En el Tema 2: Estadística descriptiva ya hemos visto que son muchos los estadísticos, los descriptores, que podemos calcular a una muestra de una variable cuantitativa. Pero es muy habitual resumir una muestra mediante sólo dos descriptores. Lo más habitual es hacerlo mediante la Media y la Desviación estándar. En estos casos se suele escribir mediante la estructura Media±Desviación estándar. Es muy habitual en revistas científicas ver descripciones de una variable en términos, por ejemplo, como de 10±3, 134±23 ó 2345±123. Sin embargo, esta generalización que se viene usando es problemática. Veamos por qué.
Si una variable se ajusta bien a una distribución normal lo más conveniente es describir esa variable, efectivamente, mediante la Media y la Desviación estándar, porque con estos dos valores tenemos perfectamente caracterizada la distribución de la población que hay detrás de la muestra que tenemos.
Si una variable, por el contrario, no se ajusta a una distribución normal es muy problemático describirla en estos términos, de esta forma. Es mucho más razonable describirla mediante la Mediana y el Rango intercuartílico.
La tendencia habitual si se tiene una variable descrita en los términos de la Media±Desviación estándar es a hacer aquellas típicas inferencias que sólo son ciertas si la variable se ajusta bien a la distribución normal: M±1DE supone el 68.5% aproximadamente de la población, M±2DE supone el 95% aproximadamente de la población y M±3DE supone el 99.5% aproximadamente de la población. Si la variable no se ajusta a una distribución normal esas inferencias en absoluto son ciertas. Para evitar esta muy habitual inferencia inconsciente es mejor trabajar, evidentemente, en estos casos de no ajuste a la normalidad, con la Mediana y el Rango intercuartílico que son medidas que digamos están más próximas a la descripción propiamente dicha y no tienen tantas connotaciones inferenciales como las tienen la Media y la Desviación estándar.
No es un problema, como suele pensarse en ocasiones, de tamaño de muestra. Hay una creencia establecida, por parte de muchos usuarios de la Estadística, que si una muestra es pequeña deben usarse descriptores tipo mediana y percentiles y si la muestra es grande puede usarse y debe usarse la media y la desviación estándar. Esto no es así. El uso de unos u otros descriptores no depende del tamaño muestral, depende de la normalidad de la muestra, de su ajuste a la campana de Gauss.
Veamos dos ejemplos que nos pueden ayudar:
El primero es una muestra de tamaño 1000 de personas adultas a las que se les ha medido la variable Altura. Veamos unos cuantos descriptores calculados a esa muestra, el Box-Plot y un interesante gráfico donde simplemente se representan todos los valores de la muestra en su posición respecto a la recta de números de abajo. Los valores se elevan con la intención que se visualice mejor la distribución de valores. Observemos que en este caso dar la Media y la Desviación estándar es muy correcto. Los valores muestrales se ajustan bien a una normal. Vemos perfectamente que si a la media le sumamos y restamos 1DE ó 2DE vemos que efectivamente quedan, dentro de esos dos intervalos, el 68.5 y el 95% de valores. Vaya, que estos valores son factibles y razonables:

La Asimetría estandarizada de esta muestra es -0.46 y la Curtosis estandarizada es 0.19. Esto es una forma más objetiva de valorar el ajuste a la distribución normal. Ambos valores están dentro del intervalo que va del -2 al 2.
El segundo ejemplo es una muestra de las edades de 1129 alumnos de la Universidad de Barcelona. Ahora observemos que si representamos esa muestra mediante la Media y la Desviación estándar corremos el peligro de que si hacemos esos intervalos nos encontremos con errores importantísimos. La media son 22.2 años y la DE es 3.89. Si ahora construimos los típicos intervalos nos encontramos con inferencias que no son reales. Simplemente por la no normalidad de los datos:

La Asimetría estandarizada de esta muestra es 67.26 y la Curtosis estandarizada es 269.24. Esto es una forma más objetiva de valorar el ajuste a la distribución normal. Ambos valores están fuera claramente del intervalo que va del -2 al 2. Por lo tanto, claramente se trata de una variable que no se ajusta a la distribución normal.
