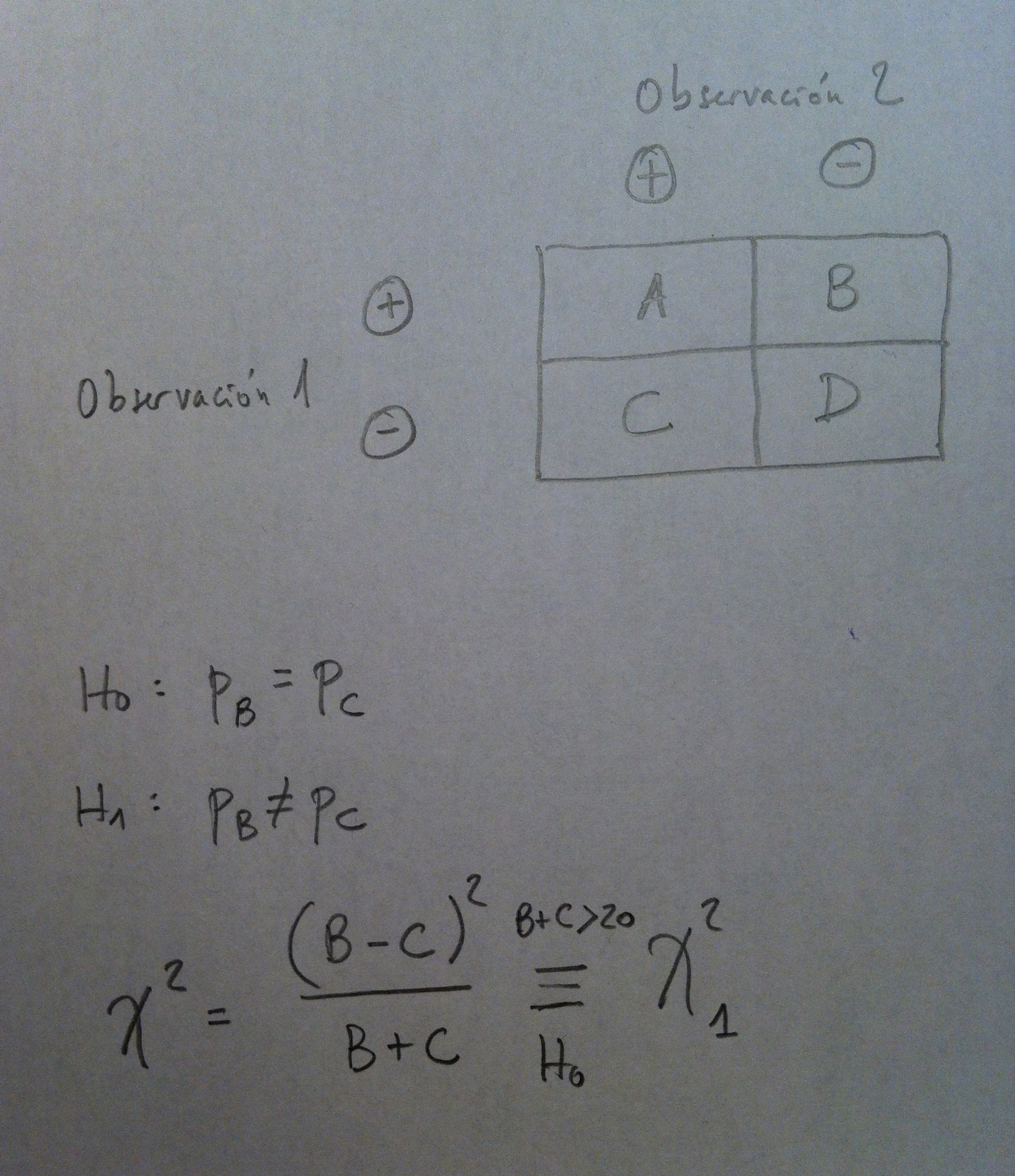
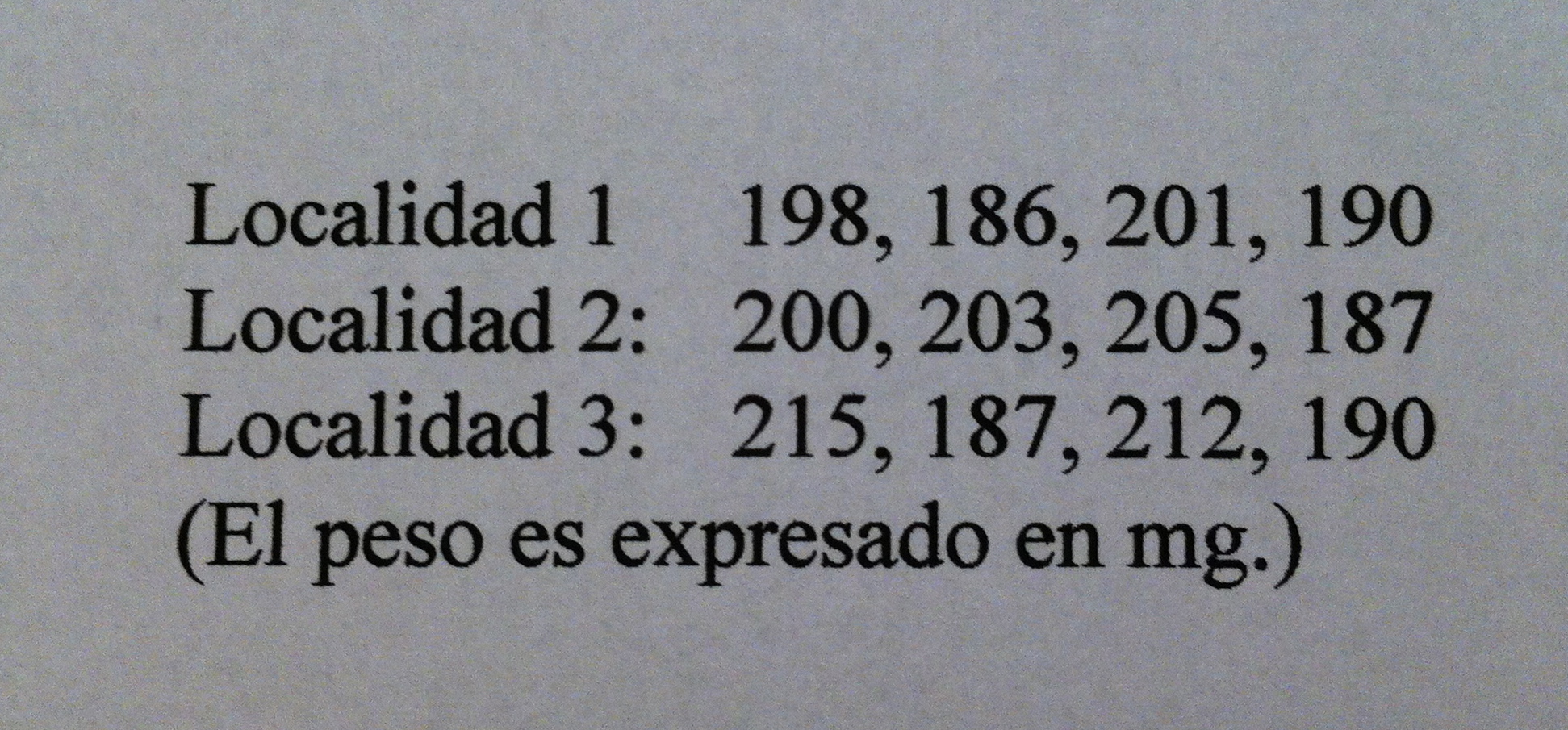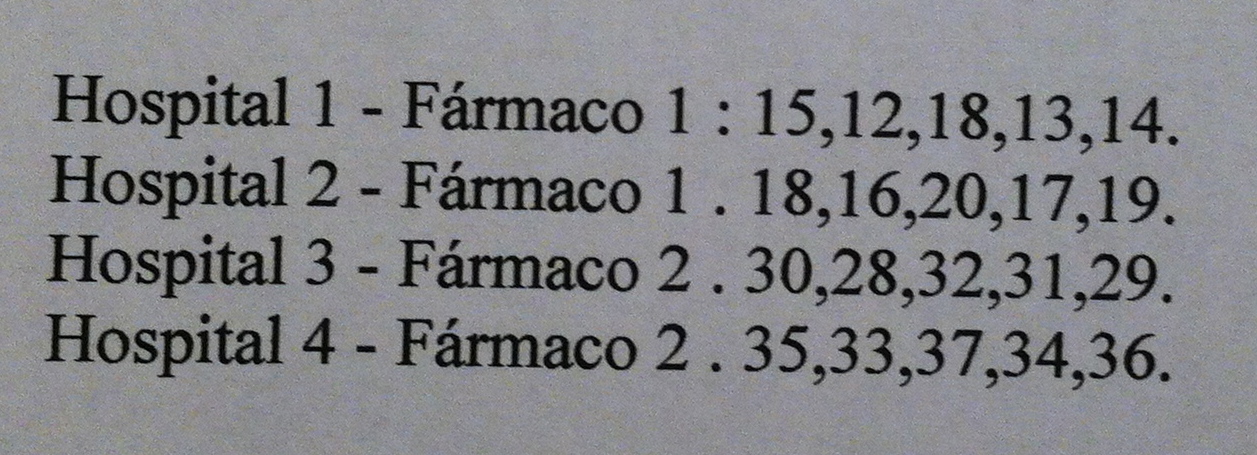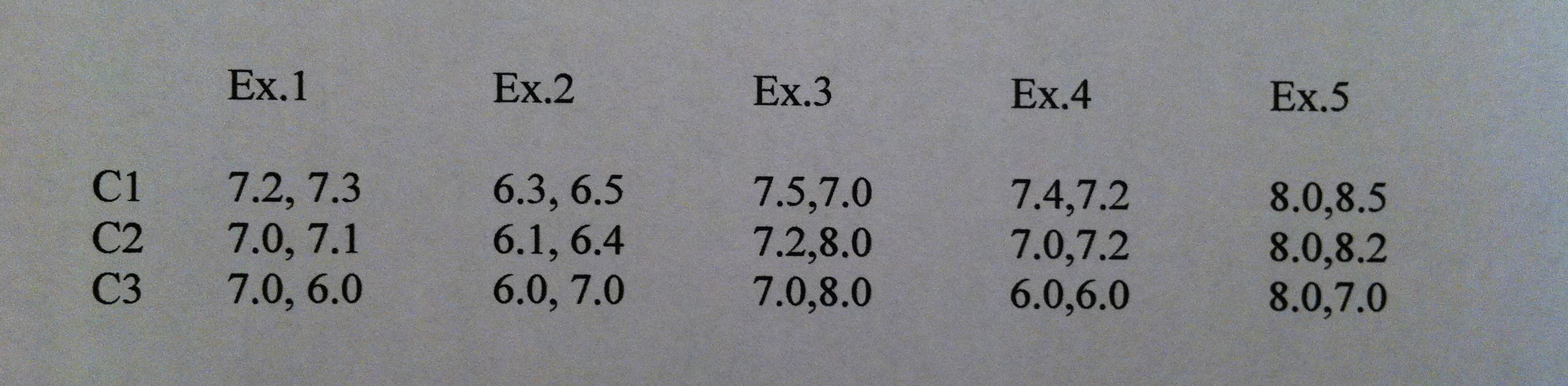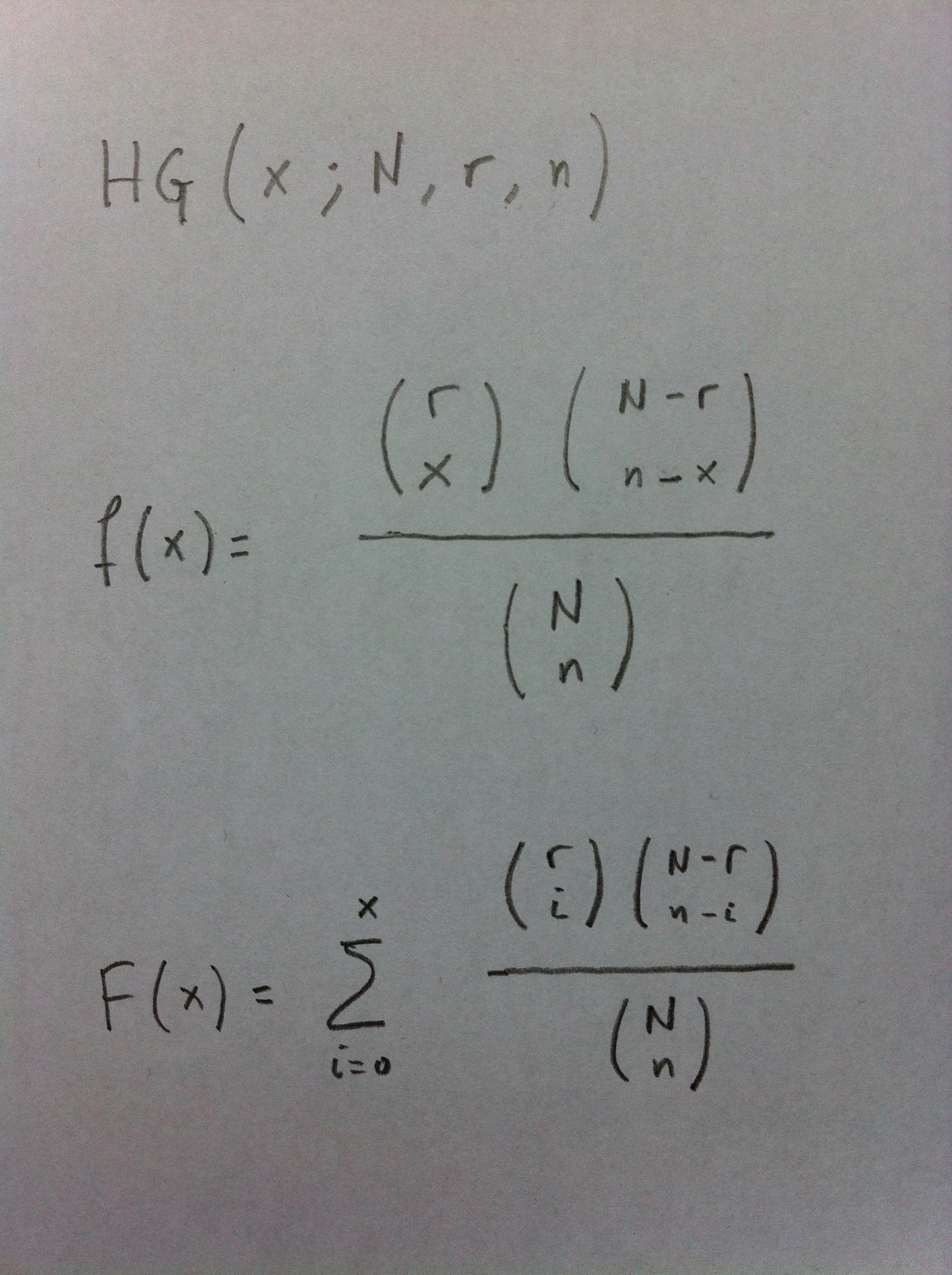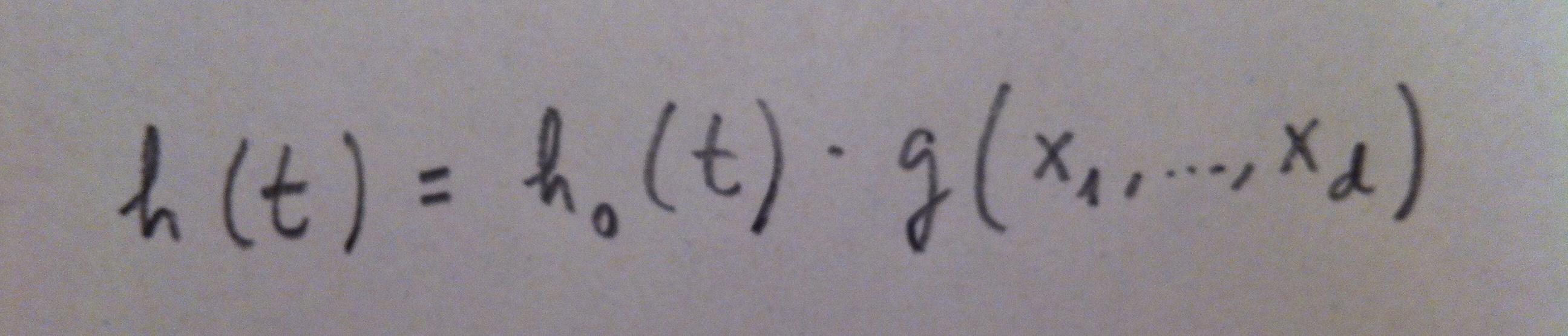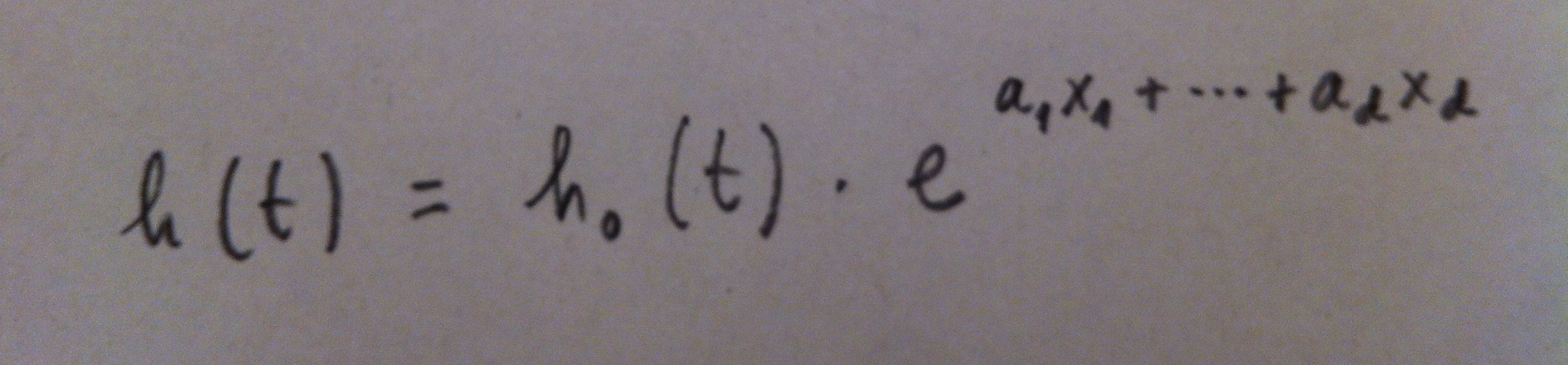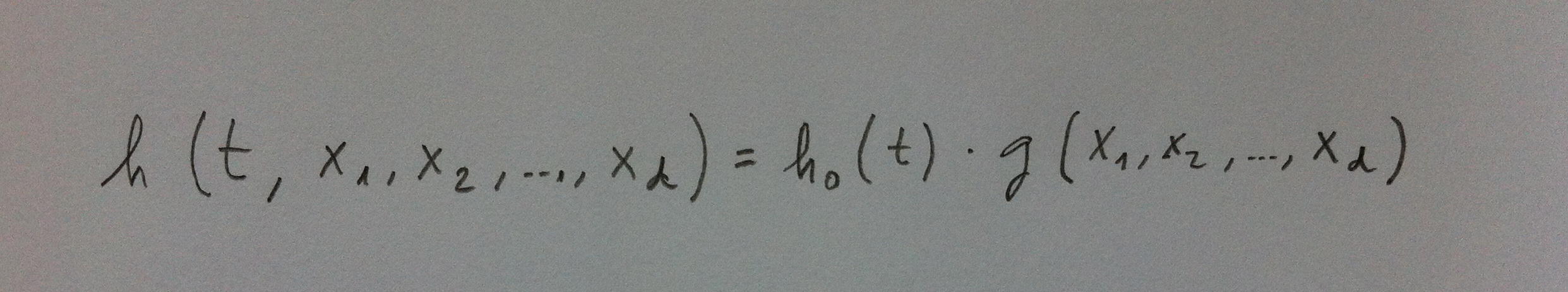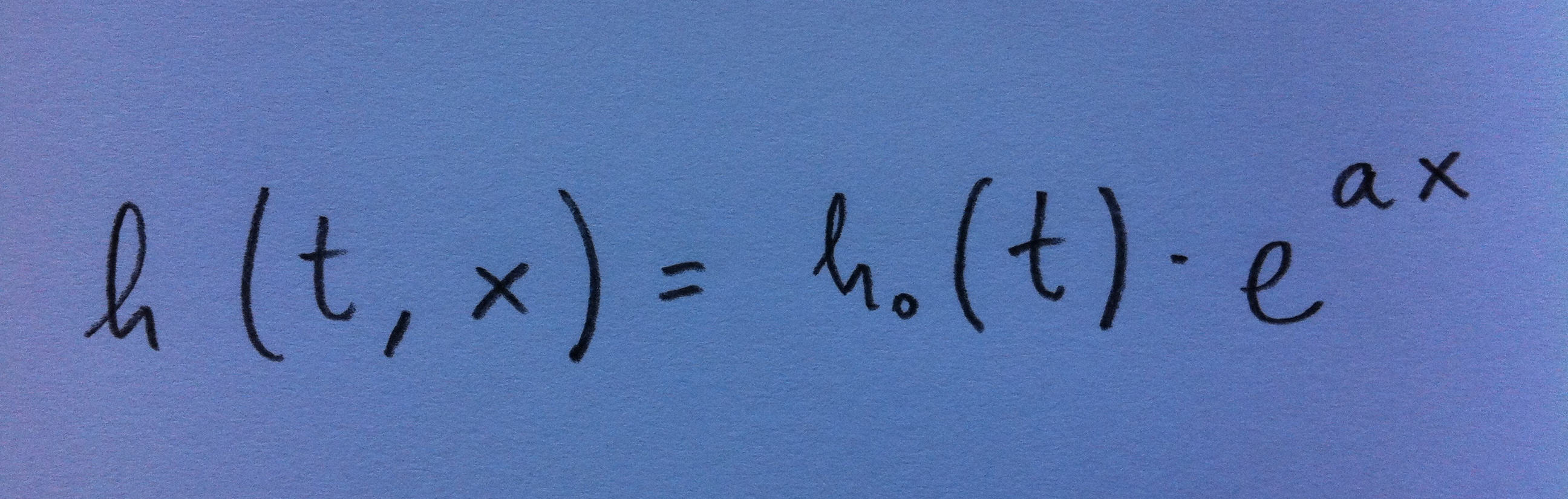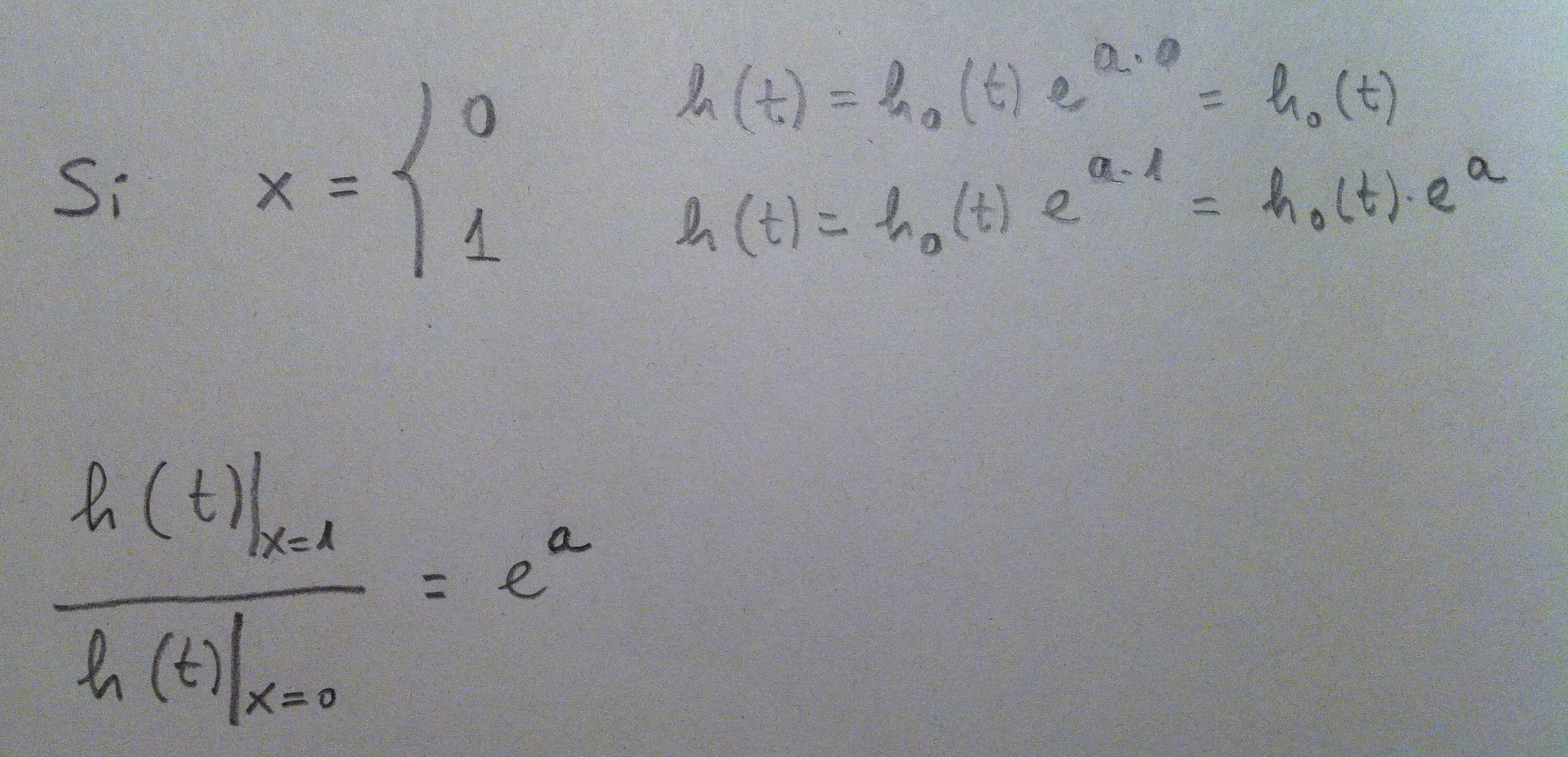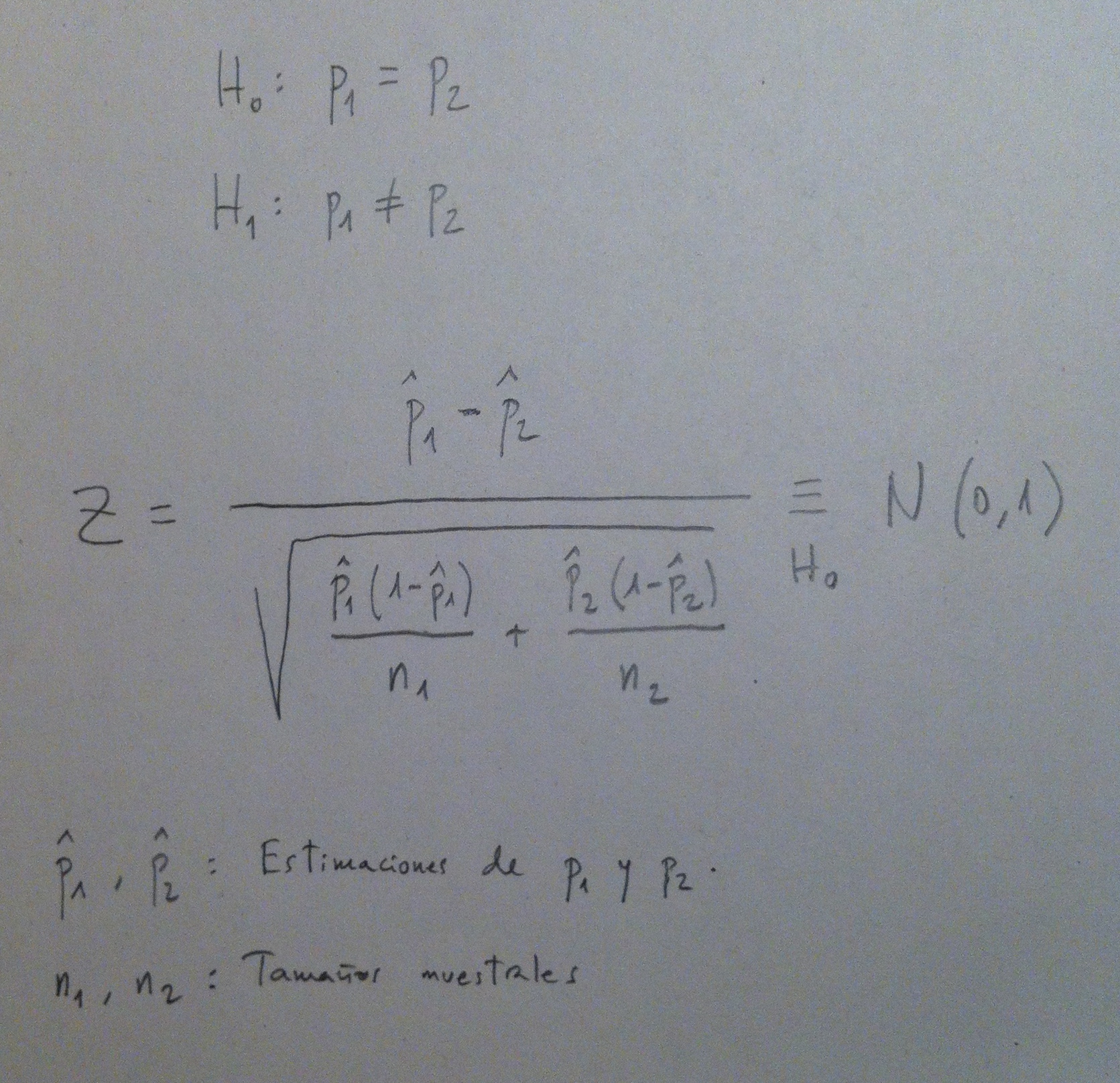El objetivo es comparar dos proporciones en datos apareados, en datos que han sufrido dos tratamiento o dos condiciones que se quieren comparar. La situación es, pues, como la expresada en el siguiente gráfico, con el siguiente contraste de proporciones y con el estadístico de test siguiente:
1) Se quiere saber si existen diferencias entre tres localidades concretas (1, 2 y 3) en el peso del insecto Tribolium castaneum. Se recogen muestras de estas tres localidades, obteniéndose los siguientes resultados:
Se quiere ver si hay diferencias significativas en cuanto al peso de este insecto entre las tres localidades.
