Vamos a plantear un estudio para poder visualizar, a partir de él, el uso de técnicas tan importantes como el ANOVA, el ANCOVA, el ANOVA de medidas repetidas, la Regresión simple y la Regresión múltiple .
Para seguir mejor la teoría de estas técnicas se pueden consultar los siguientes ficheros: Tema 15: ANOVA, Tema 30: Ampliación de ANOVA, Tema 6: Introducción a la REGRESIÓN, Tema 12: Regresión múltiple y otros links de artículos que se van encontrando en el interior de estos temas.
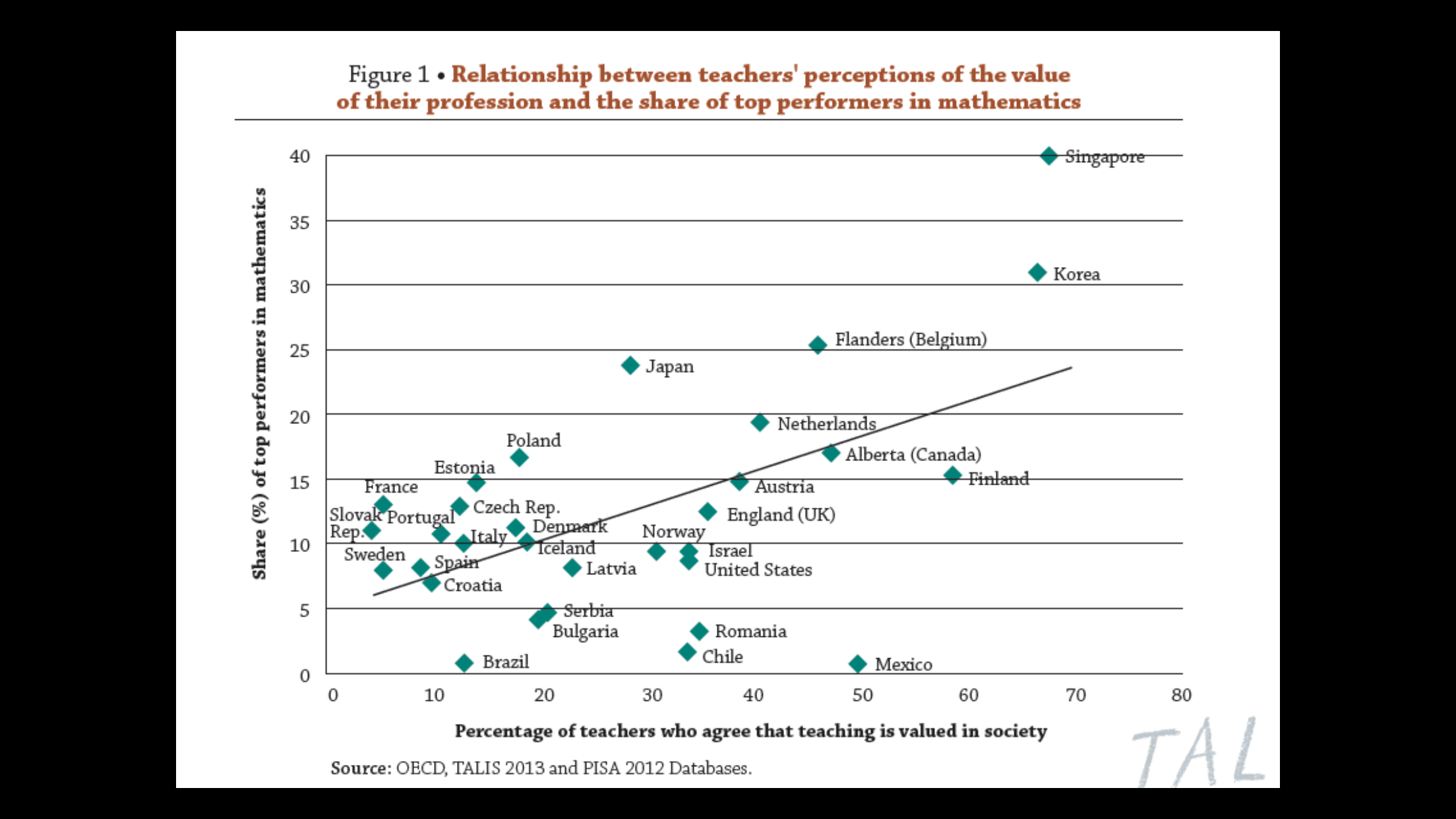
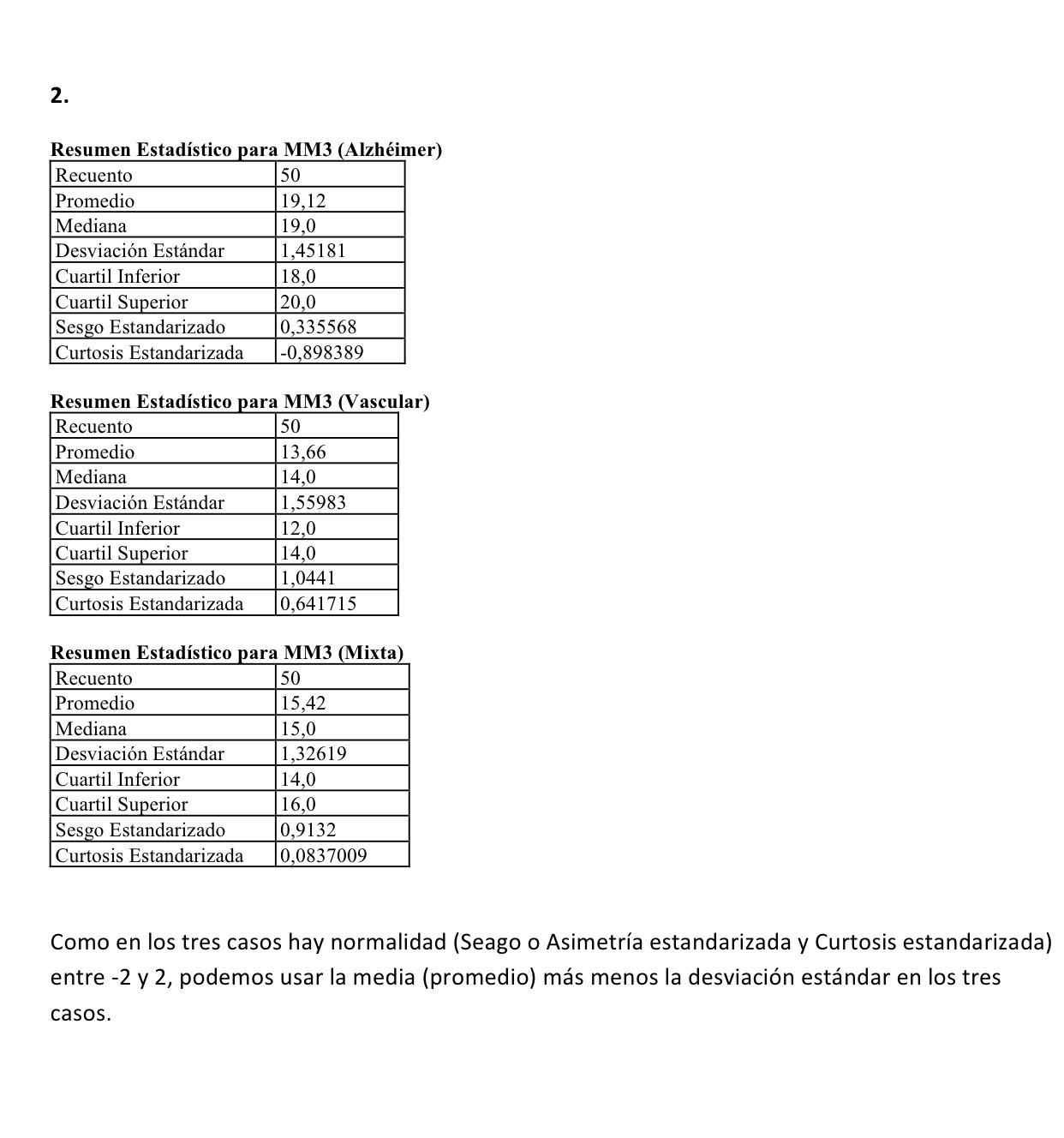
Es interesante ver, a través de ejemplos de este tipo, las peculiaridades de diferentes técnicas. Es la forma de ir delimitando qué podemos hacer con cada una de las diferentes técnicas estadísticas que tenemos a nuestro alcance.
Veamos los datos del estudio que vamos a trabajar:

