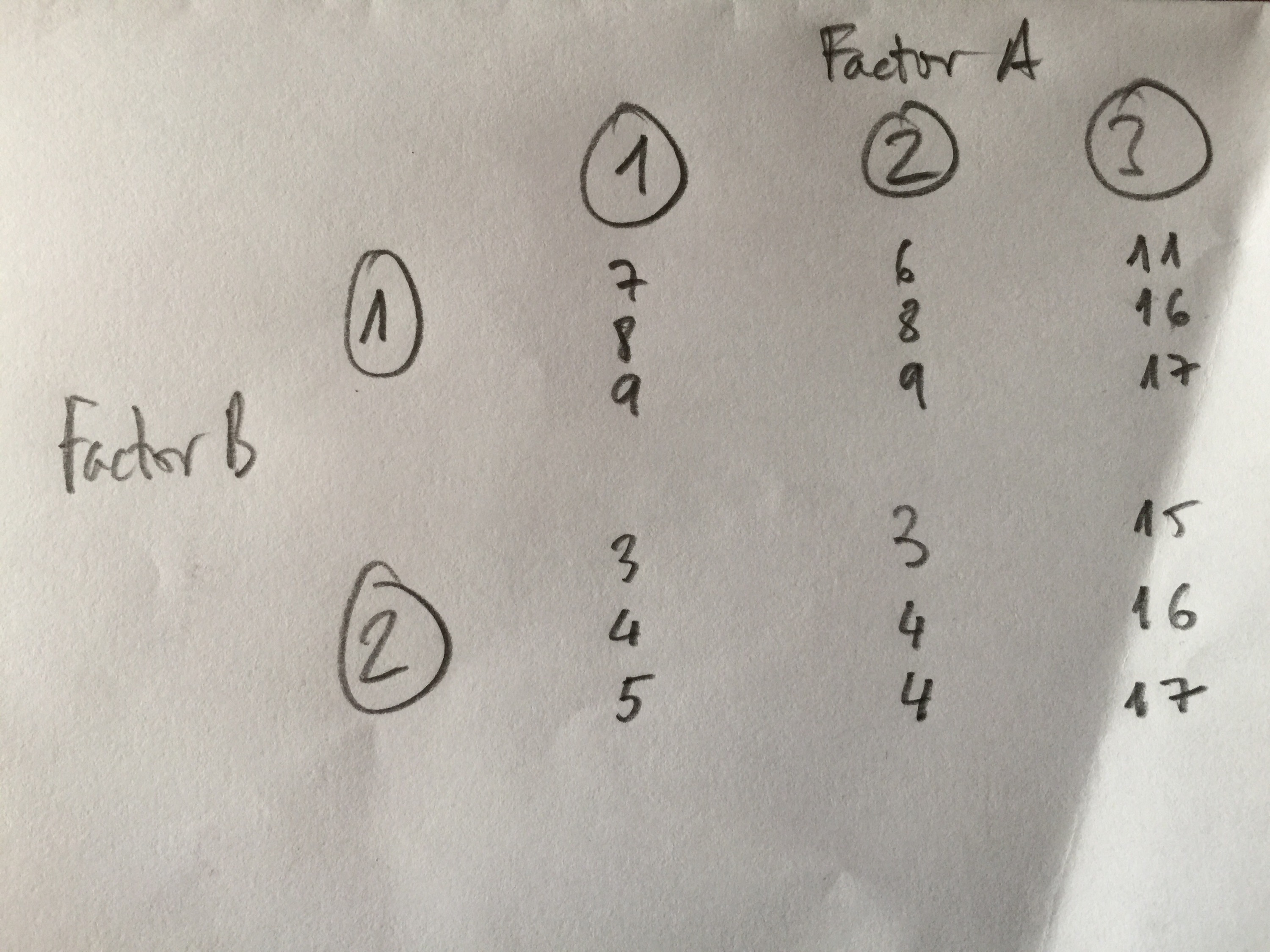
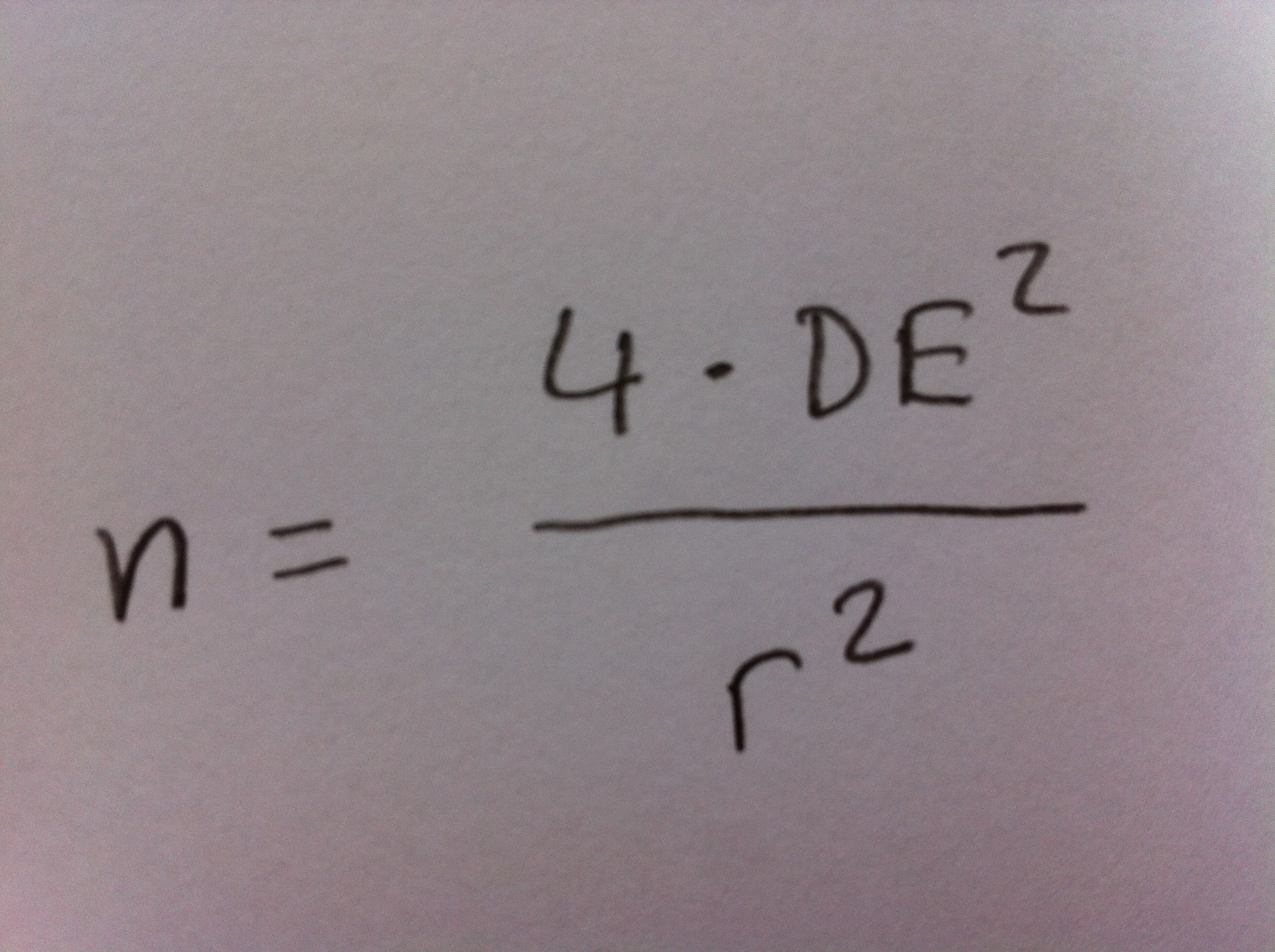1c: El p-valor de los dos factores es superior a 0.05 y el de la interacción es inferior a 0.05. Por lo tanto, los dos factores no son significativos y la interacción sí.
2c: Es evidente que no hay igualdad entre los cuatro niveles. Y si se observa con detenimiento los tres primeros niveles son muy similares y el cuarto es el que se aparta de los demás. Por lo tanto, el ANOVA tendrá un p-valor inferior a 0.05 y que en las comparaciones múltiples tendremos dos grupos homogéneos en este estudio: el formado por los niveles 1, 2 y 3 y el formado por el nivel 4.
3a: Las Odds ratio significativas son la a, c y d. La duda está entre la a y la c, entre 0.3 y 3. Es mayor 0.3 porque si dividimos 1/0.3 obtenemos 3.333333 que es mayor que 3. Si hacemos lo contrario, 1/3 es 0.33333. Y 0.3 está más alejado del 1 que 0.3333333.
4b: La variable es dicotómica porque se mira si la diferencia es positiva o no. Las muestras son relacionadas porque los dos tratamientos se ensayan con cada paciente. Por lo tanto, se debe aplicar el test de McNemar.
5c: Es la única muestra que cumple todas las propiedades exigidas.
