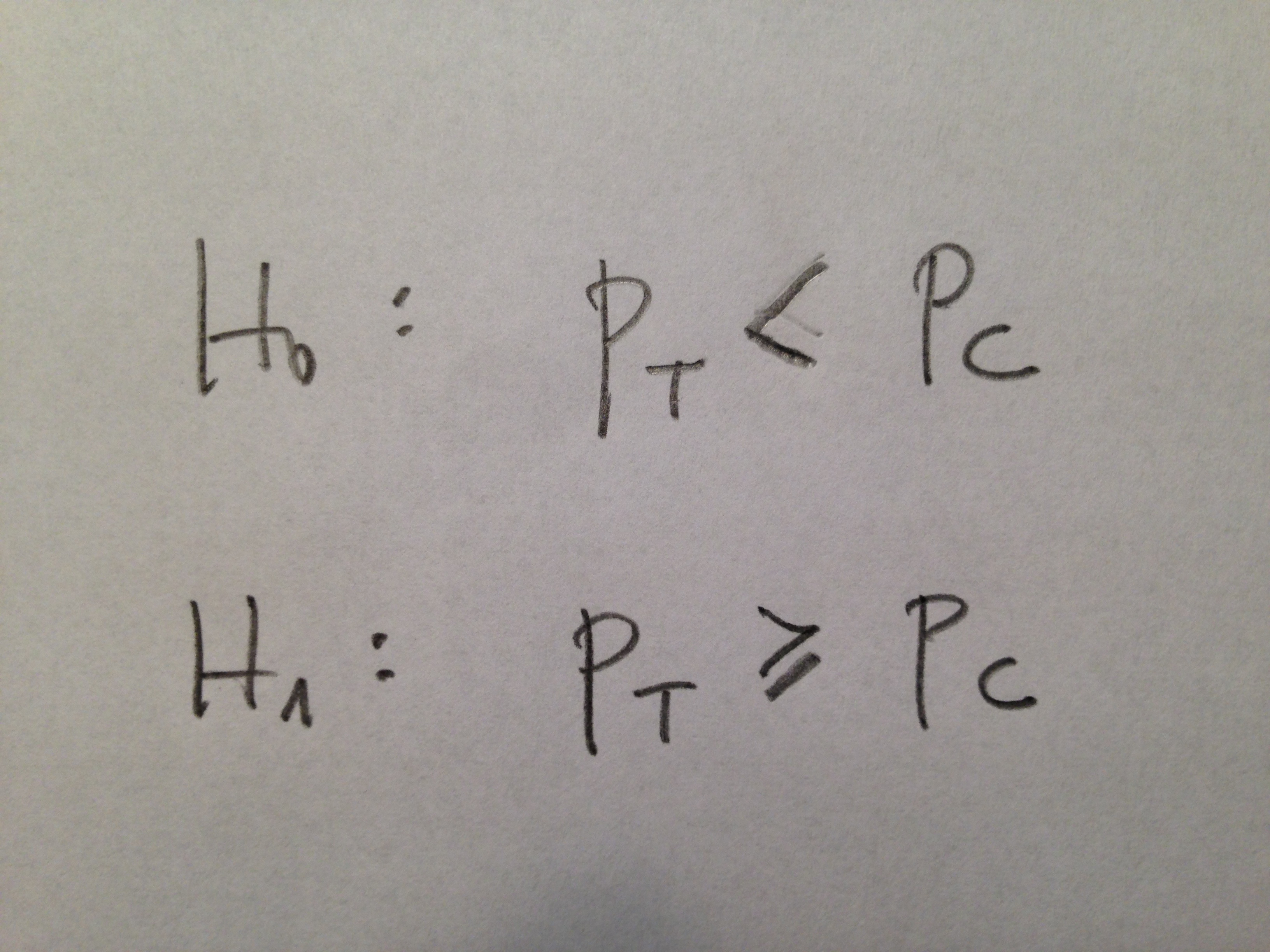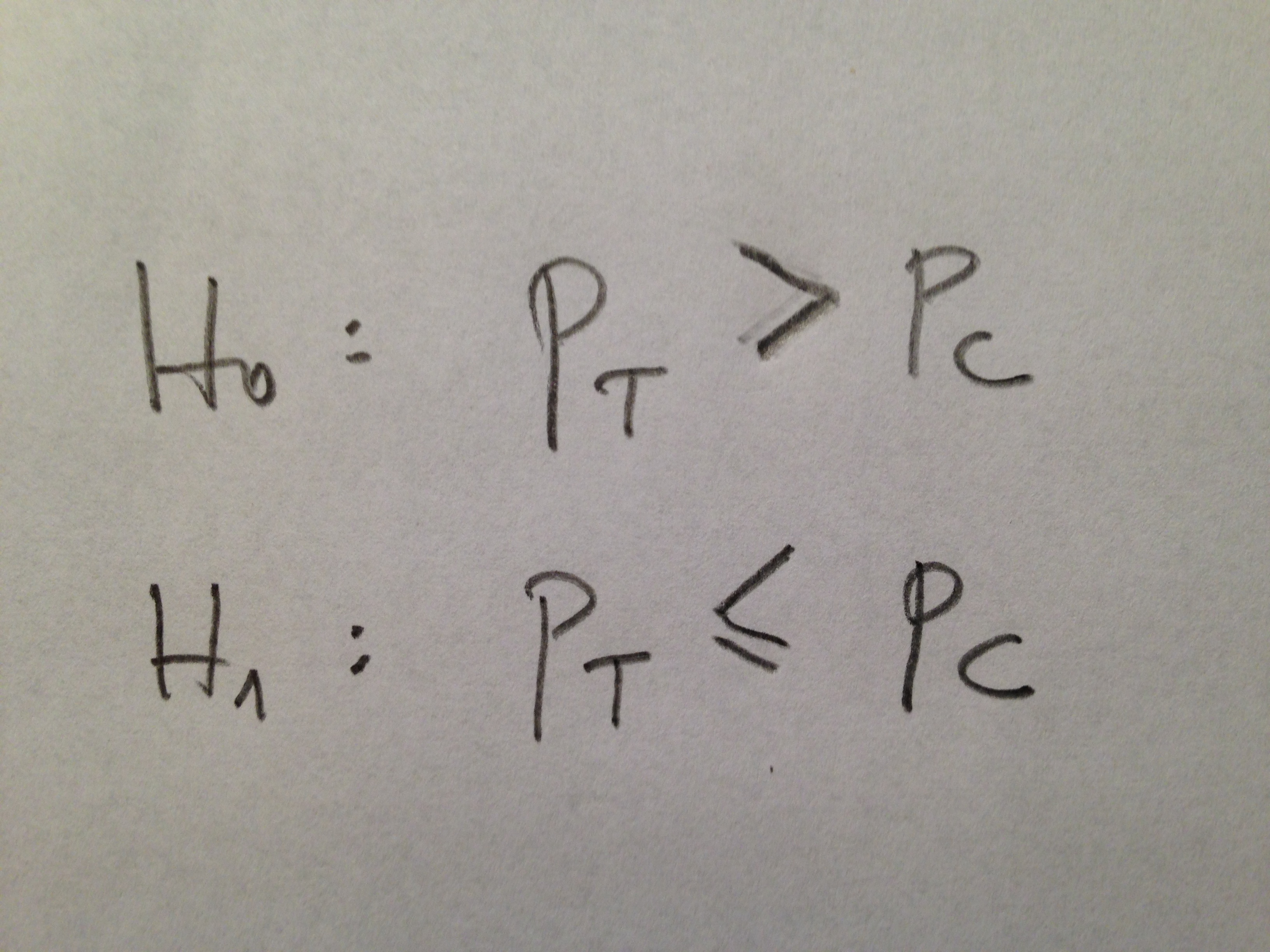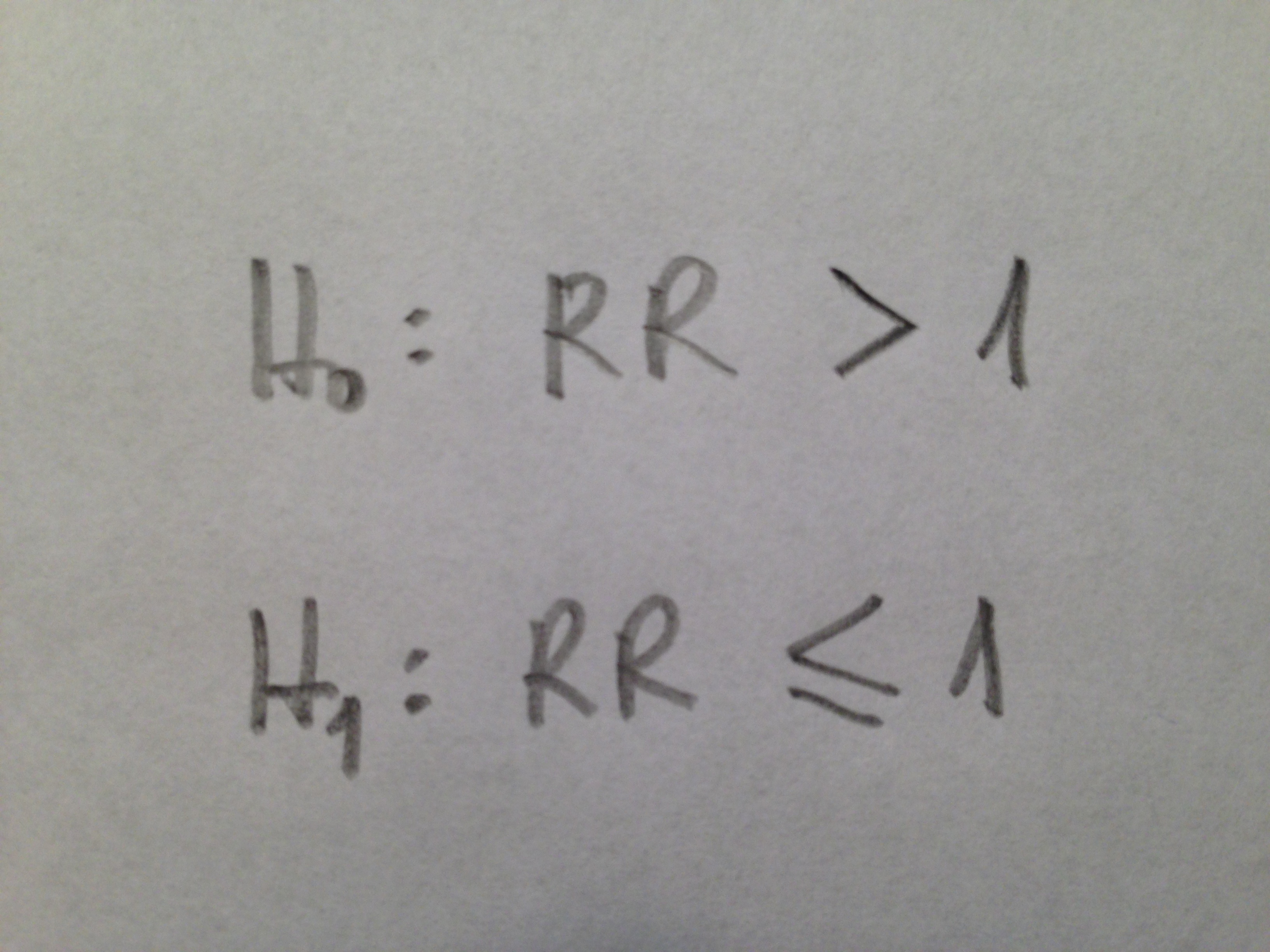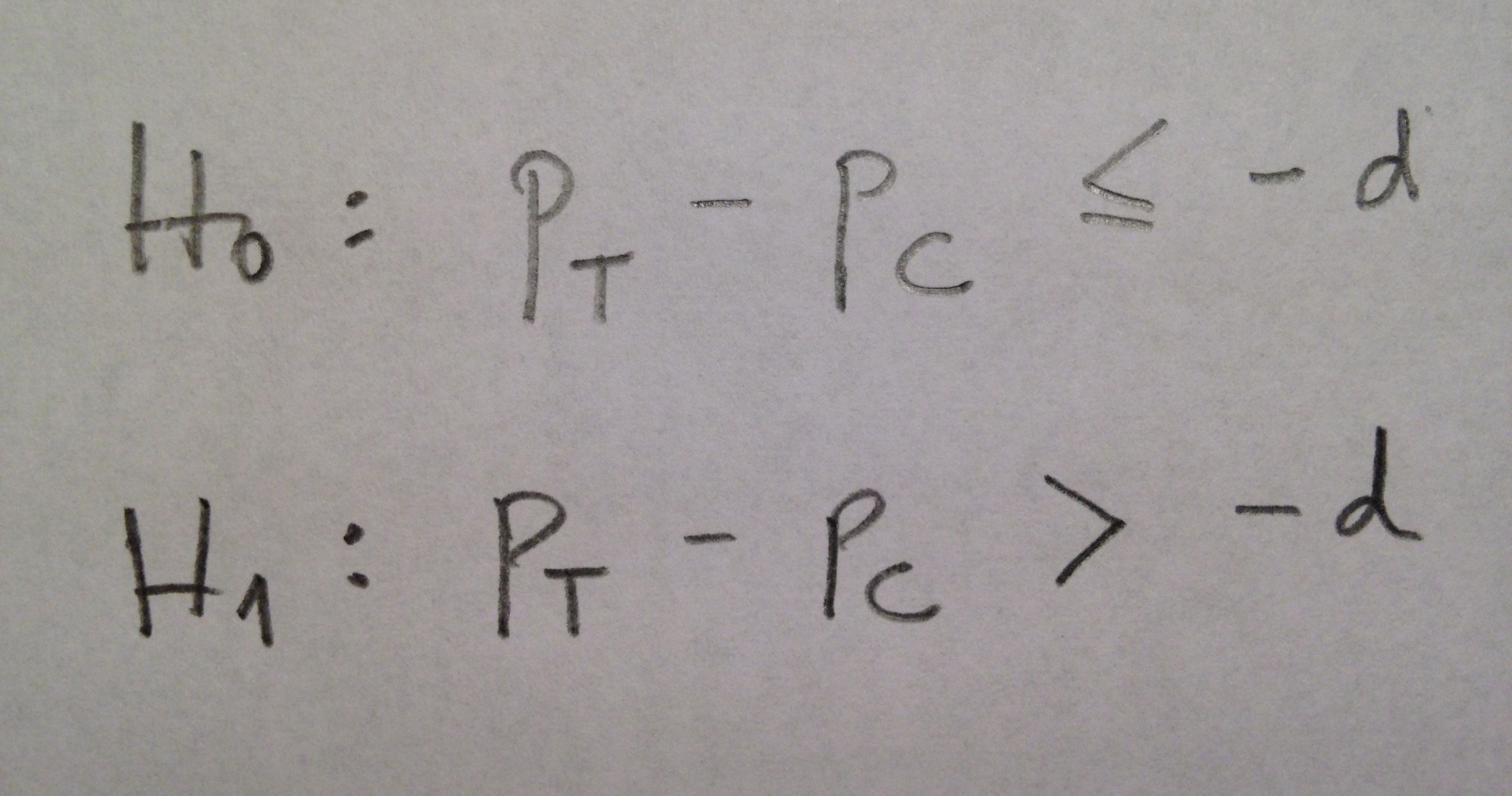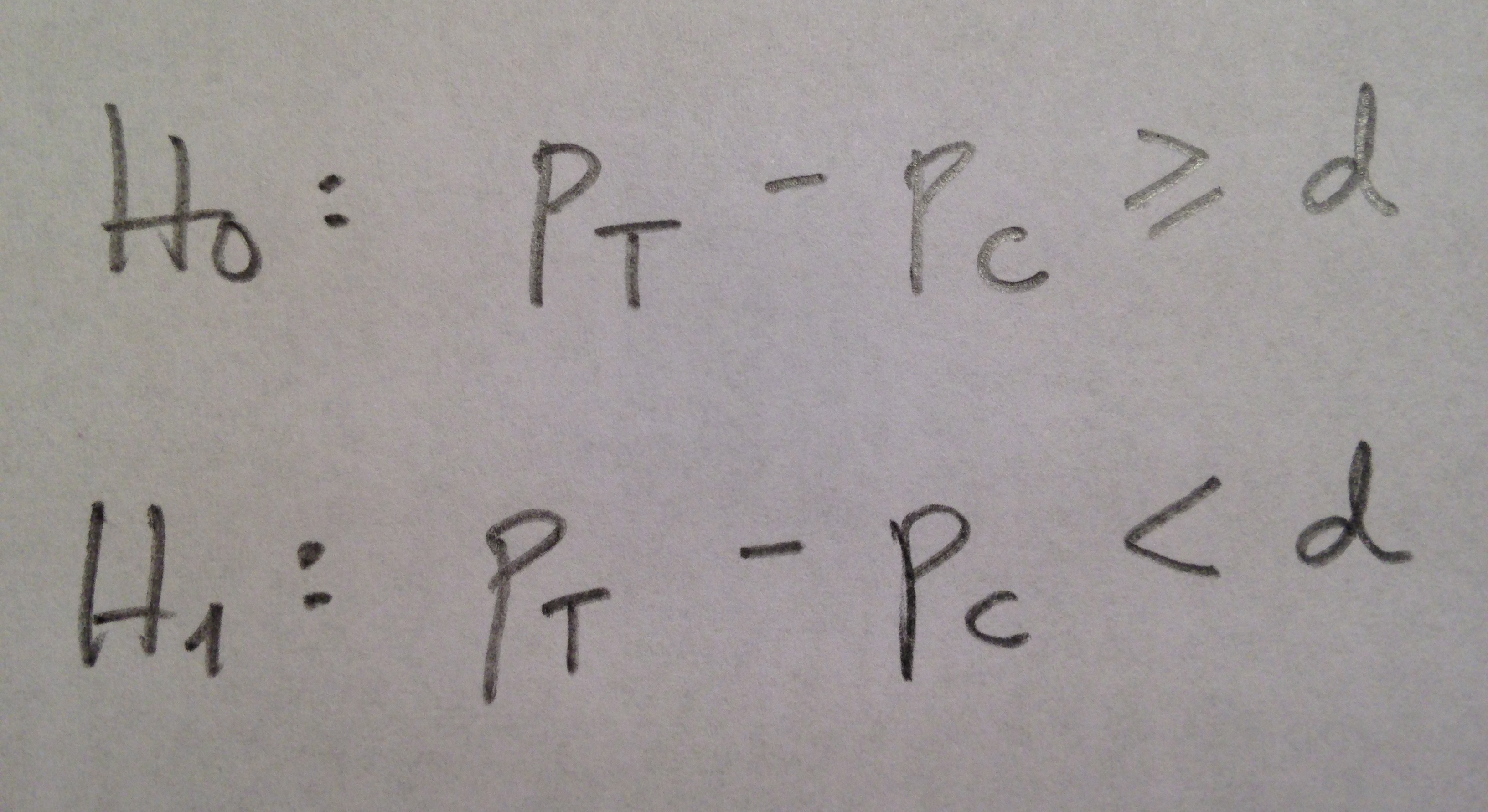La Estadística descriptiva está casi siempre presente en los artículos de las revistas de Medicina. Es interesante y conveniente destacar cuáles son los contextos de esos artículos en los que más abunda ese tipo de aproximación estadística a una muestra y cuáles son los cálculos más habituales de uso y cuál es la forma de presentación mayoritaria.
Fundamentalmente son tres los contextos en los que es más habitual el uso de la Estadística descriptiva en estos artículos. Veamos uno por uno, con ejemplos concretos tomados de revistas médicas, cuáles son esos tres contextos mayoritarios.
1. En todos los estudios donde se pretende abordar el seguimiento de una serie de personas que se han dividido en diferentes grupos que van a ser tratados de formas distintas (por ejemplo: en un ensayo clínico), se hace una Estadística descriptiva de las características más relevantes para el estudio que tiene cada uno de esos grupos, en el punto de partida. Con la finalidad básica de mostrar que para esas variables no hay diferencias destacables. Para comprobar, en definitiva, una homogeneidad entre los grupos.
