1. El Análisis de supervivencia es una técnica inferencial que tiene como objetivo esencial modelizar el tiempo que se tarda en que ocurra un determinado suceso. Por el nombre de la técnica parecería que se analizara el tiempo hasta la muerte (Análisis de supervivencia) pero, en realidad, puede analizarse cualquier otro suceso.
2. En Análisis de supervivencia la muestra consiste en el seguimiento de una serie de individuos desde el inicio del estudio hasta su final y, ante una situación de este tipo, es frecuente que se produzca la desaparición de alguno de esos individuos que entran en el estudio. También es posible que al entrar un individuo en el estudio, éste termine antes de que en ese individuo se produzca el suceso que se pretende detectar. Aunque son dos hechos distintos en realidad a efectos prácticos suponen lo mismo. A estos individuos, en el ámbito de la Estadística, se le denomina censurados.
3. Un dato censurado representa, pues, un individuo que desaparece, que lo hemos tenido pero que, antes de haberse producido el suceso que analizamos, ha desaparecido, sea porque lo perdemos del estudio o sea porque el estudio ha terminado y no se ha producido el suceso. Un dato censurado no es un dato que no nos dé información. De hecho, nos la da pero parcial, como veremos. Hay que saberlo aprovechar. Prescindir de él, sin más, sería desaprovechar información y eso, en Estadística, no es bueno.
4. Veamos en el siguiente gráfico el tipo de datos que nos podemos encontrar en un estudio de supervivencia:
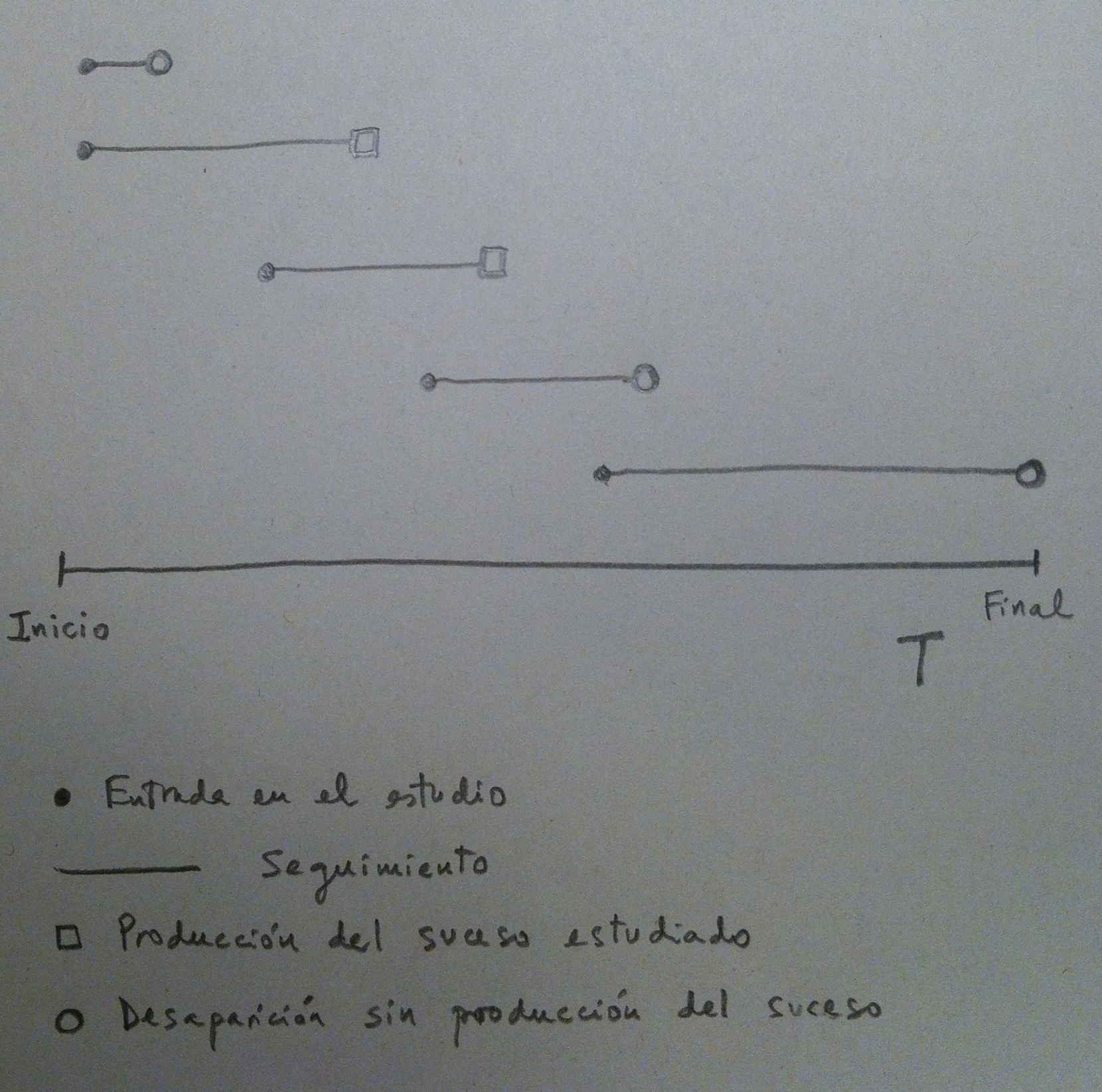
5. Observemos que un estudio de supervivencia tiene un inicio y un final, desde ese inicio al final van introduciéndose en el estudio una serie de individuos (Entrada en el estudio), se va realizando un seguimiento y puede, durante ese seguimiento, que se produzca el suceso estudiado (muerte, recidiva, etc), pero también puede ser que el individuo desaparezca del estudio por algún motivo que no sea el estudiado. También puede que acabe nuestro estudio y que a algún individuo tampoco le haya sucedido el suceso estudiado. A efectos prácticos es algo similar a los casos de desaparición.
