Se trata de un análisis con dos factores. Uno fijo (la forma de medida) y otro aleatorio (el factor medidor). Es por lo tanto un caso de ANOVA de dos factores a efectos mixtos. Un factor fijo cruzado con un factor aleatorio.
Debemos comprobar la normalidad de los residuos (con el test de Shapiro-Wilk). Debemos comprobar la igualdad de varianzas (con el test de Bartlett). Supongamos que ha sido comprobado y estamos bajo estas condiciones. De hecho, si miramos los datos, podemos comprobar que con muchas posibilidades se cumplirán esas condiciones. No hay ni aspecto de no normalidad, ni de heterogeneidad de varianzas, en cada uno de las ocho condiciones experimentales. Otra cosa sería que en algún grupo se vieran valores mucho más dispersos que en los otros, o una asimetría clara que hiciera pensar en un alejamiento de la distribución normal.
Si miramos los datos con atención podemos comprobar que hay una variabilidad residual, la que hay en cada una de las ocho condiciones experimentales. Una variabilidad residual que no es muy grande respecto a la que se aprecia en el conjunto de los datos.
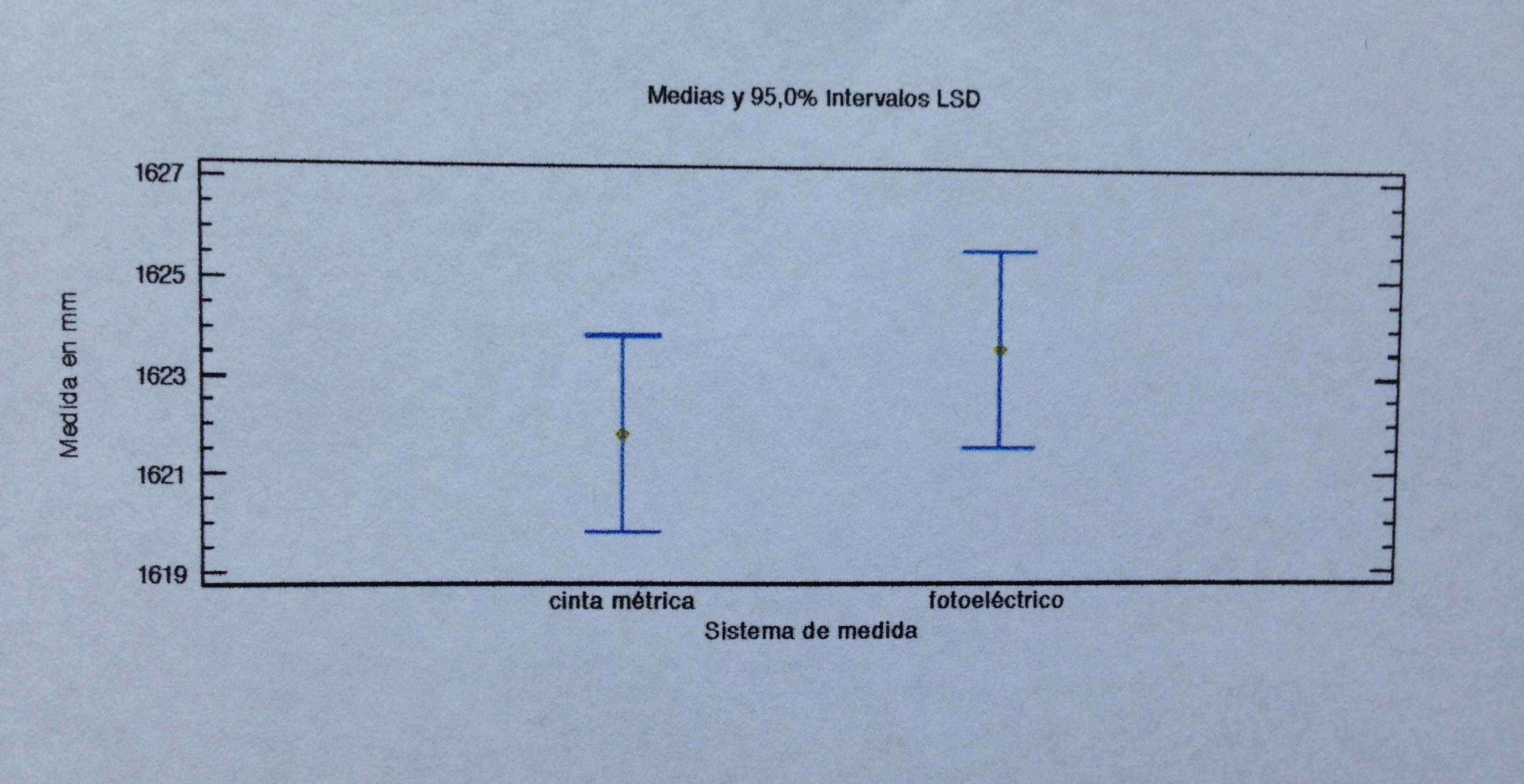
Si miramos los datos veremos que los dos niveles del factor fijo (tipo de medida: fotoeléctrica o con cinta métrica) no presentan diferencias que parezcan muy relevantes.
