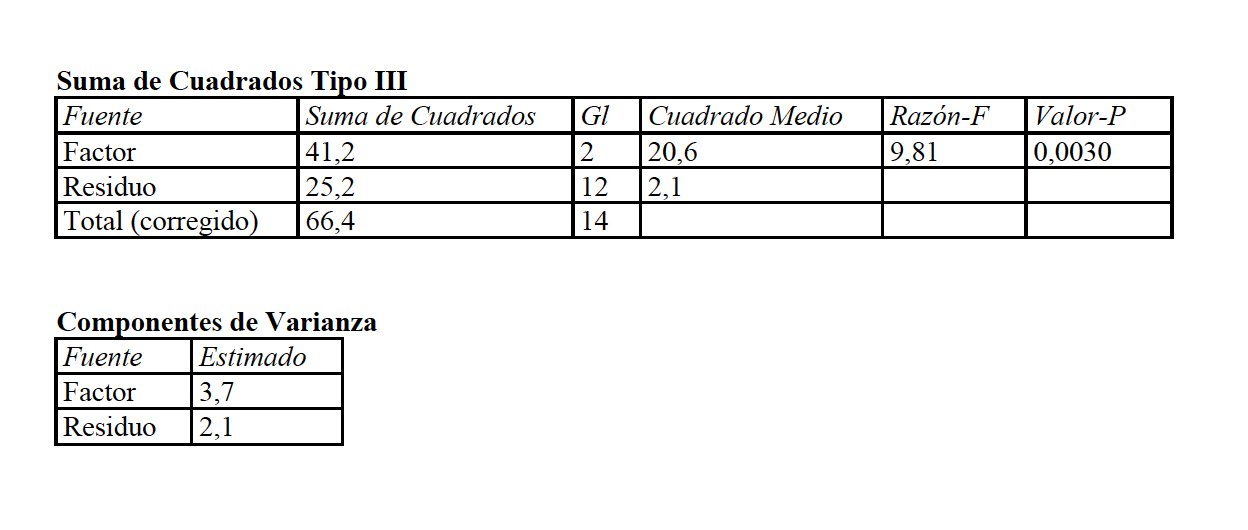
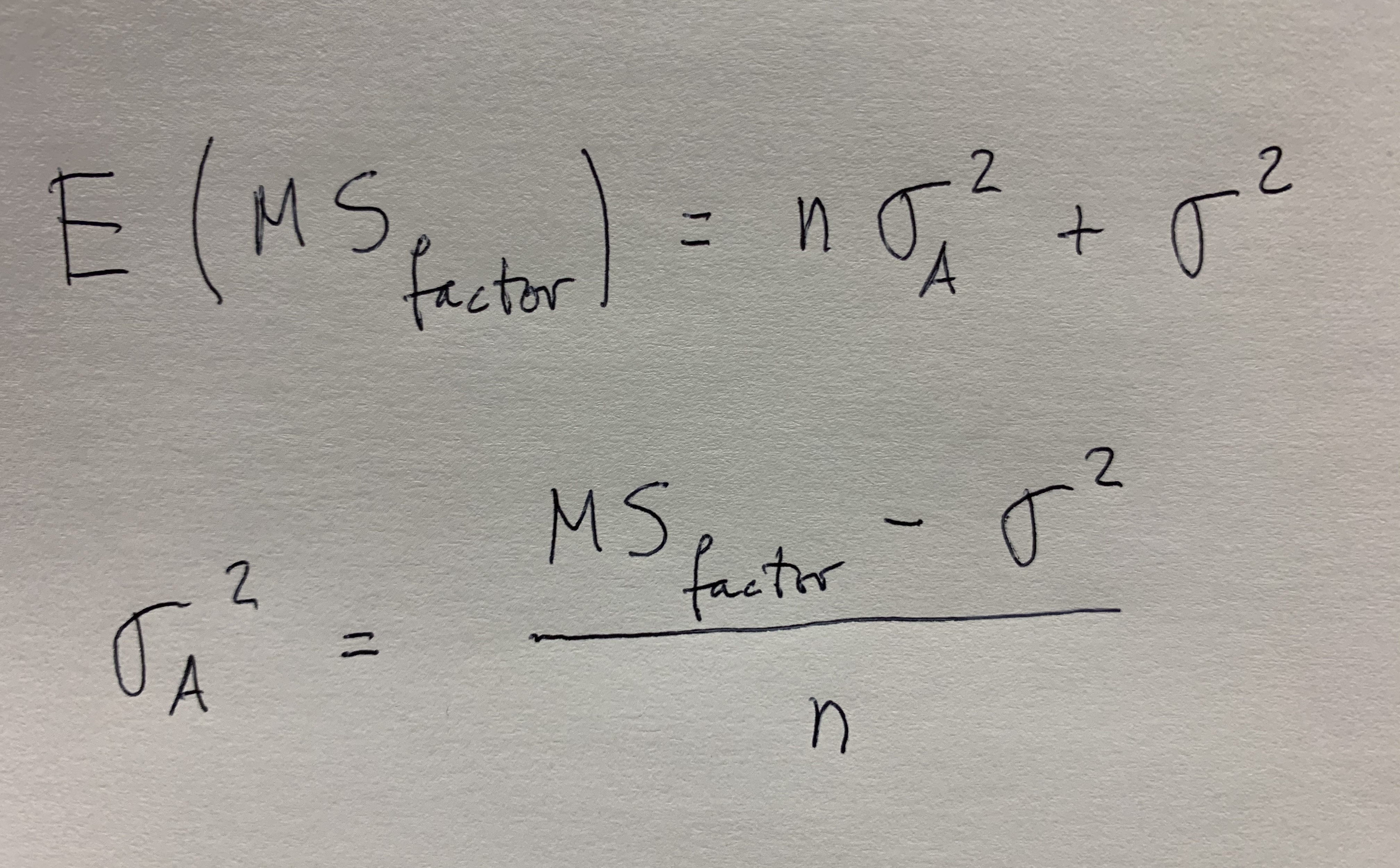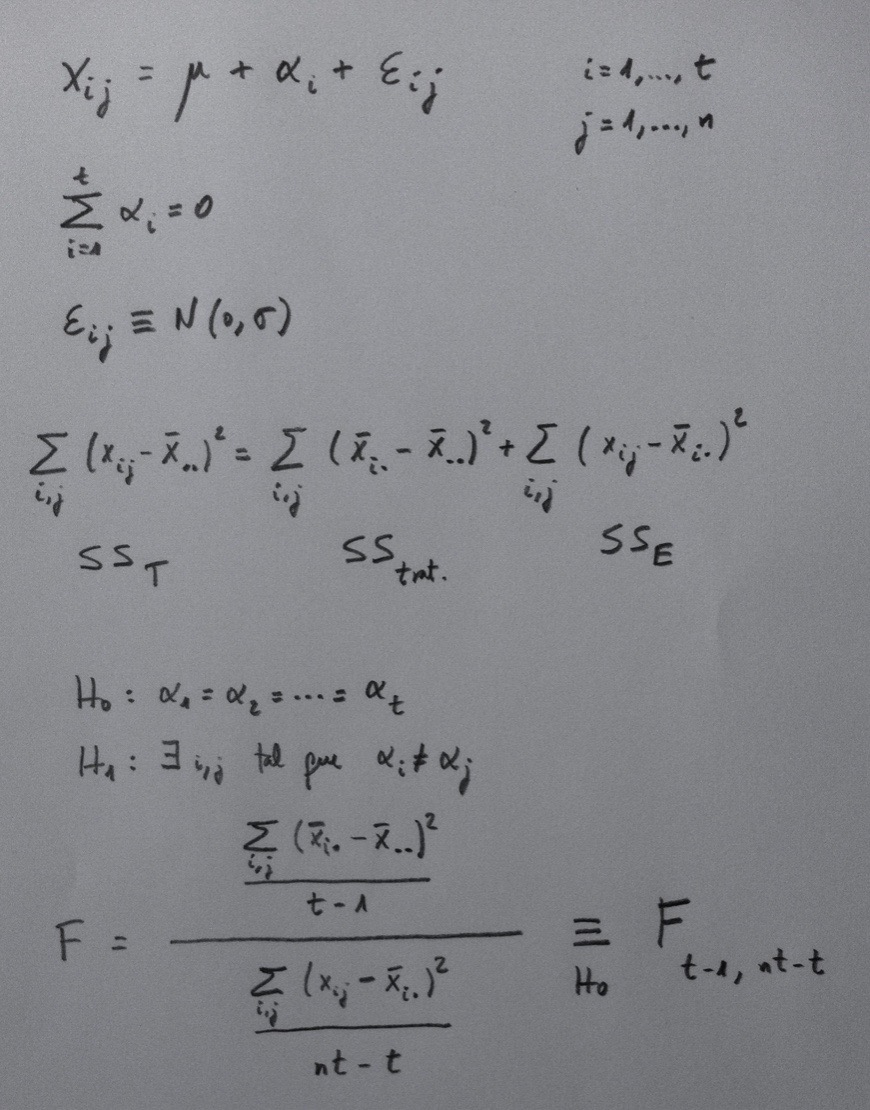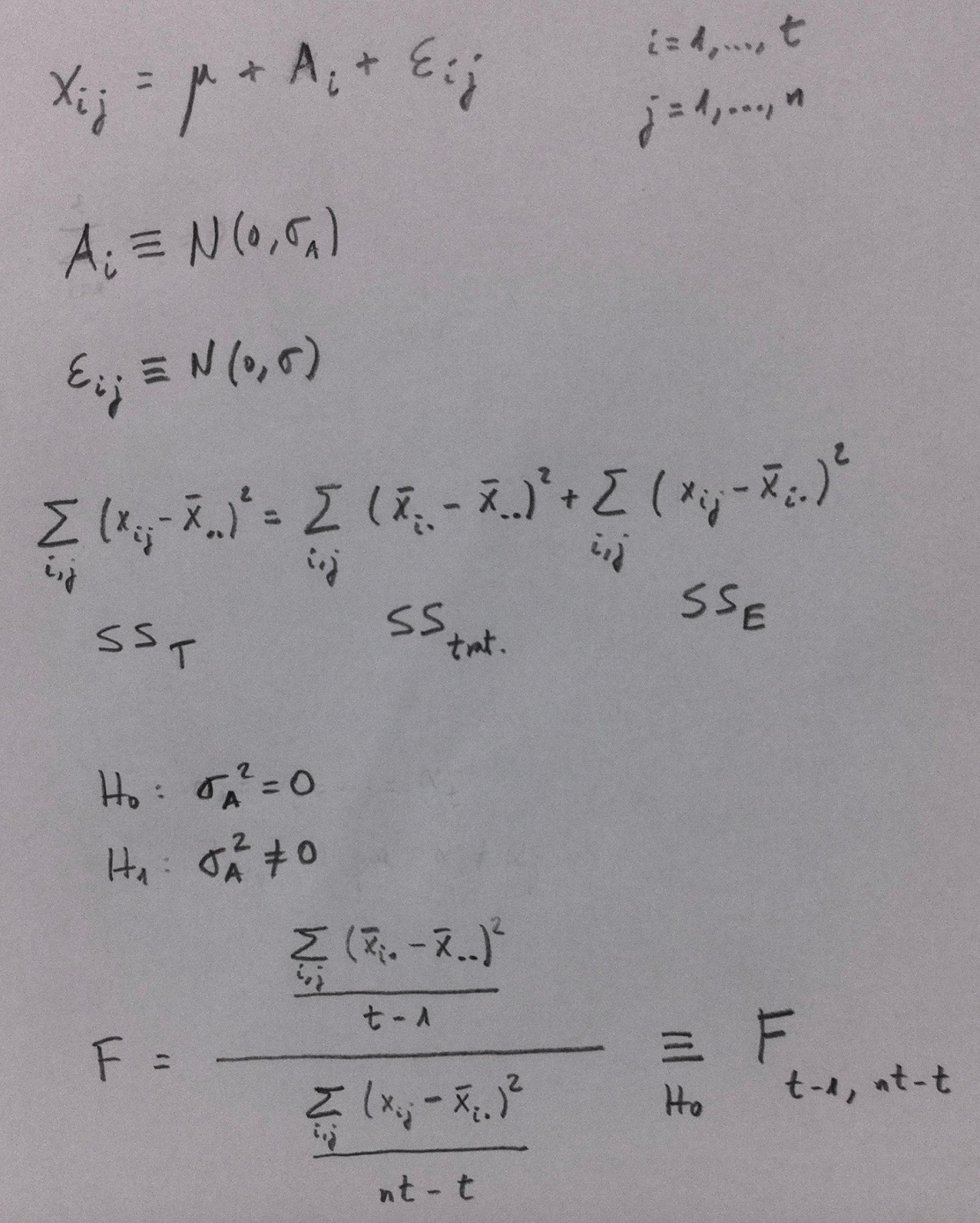Hemos visto cómo funciona la parametrización de un ANOVA de un factor. Los dos casos posible: factor fijo y factor aleatorio, son los siguientes:
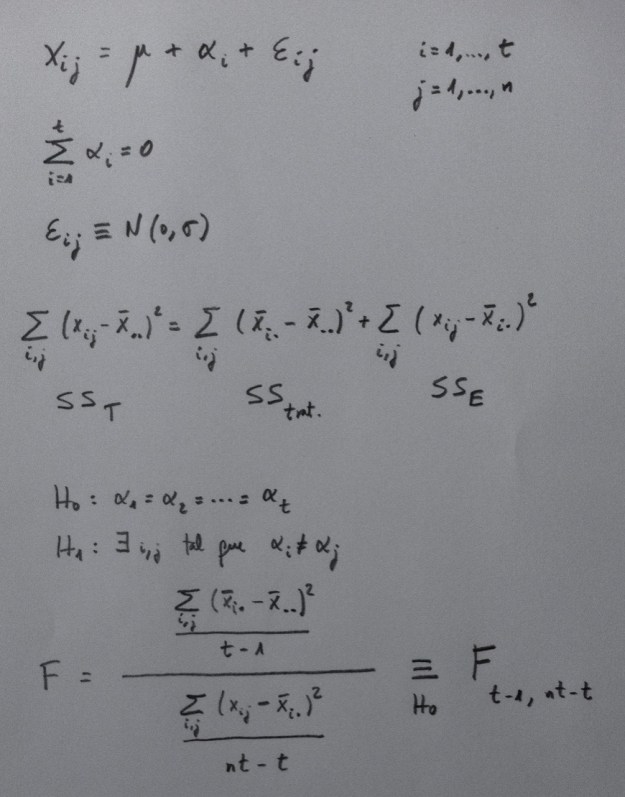
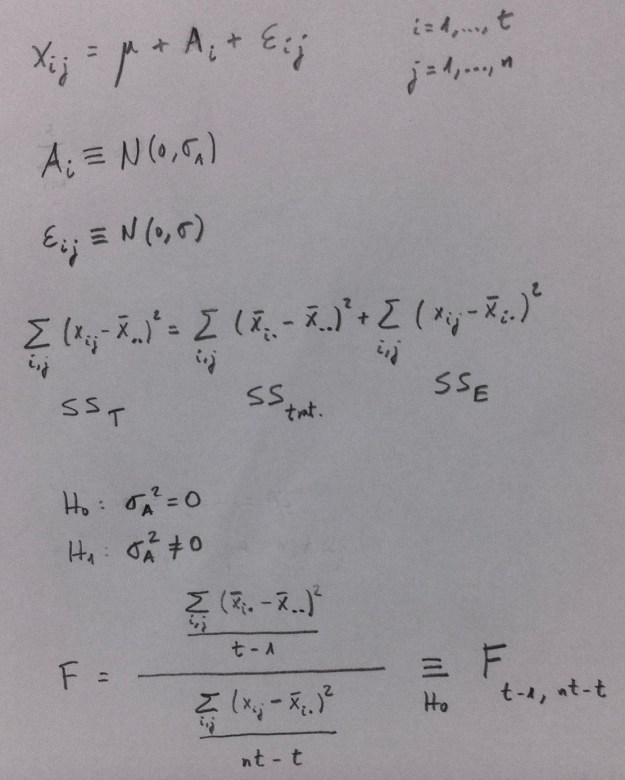
La hipótesis nula es, en ambos, igualdad y la alternativa no igualdad. Se interpreta distinto porque como ya hemos visto en otro lugar, en el factor fijo estamos comparando unos niveles que expresamente nos interesa comparar y en el factor aleatorio tenemos una muestra de niveles, y, por lo tanto, lo que nos interesa es hablar de la igualdad o no entre muchos niveles que no tenemos. Por eso aparece, en este caso, una estimación de la varianza que hay entre esos niveles, la denominada componente de la varianza.
