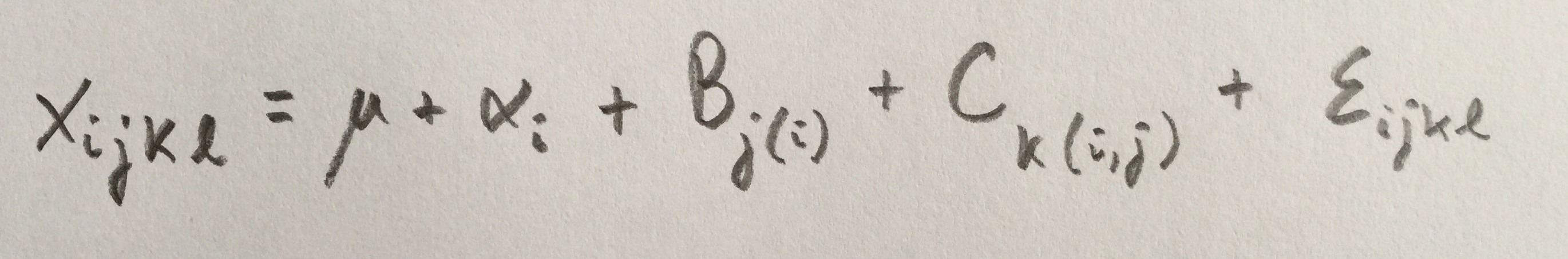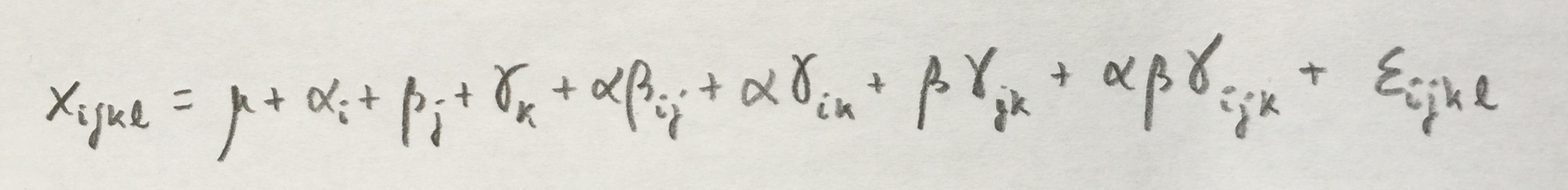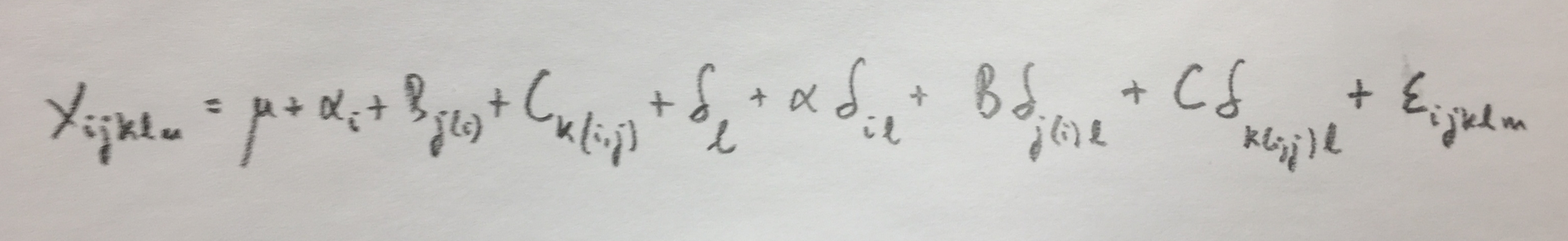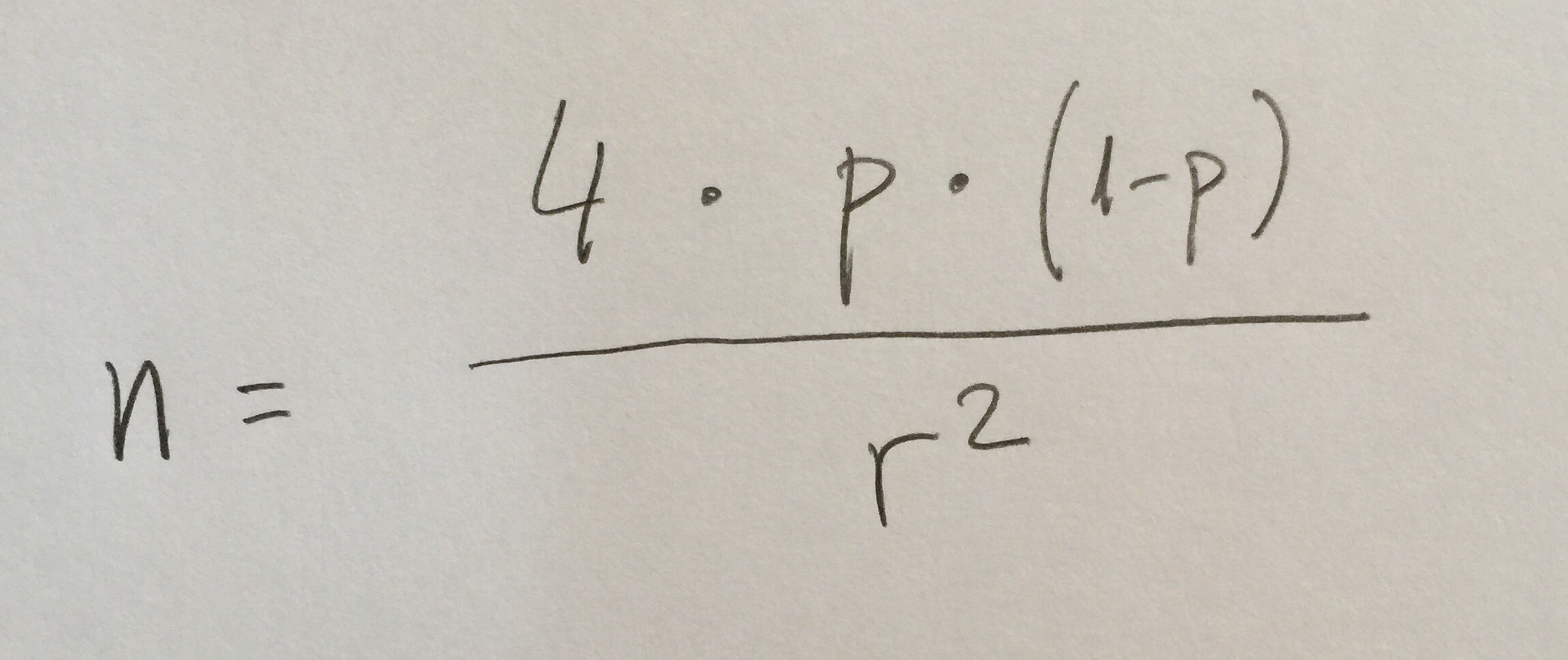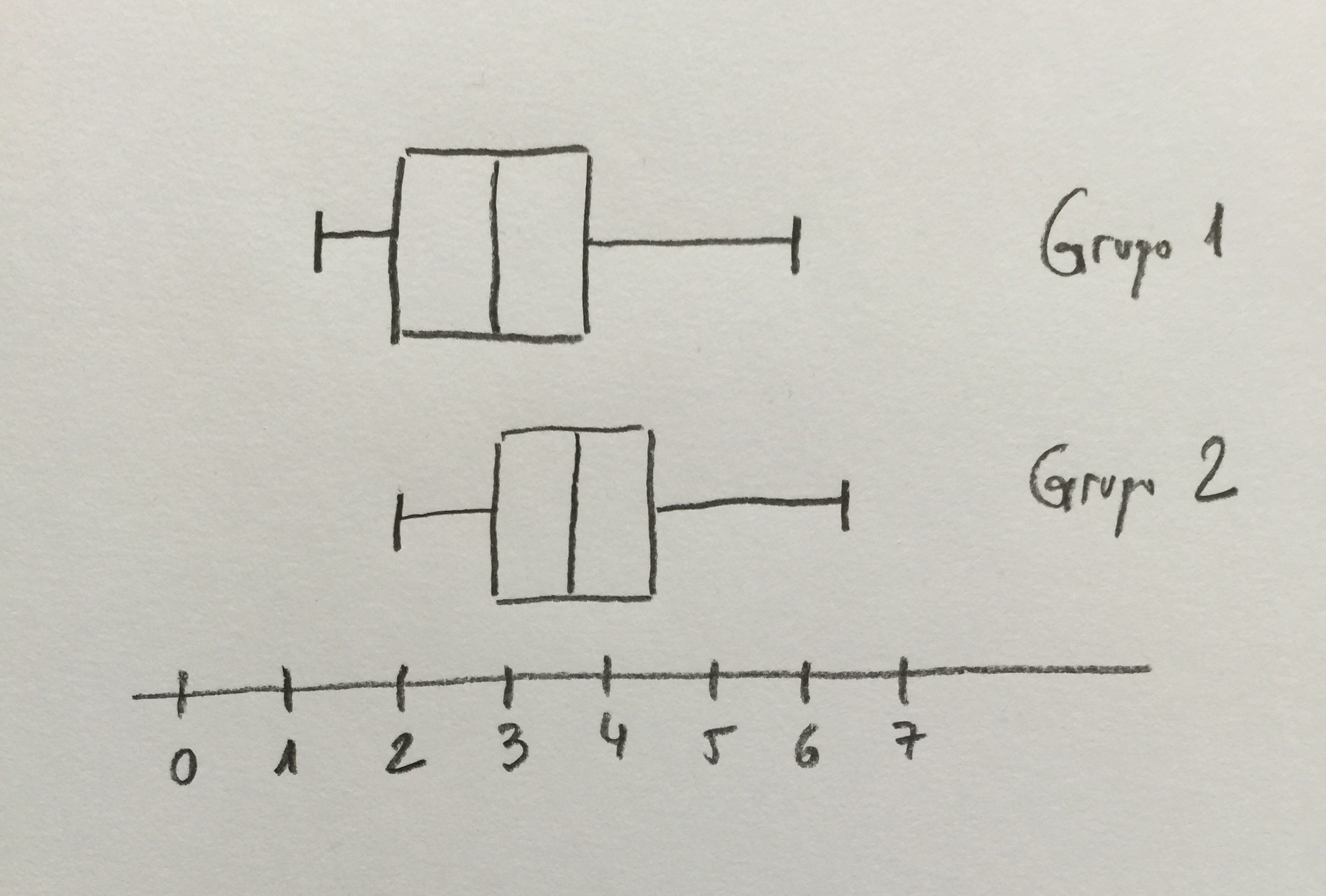1.¿Cuál de las siguientes afirmaciones no es cierta?
a)Si en una comparación de dos poblaciones debemos aplicar un Test de Fisher es que las muestras son independientes y que ambas se ajustan a la distribución normal.
b)En un contraste de hipótesis para evaluar el ajuste a la distribución normal un p-valor inferior a 0.05 indica que hay suficiente ajuste de los datos a la distribución normal.
c)Con una potencia superior al 80% nos podemos fiar del p-valor que tengamos.
d)Podemos tener en un ANOVA de dos factores no significativos (p-valor>0.05) y una interacción significativa (p-valor<0.05).
2.En un estudio donde se quiere comparar la cantidad de un contaminante en las playas de dos poblaciones distintas tenemos 50 observaciones en cada una de las dos playas. El test de Shapiro-Wilk de ambas muestras nos proporciona un p-valor mayor que 0.05. El test de Fisher-Snedecor nos proporciona una p=0.001. Es cierto lo siguiente:
a)Debemos aplicar el test de la t de Student para varianzas desiguales y si tenemos un p-valor inferior a 0.05 debemos concluir que las medias son diferentes.
b)Debemos aplicar el test de la t de Student para varianzas desiguales y si tenemos un p-valor inferior a 0.05 debemos concluir que las medias no son diferentes.
c)Debemos aplicar el Test de Mann-Whitney.
d)Debemos aplicar el Test de la t de Student de datos apareados.
