Cada ciència s’acostuma a definir delimitant el seu àmbit d’estudi. Així, per exemple, diem que la Biologia és la ciència de la vida, la Lingüística és la ciència de les llengües, la medicina és la ciència que estudia i tracta les malalties humanes, la Psicologia és la ciència del comportament humà, etc.
S’han donat diferents definicions d’Estadística. Una que pot ser apropiada i que està expressada en aquests termes de «la ciència de …» és la següent: l’Estadística és la ciència del que és SIGNIFICATIU.
Bé, com a mínim la definició sorprèn, no? No sembla, almenys a primera vista, que la noció de SIGNIFICATIU mereixi tanta atenció. Doncs no és així. Mereix atenció i molta. S’ha muntat tota una ciència al voltant d’aquesta noció degut a la importància que al llarg dels darrers dos-cents anys se li ha anat donant. I aquí tenim a l’Estadística.
«SIGNIFICATIU» no és, per cert, una paraula estranya en el nostre llenguatge quotidià. Realment no és que sigui de les paraules més habituals del nostre dia a dia, però és una paraula a la que tots seríem capaços d’assignar un significat. Segurament sense una gran precisió, és cert, però tots seríem capaços d’explicar què volem dir quan diem que alguna cosa és SIGNIFICATIVA.
En Estadística, però, és l’objecte fonamental. Pràcticament tot en Estadística està canalitzat per a poder posar l’etiqueta de SIGNIFICATIU o de NO SIGNIFICATIU al que veiem en uns resultats d’un estudi determinat.
Per tant, delimitar el que entenem per SIGNIFICATIU en Estadística és molt important. I delimitar, també, quan unes dades ens permeten dir que el que veiem és o no SIGNIFICATIU, és també nuclear en Estadística.
Vaig a tractar, a continuació, d’explicar quin és el significat de la noció SIGNIFICATIU en el llenguatge de l’Estadística. Vegem-ho, primer, mitjançant metàfores, que és un mètode de comunicar, especialment en Ciències.
Suposem un professor que després d’un llarg curs convoca els seus alumnes per a l’examen final i aquest consisteix en una única pregunta molt concreta, que es respon mitjançant una única línia. Davant d’un examen així un bon alumne, un alumne que ha estudiat molt i que té molts coneixements, pot treure perfectament un 0. Ha tingut mala sort. Li han preguntat just un detall concret que no aconsegueix recordar. I, per contra, un pèssim alumne, un alumne que no ha estudiat res, pot treure un 10. Ha tingut la sort que li han preguntat just una cosa que era del poc que recordava. Això pot passar perfectament. A més, si, davant d’una situació com aquesta, repetíssim l’examen, i ho féssim mitjançant un examen del mateix tipus, mitjançant una pregunta molt concreta que es respon en una simple línia, però, això sí, ara una pregunta diferent a l’anterior, podria passar perfectament que el que abans ha tret un 10 ara tregui un 0 i el que abans ha tret un 0 ara tregui un 10.
En termes estadístics diríem que exàmens d’aquest tipus, exàmens tan concrets, no proporcionen notes SIGNIFICATIVES dels alumnes examinats. Són notes poc fiables, que estan sotmeses massa a l’atzar del que es pregunta. Són notes que no reflecteixen el nivell de coneixements de l’alumne.
Ara suposem que l’examen és de 50 preguntes curtes que cobreixen tot el temari de l’assignatura. La nota que obté un alumne molt poc canviaria si repetíssim l’examen amb altres 50 preguntes. Ara sí que podem parlar d’una nota SIGNIFICATIVA, una nota que tornaria a ser del mateix ordre si tornéssim a fer un examen del mateix tipus.
Un altre exemple: Si un equip de bàsquet està guanyant de 10 punts a la mitja part del partit, cap aficionat al bàsquet diria que aquest partit ja està guanyat. Si miréssim en una base de dades centenars de milers de partits de bàsquet i busquéssim tots els partits en què un equip guanyava de 10 faltant encara 20 minuts de partit per jugar segur que veuríem que més del 5% de vegades aquest equip ha acabat perdent . En termes estadístics diríem que es tracta d’un resultat estadísticament NO SIGNIFICATIU.