Vamos a ver cómo funciona el contraste de hipótesis.
Vamos a situarnos en las dos situaciones posibles más extremas. Supongamos los dos experimientos siguientes:

Si calculamos el estadístico de test F en el experimento de la izquierda toda la variabilidad está en el numerador y en el denominador tenemos un valor claramente de 0. Por lo tanto, el valor de la F es infinito. En el experimiento de la derecha toda la variabilidad está en el denominador y el numerador es 0. Por lo tanto, tenemos las dos situaciones extremas posibles: En el experimiento 1 la hiótesis nula de igualdad de poblaciones es absurdo quererla mantener y en el experimento 2 lo que es absurdo es rechazar la hipósis nula; o sea, decir que hay diferencias cuando las tres muestras de esas tres poblaciones son idénticas.
Las posibilidades son pues las extremas:
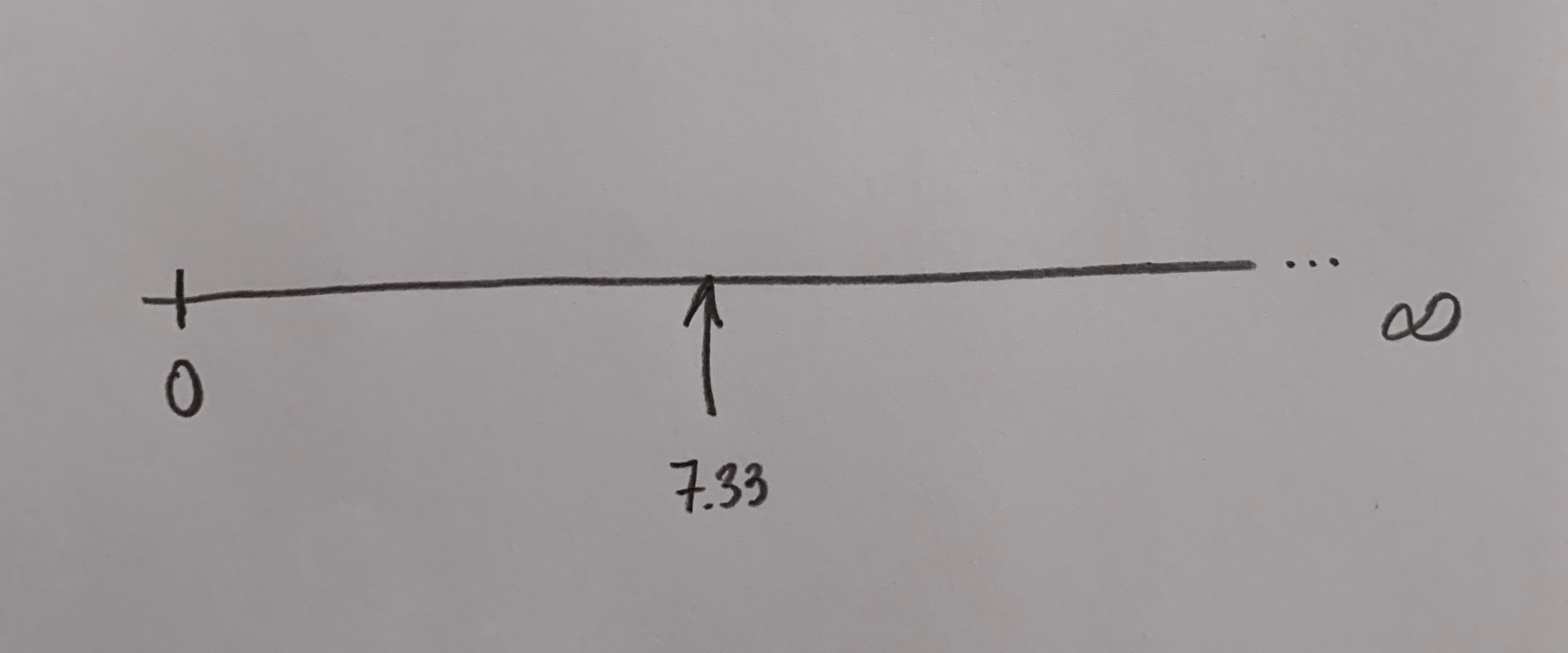
Pero lo cierto es que los estudios de ANOVA de un factor prácticamente siempre tendremos valores que no serán ninguno de estos dos valores extremos. Por ejemplo, tendremos el valor siguiente:

¿Qué decisión tenemos que tomar con un valor de F de 7.33? Si el valor está próximo al 0 mantendremos la Hipótesis nula si es próximo al infinito rechazaremos la Hipótesis nula y abrazaremos la Hipótesis alternativa. Pero, ¿dónde situamos el umbral para la toma de esta crucial decisión?
Aquí está el problema. Lo que hizo Fisher es, partiendo de unas suposiciones (valores independientes, con distribución normal y con igualdad de varianzas de cada muestra), ver cuál sería la variabilidad, la distribución de los valores posibles de este cálculo F, si fuese cierta la Hipótesis nula. Y así fue como definió, estudió y tabuló la denominada distribución F de Fisher.
