En inferencia Estadística hay tres formas básicas de decir cosas:
Estimación puntual.
Estimación por intervalos de confianza.
Contrastes de hipótesis.
Veamos un poco lo que supone cada una de estas tres formas:
En la Estimación puntual se pretende pronosticar un valor poblacional a través de un cálculo muestral. La finalidad es construir, pues, un estimador, una maquinaria matemática, como la media muestral, la mediana muestral, la Odds ratio muestral, la correlación muestral, etc, que nos proporcione un pronóstico de un valor poblacional desconocido y que lo haga con el máximo de calidad: sin sengo (que el promedio teórico de los cálculos que pudiéramos hacer con todas las muestras posibles sea justo el valor buscado), con poca Desviación estándar (que en el contexto de un estimador siempre la llamamos Error estándar, porque depende también del tamaño muestral).
En la Estimación por intervalos de confianza se pronostica, también, como en la Estimación puntual, pero mediante un intervalo de confianza. No se da un valor pronóstico sino que se da un intervalo de valores entre los cuales con una confianza prefijada (normalmente del 95%) estará el valor real que se pretende pronosticar. Es importante porque, así como la Estimación puntual únicamente nos proporciona un número, sin más, un intervalo de confianza nos da muchas cosas: nos da una predicción puntual también, pero, además, nos da un intervalo de confianza y nos proporciona, también, a través de la longitud del intervalo, una medida del nivel de información que tenemos en el estudio. Pensemos que esta longitud depende del Error estándar, por lo tanto tenemos una información adicional muy valiosa que no tenemos en la Estimación puntual.
En el contraste de hipótesis se contraponen dos afirmaciones, la llamada Hipótesis nula: H0, y la denominada Hipótesis alternativa: H1. Y después de un anàlisis de la muestra que tenemos nos decidimos por una u otra, pero de una forma un poco peculiar: La H0 parte como cierta y sólo nos decantaremos por la H1 si la H0 es absurdo mantenerla viendo lo que vemos en la muestra. Por eso a la H1 se le denomina alternativa, porque es la alternativa de la nula cuando ésta no es lógico mantenerla tras analizar la muestra. De nuevo, como en los intervalos de confianza, tenemos un procedimiento que analiza con profundidad la información y nos lo muestra a través de un p-valor, que es una medida objetiva de la posición de los que vemos respecto a lo que deberíamos ver si fuera cierta la H0. Por eso cuando el p-valor es muy pequeño rechazamos esta hipòtesis, porque està muy lejos lo que vemos de lo que deberíamos ver.
1. En la introducción de las técnicas de relación mostraba el importante gráfico siguiente:
2.. Recordémoslo: En la primera fila del dibujo se ven tres situaciones bien distintas de relación entre dos variables cuantitativas.
3. En la segunda fila del dibujo se ven tres situaciones distintas de relación entre dos variables cualitativas, ejemplificada en un caso de relación entre dos variables dicotómicas.
4. Y, finalmente, en la tercera fila del dibujo se ven tres situaciones distintas de relación entre una variable cuantitativa y una variable dicotómica.
5. Si se observa el dibujo completo con detenimiento se captará el paralelismo que hay en las tres situaciones planteadas, en las tres filas.
6. En cada una de las filas hay una relación inversa en el primer caso, una no relación en el segundo y una relación directa en el tercero
7. Para medir la relación entre variables continuas tenemos la correlación de Pearson, la de Spearman y la de Kendall, que ya hemos comentado en el tema dedicado a la correlación.
8. El caso de la izquierda tiene una correlación negativa, el de la derecha positiva y en el caso del centro no hay correlación (r=0).
9. Para medir la relación entre variables dicotómicas ya sabemos que tenemos distintos índices. El más importante de ellos, el más usado, es la Odds ratio.