Veamos algunos ejemplos:
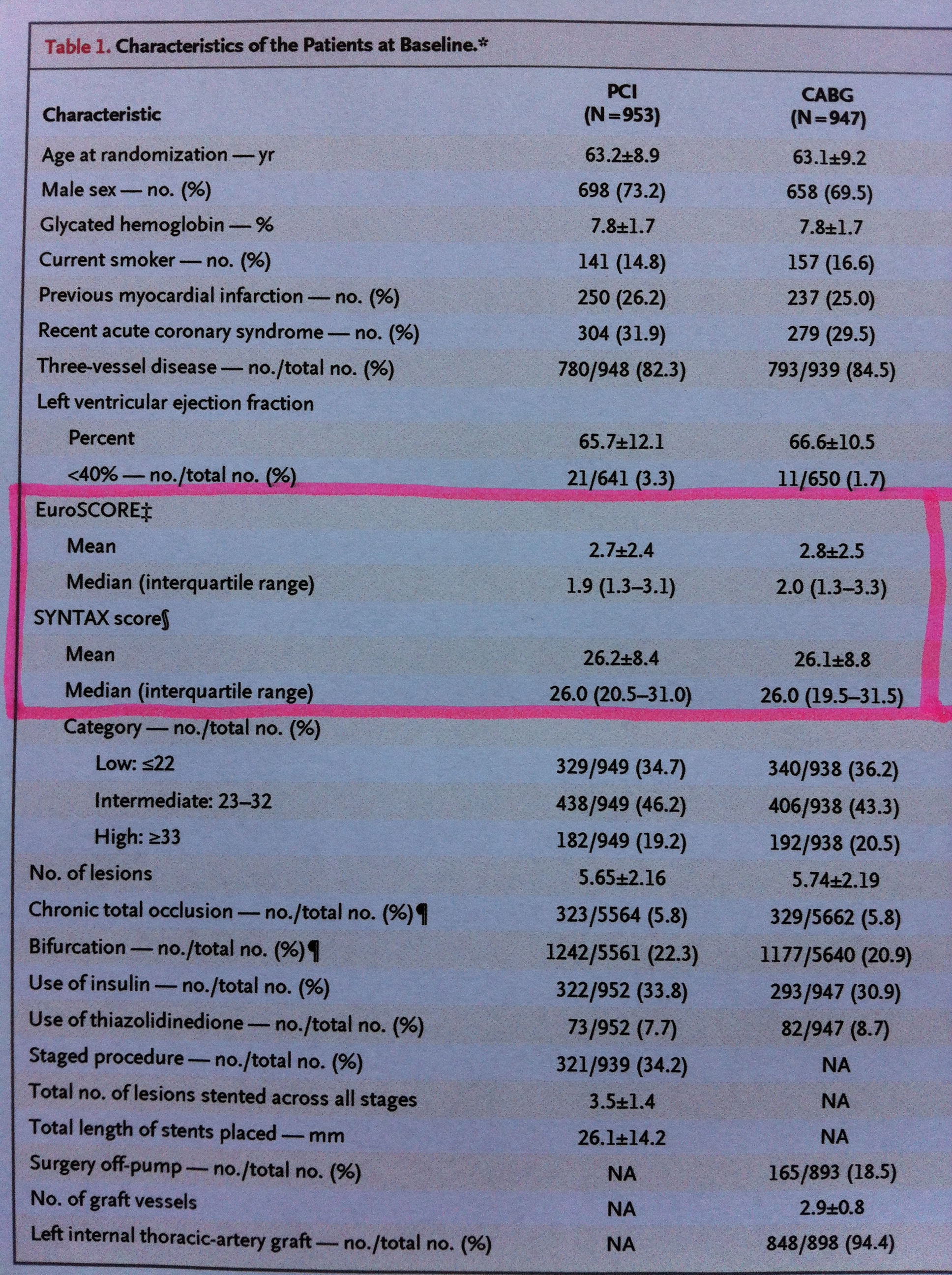
En la primera tabla consta la descripción de los grupos de pacientes a los que se les aplicaron cada uno de los dos tratamientos comparados para reparar problemas de obstrucción a nivel de arterias coronarias: el sistema percutáneo (Percutaneous coronar y intervention (PCI)) y el bypass (Coronary-artery bypass grafting (CABG)):

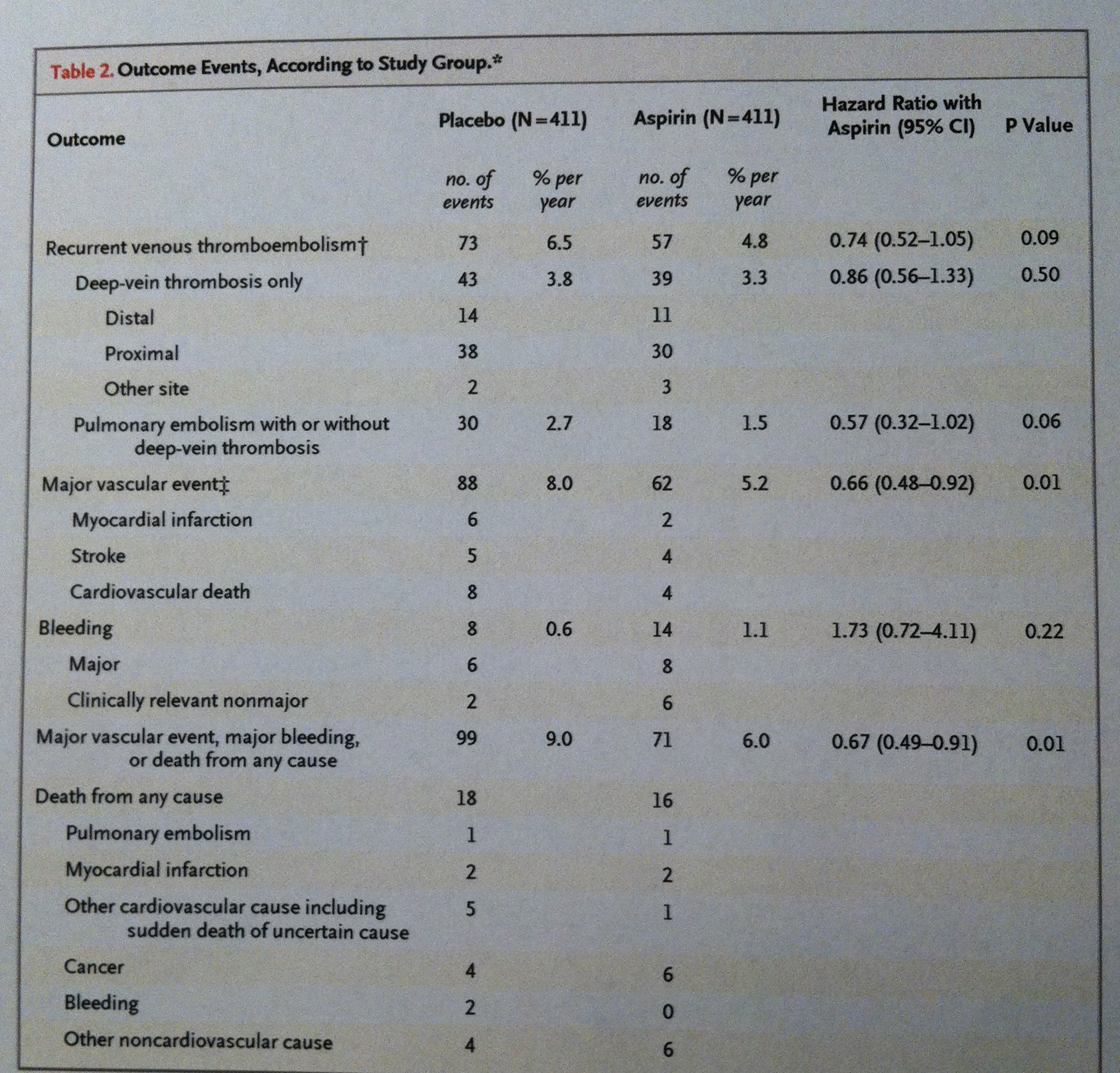
En la siguiente tabla consta la Estadística descriptiva de los dos grupos de pacientes estudiados para comparar el efecto de la aspirina, a pequeñas dosis diarias, en la prevención de problemas tromboembólicos:

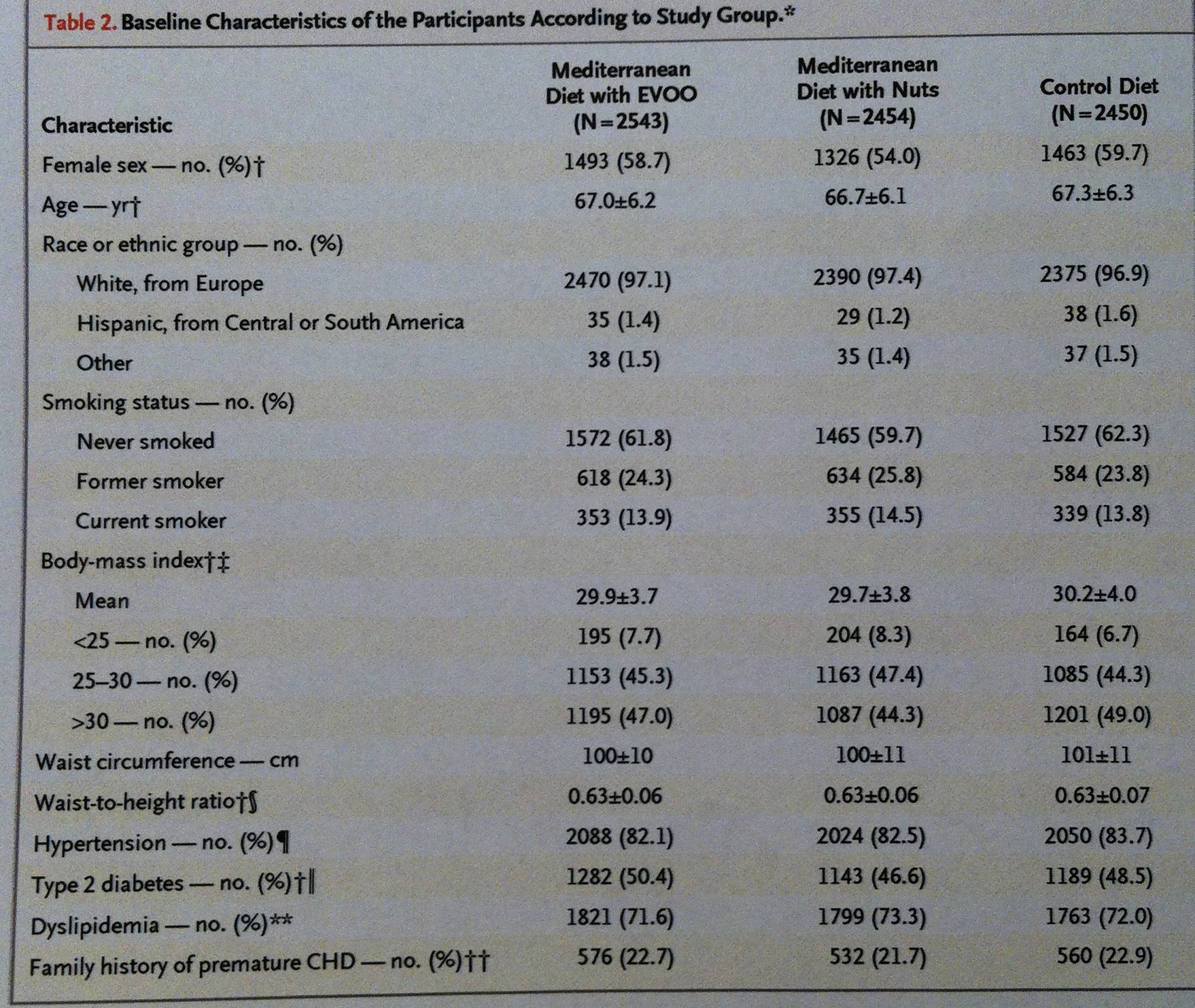
En la siguiente tabla consta la Estadística descriptiva de los tres grupos experimentales de un interesante estudio donde se pretendía valorar la eficacia de la dieta mediterránea en la prevención de enfermedades cardiovasculares. Los dos primeros grupos seguían una dieta establecida con el añadido de aceite de oliva virgen (Extra-virgin olive oil (EVOO)) o de nueces. El tercero seguía una dieta control estándar:

2. Cuando los grupos descritos comentados en el apartado anterior, en su punto de partida, al inicio del experimento, han sido sometidos cada uno de ellos a un distinto tratamiento se usa de nuevo la