1c
2c
3d
4d
5b
6b
7d
8c
9c
10d
1c
2c
3d
4d
5b
6b
7d
8c
9c
10d
Se trata de un artículo muy original de diciembre de 2014. Se trata de un ensayo para evaluar si las redes sociales pueden aumentar el acceso a los artículos de esta importante revista médica (Circulation).
El abstract es el siguiente:

El objetivo es hacer un estudio randomizado comparando artículos a los que se les hace una importante difusión mediática con artículos a los que no se les hace tal difusión.
Observemos que, en abstracto, es como un ensayo clínico. Se toman artículos y al azar se los va asignando al grupo tratamiento (difusión especial mediática) o al grupo control (la difusión habitual). En lugar de trabajar con pacientes se trabaja con artículos médicos, pero formalmente es un procedimiento idéntico.
En la parte de análisis estadístico es importante la elección del tamaño de muestra. Miremos cómo está formulado:

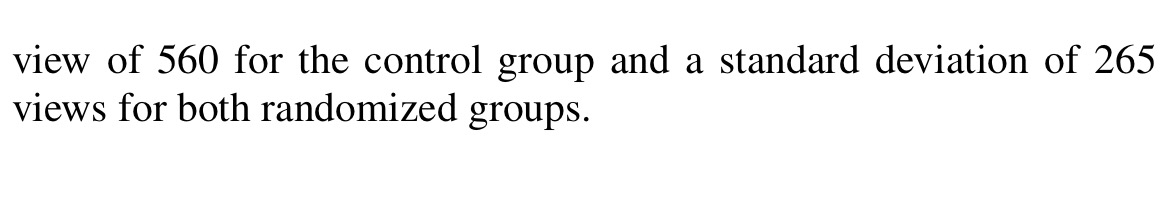
Es interesante ver cómo se elige este tamaño de muestra (119 por grupo) delimitando una potencia del 90% para detectar una diferencia de un 20% o una potencia del 80% para detectar una diferencia del 17%. Partiendo del supuesto que uno de los grupos tenga un orden de visualizaciones de 560 de media y una desviación estándar de 265. Esto significa que buscan una diferencia mínima a detectar, para considerar que el «tratamiento» (su difusión por las redes sociales) es efectivo, de un 20%, como mínimo respecto al valor medio de acceso a esos artículos.
La media y la desviación estándar estiman que puede ser 560 y 265, respectivamente. Esto significa que entre las visualizaciones a los diferentes artículos de la revista hay este nivel de media y de dispersión. Estos número seguro que salen de informaciones previas que tenían del grado de impacto de los artículos publicados en esa revista.
El 20% de 560 es 112, por lo tanto, esta diferencia de 112, ó más, es lo que se esperaría ver para poder decir que hay una diferencia destacable. Por lo tanto, establecemos, a priori, que si hay realmente una diferencia de 112 ó más, entre los dos grupos, hemos de determinar el tamaño de muestra requerido para tener esta potencia del 90%; o sea, una probabilidad del 90% ó más de detectar tal diferencia como estadísticamente significativa.
Hay diferentes calculadores para realizar esta determinación. A mí con el GRANMO (http://www.imim.cat/ofertadeserveis/software-public/granmo/) me sale que es 118 el tamaño necesario, pero esta diferencia puede ser atribuible a un distinto calculador usado. Observemos la entrada de datos necesaria en la versión del GRANMO para i-phone, para determinar el tamaño de muestra de este ensayo:
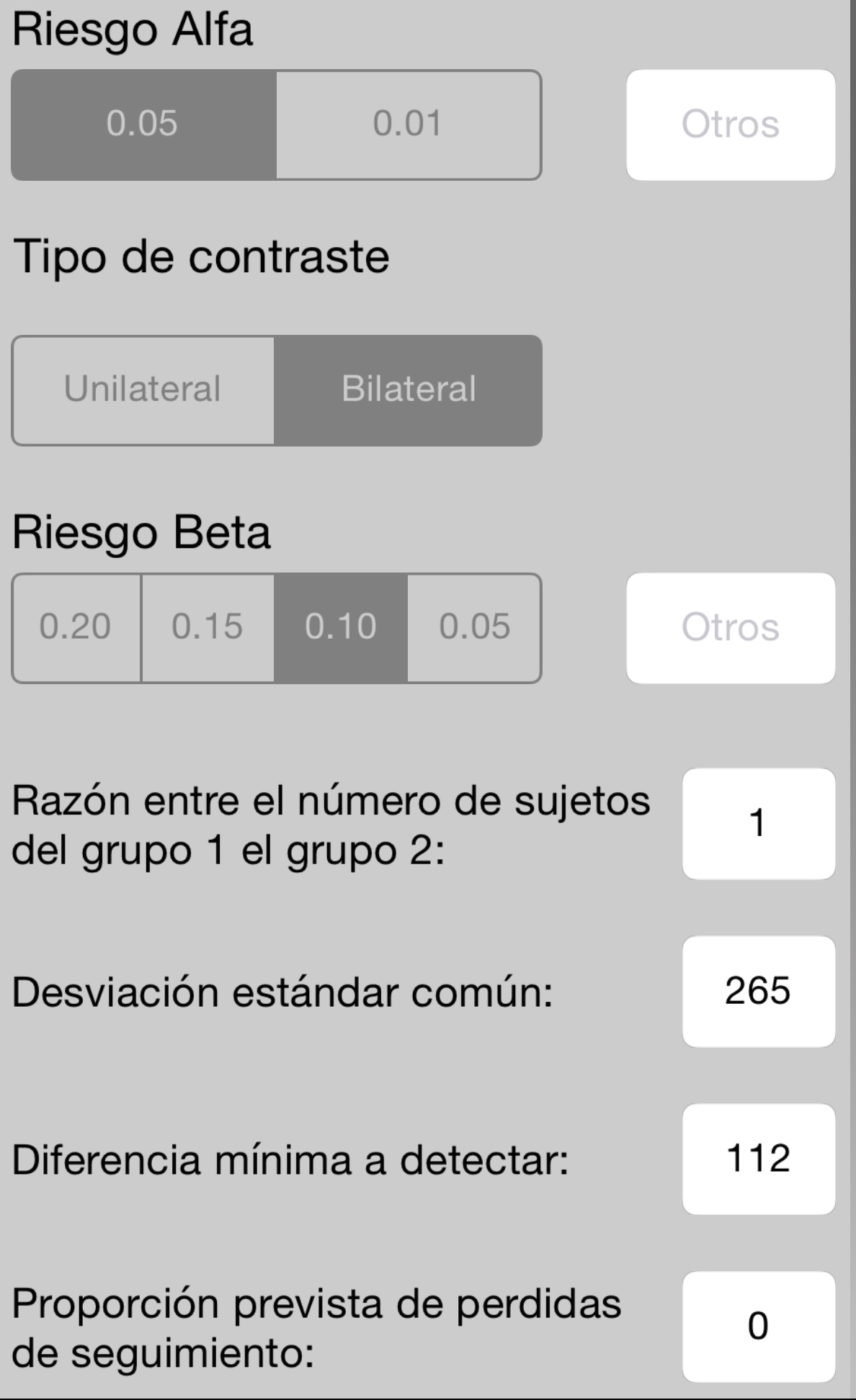
El riesgo beta es 0.1 porque para detectar una diferencia del 20% se quiere tener una potencia del 90%. La potencia es 1-Beta pasado a tanto por ciento. En nuestro caso, 1-0.1=0.9, multiplicado por 100 es, entonces, 90%. El resultado obtenido con la calculadora es el siguiente:

Al final los autores toman muestras de 121 y 122, respectivamente, por grupo.
Comparan los dos grupos para comprobar que se trata de dos grupos de artículos homogéneos:

Como puede verse, es así. Se trata de dos grupos de artículos muy similares. Es importante comprobarlo para evitar atribuir las posibles diferencias a variables que nos confundan. No obstante, la randomización acostumbra a generar, por el azar usado, grupos homogéneos, especialmente si el tamaño de muestra es considerable.
