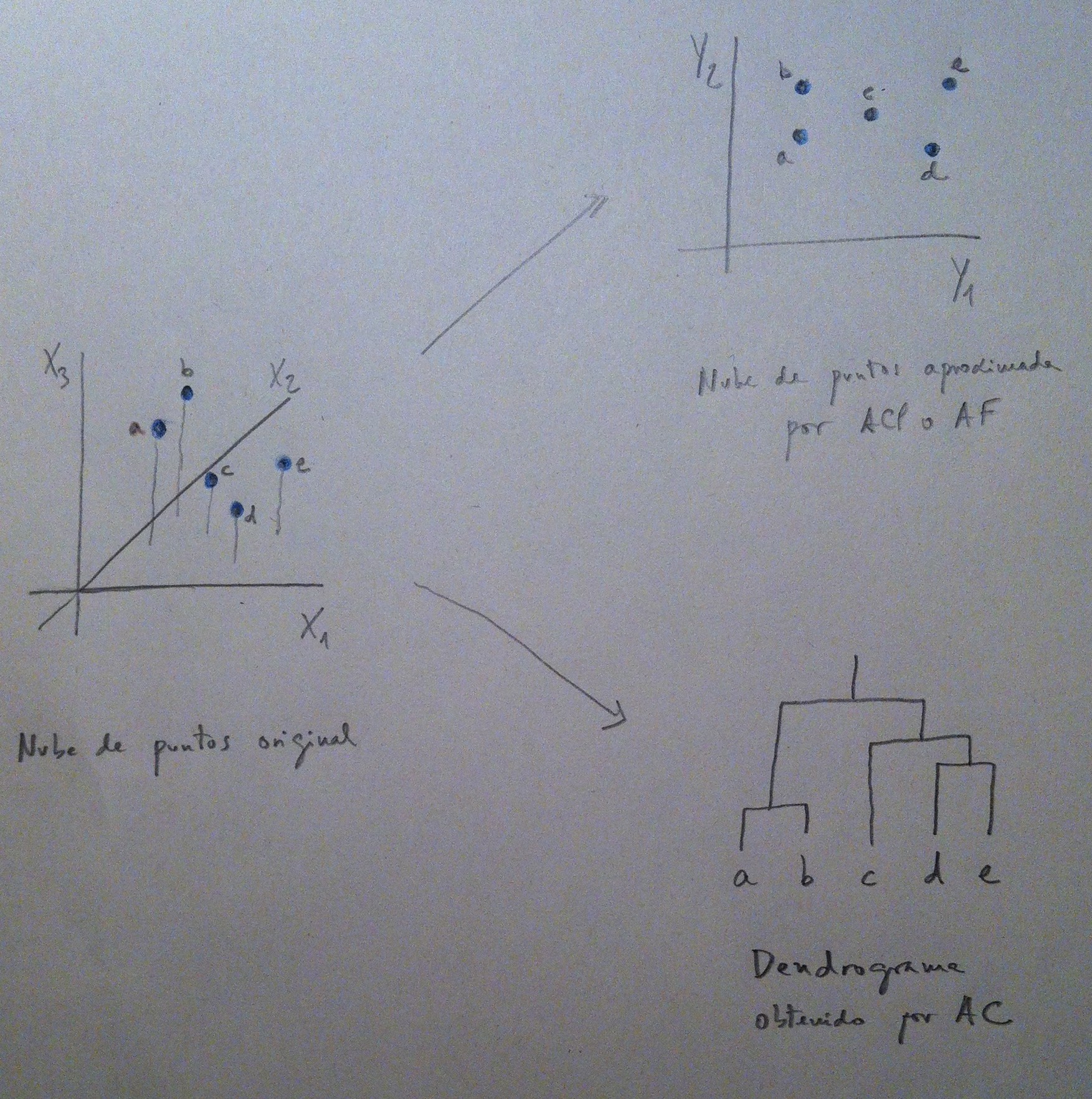
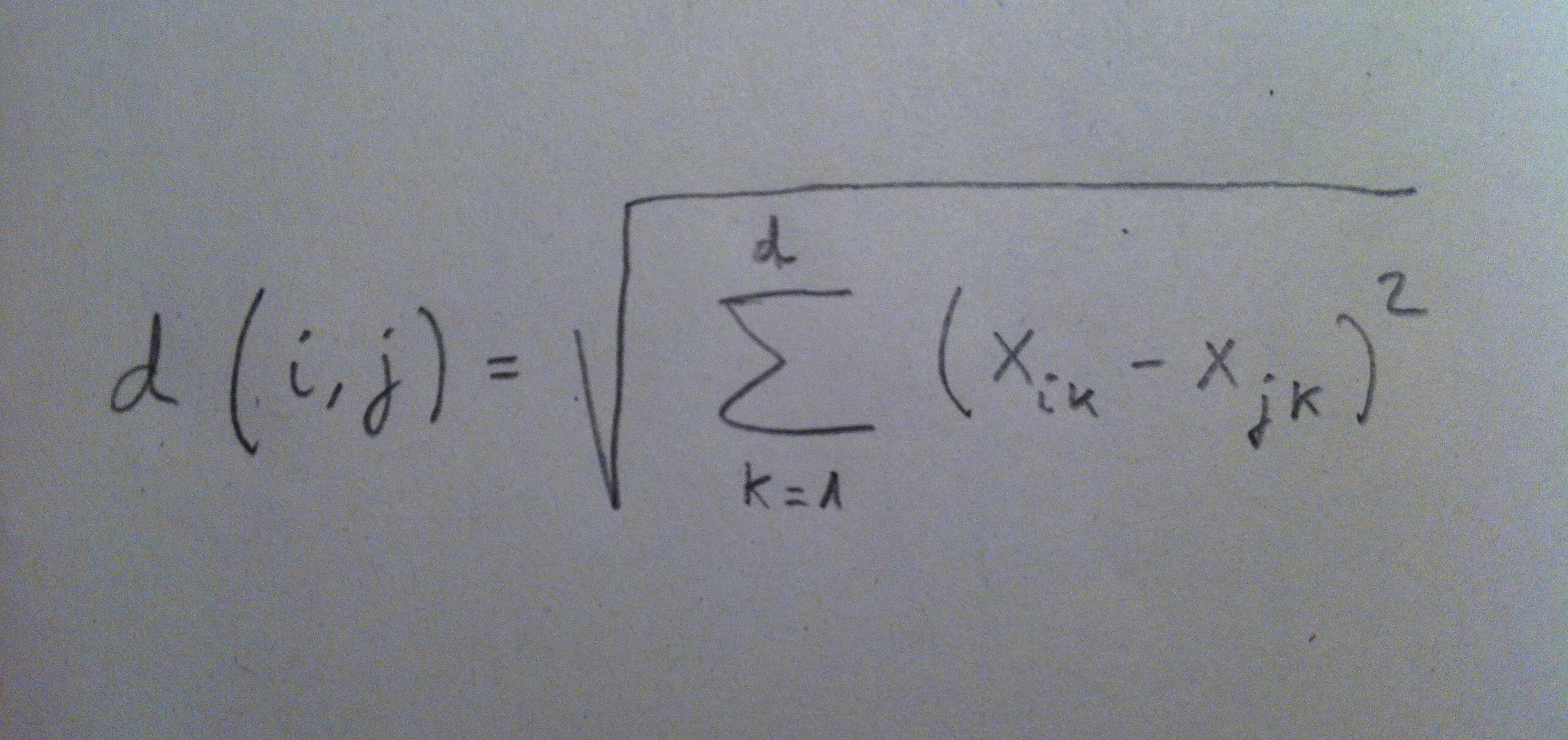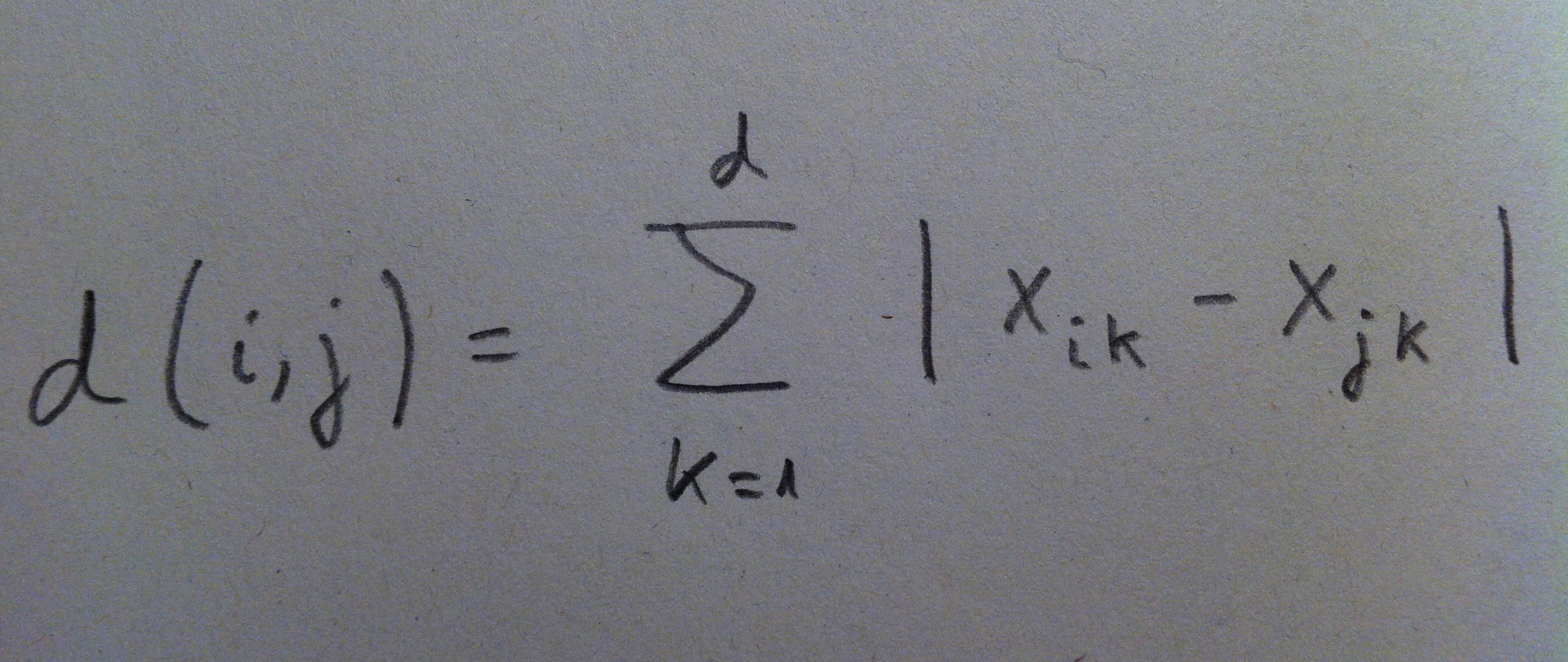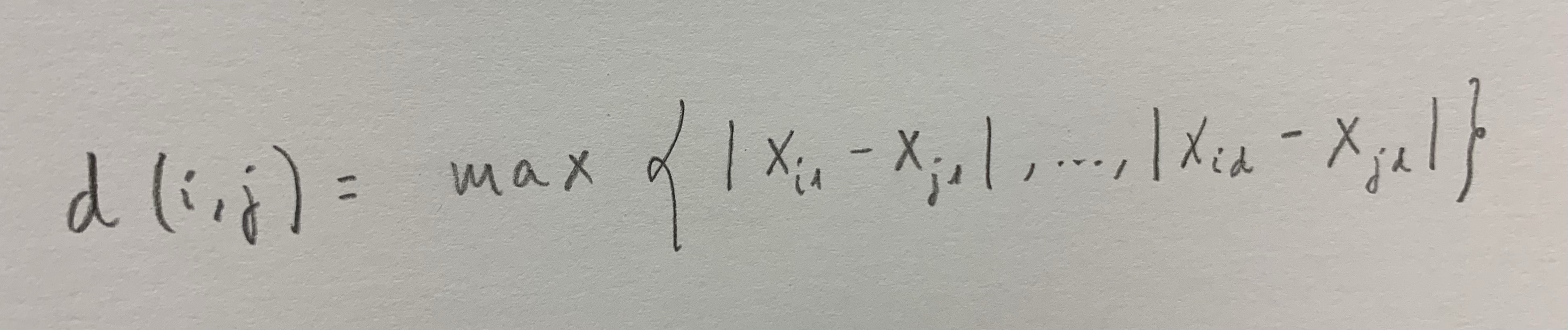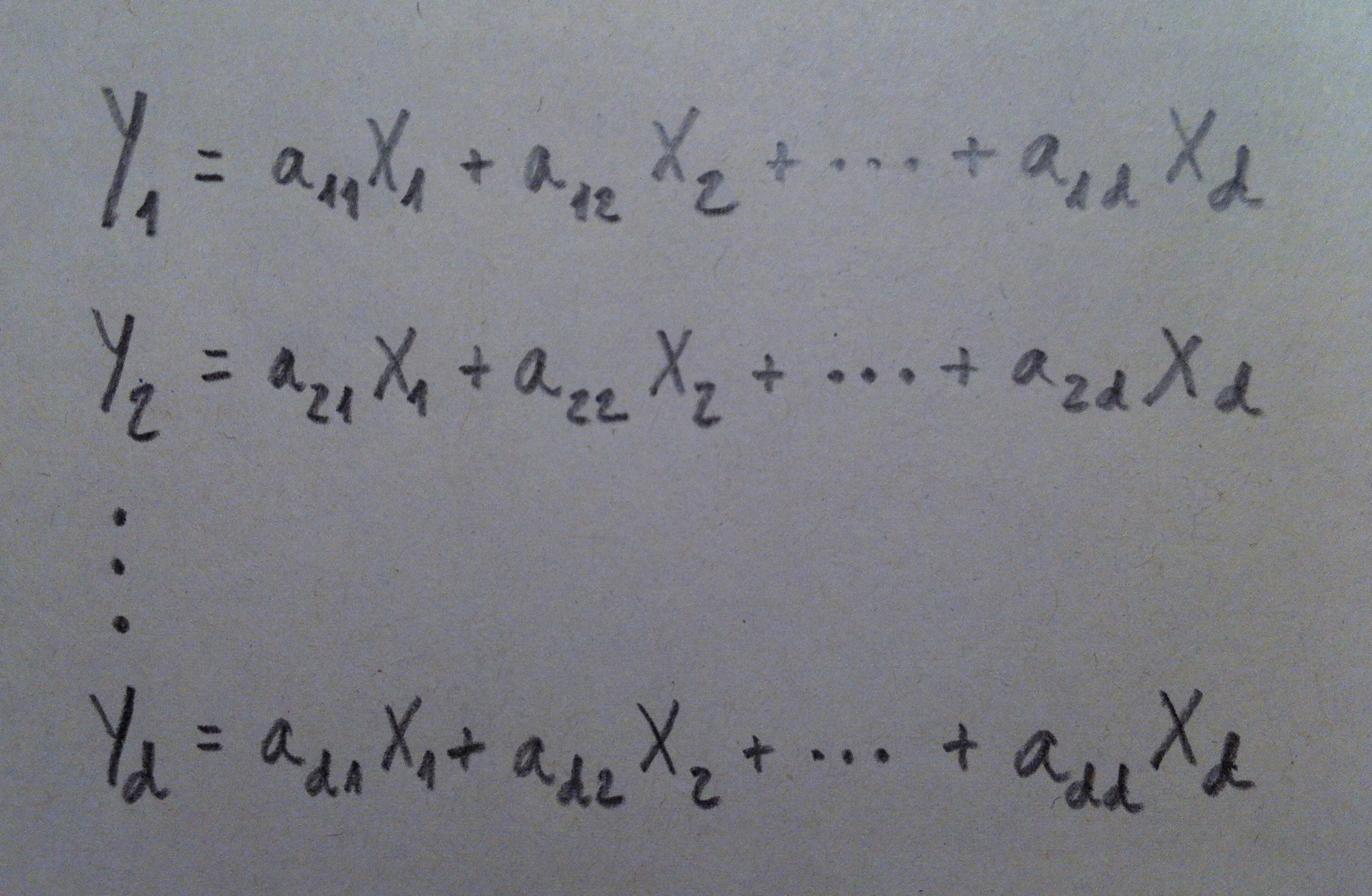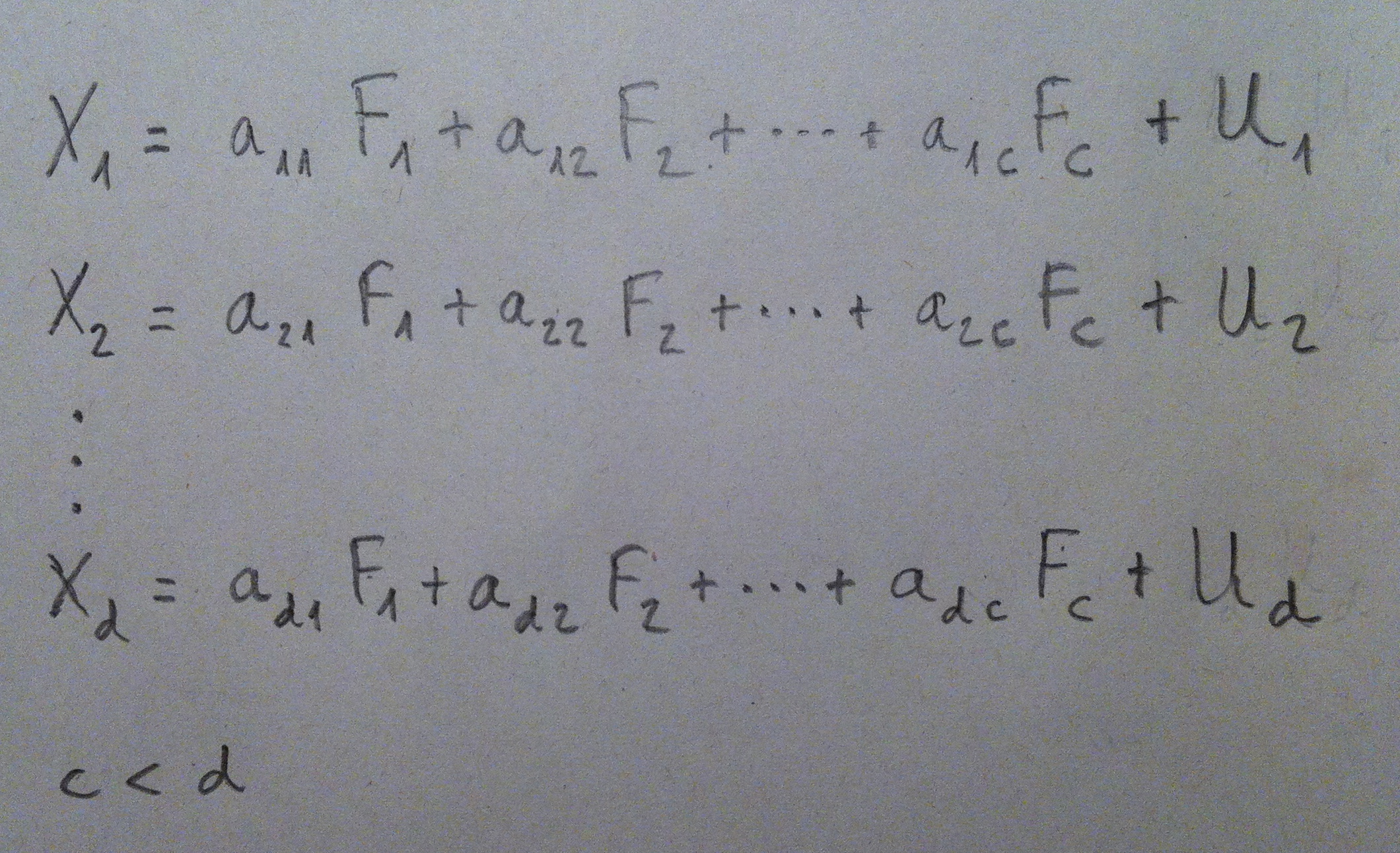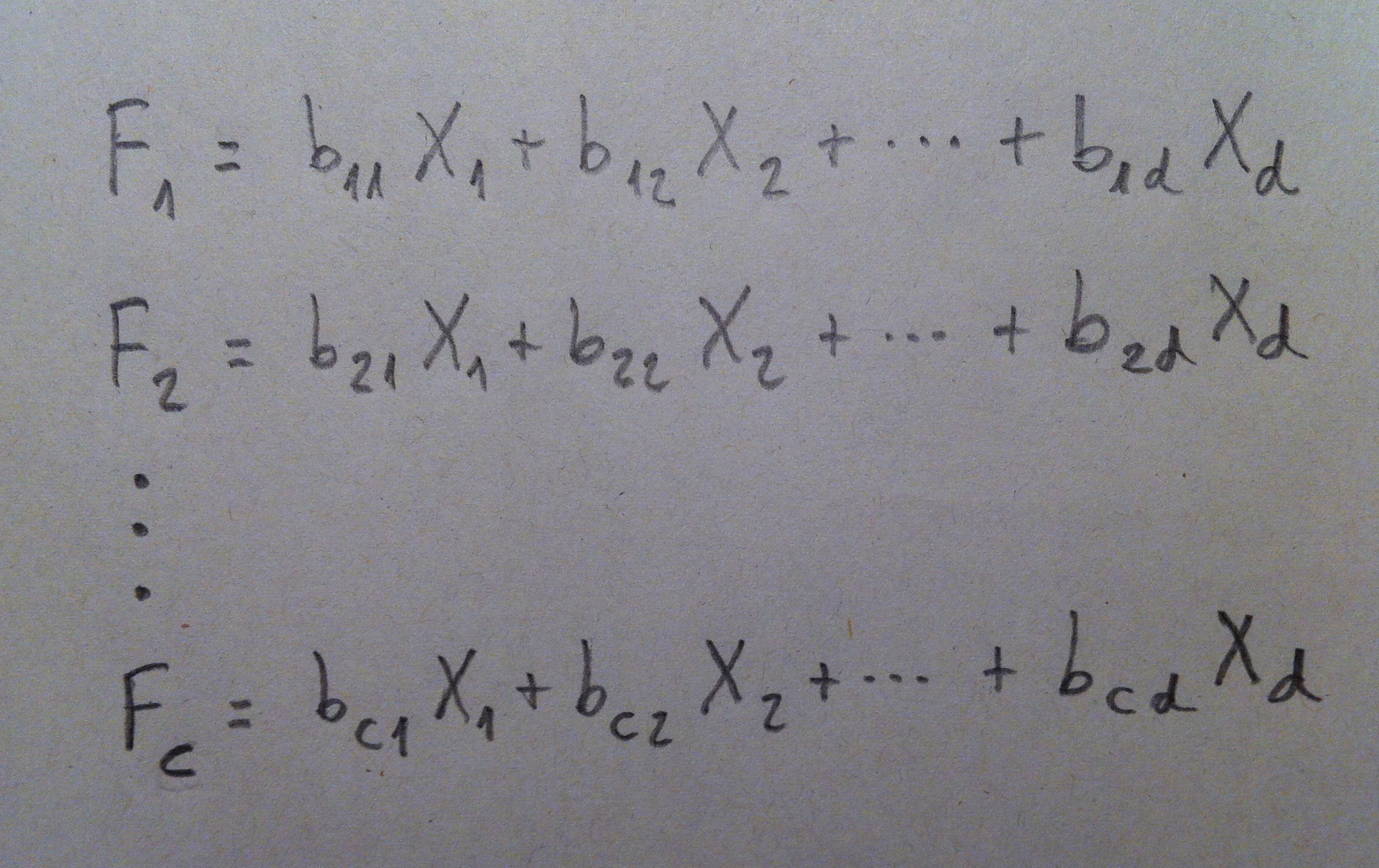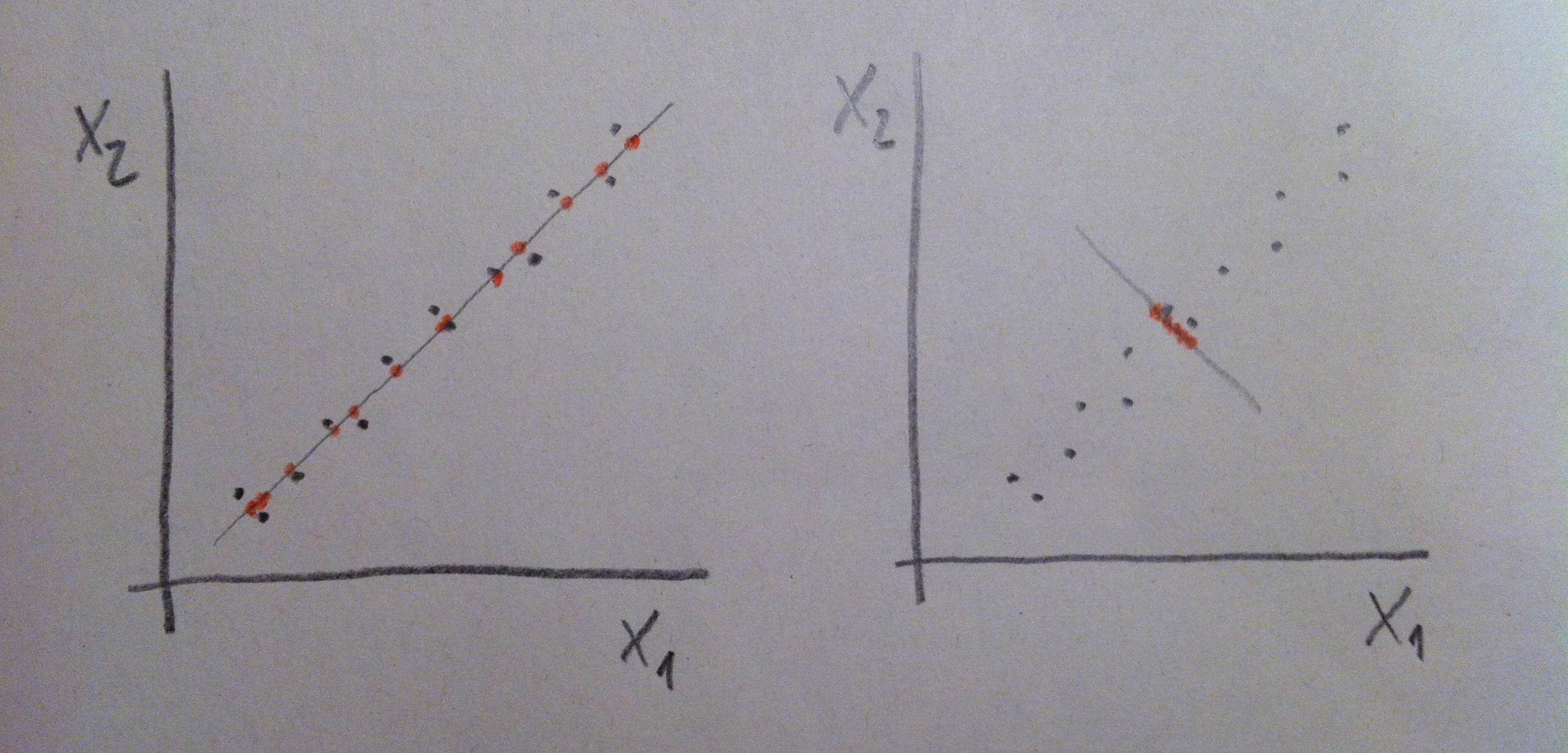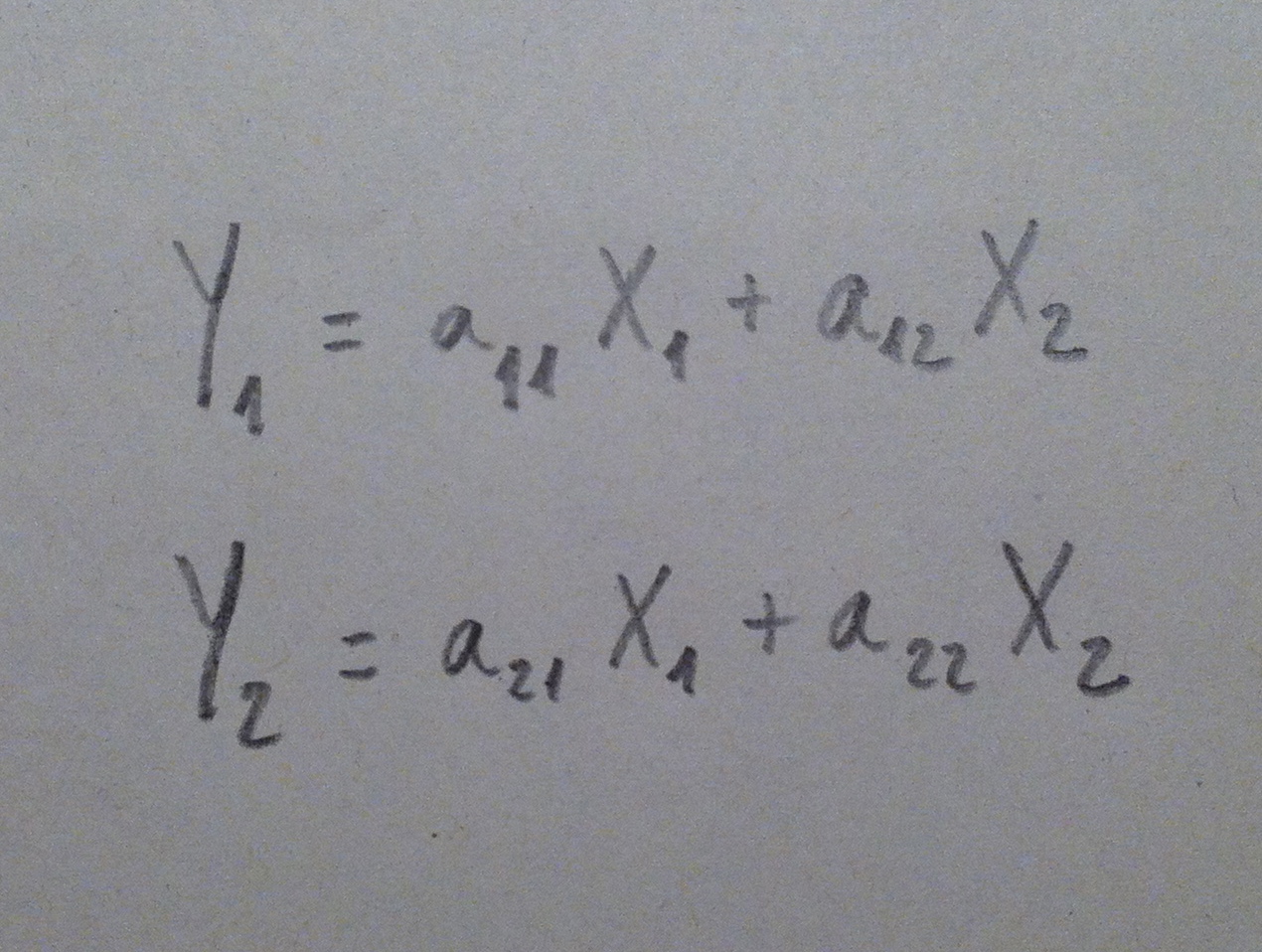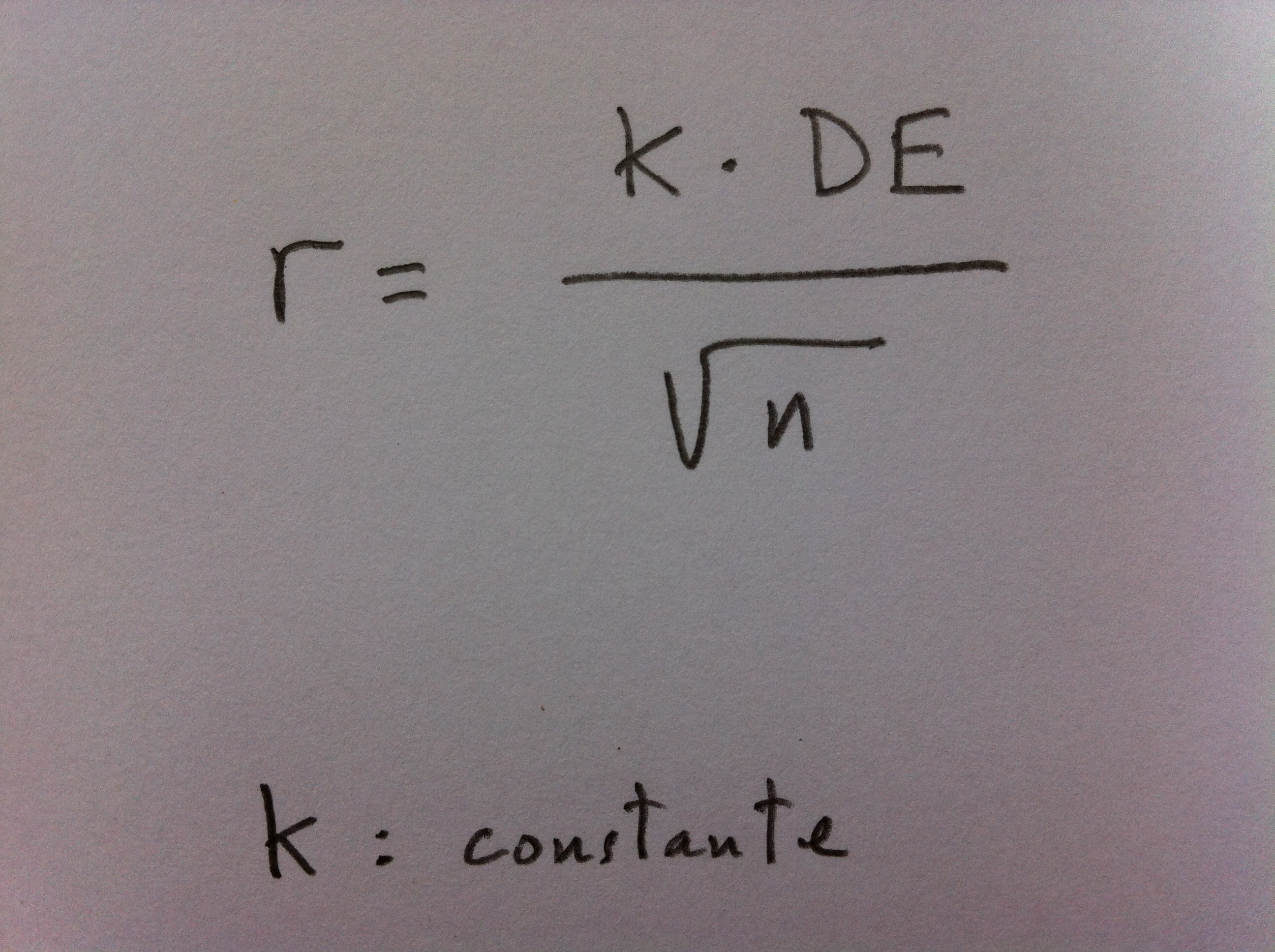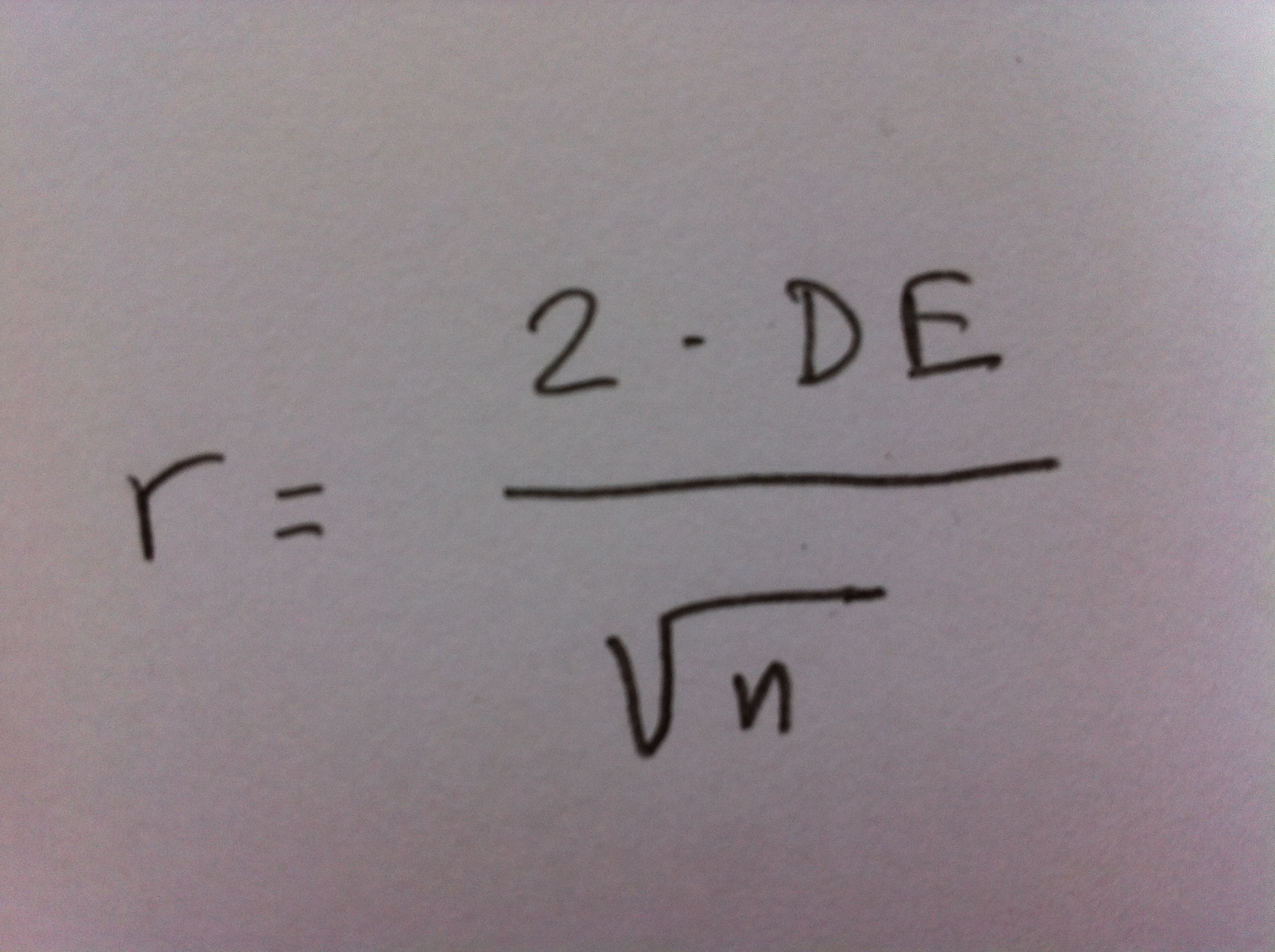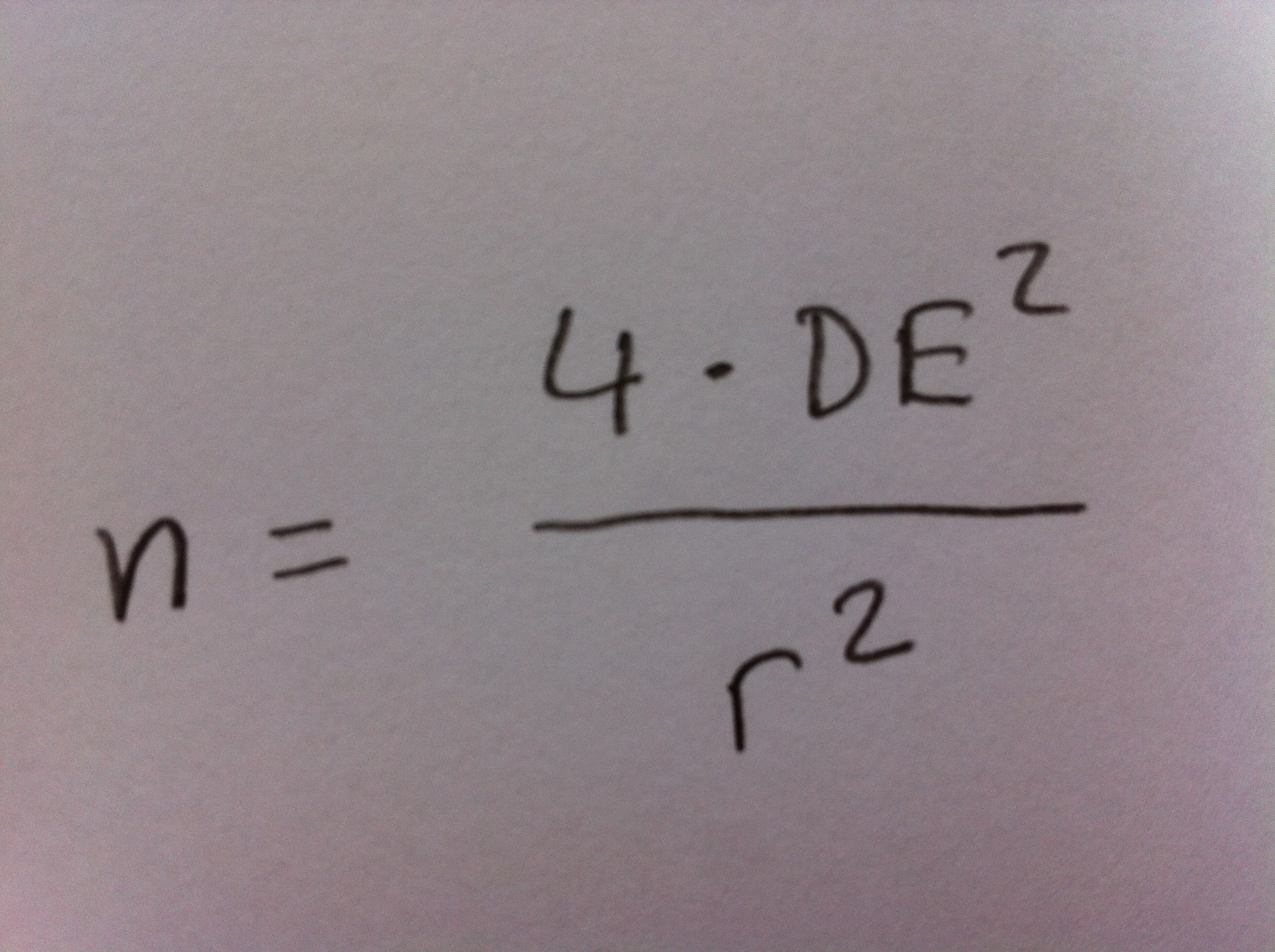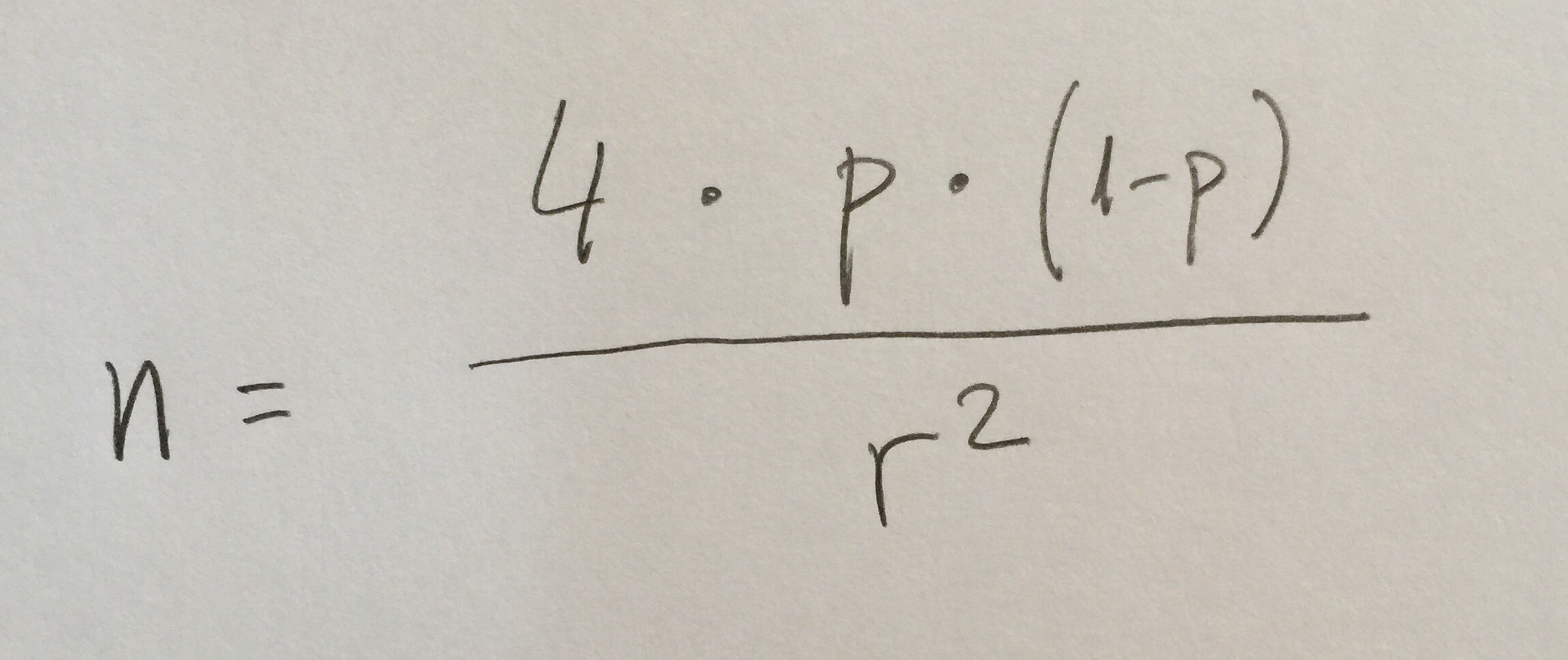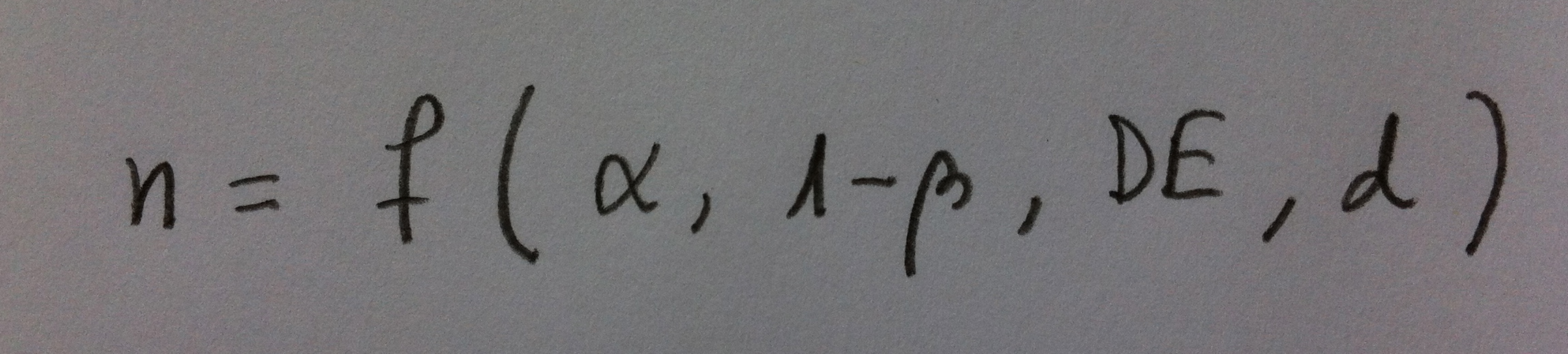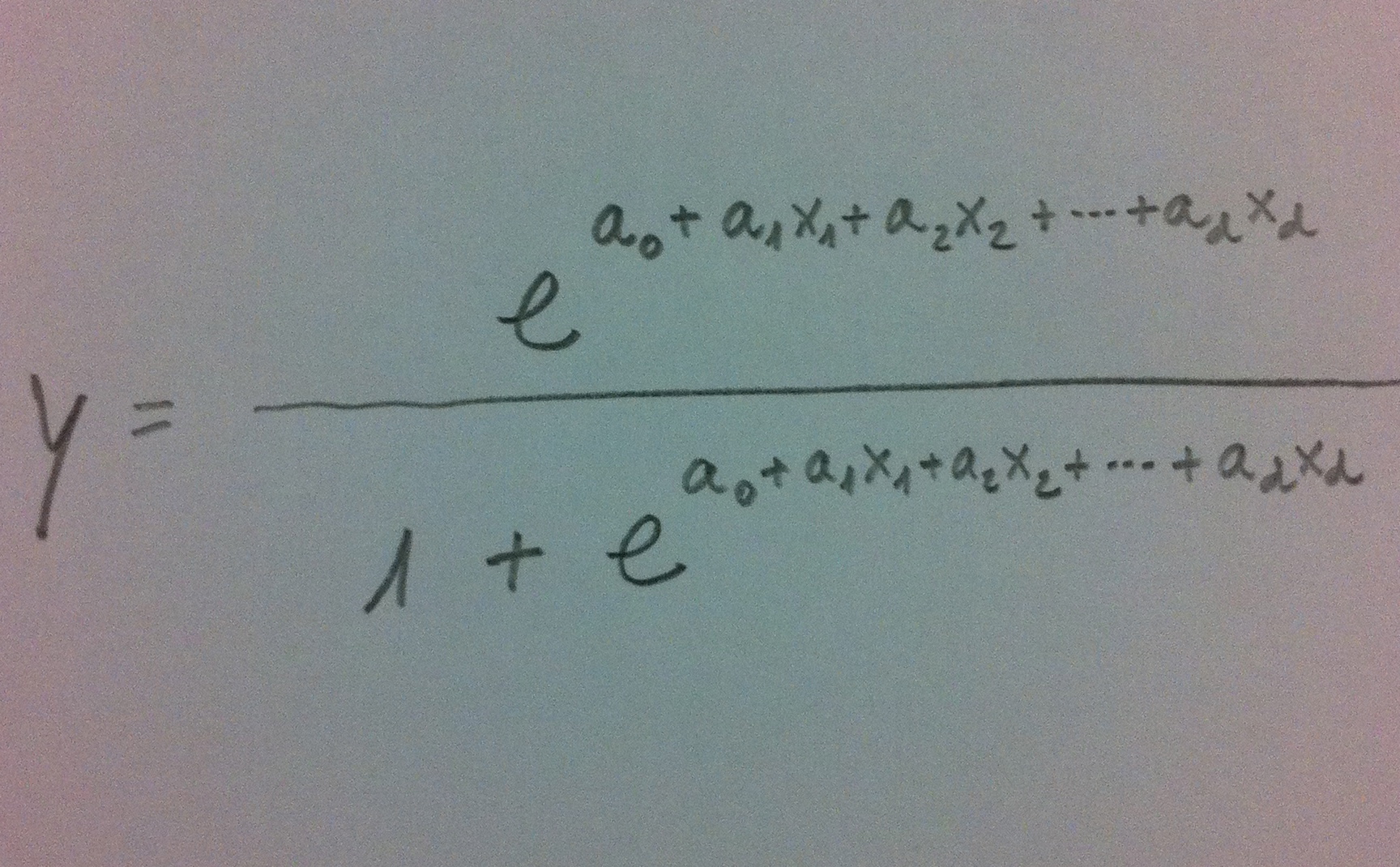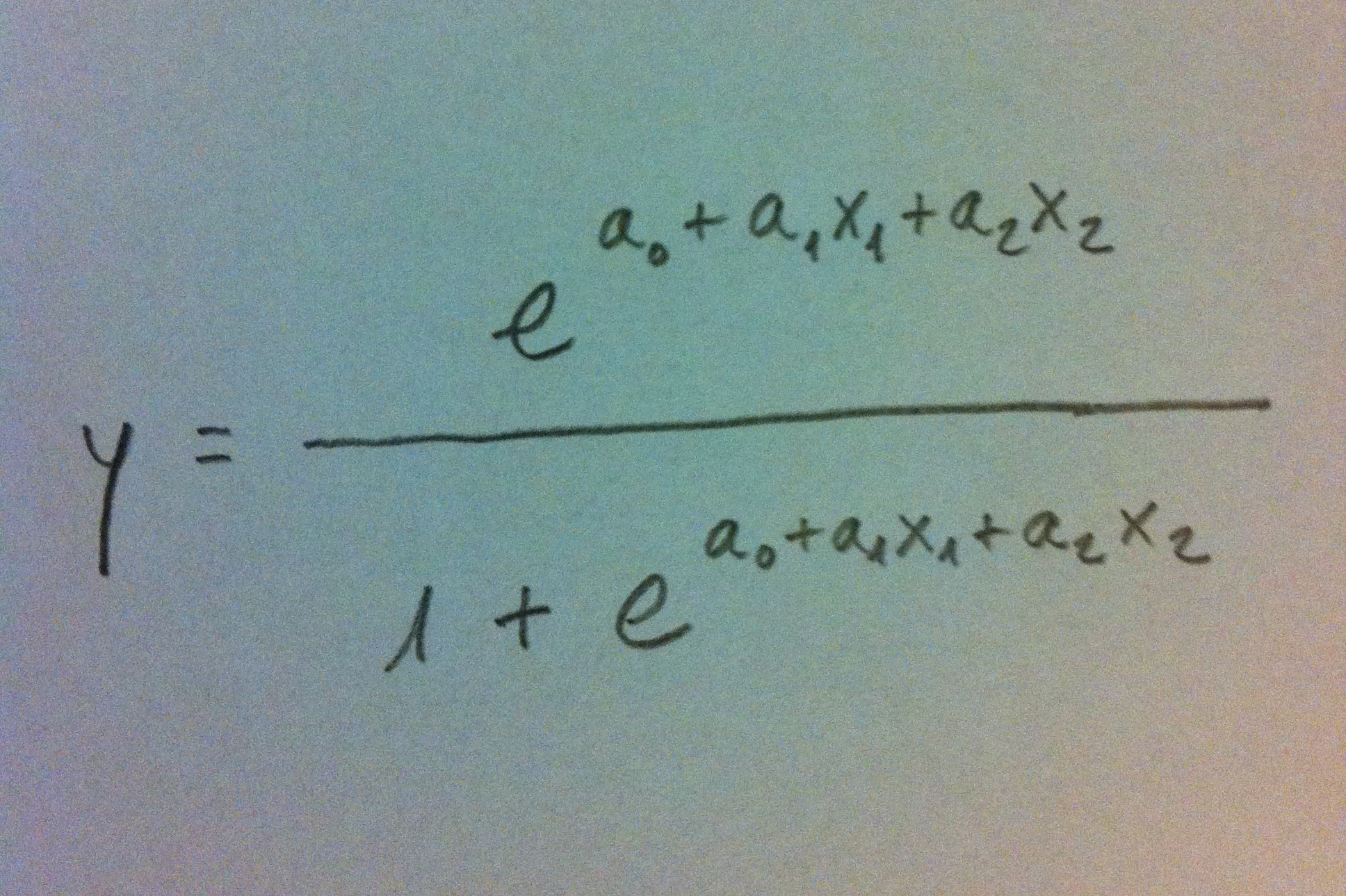1. El Análisis discriminante es una técnica inferencial. Es una técnica típicamente multivariante porque suele usarse en contextos donde tenemos varias variables, pero evidentemente puede aplicarse con pocas variables, incluso con una sola variable, pero no es lo habitual.
