1b: El Intervalo de una OR nunca puede tener valores negativos. En todo caso, el intervalo no contiene al 1, por lo tanto es incompatible con un p-valor superior a 0.05
2d: El Tratamiento no es significativo, el Grupo sanguíneo es significativo es significativo. No hay interacción significativa, porque los valores por cada población son paralelos.
3b: Como una de las dos muestras no se ajusta a la normal debe aplicarse el test de Mann-Withney.
4c: Obsérvese el cálculo de los valores de las dos componentes para los cuatro puntos:
Los puntos c y el d son los que están más a la derecha porque son los que tienen un valor mayor para la componente 1. El c es el que está más arriba, mirando los valores que tienen el c y el d en la componente 2.
5d: Al aumentar el tamaño de muestra el p-valor bajará, al disminuir la desviación estándar el p-valor bajará y al disminuir la diferencia de medias el p-valor subirá. El único perfil que supone: bajada, bajada y subida es el d.
6b: Si la OR no es significativa, porque la p es superior a 0.05, es que no hay relación. Como se trata de una tabla 2×2 el valor de la ji-cuadrado tiene que ser menor que el umbral (3.84), no mayor.
7b: Los dos factores son significativos y hay interacción. En otoño todos los fármacos van igual, cosa que no sucede en otras estaciones. Esto representa que el comportamiento de los fármacos depende de la estación en la que se apliquen: esto es lo que es la interacción.
8c: El valor esperado por grupo es 3 que, como es menor que 5 nos lleva seguro al Test exacto de Fisher.
9b: Obsérvese el cálculo de los valores de las dos componentes para los cuatro puntos:
Los puntos a y el b son los que están más a la izquierda porque son los que tienen un valor menor para la componente 1. El b es el que está más abajo, mirando los valores que tienen el a y el b en la componente 2.
10b. Al aumentar el tamaño de muestra el p-valor bajará, al aumento la desviación estándar el p-valor subirá y al aumentar la diferencia de medias el p-valor bajará. El único perfil que supone: bajada, subida y bajada es el b.
1.¿En cuál de estas afirmaciones no hay compatibilidad?
a.En un contrate de hipótesis de igualdad de medias una p=0.01 y un IC del 95% de la diferencia de medias entre ambas poblaciones de (0.15, 0.44).
b.En una Odds ratio una p=0.22 y un IC del 95% de (-0.13, 0.56).
c.En una tabla de contingencias 3×2 un valor de ji-cuadrado de 4.3 y un p-valor superior a 0.05.
d. En una ANOVA de un factor una p=0.67 y tener un único grupo homogéneo entre los cinco niveles que estamos comparando.
2.Tenemos los siguientes datos en un estudio donde se aplican dos tratamientos distintos (1 y 2) a un grupo de pacientes que tienen una determinada patología y que se han diferenciado según su grupo sanguíneo. Con los datos obtenidos se pretende ver la diferencia entre tratamientos, entre grupos sanguíneos y si hay o no interacción. ¿Cuál es la afirmación más razonable respecto a los resultados que podríamos obtener en el ANOVA?:
a.Factor Tratamiento: p<0.05. Factor Grupo sanguíneo: p>0.05. Interacción: p>0.05.
b.Factor Tratamiento: p<0.05. Factor Grupo sanguíneo: p<0.05. Interacción: p<0.05.
c.Factor Tratamiento: p>0.05. Factor Grupo sanguíneo: p<0.05. Interacción: p<0.05.
d.Factor Tratamiento: p>0.05. Factor Grupo sanguíneo: p<0.05. Interacción: p>0.05.
3.En un estudio donde se quiere comparar dos psicoterapias tenemos 100 pacientes que repartimos en dos grupos de igual tamaño. A cada grupo le aplicamos sólo uno de los dos tratamientos a comparar. Evaluamos una variable cuantitativa. El test de Shapiro-Wilk de la primera muestra tiene una p=0.22 y el de la segunda muestra tiene una p=0.03. El test de Fisher-Snedecor nos proporciona una p=0.01. Es cierto lo siguiente:
a.Debemos aplicar el test de la t de Student para varianzas desiguales.
b.Debemos aplicar el test de Mann-Whitney.
c.Debemos aplicar el test de la t de Student para varianzas iguales.
d.Debemos aplicar el test de la t de Student de datos apareados.
4.¿Cuál es el punto 4 en un Análisis de Componentes Principales con las dos siguientes primeras componentes principales:
a.(2, 1, 0, 4, 2, 4)
b.(1, 4, 4, 1, 2, 0)
c.(5, 3, 3, 5, 4, 5)
d.(3, 5, 5, 3, 5, 3)
5.En un estudio de comparación de dos poblaciones partimos de unos datos iniciales concretos y calculamos el p-valor con la técnica adecuada. Seguidamente introducimos nuevos valores de ambas muestras que no teníamos previamente aumentando, pues, el tamaño de ambas muestras y obteniendo la misma media y la misma desviación estándar en ambas muestras y volvemos a calcular el p-valor. Después detectamos que la desviación estándar era más baja de la que habíamos calculado y volvemos a calcular el p-valor. Finalmente, detectamos que la diferencia de medias es más pequeña de la que habíamos calculado previamente y volvemos a calcular el p-valor. ¿Cuál de las siguientes es la secuencia de p-valores que podríamos tener?
a.0.23/0.13/0.21/0.16.
b.0.52/0.14/0.77/0.62.
c.0.12/0.03/0.01/0.001.
d.0.12/0.01/0.001/0.01.
6.¿En cuál de las siguientes afirmaciones no hay compatibilidad?
a.En una diferencia de medias con un IC 95%: (0.85, 5.45) y un p-valor de 0.02.
b.En una OR de 1.34 con p=0.34 y una ji-cuadrado de 4.32.
c.En un ANOVA de dos factores una p=0.23 del primer factor, una p=0.89 del segundo factor y una p=0.00001 de la interacción.
d.Una V de Crámer con un valor de 0 y una ji-cuadrado con una p=1.
7.Tenemos los siguientes datos en un estudio donde se aplican tres fármacos (A, B, C) en pacientes con la misma patología de las cuatro estaciones del años. Con los datos obtenidos se pretende ver la diferencia entre fármacos, entre estaciones y ver, finalmente, si hay o no interacción. ¿Cuál es la afirmación más razonable respecto a los resultados que podríamos obtener en el ANOVA?:
8.Hemos de comparar dos formas de rehabilitación psicológica a pacientes que han sufrido un infarto cerebral. La variable analizada es si después de un año el paciente consigue superar un umbral previamente establecido en un test psicotécnico. Se ha trabajado con 100 pacientes. 50 en cada grupo. Cada paciente recibe un único tratamiento. Después del año en un grupo un 7% consigue la rehabilitación psicológica. En el otro grupo un 5% lo consigue. Para ver si esas diferencias son estadísticamente significativas debemos:
a.Aplicar un Test de Wilcoxon.
b.Aplicar un Test de proporciones.
c.Aplicar un Test exacto de Fisher.
d.Aplicar un Test de McNemar.