Ahora se trata, pues, ya, de evaluar los accesos a esos artículos seleccionados, a los artículos de los dos grupos del ensayo, durante un tiempo, y, después, compararlos mediante la técnica de comparación de dos poblaciones. En este caso como se trata de una variable continua, de dos muestras independientes y, según nos dicen los autores, de variables que no se ajustan a la distribución normal, usan una técnica no paramétrica, el Test de Mann-Whitney o el Test de Wilcoxon de la suma de rangos. Los resultados son los siguientes:
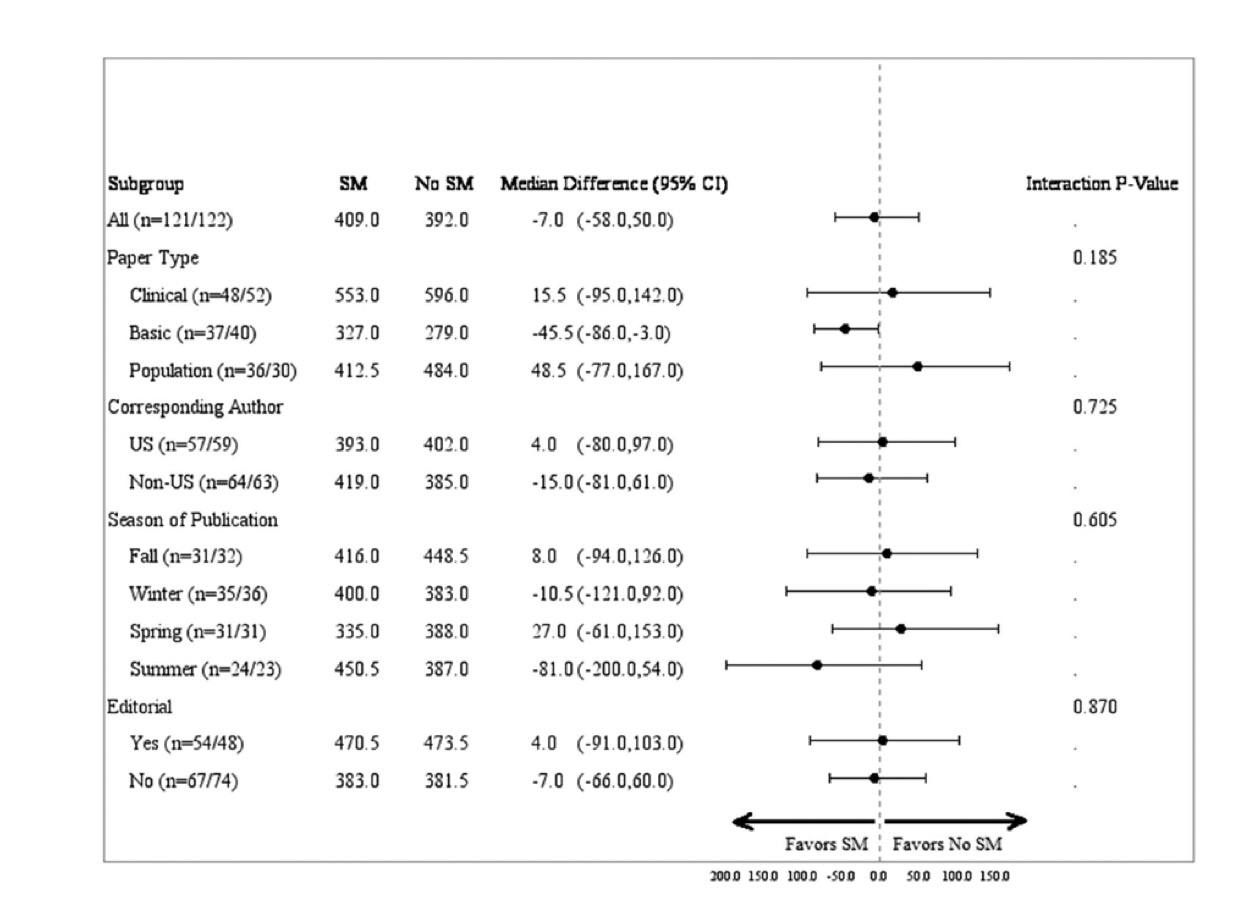
Nos muestran, los autores, los intervalos de las diferencias de medianas en el total y en distintos subgrupos de artículos. Como podemos ver se trata de diferencias no estadísticamente significativas. Los intervalos de confianza de las diferencias de medianas incluyen siempre al 0, lo que indica que se trata de diferencias no estadísticamente significativas.
La conclusión de los autores es que la propaganda a través de las redes sociales no incrementa los accesos a este tipo de artículos, que los profesionales acceden a ellos por otros canales de interés.
Distribución, por comarcas en Catalunya, del número centros públicos y privados y del número de profesores en centros públicos y privados, en el curso 2012-2013:
| Comarca | Centros públicos | Centros privados | Profesores públicos | Profesores privados |
| Alt Camp | 4 | 2 | 219 | 35 |
| Alt Empordà | 14 | 4 | 641 | 89 |
| Alt Penedès | 9 | 6 | 427 | 122 |
| Alt Urgell | 3 | 1 | 115 | 31 |
| Alta Ribagorça | 1 | 0 | 38 | 0 |
| Anoia | 11 | 9 | 513 | 165 |
| Bages | 19 | 16 | 756 | 312 |
| Baix Camp | 19 | 10 | 905 | 221 |
| Baix Ebre | 10 | 4 | 475 | 74 |
| Baix Empordà | 11 | 5 | 573 | 100 |
| Baix Llobregat | 60 | 56 | 3059 | 1121 |
| Baix Penedès | 8 | 3 | 469 | 69 |
| Barcelonès | 115 | 253 | 5620 | 6754 |
| Berguedà | 5 | 2 | 166 | 77 |
| Cerdanya | 1 | 1 | 67 | 11 |
| Conca de Barberà | 3 | 1 | 91 | 11 |
| Garraf | 13 | 7 | 596 | 142 |
| Garrigues | 3 | 1 | 76 | 17 |
| Garrotxa | 5 | 3 | 238 | 55 |
| Gironès | 15 | 14 | 897 | 377 |
| Maresme | 32 | 34 | 1509 | 793 |
| Montsià | 9 | 2 | 384 | 28 |
| Noguera | 6 | 3 | 190 | 41 |
| Osona | 16 | 15 | 609 | 341 |
| Pallars Jussà | 3 | 1 | 91 | 10 |
| Pallars Sobirà | 2 | 0 | 47 | 0 |
| Pla d’Urgell | 3 | 1 | 138 | 51 |
| Pla de l’Estany | 3 | 1 | 179 | 14 |
| Priorat | 2 | 0 | 54 | 0 |
| Ribera d’Ebre | 3 | 1 | 112 | 11 |
| Ripollès | 4 | 2 | 109 | 35 |
| Segarra | 3 | 1 | 146 | 9 |
| Segrià | 20 | 15 | 986 | 396 |
| Selva | 19 | 5 | 796 | 86 |
| Solsonès | 3 | 1 | 69 | 35 |
| Tarragonès | 23 | 15 | 1305 | 367 |
| Terra Alta | 3 | 0 | 59 | 0 |
| Urgell | 7 | 2 | 200 | 38 |
| Val d’Aran | 2 | 0 | 57 | 0 |
| Vallès Occidental | 63 | 76 | 3309 | 1715 |
A partir de datos del INE el año 2006 tenemos los siguientes datos, por comunidades autónomas, sobre recursos hídricos (con la codificación de las variables que a continuación se especifica):
| V1=Volumen de agua disponible |
| V2=Procedente de la captación propia |
| V3=Aguas superficiales |
| V4=Aguas subterráneas |
| V5=Otros recursos hídricos |
| V6=Volumen de agua abastecida |
| V7=A los hogares |
| V8=Otros usos |
| V9=Pérdidas de agua en la red de distribución |
| V10=Porcentaje de agua perdida en la distribución |
| CCAA | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 |
| Andalucía | 389 | 233 | 163 | 67 | 3 | 263 | 176 | 87 | 50 | 16,1 |
| Aragón | 342 | 150 | 138 | 12 | 0 | 240 | 150 | 90 | 58 | 19,5 |
| Asturias, Principado de | 383 | 214 | 160 | 54 | 0 | 279 | 184 | 95 | 30 | 9,6 |
| Balears, Illes | 375 | 205 | 50 | 113 | 42 | 262 | 150 | 112 | 63 | 19,5 |
| Canarias | 340 | 178 | 53 | 33 | 92 | 212 | 141 | 71 | 47 | 18,1 |
| Cantabria | 435 | 121 | 98 | 9 | 14 | 316 | 201 | 115 | 104 | 24,8 |
| Castilla y León | 409 | 267 | 213 | 54 | 0 | 250 | 147 | 103 | 52 | 17,3 |
| Castilla-La Mancha | 335 | 279 | 161 | 118 | 0 | 239 | 166 | 73 | 55 | 18,7 |
| Cataluña | 324 | 180 | 79 | 97 | 4 | 227 | 150 | 77 | 40 | 15,1 |
| Comunitat Valenciana | 363 | 253 | 91 | 153 | 9 | 240 | 185 | 55 | 71 | 22,8 |
| Extremadura | 462 | 379 | 354 | 25 | 0 | 281 | 183 | 98 | 64 | 18,5 |
| Galicia | 293 | 248 | 212 | 36 | 0 | 227 | 159 | 68 | 46 | 16,8 |
| Madrid, Comunidad de | 298 | 290 | 223 | 67 | 0 | 206 | 148 | 58 | 29 | 12,3 |
| Murcia, Región de | 307 | 71 | 56 | 15 | 0 | 240 | 166 | 74 | 41 | 14,7 |
| Navarra, Comunidad Foral de | 411 | 316 | 121 | 195 | 0 | 261 | 128 | 133 | 42 | 13,9 |
| País Vasco | 323 | 280 | 272 | 7 | 1 | 243 | 129 | 114 | 35 | 12,7 |
| Rioja, La | 383 | 361 | 230 | 131 | 0 | 269 | 148 | 121 | 53 | 16,3 |
| Ceuta y Melilla | 385 | 385 | 24 | 206 | 155 | 189 | 140 | 49 | 99 | 34,2 |
1. Si queremos predecir si un estudiante aprobará un examen en función de las horas que ha dedicado a estudiar, debemos tener una muestra previa de casos reales ya examinados y aplicar una:
a. Regresión lineal simple.