6c: Se trata de un coeficiente de determinación muy grande, pero con la información que tenemos no sabemos si se trata de una relación significativa. Ese coeficiente no marca significación sino magnitud de relación.
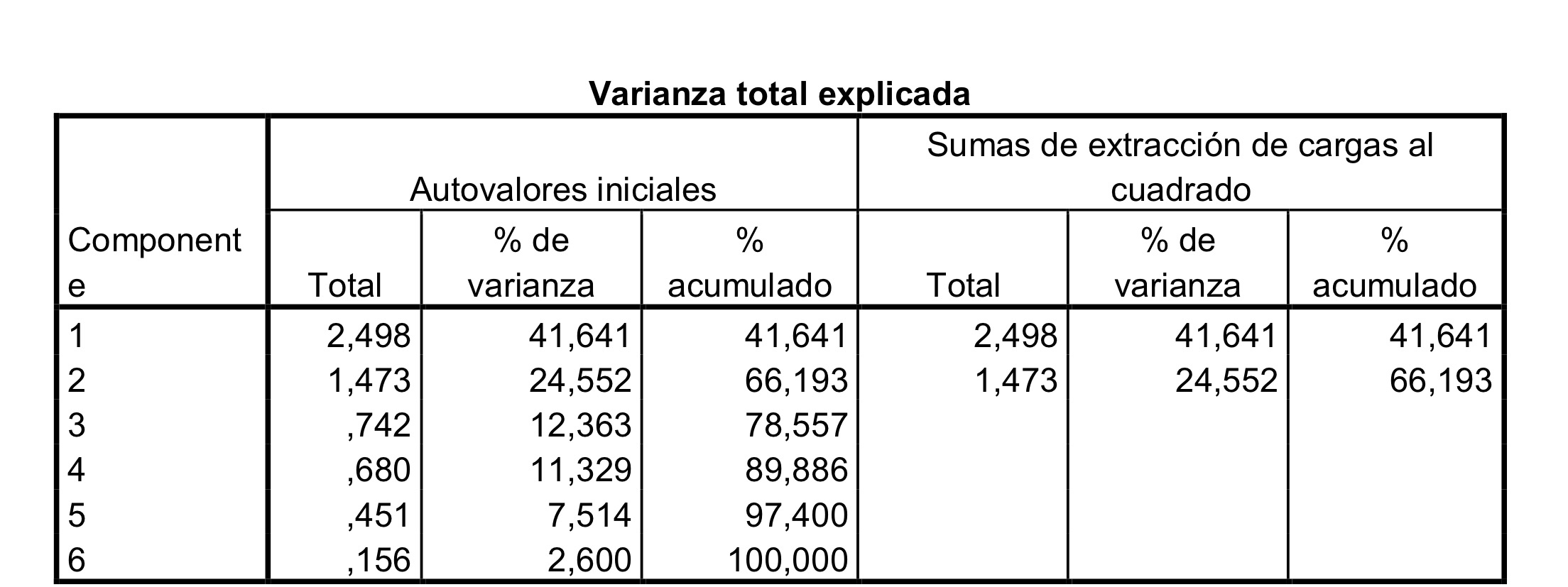
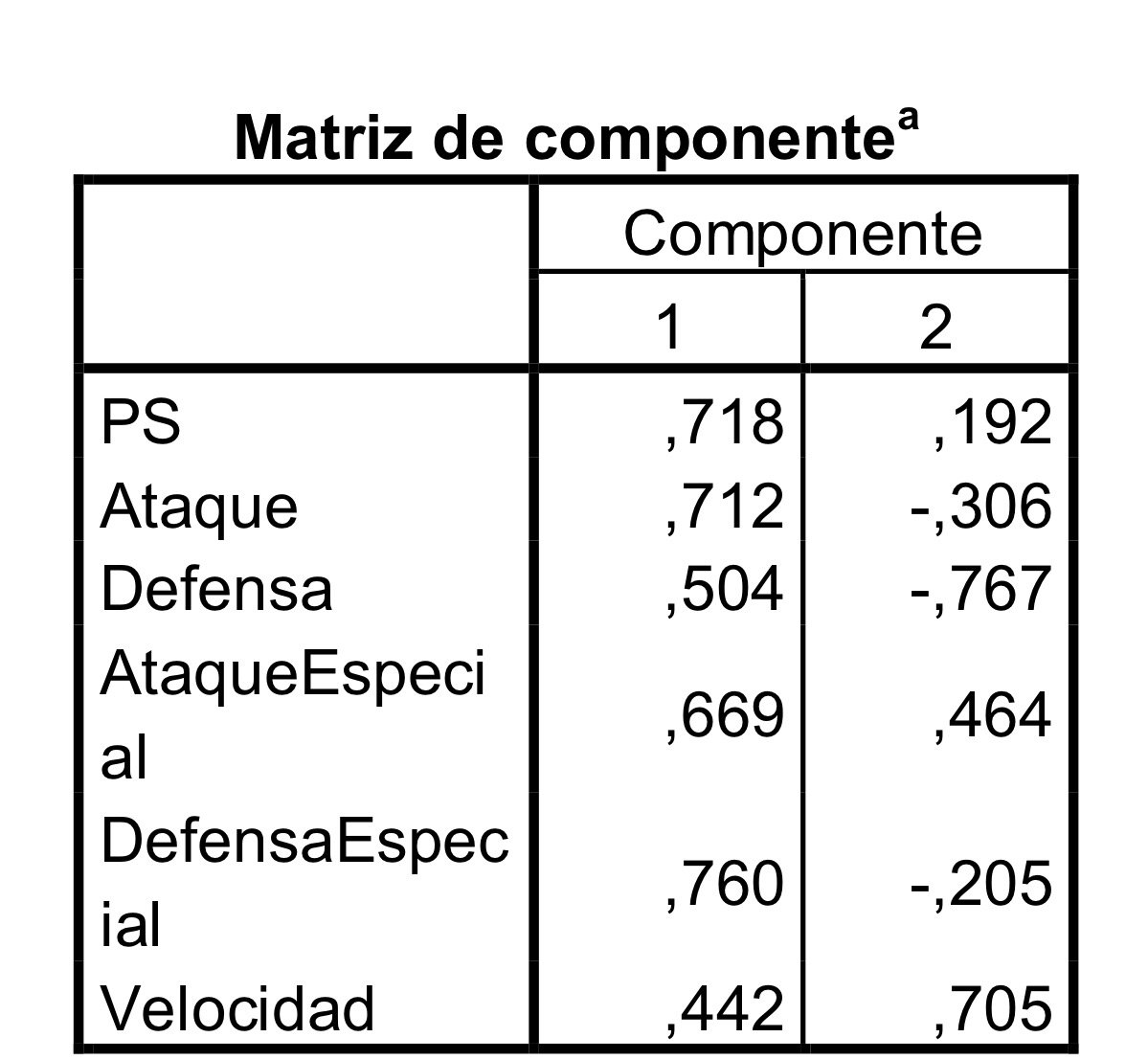
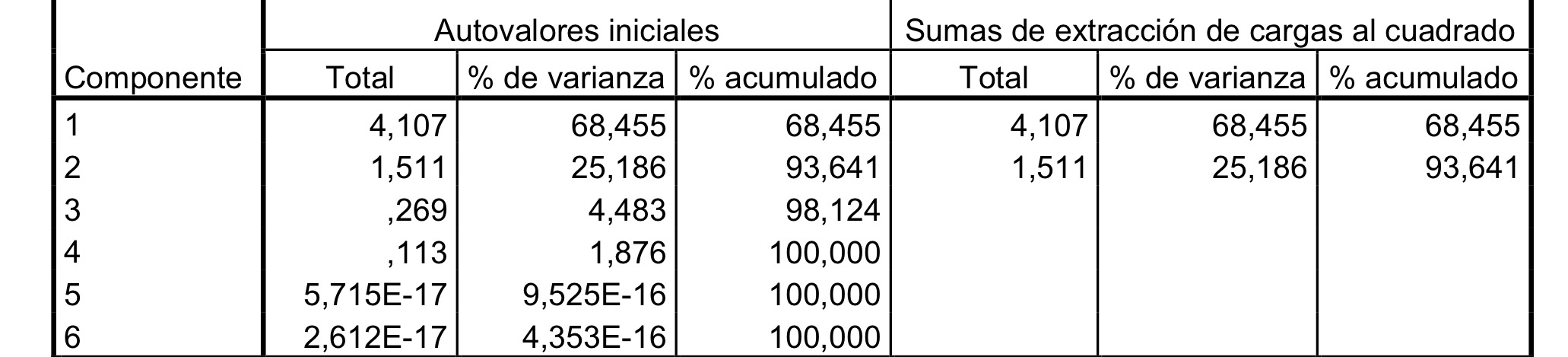