Aquest número, el 5%, és molt important en Estadística. És un valor frontera molt important, com veurem després.
Per contra, si faltant un minut un equip està guanyant de 10 punts. Ara, si busquéssim en aquesta mateixa base de dades partits que un equip, faltant un minut per acabar el partit, anava guanyant de 10 punts, segurament veuríem que menys del 5% de vegades aquest equip ha acabat perdent. Si fos així, diríem, en termes estadístics, que aquest resultat és estadísticament SIGNIFICATIU.
Una qüestió molt important: En ciència sempre estudiem mostres però la finalitat és poblacional. Volem parlar de tots a partir de l’estudi d’una part, d’una mostra. En termes de bàsquet: pronosticar el final del partit, però, evidentment, durant el partit. Un cop acabat el partit només és possible descriure el que ha passat però no hi ha pronòstics possibles.
La significació és una paraula nuclear en Ciència. La Ciència tracta de donar resultats SIGNIFICATIUS. Intenta dir coses amb fiabilitat, amb poques possibilitats d’equivocar-se. Els instruments que aporta l’Estadística per delimitar resultats SIGNIFICATIUS de resultats NO SIGNIFICATIVES és un instrument essencial en la Ciència. Vegem alguns exemples on està present la noció de estadísticament SIGNIFICATIU. Els tres exemples estan presos de la revista més prestigiosa en Medicina, el New England Journal of Medicine.
El primer cas consisteix en un estudi publicat recentment on es compara l’eficàcia d’un pàncrees artificial automatitzat, que controla la glucèmia i subministra insulina en continu, respecte a un sistema de control estàndard en pacients amb Diabetis tipus 1. Es comparen dos sistemes de control en un mateix grup de pacients amb aquest tipus de Diabetis. En dues nits diferents s’assagen cadascun d’aquests mètodes en tots els pacients. La variable resposta és si en algun moment els pacients han patit una hipoglucèmia durant la nit. La hipoglucèmia és la situació de màxima gravetat en la qual pot situar-se un diabètic.
Les dades que s’obtenen són les següents:
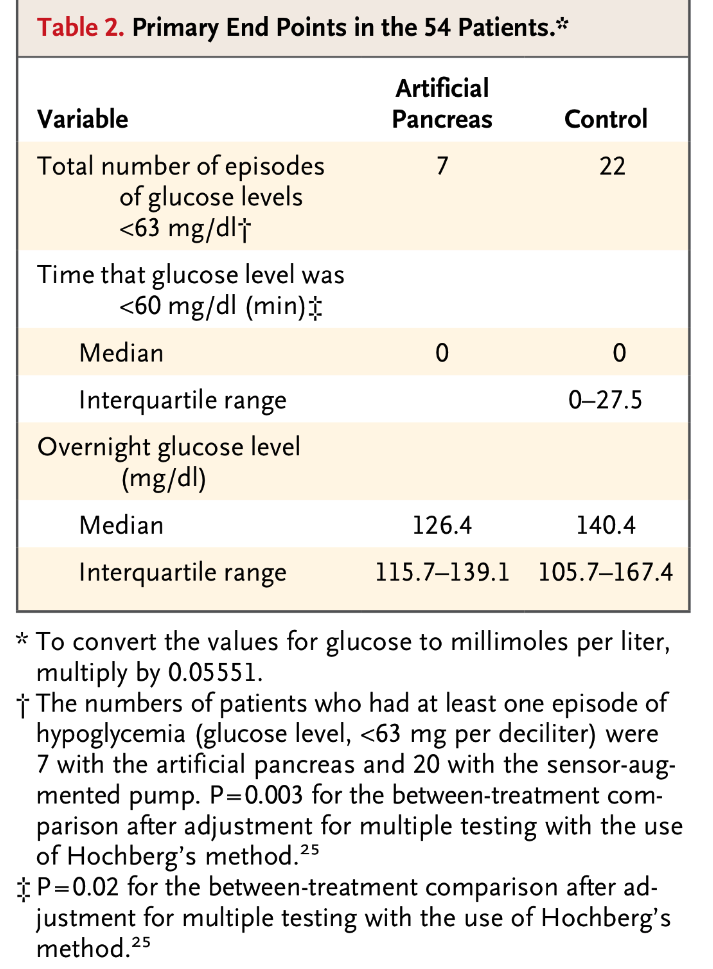
Observem que amb el pàncrees artificial 7 vegades s’ha produït una hipoglucèmia entre els 54 nens amb diabetis participants en l’estudi. Amb el control (el mètode habitual de control nocturn de la diabetis) s’han produït 22 casos d’hipoglucèmia entre 54 nens. Evidentment que 7 és menys que 22. El problema és si aquesta diferència és, o no, estadísticament SIGNIFICATIVA. I això ens ho ha de proporcionar una tècnica estadística. En aquest cas concret ens ho resoldria una tècnica estadística anomenada Test de McNemar. La tècnica ens dóna un valor que és aquest valor que veiem en el gràfic: p = 0.003, que és el valor que marca que estem davant d’un resultat estadísticament SIGNIFICATIU.
