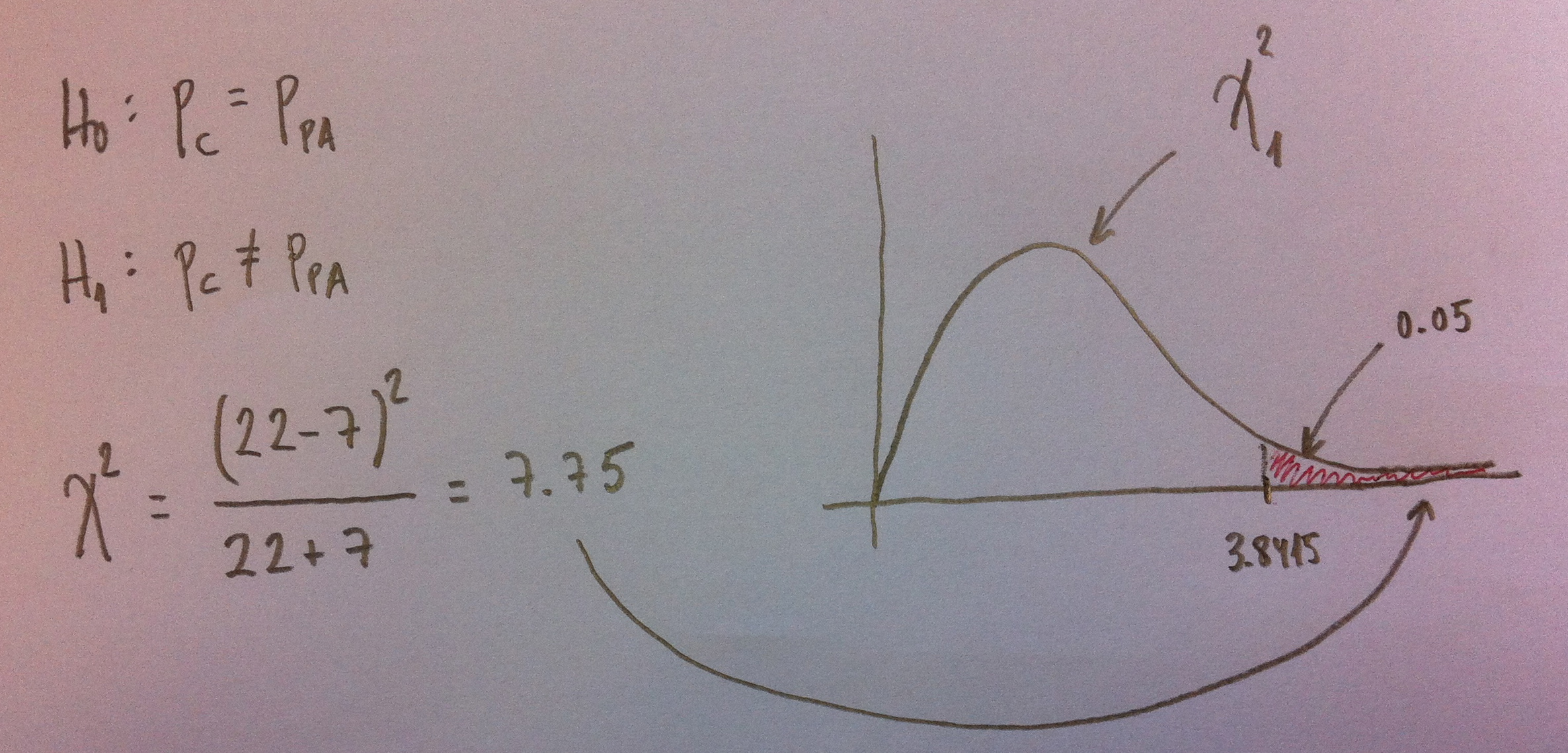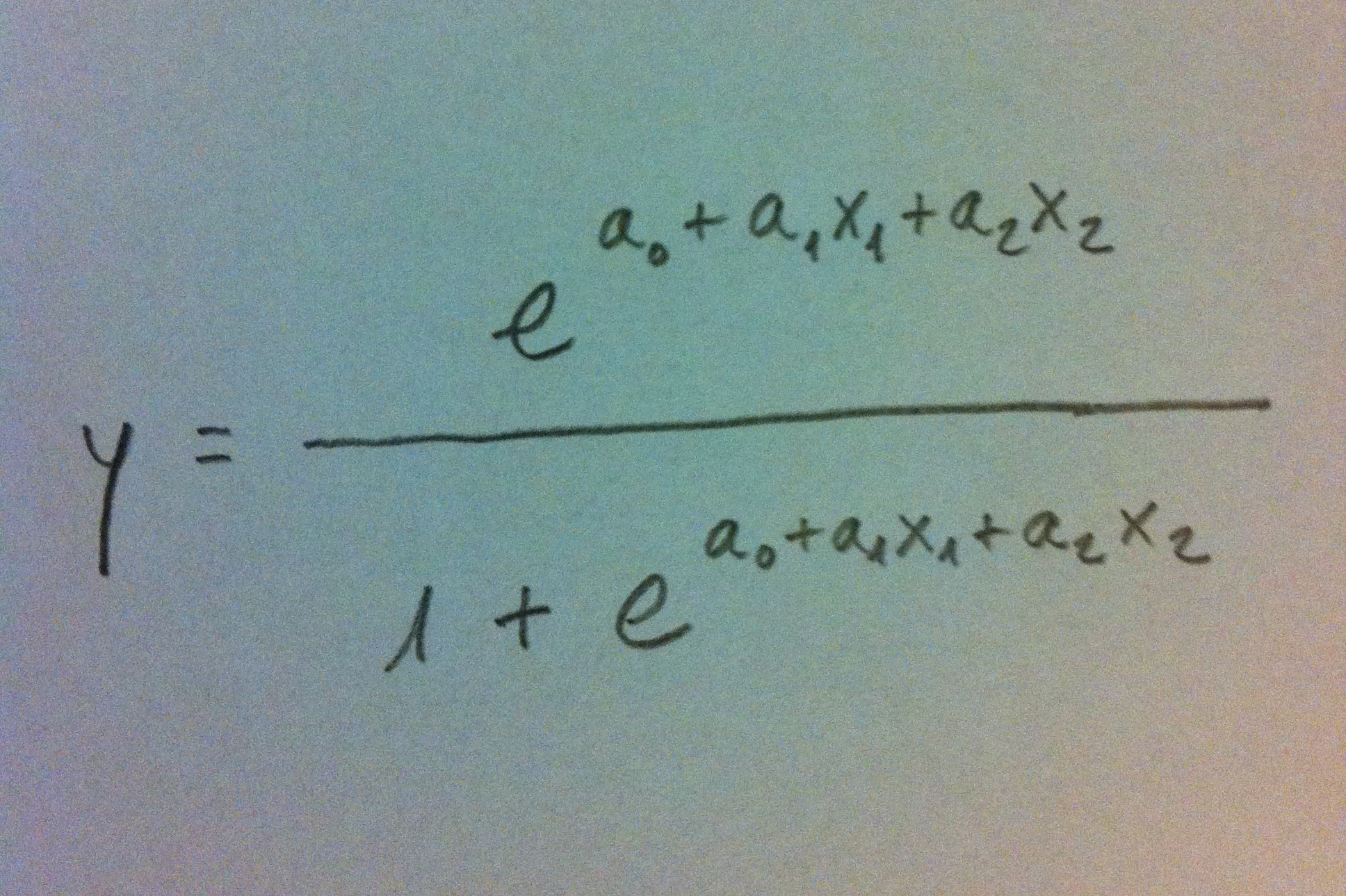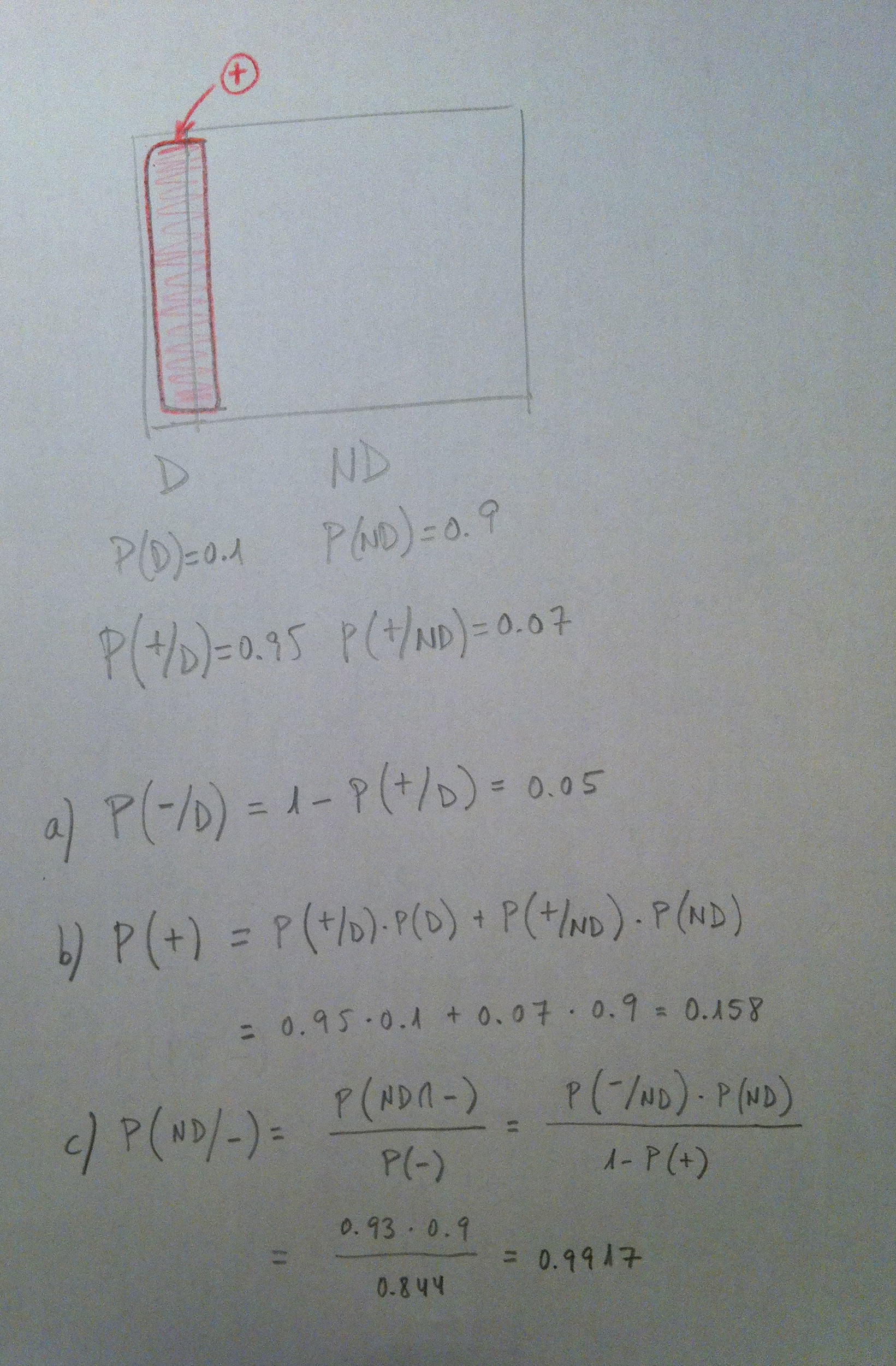En una variable cuantitativa no es el tamaño de muestra lo que condiciona que se use, para describirla, la media y la desviación estándar o la mediana y el rango intercuartílico. Depende de su ajuste a la distribución normal, a la campana de Gauss. Por lo tanto, las respuesta a y b no son ciertas.
Pero la respuesta c sí es correcta. Hemos visto en el artículo «La Estadística descriptiva en Medicina» que si la variable cuantitativa se ajusta bien a una distribución normal si a la media le restamos y le sumamos 0.68 multiplicado por la desviación estándar construimos un intervalo con un 50% de valores poblacionales. El rango intercuartílico, que es la distancia entre el primer y tercer cuartil, cubre un 50% también central. Por lo tanto, dos veces este 0.68; o sea, 1.36 la desviación estándar debe ser un valor similar al rango intercuartílico.
Si la muestra se ajusta bien a una distribución normal la media es muy próxima a la mediana y el rango intercuartílico próximo a 1.36xDE porque sabemos que la media más y menos 0.68xDE en una distribución normal construye un intervalo centrado en la media del 50% de valores.
2c:
El Rango no tiene por qué ser dos veces el Rango intercuartílico, en general. Pueden llegar incluso a ser iguales, ambos rangos. Por ejemplo, en la muestra: (0, 0, 10, 10). En esta muestra Rango y Rango intercuartílico valen lo mismo: 10.