9.¿Cuál es el punto 2 en un Análisis de Componentes Principales con las dos siguientes primeras componentes principales:
a.(2, 1, 0, 4, 2, 4)
b.(1, 4, 4, 1, 2, 0)
c.(5, 3, 3, 5, 4, 5)
d.(3, 5, 5, 3, 5, 3)
10.En un estudio de comparación de dos poblaciones partimos de unos datos iniciales concretos y calculamos el p-valor con la técnica adecuada. Seguidamente introducimos nuevos valores de ambas muestras que no teníamos previamente aumentando, pues, el tamaño de ambas muestras y obteniendo la misma media y la misma desviación estándar en ambas muestras y volvemos a calcular el p-valor. Después detectamos que la desviación estándar era más alta de la que habíamos calculado y volvemos a calcular el p-valor. Finalmente, detectamos que la diferencia de medias es más grande de la que habíamos calculado previamente y volvemos a calcular el p-valor. ¿Cuál de las siguientes es la secuencia de p-valores que podríamos tener?
Estamos interesados en determinar el tamaño de muestra en un estudio de comparación de dos tratamientos farmacológicos: el tratamiento estándar y una nueva opción creada recientemente. La variable respuesta es curación sin recidiva a los 5 años. El tratamiento estándar tiene un nivel de curación sin recidiva del 35%. Queremos comprobar si con el nuevo preparado conseguimos una mejora de, como mínimo, 10 puntos porcentuales. ¿Cuál es el tamaño de muestra necesario si queremos tener una potencia del 80% y creemos que tendremos una pérdida de seguimiento de un 20%?
Uno de los objetivos fundamentales de la Ciencia es tomar decisiones. Decisiones acerca de cómo debe de ser lo que no vemos (lo poblacional) a partir de la información que extraemos de lo que vemos (la muestra). El contraste de hipótesis estadístico es el principal método mediante el cual se toman esas decisiones en la Ciencia.
En todo contraste de hipótesis el patrón de funcionamiento es siempre el mismo. Es muy importante captar esta idea si se quiere comprender la Estadística y, también, la Ciencia. Karl Pearson decía que la Estadística es la gramática de la Ciencia. Seguramente es en el contraste de hipótesis donde podemos ver mejor los elementos nucleares de esa gramática.
Hay tres elementos básicos en la toma de la decisión:
La diferencia entre el valor muestral y el valor poblacional establecido en la Hipótesis nula. La distancia que hay entre lo que vemos muestralmente y lo que afirmamos sobre la población, en definitiva.
La dispersión que tengamos en la muestra. La variabilidad, lo alejados que estén los valores respecto de la media. La imprevisibilidad, por lo tanto, de los valores que podemos tener.
El tamaño de muestra que tengamos. La cantidad de información que tenemos de la inmensa población sobre la que queremos hablar.
El esquema general en el que relacionamos estos tres factores es siempre el siguiente:
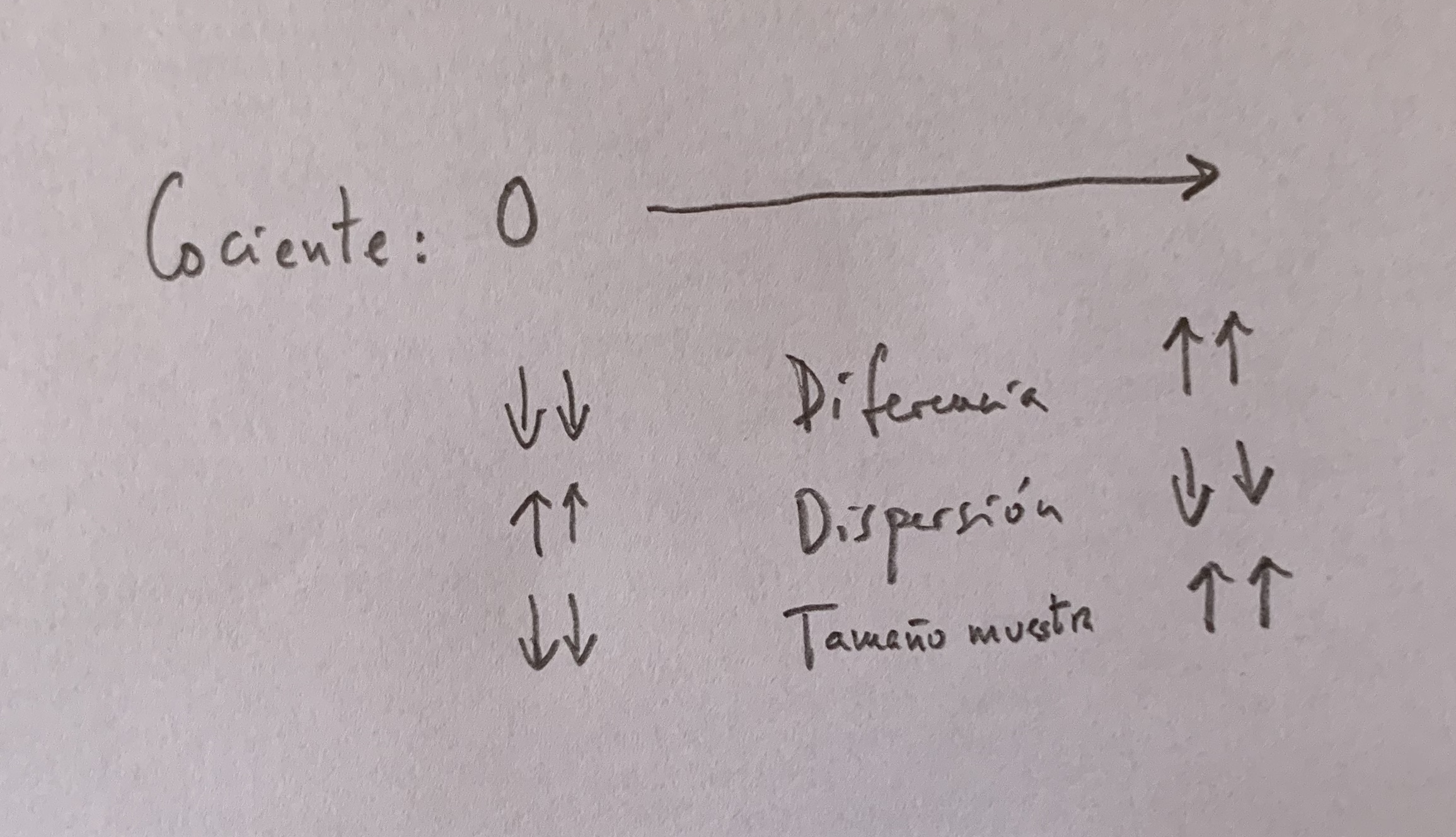
En definitiva, en un contraste de hipótesis, se trata de ver cuán diferente es el cálculo muestral respecto al que se afirma, poblacionalmente, en la Hipótesis nula, que es lo que calculamos en el numerador. Cuanto más próxima a 0 sea esa diferencia más coherente será mantener esa Hipótesis nula. Observemos que el numerador marca la distancia absoluta entre el cálculo muestral y la hipótesis sobre cómo es la población que no tengo.
