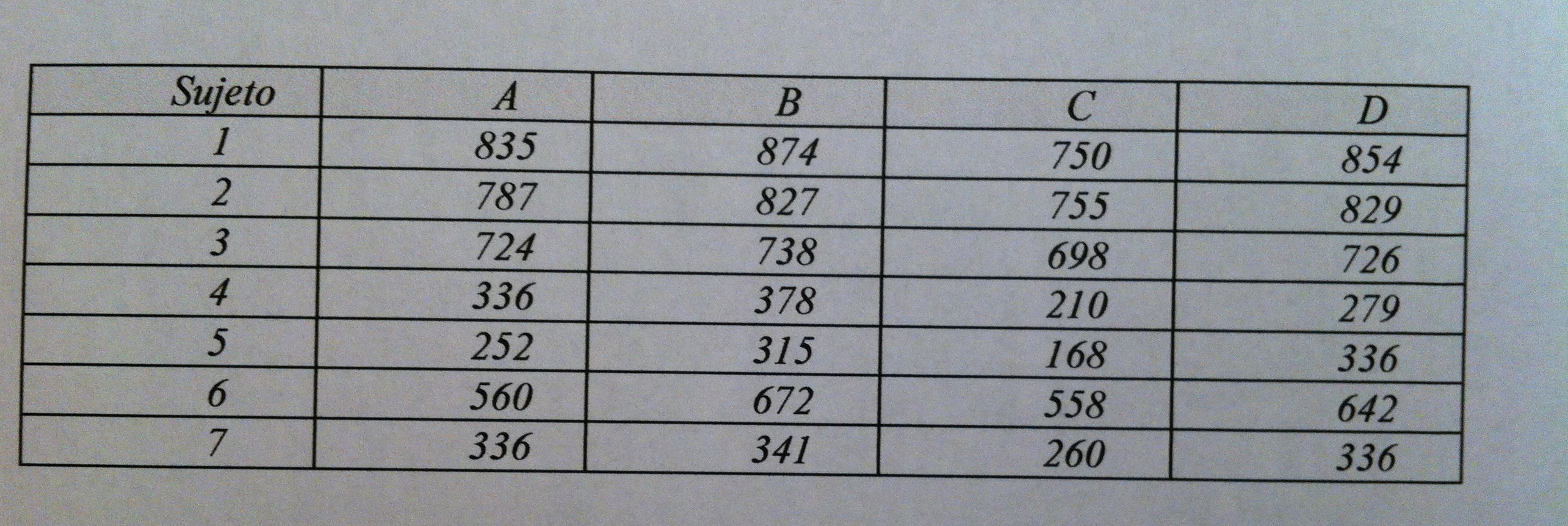
8.Si son variables continuas, como sucede en nuestro caso, si son muestras independientes, como evidentemente sucede también en nuestro caso y una de las dos muestras no es normal hay que hacer un Test de Mann-Withney para comparar dos poblaciones.
9.Si tenemos muestras, en Estadística, nunca podemos asegurar que una es mayor que otra, siempre hay una probabilidad de error, pero es que menos en nuestro caso donde no tenemos una diferencia significativa. La diferencia no es significativa, por lo tanto, nada de decir que la media B es mayor que la de A. Tampoco podemos decir que la media de B sea superior a la de A pero que nos falta tamaño muestral para confirmarlo. Falta tamaño muestral pero no para confirmar nada, sino para ver cuál es mayor porque en este momento no podemos decir nada. La afirmación correcta es decir que prácticamente seguro que serán diferentes pero con la información de que disponemos todavía no podemos decir cuál es mayor a nivel poblacional, porque la diferencia que vemos ahora es muestral y no es una diferencia significativa, como marca este p-valor de 0.45.
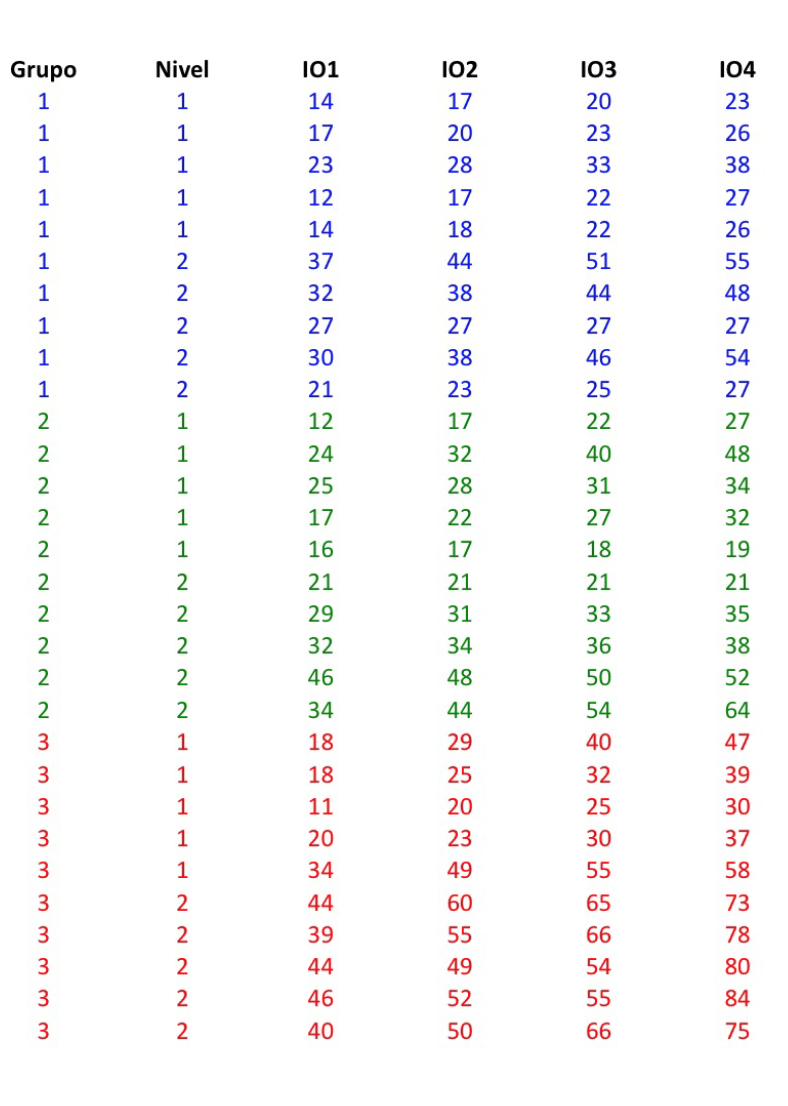
10. Un valor muestral y un valor poblacional tienen digamos naturaleza completamente distinta. El muestral es cambiante, cambia según la muestra, el poblacional es fijo, es un valor desconocido pero fijo. Es verdad que una mediana muestral se aproxima bien a la mediana poblacional si la variable estudiada sigue la distribución normal, y en general de hecho, pero esto no quiere decir que sean iguales. La normalidad de una variable significa que la mediana de una muestra sea igual a la mediana de la población. Si fuera así la Estadística sería infalible, claro. Tampoco se cumple si la media muestral es la media del primer y tercer cuartil.