La media muestral puede ser menor que la mediana muestral perfectamente. Por ejemplo, en la muestra: (0, 10, 10, 10). La mediana muestral es 10 y la media muestral es 7.5.
No necesariamente si la mediana muestral y el tercer cuartil coinciden la media muestral debe ser mayor que la mediana muestral. La muestra anterior de nuevo lo demuestra.
Y, finalmente, el primer y tercer cuartil pueden coincidir perfectamente en una muestra. Por ejemplo: (0, 5, 5, 5, 5, 5, 5, 10). Aquí primer cuartil y tercer cuartil coinciden: 5.
3c:
La especificidad es la probabilidad de que dé negativa la prueba condicionado a que el paciente no tenga la enfermedad; o sea, P(-/NE). Los falsos positivos son la P(+/NE). Y, evidentemente, P(+/NE)+P(-/NE)=1. Luego la especificidad es 1-Probabilidad de tener falsos positivos.
4d:
El “a” no es cierto en general. La simetría que transmite la idea de que la mediana sea el promedio exacto del primer y tercer cuartil no implica que esa simetría no se puede romper por la izquierda del primer cuartil o por la derecha del tercer cuartil. Un ejemplo: (0, 0, 5, 5, 5, 5, 10, 100). En esta muestra el primer cuartil es 2.5 y el tercero 7.5. La mediana, que es 5, es, en este caso, el promedio del primer y tercer cuartil, lo que indica que hay una simetría central. Obsérvese que efectivamente, si prescindimos de los dos valores extremos, el mínimo y el máximo, hay una simetría manifiesta, lo que haría pensar en que la media y la mediana podrían ser iguales. Pero observemos que la simetría se rompe en esta muestra por culpa del 100. Lo que hace que la media ascienda mucho y sea considerablemente distinta de la mediana. La media muestral es 16.2.
La “b” tampoco es cierta. Si la muestra se ajusta a una normal la media muestral y la mediana muestral se aproximarán, pero no necesariamente serán iguales.
La “c” tampoco es cierta. Veámoslo con un ejemplo: La muestra (0, 1, 2, 3, 5, 5, 6, 6). La media muestral es 3.5. El primer cuartil es 1.5 y el tercero es 5.5. El promedio de estos dos cuartiles es 3.5. Por lo tanto, en esta muestra coinciden el promedio de primer cuartil y tercer cuartil y la media muestral, pero la mediana de esta muestra es 4.
5c:
La muestra no se ajusta bien a una distribución normal, por lo tanto la inferencia del apartado «a» no es correcta.
La mediana es 4.5, no 5.
El que en la muestra el valor superior sea 60 no significa que en la población no puedan haber valores superiores a él, evidentemente.
Como el intervalo construido por el primer y tercer cuartil de nuestra muestra, que es (3, 30) cubre el 50% muestral podemos hacer perfectamente la estimación, la inferencia, de que en la población habrá un valor próximo al 50% de individuos entre estos dos valores de la variable estudiada.
Se ha publicado un interesante estudio en el New England Journal of Medicine de aplicación del Test de McNemar en Medicina que vale la pena comentar.
Se compara la eficacia de un páncreas artificial automatizado, que controla la glucemia y suministra insulina en continuo, respecto a un sistema de control estándar en pacientes con Diabetes tipo 1. Se usan los dos sistemas de control en un grupo de pacientes. En dos noches distintas se ensayan cada uno de estos métodos en todos los pacientes. La variable respuesta es si en algún momento han sufrido una hipoglucemia durante la noche. La variable es, pues, dicotómica: tener o no una hipoglucemia.
Si miramos es cuadro de elección de la técnica a aplicar en el tema «Comparación de dos poblaciones», veremos que como es una variable dicotómica y son muestras relacionadas (al mismo individuo se le aplican los dos procedimientos comparados) deberemos aplicar un Test de McNemar.
Los datos que se obtienen son los siguientes:
Como se puede ver en el Test de McNemar (Ver Herbario de técnicas) la clave es tener en cuenta únicamente las casillas donde se producen resultados contrarios en las dos técnicas. En nuestro caso, únicamente interesa cuándo se ha dado hipoglucemia en una técnica de control y no se ha dado en la otra. Nos interesan los valores 22 y 7, claro.
Veamos la aplicación del Test a nuestros datos:
Estamos contrastando la igualdad de proporciones entre ambas técnicas de control versus la desigualdad, como siempre.
En las tablas de la ji-cuadrado (Ver el artículo dedicado a la Distribución ji-cuadrado en Complementos), podemos ver que en una ji-cuadrado con valor 1 del parámetro, a partir del valor 3.8415 el área es de 0.05. Este es, pues, el nivel de significación. Al ser 7.75 mayor que este valor debemos rechazar la Hipótesis nula y decir que hay diferencias significativa. El p-valor es inferior a 0.05.
El valor de la correlación, sin tener en cuenta más cosas, no es suficiente para marcar la significación. Únicamente una r=0 tendría validez en sí mismo y sería para marcar no significación.
El error estándar siempre es igual o menor que la desviación estándar. Sería igual si el tamaño muestral fuera 1. Pero a partir de más tamaño muestral el error estándar será menor que la desviación estándar.
La Odds ratio va de 0 a infinito.
Y el error estándar es una desviación estándar. Una desviación estándar muy especial, la desviación estándar de una predicción.
2a:
El que la pendiente sea negativa no la invalida como significativa. Puede ser significativa o no serlo.
Cuando una Odds ratio no es significativa el intervalo de confianza del 95% lo que contiene es al 1.
La Odds ratio puede ir desde 0 a infinito, nunca podrá ser negativa.
En el apartado 2a consta una de las habituales definiciones de p-valor: que es la probabilidad de observar los resultados y otros aún más alejados de la Hipótesis nula, si la Hipótesis nula fuera cierta. Otra definición equivalente, que dice lo mismo de otra forma, sería: Es la probabilidad de la zona crítica más pequeña mediante la cual se rechazaría la Hipótesis nula.
3b:
El kappa no va de 0 a infinito. El máximo es 1.
El p-valor va de 0 a 1, no de -1 a +1.
Un intervalo de confianza de 95% de una pendiente de una regresión lineal simple de (-0.95, 0.65) no puede ir asociado a una r significativa, porque se trata de una pendiente que no es significativa. Observemos que en el intervalo está el 0. El que la pendiente sea 0 es posible. Esto marca que no hay relación significativa entre las variables.
Y, efectivamente, una r positiva y significativa va asociada a una pendiente positiva y, además, significativa.
4b:
Es la mitad del área que va de la media menos dos desviaciones estándar a la media más dos desviaciones estándar. Como el área total de este intervalo sería 0.95, la mitad es 0.475.
5a:
Como la desviación estándar es 5, el error estándar será 5/raíz(100); o sea, 0.5. Por lo tanto, un intervalo de confianza de la media del 95% será más menos dos errores estándar en torno a la media, por lo tanto será: (49, 51).
6d:
El rango es, evidentemente, 15 en esta muestra, no 12.5. El máximo menos el mínimo es 15.
7d:
Si el p-valor es inferior a 0.05 y rechazamos la nula lo que hacemos es, entonces, aceptar la alternativa, no rechazarla.
El p-valor no será superior a 0.05, sino inferior, si nuestro nivel de significación es, como es habitual, del 0.05.
Si el p-valor es muy bajo no debemos repetir, debemos rechazar la hipótesis nula y aceptar la alternativa, y basta.
Si el nivel previo de significación era del 0.05 y rechazamos la hipótesis nula la probabilidad de equivocarnos es, efectivamente, del 5%. Esto es lo que significa, precisamente, este nivel de significación. Es una zona de rechazo donde la probabilidad de tener valores allí, si es cierta la hipótesis nula, es una probabilidad muy baja, del 5%, y, además, en esa zona tiene mucha probabilidad de ser cierta la hipótesis alternativa. Aceptamos, por lo tanto, el riesgo del error, pero rechazamos, en este caso, la hipótesis nula, sabiendo que tenemos esa probabilidad de equivocarnos.
8d:
El test más correcto no es ninguno de los tres. El más correcto es el Test de la t de Stundent de muestras independientes. Faltará comprobar, únicamente, si el de varianzas iguales o desiguales.
9c:
El coeficiente de Gini va de 0 a 1.
Al aumentar la desviación estándar el coeficiente de Gini también aumenta, no disminuye.
Si es 1 es que todo está concentrado en un valor. Por lo tanto, indica que todos menos uno no tienen nada y uno lo tiene todo.
Si el rango es 0 significa que todos los valores son iguales y si todos los valores son iguales el coeficiente de Gini vale 0 porque la curva de Lorenz coincide, precisamente, con la diagonal.
10d:
La mediana es 3.5, no 3.
El rango intercuartílico es 2, no 3.
La Desviación estándar y la Desviación estándar corregida no son iguales. No será lo mismo, en absoluto, dividir por 8 ó por 7 a la hora de calcular el grado de dispersión.
El rango es 3 y el rango intercuartílico es 2, por lo tanto la resta entre ellos es, efectivamente, 1.
1. El Análisis de propensiones, más conocido por su nombre en inglés: Propensity analysis o, también, como Propensity score analysis, es una importante técnica estadística con una importancia creciente, especialmente en Medicina.
2. Cuando se comparan tratamientos distintos en estudios controlados, en estudios randomizados, donde se aleatoriza a los participantes en el estudio, la llamada Ley de los grandes números va generando grupos que, si el tamaño de muestra es grande, son grupos claramente homogéneos.
