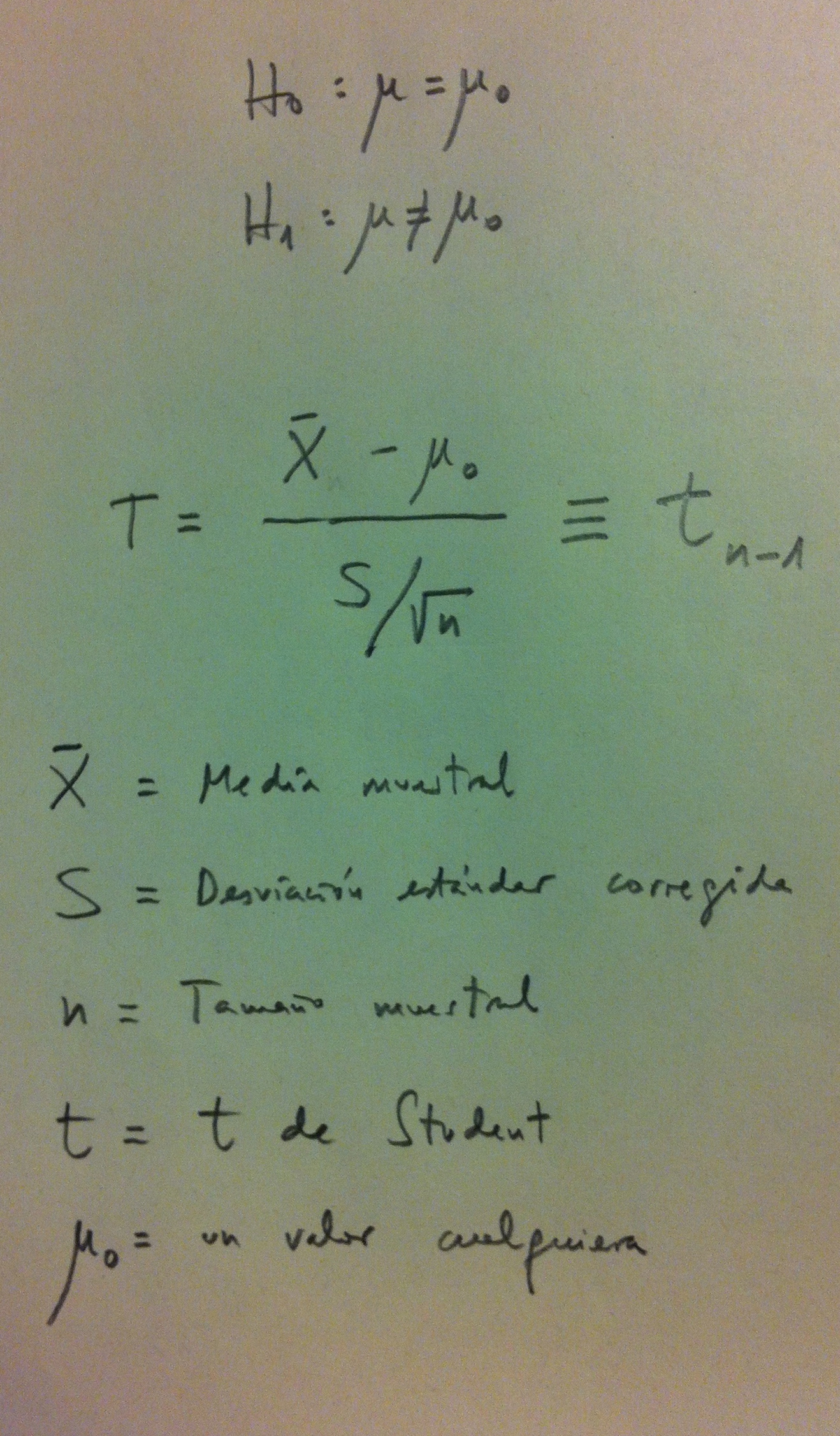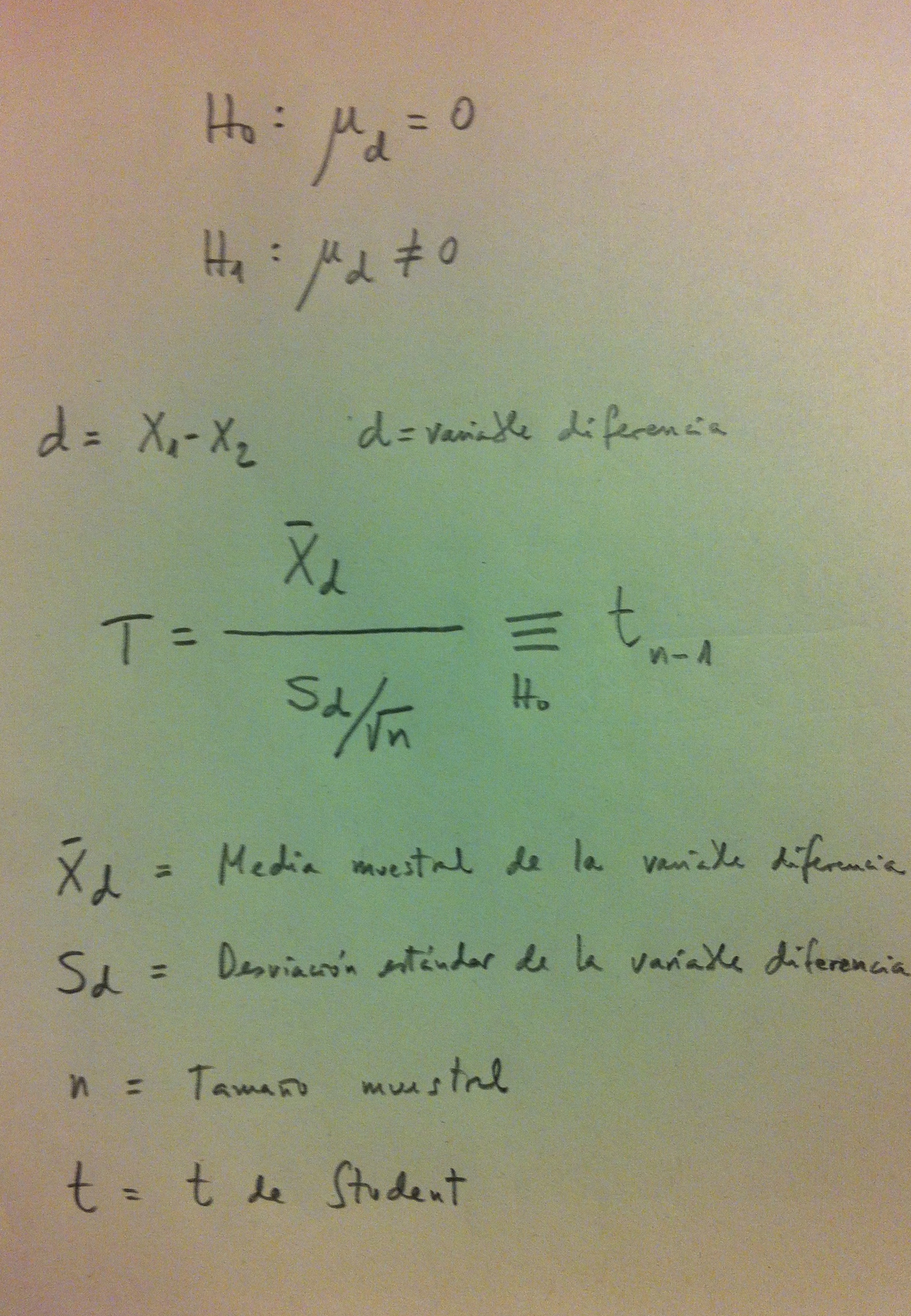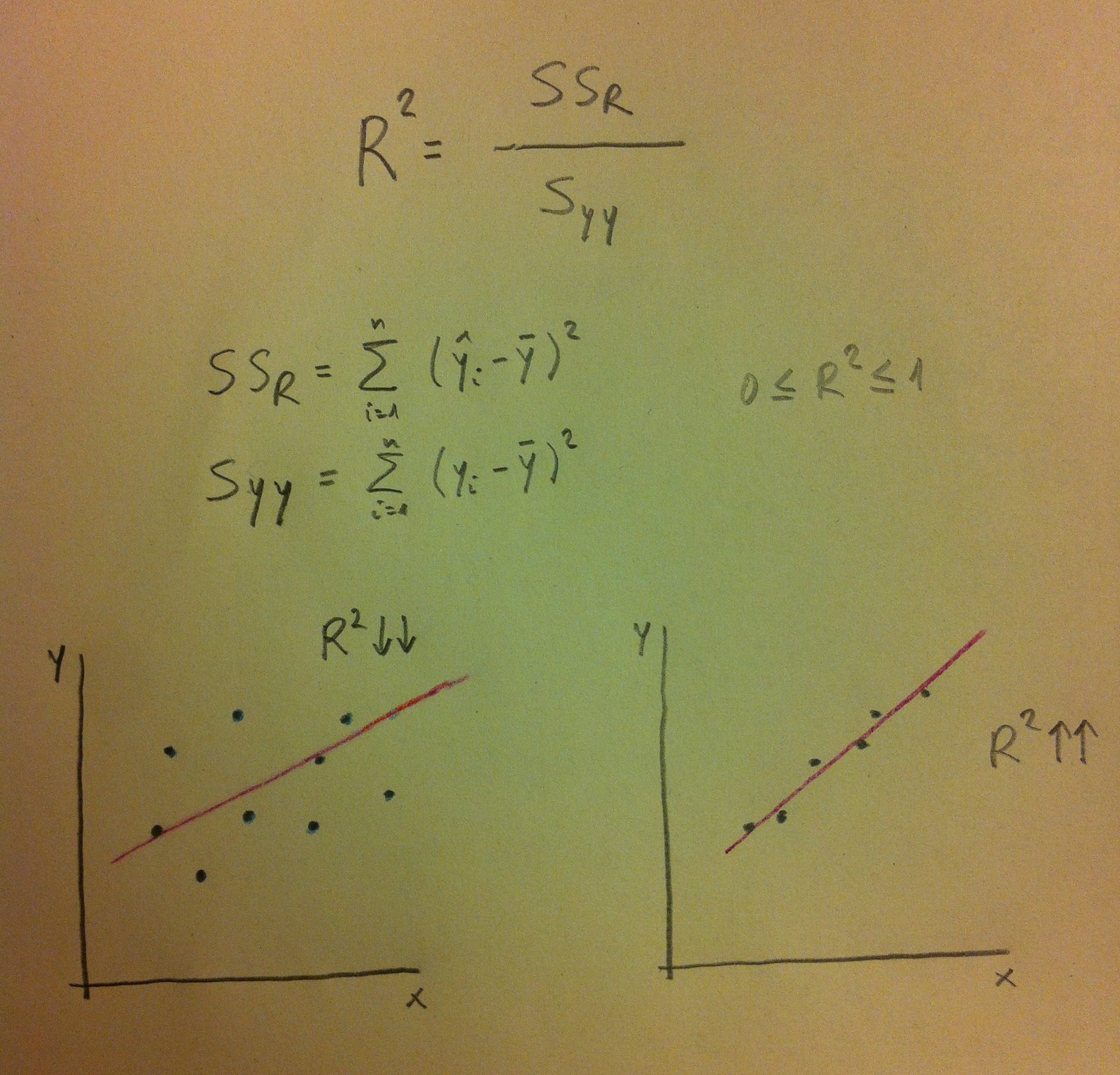Este tema está explicado en los vídeos siguientes:
1. Vamos a ver ahora técnicas estadísticas concretas de comparación de dos poblaciones.
2. Es muy importante ver con detalle cómo elegir, en una determinada situación concreta, la técnica adecuada entre las muchas disponibles.
3. Es muy importante elegir bien la técnica más adecuada en cada circunstancia para afinar así más la propia maquinaria de la técnica y que, de esta forma, las decisiones tomadas sean más fiables.
4. Voy a trazar un mapa de las técnicas más usuales de comparación de dos poblaciones y lo voy a hacer estructurado a modo de protocolo de actuación, de decisión.
5. Pensemos que dejamos una decisión trascendental (elegir entre H0 y H1) en manos de una maquinaria matemática, como es una técnica estadística, por lo que elegir la más ajustada al caso optimiza el funcionamiento de la propia técnica y su fiabilidad.
