La siguiente base de datos de pacientes de con Trastorno bipolar y controles tiene la siguientes variables:
P=Número de Paciente
G=Grupo (Control, Bipolar)
S=Sexo (h=hombre, m=mujer)
E=Edad
ES=Estudios superiores (Sí, No)
D=Diabetes mellitus (Sí, No)
V=Autovaloración negativa (Sí, No)
F=Antecedentes de bipolaridad en familia directa (Sí, No)
CI=Coeficiente de inteligencia
A=Número de amigos considerados como íntimos

- Estadística descriptiva e Intervalos de confianza:
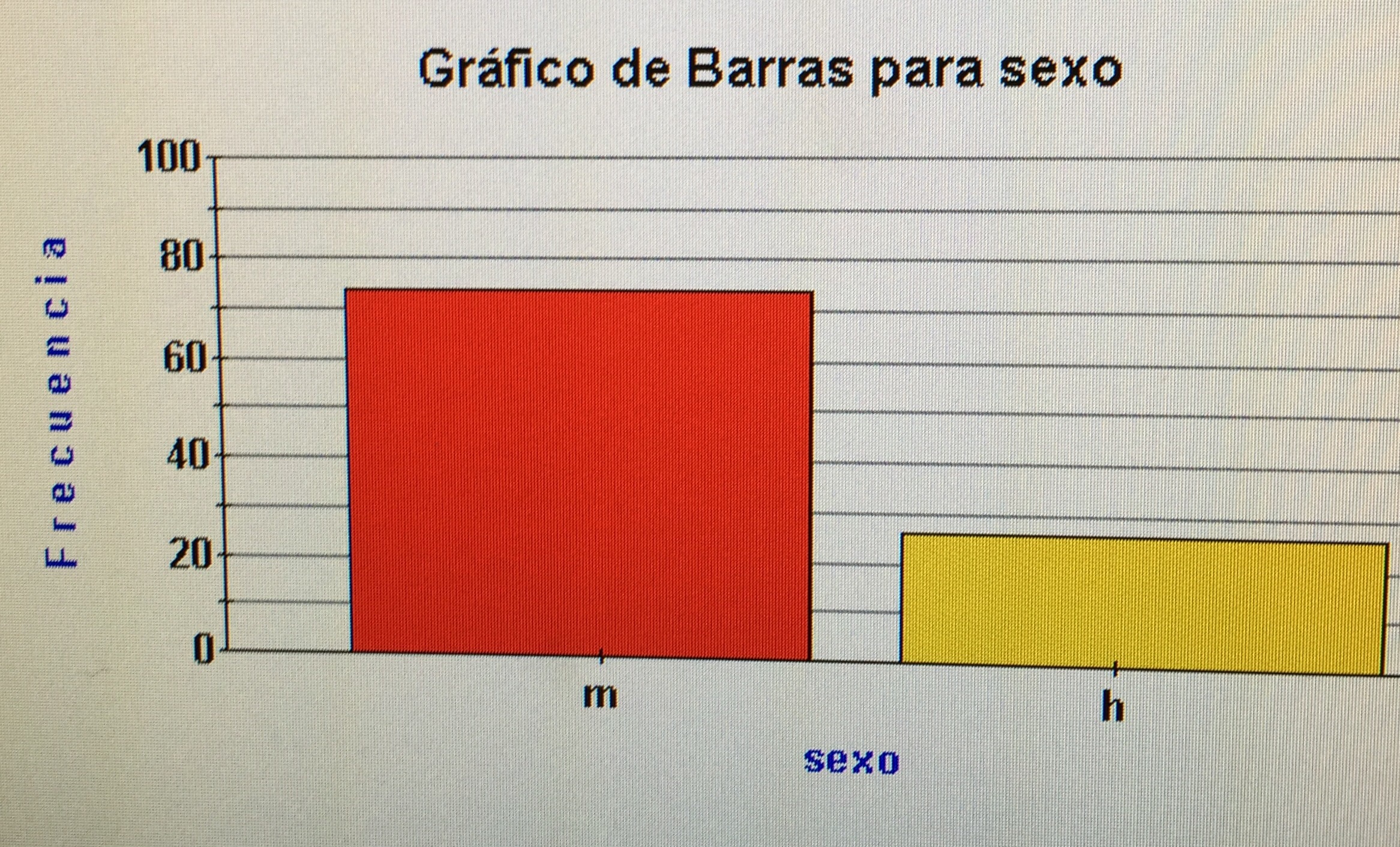
a) Hacer una estadística descriptiva de la variable Sexo en la muestra de pacientes con Trastorno bipolar y otra en el grupo control.