3.Si en una comparación de dos poblaciones al aplicar el test adecuado al caso el p-valor final es 0.1 es cierto lo siguiente:
a)Si aumentamos el tamaño de muestra y disminuimos la desviación estándar el p-valor subirá.
b)Si aumentamos la desviación estándar de ambas muestras sin modificar el tamaño de muestra el p-valor bajará.
c)Si aumentamos las diferencias de medias entre ambas muestras y disminuimos la desviación estándar el p-valor bajará.
d)Si aumentamos el tamaño de muestra y disminuimos la diferencia de medias el p-valor bajará.
4.Se analiza el porcentaje de una especie en el fitoplancton en 40 puntos del océano pacífico y 40 puntos del océano atlántico. Después de un año se hace lo mismo en los mismos puntos y se vuelve a calcular el porcentaje de esa misma especie. En el pacífico en el 10% de puntos ha disminuido el porcentaje de esta especie y en el atlántico en el 5%. Queremos comparar si esa diferencia es estadísticamente significativa. Debemos aplicar:
a)El Test de proporciones.
b)El Test exacto de Fisher.
c)El Test de Wilcoxon.
d)El Test de McNemar.
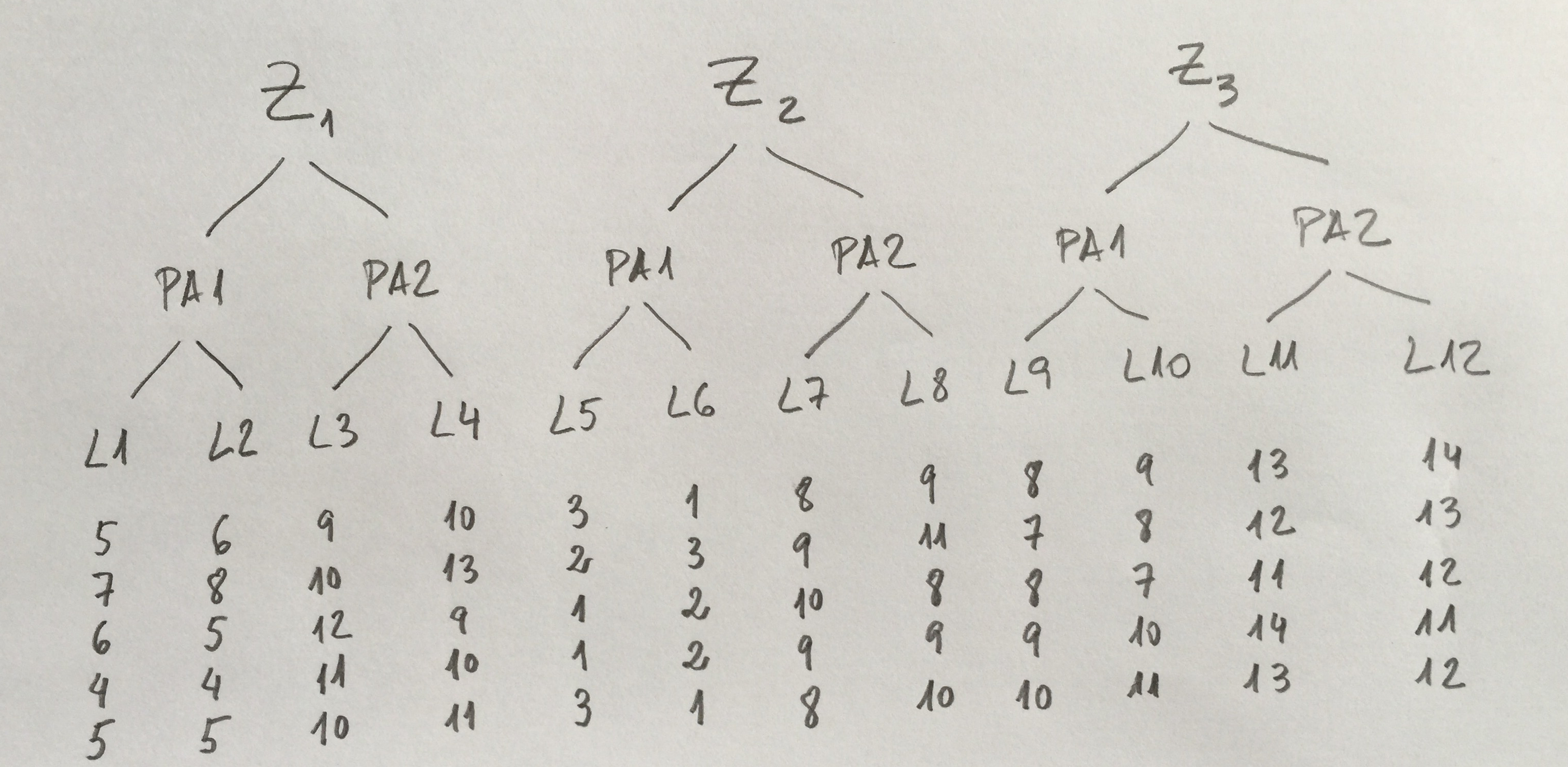
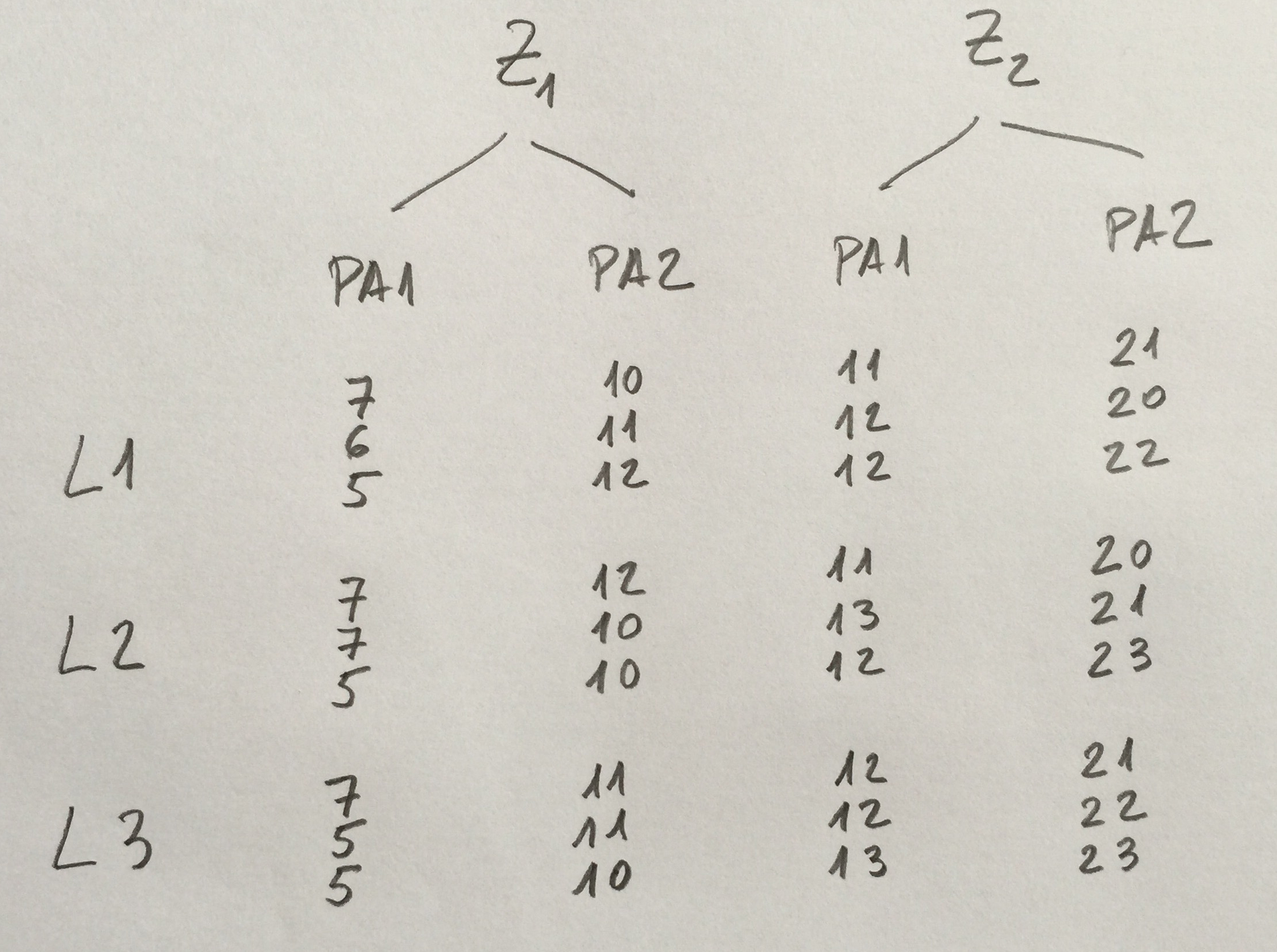
5.Hemos analizado la cantidad de biomasa en tres profundidades determinadas en tres zonas del mar distintas. En cada zona y profundidad hemos tomado tres muestras en tres botellas. Los resultados son los siguientes:
¿Cuál es la afirmación más razonable?:
a)Factor Z: p>0.05. Factor P: p>0.05. Interacción: p>0.05.
