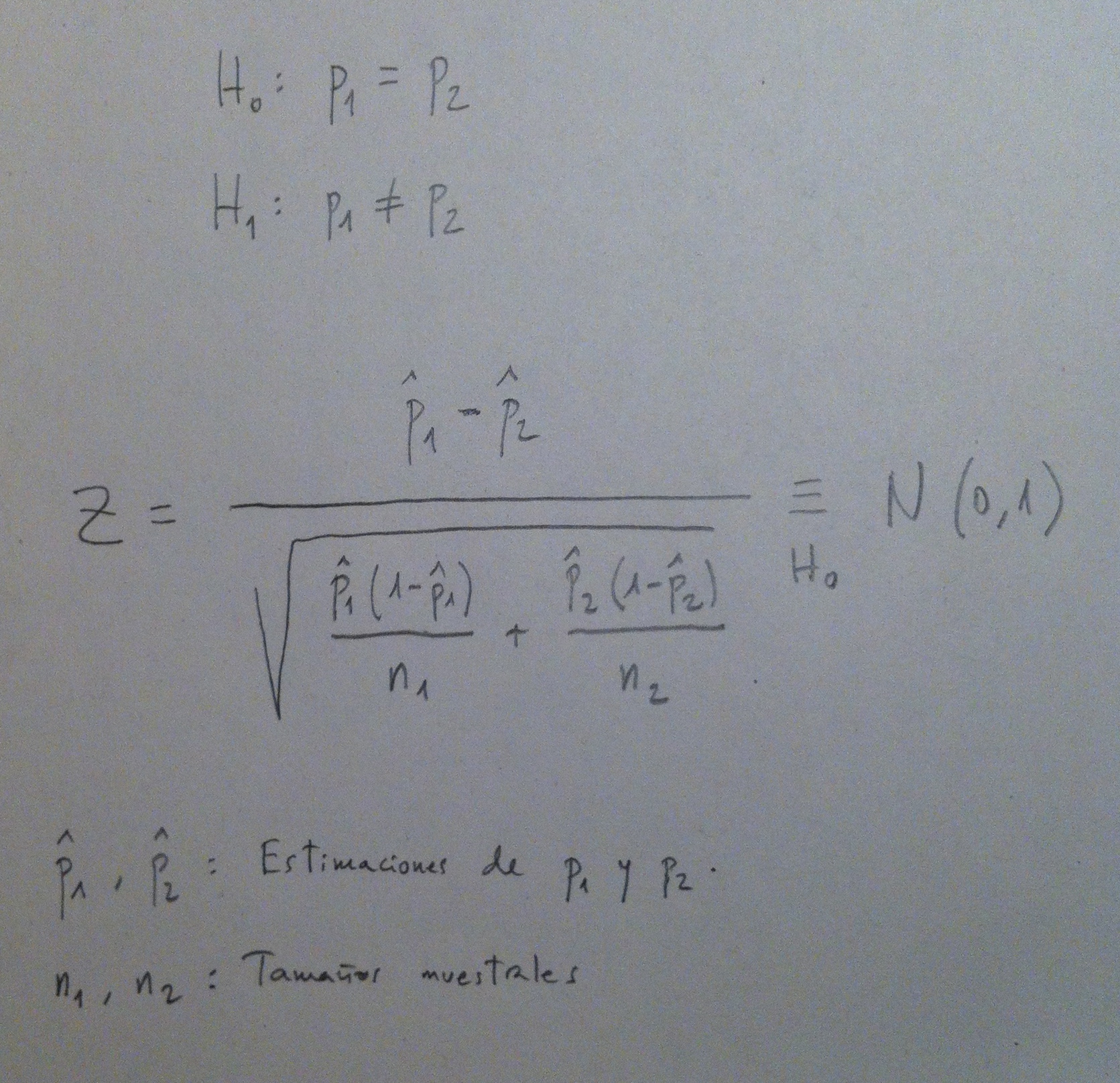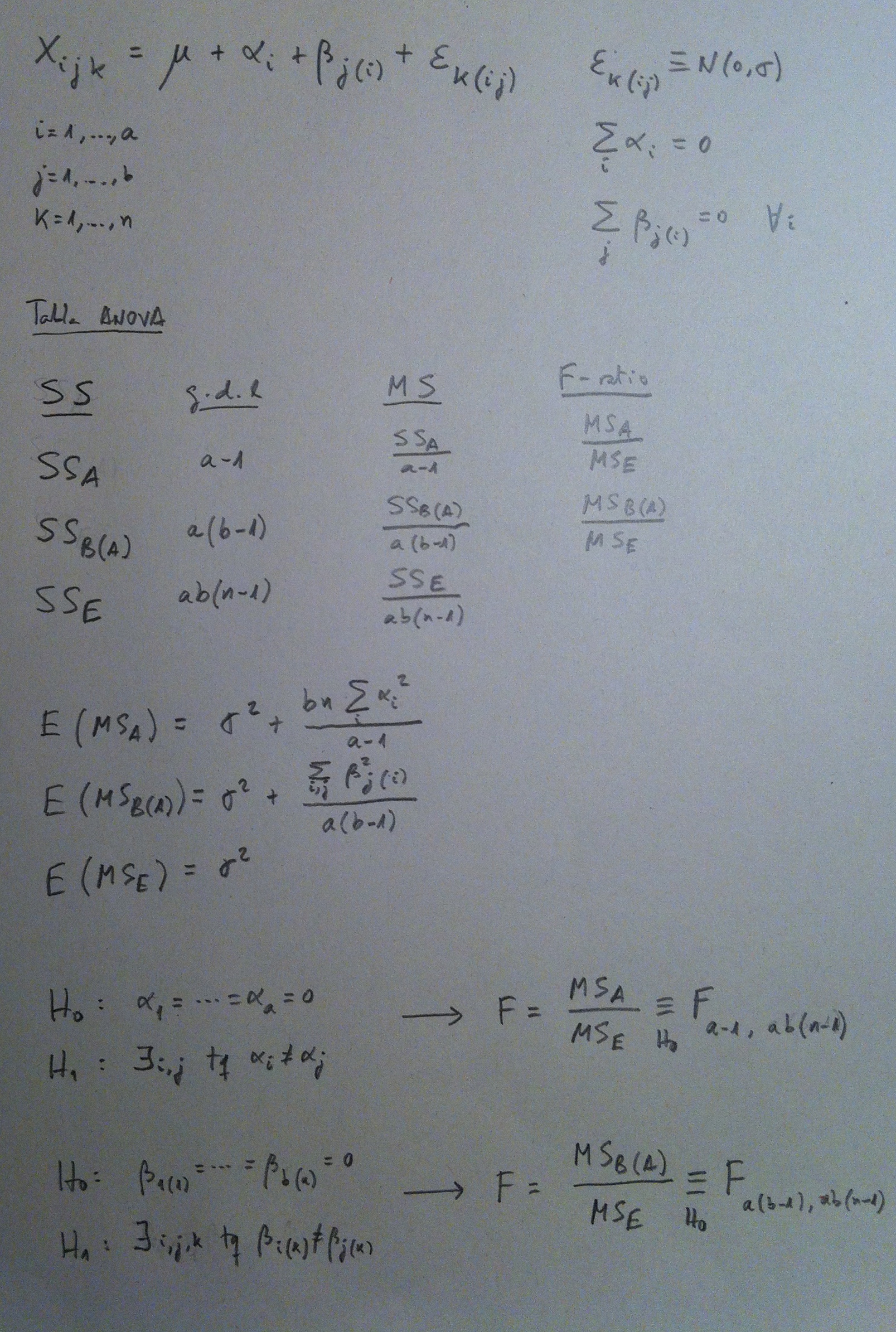El Test exacto de Fisher es un contraste de hipótesis muy interesante por sus muchas aplicaciones y porque es un muy útil escenario para aprender la lógica interna de un contraste de hipótesis.
Se aplica en las siguientes situaciones: 1) En la comparación de dos grupos respecto a una variable dicotómica. 2) En la valoración de la relación entre dos variables cualitativas dicotómicas cada una de ellas.
En ambos casos, que son equivalentes (son dos formulaciones distintas de lo mismo), los datos pueden organizarse en una tabla de contingencias de 2×2 ó mediante dos porcentajes a comparar, uno de cada grupo.
El primer caso se resuelve habitualmente con un Test de comparación de dos proporciones (Ver Herbario de técnicas y ver también el Tema dedicado a la comparación de dos poblaciones), el segundo caso se resuelve con un Test de la ji-cuadrado de tablas de contingencias. El problema que tienen ambos test es que necesitan de tamaños muestrales relativamente grandes.