Tenemos 30 alumnos que al final de sus estudios de primaria y antes de comenzar la ESO se les hace una prueba homologada de nivel de inglés escrito y de nivel de inglés oral. A continuación se distribuyen en tres grupos en un centro de bachillerato donde se va a realizar un experimento didáctico durante toda la ESO. Los primeros 10 (el grupo 1) van a un grupo Control donde realizarán la formación de inglés clásica en una asignatura anual de inglés cada uno de los cuatro cursos. El grupo 2 se integra en un grupo donde se realizan dos horas más semanales de inglés, pero mediante el método clásico. El grupo 3 se integra en un grupo donde cada año van a tener una asignatura (Biología, Física, Matemáticas, etc.) en inglés. Aunque en el centro son muchos los alumnos distribuidos de esta forma se ha hecho un seguimiento focalizado de estos 30 alumnos. (En realidad, esto se podría hacer con todos los alumnos pero lo supongo así para que el número de datos a manejar sea más pequeño y se pueda apreciar, mirando los datos, lo que las técnicas van mostrando).
Estos alumnos integrados en sus grupos respectivos van a ser sometidos a un examen de inglés oral al final de cada curso: IO1, IO2, IO3 e IO4.
De los 10 alumnos de cada grupo se han tomado 5 con un nivel de aprobado únicamente de primaria y otros 5 con un nivel de notable o sobresaliente de primaria. Son los dos grupos de la columna encabezada como Nivel.
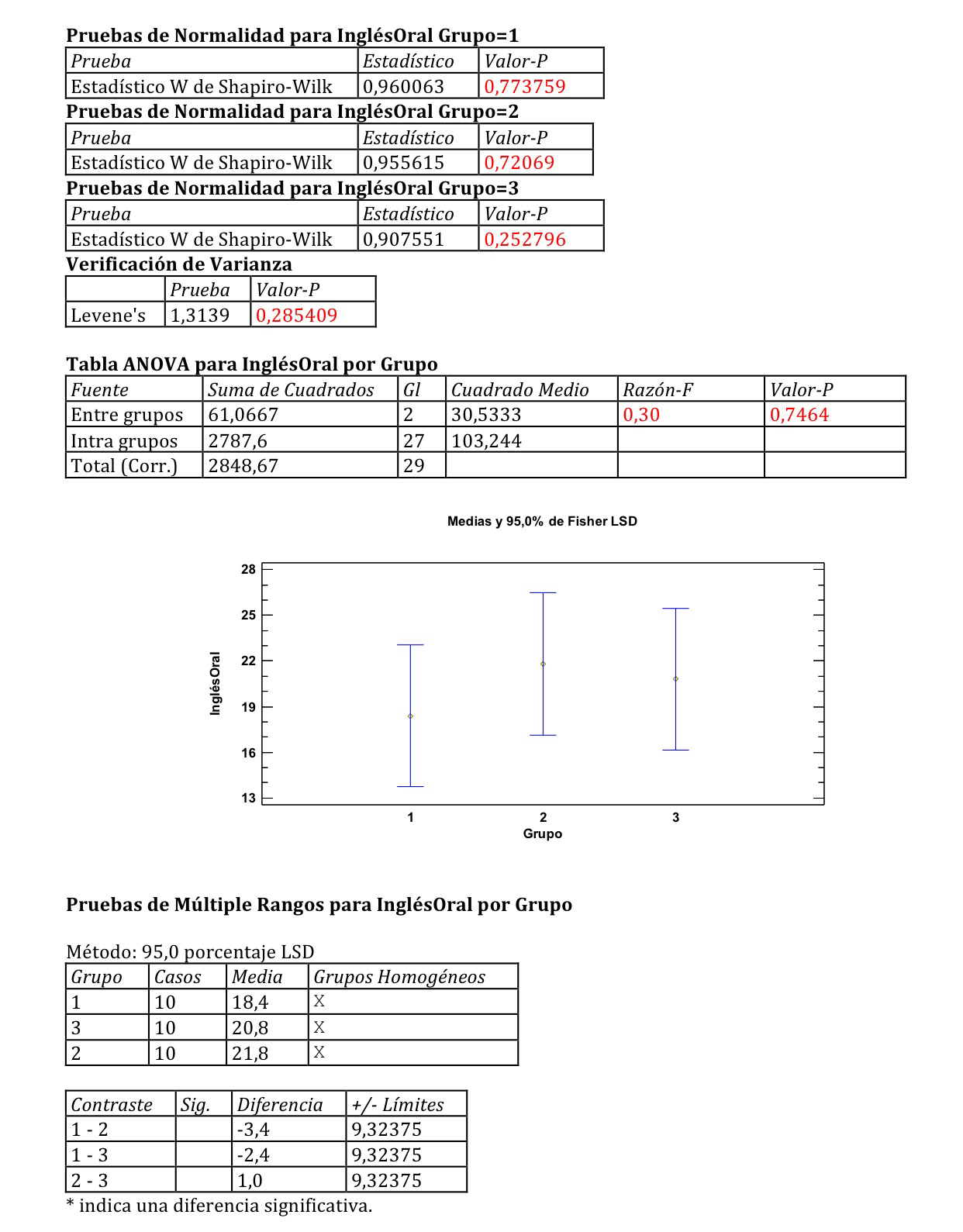
En primer lugar se realiza un ANOVA de la variable InglésOral al final de primaria, en los tres grupos, con la finalidad de comprobar que realmente empezamos el experimento con tres grupos con el mismo nivel basal de inglés.
El resultado de este ANOVA con un único factor es el siguiente:

En este primer caso mostramos la comprobación de la normalidad y la igualdad de varianzas, cosa que no haremos en el resto de casos, para ahorrar espacio, pero cosa que debe hacerse siempre, evidentemente.
La normalidad se comprueba con el Test de Shapiro-Wilk. Observemos que se hacen tres test: uno para cada uno de los grupos que tenemos. Los tres dan un p-valor por encima de 0.05, lo que permite mantener la hipótesis nula de ajuste a la normalidad. Para comprobar la igualdad de varianzas aplicamos el Test de Levene en este caso. Hay otros tests para ello, como también los hay para comprobar el ajuste a la normalidad. Mediante el Test de Levene comprobamos que, como el p-valor es también mayor que 0.05, podemos aceptar la igualdad de varianzas. Estamos pues en las condiciones del modelo ANOVA puesto que la independencia también se cumple. Son 30 alumnos elegidos en un instituto, ninguno de ellos es familiar de otro, no hay, por lo tanto, posibilidad de dependencia.
A continuación se aplica un ANOVA de un factor. Se observa que el p-valor es 0.7464. Esto nos indica que no hay diferencia de medias significativa en los niveles basales de estos tres grupos. Lo podemos visualizar en el gráfico de las medias con sus respectivos intervalos de confianza de la media del 95%. Hemos mostrado también, aunque en este caso no haría falta hacerlo, una prueba de comparaciones múltiples. En concreto el Test LSD. Evidentemente, en este caso, no hay ninguna diferencia significativa entre los tres grupos, como había mostrado previamente el ANOVA. En realidad, esta prueba únicamente se realiza si previamente el ANOVA ha detectado diferencias de medias significativas.
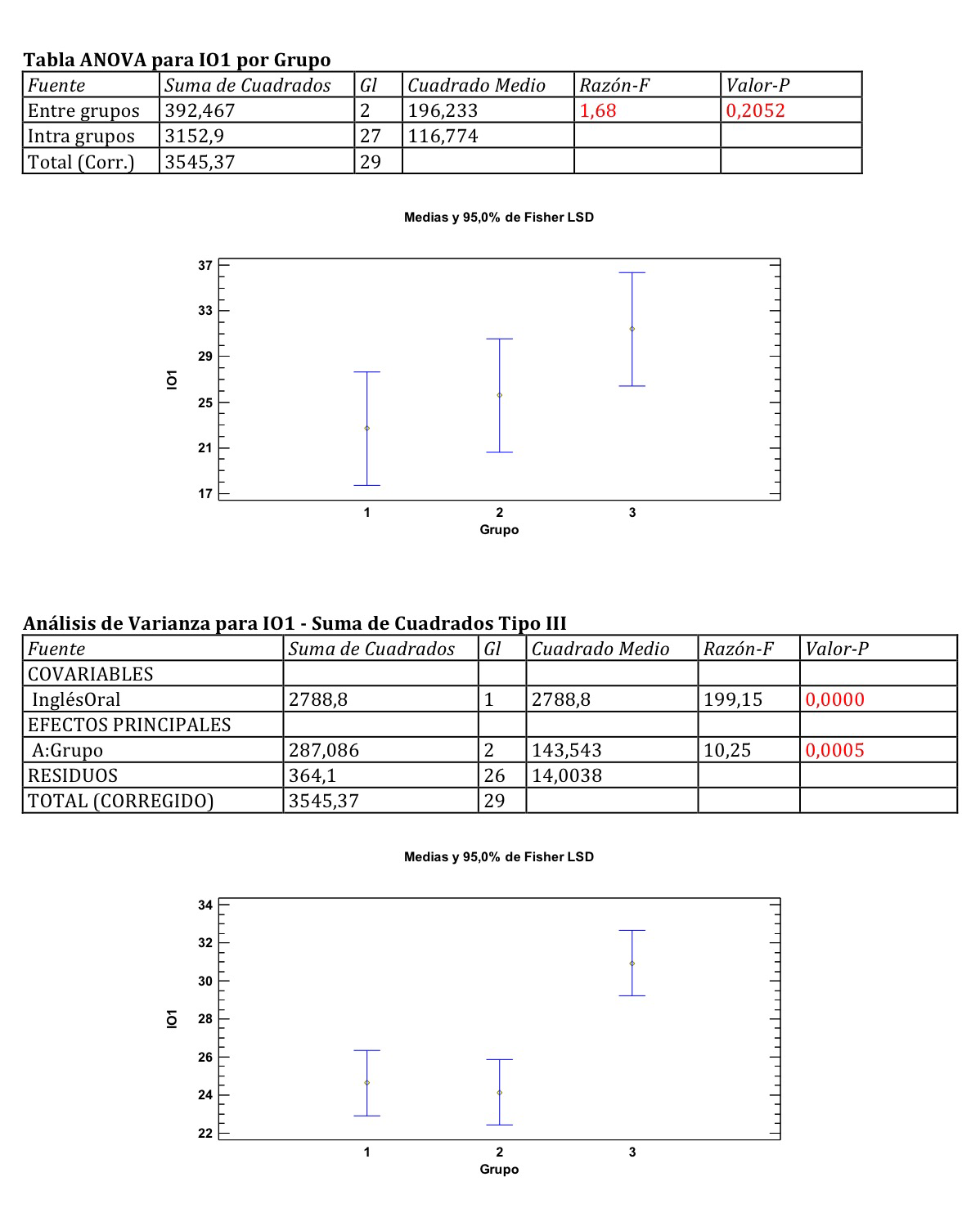
A continuación podemos hacer un ANOVA pero ahora ya con el nivel de inglés al final del primer año; o sea, con la variable IO1. Observemos que los resultados los tenemos en la primera de las dos tablas ANOVA que se muestran el el gráfico siguiente. Tenemos un p-valor de 0.2052. Con intervalos de confianza del 95% dela media todavía solapados. Es verdad que captamos un ligero aumento de la media del grupo 3 pero todavía lo capta como no significativa. Observemos que los intervalos todavía se solapan todos.
Pero debajo mostramos la aplicación de un ANCOVA. Muy importante en este caso. Porque las diferencias de media que hay entre los tres grupos no los capta como significativos el ANOVA hecho anteriormente porque ve que hay mucha dispersión de valores dentro de cada grupo. Esto la Estadística, cualquier técnica estadística, lo capta como un elemento que introduce dudas en las decisiones. Pero con el ANCOVA, al introducir como covariable el nivel de partida de los alumnos, de hecho estamos explicando esa dispersión y podemos disminuir los intervalos de confianza que ahora ya no se solapan. El grupo 3 se ha desprendido ya de los otros dos. Y el p-valor del factor grupo ya es significativo. Observemos con detenimiento la comparación del ANOVA (el primer análisis) y el ANCOVA (el segundo análisis):