b. Regresión no lineal múltiple.
c. Regresión logística simple.
d. Aquí no es posible aplicar ninguna Regresión puesto que estamos hablando de una probabilidad.
2. En una Regresión lineal simple podemos decir:
a. Que los coeficientes son positivos siempre.
b. Que los coeficientes son significativos siempre.
c. Que la decisión sobre la significación de la pendiente de la recta sigue la misma suerte que la decisión sobre la correlación entre las variables: si una es significativa la otra también lo es , si una no es significativa la otra tampoco lo es.
d. Que si la pendiente es significativa la ordenada en el origen también lo será. Y si la pendiente no es significativa la ordenada en el origen puede o no ser significativa.
3. En una Regresión lineal múltiple:
a. El modelo obtenido por el Forward stepwise y por el Backward stepwise es siempre el mismo.
b. Siempre se alcanza un modelo con al menos dos variables independientes.
c. Siempre se alcanza un modelo con al menos una variable independiente.
d. Ninguna de las tres opciones anteriores es cierta.
4. En el modelo y=5x+1, podemos decir:
a. Que la ordenada en el origen no es significativa porque es muy pequeña respecto a la pendiente.
b. Que la ordenada en el origen no es significativa porque es muy pequeña en valor absoluto.
c. Que la pendiente es significativa porque es muy grande en valor absoluto.
d. No podemos decir con seguridad ninguna de las tres cosas anteriores.
5. En un modelo y=2x-4 donde la pendiente tenga un intervalo de confianza del 95% como el siguiente: (0.5, 3.5), podemos decir:
a. No es significativo el valor de la pendiente porque en su intervalo de confianza tenemos el 1.
b. Es significativo el valor de la pendiente porque el intervalo de confianza no contiene al 0.
c. El error en las predicciones será menor del 5%.
d. El valor de la pendiente, a nivel poblacional, podemos asegurar que es 2.
6. En una Regresión logística simple con una Odds ratio igual a 2 i con un intervalo de confianza de esa Odds ratio de (0.6, 5) podemos afirmar:
a. Que hay una relación significativa entre las variables que estamos relacionando porque el intervalo no contiene al 0.
b. Que no es significativa la relación porque el intervalo contiene al 1.
c. Que al aumentar el valor de la variable cuantitativa aumenta la probabilidad de que se dé el suceso codificado con un 1.
d. Que al aumentar el valor de la variable cuantitativa disminuye la probabilidad de que se dé el suceso codificado con un 1.
7. En una Regresión logística simple con una Odds ratio igual a 0.2 i con un intervalo de confianza de esa Odds ratio de (0.05, 0.45) podemos afirmar:
a. Que no hay una relación significativa entre las variables que estamos relacionando porque el intervalo no contiene al 1.
b. Que es significativa la relación porque el intervalo no contiene al 0.
c. Que al aumentar el valor de la variable cuantitativa aumenta la probabilidad de que se dé el suceso codificado con un 1.
d. Que al aumentar el valor de la variable cuantitativa disminuye la probabilidad de que se dé el suceso codificado con un 1.
8. En una Regresión logística simple con un coeficiente b, que multiplica a la variable independiente, de 3 con un intervalo de confianza del 95% de (-1, 7), podemos afirmar:
a. Que un intervalo de confianza del 95% de la Odds ratio no incluirá al 1.
b. Que no es significativa la relación porque el intervalo de confianza contiene al 1.
c. Que no es significativa la relación porque el intervalo de confianza incluye al 0.
d. Que al aumentar el valor de la variable cuantitativa disminuye la probabilidad de que se dé el suceso codificado con un 1.
9. En una Regresión logística simple con un coeficiente b, que multiplica a la variable independiente, de -2, con un intervalo de confianza del 95% de (-4, -1) podemos afirmar:
a. Que un intervalo de confianza del 95% de la Odds ratio incluirá al 1.
b. Que no es significativa la relación porque el intervalo no contiene al 0.
c. Que es significativa la relación porque el intervalo de confianza no incluye al 0.
d. Que al aumentar el valor de la variable cuantitativa aumenta la probabilidad de que se dé el suceso codificado con un 1.
10. Cuál de las siguientes Odds ratio indica una mayor relación entre las variables:
a. 0.2 con un IC 95%: (0.1, 0.4)
b. 5 con un IC 95%: (5, 10)
c. 0.1 con un IC 95%: (0.05, 0.3)
d. 11 con un IC 95%: (9, 15)
Este es un artículo publicado en el New England Journal of Medicine el 18 de Noviembre de 2014.
Es un artículo que estudia la controversia entre si es el valor de HDL estático o bien su capacidad dinámica de eflujo de colesterol de los macrófagos lo que tiene una relación inversa con la incidencia de eventos cardiovasculares.
Este artículo es también interesante, desde el punto de vista estadístico, para aprender a manejar variables cuantitativas categorizándolas en distintos grupos, como veremos a continuación.