2. Una característica esencial de esta técnica es que tenemos previamente definidas dos o más poblaciones; o sea, tenemos dos o más muestras de esas poblaciones con una serie de individuos de cada una de ellas de los que tenemos medidas una serie de variables.
3. Su finalidad básica es preparar esa información, seleccionarla, trabajarla, con una finalidad clasificadora. Futuros individuos, a los que les podremos medir esas variables, deberemos clasificarlos como miembros de alguna de esas poblaciones.
4. Evidentemente partimos del supuesto de que esos nuevos individuos a clasificar pertenecen a una de esas poblaciones.
5. El Análisis discriminante tiene un nombre muy apropiado para lo que es su procedimiento. Porque lo que hace es iniciar, a partir de toda la información de que se dispone sobre las poblaciones y las variables, un proceso de discriminación, un proceso de separación lo mayor posible de esas poblaciones.
6. Por lo tanto, a partir de un conjunto de individuos que sabemos ciertamente a qué población pertenecen cada uno de ellos y a partir de los valores de todas las variables que disponemos mediante el Análisis discriminante tratamos de buscar qué combinaciones de esas variables nos permitirán discriminar lo más posible entre los grupos que tenemos.
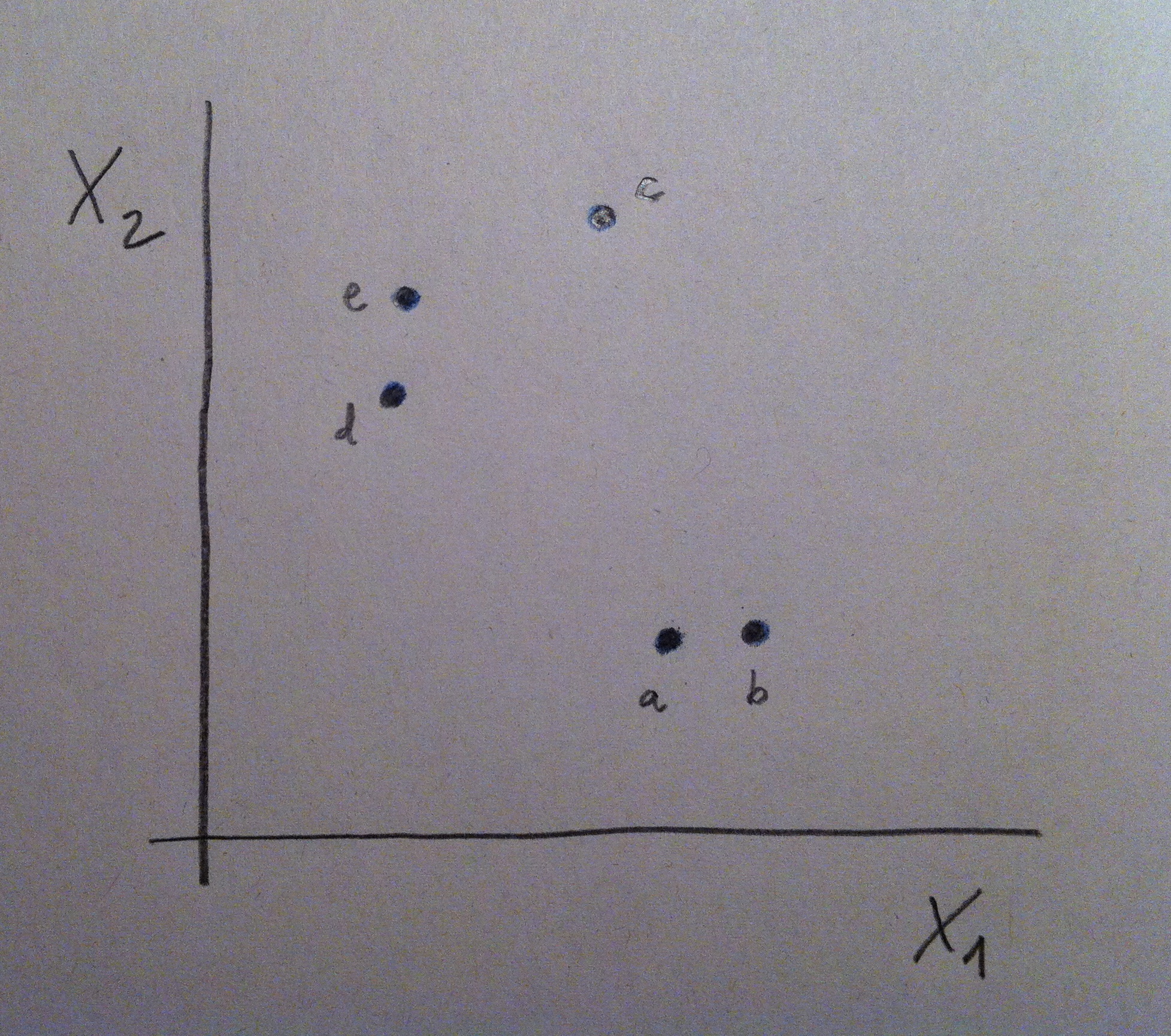
7. Pongamos un ejemplo previo sencillo que puede ayudarnos a clarificar el camino de la explicación de esta técnica: Supongamos que queremos encontrar variables que nos permitan clasificar a una persona entre hombre o mujer teniendo únicamente la información de la medida de esa variable.