Sin embargo, este cálculo del numerador que valora la distancia entre lo que veo y lo que afirmo sobre la población quedará matizado por la dispersión y por el tamaño de muestra que tengamos. Observemos bien el cociente: En el denominador tenemos un cociente entre la dispersión y el tamaño de muestra.
Si la dispersión es grande esa diferencia se verá disminuida, si esa dispersión es pequeña esa diferencia entre el valor muestral y el poblacional se verá aumentada.
Lo contrario sucede con el tamaño de muestra: si es grande el tamaño muestral esa diferencia calculada en el numerador se verá aumentada (porque al ser grande el tamaño de muestra el cociente entre la dispersión y el tamaño de muestra se hace pequeña) y si el tamaño de muestra es pequeño esa diferencia se verá disminuida (porque al ser pequeño el tamaño de muestra el cociente entre la dispersión y el tamaño de muestra se hace grande).
Cuanto más próximo a 0 sea este cociente más razonable será mantener la Hipótesis nula y, por el contrario, cuanto más alejado esté de 0 más coherente será rechazarla y pasar a la Hipótesis alternativa.
Veamos estos tres factores cómo influyen para que el cociente sea próximo a 0 ó, por el contrario, sea un valor alejado del cero:
Valores pequeños de diferencia, grandes de dispersión y pequeños de tamaño de muestra hacen que el cociente sea pequeño. Valores grandes de diferencia, pequeños de dispersión y grandes de tamaño de muestra hacen que el cociente se haga grande.
Cada contraste tendrá un umbral para hacer este paso de la Hipótesis nula a la alternativa. El umbral será ese valor que ya hace intolerable la distancia entre lo que vemos y lo que afirmamos en la Hipótesis nula sobre la población.
El p-valor, de hecho, es una forma estandarizada de evaluar este alejamiento del cero. Cuanto menor es el p-valor más alejado estamos del 0 y cuanto más próximo a 1 sea el p-valor más cerca del 0 estamos en este cociente. De hecho, si el valor de la muestra coincide con el valor poblacional de la Hipótesis nula el p-valor será 1. ¿Hay en esta situación algún argumento coherente para rechazar esa hipótesis?
La frontera del 0.05 en el p-valor es la expresión estandarizada de que estamos justo sobre el umbral de tolerancia del mantenimiento de la Hipótesis nula.
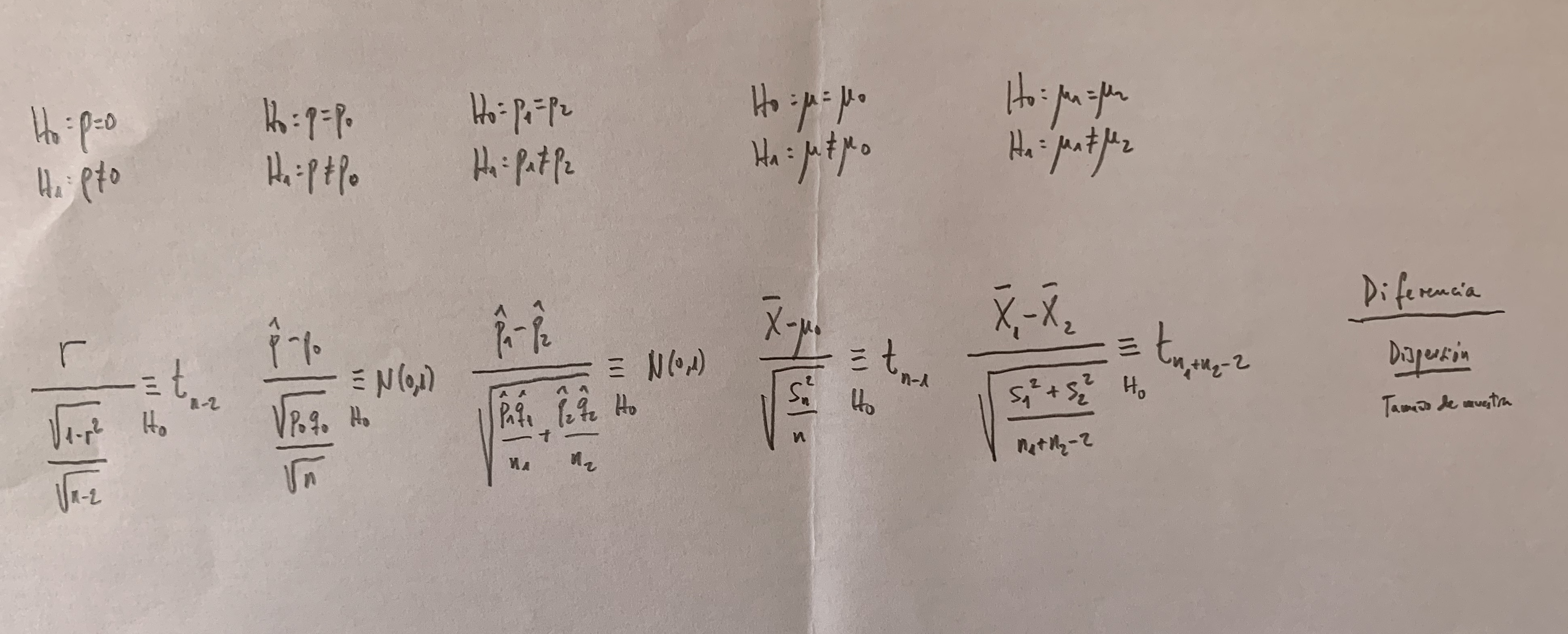
Veamos en los siguientes cinco ejemplos de contrastes de hipótesis: Contraste sobre la correlación de Pearson, Contraste de una proporción, Contraste de comparación de proporciones, Contraste de una media y Contraste de comparación de medias:
Obsérvese que siempre estamos haciendo un cociente como el que hemos escrito antes, conceptualmente, un cociente entre la diferencia entre lo muestral y lo que afirmamos poblacionalmente en la Hipótesis nula y el valor de otro cociente: el que hay entre la dispersión y el tamaño de muestra que tenemos.