1 bis) Se quiere saber si existen diferencias entre localidades en cuanto al peso del insecto Tribolium castaneum. Se recogen muestras de tres localidades elegidas al azar, entre las muchas donde se encuentra este organismo, obteniéndose los siguientes resultados:
Se quiere ver si hay diferencias significativas en cuanto al peso de este insecto entre localidades.
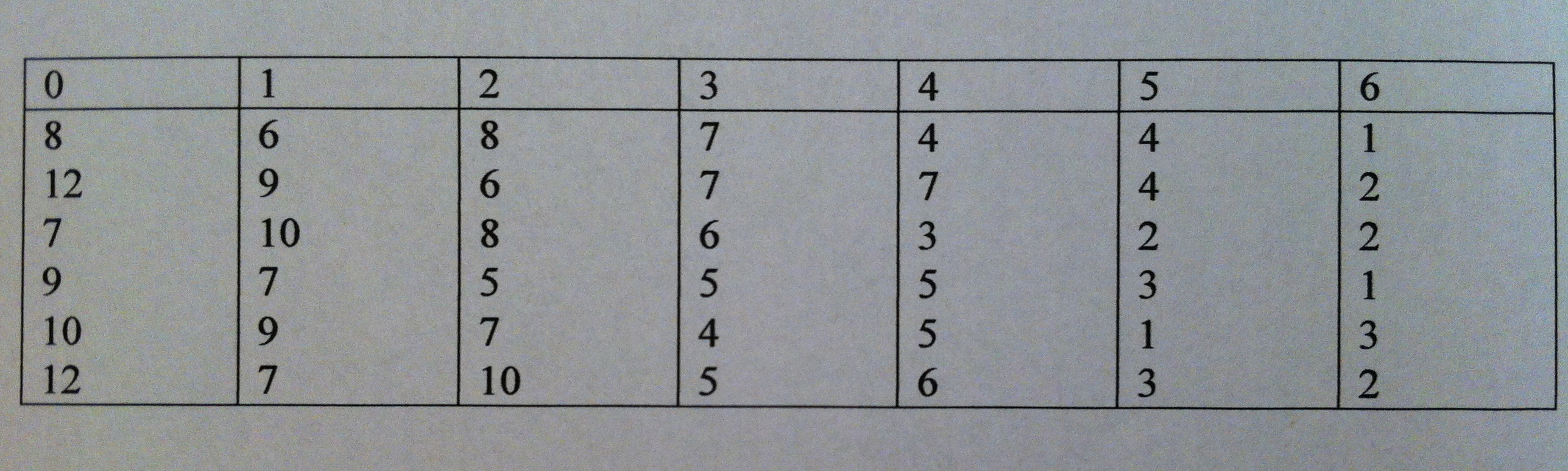
2) De las siete posibles discordancias entre alelos de HLA se ha realizado un estudio del tiempo hasta el rechazo de un trasplante de riñón. Los resultados obtenidos son los siguientes:
(Cada columna tiene en su cabecera el número de discordancias entre los seis alelos (de 0 a 6), debajo constan el tiempo hasta el rechazo, expresado en años)
¿Podemos decir que hay diferencias significativas entres los distintos niveles de discordancias?
3) Se ha realizado un estudio clínico para ver si las vitaminas A y E mejoran la resistencia de la mucosa ante la afonía. Para ello se han seleccionado 12 profesores con problemas de afonía y con un nivel de resistencia de la mucosa muy similar. Se han distribuido en cuatro grupos. Durante tres meses un grupo tomó placebo, otro sólo vitamina A, otro grupo sólo vitamina E y finalmente el cuarto grupo tomó vitamina A y vitamina E conjuntamente. Se midió un índice de resistencia de la mucosa que va del 0 al 100. Los resultados obtenidos fueron los siguientes:
¿Qué conclusiones podemos obtener de estos datos?
4) El asma bronquial es una enfermedad alérgica cuya virulencia depende de la estación. Se desean comparar tres fármacos antihistamínicos A, B, C en las cuatro estaciones del año. Se toma una muestra de 48 personas con asma crónico de intensidad análoga, que se divide en 12 grupos, uno para cada fármaco y estación, a razón de 4 enfermos por grupo. Los resultados se evaluaron en una escala objetiva que iba de 0 a 100 y fueron los siguientes:
¿Qué conclusiones podemos obtener de estos datos?
4 bis) El asma bronquial es una enfermedad alérgica cuya virulencia depende de la estación. Se desean comparar los fármacos antihistamínicos para ver si hay una variabilidad significativa entre ellos. Se elige una muestra de tres antihistamínicos (A, B y C). Se toma una muestra de 48 personas con asma crónico de intensidad análoga, que se divide en 12 grupos, uno para cada fármaco y estación, a razón de 4 enfermos por grupo. Los resultados se evaluaron en una escala objetiva que iba de 0 a 100 y fueron los siguientes:
¿Qué conclusiones podemos obtener de estos datos?
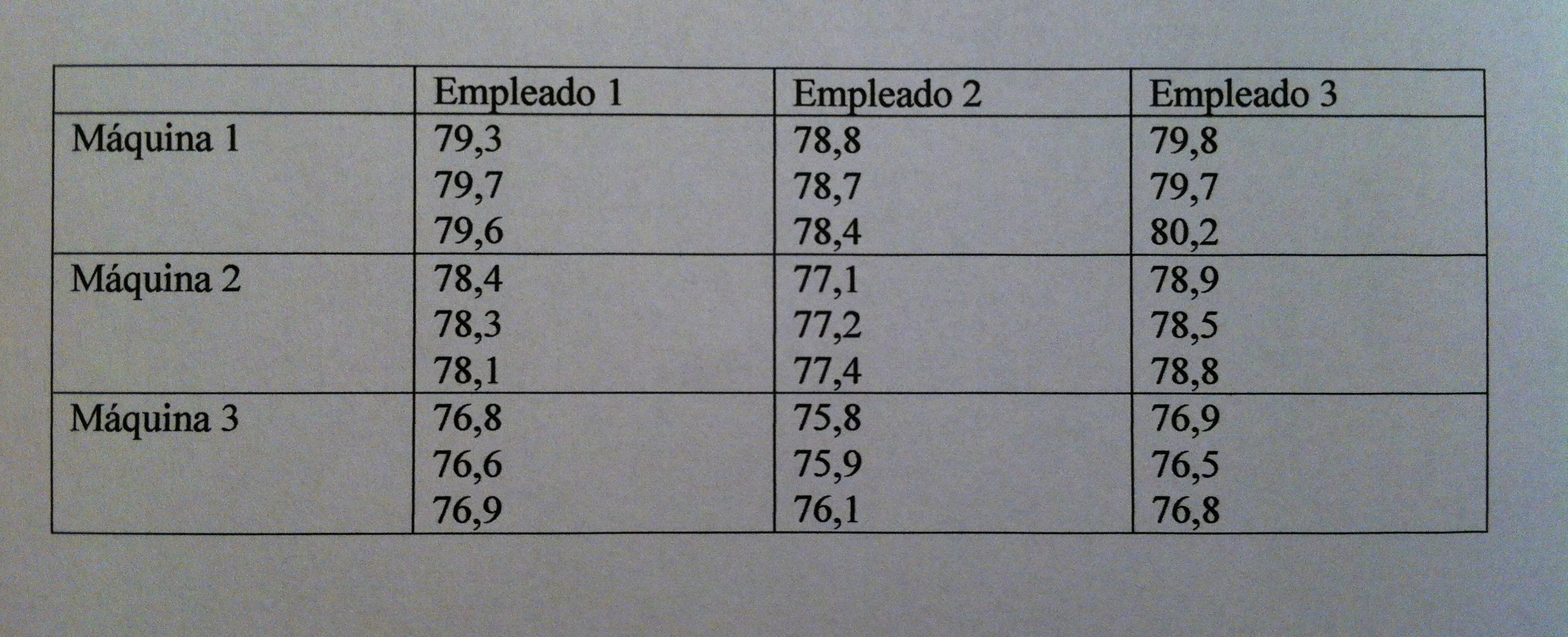
5) En una planta de producción trabajan 50 empleados y hay 25 máquinas. Existen dos turnos de trabajo. Es muy importante la rapidez en la que se elaboran unas piezas. Se quiere valorar si existe diferencia en el tiempo de producción según empleado, según máquina y, también, se quiere saber si los empleados trabajan más o menos rápido según la máquina con la que trabajen. Se eligen tres empleados al azar y tres máquinas también al azar. Se mide el tiempo, en segundos, que tardan en elaborar tres piezas cada empleado en cada máquina. Los resultados son los siguientes:
¿Qué conclusiones podemos obtener de estos datos?
6) Se quiere estudiar la contaminación por dióxido de azufre durante el verano en una zona del Montseny. El análisis se hace en tres días tomados al azar en el mes de Julio y tres días también tomados al azar en el mes de Agosto. En cada día designado se toman cuatro registros de la variable y los resultados son los siguientes:
¿Qué podemos concluir a partir de estos datos?
¿Qué cambios se producirían en el planteamiento si los tres días de Julio y los tres de Agosto se han tomado buscando que fueran: uno soleado, otro parcialmente nuboso y otro completamente nuboso?
