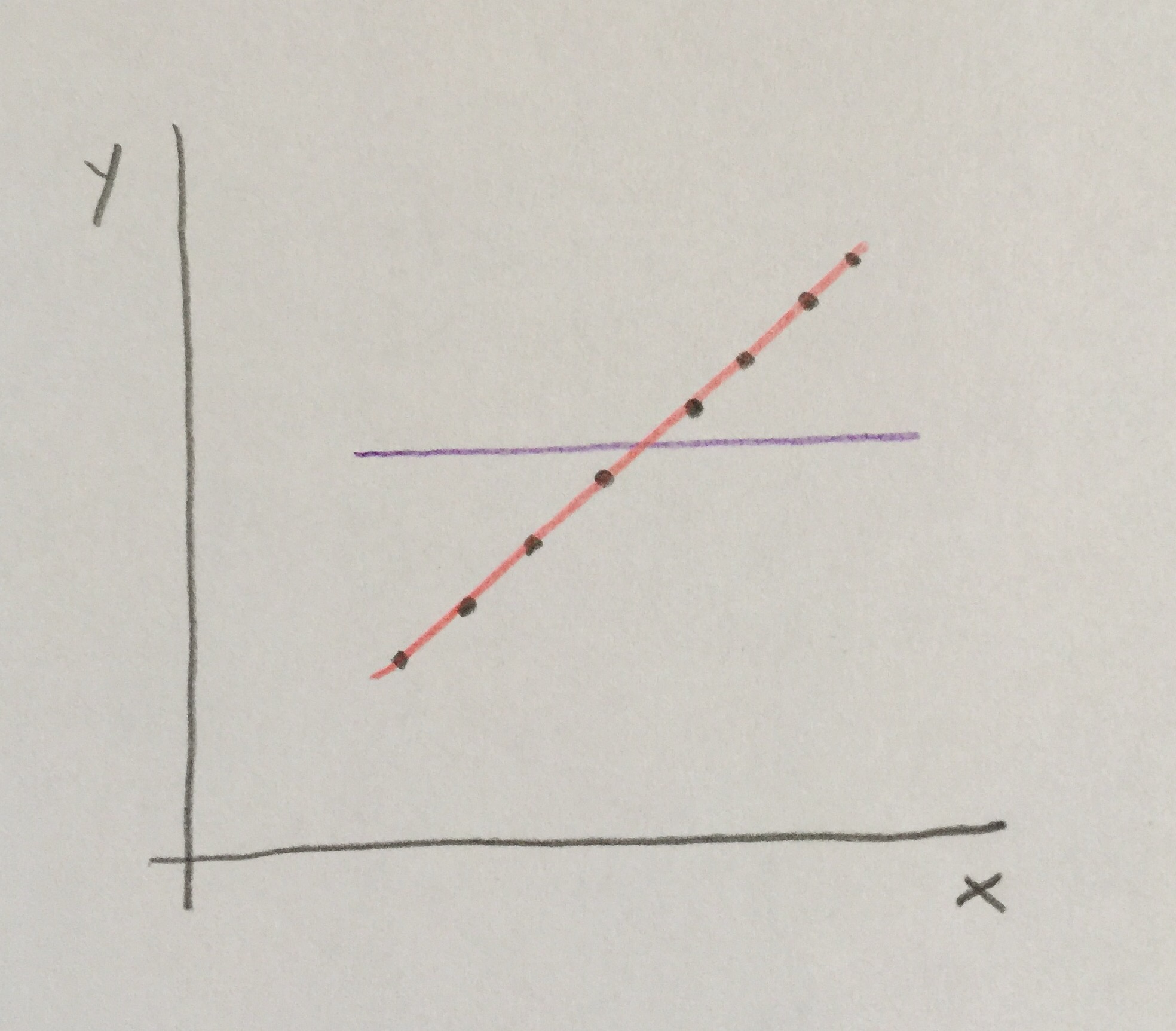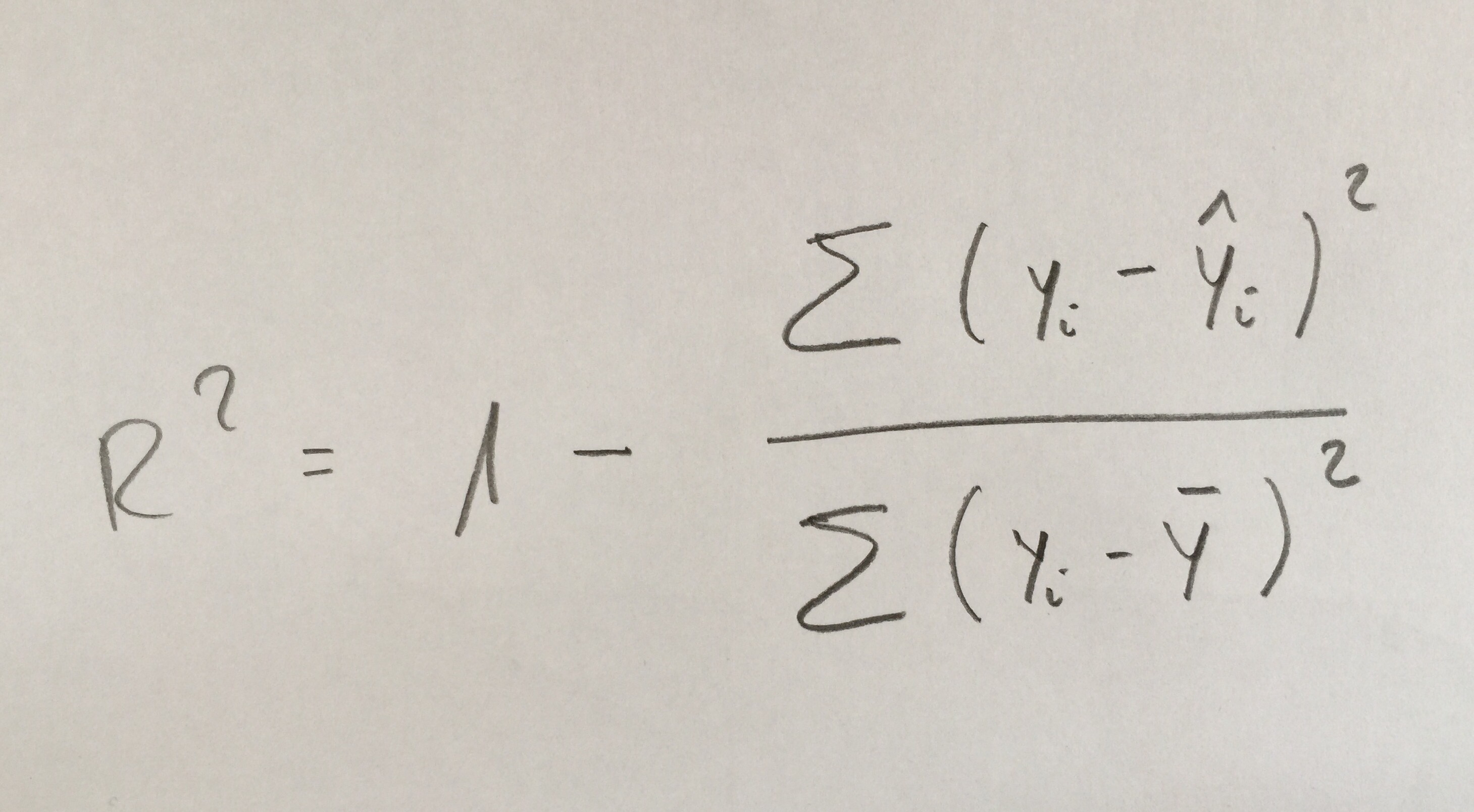Es un importante estadístico en la Regresión. Es una medida del grado de relación existente entre la variable dependiente y las variables independientes (si es una regresión simple, entonces «la variable independiente»). Mide cuánto está determinada la variable dependiente respecto a la variable o variables independientes.
Aunque es un valor que va del 0 al 1, suele darse en porcentaje.
Puede observarse el cálculo y, también, un caso de valor alto y otro de valor bajo de este coeficiente:

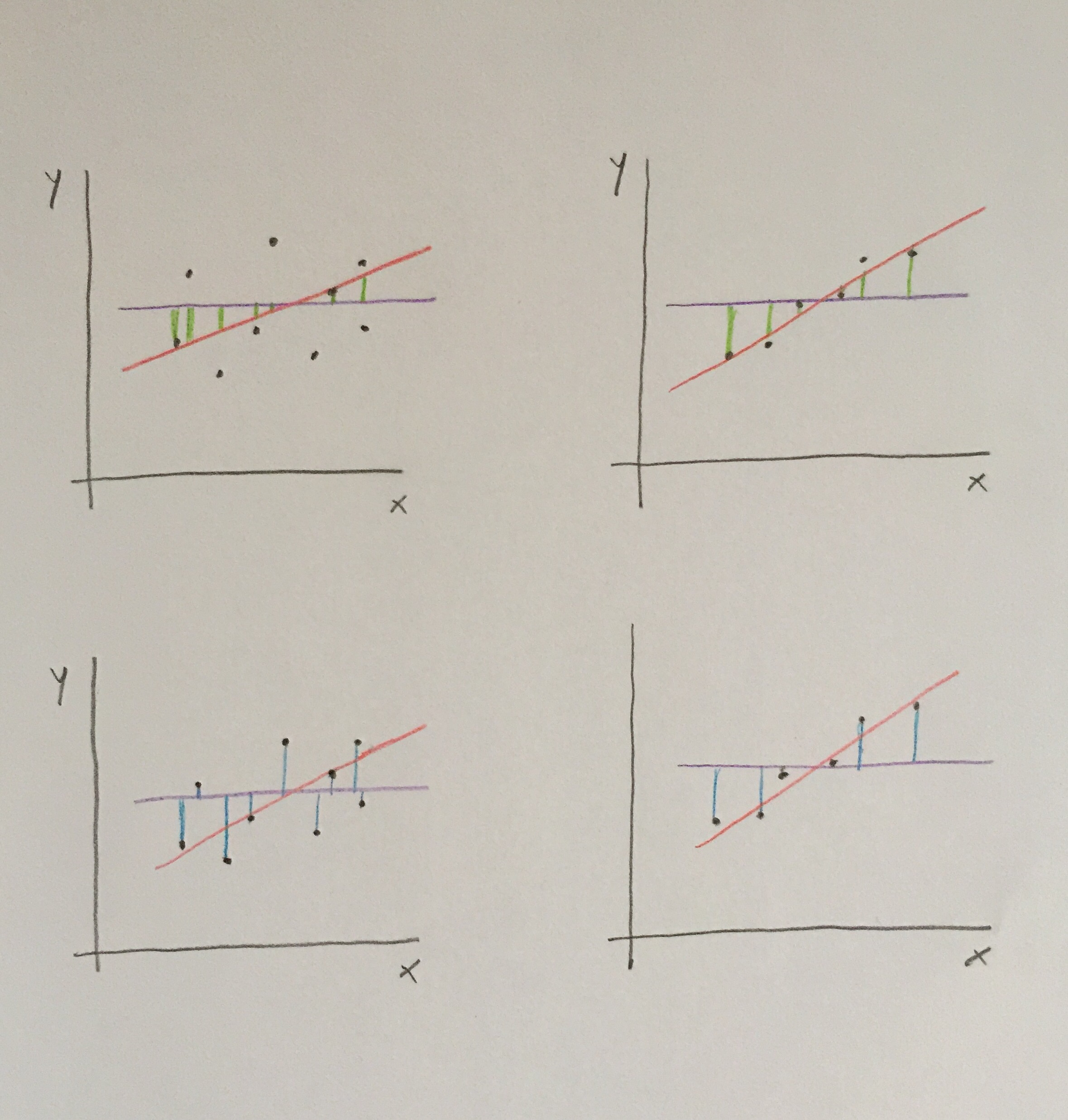
Observemos el siguiente gráfico que tal vez aclare mejor los dos ejemplos:

A la izquierda tenemos el caso con coeficiente bajo y a la derecha el caso con coeficiente de determinación alto.
En cada uno de los casos tenemos arriba el numerador del cálculo del coeficiente y abajo el denominador del cálculo. Líneas verdes para el numerador y azules para el denominador.
Observemos que en el caso de la izquierda las líneas azules son mucho más largas que las verdes. Esto indica que nuestra recta de regresión no explica mucho la posición de los valores en la relación dibujada entre las dos variables.
En cambio, en el caso de la derecha hay una gran aproximación de las líneas verdes a las azules. Esto indica que realmente nuestra recta de regresión consigue situarse muy próxima a la realidad posicional de los puntos en el diagrama de dispersión.
Observemos qué pasaría si los puntos se adaptaran totalmente a la línea recta:

En este casos las distancias verdes y azules son exactamente las mismas. No las dibujo porque se superpondrían, evidentemente. En este caso el coeficiente de determinación valdría 1.
En una regresión lineal simple el coeficiente de determinación coincide con la correlación de Pearson elevada al cuadrado.
Sin embargo, este coeficiente es utilizado en cualquier modelo de regresión.
A veces, este coeficiente de determinación se plantea de otra forma, aunque equivalente, de esta forma:

En forma más explícita:

Puede comprobarse en los dos ejemplos extremos expuestos cómo se trata de una formulación equivalente a la anterior.