Todo lo preparado en este fichero lo ha hecho un alumno al que quisiera agradecer mucho el trabajo realizado. Su nombre es Arnau Subías Baratau.
1.Se ha estudiado la presencia de microplásticos en dos poblaciones de 50 individuos de zooplancton. La primera población se encontraba en el Océano Índico y la segunda en el Océano Antártico. En la población del Índico, 14 de 50 presentaban microplásticos en su interior, en la del Antártico, sólo 5 de 50. ¿Se puede decir que hay diferencias, estadísticamente significativas, entre estos dos grupos de zooplancton, en cuanto a la presencia de microplásticos dependiendo de su localización?
2.Se ha preguntado a un grupo de mujeres y hombres si estaban de acuerdo con la aplicación de bolsas hidrosolubles para reducir la contaminación oceánica causada por los residuos plásticos. Entre las mujeres 5 de 20 personas estaban de acuerdo con la iniciativa, entre los hombres, sólo 3 de 20 estaban de acuerdo con la iniciativa. ¿Se puede decir que hay diferencias significativas entre sexos en cuanto a la opinión sobre tal iniciativa?
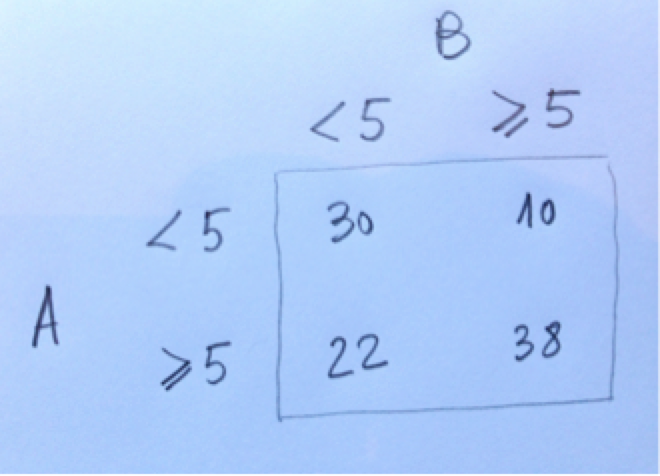
3.Se ha realizado un estudio para estudiar la acidificación en un grupo de 100 corales rojos. Cada coral se colocaba en dos medios con pH diferente. En primer lugar, a 50 de ellos se les colocaba en el medio A y a los otros 50 en el medio B, de pH un poco más ácido, durante un mes. Se dejaba entonces a todos ellos un mes en un medio de igual pH y, al mes siguiente, se colocaba a cada coral en el otro medio. La variable contemplada era si la tonalidad roja del coral (evaluada entre el 0 y el 10), durante el mes que vivía en el medio, era o no superior a 5. Los resultados obtenidos fueron los siguientes:
¿Se puede decir que el porcentaje de los que tienen igual o más de 5 de tonalidad de color rojo es distinto según el tratamiento A o el B?
4.Se quiere analizar la eficacia de un geolocalizador en una población de tiburón blanco. Para ello, se utilizan 18 individuos de tiburón y, a 9 de ellos se les aplica el geolocalizador A y a los 9 restantes el geolocalizador B. La eficacia de dicho localizador se valora del 0 al 10:
¿Podemos decir que hay diferencias estadísticamente significativas en cuanto a la eficacia de ambos geolocalizadores?
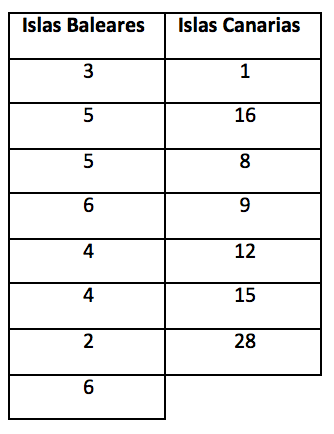
5.Estamos analizando la presencia de erizos de mar en las Islas Baleares y en las Islas Canarias. Para ello delimitamos 8 zonas costeras en las Baleares i 7 en las Canarias. Una vez hecho esto apuntamos la cantidad de erizos que observamos en cada zona:
¿Podemos afirmar que las diferencias entre Baleares y Canarias, en cuánto a la presencia de erizos, son estadísticamente significativas?
6.Estamos comparando la cantidad de huevos de tortuga que hay en dos playas diferentes de Costa Rica. En la primera playa se consigue observar la puesta de huevos de 8 tortugas y en la segunda, sólo de 6. En cada puesta se cuentan los huevos que hay:
¿Podemos afirmar que las diferencias son estadísticamente significativas?
7.Se ha analizado la concentración de fitoplancton (en alguna unidad característica) en una serie de zonas oceánicas alrededor del mundo. Dicho análisis se ha hecho dos veces en cada zona, uno en el mes de abril y otro en agosto:
¿Podemos decir que hay un descenso significativo de la concentración de fitoplancton dependiendo del mes en que nos encontremos?
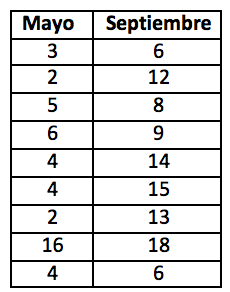
8.Estamos analizando el número de “blooms” bioluminiscentes causados por dinoflagelados que ha habido del día 1 al 9 de mayo, realizando una cuenta diferente cada día, y el número de “blooms” que ha habido los mismos días, pero en el mes de septiembre:
¿Podemos afirmar que hay diferencias significativas entre los dos meses?
A continuación se podrán seguir una serie de ejemplos de ANOVA. Hay de factores cruzados, anidados. Factores intersujetos (los que no se mencionan expresamente), factores intrasujetos. Pueden verse los valores y los resultados que se obtendrían en los contrastes de hipótesis de los diferentes efectos a buscar en cada análisis. Recordemos que si el p-valor es menor de 0.05 se entiende que hay efecto del factor, significativo, lo que quiere decir que hay diferencia entre los niveles estudiados (si el factor es fijo) o entre la población de niveles de los que los niveles estudiados son una muestra (si el factor es aleatorio). Si el p-valor es mayor de 0.05 no hay efecto significativo, lo que quiere decir que las posibles diferencias muestrales que podamos ver entre los diferentes niveles no son extrapolables a la población.
a) Hacer una descriptiva completa de la variable IMC.
b)Hacer una descritiva breve de la variable edad.
c)Hacer una descriptiva de la variable depresión.
2.Técnicas de relación
a)Calcular la correlación de Pearson entre la altura y el IMC.
b)Analizar si hay relación entre sexo y depresión.
c)Analizar si tener obesidad respecto a tener sobrepeso (Sobrepeso: 25<IMC<30. Obesidad: IMC>30) es un factor de riesgo para tener depresión.
3.Técnicas de comparación
a)Comprobar si ha diferencias estadísticamente significativas entre hombres y mujeres en cuanto la variable IMC.
b)Estamos interesados en saber si hay diferencias significativas entre los que tienen o no depresión en cuanto a una variable que consistirá en evaluar unas puntuaciones individuales que asignan un punto por tener cada una de las siguientes características: más de 50 años, obesidad, diabetes, hipertensión, trastorno del sueño, trastorno de la alimentación.
Un viaje amplio por el mundo ANOVA (Análisis de la varianza), como un viaje por una compleja ciudad como Nueva York, París o Londres, merece un previo recorrido global en autobús turístico para conocer, de entrada, cuál es la estructura global, la textura, de lo que nos encontraremos, en días sucesivos.
Vamos a hacerlo introduciendo unos conceptos que constituyen la columna vertebral de la inmensa urbe ANOVA. Se trata de los siguientes conceptos:
Factor
Nivel
Factor fijo/Factor aleatorio
Comparaciones múltiples/Componentes de la varianza
Factores cruzados/Factores anidados
Interacción entre factores
Factor intersujeto/Factor intrasujeto
Variable respuesta/Vector respuesta
Variable/Covariable
Efectos
Vayamos paso a paso con este corto viaje en autobús turístico:
1. Un factor en ANOVA es una variable cualitativa que genera o que contempla una serie de poblaciones a comparar. Por ejemplo, se ensayan tres tipos de fertilizantes en unos campos de cultivo para evaluar la productividad, se ensayan cuatro medicamentos distintos para ver si aumentan los niveles de hemoglobina en pacientes con anemia. En estos casos tenemos, en primer lugar el factor tipo de fertilizante. En el segundo, el factor fármaco.
2. Los niveles de un factor son los grupos o poblaciones que tenemos de un factor. En el primer ejemplo anterior tenemos tres niveles. En el segundo ejemplo tenemos cuatro niveles.
3. Un factor es fijo si los niveles que tenemos de él en el estudio son realmente todos los que nos interesa comparar. Un factor es aleatorio si los niveles que tenemos en nuestro estudio es una muestra de niveles tomados de una población de niveles que son los que, en realidad, queremos comparar. Los dos ejemplos anteriores si los tres fertilizantes o los cuatro fármacos son nuestro objeto de comparación, estamos ante factores fijos. Pero, observemos lo siguiente: si en otro ejemplo, estoy comparando si hay diferencias en la calidad de un producto fabricado por 100 operarios trabajando en una industria y, para hacerlo, elijo al azar a 5 de esos 100 operarios y analizo 3 productos elaborados por cada uno de ellos, pero lo que me interesa es ver si hay diferencias entre los 100, no entre esos 5, estoy ante el factor operario con 5 niveles, pero ese factor es, ahora, no fijo, sino aleatorio.
4. Si tenemos un factor fijo y detectamos que hay diferencias entre esas poblaciones, nos interesará decir cuáles son esas diferencias concretas. Las comparaciones múltiples hacen esa labor, comparan, dos a dos, de una forma muy especial, todas las poblaciones para dibujar un mapa de las diferencias. Si tenemos un factor aleatorio, el planteamiento es ahora muy diferente: debemos pasar de la muestra de muestras de poblaciones que tenemos a una población de poblaciones y eso lo haremos estimando la varianza, la dispersión que debe haber dentro de esa población de poblaciones.
5. Cuando hay más de un factor en un estudio, los factores, dos a dos, pueden estar cruzados o anidados. Tenemos factores cruzados cuando todos los niveles de un factor están combinados con todos los niveles del otro factor. Tenemos factores anidados cuando los niveles de un factor están jerarquizados entre los niveles del otro factor.
6. Cuando los factores están cruzados podemos estudiar algo muy importante en ANOVA: la interacción entre esos factores. Hay interacción cuando la respuesta, el efecto conseguido con la presencia de un nivel de un factor, depende de con qué nivel del otro factor esté combinado.
7. Un factor es intersujeto cuando cada sujeto pertenece a un único nivel del factor. Un factor es intrasujeto cuando cada sujeto está presente en cada uno de los niveles del factor.
8. Tenemos una variable respuesta, cuando la variable estudiada en la combinación de factores estudiados que tengamos es una variable cuantitativa única. Tenemos un vector respuesta cuando lo que se estudia es un vector de variables; o sea, varias variables al mismo tiempo. Se pretende buscar las diferencias en bloque, no variable a variable.
9. Una variable en ANOVA significa la respuesta en una variable cuantitativa que estamos estudiando. Una covariable es una variable cuantitativa complementaria que puede estar asociada a la variable respuesta estudiada y puede explicar las diferencias que estamos viendo en la variable respuesta estudiada. Viene a ser como un factor pero cuantititivo, no cualitativo.
10. En el lenguaje ANOVA hablamos de efectos cuando vemos diferencias. En este contexto vamos a realizar distintas comparaciones. La hipótesis de partida (la llamada hipótesis nula) es igualdad y la alternativa es diferencia. Si rechazamos la hipótesis nula y nos quedamos la alternativa decimos que estsmos viendo efectos. Por lo tanto, en ANOVA, efectos es sinónimo de diferencias y no efectos sinónimo de igualdad.
Veamos un ejemplo práctico dende ver todos estos conceptos. Se hace el siguiente estudio experimental: Se toma una muestra de 30 alumnos durante toda la ESO. Se dividen en tres clases distintas, en tres líneas distintas. Cada una va a seguir, durante los cuatro años, un plan distinto de enseñanza del inglés. Se sabe el nivel escrito y el nivel oral de esos alumnos al final de la primaria. Se han diferenciado dos niveles dentro de cada grupo, según el promedio de notas globales de esos alumnos ha sido alto o bajo, en el global de las materias. Durante los cuatro cursos de la ESO se ha hecho un seguimiento, alumno por alumno, del nivel de inglés oral de esos alumnos. Los resultados son los siguientes:
Hay dos factores fijos: Grupo y Nivel. Grupo a tres niveles y Nivel a dos niveles. Los dos factores son fijos y están cruzados. Pero hay un tercer factor: el factor ESO, con cuatro niveles fijos. La variable estudiada es el nivel de inglés oral. Los factores Grupo y Nivel son intersujetos. El factor ESO es intrasujetos. Las variables InglésEscrito e InglésOral a finales de primaria podría tratarse como covariable.