La Desviación estándar es un magnífico descriptor, pero peligroso. Debe usarse con cuidado. Demasiadas veces el no introducido con los problemas que aquí comento comete errores de inferir a partir de ella cosas que sólo son ciertas si la variable se ajusta a una distribución normal. Es por eso que estos casos suele recomendarse el uso de la median y el rango intercuartílico. En este último caso podríamos describir la variable Edad mediante los valores: 22 (20-23). Observemos que aunque se habla en estos casos de Mediana y Rango intercuartílico, en realidad, más que darse el Rango intercuartílico propiamente, suele darse primer y tercer cuartil. De esta forma se está dando el rango intercuartílico y los dos valores concretos a partir de los cuales se calcula. Por lo tanto, se está dando más información.
Es por lo tanto muy importante saber en qué momentos tiene sentido usar uno u otro sistema descriptivo. Y es muy importante, también, saber usar bien la desviación estándar, saber qué papel juega, saber cuándo puede tener mucho protagonismo y cuándo debe quedar más en un segundo plano.
Resumiendo:
1. Si la variable se ajusta bien a la distribución normal el cálculo de la Media y la Desviación estándar es la mejor opción puesto que mediante ellos se tiene perfectamente caracterizada la distribución de la población de donde se ha tomado la muestra.
2. Si la variable no se ajusta bien a una distribución normal es conveniente dar la Mediana y el Rango intercuartílico. La media y la desviación estándar, en este caso, pueden llevar a inferencias rutinarias peligrosas. De hecho, la desviación estándar es muy buen descriptor pero peligroso. Bien usado perfecto, pero mal usado puede llevar a inferencias muy alejadas de la realidad.
Observemos en la siguiente tabla de un artículo de medicina cómo se presenta la información en una Estadística descriptiva. Las variables cualitativas con la frecuencia absoluta y, entre paréntesis, la frecuencia relativa. Las variables cuantitativas cuando no se dice lo contrario se expresa la media más menos la desviación estándar y, en muchas ocasiones, indicándolo, se expresa con la mediana y el rango intercuartílico (IQR). Observemos, también, que, a veces, se presenta el rango, expresado mediante el mínimo y el máximo:
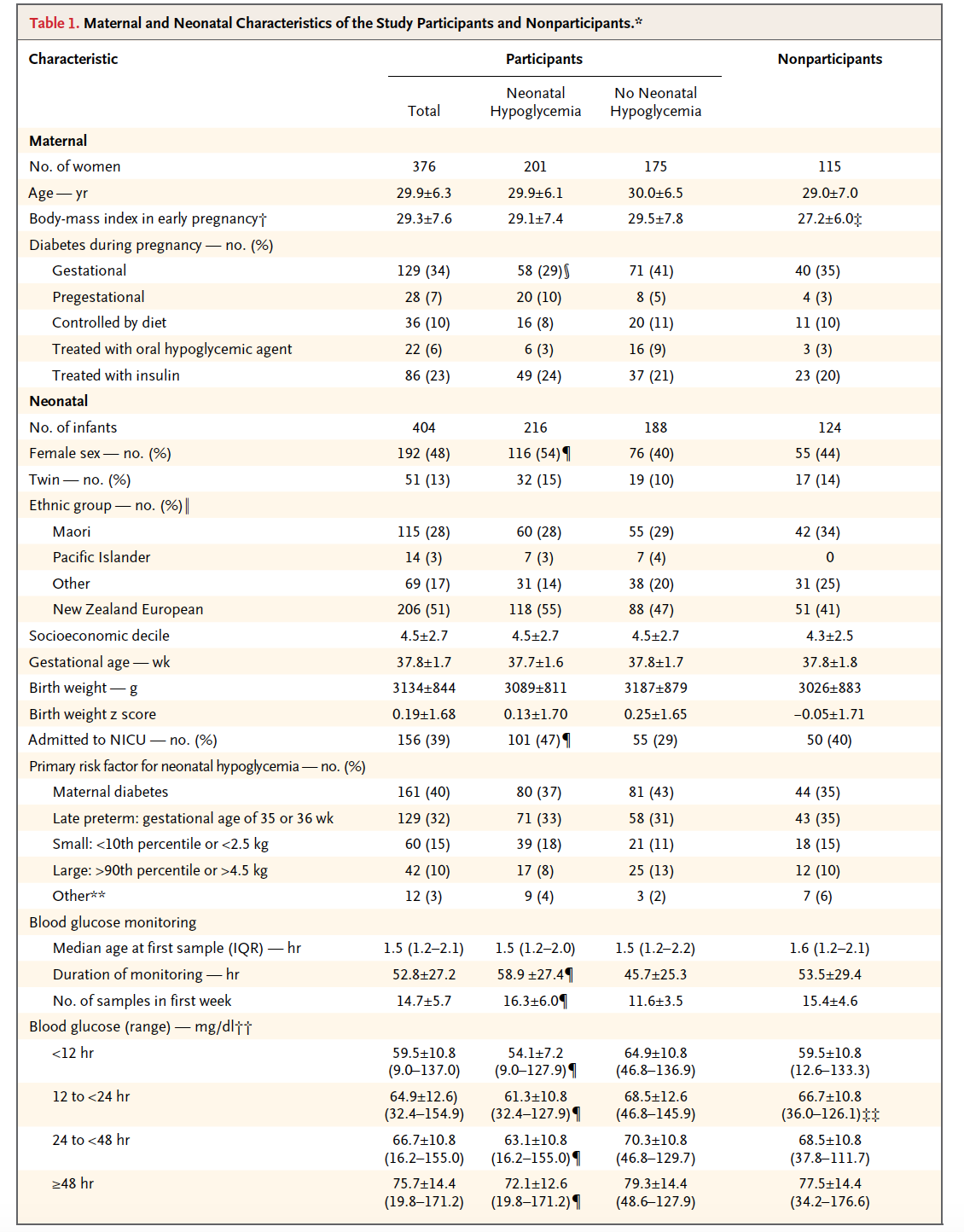
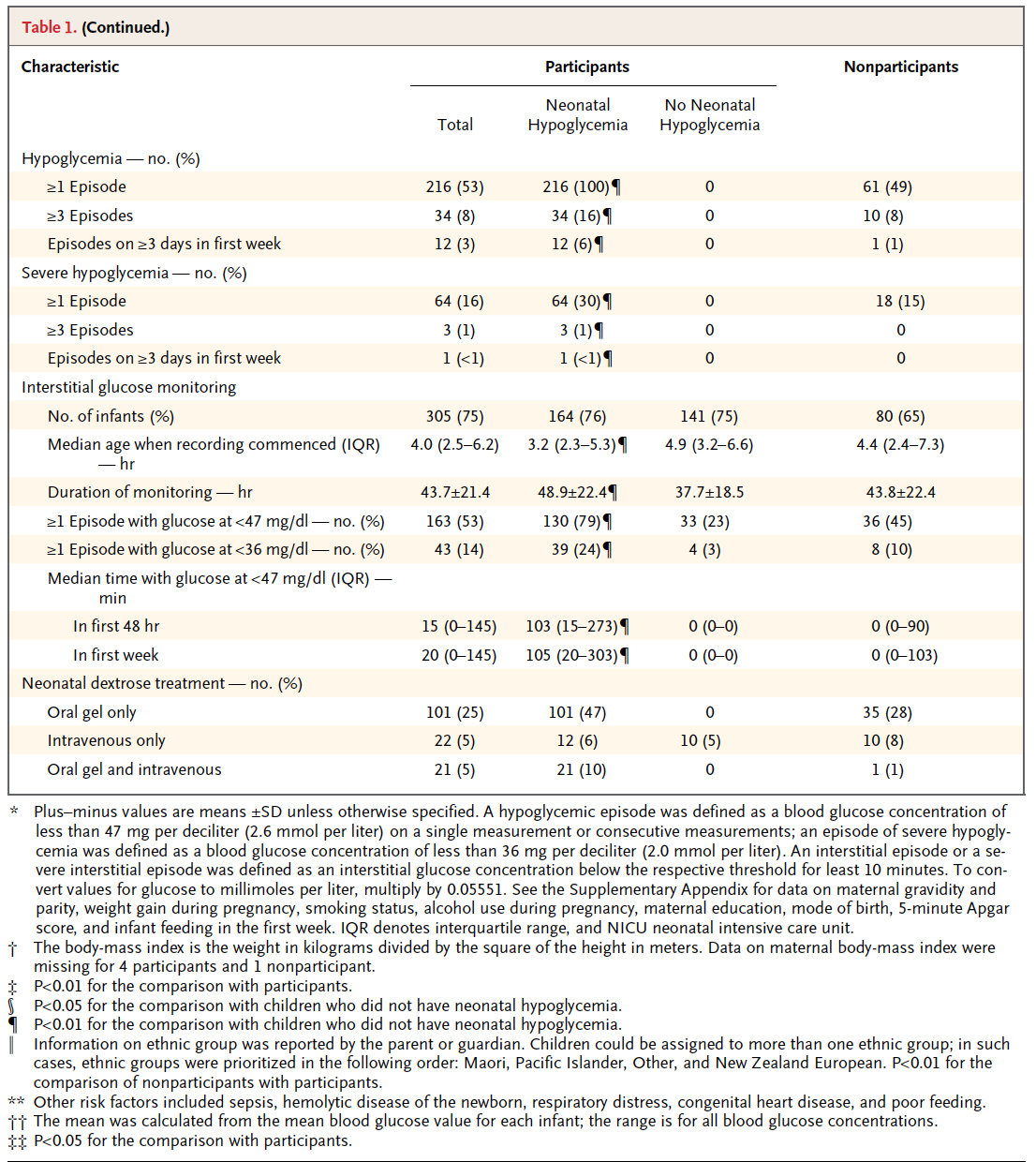

Pingback: Herramientas estadísticas en Medicina (Una hoja de ruta) | LA ESTADÍSTICA: UNA ORQUESTA HECHA INSTRUMENTO
Quisiera preguntarte una duda. Si tengo una muestra de 12 sujetos, es necesario que compruebe si sus puntuaciones en un test, siguen la distribución normal? Pensé que dado el tamaño reducido de mi muestra no era necesario comprobarlo. Pero como tal y como has comentado, el criterio para usar unos descriptivos u otros es su ajuste a la normalidad, no tanto el tamaño muestral.
Muchas gracias por el blog. Nos esta ayudando mucho con nuestros trabajos de fin de grado!
Hay una tendencia razonable que considera que si el tamaño de muestra es pequeño de poco sirve comprobar el ajuste a la normal, porque tiene poca potencia estadística, y, entonces, se trabaja como si no se ajustara a la normal. Es un criterio prudente y razonable. Sin embargo, la asimetría y la curtosis estandarizada es un buen criterio a partir del tamaño de muestra que tienes tu.
¿Que tan pequeña sería la muestra? ¿Menos de 30 individuos?
Es una frontera razonable
Tengo una duda, si tengo una media de 87.49 y una desviación estándar de 3.51, entonces el 95% de los datos estarían entre?
Si hay ajuste a la normal, el 95% de valores están entre la media menos dos veces la desviación estándar (7.02) y la media más dos veces la desviación estándar (7.02); o sea dentro del intervalo: (80.47, 94.51)
Pingback: ¿Qué es Informática Médica? – informatica médica y bioestadistica
Hola… ojalá pudieras ayudarme con lo siguiente: tengo tres muestra con 12 datos cada una que no se ajustan a una distribución normal y quisiera hacer un gráfico con barras de error utilizando la mediana de cada muestra. Mi duda es qué valor, o valores, puedo usar para crear las barras de error (ya que no estoy trabajando con las medias sino con las medianas no puedo usar la desviación estándar para hacer las barrar de error). Espero que me haya explicado y ojalá puedas ayudarme…. Gracias anticipadas.
Yo lo haría con la distancia del primer al tercer cuartil
Pero entonces sería un gráfico de cajas y bigotes, ¿no?
Sí, la opción si no hay normalidad
Entiendo, muchas gracias por la respuesta. Saludos!
Hola! Muchas gracias por la información, me fue muy útil! Te hago una pregunta, en el caso de datos normales utilicé el criterio de 6 sigma para poder definir entre que números se concentra la mayor cantidad de mis datos (más del 99% en el caso de 3 desviaciones estándar). Pero en el caso de datos no normales, es comparable utilizar la mediana y el rango intercuartil, siendo que entre el primer y tercer cuartil solo se concentran el 50% de estos? (corrígeme si estoy muy equivocada). Te agradecería mucho si pudieras aclararme.
Si no hay normalidad no hay otro remedio de trabajar o con los cuartiles o, también, si quieres hacer intervalos con más porcentaje, con percentiles. Si coges, por ejemplo, el percentil 2.5 y el 97.5 tienes un intervalo de valores de la variable del 95%.