Aquesta p, l’anomenat p-valor, és un valor que va de 0 a 1 i si és un valor menor que 0.05 indica que la diferència que veiem és SIGNIFICATIVA, indica que la diferència és fiable. Que no és fruit de l’atzar. Observem que 0.05 sobre 1 és com 5 sobre 100 (un 5%), que és la frontera que abans he citat quan parlava del partit de bàsquet. Aquest 5% o 0.05 per 1 és una frontera molt important en Estadística i en Ciències.
Un altre exemple: A principis d’aquest any un article va generar un veritable impacte entre els especialistes en malalties infeccioses. En un estudi amb persones infectades per Clostridium difficile s’aconseguien millors resultats, un major percentatge de curacions sense recaigudes, si el tractament es feia amb infusions, per sonda oro-gàstrica, de femta de pacients amb infecció crònica d’aquesta espècie bacteriana, que mitjançant un tractament amb antibiòtic. Vegem els resultats:
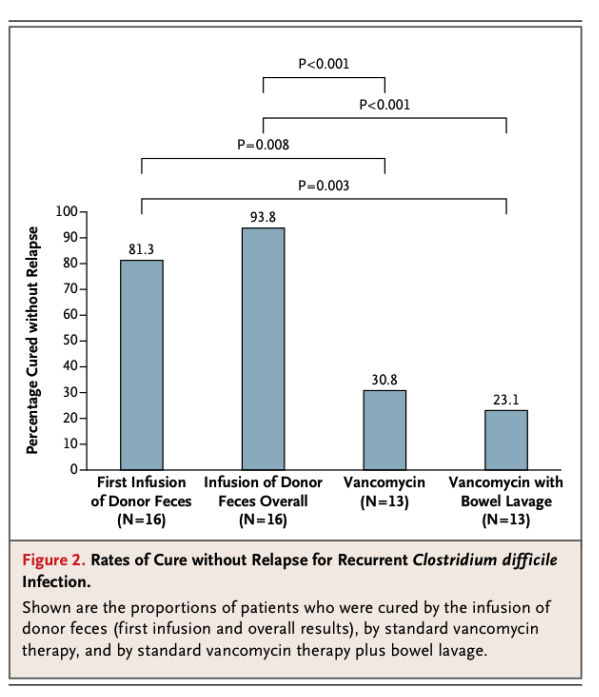
Observem les dades dels resultats dels pacients tractats amb la infusió comparats amb els resultats obtinguts amb el tractament amb l’antibiòtic més eficaç usat en aquests casos, que és la vancomicina. Com es pot observar els nivells de curació sense recaigudes són superiors en els tractaments amb les infusions que en els tractaments antibiòtics. Les quatre comparacions possibles entre els tractaments amb infusió i els tractaments amb la vancomicina són SIGNIFICATIVES (p <0.05).