Vamos a ver aquí diferentes tablas y gráficos donde se usa la Estadística en Oceanografía:
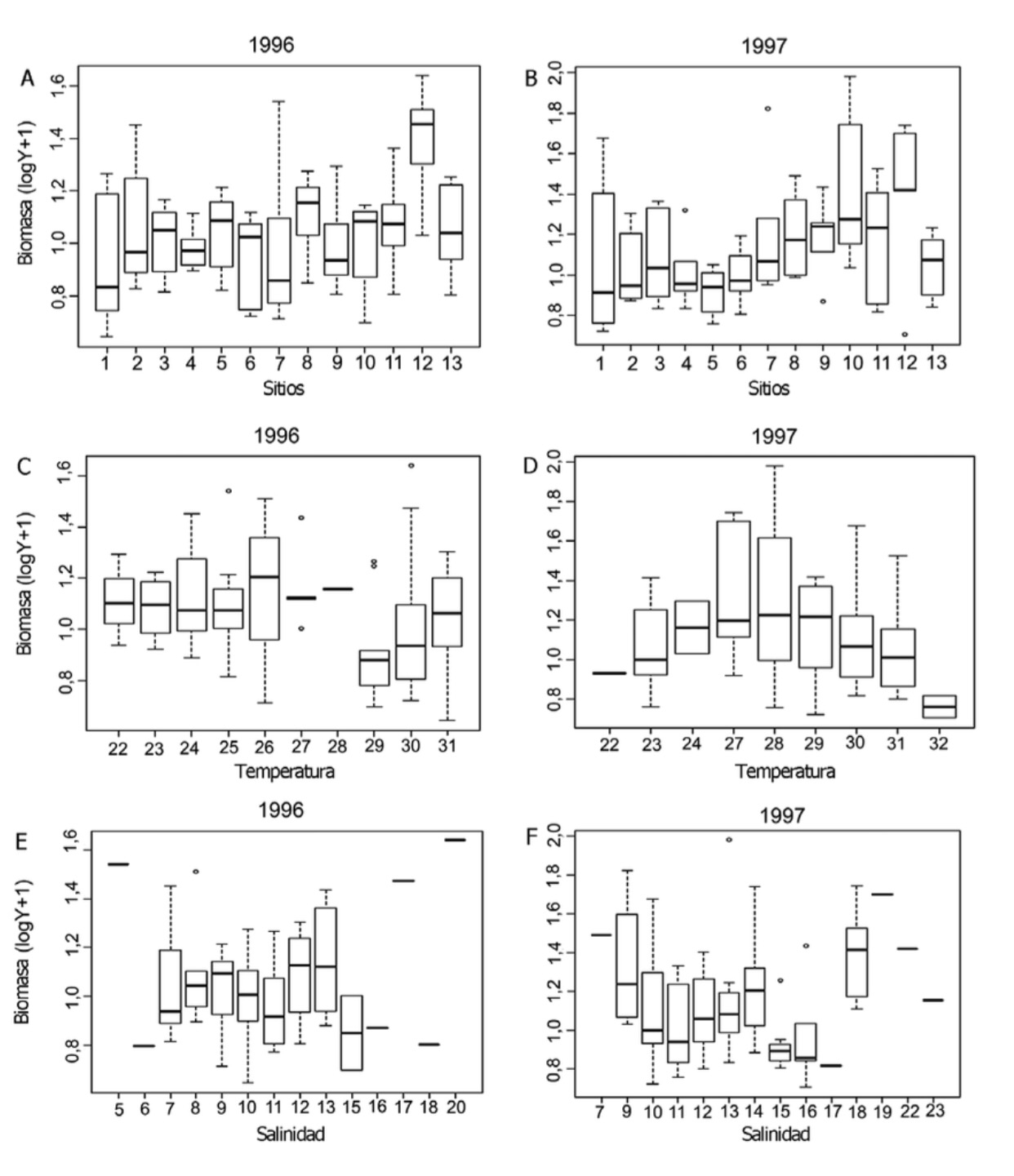
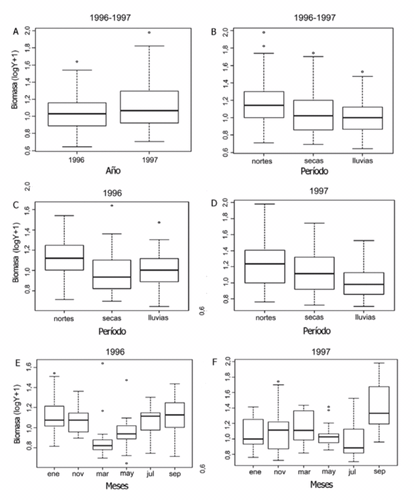
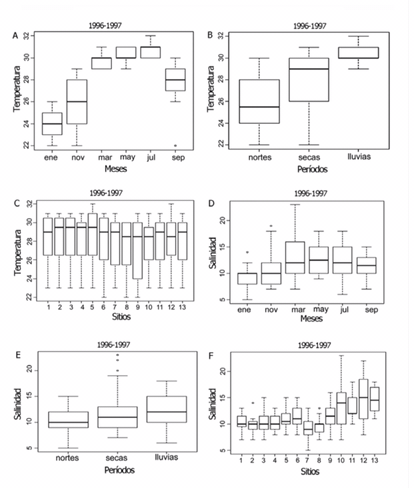
1. Veamos un ejemplo característico de uso del gráfico Box-Plot en oceanografía, donde se eligen una serie de puntos de muestreo y se evalúan en ellos una serie de variables típicas:
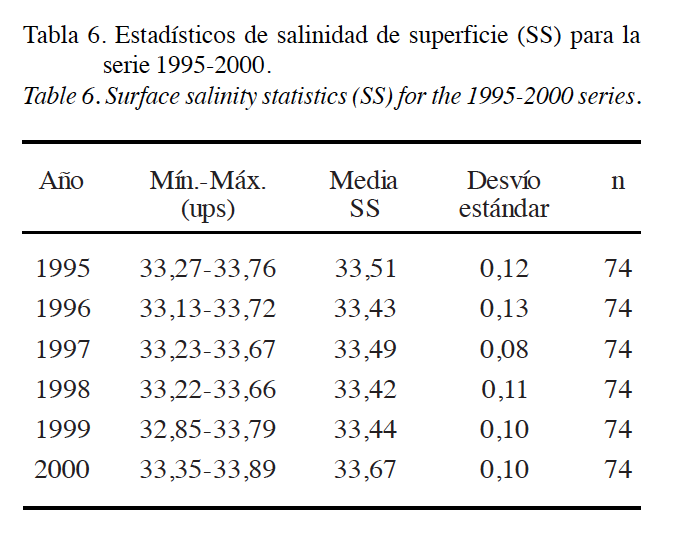
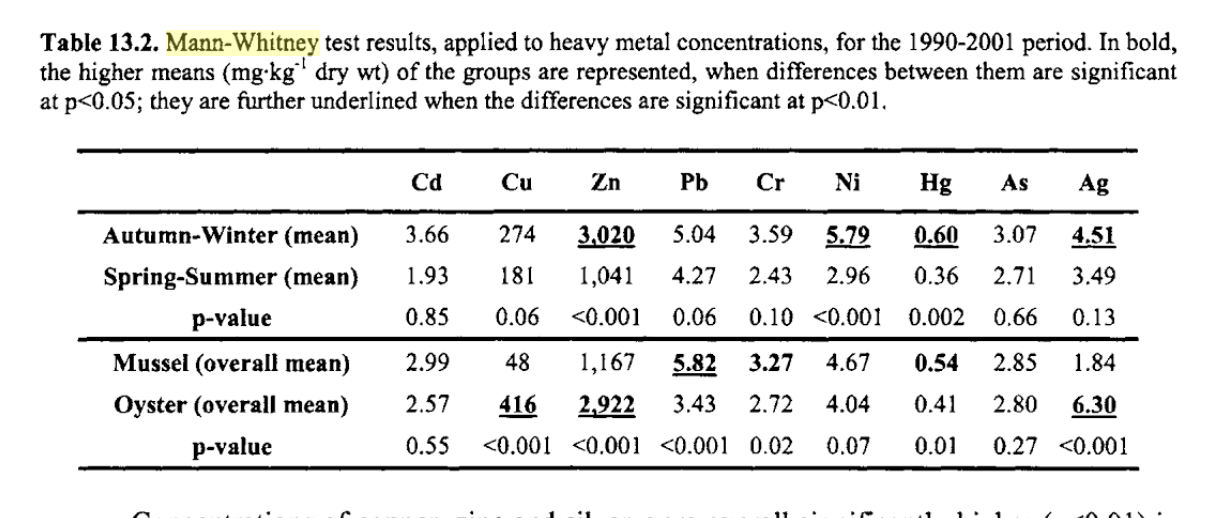
2. Veamos a continuación diferentes usos de la media, la desviación típica y el error estándar. El gran problema con el uso de esos dos conceptos (desviación estándar y error estándar) es que, en muchas ocasiones, no queda claro cuál se ha usado y el problema es que el que escribe el artículo tampoco tiene claro cuál le interesa usar en un momento determinado.
A continuación puede verse un redactado de una información descriptiva:
3. Veamos ahora diferentes usos del concepto de correlación:
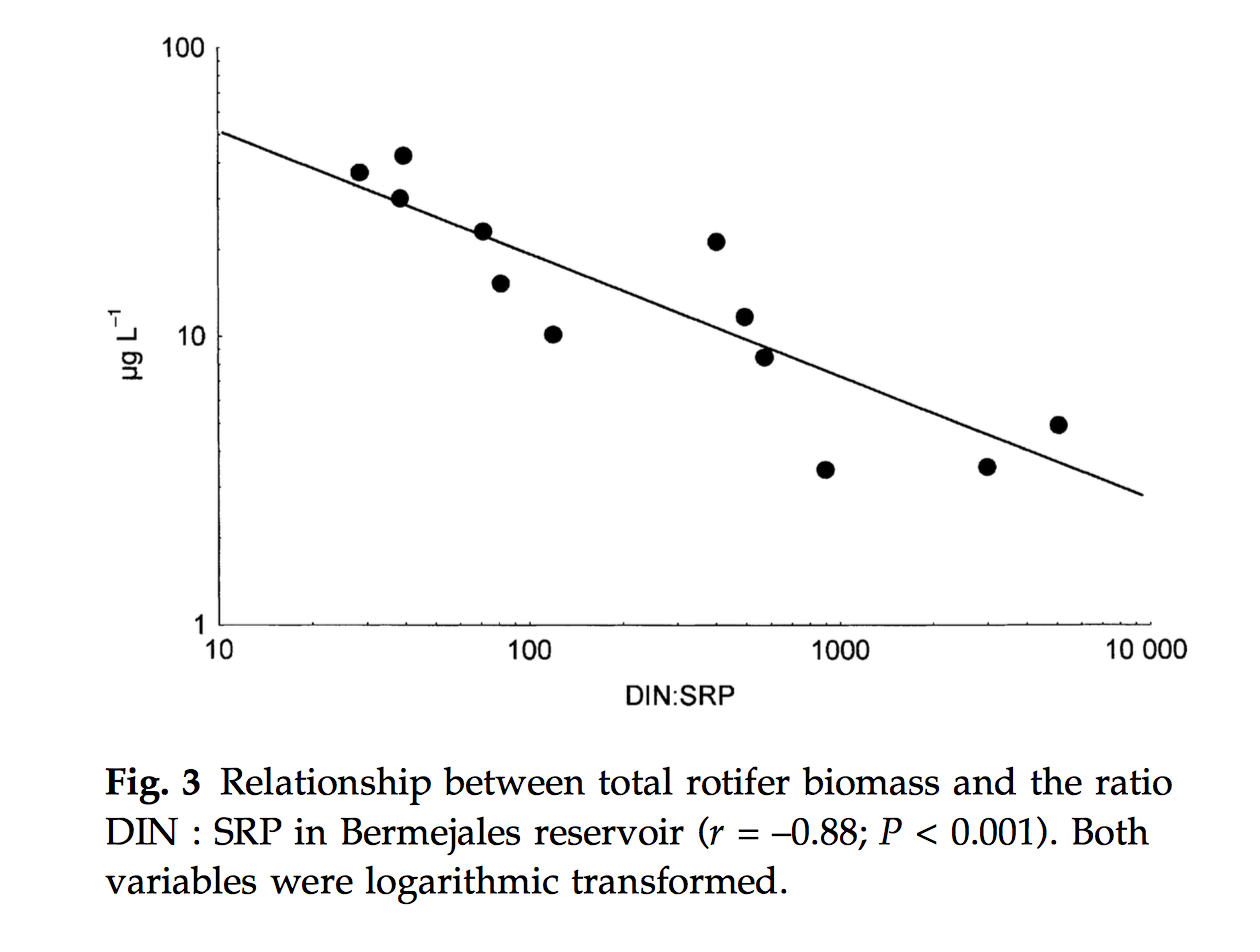
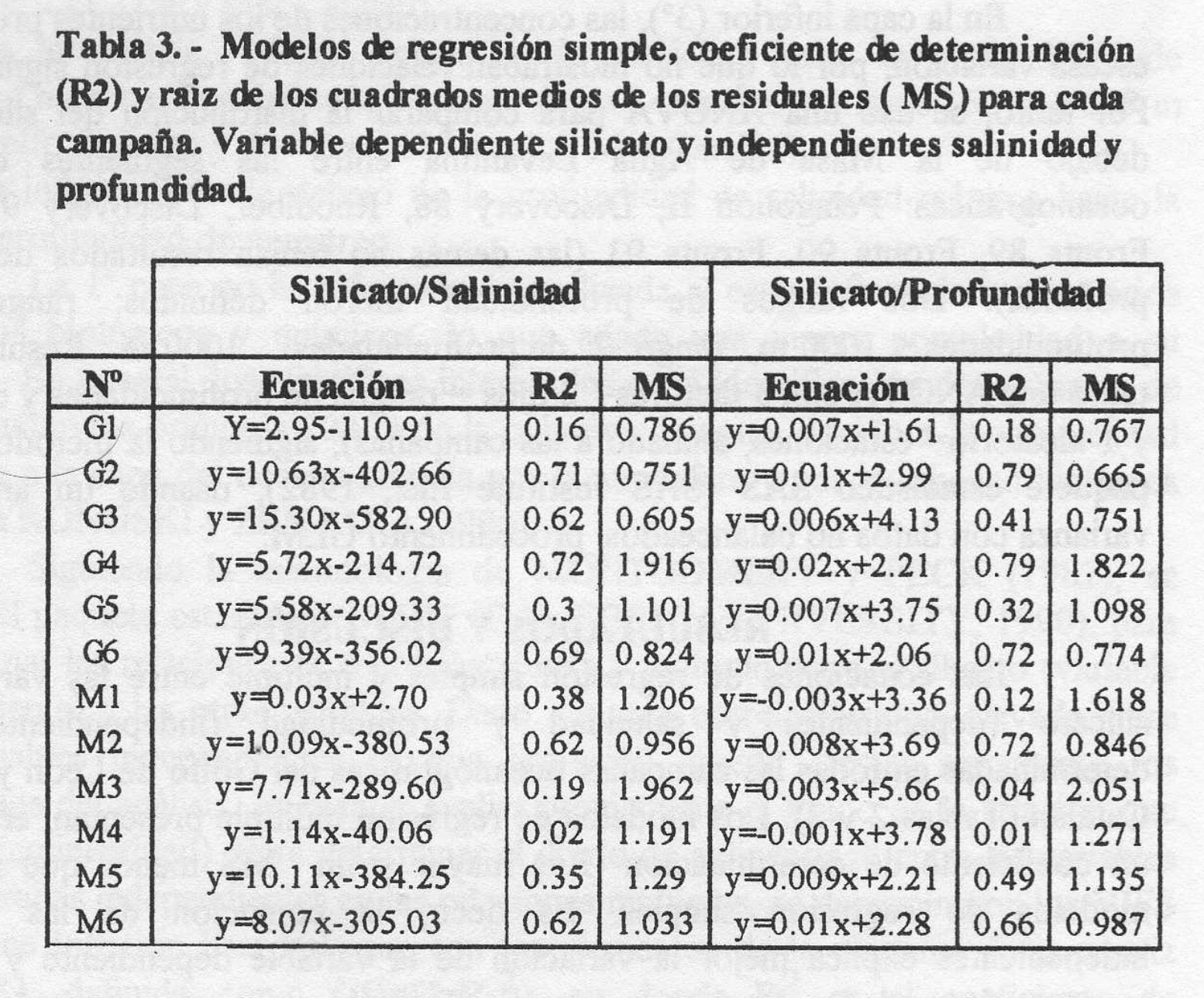
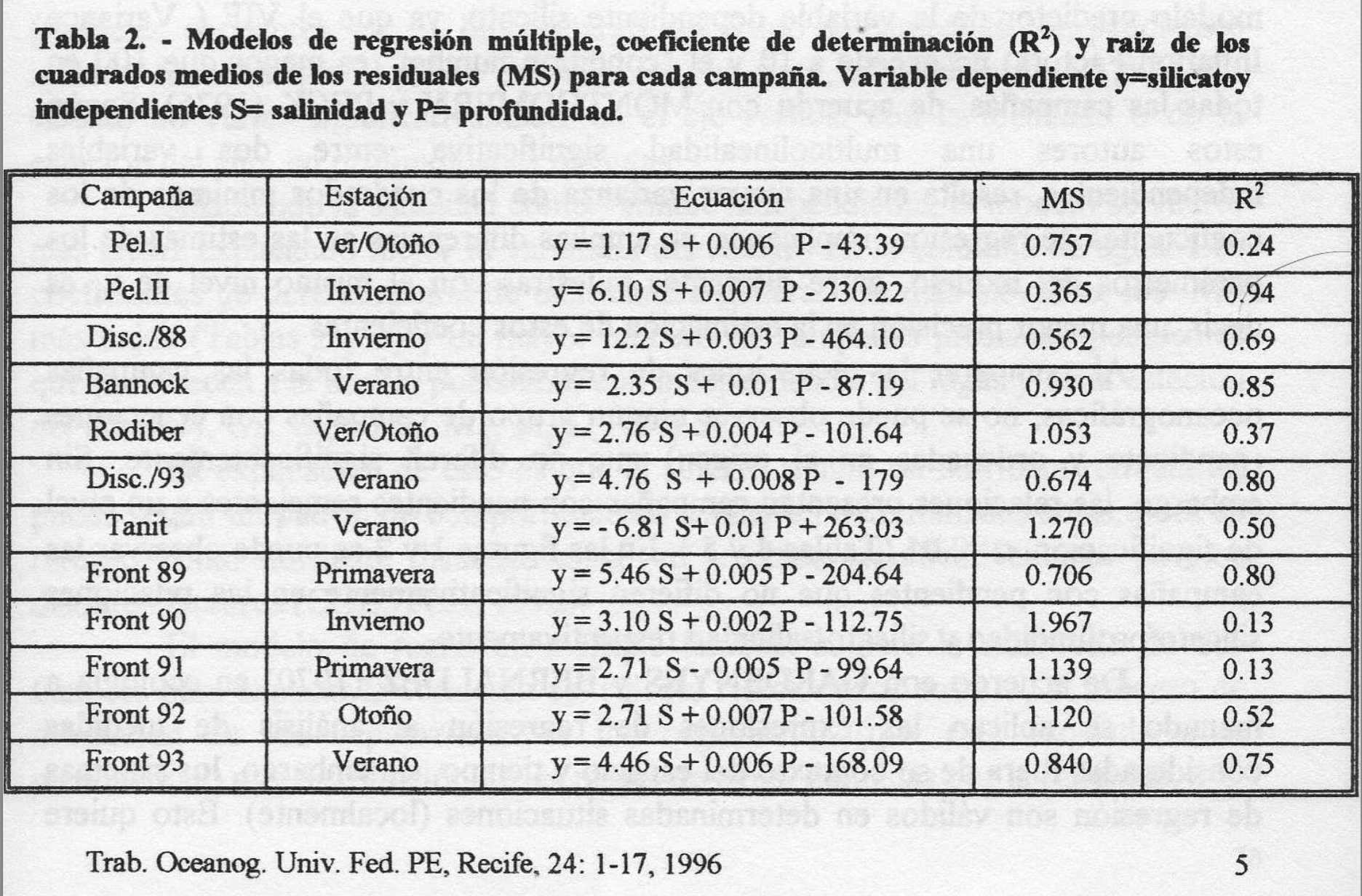
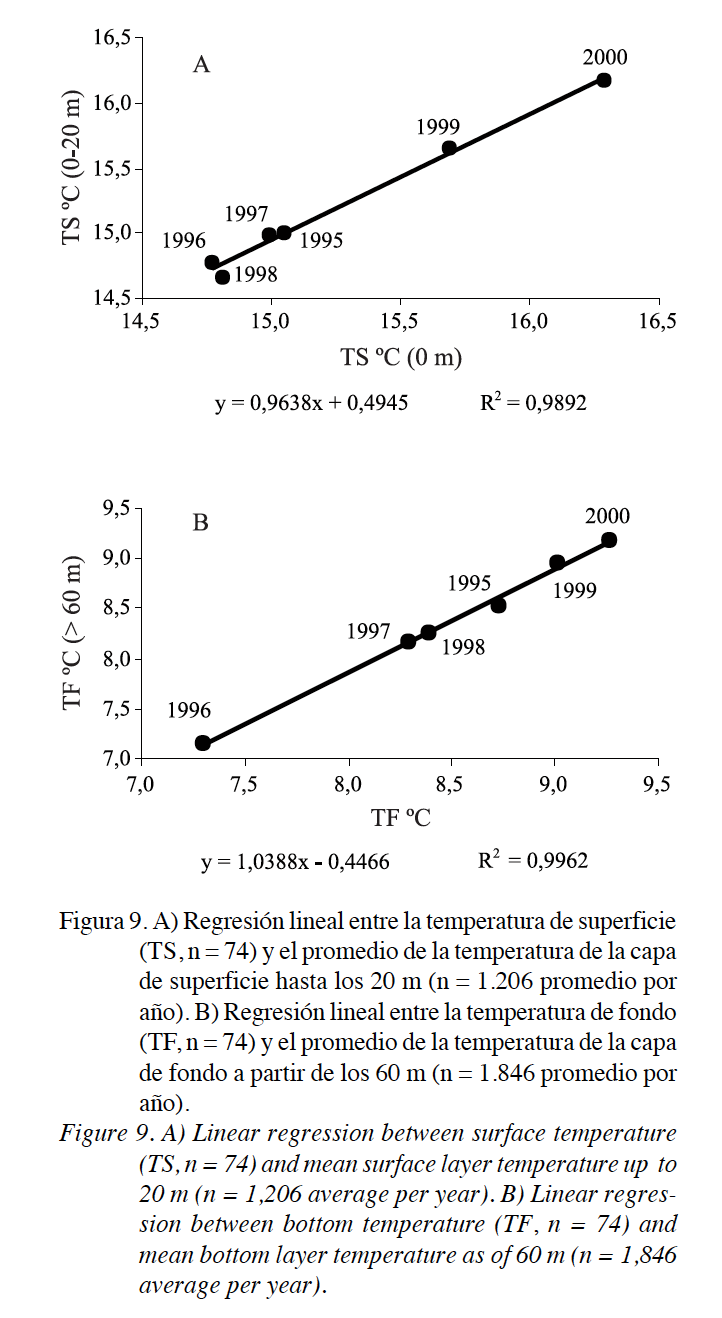
4. Veamos ahora diferentes ejemplos donde aparece la regresión:
Este es un curso de Estadística pensado para preparar para el inicio posterior de un curso universitario de Estadística. Por eso lo llamo «Curso 0». Intenta, mediante un lenguaje sencillo, introducir el lenguaje y los problemas fundamentales que aborda la Estadística.
Podéis seguir, también, si queréis, la explicación con los siguientes vídeos:
Empecemos, pues:
La Estadística es una técnica de decisión, una técnica para la toma de decisiones. Una técnica de decisión basada en procedimientos matemáticos. Una técnica que se basa en la utilización de información que tenemos o que podemos obtener.
La Estadística es la ciencia con la que, a partir de MUESTRAS, decimos cosas (tomamos decisiones) sobre POBLACIONES.
