
Solución Situación 24
Deja un comentario
Un examen tipo test consta de 100 preguntas con 5 respuestas alternativas cada una. Las posibles calificaciones finales son: no apto si el número de respuestas acertadas es inferior a 65, apto si está entre 65 y 92 (ambos inclusives) y sobresaliente si es superior a 92. No restan las que están mal. Se pregunta:
1. Un alumno está seguro de la respuesta de 50 preguntas y contesta las otras 50 al azar. ¿Cuál es la probabilidad de obtener una nota superior a no apto?
2. Otro alumno está seguro de la respuesta de 87 preguntas y contesta las 13 restantes al azar. ¿Cuál es ahora la probabilidad de obtener un sobresaliente?
El Test de Cochran-Mantel-Haenszel es un contraste de hipótesis para contrastar la igualdad de Odds ratio entre k tablas de contingencia 2×2. Es una forma de evaluar la posible influencia que pueda tener, sobre la relación entre esas variables cualitativas dicotómicas, una tercera variable también cualitativa con k valores posibles.
Es un Test usado para comprobar la posible confusión que puede generar una tercera variable en la relación entre dos variables.
El Test es el siguiente:

1b.
La a no es cierta porque la normalidad de una variable va acompañada de una media y una mediana muestral muy próximas.
La c no es cierta porque tenemos una DE muy amplia para el rango intercuartílico que tenemos. Esto hace pensar en una gran asimetría de los valores.
La d no es cierta porque la única información de la media y la DE no nos informa de ello.
La b es correcta. Porque la media± 0.68×15 construye un intervalo del 50%. Observemos que 0.68×15=10.2 y dos veces 10.2 es 20.4, muy similar a 20 que es el rango intercuartílico. Esta es, sin lugar a dudas, la información que más nos acerca a pensar en la normalidad de la variable.
2a
El Error estándar (EE) es 1, porque el intervalo de la media tiene radio 2 y es del 95%. Por lo tanto, de la fórmula EE=DE/raíz(n), sabemos EE y raíz(n), por lo tanto DE=EExraiz(n)=1×100=100.
3d
La desviación estándar de una muestra siempre se puede calcular. Otra cosa es que nos sirva o no como criterio inferencial.
El rango es 35, no 34.
La mediana es -2, no 0.
El rango intercuartílico es, efectivamente 4.5. Porque el tercer cuartil es 0.5 y el primer cuartil es -4 y 0.5-(-4) es 4.5.
1.¿Qué información nos hace pensar en una variable con distribución normal?
a. Media muestral=12 y Mediana muestral=23
b. Rango intercuartílico= 20, Media±DE=50±15
c. Rango intercuartílico= 5, Media±DE=50±25
d. Media±DE=50±15
2. Si la media muestral de una muestra de tamaño 10000 es 25 y un intervalo de confianza del 95% de la media es (23, 27), ¿cuál es la Desviación estándar (DE) muestral?
a. 100.
b. 1.
c. 1000.
d. 10.
3. En la siguiente muestra (-34, -4, -4, -4, 0, 0, 1, 1):
a. La desviación estándar no se puede calcular porque no se ajusta a una distribución normal.
b. El rango es 34.
c. La mediana es 0.
d. El rango intercuartílico es 4.5.
Las soluciones son las siguientes:
1c:
En una variable cuantitativa no es el tamaño de muestra lo que condiciona que se use, para describirla, la media y la desviación estándar o la mediana y el rango intercuartílico. Depende de su ajuste a la distribución normal, a la campana de Gauss. Por lo tanto, las respuesta a y b no son ciertas.
Pero la respuesta c sí es correcta. Hemos visto en el artículo «La Estadística descriptiva en Medicina» que si la variable cuantitativa se ajusta bien a una distribución normal si a la media le restamos y le sumamos 0.68 multiplicado por la desviación estándar construimos un intervalo con un 50% de valores poblacionales. El rango intercuartílico, que es la distancia entre el primer y tercer cuartil, cubre un 50% también central. Por lo tanto, dos veces este 0.68; o sea, 1.36 la desviación estándar debe ser un valor similar al rango intercuartílico.
Si la muestra se ajusta bien a una distribución normal la media es muy próxima a la mediana y el rango intercuartílico próximo a 1.36xDE porque sabemos que la media más y menos 0.68xDE en una distribución normal construye un intervalo centrado en la media del 50% de valores.
