1. En Estadística trabajamos con la significación estadística, que viene a ser una significación formal, una significación sin un contenido específico. Es un hablar abstracto: igualdad o diferencia, relación o no relación. Otra cosa es la significación médica, económica, biológica, psicológica, lingüística, etc, que la deben dictaminar los médicos, economistas, biólogos, psicólogos, lingüistas, etc, y que se trata de una significación material, con contenido. Es, ahora, un hablar concreto. Por ejemplo: “este aumento de respuesta genera una mejor calidad de vida”, “este tratamiento permite una movilidad que transforma a la persona en autónoma”. Sin embargo, veremos, al final de este tema, que también se han creado mecanismos matemáticos para establecer una medida lo más objetiva posible, mediante cálculos matemáticos, de la significación material.
2. Voy a centrarme, a continuación, en un tema médico y por eso hablaré de Significación médica, pero lo que diga sería perfectamente extrapolable a cualquier otro ámbito material y entonces deberíamos hablar de significación económica, biológica, psicológica, etc.
3. En un estudio nos podemos encontrar con resultados que nos lleven a una de estas cuatro combinaciones posibles: 1) Significación estadística y Significación médica. 2) Significación estadística y No Significación médica. 3) No Significación estadística y No Significación médica. 4) No Significación estadística y Significación médica.
4. El primer caso (Significación estadística y Significación médica) es la situación ideal. Nada que comentar. Todo perfecto. Hemos conseguido un resultado fiable estadísticamente y relevante médicamente.
5. El segundo caso (Significación estadística y No Significación médica) implica también un final del estudio, habitualmente.
6. La Significación estadística implica que los resultados son fiables, pero el que no sean significativos desde el punto de vista médico implica que es un resultado que no tiene ninguna trascendencia médica.
7. Supongamos que un estudio demuestra que un determinado fármaco permite un descenso en la proteinuria, en enfermos con una nefropatía.
8. Supongamos que este descenso sea desde un valor promedio de 425 mg/día a un valor de 405 mg/día, tratándose éste de un descenso estadísticamente significativo.
9. Y ahora supongamos que un nefrólogo nos dice que para obtener un descenso promedio de este nivel no compensa tomar ese fármaco.
10. Nos dice que no compensa tomarlo porque ese fármaco tiene unos efectos secundarios que no vale la pena asumir para obtener un descenso en la proteinuria que, en realidad, no cambia nada de la nefropatía del paciente.
11. Esta es una de las muchas situaciones posibles en las que podemos encontrar Significación estadística acompañada de No Significación médica.
12. Esto es muy importante tenerlo en cuenta porque a veces pensamos que el objetivo último y único es la Significación estadística. Y este es un error frecuente.
13. Tener Significación estadística pero No Significación médica sirve para muy poco, si es que sirve, en realidad, para algo. Por lo tanto, suele ser un punto y final de un estudio, habitualmente. Lo veremos de nuevo, este caso, en los puntos 53 y 54.
14. El tercer caso (No Significación estadística y No Significación médica) poco nos dice, al menos de momento. Los resultados no son fiables y tampoco apuntan una buena tendencia.
15. Además, lo que vemos promete poco desde el punto de vista médico (o económico o lingüístico, etc). Al menos de momento, claro.
16. Los estadísticos en estas situaciones acostumbramos a decir que todo está abierto, que puede pasar, todavía, cualquier cosa.
17. En estos casos conviene ampliar el estudio aunque los resultados, de momento, apunten que podemos acabar encontrando Significación estadística aumentando la muestra pero difícilmente encontremos Significación médica, porque el efecto que se observa, de momento, es muy pequeño. No obstante, en principio debemos pensar que está todavía todo abierto. Pero la perspectiva es mala.
18. El cuarto caso (No Significación estadística y Significación médica) es el que tiene más interés comentar. Además, es muy frecuente, y genera muchos dolores de cabeza en el mundo de la ciencia.
19. Veámoslo mediante un ejemplo donde se comparan dos procedimientos terapéuticos.
20. Ante el tratamiento ante un infarto de miocardio es habitual ensayar comparativamente distintos protocolos de actuación.
