Una noción misteriosa en Estadística es la noción de potencia. Pero es una noción muy importante que conviene delimitar con mucha precisión.
En un proceso de decisión entre dos estados posibles, como ocurre en Estadística en el contraste de hipótesis, siempre podemos cometer dos errores diferentes y, también, como contrapartida, dos aciertos diferentes. Veamos el siguiente gráfico:

Una cosa es nuestra elección y otra cosa distinta es lo que es cierto. Como es una tabla de dos por dos, hay cuatro situaciones posibles. Dos de acierto y dos de error.
El error de tipo I es el denominado nivel de significación. Este error lo fijamos nosotros y normalmente se elige el valor de 0.05. Recordemos que el contraste consiste en elegir una zona de la distribución del estadístico de test usado para el contraste que tenga esa baja probabilidad bajo la H0 y que esté en una zona donde pese mucho la H1. El criterio de decisión es, entonces, el siguiente: Si el valor del estadístico de test cae en esa zona nos inclinaremos por rechazar la Hipótesis nula, de lo contrario no la rechazaremos, la mantendremos.
El error de tipo II, por el contrario, no está prefijado. La distribución del estadístico de test tiene una dispersión muy distinta dependiendo de la dispersión de la variable estudiada y del tamaño de muestra; o sea, dependiendo