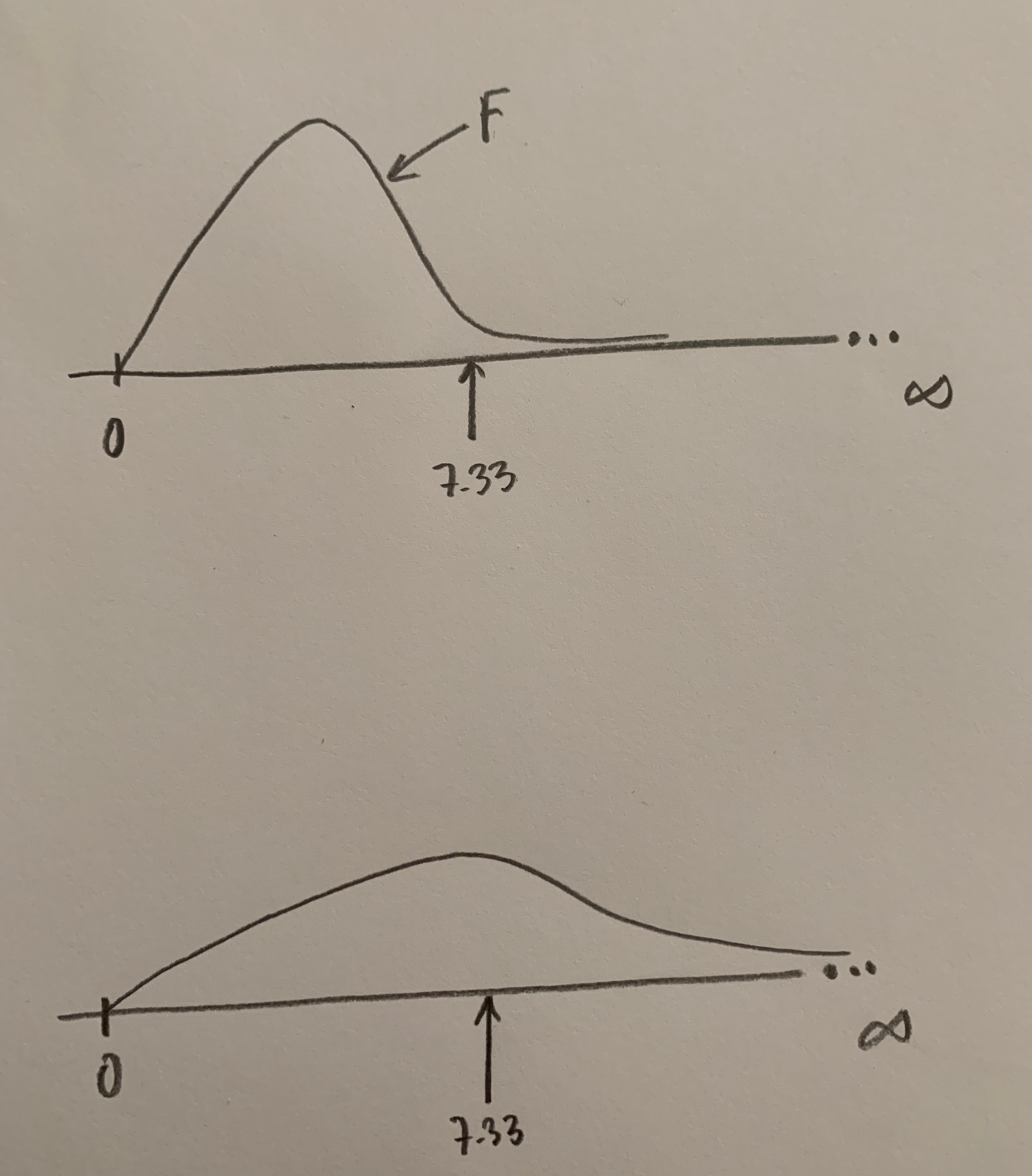
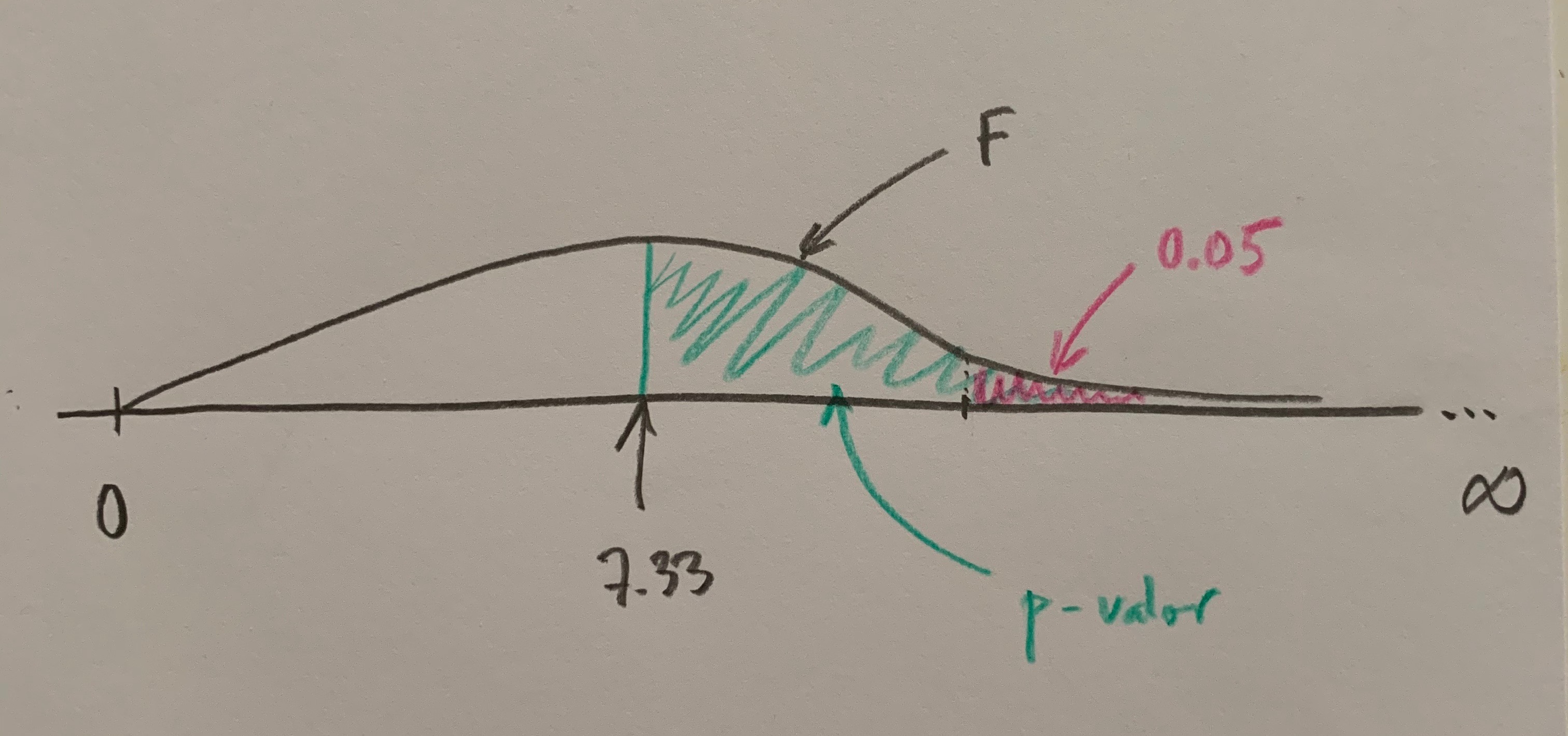
Fijaos que si dibujamos la forma de cómo deberían ser las cosas si fuese cierta la Hipótesis nula este valor de 7.33, o el que tuviésemos en un estudio concreto, adquiere sentido, te permite decantarte por una hipótesis u otra con más sentido.