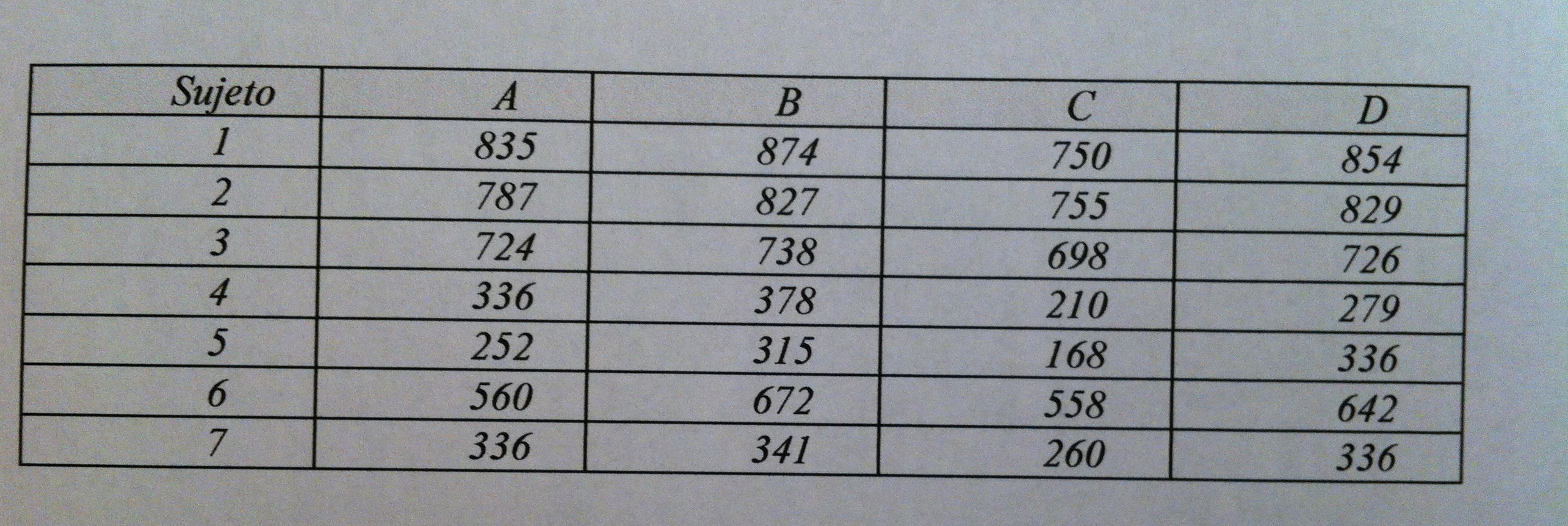
7) Los cigarrillos producen cantidades apreciables de monóxido de carbono. Cuando se inhala el humo del cigarrillo, el monóxido de carbono se combina con la hemoglobina para formar carboxihemoglobina. En un estudio reciente ( Carbon monoxide and exercise tolerance in chronic bronchitis and emphysema, Brit.Med.J. 283(1981) 877-880, Calvery,M.A. y otros) los investigadores deseaban determinar si una concentración apreciable de carboxihemoglobina reduce la tolerancia al ejercicio en aquellos pacientes que sufren de bronquitis crónica y enfisema. Se seleccionaron 7 pacientes y en un ambiente controlado, se les pidió que caminaran durante 12 minutos respirando cada una de las siguientes combinaciones gaseosas: aire, oxígeno,aire más monóxido de carbono y oxígeno más monóxido de carbono (respectivamente A,B,C,D). La cantidad de monóxido de carbono respirado fue suficiente para elevar la concentración de carboxihemoglobina de cada sujeto en 9%. Para controlar el consumo de monóxido de carbono, se pidió a los siete fumadores que dejaran de fumar 12 horas antes del experimento. Los datos representan las distancias caminadas por los sujetos (en m.) en los 12 minutos para cada condición experimental.
Estudiar si las diferencias entre las mezclas gaseosas son significativas.
8) Se ha medido la longitud del ala en dos especies de Drosophilla : melanogaster y simulans, mantenidas en condiciones de laboratorio. Las mediciones se hicieron en poblaciones capturadas en dos áreas de interés especial Los resultados fueron los siguientes :
¿Qué conclusiones podemos obtener de estos datos?
9) Se desea comparar el efecto de dos fármacos antidepresivos concretos. Se eligen 4 hospitales concretos que también nos interesa comparar. Cada hospital ensaya sólo un fármaco. Dentro de cada hospital se eligen 5 pacientes al azar. Se mide el grado de efectividad del fármaco de acuerdo a una variable que recoge la mejoría del estado después de la administración del fármaco. Se considera normalidad para la variable observada y homocedasticidad. Los datos obtenidos son:
¿Qué conclusiones podemos obtener de estos datos?
10) Se toman 15 exámenes al azar de una misma materia de las PAAU y se eligen, también al azar, 3 correctores. Estos 15 exámenes se dividen al azar en tres grupos de 5. De cada uno de estos exámenes se hace una copia. Después, cada grupo de cinco exámenes, con sus copias, se mezcla junto con 200 exámenes más que tiene que corregir cada corrector, de modo que cada corrector habrá corregido dos veces cada uno de los cinco exámenes seleccionados al azar para él, sin saberlo, evidentemente. Las notas que los profesores han proporcionado de los 15 exámenes seleccionados han sido las siguientes:
¿Qué conclusiones podemos obtener de estos datos?
11) En una zona que ha padecido recientemente una fuerte contaminación se desea estudiar la concentración de un determinado elemento. Después de ciertos análisis se supone una media de alrededor de 30 unidades. Sin embargo, una concentración superior a 37 unidades supondría un tóxico letal para la fauna que entrara en contacto. Algún científico desplazado para el estudio opina que sólo un 1% de la zona puede presentar tal concentración. No contentos con dicha afirmación, deseamos realizar un experimento con el fin de contrastar las opiniones del científico. Para ello se toman muestras de 3 zonas tomadas aleatoriamente en la zona global afectada. De cada zona se toman muestras de 2 subzonas y se realiza análisis y contraanálisis, puesto que sospecha de una cierta variabilidad en la toma de la medida. Los datos obtenidos son:
¿Qué conclusiones podemos obtener de estos datos?
12) Se ensayan tres tipos de motor de coche (A, B, C), con tres tipos de ruedas (P, Q, R) y con tres tipos de asfalto (M, N, O) para ver qué factor tiene una mayor influencia en el consumo de un tipo de gasolina durante 100 km a una velocidad constante. Para ello si diseña un experimento en cuadrados latinos y se obtienen los siguientes resultados:
¿Qué conclusiones podemos obtener de estos datos?
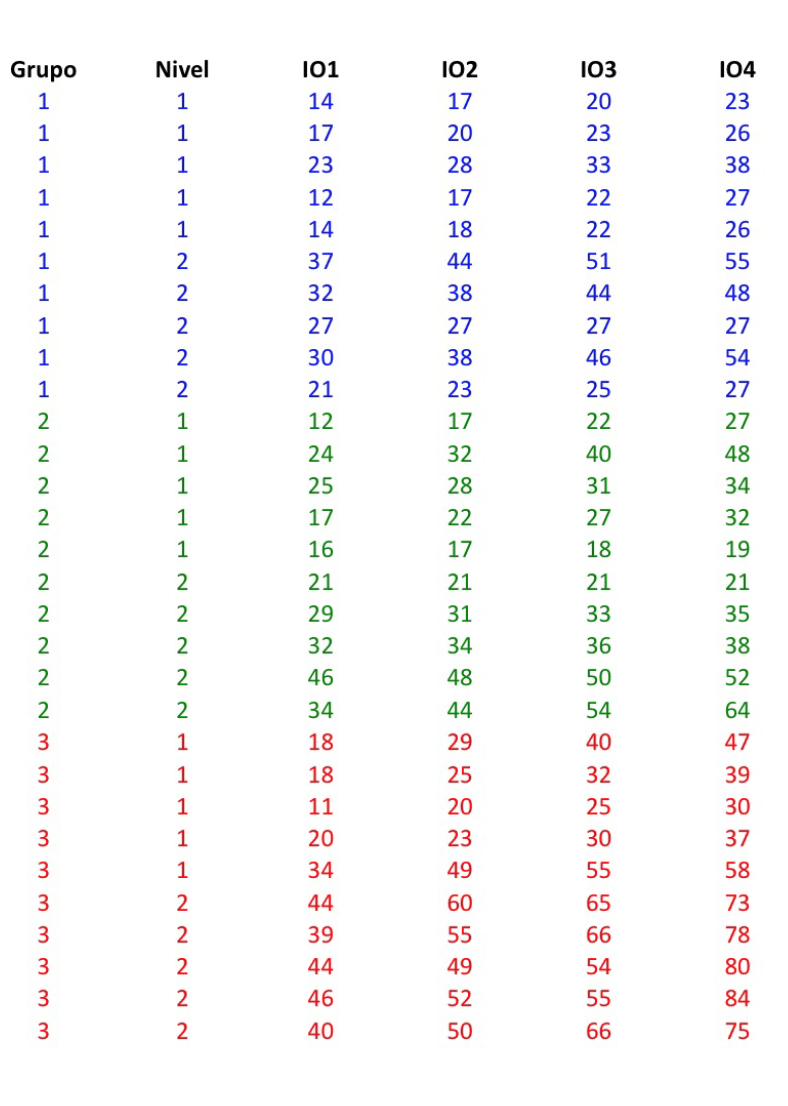
13) Tenemos 30 alumnos que al final de sus estudios de primaria y antes de comenzar la ESO se les hace una prueba homologada de nivel de inglés escrito y de nivel de inglés oral. A continuación se distribuyen en tres grupos en un centro de bachillerato donde se va a realizar un experimento didáctico durante toda la ESO. Los primeros 10 (el grupo 1) van a un grupo Control donde realizarán la formación de inglés clásica en una asignatura anual de inglés cada uno de los cuatro cursos. El grupo 2 se integra en un grupo donde se realizan dos horas más semanales de inglés, pero mediante el método clásico. El grupo 3 se integra en un grupo donde cada año van a tener una asignatura (Biología, Física, Matemáticas, etc.) en inglés. Aunque en el centro son muchos los alumnos distribuidos de esta forma se ha hecho un seguimiento focalizado de estos 30 alumnos. (En realidad, esto se podría hacer con todos los alumnos pero lo supongo así para que el número de datos a manejar sea más pequeño y se pueda apreciar, mirando los datos, lo que las técnicas van mostrando).
Estos alumnos integrados en sus grupos respectivos van a ser sometidos a un examen de inglés oral al final de cada curso: IO1, IO2, IO3 e IO4.
De los 10 alumnos de cada grupo se han tomado 5 con un nivel de aprobado únicamente de primaria y otros 5 con un nivel de notable o sobresaliente de primaria. Son los dos grupos de la columna encabezada como Nivel.
El Test exacto de Fisher es un contraste de hipótesis muy interesante por sus muchas aplicaciones y porque es un muy útil escenario para aprender la lógica interna de un contraste de hipótesis.
Se aplica en las siguientes situaciones: 1) En la comparación de dos grupos respecto a una variable dicotómica. 2) En la valoración de la relación entre dos variables cualitativas dicotómicas cada una de ellas.
En ambos casos, que son equivalentes (son dos formulaciones distintas de lo mismo), los datos pueden organizarse en una tabla de contingencias de 2×2 ó mediante dos porcentajes a comparar, uno de cada grupo.
El primer caso se resuelve habitualmente con un Test de comparación de dos proporciones (Ver Herbario de técnicas y ver también el Tema dedicado a la comparación de dos poblaciones), el segundo caso se resuelve con un Test de la ji-cuadrado de tablas de contingencias. El problema que tienen ambos test es que necesitan de tamaños muestrales relativamente grandes.
El Test de comparación de proporciones, para funcionar bien, requeriría un tamaño muestral mínimo de 30 por grupo y que el producto del tamaño muestral por el tanto por uno esperado bajo la hipótesis nula del suceso que se analiza sea superior o igual a 5 en ambas muestras (esto último suele enunciarse como que el valor esperado por grupo es de 5 observaciones del suceso analizado, como mínimo). Un ejemplo: Tenemos una muestra de 50 por cada uno de los dos grupos. En una muestra tenemos sólo un caso del suceso analizado y en la otra tenemos 4 casos. Si la hipótesis nula fuera cierta esperaríamos ver 5 casos de cada 100 y los mismos en cada grupo; o sea, un 0.05 por uno. Si multiplicamos este 0.05 por 50 nos da 2.5 sucesos esperados por grupo. Como es menor que 5 estamos fuera de las condiciones de aplicación de este Test de comparación de proporciones y deberíamos aplicar el Test exacto de Fisher.
El Test de la ji-cuadrado en una tabla 2×2 requiere que las cuatro celdillas tengan más de 5 observaciones esperadas. Ambos Test utilizan un estadístico de test cuya distribución, bajo la Hipótesis nula, es la que suponemos que es, siempre y cuando se cumplan estos requerimientos en cuanto al tamaño muestral.
Por lo tanto, si tenemos muestras pequeñas, muestras que no cumplen estos requerimientos muestrales, tanto en un caso como en el otro, debemos decantarnos por la alternativa que nos ofrece este Test exacto de Fisher.