b)Factor Z: p<0.05. Factor P: p>0.05. Interacción: p<0.05.
c)Factor Z p>0.05. Factor P: p>0.05. Interacción: p<0.05.
d)Factor Z: p>0.05. Factor P: p<0.05. Interacción: p>0.05.
6.Queremos comparar dos políticas medio-ambientales distintas que pretenden reducir el nivel de contaminación en playas. Se han escogido dos playas piloto muy similares entre sí. En cada una de ellas se eligen 30 puntos fijos detectables perfectamente por la posición de una bolla. Tenemos dos datos del contaminante: antes de la acción medio-ambiental aplicada y un mes después de la constante aplicación de la medida. La variable estudiada es una variable cuantitativa. ¿Cuáles son los pasos a seguir?:
a)Se comprueba la normalidad del antes y del después, en cada playa, y se aplica el test de datos apareados adecuado (si hay normalidad el test de la t de Student de datos apareados y si no hay normalidad el test de Wilcoxon o el test de los signos).
b)Se comprueba la normalidad de la resta del antes menos el después, en cada playa, y se aplica el test de datos apareados adecuado (si hay normalidad el test de la t de Student de datos apareados y si no hay normalidad el test de Wilcoxon o el test de los signos).
c).Se comprueba la normalidad de la resta del antes menos el después, en cada playa, y se aplica el test de muestras independientes adecuado (si hay normalidad el test de la t de Student de muestras independientes que corresponda y si no hay normalidad el test de Mann-Whitney).
d)Se comprueba la normalidad del antes y del después, en cada playa, y se aplica el test de muestras independientes adecuado (si hay normalidad el test de la t de Student de muestras independientes que corresponda y si no hay normalidad el test de Mann-Whitney).
7.¿Qué error podríamos estar cometiendo si al comparar dos tratamientos tenemos una potencia del 50% y el p-valor que obtenemos es de 0.45?
a)El error de tipo I.
b)El error de tipo II.
c)Ambos errores: El error de tipo I y el error de tipo II.
d)No podemos cometer error en este caso porque el p-valor es claramente superior a 0.05.
8.¿Cuál de las siguientes afirmaciones no es cierta?
a)Una potencia del 85% se corresponde con un error de tipo I de 0.15.
b)Si dos muestras relacionadas de una variable cuantitativa su resta no se ajusta bien a la distribución normal debemos aplicar o el test de los signos o el test de Wilcoxon.
c)En un ANOVA de dos factores anidados no puede evaluarse la interacción entre factores.
d)Un test de Mann-Whitney puede hacerse aunque haya diferencia de varianzas significativa entre los dos grupos comparados.