Un altre exemple: La fibromiàlgia és una malaltia molt freqüent en la nostra societat. S’han assajat molts mètodes per intentar buscar remei a aquesta malaltia. Recentment s’ha publicat un original estudi que demostra que el tai-txi és un mètode que aconsegueix resultats positius a l’hora d’abordar aquesta malaltia. Vegem el quadre següent:
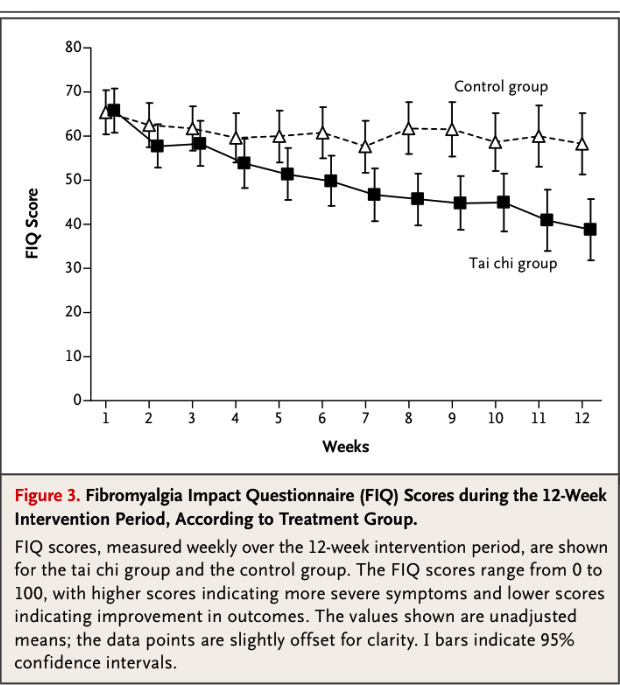
Com es pot observar els dos grups de pacients estudiats, un seguint un mètode control mitjançant fisioteràpia i l’altre seguint unes sessions de tai-txi, parteixen d’un mateix nivell de gravetat i podem veure, en el gràfic, perfectament, quina és l’evolució al llarg de les setmanes. Veiem com el grup control es manté dins d’un nivell estable i, pel contrari, els pacients que segueixen aquestes sessions de tai-txi aconsegueixen reduir significativament els nivells de dolor que tenen. Aquí el p-valor també és inferior a 0.05. La gràfica no ens el dóna, però ens dóna una cosa equivalent. Ens dóna intervals de confiança del 95%. Observem que els intervals de confiança dels dos grups en les primeres setmanes se solapen (el que indica que la diferència no és SIGNIFICATIVA) i, en canvi, a partir de la setmana 8 aquests intervals ja no es solapen. El que indica que aquesta diferència ja és SIGNIFICATIVA, és fiable.
Al final tota aquesta diversitat de situacions s’analitzen mitjançant mecanismes diferents (Tècniques estadístiques diferents) però sempre sota un mateix principi. El següent: El que es veu és una cosa que és molt probable veure-ho en el cas que els grups comparats fossin realment iguals o, pel contrari, seria molt poc probable veure-ho en aquest cas? Les tècniques estadístiques sempre funcionen fent una comparació entre el que veuen en la mostra i el que haurien de veure si els grups comparats fossin iguals.
Si els dos mecanismes de control de la diabetis són iguals, si el tractament amb infusions de femtes de malalts infectats crònicament per Clostridium difficile i el tractament amb antibiòtics donessin resultats idèntics o si fer tai-txi o fer fisioteràpia estàndard donessin resultats idèntics en pacients amb fibromiàlgia, esperaríem veure en una mostra uns certs valors. Aquests valors esperats, en el supòsit que fos cert el cas hipotètic d’igualtat entre els grups comparats, són els que les tècniques estadístiques comparen amb el que realment veuen en les mostres d’aquests estudis. En funció d’aquesta comparació, en funció de la distància entre el que s’esperava i l’observat, acaben dictaminant si això que veiem és coherent o no amb la igualtat suposada d’aquests grups comparats.
Per veure com opera una tècnica estadística per comparar el que s’esperava, sota el supòsit que els grups comparats són iguals, amb el que s’observa, ens centrarem en dos d’aquests tres casos i veurem com raona la tècnica estadística.
Recordem que el primer cas analitzat era l’estudi del pàncrees artificial. Dels 54 pacients 7 tenien problemes amb el pàncrees artificial i amb el control habitual el nombre de problemes era de 22.
7 de 54 i 22 de 54 són diferents, evidentment. Són matemàticament diferents. Però, aquesta diferència, és estadísticament SIGNIFICATIVA? Aquest és el problema. L’anàlisi estadística és qui ho dirà, és el que determinarà si aquesta diferència entre 7 i 22 és, en realitat, una diferència estadísticament SIGNIFICATIVA.