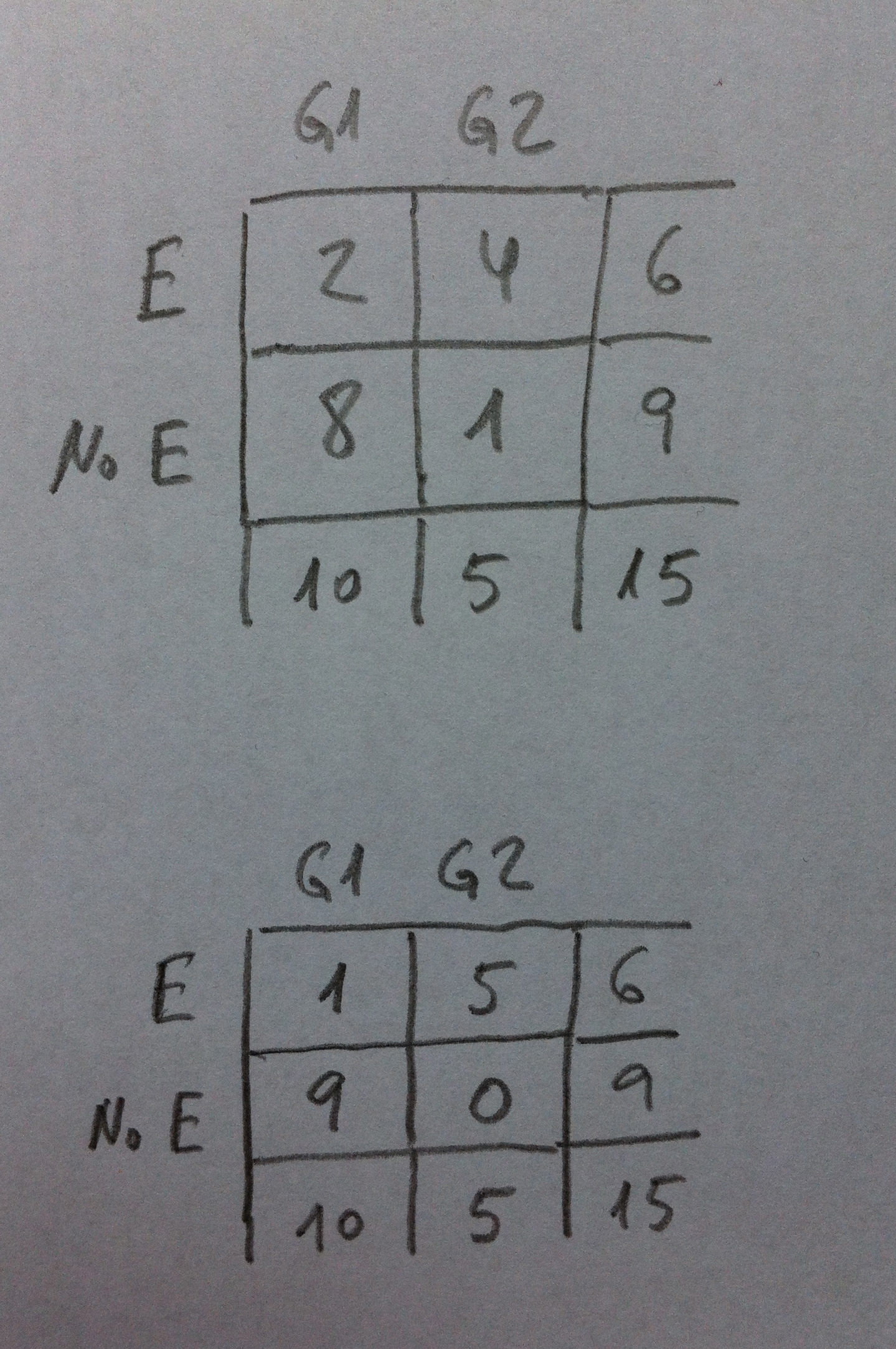
Supongamos el siguiente problema: Estamos comparando dos grupos de individuos y mirando cuántos, en cada grupo, tienen una determinada enfermedad y cuántos no la tienen. Y supongamos que tenemos los siguientes datos:
Observemos que los datos quedan organizados en forma de tabla de contingencias y que, al mismo tiempo, puede verse como un problema de comparación de dos proporciones, de dos porcentajes.
El Test exacto de Fisher se basa en la distribución hipergeométrica. Esta distribución es la que sigue una situación en la que hay N de posibles observaciones, distribuida en dos tipos distintos, en proporción r y N-r y donde realizaremos n observaciones sin repetición. La incertidumbre es ver cuántas de estas n observaciones que tenemos son de un tipo o del otro.
La distribución hipergeométrica paradigmática es la de extracciones de una urna con bolas (N) de dos colores en una determinada proporción (r y N-r), de la que se extraen bolas (n) sin reemplazamiento y se pretende ver la probabilidad de una determinada combinación (Ver en la sección de Complementos la explicación de la distribución).
Veamos ahora, a partir de los datos obtenidos, qué valores posibles hubiéramos podido tener que nos mostraran aún más diferencias entre los dos porcentajes o un patrón donde pudiéramos ver mayor relación entre grupo y enfermedad, respetando las sumas por filas y por columnas:
Observemos que la primera es nuestra tabla y la siguiente es la única tabla posible que agudiza más las diferencias o la relación entre las variables en el mismo sentido del visto en la muestra inicial.
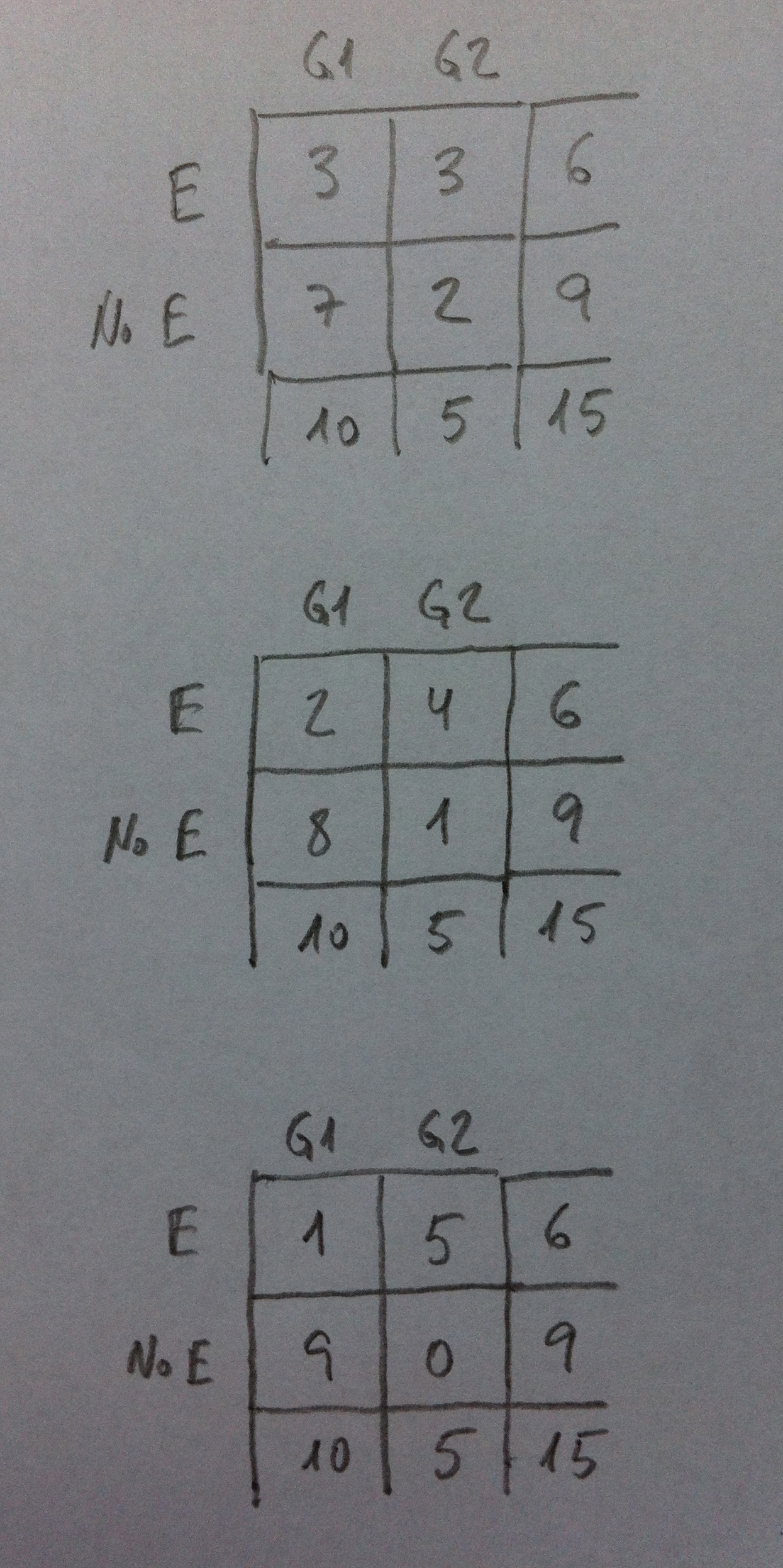
Si los datos que tuviéramos fueran estos otros:
Ahora las tablas posibles más extremas que la vista, y que respetaran las sumas por filas y por columnas, serían las siguientes:
Ahora tenemos tres tablas para evaluar.
El Test exacto de Fisher hace precisamente esto: buscar, a partir de unos datos, qué combinaciones serían más extremas que la vista. Extremas en cuanto a detectar más diferencia entre los porcentajes o más asociación entre los valores de las dos variables cualitativas que estamos relacionando.
A partir de este listado el Test calcula las probabilidades de cada una de esas situaciones: de la que tenemos y de las más extremas, mediante la distribución hipergeométrica.
Si es un Test bilateral; o sea, que contrastamos igualdad de porcentajes versus diferencia, o no relación versus relación, multiplicaremos por dos esa suma de probabilidades para tener el p-valor. Si el Test es unilateral; o sea, que estamos contrastando igualdad versus menor o versus mayor, o estamos contrastando no relación versus relación en un sentido determinado (con una Odds ratio menor o una Odds ratio mayor que 1, pero únicamente uno de los dos lados), el p-valor será sólo el de la suma de las probabilidades de las tablas extremas construidas, siempre, claro, hacia el lado donde tiene más peso la Hipótesis alternativa.
Al construir las tablas extremas, y calcular la suma de sus probabilidades, lo que hacemos es ver, de alguna forma, la posición que ocupa lo que vemos respecto a lo que podríamos ver bajo la Hipótesis nula. Entre todo lo que podríamos ver, si fuera cierta la Hipótesis nula, estamos valorando cuál es la probabilidad de ver lo que vemos más lo más extremo que tendría más posibilidades de verse bajo la Hipótesis alternativa. Esto es el p-valor. Y aquí está, en esencia, la noción de p-valor que manejamos en Estadística.
Los software estadísticos calculan estas probabilidades y nos proporcionan el p-valor según este criterio.
Veamos cómo calcularíamos estas probabilidades en las dos situaciones vistas anteriormente. Si aplicamos la función de densidad de la Distribución Hipergeométrica tendremos las siguientes probabilidades de cada una de las tablas mostradas anteriormente en las dos situaciones vistas:
Se calcula tanto el p-valor para el test unilateral como para el bilateral. El unilateral se entiende, claro, hacia el lado donde ya está inclinado el valor muestral.
Para calcular estos valores se dispone de tablas de esta distribución. Se trata de tablas muy largas, debido a que se trata de una distribución con tres parámetro y esto complica la elaboración de tablas, evidentemente.
En la siguiente tabla se muestra un pequeño fragmento de la tabla de la Hipergeométrica. Es un fragmento necesario para visualizar nuestros cálculos. Se trata de una N=15 porque el total de observaciones es 15. Como tenemos 6 y 9 valores entre enfermos y no enfermos la r será igual a 6, y la n será igual a 10, puesto que el grupo 1 está formado por 10. La tabla es de probabilidades acumuladas desde x=0 hasta el valor de interés. Por lo tanto, en nuestro caso, la primera suma de probabilidades que era 0,047 la observamos justo en el lugar de la tabla marcado en color azul. La segunda suma correspondiente al segundo caso, la suma de probabilidades (0,2868) la encontramos en el lugar marcado con el color rojo:
El Test exacto de Fisher, explicado con detalle en el Herbario de técnicas, es aplicado muy frecuentemente en Medicina.
Si son dos grupos los que se deben comparar para ver la diferencia de proporciones de una variable dicotómica o si lo que se quiere es ver la relación entre dos variables dicotómicas, y el tamaño muestral es pequeño, se impone el uso de esta técnica. Es frecuente encontrarse con pocos datos en Medicina y, por lo tanto, con la necesidad de aplicar este Test.
Veamos un caso interesante de aplicación de este Test en un artículo reciente y, además, en un artículo espectacular, sin lugar a dudas.
El artículo está publicado en Enero de 2013 en el New England Journal of Medicine y se titula Duodenal Infusion of Donor Feces for Recurrent Clostridium difficile.
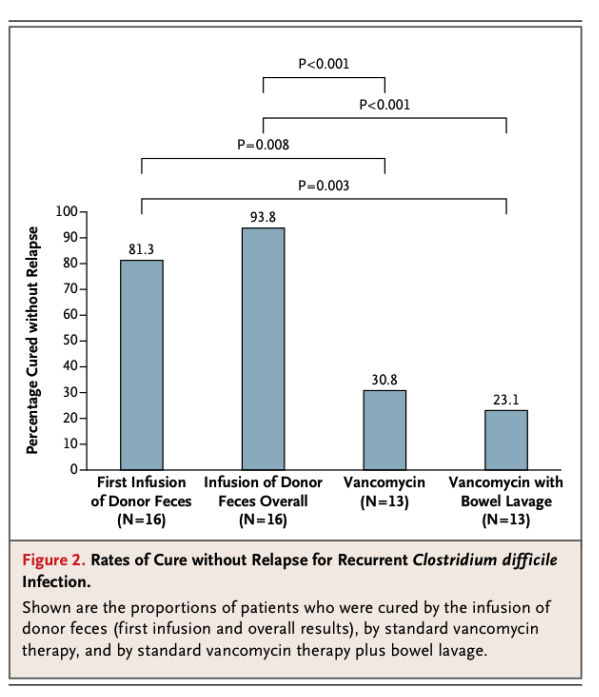
La tabla de datos fundamental del estudio es la siguiente:
Voy a aplicar el Test exacto de Fisher a uno de los casos que aparecen en este gráfico: a los datos comparativos de los pacientes tratados con «Infusión de donante de heces global» respecto a los tratados con Vancomicina. A partir de la información que nos dan podemos deducir que la tabla de 2×2 que tienen en este caso es la siguiente:
Estamos en un caso de aplicación del Test. Tenemos dos grupos: Pacientes tratados de dos formas distintas. Y una variable dicotómica: Se curan sin recidivas versus Otros casos.