21. Imaginémonos que se ha hecho una comparación entre dos protocolos y se ha contabilizado los que han muerto y los que no han muerto.
22. Tenemos, pues, dos variables cualitativas con dos categorías cada una: Mueren y No mueren, una de las variables. Protocolo 1 y Protocolo 2, la otra.
23. Supongamos la siguiente tabla de contingencias:

24. En el Protocolo 1 mueren 7 y no mueren 93; o sea, muere el 7%. En el Protocolo 2 mueren 6 y no mueren 94; o sea, muere el 6%. Ante estos datos la OR es 1.18 y un intervalo de confianza del 95% es (0.38, 3.64).
25. A partir de estos valores la conclusión estadística es que no hay una relación entre tipo de protocolo y éxito porque no podemos rechazar la hipótesis nula (OR=1).
26. Observemos que la conclusión del contraste la obtenemos a partir de observar el intervalo.
27. Pero también podemos llegar a ella a partir del p-valor. El p-valor en este caso es 0.77, por lo que al ser superior a 0.05 estamos ante una OR no significativa.
28. Por lo tanto, no podemos decir que haya diferencias significativas entre los resultados de los protocolos que estamos comparando. Pero esto nos lleva a un tema muy importante.
29. Los cardiólogos que han propuesto el Protocolo 2 pueden pensar: Con el Protocolo 1 muere un 7%, con el Protocolo 2 el 6%; o sea, de cada cien infartos salvamos una vida.
30. Esto es relevante desde el punto de vista médico. Cualquier posición que suponga salvar vidas podemos entender que es relevante médicamente, si es que no hay secuelas adicionales. Por lo tanto, estamos ante un resultado con Significación médica pero el Tribunal estadístico dice: «no significativo».
31. Y la estadística está por encima de todo. Esto es muy importante tenerlo bien claro. Es el Tribunal que dicta la última sentencia ante unos datos concretos.
32. Y si no es estadísticamente significativo no podemos decir que el Protocolo 2 salva más vidas, porque podría ser fruto del azar del muestreo.
33. Podría pasar perfectamente que pasáramos al Protocolo 2 y acabáramos viendo que al aplicarlo a miles y miles de personas los resultados obtenidos no fueran los que apuntaba el estudio. Y esto sería muy grave.
34. Esto es lo que significa que algo no sea estadísticamente significativo: que no es fiable. Que podría la realidad no ser como lo que estamos viendo en la muestra.
35. Pero pasar de un 7 a un 6% es Significativo médicamente. Tenemos, pues, la situación planteada: No Significación estadística y Significación médica.
36. En estos casos la Estadística claramente sólo debe dar una respuesta: Hay que aumentar el tamaño de muestra.
37. Al aumentar el tamaño de muestra pueden darse dos situaciones: 1) Que la Estadística tenía razón al ser cautelosa y al aumentar la muestra la diferencia que antes se veía se disuelve y ya o no existe o es tan pequeña que ya no es Significativa médicamente. 2) Que se mantenga la diferencia y al aumentar la muestra pase ya a ser Significativa estadísticamente y, por lo tanto, pasemos a una situación del primer tipo: Significación estadística y Significación médica.
38. Para situaciones de este tipo en las que una pequeña diferencia puede tener Significación médica y en las que es necesario grandes tamaños de muestra para tener Significación estadística, se han desarrollado mucho, últimamente, dos tipos de estudios: 1) Los estudios multicéntricos. 2) El metaanálisis.
42. En ambos casos la finalidad es aumentar el tamaño de muestra para encontrar, así, Significación estadística.
43. En los estudios multicéntricos se hace coordinando diferentes centros en un único estudio y en el metaanálisis coordinando en un estudio descoordinados estudios paralelos.
44. Volvamos a los datos anteriores de la comparación de protocolos. La OR era 1.18, el intervalo del 95% (0.38, 3.64) y el p-valor 0.77.
46. El Protocolo 1 tiene un 7% de muertes y, en cambio, el Protocolo 2 un 6%. Y decíamos que para un cardiólogo la diferencia es relevante. Pero no tiene Significación estadística.