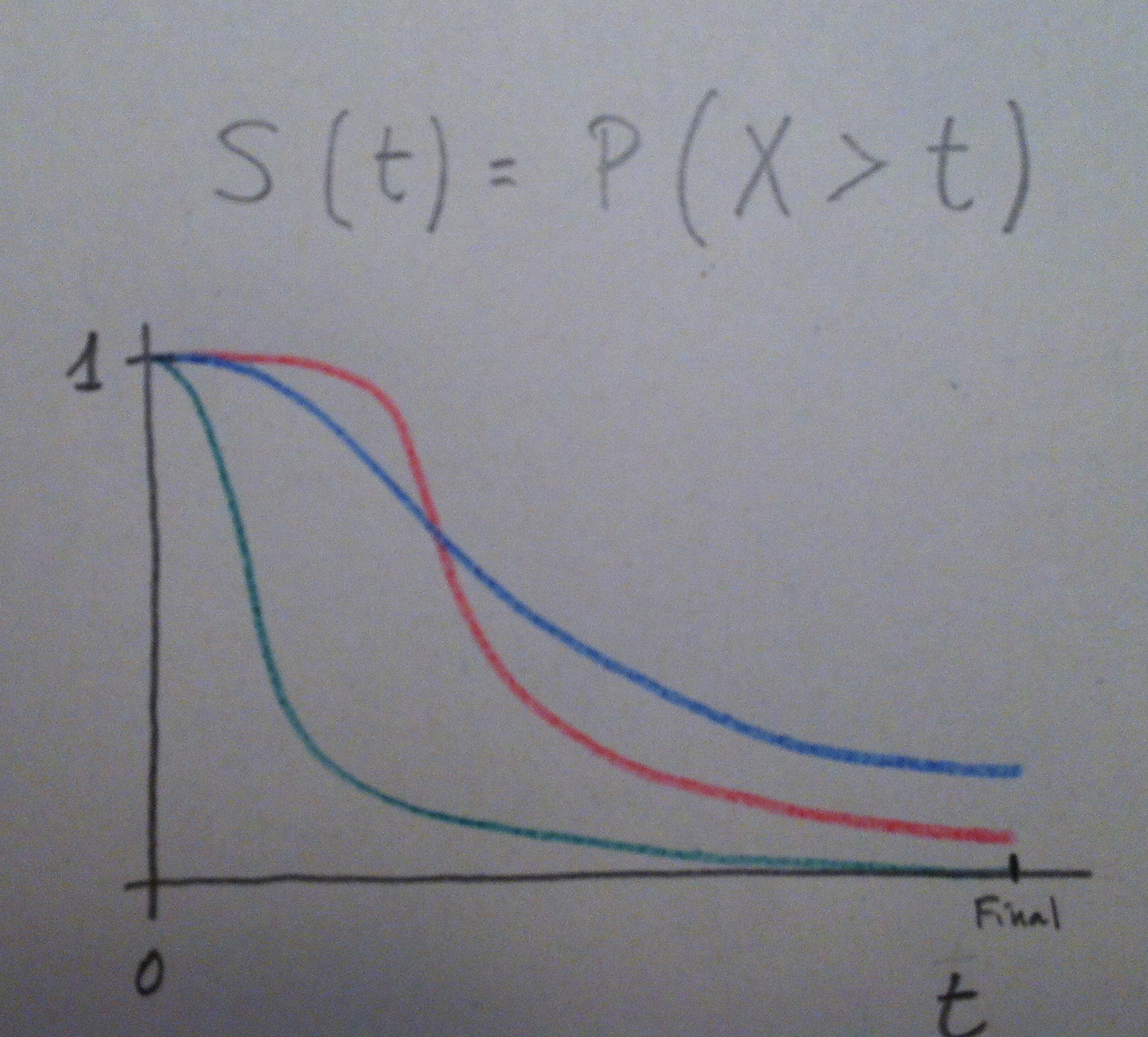
6. Se define y se dibuja la denominada función de supervivencia de la siguiente forma:
7. Hay en Análisis de supervivencia un enfoque paramétrico. Consiste en aceptar que un determinado tipo de función de distribución paramétrico nos sirve como modelo de esta evolución. Las funciones de distribución más habituales son la Exponencial y la Weibull:
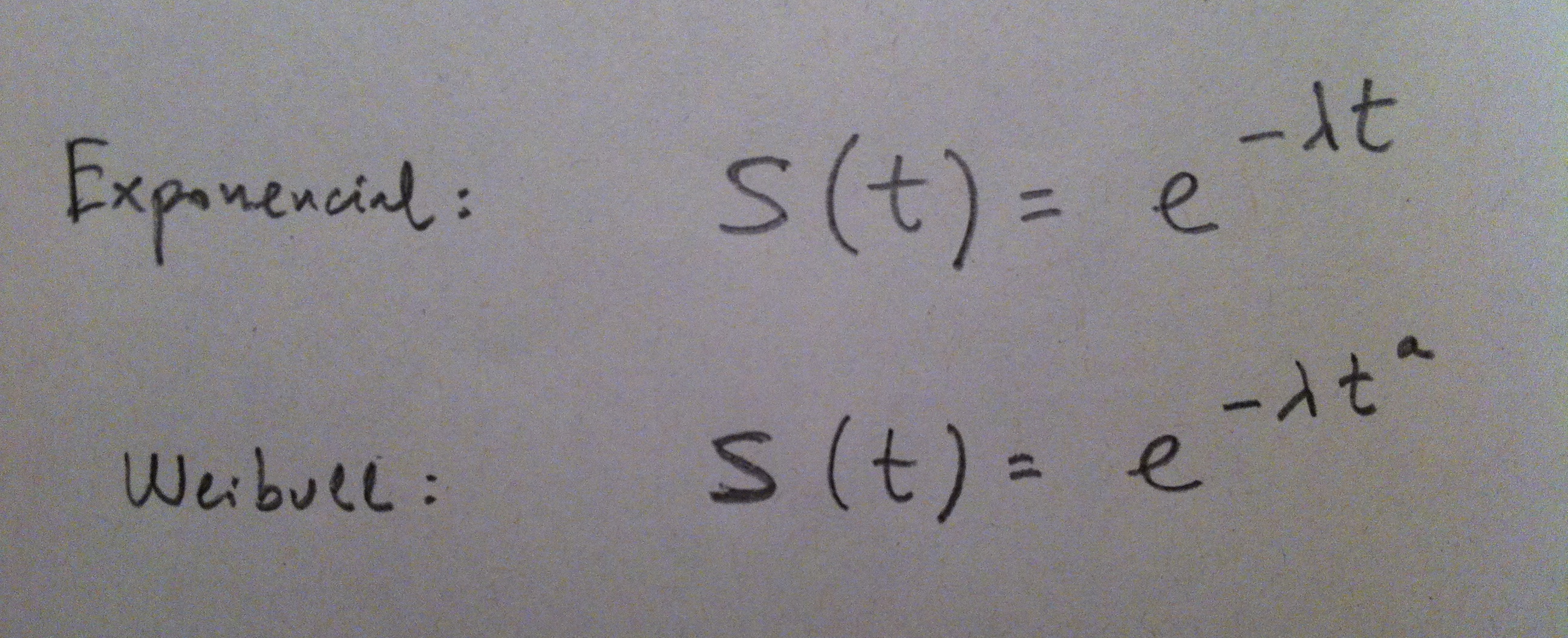
8. Una vez aceptado el modelo se trata, para una muestra determinada, de estimar el valor del parámetro único en la Exponencial o de los dos parámetros en la Weibull. Más en concreto, el modelo basado en la función de distribución exponencial, tiene las propiedades siguientes:
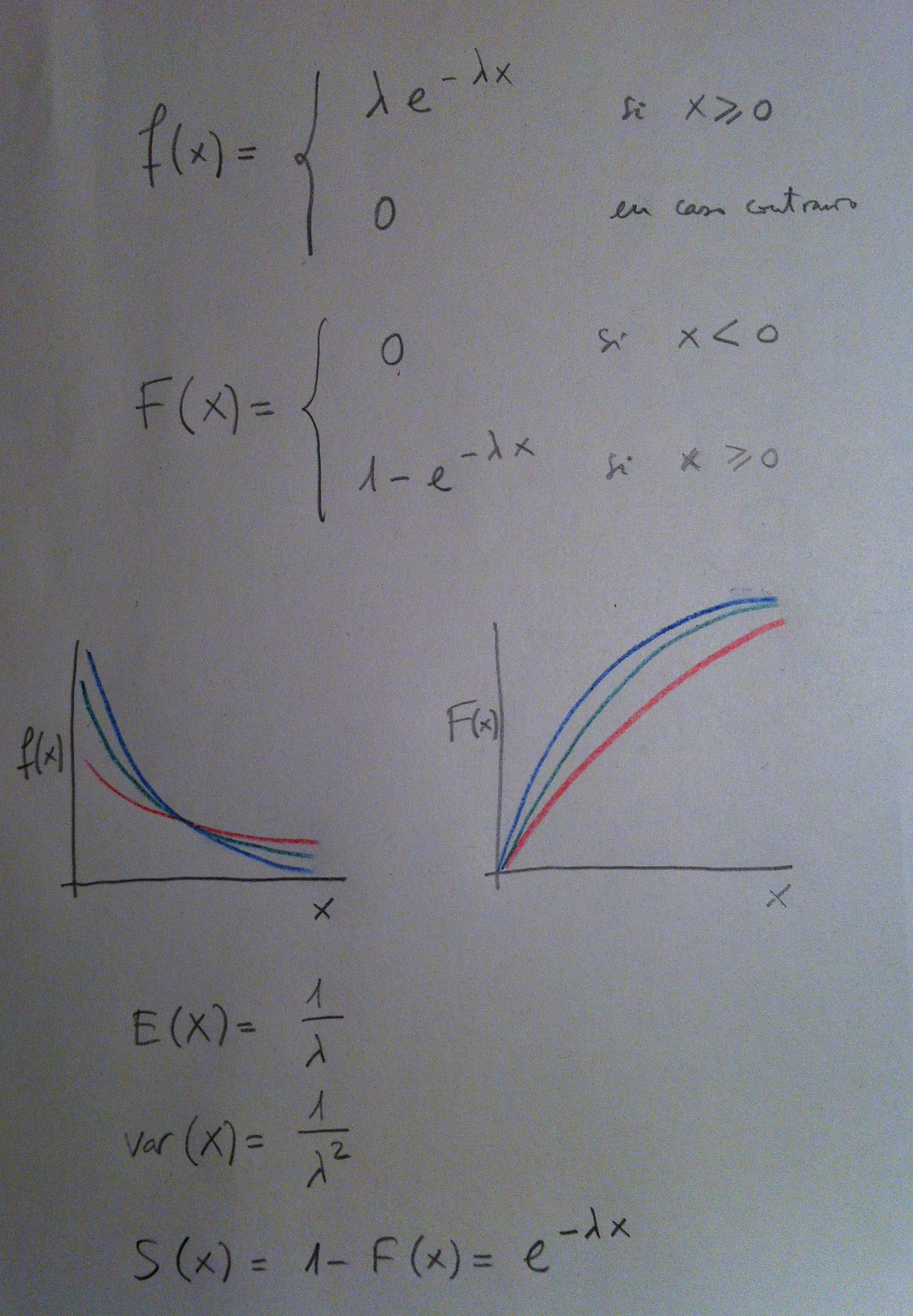
9. El Análisis de supervivencia paramétrico tiene la rigidez de tener que ajustarse los datos al modelo y esto con frecuencia no es así. Por eso, en la práctica, en Análisis de supervivencia, no es la opción más usada.