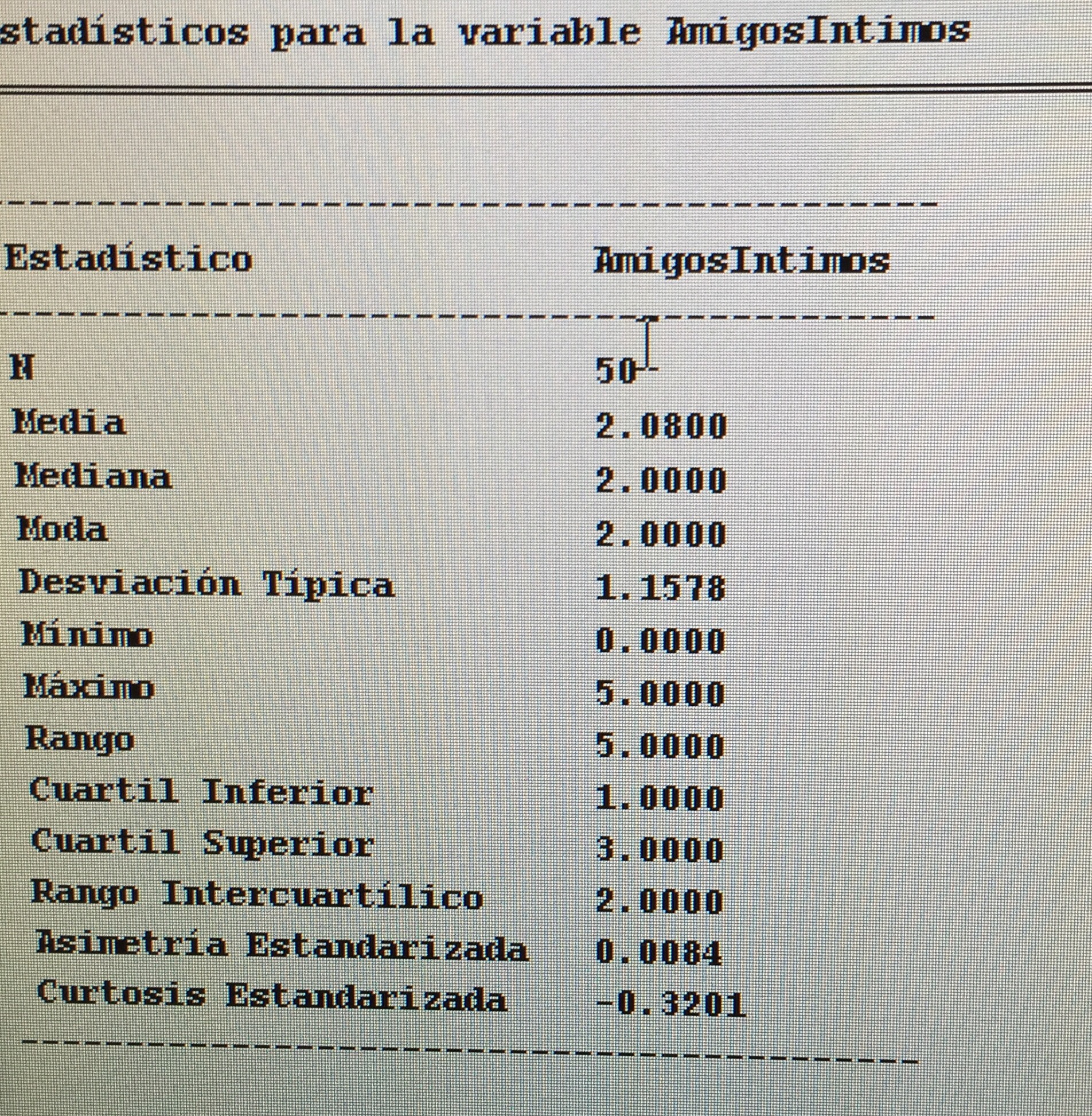
b) Hacer una estadística descriptiva de la variable Número de amigos en la muestra de pacientes con Trastorno bipolar y otra en el grupo control.