Mirad el dibujo:
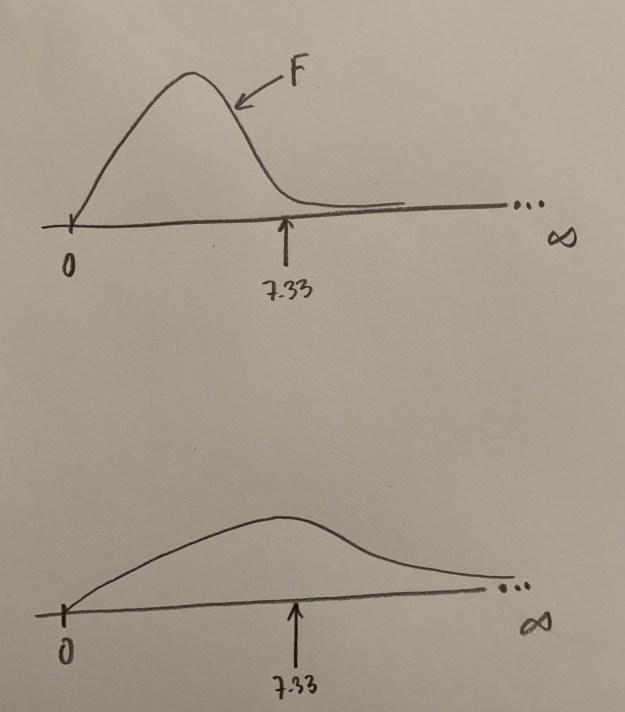
Este 7.33, que antes no sabíamos cómo interpretar ahora sí parece tener sentido. Arriba podemos decir que estamos viendo algo muy poco probable si fuese cierta la Hipótesis nula y, en cambio, debajo podemos decir que estamos viendo algo muy probable si fuese cierta esa Hipótesis nula de igualdad de poblaciones, o de ausencia de efectos.
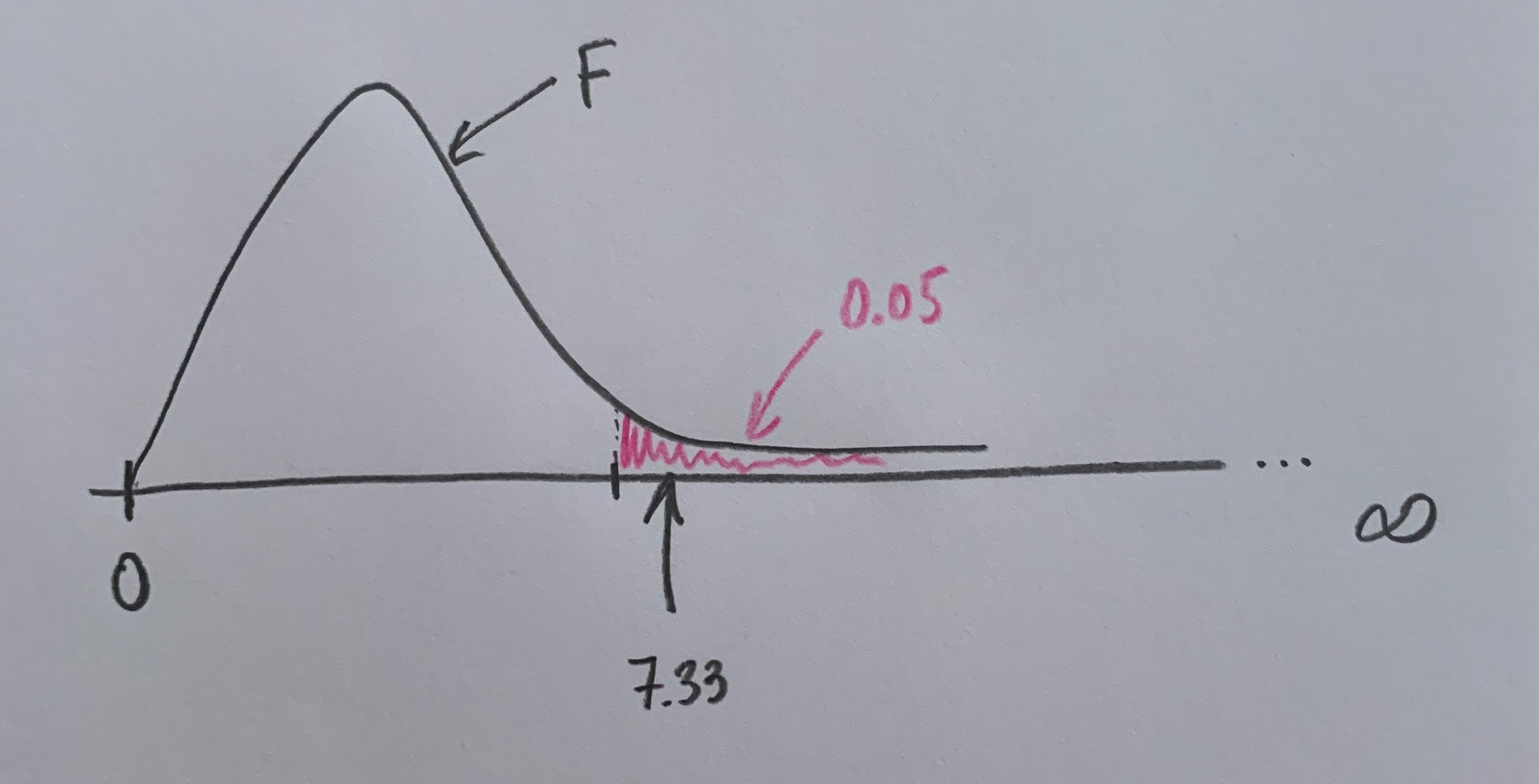
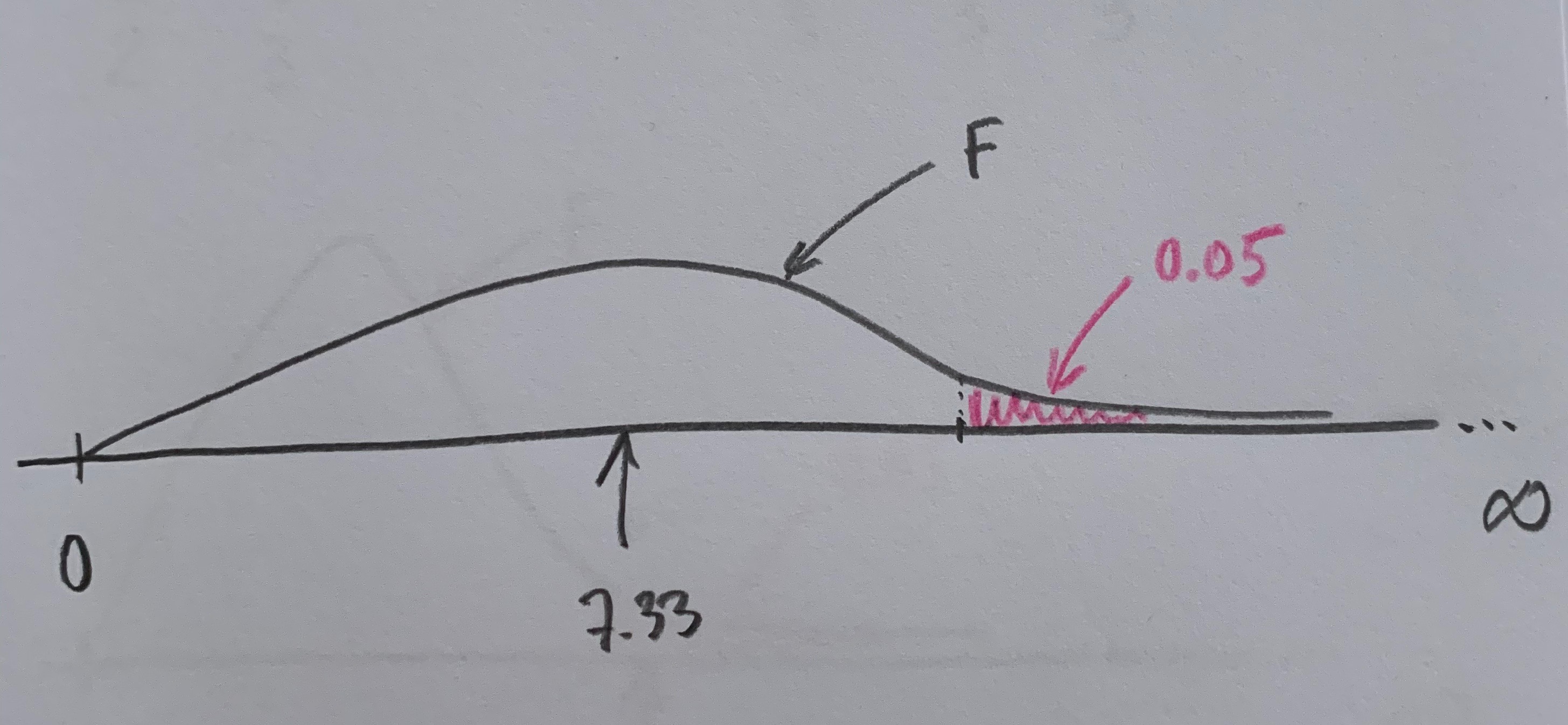
Observemos que si fijamos una área de poca probabilidad bajo el supuesto de ser cierta la Hipótesis nula, tendríamos los dos siguientes dibujos:
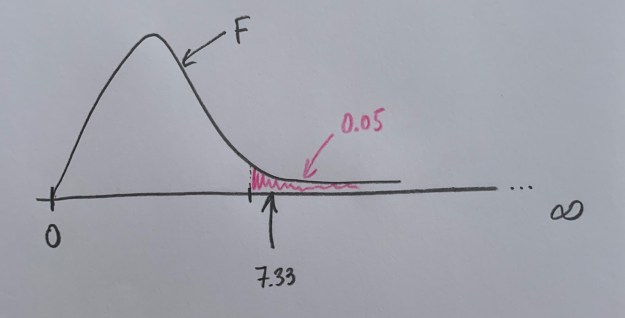
