Cada ciencia suele definirse delimitando su ámbito de estudio. Así, por ejemplo, decimos que la Biología es la ciencia de la vida, la Lingüística es la ciencia de las lenguas, la Medicina es la ciencia que estudia y trata las enfermedades humanas, la Psicología es la ciencia del comportamiento humano, etc.
Se han dado diferentes definiciones de Estadística. Una que puede ser apropiada y que está expresada en estos términos de “la ciencia de …” es la siguiente: la Estadística es la ciencia de lo SIGNIFICATIVO.
Bueno, como mínimo la definición sorprende, ¿no? No parece, al menos a primera vista, que lo SIGNIFICATIVO merezca tanta atención. Pues no es así. Merece atención y mucha. Se ha montado toda una ciencia en torno a esa noción debido a la importancia que a lo largo de los últimos doscientos años se le ha ido dando. Y ahí tenemos a la Estadística.
«SIGNIFICATIVO» no es, por cierto, una palabra extraña en nuestro lenguaje cotidiano. Realmente no es que sea de las palabras más habituales de nuestro día a día, pero es una palabra que todos seríamos capaces de asignarle un significado. Seguramente sin una gran precisión, es cierto, pero todos seríamos capaces de explicar qué queremos decir cuando decimos que algo es SIGNIFICATIVO.
En Estadística, sin embargo, es el objeto fundamental. Prácticamente todo en Estadística está canalizado para poder poner la etiqueta de SIGNIFICATIVO o de NO SIGNIFICATIVO a lo que vemos en unos resultados de un estudio determinado.
Por lo tanto, delimitar lo que entendemos por SIGNIFICATIVO en Estadística es crucial. Y delimitar, también, cuándo unos datos nos permiten decir que lo que vemos es o no SIGNIFICATIVO, es también nuclear en Estadística.
Voy a tratar, a continuación, de explicar cuál es el significado de la noción SIGNIFICATIVO en el lenguaje de la Estadística. Veámoslo, primero, mediante metáforas, que es una excelente forma de comunicar, especialmente en Ciencias.
Supongamos un profesor que después de un largo curso convoca a sus alumnos para el examen final y éste consiste en una única pregunta muy concreta, que se responde mediante una única línea. Ante un examen así un buen alumno, un alumno que ha estudiado mucho y que tiene muchos conocimientos, puede sacar perfectamente un 0. Ha tenido mala suerte. Le han preguntado justo un detalle concreto que no consigue recordar. Y, por el contrario, un pésimo alumno, un alumno que no ha estudiado nada, puede sacar un 10. Ha tenido la suerte de que le han preguntado justo algo que era de lo poco que sabía. Esto puede pasar perfectamente. Además, si, ante una situación como esta, repitiésemos el examen, y lo hiciésemos mediante un examen del mismo tipo, mediante una pregunta muy concreta que se responde en una simple línea, pero, eso sí, ahora una pregunta distinta a la anterior, podría pasar perfectamente que el que antes ha sacado un 10 ahora saque un 0 y el que antes ha sacado un 0 ahora saque un 10.
En términos estadísticos diríamos que exámenes de este tipo, exámenes tan concretos, no proporcionan notas SIGNIFICATIVAS de los alumnos examinados. Son notas poco fiables, que están sometidas demasiado al azar de lo que se pregunta. Son notas que reflejan poco el nivel de conocimientos del alumno.
Sin embargo, supongamos ahora que el examen es de 50 preguntas cortas que cubren todo el temario de la asignatura. La nota que obtiene un alumno muy poco cambiaría si repitiéramos el examen con otras 50 preguntas. Ahora sí podemos hablar de una nota SIGNIFICATIVA, una nota que volvería a ser del mismo orden si volviéramos a hacer un examen del mismo tipo aunque distinto.
Otro ejemplo: Si un equipo de baloncesto está ganando de 10 puntos en la media parte del partido, ningún aficionado al baloncesto diría que este partido ya está ganado. Si miráramos en una base de datos cientos de miles de partidos de baloncesto y buscáramos todos los partidos en los que un equipo ganaba de 10 faltando todavía 20 minutos de partido por jugar seguro que veríamos que más del 5% de veces ese equipo ha acabado perdiendo. En términos estadísticos diríamos que se trata de un resultado estadísticamente NO SIGNIFICATIVO.