A la derecha de cada cociente tenemos la distribución de ese cociente en el caso de que fuera cierta la Hipótesis nula, que es lo que nos permite fijar un umbral o calcular un p-valor como criterio para decidir si mantenemos la Hipótesis nula o, por el contrario, la rechazamos y nos quedamos con la Hipótesis alternativa.
1.¿Cuál de las siguientes afirmaciones es cierta en una regresión?
a.Una pendiente con un IC 95%: (-0.3, -0.05) es compatible con una correlación con p-valor -0.002.
b.Una pendiente con una p=0.001 es compatible con una correlación con IC 95%: (-0.4, 0.6).
c.Una pendiente con un IC 95%: (-1.5, 0.6) es compatible con una correlación con p-valor igual a 0.2.
d.Una pendiente de -0.3 con p=0.95 es compatible con una correlación con un IC del 95%: (-0.6, -0.2)
2.¿Qué valor refleja un mayor nivel de relación entre dos variables?
a.r= 0.6 (p=0.5)
b.r=-0.7 (IC 95%: (-1, 0.08))
c.r=0.5 (p=0.01)
d.r=0.4 (IC 95%: (0.39, 0.41))
3.Nos dicen que un intervalo de confianza de la media del 95% de la cantidad de un neurotransmisor en unos pacientes es (89, 91). El estudio se ha hecho con una muestra de 400 pacientes. ¿Cuál es el intervalo de confianza del 99.5% descriptivo de esa variable?
a.(30, 150)
b.(50, 130)
c.(60, 120)
d.(80, 100)
4.En una muestra como la siguiente: (4, 5, 5, 55, 55, 56), los resultados más previsibles de la asimetría estandarizada (AE) y de la curtosis estandarizada (CE) son:
6.¿Cuál de las siguientes afirmaciones no es cierta en una regresión?
a.Una pendiente con un IC 95%: (-0.3, -0.05) es compatible con una correlación con p-valor 0.02.
b.Una pendiente con una p=0.1 es compatible con una correlación con IC 95%: (-0.4, 0.6).
c.Una pendiente con un IC 95%: (-1.5, 0.6) es compatible con una correlación con p-valor igual a 0.22.
d.Una pendiente de -0.3 con p=0.01 es compatible con una correlación con un IC del 95%: (-0.6, 0.2)
7.¿Qué valor refleja un mayor nivel de relación entre dos variables?
a.r= 0.6 (p=0.01)
b.r=-0.7 (IC 95%: (-1, -0.28))
c.r=0.5 (p=0.01)
d.r=0.4 (IC 95%: (0.39, 0.41))
8.Nos dicen que un intervalo de confianza de la media del 95% de la cantidad de un neurotransmisor en unos pacientes es (88, 92). El estudio se ha hecho con una muestra de 100 pacientes. ¿Cuál es el intervalo de confianza del 68.5% descriptivo de esa variable?
a.(80, 100)
b.(85, 95)
c.(60, 120)
d.(75, 105)
9.En una muestra como la siguiente: (3.3, 4.2, 5, 5.2, 5.5, 5.7, 6.3, 7.2), los resultados más previsibles de la asimetría estandarizada (AE) y la curtosis estandarizada (CE) son:
a.AE=0 y CE=0
b.AE=15 y CE=15
c.AE=0 y CE=15
d.AE=15 y CE=0
Sea la muestra (1, 2, 3, 7, 9, 11, 14). ¿Cuál es la afirmación incorrecta?:
Tenemos la siguiente base de datos de pacientes con demencias diagnosticadas:
Variables:
P=Paciente
S=Sexo (h=hombre; m=mujer)
E=Edad
EVC=Enfermedad vascular central (s=sí; n=no)
EVP=Enfermedad vascular periférica (s=sí; n=no)
D=Diabetes (s=sí; n=no)
MM0=Mini Mental en el diagnóstico
MM3=Mini Mental a los 3 años
MM5=Mini Mental a los 5 años
P
S
E
EVC
EVP
D
MM0
MM3
MM5
1
h
60
s
n
n
21
20
18
2
h
79
n
n
n
20
19
16
3
h
71
n
s
s
23
20
17
4
h
66
n
s
s
22
19
16
5
m
69
n
n
s
21
19
16
6
m
62
n
n
s
24
22
19
7
m
60
s
n
n
21
19
16
8
m
63
s
n
n
24
22
19
9
m
77
n
s
n
23
21
18
10
h
63
n
s
n
20
18
15
11
h
79
n
s
n
24
22
19
12
h
55
n
s
s
23
21
18
13
m
72
n
n
s
21
19
16
14
m
68
n
n
n
21
21
20
15
h
81
n
n
s
23
21
18
16
h
71
n
n
n
20
19
19
17
m
61
n
s
s
24
23
20
18
m
76
s
s
s
23
22
19
19
m
72
s
s
n
22
21
18
20
m
63
n
n
n
24
23
20
21
m
67
n
n
n
21
20
17
22
h
69
n
n
n
23
22
19
23
h
60
n
n
n
21
20
17
24
m
64
n
n
s
22
21
18
25
m
73
n
n
s
21
20
17
26
m
66
s
n
n
23
21
18
27
m
76
s
n
n
22
20
17
28
h
75
n
n
n
23
21
18
29
m
62
n
n
s
21
19
16
30
m
78
n
n
n
24
22
19
31
h
57
n
s
s
23
21
18
32
h
58
n
s
s
21
19
16
33
m
63
s
s
n
23
21
18
34
m
65
n
s
n
24
22
19
35
m
74
s
s
n
20
17
14
36
m
61
n
n
n
24
22
19
37
h
71
n
n
s
23
21
18
38
m
71
n
n
n
22
21
18
39
m
63
n
n
s
24
23
20
40
h
67
n
n
s
21
20
17
41
h
69
n
n
n
21
20
17
42
m
63
n
n
n
21
20
17
43
m
75
n
s
n
22
21
18
44
m
69
n
s
n
21
20
17
45
m
62
s
s
n
24
20
17
46
m
66
s
s
s
24
20
16
47
h
57
n
s
n
23
22
19
48
h
62
n
s
s
21
18
16
49
h
59
n
n
n
21
20
17
50
m
72
n
n
s
28
27
24
51
m
78
n
n
s
24
23
20
52
m
73
s
n
n
24
23
20
53
m
63
n
n
n
23
24
21
54
h
65
s
n
n
23
22
19
55
m
67
n
s
n
23
22
21
56
m
66
n
s
n
24
23
20
57
h
75
n
n
s
22
21
18
58
h
62
n
n
n
21
20
17
59
m
71
n
n
s
23
22
19
60
m
59
s
s
n
22
17
16
61
m
66
n
n
s
24
23
20
62
m
64
n
n
s
23
22
19
63
m
65
n
n
n
22
21
18
64
h
71
n
n
n
24
23
20
65
h
68
n
n
n
21
20
17
66
h
73
n
n
n
21
20
17
67
m
64
n
n
n
21
20
17
68
m
60
s
s
s
22
18
15
69
m
76
n
n
n
21
21
18
70
m
64
n
n
s
23
23
20
71
h
68
n
n
n
22
19
16
72
m
63
n
n
s
23
19
16
73
m
68
n
n
s
21
19
16
74
h
73
n
n
n
21
22
16
75
h
62
n
n
n
23
19
16
76
m
65
n
n
n
24
23
20
77
m
76
n
n
n
20
19
16
78
m
61
n
n
n
24
23
20
79
m
67
n
n
s
22
20
17
80
m
64
n
n
n
22
21
18
81
h
64
n
n
s
23
21
18
82
m
69
n
s
s
20
17
15
83
m
74
n
n
n
22
21
20
84
m
57
n
n
n
24
23
20
85
h
67
n
n
n
23
22
19
86
h
73
n
n
n
22
21
18
87
m
74
n
n
s
21
20
17
88
m
72
s
s
n
23
20
17
89
m
78
n
n
s
24
23
20
90
m
68
s
s
s
22
20
18
91
h
73
n
n
n
21
20
17
92
m
64
n
n
n
21
20
17
93
h
75
n
n
n
23
22
19
94
h
63
n
n
n
23
23
21
95
m
79
n
n
n
20
19
16
96
m
77
s
n
s
24
20
16
97
m
76
n
n
s
23
22
19
98
m
62
n
s
n
22
21
19
99
h
70
n
n
s
24
23
21
100
m
73
n
n
s
20
20
16
A.Técnicas descriptivas:
Calcular la media, desviación estándar, mediana, primer y tercer cuartil, rango y rango intercuartílico de la variable MM0.