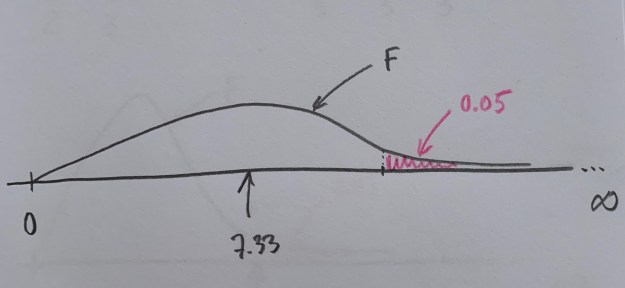
Se crea así un umbral para la toma de decisión. Si se supera se rechaza la Hipótesis nula, si no se supera se mantiene esa Hipótesis. En el primer caso hemos superado el umbra, en el segundo no. Ahora, pues, el 7.33 nos permite tomar una decisión. Suele establecerse un umbral con probabilidad baja en la zona de influencia más alejada de la Hipótesis nula, que es el extremo derecho.
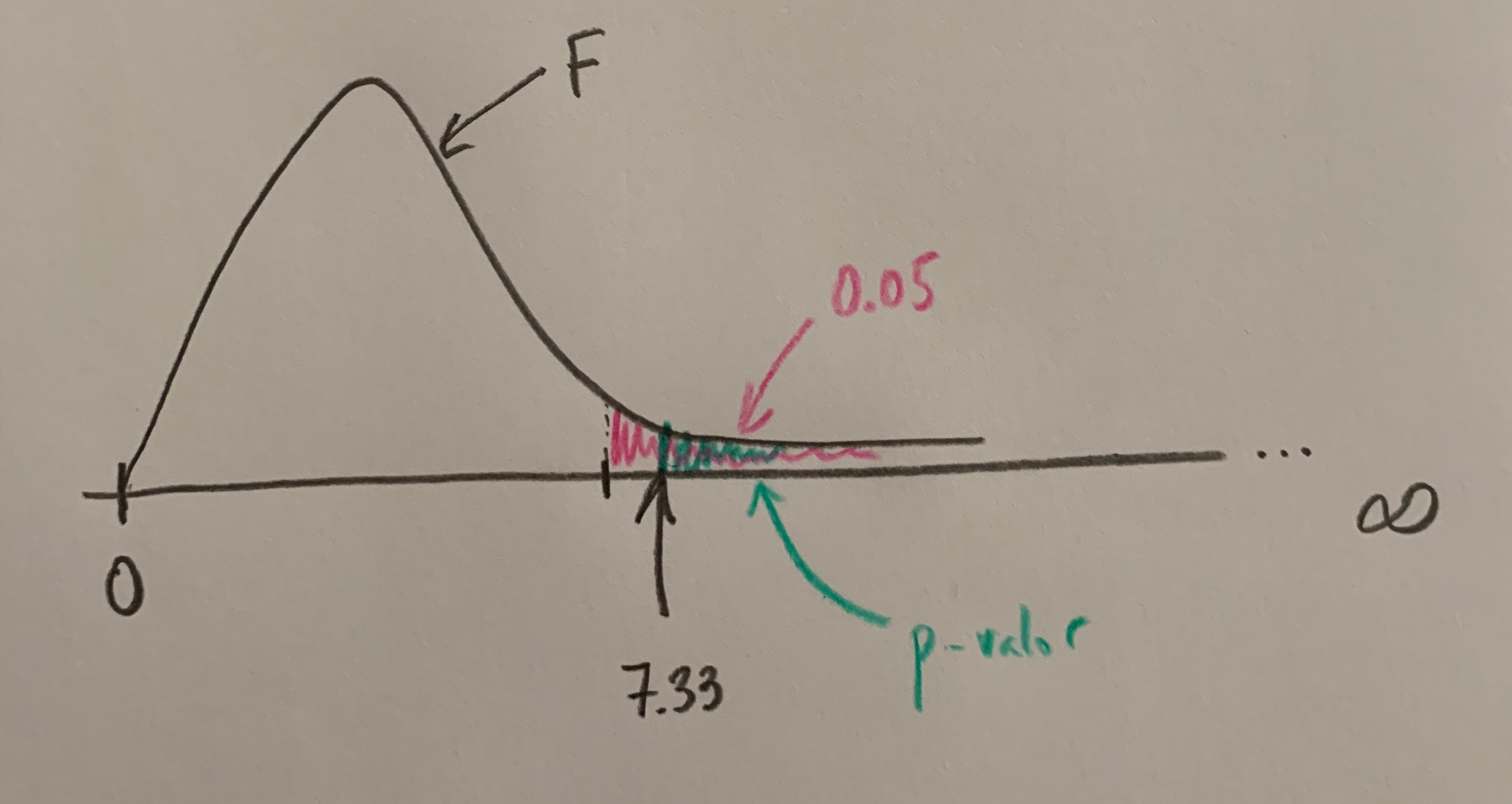
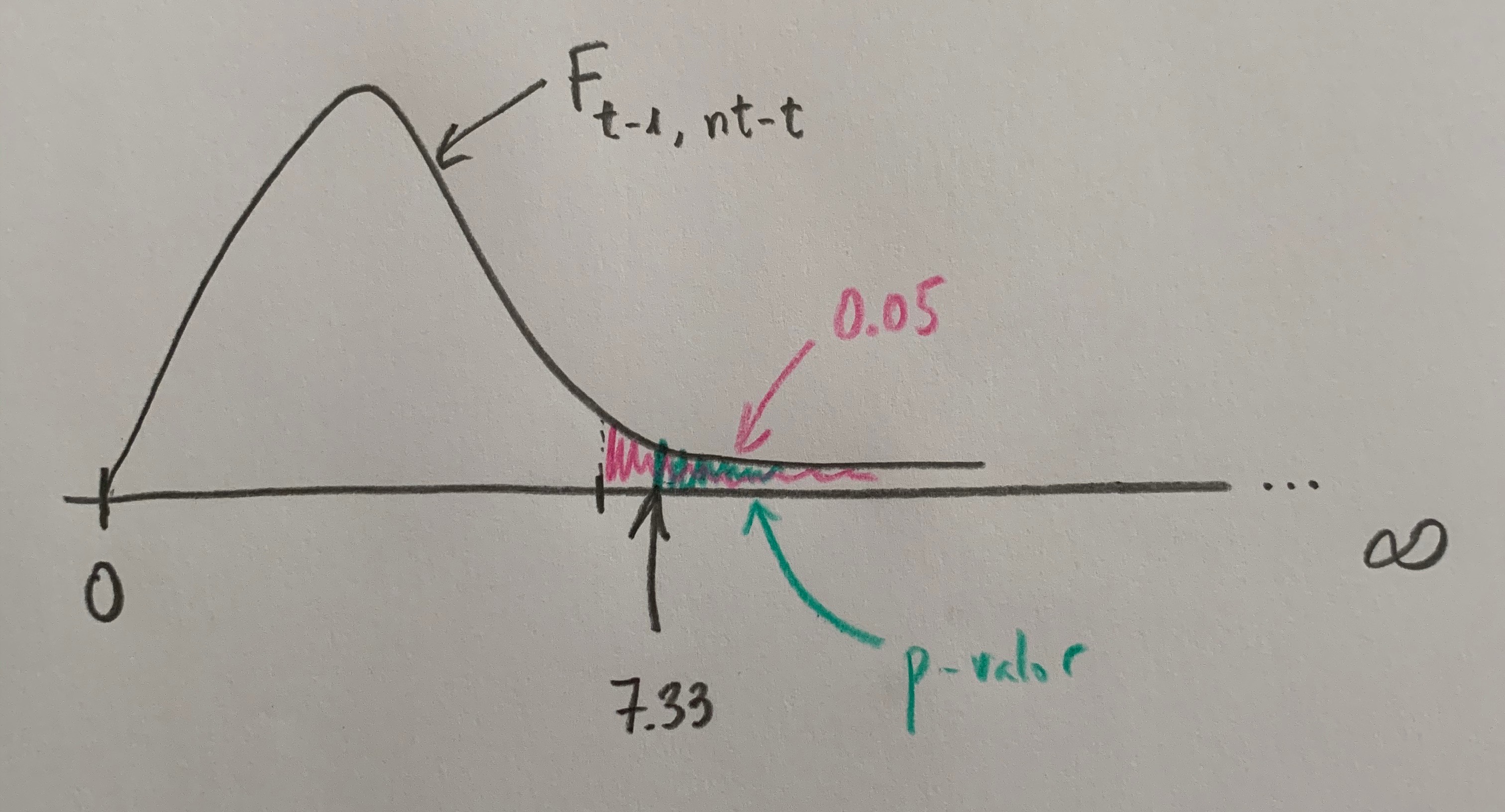
Actualmente lo que hacen los softwares estadísticos es calcular el llamado p-valor, que es el área que hay a la derecha, hacia la zona más alejada de la coherencia de la Hipótesis nula, desde el punto del valor de la F calculada a las muestras del estudio:
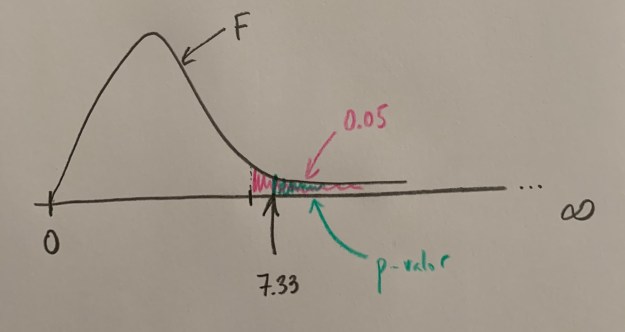
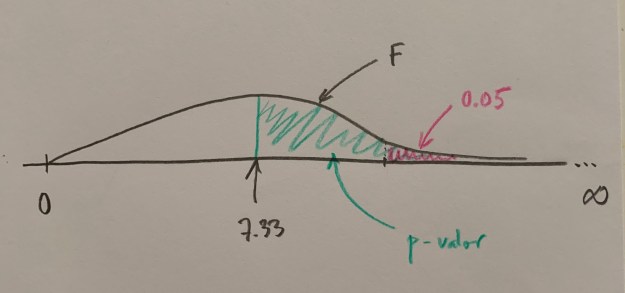
Si este p-valor es menor que 0.05 es que el valor de la F calculada está a la derecha del umbral de tolerancia para mantener la Hipótesis nula. Si este p-valor es mayor que 0.05 es que ese valor de la F calculado a la muestra está a la izquierda del umbral, está en zona donde es coherente lo que vemos con la hipótesis de igualda o de no efectos, de no diferencias entre los niveles comparados (si es un factor fijo) o de varianza cero de los niveles poblacionales compardos (si es un factor aleatorio).