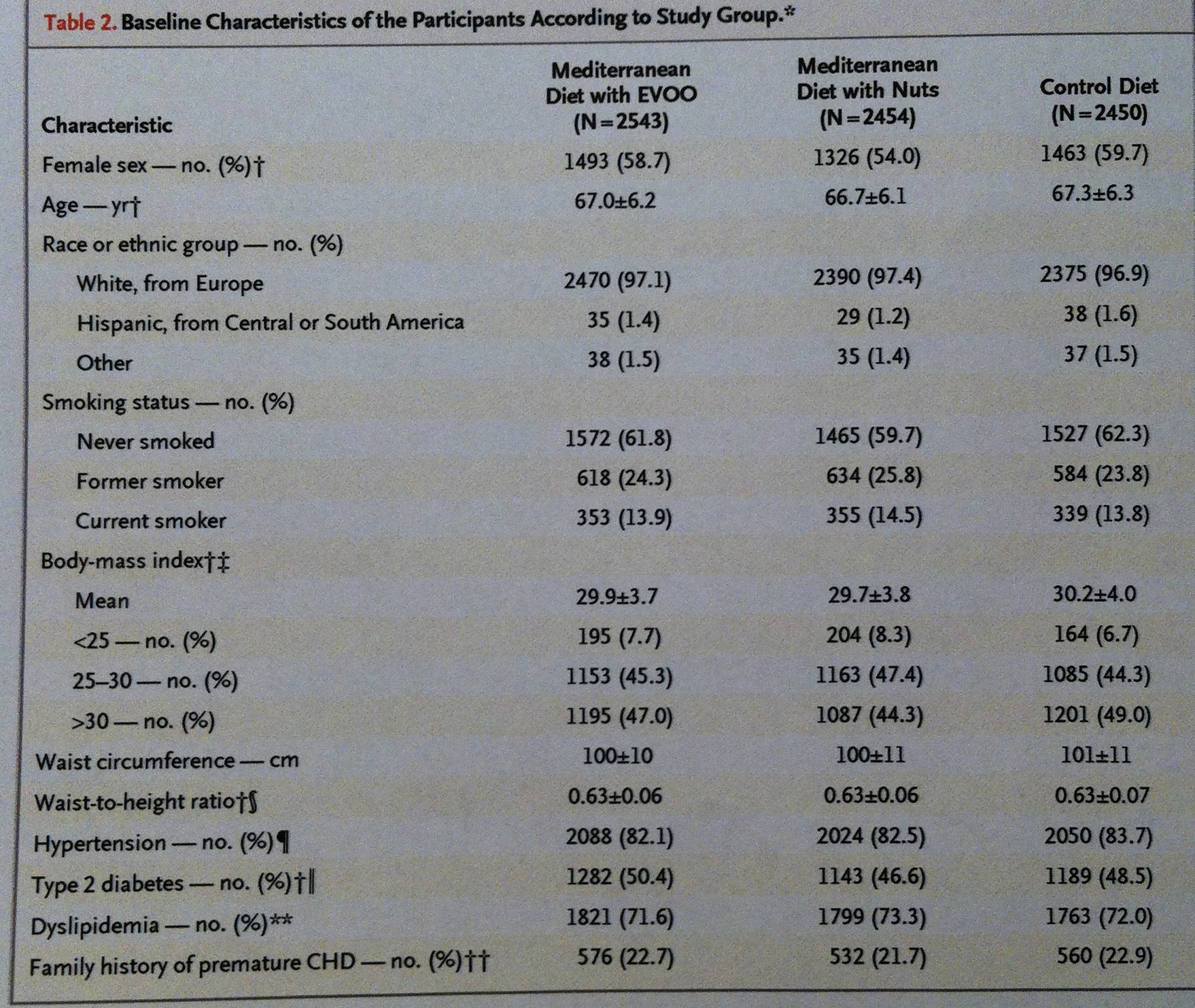
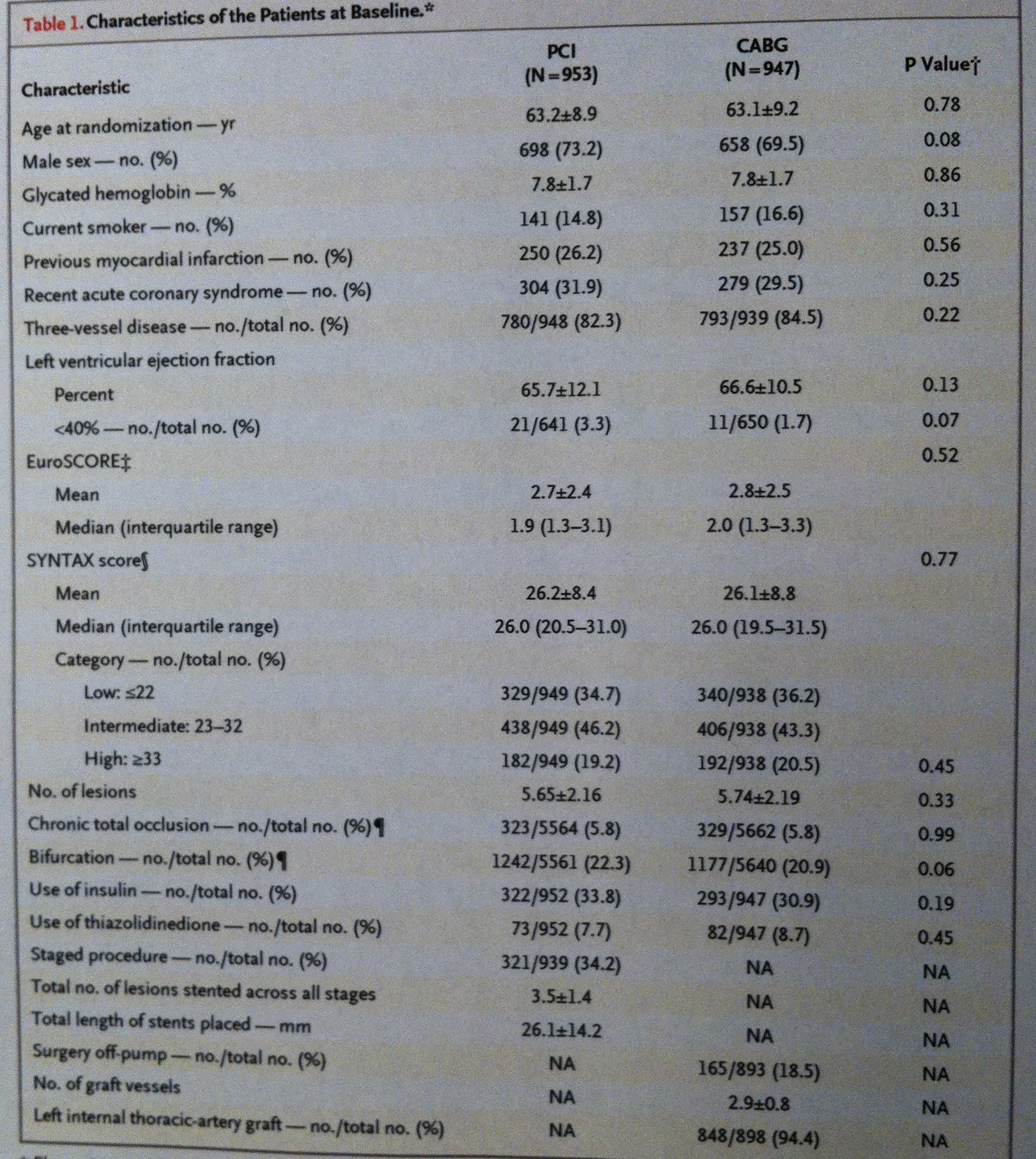
3. Como hemos comentado en el artículo La Estadística descriptiva en Medicina, en la sección de Complemento de este Curso de Estadística, una de los principales usos de la Estadística descriptiva en Medicina es comparar los grupos que van a recibir un tratamiento distinto, en el punto de partida, en la línea de partida, en el «baseline». Observemos, por ejemplo, en la tabla siguiente, uno de los ejemplos que allí hemos comentado:
4. Se trata de un estudio aleatorizado donde se comparan tres grupos: uno de pacientes siguiendo una dieta mediterránea con el añadido de Aceite virgen de oliva (EVOO), otro siguiendo una dieta mediterránea con el añadido de nueces y, finalmente, otro, siguiendo una dieta control. Observemos que los valores descriptivos de las variables que se evalúan, en cada uno de estos grupos, son muy similares. Esto es muy importante para poder evaluar los resultados que se obtengan, finalmente, en el estudio. Para que las diferencias en las variables resultado (Outcome events), se puedan atribuir a estas distintas dietas estudiadas y no a otros factores ocultos.
5. Otros ejemplos de estos estudios controlados aleatorizados: Pacientes que cumplen unas determinadas condiciones son elegidos para una cirugía u otra, o para un tratamiento farmacológico u otro, según un sistema aleatorio. El objetivo es partir de grupos homogéneos. Después de un tiempo del tratamiento asignado a cada uno de los grupos se analiza, siempre, un repertorio de variables resultado (Outcome events), ahora sí buscando diferencias, y tratándolas de atribuir a las distintas condiciones experimentales estudiadas.
6. Asignando al azar a pacientes si el tamaño de muestra es grande acabamos siempre teniendo grupos muy equilibrados. Este es el objetivo fundamental cuando se comparan grupos: que las únicas diferencias sean las del factor que se quiere comparar y que los otros factores que puedan influir estén en igualdad de condiciones. Y en los estudios aleatorizados, gracias a la propia forma de proceder, se consiguen grupos homogéneos sin dificultad.
7. En los estudios clínicos no aleatorizados y, especialmente, en los estudios observacionales, sin embargo, donde la elección de los grupos no viene dado por un proceso aleatorio sino que se hace en función de criterios fuera de control, casi siempre se acaba trabajando con grupos que no son homogéneos respecto a un buen número de variables. Y, entonces, nos encontramos ante el problema de delimitar hasta qué punto lo que vemos en las variables resultado (Outcome events) es efecto de las condiciones distintas estudias o de estas diferencias entre esas variables incontroladas.
8. Ejemplos de estudios observacionales: tenemos dos grupos de pacientes, los que han estado durante un tiempo sometidos a un cierto riesgo (por ejemplo, fumar más de cierta cantidad de tabaco, vivir más de cierto tiempo a menos de 20 Km de una central nuclear, estar embarazada y haber tomado cierto fármaco) y los que no lo han estado de sometidos a este riesgo. En uno y otro grupo podemos entonces analizar un repertorio de variables resultado (Outcome events).
9. En estos estudios observacionales la propia forma de generar los grupos lleva a que muy posiblemente tengamos variables importantes con diferencias considerables, diferencias que podrían ser la causa de las diferencias que vemos, entre los grupos, a nivel de variables resultado.
10. En los estudios observacionales esta no homogeneidad de los grupos comparados permite, pues, dudar de hasta qué punto las diferencias que se aprecian en las variables resultados que se estudian son debidas al tratamiento distintos, a las condiciones distintas comparadas, o lo son debido a que estamos trabajando con grupos con características diferentes para una serie de variables que no hemos controlado y que están latentes allá detrás.
11. Por ejemplo, y ahora voy a caricaturizar la situación, no tendría sentido comparar un fármaco respecto a un placebo donde el fármaco se aplicara a hombres y el placebo a mujeres. O donde el fármaco se aplicara a mayores de 50 años y el placebo a menores de 50 años. Si viéramos diferencias no sabríamos qué proporción de diferencias atribuirlas al fármaco y cuáles a las diferencias evidentes entre los grupos comparados.
12. Las diferencias entre los grupos, en la realidad de estos estudios no randomizados o en estudios observacionales, no son tan grandes como las apuntadas en el ejemplo anterior, pueden ser sutiles, pero puede producirse en varias variables, y puede ocurrir perfectamente que estas diferencias estén detrás justificando unas diferencias que vemos en las variables resultado. Y, muchas veces, el observador, que ignora esas no homogeneidades entre grupos, atribuye las diferencias que ve al factor de riesgo estudiado cuando tal vez esa no sea esa la principal causa de lo que está viendo.
13. El Propensity score trata de evitar este problema aportándonos herramientas para igualar los grupos para un repertorio de variables que queramos contemplar.
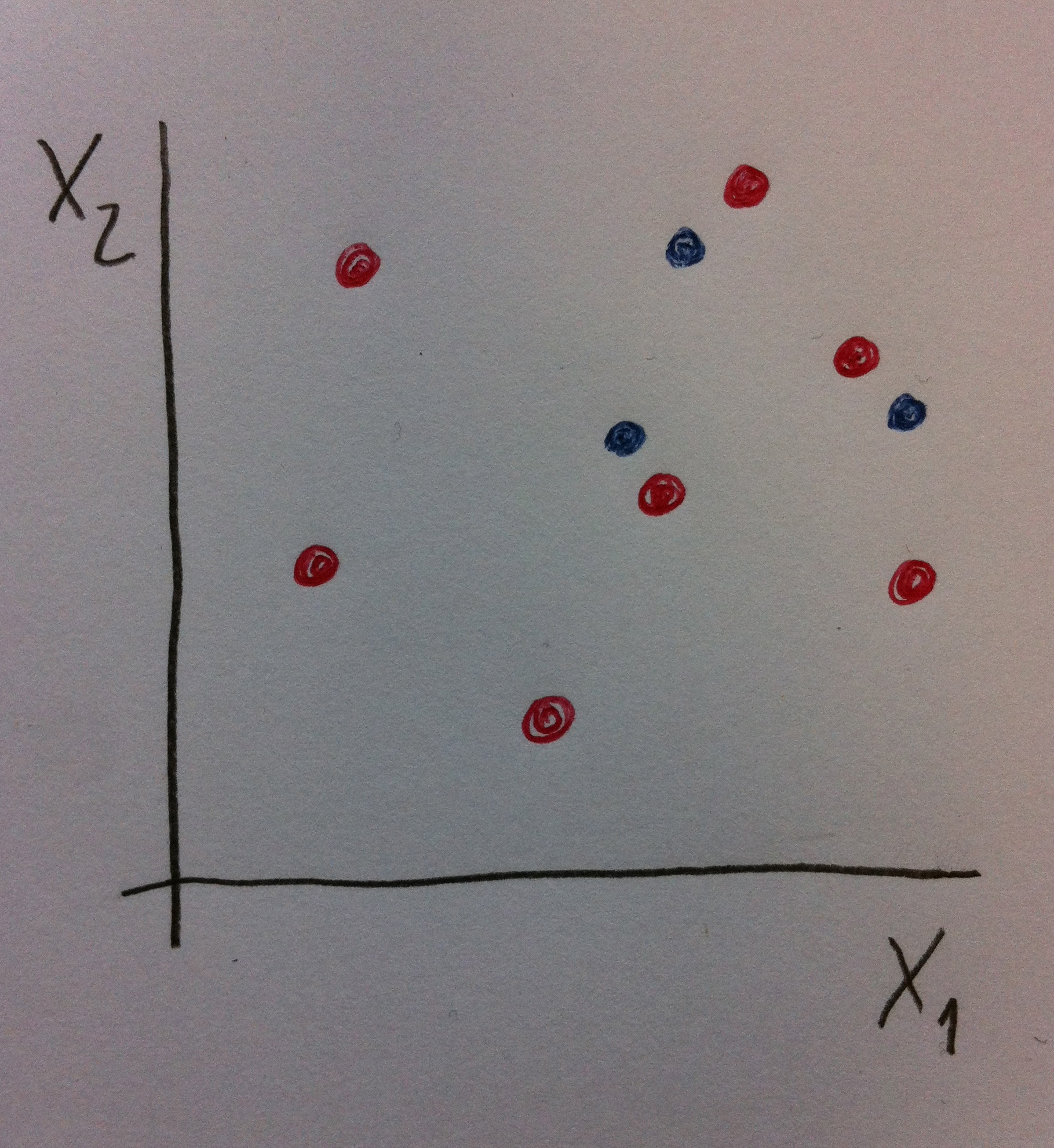
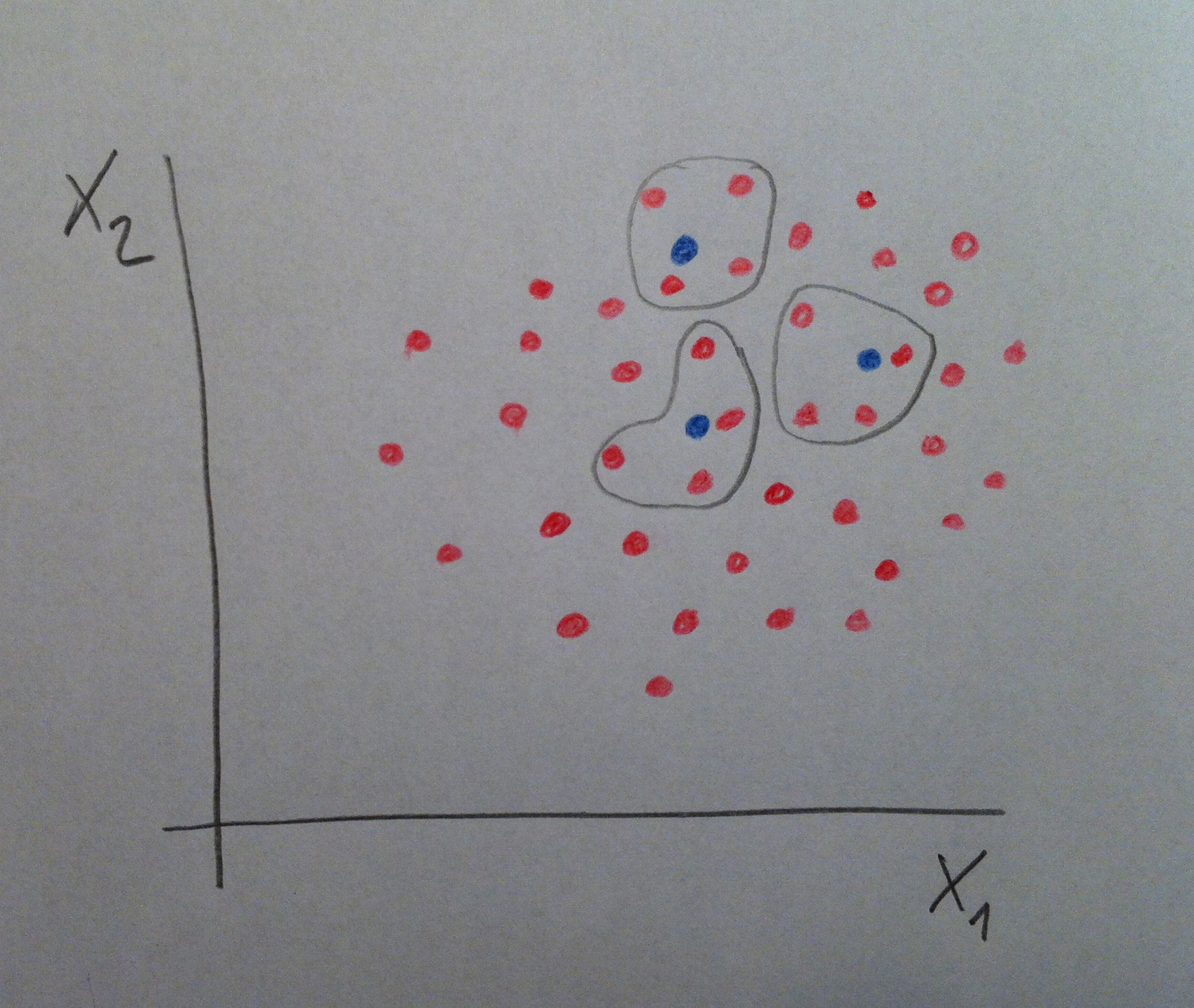