Hacer una estadística básica de la variable Edad (Media y desviación estándar o Mediana y rango intercuartílico).
Hacer un Box-Plot de la variable MM5.
Hacer una estadística de la variable Diabetes.
B.Técnicas de relación:
Calcular la correlación entre la Edad y el MM en el diagnóstico (MM0).
2. Crear una función que pronostique el MM5 a partir del MM0. Valorar la capacidad predictiva.
3. Ver si hay relación entre el sexo y el que en cinco años disminuya más de cuatro (o sea, cinco o más) puntos el MM desde el diagnóstico.
4. Calcular la Odds ratio para ver si hay riesgo o protección, cuantificándolo, entre tener algún problema de riesgo vascular (Enfermedad vascular central, periférica o diabetes) y que en cinco años disminuya más de cuatro (o sea, cinco o más) puntos el MM desde el diagnóstico.
C.Técnicas de comparación:
Comparar si hay diferencias estadísticamente significativas en el nivel del MM a los cinco años (MM5) entre hombre y mujeres.
Comparar si hay diferencias estadísticamente significativas en el nivel de diferencia entre MMO y MM5 (o sea, la caída del MM entre el diagnóstico y los 5 años desde el diagnóstico) entre los que tienen o no algún problema vascular.
1d: A la izquierda de 5 hay 5 valores, a la derecha 3. 5 de 8 supone un 62.5%.
2a: Si se aplica la fórmula vista en el tema 3 con una contante de 1 porque se trata de un intervalo de confianza del 68.5%, tenemos este resultado.
3d: Si las dos tablas, la observada y la esperada fueran iguales, el p-valor sería 1. Todo lo que no suponga esta igualdad va asociado, entonces, de un p-valor inferior a 1.
4c: El error estándar es 1, porque al tratarse de un intervalo de confianza de la media el radio del intervalo es dos veces el error estándar. Como el radio es 2 (la distancia desde el centro del intervalo, 20, hasta cualquiera de los dos extremos), el error estándar es, pues, 1. Por la ecuación fundamental vista en el tema 3 tenemos que 1=DE/Raíz(25), luego la DE tiene que ser 5. De esta forma el radio del intervalo descriptivo del 95% será dos veces la DE; o sea: 10. Por lo tanto, el intervalo será (10, 30)
5c: Las operaciones que hacemos son: 1) Disminuimos el tamaño de muestra de ambas poblaciones. 2) Detectamos que la desviación estándar era más alta de la que habíamos calculado. 3) Detectamos que la diferencia de medias es más grande de la que habíamos calculado. Esto supone subir el p-valor, primero, subirlo también, en el segundo paso y bajarlo en el tercer paso. El único perfil que se adapta a esos cambios es el c.
6d: Intervalo de la pendiente y de la correlación no tienen el mismo signo.
7b: Si el intervalo de confianza del 95% de la diferencia de medias incluye al 0 entonces el contraste de hipótesis sobre la igualdad de medias nos dará un p-valor superior a 0.05, de no diferencia de medias estadísticamente significativa.
8d: Si no es significativa la igualdad de proporciones el intervalo de confianza del 95% de la diferencia de proporciones incluirá al cero, como sucede en el que tenemos.
9b: Si hay diferencia de medias significativa, los intervalos de la media del 95% no se solaparán pero eso no tiene nada que ver con el solapamiento o no de los intervalos descriptivos. En los intervalos de la media interviene el tamaño de muestra, en los descriptivos no. Aquí está la clave.