47. Vamos a ver qué pasaría si tuviéramos un tamaño de muestra superior. Supongamos la siguiente:

48. Con esta muestra la OR sigue siendo la misma; o sea, 1.18, porque lo único que hemos hecho es multiplicar por 10 cada valor.
49. El intervalo de confianza del 95% es, ahora, (0.86, 1.68) y el p-valor es 0.36. Seguimos igual, por lo tanto. Aumentemos aún más el tamaño muestral.
50. Supongamos que tenemos ahora:

Ahora hemos multiplicado por 100. La muestra es muy grande.
51. La OR sigue, lógicamente, siendo 1.18, porque las proporciones no han cambiado, pero el intervalo del 95% sí que ha cambiado. Ahora es: (1.05, 1.32) y el p-valor también: 0.004. Ahora ya es estadísticamente significativo.
52. Observemos que ahora el 1 no está dentro del intervalo de confianza de la OR. Ahora la Estadística apuesta por pensar en una diferencia fiable. Ahora esta diferencia entre un 7% y un 6% entre los dos protocolos comparados tiene Significación estadística y Significación médica. Hemos alcanzado la situación ideal. Pero, en circunstancias como estas, a unos resultados así, con un tamaño de muestra tan grande, únicamente es posible llegar o mediante estudios multicéntricos o de metaanálisis, como hemos comentado.
53. El aumentar mucho el tamaño de muestra nos puede llevar, no obstante, en ocasiones, a una situación peligrosa. A encontrar Significación estadística (formal) pero no Significación médica o del tipo que sea (material), como hemos visto antes en el segundo caso posible (puntos 5-13) . Esto seguramente se entendería si en lugar de hablar de medicina estuviéramos hablando de otro ámbito puesto que en Medicina es posible que cualquier mejora, por pequeña que sea, resulte verse como significativa. Pero, esto no siempre es así. Vemos la situación planteada en el punto siguiente.
54. Supongamos que en el caso médico planteado anteriormente valoramos que o bien el coste del Protocolo 2 es muy elevado, y entendemos que es inasumible puesto que la mejora obtenidad es muy leve para el coste económico-social que supone; o bien que este Protocolo 2 implica un riesgo muy elevado para la vida futura del paciente, por la aparición muy frecuente de complicaciones secundarias. Posiblemente en este caso diríamos que estamos ante una situación en la que tenemos Significación estadística pero no Significación médica. En términos técnicos diríamos que el «Tamaño del efecto» es demasiado pequeño.
55. En Estadística, tradicionalmente, como hemos estado comentando a lo largo de todo este tema, el problema ha sido valorar si hay significación estadística o no, lo que quiere decir que la Estadística se ha preocupado, fundamentalmente, de la Significación formal, no de la Significación material. Y la Significación formal es, también, muy importante.
56. En ciertos campos del conocimiento, especialmente en Psicometría y en Ciencias humanas y sociales, se han desarrollado unos procedimientos para medir la Significación material, el denominado “Tamaño del efecto”. En inglés: “Effect size”.
57. Así como en un juicio se evalúa fundamentalmente la culpabilidad o la inocencia, en Estadística nos interesa, básicamente, ver la igualdad versus la diferencia, la no relación respecto a la relación, etc. En definitiva, lo que se pretende es establecer mecanismos para decidir entre dos opciones.
58. En Estadística nos interesa ver si, con lo que vemos, con la información de que disponemos, podemos afirmar, con pocas probabilidades de equivocarnos, si dos medias poblacionales son distintas porque podamos delimitar ya el signo de tal desigualdad, o podemos afirmar que hay relación entre dos variables pudiendo delimitar el signo de esa relación, etc. No nos interesa tanto precisar el grado de esa diferencia, el grado de esa relación. Esto se suele reservar más a los especialistas.
59. Es como lo que sucede en el mundo judicial con un tribunal: le interesara delimitar, básicamente, la inocencia o la culpabilidad y luego, una vez establecida la culpabilidad, si es que acaba estableciéndose, reservar a otros el papel de aplicar la pena adecuada al infractor.
60. La Estadística centra sus esfuerzos en ver si alguien es un ladrón o no, no en precisar si lo que ha robado es poco o mucho. Esto es otro problema. Un problema distinto. En definitiva, la Estadística fundamentalmente se centra en esta Significación formal.
