Los siguientes vídeos explican el tema:
1. Una vez introducidas las técnicas de relación vamos a ver el elemento nuclear en torno al cual gira la valoración de la relación entre variables cuantitativas: la correlación.
2. También la correlación es usada para variables ordinales; o sea, variables cuyos valores son posiciones de orden: primero, segundo, etc.
3. La correlación más usada para variables cuantitativas es la correlación de Pearson. Es especialmente apropiada cuando la distribución de las variables es la normal.
4. Para las variables ordinales las correlaciones más usadas son la correlación de Spearman o la correlación de Kendall. Sin embargo, estas dos correlaciones pueden aplicarse a variables cuantitativas, especialmente es recomendable usarlas si las variables no siguen la distribución normal.
5. En este tema hablaremos de la correlación en general aunque la mayor parte de ejemplos y comentarios se centrarán en la correlación de Pearson, pero todo lo que digamos aquí acerca de la noción de esta correlación es válido para explicar esas otras dos correlaciones.
6. Repito, porque es muy importante: Las diferencias fundamentales entre estas tres correlaciones son las siguientes: La correlación de Pearson funciona bien con variables cuantitativas y que sigan bien la distribución normal. Las otras dos correlaciones funcionan especialmente bien con variables cuantitativas que no sigan la distribución normal o con variables de las que lo único que tengamos sean posiciones de orden (variables ordinales).
7. Cuando hablamos de variables cuantitativas estamos hablando de variables como: altura, peso, renta, goles de un equipo en una temporada, número de empleados de una empresa, etc. De la comprobación de la normalidad ya hemos hablado en el tema de los intervalos de confianza y hablaremos con más detalle en temas futuros.
8. La correlación de Pearson es tan universal, es tan usada, que ha quedado implementada en prácticamente todas las máquinas de calcular. Pero se usa indiscriminadamente y en muchas ocasiones sería más apropiado usar alguna de las otras dos correlaciones: Spearman o Kendall.
9. Hay tres elementos básicos a tener en cuenta al analizar una correlación: signo, magnitud y significación. Veamos cada uno de estos elementos con detalle.
10. La correlación, como cuantificación del grado de relación que hay entre dos variables, es un valor entre -1 y +1, pasando, claro, por el cero.
11. Hay, por lo tanto, correlaciones positivas y negativas. El signo es, pues, el primer elemento básico a tener en cuenta.
12. Correlación positiva significa que las variables tienen una relación directa.
13. En este caso, valores pequeños de una variable van asociados a valores también pequeños de la otra; y, paralelamente, valores grandes de una van asociados a valores grandes de la otra. Pe: La altura y la longitud del pie.
14. Más ejemplos de correlación positiva: Goles a favor y puntos de un equipo de fútbol. Asistencias y puntos de 3 en básquet.
15. Número de oficinas y número de empleados en entidades financieras también tiene una correlación positiva.
16. La correlación negativa la tienen, por el contrario, variables con una relación inversa.
17. En este caso, valores pequeños de una variable van asociados, ahora, a valores grandes de la otra; y, equivalentemente, valores grandes de una van asociados a valores pequeños de la otra.
18. Pe: Goles a favor y Goles en contra en una liga de fútbol. Asistencias y rebotes. Valores altos de una variable van con bajos de la otra.
19. La correlación suele abreviarse con una r. Por lo tanto, r=0,7 es una correlación positiva y r=-0,9 es una correlación negativa.