10. Ahora, en la segunda fila, al relacionar dos variables dicotómicas, el caso de la izquierda y en el de la derecha tendremos una Odds ratio distinta de uno, uno mayor que uno y otro menor que uno, según coloquemos los valores en la tabla, y en el caso del centro una Odds ratio de uno.
11. Para medir la relación entre una variable continua y una dicotómica, que es la situación dibujada en la tercera fila del gráfico, también se usa una Odds ratio. Veremos luego de qué forma se adapta esta noción a un caso tan distinto como éste.
12. En esta situación tercera, que es la que ahora nos va a ocupar, el caso de la izquierda del dibujo tendrá una Odds ratio menor que uno, el de la derecha mayor que uno y el del centro tendrá una Odds ratio muy próxima a uno.
13. Para situar a la Regresión logística veamos primero el caso de la relación entre una variable dicotómica con una única variable independiente continua. Se suele denominar una Regresión logística simple. Luego veremos que esto se puede ampliar a más de una variable independiente y hablaremos, entonces, de Regresión logística múltiple.
14. Veamos cómo es la función matemática que relaciona una variable dependiente dicotómica «y», con valores de 0 y 1, con una variable independiente «x» continua. El valor de 1 lo reservamos siempre al acontecimiento que especialmente queramos detectar, los casos, en términos médicos (Ver el Tema 9). El valor 0 lo asignamos a los que van asociados al acontecimiento contrario: los controles, en términos médicos.
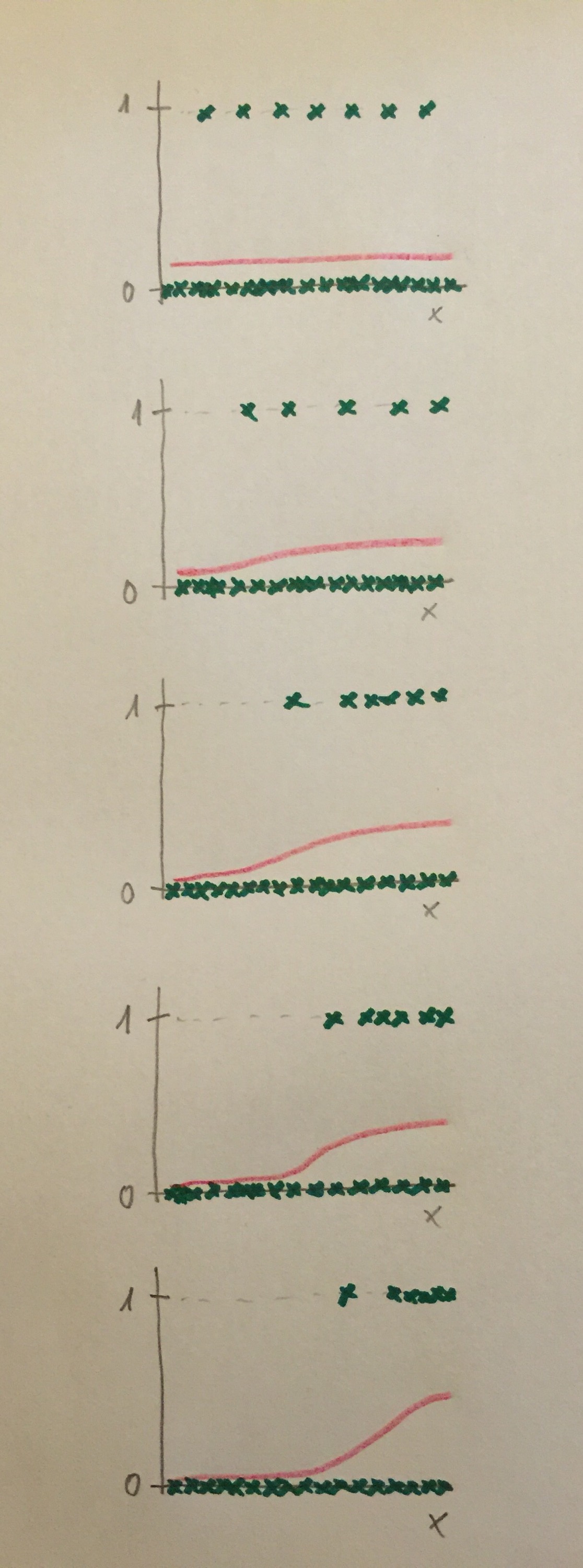
15. En los tres gráficos de la tercera fila, que es el caso que ahora planteamos, veremos que no tiene sentido allí usar una recta para representar esos datos. Debemos usar una función no lineal un tanto especial. Pero veamos primero, intuitivamente, esta situación en unos casos posibles. Supongamos los siguientes casos con datos factibles. Veamos, en primer lugar, que hay una mayor cantidad de valores con la variable dependiente con el valor 0. Y veamos que los valores de arriba; o sea, los valores con el valor 1, se van desplazando, en los diferentes gráficos, hacia la derecha:
A la hora de construir una función que modelice las proporciones de valores abajo (valor 0) y arriba (valor 1) debemos establecer unas curvas como las siguientes:
16. El tipo de función que se adapta mejor a valores que se estructuran en dos líneas paralelas es el llamado modelo de Regresión logística simple. Veamos la fórmula general de ese modelo de Regresión y las formas de las curvas que puede dibujar este modelo:
17. Esta función tiene dos parámetros: la «a» y la «b». Veamos qué papel juega cada uno de ellos a la hora de configurar la mejor adaptación de una función de ellas a unos datos concretos que tengamos en una muestra determinada:
18. El parámetro «b» es el elemento más importante del modelo de regresión logística. Obsérvese que puede ser positivo, cero o negativo.
19. Es cero cuando no hay relación entre la variable dicotómica y la variable continua. Y su valor absoluto marca el grado de relación.
20. De hecho, la Odds ratio, como medida de la relación entre estas dos variables, es:
21. Si b=0, la OR vale 1 (e0=1), que significa que no hay relación.
22. Cuando la «b» es positiva la OR será mayor que 1 y cuanto mayor sea evidentemente mayor será la OR.
23. Cuando la «b» sea negativa, la OR será menor que 1 y cuanto mayor sea, en valor absoluto, menor será, entonces, la Odds ratio, será un valor más próximo a cero.
24. Recordemos que la Odds ratio puede tomar valores de cero a infinito. Mayor o menor que uno indica que hay relación. Cuanto más alejada de 1 más relación. El que sea menor o mayor que 1 indica un diferente tipo de asociación entre la variable cuantitativa y la variable dicotómica.
25. Es cierto que la Odds ratio tiene un rango de valores un poco especial. De cero a infinito, con el uno como punto de bifurcación. Punto que separa dos tipos cualitativamente distintos de relación.
26. A un lado y al otro del 1 tenemos dos espacios infinitos de valores. Del 1 a infinito es tan infinito como del 0 a 1.
27. Es cierto que es un tanto peculiar la asimetría que hay en cuanto al aspecto de los dos espacios a derecha e izquierda del 1 en la OR.
28. Estamos acostumbrados a la correlación donde el espacio que hay desde el -1 al 0 es el mismo que el que hay del 0 al 1.
29. Pero a la hora de posibilidades de expresar una relación son exactamente las mismas las que hay con la correlación de las que hay con la OR.
31. Una OR=100 es equivalente a una OR=0.01, una OR=10000 a una OR=0.0001, y así. Equivalen pero marcan relaciones de distinto tipo, claro.
32. Para entender bien cuándo tenemos relaciones fuertes o débiles es muy importante mirarse y remirarse bien los ejemplos mostrados en el gráfico anterior.
33. El valor absoluto de la b será grande, y por lo tanto la OR estará muy alejada de 1, si los puntos con valores 0 ó 1 están muy segregados, si la transición del 0 al 1 ó del 1 al 0 es muy rápida.