Vamos a ver, en primer lugar, pues, qué entendemos por Poblaciones y por Muestras en Estadística.
Una POBLACIÓN es un conjunto, generalmente muy grande, de personas, de seres vivos, de cosas, etc.
Ejemplos:
La población de todos los menores de 14 años en España.
La población de todos los enfermos de Alzheimer de España.
La población de todos los colegios de Barcelona.
La población de todos los estudiantes de sexto de primaria de Cataluña.
La población de todos los pokémons.
La población de todas las ciudades del mundo.
La población de todos los perros de España.
Una MUESTRA es una parte, generalmente pequeña, de una POBLACIÓN.
Ejemplos:
Hemos seleccionado al azar 100 niños menores de 14 años en España.
Hemos seleccionado, también al azar, 50 personas con Alzheimer en España.
Hemos seleccionada al azar 20 colegios de Barcelona.
Hemos seleccionado 70 estudiantes de sexto de primaria de Cataluña.
Hemos seleccionado al azar 20 pokémons.
Hemos seleccionado al azar 1000 ciudades del mundo.
Hemos seleccionado al azar 200 perros de España.
Observa que la estructura de la relación entre POBLACIÓN y MUESTRA es siempre la que se ve en el siguiente dibujo:
Siempre una MUESTRA es una parte de una POBLACIÓN. Y el objetivo de la Estadística es, precisamente, a partir de lo que podremos saber de esta MUESTRA, a base de estudiarla, de calcular cosas con ella, intentar decir cosas de cómo es la POBLACIÓN que no tenemos.
Evidentemente, no toda MUESTRA tiene la misma calidad. Hay muestras más representativas de la POBLACIÓN que otras. A la hora de elegir la muestra se trata de hacerlo con el máximo de coherencia para tratar que la MUESTRA sea lo más parecido a la POBLACIÓN pero en miniatura. De momento, en este curso 0, basta con saber esto, pero, parece claro que la elección de la muestra es un paso fundamental puesto que, como ya hemos dicho, la Estadística pretende decir cosas de las POBLACIONES a partir del estudio de MUESTRAS. Si la elección de ésta es incoherente mala ciencia estaremos haciendo.