El Abstract es el siguiente:

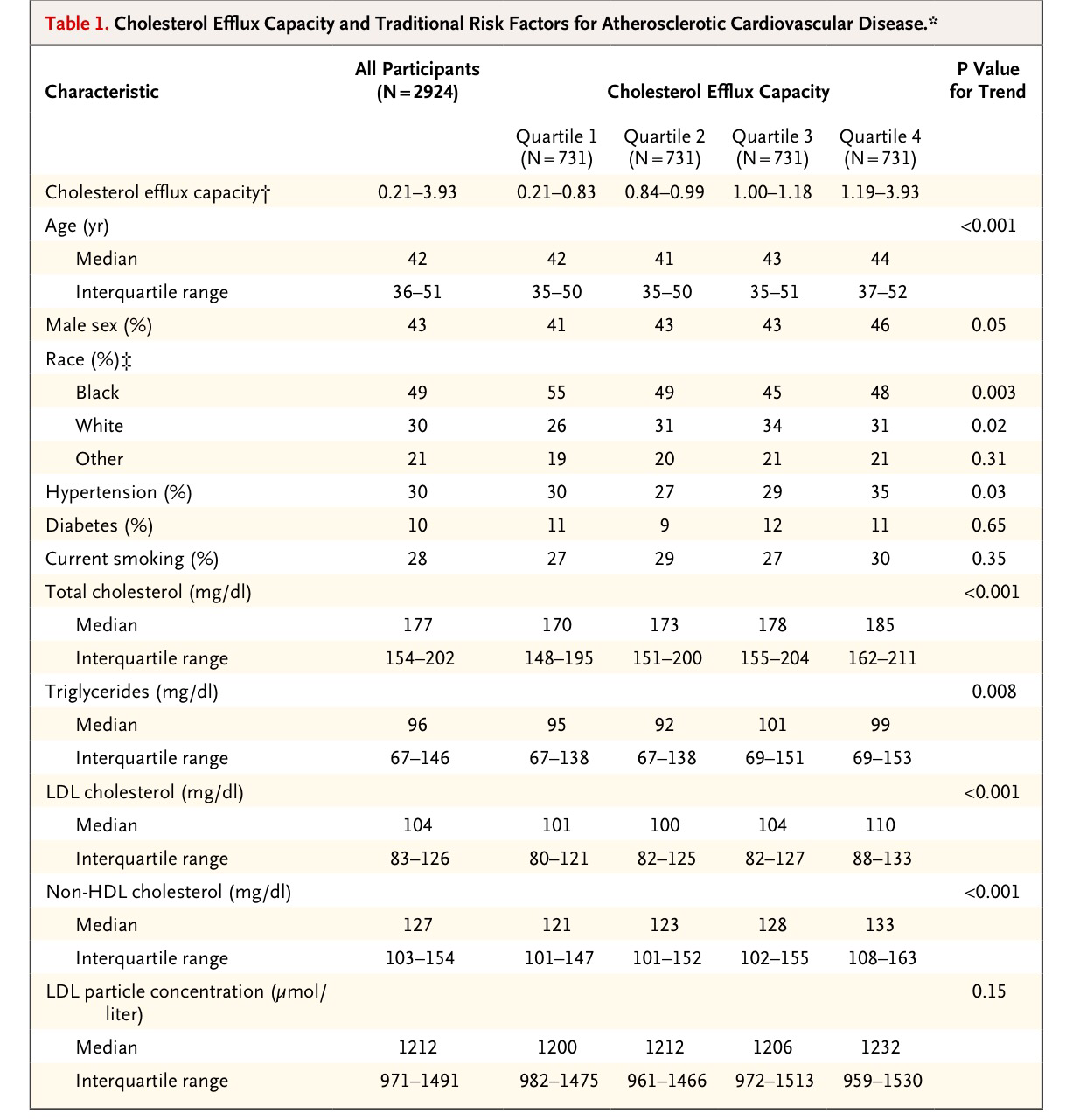
De un total de 2924 participantes en el estudio midieron analíticamente la capacidad de eflujo de colesterol y dividieron a esa muestra en cuatro cuartos según el valor de esa capacidad de eflujo. A continuación puede verse la estadística descriptiva de estos cuatro grupos:
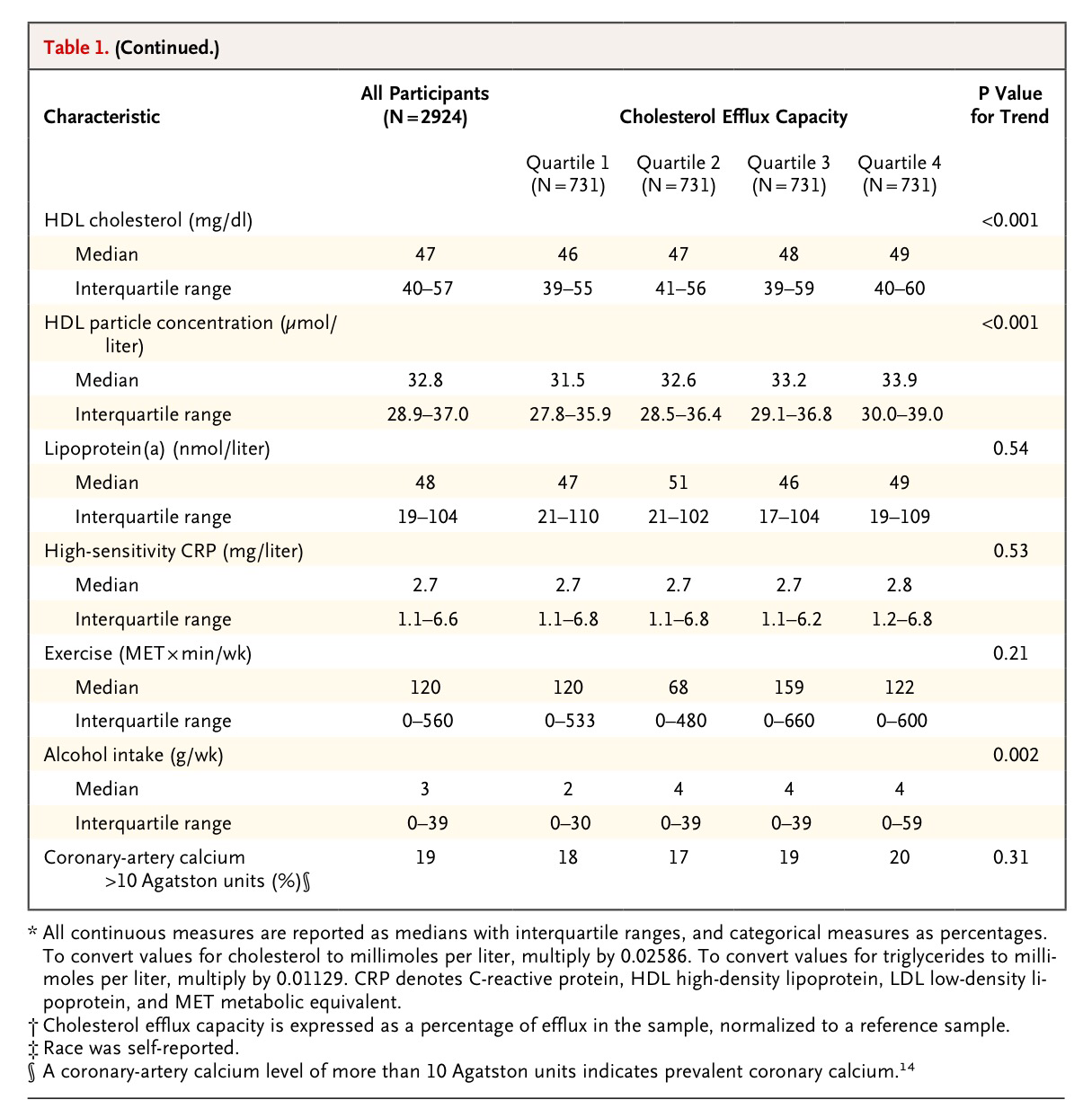
El siguiente paso es mostrar que el nivel de HDL y el eflujo de colesterol son variables no correlacionadas:
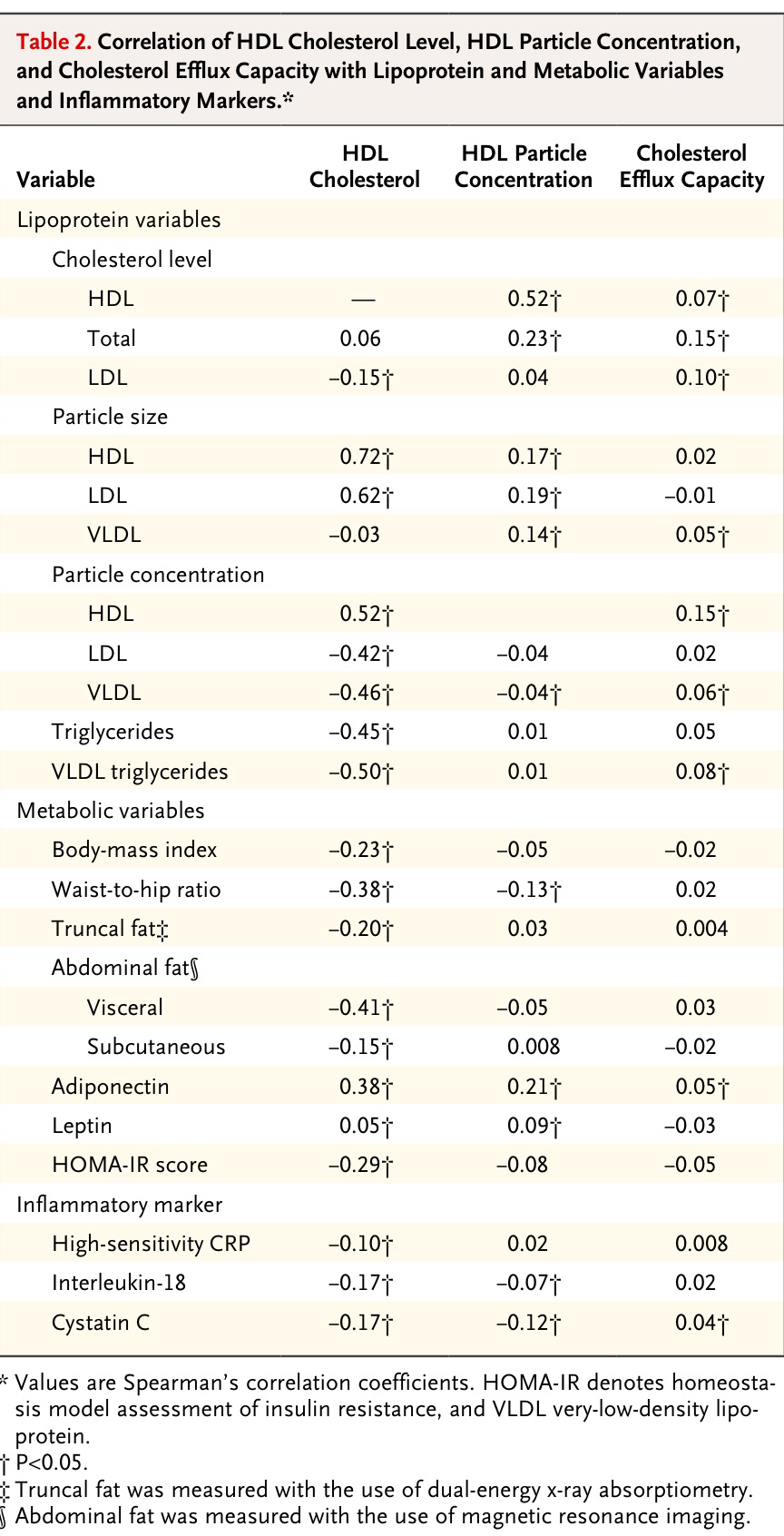
A continuación se trata de ver que es la capacidad del HDL para el eflujo de colesterol y no el valor de HDL estático el que está asociado, de forma favorable, con los eventos cardiovasculares; o sea, que es el factor de protección para tales eventos:

Observemos que la Hazard Ratio de la relación del nivel de HDL con los eventos cardiovasculares no es significativamente distinta de 1. Sin embargo, la del eflujo de colesterol sí lo es. Su intervalo de confianza no incluye al 1 y está por debajo de 1, lo que indica que un eflujo de colesterol mayor va asociado de una protección ante tal tipo de eventos. En cambio, no sucede así con los niveles de HDL, indicando que no son ellos, en sí los que son protectores sino su capacidad de movilizar el colesterol de los macrófagos.