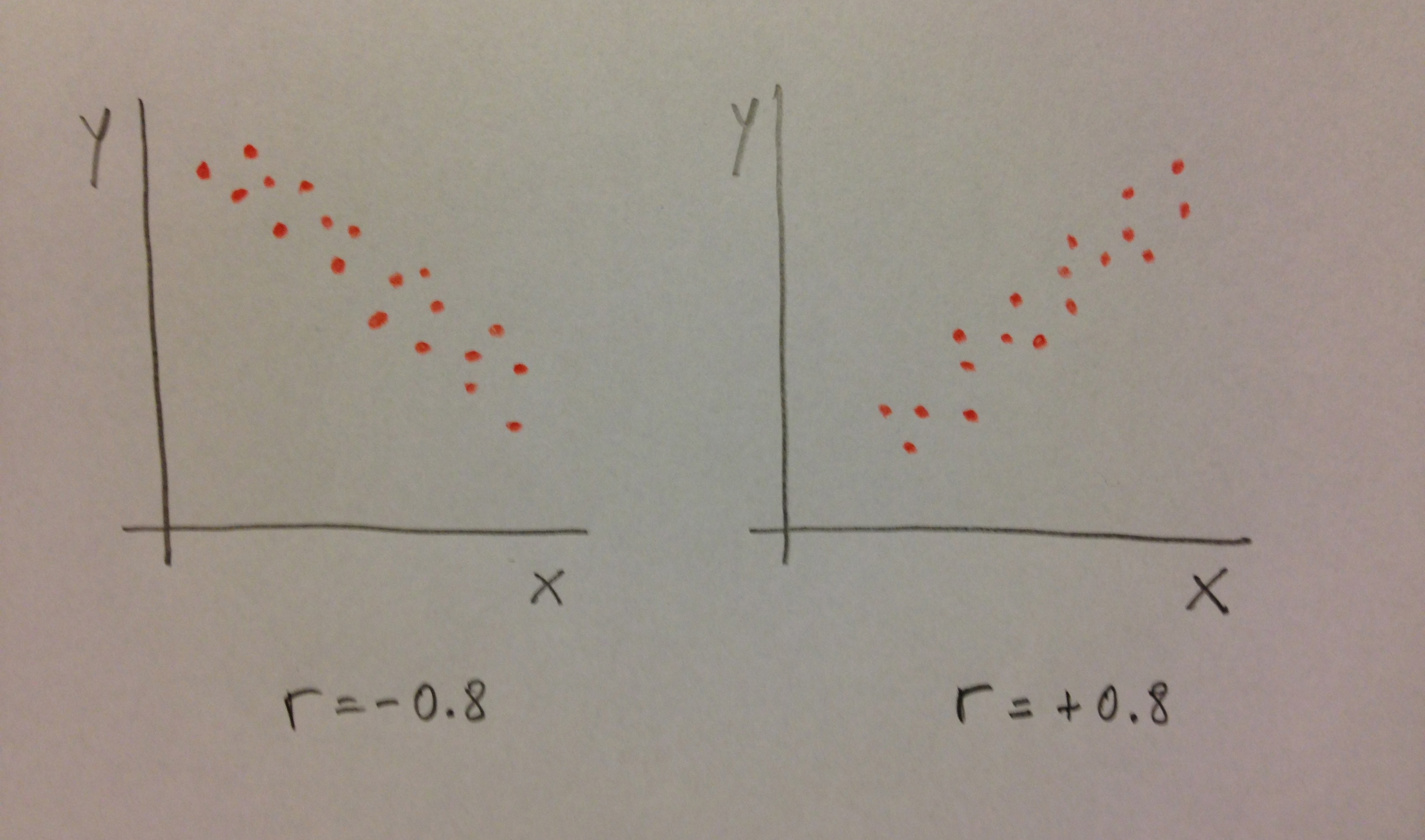
20. Observemos, gráficamente, cómo se distribuyen los valores de dos variables con correlación negativa y de dos variables con correlación positiva:
21. Lo segundo a tener en cuenta en la correlación es la magnitud. Y esto lo marca el valor absoluto de la correlación.
22. En la magnitud se valora se valora la correlación sin el signo, valorando la magnitud del número puro.
23. Esto significa que cuanto más cerca estemos de los extremos del intervalo de valores posibles: -1 y +1, más correlación tenemos. Por eso, r=-0,9 es más correlación que r=0,8, porque 0,9 es más grande que 0,8.