Si miramos con atención los datos también podemos ver que los medidores sí que aportan una variabilidad considerable.
Y, finalmente, podemos apreciar, también, a simple vista, que no hay interacción: no parece que los resultados de un medidor cambien mucho si la medición la hace mediante un método u otro. El medidor que tiene tendencia a dar valores bajos los da bajos con ambos métodos. Y el medidor que tiende a dar valores altos los da altos con ambos métodos.
Veamos que todo esto está en consonancia con el análisis:
La tabla ANOVA es la siguiente:
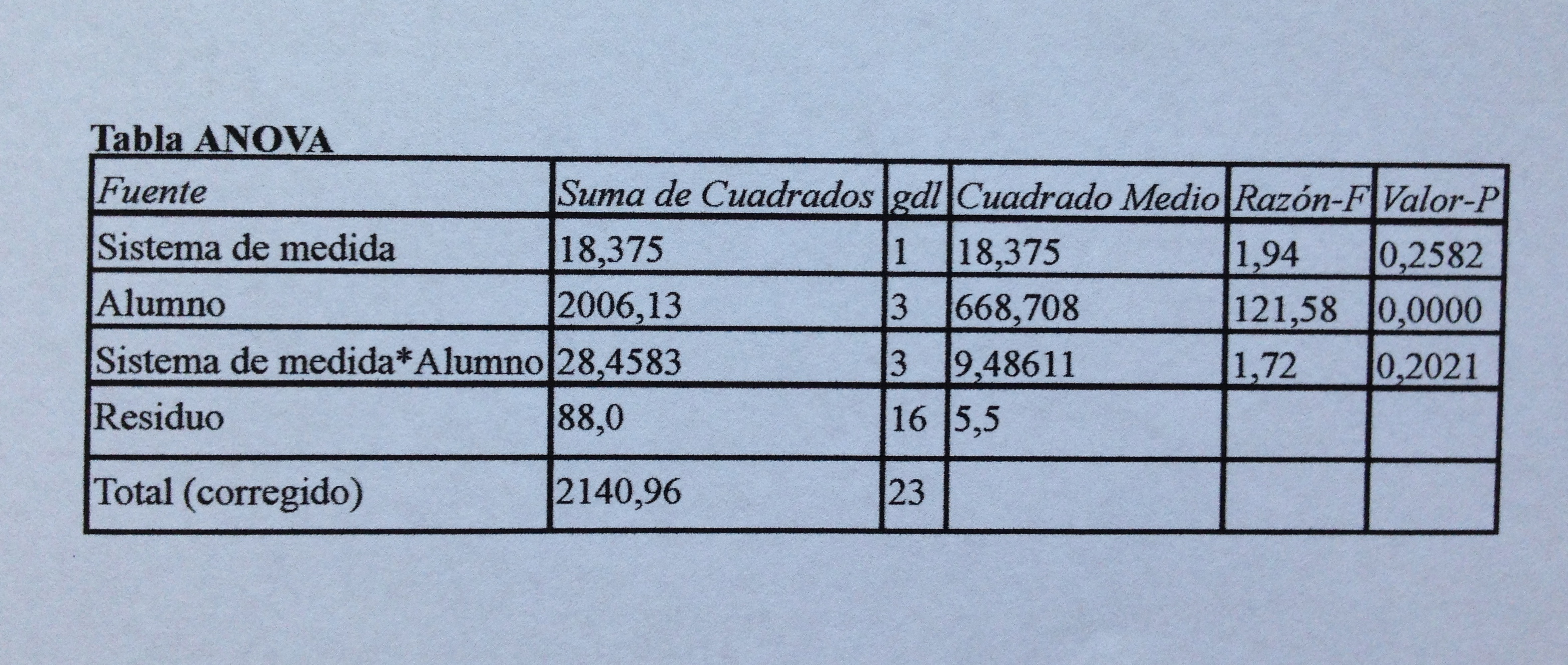
Comprobar que aquí los cocientes de cuadrados medios se han hecho tal como dispone el ANOVA de dos factores a efectos aleatorios. El factor fijo va dividido por la interacción y el factor aleatorio por el residuo.
El factor fijo, tipo de medida, no presenta diferencias significativas (p-valor=0.2582), como puede apreciarse también en los intervalos de confianza del 95%:
El factor medidor, que es aleatorio, porque hemos elegido una muestra de alumnos para ver si, en general, el medidor introduce variabilidad, sí que es un factor significativo. No hace falta representar sus intervalos de confianza porque, al tratarse de una muestra de niveles, lo que nos interesa de esos alumnos es estimar la componente de la varianza que introduce el medidor en general.