Este número, el 5%, es muy importante en Estadística. Es un valor frontera muy importante, como veremos más tarde.
Por el contrario, si faltando un minuto un equipo está ganando de 10 puntos. Ahora si buscásemos en esa misma base de datos partidos que un equipo, faltando un minuto para acabar el partido, iba ganando de 10 puntos, seguramente veríamos que menos del 5% de veces ese equipo ha acabado perdiendo. Si fuera así, diríamos, en términos estadísticos, que este resultado es estadísticamente SIGNIFICATIVO.
Una cuestión muy importante: En ciencia siempre estudiamos muestras pero la finalidad es poblacional. Queremos hablar de todos a partir del estudio de una parte, de una muestra. En términos de baloncesto: Pronosticamos el final del partido, pero, evidentemente, durante el partido. Una vez acabado el partido sólo es posible describir lo que ha sucedido pero no hay pronósticos posibles.
La significación es una palabra nuclear en la Ciencia. La ciencia persigue dar resultados SIGNIFICATIVOS. Persigue decir cosas con fiabilidad, con pocas posibilidades de equivocarse. Los instrumentos que aporta la Estadística para delimitar resultados SIGNIFICATIVOS de resultados NO SIGNIFICATIVOS es un instrumento esencial en la Ciencia. Veamos algunos ejemplos donde está presente la noción de estadísticamente SIGNIFICATIVO. Los tres ejemplos están tomados de la revista más prestigiosa en Medicina, el New England Journal of Medicine.
El primer caso consiste en un estudio publicado recientemente donde se compara la eficacia de un páncreas artificial automatizado, que controla la glucemia y suministra insulina en continuo, respecto a un sistema de control estándar en pacientes con Diabetes tipo 1. Se usan los dos sistemas de control en un mismo grupo de pacientes con este tipo de Diabetes. En dos noches distintas se ensayan cada uno de estos métodos en todos los pacientes. La variable respuesta es si en algún momento han sufrido una hipoglucemia durante la noche. La hipoglucemia es la situación de máxima gravedad en la que puede situarse un diabético.
Los datos que se obtienen son los siguientes:
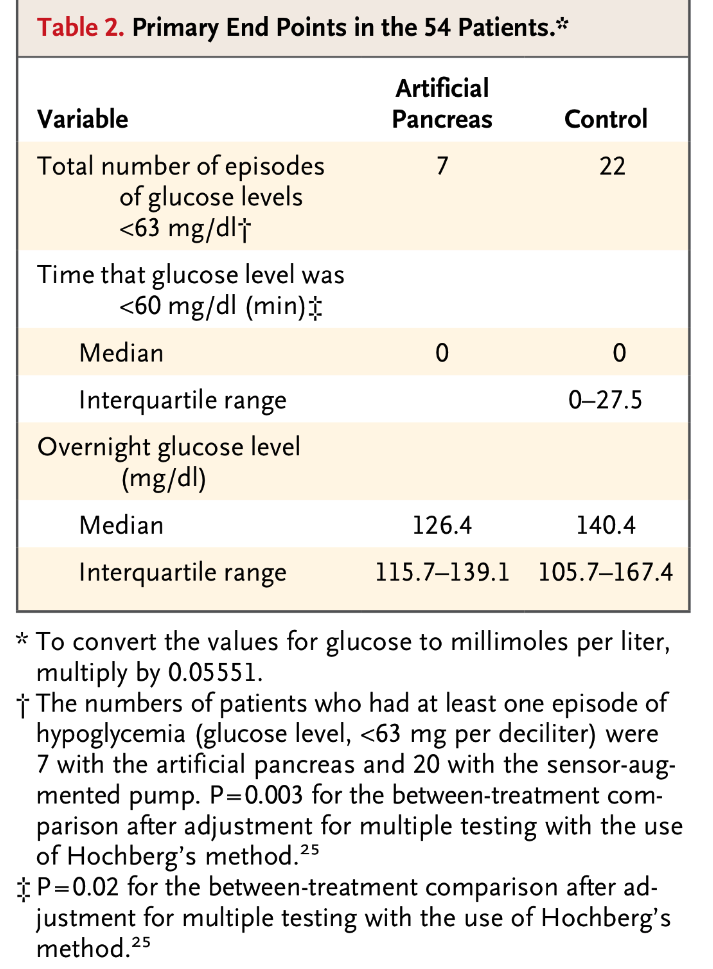
Observemos que con el páncreas artificial 7 veces se han producido una hipoglucemia entre los 54 niños con diabetes participantes en el estudio. Con el control (el método habitual de control nocturno de la diabetes) se han producido 22 casos de hipoglucemia entre 54 niños. Evidentemente que 7 es menos que 22. El problema es si esta diferencia es, o no, estadísticamente SIGNIFICATIVA. Y esto nos lo debe proporcionar una técnica estadística. En este caso concreto nos lo resolvería una técnica estadística llamada Test de McNemar. La técnica nos da un valor que es este valor que vemos: p=0.003, que es el valor que marca que estamos ante un resultado estadísticamente SIGNIFICATIVO.