Observemos, a continuación, la distinta asociación entre los cuatro cuartiles de la variable cuantitativa «eflujo de colesterol» y los eventos cardiovasculares:
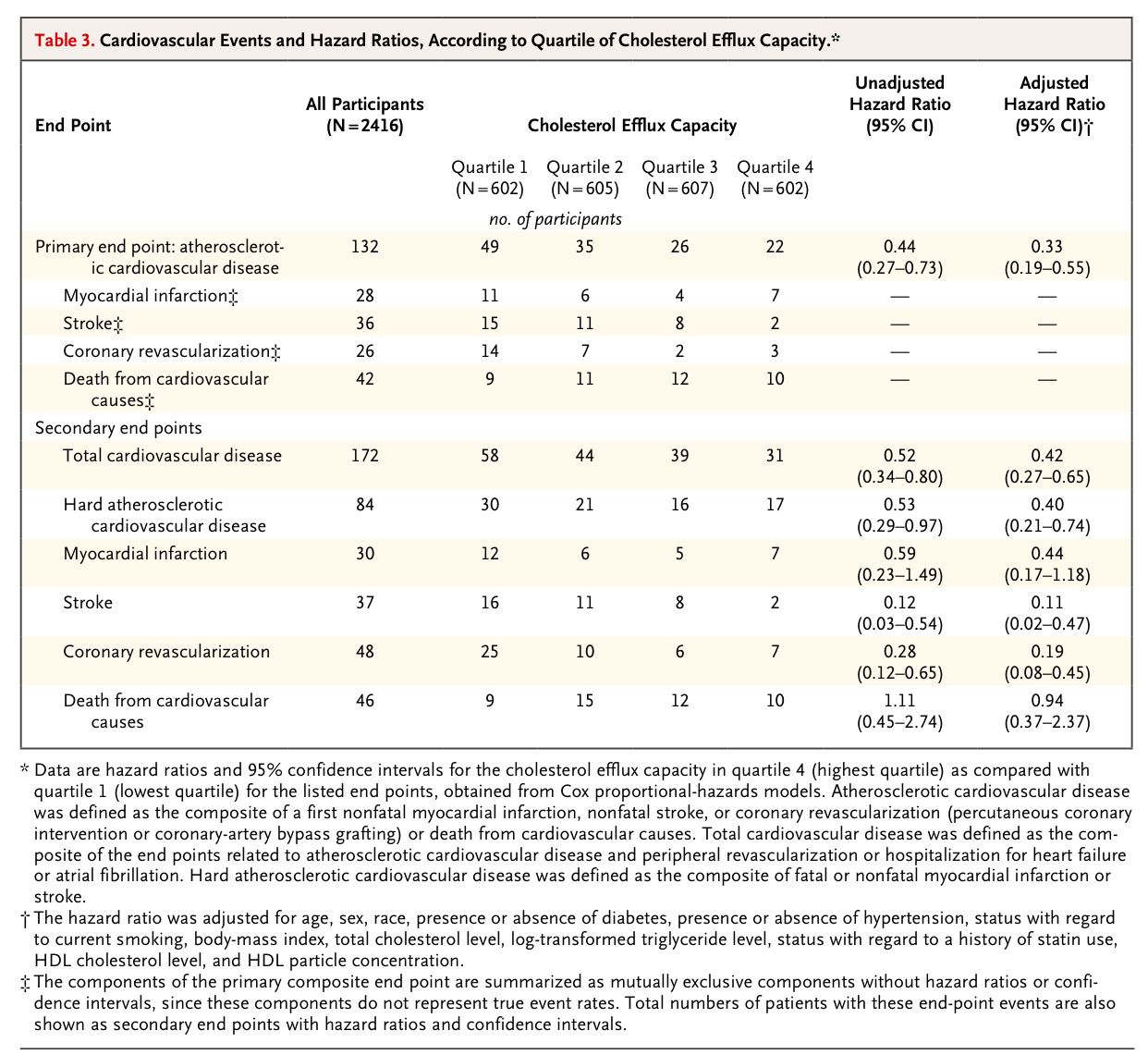
Y observemos, finalmente, a continuación, los gráficos de las curvas de Kaplan-Meier expresadas como funciones de riesgo:
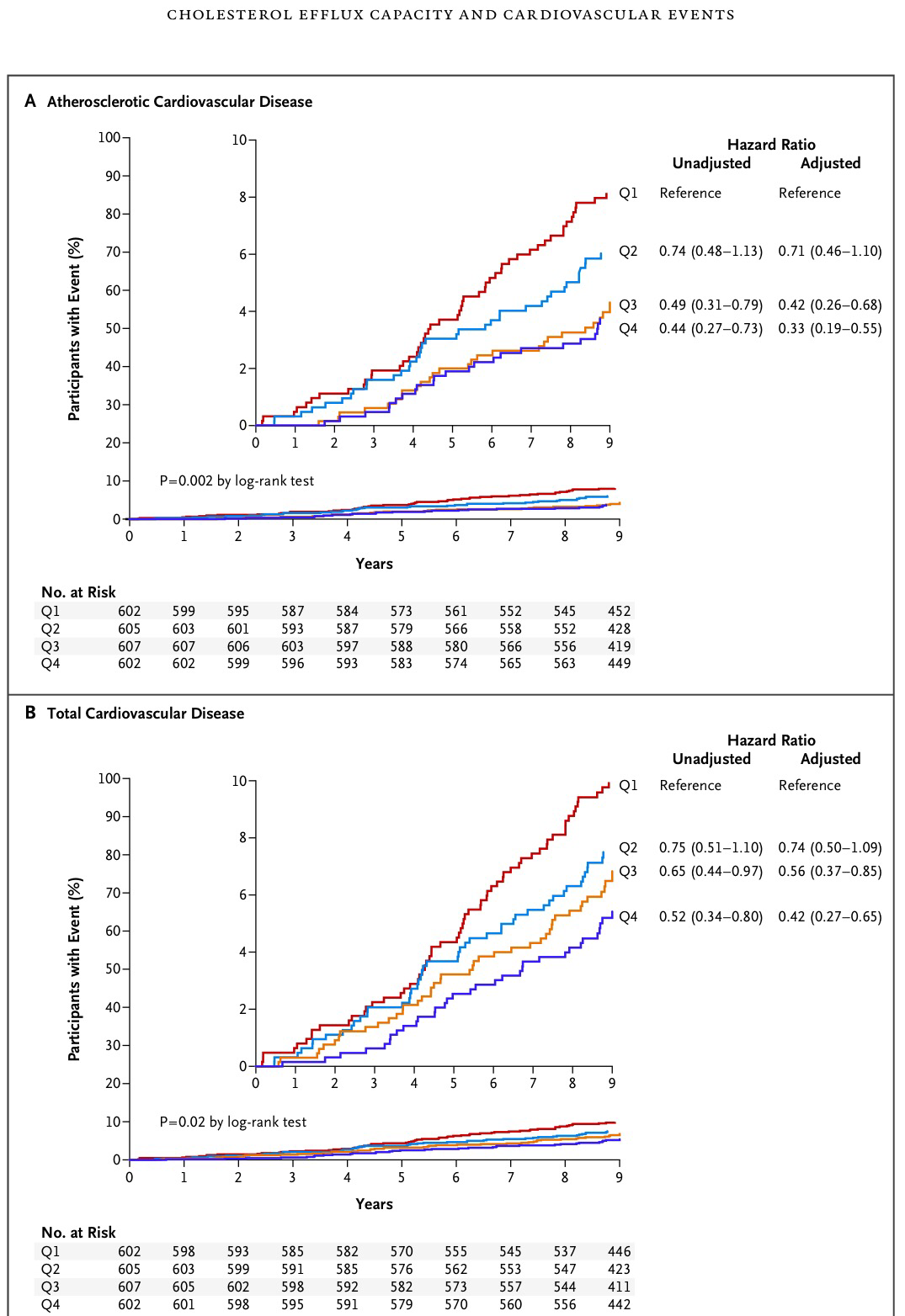

Es interesante ver estos gráficos y saberlos interpretar. Es interesante porque ello nos puede llevar a saber combinar nociones tan importantes en la investigación clínica en Medicina como «curvas de supervivencia», «funciones de riesgo» y «Hazard ratio».
Unos artículos del Blog son recomendables para poder entender bien estos resultados: Para ver el concepto de curva de supervivencia, estimador de Kaplan-Meier y función de riesgo ir al artículo: Tema 25: Análisis de supervivencia. Para ver el concepto de Hazard Ratio y sus similaridades y diferencias con el concepto de Odds ratio ir al artículo: Odds ratio y Hazard ratio. Para ver la conexión entre Hazard ratio, curvas de supevivencia y funciones de riesgo ir al artículo: Tema 22: Regresión de Cox.