Esto es, pues, la Estadística: Intentar saber cómo es un todo (una POBLACIÓN) que no tienes a partir del estudio de una parte (una MUESTRA) que sí que tienes.
Por lo tanto, estos dos conceptos (MUESTRA y POBLACIÓN) están siempre presentes en la Estadística.
A las personas, seres vivos o cosas de las muestras que tenemos las analizamos para obtener de ellos alguna característica. A estas características las llamamos VARIABLES.
Ejemplos (Observa que cada punto está constituido por los elementos de las POBLACIONES y MUESTRAS vistas en la lección anterior):
La presión arterial de niños menores de 14 años.
El valor del Mini-Mental (es una prueba con una serie de preguntas que finalmente da una puntuación que marca el nivel de gravedad de la enfermedad) que tiene un enfermo con Alzheimer.
La cantidad de alumnos matriculados en un colegio.
La nota de matemáticas de estudiantes de sexto de primaria.
La velocidad de un pokémon.
El número de habitantes en una ciudad.
Si un perro lleva o no un chip identificativo.
Observa que hemos definido una VARIABLE en cada caso pero podríamos escoger otras. Para que lo veas puedo tomar una POBLACIÓN de donde podríamos tener una MUESTRA y definir una larga lista de VARIABLES distintas. Un ejemplo, con los alumnos de sexto de primaria:
Nota de sociales.
Días que no han ido al colegio en el curso pasado.
Nota promedio de quinto.
Nota que le pondría él al tutor que ha tenido.
Si prefiere un hombre o una mujer como tutor.
A qué distancia vive de su escuela.
Si ha repetido o no anteriormente un curso.
Deberá o no repetir quinto.
Observemos, pues, que hasta ahora hemos visto tres conceptos en Estadística que son nucleares y que están siempre presentes en cualquier estudio realizado en cualquier ciencia:
POBLACIÓN.
MUESTRA.
VARIABLE.
Es muy importante, siempre, situar bien cada uno de estos tres conceptos cuando se hace un estudio.
Veamos un ejemplo práctico:
Se quiere ver, en personas que tienen una enfermedad, si un nuevo medicamento que se quiere probar consigue más, menos o igual número de curaciones que el medicamento que se utiliza actualmente.
Llamemos al medicamento habitual como A y al nuevo como B.
Tenemos la POBLACIÓN de todos los enfermos de esa patología. Que pueden ser miles y miles.
El medicamento A lo damos a 100 personas con esa enfermedad y a los que seguiremos con detalle para ver si se curan o no. Estas 100 personas son una MUESTRA de la POBLACIÓN de todos los enfermos.
El medicamento B lo damos a otras 100 personas con esa enfermedad. Evidentemente, personas diferentes a las anteriores. Personas que también seguiremos detalladamente para ver si se curan o no con ese tratamiento. Estas 100 personas son una MUESTRA de la misma POBLACIÓN anterior, la POBLACIÓN de todos los enfermos de esa enfermedad.
La VARIABLE en este estudio es si el enfermo se cura o no con el tratamiento.
Veamos todo el planteamiento del estudio con un dibujo:
Unos resultados que podríamos obtener finalmente del estudio podrían ser los siguientes:
Medicamento A:
70 se curan.
30 no se curan.
Medicamento B:
90 se curan.
10 no se curan.
Observa que entre las dos MUESTRAS hay diferencias. Con el medicamento B se curan más personas que con el medicamento A. Es muy claro. De las 100 personas tratadas con el medicamento B se han curado 90. Esto lo expresamos así: un 90 por 100 (lo solemos escribir así: 90%). Sin embargo, con el medicamento A se han curado sólo 70: un 70 por 100 (70%).
Pero, algo muy importante: esto que vemos lo vemos en las MUESTRAS. ¿Pasaría lo mismo si estos tratamientos se aplicaran a la POBLACIÓN entera, a todos los enfermos? Observemos que esto no lo podremos decir hasta que no lo apliquemos. Pero sería interesante predecir si las diferencias que vemos en esas MUESTRAS las veríamos también si cada uno de esos medicamentos se aplicara a toda la POBLACIÓN.
Pues éste es el papel de la Estadística. A eso nos dedicamos los estadísticos y para saber hacer este paso de las MUESTRAS a las POBLACIONES todos los científicos estudian Estadística.
Ya veremos que el gran problema de la Estadística será saber cuándo podemos decir que lo que vemos en las MUESTRAS es lo que veríamos, también, en las POBLACIONES. Cuando decimos, en Estadística, que lo que vemos es ESTADÍSTICAMENTE SIGNIFICATIVO es porque, con muchas posibilidades de no equivocarnos, lo que vemos en las MUESTRAS es lo que veríamos, también, en las POBLACIONES. Pero esto ya lo veremos más adelante. Sigamos, poco a poco.
Veamos ahora un poco más en detalle el tercero de esos tres conceptos que estamos viendo como nucleares en Estadística: el concepto de VARIABLE.
Hay dos tipos básicos de VARIABLES (esas características que medimos o evaluamos a las personas, seres vivos o cosas de una muestra o de una población): las variables cuantitativas y las variables cualitativas.
Las variables cuantitativas son variables que miden una cantidad. Nos dan un número a cada individuo de la muestra que tengamos.
Las variables cualitativas, también llamadas variables nominales, nos valoran una cualidad. Por eso se les llama también nominales, porque los valores de cada individuo son nombres.
Observemos las variables que listábamos antes en referencia a alumnos de sexto de primaria:
Nota de sociales.
Días que no han ido al colegio en el curso pasado.
Nota promedio de quinto.
Nota que le pondría él al tutor que ha tenido.
Si prefiere un hombre o una mujer como tutor.
A qué distancia vive de su escuela.
Si ha repetido o no anteriormente un curso.
Deberá o no repetir quinto.
Las variables 1, 2, 3, 4, 6 son variables cuantitativas. Son o una nota (una nota entre 0 y 10, suponemos) o un número de días o una distancia (en metros o kilómetros). Sin embargo, las variables 5, 7 y 8 son cualitativas. No son una cantidad numérica, sino una cualidad: prefiere un hombre o una mujer como tutor, ha repetido o no anteriormente un curso, debe o no repetir quinto.
Observemos que podríamos definir muchas más variables, tanto de cualitativas como de cuantitativas.
Veamos más ejemplos de variables cualitativas, en esa misma muestra de estudiantes de sexto de primaria:
El sexo del alumno: niño o niña.
El grupo sanguíneo: A, B, AB, O.
Ciudad donde nació.
Tiene o no ordenador en la habitación.
Veamos más ejemplos de variables cuantitativas:
Altura.
Peso.
Metros cuadrados del piso donde vive.
Número de hermanos que tiene.
Ya tenemos los elementos básicos con los que se trabaja, siempre, en Estadística: POBLACIONES, MUESTRAS y VARIABLES.
Ahora vamos a empezar a manejarlos.
La Estadística es una ciencia que actúa manejando Técnica analíticas. Con ellas es como hace este proceso de decir cosas de POBLACIONES a partir de las MUESTRAS.
Existen tres tipos de técnicas en Estadística. Técnicas descriptivas, de relación y de comparación. Vamos a dividir el resto de este curso 0 en tres apartados: uno para cada uno de estos tres tipos de técnicas.
Técnicas descriptivas:
Con las técnicas descriptivas pretendemos resumir nuestras muestras. Hacer una síntesis de la inmensa cantidad de información que hay en ellas.
Lo primero que podemos hacer con una muestra es, siempre, hacer una descripción, un resumen de ella, que es lo que llamamos habitualmente: Estadística descriptiva.
Veamos las principales técnicas descriptivas que se engloban en la llamada Estadística descriptiva.
Con estas técnicas descriptivas conseguiremos una serie de valores que nos proporcionan una serie de rasgos característicos de la MUESTRA que podremos generalizar a la POBLACIÓN, si es que esta MUESTRA es representativa de la POBLACIÓN. Ya sabemos que este es el objetivo de la Estadística como ciencia.
Supongamos que tenemos una muestra de 10 alumnos de sexto de primaria y tenemos los siguientes valores de dos variables: Sexo (niño o niña) y nota de matemáticas:
Alumno
Sexo
Nota
1
h
3
2
m
5
3
m
2
4
m
8
5
h
4
6
h
6
7
h
5
8
m
7
9
m
9
10
h
4
Las técnicas descriptivas que tenemos son distintas según las variables sean cualitativas o cuantitativas.
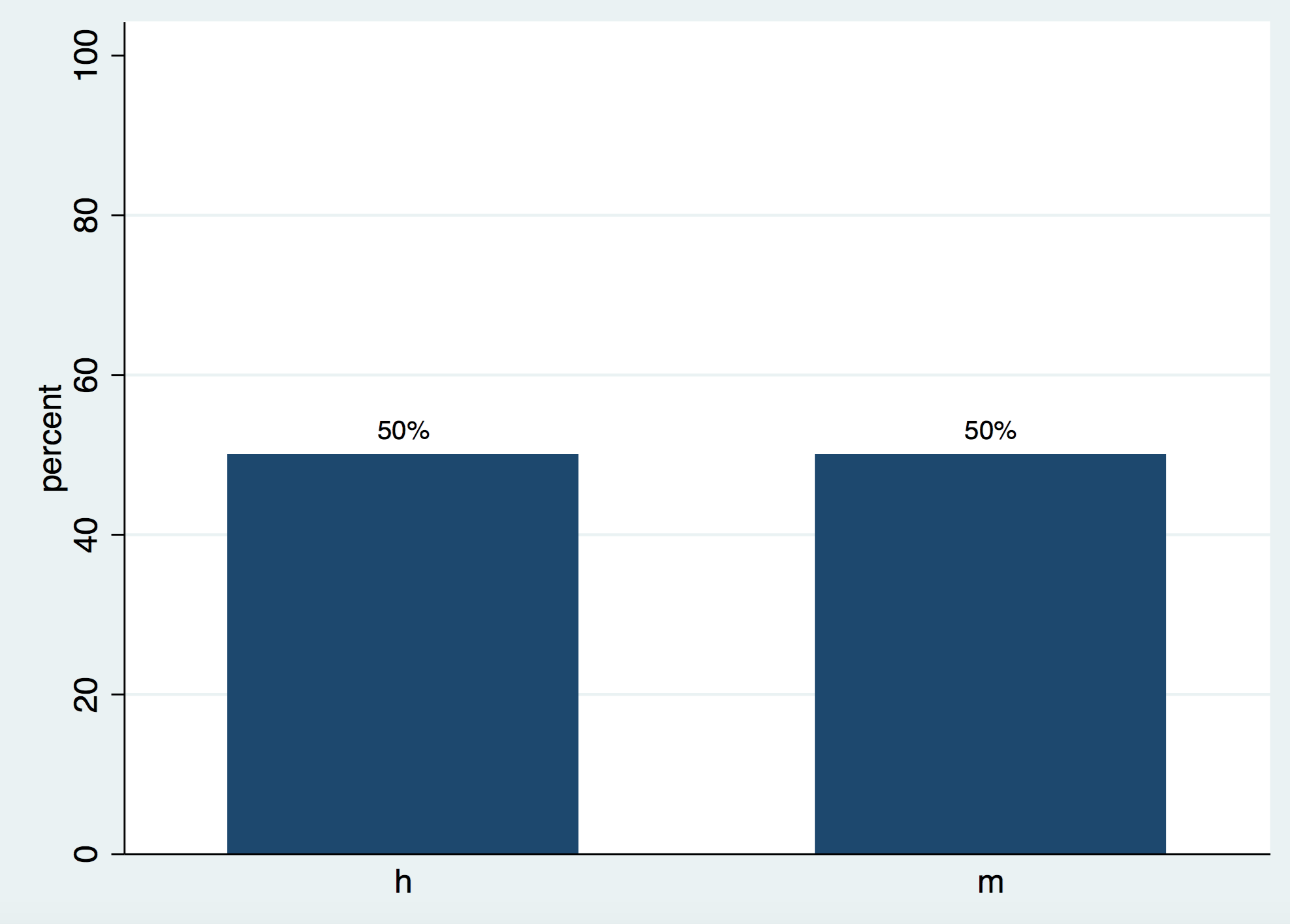
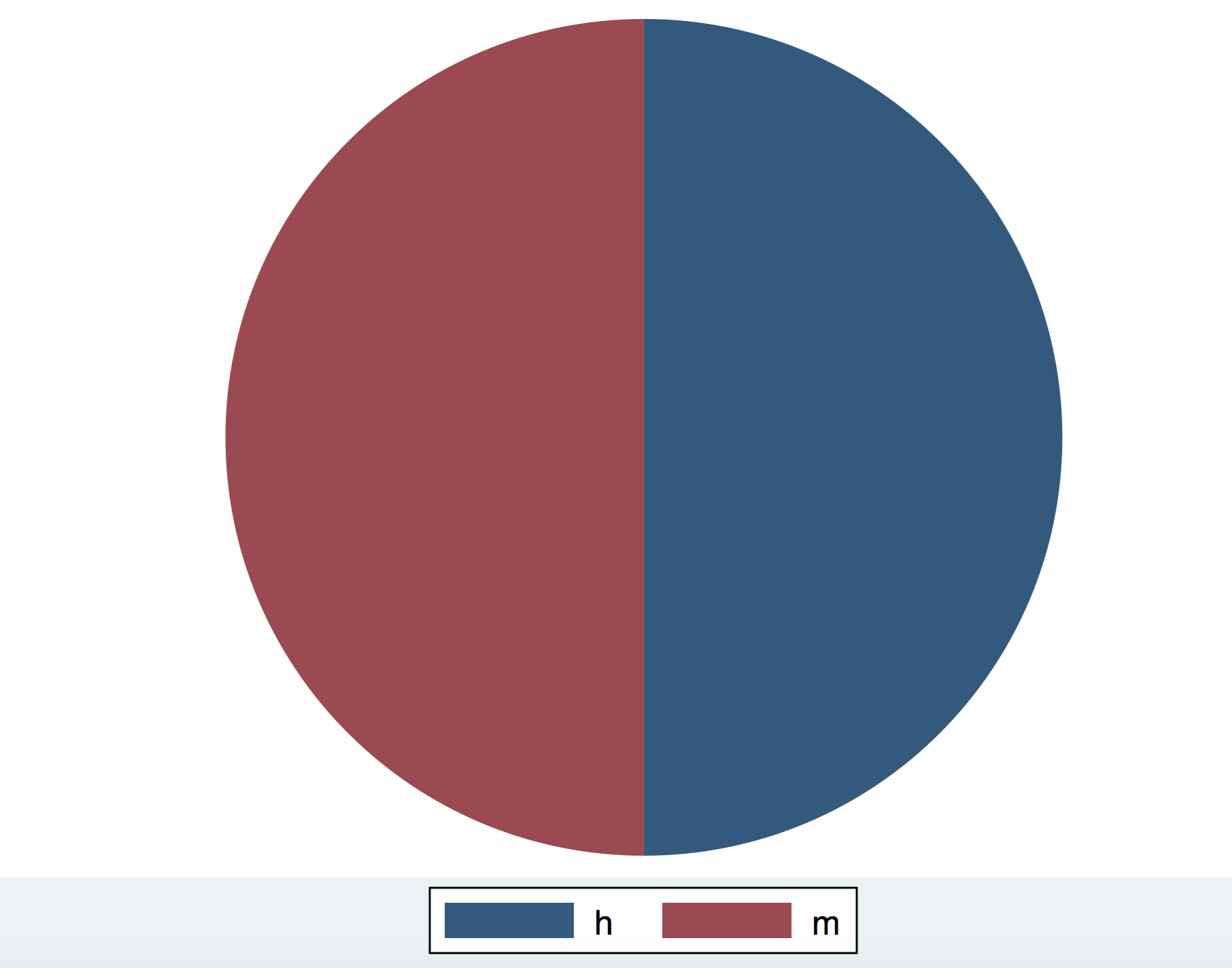
En las cualitativas suele hacerse únicamente un recuento de cada uno de los valores. Consiste, simplemente, en contar cuántos individuos hay de cada una de las diferentes cualidades. En nuestro caso la variable Sexo sólo tiene dos valores posibles: hombres y mujeres. En nuestro caso: 5 hombres y 5 mujeres. Suele también expresarse en porcentaje. En nuestro caso: 50% de hombres y 50% de mujeres. Si se dan los valores sin porcentaje se dice que se dan las frecuencias absolutas, si se dan en porcentaje se dice que se dan las frecuencias relativas.