14. Una intuitiva introducción: Supongamos que vamos a comparar dos grupos de individuos tratados de forma diferente y que respecto a dos variables X1 y X2 estos dos grupos tengan los valores siguientes:
15. Un grupo está señalado de color rojo y el otro de color azul. Las muestras son pequeñas pero ahora esto no es lo importante. Lo trascendental es entender el concepto. Un grupo, el rojo, es más grande que el otro, el azul. Ya sucede esto con frecuencia en los estudios observacionales. El grupo control, el grupo no sometido a un riesgo a estudiar, suele ser mucho más grande que el grupo sometido a un determinado tipo de riesgo.
16. Observemos que estos dos grupos no son homogéneos para estas dos variables s X1 y X2. Si comparamos ciertas variables resultado en estos dos grupos podemos dudar si las diferencias son atribuibles al efecto de un posible factor de riesgo o debido a que, intrínsecamente, son dos grupos diferentes, dos grupos no comparables.
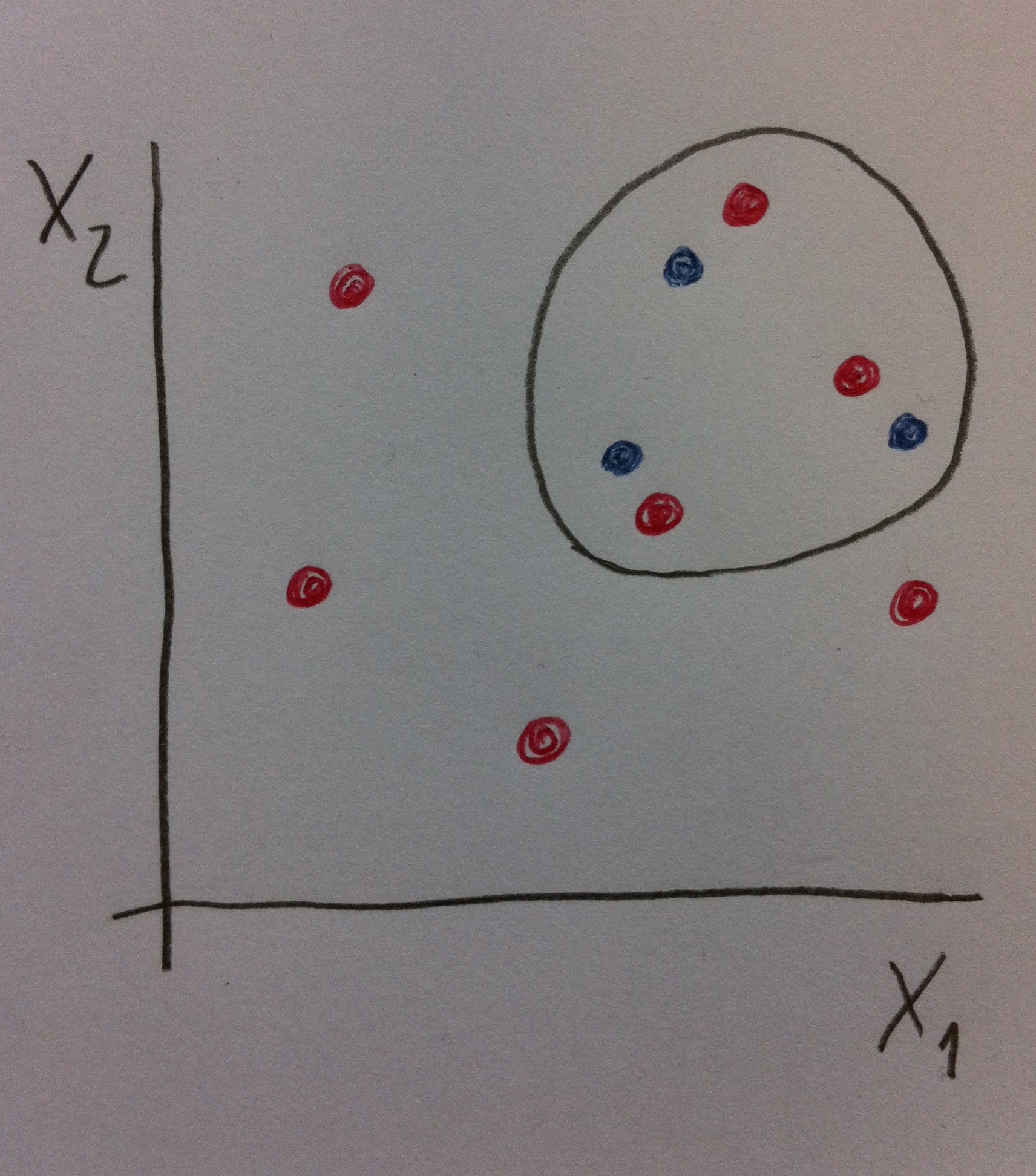
17. Supongamos que hacemos la siguiente operación. Nos quedamos con los tres valores azules pero de rojos no los cogemos todos sino que cogemos únicamente los más cercanos a la esfera de los azules. En definitiva, que acabamos trabajando únicamente con los situados dentro del círculo dibujado en la siguiente figura:
18. Si ahora trabajamos únicamente con los tres rojos y los tres azules remarcados las diferencias que veamos en las variables resultado no podremos pensar que son debidas a que estamos trabajando con dos grupos que respecto a las variables X1 y X2 son muy diferentes. Ahora estamos realmente comparando dos grupos que, respecto a estas dos variables, son homogéneos. Esta es, en definitiva, la idea del Análisis de propensiones: detectar estas situaciones mediante unos mecanismos estadísticos y aportar unas posibles soluciones que nos permitan reconducir comparaciones entre grupos heterogéneos a comparaciones entre grupos homogéneos. En términos populares: Se trata no de comparar manzanas con naranjas, sino manzanas con manzanas.
19. El índice de propensión, el Propensity score, se formula, habitualmente, en forma de probabilidad condicionada (Ver en el apartado de Complementos el artículo Probabilidad y Probabilidad condicionada). Es una forma de expresar, con conceptos matemáticos, probabilísticos, si el reparto entre grupos se ha hecho homogéneamente o no respecto a una serie de variables que podrían confundirnos a la hora de interpretar los resultados finales. Porque es posible que, de no ser así, parte de lo que le estuviéramos atribuyendo al factor estudiado lo deberíamos atribuir, en realidad, a estas diferencias entre las variables confusoras.
20. Con el Propensity score se trata de evaluar y contrastar dos probabilidades. Por un lado:
P(Ser sometido a una determinada condición/Ciertos valores concretos de las variables consideradas).
Y, por el otro:
P(Ser sometido a una determinada condición).
Si estas dos probabilidades son iguales significa que valores concretos de esas variables, potencialmente contaminadoras, no están repartidos heterogéneamente entre los grupos sometidos de forma diferente a la condición que se quiere estudiar. Y si estas dos probabilidades son distintas significa que sí que hay un reparto heterogéneo y, por lo tanto, debería reconducirse la muestra que tenemos para conseguir una homogeneidad que no tenemos.
21. Veamos cómo se trabajaría con esta probabilidad condicionada. Si se ha seleccionado para un estudio la misma proporción de hombres que de mujeres y a los hombres, a todos, se les ha dado un tratamiento y a las mujeres, también a todas, un placebo. Entonces:
P(Ser sometido al tratamiento/Hombre)=1>0.5=P(Ser sometido al tratamiento).
P(Ser sometido al tratamiento/Mujer)=0<0.5=P(Ser sometido al tratamiento).
Cuando eres hombre hay mayor propensión a ser sometido al tratamiento y cuando eres mujer menor propensión.
22. Si, ahora, en el caso anterior, de nuevo con la misma proporción de hombres que de mujeres, el 90% de hombres se trataran y sólo el 10% de mujeres, ahora tendríamos:
P(Ser sometido al tratamiento/Hombre)=0.9>0.5=P(Ser sometido al tratamiento).
P(Ser sometido al tratamiento/Mujer)=0.1<0.5=P(Ser sometido al tratamiento).
De nuevo cuando eres hombre hay mayor propensión, aunque no tanta como antes, a ser sometido al tratamiento y cuando eres mujer menos propensión, aunque no tan poca como antes.
23. Sin embargo, si el 50% de hombres y mujeres fueran tratados, entonces:
P(Ser sometido al tratamiento/Hombre)=0.5=0.5=P(Ser sometido al tratamiento).
P(Ser sometido al tratamiento/Mujer)=0.5=0.5=P(Ser sometido al tratamiento).
Y ahora el ser hombre o mujer no cambia la propensión a ser sometido al tratamiento.
24. Esto último es lo que se busca. Esta es la situación a la que se pretende llegar. Para igualar las condiciones, para que ninguna variable nos confunda. Para que la comparación entre un tratamiento u otro, entre la presencia o no de un riesgo, etc., sea lo más pura posible.
25. Por lo tanto, con el Análisis de propensiones se busca que el ser sometido a una determinada condición, a un determinado riesgo, no dependa del valor de unas variables que pudieran influir en la respuesta que se quiere valorar.
