Los siguientes vídeos explican el tema:
1. Una buena forma de empezar la Inferencia estadística es hacerlo mediante los Intervalos de confianza, porque aunque sean procedimientos inferenciales, mantienen una importante conexión con la descriptiva. Por esto lo planteo en este capítulo a modo de bisagra entre la Estadística descriptiva y la Estadística inferencial.
2. En una buena parte de muestras, sabiendo la media y la Desviación estándar podemos deducir todos los demás cálculos que podemos hacer a una muestra. Por esto es tan habitual resumir una variable cuantitativa mediante estos dos descriptores.
3. Cuanto más forma de campana de Gauss siga la distribución de los valores de la muestra más será cierto lo dicho en el punto anterior.
4. Una muestra se distribuye de forma normal, o según una campana de Gauss, básicamente cuando se cumplen dos condiciones: 1) Cerca de la media está la mayoría de valores. 2) De forma progresiva y simétrica va disminuyendo la densidad de valores al alejarse, por ambos lados, de la media de la muestra. Hay formas precisas para comprobar la normalidad de una muestra (como veremos en el Tema 14: Comparación de dos poblaciones), y hay formas más aproximadas como son que la Asimetría estandarizada y la Curtosis estandarizada de la muestra sean, ambos, valores que estén entre -2 y 2, como hemos visto en el Tema 2.
5. La muestra (1, 4, 6, 6, 7, 7, 7, 8, 9, 11, 13) sigue bien el carácter de normalidad. La muestra (3, 3, 3, 4, 11, 12, 12, 123) no lo sigue.
6. En la primera está claro que la mayor parte de valores están cercanos al valor central de la muestra y a derecha e izquierda de ese valor central hay más o menos el mismo número de valores; o sea, que hay simetría entre ambos lados.
7. En la segunda, sin embargo, esto no es así. Observemos que hay como tres focos en la muestra: uno próximo a 3, otro próximo a 12 y otro en torno a 123. Esto no se ajusta al ritmo de la campana de Gauss.
8. Ante toda muestra que sigue bien una distribución normal podemos hacer unas importantes afirmaciones acerca de la población:
9. Dentro del intervalo que va de la media menos una Desviación estándar (DE) hasta la media más una DE tenemos aproximadamente el 68.5% de los valores.
10. Esto lo escribimos normalmente así: M±DE. También escribiremos: (M-DE, M+DE).
11. Ejemplo: Supongamos una muestra de alturas de personas, que sigue bien una distribución normal, y que tiene una media de 170 y una DE de 8.
12. En esta población el 68.5% de las personas mide entre 162 y 178 cm, o sea, dentro del intervalo (170-8, 170+8)= (162, 178).
13. De la misma forma, la media más menos dos DE cubre el 95% y la media más menos tres DE cubre aproximadamente el 99.5%.
14. En el intervalo (154, 186) tenemos el 95% de individuos de la población y en (146, 194) el 99.5%.
15. Media más menos una DE, más menos dos DE y más menos tres DE, cubren, pues, el 68.5, el 95 y el 99.5%, respectivamente, de la población.
16. Muestra: (1, 2, 4, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 7, 7, 8, 8, 10, 11, 15). Sigue la distribución normal. La media es 6.75, la DE es 3.
17. Podemos decir que la población de donde hemos tomado esta muestra es una Normal de media 6.75 y DE 3. Escrito así: N(6.75, 3).
18. Esta población queda modelizada por esa distribución. Lo que calculemos a la N(6.75, 3) es como si le calculásemos a la población.
19. Por eso es un modelo, porque sustituye a una realidad, porque la aproxima, porque la representa, porque, en cierto sentido, puede ocupar su lugar.
20. La distribución normal, como modelo de la realidad, es muy usual porque muchas variables se distribuyen de esta forma.
21. Gauss creó una maquinaria matemática (la campana de Gauss) que es una buena maqueta de la variabilidad de muchas variables.
22. De Campanas de Gauss tenemos infinitas. El símbolo general de una de ellas es N(μ, σ). ¿Qué significan la μ y la σ?
23. La μ y la σ son los llamados parámetros de la normal, son como las tallas. Como cuando pedimos unos zapatos del 42.
24. Pero aquí pedimos dos números. Como si para los zapatos necesitáramos pedir mediante dos números: uno para la longitud y otro para la anchura.