61. Lo importante, en primer lugar, en Estadística, es, pues, delimitar eso. ¿De qué sirve decir que a alguien se le acuse de robar mil millones de euros si, después, se acaba demostrando que no es culpable? Hasta que no se ha demostrado que es un ladrón aunque sea mucho lo que presuntamente ha robado en realidad no podemos decir que lo ha robado. La Estadística se reserva a este paso: Es o no un ladrón. Y aquí básicamente se acaba nuestro trabajo. Valorar si es mucho o no es otro tema, ya no estadístico.
62. La d de Cohen, el factor F, la eta al cuadrado, son ejemplos de cálculo del tamaño del efecto. Existen y pueden crearse muchos mecanismos para evaluar el tamaño del efecto; o sea, el tamaño de la diferencia de las medias de dos grupos o el tamaño de la relación que hay entre dos variables, etc.
62. Veamos la d de Cohen. Se aplica en el contexto de la t de Student, en la comparación de las medias de dos poblaciones, una técnica que veremos en el tema 14. Pero el caso, por su sencillez, nos puede servir para delimitar con precisión de lo que estamos hablando en este tema.
63. La d de Cohen es el siguiente cálculo:

64. El objetivo, como puede verse perfectamente en la fórmula, es ver si la diferencia entre las medias muestrales es muy distinta relativamente a la dispersión que tenemos en las muestras que comparamos. Distingue situaciones como las siguientes:

65. Observemos que en estas tres comparaciones de dos grupos, la diferencia de medias muestrales es la misma, sin embargo, arriba la dispersión es muy pequeña y, por el contrario, abajo, la dispersión es muy grande. Relativamente son mucho más distantes las medias de arriba que las de abajo. Esto es lo que mide la d de Cohen y, en definitiva, lo que miden todos los procedimientos enmarcado en este ámbito del Tamaño del efecto (Effect size).
66. Se pretende medir, pues, el grado de separación, el grado de efecto distancia, el grado de segregación que hay entre los grupos que estamos comparando.
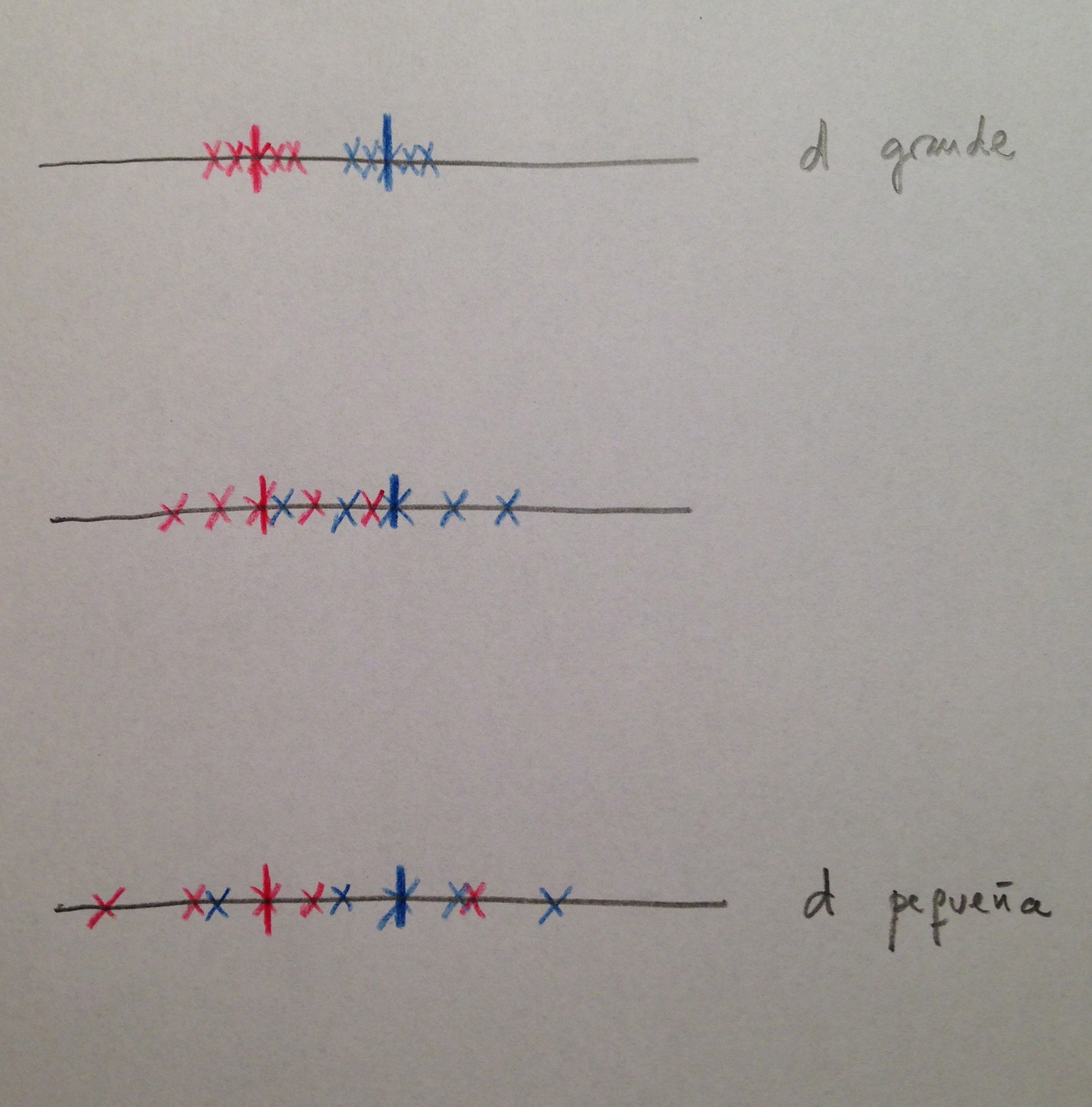
67. En cuanto a cómo interpretar un determinado valor de d de Cohen, suele considerarse que una d en torno a 0,2 es un efecto pequeño, una d en torno a 0,5 un efecto moderado y una d por encima de 0,8 un efecto grande. El valor de d puede ser potencialmente muy grande.
68. Es importante entender bien que aquí no se tiene en cuenta el tamaño de muestra. El tamaño muestral no juega ningún papel. Todo lo contrario que en la Significación formal, donde el tamaño de muestra juega un papel decisivo. Esto es muy importante. En los cálculos del Tamaño del efecto no se tiene en cuenta el tamaño muestral, como puede verse en el cálculo de la d de Cohen.
69. Observemos los siguientes dos casos:

70. Como la d de Cohen sólo tiene en cuenta la diferencia de medias y la desviación estándar, en el caso de arriba tenemos una d pequeña, sin embargo, abajo tenemos una d grande porque las medias de las dos muestras están bastante separadas para el nivel de dispersión que tenemos. Como en el cálculo de la d de Cohen no juega ningún papel el tamaño muestral estaríamos viendo como mucho más interesante la situación de abajo que la de arriba desde el punto de vista del Tamaño del efecto, pero desde el punto de vista estadístico, de Estadística formal, de Estadística donde la Significación formal es lo esencial, el caso de arriba es fiable, es significativo, es estable; sin embargo, el de abajo no lo es, es poco fiable, no está establecido de forma sólida.
71. Es como si tuviéramos dos presuntos ladrones: Uno ha robado presumiblemente mil millones de euros y el otro mil euros. Parece que el primero ha conseguido un robo más censurable. El Tamaño del efecto es mayor. Pero hasta que no tengamos la significación formal de este robo no podemos valorar su importancia. Es posible que al final no sea aquél el que ha materializado el robo, o no se pueda demostrar y, a lo mejor, el segundo ladrón, con poco Tamaño del efecto, se demuestre claramente que fue realmente él el que materializó el robo.
72. Es cierto que una vez vista la Significación formal es interesante valorar aspectos cuantitativos de la Significación material. Pero, siempre, como un segundo nivel. Jerárquicamente es claro que debe estar una Significación (la formal) por encima de la otra (la material).