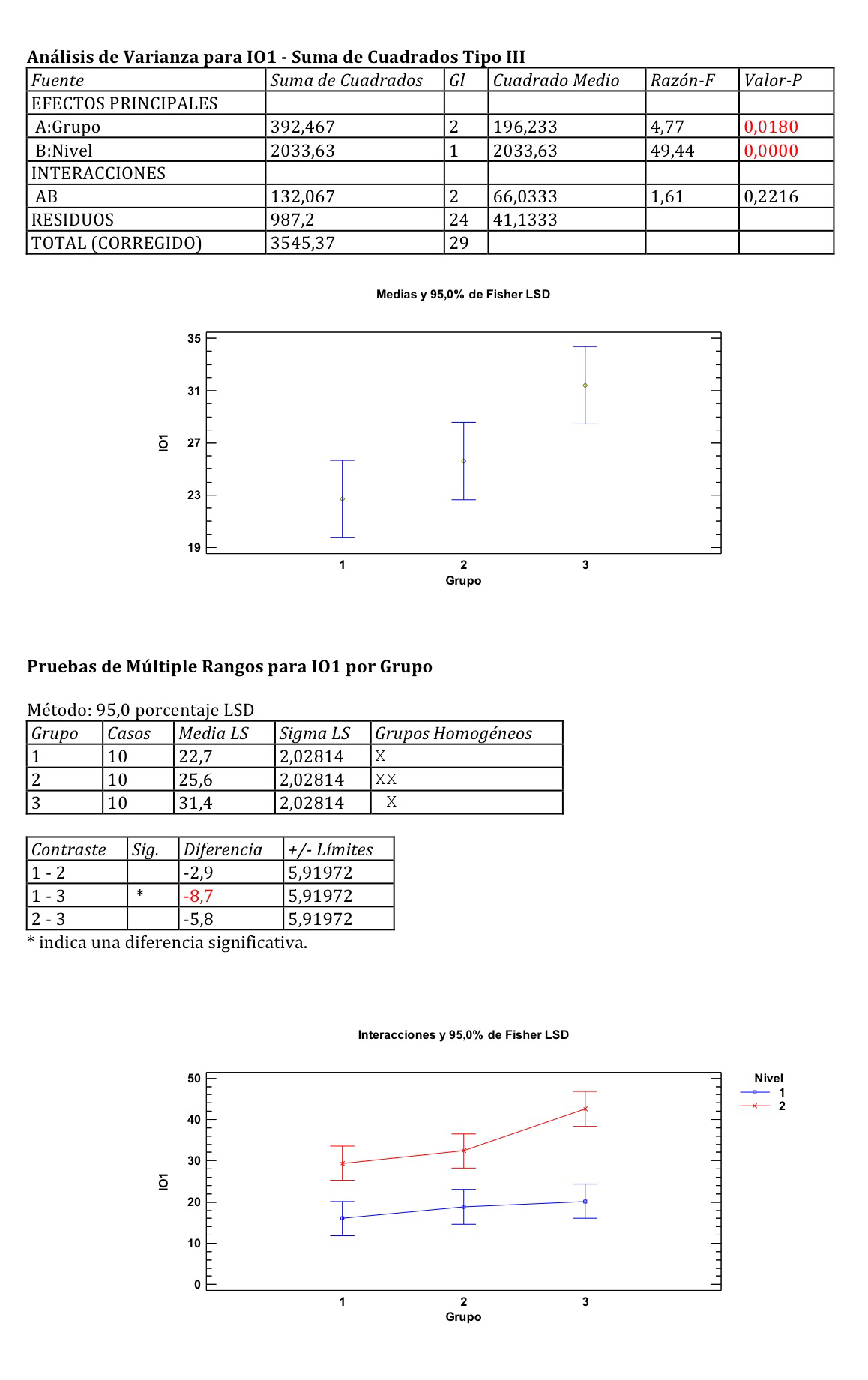
Si aplicamos a esa misma variable un ANOVA de dos factores: Grupo y Nivel, observemos que obtenemos algo en cierta forma similar a lo que obteníamos con el ANCOVA: ver diferencias entre los tres grupos, porque ahora, al introducir el factor Nivel, estamos comparando no los tres grupos entre sí, sino que comparamos los tres grupos pero nivel a nivel. Esto es más fino, porque comparamos grupos más homogéneos. De hecho, el ANCOVA, al introducir la covariable hace esto pero con una variable más fina, porque es cuantitativa y no cualitativa. Aunque en este caso hemos de tener en cuenta que una variable no es la discretización del nivel de inglés oral, es la discretización del nivel global que ha tenido el alumno a lo largo de los estudios primarios. Observemos los resultados:

Observemos varias cosas en estos resultados:
En los tres grupos observamos unas comparaciones múltiples curiosas: el grupo 1 y el 3 muestra diferencias significativas, pero el 1 y 2 así como el 2 y 3 no son diferentes significativamente. Observemos que los intervalos de confianza de 1 y 2 se tocan y los de 2 y 3, aunque muy poco, se tocan un poquito también.
Y otra cosa importante: La interacción no es significativa. Observemos que en el gráfico de interacciones se observa un progresivo aumento en los grupos, del nivel de inglés oral, pero aunque se aprecia una cierta pérdida del paralelismo al llegar al grupo 3 (las medias están más separadas que en los otros grupos) no se trata de una interacción significativa puesto que el p-valor es 0.2216.
Si aplicamos ese mismo ANOVA pero con la variable IO4 observamos que las diferencias son claramente entre 3 y los otros dos grupos y observamos, también, cosa muy importante, que hay interacción ahora sí significativa (p=0.0363):

Esta interacción es muy interesante porque está indicando que son los buenos alumnos los que aprovechan mejor un sistema como el ensayado en el grupo 3. Obsérvese que la IO4, en conjunto, aumenta, en el grupo 3, respecto a los otros dos grupos, pero, además, obsérvese que la diferencia entre el nivel bajo y el alto de alumnos es mucho mayor en el grupo 3 que no en los otros dos grupos: esto es lo que nos indica que hay interacción estadísticamente significativa.
Si quisiéramos analizar no un punto, como hemos hecho estudiando al final de la ESO, en cuarto, sino si quisiésemos analizar la evolución de los cuatro tiempos, ver si hay cambios y relacionarlo con los factores estudiados, deberíamos aplicar el ANOVA de medidas repetidas. Las notas al final de cada curso de la ESO se puede ver como un nivel de un factor intrasujetos; o sea, de un factor que tiene cuatro niveles temporales que se van midiendo a cada uno de los alumnos, a cada uno de los sujetos. Esto se podría analizar solo, con una ANOVA de medidas repetidas con ese único factor intrasujetos, pero también se podría analizar con un ANOVA de medidas repetidas que incorporara factores intersujetos; o sea, factores como los que hemos visto antes: los factores típicos del ANOVA, los factores donde en cada nivel hay diferentes individuos, diferentes sujetos a estudiar.
Si incorporarmos los dos factores intersujetos: Grupo y Nivel podemos hacer un ANOVA de medidas repetidas de un factor intrasujeto (los cuatro finales de los cuatro cursos de ESO) y los dos factores intersujetos que ya hemos estudiado. Ahora se analizarán no valores sino, digamos: perfiles de valores a lo largo de esos cuatro años. Se verá si hay cambios significativos en los cuatro años y si eso cambios son distintos según el Grupo, según el Nivel y según la interacción Grupo con Nivel.
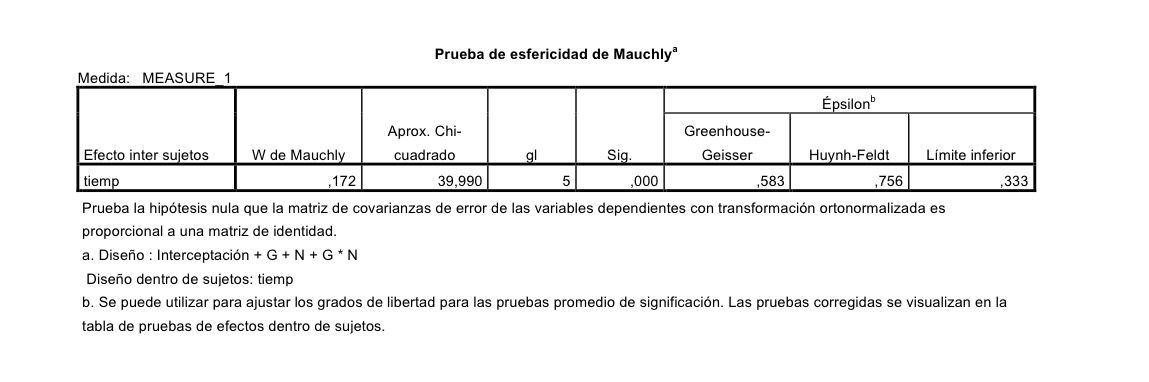
Los resultados son los siguientes. Lo primero es la comprobación de la esfericidad de los datos. Esto es equivalente a la prueba de comparación de varianzas del ANOVA. El resultado es el siguiente:

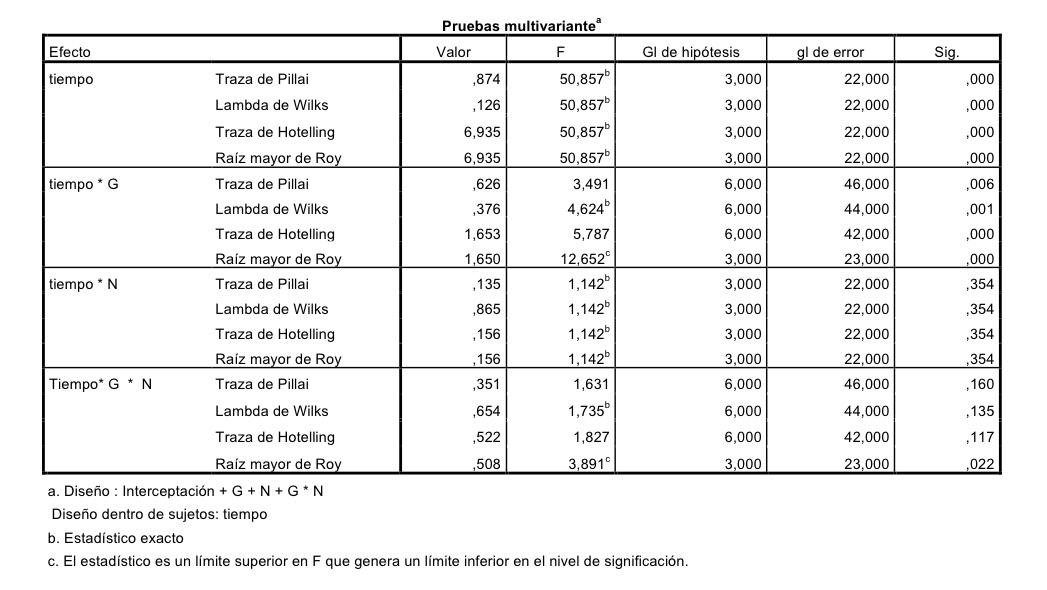
No hay esfericidad. La hipótesis nula es que hay esfericidad, como el p-valor es menor que 0.05 debemos rechazar tal hipótesis. Esto nos lleva a evaluar el ANOVA de medidas repetidas mediante métodos multivariantes; o sea, con los estadístico que se dan en la siguiente tabla:

O con las modificaciones de los grados de libertad de la distribución F de referencia que introduce en el típico análisis de una tabla ANOVA unas correcciones que se han propuesto históricamente para estos casos (Greenhouse-Geise, Huynh-Feldt o la llamada del «límite inferior»):

En todo caso se llega a lo mismo prácticamente. Hay un cambio a lo largo del tiempo, cosa evidente si se ven los datos. Se podría decir: «sólo faltaría que no hubiera cambio a lo largo de los cuatro años en el nivel de inglés». Lo interesante es aquí ver si hay interacciones entre el tiempo y los factores intersujetos: Grupo y Nivel. Tiempo con Grupo es claramente significativo, lo que nos indica que los perfiles de cambio a lo largo del tiempo son distintos según el grupo. No es significativo, sin embargo, Tiempo con Nivel, lo que nos indica que los dos niveles en conjunto no presentan una diferencia significativa en el perfil. Respecto a Tiempo con la interacción Grupo y Nivel estamos en la frontera: observemos que con métodos multivariantes estamos un poco por encima de 0.05 y, sin embargo, con el método ANOVA modificado estamos un poco por debajo o en la frontera (debemos tener en cuenta que estamos trabajando con pocos datos, con un tamaño de muestra expresamente pequeño para poder visualizar las cosas) del nivel de significación 0.05.
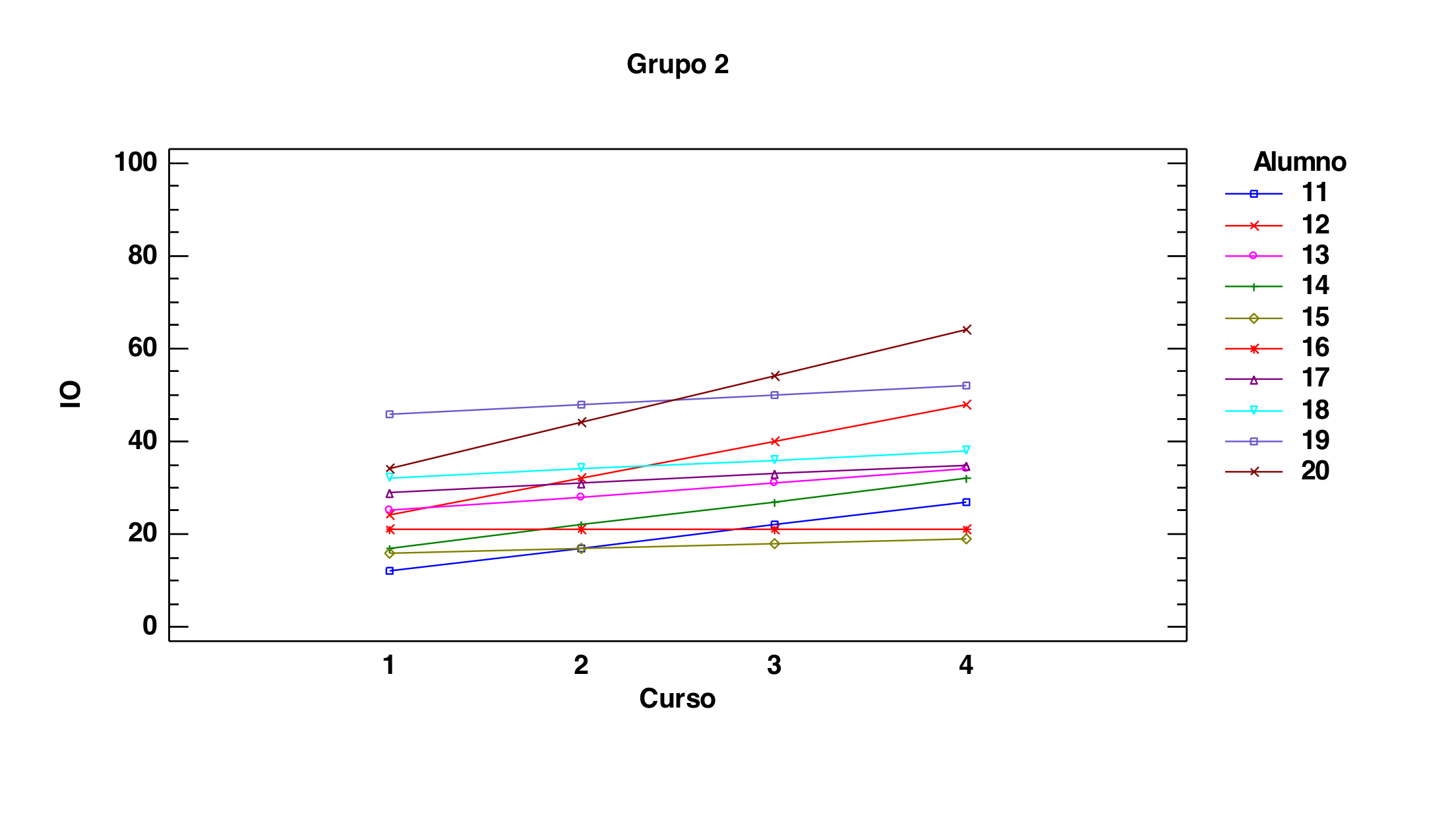
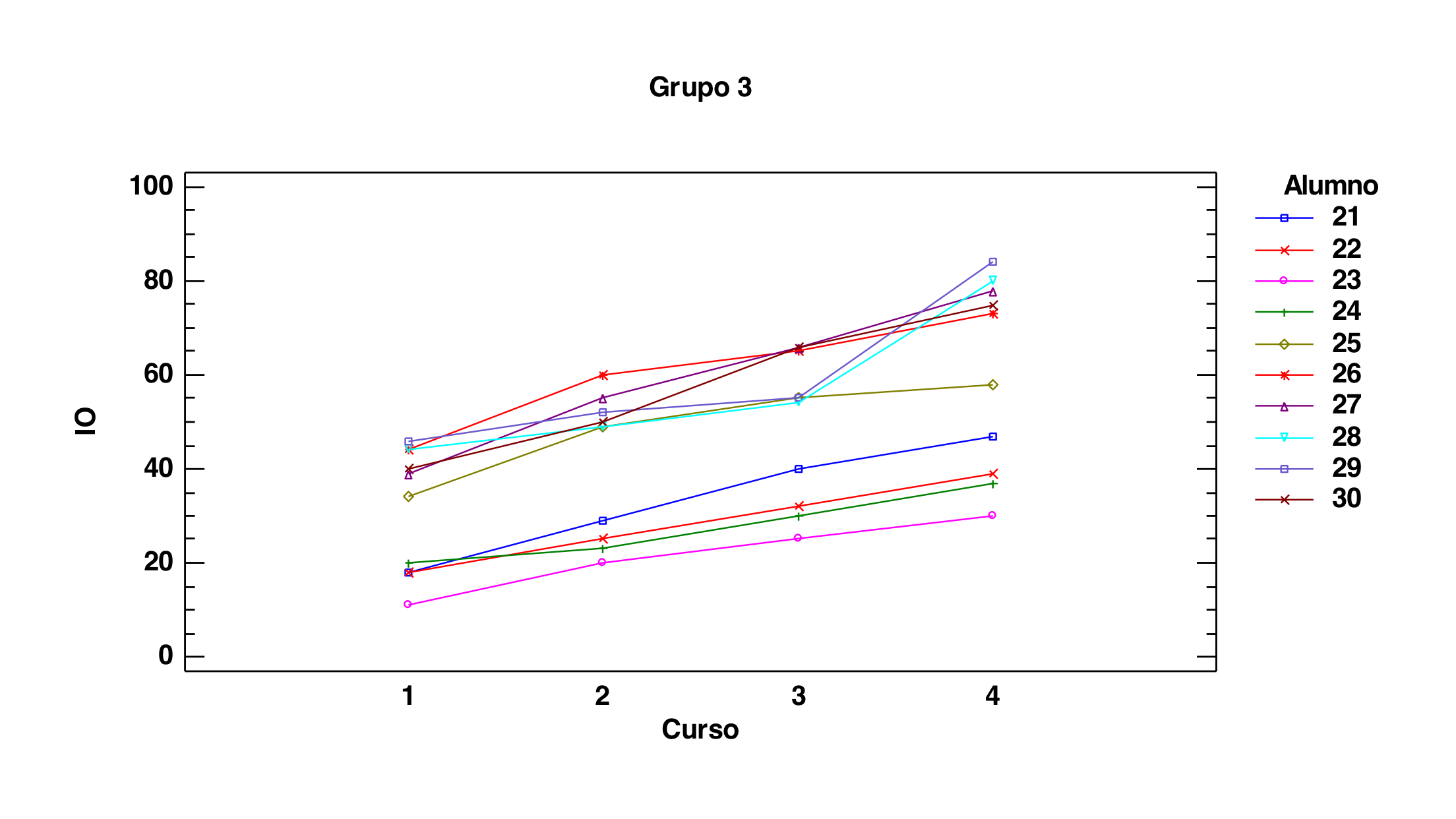
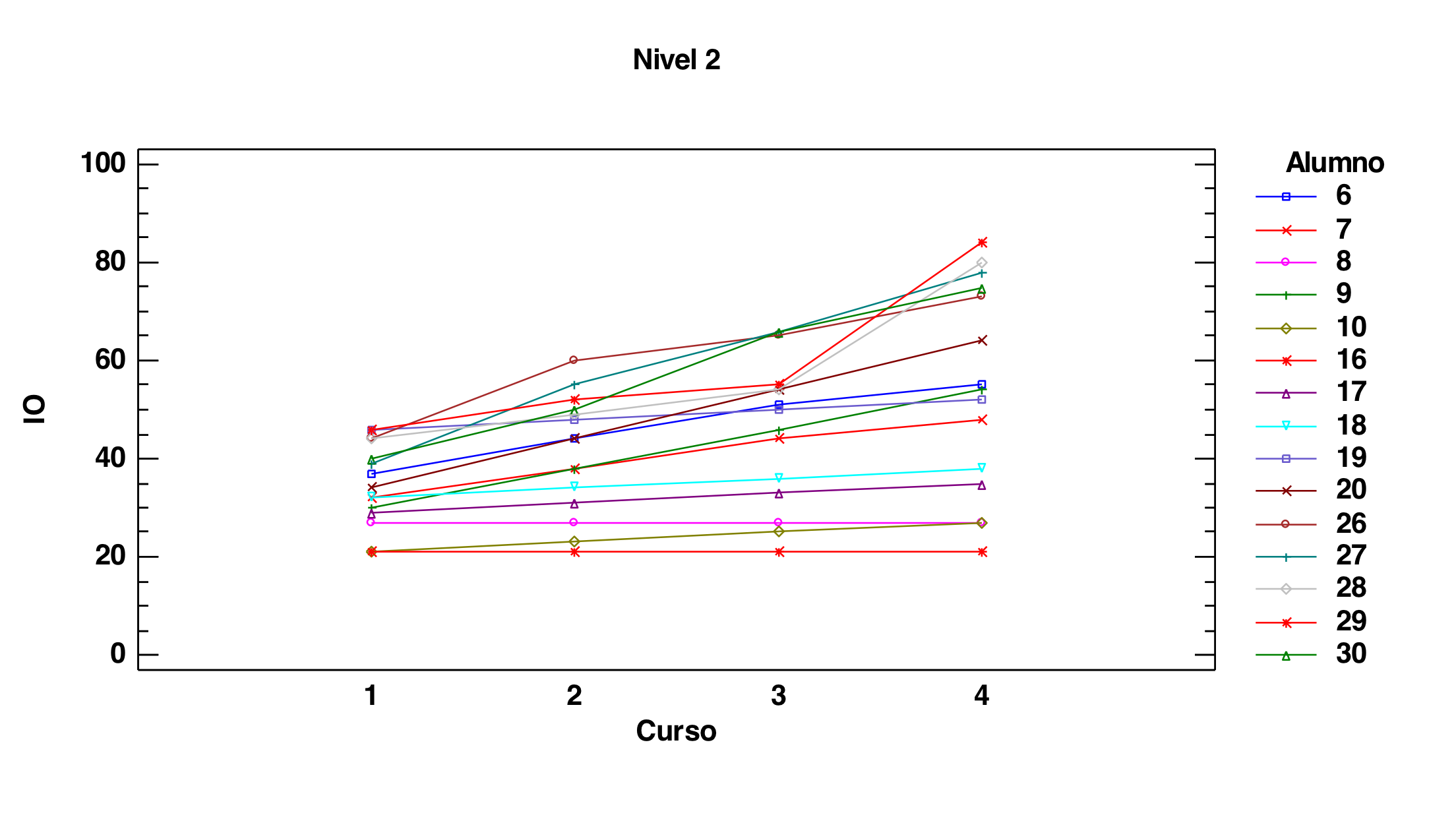
Observemos que es lógico ver lo que estamos viendo. Miremos, en primer lugar, los tres gráficos siguientes que son los dibujos de los perfiles, alumno a alumno, en función del grupo al que pertenecen. Recordemos que grupo 1 es el grupo control, que grupo 2 reciben alguna clase más de inglés tradicional y que el grupo 3 es que al que se le da una asignatura en inglés:



Observemos que se trata de tres grupos de perfiles donde el tercero presenta una diferencia relevante con los otros dos. Es cierto que hay variación dentro de cada grupo pero hay una cierta homogeneidad en la forma de aumentar entre dentro de cada grupo y, además, la forma de aumentar en el grupo 3 es con mayor pendiente. Esto es lo que capta como significativo el análisis.
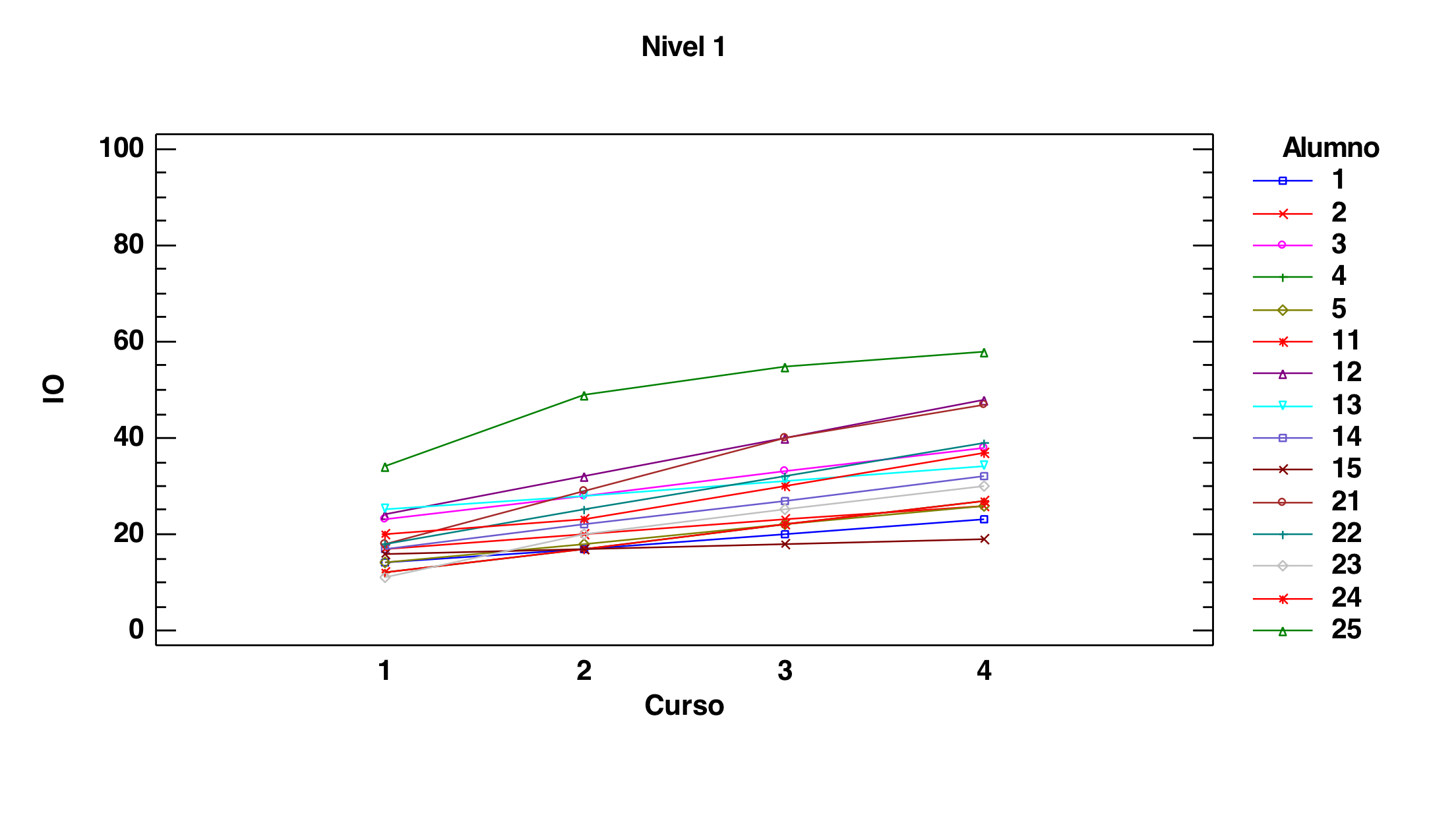
Veamos ahora lo mismo pero organizado por los dos niveles:


Ahora podemos observar perfectamente que hay bastante heterogeneidad de perfiles en cada uno de los dos grupos: en algunos alumnos hay bastante pendiente, en otros no. Esto impide poder decir que sea significativa la tendencia a tener mayor pendiente que tiene el nivel 2. No lo detecta como significativo. Cuando hay mucha dispersión interna en los grupos comparados es difícil que la estadística marque como significativas diferencias globales que haya entre esos grupos. Es lo que sucede aquí.
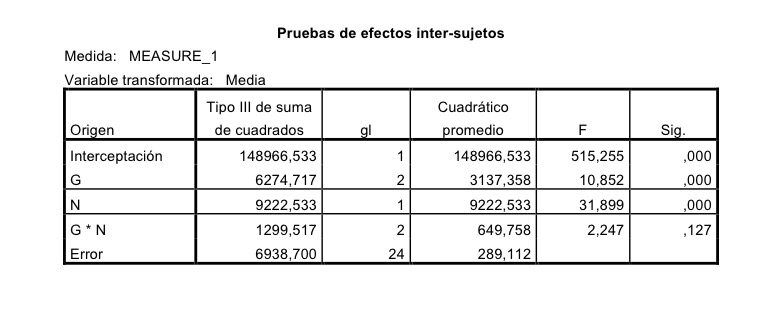
Respecto a los factores intersujetos individualmente los resultados son los siguientes:

Grupo y Nivel son significativos y la interacción no. Aquí se miran los datos del tiempo agregados, sin tener en cuenta el perfil.
Regresiones es posible hacer muchas en este contexto. Una posible sería relacionar el Nivel oral de inglés con el escrito que tenemos de los alumnos al final de la primaria para pronosticar el nivel escrito de un alumno, y que aquí no tenemos, de los alumnos en cualquier momento. Es cierto que es posible que esta relación cambie con el tiempo. Es verdad, pero si no se tuviera más información sería factible hacerlo, teniendo en cuenta, como siempre que se hacen predicciones, que estamos en un territorio complejo.
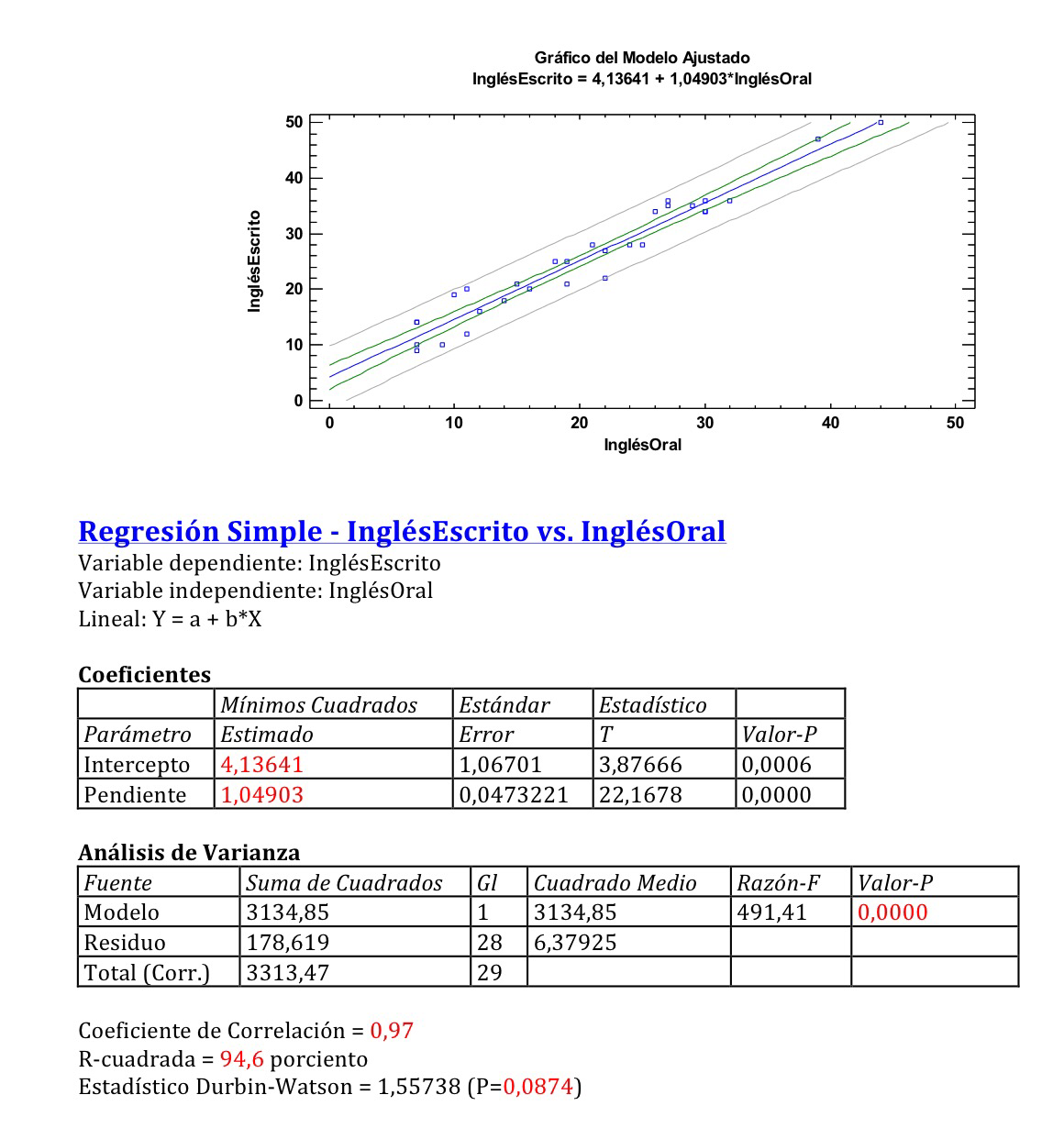
Si hacemos una Regresión lineal simple entre el Nivel de Inglés escrito y el oral, como lo que querremos pronosticar será el escrito, esa variable será la que deberemos poner en la posición de la variable dependiente. Veamos el resultado:

Tenemos un buen ajuste, con una buena R al cuadrado (94.6%). El modelo es:
InglésEscrito=1.04903*InglésOral+4.13641
Se traba de una buena modelización. En realidad, como hemos dicho, para pronosticar el nivel de inglés escrito a partir del conocimiento el nivel de inglés oral a finales de primaria. No tiene porque ser esa la relación que haya siempre, a cualquier nivel de la enseñanza. Sin embargo, esto nos enseña que uno tiene que usar, de la forma más coherente, la información que tiene, sabiendo las limitaciones en cada situación.
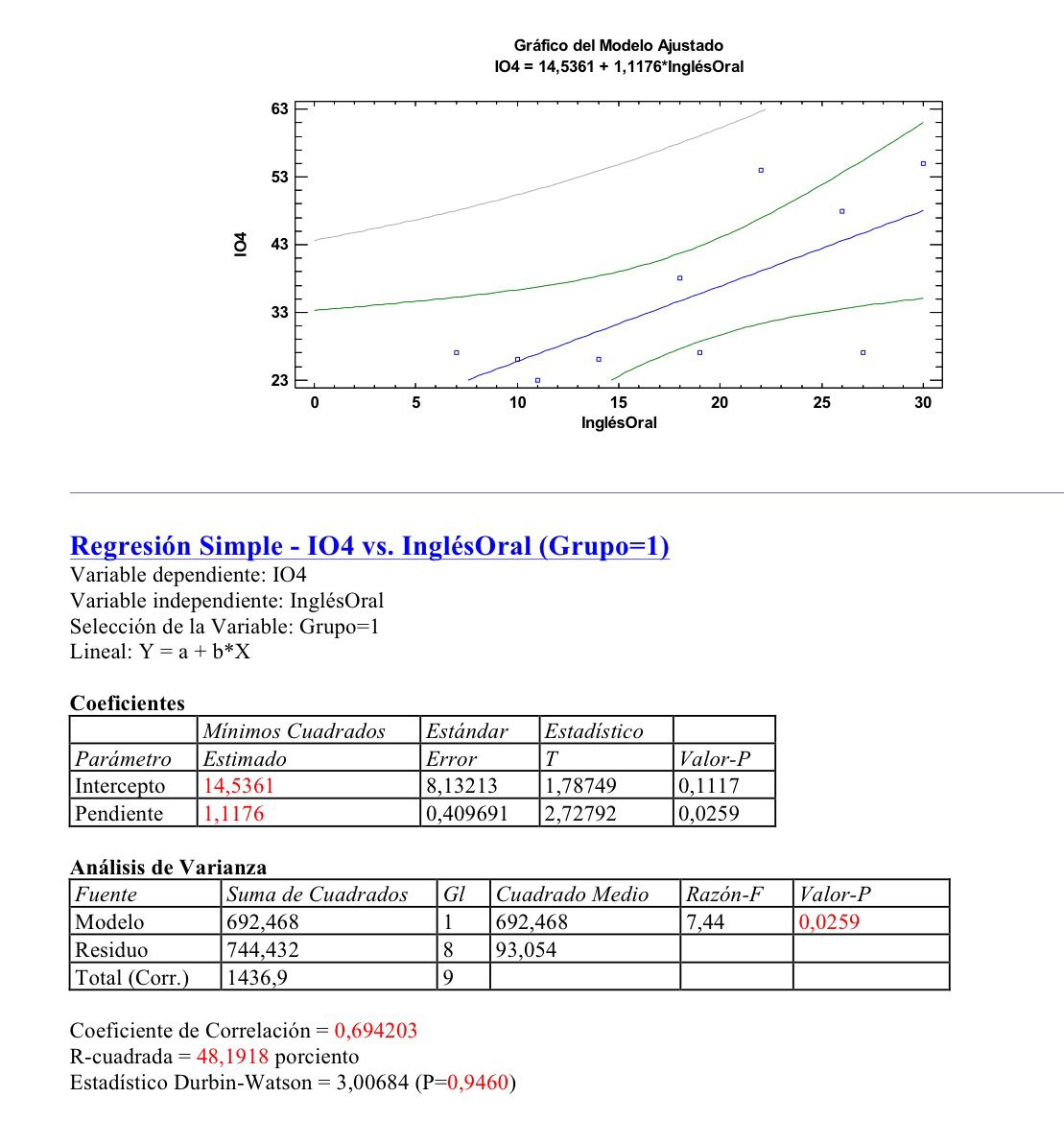
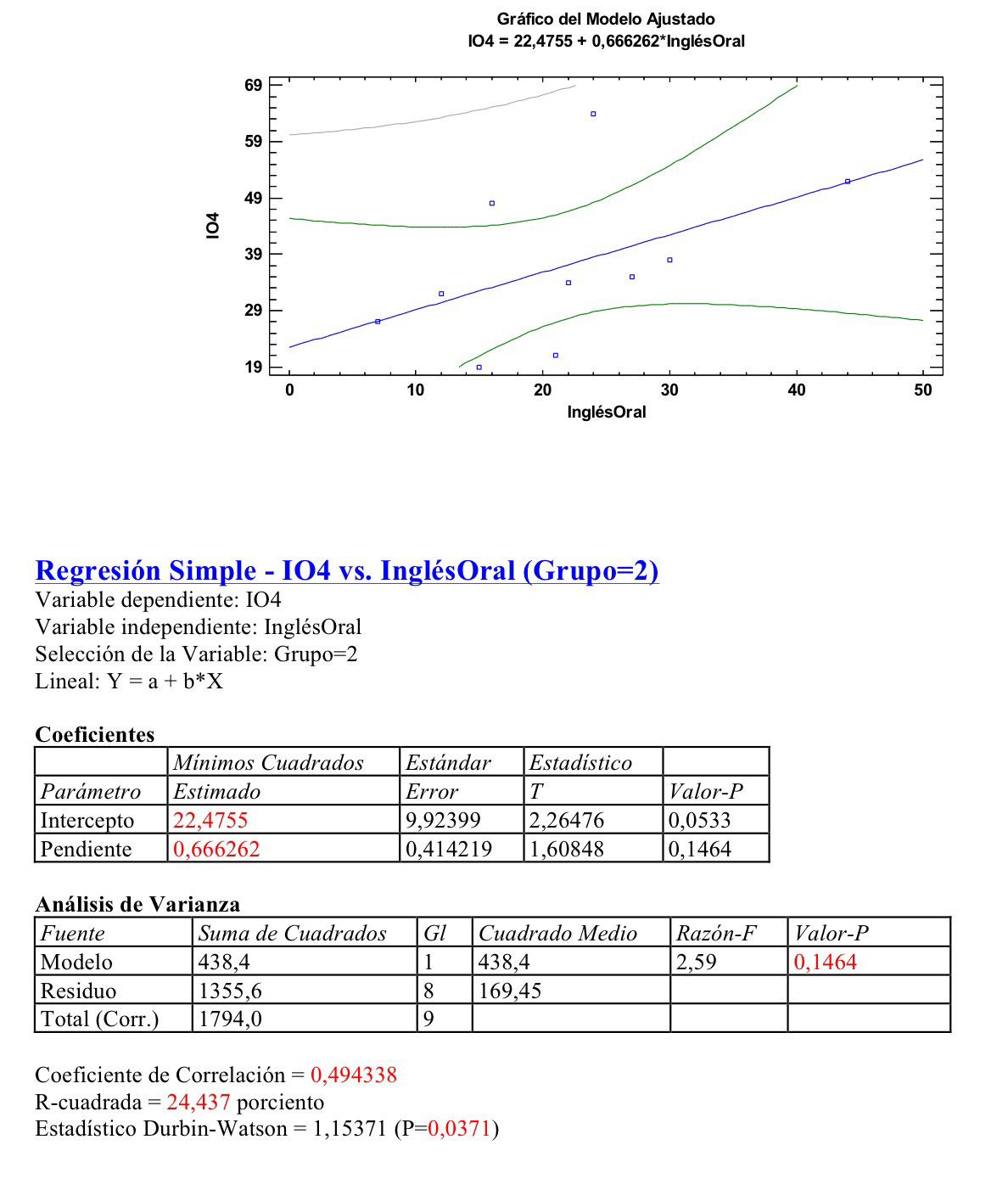
Otras regresiones podrían hacerse. Por ejemplo, grupo por grupo, podría hacerse el pronóstico, al acabar la primaria, del nivel de inglés oral que tendrá el niño o niña al final de la ESO. A continuación se muestran esas tres regresiones lineales simples. Con variable dependiente el nivel de inglés oral a los 4 años de ESO (IO4) y la variable independiente nivel de inglés al final de primaria (InglésOral):