24. Respecto a la magnitud de la correlación hemos de matizar un poco su significado. El valor de las cosas en euros y en pesetas tiene r=1.
25. En este caso estamos en la situación de máxima magnitud de correlación. Se trata de un caso de total dependencia entre dos variables.
26. Al saber el valor en euros de un producto sabes el valor en pesetas. Aquí no hay incertidumbre. Otra cosa es la relación entre la altura y el pie.
27. La correlación posiblemente sea próxima a 0,9. Ahora medir 1,80 no determina exactamente el pie que calzas. Hay una cierta variación.
28. Entre altura y peso posiblemente tengamos una r=0,6. Claro que hay una correlación positiva, pero de menor magnitud.
29. Si sabemos la altura de una persona las longitudes de pie que esta persona pueda tener tienen menos dispersión que los pesos que pueda tener. Los pesos posibles varían más las alturas posibles.
30. Mayor magnitud de la correlación significa, pues, mayor dependencia, mayor proximidad a la relación que tienen pesetas y euros.
31. Observemos en el gráfico adjunto cómo cambia la disposición de los valores de dos variables en función tanto del signo como de la magnitud de la correlación entre ellas:

32. Decíamos antes que hay tres elementos a tener en cuenta en la correlación: signo, magnitud y significación. Hemos visto hasta ahora signo y magnitud.
33. Vamos a ver ahora el más complejo: la significación. Este es un concepto nuclear en Estadística, como iremos viendo.
34. De hecho, la noción de significación es nuclear en Estadística. Se podría decir, en realidad, que la Estadística, en buena parte, es la ciencia que estudia la significación. Ya iremos viendo realmente, en este curso, la trascendencia que tiene este concepto en la Estadística.
35. Significación en Estadística significa algo así como fiabilidad. Un resultado significativo es un resultado por el que podemos apostar.
36. Ante una afirmación estadísticamente significativa podemos pensar que si volviésemos a hacer lo mismo, en las mismas circunstancias, pero con otra muestra, acabaríamos diciendo algo similar, algo equivalente.
37. Podemos pensar, pues, que estamos ante una muestra tipo, ante una buena muestra de muestras, ante una muestra que es representativa del conjunto de todas las muestras que hubiéramos podido tener.
38. Por lo tanto, lo que estamos calculando a la muestra que tenemos es un valor fiable, un valor que no cambiaría mucho con otra muestra tomada en las mismas circunstancias. Por lo tanto, nos acercamos mucho al valor poblacional.
39. Una afirmación si es estadísticamente significativa representa que la Estadística cree que aquel resultado es muy poco probable que sea fruto del azar de un muestreo.
40. Si una técnica estadística duda de la representatividad de un muestreo dice: «no significativo». Es muy precavida, muy prudente. La ciencia tiene que ser así, evidentemente.
41. La significación estadística se mide mediante el p-valor. Éste es un valor que va del 0 al 1, con dos zonas, dentro de este intervalo, bien diferenciados.
42. Estas dos zonas son: del 0 al 0,05 y del 0,05 al 1. Una metáfora posible es la de las notas: En nuestro sistema educativo las notas van del 0 al 10.
43. Y en este intervalos del 0 al 10 es bien distinta la zona de notas que va del 0 al 5 que la que va del 5 al 10. Esto mismo sucede con el p-valor.
44. La frontera del 0,05 en el p-valor es, en cierto modo, equivalente al 5 en las notas. Pero cuidado: 0,05, no 0,5.
45. Una correlación será significativa si su p-valor es inferior a 0,05. Si no es significativa hemos de presuponer que, entonces, r=0.
46. Siguiendo la metáfora de las notas, es como si se examinara la afirmación r=0. Si el p-valor es igual o superior a 0,05, entonces esta afirmación aprueba. En este caso, mantenemos la afirmación de no correlación entre las variables estudiadas.
47. Pero si, por el contrario, el p-valor es inferior a 0,05 tal afirmación entonces suspende y decidimos que la r no es 0 y nos quedamos con el signo y la magnitud de la r calculada.