Estadística descriptiva para cuantificar variables resultado, variables que detecten problemas. Ahora se busca la diferencia, se busca si en algún grupo hay menos casos de alguna patología que en otro, etc.
Veamos ejemplos:
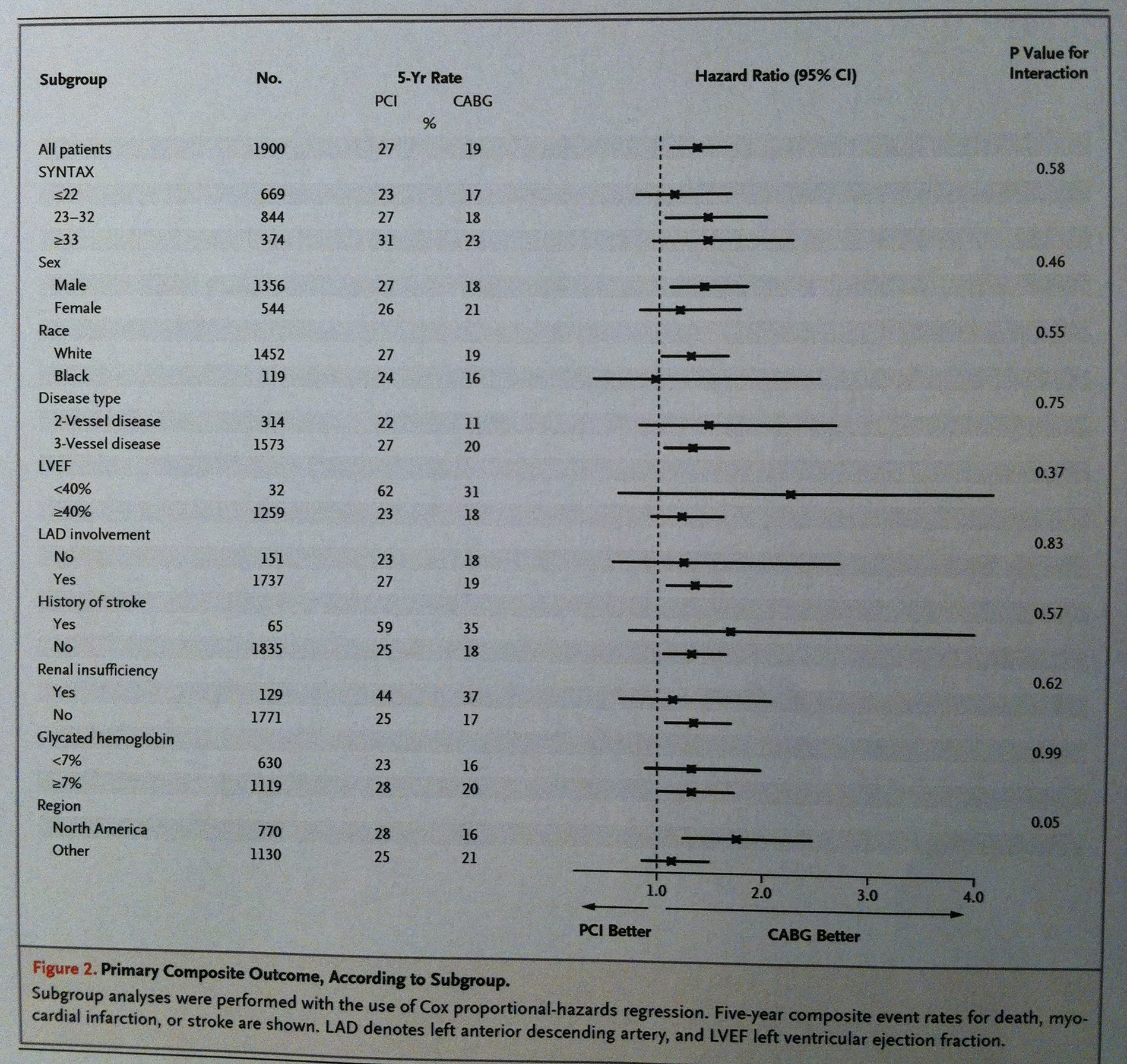
En la primera tabla constan los resultados de la comparación de los dos grupos que antes hemos visto del estudio comparativo de la reparación percutánea o mediante bypass de problemas de obstrucción coronaria:

En la siguiente constan los resultados de los grupos donde se estudiaba el efecto protector de la aspirina a dosis bajas diarias:

En el caso del estudio del efecto de distintas dietas sobre los problemas cardiovasculares los resultados descriptivos finales son los siguientes:

3. Finalmente, hay un tercer tipo de contexto en el que se suele hacer una Estadística descriptiva. En ocasiones es el propio estudio el que llega a generar una serie de grupos homogéneos, pero ahora se trata de una homogeneidad final, de resultados, no una homogeneidad de partida como en el caso del punto 1. Por ejemplo: Pacientes que acaban siendo diagnosticados de alguna enfermedad o no. Pacientes que acaban muriendo o no, etc. Se trata, entonces, en estos casos, de visualizar descriptores que los caractericen mediante la Estadística descriptiva.
