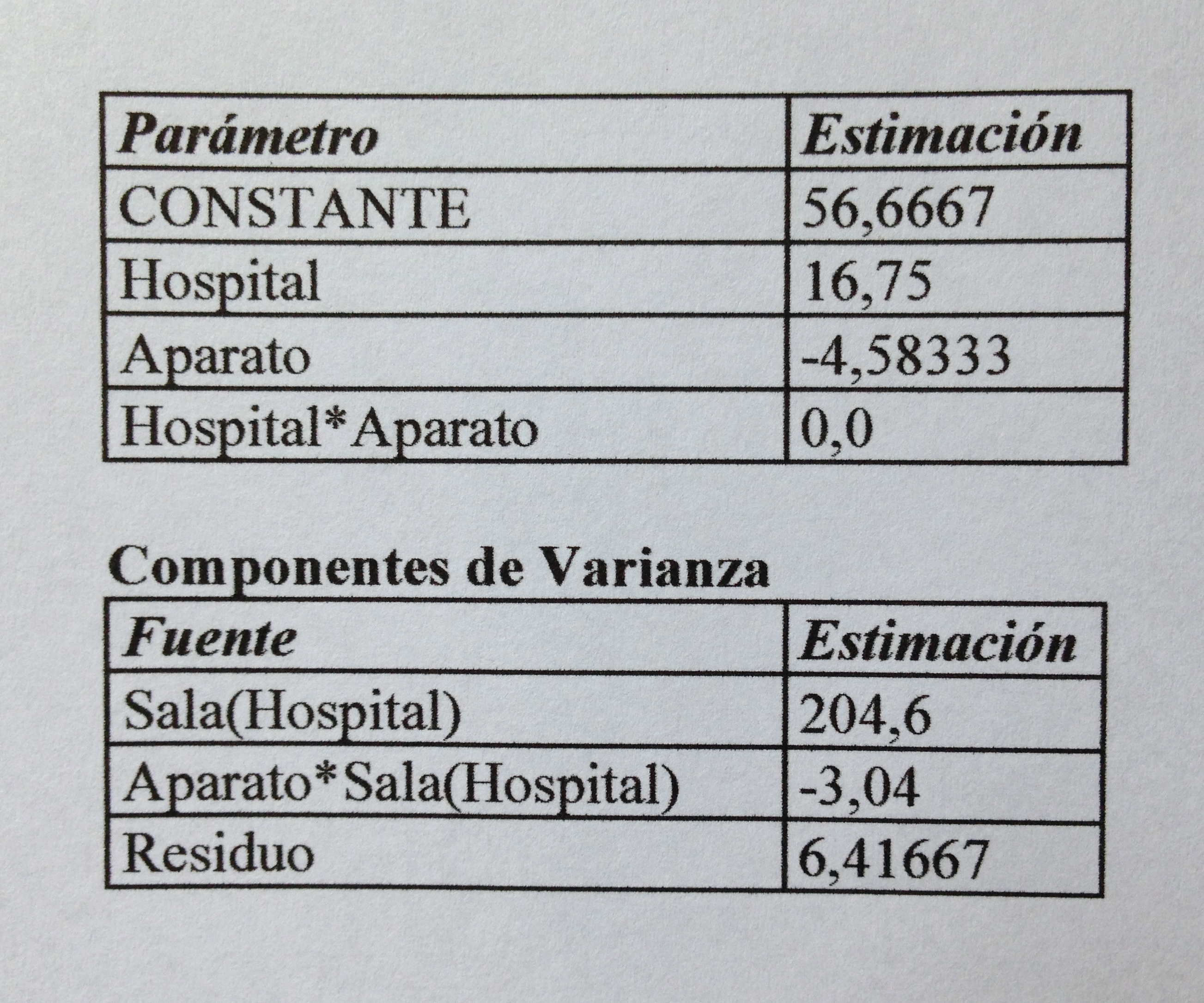
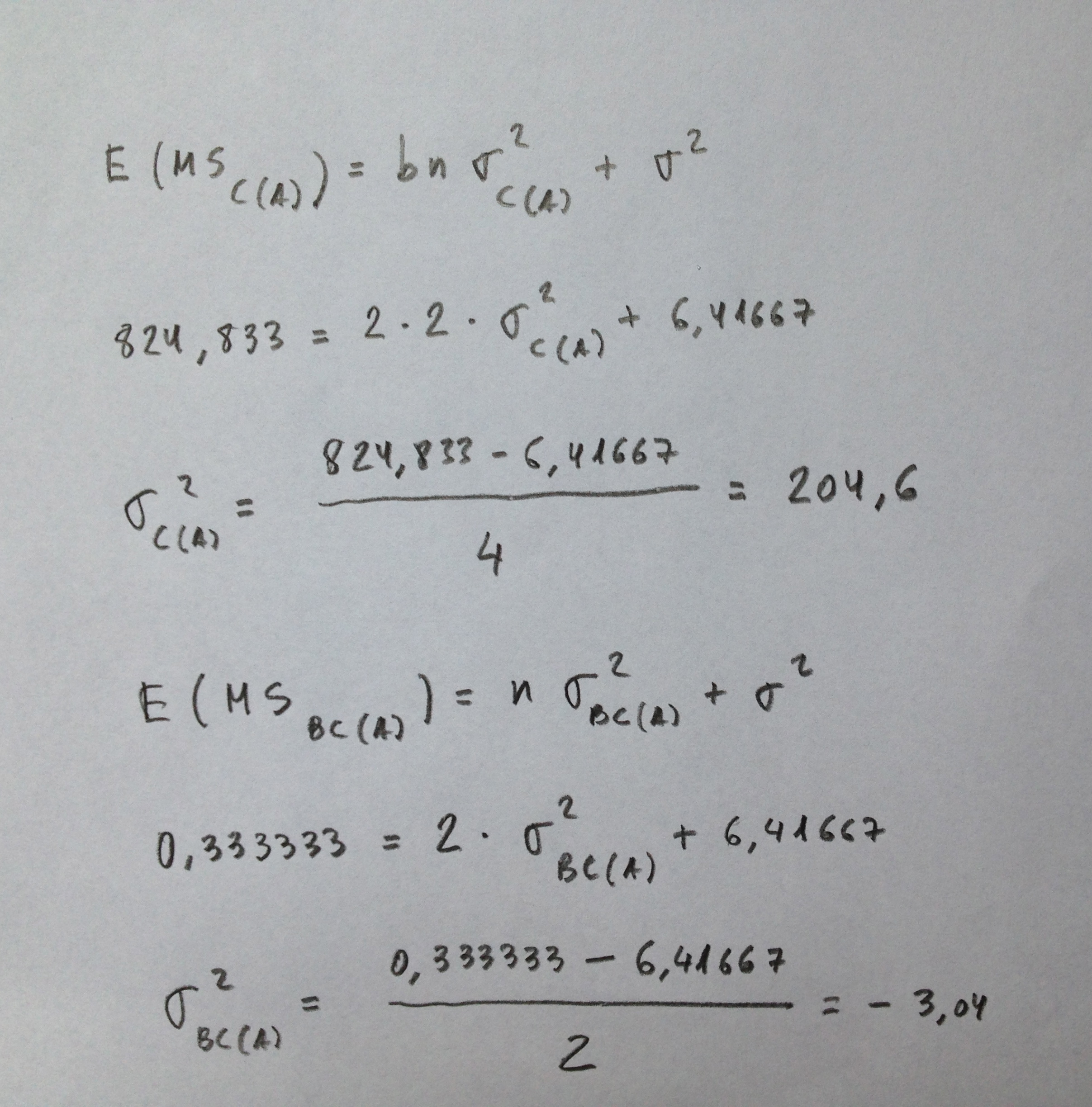1c:
Si se calcula la V de Cramer, resulta ser, efectivamente, 0.6.
La «a» es incorrecta. La correlación de Pearson no puede usarse para variables cualitativas.
La «b» también es incorrecta. La V de Cramer no puede dar valores negativos.
La «d» es también incorrecta. Estos datos no son de independencia de las variables. Todo lo contrario, parece haber una clara relación, una clara asociación, entre el sexo y estos dos tipos de estudios.
2c:
La «c» es la incorrecta. La ji-cuadrado es una técnica para valorar la relación entre variables cualitativas, no cuantitativas. Y nos dicen que para evaluar la significación de una correlación de Pearson realizamos una ji-cuadrado. Esto no es cierto.
La «a» es cierta. El p-valor es el valor que proporciona la significación de la correlación de Pearson.
También es cierta la «b». Tenemos una correlación de elevada magnitud pero no significativa. Lo que indica que tenemos una tamaño muestral pequeño.
La «d» también es cierta. Tenemos una V de Cramer de elevada magnitud (0.9). Recordemos que va del 0 al 1. Además, ciertamente, es significativa. El p-valor es menor que 0.05. En este caso se suele dar el p-valor de la ji-cuadrado calculada a la tabla de contingencias.
3c:
La «a» es cierta. Tenemos dos únicas variables. Aquí sólo cabe una Regresión simple.
La «b» también es cierta. Como nos dicen que la relación es lineal la Regresión que haremos será una Regresión lineal simple.
La «d» también es cierta. Si la correlación es positiva la pendiente de la recta de regresión será positiva. Y si la correlación es negativa la pendiente de la recta será negativa.