La distribución F de Fisher tiene, como se ve formas distintas, siguiendo siempre ese patrón que se ve dibujado en estos gráficos. La concreta forma que tenga va a depender del número de niveles del factor y del tamaño de muestra que estemos estudiando en global:
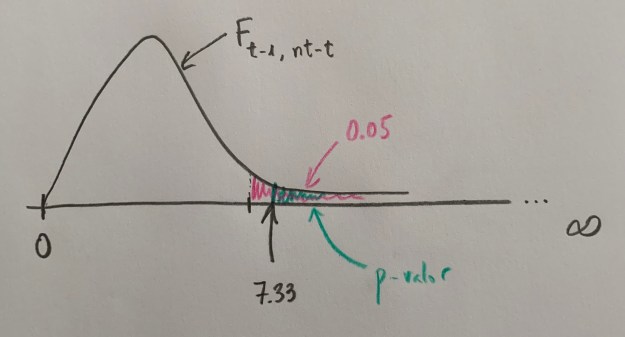
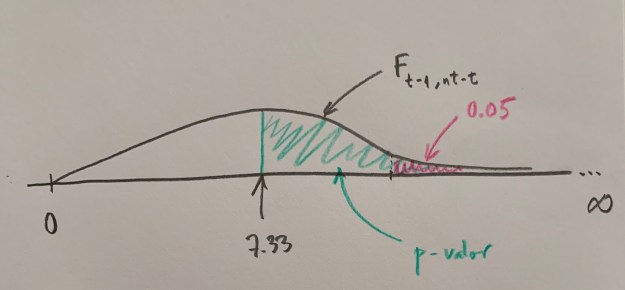
Tiene dos parámetros y el primero es t-1, el número de niveles del estudio menos uno, y el segundo parámetro es el número de observaciones totales (nt) menos el numero de niveles; o sea, nt-t.
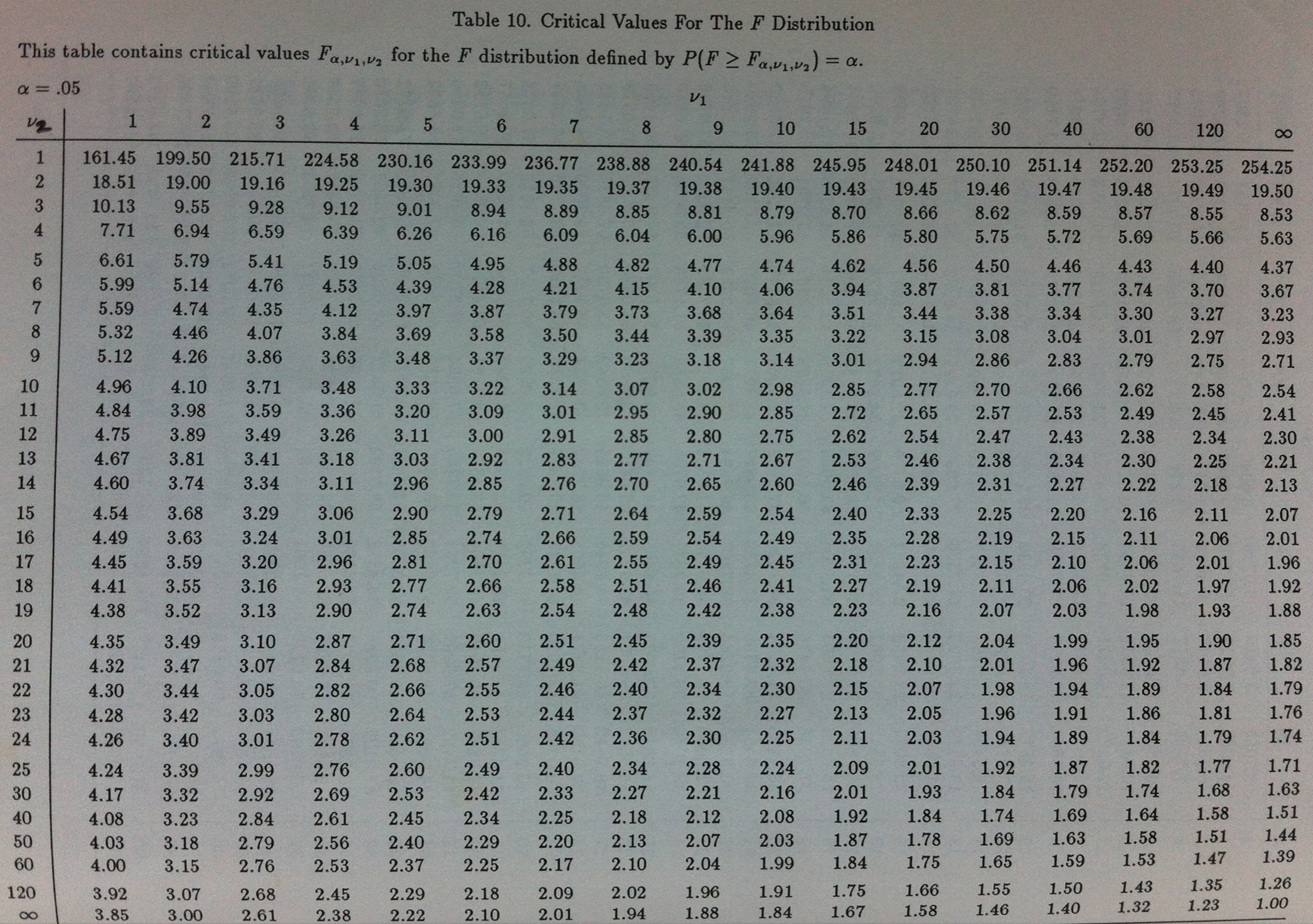
Y el umbral lo obtenemos de unas tablas como esta:
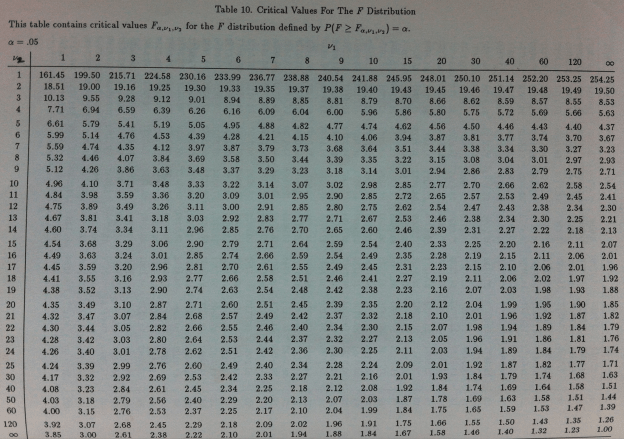
En las columnas encontramos el valor del primer parámetro y en las filas el del segundo parámetro.
Por ejemplo: supongamos que estamos comparando tres niveles de un factor y tenemos tres valores por cada nivel, como en los ejemplos ficticios de antes. Entonces t-1 sería 2 porque tenemos tres niveles y nt-t sería 8, porque, como la n es 3 y la t también 3, la F sería una F(2,6), que es como también se suele escribir. El valor umbral sería, mirando la tabla, el valor de 5.14. Este valor sería el valor que nos permitiría, dados unos datos concretos, tomar una decisión según el valor de la F fuera menor o mayor que este umbral.