c) Hacer una descriptiva reducida, en dos o tres valores fundamentales, de la variable Coeficiente de inteligencia, en cada uno de los dos grupos del estudio.
d) Hacer una predicción, mediante un intervalo de confianza, del porcentaje de Antecedentes de bipolaridad en familia directa en pacientes con diagnóstico de Trastorno bipolar.
e) Hacer una predicción, mediante un intervalo de confianza, del coeficiente de inteligencia medio poblacional de los pacientes con Trastorno bipolar y otra predicción en el grupo de las personas que no lo tienen.
Soluciones:
a) En el grupo control:

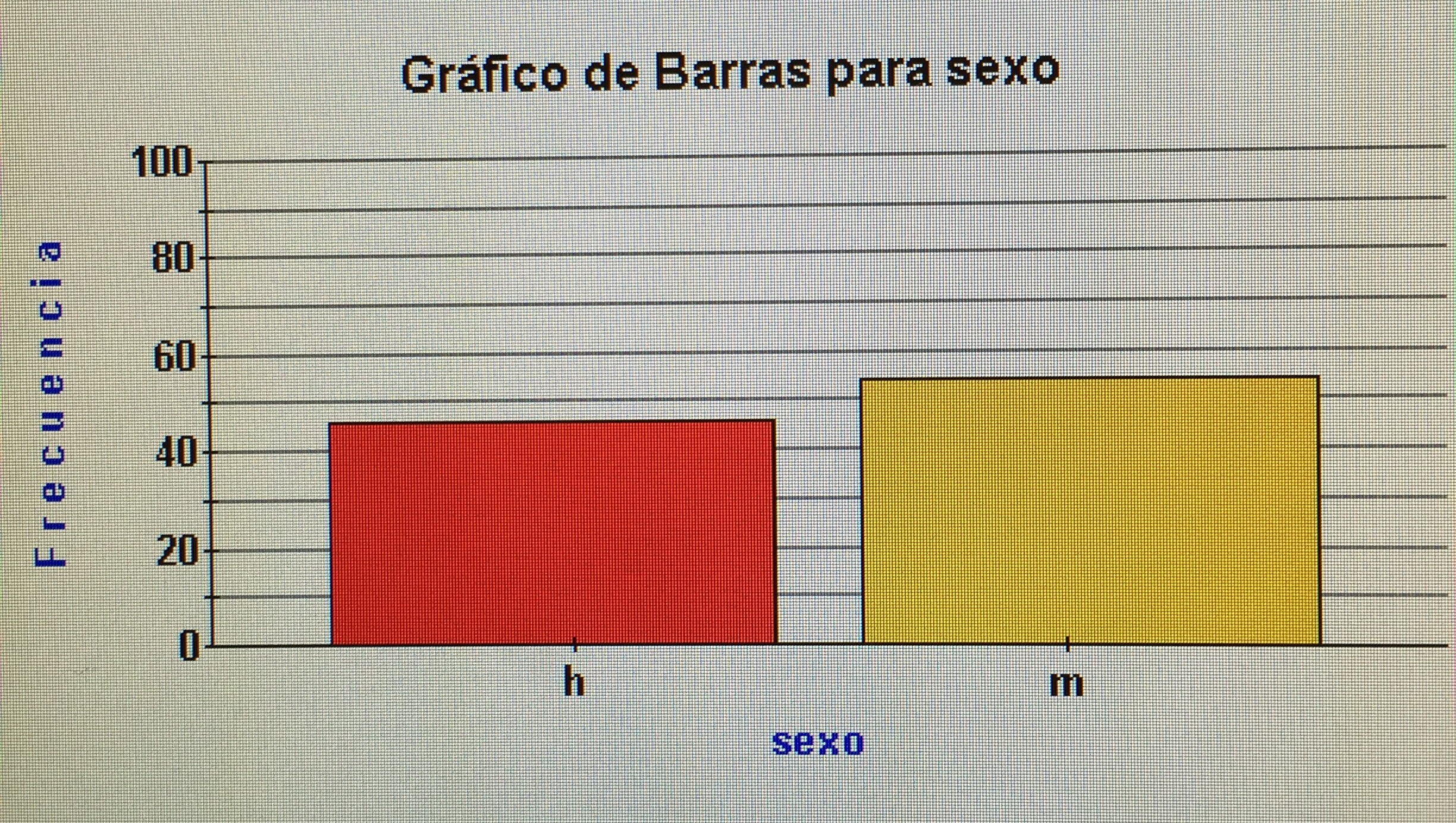
En el grupo con trastorno bipolar:

b) Es una variable cuantitativa, y así la describo, pero es de esas variables que podría describirse como cualitativa por el pequeño número de valores posibles que maneja.
En el grupo control:
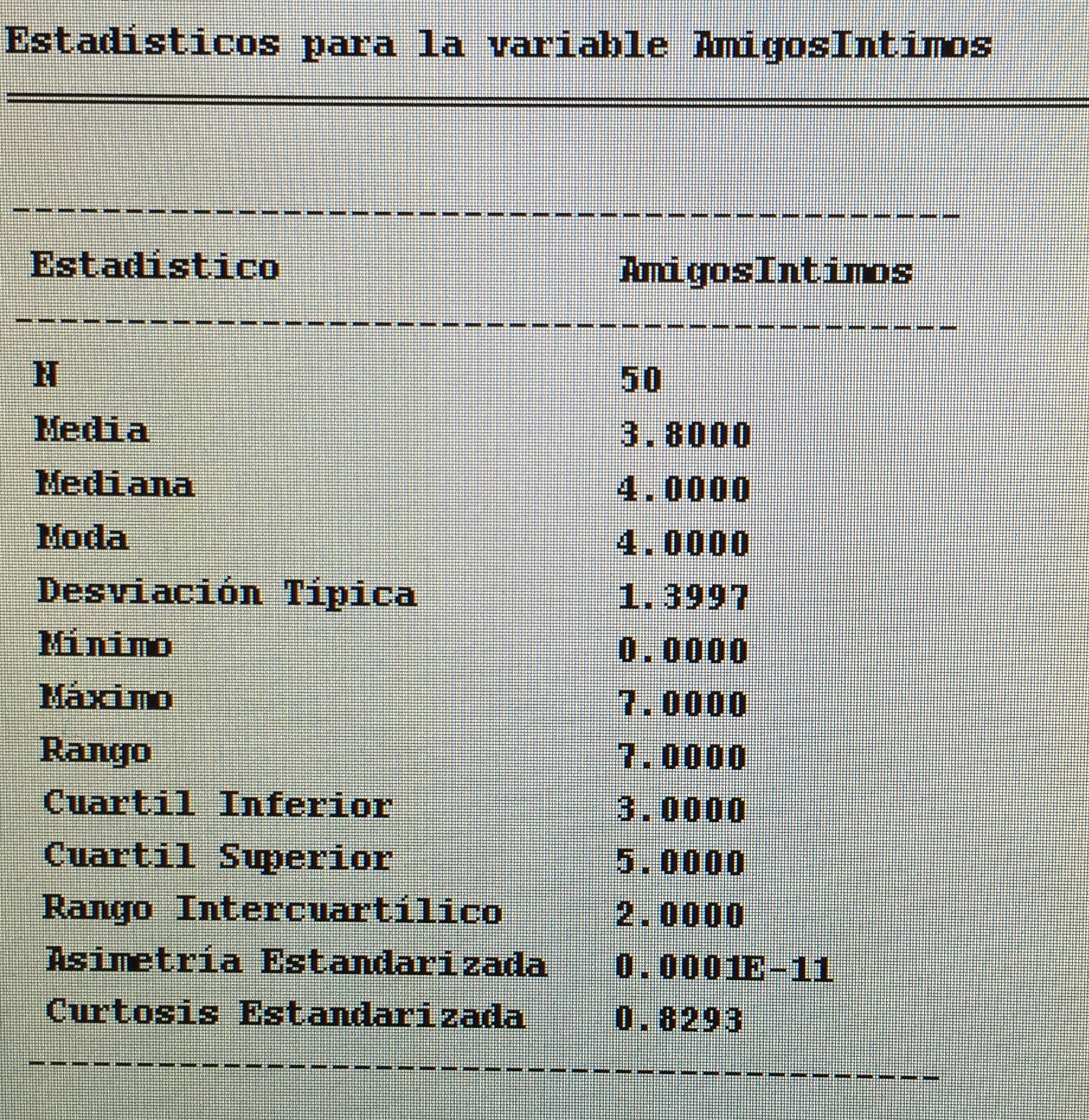
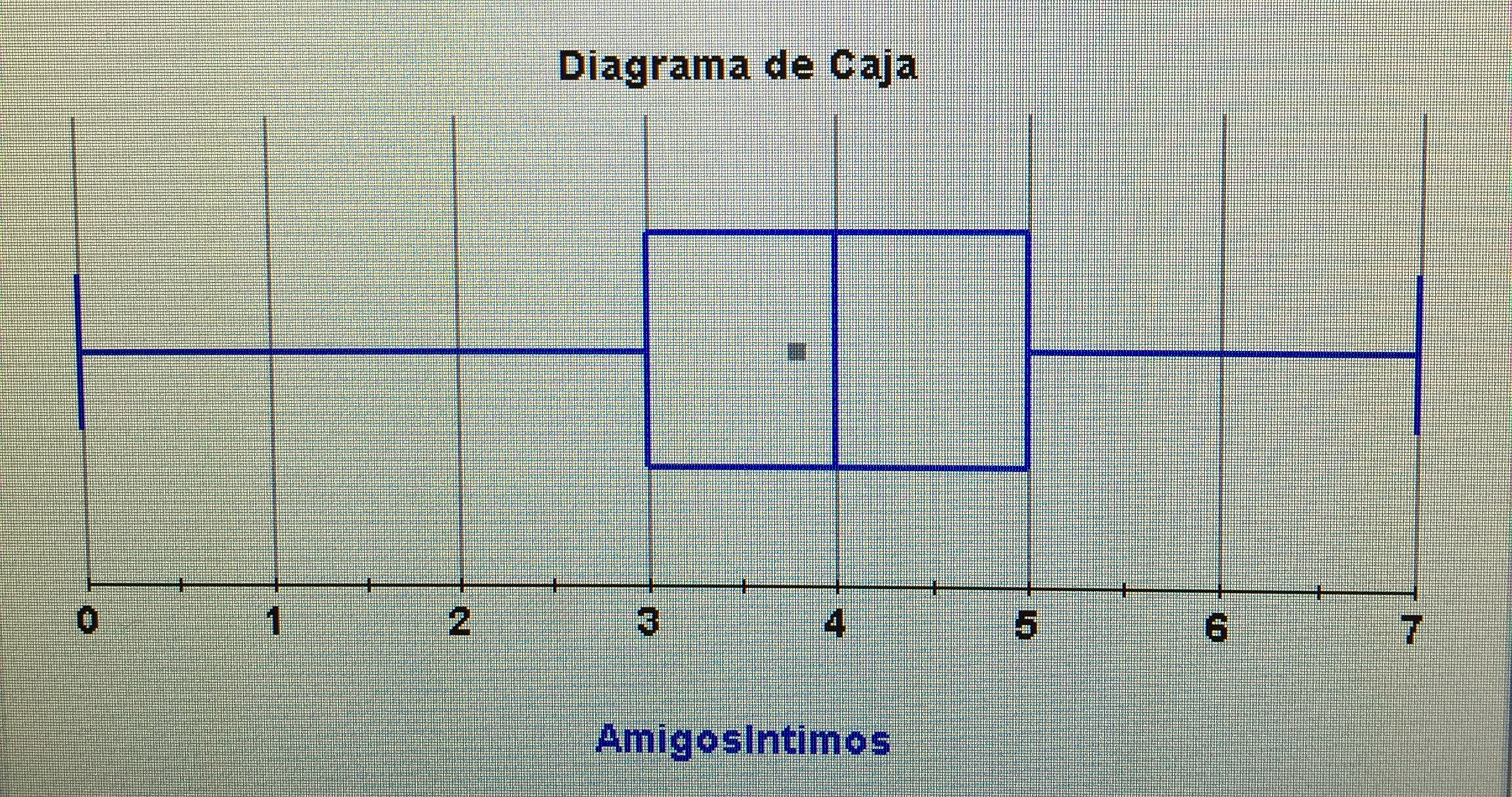
En el grupo con trastorno bipolar:
c) Para describir brevemente una variable cuantitativa basta ver si hay o no ajuste a la distribución normal.
En el grupo control una descriptiva sería:

Como tanto la Asimetría estandarizada como la Curtosis estandarizada están entre -2 y +2 podemos resumir esa variable en ese grupo con la media y la Desviación estándar; o sea, 105.78±11.67.
En el grupo de transtorno bipolar la descriptiva es:
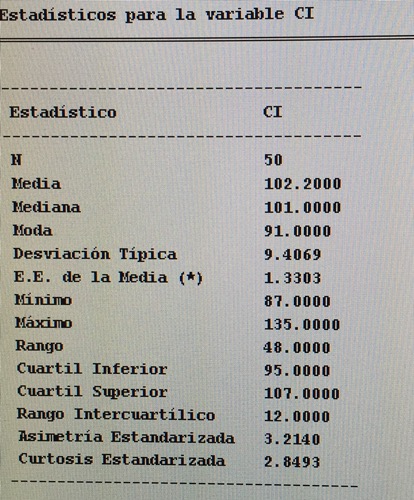
Como tanto la Asimetría estandarizada como la Curtosis estandarizada están fuera del intervalo -2 y +2 debemos resumir esa variable con la mediana y el primer y tercer cuartil; o sea: 101 (95-107).
d) Entre los pacientes con trastorno bipolar los que tienen antecedentes son un 54%:

Para construir el intervalo de confianza del valor del porcentaje poblacional debemos calcularlo o mediante la fórmula que aparece en el tema 3 ó mediante un software.
Mediante el software calculamos:

En concreto sale que ese intervalo, expresado en porcentajes, es: (39.32%, 68.19%).