25. La μ es el punto más alto de la campana de Gauss y la σ es una medida del grosor de la campana, de su estilización.
26. He escrito ahora N(μ, σ) pero antes he usado la expresión N(M, DE), ¿por qué?
27. Porque la media M, de una muestra, estima la media de la población que, matemáticamente, es representada por la μ de la normal.
28. La DE de una muestra estima la σ, que es una medida de la dispersión poblacional. Por eso M es a μ lo que DE es a σ.
29. Cuando decimos que utilizaremos una N(μ, σ) es como decir que queremos comprar un determinado modelo de zapato.
30. Cuando decimos que utilizamos una N(M, DE) es como cuando pedimos el número 42 de un determinado modelo de zapato, porque la M y la DE siempre serán dos números concretos calculados a la muestra que tengamos.
31. La M y la DE calculada a una muestra que se ajusta a una normal nos eligen la talla de la campana de Gauss que se ajusta mejor a nuestro caso.
32. Una vez tenemos una normal concreta como modelo de una población lo que calculemos al modelo es como si, en realidad, lo calculásemos a la población.
33. Esta es la ventaja de tener modelos en ciencia: sustituyen a la realidad, son maquetas matemáticas que podemos manejar.
34. Maquetas a las que les podemos preguntar cosas: lo que ellas nos respondan es, aproximadamente, lo que nos respondería la población modelizada.
35. Lo de media más menos una, dos y tres DE y los porcentajes vistos son ejemplos de esas preguntas posibles.
36. Modelizar, crear modelos, sirve, pues, para representar una realidad con piezas de otros materiales. Piezas y materiales que son mucho más fácilmente manejables, a los que se les puede alterar cosas y ver su comportamiento, su respuesta.
37. En matemáticas a los modelos se les puede calcular cosas con mucha facilidad. En Estadística un modelo representa, dibuja una realidad determinada, una población, por lo tanto, estos cálculos que hagamos en él son como si les hiciésemos a estas poblaciones.
38. Al calcularle cosas al modelo es como si estuviéramos calculándole cosas a algo que en realidad no tenemos. Este juego es importante entenderlo bien. Es clave para comprender el proceder de la Estadística.
39. Veamos, ahora, un dibujo de la campana de Gauss y de los tres intervalos (media más menos una, dos y tres desviaciones estándar) asociados a los tres números (68.5%, 95% y 99.5%), respectivamente; números que ya no debemos olvidar nunca para poder manejar con propiedad estos dos básicos descriptores de una muestra que son la media y la desviación estándar:

40. Si no hay ajuste a la distribución normal es más recomendable, entonces, usar la mediana y el rango intercuartílico porque al usar la media y la desviación estándar, con el más y el menos entre ellas, resulta una invitación a una inferencia que en absoluto es correcta. Incluso pueden resultar muy incorrectas las inferencias que hagamos a partir de estos dos valores. Ver el importante artículo ¿La media y la desviación estándar o la mediana y el rango intercuartílico? para aclarar cuándo resumir una variable de una u otra forma.
41. Veamos, ahora, otra cuestión que lleva a muchos errores. Una de las confusiones más frecuentes que cometen los usuarios de la Estadística se da entre dos nociones de intervalo de confianza bien distintas que pueden usarse y que, si no están claramente perfiladas, es fácil intercambiar y mezclar. Vamos a intentar clarificar estas dos nociones de intervalo de confianza porque hasta ahora hemos visto únicamente una de ellas:
42. Supongamos que un estudio dice que un intervalo del 95% de la media de la altura de adultos en una población es (169, 171). ¿Significa esto que el 95% de la gente de esa población mide entre 169 y 171?
43. Supongamos dos equipos de investigación que estudian las alturas de una misma población: el equipo A y el equipo B.
44. El equipo A toma una muestra de tamaño 100 de esta población y la media resulta que es 170 y la desviación estándar (DE) es 10.
45. El equipo B toma una muestra de tamaño 400 de la misma población y resulta que al calcular la media y la DE obtiene los mismos valores: 170 y 10.
46. El que la media y la DE den lo mismo es porque estamos teorizando y me va bien que sea así, pero no sería extraño que dieran valores muy parecidos.
47. Pensemos que ambos equipos están estudiando la misma población. Es lógico que no haya mucha diferencia entre los descriptores calculados a sus muestras.