del Error estándar. Pero esa distribución será distinta según sea cierta la Hipótesis nula o lo sea la Hipótesis alternativa. Y, además, esas distribuciones al aumentar el tamaño de muestra con la que nos basamos para tomar decisiones, van segregándose, van separándose más. Esto hace cambiar el error de tipo II porque al optar por mantener la Hipótesis nula la probabilidad de que la Hipótesis alternativa sea cierta se reduce muchísimo. En definitiva, el error de tipo II viene dado por las condiciones concretas del test. Al tratar con muestras pequeñas el Error estándar es alto y las distribuciones bajo la Hipótesis nula y bajo la Hipótesis alternativa se solapan mucho. Sin embargo, al tratar con muestras grandes el Error estándar se reduce mucho y esas misma distribuciones se separan y es más factible tomar decisiones con menos posibilidades de error de tipo II.
La potencia es el complementario de ese error de tipo II. Potencia más Error de tipo II suman 1 ó, en tanto por ciento, suman 100. Por lo tanto, minimizar el error de tipo II supone, automáticamente, maximizar la Potencia.
Vamos a ver, todo esto, gráficamente. Observemos el siguiente gráfico:
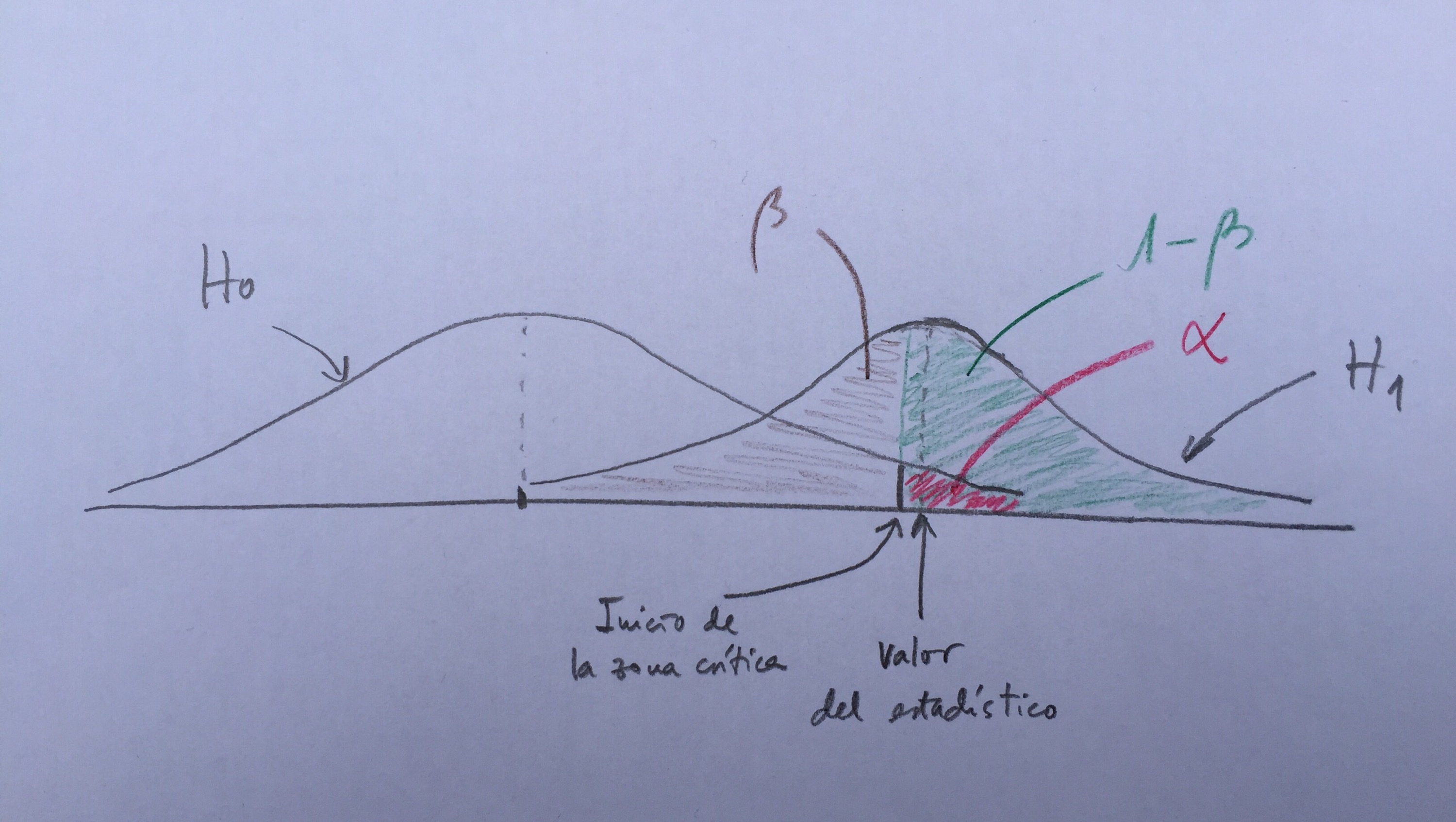
La distribución de la izquierda es la distribución supuesta si es cierta la hipótesis nula. Supongamos que es un test unilateral y contrastamos, en la alternativa, que la media es mayor que un cierto valor prefijado en la nula. Por lo tanto, la zona de rechazo de la hipótesis nula está hacia la derecha. Se construirá, entonces, una zona crítica de rechazo, de probabilidad 0.05 (la alfa), que es la zona roja. Si el valor del estadístico es donde apunta la flecha y construyo una distribución con media en ese punto y con la misma dispersión que en la nula podemos calcular todos los valores que nos interesan. La beta, la 1-beta (la potencia). Y esto se expresaría así:
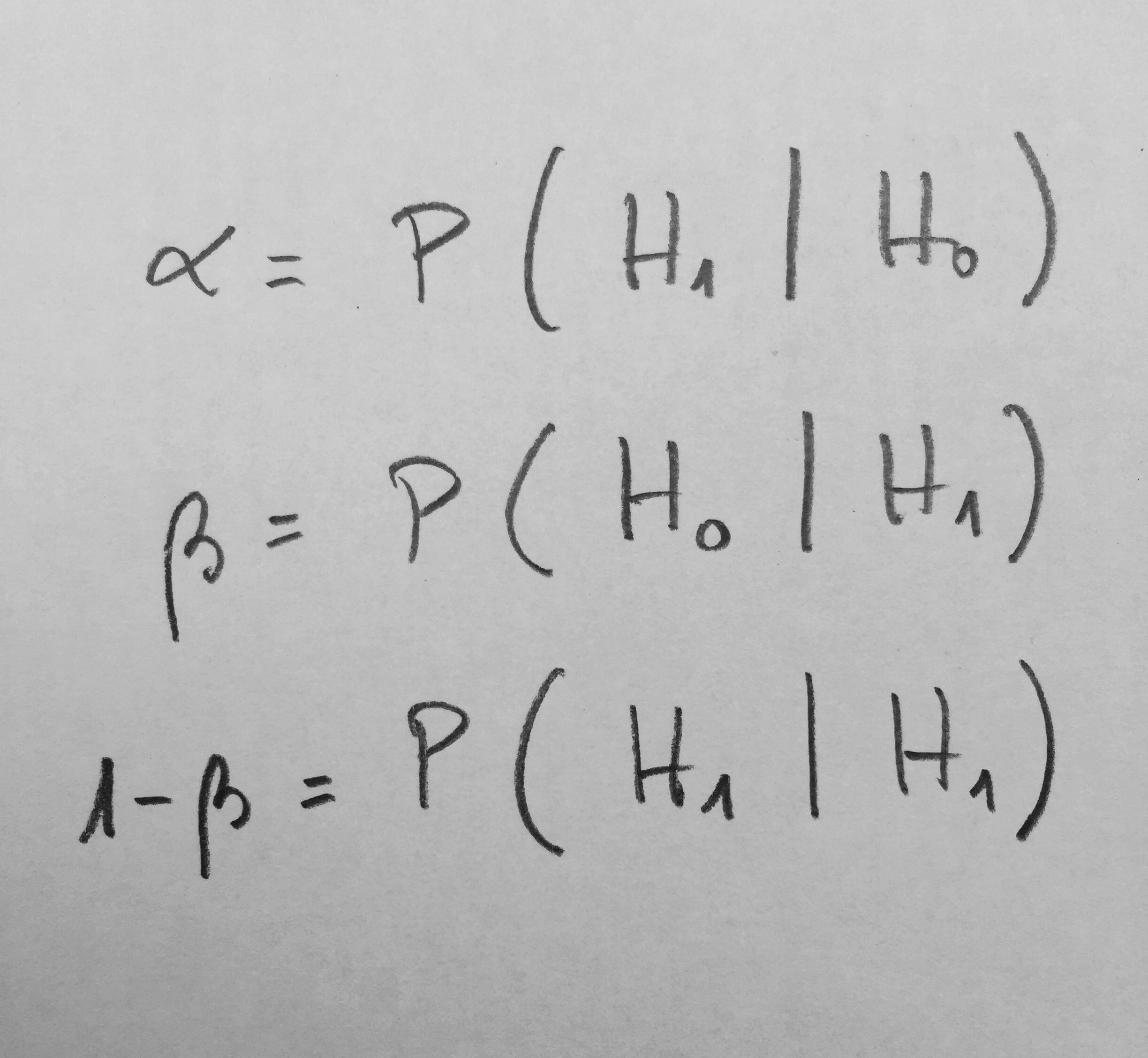
donde P(A/B) significa la probabilidad de decir A si es cierto B.
En este caso dibujado la beta es muy grande (próxima a 0.5) y la potencia, por lo tanto, es pequeña. En un contraste de hipótesis es muy importante tener potencia elevada. Una potencia igual o superior a 80% se considera ya una potencia elevada. De esta forma minimizamos la posibilidad de equivocarnos en nuestras decisiones. El 5% del error de tipo I es fijo y el error de tipo II lo debemos hacer lo más pequeño posible. Esto lo conseguimos con contrastes basados en muestras lo suficientemente grandes para alcanzar estos valores de referencia. Así conseguimos crear en Estadística procedimientos de decisión de mayor calidad, procedimientos más fiables, con menos errores.
La dispersión de estas curvas dibujadas depende del error estándar que tengamos; o sea, de la DE y de la n. La DE no depende de nosotros, pero la n sí. Veamos cómo quedan dibujados los diferentes conceptos implicados:
Podemos aumentar el tamaño de muestra del estudio. Si aumentamos el tamaño de muestra nos encontraremos con una situación considerablemente mejor. Menor beta y mayor potencia:
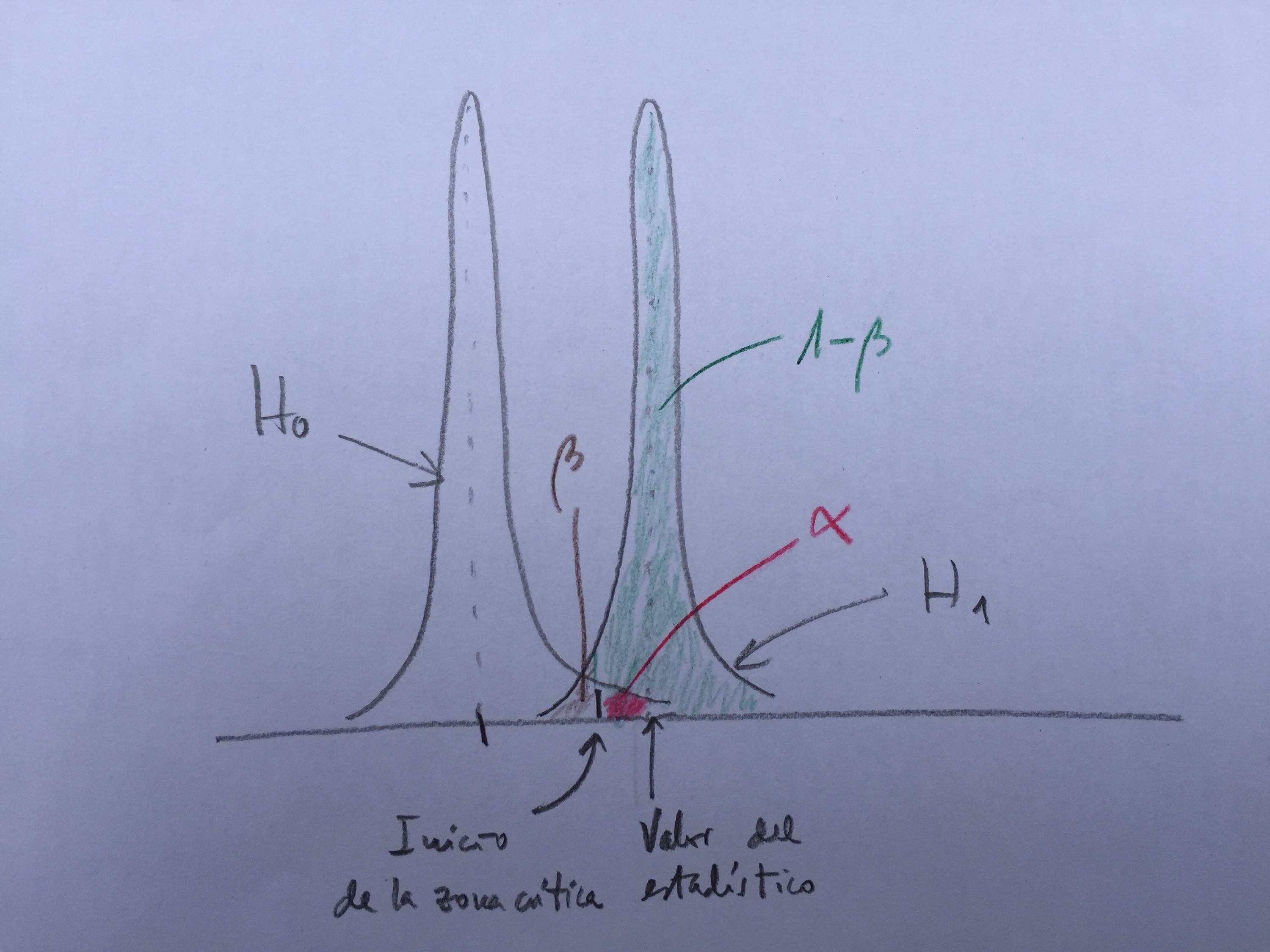
Tenemos, ahora, un contraste muy bueno. Con una beta muy baja y una potencia elevada.
Suele decirse que una baja potencia nos sirve para delimitar aquellas situaciones en las que no rechazamos la Hipótesis nula muy posiblemente por tener tamaños de muestra pequeños. Esto es cierto. Muchas veces, tamaños de muestra pequeños impiden ver diferencias que existen en la realidad. Pero la potencia, también, nos puede servir para criticar un estudio en el que ha salido un p-valor inferior a 0.05. Si es un estudio con poca potencia tampoco tiene el nivel de fiabilidad que, a priori, le podríamos dar viendo el p-valor que vemos.
De hecho, para darle una vuelta más a este importantísimo concepto estadístico, se puede decir que con la potencia tenemos un segundo mecanismo de seguridad en un contraste de hipótesis. Es como asegurarse más de las decisiones. Si sólo tuviéramos el nivel de significación, el p-valor, tendríamos menos protección. Al añadir la potencia tenemos un segundo mecanismo de seguridad, de control.
Por lo tanto, en un contraste no basta tener un p-valor pequeño sino tener una potencia grande. Observemos los tres gráficos mostrados a continuación. En los tres veremos que el valor del estadístico cae en zona crítica; o sea, el p-valor es menor que 0.05 pero la potencia es completamente distinta. El tamaño de muestra en el primer caso es bajo y por eso hay mucha dispersión en la distribución del estadístico de test. Sin embargo, el caso del medio y, especialmente el de abajo, en el que hay más tamaños de muestra progresivamente, conseguimos, al tener menor error estándar, separar más la distribución bajo la hipótesis nula y bajo la hipótesis alternativa (que es la construida sobre el valor obtenido en el estadístico de test). Ambas distribuciones se van separando cuanto más tamaño de muestra tengamos. Esto genera una situación de mayor potencia.
Supongamos los dos casos que se plantean a continuación:

A la izquierda estamos comparando dos muestras de tamaño 3 con una diferencia de medias considerable (las medias muestrales son 10 y 25) y con una Desviación estándar de 10. El p-valor que obtenemos es de 0.29, luego mantendríamos la Hipótesis nula de igualdad de medias. Pero mediante un calculador de la potencia, como el GRANMO, tenemos que la potencia es del 46%; o sea, que el error de tipo II es del 54%. Esto es demasiado error. El estudio no sería aceptable.
A la derecha estamos comparando dos muestras de tamaño 10 con una diferencia de medias considerable (las medias muestrales son, también, aquí, 10 y 25) y con una Desviación estándar de 15. El p-valor que obtenemos es de 0.048, luego rechazaríamos la Hipótesis nula de igualdad de medias. Pero mediante un calculador de la potencia, como el GRANMO, tenemos que la potencia es del 61%; o sea, que el error de tipo II es del 39%. Esto es, también, demasiado error. El estudio no sería aceptable.
Por lo tanto, con la potencia tenemos un segundo mecanismo de control, un segundo nivel de seguridad. El p-valor nos ayuda a decidir si hemos de mantener la hipótesis nula o pasarnos a lo que dice la hipótesis alternativa, pero la potencia da un segundo nivel de control. Una potencia elevada (superior al 80%) nos dirá que la interpretación que hagamos del p-valor está basada en un contraste lo suficientemente fiable desde el punto de vista del tamaño de muestra.
Por lo tanto, es muy importante, antes de hacer un estudio, delimitar el tamaño de muestra necesario para tener la potencia mínima exigible. De esta forma optimizamos el proceso de decisión.
Todo esto que acabamos de ver puede quedar complementado con el Tema 16: Determinación del tamaño de muestra que es un ámbito en el que la noción de potencia adquiere una importancia capital.
Veamos los tres casos siguientes:
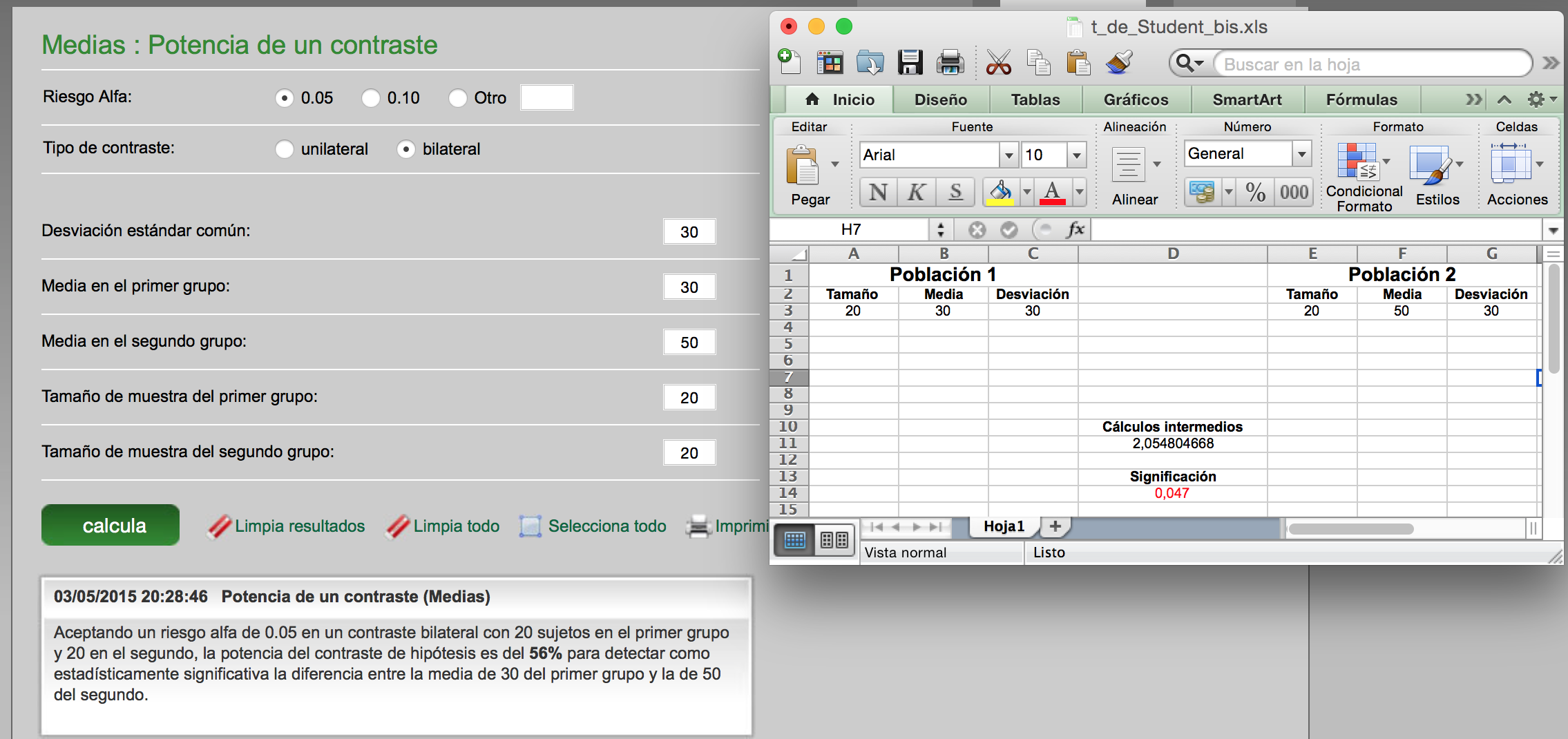
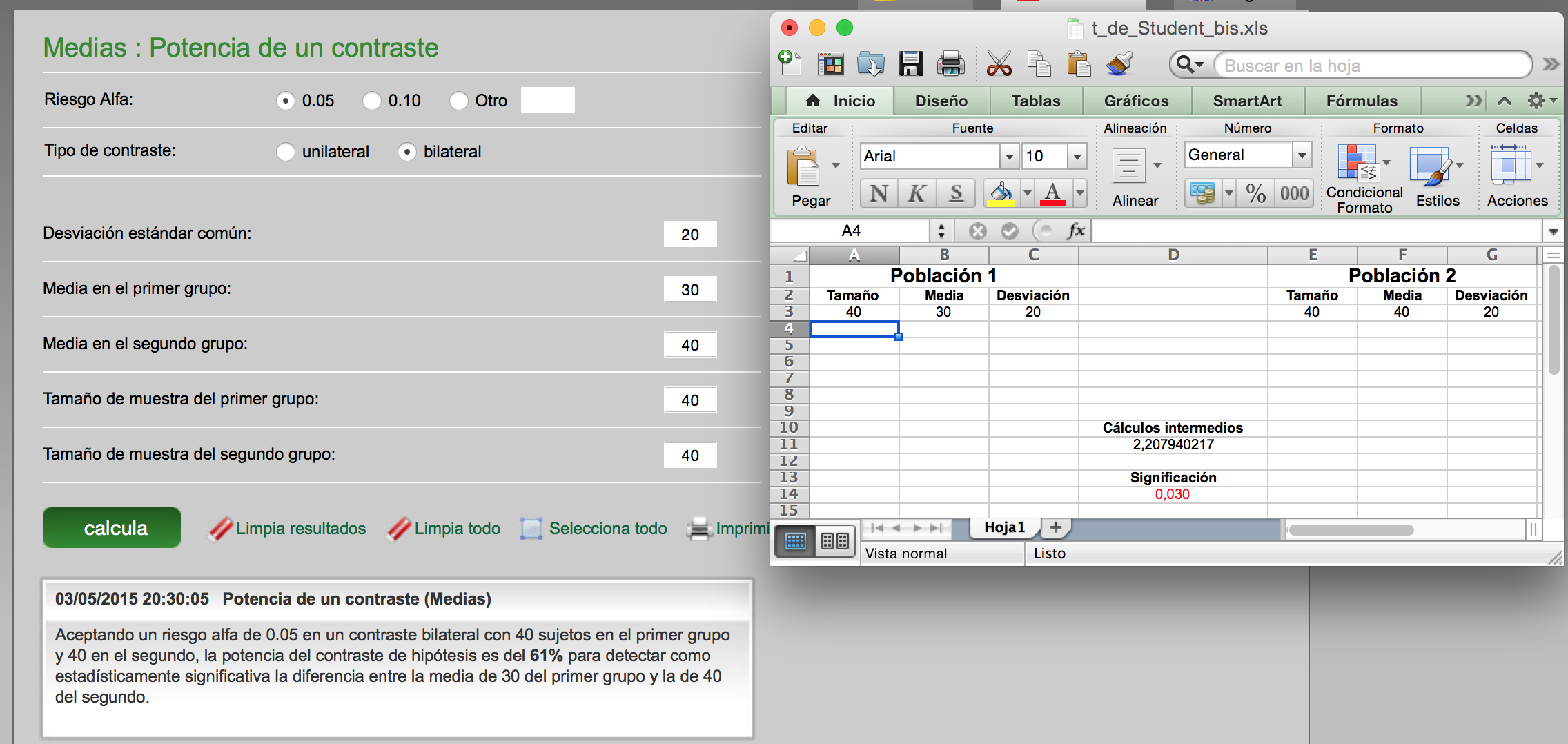
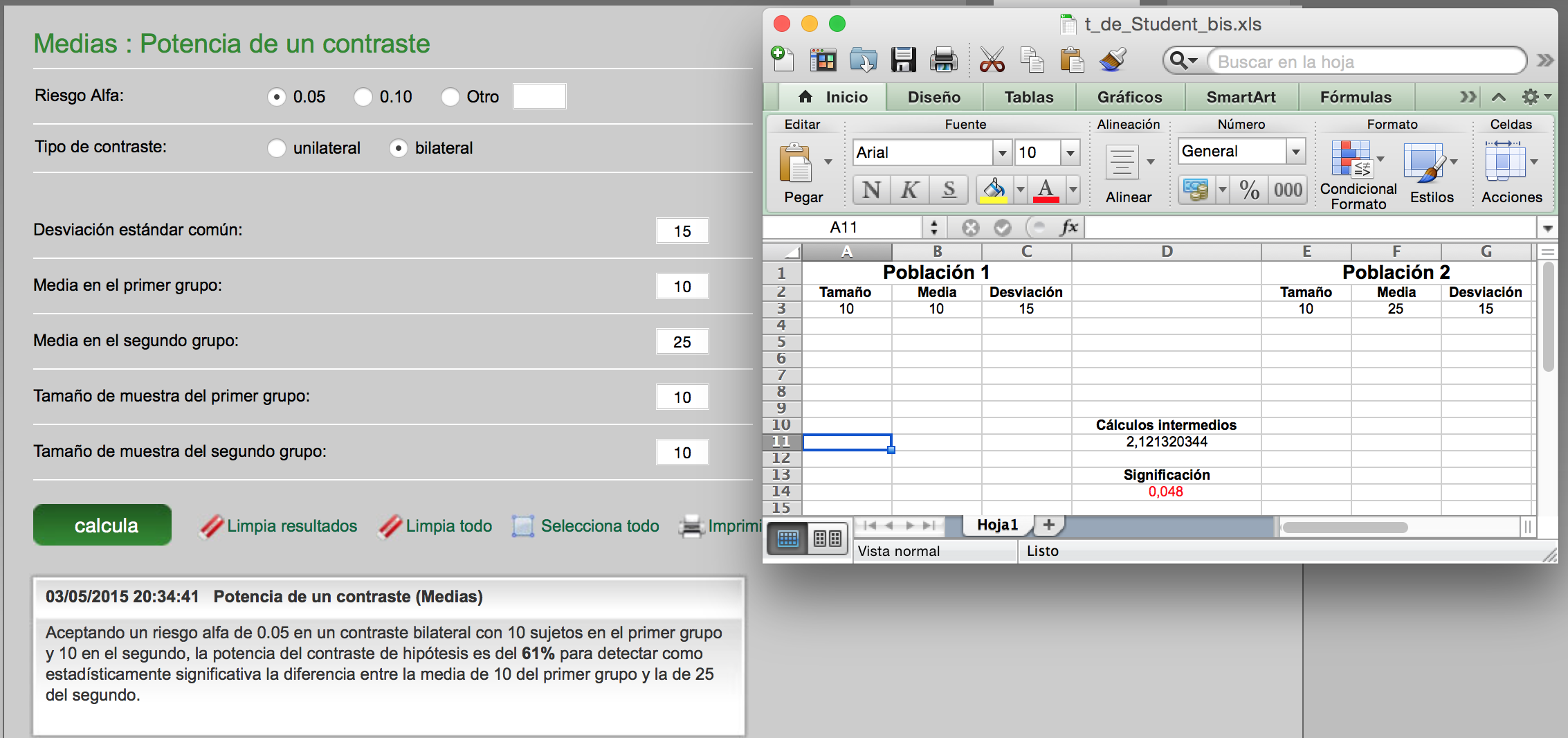
Son tres ejemplos donde si hacemos una t de Student de varianzas iguales tenemos un p-valor inferior a 0.05 (marcado en rojo) pero mediante el calculador de tamaño de muestras GRANMO se observa que la potencia es muy baja. Menor del mínimo aceptable del 80%.