También se suele acompañar de un gráfico con diagramas de frecuencias o con un diagrama pastel. A continuación veréis cómo quedarían estos gráficos:
Con las variables cuantitativas las posibilidades son mucho mayores. Suelen calcularse diferentes valores que resuman la muestra, respecto a un determinado aspecto. Es muy habitual dar la media y la desviación estándar. En la variable Nota, de nuestro ejemplo, estos dos valores serían:
La media (Mean) y la desviación estándar (Std. Dev.) son las que ahora nos interesan. La media es el centro de gravedad de los valores de la muestra. La desviación estándar es una medida de dispersión de los valores de la muestra. Son dos valores muy importantes que se estudian con mucho detalle en un curso de Estadística. Ahora, de momento, nos basta tener en cuenta que son dos valores que se usan con mucha frecuencia para resumir numéricamente una variable cuantitativa.
Basta saber, de momento, que la media es la suma de todos los valores de la muestra dividido por el tamaño muestral, y que la desviación estándar es un valor que va de 0 hacia arriba y que cuanta más dispersión de valores mayor es su valor.
Por ejemplo, la muestra: (5, 5, 5, 5) tiene desviación estándar 0. Y la muestra (0, 5, 5, 10) tiene mayor desviación estándar que la muestra (4, 5, 5, 6). También es bueno saber que la muestra (10, 11, 11, 12) tiene la misma desviación estándar que esta última y que la siguiente: (105, 106, 106, 107). Es muy importante, de momento, tener muy claro todo esto.
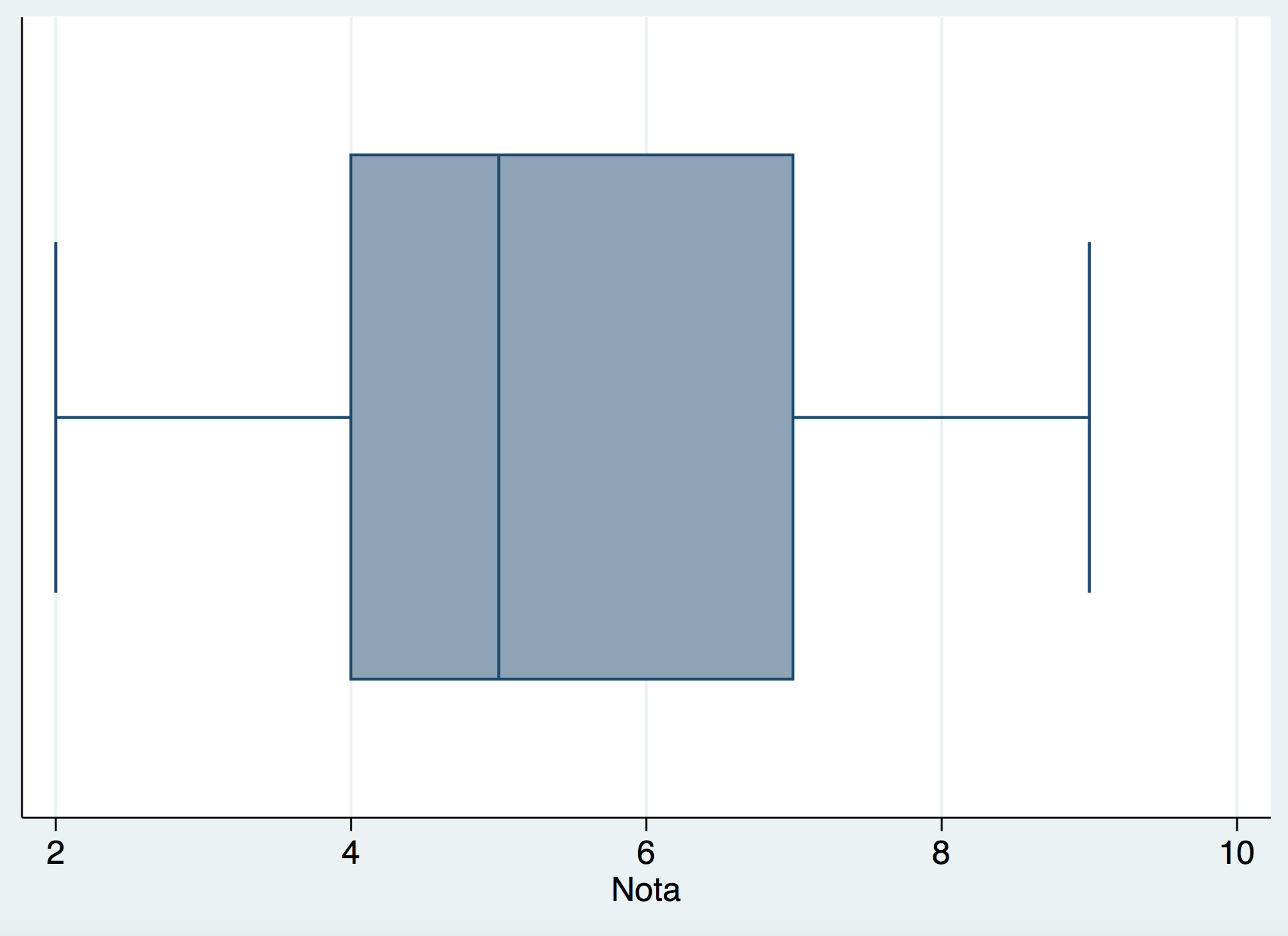
También en las variables cuantitativas es muy importante el denominado Box-Plot. En la variable Nota el Box-Plot es el siguiente:
Este gráfico es muy importante. Pero para entenderlo bien es mejor verlo en otra muestra.
El valor extremo de la izquierda es el valor mínimo de la muestra, el valor extremo de la derecha es el valor máximo. El punto donde empieza la caja es el primer cuartil o percentil 25. Donde acaba la caja es el tercer cuartil o percentil 75. La línea que fragmenta la caja en dos rectángulos es el segundo cuartil, percentil 50 ó Mediana (esta última denominación es la más habitual).
Para ver cómo se calculan esos importantes valores resumen de la muestra, veamos un caso de una muestra un poco más sencilla de manejar.
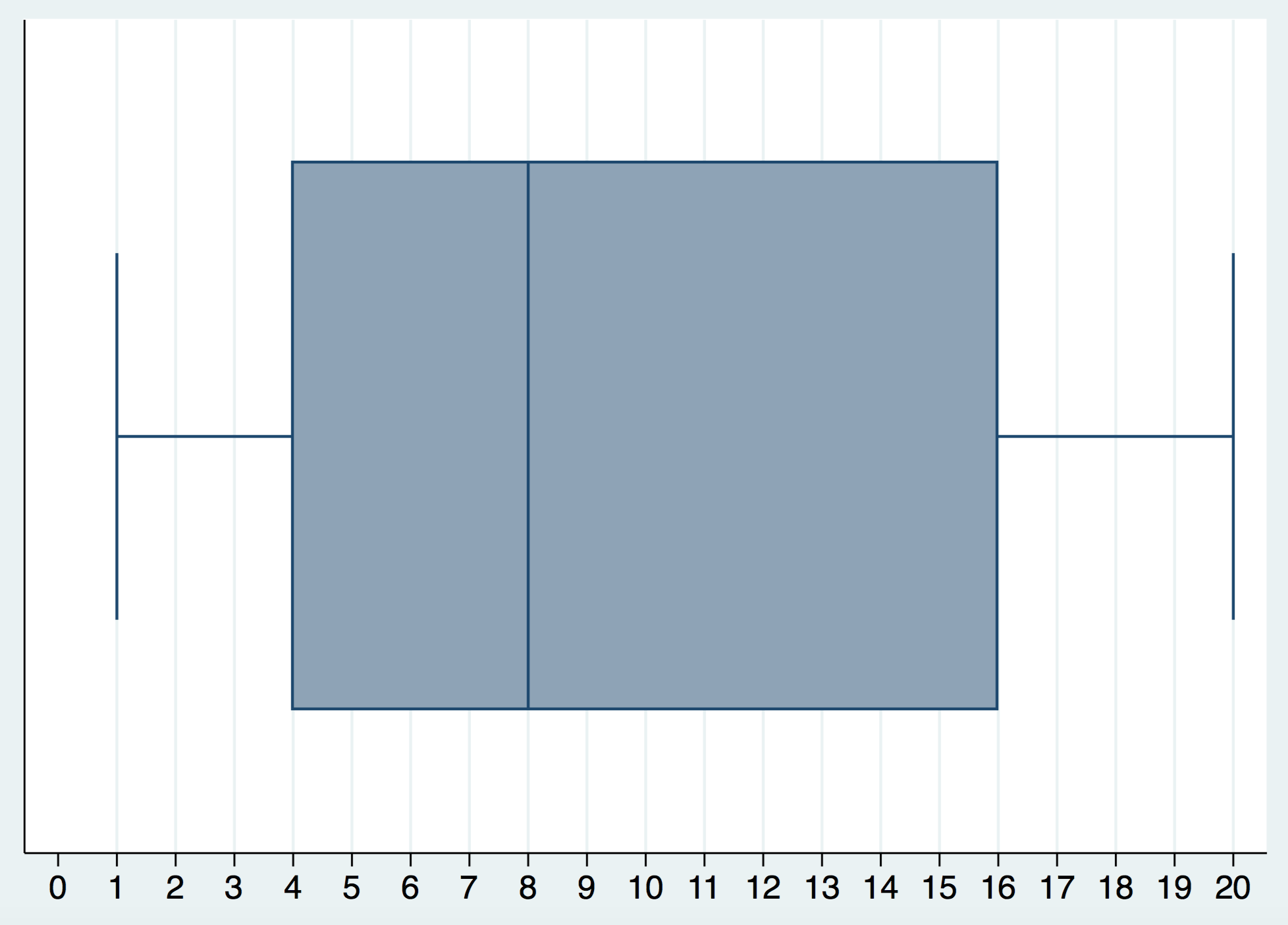
Supongamos la siguiente muestra: (1, 3, 5, 7, 9, 15, 17, 20). El Box-Plot sería el siguiente:
Lo primero que hay que hacer para realizar estos cálculos es ordenar la muestra de menor a mayor. El mínimo y el máximo de la muestra es claro cómo se obtienen. El primer cuartil o percentil 25 es aquel valor que divide la muestra es un 25% de valores a la izquierda y un 75% de valores a la derecha. El tercer cuartil o percentil 75 es aquel valor que divide la muestra es un 75% de valores a la izquierda y un 25% de valores a la derecha. La mediana es aquel valor que divide la muestra es un 50% de valores a la izquierda y un 50% de valores a la derecha.