2c:
El Rango no tiene por qué ser dos veces el Rango intercuartílico, en general. Pueden llegar incluso a ser iguales, ambos rangos. Por ejemplo, en la muestra: (0, 0, 10, 10). En esta muestra Rango y Rango intercuartílico valen lo mismo: 10.
La media muestral puede ser menor que la mediana muestral perfectamente. Por ejemplo, en la muestra: (0, 10, 10, 10). La mediana muestral es 10 y la media muestral es 7.5.
No necesariamente si la mediana muestral y el tercer cuartil coinciden la media muestral debe ser mayor que la mediana muestral. La muestra anterior de nuevo lo demuestra.
Y, finalmente, el primer y tercer cuartil pueden coincidir perfectamente en una muestra. Por ejemplo: (0, 5, 5, 5, 5, 5, 5, 10). Aquí primer cuartil y tercer cuartil coinciden: 5.
3c:
La especificidad es la probabilidad de que dé negativa la prueba condicionado a que el paciente no tenga la enfermedad; o sea, P(-/NE). Los falsos positivos son la P(+/NE). Y, evidentemente, P(+/NE)+P(-/NE)=1. Luego la especificidad es 1-Probabilidad de tener falsos positivos.
4d:
El “a” no es cierto en general. La simetría que transmite la idea de que la mediana sea el promedio exacto del primer y tercer cuartil no implica que esa simetría no se puede romper por la izquierda del primer cuartil o por la derecha del tercer cuartil. Un ejemplo: (0, 0, 5, 5, 5, 5, 10, 100). En esta muestra el primer cuartil es 2.5 y el tercero 7.5. La mediana, que es 5, es, en este caso, el promedio del primer y tercer cuartil, lo que indica que hay una simetría central. Obsérvese que efectivamente, si prescindimos de los dos valores extremos, el mínimo y el máximo, hay una simetría manifiesta, lo que haría pensar en que la media y la mediana podrían ser iguales. Pero observemos que la simetría se rompe en esta muestra por culpa del 100. Lo que hace que la media ascienda mucho y sea considerablemente distinta de la mediana. La media muestral es 16.2.
La “b” tampoco es cierta. Si la muestra se ajusta a una normal la media muestral y la mediana muestral se aproximarán, pero no necesariamente serán iguales.
La “c” tampoco es cierta. Veámoslo con un ejemplo: La muestra (0, 1, 2, 3, 5, 5, 6, 6). La media muestral es 3.5. El primer cuartil es 1.5 y el tercero es 5.5. El promedio de estos dos cuartiles es 3.5. Por lo tanto, en esta muestra coinciden el promedio de primer cuartil y tercer cuartil y la media muestral, pero la mediana de esta muestra es 4.
5c:
La muestra no se ajusta bien a una distribución normal, por lo tanto la inferencia del apartado «a» no es correcta.
La mediana es 4.5, no 5.
El que en la muestra el valor superior sea 60 no significa que en la población no puedan haber valores superiores a él, evidentemente.
Como el intervalo construido por el primer y tercer cuartil de nuestra muestra, que es (3, 30) cubre el 50% muestral podemos hacer perfectamente la estimación, la inferencia, de que en la población habrá un valor próximo al 50% de individuos entre estos dos valores de la variable estudiada.
Se ha publicado un interesante estudio en el New England Journal of Medicine de aplicación del Test de McNemar en Medicina que vale la pena comentar.
Se compara la eficacia de un páncreas artificial automatizado, que controla la glucemia y suministra insulina en continuo, respecto a un sistema de control estándar en pacientes con Diabetes tipo 1. Se usan los dos sistemas de control en un grupo de pacientes. En dos noches distintas se ensayan cada uno de estos métodos en todos los pacientes. La variable respuesta es si en algún momento han sufrido una hipoglucemia durante la noche. La variable es, pues, dicotómica: tener o no una hipoglucemia.
Si miramos es cuadro de elección de la técnica a aplicar en el tema «Comparación de dos poblaciones», veremos que como es una variable dicotómica y son muestras relacionadas (al mismo individuo se le aplican los dos procedimientos comparados) deberemos aplicar un Test de McNemar.
Los datos que se obtienen son los siguientes:

Como se puede ver en el Test de McNemar (Ver Herbario de técnicas) la clave es tener en cuenta únicamente las casillas donde se producen resultados contrarios en las dos técnicas. En nuestro caso, únicamente interesa cuándo se ha dado hipoglucemia en una técnica de control y no se ha dado en la otra. Nos interesan los valores 22 y 7, claro.