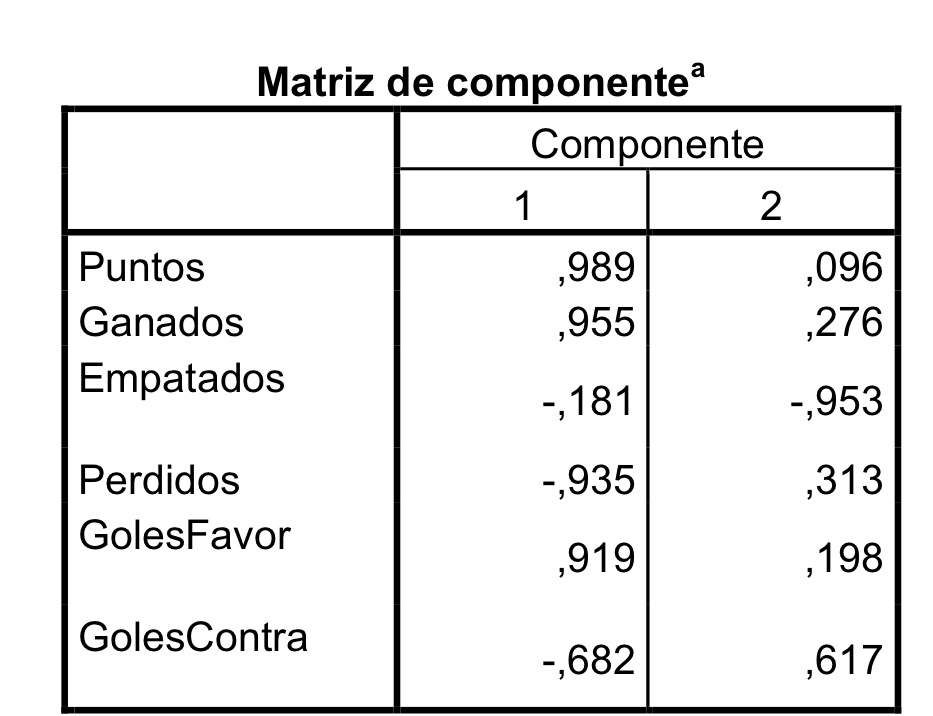
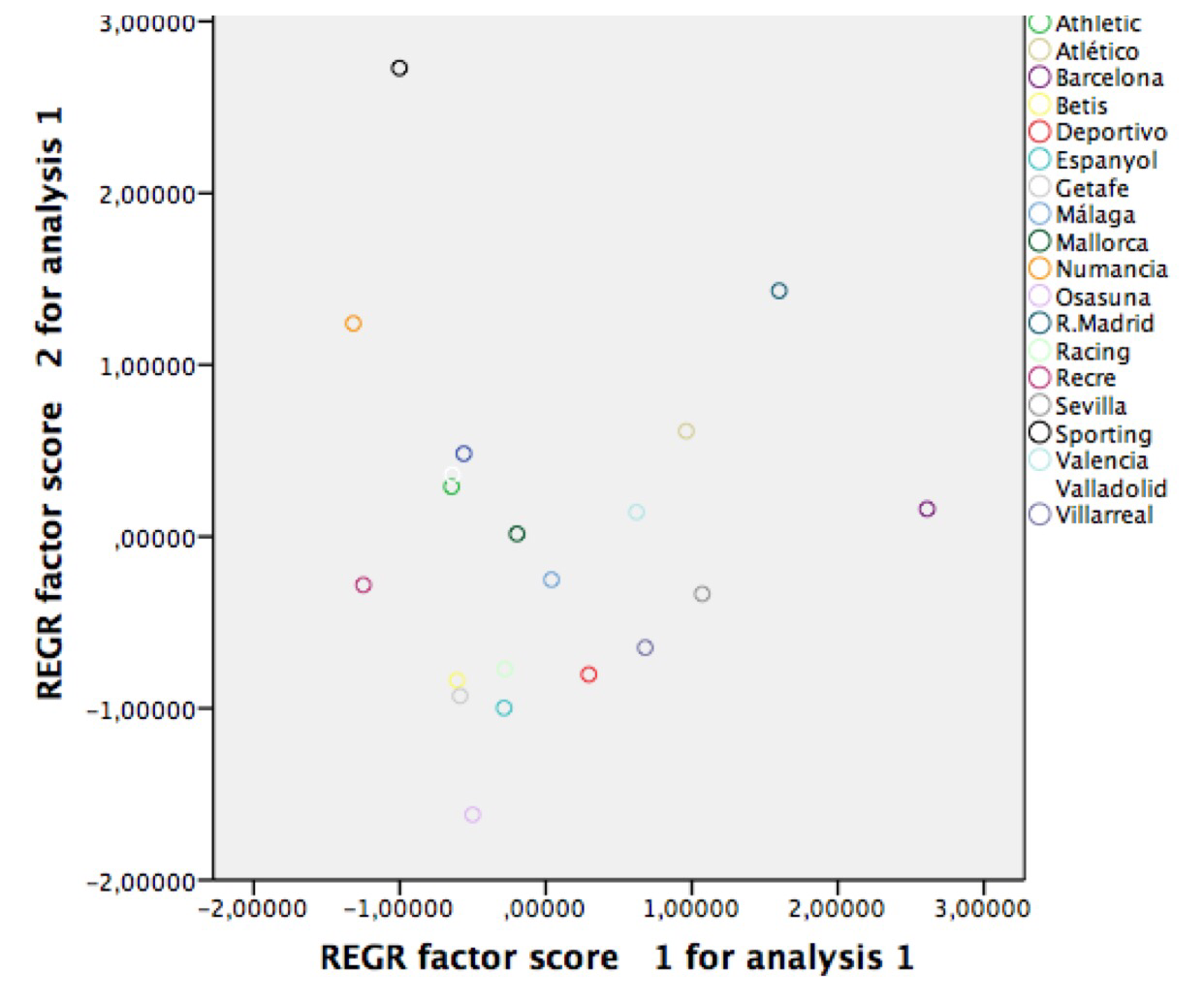
7c: Un individuo con los cinco valores de 1 tendría un valor de 1.5 no de 2.5 de la primera componente.