Veamos el cálculo del primer cuartil: Si nos situamos entre el 3 y el 5 tenemos un 25% de valores a la izquierda y un 75% de valores a la derecha. En este caso se hace el promedio de estos dos valores para tener el primer cuartil, que es 4.
Veamos el cálculo del tercer cuartil: Si nos situamos entre el 15 y el 17 tenemos un 75% de valores a la izquierda y un 25% de valores a la derecha. En este caso se hace el promedio de estos dos valores para tener el tercer cuartil, que es 16.
Veamos el cálculo de la mediana: Si nos situamos entre el 7 y el 9 tenemos un 50% de valores a la izquierda y un 50% de valores a la derecha. En este caso se hace el promedio de estos dos valores para tener la mediana, que es, en este caso: 8.
A veces el primer o tercer cuartil o la mediana no se sitúa entre dos valores sino que es un valor mismo de la muestra. Un ejemplo: En la muestra (2, 5, 7, 9, 20) la mediana es 7. Observemos que a la izquierda de 7 tenemos el 50% de valores y a su derecha tenemos, también, un 50% de valores.
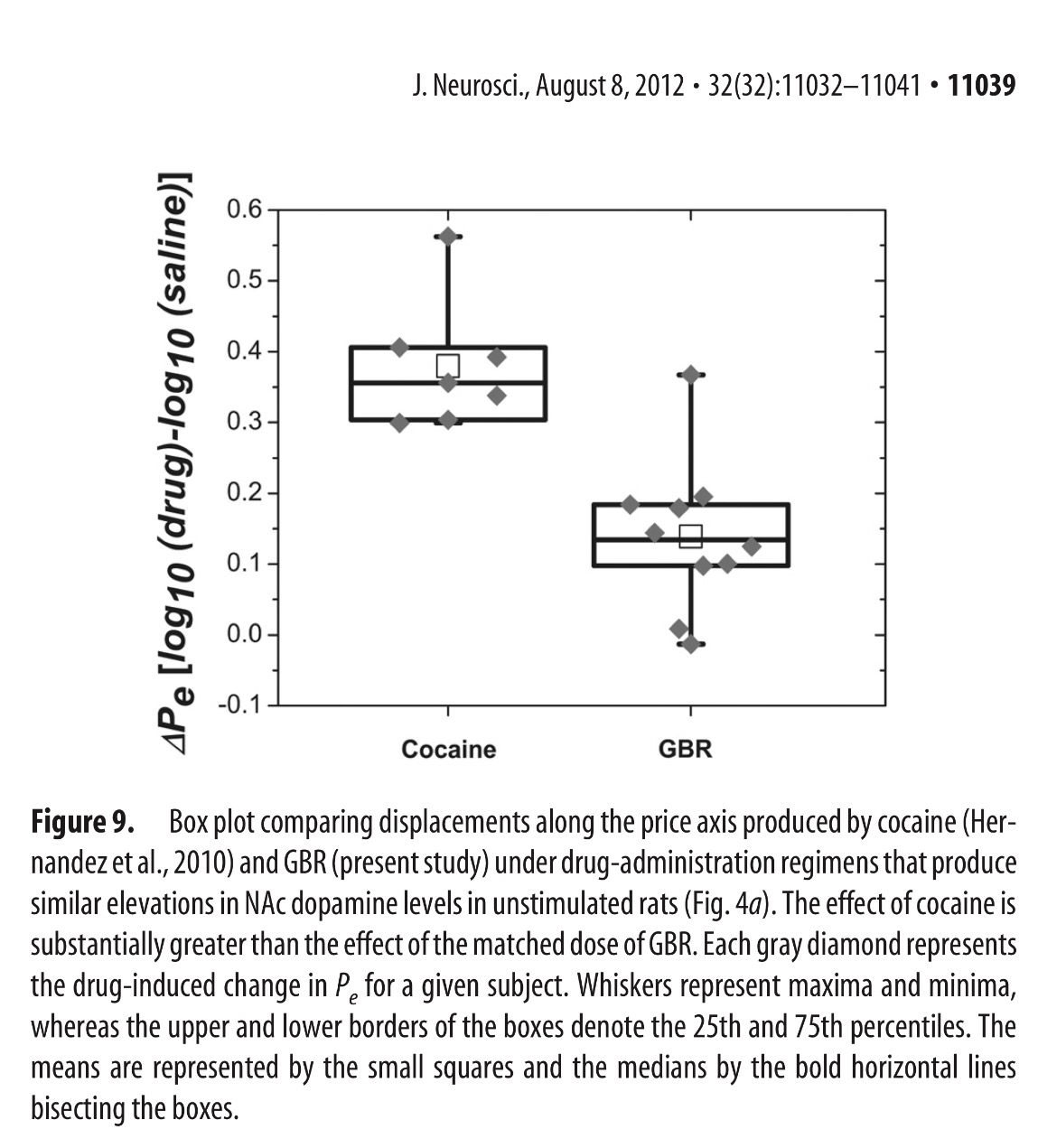
Encontraréis Box-Plots en muchos artículos de cualquier ciencia, pero mirad a continuación un ejemplo muy sorprendente. Raramente veréis un Box-Plots con los valores muestrales superpuestos:
2. Técnicas de relación
Con las técnicas de relación, como dice bien su nombre, tratamos de detectar relación entre diferentes variables de nuestra muestra. Como siempre, el objetivo será ver si las relaciones que detectamos en la MUESTRA son generalizables a la POBLACIÓN. Esto siempre está presente porque, como ya hemos dicho desde el principio, este es el objetivo de la Estadística como ciencia.
Detectar relación entre variables es muy importante en cualquier ciencia. Detectar si hay o no relación y, si la hay, mirar de cuantificarla, mirar de ver su intensidad. Porque hay grados distintos de relación.
Un ejemplo sencillo: la variable altura y peso en humanos tiene relación. Personas altas pesan más y personas bajas pesan menos. Esto indica que hay relación entre esas dos variables. Pero entre altura y número de pie hay mucha más relación. Y entre altura y longitud del fémur aún hay más relación. A esto nos referimos al decir que hay que detectar relación, primero, y, después, ver qué cantidad de relación tenemos.
Las dos técnicas más importantes y más usadas para detectar y cuantificar la relación entre dos variables son: la correlación de Pearson y la Odds ratio.
La correlación de Pearson cuantifica la relación entre dos variables cuantitativas.
La Odds ratio cuantifica la relación entre dos variables cualitativas dicotómicas (una variable dicotómica es una variable con sólo dos valores posibles).
En este curso 0 para introducirnos en el mundo de las técnicas de relación vamos a centrarnos en la Odds ratio, que es una medida extraordinariamente importante, especialmente en el ámbito de las ciencias de la salud.
Lo vamos a hacer viendo una serie de artículos de este blog que están pensados especialmente para introducirnos en esta importante técnica estadística. Los artículos son los siguientes:
Con las técnicas de comparación tratamos de comparar los valores de una variable en diferentes muestras. El objetivo será, evidentemente, como siempre, ver si las diferencias que detectamos en las MUESTRAS son generalizables a las POBLACIONES que hay detrás de ellas. Esto siempre está presente porque, no lo olvidemos, de nuevo, este es el objetivo de la Estadística como ciencia.
Hay que distinguir, a la hora de realizar una comparación estadística, varias situaciones distintas muy importantes:
a. Comparación de dos poblaciones/Comparación de más de dos poblaciones.
b. Comparación de una variable dicotómica/Comparación de una variable cuantitativa.
c. Comparación de muestras independientes/Comparación de muestras relacionadas.
d. Comparación de variables cuantitativas normales/Comparación de variables cuantitativas no normales.
e. Comparación de proporciones/Comparación de medias/Comparación de medianas/Comparación de distribuciones/Comparación de correlaciones/Comparación de Odds ratio.
Y todo esto porque así como en las técnicas de relación hay realmente un listado pequeño de técnicas analíticas (la correlación de Pearson y la Odds ratio son muy mayoritarias), en las técnicas de comparación son muchísimas las técnicas de comparación que se aplicar en la realidad. Y es en función de estos conceptos vistos cómo van delimitándose cuáles son las técnica a aplicar en un momento determinado.
Un esquema de las principales técnicas estadística que suelen usarse en Medicina es el siguiente:
Como puede verse hay tres tipos de técnicas estadística: las descriptivas, las de relación y las de comparación. Cada familia de estas técnicas hace justo lo que dice su nombre: describir, relacionar y comparar. En los temas del curso pueden encontrarse los detalles de cada una de estas técnicas.
La determinación del tamaño de muestra es algo común a todo estudio. Siempre debemos determinar el tamaño de muestra. Ni poca muestra ni demasiado muestra. El tamaño justo. También el tema 16 y otros artículos del apartado de complementos y del apartado de Estadística y Medicina explican la complejidad de esta determinación.