Veamos la aplicación del Test a nuestros datos:
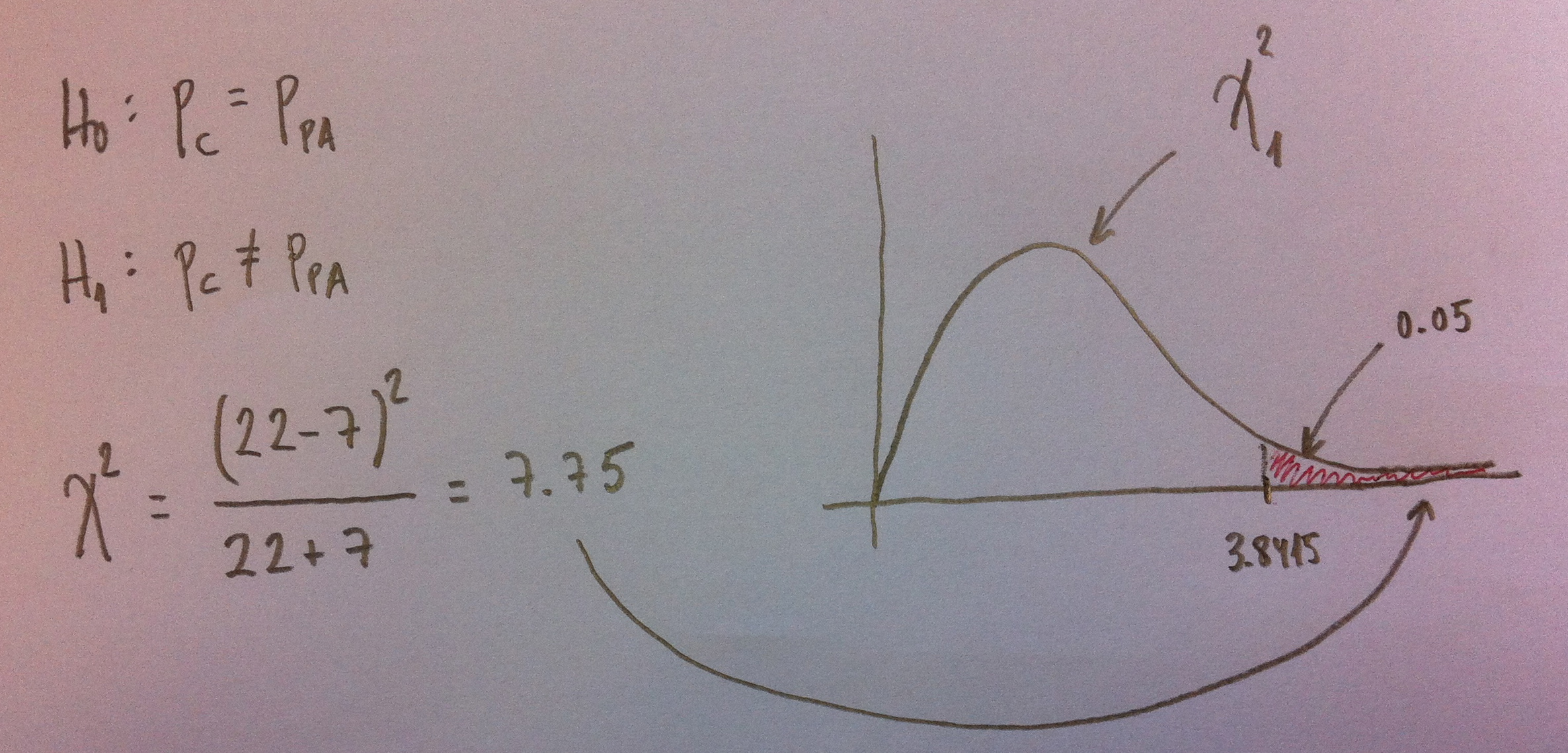
Estamos contrastando la igualdad de proporciones entre ambas técnicas de control versus la desigualdad, como siempre.
En las tablas de la ji-cuadrado (Ver el artículo dedicado a la Distribución ji-cuadrado en Complementos), podemos ver que en una ji-cuadrado con valor 1 del parámetro, a partir del valor 3.8415 el área es de 0.05. Este es, pues, el nivel de significación. Al ser 7.75 mayor que este valor debemos rechazar la Hipótesis nula y decir que hay diferencias significativa. El p-valor es inferior a 0.05.