48. Observemos que el margen de la afirmación r=0 es muy amplio: va del 0,05 al 1; o sea, es una longitud de 0,95 sobre 1. Esto es lo que permite hablar de «significativo» cuando suspende.
49. Si la hipótesis examinada teniendo tanto margen, suspende, es que podemos rechazarla con un buen nivel de confianza de que no nos estamos equivocando al hacerlo.
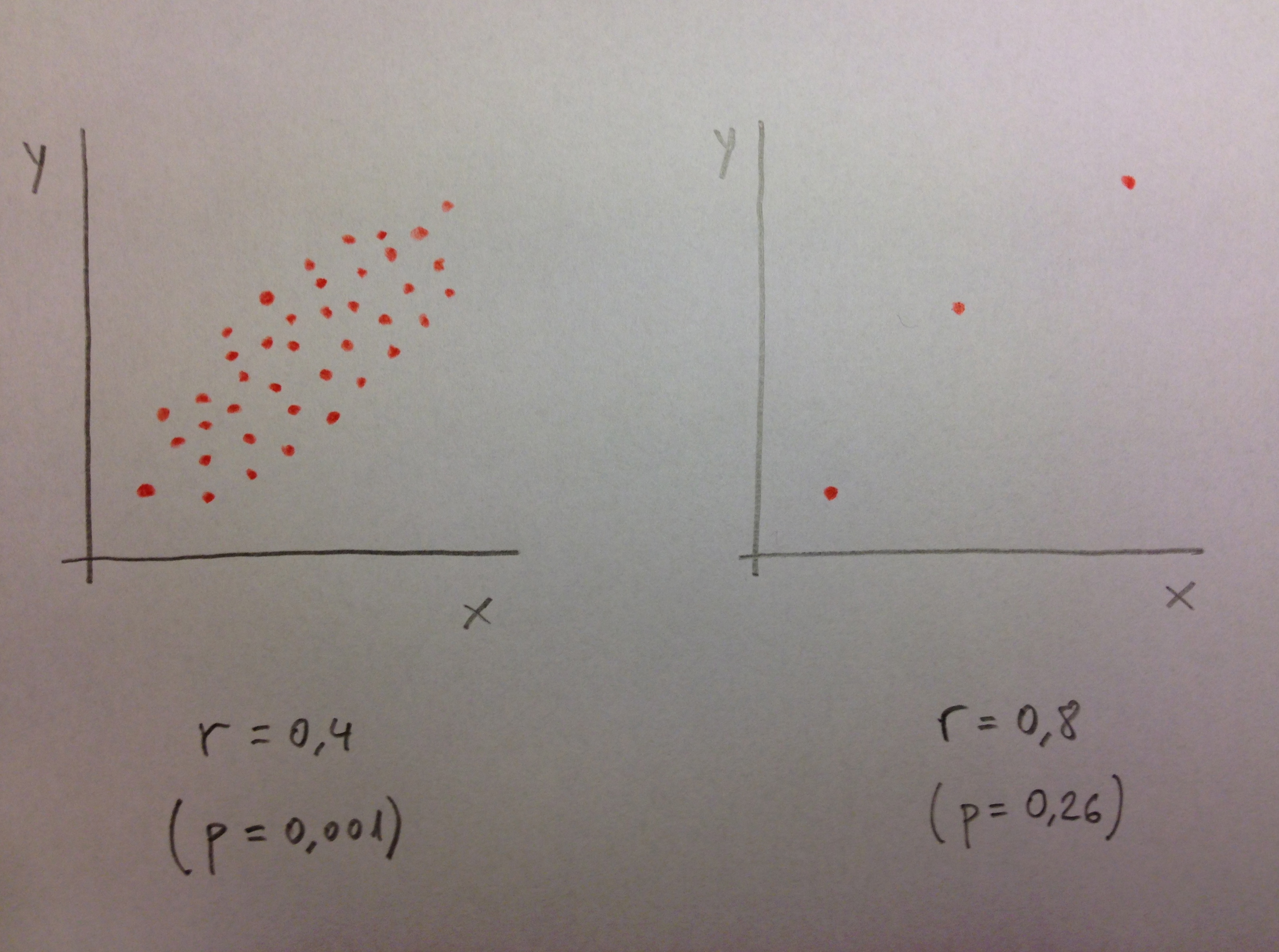
50. De esta forma podemos decir que una r=0,8 con un p-valor de 0,26 es, en realidad, una correlación más baja que una r=0,4 con p=0,001.