Veamos algún ejemplo:
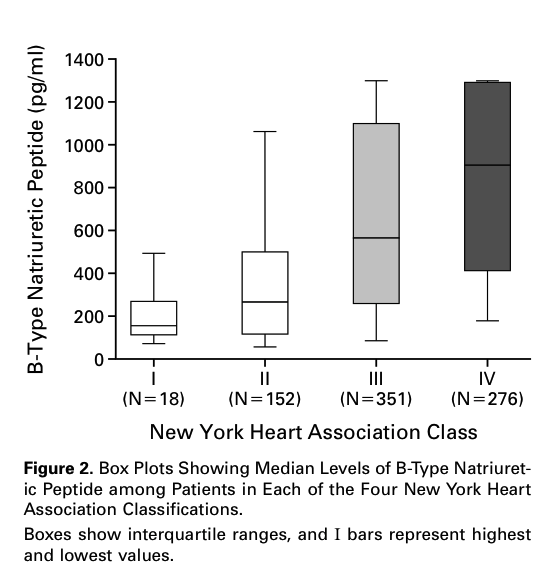
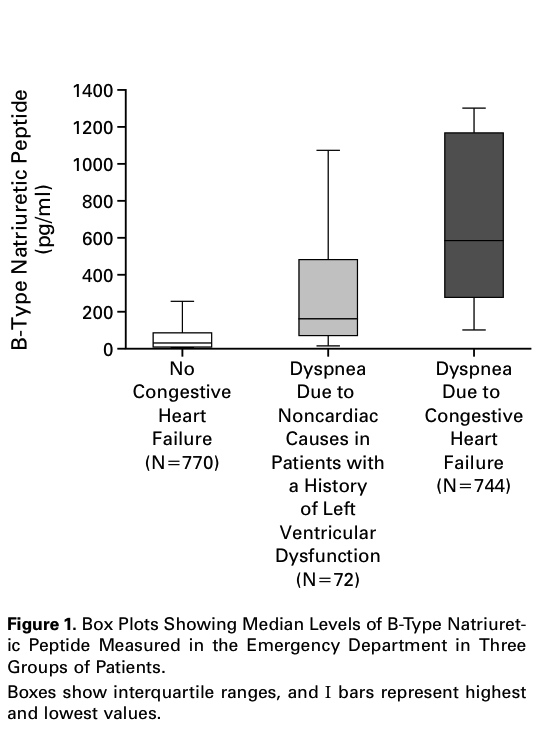
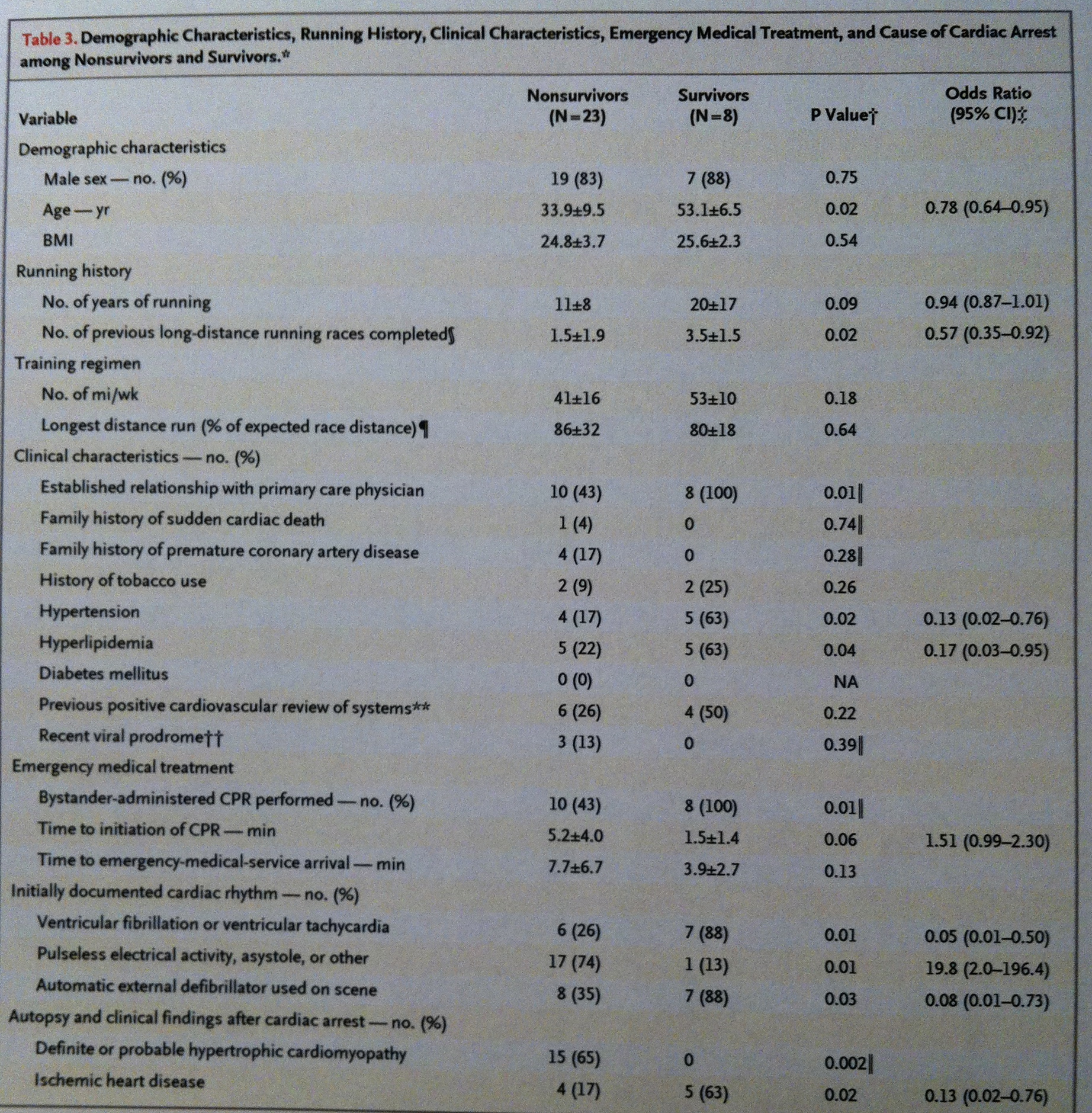
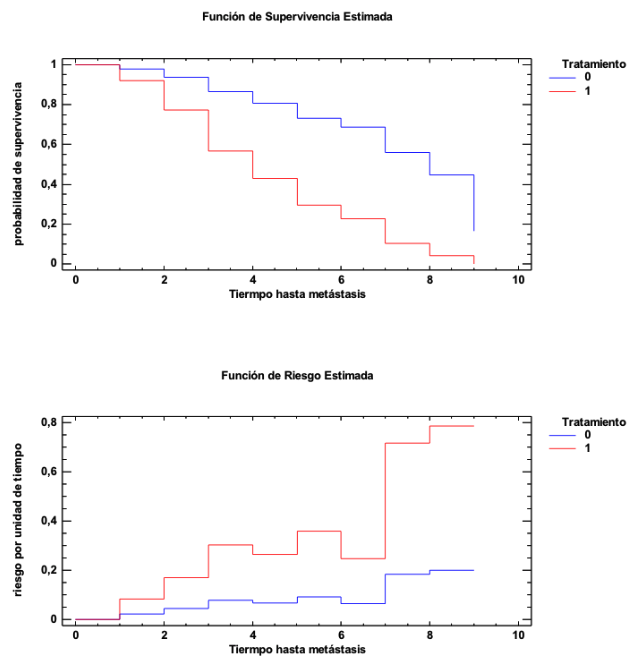
En la siguiente tabla consta la Estadística descriptiva de los datos comparativos entre atletas que no han sobrevivido o que sí han sobrevivido después de haber sufrido un infarto de miocardio en carrera. En este caso la muestra inicial era del registro, en EEUU, desde el año 2000 hasta el 2010, de los casos de infarto de miocardio habidos en marathones o en medias marathones. Pero aquí la focalización está puesta en separar los grupos según el resultado, describirlos y compararlos:

Otro caso de este tipo es el de la siguiente tabla. Se trata de un estudio de infecciones localizadas en marcapasos. Se presenta una Estadística descriptiva separando los que a corto plazo han sobrevivido y los que también a corto plazo han fallecido. De nuevo, pues, una descriptiva separada por grupos según el resultado final:

En cualquiera de estos tres tipos de situaciones, cuando son varios los grupos a los que se les calculan estos valores descriptivos es habitual aplicar alguna técnica inferencial para ver si hay diferencias significativas entre esos grupos. Como puede verse en las tablas adjuntas, es habitual añadir una columna con los respectivos p-valores de cada una de esas comparaciones. Cuando se trata de la descripción de grupos, como hemos visto en el primer tipo de tablas, a los que se les ha sometido a un tratamiento distinto interesa que en las variables descritas a nivel de punto de partida del estudio no se detecten diferencias significativas para comprobar, así, que las condiciones de partida eran equivalentes. Sin embargo, como hemos visto en el segundo tipo de tablas, cuando a estos mismos grupos, después del tratamiento, se comparan variables resultado ahí sí que interesa ver diferencias. Y en el caso del tercer tipo de tablas, como en el segundo, interesa que esas comparaciones muestren diferencias significativas también.
La descripción variable por variable suele hacerse, como se ha visto en las tablas anteriores, en cantidad absoluta y relativa (habitualmente, ésta, en porcentaje) si se trata de una variable cualitativa dicotómica. Si la variable es cuantitativa suele o darse mediante la media±desviación estándar o bien mediante la mediana y el rango intercuartílico, normalmente entre paréntesis. Y ese rango no expresado precisamente como rango sino dando explícitamente los valores del primer y el tercer cuartil, que son los valores cuya resta constituyen, realmente, el rango intercuartílico.