Respuestas correctas:
1c:
El valor de la correlación, sin tener en cuenta más cosas, no es suficiente para marcar la significación. Únicamente una r=0 tendría validez en sí mismo y sería para marcar no significación.
El error estándar siempre es igual o menor que la desviación estándar. Sería igual si el tamaño muestral fuera 1. Pero a partir de más tamaño muestral el error estándar será menor que la desviación estándar.
La Odds ratio va de 0 a infinito.
Y el error estándar es una desviación estándar. Una desviación estándar muy especial, la desviación estándar de una predicción.
2a:
El que la pendiente sea negativa no la invalida como significativa. Puede ser significativa o no serlo.
Cuando una Odds ratio no es significativa el intervalo de confianza del 95% lo que contiene es al 1.
La Odds ratio puede ir desde 0 a infinito, nunca podrá ser negativa.
En el apartado 2a consta una de las habituales definiciones de p-valor: que es la probabilidad de observar los resultados y otros aún más alejados de la Hipótesis nula, si la Hipótesis nula fuera cierta. Otra definición equivalente, que dice lo mismo de otra forma, sería: Es la probabilidad de la zona crítica más pequeña mediante la cual se rechazaría la Hipótesis nula.
3b:
El kappa no va de 0 a infinito. El máximo es 1.
El p-valor va de 0 a 1, no de -1 a +1.
Un intervalo de confianza de 95% de una pendiente de una regresión lineal simple de (-0.95, 0.65) no puede ir asociado a una r significativa, porque se trata de una pendiente que no es significativa. Observemos que en el intervalo está el 0. El que la pendiente sea 0 es posible. Esto marca que no hay relación significativa entre las variables.
Y, efectivamente, una r positiva y significativa va asociada a una pendiente positiva y, además, significativa.
4b:
Es la mitad del área que va de la media menos dos desviaciones estándar a la media más dos desviaciones estándar. Como el área total de este intervalo sería 0.95, la mitad es 0.475.
5a:
Como la desviación estándar es 5, el error estándar será 5/raíz(100); o sea, 0.5. Por lo tanto, un intervalo de confianza de la media del 95% será más menos dos errores estándar en torno a la media, por lo tanto será: (49, 51).
6d:
El rango es, evidentemente, 15 en esta muestra, no 12.5. El máximo menos el mínimo es 15.
7d:
Si el p-valor es inferior a 0.05 y rechazamos la nula lo que hacemos es, entonces, aceptar la alternativa, no rechazarla.
El p-valor no será superior a 0.05, sino inferior, si nuestro nivel de significación es, como es habitual, del 0.05.
Si el p-valor es muy bajo no debemos repetir, debemos rechazar la hipótesis nula y aceptar la alternativa, y basta.
Si el nivel previo de significación era del 0.05 y rechazamos la hipótesis nula la probabilidad de equivocarnos es, efectivamente, del 5%. Esto es lo que significa, precisamente, este nivel de significación. Es una zona de rechazo donde la probabilidad de tener valores allí, si es cierta la hipótesis nula, es una probabilidad muy baja, del 5%, y, además, en esa zona tiene mucha probabilidad de ser cierta la hipótesis alternativa. Aceptamos, por lo tanto, el riesgo del error, pero rechazamos, en este caso, la hipótesis nula, sabiendo que tenemos esa probabilidad de equivocarnos.
8d:
El test más correcto no es ninguno de los tres. El más correcto es el Test de la t de Stundent de muestras independientes. Faltará comprobar, únicamente, si el de varianzas iguales o desiguales.
9c:
El coeficiente de Gini va de 0 a 1.
Al aumentar la desviación estándar el coeficiente de Gini también aumenta, no disminuye.
Si es 1 es que todo está concentrado en un valor. Por lo tanto, indica que todos menos uno no tienen nada y uno lo tiene todo.
Si el rango es 0 significa que todos los valores son iguales y si todos los valores son iguales el coeficiente de Gini vale 0 porque la curva de Lorenz coincide, precisamente, con la diagonal.
10d:
La mediana es 3.5, no 3.
El rango intercuartílico es 2, no 3.
La Desviación estándar y la Desviación estándar corregida no son iguales. No será lo mismo, en absoluto, dividir por 8 ó por 7 a la hora de calcular el grado de dispersión.
El rango es 3 y el rango intercuartílico es 2, por lo tanto la resta entre ellos es, efectivamente, 1.