Esta p, el denominado p-valor, es un valor que va de 0 a 1 y si es un valor menor que 0.05 indica que la diferencia que vemos es SIGNIFICATIVA, indica que la diferencia es fiable. Que no es fruto del azar. Observemos que 0.05 sobre 1 es como 5 sobre 100 (un 5%), que es la frontera que antes he citado cuando hablaba del partido de baloncesto. Este 5% ó 0.05 por 1 es una frontera muy importante en Estadística y en Ciencias.
Otro ejemplo: A principios de este año un artículo creó un verdadero impacto entre los especialistas en enfermedades infecciosas. En un estudio con personas infectadas por Clostridium difficile conseguían mejores resultados, un mayor porcentaje de curaciones sin recaídas, si el tratamiento se hacía con infusiones, por sonda orogástrica, de heces de pacientes con infección crónica de esta especie bacteriana, que mediante un tratamiento con antibiótico. Veamos los resultados:
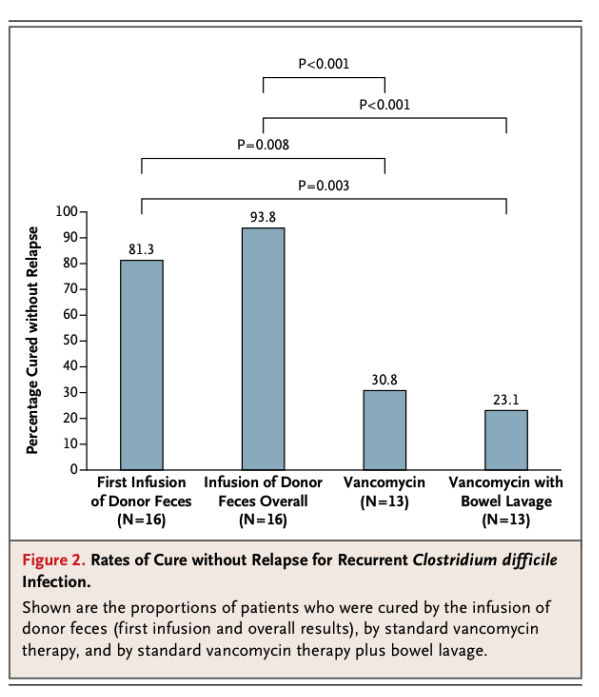
Observemos los datos de los resultados de los pacientes tratados con la infusión comparados con los resultados obtenidos con el tratamiento con el antibiótico más eficaz usado en estos casos, que es la vancomicina. Como puede observarse los niveles de curación sin recaídas son superiores en los tratamiento con infusiones con heces que en los tratamientos antibióticos. Las cuatro comparaciones posibles entre los tratamientos con infusión y los tratamientos con la vancomicina son SIGNIFICATIVAS (p<0.05).