51. Porque, en este caso, la r=0,8, al no ser significativa, no podemos fiarnos de ella. Puede ser un efecto del azar del muestreo.
52. De la misma forma que en esta muestra hemos calculado una r=0,8 en otra muestra tomada en las mismas condiciones podríamos tener r=-0,8. Por lo tanto, este 0,8 no es fiable.
53. Por eso ante esta posibilidad la técnica estadística nos dice: Ante la duda mejor afirmar que no hay relación; o sea, que r es igual a 0.
54. Veamos en el gráfico que sigue cómo serían los valores de dos muestras donde se pudieran ver estas dos situaciones planteadas. Si se observa en la muestra con la correlación r=0,8 la fiabilidad de esta correlación es baja. Al estar basado el cálculo en una muestra muy pequeña no tenemos la garantía de que al aumentar la muestra se mantendrá este nivel de correlación. Sin embargo, en el caso de la correlación r=0,4, no se trata de una gran correlación pero sí es fiable. Parece que a la luz de lo que vemos en la muestra, si aumentamos el tamaño de muestra no es previsible que cambie mucho el nivel de correlación. Podemos decir, pues, que la correlación r=0,8 es inestable, con el nivel de información que tenemos, está poco solidificada. En cambio, la correlación r=0,4 es una correlación sólida, fiable:
Si las variables x e y realmente fueran independientes, si tuvieran r=0, a nivel poblacional tendríamos algo así:

Observemos a continuación los datos muestrales de antes pero sobre este fondo:
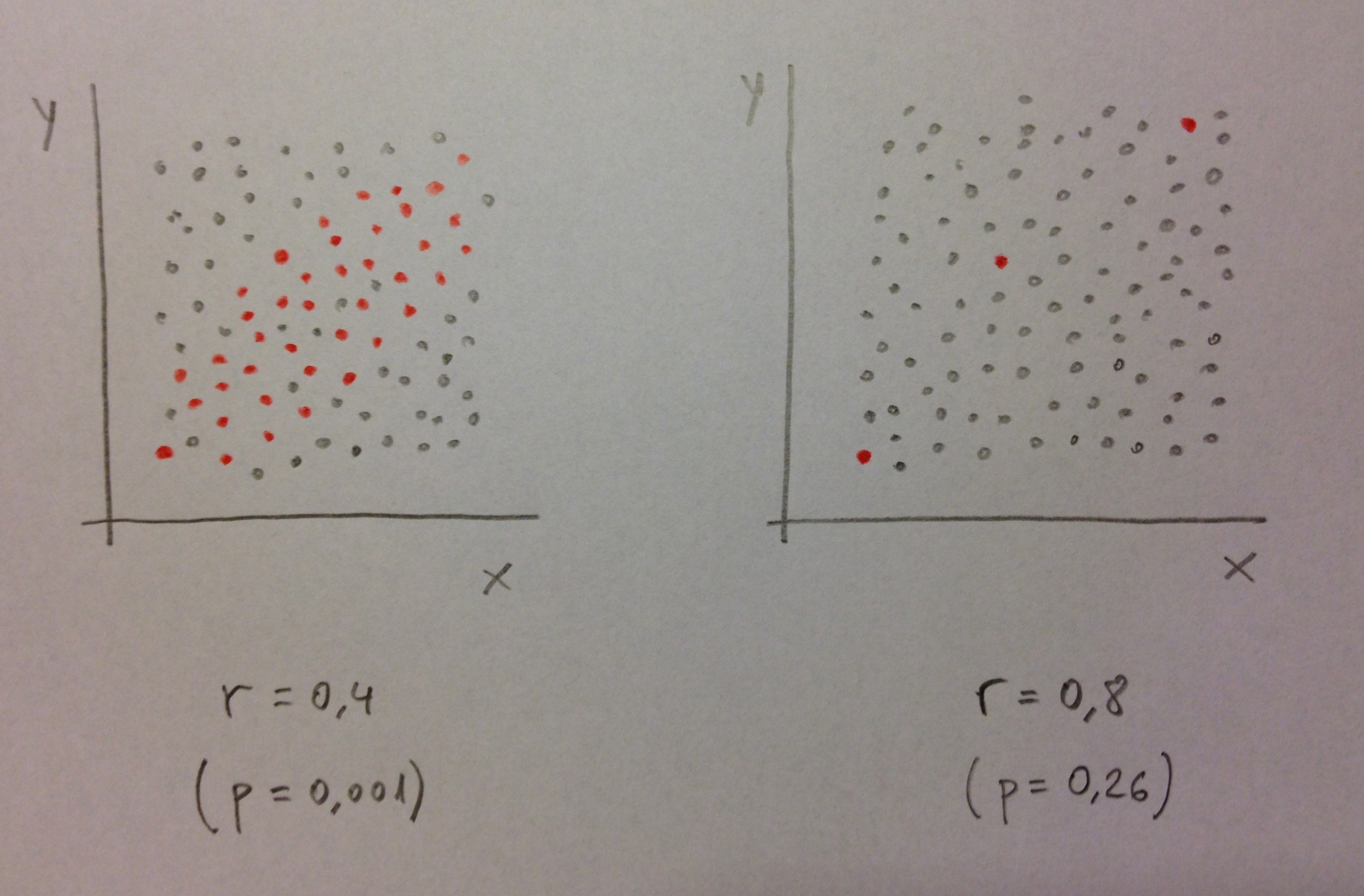