¿Cuándo usar una u otra formulación en una variable cuantitativa? Si el comportamiento de una variable es de distribución normal lo más conveniente es describir aquella variable mediante la media±desviación estándar, porque con estos dos valores lo tenemos todo, porque teniendo estos dos números lo podemos saber todo de la variabilidad de esa variable. Incluso, evidentemente, el propio rango intercuartílico. Si el comportamiento de una variable no es el de una distribución normal es mucho más razonable describirla mediante la mediana y el rango intercuartílico. Porque la tendencia habitual si se tiene la media±desviación estándar es a hacer aquellas típicas inferencias que sólo son ciertas si la variable sigue la distribución normal: M±1DE supone el 68.5% aproximadamente de la población, M±2DE supone el 95% aproximadamente de la población y M±3DE supone el 99.5% aproximadamente de la población. Esto si la variables no es normal no es cierto. Para evitar esta inferencia inconsciente, muy habitual por desgracia, es mejor trabajar, evidentemente, con la mediana y el rango intercuartílico que son medidas que digamos están más próximas a la descripción propiamente dicha y no tienen tantas connotaciones inferenciales como las tienen la media y la desviación estándar.
No es un problema, como suele pensarse en ocasiones, de tamaño de muestra. Hay una creencia establecida, por parte de muchos usuarios de la Estadística, que si una muestra es pequeña deben usarse descriptores tipo mediana y percentiles y si la muestra es grande puede usarse y debe usarse la media y la desviación estándar. Esto no es así. El uso de unos u otros descriptores no depende del tamaño muestral, depende de la normalidad de la muestra, de su ajuste a la campana de Gauss.
Si la muestra sigue la distribución normal (sea el tamaño de muestra grande o pequeño) al describir la muestra en términos de media±desviación estándar se está dando, también, implícitamente, una aproximación muy buena de la mediana y del rango intercuartílico de esa muestra.
Si repasamos la forma de trabajar la tabla de la normal N(0, 1), en el artículo “La Distribución normal” del apartado de Complementos, podemos ver que si la distribución es normal calcular la media±0.68*desviación estándar nos da un valor muy similar al de mediana y rango intercuartílico. O sea, en una distribución normal cualquiera la media±0.68*desviación estándar construye un intervalo del 50% de valores poblacionales.