Otro ejemplo: La fibromialgia es una enfermedad muy frecuente en nuestra sociedad. Se han ensayado muchos métodos para intentar buscar remedio a esta dolencia. Recientemente se ha publicado un original estudio que demuestra que el Tai-chi es un método que consigue resultados positivos a la hora de abordar esta enfermedad. Veamos el cuadro siguiente:
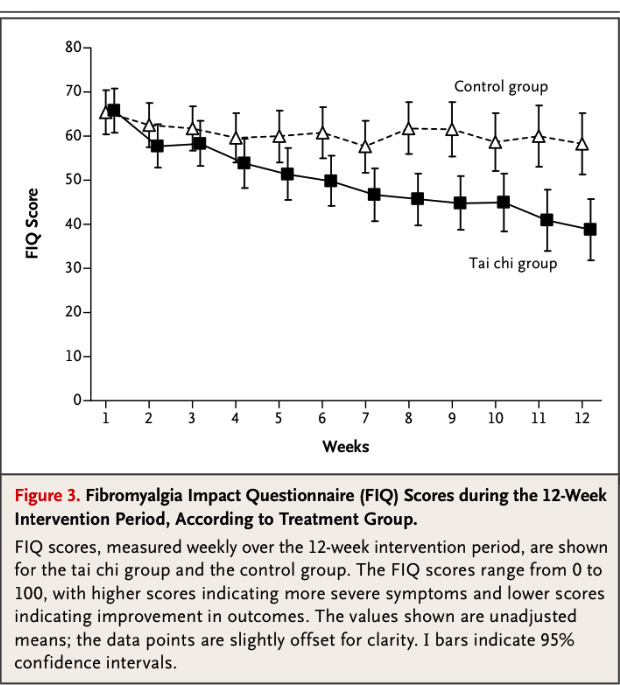
Como puede observarse los dos grupos de pacientes estudiados, uno siguiendo un método control mediante fisioterapia y el otro siguiendo unas sesiones de tai-chi, parten de una mismo nivel de gravedad y podemos ver en el gráfico, perfectamente, cuál es la evolución a lo largo de las semanas. Vemos cómo el grupo control se mantiene dentro de un nivel estable y, sin embargo, los pacientes que siguen esas sesiones de tai-chi consiguen reducir significativamente los niveles de dolor que tienen. Aquí el p-valor también es inferior a 0.05. La gráfica no nos lo da, pero nos da algo equivalente. Nos da intervalos de confianza del 95%. Observemos que los intervalos de confianza de los dos grupos en las primeras semanas se solapan (lo que indica que la diferencia no es SIGNIFICATIVA) y, sin embargo, a partir de la semana 8 esos intervalos ya no se solapan. Lo que indica que esa diferencia ya es SIGNIFICATIVA, es fiable.
Al final toda esta diversidad de situaciones se analizan mediante mecanismos diferentes (Técnicas estadísticas distintas) pero siempre bajo un mismo principio. El siguiente: ¿Lo que se ve es algo que es muy probable verlo en el caso que los grupos comparados fueran realmente iguales o, por el contrario, sería muy poco probable verlo en ese caso? Las técnicas estadísticas siempre funcionan haciendo una comparación entre lo que ven en la muestra y lo que deberían ver si los grupos comparados fueran iguales.
Si los dos mecanismos de control de la diabetes fueran iguales, si el tratamiento con infusiones de heces y el tratamiento con antibióticos dieran resultados idénticos o si hacer tai-chi o hacer fisioterapia estándar dieran resultados idénticos en pacientes con fibromialgia, esperaríamos ver en una muestra unos ciertos valores. Estos valores esperados, en el supuesto de que fuera cierto el caso hipotético de igualdad entre lo comparado, son los que las técnicas estadísticas comparan con lo que realmente ven en las muestras de esos estudios. En función de esta comparación, en función de la distancia entre lo esperado y lo observado, acaban dictaminando si eso que vemos es coherente o no con la igualdad presupuesta de esos grupos comparados.
Para ver cómo opera una técnica estadística para comparar lo esperado, bajo el supuesto de que los grupos comparados son iguales, con lo observado, vamos a centrarnos en dos de esos tres casos y vamos a ver, en ellos, cómo opera la técnica estadística.
Recordemos que el primer caso analizado era el estudio del páncreas artificial. De los 54 pacientes 7 tenían problemas con el páncreas artificial y con el control habitual el número de problemas ascendía a 22.
7 de 54 y 22 de 54 son distintos, evidentemente. Son matemáticamente distintos. Pero, esta diferencia, ¿es estadísticamente SIGNIFICATIVA? Este es el problema. El análisis estadístico es quien lo dirá, es el que determinará si esa diferencia entre 7 y 22 es una diferencia estadísticamente SIGNIFICATIVA.
Para empezar el análisis vamos a suponer, vamos a partir de la suposición, de que los dos métodos, los dos tratamientos, tienen la misma eficacia. Por lo tanto, elaboraremos un mundo ficticio donde los dos métodos que estamos comparando fueran, en realidad, idénticos.