Se puede observar en los gráficos la presencia del Log-rang test. Es un test estadístico para contrastar la hipótesis de igualdad de curvas de supervivencia o de igualdad de funciones de riesgo. Vemos que en ambos casos, en ambas comparaciones, de los gráficos anteriores, el p-valor es inferior a 0.05, lo que indica que esas curvas no son iguales significativamente.
En este artículo publicado en el New England Journal of Medicine en este año 2014 se realiza un importante estudio de la relación y la cuantificación del riesgo de mortalidad en general y mortalidad por causas cardiovasculares en función del nivel de control de la glucemia en diabéticos tipo 1.
El Abstract es el siguiente:

Observemos a continuación una tabla descriptiva de los diferentes grupos de estudio según el distinto nivel de control de la diabetes, evaluado mediante el nivel de Hemoglobina glicada:
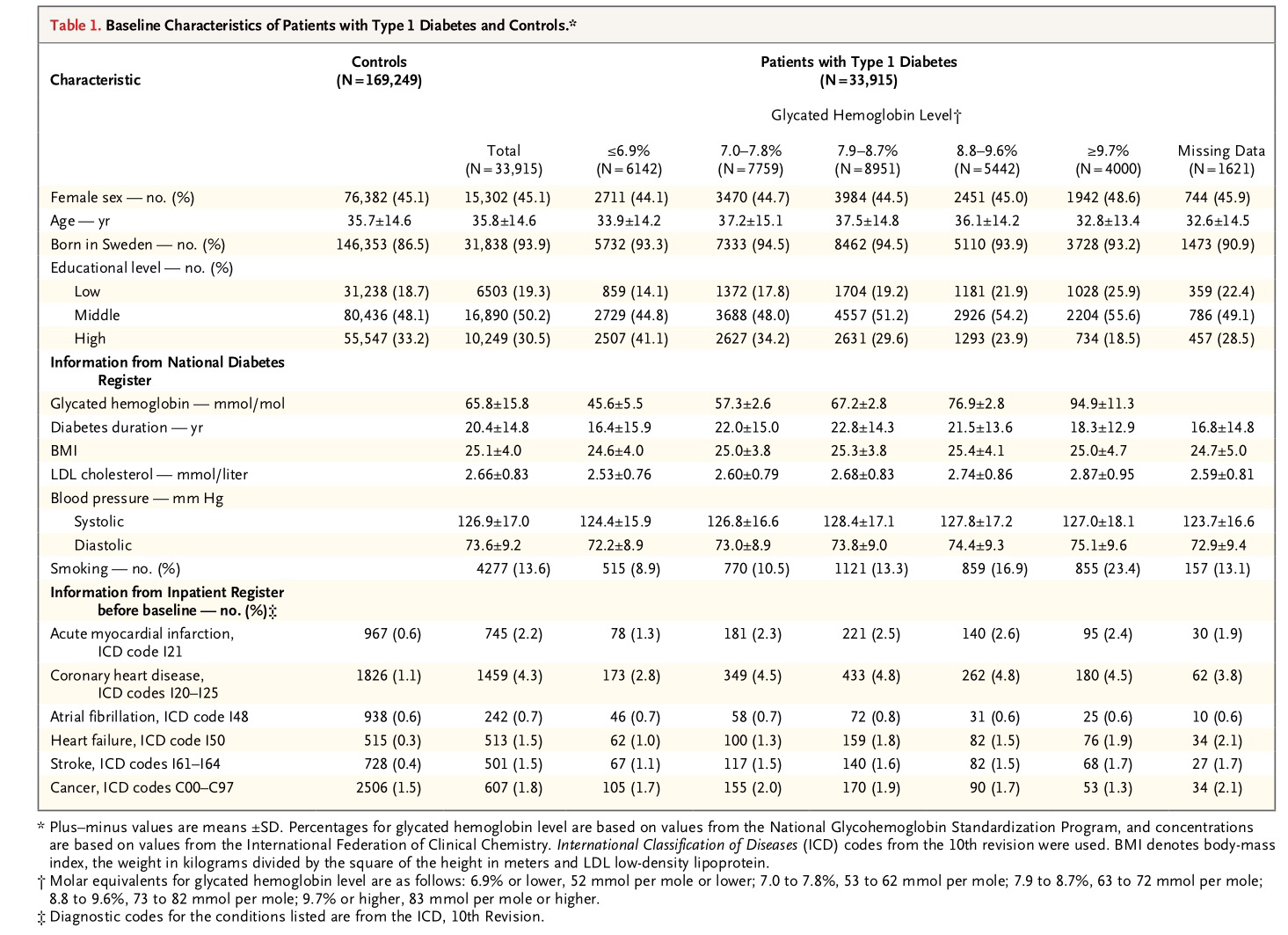
La siguiente tabla analiza la mortalidad en los diferentes grupos delimitados:
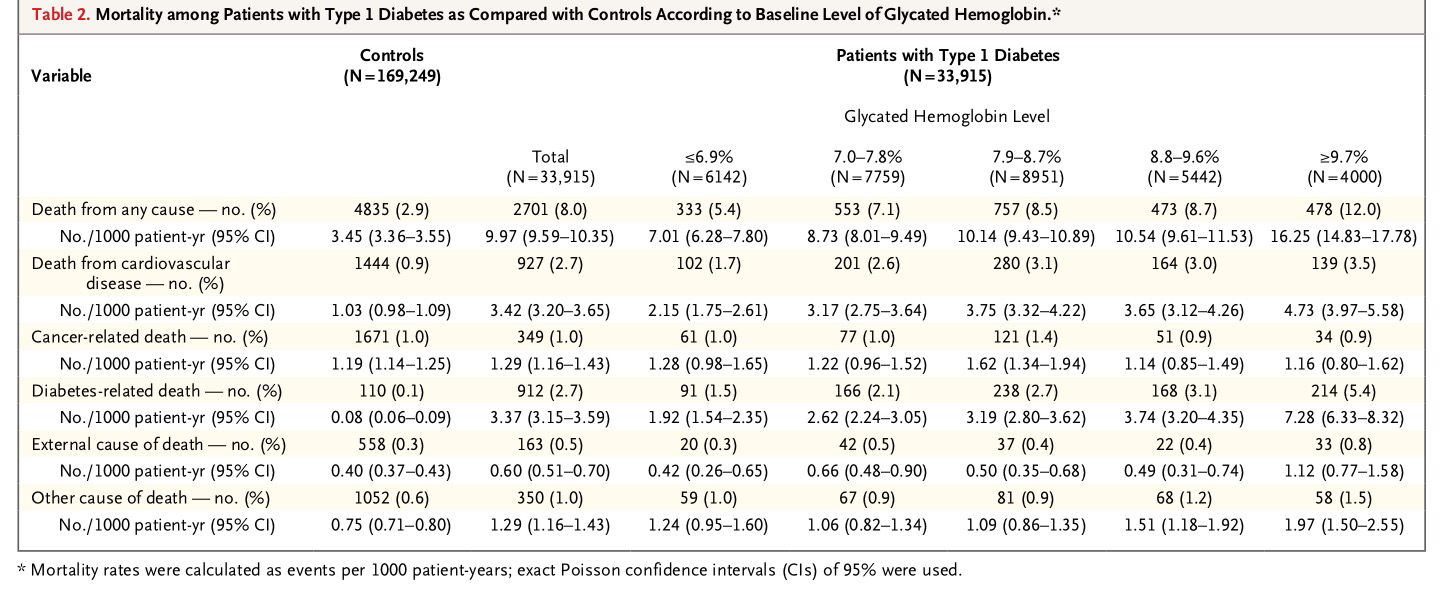
En la tabla y gráfico siguiente se calcula la Hazard ratio según sexo y según grupo de edad, separando la muerte por cualquier causa de la muerte por causas cardiovasculares:
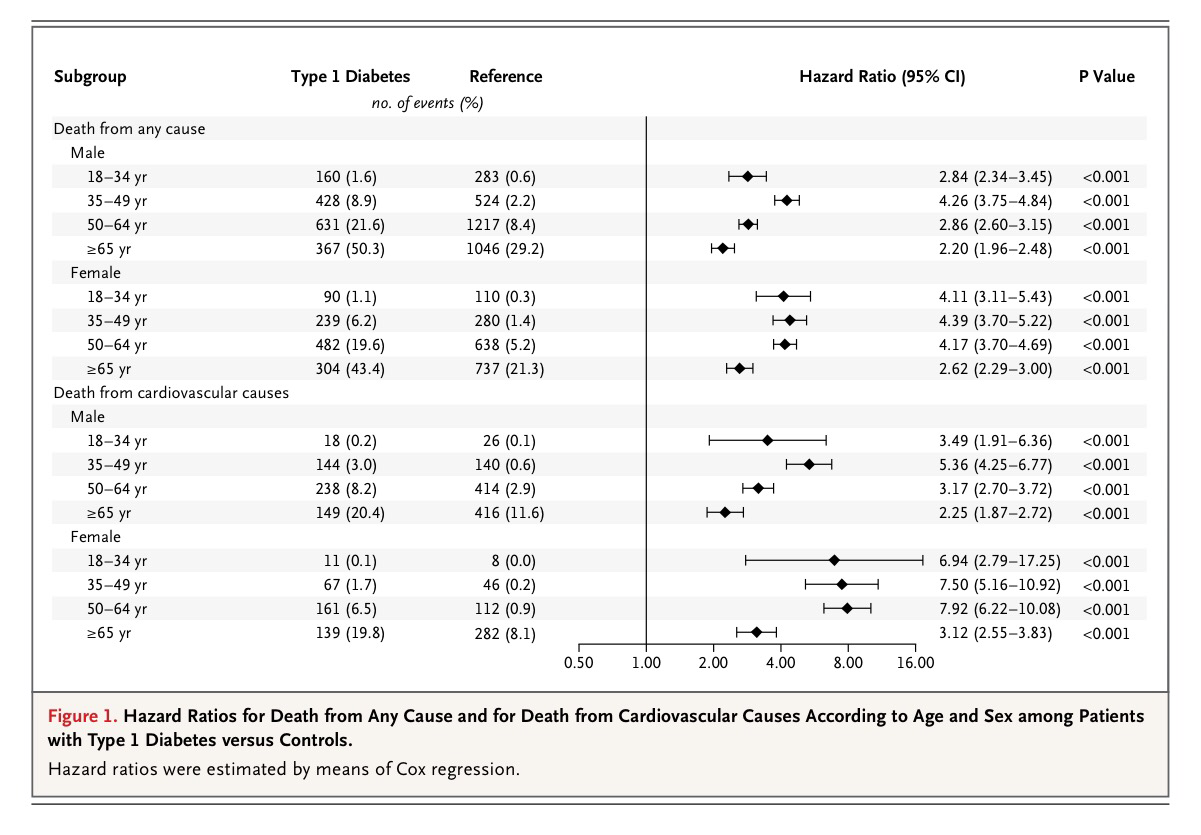