Observemos que en el gráfico de la izquierda tener una población así y obtener una muestra así es muy poco probable. Por eso descartamos la posibilidad de la independencia entre las variables, descartamos que la correlación poblacional r sea 0. Sin embargo, en el de la derecha, tener una población como la que tenemos en el fondo y obtener una muestra así es muy probable, como también sería muy probable ver una muestra incluso con una correlación negativa. En este caso no podemos descartar que la r sea 0 porque es posible ver lo que vemos y que a nivel poblacional no exista, en realidad, relación entre esas variables.
55. Es fundamental entender esto. Ver que la significación es algo distinto a la magnitud de una correlación es importantísimo para entender el peculiar lenguaje de la Estadística.
56. La significación tiene mucho que ver, evidentemente, con el tamaño de muestra. Si ese tamaño es pequeño es difícil que la Estadística se fíe de ella.
57. Las muestras de tamaño pequeño son muy imprevisibles porque las diferentes muestras posibles son muy diversas entre ellas.
58. En muestras grandes hay mucha homogeneidad entre las diferentes muestras posibles. Por eso será más fiable lo que una de ellas diga.
59. La metáfora de las notas, del aprobado y suspenso para explicar el contraste de hipótesis y el p-valor tal vez habrá que explicarla un poco más, por la importancia que tiene.
60. La correlación es significativa si el p-valor es inferior a 0,05.
61. El p-valor se mueve entre 0 y 1. Si éste es mayor o igual que 0,05 decimos entonces que no hay correlación; o sea, que no tenemos ningún argumento firme para dudar de la afirmación: r=0.
62. Por eso digo que se puede ver como si quien se examinara fuera r=0 y que el p-valor fuera como la nota de ese examen.
63. Si es menor que 0,05 suspende r=0 y hablamos, pues, de correlación significativa; y si es mayor o igual que 0,05 entonces r=0 no suspende. Se mantiene tal afirmación. De momento ésta no se contradice con lo que sabemos, con lo que vemos.