48. Ambos equipos dirán que entre 150 y 190 tenemos el 95% de alturas poblacionales, por todo lo dicho antes.
49. Para decir eso ambos equipos miran primero la normalidad de la muestra y toman, luego, la media y le suman y restan dos veces la DE.
50. Estarían aplicando, ambos equipos, esta regla general que en toda distribución normal la media más menos dos desviaciones estándar cubren el 95% de los valores individuales.
51. Pero si ambos equipos nos dieran un intervalo del 95% de la media sería: (168, 172) el del equipo A y (169, 171) el del equipo B.
52. Porque el intervalo es ahora «de la media». Este intervalo no significa que el 95% de alturas están entre sus límites.
53. Significa que tenemos una confianza del 95% de que la verdadera media poblacional esté dentro del intervalo.
54. Y en este tipo de intervalo de la media el tamaño de la muestra es determinante porque marca la precisión que tenemos para hacer una predicción.
55. Cuanto mayor sea el tamaño de la muestra más precisión y, por lo tanto, más estrecho será el intervalo.
56. Para entender esto hay que profundizar en la noción de variable en Estadística.
57. Una variable cuantitativa es una medida que podemos evaluar a unas entidades determinadas. El peso, la altura, la renta en 2010 son variables que podemos medir a personas.
58. El número de sílabas es una variable que podemos medir a toda palabra del castellano. El número de trabajadores lo es para empresas, etc.
59. Pues bien, algo muy importante: la media muestral es una variable que se puede medir a toda muestra de un tamaño n en una población. Esto es muy importante. Esta noción de media muestral, con su dualidad (el ser un número para una muestra y el ser una variable para el conjunto de todas las muestras posibles), es realmente uno de los temas esenciales de la Estadística.
60. Cuando tomamos una muestra de una población la muestra que tenemos es una de las muchísimas muestras que podríamos tener.
61. Claro que nosotros únicamente tenemos una, pero el número de muestras que hubiéramos podido tener y no tenemos es enorme.
62. Es sorprendente pero en Estadística para sacarle provecho a una muestra debemos pensar no únicamente en ella sino en todo el repertorio de muestras que hubiéramos podido tener y no tenemos. Es como si el significado de lo que tenemos quedara explicitado por todo lo que no tenemos pero que hubiéramos podido tener.
63. Por lo tanto, la media muestral como variable que es tiene media y DE. Si la media muestral es una variable, como toda variable tiene media y desviación estándar, también las tendrá, evidentemente, la media muestral o cualquier estadístico, cualquier descriptor, cualquier estimador que calculemos a una muestra.
64. Media y DE que nunca tendremos realmente pero sí idealmente, teóricamente, conceptualmente; que significa, en Estadística, algo así como aproximadamente. Y no tendremos todas las muestras posibles nunca porque para tenerlas necesitaríamos tener toda la población y si tuviéramos toda la población, evidentemente, no nos haría falta para nada la Estadística.
65. Pues aquí va un concepto muy importante: Si una variable sigue la N(M, DE) la media de esta variable también es una normal.
66. Una normal también con su media y su desviación estándar. Su media es, exactamente, la misma que la de la variable original; o sea: M.
67. Su DE es la de la variable original dividido por la raíz cuadrada del tamaño de muestra: DE/raíz(n).
68. O sea, si una variable sigue una distribución N(M, DE) la media muestral sigue una distribución N(M, DE/raíz(n)).
69. De ahí que la precisión a la hora de construir intervalos de confianza de la media dependa del tamaño de muestra.
70. Cuanto mayor es el tamaño de la muestra, como la n está en el denominador, el cociente DE/raíz(n) es menor.
71. Por lo tanto, los intervalos construidos a partir de esta desviación estándar serán, así, más estrechos, más precisos.
72. Y es muy importante tener en cuenta que ahora el intervalo construido es un intervalo de la media poblacional. Por esto hablamos de intervalo de la media y no de intervalo a secas.
73. Cuando se habla de intervalo sin más, como lo hemos hecho al comienzo de este tema, nos estaremos refiriendo habitualmente a intervalos de valores individuales de la variable estudiada.
74. Es obvio que estamos hablando, pues, de dos tipos de intervalos completamente distintos, aunque, como tales, funcionan igual: creando un intervalo de un determinado nivel de confianza. Pero con objetivos diametralmente distintos, evidentemente.