34. Obsérvese, en el gráfico anterior, que al estar los puntos segregados tiene más lógica crear una función con mucha pendiente.
35. Y una pendiente más grande significa una b con mayor valor absoluto y, por lo tanto, un valor de eb, una OR, más alejado de 1.
36. Cuando los valores con 0 ó 1 están poco segregados entonces la pendiente de la función es baja, el valor absoluto de la b es pequeño y la OR es, entonces, un valor próximo a 1. Lo que indica que hay poca relación entre la variable continua y la dicotómica.
38. En una regresión logística debe, evidentemente, evaluarse su significación estadística. Una forma de hacerlo es mediante la significación estadística de la OR.
39. Y la significación de una OR, ya lo hemos visto, se puede valorar mediante un p-valor o mediante un intervalo de confianza del 95%.
40. Por ejemplo, una información así: OR=2, IC 95%: (0.2, 20), es equivalente a una información así: OR=2, p>0.05. No es significativa.
41. Y una información así: OR=1.33, IC 95%: (1.23, 1.44), es equivalente a una información así: OR=1.33, p<0.05. Ahora sí es significativa.
42. En una OR para que un IC del 95% nos indique significación el intervalo no debe contener el 1. Es lógico que sea así. Si el intervalo contiene al 1, indica que hay confianza de que el verdadero valor poblacional pueda ser 1.
43. Una peculiaridad de la OR vista aquí, respecto a la vista en el Tema 9, es que depende de las unidades de la variable independiente. Una OR=2 significa que por cada unidad de aumento de la variable independiente x, doblamos el riesgo de que suceda lo que la variable dicotómica delimita. Si queremos cambiar de unidades debemos hacer un cambio de escala. Veamos a continuación un ejemplo para la variable independiente Edad. Si la variable es en años y obtenemos un valor de b de 0,1 y, por lo tanto, una OR de 1,105 eso significa que cada año de aumento de edad aumenta en 1,105 el riesgo. Si queremos ver qué pasa en intervalos de 10 los debemos aplicar el siguiente cálculo que nos lleva a una OR de 2,718. No cometamos el error de multiplicar la OR por 10:
44. En la regresión logística múltiple el problema es el mismo pero ahora las variables predictoras, las variables independientes, son más de una.
45. La ecuación de la regresión logística múltiple es la siguiente:
46. Es una ecuación equivalente a la vista en el modelo anterior de Regresión logística simple. El recorrido de la función sigue siendo 0 y 1, pero el dominio es, eso sí, ahora, multidimensinal.
47. Supongamos que tenemos sólo dos variables independientes: x1 y x2. El espacio dibujado por ellas es, entonces, un plano.
48. Si ahora añadimos la variable dependiente dicotómica «y» a las dos variables independientes x1 y x2 se dibuja un espacio tridimensional.
49. En este caso al representar los puntos muestrales éstos ocupan dos planos, uno a altura y=0 y el otro a altura y=1.
50. La ecuación de la regresión logística múltiple con dos variables independientes es la siguiente:
51. En la regresión logística múltiple hay un procedimiento de elección de las variables independientes que influyen en la dependiente.
52. Y ese procedimiento consiste en una generalización a más variables de lo que hemos visto en la regresión logística simple.
53. Las variables independientes que se relacionan con la dependiente tendrán sus coeficientes, las a1, a2, con alto valor absoluto.
54. Las variables independientes que no se relacionan con la dependiente tendrán sus coeficientes con valores muy próximos a cero.
55. Si consideramos la regresión logística múltiple de dos variables independientes la posición de los puntos en los dos planos es clave a la hora de ver qué variables independientes influyen en la dependiente y cuáles no, cuáles tienen valores absolutos grandes y cuáles no, cuándo únicamente influye una variable, cuándo influyen las dos y cuándo no influye ninguna.