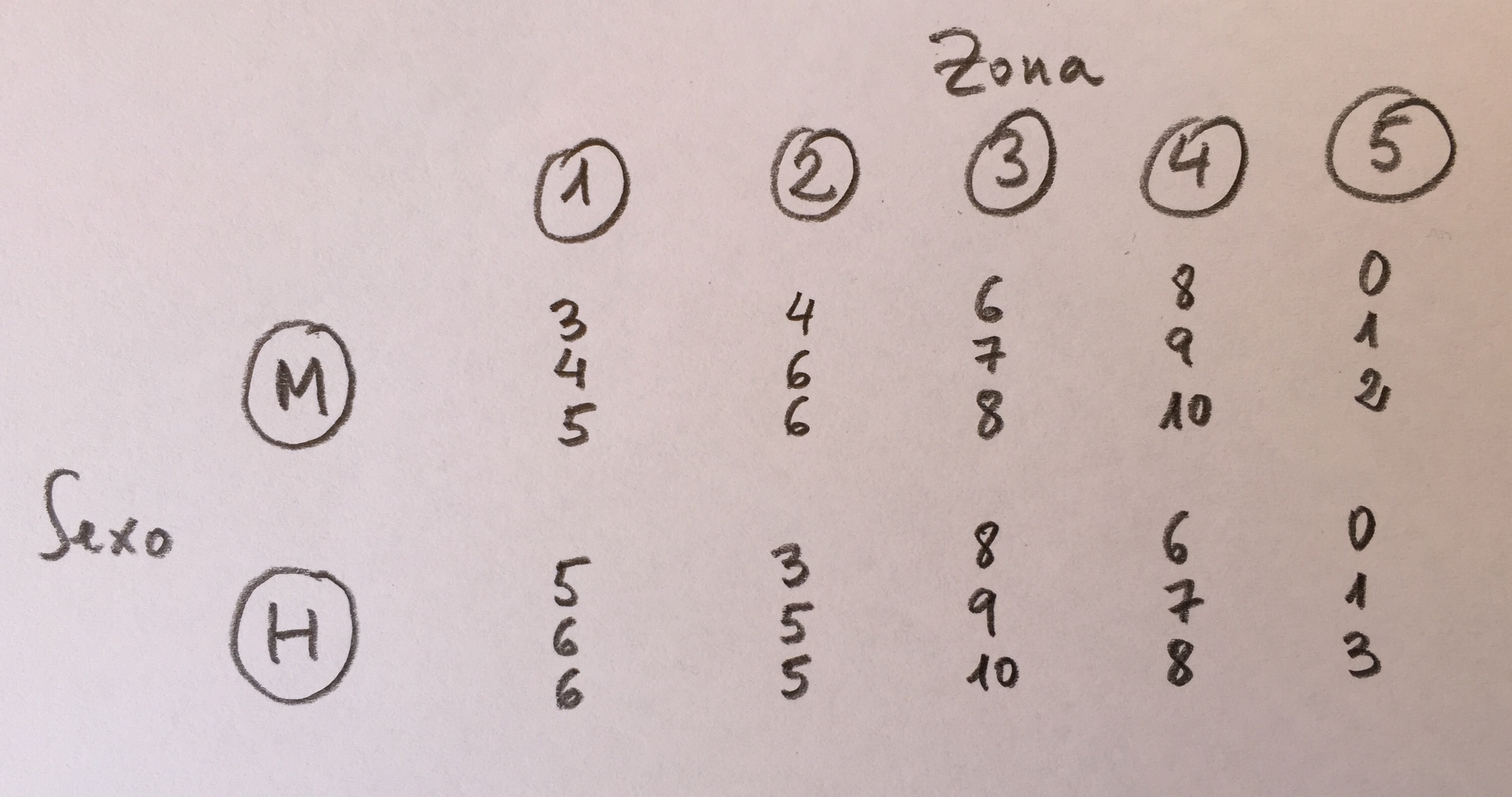
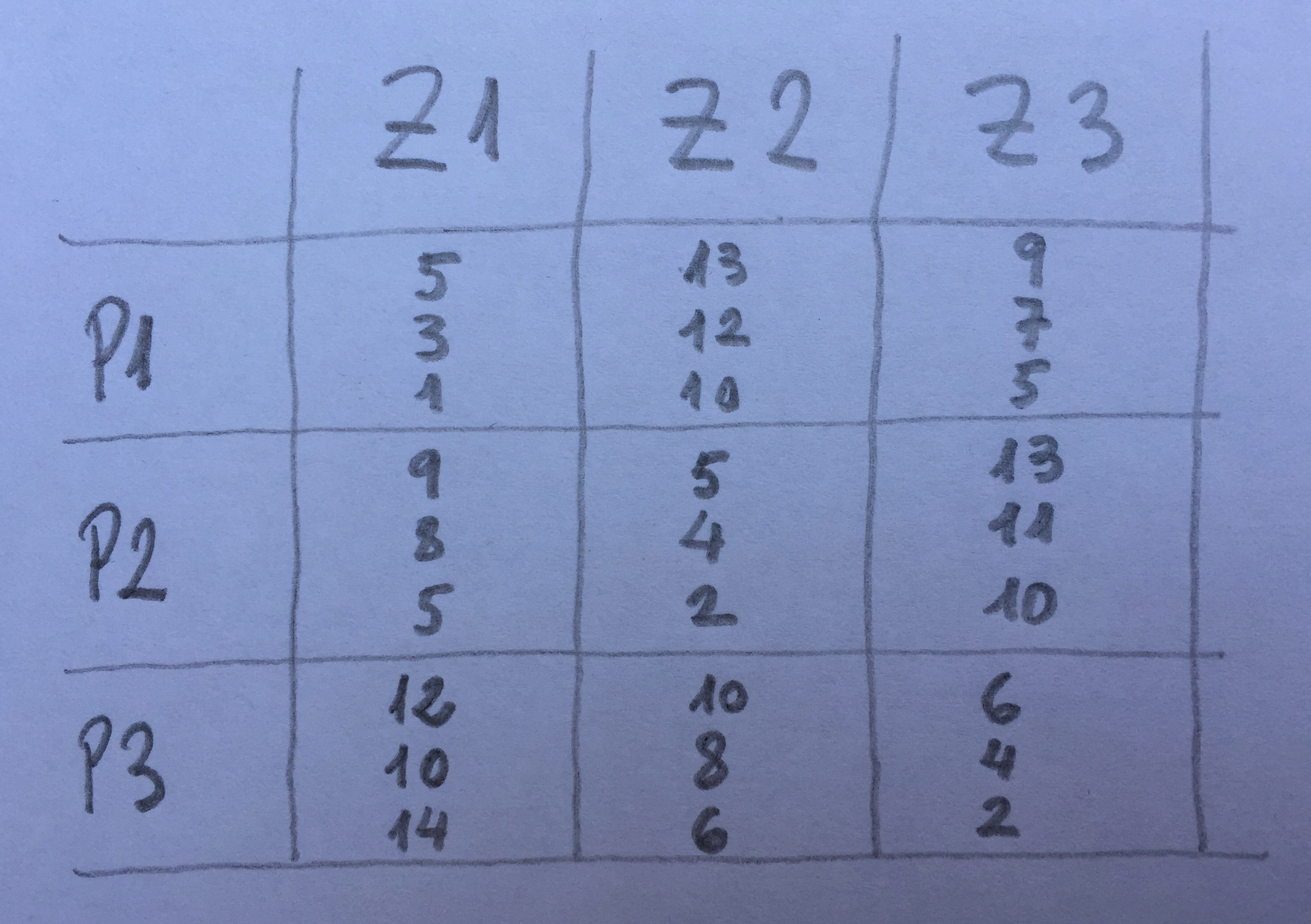
9.Hemos hecho un estudio en tres playas del litoral. En cada una de ellas se ha elegido, al azar, dos subzonas. Se han tomado muestras a 0, 10 y 20 metros. Se han tomado tres botellas en cada punto de muestreo. Se ha cualificado la cantidad de un contaminante. Los resultados son los siguientes:

¿Cuál es la afirmación más razonable?:
a)Estamos ante un estudio con tres factores cruzados. El factor profundidad será significativo y tendrá dos grupos homogéneos.
b)El factor profundidad será significativo y tendrá tres grupos homogéneos en las comparaciones múltiples
c)El factor subzona está anidado dentro de zona y tanto el factor zona como el factor subzona están cruzados con el factor profundidad. El factor profundidad es significativo y el factor subzona también.
d)El factor subzona está anidado dentro de zona y el factor profundidad está anidado dentro de subzona. El factor profundidad es significativo y el factor zona no.
10.Se quiere hacer un pronóstico de la media poblacional de la cantidad de un contaminante en aguas marinas. ¿Qué tamaño de muestra necesitamos tomar para tener un intervalo del 95% de radio 2 si la Desviación estándar que tenemos en una muestra piloto es de 5?:
a)20.
b)25.
c)30.
d)50.