El Test de comparación de proporciones, para funcionar bien, requeriría un tamaño muestral mínimo de 30 por grupo y que el producto del tamaño muestral por el tanto por uno esperado bajo la hipótesis nula del suceso que se analiza sea superior o igual a 5 en ambas muestras (esto último suele enunciarse como que el valor esperado por grupo es de 5 observaciones del suceso analizado, como mínimo). Un ejemplo: Tenemos una muestra de 50 por cada uno de los dos grupos. En una muestra tenemos sólo un caso del suceso analizado y en la otra tenemos 4 casos. Si la hipótesis nula fuera cierta esperaríamos ver 5 casos de cada 100 y los mismos en cada grupo; o sea, un 0.05 por uno. Si multiplicamos este 0.05 por 50 nos da 2.5 sucesos esperados por grupo. Como es menor que 5 estamos fuera de las condiciones de aplicación de este Test de comparación de proporciones y deberíamos aplicar el Test exacto de Fisher.
El Test de la ji-cuadrado en una tabla 2×2 requiere que las cuatro celdillas tengan más de 5 observaciones esperadas. Ambos Test utilizan un estadístico de test cuya distribución, bajo la Hipótesis nula, es la que suponemos que es, siempre y cuando se cumplan estos requerimientos en cuanto al tamaño muestral.
Por lo tanto, si tenemos muestras pequeñas, muestras que no cumplen estos requerimientos muestrales, tanto en un caso como en el otro, debemos decantarnos por la alternativa que nos ofrece este Test exacto de Fisher.
Supongamos el siguiente problema: Estamos comparando dos grupos de individuos y mirando cuántos, en cada grupo, tienen una determinada enfermedad y cuántos no la tienen. Y supongamos que tenemos los siguientes datos:

Observemos que los datos quedan organizados en forma de tabla de contingencias y que, al mismo tiempo, puede verse como un problema de comparación de dos proporciones, de dos porcentajes.
El Test exacto de Fisher se basa en la distribución hipergeométrica. Esta distribución es la que sigue una situación en la que hay N de posibles observaciones, distribuida en dos tipos distintos, en proporción r y N-r y donde realizaremos n observaciones sin repetición. La incertidumbre es ver cuántas de estas n observaciones que tenemos son de un tipo o del otro.