8d: El error estándar es 0.5 por lo que un intervalo de confianza del 99.5% de la media será el resultado de restar y sumar tres veces ese error estándar a la media. Por lo tanto, ese intervalo es correcto.
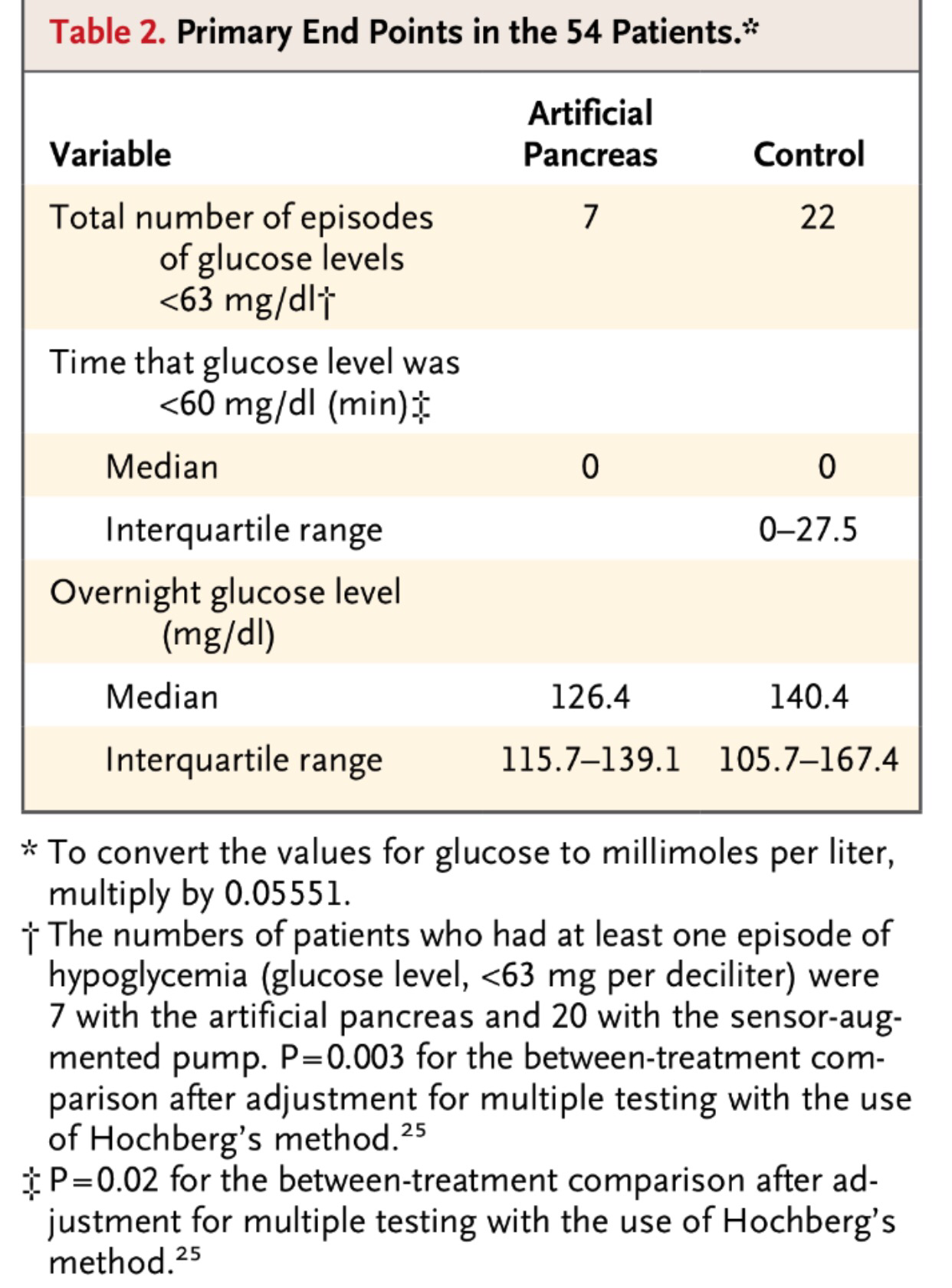
9b: Si se aplica la fórmula del Tema 16 para obtener el tamaño se obtiene de forma directa, pero hay otra forma de razonarlo. El error estándar que se pretende tener es de 0.05 porque se pretende un radio de intervalo de 0.1 en un intervalo de confianza del 95%. Si la DE es 2 para obtener un error estándar de 0.05 debemos dividir 2 por 40 (2/40=0.05). Por lo tanto, 40 es igual a la raíz cuadrada del tamaño de muestra que necesitamos; o sea, 1600.