26. Esta es la esencia del Análisis de propensiones, del Propensity analysis. Ahora de lo que se trata es de ver de qué formas se hace esta homogeneización, de qué formas se consigue reconducir una, muchas veces, muy amplia muestra para conseguir estar en una situación de homogeneidad. Saber todo lo que hemos visto hasta ahora nos ayudará a entender los mecanismos que tenemos para esta reconducción de la información. Porque se trata de esto, de focalizar en una parte de lo que tenemos en busca de una situación que nos permita eliminar todo aquello que nos confunda de lo que es nuestro objetivo. En realidad, siempre vamos a girar en torno a las ideas expresadas en los dos gráficos anteriores.
27. El Análisis de propensiones trata de buscar esas propensiones, si es que las hay, esas desigualdades, esas heterogeneidades con la finalidad de igualar, con la finalidad de buscar grupos homogéneos. Busca, pues, que las diferencias entre los grupos estudiados, entre los factores de riesgo estudiados se puedan atribuir a ellos y no a otros efectos.
28. Y pensemos, evidentemente, que son muchas las potenciales variables que nos pueden hacer pensar que las diferencias que vemos entre los grupos a comparar sean debidas no al factor de riesgo estudiado sino a unas distintas distribuciones de valores de estas variables entre esos grupos.
29. Por lo tanto, esta técnica, como veremos ahora, es una técnica, en realidad, multivariante, porque el problema es realmente multivariante. Cuantas más variables contemplemos en el análisis más capacidad de homogeneizar tendremos.
30. Pensemos que no porque tengamos, por ejemplo, la misma proporción de hombres y mujeres en los dos grupos a comparar, por eso debamos ya pensar que estamos ante grupos homogéneos. En realidad, la búsqueda de la homogeneidad es potencialmente infinita, siempre podríamos continuar definiendo variables a controlar. En algún punto nos debemos quedar.
31. La elección de las variables a usar en el análisis no es un problema estadístico. Debe ser una elección del experto: del médico si se trata de un estudio médico. Él debe delimitar cuáles son las variables que deben igualarse, porque, de no ser así, podrían enmascarar la interpretación final de los resultados.
32. Hay tres modalidades básicas de técnicas para realizar este Análisis de propensiones. Vamos a ver cada una de ellas.
33. La primera modalidad es el Matching, que podríamos traducir algo así como: Apareamiento. Consiste en hacer una selección entre los grupos en función del posicionamiento de los puntos en el espacio de tantas dimensiones como variables queramos contemplar en el estudio.
34. Se trata de elegir, para cada elemento de un grupo, por ejemplo, el grupo expuesto a un riesgo, otro del otro grupo, el más próximo en el espacio de las variables que estemos considerando. Este sería un sistema de elección 1:1. Si el grupo de los no expuestos al riesgo es bastante más grande que el de los expuestos se puede elegir por cada uno de los expuestos un determinado número de no expuestos. Por ejemplo, en una relación 1:4, u otra combinación.
35. Por eso es un Matching, un apareamiento, porque se trata de elegir en la muestra en base a proximidades, se trata de aparear. Las formas de cómo establecer esas proximidades pueden ser muchas. En realidad, si repasamos el tema dedicado al Análisis clúster podemos ver que se hablaba de diferentes distancias entre puntos. La distancia de Mahalanobis, vista y comentada allí, es muy usada en este contexto.
36. Sigamos el criterio de distancia que sigamos, la idea básica del Matching es para cada valor del grupo más pequeño elegir un número determinado del grupo más grande y elegir siempre los más próximos. Veamos que en el gráfico siguiente, para cada uno del grupo de los expuestos (en azul) elegimos cuatro de los no expuestos (en rojo), por lo tanto estamos hablando de una relación 1:4.
37. Observemos que serán los individuos enmarcados los que se extraerán y constituirán los elementos de los dos grupos a comparar finalmente con las variables resultado a estudiar. Serán dos grupos homogéneos para las variables consideradas. En este caso estamos dibujando el ejemplo con dos variables, pero hay que pensar que esto se hará con muchas más variables.
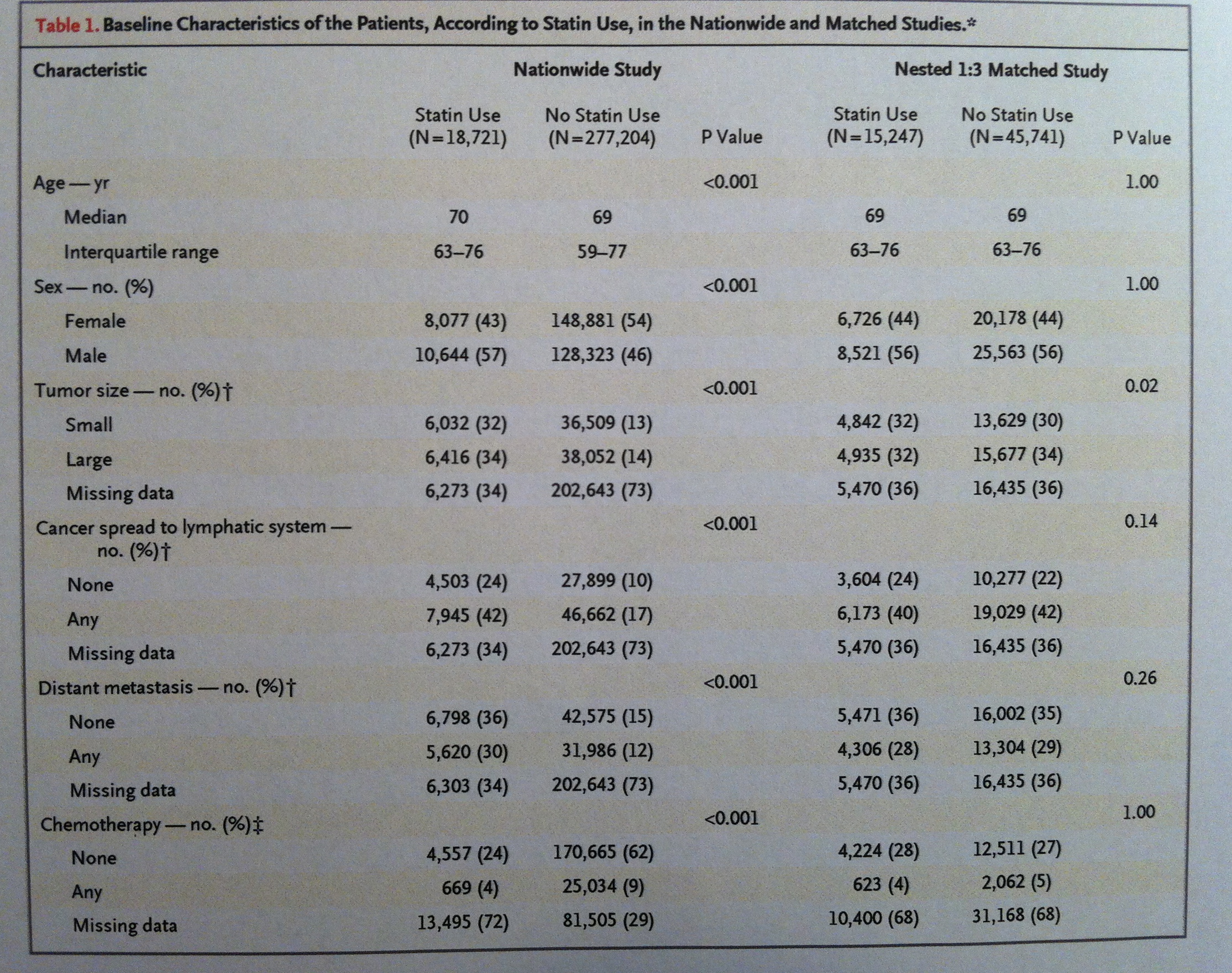
38. Observemos en la siguiente tabla extraída de un estudio donde se analizaba, en un estudio observacional, enfermos de cáncer que tomaban estatinas y enfermos que no las tomaban. Se quería analizar el efecto de la exposición, a este tipo de fármaco, sobre el tiempo de vida de esos pacientes. Observemos cómo a la izquierda tenemos los valores totales y a la izquierda los valores después de hacer un Matching:
39. Puede observarse que no todos los tratados con estatinas son seleccionados finalmente y mucho menos todos los controles. Se ha seguido un sistema 1:3, por cada sometido a estatinas tres no sometidos a ellas.
40. Muchas veces se eliminan individuos del grupo de expuestos por no tener ningún individuo del grupo control lo suficientemente cerca. Puede establecerse una distancia mínima para ser incluido, etc.
41. El Matching viene a ser, pues, en estos términos, visto como un elegir individuos, de ambos grupos, con las mismas posiciones en el espacio de muchas variables. Esto evita que un tipo de individuos dentro de ese espacio tenga más propensión que otro a ser incluido en un grupo u otro de los que se pretende comparar.
42. Como puede observarse es una forma de reordenar la información que se tiene, las muestras que se tienen, con la finalidad de crear grupos homogéneos, grupos con el mismo repertorio de valores de esas variables que podrían influir en las variables resultado, para poder focalizar, así, en el factor que se quiere estudiar, en el efecto del factor de riesgo estudiado.
43. La segunda modalidad de Propensity score es la Estratificación. Consiste en focalizar en el conjunto global de individuos de los grupos a comparar, respecto a las variables que se pretende homogeneizar, y crear subconjuntos en cada uno de los grupos (expuestos o no expuestos al factor de riesgo estudiado) que sean homogéneos entre sí. A estos grupos homogéneos les llamamos estratos. Al final acabamos mezclando estos estratos y dejando fuera a los que no encajen en esos estratos.
44. Mediante un Análisis clúster (Ver el tema 19: Análisis clúster) se pueden construir esos estratos. Se trata de elegir estratos generados a través del dendrograma, estratos homogéneos que tengan representantes de los dos grupos que queramos comparar y que tendrán, al estar cerca en el dendrograma, propensiones similares.
45. La tercera modalidad de Propensity score es la Regresión logística. Consiste en hacer una Regresión logística con la siguiente variable dicotómica: ser del grupo de riesgo o del grupo control y como variables independientes se toma las variables que se pretende igualar. Y se trata, entonces, de ver cómo se comportan los coeficientes de esa Regresión. Se trata de ver si esos coeficientes son o no estadísticamente significativos.
46. Se trata de buscar, mediante este mecanismo, submuestras de la muestra para los que los coeficientes de esas variables independientes, en la Regresión, sean no estadísticamente significativos, lo que implicará que estamos ante grupos homogéneos. Si se trata de dos grupos homogéneos significa que los dos grupos de individuos están en hiperplanos paralelos con valores solapados paralelamente.
47. Recordemos (Ver el tema 11: Regresión logística) que en una Regresión logística podemos imaginar cómo están distribuidos los puntos en los dos planos en situaciones distintas posibles y visualizar cómo son los coeficientes del modelo de Regresión. Dos planos porque la respuesta es dicotómica. En nuestro caso: expuestos o no al riesgo estudiado, si es que se trata de un estudio observacional.
