Lo primero que hay que comprobar es si podemos usar una distribución normal como modelo de la variable que estamos estudiando. Nos dicen que la variable se ajusta bien a la Distribución normal. Como la media y la desviación estándar son, 6 y 1, respectivamente, la valoración que los consumidores hacen de ese producto sigue una distribución normal N(6, 1). Con esta distribución tenemos, pues, una maqueta, un buen dibujo de la población total de consumidores de ese producto y la valoración que ellos hacen de él.
Vamos, pues, a utilizar este modelo para calcular lo que se nos pide:
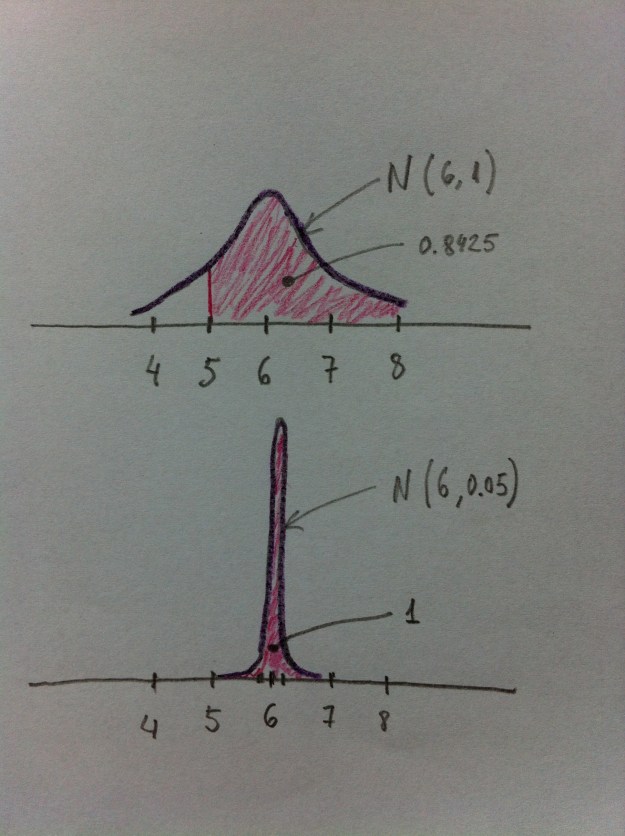
1) Como 5 es igual a 6-1, que es la media menos una desviación estándar, por encima de una valoración de 5 debe haber el 68.5 % de consumidores que hay en el intervalo que va desde la media menos una DE hasta la media más una DE, más los consumidores que hay en una de las dos colas de ese intervalo, por lo tanto, por encima de 5 tenemos: 68.5+15.75=84.25. Observemos que 15.75 es la mitad de 31.5 que es el total de lo que queda en las dos colas (los dos extremos) de la campana de Gauss en un intervalo que vaya de la media menos una DE a la media más una DE.
2) Para la segunda pregunta necesitamos saber el Error estándar (EE=DE/raíz(n)) que, en este caso, es 1/raiz(400)=0.05. Por lo tanto, tenemos una confianza del 95% de que la media poblacional esté entre 5.9 y 6.1 (este intervalo se obtiene sumando y restando a la media dos veces, ahora, el Error estándar), por lo tanto, la probabilidad de que la media esté por encima de 5 es una probabilidad muy grande, prácticamente 1.
En el gráfico adjunto pueden verse las dos distribuciones normales: la de arriba, la N(6, 1), es la de la variable valoración individual de los consumidores; la de abajo, la N(6, 0.05) es la de la media. Puede verse dibujado en rojo el área que hay, por encima de 5, en ambas distribuciones.
Observemos en este problema la diferencia entre la primera pregunta y la segunda. Es importante. En la primera hablamos de valores individuales de consumidores. El 84.25% puntúan al producto por encima de 5. En la segunda pregunta hablamos de la media poblacional, no de valores individuales. La probabilidad de que la media poblacional esté por encima de 5 es prácticamente 1.