10. En Análisis de supervivencia han triunfado sin precedentes las técnicas no paramétricas. Posiblemente porque estamos ante un tipo de técnicas y de problemas que aparecen muchas más recientemente que otras técnicas clásicas en Estadística y esto ha provocado que ya se hayan desarrollado y utilizado mayoritariamente los procedimientos no paramétricos que tienen validez mucho más general.
11. De las técnicas de Análisis de supervivencia no paramétricas la más usada y popular es, sin lugar a dudas, el Estimador de Kaplan-Meier de la función de supervivencia.
12. El Estimador de Kaplan-Meier tiene la siguiente formulación:
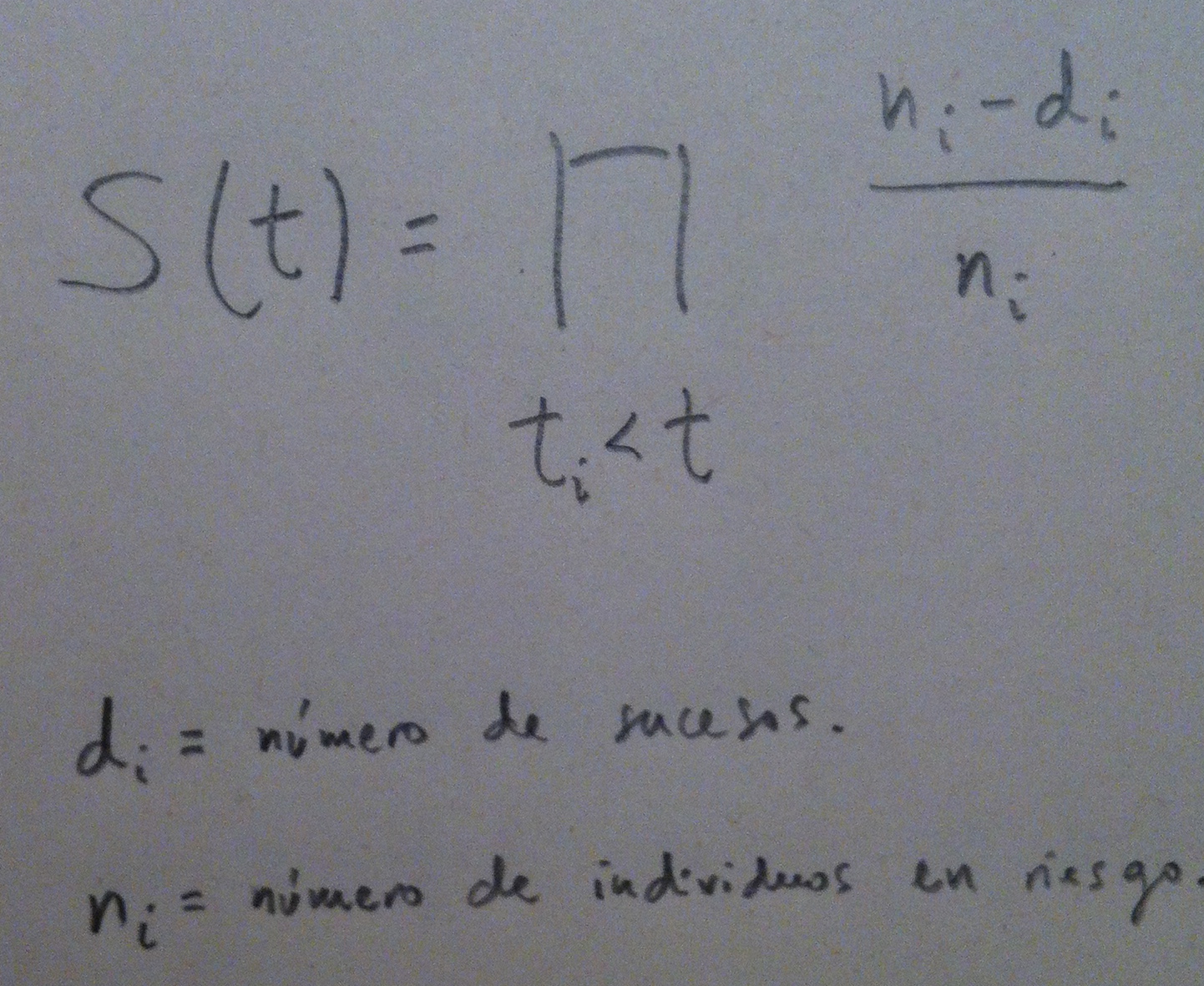
13. Los gráficos que aparecen tras calcular su fórmula a una muestra tienen el aspecto siguiente:
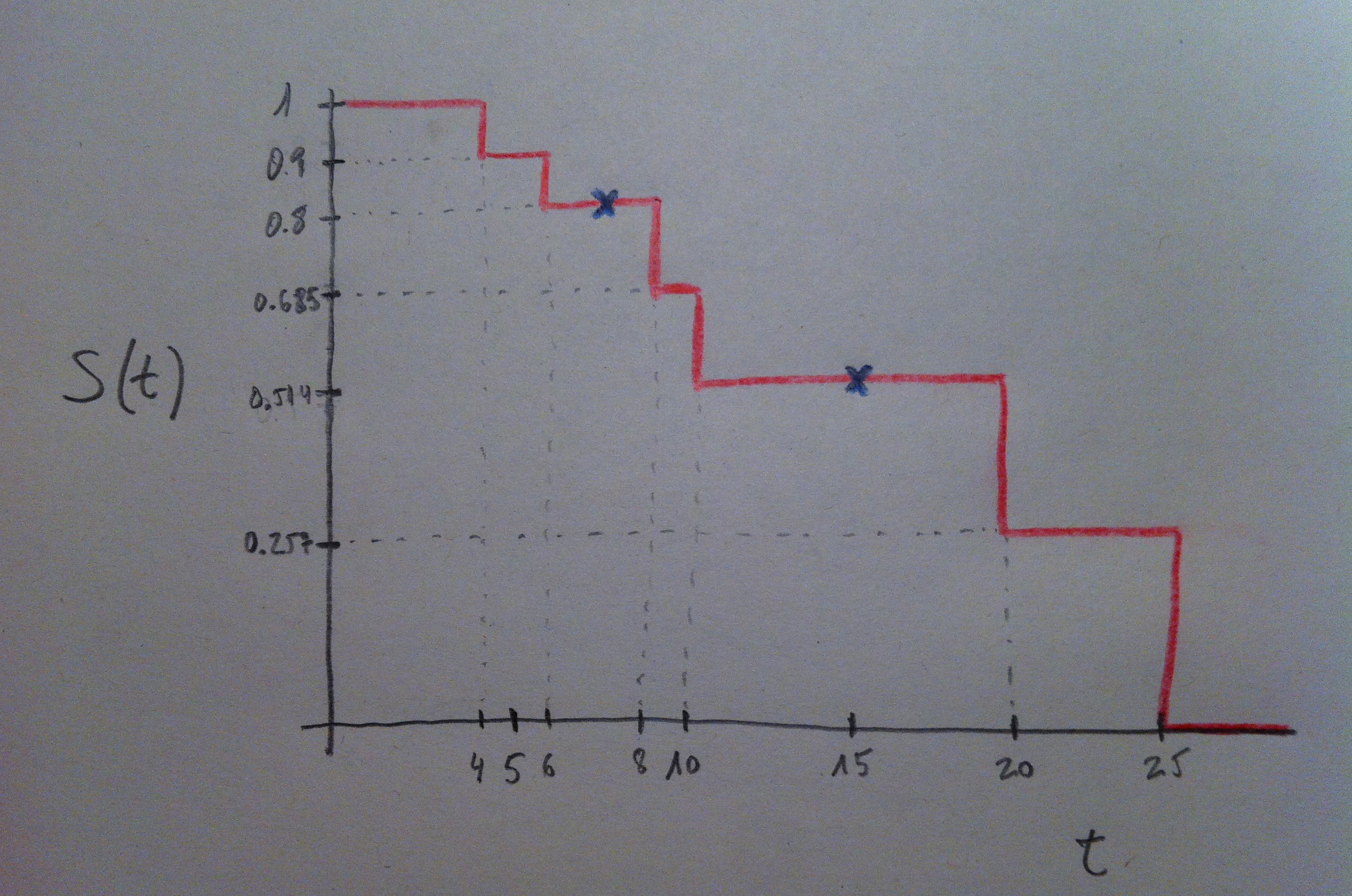
14. En el artículo Estimador de Kaplan-Meier puede verse cómo, a partir de una muestra, se puede construir una curva de supervivencia como ésta.