Mediante la fórmula del tema 3:
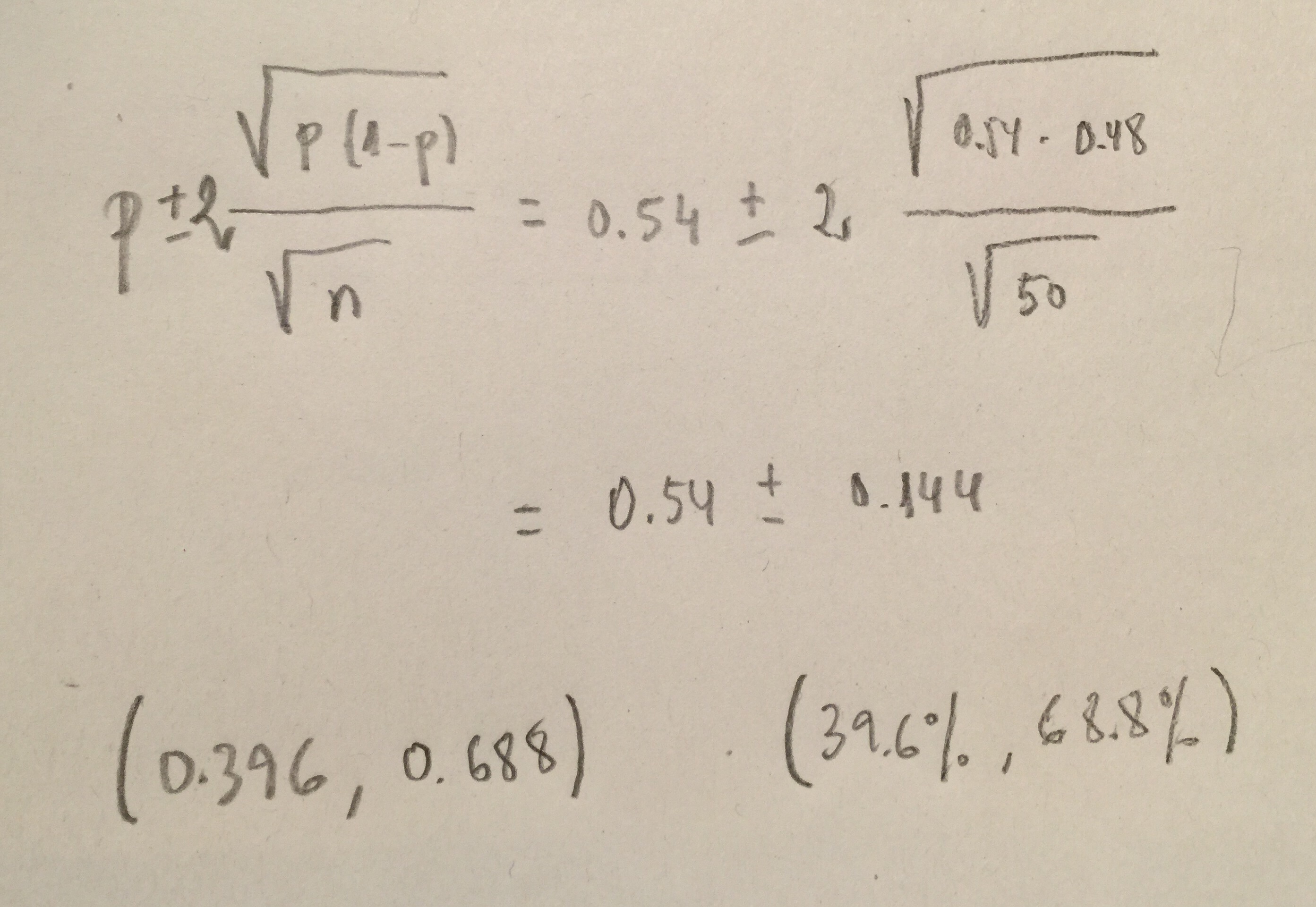
Los resultados no son exactamente iguales porque aunque la fórmula se use el 2, el valor correcto es 1,96 lo que hace que el intervalo exacto, que es el que calcula todo software, sea un poco más estrecho.
e) Para construir un IC del 95% de la media del coeficiente de inteligencia basta tener la media y sumarle y restarle dos veces el error estándar, porque estamos ante una predicción y porque el intervalo es del 95%.