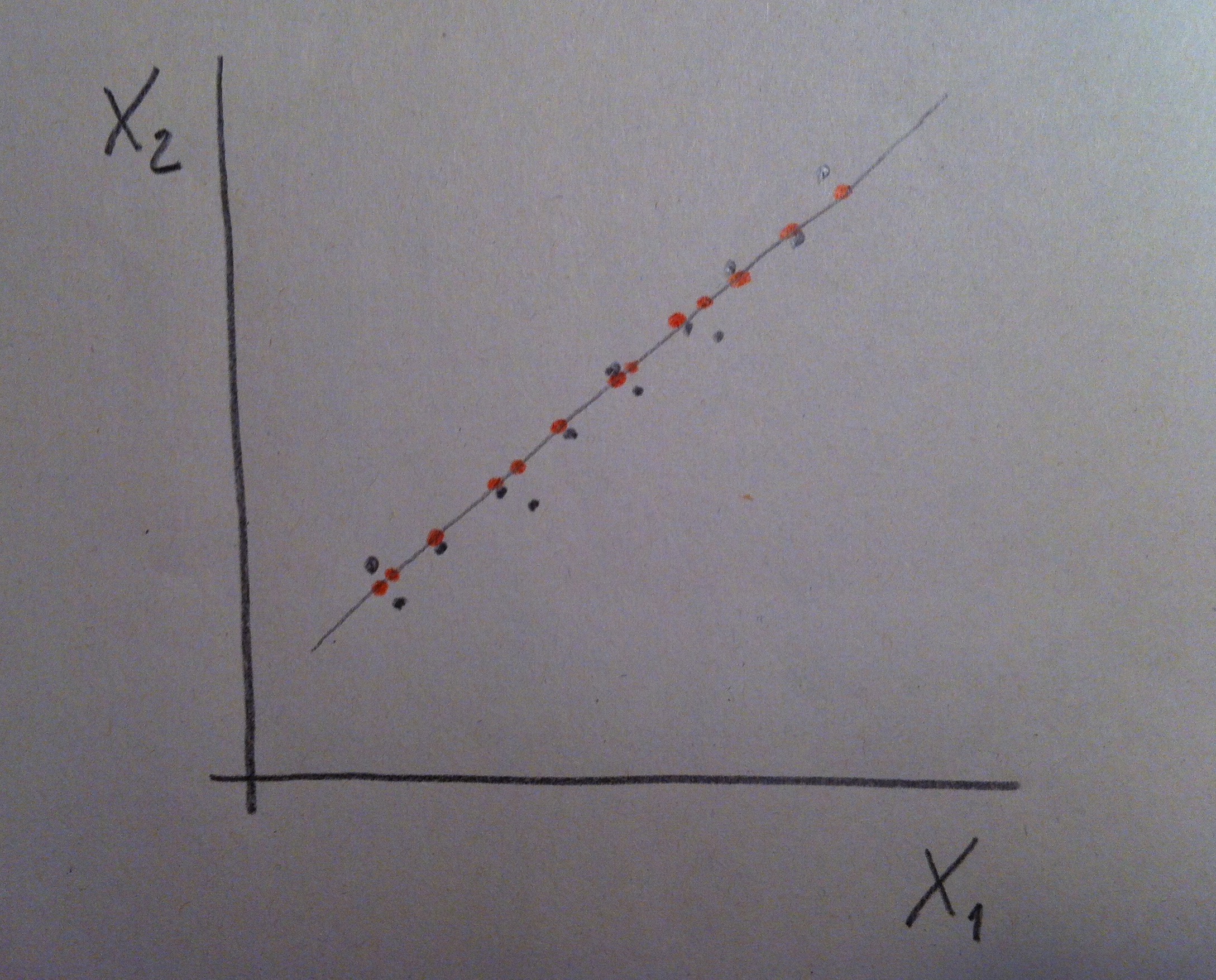
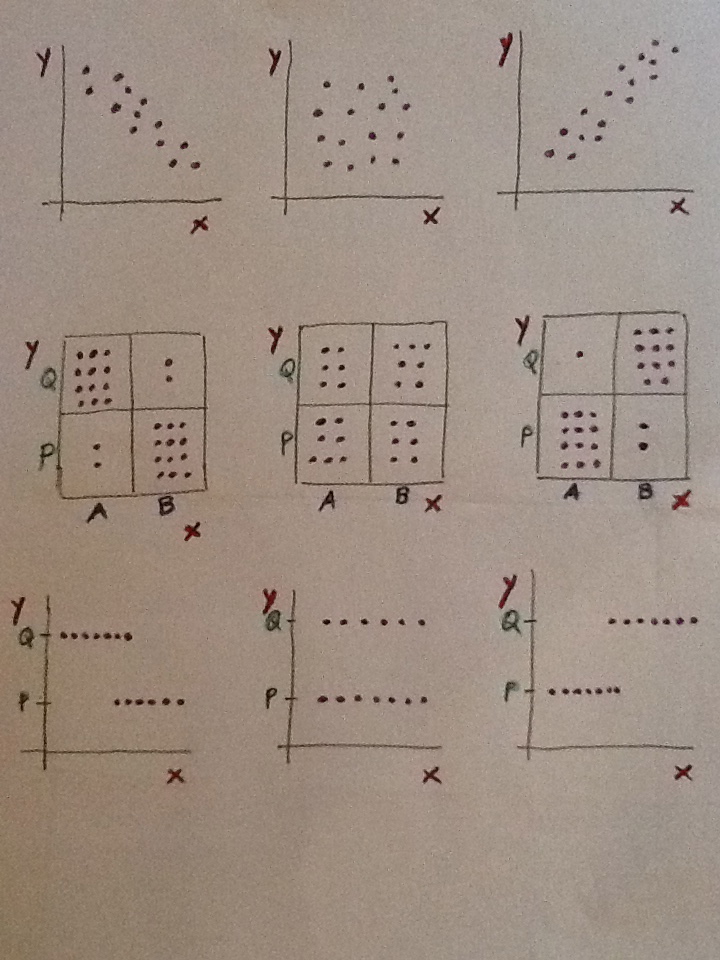
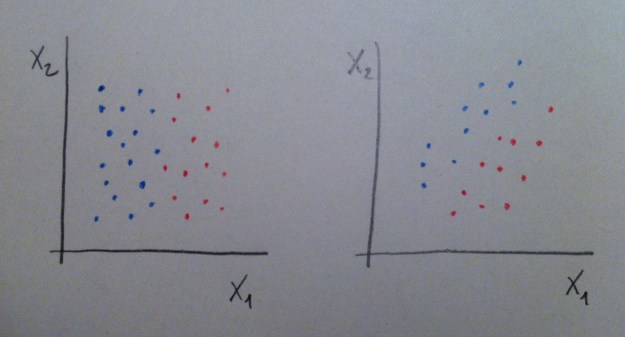
8. La variable edad no discrimina entre hombres y mujeres, no separa bien esos dos grupos. La variable altura ya discrimina más. La variable pie que calza discrimina más aún. Veámoslo en unos datos posibles: En rojo tendríamos una muestra de mujeres y en azul una de hombres:

9. Elegir la edad para pronosticar el sexo nos llevaría a mucho error. La mitad de las veces nos equivocaríamos. Elegiendo la altura ya cometeríamos menos errores porque las poblaciones están más discriminadas, más separadas, respecto a esta variable. Eligiendo el pie que calza cometeríamos menos errores aún porque de las tres variable es la que discrimina mejor, es la que separa mejor a los dos grupos, como puede apreciarse en este gráfico. Esto es así en la realidad: en mujeres y hombres con la misma altura los hombres tienen el pie más grande que las mujeres.
10. Si se entiende bien esta idea simple se entenderá perfectamente lo que persigue el Análisis discriminante. Porque esto es lo que hace la técnica: entre las variables de que disponemos y con las muestras que tenemos de las poblaciones en estudio debemos buscar qué variables y qué combinación de ellas es la que consigue separar más, discriminar más, esos grupos. La finalidad es usarlo como mecanismo para clasificar a un individuo futuro del que tendremos los valores que tiene de esas variables pero del que no sabremos a qué población pertenece.
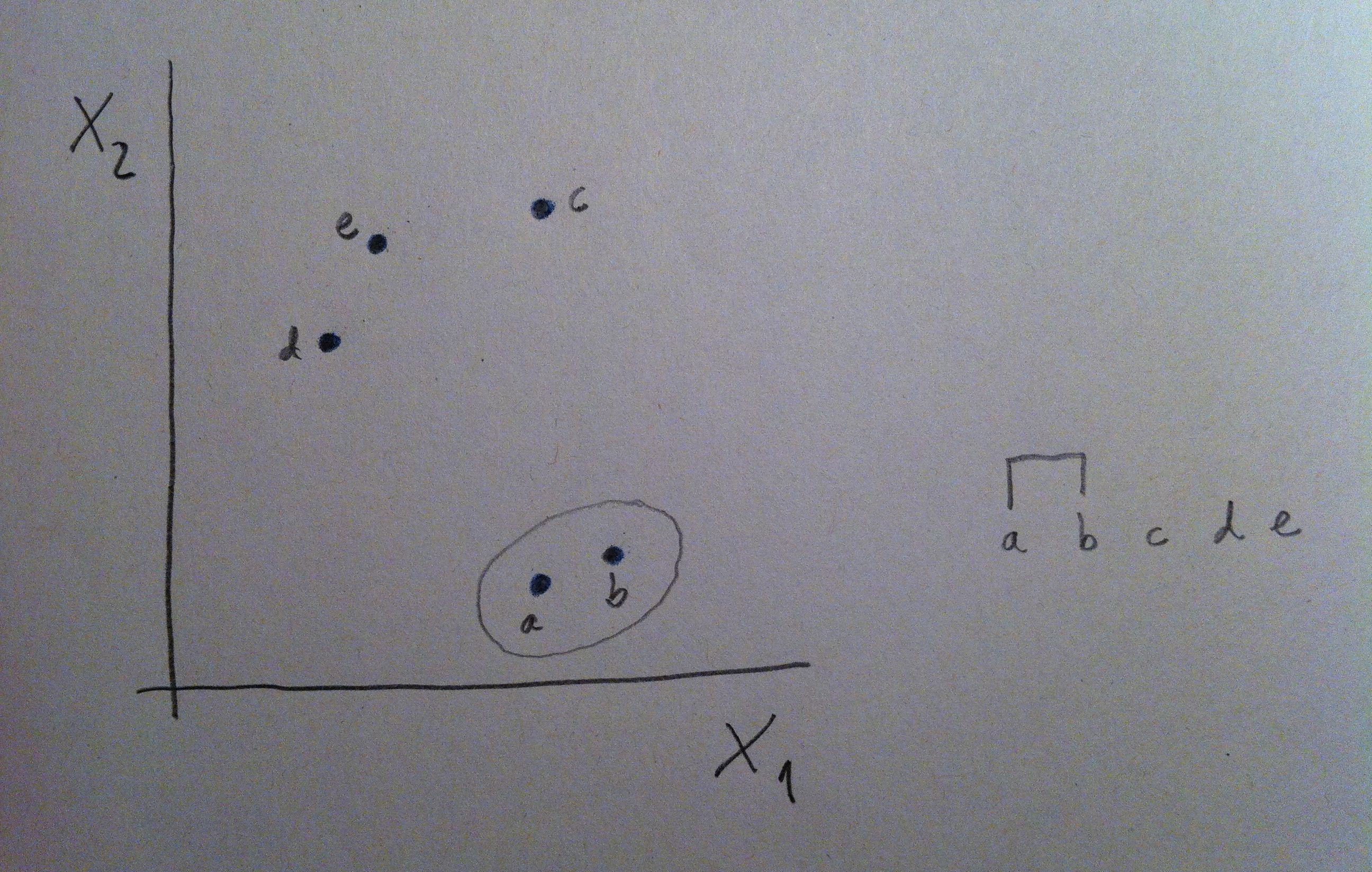
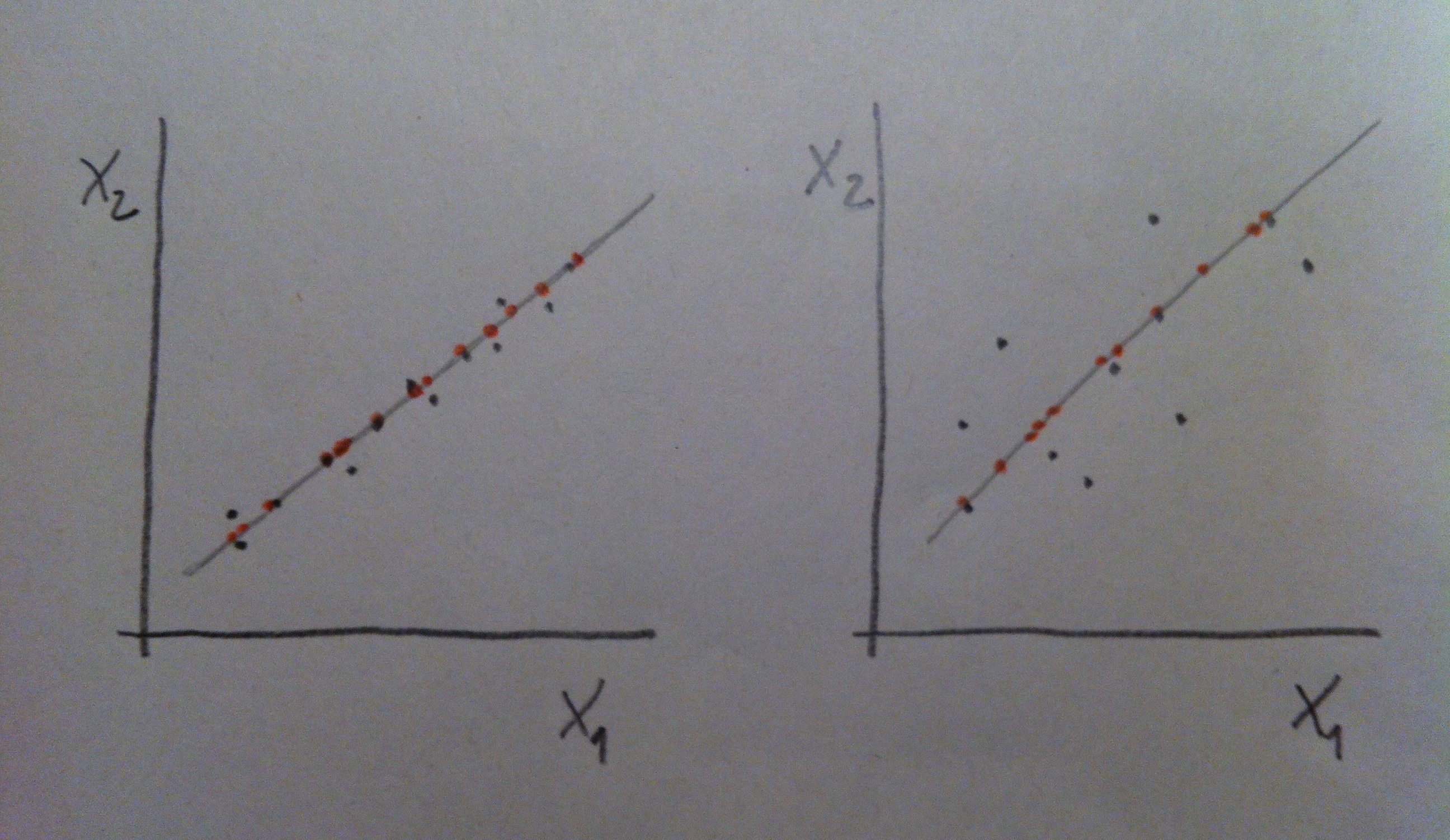
11. A veces si tenemos más de una variable con una de esas variables nos bastará para conseguir una buena discriminación, pero a veces ninguna de ellas individualmente nos irá bien y sí, en cambio, una combinación de ellas. Miremos el siguiente gráfico:
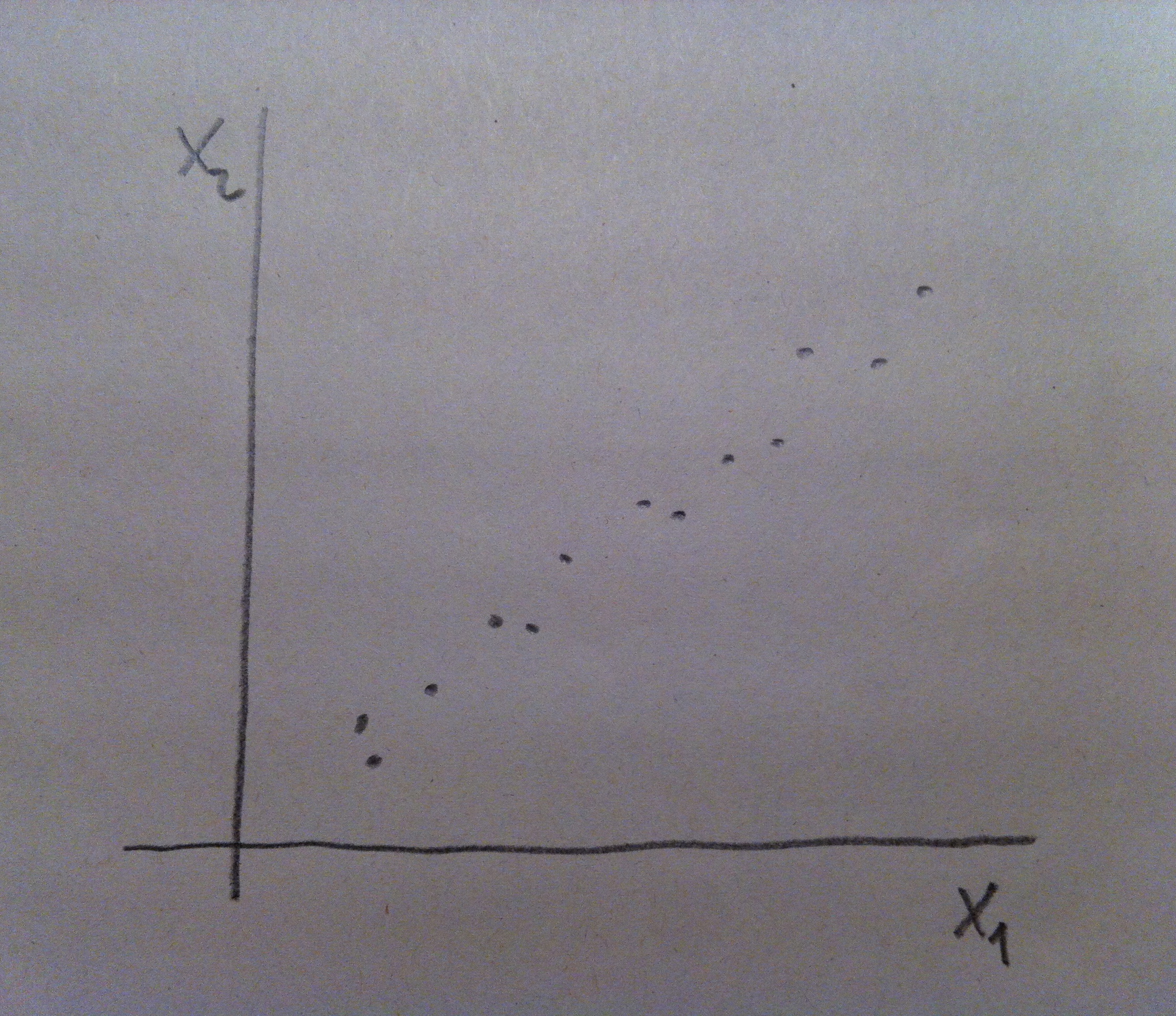
12. Puede observarse que en el caso de la izquierda la variable X1 es muy buena discriminadora de las dos poblaciones: la roja y la azul. Desde X1 las dos poblaciones se visualizan bien separadas. Tener el valor de X1 de un individuo que no sabemos si pertenece a la población roja o a la azul nos permitiría, con cierta tranquilidad, clasificarlo de una u otra población y parece que la probabilidad de error sería bajo. En cambio la X2 no discrimina, no nos separa las dos poblaciones. Esa variable es, pues, un mal referente para clasificar entre esas dos poblaciones.
13. En el caso de la derecha del gráfico anterior la situación nos permite decir que ni X1 ni X2 son buenos discriminadores por separado. Si miramos la nube de puntos tanto desde X1 como desde X2 las dos poblaciones se ven mezcladas, no están discriminadas. Pero si hacemos un giro de los ejes, si hacemos una combinación de esas dos variables, podremos discriminar bien. Miremos el giro que hacemos en el gráfico siguiente:
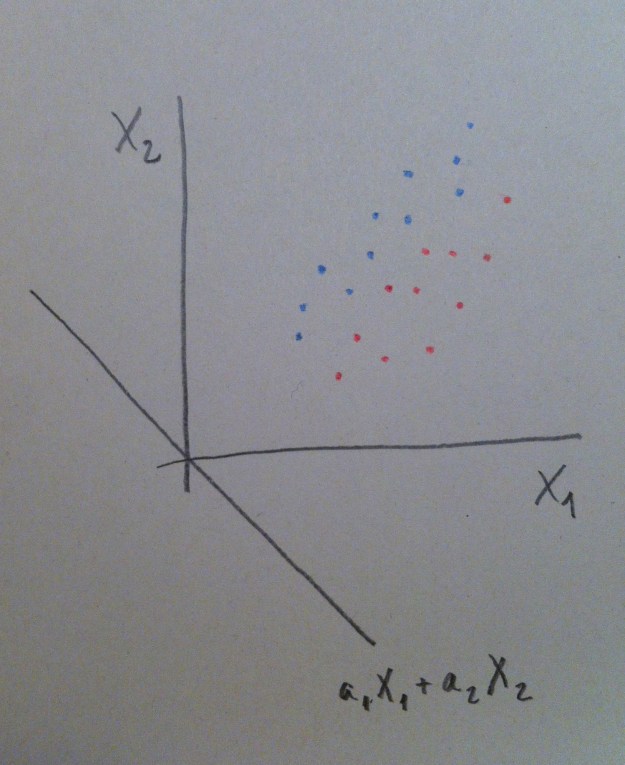
14. Ahora la variable a1X1+a2X2 sí que discrimina bien. Ver la nube de puntos desde este nuevo eje nos permite visualizar las dos poblaciones bien separadas. Por lo tanto, el valor que tengamos de un nuevo individuo de esta combinación de las dos variables originales nos permitirá establecer un criterio de clasificación con pocas probabilidades de error. Y no olvidemos que hacer este giro va asociado de una fórmula como ésta, una fórmula que combina de una forma peculiar y lineal esos dos ejes originales.