La siguiente tabla es una tabla ajustada:
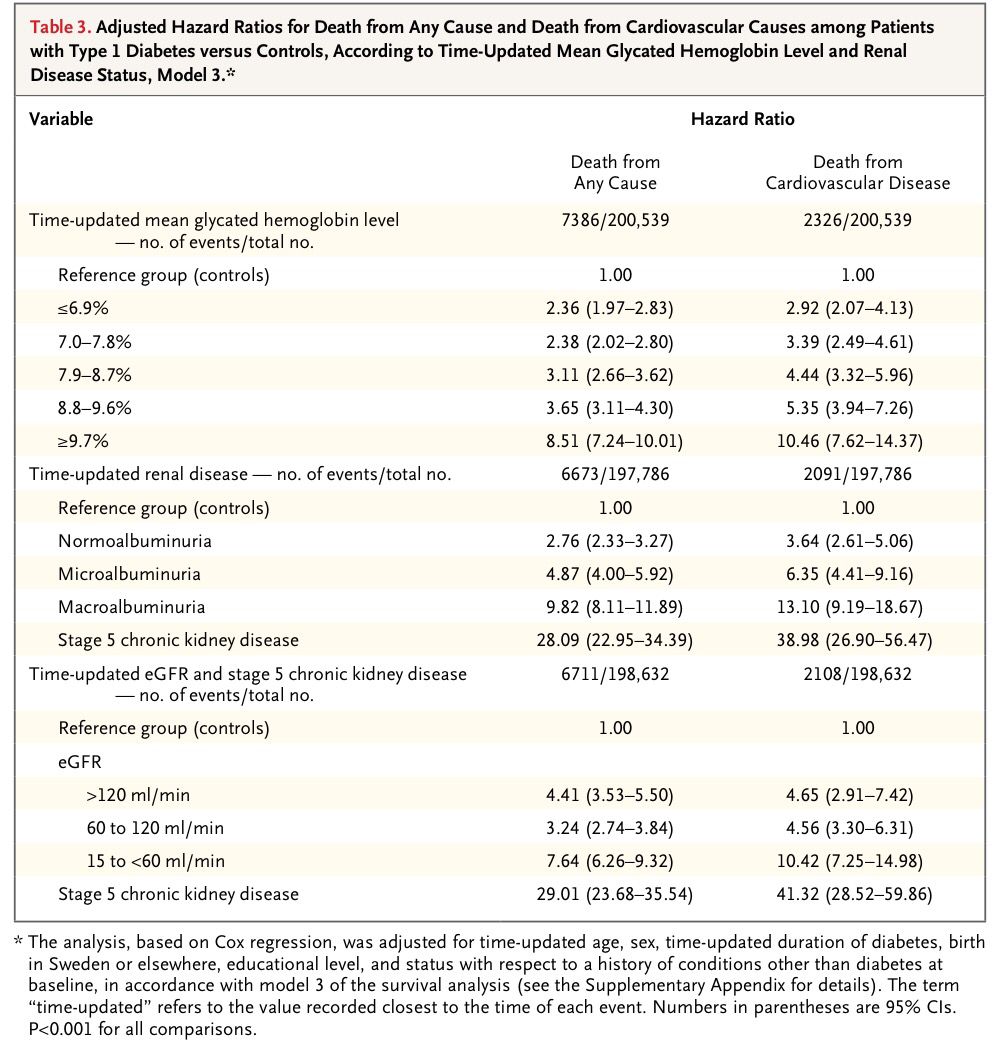
Como puede verse los autores obtienen unas medidas del aumento relativo del riesgo de morir por cualquier causa o morir por causas cardiovasculares, en diabéticos tipo I. Los números, con sus correspondientes intervalos de confianza, estiman el aumento del riesgo. Por ejemplo, si tenemos una Hazard ratio, en la relación de dos grupos, de 3, significa que a lo largo del tiempo que se ha estudiado la mortalidad de ambos grupos el grupo con valor de 3 respecto al grupo referencia, la probabilidad de morir es tres veces mayor. Si a tiempo 1 la mortalidad en el grupo referencia es de 2/1000 en el grupo de estudio es de 6/1000 y si a tiempo 10 la mortalidad en el grupo referencia es de 10/1000 en el grupo de estudio es de 30/1000. Se mantiene constante esta relación (Esta es una condición para que la Regresión de Cox sea aplicable).
Es muy importante ver que al manejar la Hazard ratio estamos hablando de evolución temporal. Si el estudio se hiciera en un momento puntual determinado (por ejemplo, a los 10 años) manejaríamos la Odds ratio y aplicaríamos la Regresión logística.
En la siguiente tabla se dan valores de mortalidad según diferentes modelos:
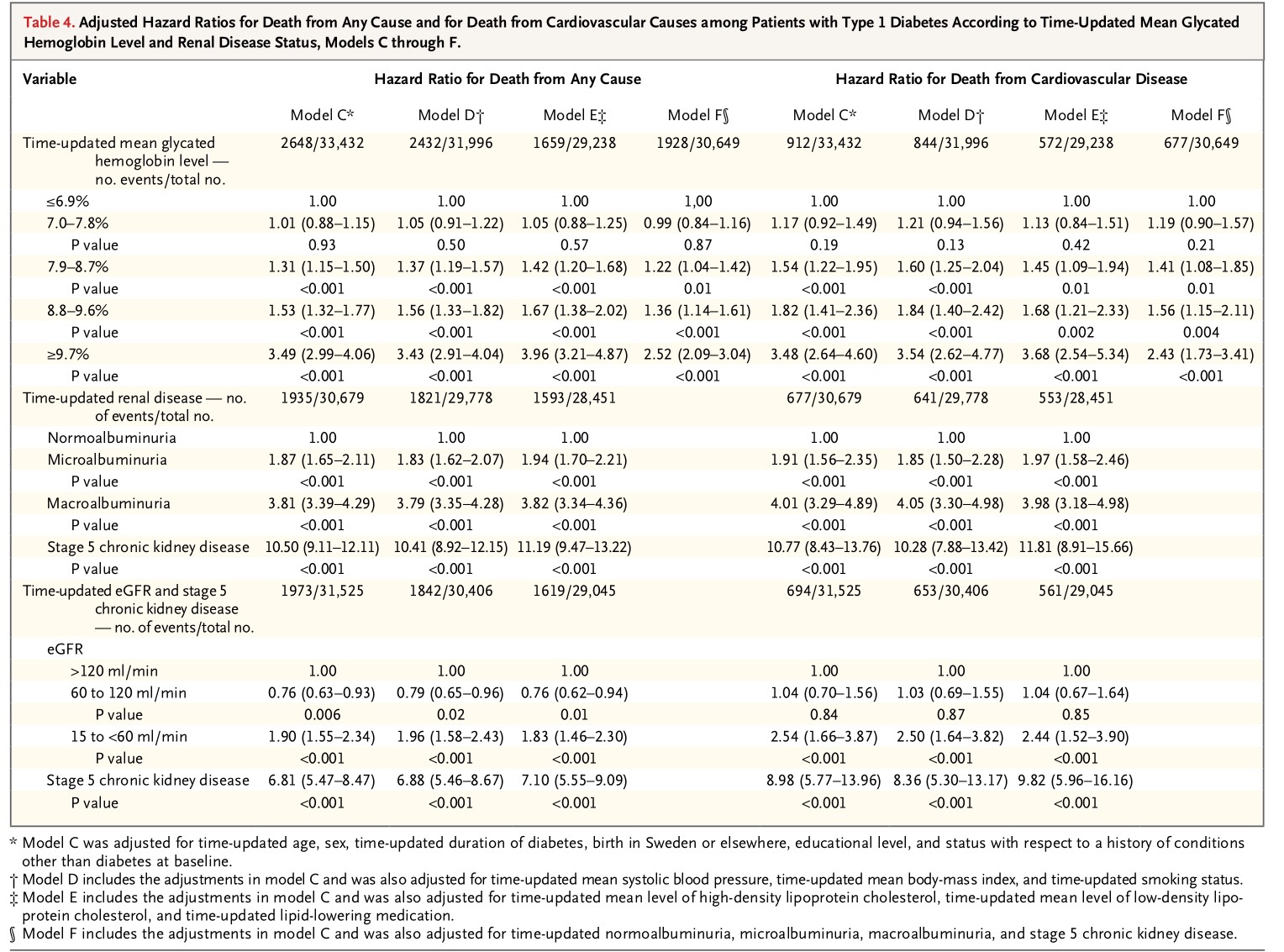
En este artículo es interesante ver cómo ensayan la comparación de distintos ajustes. ¿Qué significa ajustar? Significa evitar la incidencia de variables confusoras. Ver el Tema 26: Análisis estadístico de variables confusos. En este caso, como calculan las Hazard ratio, el ajuste lo hacen introduciendo las variables que quieran evitar la confusión en la Regresión de Cox necesaria para calcular esa Hazard ratio (Ver el Tema 22: Regresión de Cox).
Hay dos grandes formas de ajuste de un cálculo de riesgo (de una Odds ratio o de una Hazard ratio (Ver artículo La Odds ratio versus la Lazard ratio)):
1. Mediante el Propensity Score Analysis (Ver el Tema 24: Análisis de propensiones (Propensity Score Analysis).
2. Introduciendo la variable de ajuste en la Regresión logística o en la Regresión de Cox que se realice. La diferencia entre estas dos regresiones está fundamentalmente en que en la primera se mira el resultado a un tiempo fijo, por eso acabamos manejando una Odds ratio, mientras que en la segunda, en la Regresión de Cox, nos interesa la evolución, nos interesa analizar la curva de supervivencia o la función de riesgo, por eso acabamos manejando la Hazard ratio.