Tampoco hay interacción. El gráfico de interacción también lo muestra:
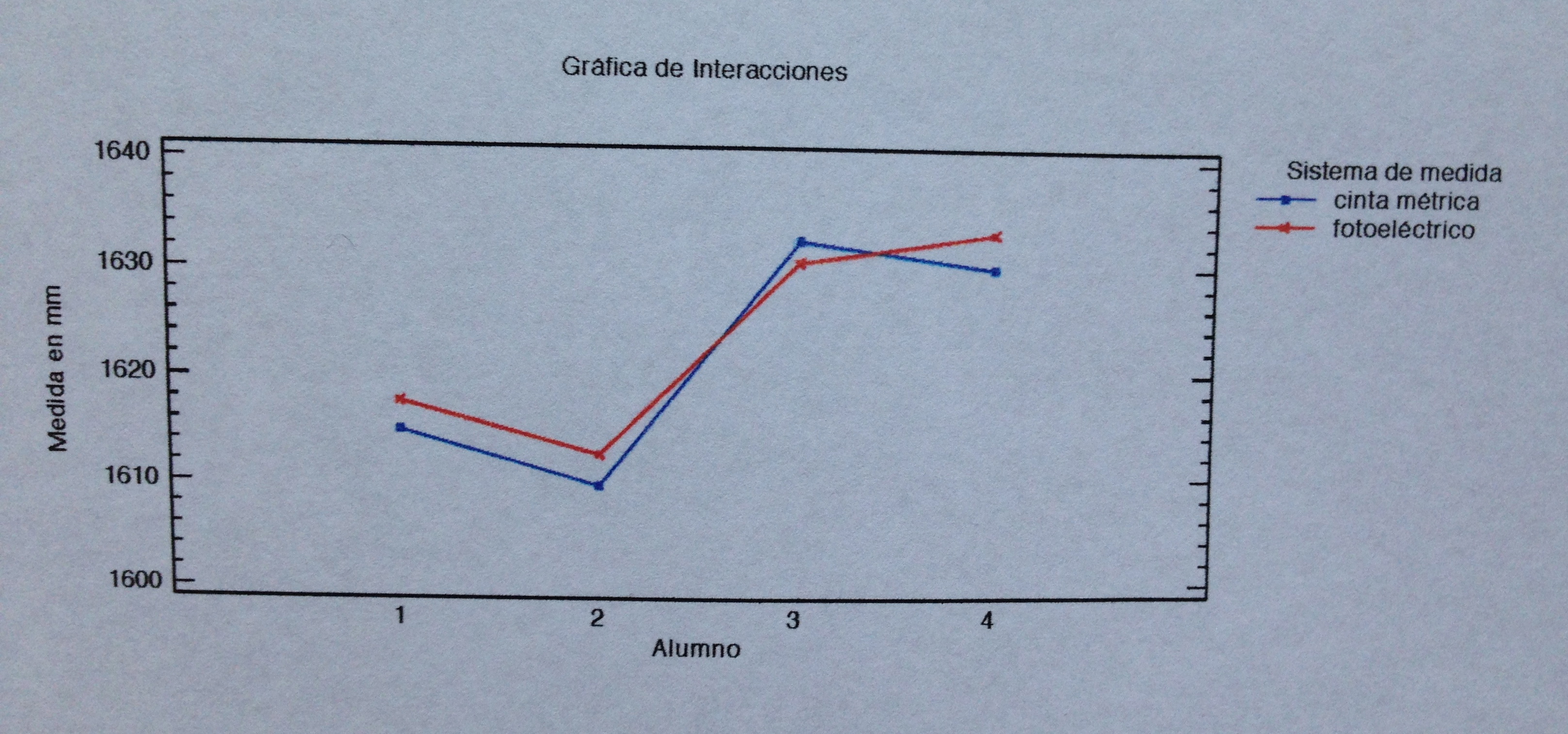
Aunque hay un ligero cruce de líneas entre el alumno 3 y 4 no se trata de una interacción significativa, como muestra el p-valor de 0.2021.
Los parámetros del modelo son la constante, el efecto del factor fijo, que no es significativo, y las tres componentes de la varianza: la de medidor, la de la interacción, que tampoco es significativa, y la residual.
Los valores de estos parámetros son:

Este 1662.71 es el valor de la constante, la mu del modelo. La alfa1 sería -0.875 y la alfa2 sería 0.875. Pero esto es una estimación. Hemos de tener en cuenta que el contraste de hipótesis nos muestra que este efecto no es significativo.
Finalmente las componentes de la varianza. La estimación es la siguiente:

La componente de la varianza residual es el valor del cuadrado medio residual de la tabla ANOVA; o sea, 5.5. Las demás se calculan, como puede verse, a partir de la esperanza de los cuadrados medios del factor Alumno y de la esperanza de los cuadrados medios de la interacción. Ver de nuevo el fichero ANOVA de dos factores a efectos mixtos.
Se trata de estimaciones. El de la interacción, como hemos visto antes, no es una componente significativa.
Todo ello confirma que, realmente, a partir de estos datos del experimento, la variabilidad de la medición de la altura, es fundamentalmente una variabilidad introducida por el medidor. Que los dos sistemas de medida evaluados presentan diferentes importantes, ni las propias repeticiones del medidor. La variabilidad es entre medidores. Se maneja de forma muy distinta al paciente, por parte del medidor, a la hora de poner en posición al paciente para medirlo.