15. En Análisis de supervivencia uno de los problemas estadísticos más frecuentes e interesantes es la comparación de curvas de supervivencia. El problema surge cuando tenemos dos o más grupos, cada uno con su muestra, y queremos ver si tenemos igualdad de curvas de supervivencia. El problema, pues, es comprobar si el Estimador de Kaplan-Meier aplicado a cada una de esas muestras nos permite deducir que las diferencias que vemos entre ellas son estadísticamente significativas o, por el contrario, pueden ser atribuibles al azar.
16. La Hipótesis nula será, en este caso, igualdad de curvas. En Estadística siempre se presupone la igualdad. También de curvas de supervivencia, que es lo que ahora nos ocupa. La Hipótesis alternativa será que hay diferencia entre esas curvas y que, por lo tanto, el suceso analizado se produce con ritmo distinto a lo largo del tiempo en los diferentes grupos analizados.
17. La técnica más usual para realizar esta comparación de curvas de supervivencia es el Test Log-Rank (Ver Herbario de técnicas). Es, de hecho, una técnica ji-cuadrado, donde se realiza una comparación entre un observado (las curvas de supervivencia muestrales) y un esperado (reuniendo todos los valores en una única muestra).
18. Vamos a ver una aplicación concreta de Análisis de supervivencia y de comparación de curvas de supervivencia. Supongamos un caso donde, pacientes con una misma patología, un grupo de ellos son tratados con placebo y otro grupo con un determinado tratamiento que se quiere evaluar. Y obtenemos los siguientes tiempos (en las unidades temporales que se sean, aquí es lo de menos):
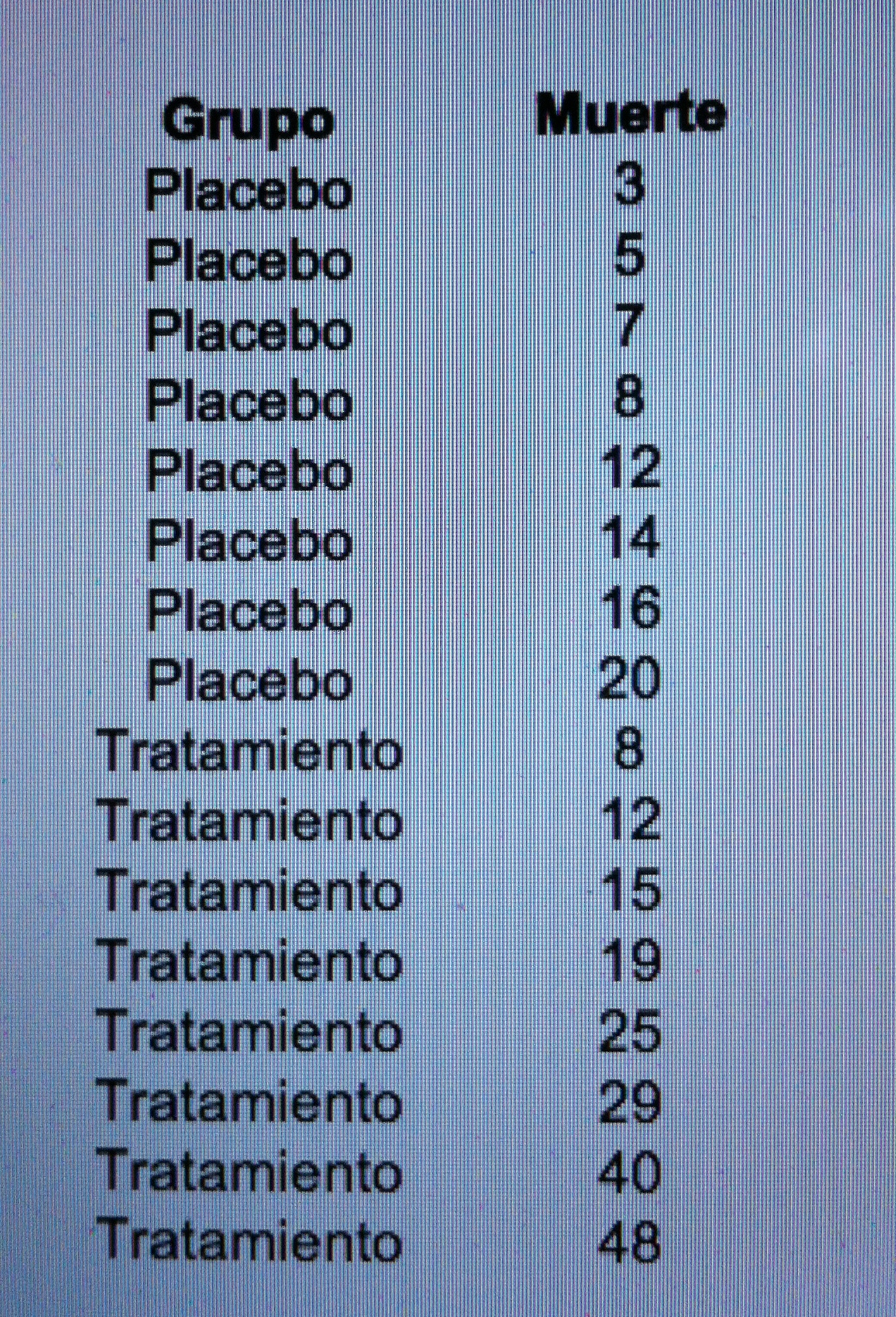
19. Si calculamos el Estimador de Kaplan-Meier a estos dos grupos tenemos los siguientes valores:
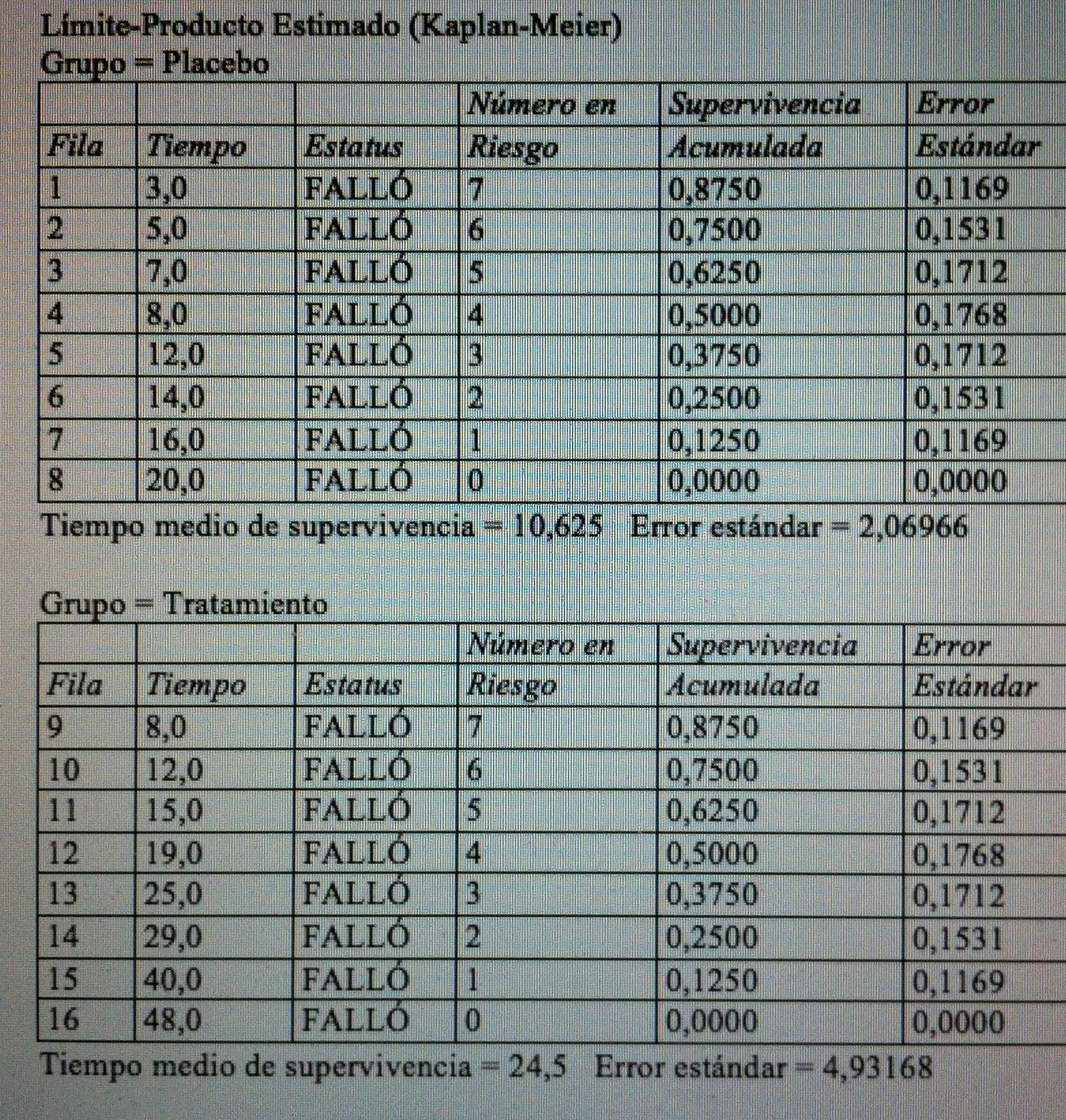
20. Y estos valores se materializan en las siguientes curvas de supervivencia:
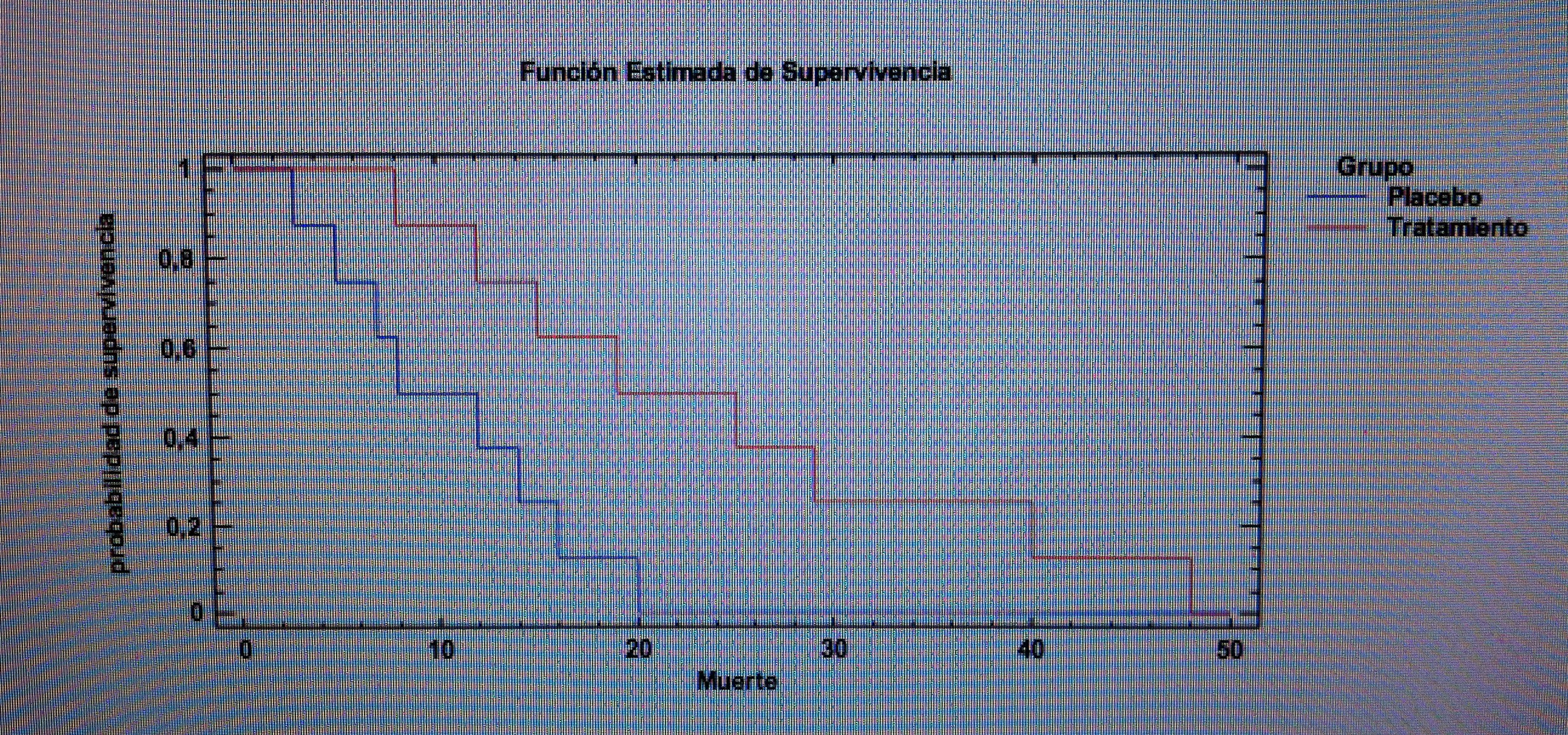
21. Si ahora aplicamos el Test Log-Rank para comprobar si estas diferencias muestrales son diferencias significativas obtenemos el resultado siguiente:
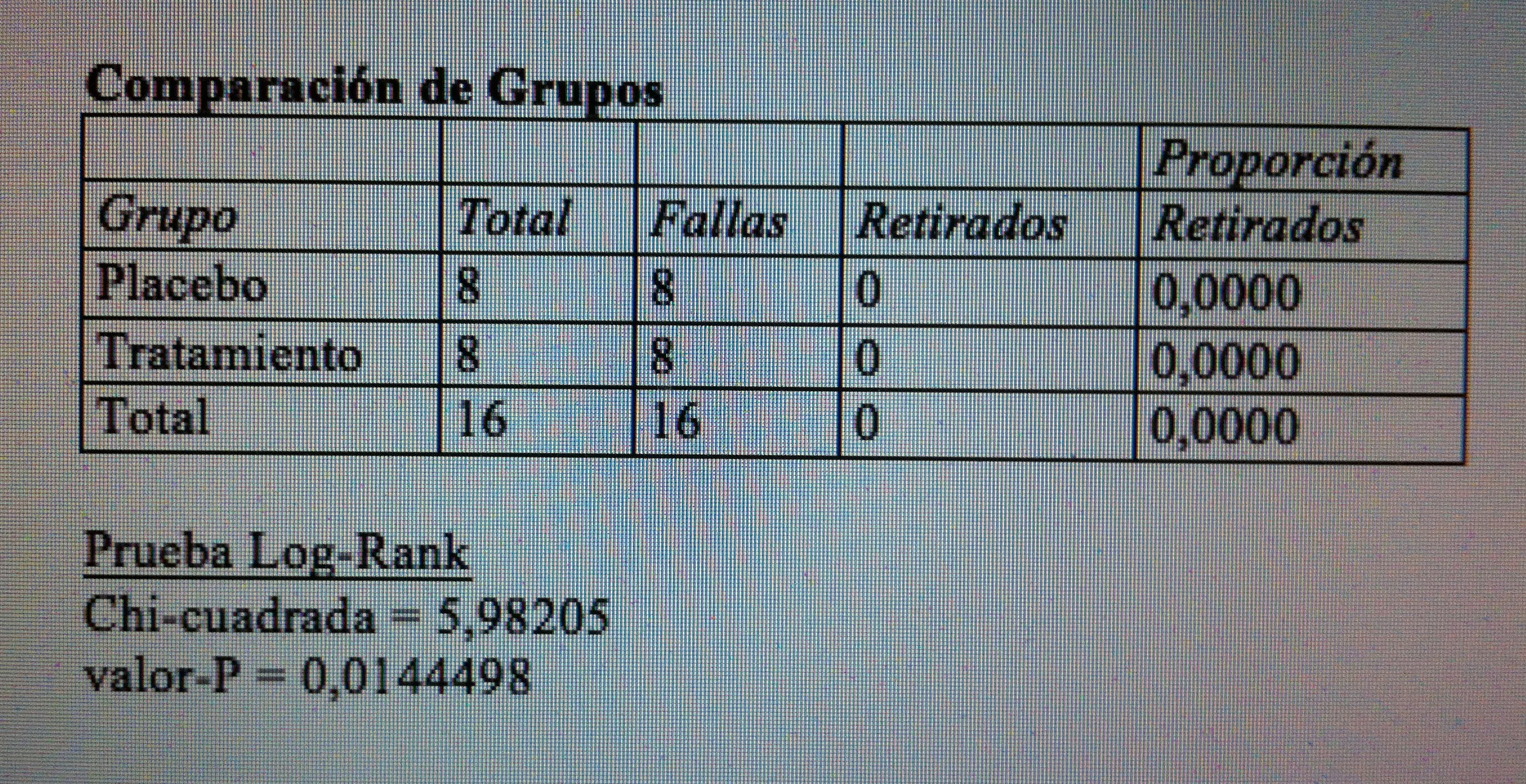
22. Este test nos indica que las diferencias entre ambas curvas no son debidas al azar, son significativas. El p-valor del test es 0.0144 y como es menor que 0.05 rechazamos la Hipótesis nula de igualdad de curvas. Lo que indica que la supervivencia se alarga como consecuencia del tratamiento.
23. En el contexto del Análisis de supervivencia es muy usual trabajar con la función de riesgo (Hazard function). La definición de esta función es la siguiente:
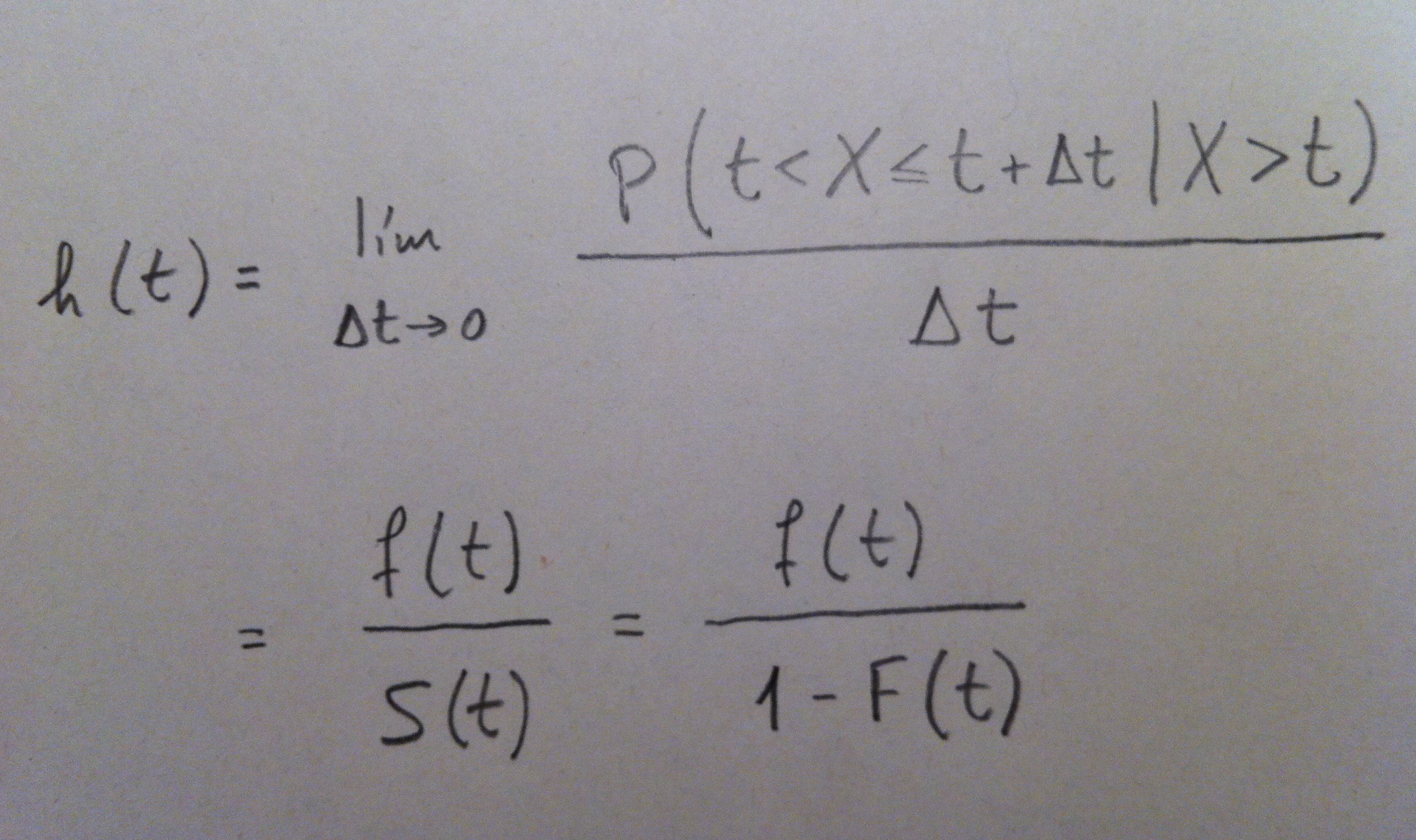
24. Observemos que la función de riesgo h(t) es una medida de la probabilidad de que se produzca el suceso estudiado entre los que quedan sin haber sufrido todavía tal suceso. Es realmente una función que evalúa, puntualmente, en un período de tiempo determinado, la probabilidad de que un individuo de los que todavía no han sufrido tal suceso lo sufra precisamente en ese período de tiempo. Es, por lo tanto, realmente, una función que mide el riesgo en un período de tiempo concreto.