15. De hecho, lo que acabamos de hacer no nos debe extrañar, lo hemos hecho ya en el Análisis de componentes principales y en el Análisis factorial. Hemos hecho combinaciones de las variables originales, hemos hecho giros de los ejes, hemos creado componentes, factores. Ahora, en el contexto del Análisis discriminante estas combinaciones de las variables originales las llamamos funciones discriminantes. Pero, en abstracto, es como una componente o un factor: una combinación lineal de las variables originales.
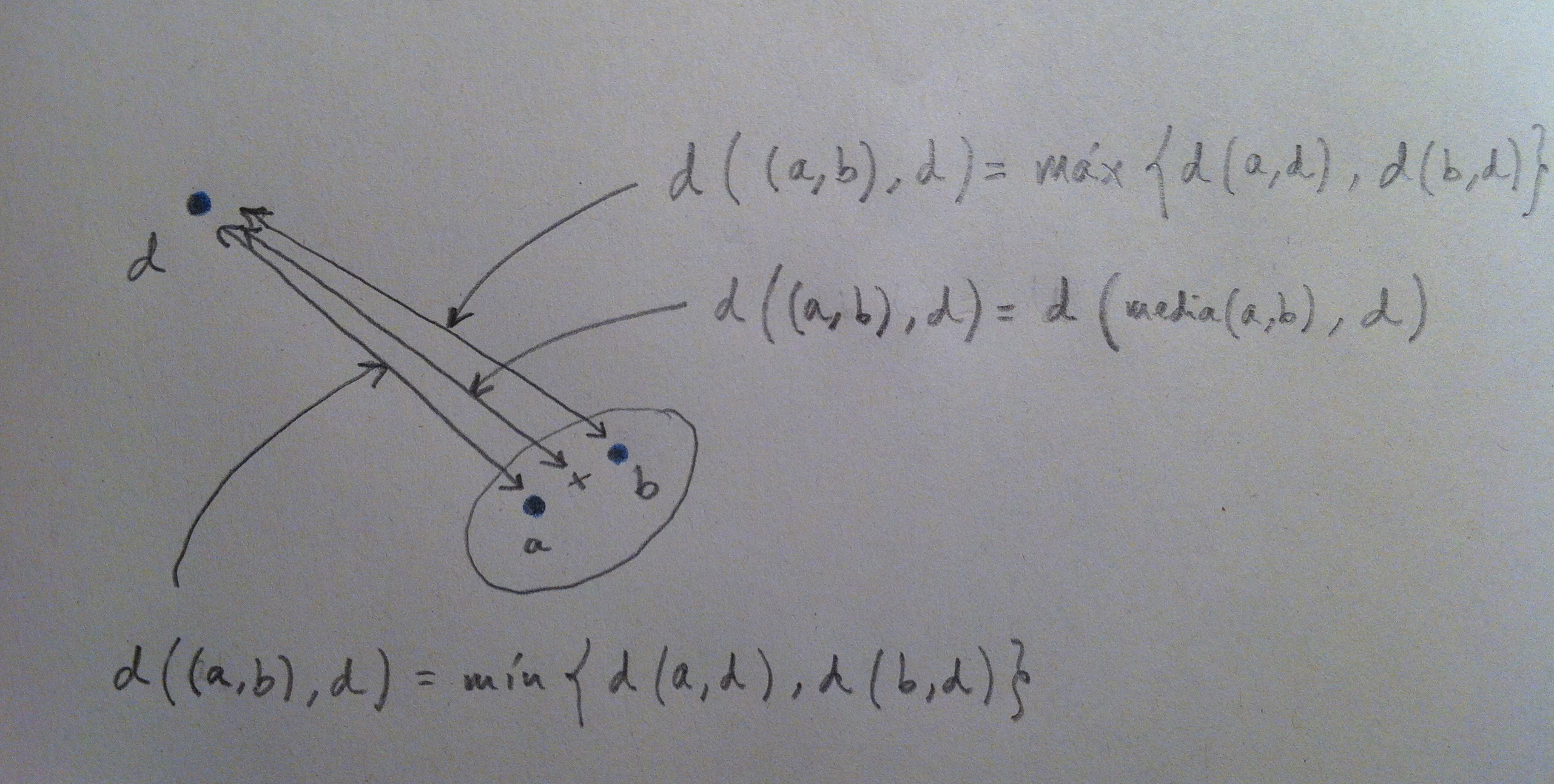
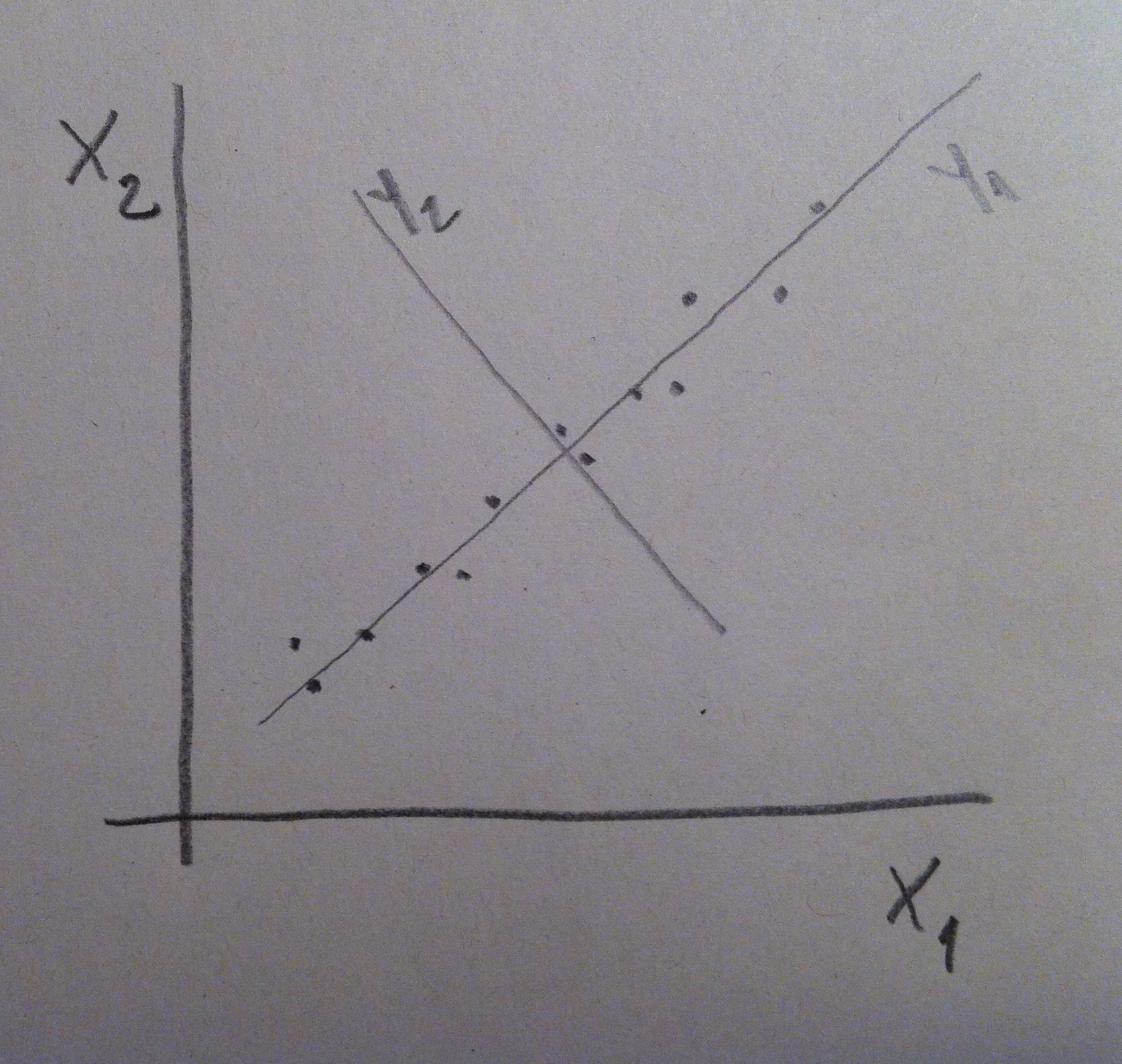
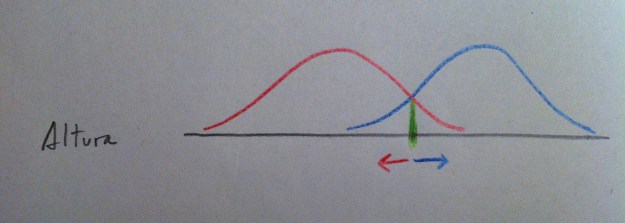
16. Y sea el tipo que sea de Análisis discriminante el que realicemos, de entre los que veremos a continuación, el procedimiento siempre es el mismo: se trata de crear un mecanismo de decisión a través del cuál al nuevo individuo se lo clasifica según el peso que tenga respecto a las densidades de las diferentes poblaciones. Lo veremos mejor con un ejemplo: Supongamos uno de los casos vistos antes: la altura como variable que discrimine entre hombres y mujeres. Lo que haremos es crear una función de densidad a partir de la muestra de hombres, otra a partir de la muestra de mujeres y entonces al nuevo individuo clasificarlo de la población que le tocaría más densidad; o sea, en el gráfico establecemos una frontera (en color verde) justo donde cambia la zona de mayor influencia de una u otra población. Si cae el nuevo valor a la derecha de esa frontera lo clasificamos de azul, si cae a la izquierda lo clasificamos de rojo:
17. Hay diferentes técnicas de Análisis discriminante. Hay el Análisis discriminante lineal, el Análisis discriminante cuadrático y hay, también, todo un repertorio de técnicas que se suelen encajar bajo la denominación de Análisis discriminante no paramétrico.
18. La creación de funciones discriminantes, combinaciones de las variables originales desde donde establecer buenos mecanismos de discriminación, tal como lo hemos planteado antes, es una idea ligada al Análisis discriminante lineal, pero es cierto que aunque los mecanismos usados por los diferentes tipos de Análisis discriminante son distintos, todos comparten la atmósfera general que he intentado transmitir hasta ahora.
19. El Análisis discriminante lineal y el cuadrático parten de una serie de suposiciones que no siempre se cumplen, por eso se han desarrollado una serie de técnicas que son válidas sin el cumplimiento de las suposiciones rígidas que exigen las técnicas paramétricas. La discriminación lineal y la cuadrática requieren que cada una de las poblaciones siga la distribución Normal multivariante. Además, la discriminación lineal requiere que la matriz de varianzas-covarianzas sea la misma en todas las poblaciones. La discriminación cuadrática, de hecho, está diseñada para no tener que soportar esta suposición.
20. Las técnicas no paramétricas en Análisis discriminante tratan, mediante métodos diferentes y muy imaginativos, establecer procedimientos de clasificación de los nuevos individuos dentro del conjunto de poblaciones candidatas.
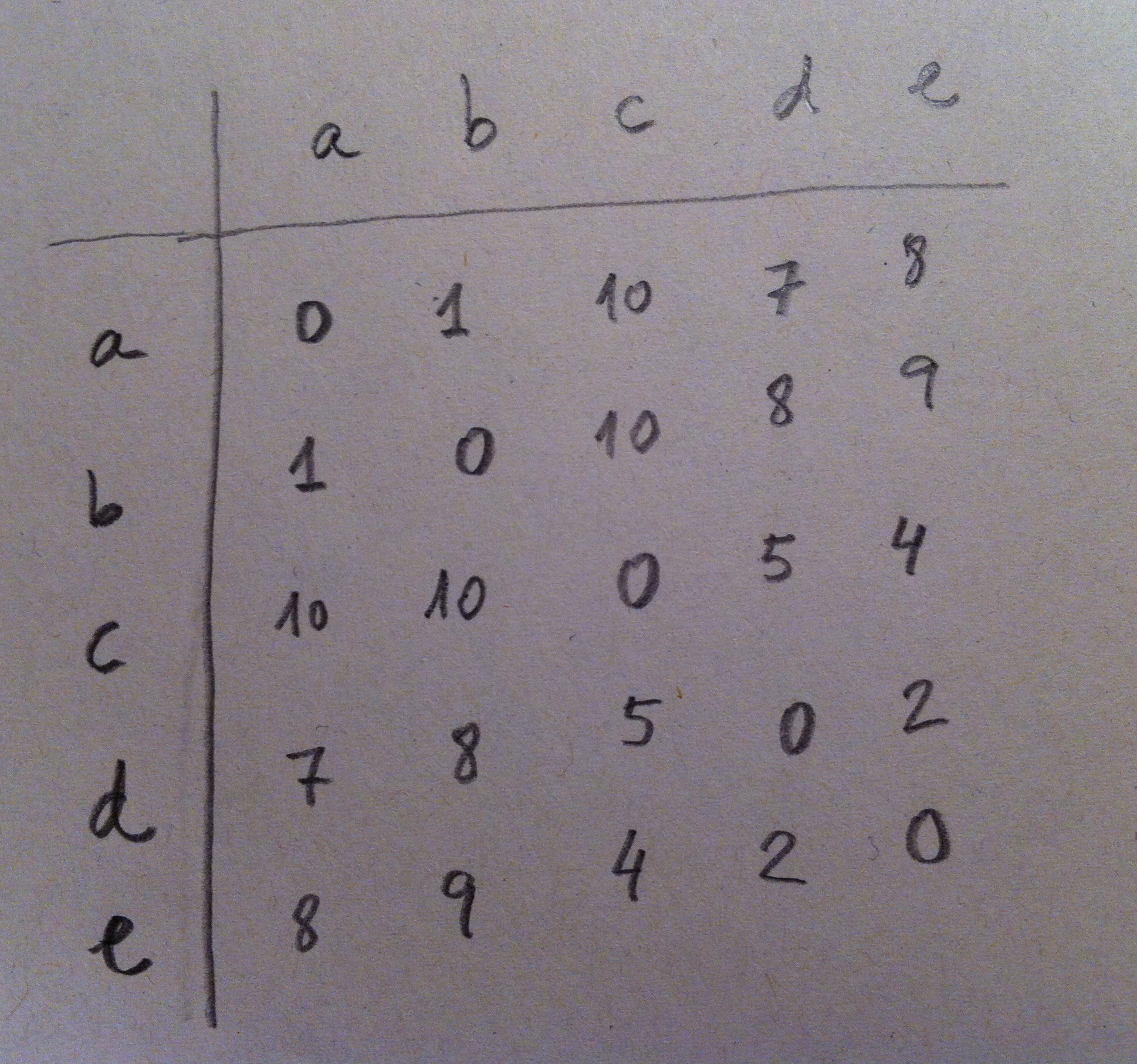
21. Uno de esos métodos no paramétricos de Análisis discriminante es el basado en la Estimación no paramétrica de funciones de densidad. Veamos un poco la operatividad de este método porque es conceptualmente muy sencillo e interesante. Supongamos los siguientes datos:
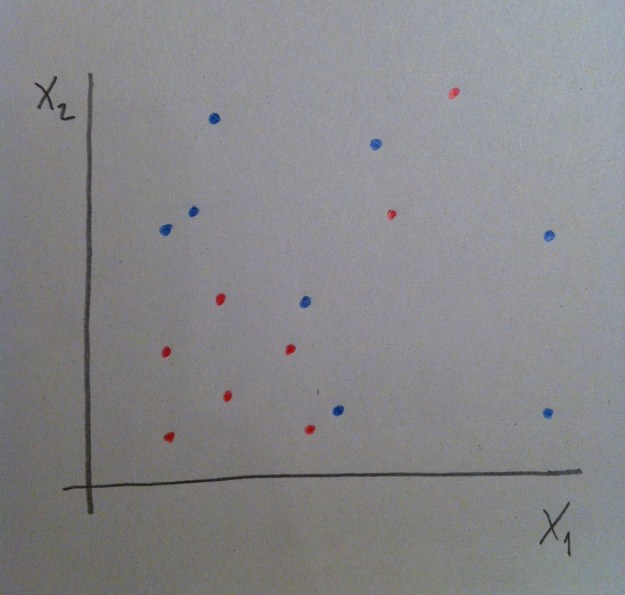
22. Tenemos dos muestras de dos poblaciones distintas: la roja y la azul. El método construye, entonces, para cada muestra, una función de densidad mediante el método Kernel y clasifica al nuevo individuo simplemente asignándolo a la población donde haya más valor de densidad, que querrá decir que por allí hay más influencia de esa población, hay más valores muestrales y, por lo tanto, parece lógico arriesgarse a clasificarlo de la población que tenga más representantes por la zona. Es la misma idea que la mostrada antes con la variable Altura pero en lugar de mediante una campana de Gauss, mediante una función de densidad estimada a partir de la propia muestra.
23. Como hemos dicho al principio del tema, y se ha podido comprobar a lo largo de su explicación, el Análisis discriminante es una técnica inferencial, una técnica que hace inferencias, que va más allá de lo que tenemos, que usa la muestra como medio para decir cosas que no sabemos. En este caso, para clasificar a individuos dentro de dos o más poblaciones.