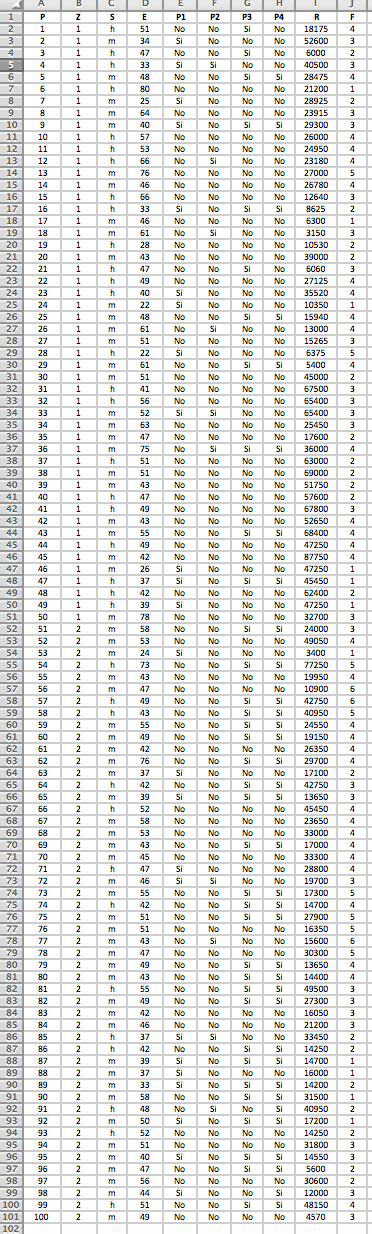
La siguiente base de datos de una investigación de mercados tiene la siguientes variables:
P=Persona
Z=Zona (1, 2)
S=Sexo (h=hombre, m=mujer)
E=Edad
P1=Producto 1 (Si=Consumiría, No=No consumiría)
P2=Producto 2 (Si=Consumiría, No=No consumiría)
P3=Producto 3 (Si=Consumiría, No=No consumiría)
P4=Producto 4 (Si=Consumiría, No=No consumiría)
R=Renta anual
F=Número de miembros en su unidad familiar
Estadística descriptiva e Intervalos de confianza:
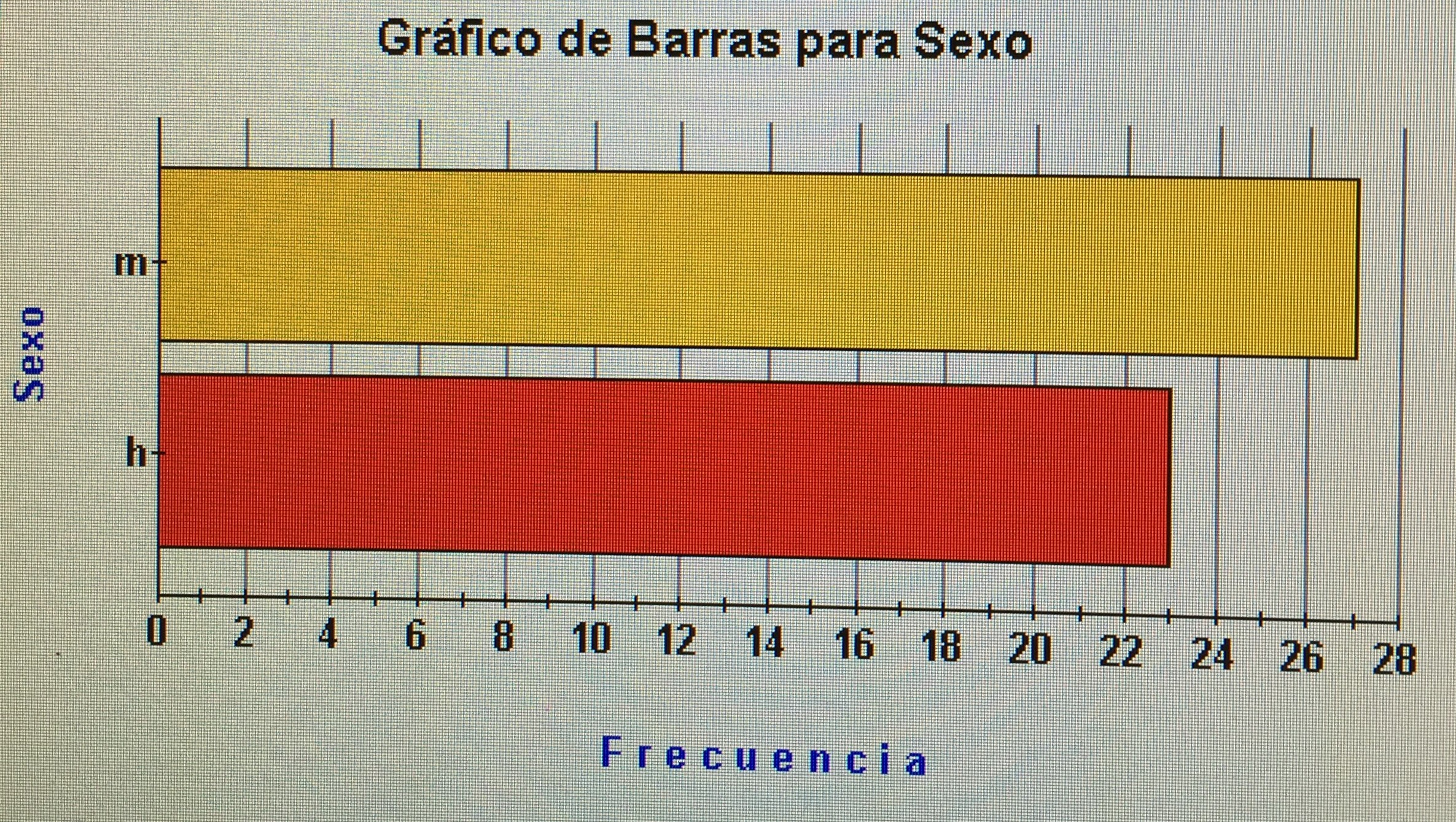
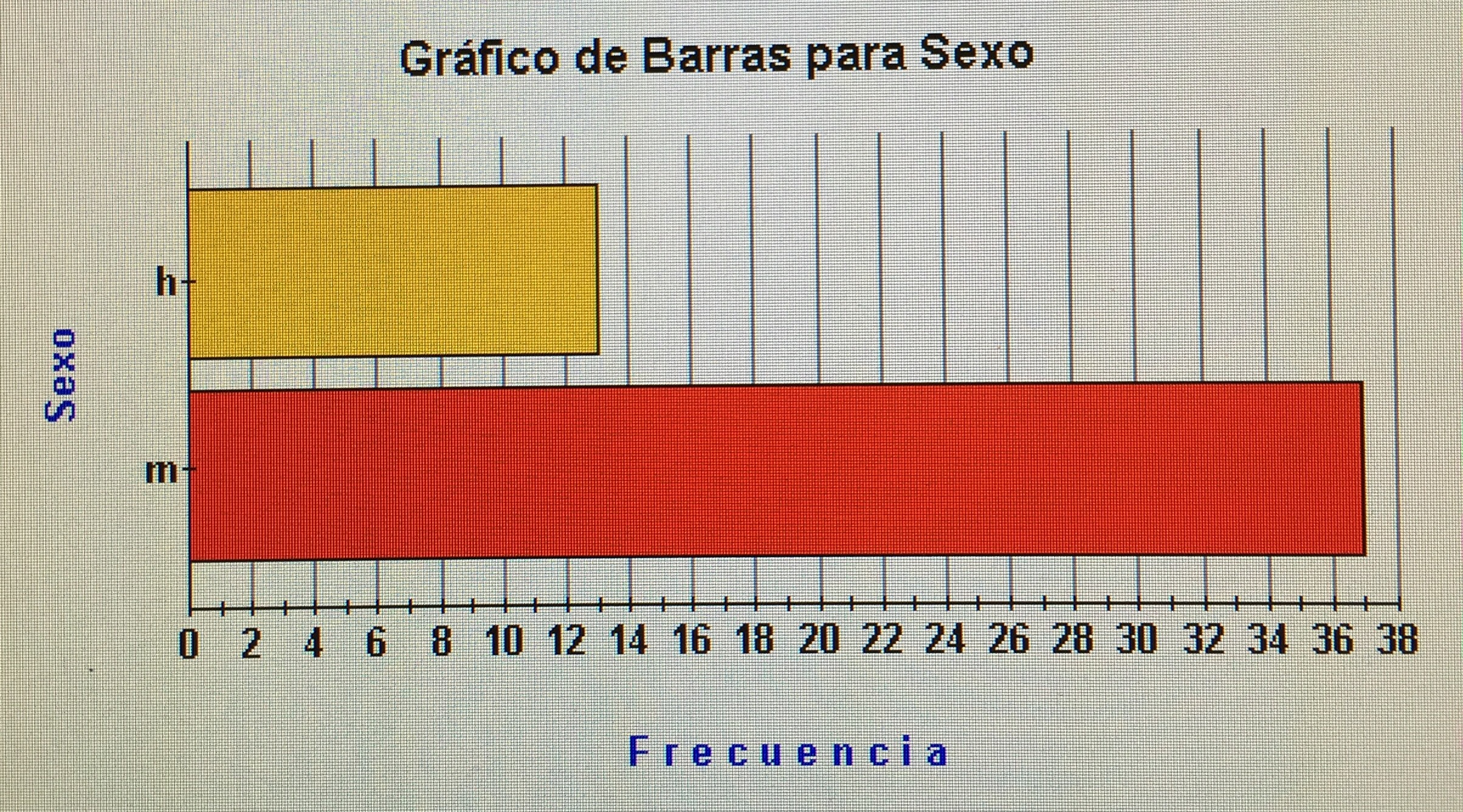
a) Hacer una estadística descriptiva de la variable Sexo en la muestra de la Zona 1 y otra en la muestra de la Zona 2.
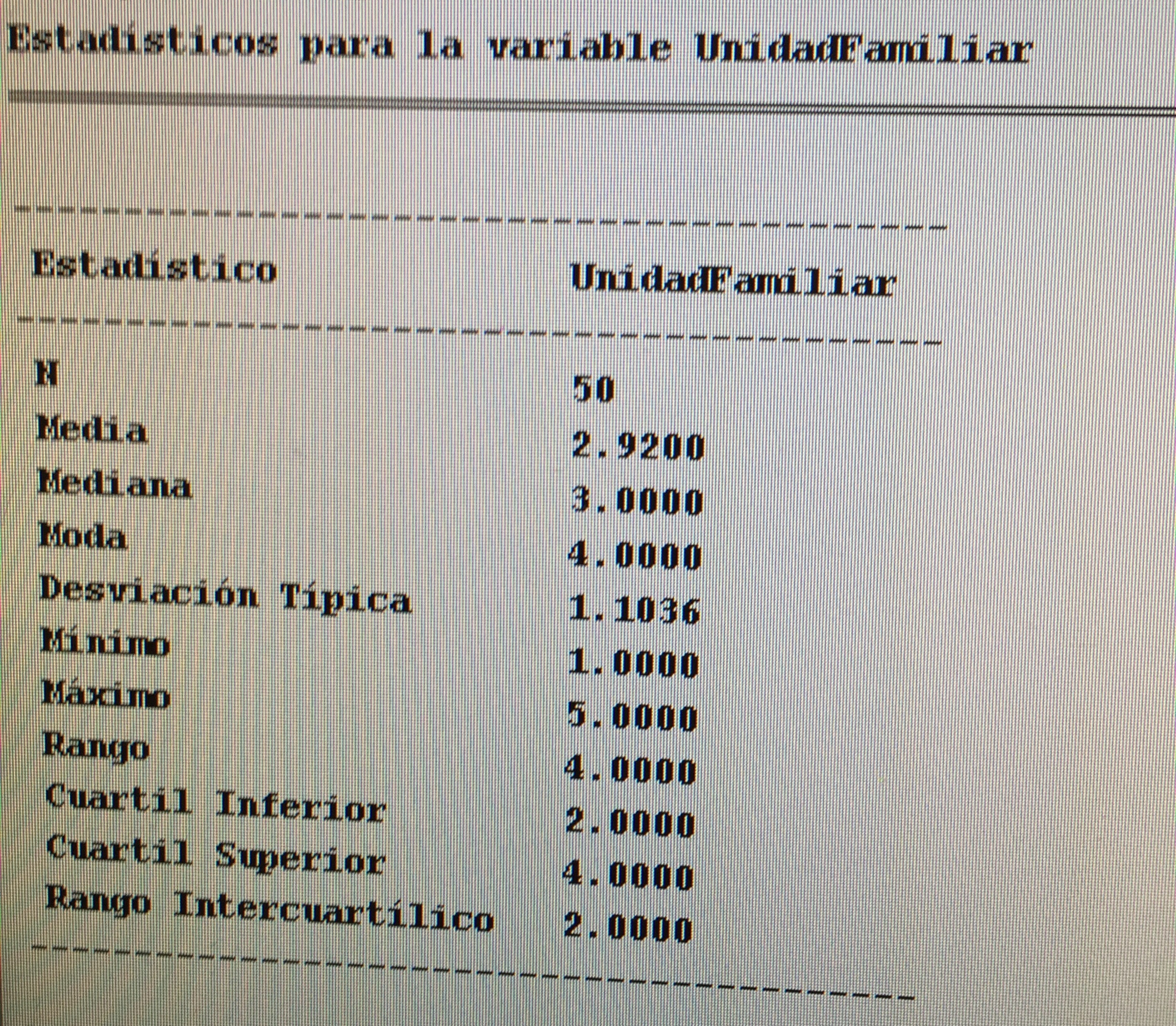
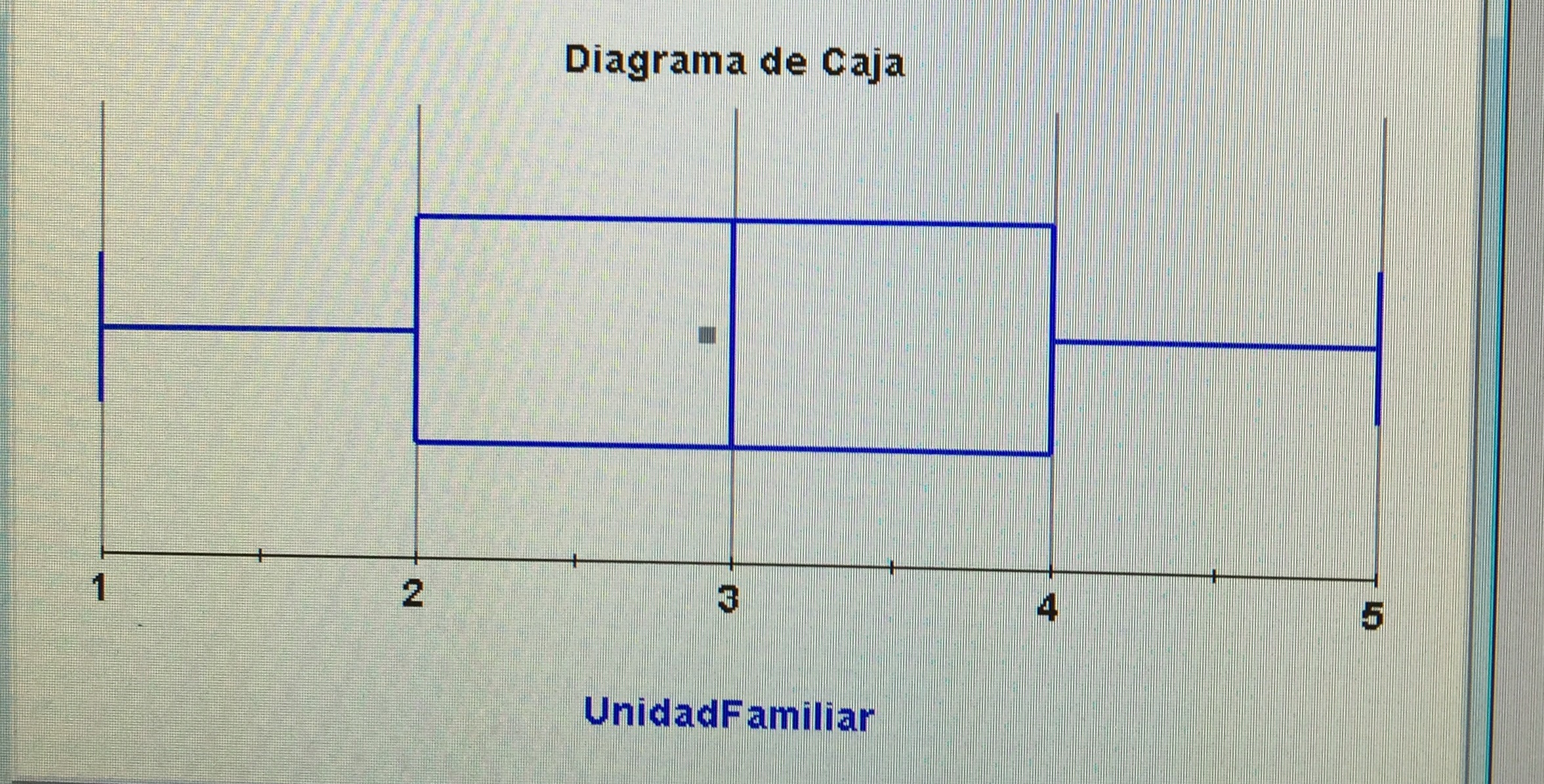
b) Hacer una estadística descriptiva de la variable Número de miembros de la unidad familiar en la muestra de cada una de las dos zonas.
c) Hacer una descriptiva reducida, en dos o tres valores fundamentales, de la variable Renta, en cada uno de los dos grupos del estudio.
d) Hacer una predicción, mediante un intervalo de confianza, del porcentaje de consumo del producto 1.
e) Hacer una predicción, mediante un intervalo de confianza, de la Renta media poblacional en cada una de las dos zonas.