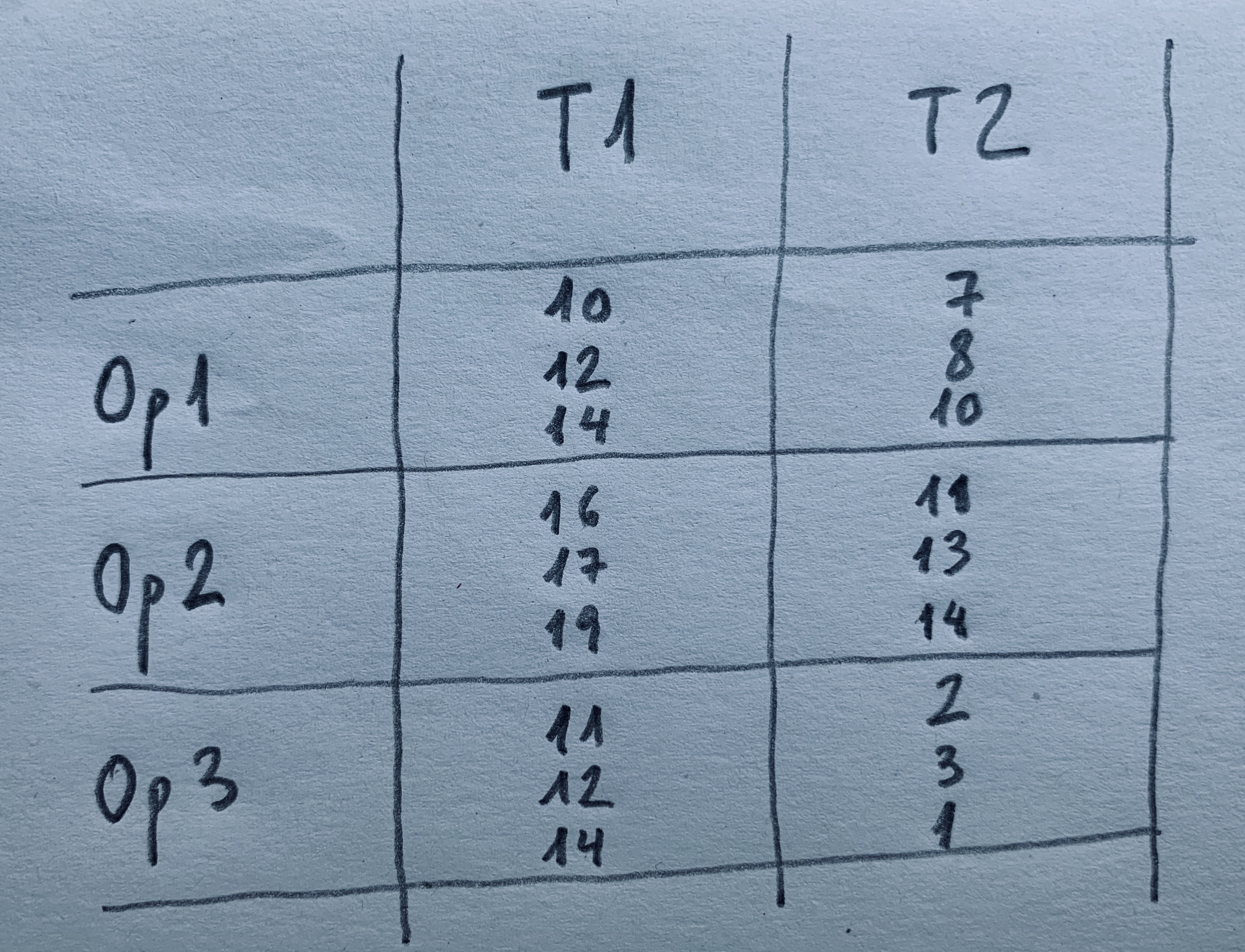
10c: Todo es significativo. Tratamiento, operario e interacción.
2.Estamos interesados en saber en cuántos puntos de una playa se supera un cierto nivel de un contaminante. Para ello se toman al azar 4000 muestras a lo largo del río. En 200 de ellas se supera ese nivel. Un intervalo de confianza del 68.5% del porcentaje de puntos del río donde se supera dicho nivel es:
a.(4.66, 5.34).
b.(4.31, 5.69).
c.(3.97, 6.03).
d.(3.62, 6.38).
3.¿Cuál de las siguientes afirmaciones es cierta?
a.La ji-cuadrado evalúa si hay relación entre una variable cualitativa y una cuantitativa.
b.El coeficiente de determinación superior al 50% indica buena capacidad predictiva sólo si el p-valor de la correlación es superior a 0.05.
c.Una V de Crámer es significativa si es mayor de 0.5.
d.Si la tabla de contingencias observada y la tabla de contingencias esperada no son iguales el p-valor será menor que 1.
4.Tenemos un intervalo de la media del 95% de una variable que se distribuye ajustándose a una normal que es (18, 22). La muestra era de tamaño 25. ¿Cuál sería un intervalo del 95% descriptivo de esa variable?
a.(18, 22), igualmente.
b.(15, 25).
c.(10, 30).
d.(0, 40).
5.En un estudio de comparación de dos poblaciones partimos de unos datos iniciales concretos y calculamos el p-valor con la técnica adecuada. Seguidamente disminuimos el tamaño de muestra de ambas poblaciones obteniendo la misma media y desviación estándar en ambas muestras y volvemos a calcular el p-valor. Después detectamos que la desviación estándar era más alta de la que habíamos calculado y volvemos a calcular el p-valor. Finalmente, detectamos que la diferencia de medias es más grande de la que habíamos calculado previamente y volvemos a calcular el p-valor. ¿Cuál de las siguientes es la secuencia de p-valores que podríamos tener?
a.0.54/0.23/0.25/0.12.
b.0.66/0.86/0.44/0.22.
c.0.23/0.25/0.34/0.23.
d.0.23/0.31/0.19/0.31.
6.En cuál de las siguientes regresiones simples hay información incoherente:
a.y=0.02x+1 con IC del 95% de la pendiente (0.01, 0.03) e IC del 95% de la correlación (0.1, 0.2).
b.y=0.2x+1 con IC del 95% de la pendiente (0.1, 0.3) e IC del 95% de la correlación (0.1, 0.3).
c.y=20x+1 con IC del 95% de la pendiente (10, 30) e IC del 95% de la correlación (0.1, 0.2).
d.y=-0.8x+1 con IC del 95% de la pendiente (-1.3, -0.4) e IC del 95% de la correlación (0.1, 0.2).
7.¿Cuál de las siguientes afirmaciones es cierta?:
a.La comprobación de si dos medias son iguales la hacemos con el test de Shapiro-Wilk.
b.Si un intervalo de confianza del 95% de la diferencia de medias es (-0.23, 0.45) el p-valor del contraste de igualdad de medias nos dará un p-valor superior a 0.05.
c.Si dos intervalos de la media del 95% se solapan en dos muestras independientes podemos afirmar que el p-valor en un contraste de hipótesis de igualdad de medias será inferior a 0.05.
d.En un ANOVA con dos factores anidados obtendremos tres p-valores porque tenemos que resolver tres contrastes de hipótesis.
8.¿Cuál de las siguientes afirmaciones es cierta?:
a.En una regresión si la R2 es inferior al 50% podemos decir ya que no tenemos una relación estadísticamente significativa entre las variables de la regresión.
b.Si en un estudio tenemos una potencia inferior al 80% el contraste que hagamos dará un p-valor superior a 0.05.
c.Si hacemos una comparación de medias entre dos muestras y el p-valor es inferior a 0.05 los intervalos de confianza del 95% de la media de ambas poblaciones se solaparán.
d.En una comparación de proporciones con p-valor igual a 0.12 un intervalo de confianza del 95% de la diferencia de proporciones puede ser (-0.05, 0.08).
9.Hemos realizado una comparación de medias de dos poblaciones que se ajustan a la normalidad. El p-valor ha resultado ser 0.001. ¿Cuál es la única respuesta que puede ser cierta?
a.Los intervalos de confianza del 95% de la media de ambas muestras son: (90, 110) y (95, 115).
b.Los intervalos de confianza del 95% descriptivos de ambas muestras son: (80, 120) y (90, 130).
c.Los intervalos de confianza del 95% de la media de ambas muestras son: (90, 110) y (95, 115) y los descriptivos son: (69, 109) y (101, 131).
d.Ninguna de las tres es posible.