48. Recordemos el modelo de Regresión logística en dos variables. Evidentemente el número de variables que nos interesarán en un Análisis de propensiones será mucho mayor, pero planteo la situación con dos variables para poder visualizar cómo son las cosas:
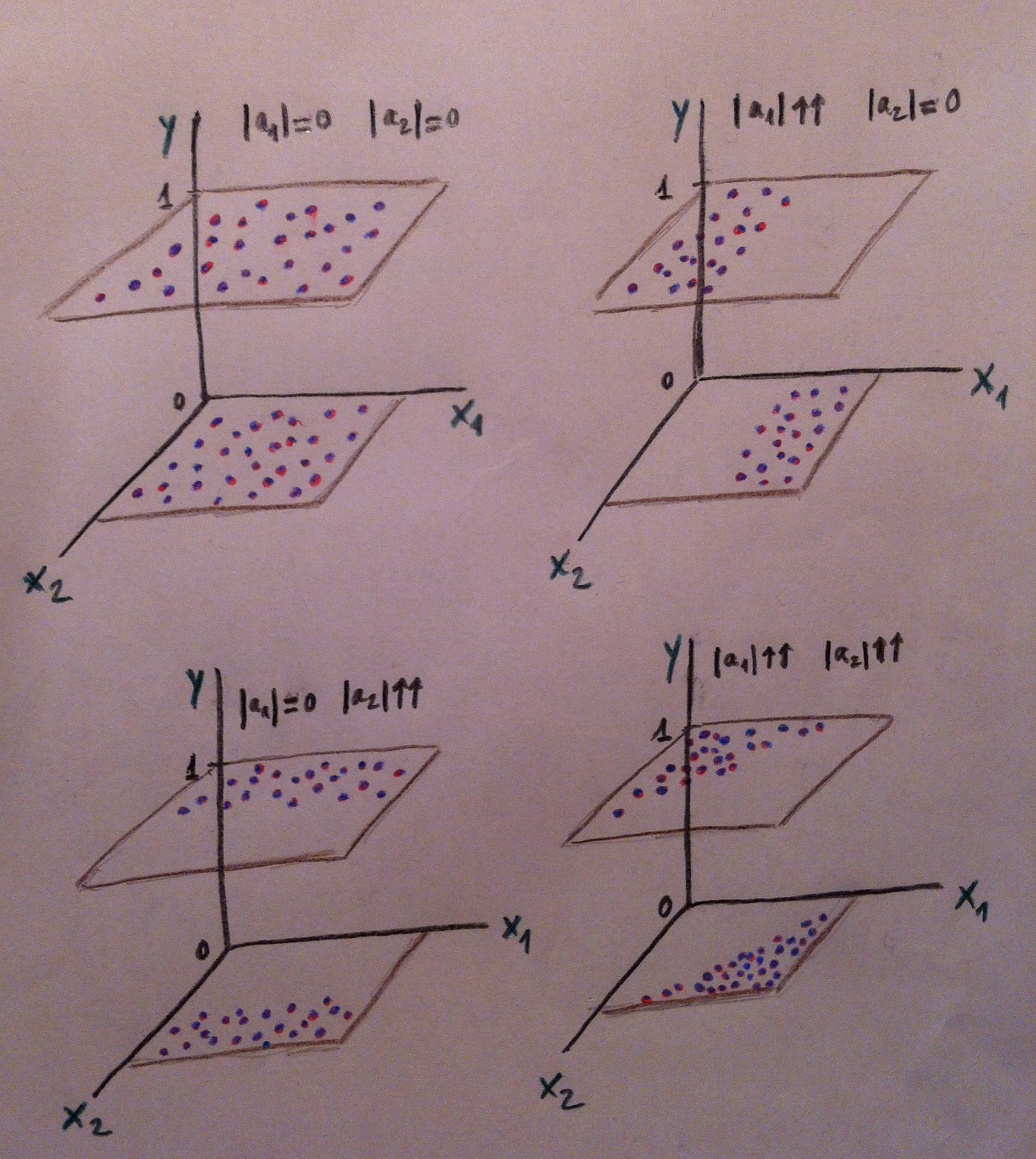
49. Este modelo con dos variables independientes nos proporciona, según sean los valores de estos coeficientes, los siguientes dibujos en el gráfico ya visto y comentado en el tema dedicado a la Regresión logística:
50. Si los puntos están en paralelo, como sucede arriba a la izquierda, significa que estamos ante grupos homogéneos. Y los coeficientes serán los dos cero, o no estadísticamente distintos de cero.
51. Si algún o algunos coeficientes son significativamente distintos de cero, los valores no están en paralelo, como ocurre en nuestro dibujo en los otros tres casos. El repertorio de coeficientes significativos nos ayudarán a ver cuál o cuáles son las variables que nos están rompiendo la homogeneidad en el reparto de ambos grupos. Por lo tanto, los coeficientes nos ayudarán a diagnosticar dónde se produce la pérdida de homogeneidad. Y, por lo tanto, a partir de esta información se podrá producir una mejor selección de individuos.
52. La Regresión logística nos puede servir, como he comentado en el apartado anterior, para retocar los grupos, basándonos en la información de las variables que rompen la homogeneidad, y comprobar, sucesivamente, si hemos elegido bien y así, secuencialmente, llegar a generar grupos homogéneos. Sin embargo, la Regresión logística suele usarse, más frecuentemente, de otra forma.
53. Este otro uso más frecuente de la Regresión logística en Análisis de propensiones es el siguiente: se trata de asignar, mediante la Regresión, un valor, un score, un Propensity score. Este Propensity score, como ya hemos definido antes, es la probabilidad de ser asignado a un grupo en función de unos valores concretos de unas variables independientes. Una vez se tienen estos scores para todos los individuos de un grupo y del otro que se quieren comparar, se procede a hacer un Matching, como hemos visto antes, mediante la elección de individuos de ambos grupos con scores similares.
54. Voy a intentar explicar, mediante unos dibujos, esto que estoy comentando. Supongamos que en el dibujo siguiente en el eje simbolizado con una «x» contemplamos un conjunto amplio de variables independientes. Al hacer una Regresión logística lo que construimos es una función que se mueve entre 0 y 1. Si se mueve como el siguiente gráfico estamos ante variables independientes que generan grupos homogéneos. Los Propensity scores de los diferentes individuos son todos iguales prácticamente. Tendríamos que todos los individuos tienen el mismo valor, por esto se vería esta función constante:
55. En cambio, en el gráfico siguiente tenemos que hay una clara diferencia de Propensity scores según el individuo:
55. En una situación como ésta, que es la que suele darse al analizar estudios observacionales, para solventar el problema lo que se hace es hacer un Matching: un apareamiento de individuos de los dos grupos con valores iguales en esta curva. Es una forma de igualar, de homogeneizar.
56. Veámoslo con unos datos posibles. Supongamos que tenemos en un estudio una serie de individuos que pertenecen al grupo en contacto con un factor de riesgo (los que están sobre la línea del 1) y los que no han estado en contacto con ese factor de riesgo (los individuos que están sobre la línea del 0):
57. Los individuos, tanto los del grupo de riesgo como los del grupo que no ha estado en contacto con el factor de riesgo estudiado, están más a la izquierda o más a la derecha respecto a los valores de x según sea el valor de las variables independientes. Si suponemos que sólo estamos contemplando una variable independiente, por ejemplo: la edad, estaríamos ante una situación en la que los del grupo en contacto con el riesgo son mayores y los del grupo que no ha estado en contacto con el riesgo son más jóvenes.
58. Pues bien, al aplicar una Regresión logística donde la variable dependiente, expresada como 0 y 1, según el individuo no haya estado en contacto con el factor de riesgo o sí, obtenemos una curva de este tipo. El valor que cada individuo tiene en esta curva es el llamado Índice de propensión (Propensity score). Agrupar, entonces, por índice de propensión sería reestructurar el estudio únicamente con individuos emparejados (en una relación 1:1 ó con cualquier otra, como hemos visto al plantear el Matching). En el caso anterior elegiríamos las parejas marcada por las flechas:
59. Reducimos el tamaño de la muestra final pero conseguimos tener grupos homogéneos respecto a la variables independientes de interés. Observemos que si la variable independiente x contemplada fuera únicamente la variable edad acabaríamos teniendo los dos grupos (los que han estado en contacto con el factor de riesgo y los que no lo han estado) sin diferencias en cuanto a la variable edad. Por lo tanto, la variable edad no nos podría estar confundiendo en cuanto a cómo el contacto con el factor de riesgo influye en las variables resultado, en los Outcome events estudiados.
La Estadística descriptiva está casi siempre presente en los artículos de las revistas de Medicina. Es interesante y conveniente destacar cuáles son los contextos de esos artículos en los que más abunda ese tipo de aproximación estadística a una muestra y cuáles son los cálculos más habituales de uso y cuál es la forma de presentación mayoritaria.