Y si aplicamos el Test exacto de Fisher (Ver Herbario de técnicas) hemos de proceder buscando todas las tablas que, respetando el recuento de la suma por filas y por columnas, se decanten más hacia la Hipótesis alternativa, extremen más las diferencias. Veamos el cálculo:
Únicamente son dos las tablas a condiserar: la de los propios datos y la de debajo.
Como no he visto tablas para una N=29, he hecho los cálculos basándome en la Distribución Hipergeométrica (Ver Complementos).
El p-valor se calcula sumando estas dos probabilidades dando 0,000584. Como dice en el artículo se trata de un p-valor inferior a 0,001. Diferencias, pues, significativas.
Este es un caso claro de test unilateral, por eso no multiplicamos por 2 esa probabilidad, como haríamos si el test fuera bilateral. Observemos que se ensaya un método sorprendente: la infusión de heces de donante a un paciente con infección por Clostridium difficile. Únicamente tiene sentido una Hipótesis alternativa que vaya a favor del nuevo método. Es por esto que el test es unilateral. Si hacemos una prueba alternativa como ésta es para mejorar el tratamiento convencional.
La distribución hipergeométrica es la distribución que sigue la siguiente situación de incertidumbre: Tenemos N posibles observaciones, distribuidas en dos tipos distintos, en proporción r y N-r, y donde realizaremos n observaciones sin repetición. La incertidumbre es ver cuántas de estas n observaciones que tenemos son de un tipo o del otro.
La distribución hipergeométrica paradigmática es la de extracciones de una urna con bolas (N) de dos colores en una determinada proporción (r y N-r), de la que se extraen bolas (n) sin reemplazamiento y se pretende ver la probabilidad de una determinada combinación.
La función de densidad y la función de distribución de la distribución hipergeométrica es la siguiente:
Veamos un ejemplo con la situación paradigmática de urna y bolas de dos colores:
Existen tablas para valores concretos de N, de r y de n. Pero ocupan muchas páginas por la necesidad de ir combinando tres parámetros al mismo tiempo.
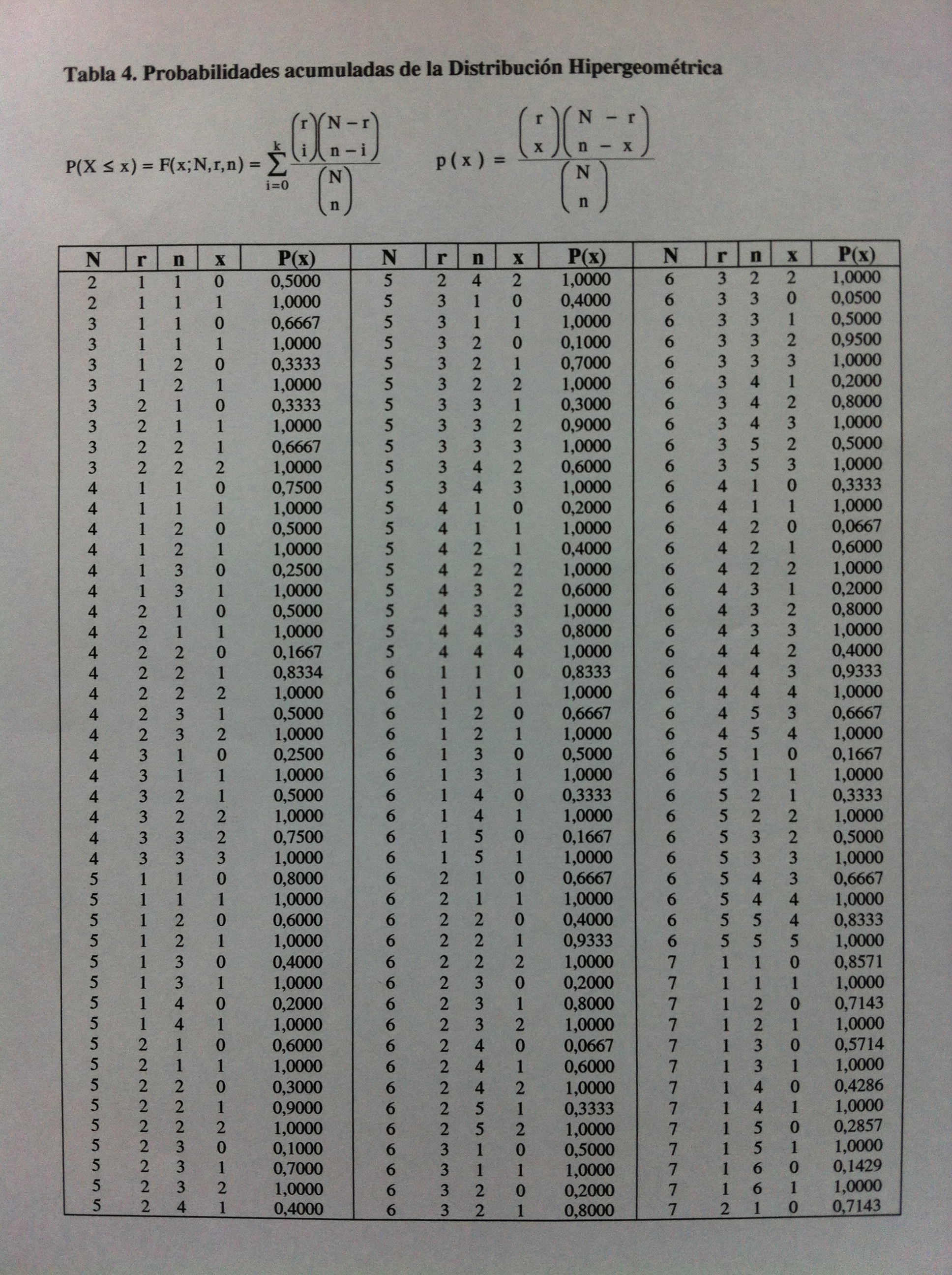
Para ver cómo funcionan las tablas aquí va la primera página. En ella se contemplan las situaciones en las que N es igual a 2, a 3, a 4, a 5 y a 6. El 7 no está completo:
Debe tenerse en cuenta que son tablas donde aparece el acumulado.
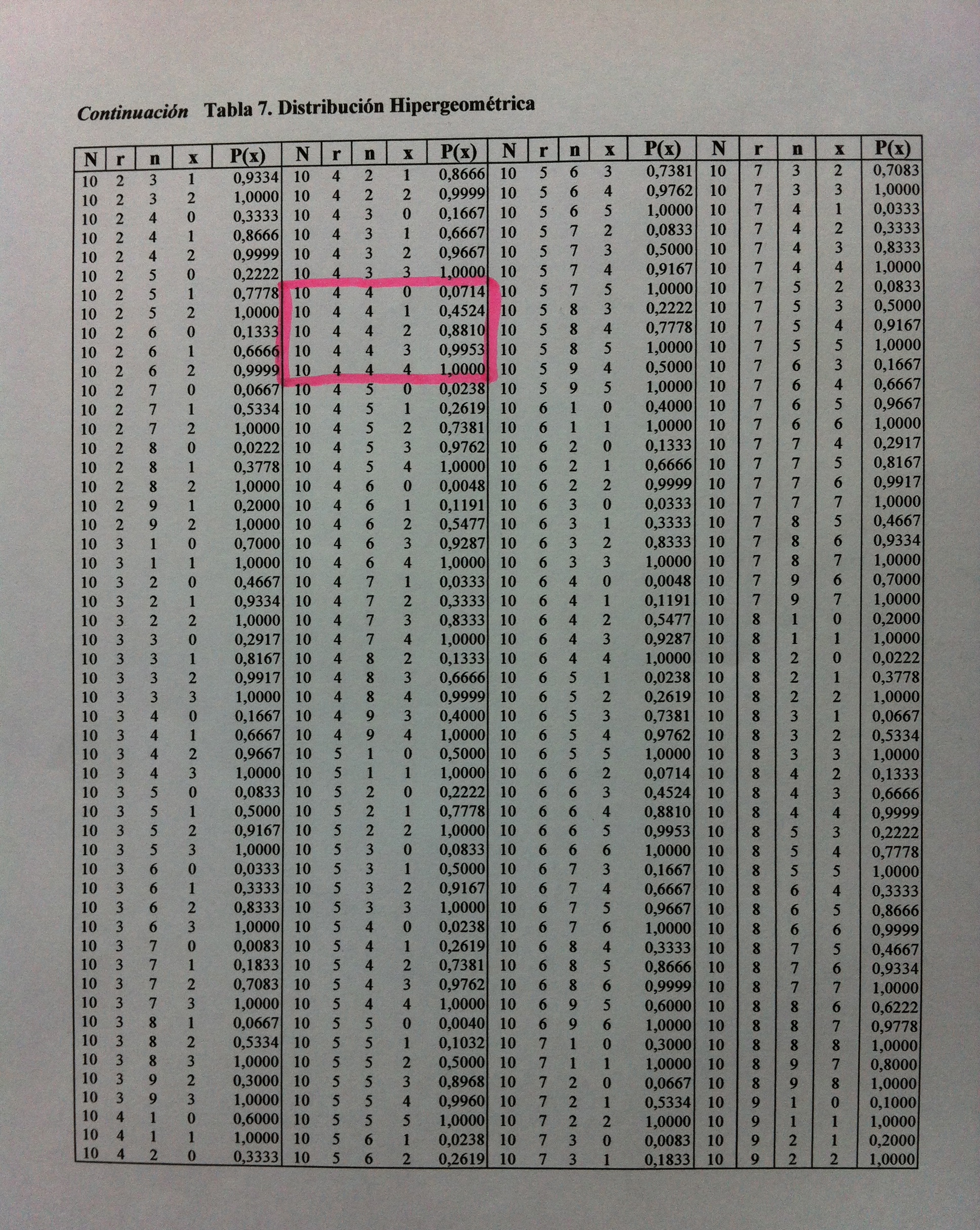
Para practicar un poco cuelgo el fragmento de la tabla donde poder calcular las probabilidades del ejemplo anterior. Nuestro caso tenía los siguientes parámetros: N=10, r=4 y n=4. Está enmarcada la zona de las probabilidades buscadas, para x=0, x=1, x=2, x=3 y x=4:
Para x=0, como puede verse, la probabilidad es 0,0714. Para x=1 hay que restarle a 0,4524 el valor de x=0. Será pues: 0,4524-0,0714=0,381. Para x=2 hay que restarle a 0,8810 el valor de x=1. Sólo este, porque en él ya está contemplado el valor x=0. Será pues: 0,8810-0,4524=0,4286. Y así podemos ir obteniendo las probabilidades de cada una de las posibles situaciones, obteniendo los valores vistos en el ejemplo anterior.
1. La Regresión de Cox se ha transformado, en los últimos años, en un instrumento de análisis estadístico muy utilizado, especialmente en el ámbito de la Medicina. En ese tipo de Regresión el interés es buscar variables independientes que se relacionen con variaciones en la función de supervivencia, o en la función de riesgo, de unos individuos respecto a un determinado suceso estudiado.
2. Estamos, pues, realmente, ante una Regresión. Una Regresión ciertamente especial porque el tiempo está siempre presente y porque la variable dependiente es siempre una función de riesgo o una función de supervivencia.
3. Con la Regresión de Cox se pretende, pues, detectar alguna relación entre el riesgo de que se produzca un determinado suceso estudiado (muerte, recidiva de un tumor, fracaso de un implante dental, diagnóstico de hipertensión, etc.), y una o varias variables independientes o explicativas.
4. La Regresión de Cox trabaja especialmente con la función de riesgo (Hazard función) que ya hemos visto en el tema dedicado al Análisis de supervivencia, pero, como veremos, cuando hablemos de función de riesgo podremos trasladar perfectamente las conclusiones a nivel de función o curva de supervivencia.
5. Se han desarrollado distintos modelos matemáticos que pretenden establecer una especie de desglose entre lo que podríamos llamar una función de riesgo subyacente, o pura, y un efecto de otras variables independientes explicando cambios en esta función de riesgo. En general, este modelo general se suele escribir así:
6. En concreto, la Regresión de Cox consiste en el siguiente caso concreto de esta relación, el expresado por la siguiente función:
7. Aunque ésta es la forma en la que suele escribirse el modelo de la Regresión de Cox, desde un punto de vista matemático lo correcto es escribirlo como una función de varias variables y, por lo tanto, quedarían, tanto la función general como la más concreta, en realidad, así:
8. Veremos luego, al visualizar estas funciones, al ver su representación, cómo estamos realmente tratando con funciones de varias variables. De la variable tiempo, siempre presente aquí, y de una o más variables independientes.
9. La Regresión de Cox nos permite evaluar, pues, de entre un conjunto de variables independientes candidatas, cuáles de ellas tienen una relación, una influencia, significativa, sobre la función de riesgo. Y, en definitiva, evidentemente, también, sobre la función de supervivencia, porque ambas funciones están íntimamente conectadas.
10. El instrumento fundamental de la Regresión de Cox es el Hazard ratio, la razón de riesgos, que no es más, como ya hemos visto en el tema dedicado al Análisis de supervivencia, que el cociente entre dos funciones de riesgo.
11. Supongamos, para simplificar las cosas, un caso de Regresión de Cox con una única variable independiente. El modelo sería, ahora, escrito ya en forma de función de dos variables (el tiempo y una única variable independiente), el siguiente:
12. La función Hazard ratio, en este caso, será la relación entre las dos funciones de riesgo que se establece en función de los cambios operados en esta variable independiente x.