64. Decimos entonces que no tenemos pruebas que nos permitan afirmar, de forma fiable, que hay correlación entre esas variables.
65. No tenemos pruebas suficientes para afirmar cuál debe ser el signo y la magnitud de la correlación a nivel poblacional. Pensemos que estamos intentando sacar conclusiones poblacionales a partir de una información puramente muestral. Esto es un elemento que está siempre presente en Estadística.
66. Al basarse la decisión en un número entre 0 y 1 y en una frontera (0,05), el paralelismo con la enseñanza es claro.
67. En España, las notas son un número que va del 0 al 10, con una frontera muy clara en el 5.
68. Como puede verse la frontera establecida en el p-valor sugiere realmente un trato de favor para el aprobado. Esto es para que cuando suspenda r=0 tengamos muy pocas posibilidades de errar.
69. Por eso hablamos de correlación significativa cuando el p-valor traspasa ese límite.
70. Le hemos dado mucho margen a r=0 y acabamos viendo, en ese caso, si el p-valor es menor que 0,05, que no es coherente mantener esta afirmación a la luz de lo que estamos viendo en la muestra que tenemos.
71. Entender este razonamiento es fundamental en Estadística. Estamos abordando, con esto, en realidad, el núcleo básico de la Estadística.
72. En Estadística a todo esto que estamos viendo le denominamos «Contraste de hipótesis». Vamos a ver, ahora, la terminología que usamos.
73. En Contraste de hipótesis se habla de Hipótesis nula: H0, y de Hipótesis alternativa: H1. Y de que hemos de decidirnos por una u otra.
74. La decisión no es como cuando compramos una camisa poniendo una al lado de la otra para ver cuál nos gusta más.
75. La H0 parte como cierta y sólo nos decantaremos por la H1 si la H0 es absurdo mantenerla viendo lo que vemos en la muestra.
76. Por eso H1 se le denomina alternativa, porque es la alternativa de la nula cuando no es lógico mantenerla tras analizar la muestra.
77. En todo lo visto con la correlación podemos ahora conectar: H0 es r=0 y H1 es r distinta de 0.
78. El p-valor es el criterio objetivo basado en el análisis de la muestra que nos permite decidirnos por mantener H0 o pasarnos a la H1.
79. Esta lógica de funcionamiento va a ser el tema nuclear de casi todas las técnicas que iremos viendo a lo largo de este curso.
80. Siempre digo que la estructura de la Estadística es como la del Bolero de Ravel: un mismo tema que va repitiéndose machaconamente.
81. El tema machacón del Bolero de Ravel de la Estadística es esta noción de contraste de hipótesis y el p-valor como criterio de decisión.
82. Pero volvamos a la correlación: Ésta se calcula por dos razones básicas: 1) Para cuantificar el grado de relación entre las dos variables.
83. 2) Para crear una función matemática que modelice la relación entre esas variables. A esto segundo se le denomina «Regresión». Será el siguiente tema.
84. Un último apunte: En ocasiones el contraste de hipótesis; o sea, la decisión de si estamos antes una correlación significativa o no, se realiza mediante un intervalo de confianza del 95%. Pensemos que una correlación muestral es, en realidad, una predicción de una correlación poblacional. Si el intervalo de confianza incluye al 0 significa que es posible tener, en la población, una correlación de 0; o sea, no haber correlación entre las variables. Sin embargo, si ese intervalo no incluye al 0 es muy poco probable pensar, a la luz de lo que vemos, que la correlación poblacional sea 0. Por eso, diremos, en estas circunstancias, que la correlación es estadísticamente significativa.
85. Ejemplo: Si tenemos un intervalo de confianza del 95% de una correlación poblacional así: (-0.12, 0.24), esto es equivalente a un contraste de hipótesis sobre la correlación con un p-valor superior a 0.05. Por el contrario, si el intervalo es (0.13, 0.45), esto es equivalente a un p-valor inferior a 0.05.