6. Protocolo de decisión entre técnicas de comparación de dos grupos:

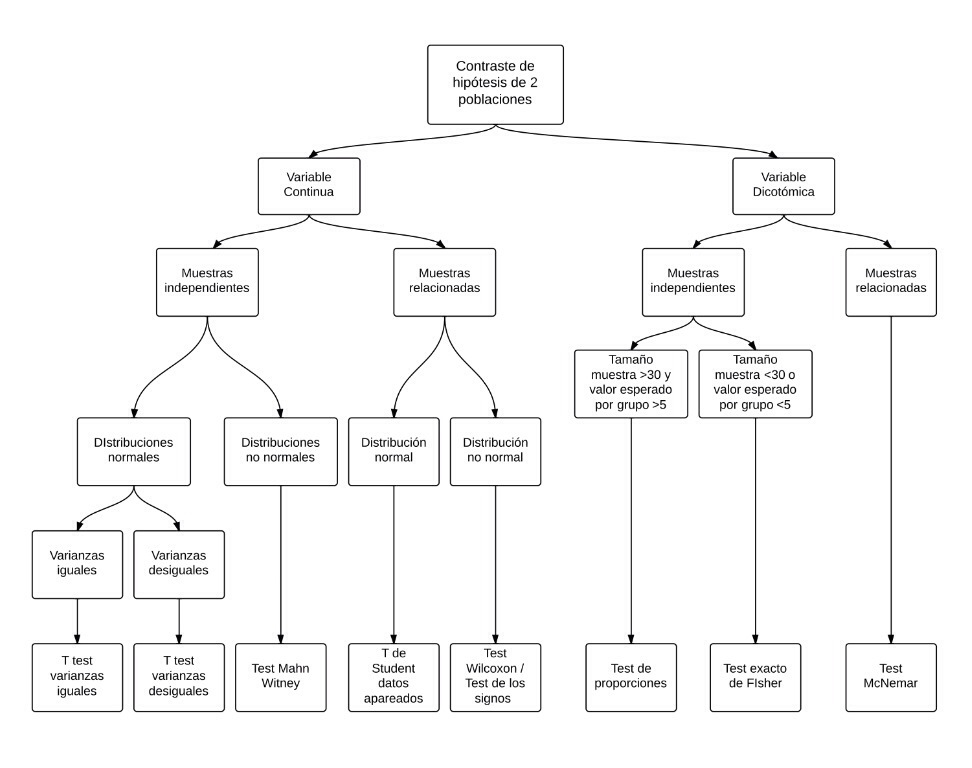
Este mismo protocolo puede presentarse en forma de diagrama de flujo. Este gráfico lo ha elaborado un alumno de este curso (Bruno Splendiani):
Otras dos presentaciones de este mismo esquema me los ha facilitado Laura Ripoll muy amablemente:
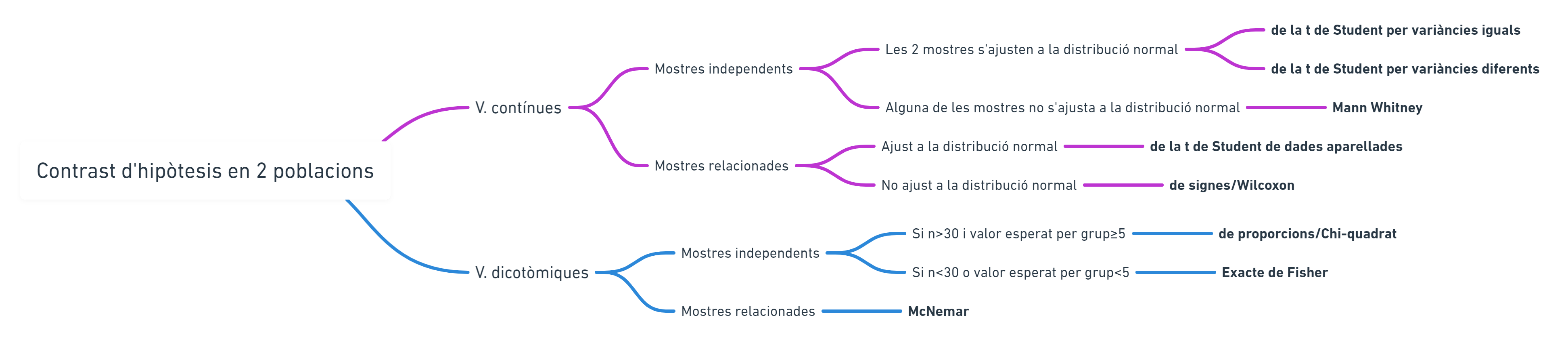
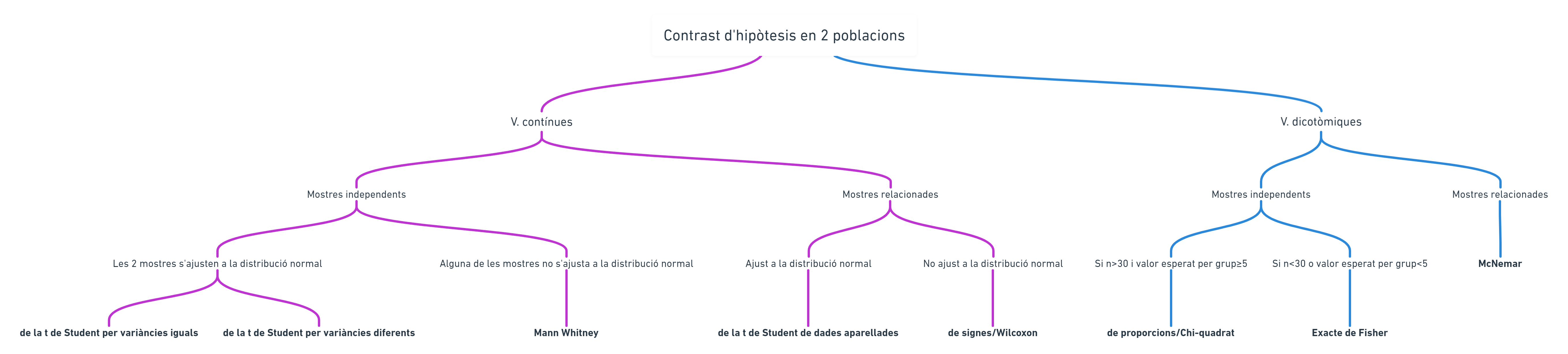
Utilizad el que os resulte más cómodo.
7. Veamos con detalle el funcionamiento de este protocolo de actuación: Lo primero es ver si estamos ante una variable continua o dicotómica.
8. Se trata de ver si continuamos por el apartado 1 ó el 2 del protocolo. Si es una variable continua iremos por 1, si es dicotómica, por 2.
9. Supongamos que nuestro objeto de estudio es una variable dicotómica, con sólo dos valores posibles, por ejemplo: hombre/mujer, enfermo/sano, dolor/no dolor, opina A/opina B, etc. Estamos, claramente, en el punto 2. Y habremos de decidir si las dos muestras comparadas son independientes o relacionadas. En definitiva, si son dos poblaciones formadas por individuos distintos (independientes) o por los mismos individuos a los que se les mide la variable dicotómica en dos momentos distintos (muestras relacionadas).
10. Supongamos primero que estamos estudiando si la proporción de estudiantes mujeres en una facultad de Medicina y en una de Económicas es distinta. Tomaremos dos muestras, una de cada facultad, y veremos qué proporción de mujeres hay en cada muestra. Pe: obtenemos: 60% y 50%.