10c: Variable continua, muestras relacionadas, ajuste a la normal. Por lo tanto, el test adecuado es el de Student de datos apareados.
11b: Son muestras independientes de una variable continua. Una se ajusta a la distribución normal (p>0.05) y la otra no (p<0.05) por lo que debemos aplicar un test de Mann-Whitney. Para aplicar algunos de los dos test de la t de Student hace falta que las dos distribuciones sean normales.
12b: El p-valor es un criterio que debe ir acompañada de otro mecanismo de control, de la potencia. Si en una comparación tenemos un p-valor de 0.55 si no hay suficiente potencia, que lo marcará un determinado tamaño de muestra, no podremos decir que no haya diferencia entre los dos grupos comparados. Se precisa una potencia al menos del 80%.
13d: Se trata de una correlación significativa, como es positiva la pendiente de la recta de regresión también será positiva. Y como es una correlación significativa también lo será la pendiente. Siempre lo que le sucede a la correlación, en materia de significación, y en materia de signo, es lo mismo que le sucede a la pendiente.
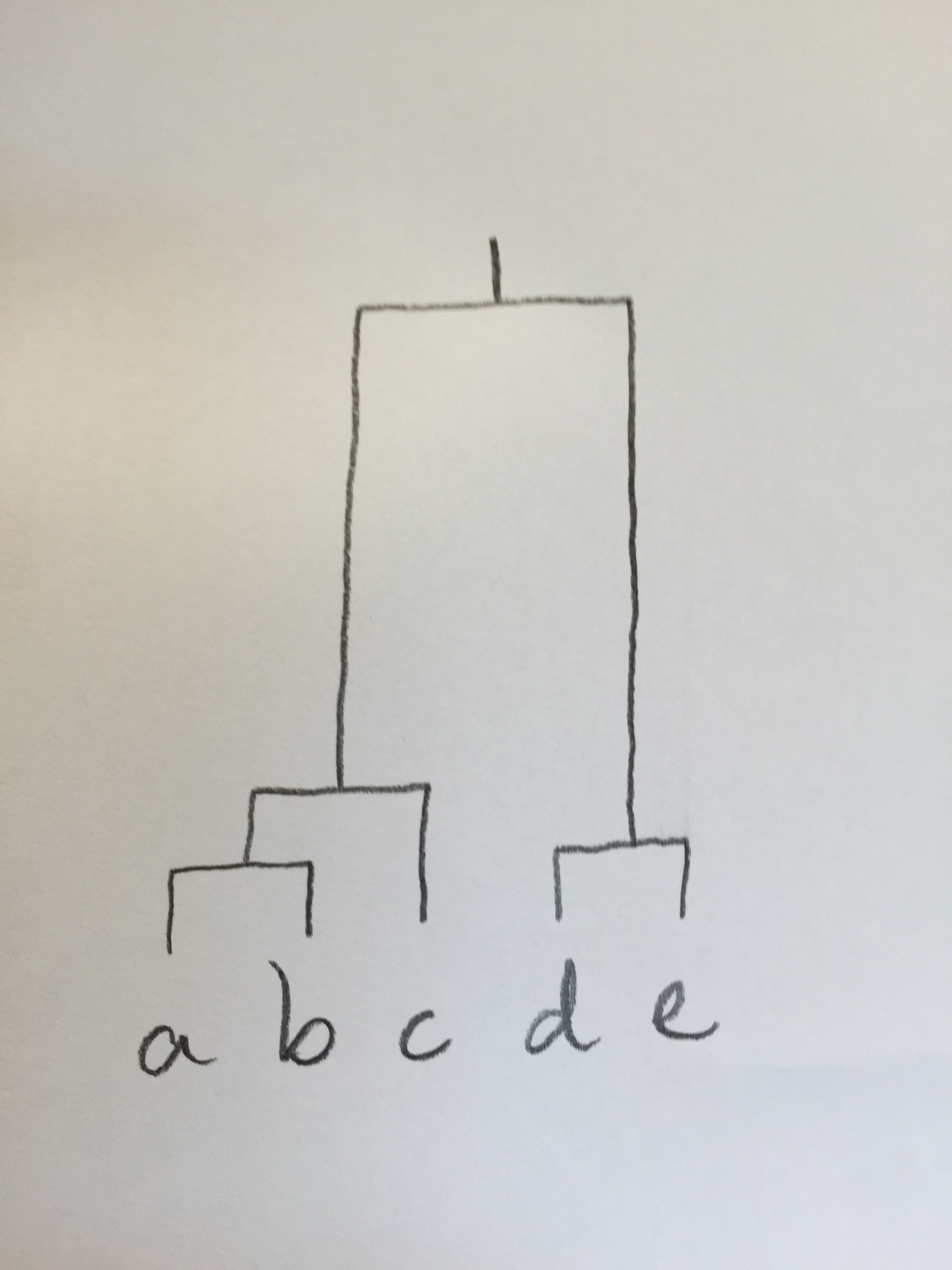
14c: Observemos que a y b están a la misma distancia que d y e. Por eso empiezan igual en el dendrograma. Pero, al mismo tiempo el grupo de a y b está muy alejado del grupo formado por d y e. A continuación, el siguiente en unirse es c al grupo formado por a y b, porque está muy próximo a ellos. Entre el grupo formado, ahora, por a, b y c y el grupo formado por d y e sí que hay mucha distancia.
15a: Como es un intervalo de la media debemos fijarnos en el error estándar, que es 1.5 (15/raiz(100)). Por lo tanto, si el intervalo es del 95% debemos sumar y restar dos veces ese error estándar. El intervalo es, pues, (97, 103).