Si los dos métodos fueran idénticos, que dieran el mismo número de problemas, el mismo número de situaciones de hipoglucemia, esperaríamos una probabilidad de hipoglucemia, durante una noche, del 26,8%, porque tenemos, en un método, un 12,9% de hipoglucemias y, en el otro, un 40,7%. El 26,8% es el promedio de estos dos porcentajes. Por lo tanto, este mundo ficticio que construimos lo hacemos adoptando un valor que, en global, refleja la realidad. En lo que hemos visto, en el estudio, en total, se produce un 26,8% de hipoglucemias (si juntamos las de un método y las del otro).
Vamos a hacer una simulación, vamos a construir experimentos posibles. Esto actualmente no es nada extraño. Vivimos rodeados de simulación: de una carrera de motos, de un partido de fútbol, etc. Esto que nos proponemos hacer, ahora, es posible gracias a la informática. Generaremos experimentos posibles pero bajo el supuesto de que los dos métodos tienen el mismo porcentaje de problemas, bajo el supuesto de esta ficción que hemos creado. Generaremos 100.000 experimentos equivalentes al del estudio, pero bajo el supuesto de que los dos métodos son igual de eficaces; o sea, con una probabilidad de hipoglucemia, en ambos métodos, del 26,8%.
Haciendo esto estaremos viendo qué variaciones posibles veríamos en experimentos donde fuera cierto que los dos métodos son iguales. De esta forma podremos situar nuestro experimento real, que sólo tenemos uno, dentro de este inmenso conjunto de experimentos simulados bajo el supuesto de igualdad. Será ésta la forma de evaluar la posición relativa de lo que vemos en el conjunto de lo que deberíamos ver si fuera cierto que los dos métodos son iguales.
Si hacemos estos 100.000 experimentos obtendremos parejas de valores como, por ejemplo: (15, 17), (14, 15), (17, 13), (16, 16), etc, que serán valores posibles a ver de hipoglucemias entre 54 pacientes en cada uno de los dos métodos, pero, siempre, bajo el supuesto que la probabilidad de hipoglucemia es la misma en cada uno de los dos sistemas: 26,8%.
En el estudio real la pareja de valores que hemos obtenido era (7, 22). Una diferencia de 15. Vamos a restar nosotros las 100.000 parejas de valores del número de hipoglucemias simuladas con un tratamiento y con el otro. Los valores de esas 100.000 resta que obtenemos son los presentados en el siguiente gráfico:

Como puede verse lo habitual, lo más frecuente, es que la diferencia sea pequeña. Diferencias de 0, 1, -1, 2, -2, 3, -3, 4 y -4 son las más frecuentes. Conforme buscamos restas mayores vamos viendo que la frecuencia va decreciendo. Pero lo trascendente aquí es ver que la diferencia de 15, que es justo la diferencia entre 22 y 7 que nosotros vemos en el estudio, es extraordinariamente improbable. Aparece en poquísimas ocasiones. Esto es lo que hace dudar de que lo que vemos sea algo procedente de dos métodos equivalentes. Ante esta poca probabilidad es razonable pensar que la diferencia observada obedezca a una diferencia real. Que si lo lleváramos a millones y millones de personas, no sólo a 54 personas, acabaríamos viendo un resultado equivalente al que estamos viendo en este estudio.
Esto es como cuando decimos que un partido de baloncesto ya está ganado cuando, faltando 1 minuto, nuestro equipo gana de 10. La probabilidad de perder es lo suficientemente baja como para pensar que este partido ya está ganado. Por eso hablamos de un resultado SIGNIFICATIVO, porque es muy poco probable ver lo que estamos viendo en el caso de que los grupos comparados realmente se comportaran poblacionalmente de forma equivalente y, muestralmente, viéramos lo que estamos viendo.
Veamos el segundo caso, el del Clostridium difficile. Cojamos de las cuatro situaciones experimentadas los datos de las dos situaciones descritas en el centro de la tabla: el caso de tratamiento con infusión que tiene un 93,8% de éxito y el de la vancomicina, que tiene un 30,8% de éxito. Se trata ahora de simular experimentos de los que supusiésemos que la probabilidad de éxito es la misma entre entre ellos. Para ello podemos pensar en un valor promedio de los dos vistos: un promedio entre 93,8 y 30,8; o sea, 62,3%.