Fundamentalmente son tres los contextos en los que es más habitual el uso de la Estadística descriptiva en estos artículos. Veamos uno por uno, con ejemplos concretos tomados de revistas médicas, cuáles son esos tres contextos mayoritarios.
1. En todos los estudios donde se pretende abordar el seguimiento de una serie de personas que se han dividido en diferentes grupos que van a ser tratados de formas distintas (por ejemplo: en un ensayo clínico), se hace una Estadística descriptiva de las características más relevantes para el estudio que tiene cada uno de esos grupos, en el punto de partida. Con la finalidad básica de mostrar que para esas variables no hay diferencias destacables. Para comprobar, en definitiva, una homogeneidad entre los grupos.
Veamos algunos ejemplos:
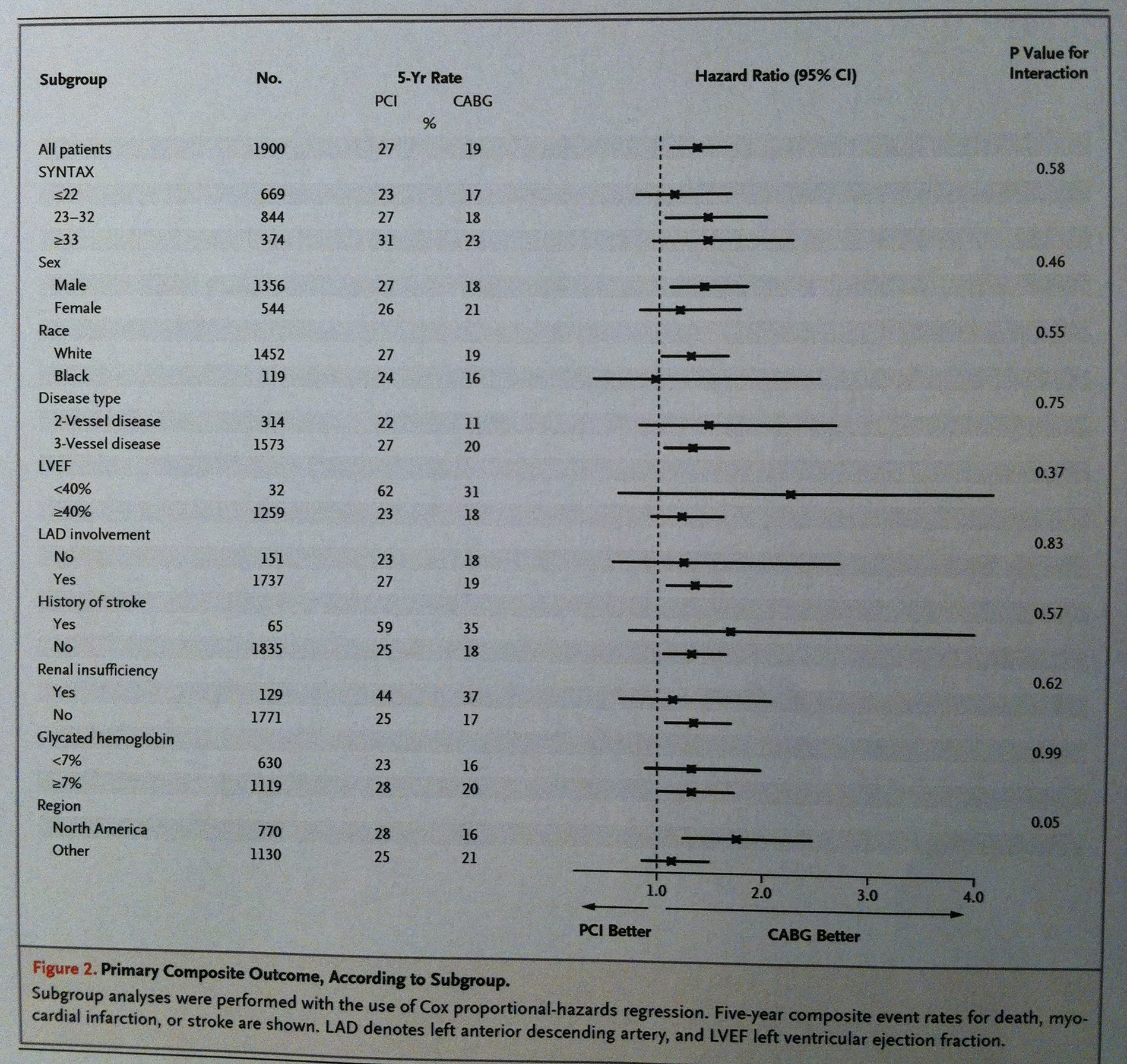
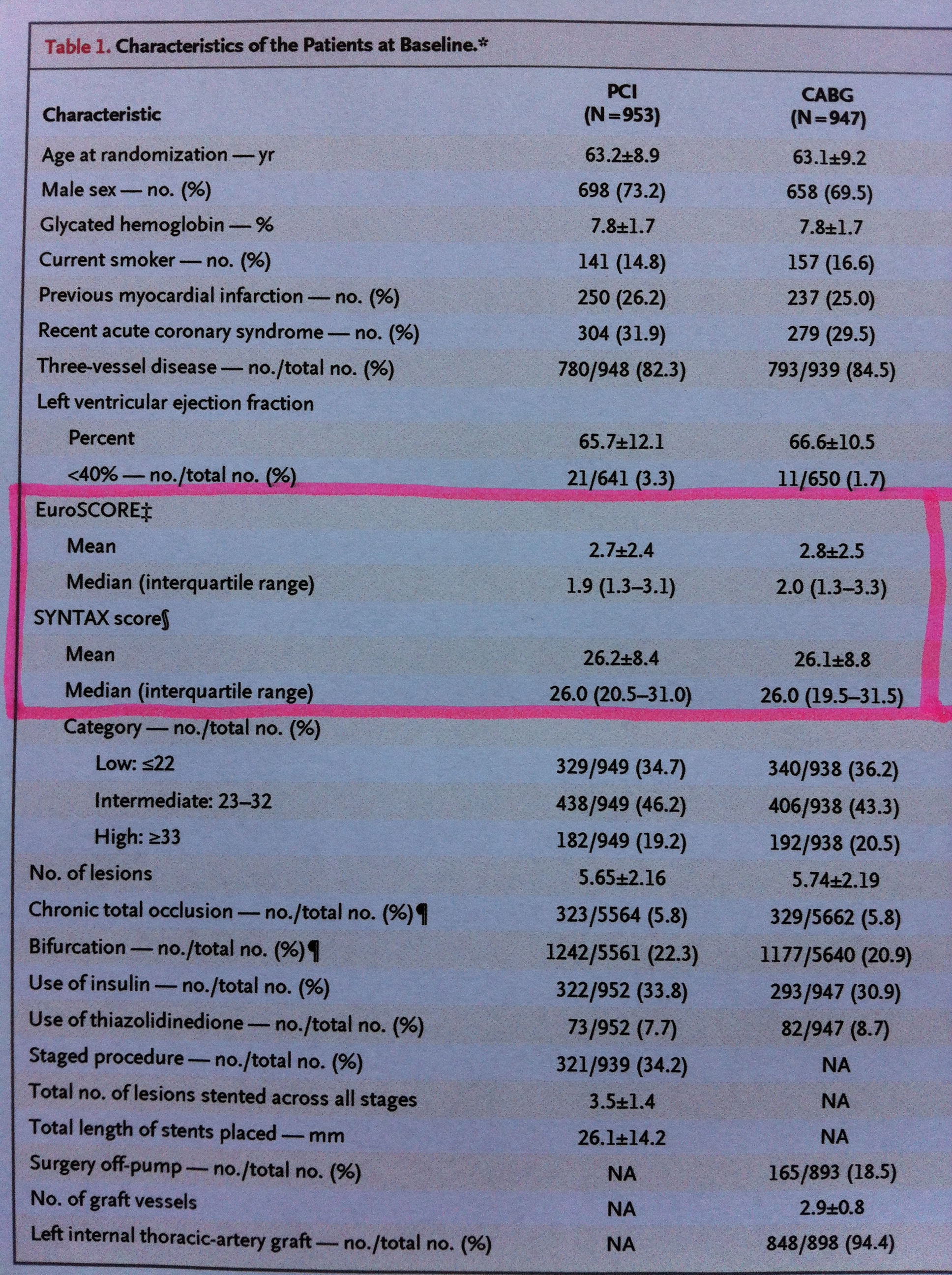
En la primera tabla consta la descripción de los grupos de pacientes a los que se les aplicaron cada uno de los dos tratamientos comparados para reparar problemas de obstrucción a nivel de arterias coronarias: el sistema percutáneo (Percutaneous coronar y intervention (PCI)) y el bypass (Coronary-artery bypass grafting (CABG)):
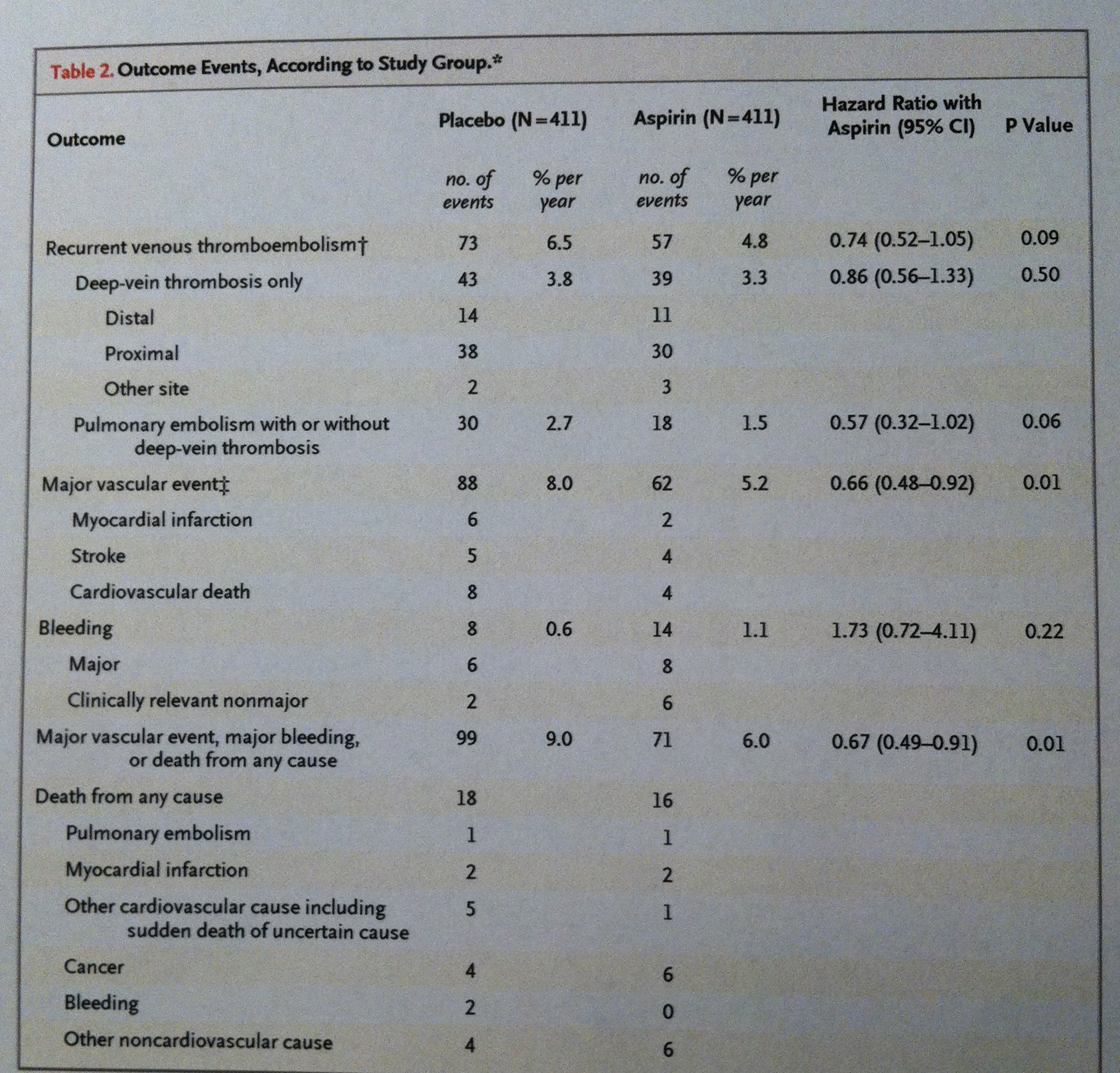
En la siguiente tabla consta la Estadística descriptiva de los dos grupos de pacientes estudiados para comparar el efecto de la aspirina, a pequeñas dosis diarias, en la prevención de problemas tromboembólicos:
En la siguiente tabla consta la Estadística descriptiva de los tres grupos experimentales de un interesante estudio donde se pretendía valorar la eficacia de la dieta mediterránea en la prevención de enfermedades cardiovasculares. Los dos primeros grupos seguían una dieta establecida con el añadido de aceite de oliva virgen (Extra-virgin olive oil (EVOO)) o de nueces. El tercero seguía una dieta control estándar:
2. Cuando los grupos descritos comentados en el apartado anterior, en su punto de partida, al inicio del experimento, han sido sometidos cada uno de ellos a un distinto tratamiento se usa de nuevo la Estadística descriptiva para cuantificar variables resultado, variables que detecten problemas. Ahora se busca la diferencia, se busca si en algún grupo hay menos casos de alguna patología que en otro, etc.
Veamos ejemplos:
En la primera tabla constan los resultados de la comparación de los dos grupos que antes hemos visto del estudio comparativo de la reparación percutánea o mediante bypass de problemas de obstrucción coronaria:
En la siguiente constan los resultados de los grupos donde se estudiaba el efecto protector de la aspirina a dosis bajas diarias:
En el caso del estudio del efecto de distintas dietas sobre los problemas cardiovasculares los resultados descriptivos finales son los siguientes:
3. Finalmente, hay un tercer tipo de contexto en el que se suele hacer una Estadística descriptiva. En ocasiones es el propio estudio el que llega a generar una serie de grupos homogéneos, pero ahora se trata de una homogeneidad final, de resultados, no una homogeneidad de partida como en el caso del punto 1. Por ejemplo: Pacientes que acaban siendo diagnosticados de alguna enfermedad o no. Pacientes que acaban muriendo o no, etc. Se trata, entonces, en estos casos, de visualizar descriptores que los caractericen mediante la Estadística descriptiva.
Veamos algún ejemplo:
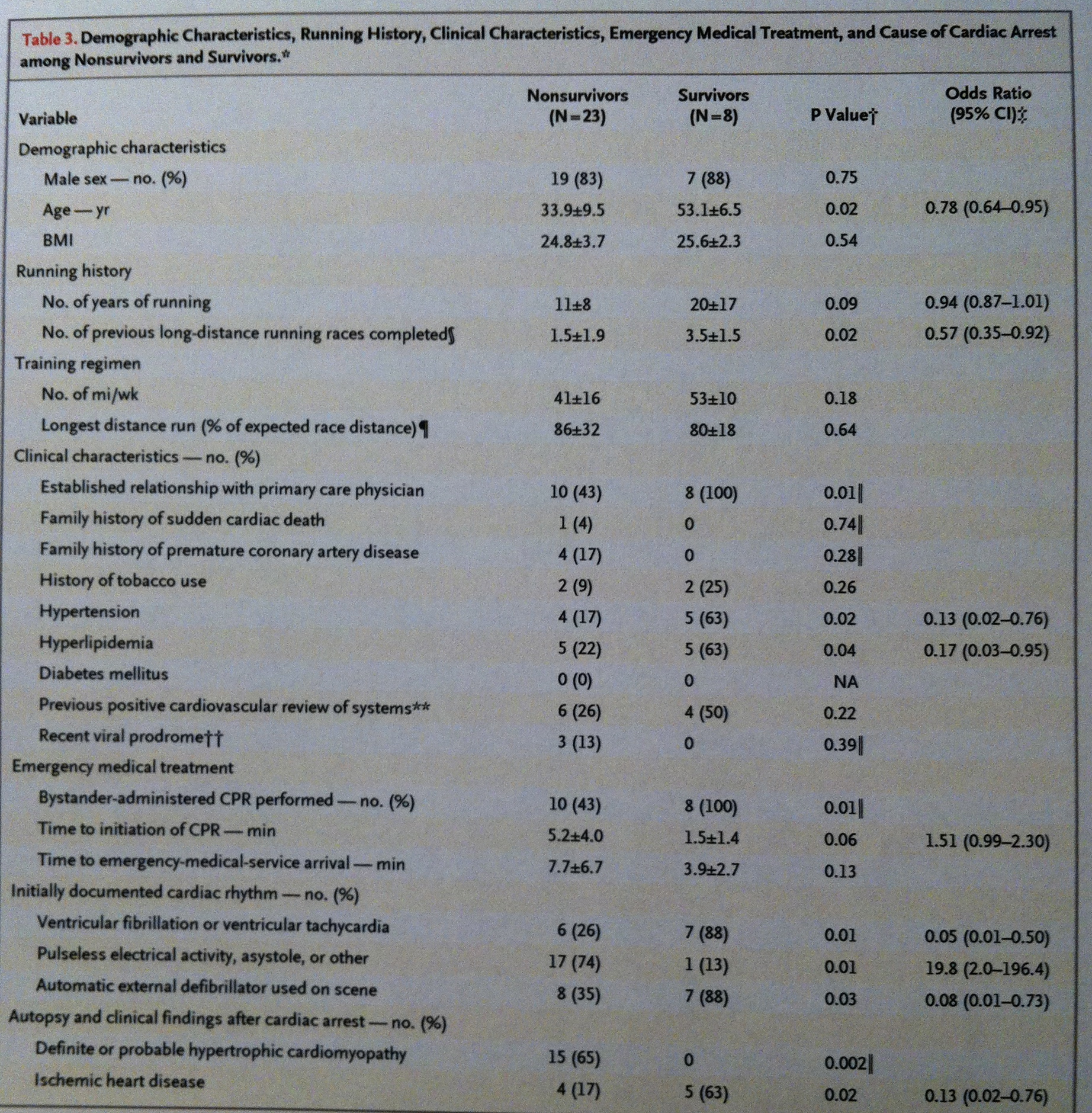
En la siguiente tabla consta la Estadística descriptiva de los datos comparativos entre atletas que no han sobrevivido o que sí han sobrevivido después de haber sufrido un infarto de miocardio en carrera. En este caso la muestra inicial era del registro, en EEUU, desde el año 2000 hasta el 2010, de los casos de infarto de miocardio habidos en marathones o en medias marathones. Pero aquí la focalización está puesta en separar los grupos según el resultado, describirlos y compararlos:
Otro caso de este tipo es el de la siguiente tabla. Se trata de un estudio de infecciones localizadas en marcapasos. Se presenta una Estadística descriptiva separando los que a corto plazo han sobrevivido y los que también a corto plazo han fallecido. De nuevo, pues, una descriptiva separada por grupos según el resultado final:
En cualquiera de estos tres tipos de situaciones, cuando son varios los grupos a los que se les calculan estos valores descriptivos es habitual aplicar alguna técnica inferencial para ver si hay diferencias significativas entre esos grupos. Como puede verse en las tablas adjuntas, es habitual añadir una columna con los respectivos p-valores de cada una de esas comparaciones. Cuando se trata de la descripción de grupos, como hemos visto en el primer tipo de tablas, a los que se les ha sometido a un tratamiento distinto interesa que en las variables descritas a nivel de punto de partida del estudio no se detecten diferencias significativas para comprobar, así, que las condiciones de partida eran equivalentes. Sin embargo, como hemos visto en el segundo tipo de tablas, cuando a estos mismos grupos, después del tratamiento, se comparan variables resultado ahí sí que interesa ver diferencias. Y en el caso del tercer tipo de tablas, como en el segundo, interesa que esas comparaciones muestren diferencias significativas también.