10.Hemos analizado la cantidad de biomasa en una zona en dos tiempos distintos (T1 y T2). El análisis lo han realizado tres operadores, tres analistas distintos que se quieren comparar. Cada muestra cada operario la analiza por duplicado. Los resultados son los siguientes:
Una de las primeras cosas que uno se plantea ante un curso de Estadística es entender qué es la Estadística. En qué consiste. En este artículo vamos a hacer un viaje rápido por toda la ciudad de la Estadística. Sin entrar en detalles concretos, pero tratando de hacer una visión de conjunto, una visión que nos transmita, con cierta claridad, qué es lo que nos vamos a encontrar a lo largo de todo un curso de Estadística. Vamos a hacer un viaje que nos proporciones una visión similar a la que tenemos desde un autobús turístico de cualquier ciudad del mundo.
El siguiente vídeo comenta este viaje escrito:
Empecemos el viaje:
La Estadística es la ciencia con la que, a partir de MUESTRAS, decimos cosas de POBLACIONES. Es muy importante tener siempre en cuenta esta idea. Con MUESTRAS decir cosas de POBLACIONES. A partir, pues, de unos POCOS hablar de TODOS.
Y todo científico continuamente tiene que enfrentarse a esta dualidad: Sólo tiene MUESTRAS pero su intención es hablar de POBLACIONES. Tiene sólo información de unos POCOS pero su finalidad es hablar de TODOS. Todo científico: un biólogo, un psicólogo, un médico, un economista, un sociólogo, un lingüista, un geólogo, etc.
Vamos a ver, en primer lugar, qué entendemos por POBLACIONES y por MUESTRAS en Estadística.
Una POBLACIÓN es un conjunto, generalmente muy grande, de personas, de seres vivos, de cosas, etc.
Ejemplos:
La población de todos diabéticos de España.
La población de todos los menores de 18 España.
La población de todos los pokémons.
La población de todas las ciudades del mundo de más de 100000 habitantes.
La población de todos los perros de España.
Una MUESTRA es una parte, generalmente pequeña, de una POBLACIÓN.
Ejemplos:
Hemos seleccionado al azar 100 diabéticos al azar en España.
Hemos seleccionado 50 menores de 18 años en España al azar.
Hemos seleccionado al azar 20 pokémons.
Hemos seleccionado al azar 80 ciudades del mundo de más de 100000 habitantes al azar.
Hemos seleccionado al azar 200 perros de España.
Observemos que la estructura de la relación entre POBLACIÓN y MUESTRA es siempre la que se ve en el siguiente dibujo:
Siempre una MUESTRA es una parte de una POBLACIÓN. Y el objetivo de la Estadística es, precisamente, a partir de lo que podremos saber de esta MUESTRA, a base de estudiarla, de calcular cosas en ella, intentar decir cosas de cómo es la POBLACIÓN que no tenemos.
Evidentemente, no toda MUESTRA tiene la misma calidad. Hay muestras más representativas de la POBLACIÓN que otras. A la hora de elegir la muestra se trata de hacerlo con el máximo de coherencia para tratar que la MUESTRA sea lo más parecida posible a la POBLACIÓN, pero en miniatura. La elección de la MUESTRA es un paso fundamental puesto que, como ya hemos dicho, la Estadística pretende decir cosas de las POBLACIONES a partir del estudio de MUESTRAS. Si la elección de ésta es incoherente mala ciencia estaremos haciendo, evidentemente.
Esto es, pues, repitamos, la Estadística: Intentar saber cómo es un todo (una POBLACIÓN) que no tenemos a partir del estudio de una parte (una MUESTRA) que sí que tenemos.
Por lo tanto, estos dos conceptos (MUESTRA y POBLACIÓN) están siempre presentes, como hemos dicho, en la Estadística. Pero no sólo en la Estadística. Como hemos dicho, es un problema íntimamente asociado a toda Ciencia.
A las personas, seres vivos o cosas de las muestras que tenemos las analizamos para obtener de ellos alguna característica. A estas características las llamamos VARIABLES.
Ejemplos (Observa que cada punto está constituido por los elementos de las POBLACIONES y MUESTRAS vistas en la lección anterior):
La cantidad de Hemoglobina glicada de un diabético.
El número de veces que ha ido al dentista un menor de 18 años.
La velocidad de un pokémon.
La cantidad de un determinado contaminante en una ciudad de más de 100000 habitantes.
Si un perro lleva o no un chip identificativo.
Observemos que hemos definido una VARIABLE en cada caso visto, pero podríamos escoger otras muchas, por supuesto.
Observemos, pues, que hasta ahora hemos visto tres conceptos en Estadística que son nucleares y que están siempre presentes en cualquier estudio realizado en cualquier ciencia:
POBLACIÓN.
MUESTRA.
VARIABLE.
Es muy importante, siempre, situar bien cada uno de estos tres conceptos cuando se hace un estudio.
Veamos un ejemplo práctico:
Se quiere ver, en un estudio clínico, en personas que tienen una determinada enfermedad, si un nuevo medicamento que se quiere ensayar consigue más, menos o igual número de curaciones que el medicamento que se utiliza actualmente.
Llamemos al medicamento habitual como A y al nuevo como B.
Tenemos la POBLACIÓN de todos los enfermos de esa patología. Que pueden ser miles y miles.
El medicamento A lo damos a 100 personas con esa enfermedad y a los que seguiremos con detalle para ver si se curan o no. Estas 100 personas son una MUESTRA de la POBLACIÓN de todos los enfermos.
El medicamento B lo damos a otras 100 personas con esa enfermedad. Evidentemente, personas diferentes a las anteriores. Personas que también seguiremos detalladamente para ver si se curan o no con ese tratamiento. Estas 100 personas son una MUESTRA de la misma POBLACIÓN anterior, la POBLACIÓN de todos los enfermos de esa enfermedad.
La VARIABLE en este estudio es si el enfermo se cura o no con el tratamiento después de un cierto tiempo de tratamiento.
Veamos todo el planteamiento del estudio con un dibujo:
Unos resultados que podríamos obtener, finalmente, del estudio podrían ser los siguientes:
Medicamento A:
70 se curan.
30 no se curan.
Medicamento B:
90 se curan.
10 no se curan.
Observemos que entre las dos MUESTRAS hay diferencias. Con el medicamento B se curan más personas que con el medicamento A. Es muy claro. De las 100 personas tratadas con el medicamento B se han curado 90. Esto lo expresamos así: un 90 por 100 (lo solemos escribir así: 90%). Sin embargo, con el medicamento A se han curado sólo 70: un 70 por 100 (70%).