Como puede observarse la R al cuadrado, el denominado coeficiente de determinación es más grande en este tercer grupo, lo que indica que la capacidad predictiva es superior, en este caso.
Si ahora intentamos pronosticar una variable dependiente con dos o más variables independientes entramos en el ámbito de la Regresión múltiple.
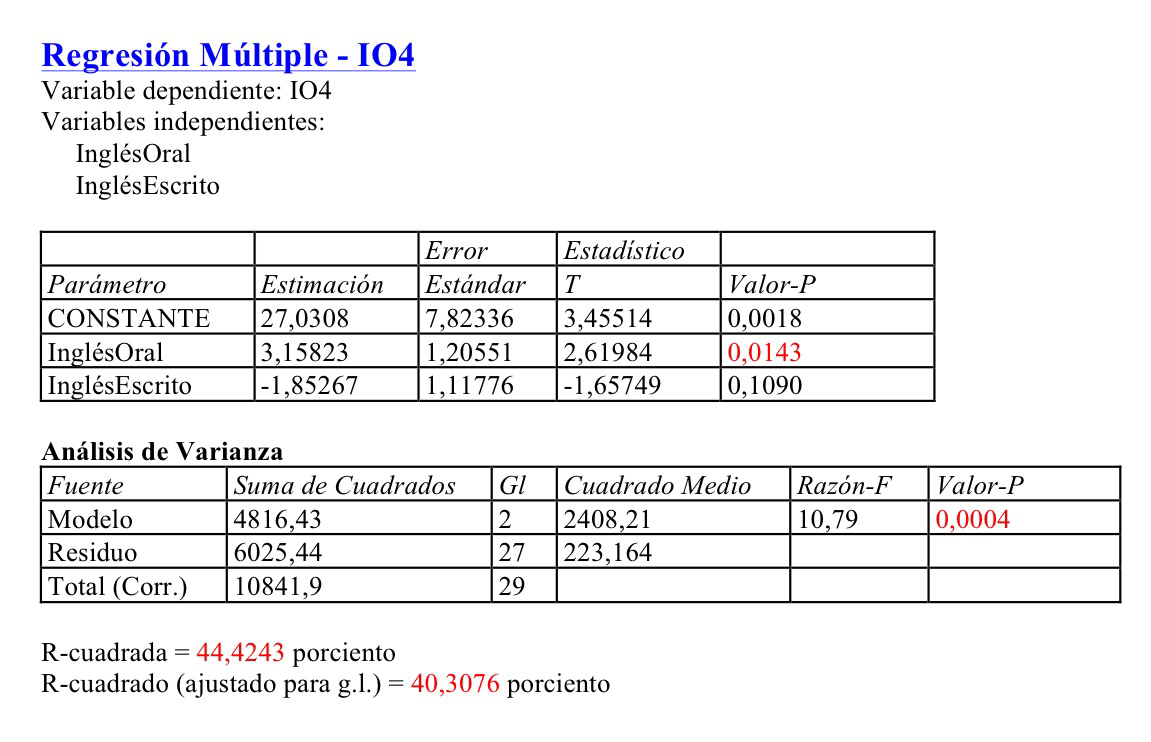
Vamos a intentar, en primer lugar, pronosticar IO4 mediante InglésOral e InglésEscrito; o sea, mediante los dos datos que tenemos a finales de primaria. Por lo tanto, se trata de la construcción de un modelo que intenta pronosticar con esa información lo que sucederá cuatro años después. La regresión da lo siguiente:

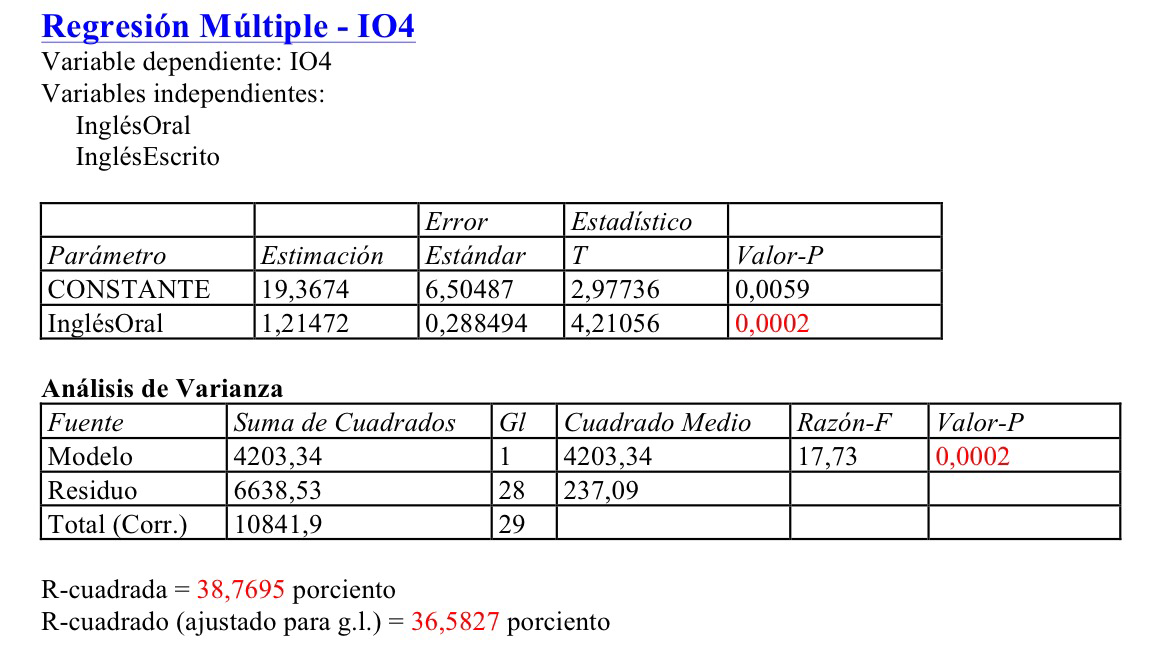
Si aplicamos el Stepwise regression, en su versión forward (hacia delante), el procedimiento acaba eliminado una variable, la InglésEscrito, puesto que el muy pequeño aumento de precisión que introduce teniendo ya la variable InglésOral no justifica su entrada puesto que existe colinealidad entre esas dos variables independientes y esto es muy perjudicial en las estimaciones de los coeficientes del modelo final. El resultado es, pues, el siguiente:

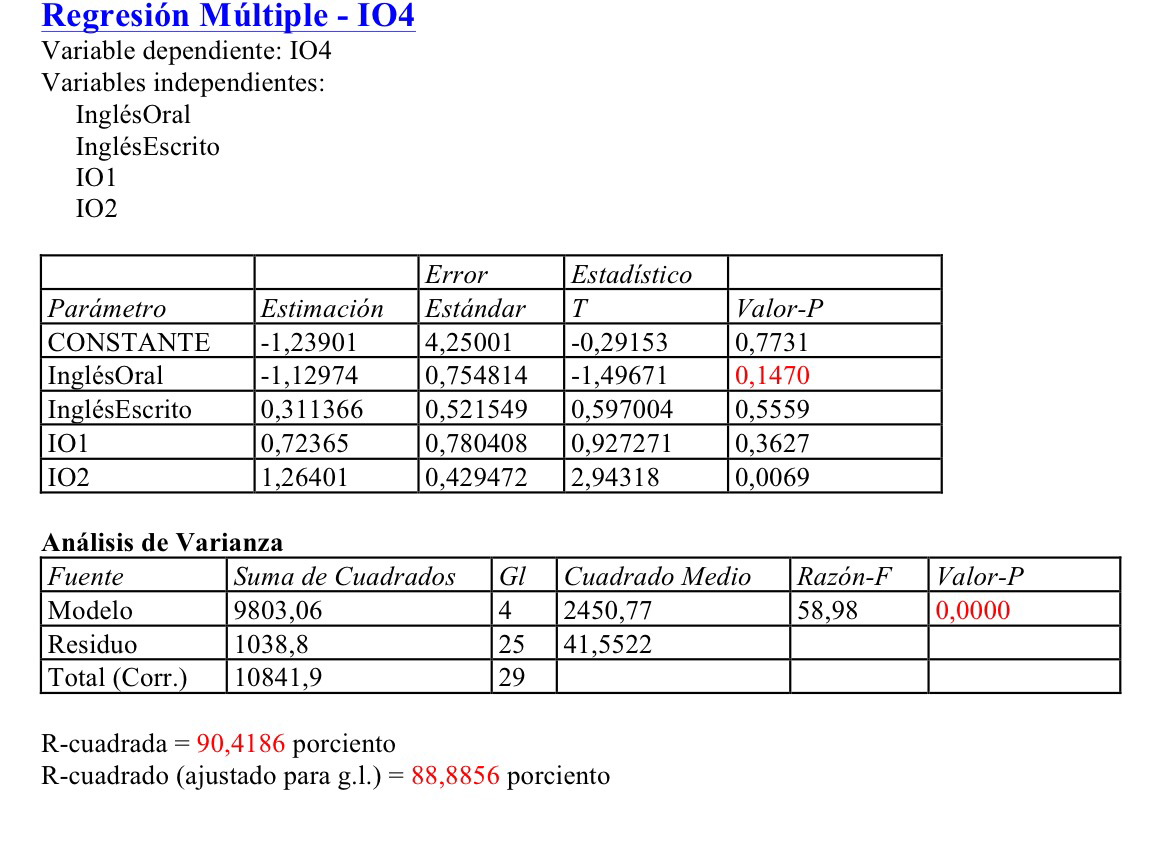
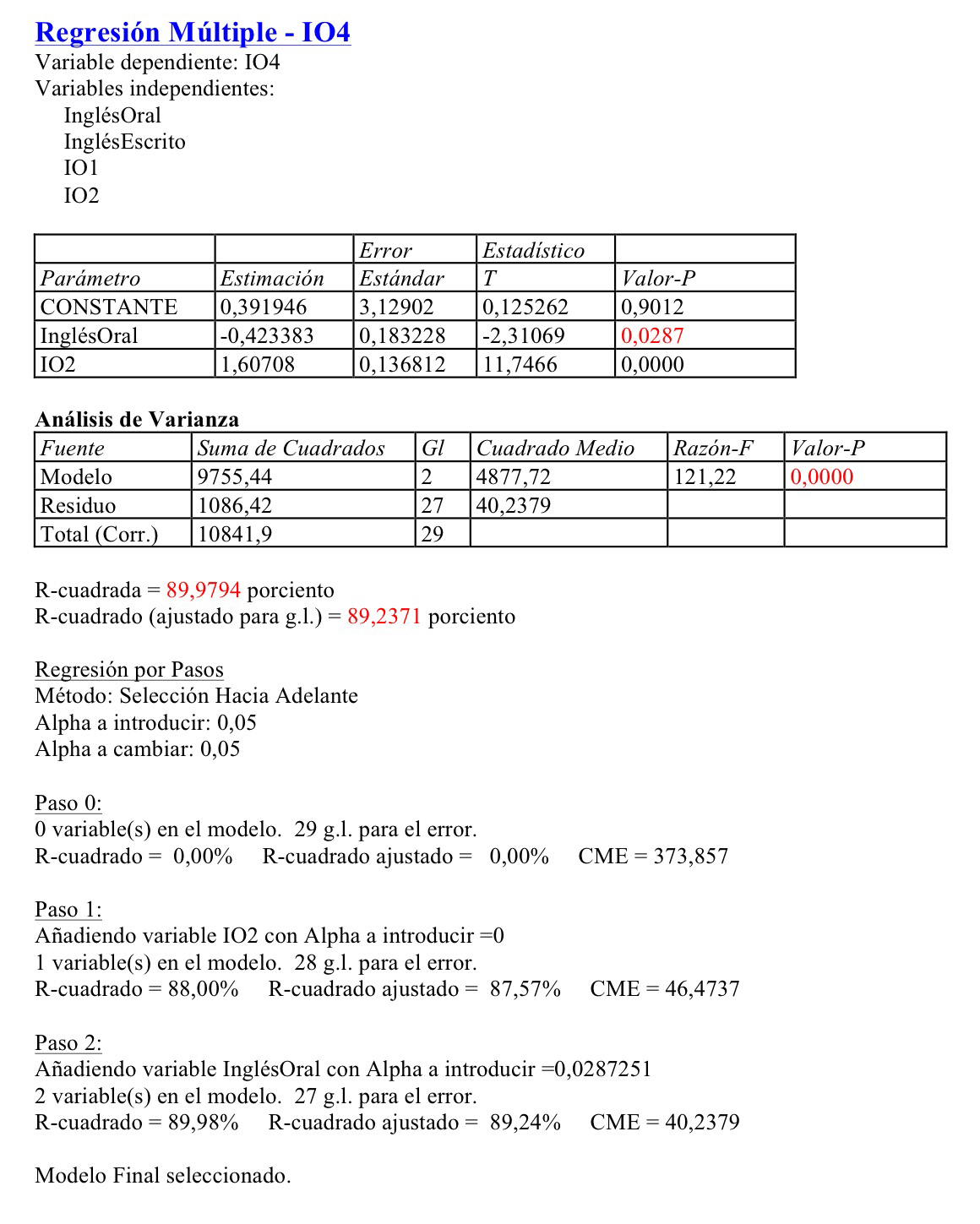
Supongamos que estamos a comienzos de tercero de ESO y por lo tanto tenemos cuatro de las variables que hemos registrado. Y queremos hacer un pronóstico de la variable IO4; o sea, del nivel de inglés oral de un alumno al final de la ESO. La Regresión múltiple nos daría:

Si aplicamos Stepwise regression:

Como puede verse, puesto que se muestra el procedimiento paso a paso que sigue el procedimiento, al final acaba seleccionando únicamente dos de las cuatro variables independientes, en el modelo: InglésOral e IO2.
Aquí no estamos distinguiendo por grupos, hemos trabajado con los tres grupos por separado. Parece evidente que sería recomendable trabajar grupo por grupo para conseguir mejores predicciones.
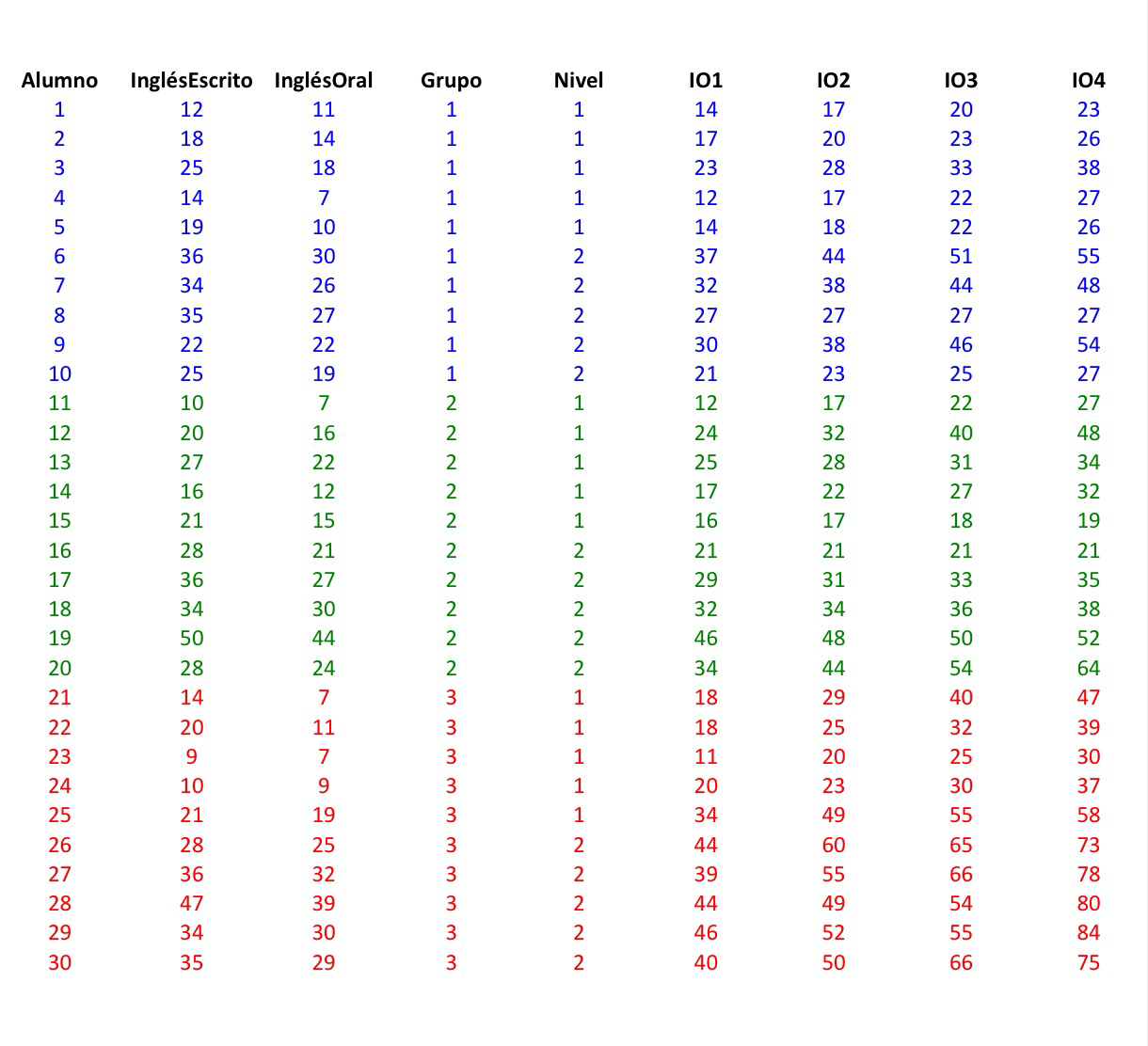
Finalmente, facilito los datos por si alguien los quiere descargar y trabajar con ellos:
| Alumno |
InglésEscrito |
InglésOral |
Grupo |
Nivel |
IO1 |
IO2 |
IO3 |
IO4 |
| 1 |
12 |
11 |
1 |
1 |
14 |
17 |
20 |
23 |
| 2 |
18 |
14 |
1 |
1 |
17 |
20 |
23 |
26 |
| 3 |
25 |
18 |
1 |
1 |
23 |
28 |
33 |
38 |
| 4 |
14 |
7 |
1 |
1 |
12 |
17 |
22 |
27 |
| 5 |
19 |
10 |
1 |
1 |
14 |
18 |
22 |
26 |
| 6 |
36 |
30 |
1 |
2 |
37 |
44 |
51 |
55 |
| 7 |
34 |
26 |
1 |
2 |
32 |
38 |
44 |
48 |
| 8 |
35 |
27 |
1 |
2 |
27 |
27 |
27 |
27 |
| 9 |
22 |
22 |
1 |
2 |
30 |
38 |
46 |
54 |
| 10 |
25 |
19 |
1 |
2 |
21 |
23 |
25 |
27 |
| 11 |
10 |
7 |
2 |
1 |
12 |
17 |
22 |
27 |
| 12 |
20 |
16 |
2 |
1 |
24 |
32 |
40 |
48 |
| 13 |
27 |
22 |
2 |
1 |
25 |
28 |
31 |
34 |
| 14 |
16 |
12 |
2 |
1 |
17 |
22 |
27 |
32 |
| 15 |
21 |
15 |
2 |
1 |
16 |
17 |
18 |
19 |
| 16 |
28 |
21 |
2 |
2 |
21 |
21 |
21 |
21 |
| 17 |
36 |
27 |
2 |
2 |
29 |
31 |
33 |
35 |
| 18 |
34 |
30 |
2 |
2 |
32 |
34 |
36 |
38 |
| 19 |
50 |
44 |
2 |
2 |
46 |
48 |
50 |
52 |
| 20 |
28 |
24 |
2 |
2 |
34 |
44 |
54 |
64 |
| 21 |
14 |
7 |
3 |
1 |
18 |
29 |
40 |
47 |
| 22 |
20 |
11 |
3 |
1 |
18 |
25 |
32 |
39 |
| 23 |
9 |
7 |
3 |
1 |
11 |
20 |
25 |
30 |
| 24 |
10 |
9 |
3 |
1 |
20 |
23 |
30 |
37 |
| 25 |
21 |
19 |
3 |
1 |
34 |
49 |
55 |
58 |
| 26 |
28 |
25 |
3 |
2 |
44 |
60 |
65 |
73 |
| 27 |
36 |
32 |
3 |
2 |
39 |
55 |
66 |
78 |
| 28 |
47 |
39 |
3 |
2 |
44 |
49 |
54 |
80 |
| 29 |
34 |
30 |
3 |
2 |
46 |
52 |
55 |
84 |
| 30 |
35 |
29 |
3 |
2 |
40 |
50 |
66 |
75 |