75. Volvamos al ejemplo de antes. Teníamos dos equipos: el A y el B, estudiando las alturas de una misma población.
76. Los dos equipos trabajaban con distinto tamaño de muestra: el A con tamaño 100 y el B con tamaño 400. Pero los dos tenían igual M y DE.
77. Como las M y las DE son las mismas en ambas muestras, decía antes que el intervalo del 95% de valores que dan es el mismo.
78. Porque ambos equipos modelizan la población de la misma forma: con una distribución normal N(170, 10).
79. Pero veíamos también que el intervalo de confianza del 95% de la media que da cada equipo es distinto: (168, 172) y (169, 171).
80. Veamos cómo calcula cada equipo su intervalo de confianza del 95% de la media.
81. Para el equipo A, DE/raíz(n) vale 10/raíz(100)=10/10=1. Por lo tanto, la media muestral sigue una distribución N(170, 1).
82. Para el equipo B, DE/raíz(n) vale 10/raíz(400)=10/20=0.5. Por lo tanto, la media muestral sigue una distribución N(170, 0.5).
83. Puede entenderse, pues, que si construyen un intervalo de confianza del 95% de la media tomen la media más menos dos DE/raíz(n).
84. El cociente DE/raíz(n) es la DE de la media muestral. A esta DE de la media muestral, vista ésta como variable, se le denomina Error estándar (EE). La relación entre el EE y la DE es la siguiente:

85. El Error estándar es, por lo tanto, una Desviación estándar, pero se le denomina así para singularizarla. Es una Desviación estándar pero de una predicción: en nuestro caso de la media poblacional, pero podría ser de otro valor poblacional.
86. A toda Desviación estándar de una predicción se le denomina Error estándar. Y lo que tienen todos esos Errores estándar en común es que se trata de una operación donde en el numerador hay una medida de la Desviación estándar de la variable estudiada y en el denominador está de alguna forma contemplado el tamaño de muestra.
87. Por lo tanto, el tamaño de muestra condiciona completamente la magnitud del Error estándar, en cambio no lo hace así con la Desviación estándar de una variable, la cual se debe a las peculiaridades de la distribución de valores de esa variable en la naturaleza.
88. El error estándar es, pues, una DE, pero una DE de la media muestral, una DE que se construye a partir de la DE de la variable original.
89. Se entiende, pues, que el intervalo del 95% del equipo A sea (168, 172) y el del B sea (169, 171), basta con sumar y restar dos errores estándar (EE).
90. El EE que tenía la media muestral del equipo A hemos visto que era 1, de ahí el 170±2: (168, 172).
91. El EE que tenía la media muestral del equipo B hemos visto que era 0.5. Dos veces ese EE nos lleva al intervalo 170±1: (169, 171). A continuación un resumen en forma de tabla de este ejemplo:

92. Tener muestras más grandes, pues, nos permite construir intervalos más estrechos a la hora de hacer predicciones.
93. Es básico tener en cuenta siempre en Estadística una cosa que es muy importante: Cuando una muestra es grande habrá poca diferencia entre las diferentes muestras que hubiéramos podido obtener pero que no tenemos. Por lo tanto, es más fiable, estamos muy posiblemente más cerca de lo que buscamos, de lo que pretendemos estimar, en estas circunstancia. Por lo tanto, los intervalos que construyamos podrán ser relativamente estrechos.
94. Sin embargo, cuando una muestra es pequeña las diferentes muestras que hubiéramos podido obtener pero que no tenemos son, ahora, muy diversas entre ellas. Evidentemente, lo que calculemos a la que tenemos es, ahora, menos fiable. Es muy posible que estemos considerablemente lejos del valor que queremos pronosticar. Por lo tanto, los intervalos deben ser, en estas circunstancias, mayores, porque tenemos mucha inseguridad en lo que le calculemos a esta muestra.
95. Es, pues, muy importante diferenciar: En ocasiones se dan intervalos de la variación de una variable, como cuando se daba el intervalo (150, 190).
96. En otras ocasiones se dan intervalos de la media como los (168, 172) o (169, 171). Es básico ver esta diferencia. Es fundamental distinguir cuándo tenemos un tipo de intervalo y cuándo tenemos el otro tipo, porque son sustancialmente distintos.