58. En el gráfico siguiente se ven cuatro casos con posiciones de puntos bien distintas con sus respectivos coeficientes:
59. Comentemos los cuatro casos del gráfico anterior y así veremos cómo la distribución de los puntos en los dos planos es clave.
60. En el caso que ocupa la posición de arriba a la izquierda los valores están distribuidos igual por los dos planos. Aquí no hay relación posible. Por eso tanto a1 como a2 son iguales a cero, no son diferentes significativamente a cero. Ni x1 ni x2 se relacionan con la variable y.
62. En el caso de arriba a la derecha los valores están en posiciones diferentes en los dos planos. Y la diferencia es atribuible a la x1. Es, pues, aquí la variable x1 la que está en relación con la variable y. Por esto el valor absoluto de a1 es grande y a2=0.
64. En el caso de abajo a la izquierda los valores están también en posiciones diferentes en los dos planos. Y ahora es debido a x2. Es, pues, aquí la variable x2 la que está en relación con la variable y. Por esto el valor absoluto de a2 es ahora grande y a1=0.
66. En el caso de abajo a la derecha los valores están también en posiciones diferentes en los dos planos. Y debido tanto a x1 como a x2. Ahora las dos variables están en relación con la variable y. Por esto tanto el valor absoluto de a1 como el de a2 son grandes.
68. Cuando la relación de una variable independiente con la variable dependiente es fuerte el valor absoluto del coeficiente es grande.
69. Como decía antes, y es muy importante, cuando los valores con y=0 e y=1 están más segregados es posible crear más pendiente en la función.
70. En cambio si la segregación es sólo parcial debe establecerse un suave pase de un nivel al otro, lo que implica pendiente pequeña.
71. Para calcular la Odds ratio debe elevarse, como en la Regresión logística simple, el número e al valor del coeficiente correspondiente.
72. La OR de la variable x1 es, pues, ea1 y la de la variable x2 es ea2.
La multicolinealidad genera Error estándar; o sea, aumenta la dispersión de las predicciones:
El Test de Belsey, Kuh y Welsch permite detectar un exceso de colinealidad. Si para algún valor propio de la matriz de varianzas-covarianzas el valor del cálculo de la raíz cuadrada del cociente entre el valor máximo y ese valor propio es mayor que 30 se entiende que tenemos un exceso de colinealidad. Entre 5-10 la colinealidad es debil y entre 10-30 todavía no es lo sufiencientemente fuerte como para resultar no aceptable.
A este valor calculado se le suele llamar, también, índice de condición.
La estimación no paramétrica de funciones de densidad, mediante el método Kernel, es una ingeniosa forma de estimar una función de densidad que no siga un modelo conocido (Normal, Binomial, Exponencial, etc). Tiene una enorme flexibilidad y lo que hace es construir una función de densidad girando en torno a los valores muestrales.
El valor h, denominado normalmente la ventana, es un valor que representa el área de influencia que se le pretende dar a cada valor muestral. Su elección se le suele hacer depender de la dispersión de los valores. Posiblemente, para entender mejor la operatividad del estimador, es mejor pensar que h es igual a 1 y así ya aparecen en la expresión elementos más fáciles de controlar y asimilar.
Veamos cómo sería la construcción de este estimador en un ejemplo concreto, paso a paso:
Arriba vemos los cinco puntos muestrales. En la imagen del medio vemos que hemos construido una Normal sobre cada valor muestral, una Normal con media cada uno de esos valores. Y con densidad, cada una de esas normales 1/n, en nuestro caso: 1/5, para darle el mismo peso a cada valor muestral y que, al final, la suma de las áreas sea 1.
En la imagen final integramos esas cinco funciones en una sola. Y nos queda una imagen como ésta. Esto es una estimación coherente de cómo debe de ser la distribución poblacional.
Este procedimiento tiene muchas aplicaciones. Una de ellas es en Análisis discriminante. Si tenemos varias muestras, una por cada población distinta, y no siguen la normalidad, podemos construir para cada muestra una función de densidad según este criterio y clasificar al nuevo individuo simplemente asignándolo a la población donde haya más valor de densidad, que querrá decir que por allí hay más influencia de esa población.
El Test de Durbin-Watson permite evaluar si existe autocorrelación en una Regresión lineal, sea simple o múltiple. Con ello se pretende ver si los valores presentan algún tipo de dependencia en cuanto al orden de obtención. Si fuera así se estaría incumpliendo una de las condiciones del modelo y cuando se incumplen las condiciones de un modelo de Regresión lineal (normalidad, homogeneidad de varianzas, independencia de los datos) las estimaciones de los parámetros del modelo (los coeficientes del modelo) no tienen los criterios de calidad que se suponen. Por ejemplo, la desviación estándar de esas estimaciones (el llamado error estándar) aumenta, etc.
El contraste de hipótesis (Ver el artículo La maquinaria de un contraste de hipótesis) tiene como Hipótesis nula que la autocorrelación es cero versus la alternativa que afirma que es distinta de cero:
En el planteamiento del Test, por tradición, se suele hablar de la variable independiente tiempo, por eso aparece el signo «t», pero el planteamiento valdría para cualquier variable independiente o cualquier juego de variables independientes.
En una Regresión la noción de residuo es la diferencia entre el valor de la variable dependiente de un valor muestral y el valor estimado, el valor que le correspondería hipotéticamente a ese individuo, mediante el modelo contruido mediante esa Regresión. Supongamos que un individuo tiene un valor de y=8 y x=4 y el modelo de Regresión lineal simple es y=1.5x+1. A ese individuo con valor de «x» igual a 4 y con valor de «y» igual a 8, en el modelo le correspondería una estimación de la variable «y» de y=7. El residuo asociado a ese individuo sería 8-7=1.
En la tabla siguiente pueden verse los valores críticos de Durbin-Watson que permiten tomar la decisión de mantener la Hipótesis nula, pasar a la Hipótesis alternativa o permite estar en una zona de indecisión:
Este Test lo que hace es evaluar si la disposición de los valores en función de las variables independientes es una disposición al azar o, por el contrario, si hay algún tipo de dependencia, algún tipo de conexión entre los valores.
El Test de Glesjer permite comprobar la igualdad de varianzas en un modelo de regresión múltiple. Lo hace de una forma muy ingeniosa. Consiste en buscar una variable que esté en regresión con el valor absoluto de los residuos.
Con la información que tenemos no podemos contestar a esta pregunta. Es evidente que 30 y 40 son más distintos matemáticamente que 30 y 31. Pero estadísticamente no necesariamente. Estadísticamente puede haber más diferencia entre 30 y 31 que entre 30 y 40. En Estadística lo que marca la diferencia es la significación. Y la diferencia entre la media de dos poblaciones no la podemos certificar sin una prueba de significación. Porque es importante que en Estadística aunque tengamos valores muestrales las afirmaciones pretenden ser poblacionales.
Observemos que en el planteamiento de la Situación tenemos medias de muestras pero la pregunta no es si la diferencia mayor es de las medias muestrales sino de las medias poblacionales. Es evidente que 30 y 40 como medias muestrales son más diferentes que 30 y 31, pero la pregunta es sobre las medias poblacionales.
Para contestar a esta pregunta es imprescindible, además de las medias muestrales, las desviaciones estándar muestrales y el tamaño muestral. Diferencia de medias, desviación estándar y tamaño muestral son decisivos para hablar de la diferencia de medias entre poblaciones. Los tres factores deben tenerse en cuenta articularmente, conjuntamente, integralmente. Es la valoración conjunta de estos tres factores lo que nos permite tomar decisiones en Estadística. Y en el planteamiento de la Situación únicamente tenemos las medias muestrales. Así es imposible tomar decisiones en Estadística. Necesitamos los tres elementos para tomar decisiones.
Se han realizado dos estudios donde se compara las medias de dos poblaciones. En uno de esos estudios las medias muestrales son 30 y 40 respectivamente. En otro las medias muestrales son 30 y 31. ¿En cuál de los dos estudios la diferencia de medias poblacionales es mayor?
La Estadística es como un partido de baloncesto. En Estadística buscamos la significación, que es equivalente a preguntarnos en qué momento, a lo largo de un partido de baloncesto, podemos decir que el partido está ganado.
En Estadística casi todo gira en torno a la noción de contraste de hipótesis: una decisión entre dos afirmaciones. A una de ellas, que es la preferente, que afirma lo que podemos decir antes de empezar cualquier estudio, la llamamos Hipótesis nula. A la otra, la que aceptaremos sólo cuando rechacemos la Hipótesis nula, la llamamos Hipótesis alternativa. Otra forma de decisión en Estadística es a través de un intervalo de confianza, que, desde otro punto de vista, es otra forma de contrastar. Si dentro del intervalo está lo afirmado en la Hipótesis nula, la mantenemos, sino la rechazamos y aceptamos la Hipótesis alternativa.
En los contrastes de hipótesis contrastamos: Igualdad versus diferencia, No relación versus relación, Odds ratio igual a uno versus Odds ratio diferente de uno, Pendiente de una recta de regresión igual a cero versus Pendiente de la recta distinta de cero, Distribución normal versus Distribución no normal, etc. Partiendo, siempre, de que, «a priori», es cierta la Hipótesis nula. O sea, que lo que podemos decir, antes de hacer cualquier estudio, son cosas como: las poblaciones que comparamos son iguales, las variables que estamos estudiando no tienen relación, la Odds ratio es uno, la pendiente de una recta de regresión es cero, la distribución de una variable es la normal, etc.
En Ciencias, son las diferencias, las relaciones, la no normalidad, lo que debe demostrarse. Las igualdades, las no relaciones o la normalidad parten como ciertas. La Estadística, como lenguaje de las Ciencias que es, está centrada en esta fundamental actividad de contraste de hipótesis.
Bueno, y ¿todo esto que tiene que ver con el baloncesto? Pues mucho. Muchísimo. Veamos.
Una cosa muy importante: en baloncesto no existe el empate. Siempre gana un equipo u otro. Si se acaba con los mismos puntos se hace una prórroga de 5 minutos. Si aún así no gana ninguno se continúa haciendo prórrogas hasta que uno acabe ganando.
En los contrastes de hipótesis podemos decir claramente que, en realidad, siempre es cierta la Hipótesis alternativa. Sorprendente, ¿no? O sea, las medias de dos poblaciones que comparamos son siempre distintas, la correlación entre dos variables nunca es cero, siempre es distinta de cero. Una Odds ratio nunca es uno, es siempre distinta de uno. La pendiente de una recta nunca es cero. Una variable nunca sigue una campana de Gauss. Siempre la cierta es, en realidad, la Hipótesis alternativa. El problema es en qué momento lo podemos decir. En qué momento podemos decir que una población es mayor que la otra y no al revés. En qué momento podemos decir que la correlación es positiva y no negativa. En qué momento podemos decir que la Odds ratio es mayor o menor que 1. Que la pendiente no es cero. Que la distribución no es normal. Etc.
También es así en un partido de baloncesto. En qué momento podemos decir, con pocas probabilidades de equivocarnos, que el que está ganando ahora va a ganar.
Si el resultado de un partido lo expresáramos en términos estadísticos, lo haríamos así:
H0: Empate.
H1: Gana algún equipo de los dos.
Sabemos ciertamente que la nula (H0) no es cierta, que la cierta es la alternativa (H1). El problema es en qué momento podemos decir que la nula la rechazamos porque ya sabemos, con muchas posibilidades de acertar, cómo es lo afirmado en la Hipótesis alternativa. A la Hipótesis alternativa vamos a ir únicamente cuando sea fiable lo que podamos decir. Como en un partido de baloncesto: únicamente diremos que no se empata (que, en realidad, no se acabará empatando nunca) cuando podamos concretar con precisión qué equipo romperá el empate.
Antes de empezar el partido no podemos decir quién va a ganar, por lo que es razonable partir de una hipótesis nula como ésta. Pero sabiendo que no es cierta, sabiendo que es una provisionalidad que mantendremos hasta que no podamos concretar con mucha verosimilitud quién va a ganar. El problema, pues, es en qué momento lo podremos decir. En qué momento del partido podremos decir quién lo ganará. En qué momento podremos decir quién ganará y que tal afirmación esté hecha con una probabilidad muy baja de equivocarnos. Sólo en ese momento rechazaremos la H0, a pesar de que sabemos que no es cierta.
A los 10 minutos de partido si nuestro equipo gana de 15 puntos no diremos que ya hemos ganado, porque muchas veces, en situaciones como ésta, faltando 30 minutos de partido, y con una diferencia de 15 puntos, el equipo que iba ganando ha acabado perdiendo. Esta misma diferencia de 15 puntos faltando dos minutos sí que muy posiblemente nos permita decir que el partido está ganado.
Si pudiéramos ver entre millones de partidos de baloncesto en cuántos partidos, faltando el tiempo que falta para acabar y con la diferencia de puntos que hay en ese momento, ha acabado perdiendo el equipo que estaba ganando, podríamos decidir con más criterio. Por ejemplo, se podría establecer el protocolo siguiente: si ha cambiado el resultado final en menos del 5% de los casos, podemos decir que el partido está ya ganado. Si hiciéramos esto estaríamos haciendo algo equivalente al procedimiento seguido en la decisión estadística en un contraste de hipótesis.
Si la diferencia de puntos es muy pequeña deberemos esperar siempre mucho para hacer un pronóstico fiable, un pronóstico significativo. A veces, en ciertos partidos muy igualados, necesitaremos mucho tiempo de partido para decir, con significación, quién ganará. En Estadística para decir que hay una diferencia significativa o que hay una correlación significativa, necesitamos, a veces, una muestra muy grande. Otras veces, con un tamaño de muestra relativamente pequeño nos bastará para afirmar diferencias o relaciones significativas. Dependerá, como en el baloncesto, de la cantidad de muestra que tengamos y de la diferencia que haya entre las medias de las muestras a comparar, del valor de correlación muestral o de la Odds ratio que tengamos.
La Estadística es, pues, como un partido de baloncesto. La equivalencia está en la voluntad de pronosticar qué sucederá al final del partido (cuando tengamos toda la población) durante el partido (con una muestra). Y hacer no un pronóstico cualquiera, no un pronóstico un tanto al azar, sino un pronóstico significativo, un pronóstico casi seguro, un pronóstico que tenga muy pocas posibilidades de ser erróneo, porque en miles y miles de circunstancias equivalentes casi nunca ha sucedido algo diferente a lo que se está afirmando en el pronóstico.
El concepto de significación es nuclear en la Estadística. Posiblemente pueda definirse a la Estadística como la ciencia de la significación.
Ninguna de las tres correlaciones es significativa. En las dos primeras los p-valores son mayores que 0,05. En la tercera correlación no tenemos p-valor pero sí un intervalo de confianza del 95% de su estimación. Como ese intervalo incluye al cero, se trata de una correlación no significativa. No es descartable una correlación poblacional de cero, por lo tanto el cálculo de r=0.46 no nos ofrece un valor fiable de correlación. La correlación poblacional podría ser incluso de signo contrario. Con la información que tenemos, pues, ninguna de las tres correlaciones es mayor a otra, porque en los tres casos se aceptaría la Hipótesis nula de que la correlación, a nivel poblacional, es igual cero. No tenemos suficientes razones para creer ni en la correlación 0.78, ni en la 0.82 ni en la 0.46.