Pero, algo muy importante: esto que vemos lo vemos en las MUESTRAS. ¿Pasaría lo mismo si estos tratamientos se aplicaran a la POBLACIÓN entera, a todos los enfermos? Observemos que esto no lo podremos decir, ciertamente, hasta que no lo apliquemos. Pero sería extremadamente importante poder predecir si las diferencias que vemos en esas MUESTRAS las veríamos también si cada uno de esos medicamentos se aplicara a toda la POBLACIÓN.
Pues éste es el papel de la Estadística. A eso nos dedicamos los estadísticos y para saber hacer este paso de las MUESTRAS a las POBLACIONES todos los científicos estudian Estadística.
Ya veremos que el gran problema de la Estadística será saber cuándo podemos decir que lo que vemos en las MUESTRAS es lo que veríamos, también, en las POBLACIONES. Cuando decimos, en Estadística, que lo que vemos es ESTADÍSTICAMENTE SIGNIFICATIVO es porque, con muchas posibilidades de no equivocarnos, lo que vemos en las MUESTRAS es lo que veríamos, también, en las POBLACIONES.
Ya tenemos, pues, los elementos básicos con los que se trabaja, siempre, en Estadística: POBLACIONES, MUESTRAS y VARIABLES.
Ahora vamos a empezar a manejarlos.
La Estadística es una ciencia que actúa manejando Técnicas analíticas, que solemos denominar TÉCNICAS ESTADÍSTICAS. Con ellas es como hacemos este proceso de decir cosas de POBLACIONES a partir de MUESTRAS. Hay muchos problemas distintos que precisan técnicas distintas. En el caso que hemos visto antes necesitamos utilizar una técnica analítica concreta. Una técnica estadística que nos permita decir si la diferencia que vemos a nivel MUESTRAL es, también, con muchísimas posibilidades, una diferencia POBLACIONAL. Si, por ejemplo, estuviéramos comparando tres tratamientos y lo que quisiéramos ver fuera si una cantidad cambia (por ejemplo, la cantidad de hemoglobina glicada), deberíamos aplicar otra técnica distinta.
La clave será aprender diferentes técnicas estadísticas, en qué situaciones se aplican y cómo, aplicándolas, podemos hacer este salto desde las MUESTRAS a las POBLACIONES.
Hay centenares de técnicas. En un curso de Estadística se suelen ver unas 15 ó 20. Se ven, por supuesto, las más utilizadas. Pero hay una cosa importante respecto a esas distintas técnicas. Se pueden clasificar en tres tipos, en tres familias de técnicas: Técnicas DESCRIPTIVAS, técnicas de RELACIÓN y técnicas de COMPARACIÓN.
En cada uno de estos tipos de técnicas decimos cosas de POBLACIONES a partir de las MUESTRAS.
En las técnicas DESCRIPTIVAS resumimos la muestra y vemos hasta qué punto con esos valores podemos pasar a valores poblacionales. Supongamos que en una muestra de 100 personas hay 10 que son diabéticos. En la muestra tengo un 10% de diabéticos. ¿Hasta qué punto puedo decir que eso también es, por ejemplo, de toda España, que es de donde he cogido la muestra? Para ello lo que solemos hacer los estadísticos es construir lo que llamamos un intervalo de confianza del 95% del porcentaje poblacional. No del muestral sino del poblacional. Si lo calculáramos veríamos que este intervalo es (4%, 16%). Si fueran 100 diabéticos entre 1000 sería (8,1%, 11.9%) y si fueran 1000 entre 10000 sería (9.4%, 10.6%). Cambian las cosas, ¿verdad? Cambia lo que podemos decir de la población, pero en la muestra siempre teníamos un 10%. Eso no cambiaba. Pero en las tres situaciones distintas lo que cambia, fundamentalmente, es nuestra posibilidad de decir cosas de las POBLACIONES a partir de las MUESTRAS. Como veremos, dependerá, entre otras cosas, del tamaño MUESTRAL que tengamos.
En las técnicas de RELACIÓN buscamos si ciertas asociaciones que detectamos entre variables, en las MUESTRAS, las podemos generalizar a las POBLACIONES. Por ejemplo, en personas con anorexia, ¿hay relación entre el tiempo que lleva esa persona con un trastorno alimentario y la pérdida de densidad ósea que se va a producir en ella? ¿Tener un determinado comportamiento está asociado a tener una determinada enfermedad?
En las técnicas de COMPARACIÓN buscamos ver si las diferencias que vemos entre MUESTRAS son generalizables a las POBLACIONES. Es el caso del ejemplo de antes de los medicamentos A y B que aplicábamos a diferentes pacientes y buscábamos si la respuesta es distinta o no.
Las técnicas de relación o de comparación se conducen, siempre, a un mismo esquema que en Estadística denominamos CONTRASTE DE HIPÓTESIS, donde, como dice el nombre: contrastamos, comparamos, dos hipótesis, dos afirmaciones, siempre (muy importante), POBLACIONALES.
HIPÓTESIS NULA: No hay relación (en técnicas de relación). Hay igualdad (en técnicas de comparación).
HIPÓTESIS ALTERNATIVA: Hay relación (en técnicas de relación). Hay diferencias (en técnicas de comparación).
Las técnicas de relación y de comparación siempre tienen por objetivo decidir, a la luz de la información MUESTRAL cuál es la afirmación POBLACIONAL más coherente por la cual decantarse: Por la HIPÓTESIS NULA, que es la que con la que partimos el estudio como cierta, o por la HIPÓTESIS ALTERNATIVA, que sólo abrazaremos si la NULA no tiene sentido mantenerla a la luz de la información muestral que tenemos.
Y, para acabar, un paralelismo sorprendente: Este esquema recuerda mucho a lo que sucede en un juicio. Cuando se juzga a una persona existen dos hipótesis a contrastar: Inocencia y Culpabilidad. Una hipótesis parte como cierta: es la célebre presunción de inocencia. Podríamos decir, por lo tanto, que en Ciencia hay presunción de no relación o de igualdad porque es lo que afirma siempre la HIPÓTESIS NULA, que es la que parte siempre como cierta. Además, otro paralelismo: el juez o el tribunal, en el juicio tiene una MUESTRA, pero su voluntad es saber la verdad que sería, aquí, lo equivalente a la POBLACIÓN, en Estadística, a tener toda la información exacta de lo que sucedió en los hechos que se juzgan.
Podemos decir, pues, para concluir este viaje en autobús turístico, que el DERECHO es a la SOCIEDAD lo que la ESTADÍSTICA es a la CIENCIA. Las grandes decisiones en el ámbito de la CIENCIA ( si un medicamento funciona o no, si un determinado comportamiento está relacionado o no con cierta patología, etc) las toman técnicas estadísticas; exactamente lo mismo que en la sociedad reservamos las decisiones conflictivas en manos del DERECHO.