97. Repito: aquí hablo de intervalos de la media, pero deberíamos hablar de intervalos de una predicción. Cualquier predicción va asociada de un tipo de intervalo que representa un intervalo de confianza sobre un determinado valor poblacional y se construye mediante un Error estándar.
98. Iremos viendo, a lo largo de este curso, valores poblacionales que suelen estimarse mediante intervalos de confianza de este tipo: la media, la correlación de dos variables, la Odds ratio, los coeficientes de una regresión entre dos o más variables, etc.
99. Los dos intervalos de confianza más usuales son el de la media y el de una proporción. A continuación vemos cómo se construye un intervalo del 95% de ambos valores poblacionales:

100. Observemos cómo se aplicaría el segundo de estos intervalos. El primero ya lo hemos visto a lo largo de la exposición del tema. Supongamos que hemos hecho un estudio mediante el cual queremos estimar la prevalencia de la diabetes en España. La muestra, supongamos, que es de tamaño 10000 y que 700 tienen diabetes; o sea, un 7% ó un 0.07, hablando en proporciones, en tanto por uno. Si queremos construir un intervalo de confianza del 95% para estimar la proporción poblacional de diabéticos en España aplicaríamos, entonces, la segunda formulación de la siguiente forma:
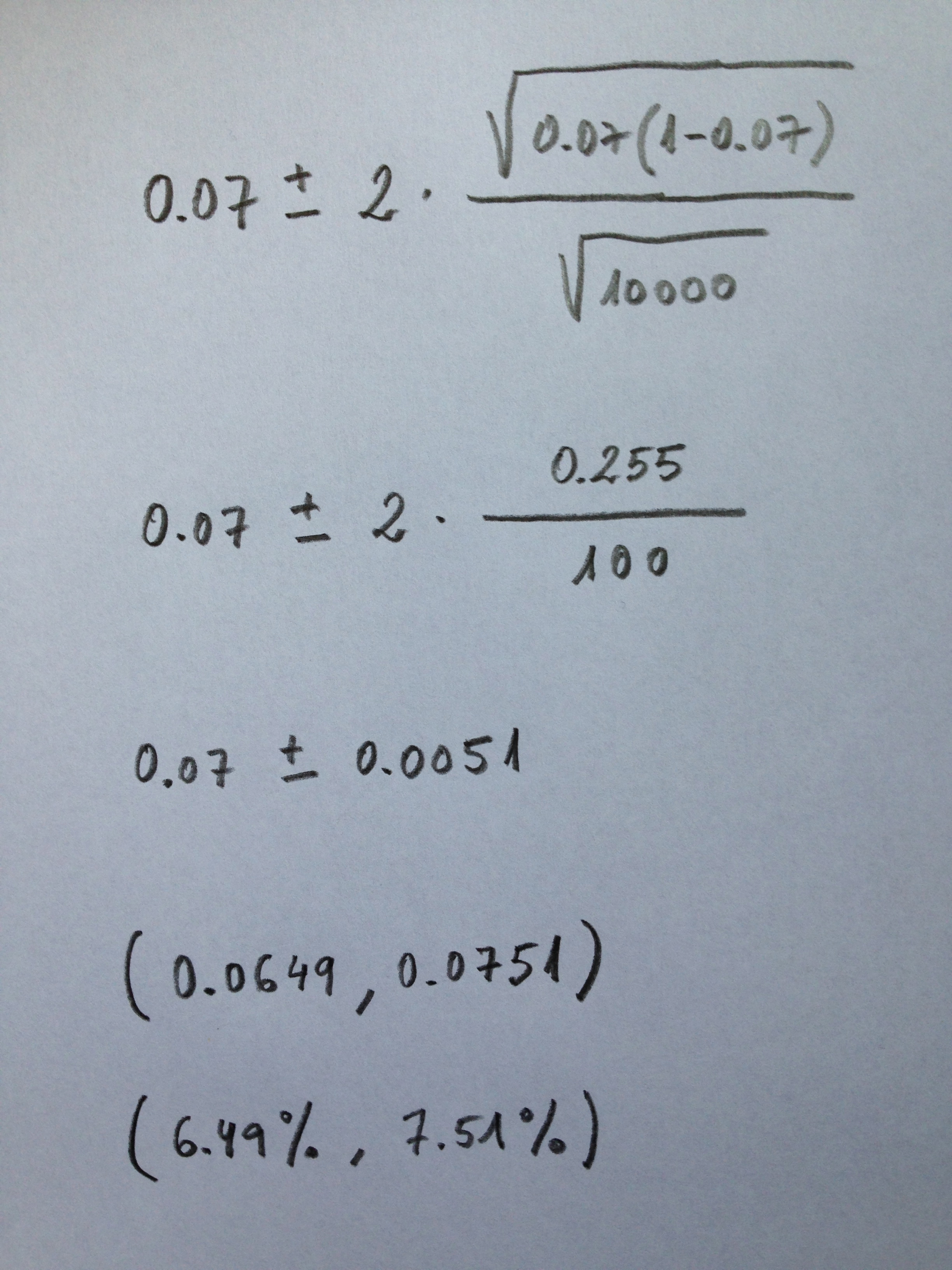
101. Como puede observarse aunque el cálculo se haga en tanto por uno, porque esta es la formulación habitual, al final el intervalo del 95% lo expresamos en términos porcentuales. Estaríamos, pues diciendo que con una confianza del 95% la proporción de diabéticos en España está entre el 6.49% y el 7.51%.