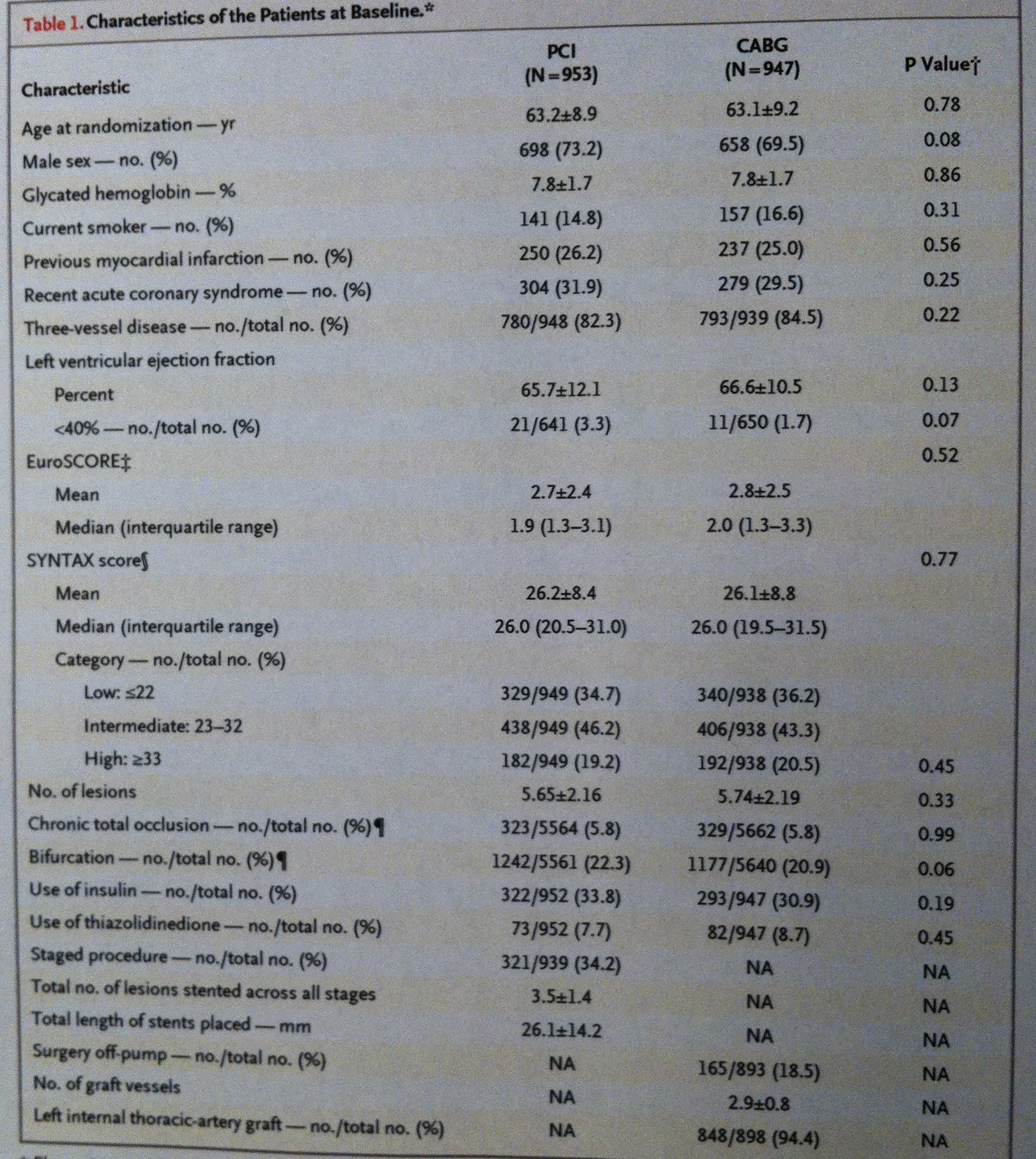
Observemos esto que digo en la tabla descriptiva siguiente, que es una de las que hemos visto antes, pero focalizando en un sector más pequeño de ella, en el sector remarcado en rojo:

Si se observa la variable SYNTAX score podemos ver que, curiosamente, porque no es habitual que sea así, la información se da en las dos formas. Aprovechémonos de ello para compararlas. Observemos que en los pacientes tratados con el sistema PCI la media y la desviación estándar se nos muestra mediante la expresión: 26.2±8.4. Si cogemos esta Desviación estándar y la multiplicamos por 0.68 tenemos un valor de 5.7 lo que nos da un intervalo de valores que va de 20.5 a 31.9. Observemos la similitud con el valor de rango intercuartílico en la muestra: (20.5-31.0). Como puede apreciarse se trata de dos intervalos muy similares el calculado basándonos en la información de la desviación estándar y el calculado basándonos exclusivamente en la muestra. También la mediana y la media son muy similares: 26.0 y 26.2, respectivamente. Esto es porque la variable debe tener una distribución muy bien ajustada a una normal.
Lo mismo sucede con los tratados con el sistema CABG donde la media es 26.1±8.8. Si cogemos de nuevo, ahora, esta Desviación estándar y la multiplicamos por 0.68 tenemos un valor de 5.98 lo que nos da un intervalo de valores que va de 20.12 a 32.08. Observemos también ahora la similitud con el valor de rango intercuartílico de la muestra: (19.5-31.5). Como puede apreciarse se trata también ahora de dos intervalos muy similares. También la mediana y la media son muy similares ahora: 26.0 y 26.1, respectivamente.
Si ahora observamos la variable EuroSCORE sucede una cosa completamente contraria. La media y la mediana son bien distintas. Además, si tomamos la media y le sumamos y le restamos 0.68 multiplicado por la desviación estándar, para conseguir un intervalo del 50%, veremos que ahora en absoluto se parece al rango intercuartílico. Cojamos el caso del grupo PCI: 0.68 multiplicado por 2.4 es 1.63. Si sumamos y restamos a 2.7, que es la media construimos una intervalo del 50% que va de 1.07 a 4.33, que es bien distinto al del rango intercuartílico: (1.3-3.1). Es más: observemos que si le restamos a la media dos veces la desviación estándar (2.7- 2×2.4) nos posicionamos en el valor -2.1, un valor negativo. El EuroScore no puede ser menor que cero. Esto indica, claramente, que el EuroScore no sigue la distribución normal. Observemos que la media del grupo PCI (2.7) está próxima al tercer cuartil (3.1). Esto es claramente indicativo de la asimetría de la variable, de la no normalidad. Con el grupo CABG sucede exactamente lo mismo. Por lo tanto, claramente, a partir de la media y la desviación estándar no podemos hacer las inferencias que se suelen hacer habitualmente. En esta situación la desviación estándar no tiene la misma trascendencia como descriptor. Por esto, en estos casos, es más recomendable manejar la mediana y el rango intercuartílico.
Es por lo tanto muy importante saber en qué momentos tiene sentido usar uno u otro sistema descriptivo. Y es muy importante, también, saber usar bien la desviación estándar, saber qué papel juega, saber cuándo puede tener mucho protagonismo y cuándo debe quedar más en un segundo plano.
Resumiendo:
1. Si la variable sigue la distribución normal el cálculo de la media y la desviación estándar es mejor porque además de proporcionarte la información de la dispersión de los valores a distintos niveles te da también la información de la mediana y el rango intercuartílico.
2. Si la variable no se distribuye según una normal es conveniente dar la mediana y el rango intercuartílico. La media y la desviación estándar, en este caso, pueden llevar a inferencias rutinarias peligrosas. De hecho, la desviación estándar es muy buen descriptor pero peligroso. Bien usado perfecto, pero mal usado puede llevar a inferencias muy alejadas de la realidad.