La «c», sin embargo, es incorrecta. No puede darse contradicción entre la significación de la correlación y de la pendiente. Si una es significativa la otra también. Si una no lo es la otra tampoco. Van de la mano. Es lógico que sea así. Sólo tiene sentido hacer una regresión si hay correlación significativa.
4d:
La «a» no es cierta. Siempre hay un elemento de imprecisión en una regresión.
La «b» tampoco es correcta. Lo que se le suma a la predicción son valores positivos o negativos, dependiendo de cada caso, de cada observación.
La «c» tampoco es correcta. Ni mucho menos la predicción dará eso necesariamente.
La correcta es ahora la «d». Las imprecisiones serán valores que girarán en torno a cero. Y esas imprecisiones serán, en valor absoluto, tanto más grandes cuanto menor sea la correlación entre esas variables.
5d:
La «a» es incorrecta. En absoluto tenemos una buena R2. Ésta tiene una valor del 36%. Esto es muy bajo. Es menor del 50%, que suele ser el límite aceptable.
La «b» es incorrecta.La correlación no es significativa, efectivamente, pero no por ser menor que 0.7, sino por tener un p-valor inferior a 0.05.
La «c» también es incorrecta. La utilidad de una correlación no la marca el p-valor. Lo marca la R2. Esta correlación es poco útil para predecir porque tiene bajo coeficiente de determinación: 36%.
La «d» es la correcta. La correlación es, efectivamente, significativa, el p-valor es inferior a 0.05, pero la capacidad predictiva es baja. Tiene una capacidad de determinación del 36%, que es bajo.