16a: Sabemos que en toda tabla 2×2 el valor de referencia para la significación es 3.84. Como 4.6 es mayor que ese valor sabemos que se trata de una relación significativa. Siempre, una tabla de contingencias, con un número de filas y columnas determinado, tiene un valor de referencia a partir del cual el valor de la ji-cuadrado que obtengamos marcará que no podemos mantener la hipótesis nula de no relación entre las variables cualitativas estudiadas. En general, no sabemos cuál es ese valor, pero en el tema 8 donde todos los ejemplos se ponen en tablas 2×2, se puede observar que el 3.84 es el valor de referencia para todas las tablas que tengan 2 filas y 2 columnas. Revisar la importante tabla del final del tema 8.
17d: La V de Crámer tiene la enorme ventaja que es calculable para cualquier tabla de contingencias, tenga el número de filas que tenga y el número de columnas que tenga.
18d: Si r=0.9 es evidente que el coeficiente de determinación será del 81%, y ese coeficiente marca la cantidad que una variable determina a la otra. Las otras respuestas no son correctas. Las otras tres respuestas serían únicamente correctas si la correlación fuera r=1, que no es el caso. Hay, por lo tanto, un error, lo que no garantiza que ni en la muestra ni en futuras observaciones cuando tengamos un valor de x=5 tendremos un valor de y=15.
19d: Toda variable tiene desviación estándar, aunque sea dicotómica. En concreto, en una dicotómica DE=raiz(p(1-p)), siendo p la proporción de unos que tengamos.
20d: La significación de cualquier tabla de contingencias depende de un valor de referencia. Valor de referencia que, como hemos visto en el tema 8, depende del número de filas y de columnas, pero no del tamaño de muestra. Observad, de nuevo, el gráfico final del tema 8. Podéis ver que el valor de 3.84 es el mismo para un caso de tabla con mucho tamaño de muestra y para otro con menor tamaño de muestra. Sólo depende de que sea una tabla con dos filas y dos columnas. Otra tabla, por ejemplo, una tabla 4×3 tiene otro valor de referencia que depende, de nuevo, de las filas y columnas que tengamos, no de la cantidad de muestra que tengamos.