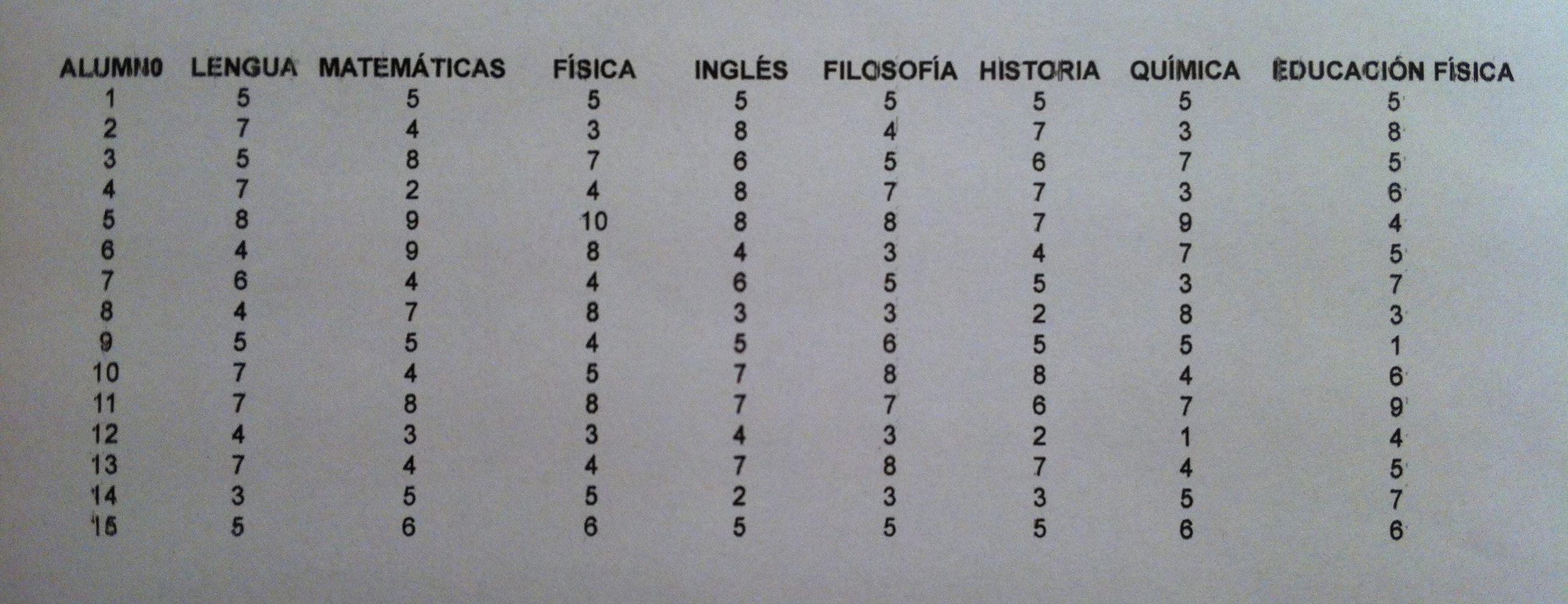
24. Veamos un ejemplo de Análisis discriminante lineal. Vamos a trabajar unos datos de años de supervivencia después del diagnóstico de cáncer de pulmón de células pequeñas. Los datos son los siguientes:

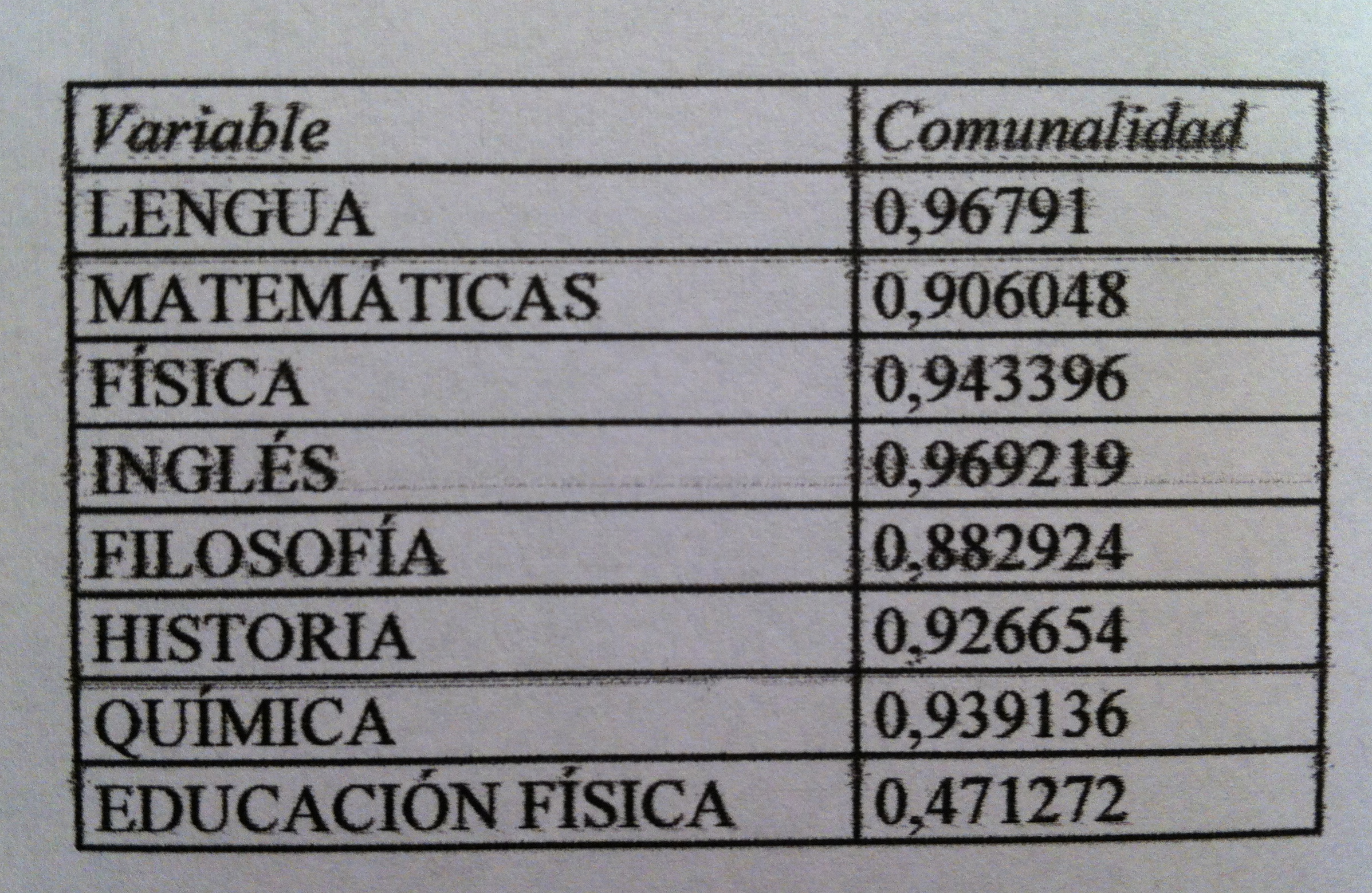
25. No vamos a entrar en detalles sobre cada una de las variables. Sólo decir que son típicas variables bioquímica y citológicas en una analítica sanguínea. La última columna es la Supervivencia, catalogada con tres valores: <1, 1-2 y >2, que representan: menos de un años, entre 1 y 2 años y más de 2 años. Esta es la columna que nos distingue las poblaciones. Son datos de enfermos que al diagnóstico tenían esta analítica y que acabaron sobreviviendo este tiempo especificado en la última columna.
26. El objetivo es, pues, aplicar el Análisis discriminante para establecer un mecanismo de clasificación, de pronóstico en este caso. Tenemos tres poblaciones definidas: Supervivencia de <1, de 1-2 y de >2 años. Tenemos tres muestras y 12 variables. Se trata de discriminar esas tres poblaciones, mediante esas 12 variables, con la finalidad de que a un nuevo paciente diagnosticado de esa enfermedad le podamos hacer un pronóstico con bastantes posibilidades de acertar.
27. En primer lugar deberíamos comprobar la normalidad de los datos y la igualdad de la matriz de varianzas-covarianzas. La normalidad multivariante es de compleja comprobación. Aunque la normalidad de cada variable individual no representa normalidad multivariante los software estadísticos acostumbran a comprobar esta normalidad univariante con cualquiera de las técnicas de bondad de ajuste a la normal, como el Test de Kolmogorov o el de la ji-cuadrado. Respecto a la homogeneidad de las matrices de varianzas-covarianzas una prueba habitual es el Test M de Box, que es una generalización del Test de Barlett univariante.
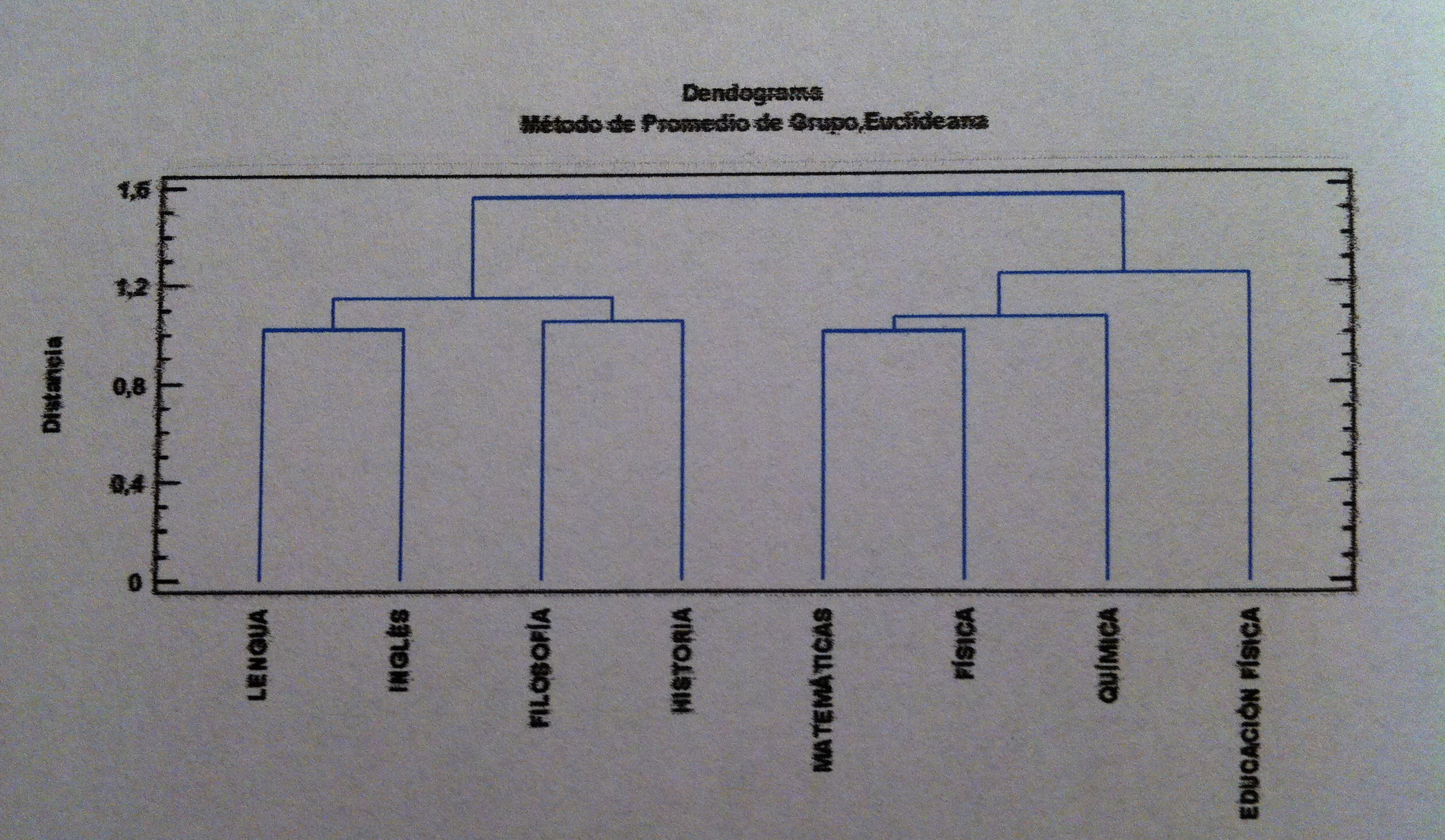
28. Una vez comprobadas estas suposiciones pasamos a la realización de un Análisis discriminante lineal. Dibujamos los datos mediante un gráfico en tres dimensiones con las dos funciones discriminantes que nos calcula el programa:
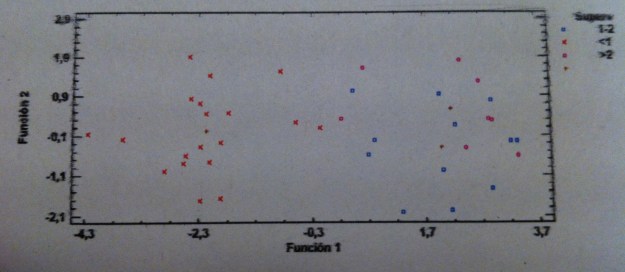
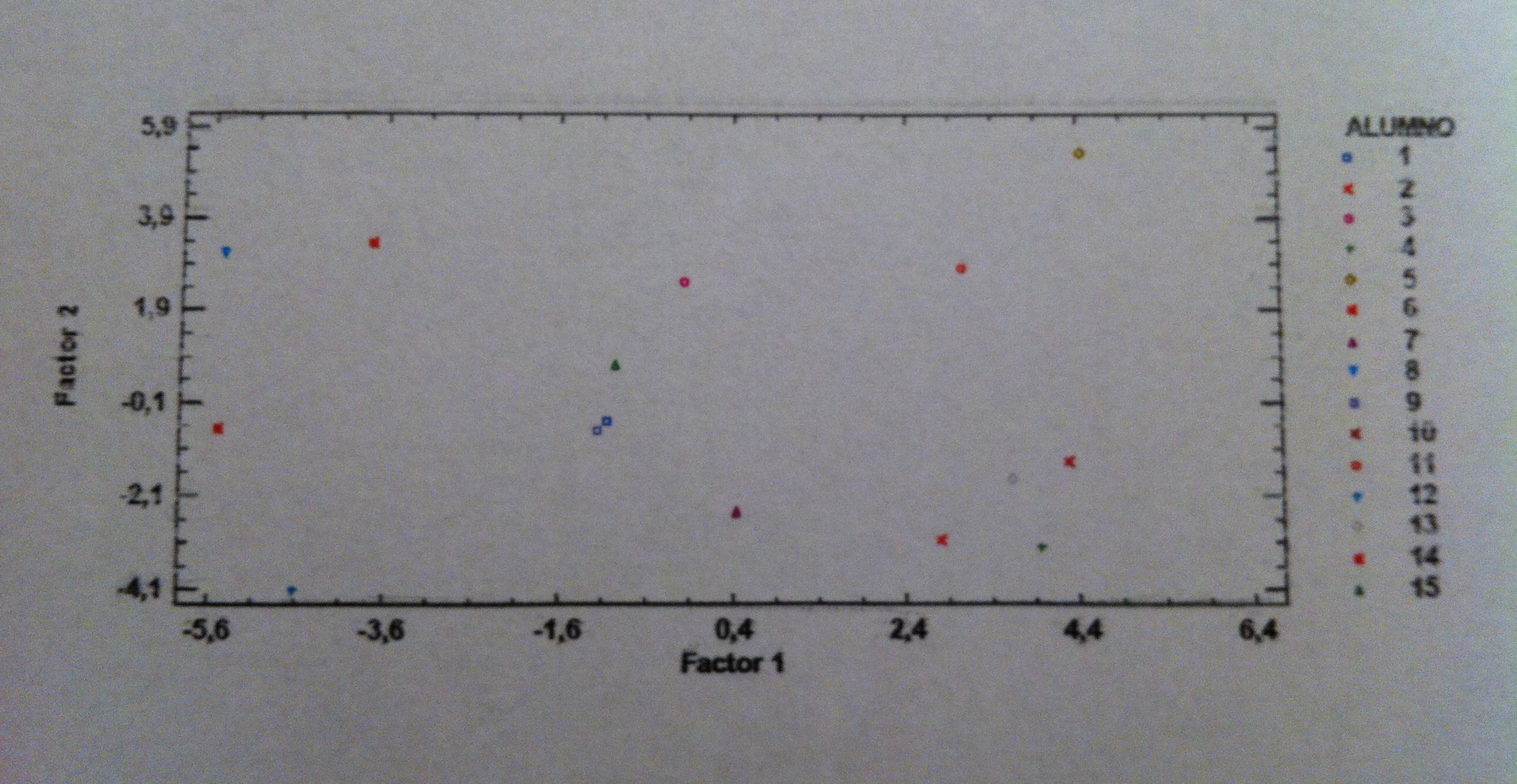
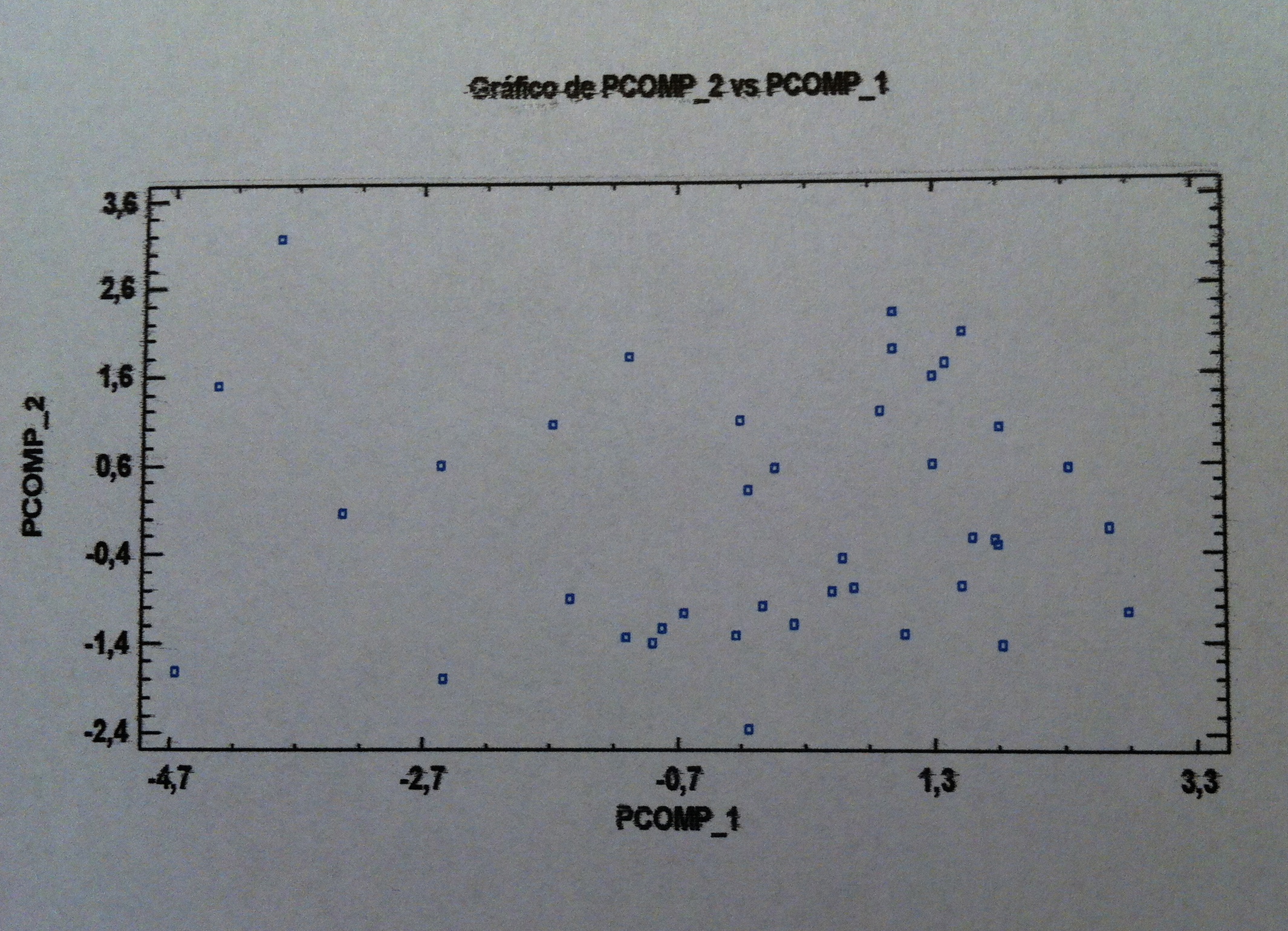
29. Las tres cruces que tienen forma de suma corresponden a los valores promedios de cada una de las tres poblaciones, de cada uno de los tres grupos de supervivencia.
30. De entrada, ya sólo viendo este gráfico y recordando lo que hemos dicho antes, parece claro que la Función discriminante 1 parece discriminar bien pero la Función discriminante 2 no parece que nos discrimine nada.
31. Veamos la siguiente tabla:
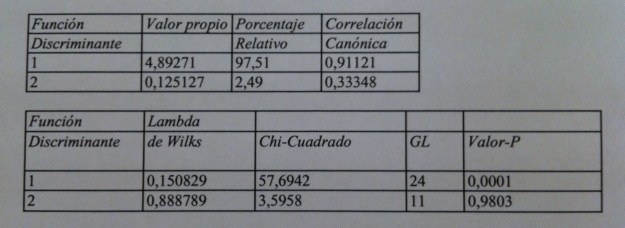
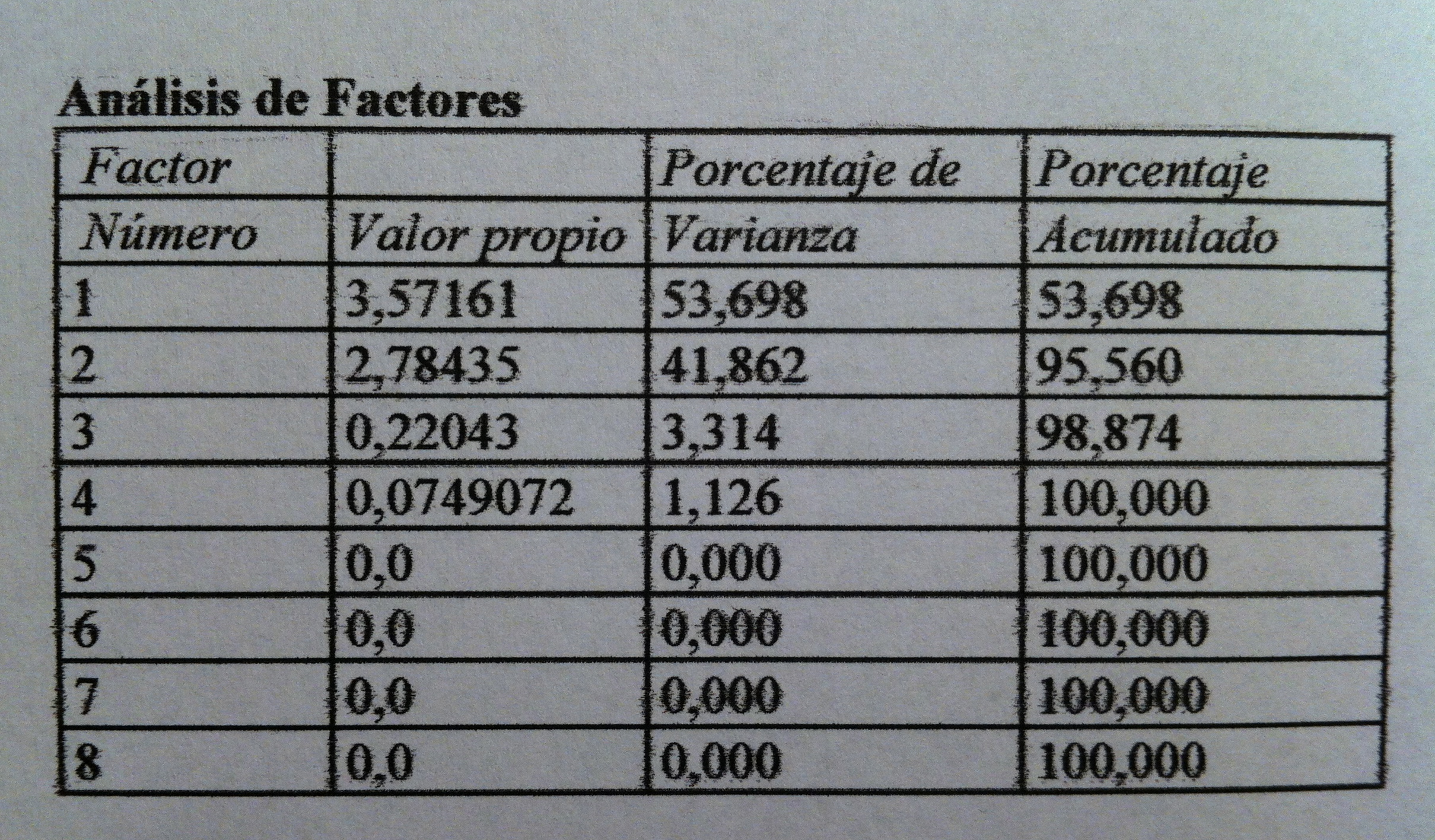
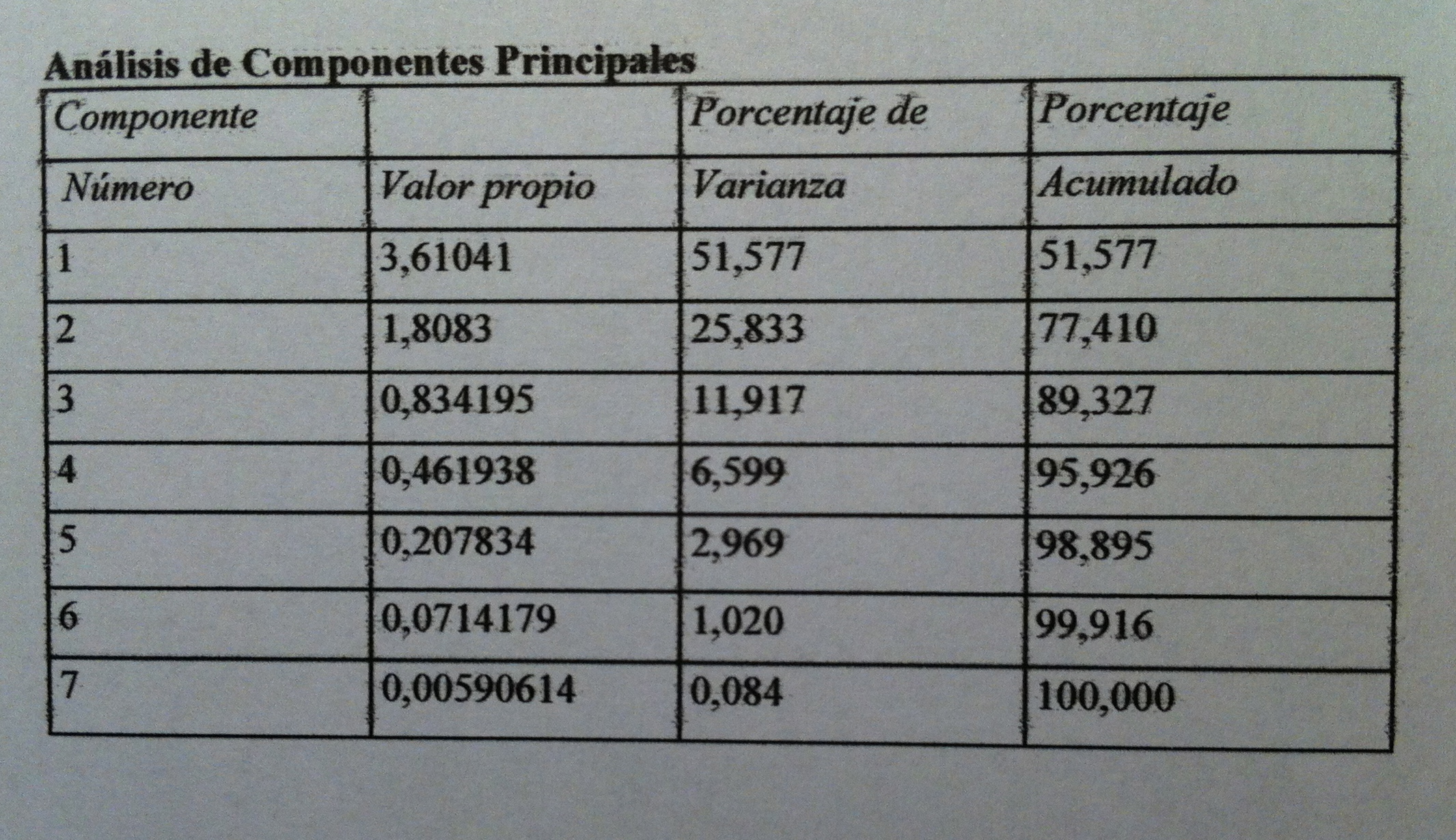
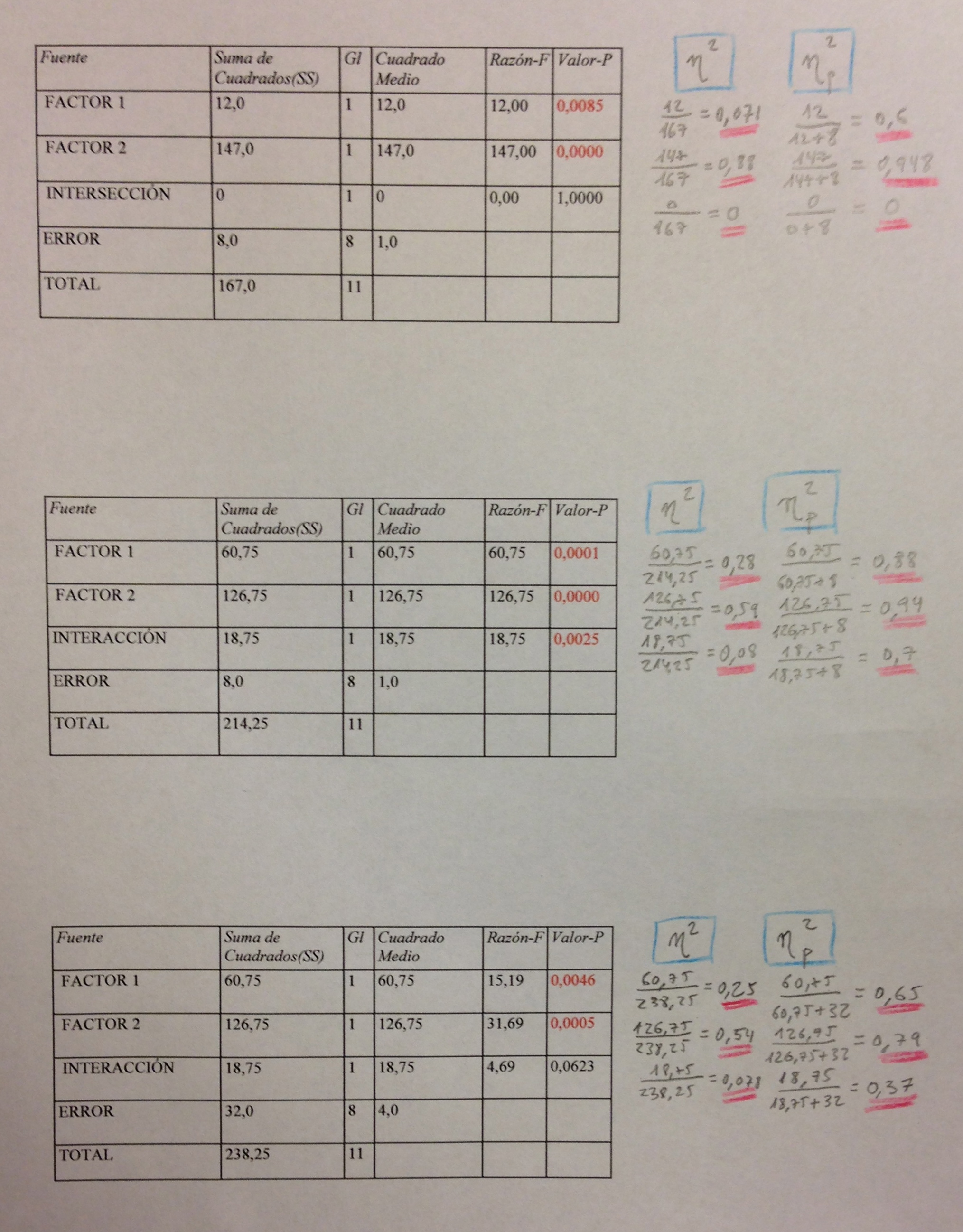
32.Los dos valores propios muestran que la primera función discriminante está mucho más relacionada que la segunda con los grupos de supervivencia. La correlación canónica así lo muestra también. Pero, además, gracias a la Lambda de Wilks podemos comprobar que, además, la primera función discriminante separa significativamente grupos, discrimina. Sin embargo, la segunda función discriminante no consigue una separación significativa. El Test de la Lambda de Wilks es básico en muchos ámbitos inferenciales multivariantes. Es un test que básicamente trata de establecer una relación entre la dispersión dentro de los grupos respecto a la dispersión total, sin tener en cuenta los grupos. Si
33. Veamos cuáles son esas funciones discriminantes:
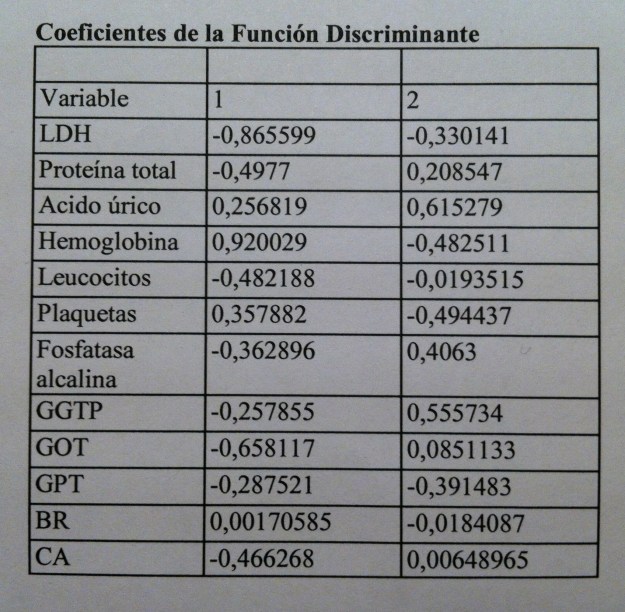
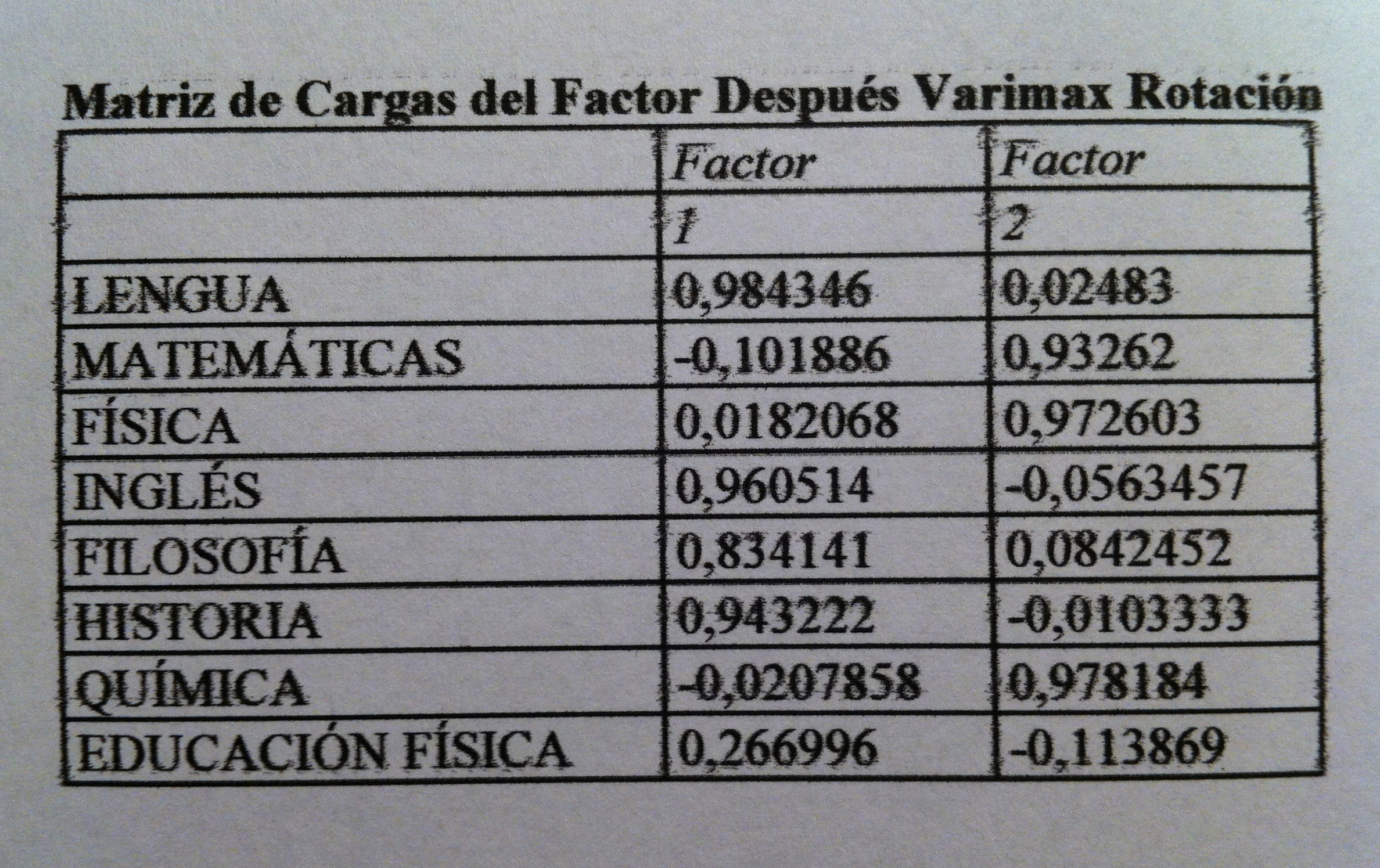
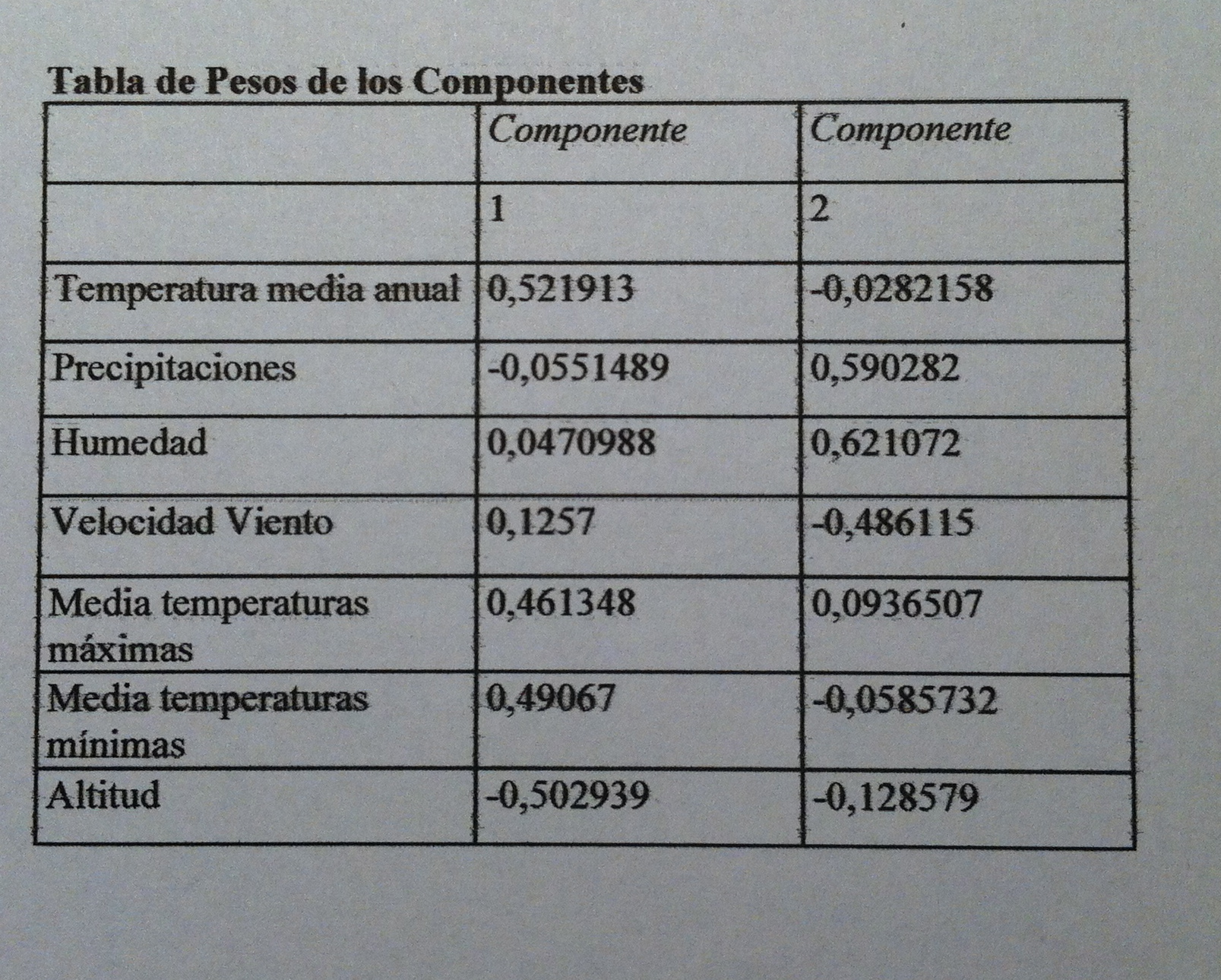
34. Tenemos las dos pero en realidad sólo debemos mirar la primera porque la segunda no nos discrimina. Como puede verse se trata de macrovariables, como las componentes o los factores. Pero ahora, debido al contexto donde las hemos creado las llamamos funciones discriminantes. El programa estadístico nos da dos pero sólo una es significativa.
35. En Análisis discriminante no suele haber una preocupación por la interpretación de esas macrovariables, de las funciones discriminantes. De hecho, el análisis está canalizado a la creación de un método que funciones, que sea útil, no suele haber un interés en ponerle nombre a esas funciones como sí ocurre, por el contrario, en Análisis de componentes principales o en Análisis factorial.
36. Para clasificar a un nuevo individuo diagnosticado de cáncer de pulmón de células pequeñas después de hacerle una analítica con todos estos parámetros deberíamos aplicar los valores de la siguiente tabla con las llamadas funciones de clasificación:

37. Estas funciones de clasificación de los nuevos individuos es creada a partir de las muestras que tenemos de los tres grupos de supervivencia. La operatividad es la siguiente: Se calculan los tres valores correspondientes para cada columna con los valores del individuo. El valor más alto es el valor más probable. Digamos que es una forma de calcular bajo qué distribución de las tres tiene más probabilidad.
38. Observemos que el procedimiento liga mucho con la idea del uso de Estimadores no paramédicos de la función de densidad con el método Kernel, comentado antes. Y, de hecho, liga con la idea nuclear que guía todo lo visto en este tema: hay que clasificar allá donde haya más influencia entre las muestras previamente establecidas.
39. ¿Cómo podemos cuantificar la eficacia del método de discriminación? ¿Cuál será su eficacia? ¿Podemos predecirla? Miremos este interesante método para hacer esta previsión:
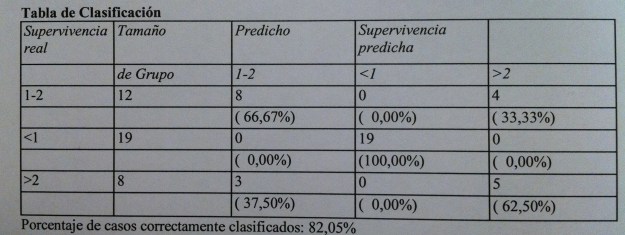
40. Se trata de un método ingenioso de estimación de la eficacia clasificatoria. Consiste en ir tomando uno a uno cada uno de los individuos de la muestra. Individuos de los que ya sabemos su supervivencia. Pues bien, aplicamos la tabla de clasificación establecida a partir de estos datos que hemos visto antes y miramos dónde quedaría clasificado este individuo si no supiéramos su supervivencia. Y esto lo hacemos con todos los individuos de la muestra. De esta forma tenemos de cada uno de los individuos dos valores de supervivencia: el real y el pronosticado. Construimos, entonces, esta tabla de clasificación donde vemos es las filas la supervivencia real (porque es nuestra muestra y la sabemos) y la supervivencia prevista aplicando nuestro método de clasificación. Así vemos si acertamos o no. Lo bueno es que los valores estén en la diagonal principal que es la que hace coincidir grupo real con grupo predicho. De esta forma se acaba calculando un porcentaje de casos correctamente clasificados, que, en nuestro caso, es del 82.05%. Que no es malo debido a la complejidad de los que estamos hablando.
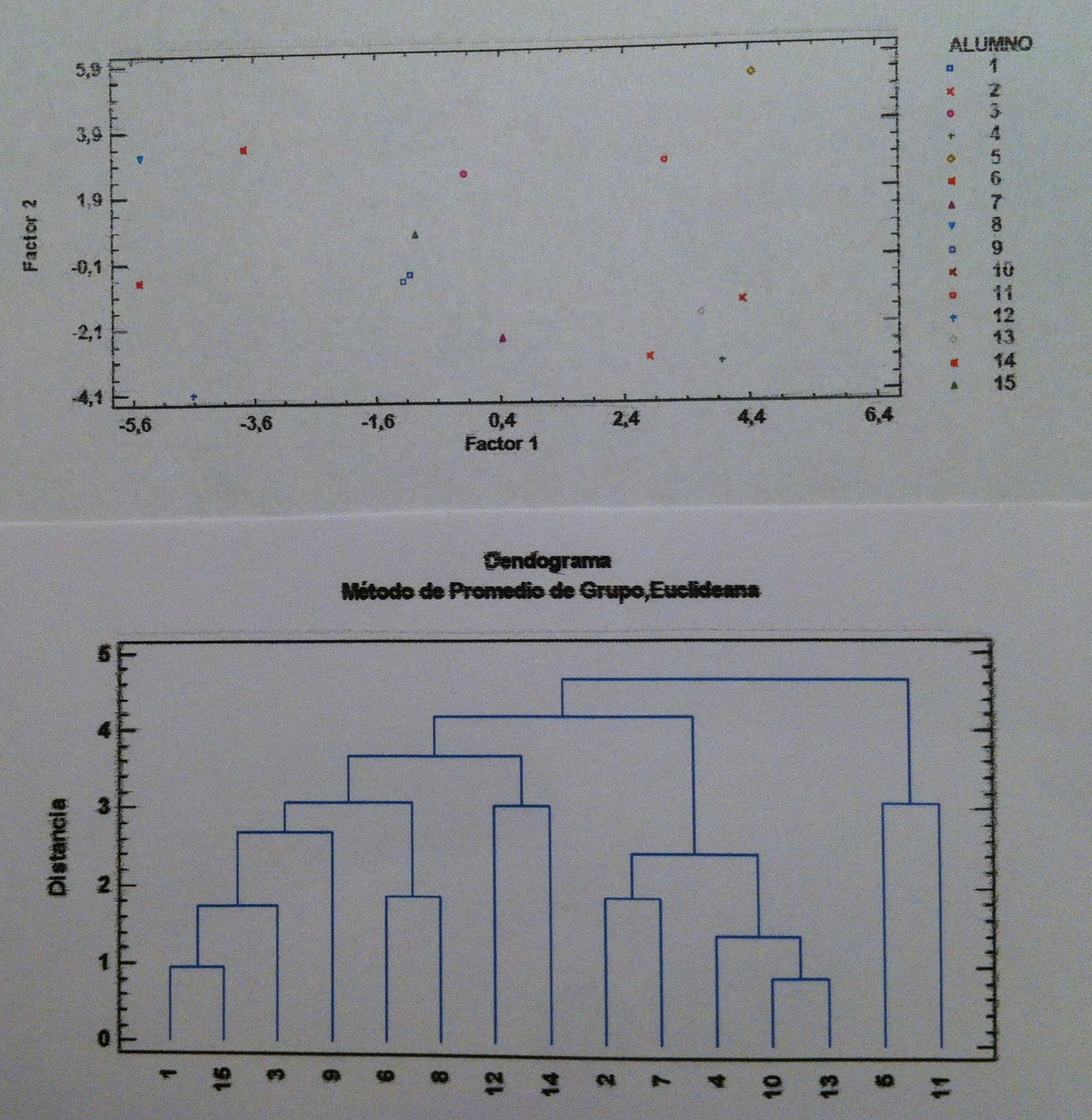
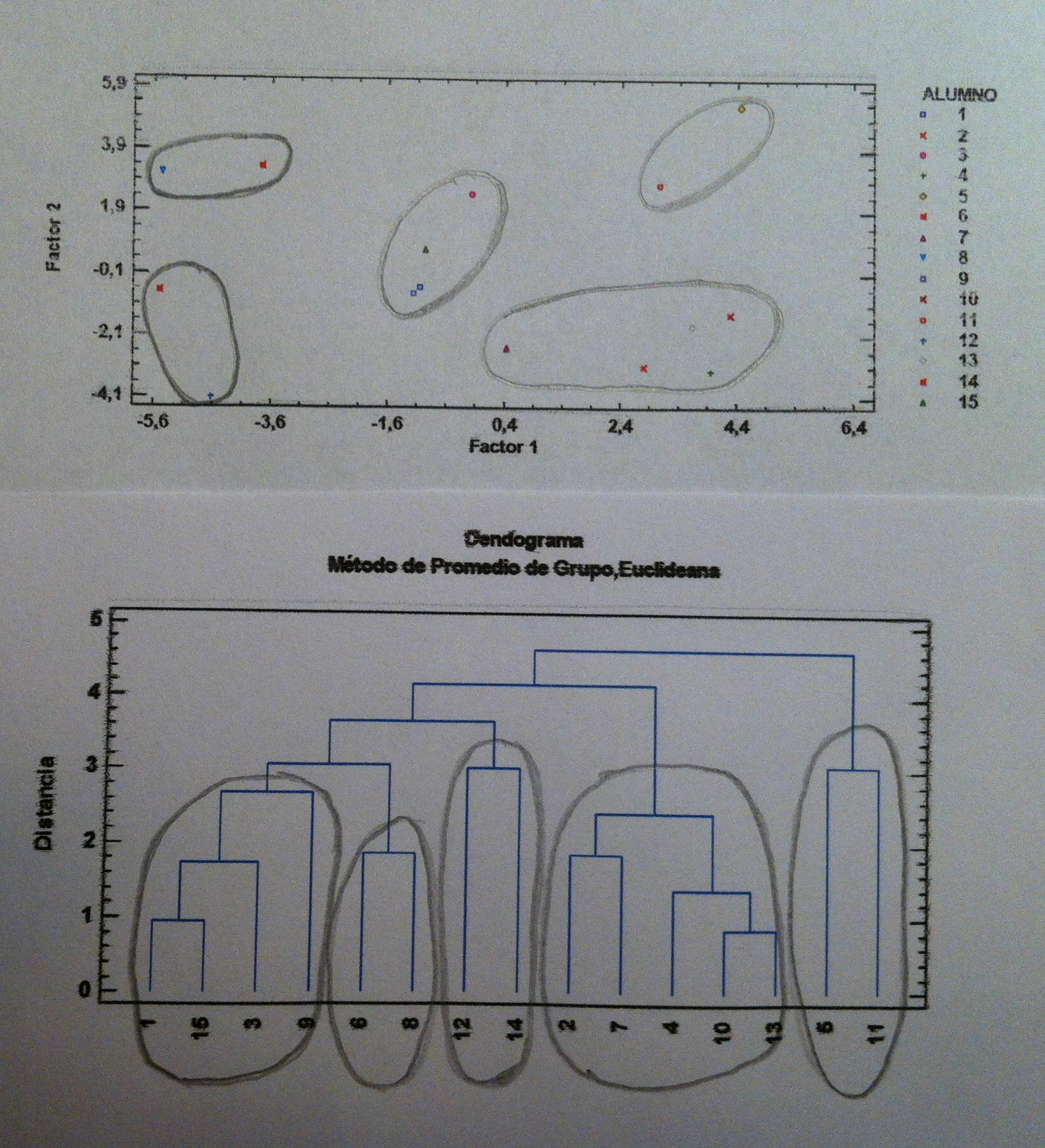
41. Observemos que hemos trabajado con todas las variables del estudio. Pero aquí, en Análisis discriminante lineal también podemos hacer una Selección de variables hacia adelante o hacia atrás, como en la Regresión múltiple. Si hiciésemos esto a estos datos obtendríamos, en primer lugar, la siguiente representación de los individuos según las dos funciones discriminantes:

42. Los valores de significación siguen marcando la primera función discriminante como única función que discrimina realmente:
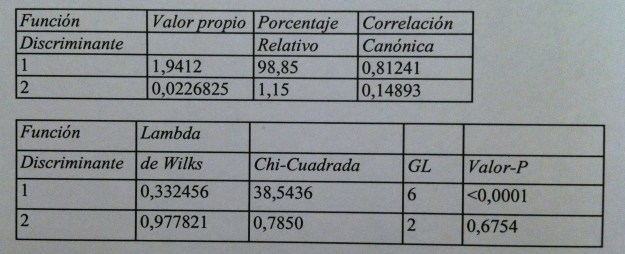
43. El proceso de selección del modelo encuentra que con tres variables basta. Con las variables LDH, Hemoglobina y GPT ya es suficiente. Las funciones discriminantes son:

44. La tabla de funciones de clasificación es ahora la siguiente:

45. Y la tabla de clasificación que nos mide la calidad de la clasificación con los valores muestrales es la siguiente:
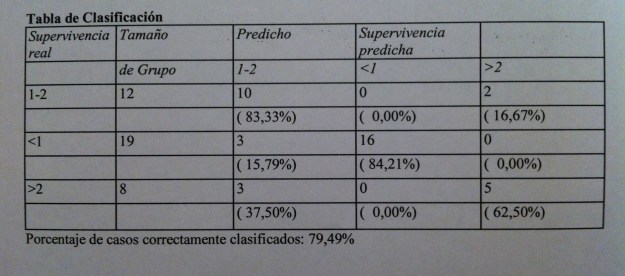
46. Tenemos un 79.49% de aciertos, un poco menor que el 82.05% de antes, pero con muchas menos variables.
47. Un breve comentario para acabar: Es interesante establecer conexiones entre el Análisis discriminante y la Regresión logística. De hecho, tienen profundas similaridades. De hecho, se trata de dos formas de enfrentarse a lo mismo. Observemos que las poblaciones en las que queremos clasificar a un nuevo individuo se puede ver, en realidad, como una variable cualitativa. Y el procedimiento de discriminación es como la búsqueda del modelo de regresión.
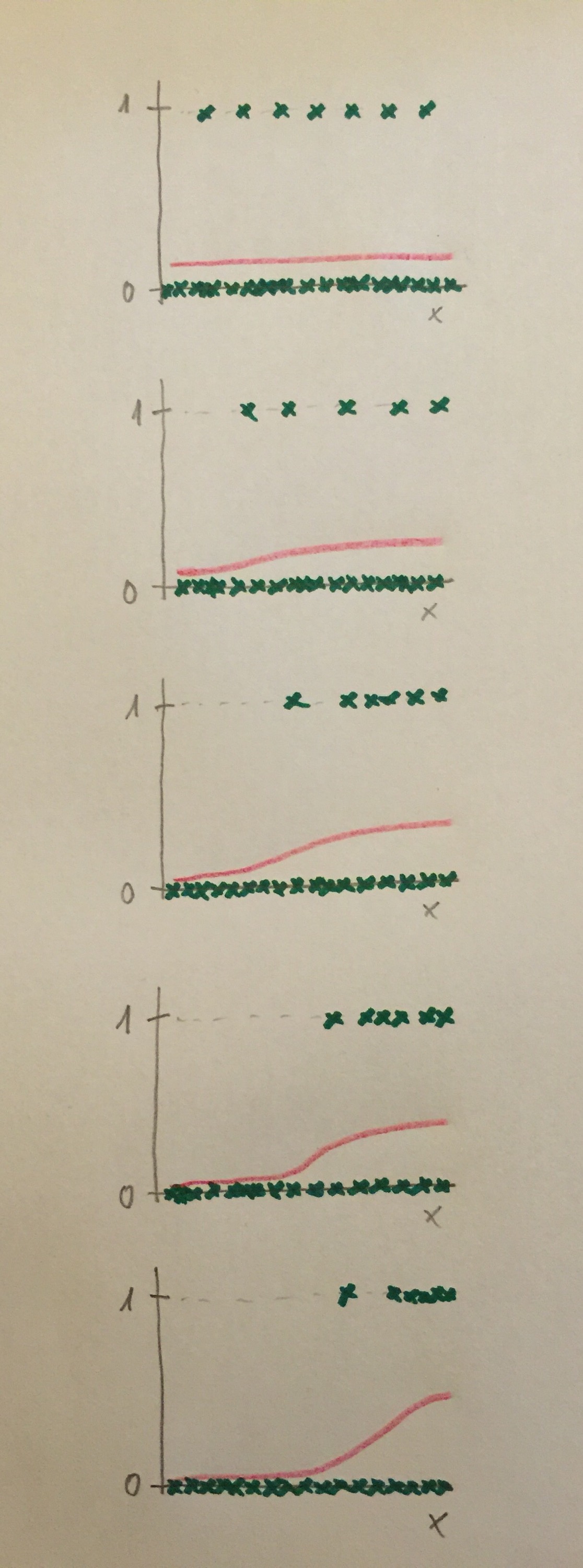
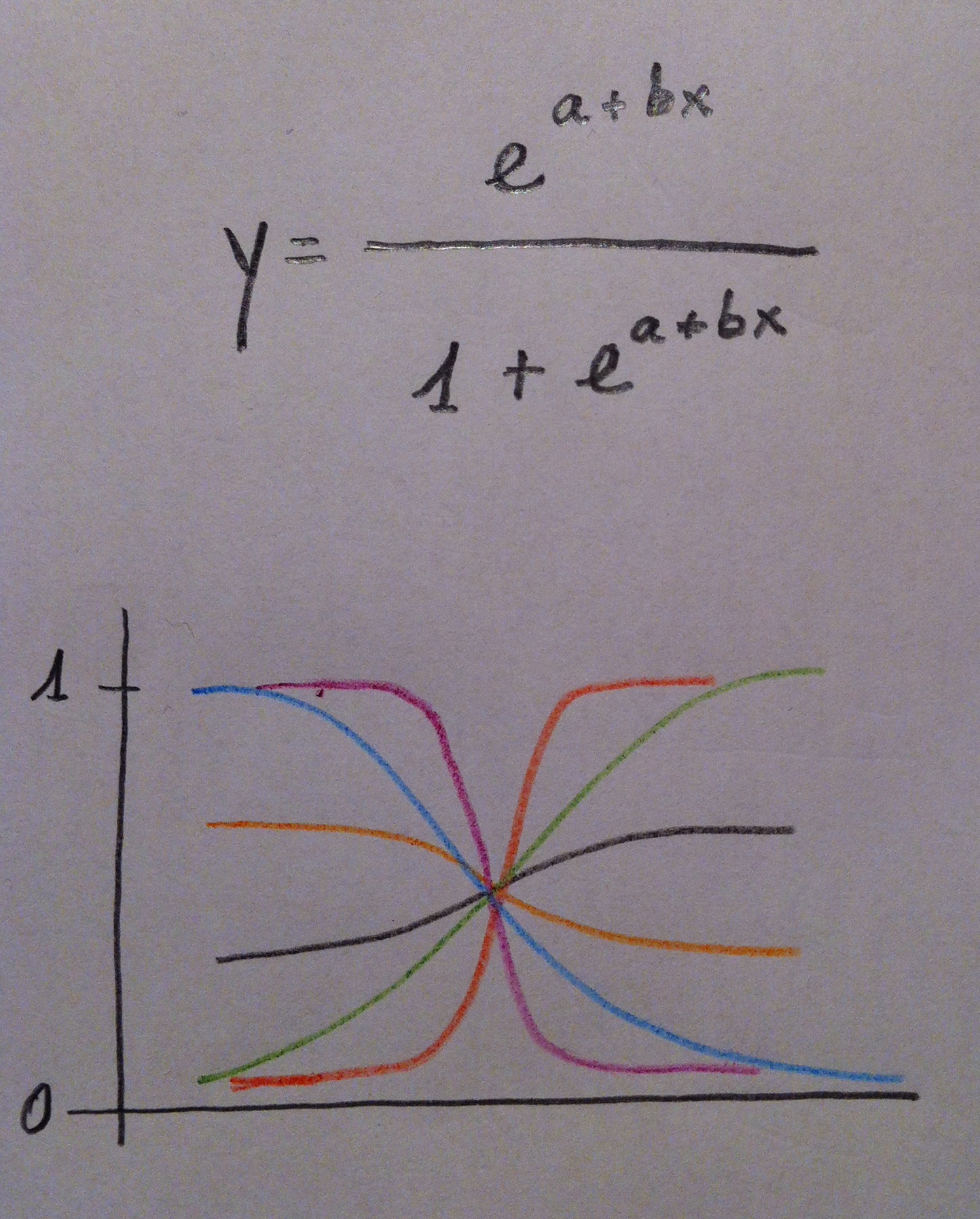
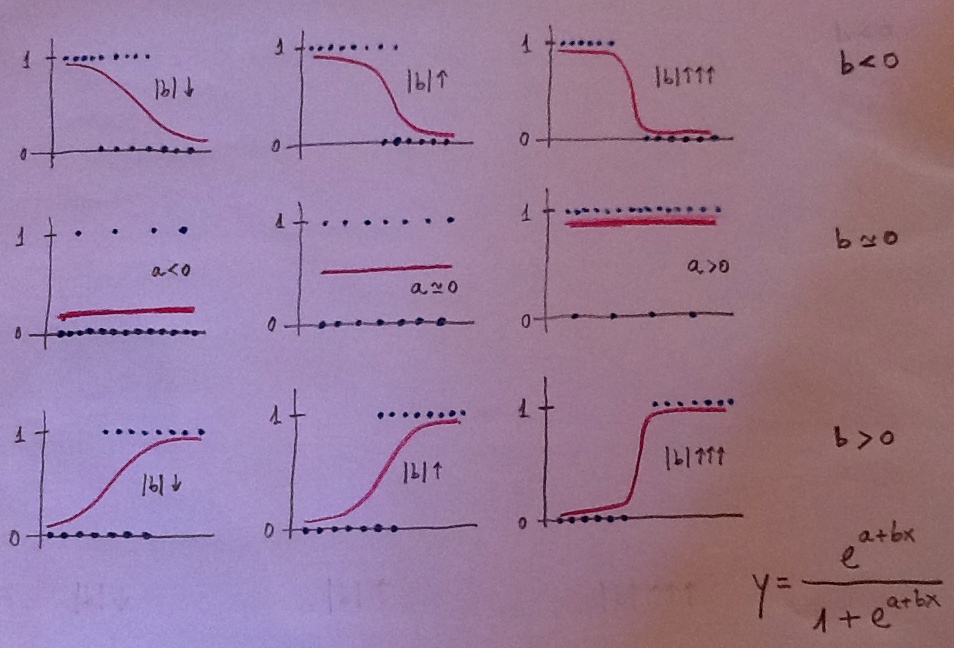
48. Cuando la variable es dicotómica y se pretende modelizar la situación y establecer relaciones entre la variable dicotómica y un conjunto de variables predictoras mediante Odds ratio, entonces es más habitual usar la Regresión logística. Cuando hay más de dos poblaciones y además hay especialmente una voluntad práctica clasificatoria suele usarse el Análisis discriminante. También para el uso de una u otra técnica juegan cuestiones de tradición, culturales. Por ejemplo, en Medicina es más usual la Regresión logística por tradición y por el papel tan destacado que en ese campo juega la Odds ratio. Sin embargo, en ámbitos como la Biología, la Ecología, la Sociología y otros es más habitual el uso del Análisis discriminante.