En el grupo control:
Media=105.78
EE=1.65
IC95% de la media: (102.48, 109.08)
En el grupo del trastorno bipolar:
Media=102.2
EE=1.33
IC95% de la media: (99.54, 104.86)
2. Técnicas de relación:
a) Calcular la correlación entre la variable Edad y la variable Coeficiente de inteligencia.
b) ¿Hay relación entre el sexo y tener o no trastorno bipolar?
c) Estudiar si son factores de riesgo o de protección para tener Trastorno bipolar las siguientes variables: Diabetes, Autovaloración negativa, Antecedentes de trastorno bipolar.
Soluciones:
a) Si se calcula la correlación de Pearson se obtiene una R=-0.2593 (p=0.009). Por lo tanto, hay una correlación negativa significativa. Es cierto que una variable (la Edad) no se ajusta bien a la distribución normal y podría calcularse la correlación de Spearman, pero la anormalidad es muy poca y no es tan problemático su incumplimiento a la hora de calcular una correlación de Pearson. No obstante, calcular la de Spearman es perfectamente correcto.
Vista esta correlación deberíamos decir que la gente más joven es ligeramente más inteligente, al ser la correlación negativa. Sin embargo, se trata de una correlación muy débil.
b) Si se hace una ji-cuadrado se detecta una relación estadísticamente significativa (p=0.037 entre sexo y Trastorno bipolar. Los que indica una asociación entre el sexo y esa patología.
c) Las Odds ratio y su intervalo de confianza del 95% son las siguientes:
Diabetes: OR=0.64 (0.12, 2.91)
Autovaloración negativa: OR= 3.54 (1.37, 9.38)
Antecedentes familiares: OR= 6.16 (2.23, 18.05)
Por lo tanto, la diabetes no es un factor ni de riesgo ni de protección. La autovaloración negativa es un factor de riesgo. Tener antecedentes familiares es un factor de riesgo. Observemos que con antecedentes tendrías 6 veces más probabilidad de tener ese trastorno que sin tenerlos.
3. Técnicas de comparación:
a) Hacer una comparación de las medias de la variable Edad entre el grupo control y el grupo de pacientes con trastorno bipolar.
b) Hacer una comparación de los porcentajes de mujeres entre el grupo control y el grupo de pacientes con trastorno bipolar.
c) Hacer una ANOVA de dos factores con interacción de la variable Coeficiente de inteligencia y los factores grupo (Control y Trastorno bipolar) y sexo (Hombre y Mujer).
Soluciones:
a) La variable es continua, las muestras son independientes. Si se aplica el test de Shapiro-Wilk para comprobar la normalidad la muestra del grupo control da un p-valor superior a 0.05 y la muestra del grupo del transtorno bipolar da un p-valor inferior a 0.05. Como no ambas muestras se ajustan a la distribución normal debemos aplicar el Test de Mann-Whitney. Si aplicamos este test el p-valor es superior a 0.05, por lo que la mediana de edad de ambos grupos no es distinta significativamente.
b) La variable es dicotómica. La muestras son independientes. El tamaño de muestras es superior a 30 y el valor esperado por grupo mayor que 5. Debemos aplicar un test de proporciones. Da un p-valor de 0.032, lo que indica que la proporción de mujeres en ambos grupos es distinta significativamente.
c) El ANOVA de dos factores da un p-valor menor que 0.05, en cada uno de los dos factores, y un p-valor superior a 0.05 en la interacción. Como se trata de dos factores con dos niveles cada uno es evidente que únicamente tenemos dos grupos homogéneos en cada uno de los dos factores.