Per començar l’anàlisi anem a suposar, anem a partir de la suposició, que els dos mètodes, els dos tractaments, tenen la mateixa eficàcia. Per tant, elaborarem un món fictici on els dos mètodes que estem comparant fossin, en realitat, idèntics.
Si els dos mètodes fossin idèntics, que donessin el mateix nombre de problemes, el mateix nombre de situacions d’hipoglucèmia, esperaríem una probabilitat d’hipoglucèmia, durant una nit, del 26,8%, perquè tenim, en un mètode, un 12,9 % d’hipoglucèmies i, en l’altre, un 40,7%. El 26,8% és la mitjana d’aquests dos percentatges. Per tant, construïm un món fictici adoptant un valor que, en global, reflecteix la realitat. Pel que hem vist, en l’estudi, en total, es produeix un 26,8% d’hipoglucèmies (si ajuntem les d’un mètode i les de l’altre).
Farem una simulació, anem a construir experiments possibles. Això actualment no és gens estrany. Vivim envoltats de simulació: d’una carrera de motos, d’un partit de futbol, etc. Això que ens proposem fer, ara, és possible gràcies a la informàtica. Generarem experiments possibles però sota el supòsit que els dos mètodes tenen el mateix percentatge de problemes, sota el supòsit d’aquesta ficció que hem creat. Generarem 100.000 experiments equivalents al de l’estudi, però sota el supòsit que els dos mètodes són igual d’eficaços, o sigui, amb una probabilitat d’hipoglucèmia, en ambdós mètodes, del 26,8%.
Fent això estarem veient quines variacions possibles veuríem en experiments on fos cert que els dos mètodes són iguals. D’aquesta manera podrem situar el nostre experiment real, que només tenim un, dins d’aquest immens conjunt d’experiments simulats sota el supòsit d’igualtat. Serà aquesta la manera d’avaluar la posició relativa del que veiem en el conjunt del que hauríem de veure si fos cert que els dos mètodes són iguals.
Si fem aquests 100.000 experiments obtindrem parelles de valors com, per exemple: (15, 17), (14, 15), (17, 13), (16, 16), etc, que seran valors possibles a veure d’hipoglucèmies entre 54 pacients en cada un dels dos mètodes, però, sempre, sota el supòsit que la probabilitat d’hipoglucèmia és la mateixa en cada un dels dos sistemes: 26,8%.
En l’estudi real la parella de valors que hem obtingut era (7, 22). Una diferència de 15. Anem a restar nosaltres les 100.000 parelles de valors del nombre d’hipoglucèmies simulades amb un tractament i amb l’altre. Els valors d’aquestes 100.000 restes que obtenim són els presentats en el següent gràfic:

Com es pot veure, el més habitual, el més freqüent, és que la diferència sigui petita. Diferències de 0, 1, -1, 2, -2, 3, -3, 4 i -4 són les més freqüents. Les restes més grans són d’una freqüència molt petita. Però és molt important veure aquí que la diferència de 15, que és just la diferència entre 22 i 7 que nosaltres veiem en l’estudi, és extraordinàriament improbable. Apareix en poquíssimes ocasions. Això és el que fa dubtar que el que veiem procedeixi de dos mètodes equivalents. Davant d’aquesta poca probabilitat és raonable pensar que la diferència observada es tracta realment d’una diferència real. Que si el portéssim a milions i milions de persones, no només a 54 persones, acabaríem veient un resultat equivalent al que estem veient en aquest estudi.
Això és com quan diem que un partit de bàsquet ja està guanyat quan, faltant 1 minut, el nostre equip guanya de 10. La probabilitat de perdre és prou baixa com per pensar que aquest partit ja està guanyat.
Per això parlem d’un resultat SIGNIFICATIU, perquè és molt poc probable veure el que estem veient en el cas que els grups comparats realment es comportessin poblacionalment de forma equivalent i, a la mostra, veiéssim el que estem veient.
Anem al segon cas, el del Clostridium difficile. Agafem de les quatre situacions experimentals les dades de les dues situacions descrites en el centre de la taula: el cas de tractament amb infusió que té un 93,8% d’èxit i el de la vancomicina, que té un 30,8% d’èxit . Es tracta ara de simular experiments dels que suposem que la probabilitat d’èxit dels dos mètodes comparats és la mateixa. Per això podem pensar en un valor mitjà dels dos vistos: una mitjana entre 93,8% i 30,8%, o sigui, 62,3%.