25. Supongamos que estamos evaluando, como sucede muchas veces, el tiempo de vida de una serie de personas que están bajo ciertas condiciones. En estas circunstancias, la función de riesgo cuantifica puntualmente la probabilidad de muerte entre los que quedan en vida. Si se analiza con un poco de detenimiento su formulación esto es lo que realmente mide la función de riesgo h(t).
26. La forma de la función de riesgo puede ser muy distinta según los datos que estemos analizando. Nos podemos encontrar con funciones de riesgo tan distintas como las siguientes:
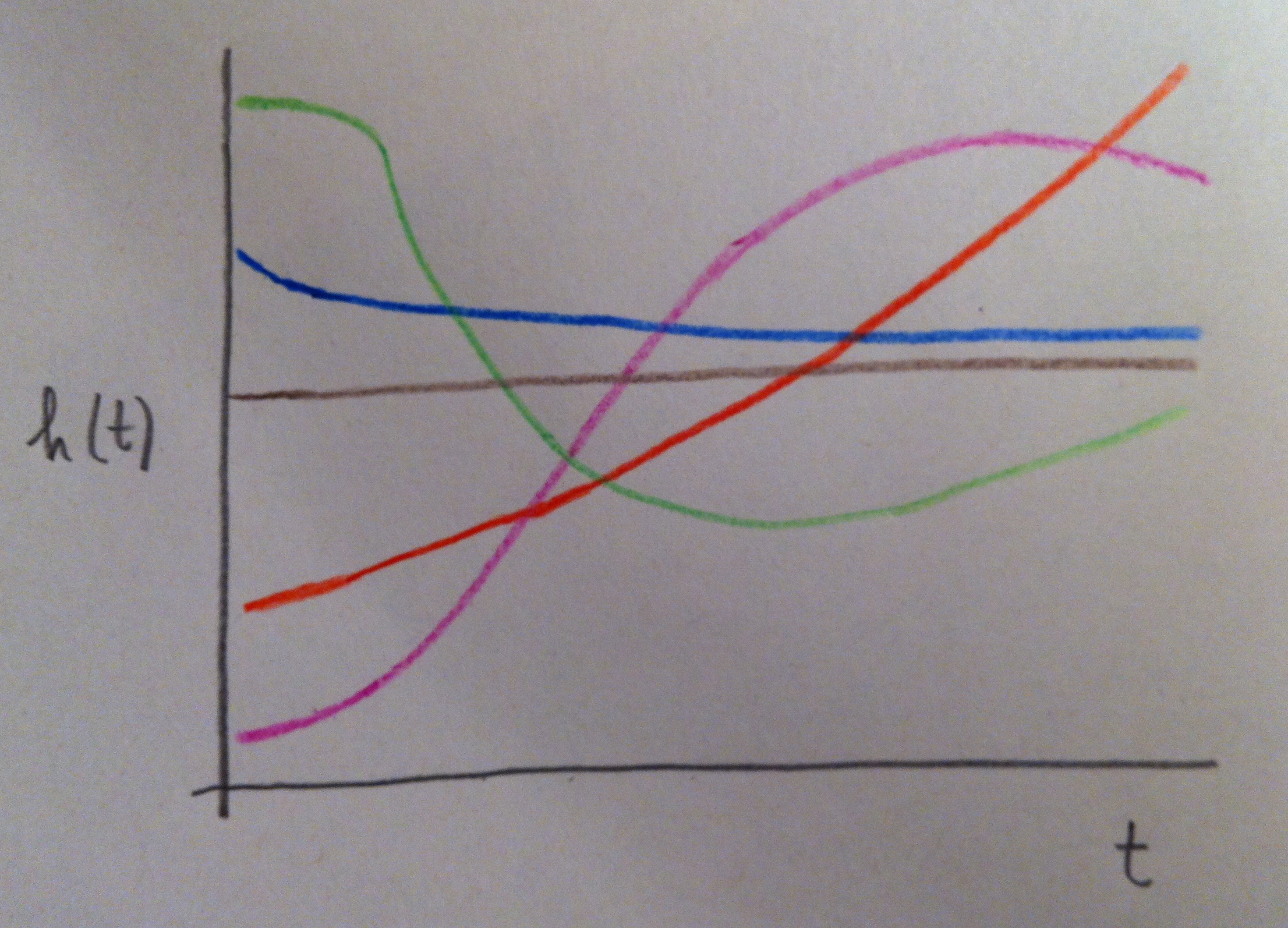
27. La función de riesgo puede ser creciente, decreciente, constante, y cualquier combinación de estas últimas a trozos dentro del dominio t.
28. Por ejemplo, la función exponencial, como modelo paramétrico, cuya función ya hemos visto antes, nos aporta un modelo con función de riesgo constante. Veamos por qué:

29. Observemos las tres curvas de supervivencia asociadas a las tres distintas funciones exponenciales. El hecho de que la función de riesgo sea constante indica que la altura de la curva respecto al área que queda a la derecha del punto temporal en el que estemos es siempre el mismo valor: lambda, que es el parámetro de esta función de distribución.
30. Muchas veces además de la función de riesgo se usa también la función acumulada del riesgo, que es la siguiente función:
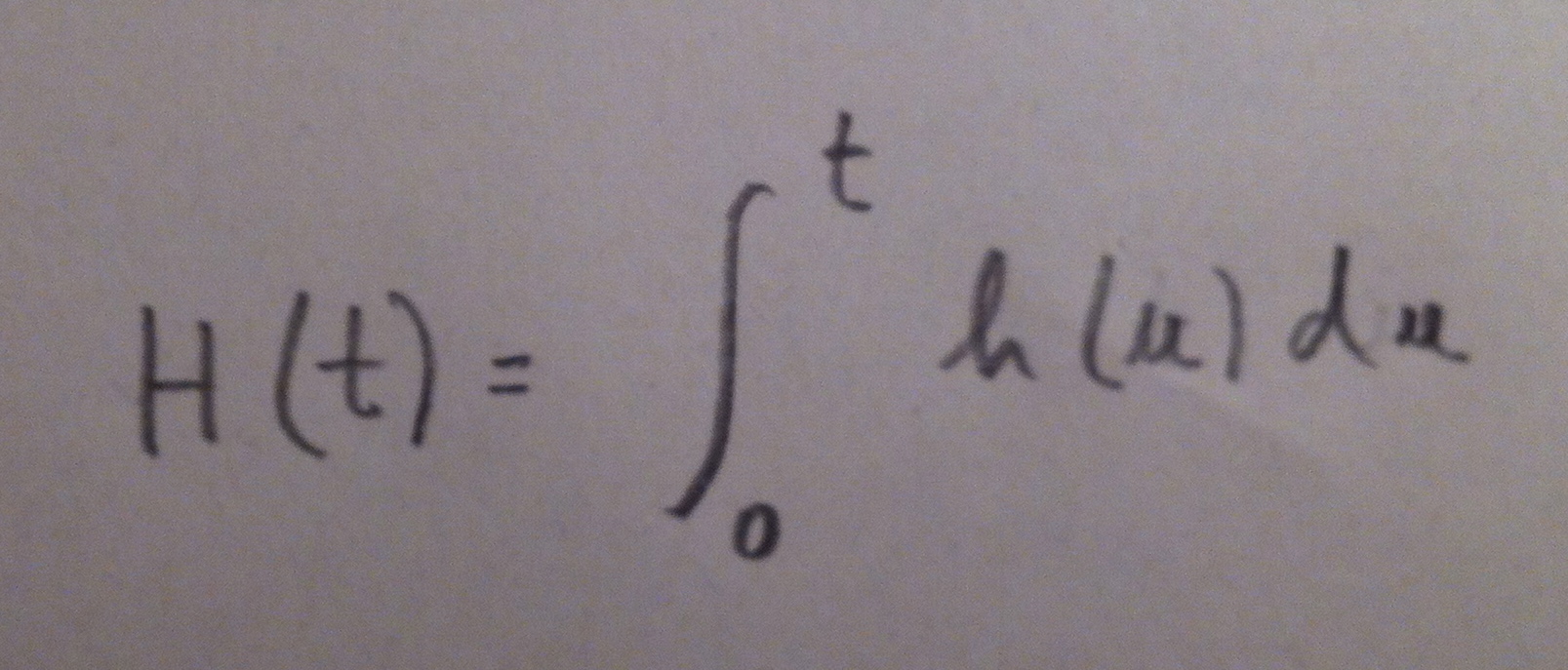
31. Otro concepto importante en Análisis de supervivencia es el de Hazard ratio que es una razón de riesgos. El Hazard ratio no es más que el cociente entre dos funciones de riesgo.
