En el número publicado el 5 de diciembre de 2013 de la revista The New England Journal of Medicine hay un muy interesante artículo titulado «How Early Should Obesity Prevention Start?». Se presentan factores de riesgo temprano de obesidad. El gráfico que se adjunta es el siguiente:
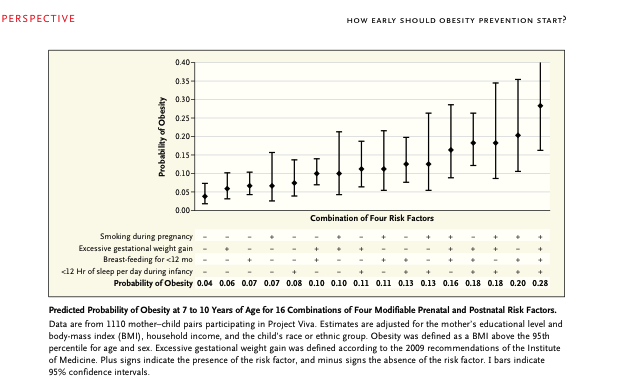
En este gráfico pueden observarse las cuatro variables tempranas analizadas (prenatales y postnatales) y todas sus combinaciones posibles asociadas con la probabilidad de obesidad entre los 7 y 10 años. Las predicciones se dan, como se puede ver, en una probabilidad y un intervalo de confianza.
Los factores de riesgo son elementos importantes en Medicina. Son factores que anuncian patologías y, por lo tanto, son semáforos que nos advierten y que nos recomiendan que pongamos los medios que tengamos a nuestro alcance para evitar, en la medida de nuestras posibilidades, lo que anuncian.
¿Cómo se calculan estas predicciones de probabilidad de obesidad? ¿Cómo se calculan estos intervalos de confianza? Evidentemente se trata de un estudio que necesita partir de una muestra bastante amplia puesto que al final por la combinación de estas cuatro variables surgen muchas situaciones distintas a estudiar individualmente. Son 16 situaciones distintas. Tantas como combinaciones distintas pueden darse con el SÍ o NO de estas cuatro variables estudiadas.
Una vez tengamos distribuidos los diferentes casos estudiados en uno de las 16 combinaciones posibles, el cálculo es muy sencillo. Se trata de ver cuántos son casos de obesidad y cuántos no. El cálculo de la probabilidad que aparece para cada uno de estas 16 combinaciones es tan sencillo como dividir los casos de obesidad por los casos totales que tengamos de esa combinaciones.
El intervalo de confianza es el de una proporción. Para construir un intervalo de confianza del 95% de una proporción la formulación más habitual es la siguiente:
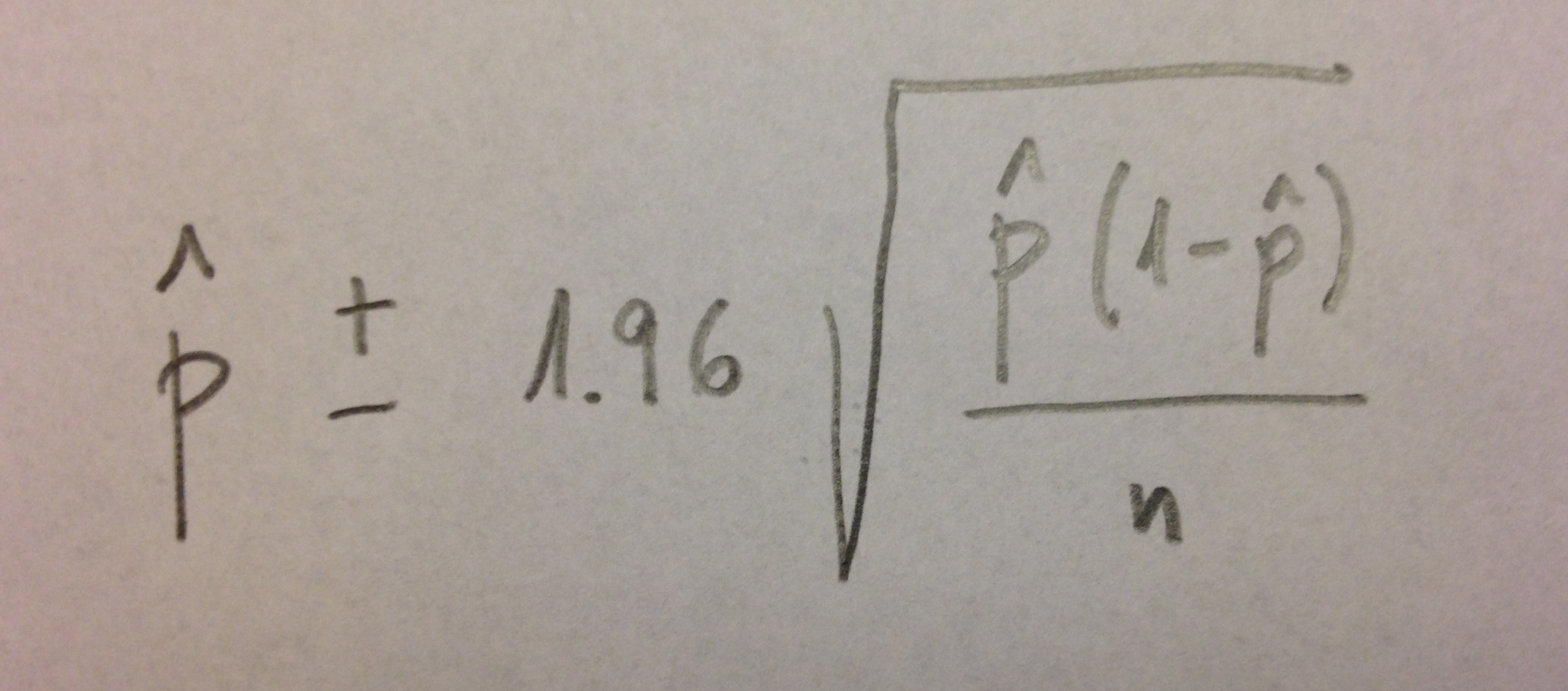
donde la p con el sombrerito encima significa la proporción de casos obtenidos por cada combinación y n el tamaño de muestra con el que se ha trabajado en esa combinación.
En el estudio que comento no se ha trabajado con este intervalo puesto que los valores que se dan no son simétricos respecto al valor central del intervalo, pero esta opción que comento sería una con la que obtendríamos resultados similares.
El que los intervalos de confianza tengan distintas amplitudes en los 16 casos es debido a que según sea el valor de p con sombrerillo y, especialmente, según sea el valor del tamaño muestral, de la n, el intervalo es más o menos amplio. Por ejemplo, muestras más grandes permiten construir intervalos más estrechos; muestras más pequeñas, por el contrario, van acompañadas de intervalos más amplios.
Observemos que, viendo el gráfico del artículo, y teniendo el cuenta lo que acabo de decir, la situaciones con más valores negativos de la variables son las situaciones donde se dispone de más casos (intervalos más estrechos). Sin embargo, las situaciones con más valores positivos de esas mismas variables son de las que se dispone de menos casos (intervalos más amplios).