Podem ara simular 100.000 experiments equivalents però sota el supòsit que siguin iguals les probabilitats d’èxit mitjançant els dos procediments. Generar, per tant, parelles de valors basats en mostres de grandària 16 i 13, en cada experiment, cadascú amb una probabilitat d’èxit del 62,3%. Així tindríem parelles de valors com: (10, 7), (11, 6), (9, 7), etc. Ara les 100.000 parelles les transformem a percentatges d’èxit, relatiu sempre als 16 i 13 de mida mostral de cada un dels dos experiments: el primer sempre respecte a 16 i el segon respecte a 13. Així tindríem, en els casos exemplificats abans: (62.5, 53.8), (68.7, 46.1), (56.2, 53.8), etc. Si ara fem les 100.000 restes d’aquestes parelles de percentatges tindrem el següent histograma:
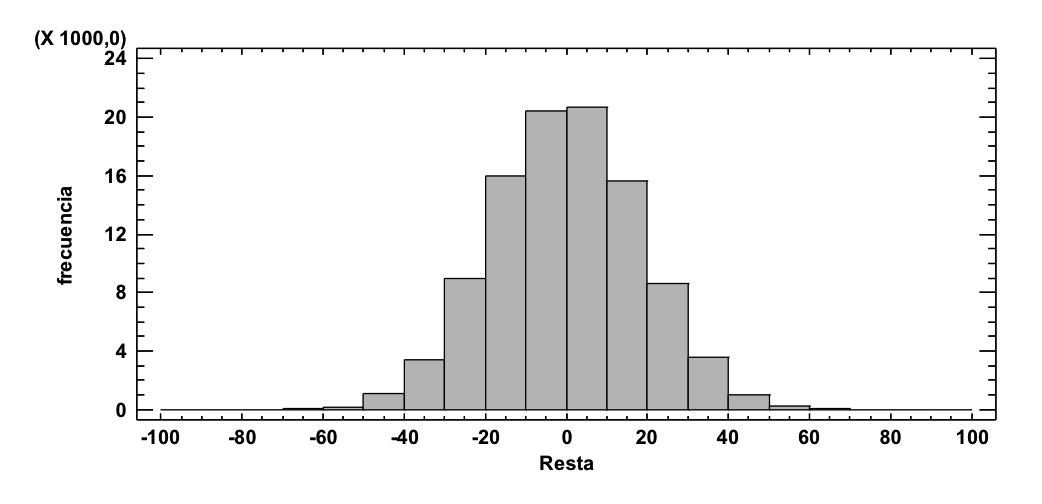
Com es pot apreciar, sota el supòsit que els dos mètodes tinguin la mateixa probabilitat d’èxit els valors de les restes obtingudes a l’atzar se situen majoritàriament entre -40 i 40 . En els valors observats: (93.8, 30.8) tenim una resta de 63. Una resta, per cert, amb un valor molt estrany, un valor que és molt poc probable veure si els dos tractaments són iguals. Per tant, hem de decantar-nos per pensar que realment no han de ser iguals SIGNIFICATIVAMENT les probabilitats d’èxit d’aquests dos tractaments, perquè de ser-ho hauríem de veure, en un experiment, més proximitat de valors de la que veiem.
De nou això és com quan en un partit de bàsquet, en què falta 1 minut per acabar i el nostre equip guanya de 10 punts, diem que el partit està guanyat. La probabilitat de perdre és prou baixa com per pensar que el partit està guanyat.
Per això parlem de que estem davant d’un resultat SIGNIFICATIU, perquè és molt poc probable veure el que estem veient i que sigui cert que els dos tractaments siguin iguals.
Pot semblar sorprenent però el cert és que l’Estadística i totes les Ciències es basen, es recolzen, en anàlisis estadístiques com aquestes que acabem de veure. L’Estadística elabora i aplica mètodes per diagnosticar el que és o no SIGNIFICATIU i tots ells tenen com a principi bàsic aquestes idees que hem intentat explicar aquí.