13. Es importante comparar la Regresión de Cox con la Regresión logística. En la Regresión logística la variable dependiente dicotómica se ponía en relación con una variable independiente sin contemplar el tiempo o contemplándolo sólo de forma estática, viendo en un punto fijo del tiempo si el suceso estudiado ha acontecido o no, pero no teniendo en consideración en qué momento ha sucedido. Se llegaba a una situación como la siguiente (Ver el tema dedicado a la Regresión logística):
14. En la Regresión de Cox la variable dependiente dicotómica (ha sucedido o no el acontecimiento estudiado: muerte, recidiva, fracaso de un implante dental, diagnóstico de hipertensión, etc) no se analiza desglosada del tiempo, se analiza en el tiempo, en el momento de aparición, si es que aparece. No mira un punto fijo del tiempo para ver si ha acontecido o no el suceso estudiado, sino que se contempla en qué momento ha sucedido.
15. El Análisis de la Regresión de Cox es, pues, más fino. No analiza en un momento temporal si tal acontecimiento ha sucedido o no ha sucedido sino cuándo ha sucedido, si es que ha sucedido, y comparar esa función respecto a una o varias variables independientes. Por todo esto la Regresión logística trabaja con la Odds ratio y la Regresión de Cox con la Hazard ratio (Ver el artículo Odds ratio versus Hazard ratio).
16. Veamos, con un cierto detalle, qué sucede si la variable independiente x, en la Regresión de Cox, es dicotómica:
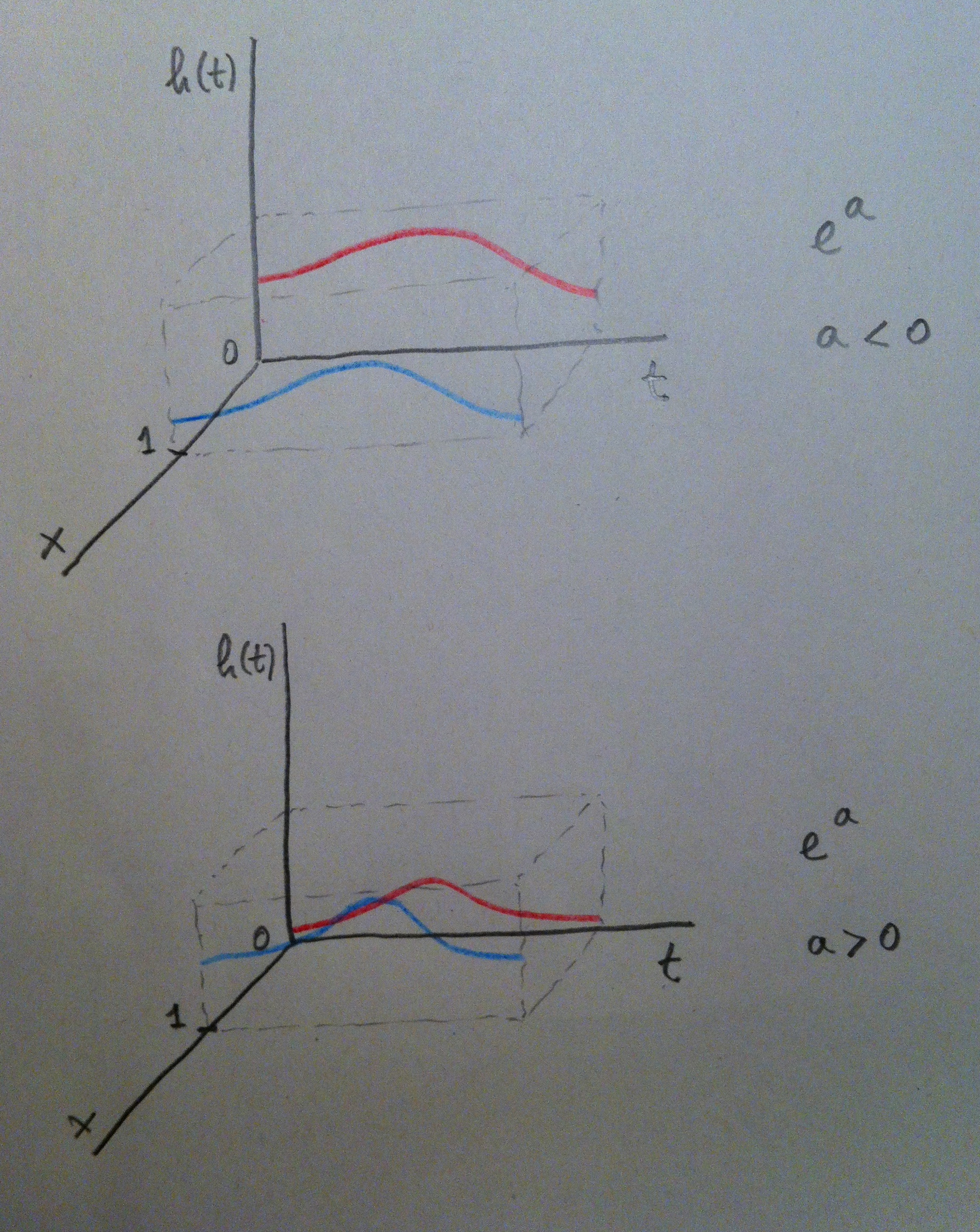
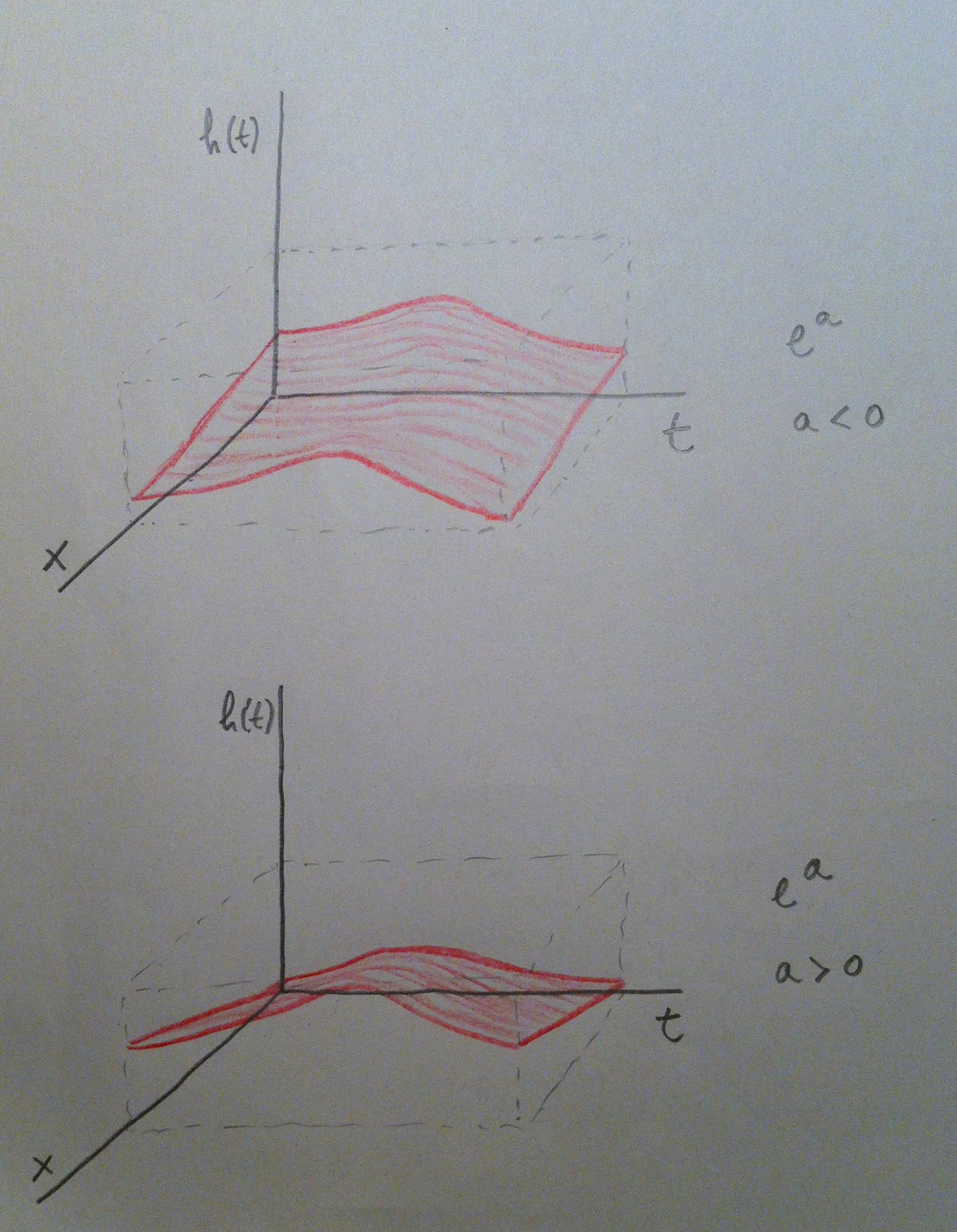
17. La variable independiente tiene así únicamente dos valores (el 0 y el 1). Si aplicamos la fórmula de la Regresión de Cox y luego hacemos el cociente de ambas funciones de riesgo observamos que obtenemos el valor Exp(a). Veamos cómo se entiende, gráficamente, el valor de este coeficiente a:
18. Veamos ahora una variable independiente continua, una variable con muchos valores posibles:
19. Y veamos cómo se entiende gráficamente:
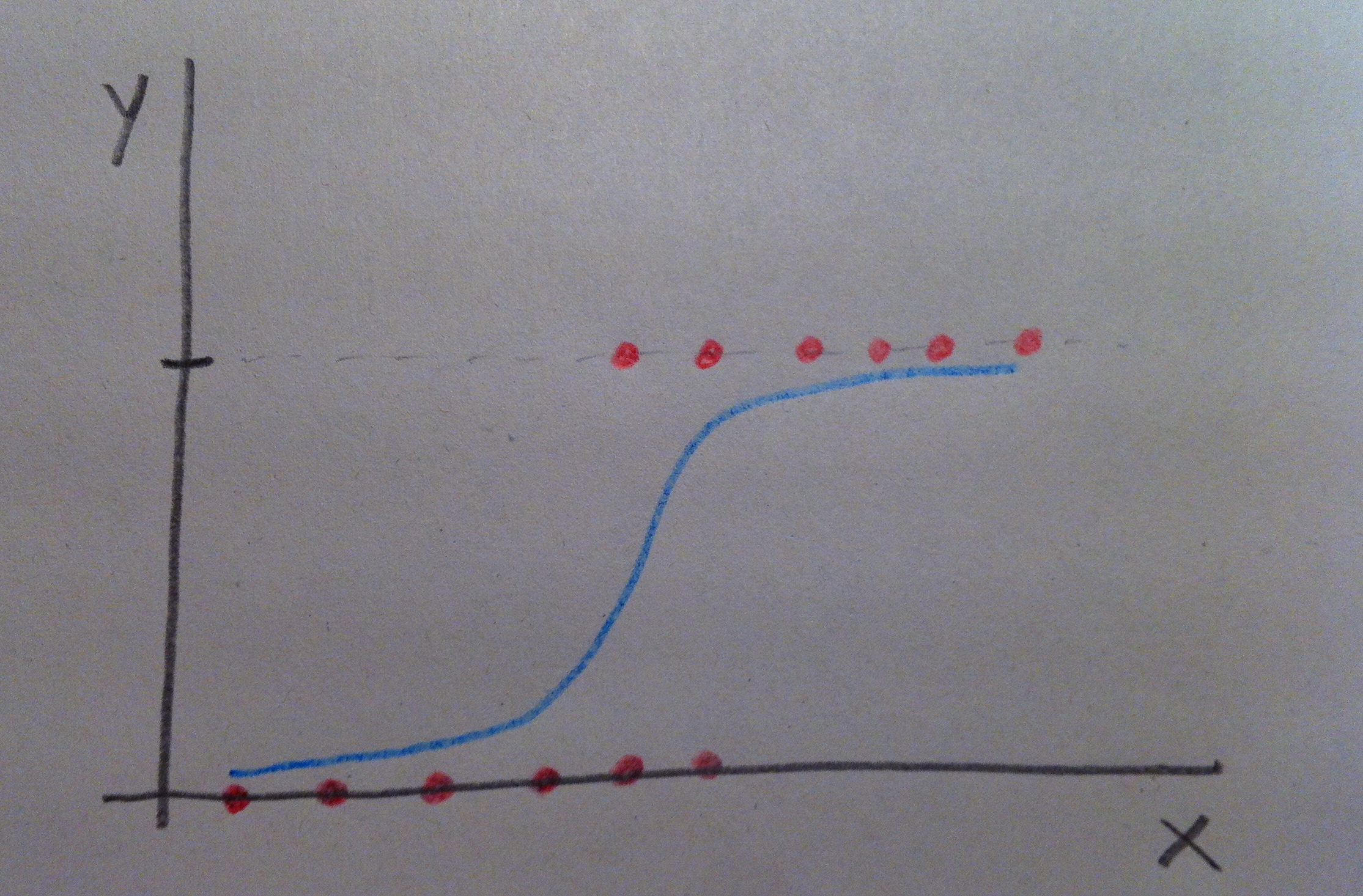
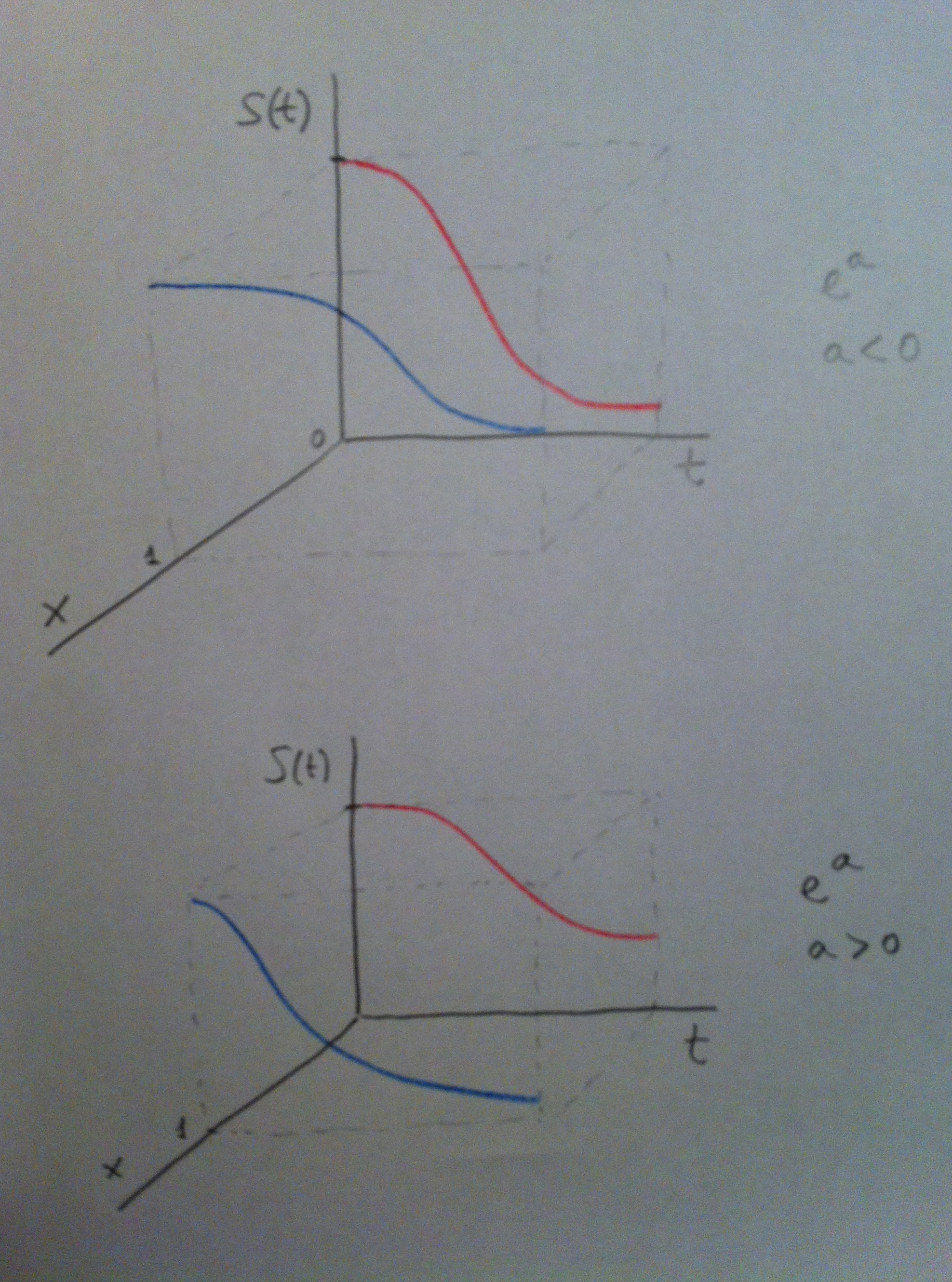
20. Suele trabajarse con las funciones de riesgo en la Regresión de Cox pero evidentemente lo mismo que se ve con ellas se podría ver con las funciones de supervivencia. Veamos en el siguiente gráfico el equivalente al anterior donde la variable x era dicotómica pero ahora respecto a la función de supervivencia S(t) no respecto a la función de riesgo h(t):