por que en algunos libros uno encuentra el intervalo de confianza relacionado con la tabla t de student y aquí no la mencionan para nada?
En el cálculo de los intervalos de confianza de distintos valores poblacionales pueden estar implicadas distintas distribuciones (la t de Student, la normal, la ji-cuadrado, etc). En ellas es donde se acaba de perfilar el valor concreto a aplicar para multiplicar al Error estándar según la confianza deseada. Verás en este artículo que para obtener un intervalo de confianza del 95% deben sumar y restarse dos veces el Error estándar. Este 2 en una aproximación. En cada caso puede cambiar un poco pero siempre será un valor próximo a 2. Como es una introducción a la noción de intervalo de confianza he preferido hacerlo de esta forma genérica.
Lo primero enhorabuena por tu página. Soy novata en el tema de las estadística y me surgen algunas dudas.
Tengo una serie de datos de valores de producciones y quiero obtener un valor medio representativo. El tema es que tengo valores muy muy elevados que no se si tendria que eliminarlos para sacar un valor medio. Y por otro lado, tampoco se si tendría que utilizar la media o la mediana. Siguiendo tus indicaciones he calculado la curtosis y el coeficiente de asimetria y me salen entre -2 y 2, por tanto que los datos son distribución normal, no? Y en este caso, podría utilizar la media en vez de la mediana. Decir que ambos valores no son iguales. Pero me surge la duda de si tendría que quitar los valores elevados… vamos que cuando tengo que tener en cuenta si tengo valores atípicos, y en ese caso cómo sé que realmente son atípicos.
Gracias
Si la curtosis y asimetría estandarizadas están dentro de este intervalo la media y la mediana deben estar relativamente próximas. Yo no eliminaría datos a no ser que tuviera la certeza de que hay algún error en él. Con la media y la desviación estándar o típica tienes perfectamente descrita la distribución de esa muesta y de la población que hay detrás.
FELICITACIONES POR ESTE TEMA ESTA INTERESANTE. MI PREGUNTA ES LA SIGUIENTE: ¿COMO SE INTERPRETA LOS RESULTADOS DE CORRELACION NEGATIVA -,013 Y SIGNIF BILATERAL ,898 YA EN LOS RESULTADOS? GRACIAS…
Como el p-valor es 0,898 la correlación muestral -0,013 no es estadísticamente significativa. Obviamente, como puedes ver es casi 0 la correlación muestral. Y siempre la hipótesis nula, que es la que parte como cierta, afirma que la correlación poblacional es 0.
Es lo mismo intervalo de confianza del 95% que rango intercuartílico?
No. El rango intercuartílico es un intervalo centrado del 50% de los valores de una variable. El intervalo de confianza del 95% si es descriptivo de una variable indica los límites entre los que se encuentran el 95% de los individuos. Si es predictivo, que es lo más habitual, es un intervalo donde se confía que estará el valor poblacional que se trata de predecir.
Me encanta tu blog, tengo un pequeña duda que no ha quedado bien aclarada; ¿que es el intervalo de confianza?
En una predicción el intervalo del 95% es una predicción de entre qué valores estará el verdadero valor poblacional.
Buena explicación!