La distribución hipergeométrica paradigmática es la de extracciones de una urna con bolas (N) de dos colores en una determinada proporción (r y N-r), de la que se extraen bolas (n) sin reemplazamiento y se pretende ver la probabilidad de una determinada combinación (Ver en la sección de Complementos la explicación de la distribución).
Veamos ahora, a partir de los datos obtenidos, qué valores posibles hubiéramos podido tener que nos mostraran aún más diferencias entre los dos porcentajes o un patrón donde pudiéramos ver mayor relación entre grupo y enfermedad, respetando las sumas por filas y por columnas:
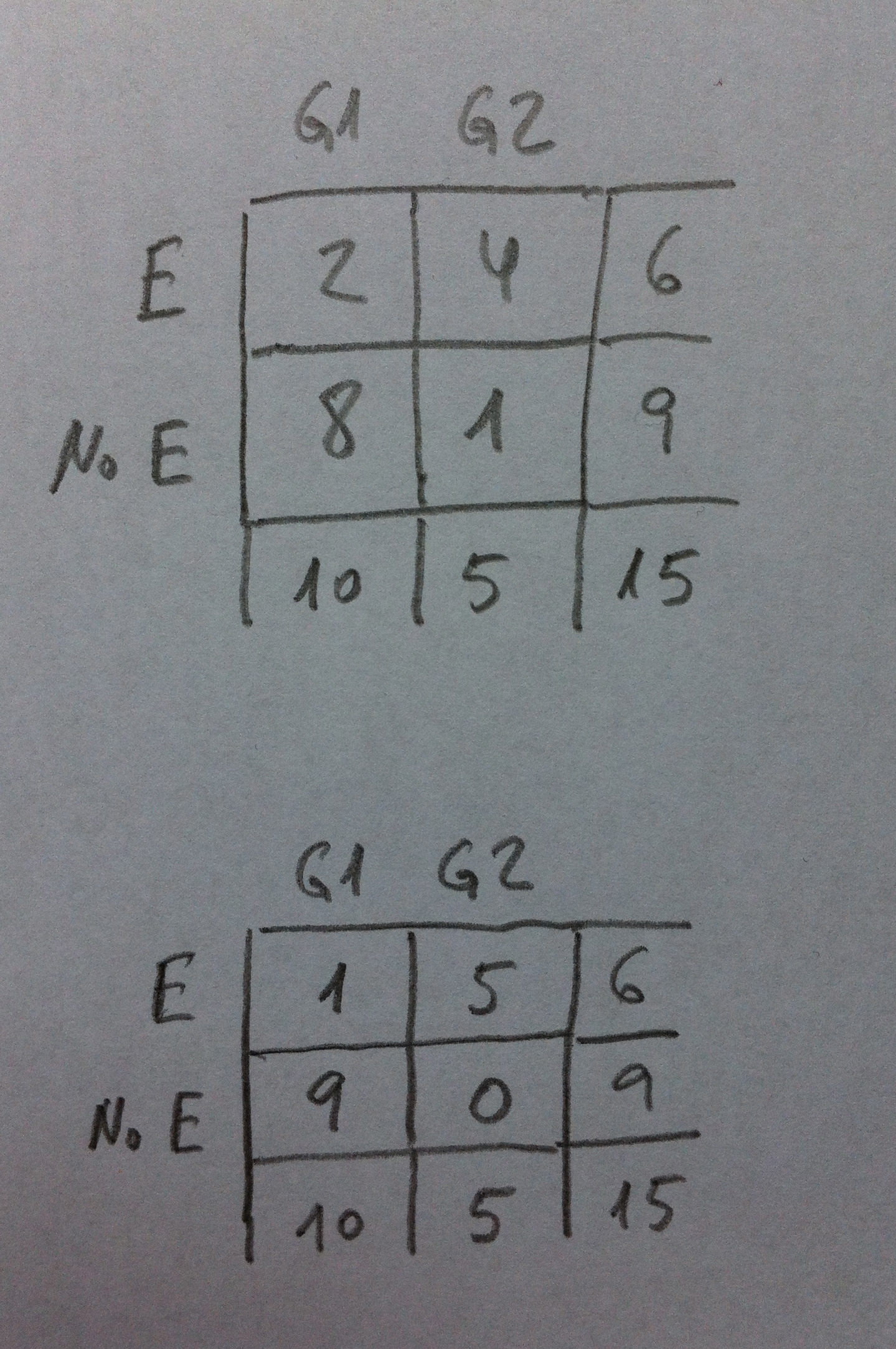
Observemos que la primera es nuestra tabla y la siguiente es la única tabla posible que agudiza más las diferencias o la relación entre las variables en el mismo sentido del visto en la muestra inicial.
Si los datos que tuviéramos fueran estos otros:

Ahora las tablas posibles más extremas que la vista, y que respetaran las sumas por filas y por columnas, serían las siguientes:
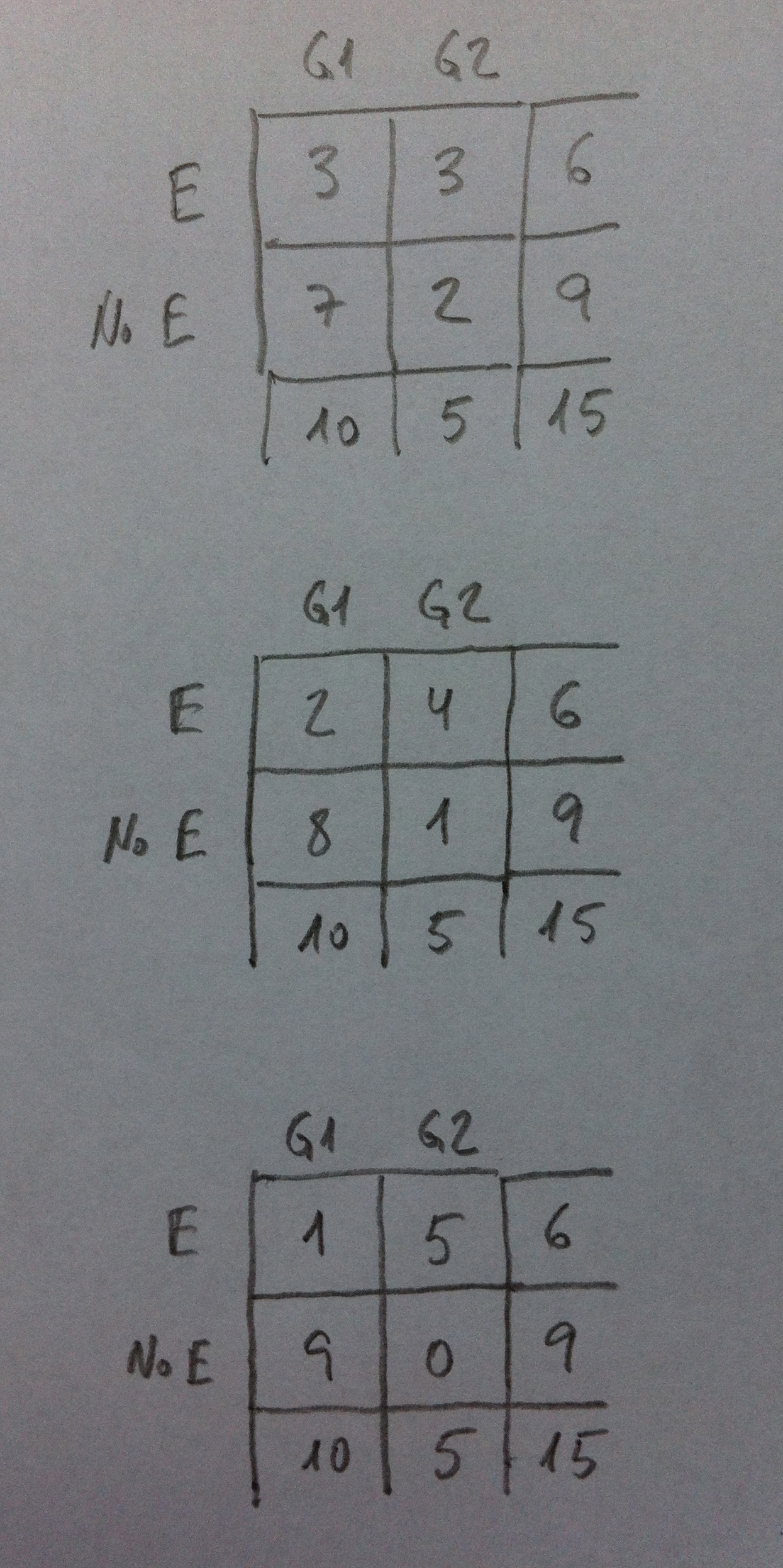
Ahora tenemos tres tablas para evaluar.
El Test exacto de Fisher hace precisamente esto: buscar, a partir de unos datos, qué combinaciones serían más extremas que la vista. Extremas en cuanto a detectar más diferencia entre los porcentajes o más asociación entre los valores de las dos variables cualitativas que estamos relacionando.
A partir de este listado el Test calcula las probabilidades de cada una de esas situaciones: de la que tenemos y de las más extremas, mediante la distribución hipergeométrica.
Si es un Test bilateral; o sea, que contrastamos igualdad de porcentajes versus diferencia, o no relación versus relación, multiplicaremos por dos esa suma de probabilidades para tener el p-valor. Si el Test es unilateral; o sea, que estamos contrastando igualdad versus menor o versus mayor, o estamos contrastando no relación versus relación en un sentido determinado (con una Odds ratio menor o una Odds ratio mayor que 1, pero únicamente uno de los dos lados), el p-valor será sólo el de la suma de las probabilidades de las tablas extremas construidas, siempre, claro, hacia el lado donde tiene más peso la Hipótesis alternativa.