SOLUCIONES:
1.
a) En la zona 1:
En la zona 2:
b) La variable Número de miembros de la unidad familiar se podría resumir tanto como variable cuantitativa como variable cualitativa. Lo hago como cuantitativa, pero como cualitativa sería perfectamente factible.
Zona 1:
Zona 2:
c) La descriptiva de la variable Renta en la zona 1:
Como se ajusta a la distribución normal, porque tanto la Asimetría estandarizada como la Curtosis estandarizada están entre -2 y 2 podemos resumirla brevemente con la media y la desviación estándar:
34297.6±21.730.26
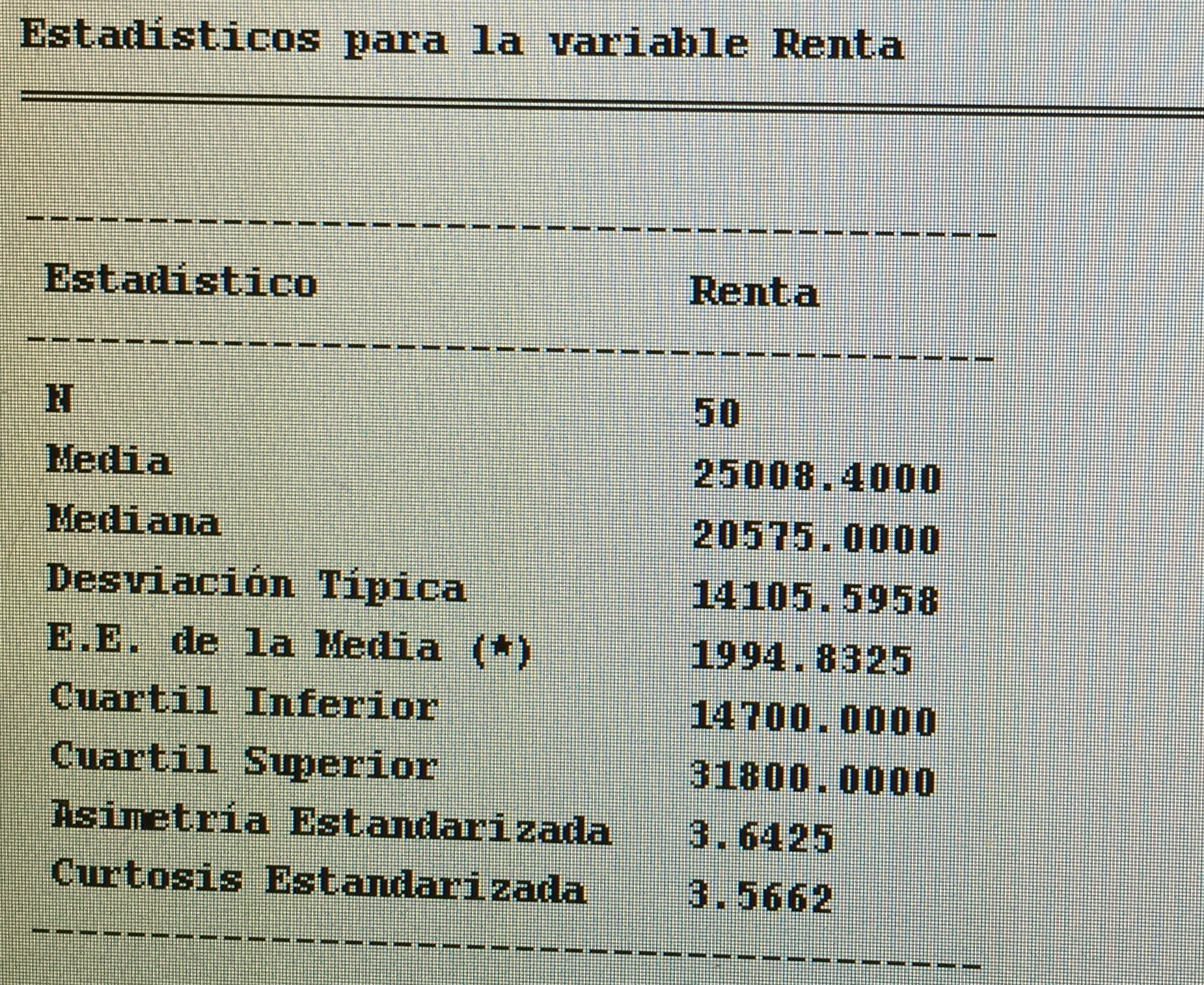
La descriptiva de la variable Renta en la zona 2:
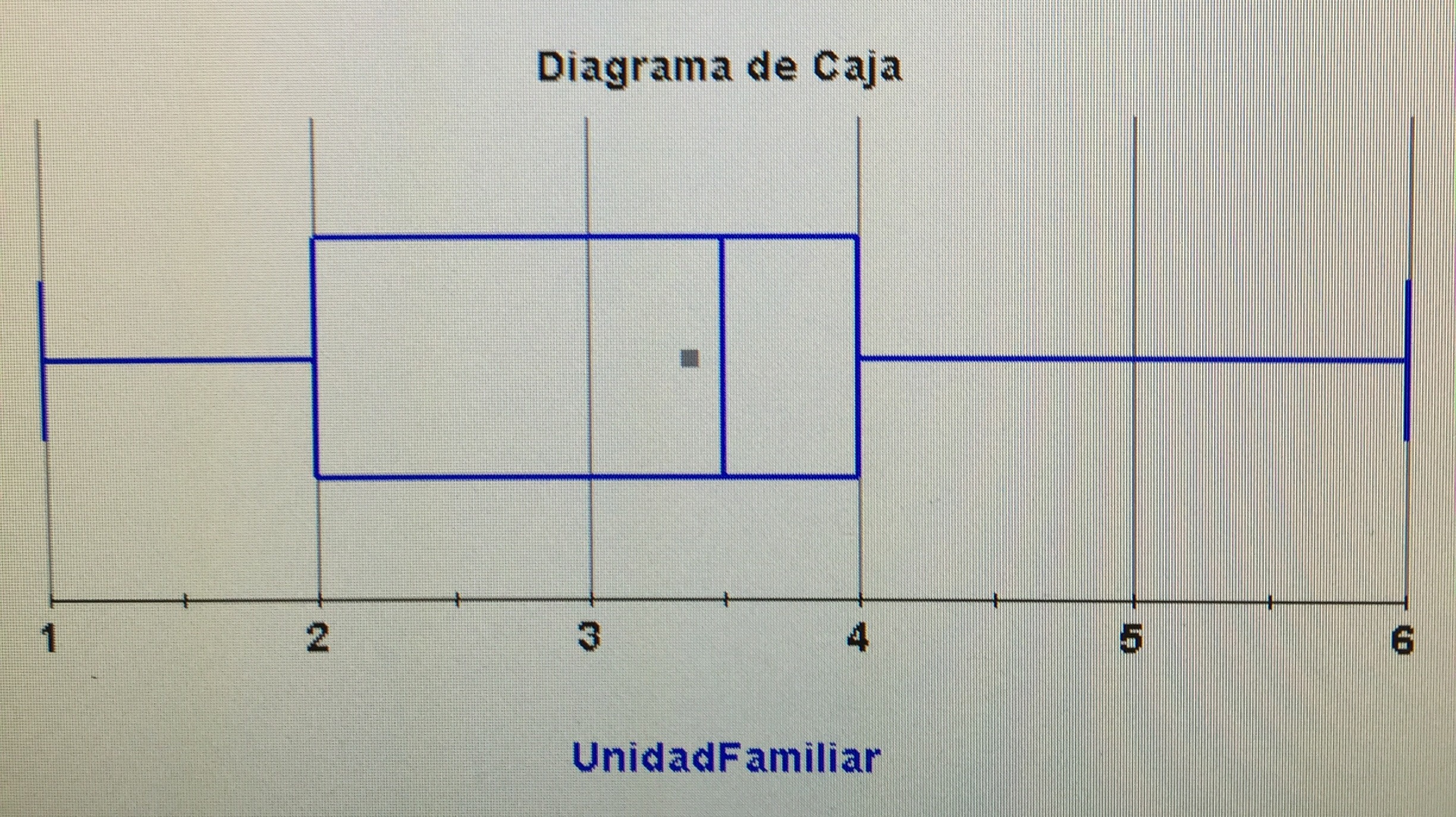
Como no se ajusta a la distribución normal, porque tanto la Asimetría estandarizada como la Curtosis estandarizada están fuera del -2 y 2, no podemos resumirla brevemente con la media y la desviación estándar y debemos hacerlo con la mediana y el rango intercuartílico, expresado con el primer y tercer cuartil:
20575 (14700-31800)
d) El producto 1 reuniendo las dos zonas tenemos la siguiente descriptiva:
El 24% parece que consumirá el producto. Esto es la estimación, pero debemos construir un intervalo de confianza. Aplicando el procedimiento de construcción de intervalos de confianza del 95% para una proporción visto en el tema 3 obtenemos:
e) Para hacer un intervalo de confianza de la media de la renta en la zona 1 y en la zona 2 debemos usar la media y el error estándar. Al construir intervalos de confianza de la media no es preciso la comprobación de la normalidad de la muestra, especialmente si el tamaño de muestra es a partir de 30 valores, porque en estos casos siempre se cumple la normalidad. Pensemos que estamos hablando de la normalidad de la variable media, no de la variable original, que en la zona 2 hemos visto que claramente no se ajusta a la normalidad. Pero la media sí se ajusta porque el tamaño de muestra es 50, que es mayor que 30.
Zona 1:
34297.6±2×3073.12
34297.6±6146.24
Zona 2:
25008.4±2×1994.8
25008.4±3989.6
2. Técnicas de relación:
a) Calcular la correlación de Pearson entre Edad y Renta. ¿Es estadísticamente significativa?
b) ¿Hay alguna relación, estadísticamente significativas, entre el consumo de los productos 3 y 4?
c) ¿Dónde hay más relación entre el consumo de los productos 3 y 4, en los hombres o en las mujeres?
Soluciones:
a) La correlación de Pearson es r=0.10 con un p-valor de 0.318. Por lo tanto, es una correlación que no es estadísticamente significativa.
b) La ji-cuadrado de la relación entre el consumo del producto 3 y 4 es de 79.39 con una p<0.05 y una V de Crámer V=0.89.
c) En Hombres la relación entre el consumo del producto 3 y 4 es estadísticamente significativa con una ji-cuadrado de 20.61 y una p<0.05. Y una V=0.76.
En Mujeres la relación entre el consumo del producto 3 y 4 es, también, estadísticamente significativa, con una ji-cuadrado de 59.84 y una p<0.05. Y una V=0.97.
La relación es más intensa en las mujeres puesto que la V es mayor.
3. Técnicas de comparación:
a) Hacer una comparación entre las dos zonas de la muestra para la variable Renta.
b) Hacer una comparación entre las dos zonas para la variable Consumo de P2.
c) Hacer un ANOVA de dos factores con interacción para la variable Renta con los factores Zona y Sexo.
Soluciones:
a) La variable renta es continua, las muestras son independientes y ninguna de las dos se ajusta a la distribución normal (p<0.05 con el Test de Shapiro-Wilk). Por lo tanto, hay que aplicar el Test de Mann-Whitey. El p-valor es 0.0553, por lo que no podemos decir que haya diferencias estadísticamente significativas. Es cierto que es muy justo este p-valor. Sólo que la muestra fuera un poco más grande la diferencia sería significativa, con toda probabilidad.
b) La variable es dicotómica, las muestras son independientes, el tamaño de muestra es mayor que 30 y el valor esperado por grupo es mayor o igual que 5, por lo que podemos aplicar el test de proporciones o el test de la ji-cuadrado. Al hacerlo el p-valor es mayor que 0.05, por lo que no puede considerarse que hay una diferencia estadísticamente significativa entre ambas zonas en cuanto al consumo del P2.
c) Si se realiza un ANOVA de dos factores observamos que hay diferencia entre zonas, que hay diferencia entre sexos y que hay interacción. Los tres p-valores son menores que 0.05. En la zona 1 hay mucha igualdad de rentas entre sexos y, sin embargo, en la zona 2 hay una marcada diferencia entre las rentas de ambos sexos en perjuicio de las mujeres.