Podemos ahora simular 100.000 experimentos equivalentes pero bajo el supuesto que sean iguales las probabilidades de éxito mediante los dos procedimientos. Generar, por lo tanto, parejas de valores basados en muestras de tamaño 16 y 13 cada experimento con una probabilidad de éxito del 62,3%. Así tendríamos parejas de valores como: (10, 7), (11, 6), (9, 7), etc. Ahora las 100.000 parejas las transformamos a porcentajes de éxito de porcentaje, relativo siempre a los 16 y 13 de tamaño muestral de cada uno de los dos experimentos: el primero siempre respecto a 16 y el segundo respecto a 13. Así tendríamos, en los casos ejemplificados antes: (62.5, 53.8), (68.7, 46.1), (56.2, 53.8), etc. Si ahora hacemos las 100.000 restas de estas parejas de porcentajes tendremos el siguiente histograma:
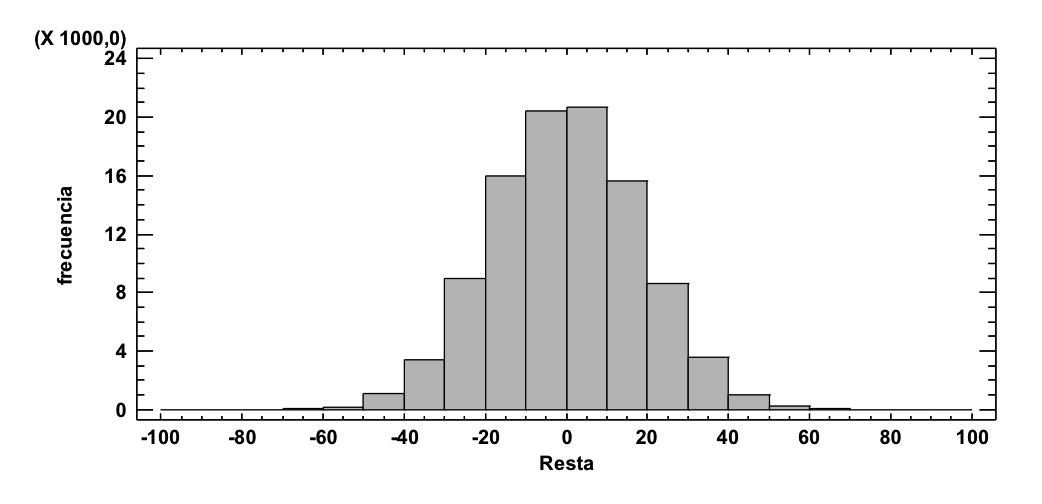
Como puede apreciarse, bajo el supuesto de que los dos métodos tengan la misma probabilidad de éxito los valores de las restas obtenidas al azar se sitúan mayoritariamente entre -40 y 40. Luego, los valores observados: (93.8, 30.8) que tienen una resta de 63 se trata de un valor muy extraño, muy poco probable verlo. Por lo tanto, debemos decantarnos por pensar que realmente no deben ser iguales SIGNIFICATIVAMENTE las probabilidades de éxito de estos dos tratamientos, porque de serlo deberíamos, en un experimento, ver mayor proximidad.
De nuevo esto es como cuando en un partido de baloncesto, en el que falta 1 minuto para acabar y nuestro equipo gana de 10 puntos, decimos que el partido está ganado. La probabilidad de perder es lo suficientemente baja como para pensar que el partido está ganado.
Por eso hablamos de que estamos ante un resultado SIGNIFICATIVO, porque es muy poco probable ver lo que estamos viendo y que sea cierto que los dos tratamientos sean iguales.
Puede parecer sorprendente pero lo cierto es que la Estadística y todas las Ciencias se basan, se apoyan, en análisis estadísticos como estos que acabamos de ver. La Estadística elabora y aplica métodos para diagnosticar lo SIGNIFICATIVO y todos ellos tienen como principio básico estas ideas de hemos intentado explicar aquí.

Pingback: Herramientas estadísticas en Medicina (Una hoja de ruta) | LA ESTADÍSTICA: UNA ORQUESTA HECHA INSTRUMENTO
Pingback: ¿Qué es Informática Médica? – informatica médica y bioestadistica