Al construir las tablas extremas, y calcular la suma de sus probabilidades, lo que hacemos es ver, de alguna forma, la posición que ocupa lo que vemos respecto a lo que podríamos ver bajo la Hipótesis nula. Entre todo lo que podríamos ver, si fuera cierta la Hipótesis nula, estamos valorando cuál es la probabilidad de ver lo que vemos más lo más extremo que tendría más posibilidades de verse bajo la Hipótesis alternativa. Esto es el p-valor. Y aquí está, en esencia, la noción de p-valor que manejamos en Estadística.
Los software estadísticos calculan estas probabilidades y nos proporcionan el p-valor según este criterio.
Veamos cómo calcularíamos estas probabilidades en las dos situaciones vistas anteriormente. Si aplicamos la función de densidad de la Distribución Hipergeométrica tendremos las siguientes probabilidades de cada una de las tablas mostradas anteriormente en las dos situaciones vistas:


Se calcula tanto el p-valor para el test unilateral como para el bilateral. El unilateral se entiende, claro, hacia el lado donde ya está inclinado el valor muestral.
Para calcular estos valores se dispone de tablas de esta distribución. Se trata de tablas muy largas, debido a que se trata de una distribución con tres parámetro y esto complica la elaboración de tablas, evidentemente.
En la siguiente tabla se muestra un pequeño fragmento de la tabla de la Hipergeométrica. Es un fragmento necesario para visualizar nuestros cálculos. Se trata de una N=15 porque el total de observaciones es 15. Como tenemos 6 y 9 valores entre enfermos y no enfermos la r será igual a 6, y la n será igual a 10, puesto que el grupo 1 está formado por 10. La tabla es de probabilidades acumuladas desde x=0 hasta el valor de interés. Por lo tanto, en nuestro caso, la primera suma de probabilidades que era 0,047 la observamos justo en el lugar de la tabla marcado en color azul. La segunda suma correspondiente al segundo caso, la suma de probabilidades (0,2868) la encontramos en el lugar marcado con el color rojo: