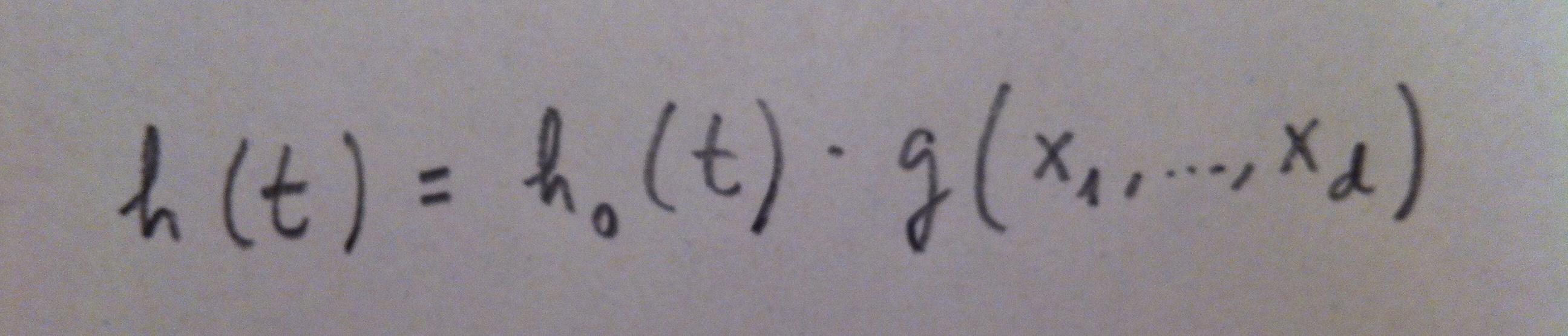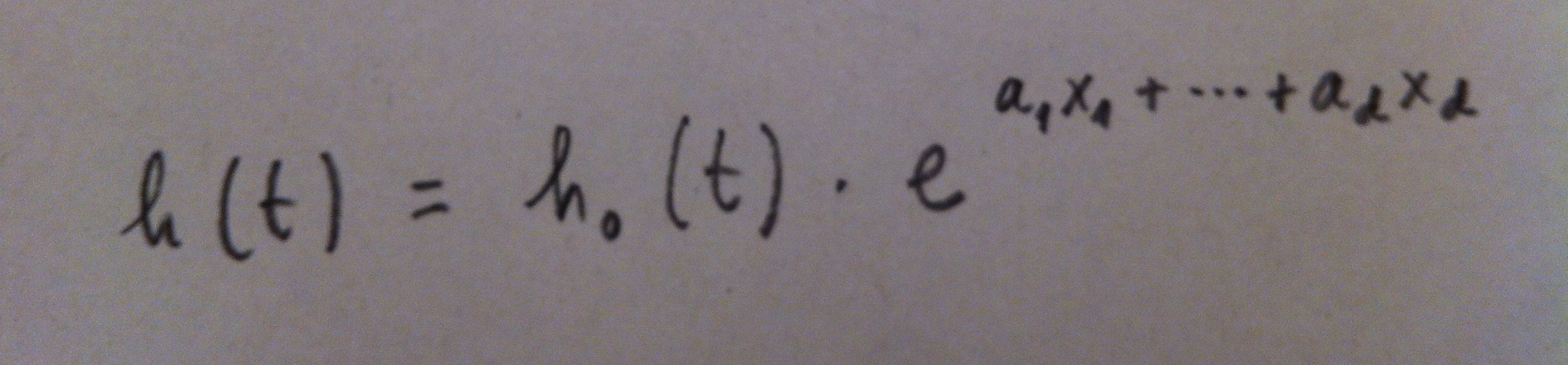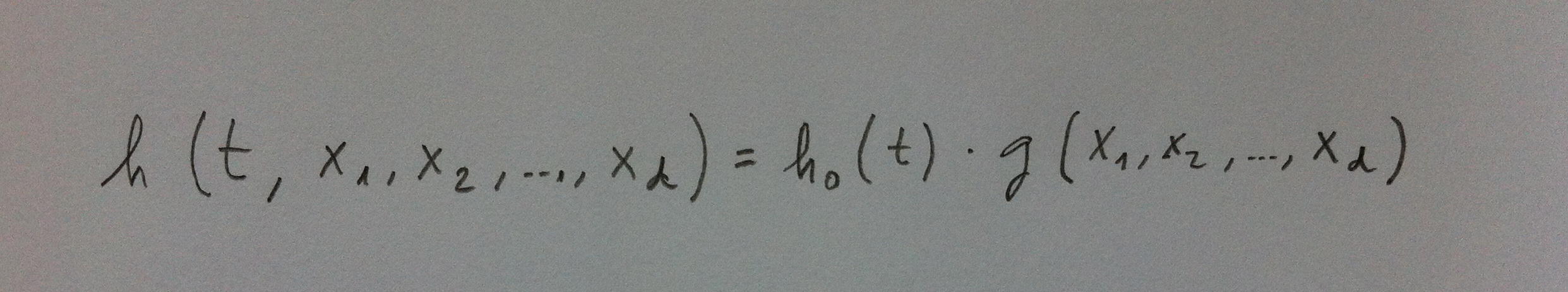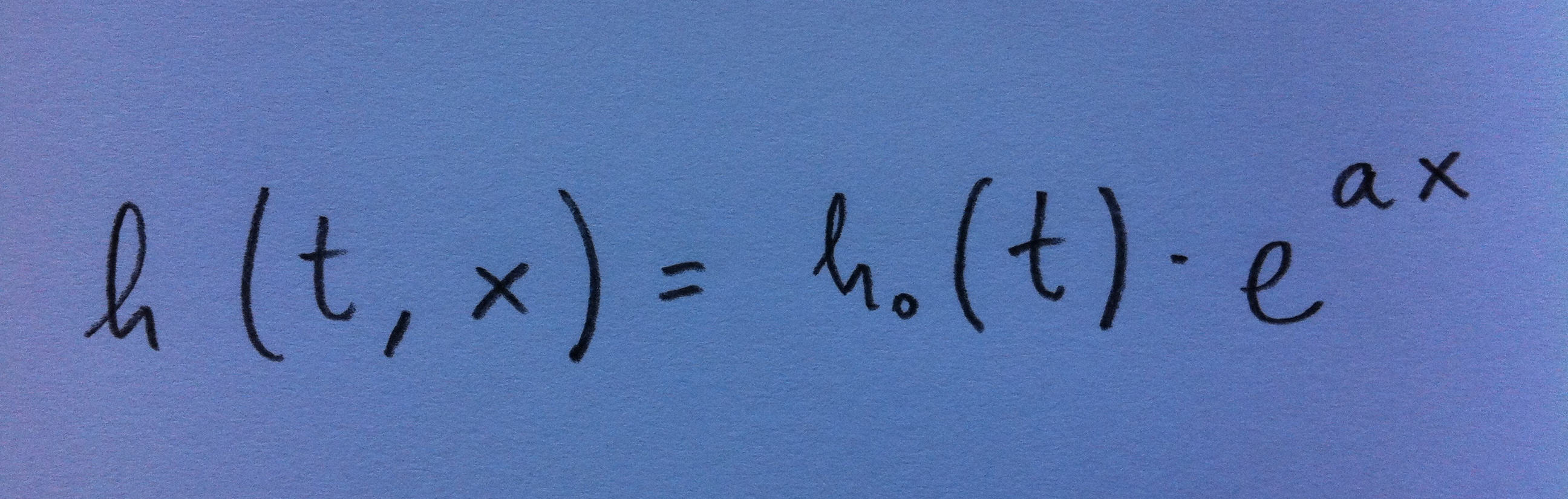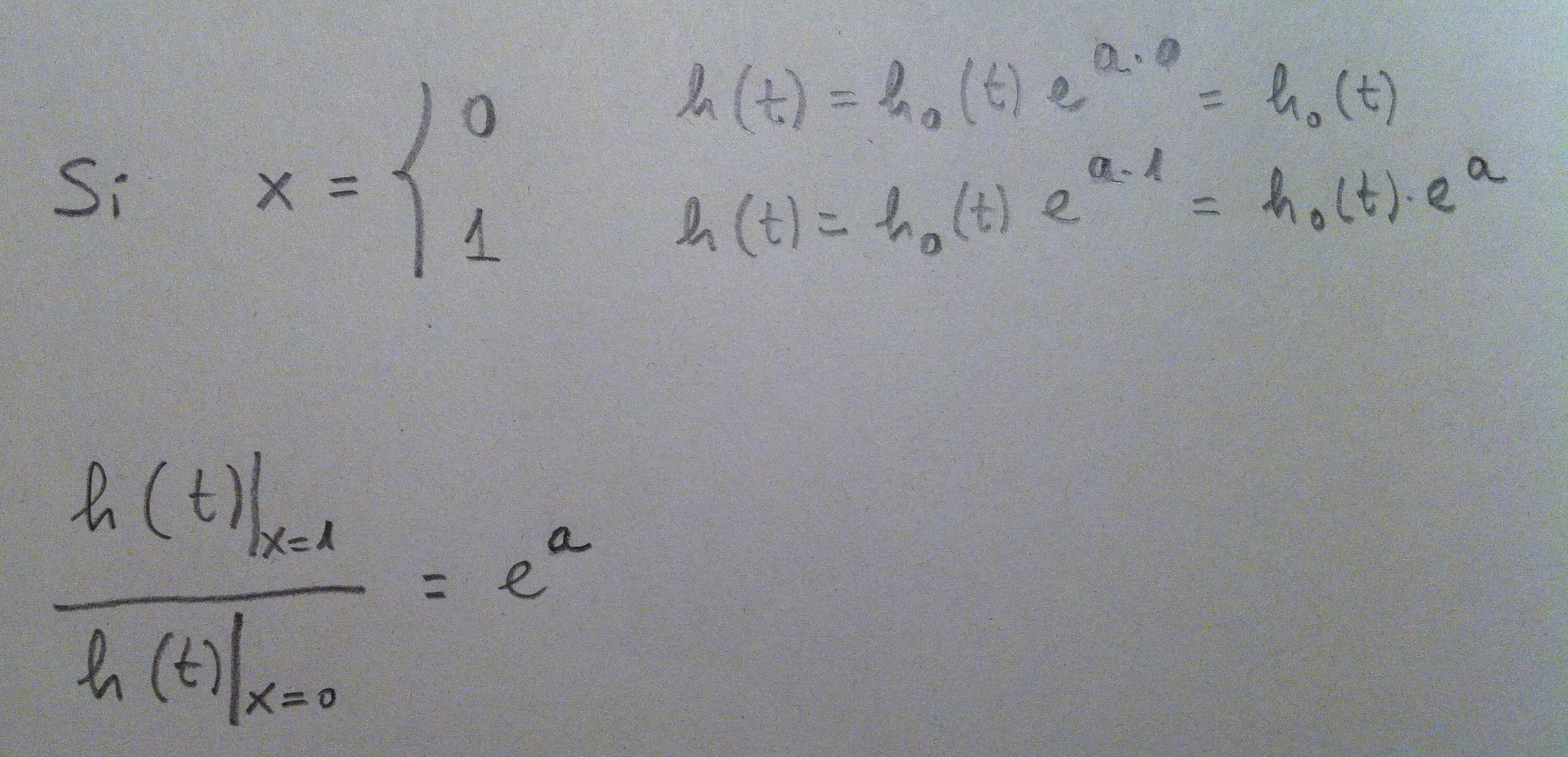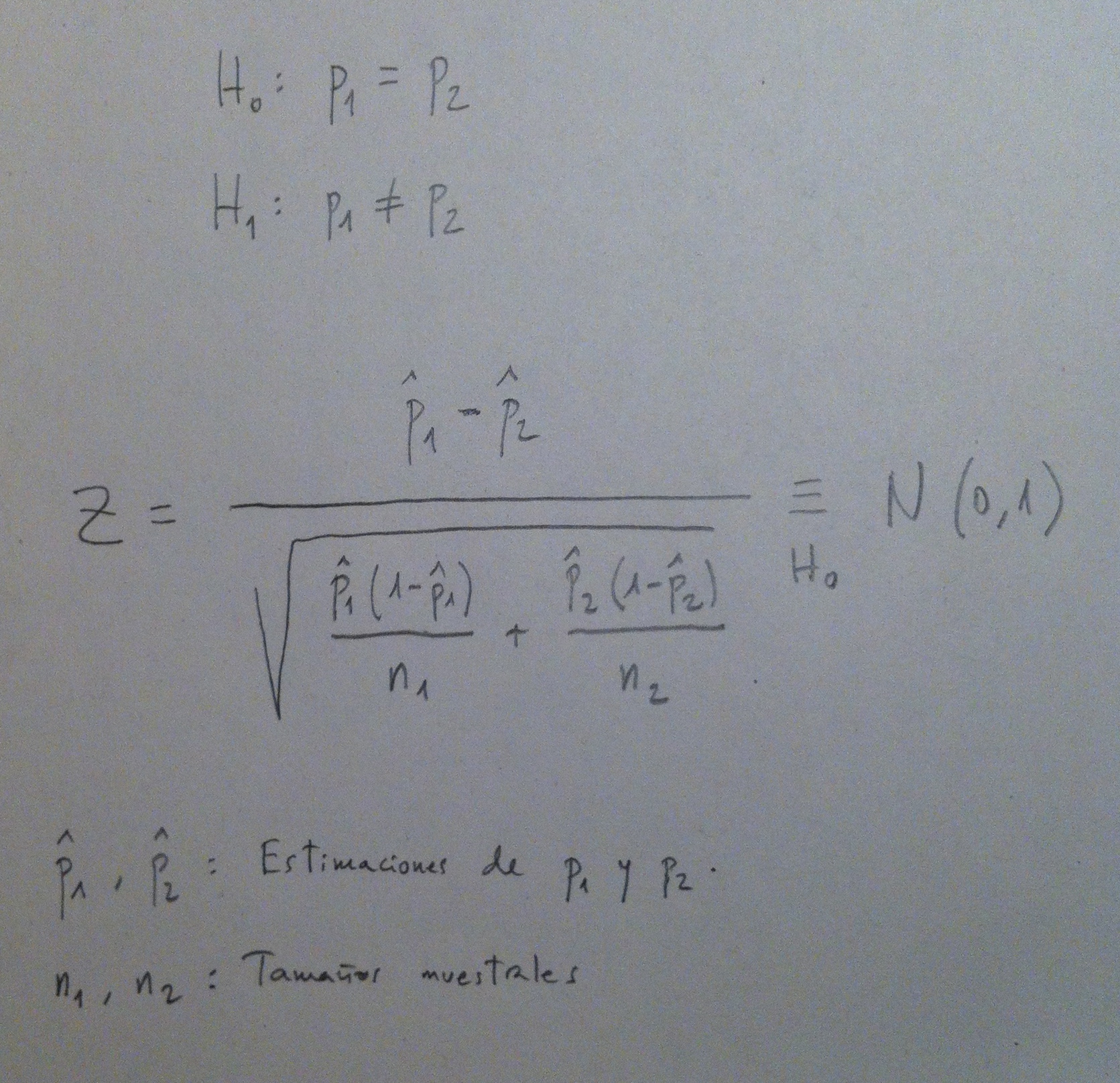1. La Regresión de Cox se ha transformado, en los últimos años, en un instrumento de análisis estadístico muy utilizado, especialmente en el ámbito de la Medicina. En ese tipo de Regresión el interés es buscar variables independientes que se relacionen con variaciones en la función de supervivencia, o en la función de riesgo, de unos individuos respecto a un determinado suceso estudiado.
2. Estamos, pues, realmente, ante una Regresión. Una Regresión ciertamente especial porque el tiempo está siempre presente y porque la variable dependiente es siempre una función de riesgo o una función de supervivencia.
3. Con la Regresión de Cox se pretende, pues, detectar alguna relación entre el riesgo de que se produzca un determinado suceso estudiado (muerte, recidiva de un tumor, fracaso de un implante dental, diagnóstico de hipertensión, etc.), y una o varias variables independientes o explicativas.
4. La Regresión de Cox trabaja especialmente con la función de riesgo (Hazard función) que ya hemos visto en el tema dedicado al Análisis de supervivencia, pero, como veremos, cuando hablemos de función de riesgo podremos trasladar perfectamente las conclusiones a nivel de función o curva de supervivencia.
5. Se han desarrollado distintos modelos matemáticos que pretenden establecer una especie de desglose entre lo que podríamos llamar una función de riesgo subyacente, o pura, y un efecto de otras variables independientes explicando cambios en esta función de riesgo. En general, este modelo general se suele escribir así:
6. En concreto, la Regresión de Cox consiste en el siguiente caso concreto de esta relación, el expresado por la siguiente función:
7. Aunque ésta es la forma en la que suele escribirse el modelo de la Regresión de Cox, desde un punto de vista matemático lo correcto es escribirlo como una función de varias variables y, por lo tanto, quedarían, tanto la función general como la más concreta, en realidad, así:
8. Veremos luego, al visualizar estas funciones, al ver su representación, cómo estamos realmente tratando con funciones de varias variables. De la variable tiempo, siempre presente aquí, y de una o más variables independientes.
9. La Regresión de Cox nos permite evaluar, pues, de entre un conjunto de variables independientes candidatas, cuáles de ellas tienen una relación, una influencia, significativa, sobre la función de riesgo. Y, en definitiva, evidentemente, también, sobre la función de supervivencia, porque ambas funciones están íntimamente conectadas.
10. El instrumento fundamental de la Regresión de Cox es el Hazard ratio, la razón de riesgos, que no es más, como ya hemos visto en el tema dedicado al Análisis de supervivencia, que el cociente entre dos funciones de riesgo.
11. Supongamos, para simplificar las cosas, un caso de Regresión de Cox con una única variable independiente. El modelo sería, ahora, escrito ya en forma de función de dos variables (el tiempo y una única variable independiente), el siguiente:
12. La función Hazard ratio, en este caso, será la relación entre las dos funciones de riesgo que se establece en función de los cambios operados en esta variable independiente x.
13. Es importante comparar la Regresión de Cox con la Regresión logística. En la Regresión logística la variable dependiente dicotómica se ponía en relación con una variable independiente sin contemplar el tiempo o contemplándolo sólo de forma estática, viendo en un punto fijo del tiempo si el suceso estudiado ha acontecido o no, pero no teniendo en consideración en qué momento ha sucedido. Se llegaba a una situación como la siguiente (Ver el tema dedicado a la Regresión logística):
14. En la Regresión de Cox la variable dependiente dicotómica (ha sucedido o no el acontecimiento estudiado: muerte, recidiva, fracaso de un implante dental, diagnóstico de hipertensión, etc) no se analiza desglosada del tiempo, se analiza en el tiempo, en el momento de aparición, si es que aparece. No mira un punto fijo del tiempo para ver si ha acontecido o no el suceso estudiado, sino que se contempla en qué momento ha sucedido.
15. El Análisis de la Regresión de Cox es, pues, más fino. No analiza en un momento temporal si tal acontecimiento ha sucedido o no ha sucedido sino cuándo ha sucedido, si es que ha sucedido, y comparar esa función respecto a una o varias variables independientes. Por todo esto la Regresión logística trabaja con la Odds ratio y la Regresión de Cox con la Hazard ratio (Ver el artículo Odds ratio versus Hazard ratio).
16. Veamos, con un cierto detalle, qué sucede si la variable independiente x, en la Regresión de Cox, es dicotómica:
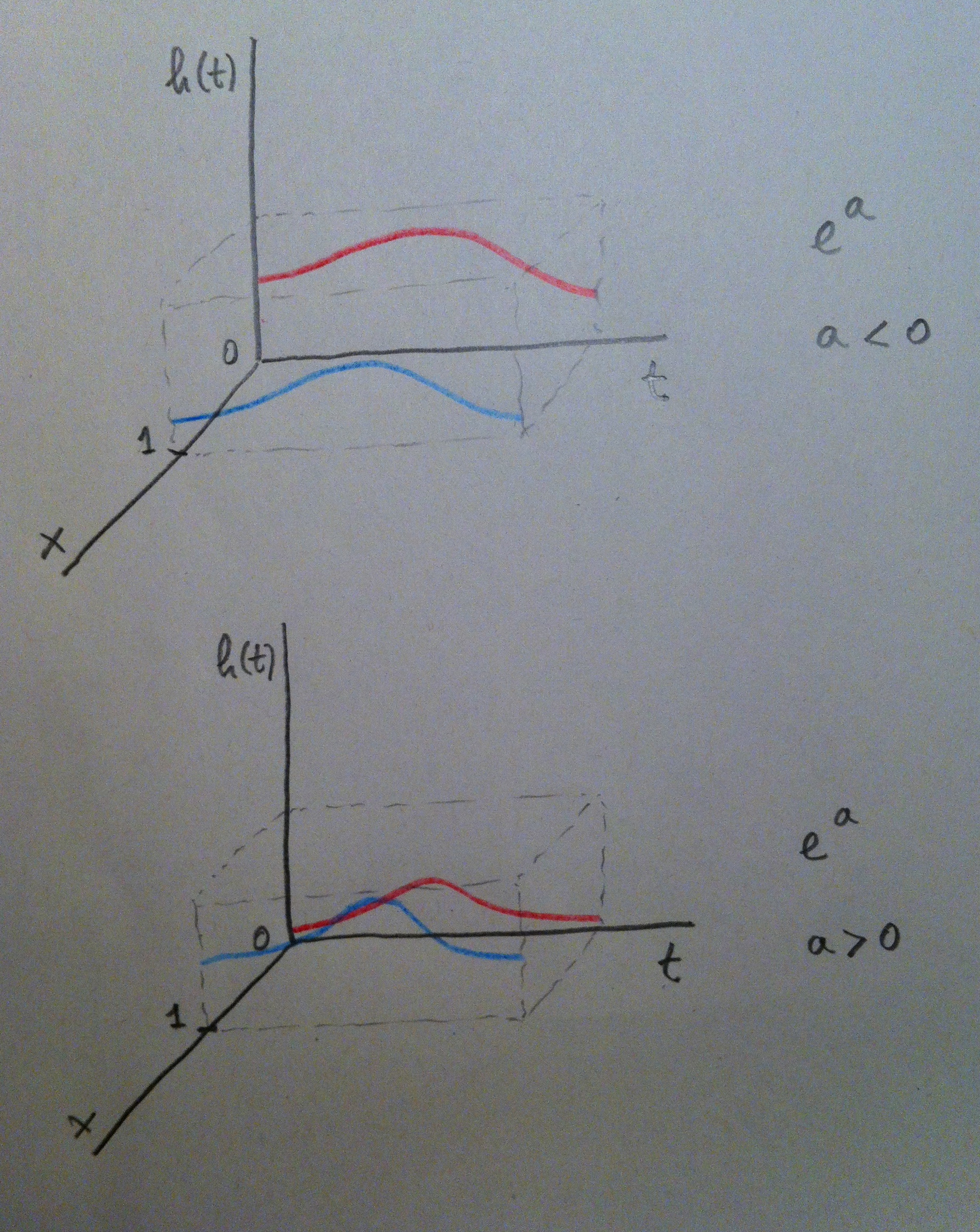
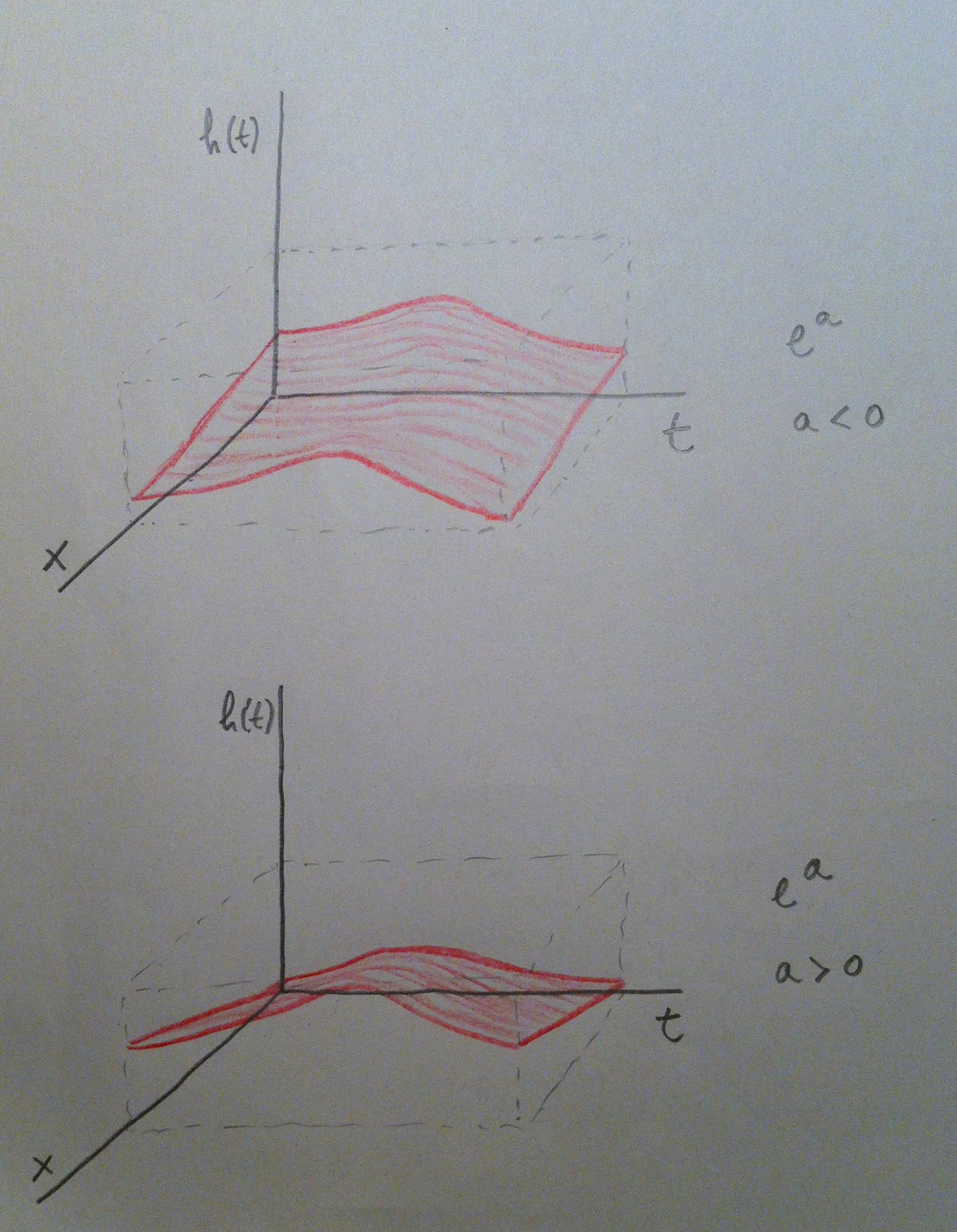
17. La variable independiente tiene así únicamente dos valores (el 0 y el 1). Si aplicamos la fórmula de la Regresión de Cox y luego hacemos el cociente de ambas funciones de riesgo observamos que obtenemos el valor Exp(a). Veamos cómo se entiende, gráficamente, el valor de este coeficiente a:
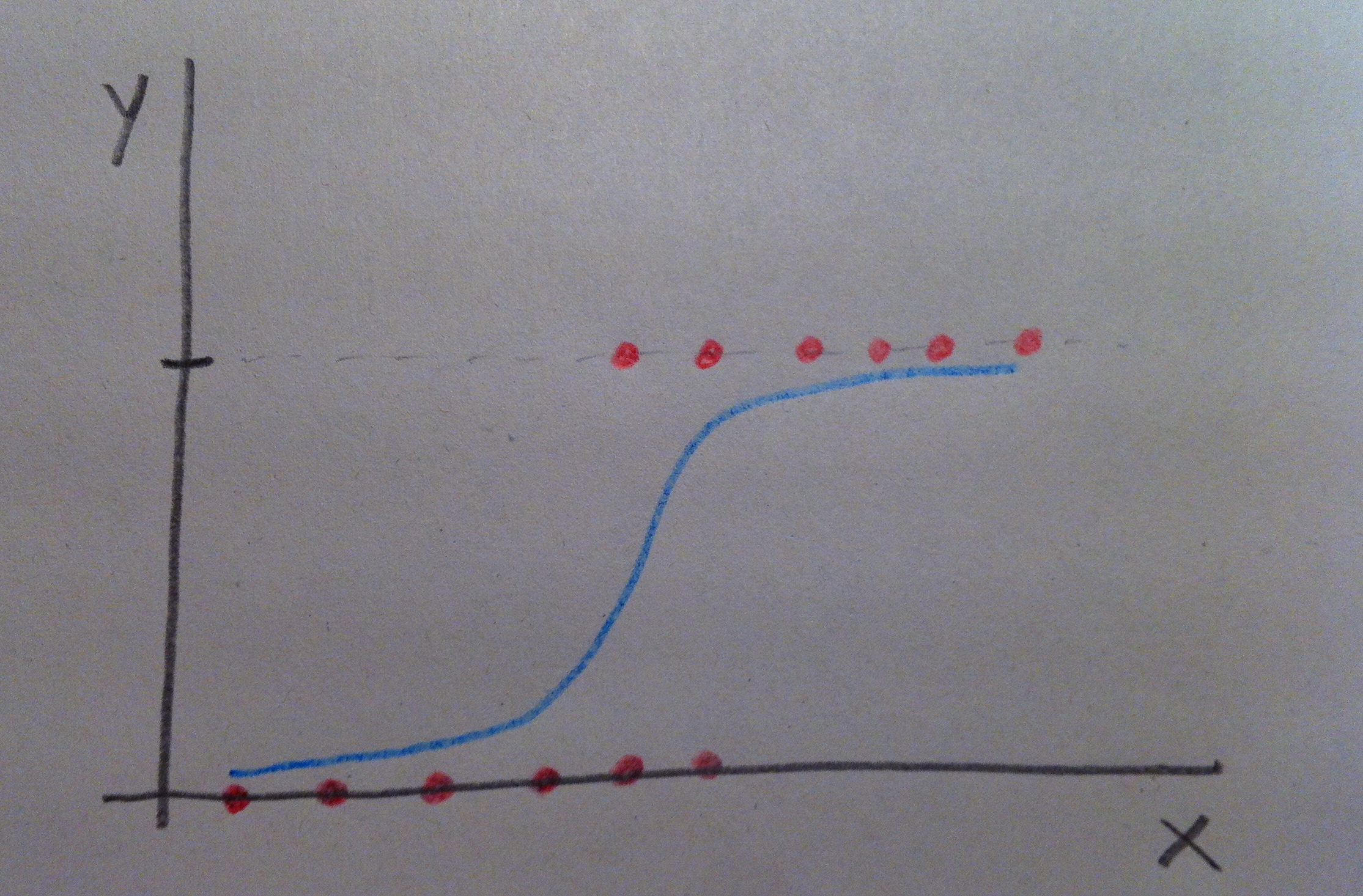
18. Veamos ahora una variable independiente continua, una variable con muchos valores posibles:
19. Y veamos cómo se entiende gráficamente:
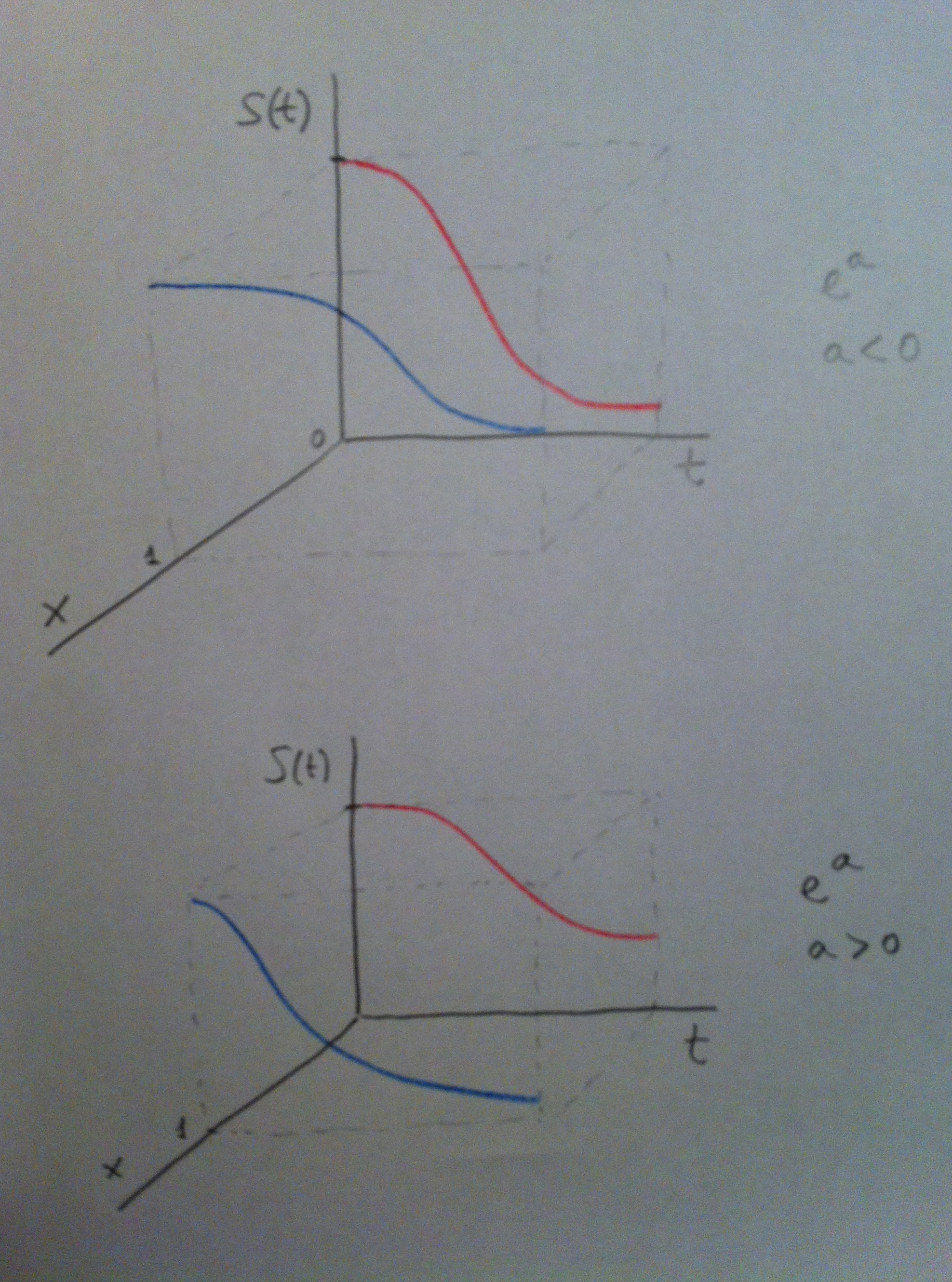
20. Suele trabajarse con las funciones de riesgo en la Regresión de Cox pero evidentemente lo mismo que se ve con ellas se podría ver con las funciones de supervivencia. Veamos en el siguiente gráfico el equivalente al anterior donde la variable x era dicotómica pero ahora respecto a la función de supervivencia S(t) no respecto a la función de riesgo h(t):
21. Puede observarse perfectamente cómo cambia según la x valga 0 ó 1 la pendiente de la función de supervivencia. En el caso de arriba al pasar de 0 a 1 la supervivencia aumenta. En el caso de abajo al pasar de 0 a 1 la supervivencia disminuye. Contrariamente a lo que sucedía al tratar con la función de riesgo.
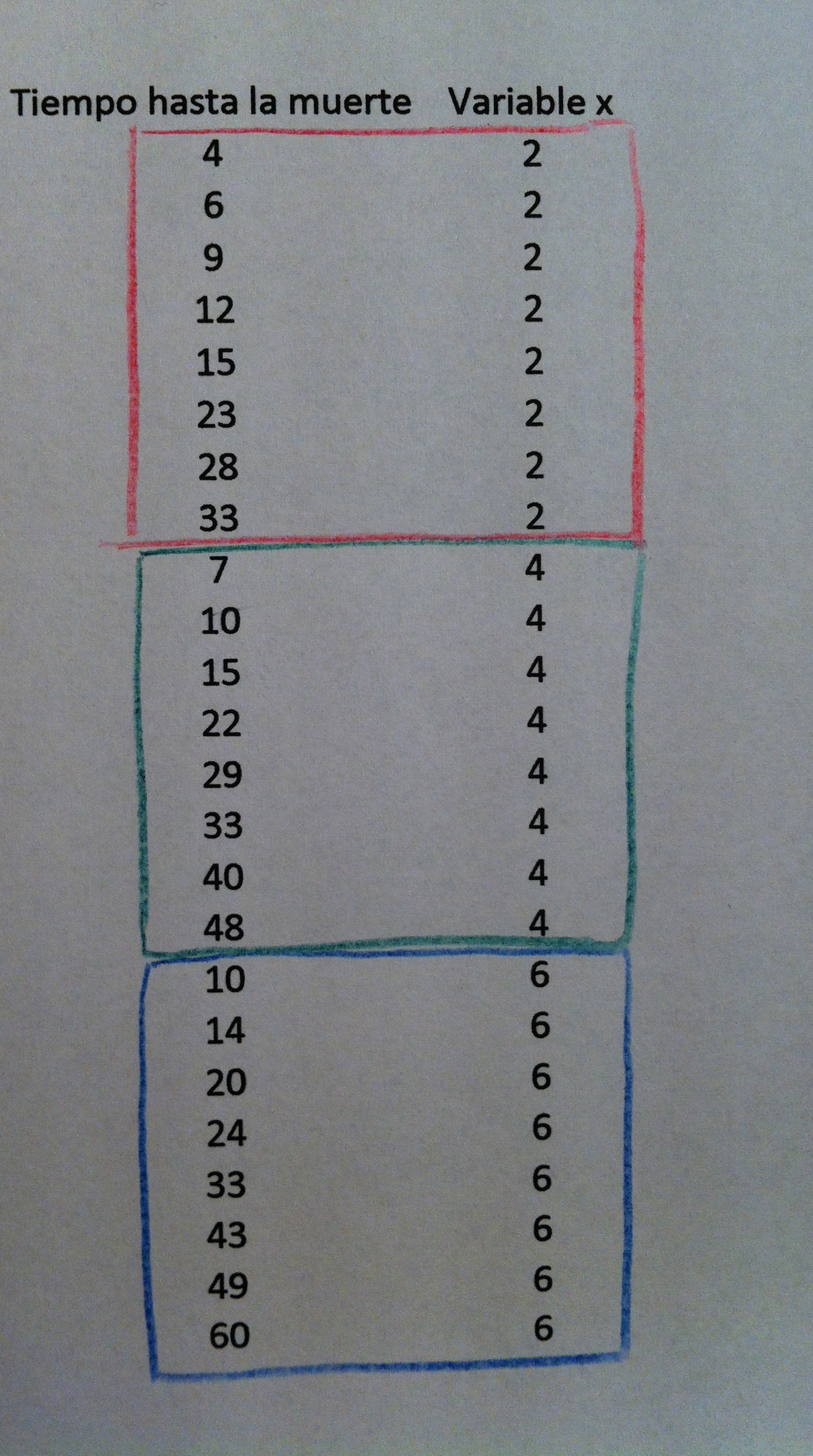
22. Veamos todo esto pero con un ejemplo numérico. Supongamos que tenemos los siguientes tiempos hasta la muerte de personas que respecto a una variable x tenemos los valores 2, 4 y 6. Veamos los datos concretos:
23. Marco con tres colores distintos a los individuos que tienen el valor 2, 4 y 6 de la variable x. Estos valores están ordenados según tengan cada uno de estos tres valores de la variable x y dentro de estos valores están ordenados por tiempos de vida. Se puede ver perfectamente que los individuos con valores mayores de x viven más, hay un progresivo aumento de tiempo de vida al aumentar el valor de x. Claro que hay que viven poco y que viven mucho en los tres grupos, pero los tiempos bajos son más bajos cuando la x es 2 y los tiempos altos son más altos cuando el valor de x es 6.
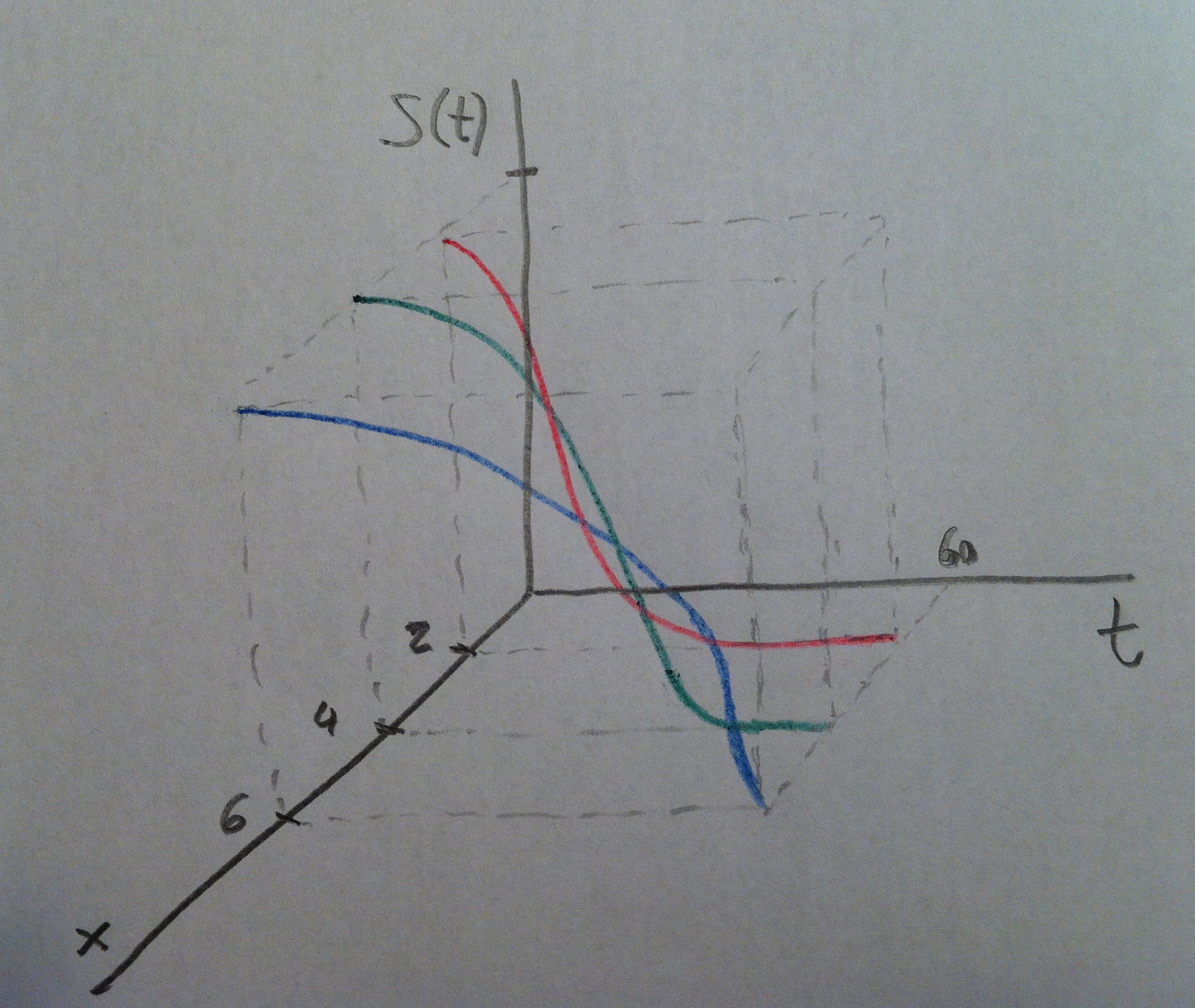
24. Esto se refleja en el gráfico siguiente donde se dibujan las tres curvas de supervivencia en los mismo colores. Se ve que la curva roja refleja una supervivencia menor que la verde y ésta menor que azul. La curva roja cae rápidamente, la verde lo hace más lentamente y la azul tarda más que las otras en caer:
25. Esto es lo que busca la Regresión de Cox: detectar este tipo de relaciones. Detectar que la curva de supervivencia o la función de riesgo cambia según los valores de una o más variables independientes. Trata de captar este tipo de regularidades. Y esto, evidentemente, tiene una importancia extraordinaria en muchos campos del conocimiento, especialmente en Medicina donde se ha transformado en una herramienta de análisis fundamental.
El Test de comparación de dos proporciones nos permite comparar dos proporciones de dos poblaciones a través de proporciones muestrales de dos muestras independientes obtenidas en las dos poblaciones a comparar.
El Test de Bartlett es un contraste de hipótesis de igualdad de desviaciones estándar. Muy utilizado en ANOVA, donde se requiere homogeneidad de varianzas.
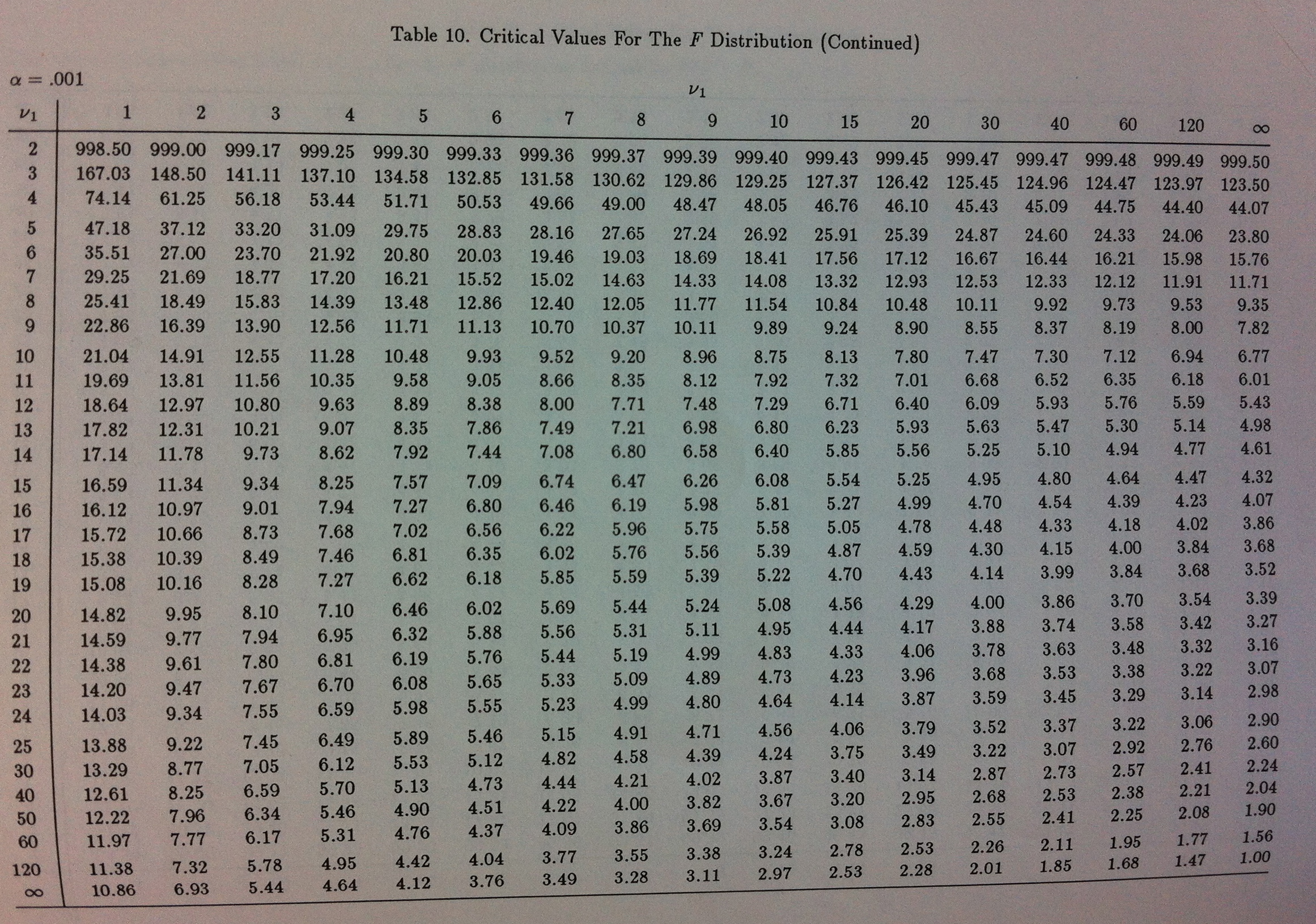
La distribución F de Fisher es una distribución que depende de dos parámetros. Es una distribución que aparece, con frecuencia, como distribución de un estadístico de test, en muchos contrastes de hipótesis bajo las suposiciones de normalidad. Por ejemplo, todos los contrastres ANOVA (Ver Herbario de técnicas).
Su tabla es compleja porque al depender de dos parámetros complica su diseño. Se acostumbran, pues, a publicar tantas tablas como niveles de significación interese manejar. Aquí adjunto la del 0.05, la del 0.01 y la del 0.001:
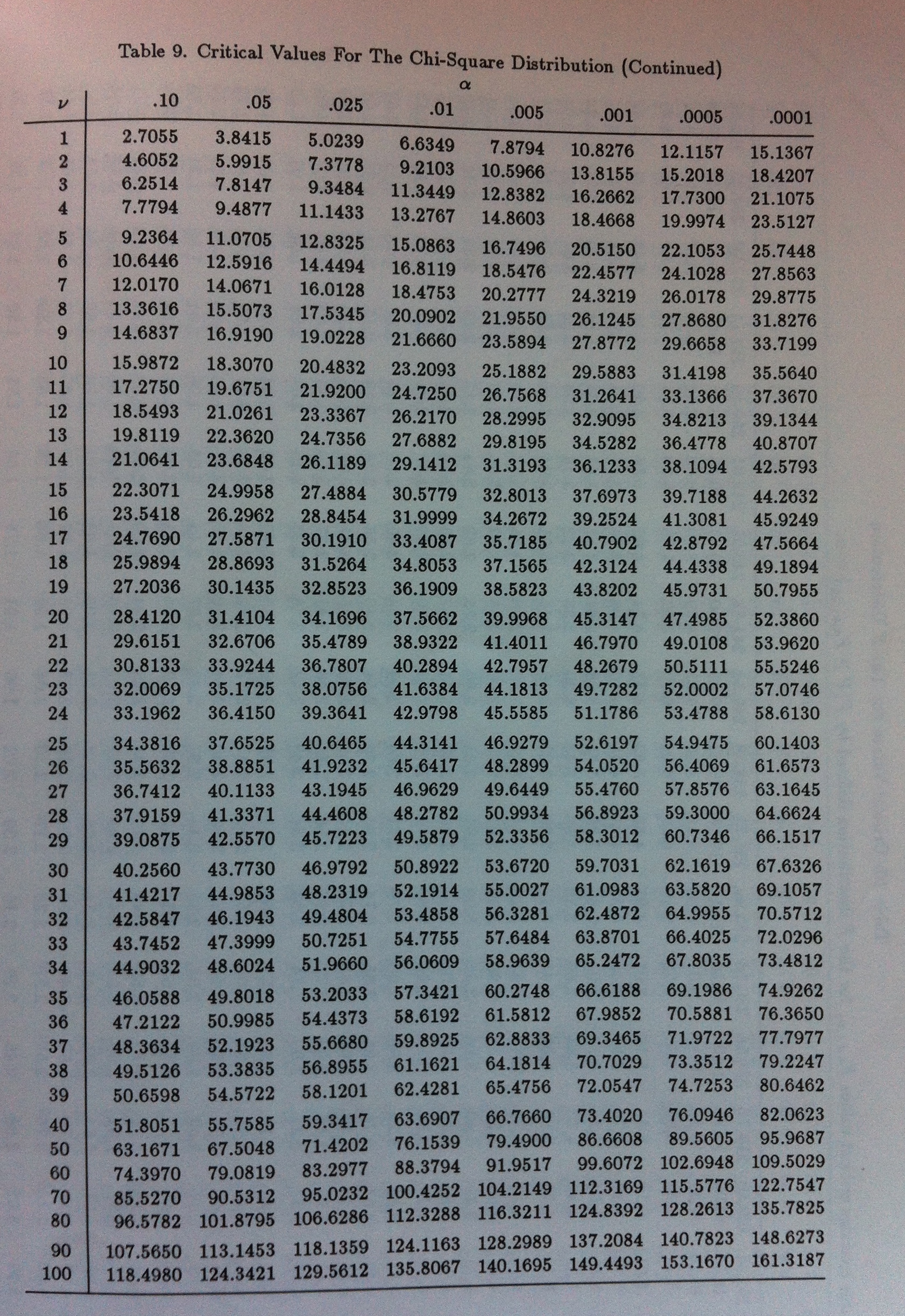
La distribución ji-cuadrado tiene un único parámetro. Es una distribución muy importante en muchos ámbitos de la Estadística. Es una distribución muy usada en muchos test estadísticos. Además, es habitual tanto en tests paramétricos como en tests no paramétricos. Es muy importante saber manejarla con soltura.
Veamos la tabla de esa distribución en función de los valores de su parámetro que aparecen en la primera columna encabezados por la letra v. Veremos dos tablas. En la primera se nos muestra valores a partir de los cuales tenemos las áreas señaladas en la primera columna: 0.9999, 0.9995, etc. El valor de la intersección de fila con columna es el valor a partir del cual hay una área señalada en el valor de arriba en una distribución ji-cuadrado con valor del parámetro el valor que hay en la izquierda. Por ejemplo, en una ji cuadrado de parámetro 5, a la derecha de 1.1455 hay un área de 0.95:
Esta primera parte de la tabla es importante para controlar el lado izquierdo de la distribución ji-cuadrado, la zona próxima a cero. Y la siguiente parte es para controlar el lado derecho de la distribución. La lectura es la misma. Un ejemplo: En una distribución ji-cuadrado de parámetro 5 a la derecha del valor 11.0705 hay un área de 0.05:
Ejemplos de uso de esta tabla en casos concretos pueden verse en el Tema 8: Relación entre variables cualitatitcas. Y también en el artículo «Un ejemplo de Test de McNemar en Medicina» en la sección Estadística y Medicina.