La descripción variable por variable suele hacerse, como se ha visto en las tablas anteriores, en cantidad absoluta y relativa (habitualmente, ésta, en porcentaje) si se trata de una variable cualitativa dicotómica. Si la variable es cuantitativa suele o darse mediante la media±desviación estándar o bien mediante la mediana y el rango intercuartílico, normalmente entre paréntesis. Y ese rango no expresado precisamente como rango sino dando explícitamente los valores del primer y el tercer cuartil, que son los valores cuya resta constituyen, realmente, el rango intercuartílico.
¿Cuándo usar una u otra formulación en una variable cuantitativa? Si el comportamiento de una variable es de distribución normal lo más conveniente es describir aquella variable mediante la media±desviación estándar, porque con estos dos valores lo tenemos todo, porque teniendo estos dos números lo podemos saber todo de la variabilidad de esa variable. Incluso, evidentemente, el propio rango intercuartílico. Si el comportamiento de una variable no es el de una distribución normal es mucho más razonable describirla mediante la mediana y el rango intercuartílico. Porque la tendencia habitual si se tiene la media±desviación estándar es a hacer aquellas típicas inferencias que sólo son ciertas si la variable sigue la distribución normal: M±1DE supone el 68.5% aproximadamente de la población, M±2DE supone el 95% aproximadamente de la población y M±3DE supone el 99.5% aproximadamente de la población. Esto si la variables no es normal no es cierto. Para evitar esta inferencia inconsciente, muy habitual por desgracia, es mejor trabajar, evidentemente, con la mediana y el rango intercuartílico que son medidas que digamos están más próximas a la descripción propiamente dicha y no tienen tantas connotaciones inferenciales como las tienen la media y la desviación estándar.
No es un problema, como suele pensarse en ocasiones, de tamaño de muestra. Hay una creencia establecida, por parte de muchos usuarios de la Estadística, que si una muestra es pequeña deben usarse descriptores tipo mediana y percentiles y si la muestra es grande puede usarse y debe usarse la media y la desviación estándar. Esto no es así. El uso de unos u otros descriptores no depende del tamaño muestral, depende de la normalidad de la muestra, de su ajuste a la campana de Gauss.
Si la muestra sigue la distribución normal (sea el tamaño de muestra grande o pequeño) al describir la muestra en términos de media±desviación estándar se está dando, también, implícitamente, una aproximación muy buena de la mediana y del rango intercuartílico de esa muestra.
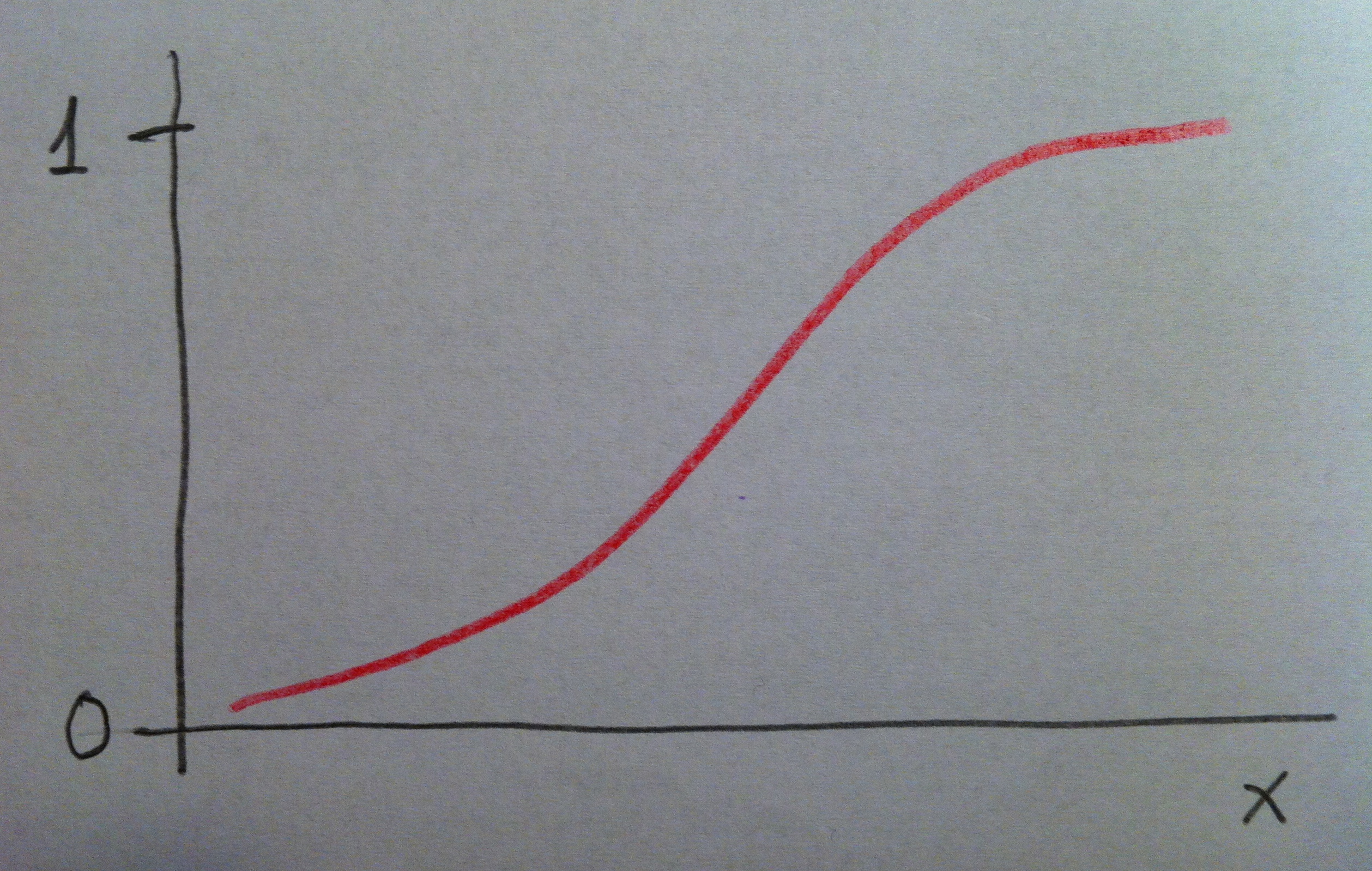
Si repasamos la forma de trabajar la tabla de la normal N(0, 1), en el artículo “La Distribución normal” del apartado de Complementos, podemos ver que si la distribución es normal calcular la media±0.68*desviación estándar nos da un valor muy similar al de mediana y rango intercuartílico. O sea, en una distribución normal cualquiera la media±0.68*desviación estándar construye un intervalo del 50% de valores poblacionales.
Observemos esto que digo en la tabla descriptiva siguiente, que es una de las que hemos visto antes, pero focalizando en un sector más pequeño de ella, en el sector remarcado en rojo:
Si se observa la variable SYNTAX score podemos ver que, curiosamente, porque no es habitual que sea así, la información se da en las dos formas. Aprovechémonos de ello para compararlas. Observemos que en los pacientes tratados con el sistema PCI la media y la desviación estándar se nos muestra mediante la expresión: 26.2±8.4. Si cogemos esta Desviación estándar y la multiplicamos por 0.68 tenemos un valor de 5.7 lo que nos da un intervalo de valores que va de 20.5 a 31.9. Observemos la similitud con el valor de rango intercuartílico en la muestra: (20.5-31.0). Como puede apreciarse se trata de dos intervalos muy similares el calculado basándonos en la información de la desviación estándar y el calculado basándonos exclusivamente en la muestra. También la mediana y la media son muy similares: 26.0 y 26.2, respectivamente. Esto es porque la variable debe tener una distribución muy bien ajustada a una normal.
Lo mismo sucede con los tratados con el sistema CABG donde la media es 26.1±8.8. Si cogemos de nuevo, ahora, esta Desviación estándar y la multiplicamos por 0.68 tenemos un valor de 5.98 lo que nos da un intervalo de valores que va de 20.12 a 32.08. Observemos también ahora la similitud con el valor de rango intercuartílico de la muestra: (19.5-31.5). Como puede apreciarse se trata también ahora de dos intervalos muy similares. También la mediana y la media son muy similares ahora: 26.0 y 26.1, respectivamente.
Si ahora observamos la variable EuroSCORE sucede una cosa completamente contraria. La media y la mediana son bien distintas. Además, si tomamos la media y le sumamos y le restamos 0.68 multiplicado por la desviación estándar, para conseguir un intervalo del 50%, veremos que ahora en absoluto se parece al rango intercuartílico. Cojamos el caso del grupo PCI: 0.68 multiplicado por 2.4 es 1.63. Si sumamos y restamos a 2.7, que es la media construimos una intervalo del 50% que va de 1.07 a 4.33, que es bien distinto al del rango intercuartílico: (1.3-3.1). Es más: observemos que si le restamos a la media dos veces la desviación estándar (2.7- 2×2.4) nos posicionamos en el valor -2.1, un valor negativo. El EuroScore no puede ser menor que cero. Esto indica, claramente, que el EuroScore no sigue la distribución normal. Observemos que la media del grupo PCI (2.7) está próxima al tercer cuartil (3.1). Esto es claramente indicativo de la asimetría de la variable, de la no normalidad. Con el grupo CABG sucede exactamente lo mismo. Por lo tanto, claramente, a partir de la media y la desviación estándar no podemos hacer las inferencias que se suelen hacer habitualmente. En esta situación la desviación estándar no tiene la misma trascendencia como descriptor. Por esto, en estos casos, es más recomendable manejar la mediana y el rango intercuartílico.
Es por lo tanto muy importante saber en qué momentos tiene sentido usar uno u otro sistema descriptivo. Y es muy importante, también, saber usar bien la desviación estándar, saber qué papel juega, saber cuándo puede tener mucho protagonismo y cuándo debe quedar más en un segundo plano.
Resumiendo:
1. Si la variable sigue la distribución normal el cálculo de la media y la desviación estándar es mejor porque además de proporcionarte la información de la dispersión de los valores a distintos niveles te da también la información de la mediana y el rango intercuartílico.
2. Si la variable no se distribuye según una normal es conveniente dar la mediana y el rango intercuartílico. La media y la desviación estándar, en este caso, pueden llevar a inferencias rutinarias peligrosas. De hecho, la desviación estándar es muy buen descriptor pero peligroso. Bien usado perfecto, pero mal usado puede llevar a inferencias muy alejadas de la realidad.
Por los síntomas observados en un enfermo, y según la experiencia acumulada en un gran número de situaciones similares, se deduce que ha podido coger la enfermedad A con probabilidad 1/3 o la enfermedad B con probabilidad 2/3. Para precisar el diagnóstico se hace un análisis clínico al enfermo con dos resultados posibles: positivo o negativo. Se sabe, también por la experiencia, que en los pacientes que tienen la enfermedad A el análisis es positivo con 0.99 y en los que padecen la enfermedad B lo es con probabilidad 0.06.
a) ¿Cuál es la probabilidad que el análisis dé un resultado negativo?
b) Si el resultado ha sido positivo, ¿cuál es la probabilidad que el paciente padezca la enfermedad A? ¿Y la probabilidad que padezca la enfermedad B?