21. Puede observarse perfectamente cómo cambia según la x valga 0 ó 1 la pendiente de la función de supervivencia. En el caso de arriba al pasar de 0 a 1 la supervivencia aumenta. En el caso de abajo al pasar de 0 a 1 la supervivencia disminuye. Contrariamente a lo que sucedía al tratar con la función de riesgo.
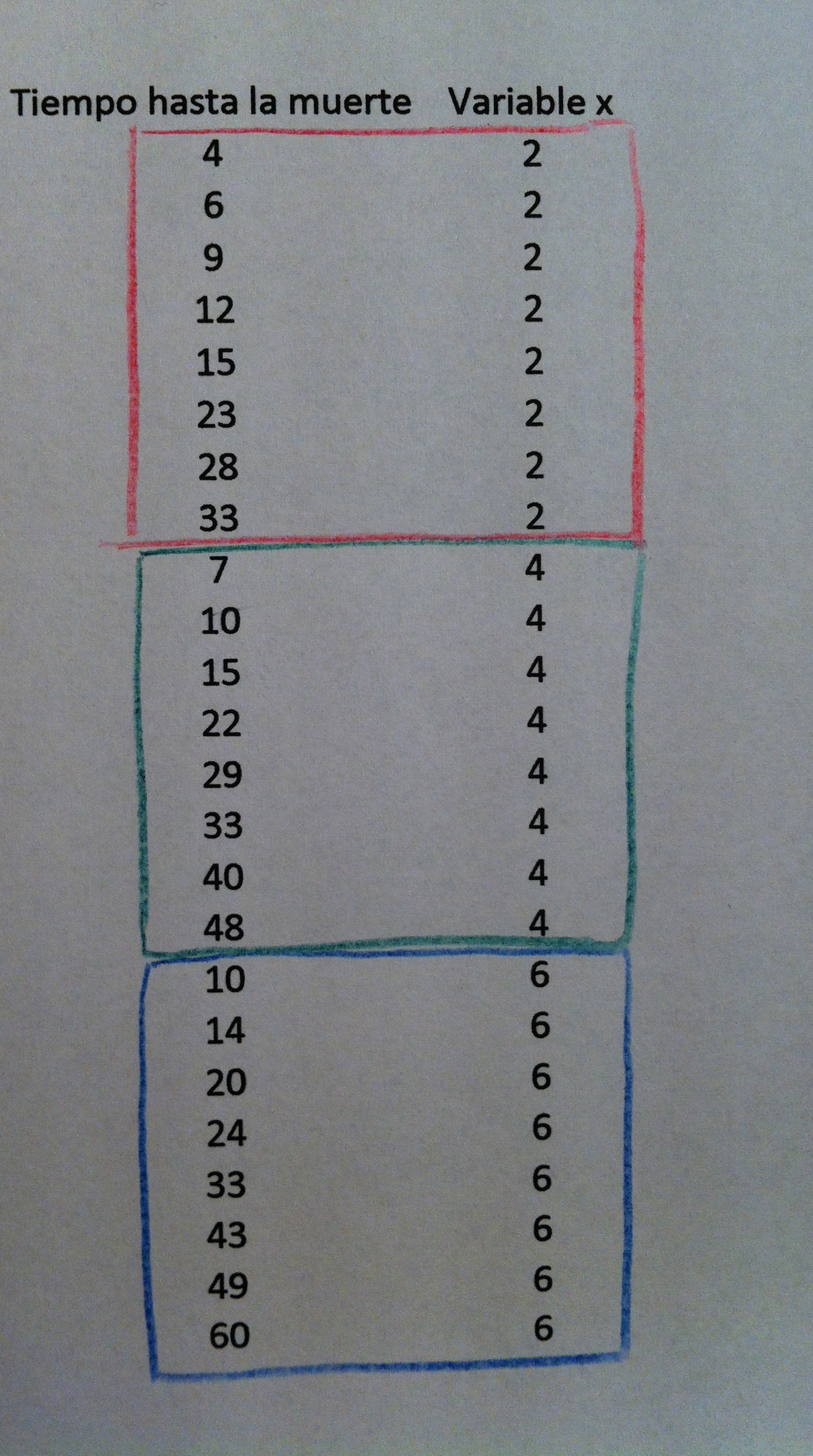
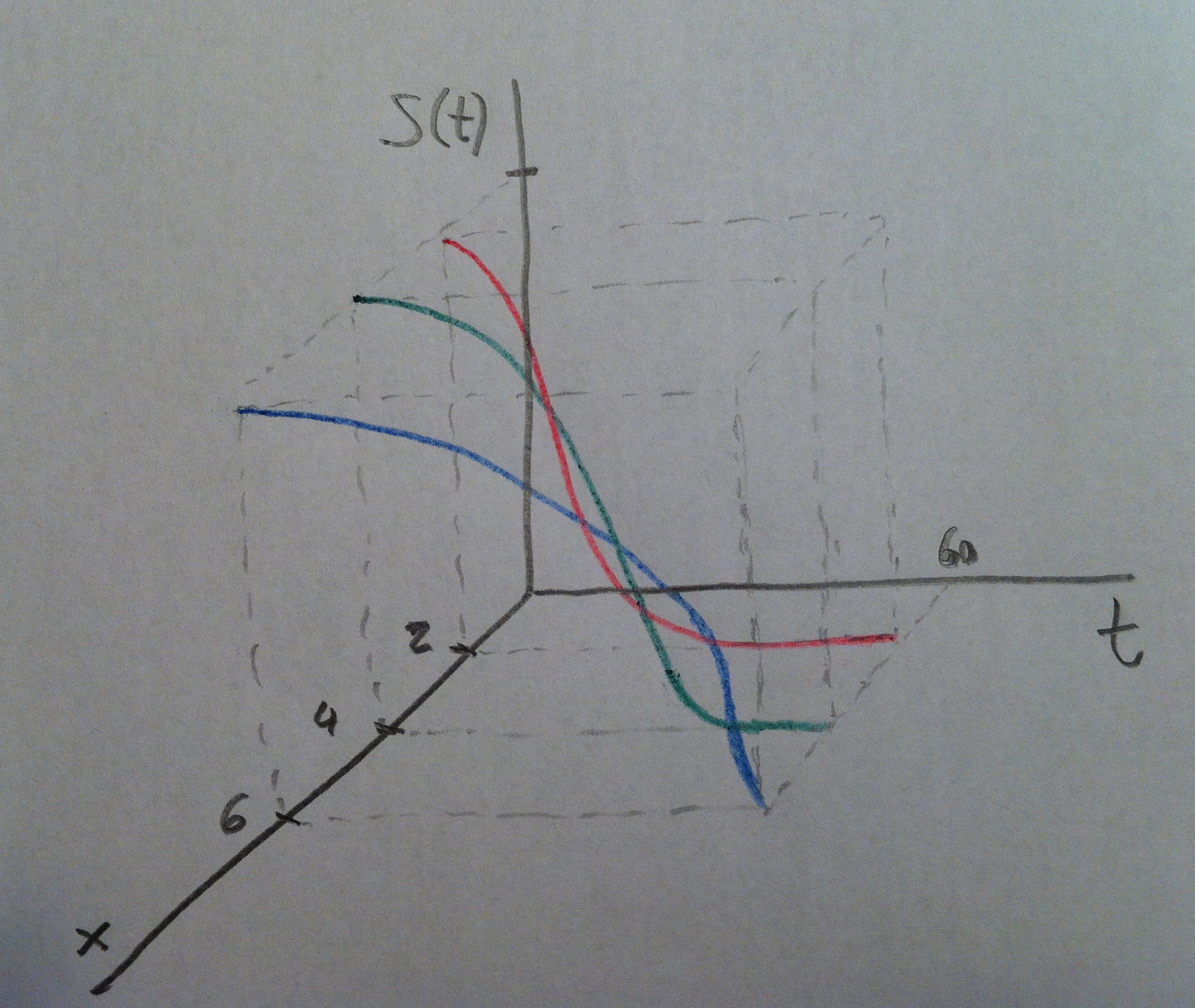
22. Veamos todo esto pero con un ejemplo numérico. Supongamos que tenemos los siguientes tiempos hasta la muerte de personas que respecto a una variable x tenemos los valores 2, 4 y 6. Veamos los datos concretos:
23. Marco con tres colores distintos a los individuos que tienen el valor 2, 4 y 6 de la variable x. Estos valores están ordenados según tengan cada uno de estos tres valores de la variable x y dentro de estos valores están ordenados por tiempos de vida. Se puede ver perfectamente que los individuos con valores mayores de x viven más, hay un progresivo aumento de tiempo de vida al aumentar el valor de x. Claro que hay que viven poco y que viven mucho en los tres grupos, pero los tiempos bajos son más bajos cuando la x es 2 y los tiempos altos son más altos cuando el valor de x es 6.
24. Esto se refleja en el gráfico siguiente donde se dibujan las tres curvas de supervivencia en los mismo colores. Se ve que la curva roja refleja una supervivencia menor que la verde y ésta menor que azul. La curva roja cae rápidamente, la verde lo hace más lentamente y la azul tarda más que las otras en caer:
25. Esto es lo que busca la Regresión de Cox: detectar este tipo de relaciones. Detectar que la curva de supervivencia o la función de riesgo cambia según los valores de una o más variables independientes. Trata de captar este tipo de regularidades. Y esto, evidentemente, tiene una importancia extraordinaria en muchos campos del conocimiento, especialmente en Medicina donde se ha transformado en una herramienta de análisis fundamental.
El Test de comparación de dos proporciones nos permite comparar dos proporciones de dos poblaciones a través de proporciones muestrales de dos muestras independientes obtenidas en las dos poblaciones a comparar.
El Test de Bartlett es un contraste de hipótesis de igualdad de desviaciones estándar. Muy utilizado en ANOVA, donde se requiere homogeneidad de varianzas.