32. El Hazard ratio es una función que toma valores que van de cero a infinito, como la Odds ratio. Cuando toma valores por encima de 1 significa que una de las funciones de riesgo va por encima y si es menor que 1 que las posiciones de las curvas es la contraria. Si toma el valor de 1 las dos curvas están a la misma altura. Se construyen, evidentemente, intervalos de confianza de estos Hazard ratios, para ver si se solapan o no. Se realizan, también, por supuesto, contrastes de hipótesis, donde la Hipótesis nula es que el Hazard ratio es 1.
33. El Hazard ratio, como decimos, es, en realidad, una función, porque la posición relativa de ambas funciones de riesgo puede cambiar a lo largo del tiempo. Sin embargo, en muchos ocasiones, se supone una función constante y, por esto, en muchas ocasiones, el Hazard ratio, se maneja como un número, pero, esencialmente, es una función: la función cociente de las dos funciones de riesgo.
34. El siguiente gráfico aclarará posiblemente la noción de Hazard ratio (HR):
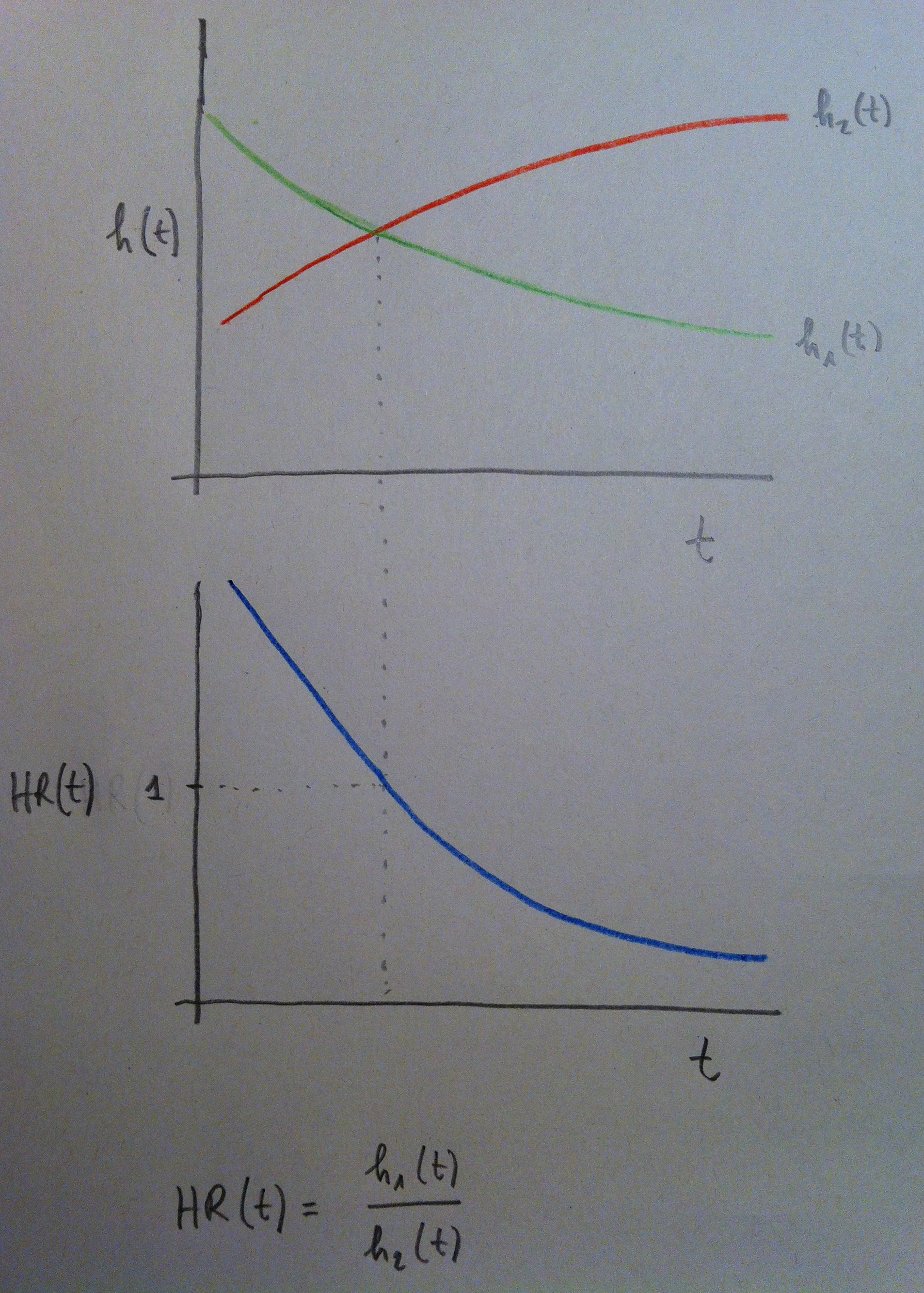
34. Como puede apreciarse el HR es una función del tiempo. Es una relación temporal entre funciones de riesgo. Puede ser constante, pero en general no lo será.
35. Observemos, pues, que en Análisis de supervivencia la finalidad básica es estimar la función de supervivencia, función que en ocasiones se expresa en forma de función de riesgo. Y una vez dibujada esta estimación de la función de supervivencia uno de los objetivos más frecuentes es compararla con otra y valorar si la diferencia muestral que vemos es una diferencia estadísticamente significativa.

Pingback: Herramientas estadísticas en Medicina (Una hoja de ruta) | LA ESTADÍSTICA: UNA ORQUESTA HECHA INSTRUMENTO
Hola, muy interesatante este tema. Con respecto a la estimacion de Kaplan Meier tengo dos preguntas:
1. Estaria interesante que hablara de la media y de los intervalos de confianza que se pueden extraer de esta grafica, datos muy importantes en el analisis de supervivencia.
2. He visto que en algunos calculos, la funcion de supervivencia S(t) no alcanca la mediana, p(50), obteniendose una media No Evaluable, pero si un valor para el limite inferior de confianza. Con una grafica representando las bandas de confianza, supongo que podria explicar bien ese caso.
Gracias, y de nuevo, enhorabuena.
Muy interesante muestra de manera entendible la tematica.
Da una vision panorámica de la técnica.
Magnifica explicación.Muy Util. Gracias al autor.
Pingback: ¿Qué es Informática Médica? – informatica médica y bioestadistica
Muchísimas gracias por el contenido
Me alegro mucho, Pamela