11. ¿Es esta diferencia estadísticamente significativa? Que hay diferencia muestral es evidente. 60% y 50% evidentemente son distintos. Pero esto es muestral, es diferencia muestral. Y nuestro interés es poblacional, como siempre. Debemos aplicar una técnica estadística para ver si esta diferencia es significativa, si es extrapolable a la población.
12. Deberemos aplicar un Test de comparación de dos proporciones, también llamado, sencillamente, Test de proporciones. Se trata de dos muestras claramente independientes. En éste, como siempre, en la H0 tendremos la igualdad de proporciones poblacionales (p1=p2) y en la H1 la desigualdad (p1<>p2).Y el p-valor del contraste de hipótesis nos dirá si, por el tamaño de muestra que tenemos, podemos considerar que esa diferencia del 10% es o no significativa. Esta misma situación resuelta por este Test de proporciones podría plantearse con el Test de la ji-cuadrado. De hecho, si repasamos los visto en el tema 8, una situación de comparación de proporciones puede resolverse, también, desde este Test de la ji-cuadrado.
13. El Test proporciones, para funcionar bien, requiere un tamaño muestral mínimo de 30 por grupo y que el producto del tamaño muestral por el tanto por uno esperado bajo la hipótesis nula del suceso que se analiza sea superior o igual a 5, en ambas muestras. Por ejemplo: Supongamos que tenemos una muestra de 50 por cada uno de los dos grupos a comparar. En una muestra tenemos sólo un caso del suceso analizado y en la otra tenemos 4 casos. Si la hipótesis nula (igualdad de proporciones) fuera cierta esperaríamos ver 5 casos de cada 100; o sea, un 0.05 por uno. Si multiplicamos este 0.05 por 50 nos da 2.5 sucesos esperados por grupo. Como es menor que 5 estamos fuera de las condiciones de aplicación de este Test de proporciones y deberíamos aplicar el Test exacto de Fisher.
14. Supongamos, ahora, que queremos ver antes y después de un determinado acontecimiento si un cierto número de personas opinan A o si opinan B (Por ejemplo, si votarían sí o no en un determinado referéndum). Habrá los que opinaban A y después B, los que opinaban A y continúan opinando A, los que opinaban B y luego continúan opinando B y, finalmente, los que opinaban B y pasan a opinar A. Es un claro ejemplo de muestras relacionadas. La variable es dicotómica pero es un mismo grupo de individuos a los que se les mide la misma variable en dos momentos distintos. Aplicaremos, en este caso, el Test de McNemar (Ver Herbario de técnicas).
15. Supongamos que ahora queremos ver el nivel de inglés de los estudiantes en esas mismas facultades vistas antes (Medicina y Económicas) mediante un examen con notas del 0 al 10, estaremos ahora ante una variable claramente continua.
16. Hay muchos valores posibles potencialmente entre 0 y 10. Estamos, ahora, en el apartado 1 de nuestro protocolo de decisión.
17. Y ahora no tenemos todavía el test a realizar, sino que debemos continuar examinando las especificaciones del protocolo y, nos tocaría, como siguiente paso, decidir si las muestras son independientes o relacionadas.
18. Aquí se trata de ver si los individuos de las dos muestras son los mismos o si son distintos.
19. En este caso que planteo, el del nivel de inglés de alumnos en dos facultades, es claro que se trata de dos muestras con individuos distintos. Se trata, por lo tanto, de muestras independientes.
20. Pero, imaginemos que en lugar de ser dos facultades, las estudiadas, fueran unos mismos estudiantes de una facultad (Pe: Medicina) y que tenemos el nivel de inglés de una muestra de estudiantes al empezar sus estudios universitarios y al final de esos mismos estudios. Y queremos comprobar si ha habido un cambio en ese nivel.
21. En este caso estaríamos ante muestras relacionadas. De unos mismos individuos tenemos dos medidas y queremos ver si hay diferencias. Es muy importante saber distinguir, pues, si las muestras son independientes o relacionadas (a veces se les denomina también apareadas, porque los valores van por pares: dos de cada individuo).
22. En el caso, pues, de las dos facultades, con muestras independientes, estaríamos en el caso 1a del protocolo y en el caso de una única facultad, con muestras relacionadas, estaríamos en el 1b.
23. El siguiente paso, que nos llevará a los apartados 1ai, 1aii, 1bi o 1bii del protocolo, es la comprobación de la normalidad, o no, de ambas muestras.
24. En el tema dedicado a Intervalos de confianza hemos hablado de la noción de ajuste de una muestra a una distribución normal. Y hemos presentado allí que la curtosis estandarizada y la asimetría estandarizada eran unos criterios útiles para comprobar el ajuste de una muestra a la distribución normal. Ahora hemos de dar un paso más y presentar la noción de comprobación estadística de la normalidad de una muestra mediante un contraste de hipótesis.
25. Para decidir si la variabilidad de una muestra sigue una determinada distribución, mediante un contraste de hipótesis, disponemos de las denominadas técnicas de «Bondad de ajuste».
26. Para la comprobación de la normalidad de una muestra existen diferentes técnicas de «Bondad de ajuste a la normal».
27. Todas ellas tienen la misma estructura:
H0: Normalidad.
H1: No normalidad.
Hay, pues, en Estadística, presunción de normalidad, porque la normalidad está en la Hipótesis nula.
28. Por lo tanto, en un Test de Bondad de ajuste a la normal con un p-valor superior a 0.05 mantendremos la suposición de normalidad. Estaremos ante una muestra que podríamos ver en el caso de tener en la población una distribución normal.
29. Como siempre en un contraste de hipótesis valoramos si lo que vemos en la muestra, lo que observamos en ella, encaja, es factible verlo, en el caso de ser cierto lo afirmado en la Hipótesis nula. O sea, que lo que vemos, lo Observado está dentro de la esfera de lo Esperado bajo la Hipótesis nula.
30. En cambio, si la p es inferior a 0.05 debemos rechazar la normalidad: la estructura de los datos no nos permiten pensar que la población de donde se ha tomado la muestra tenga una variabilidad en forma de campana de Gauss.
31. Los tests de bondad de ajuste a la normal más usados son el Test de la ji-cuadrado de ajuste a una distribución, Test de kolmogorov de bondad de ajuste a una distribución normal y el Test de Shapiro-Wilk (Ver Herbario de técnicas).
32. En las muestras independientes, para seguir por la vía 1ai las dos muestras deben seguir la normalidad. Si no es así seguimos por 1aii.
33. En las muestras relacionadas, apareadas, se suele calcular la muestra resta a partir de las dos muestras.
34. Como son una serie de individuos de los que se tienen dos valores: uno en cada muestra, se hacen las restas de los valores por individuo, creando una única muestra: la muestra de la resta de los valores de la variable en los dos tiempos o, en general, de los dos valores relacionados.
35. La normalidad se contrasta en esa muestra de restas obtenida a partir de los valores de las dos muestras relacionadas.
36. Si sigue la normal estaremos en 1bi y si no la sigue estaremos en 1bii. En el primer caso, siguiendo el protocolo, aplicaremos el Test de la t de Student para datos apareados (o relacionados) y, en el segundo caso, aplicaremos el Test de los signos o el Test de Wilcoxon (Ver Herbario de técnicas).
37. En muestras independientes, si no hay normalidad de las dos muestras (estamos, pues, en 1aii) aplicaremos el Test de Mann-Whitney (Ver Herbario de técnicas). A este Test también se le llama, a veces, Test de Mann-Whitney-Wilcoxon o, también, Test de Wilcoxon de la suma de rangos. Si, por el contrario, hay normalidad y, por lo tanto, estamos en el apartado 1ai, necesitamos realizar un nuevo paso.
38. Para decidir si aplicar el Test de la t de Student para muestras independientes y varianzas iguales o el Test de la t de Student para muestras independientes y varianzas distintas hay que aplicar un Test sobre las varianzas, un Test que nos permita decidir si las varianzas poblacionales son o no distintas.
39. El Test tiene la estructura de siempre: presunción de igualdad. De igualdad, en este caso, de varianzas o de desviaciones estándar.
40. El contraste es: H0: σ1=σ2, H1: σ1<>σ2. El Test más conocido y usado para resolver este contraste es el denominado Test de Fisher de igualdad de varianzas o también llamado Test de Fisher-Snedecor (Ver Herbario de técnicas). Evidentemente estamos hablando de Desviaciones estándar poblacionales, no muestrales. El problema es, ahora, decidir si las diferencias muestrales entre las Desviaciones muestrales nos permite pensar que son inferibles a nivel poblacional, o no.
41. Si el p-valor es mayor que 0,05 mantendremos la hipótesis de iguadad y aplicaremos, entonces, para comparar las medias de las dos poblaciones, el Test de la t de Student de varianzas iguales.
42. Si el p-valor es menor que 0,05 rechazaremos H0, aceptaremos H1 y aplicaremos el Test de la t de Student de varianzas desiguales.
43. Con esto tenemos, pues, explicado todo el mapa trazado en el esquema del protocolo.
44. Las diferentes técnicas de la t de Student son técnicas llamadas «paramétricas», porque para funcionar bien necesitan que las variables sigan una distribución concreta: la distribución normal.
45. El Test de Mann-Whitney, el Test de los signos y el Test de Wilcoxon son, por el contrario, técnicas llamadas «no paramétricas». Estas técnicas precisan pocas condiciones previas.
46. Observemos que se trata de técnicas donde las variables no necesitan seguir una distribución concreta: ni una dicotómica ni una normal.
47. Estas técnicas sólo precisan la continuidad de las variables; o sea, que sean variables con muchos valores posibles.
48. Las técnicas de la Estadística no paramétrica son técnicas «todo terreno». Aplicables en muchas más situaciones. Al no precisar una determinada distribución son más versátiles.
49. Esta mayor versatilidad la pagan con menor potencia: Son técnicas más conservadoras que las denominadas paramétricas, lo que significa que cuesta más rechazar la hipótesis nula. Tienen menor capacidad de detectar diferencias.
50. Una peculiaridad de las técnicas no paramétricas es que los contrastes de hipótesis no son sobre la media sino que lo son sobre la mediana; o sea: H0: Mediana1=Mediana2 y H1: Mediana1<>Mediana2, o sobre la igualdad o desigualdad entre las distribuciones.