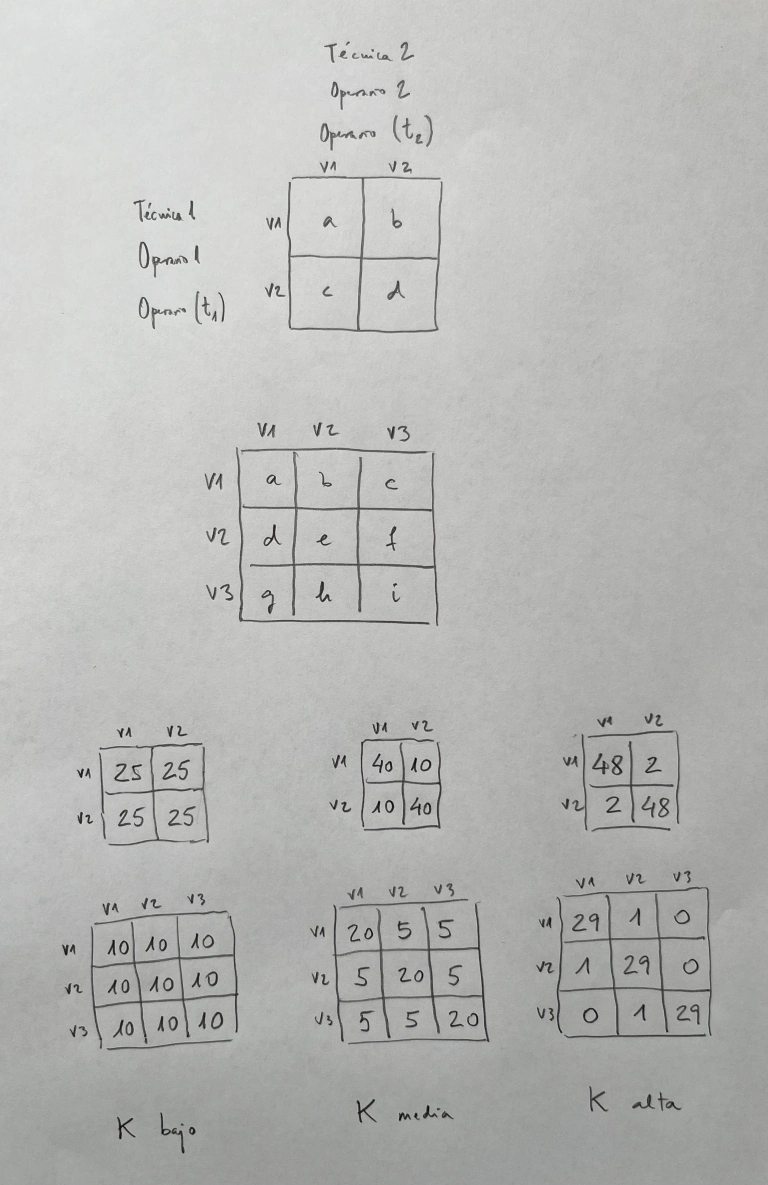
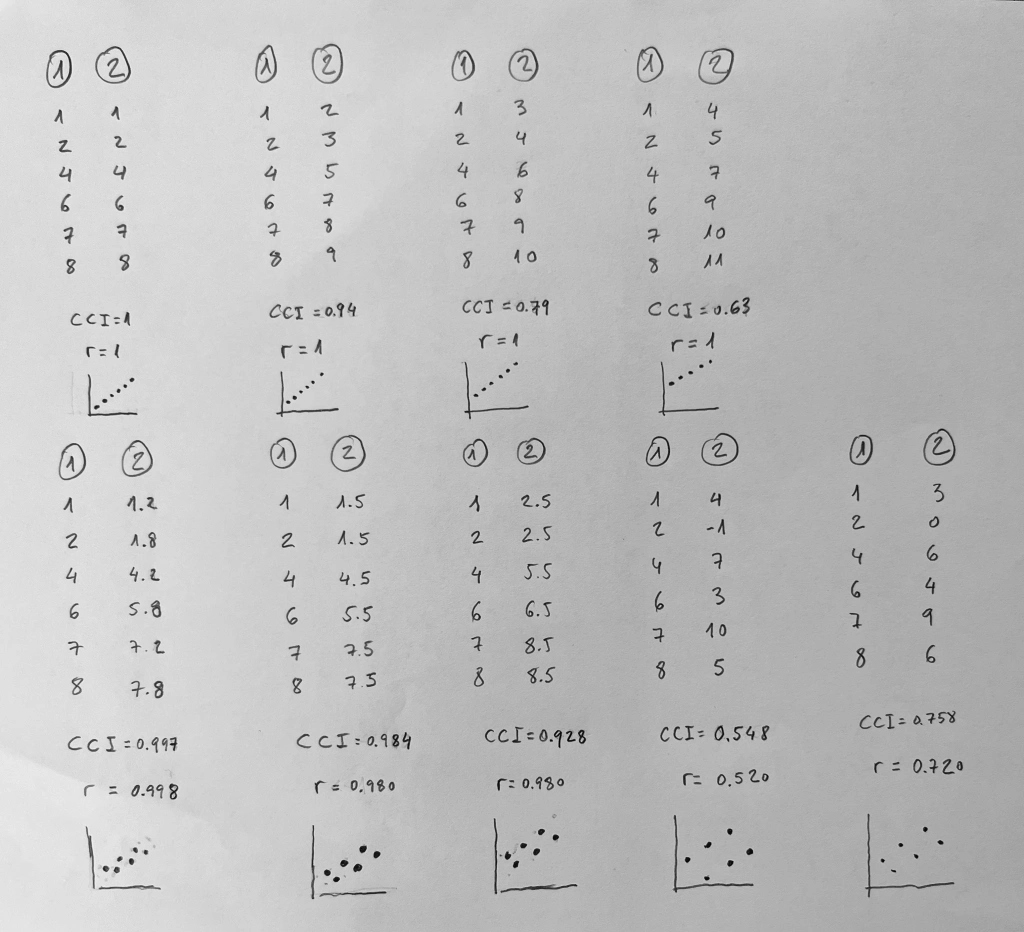
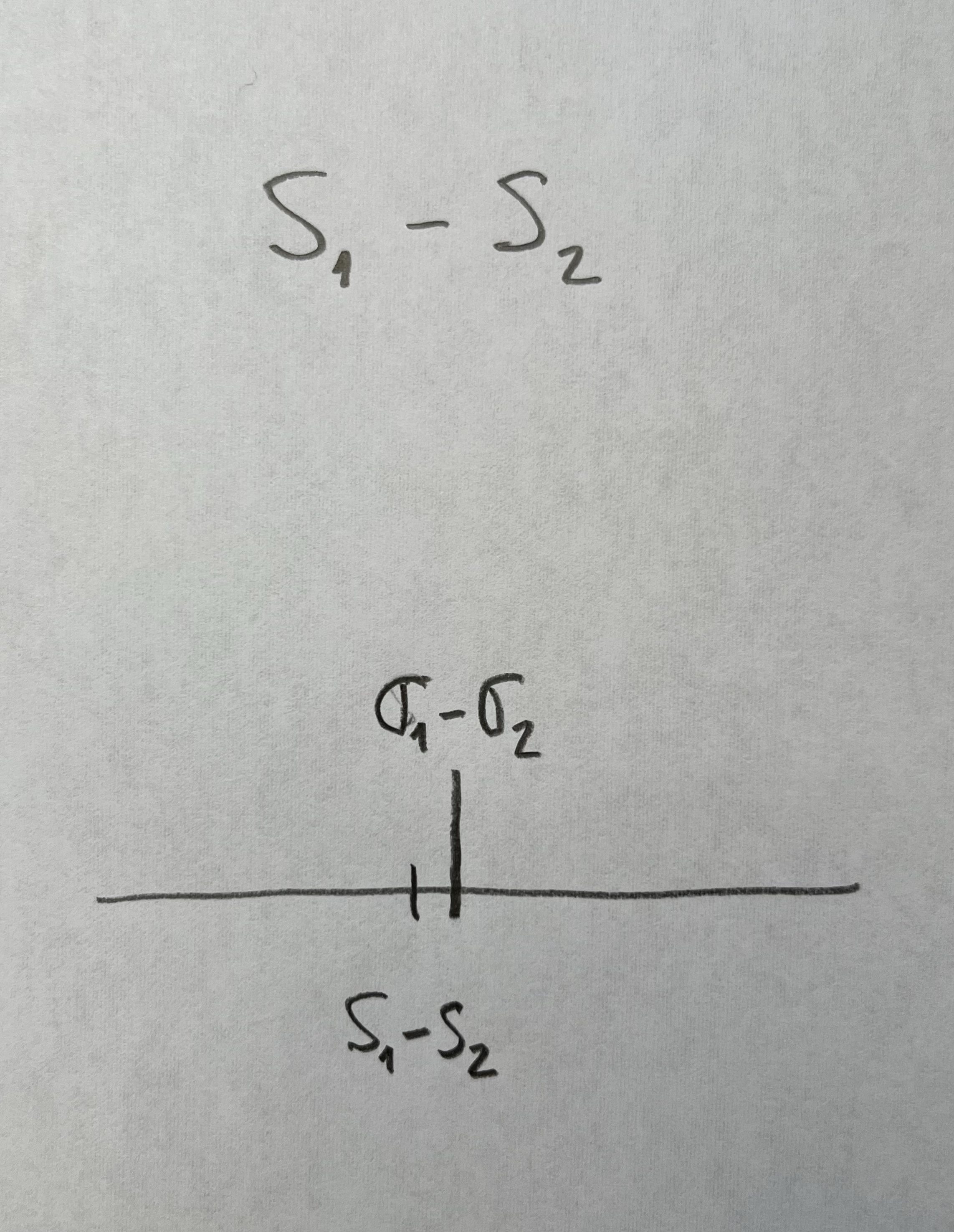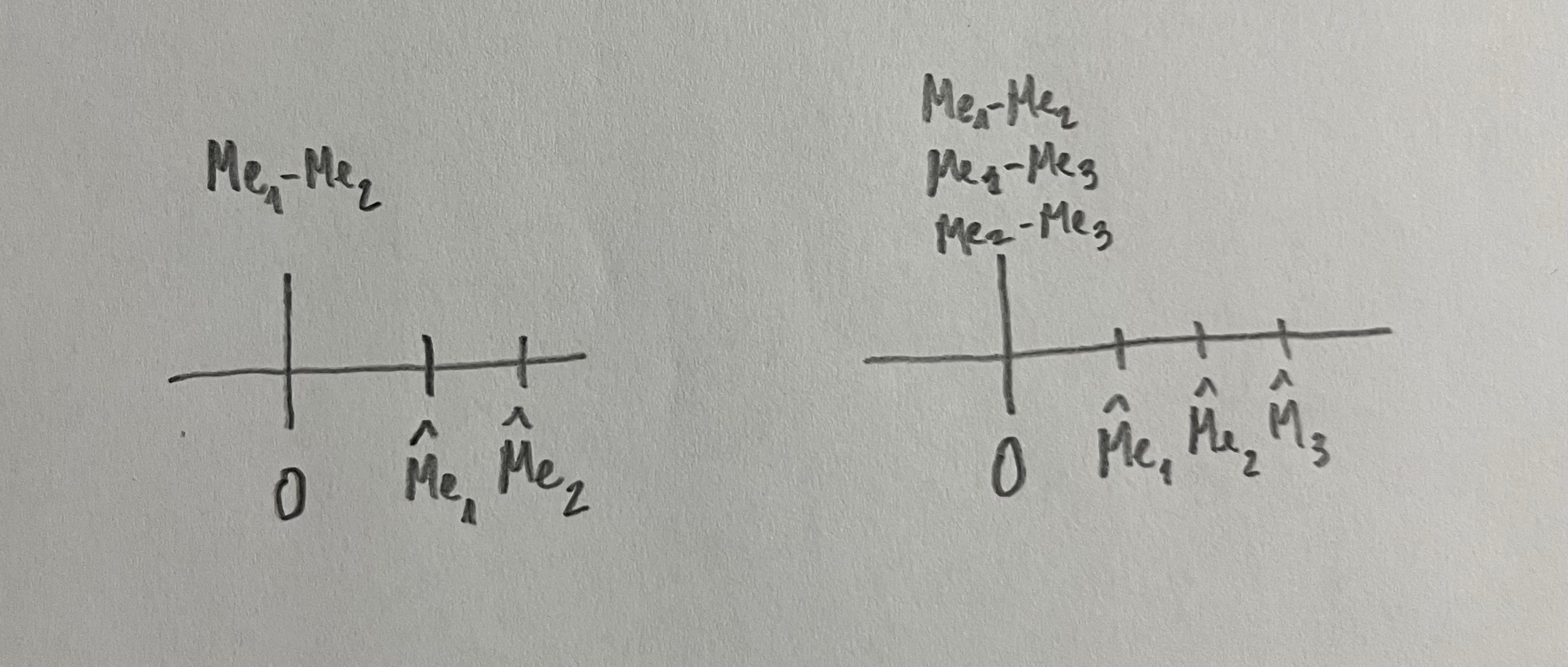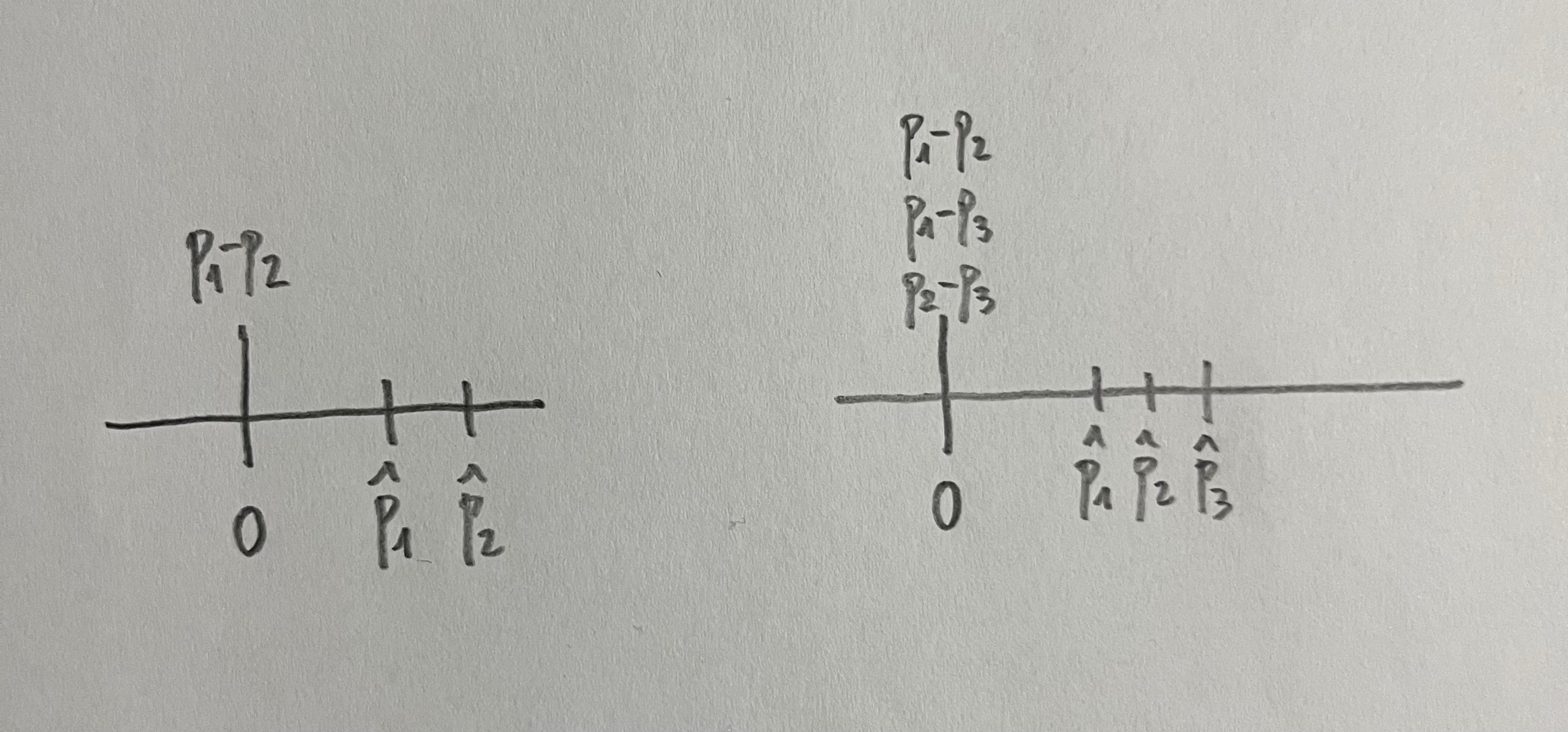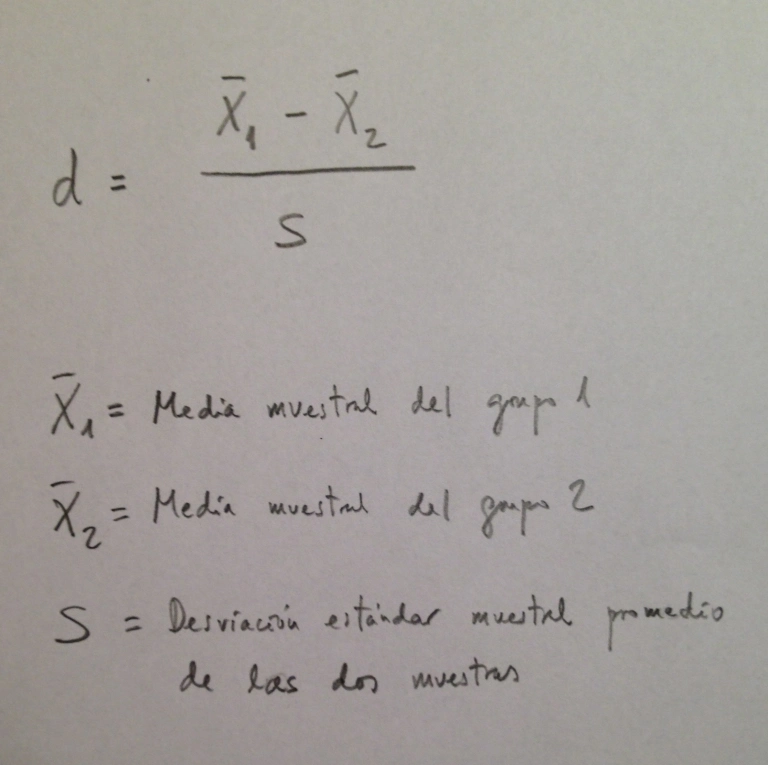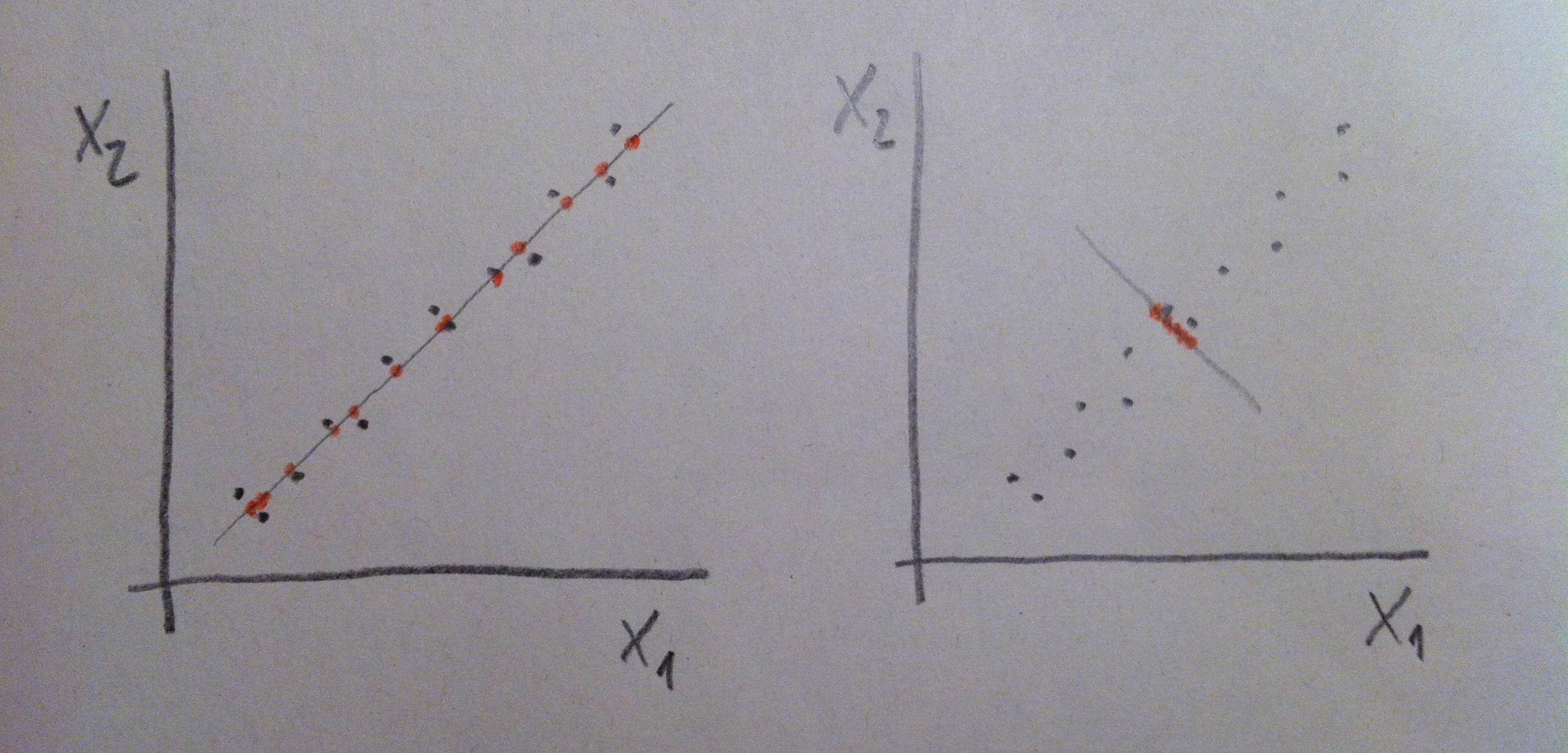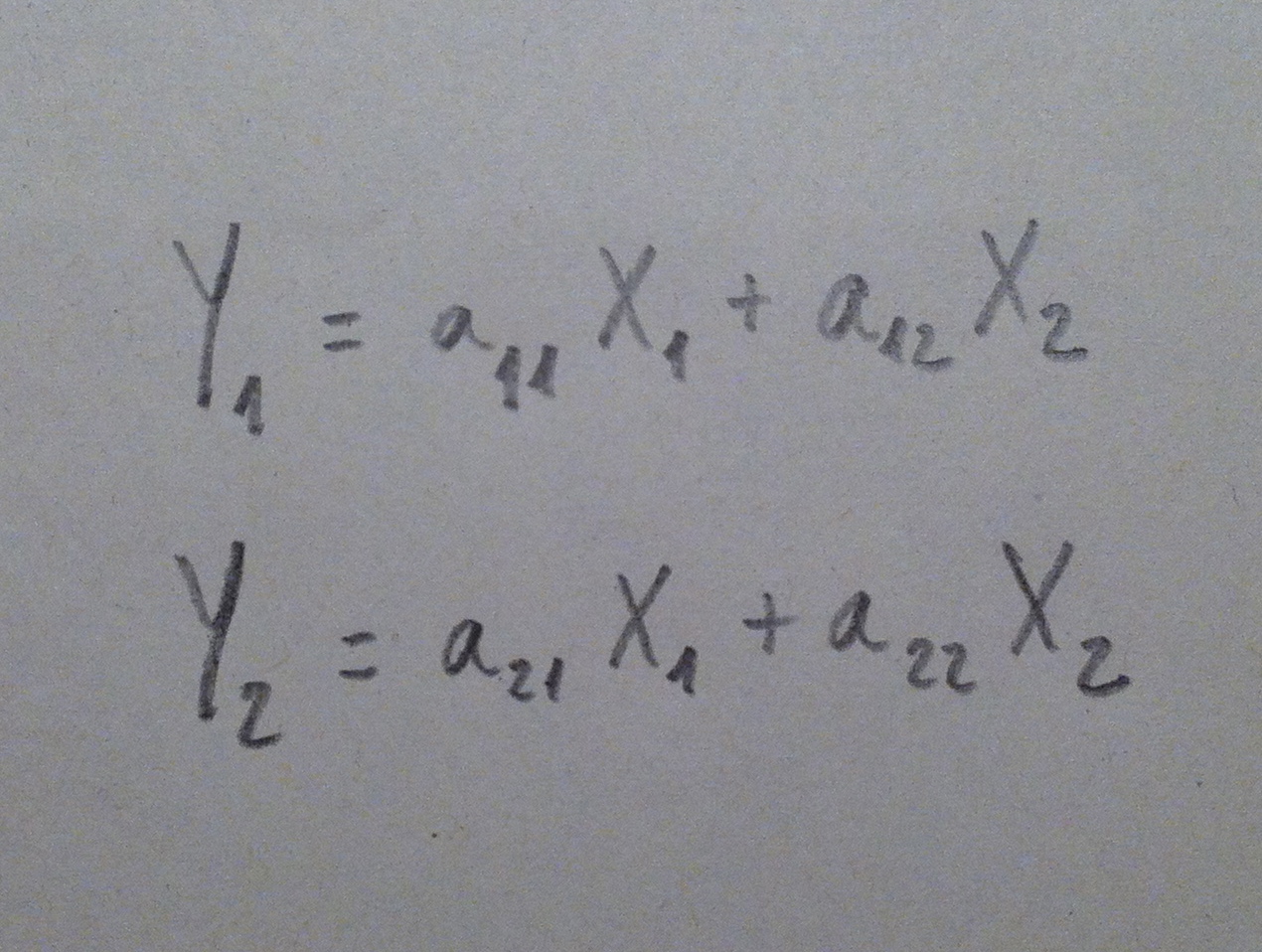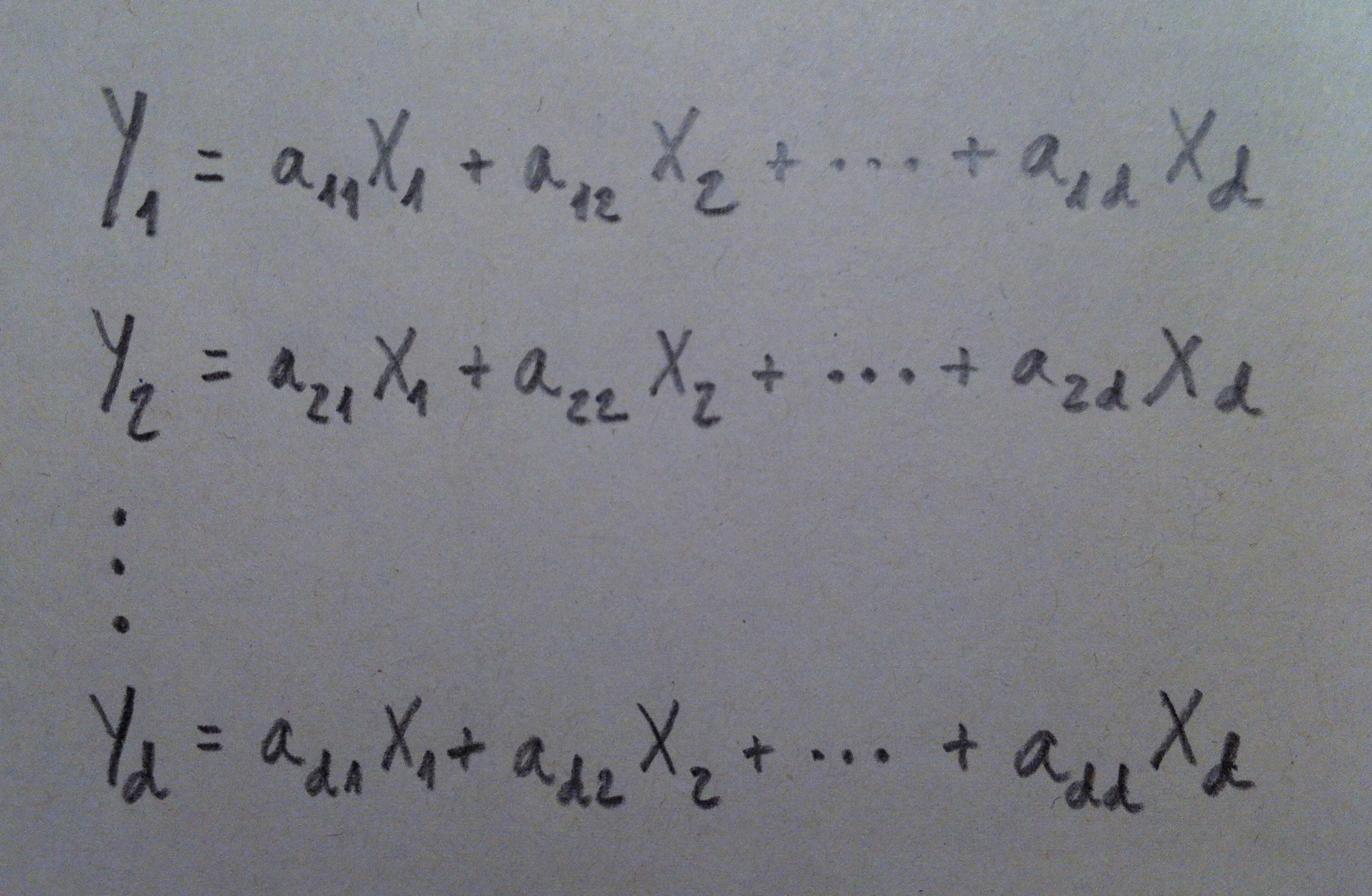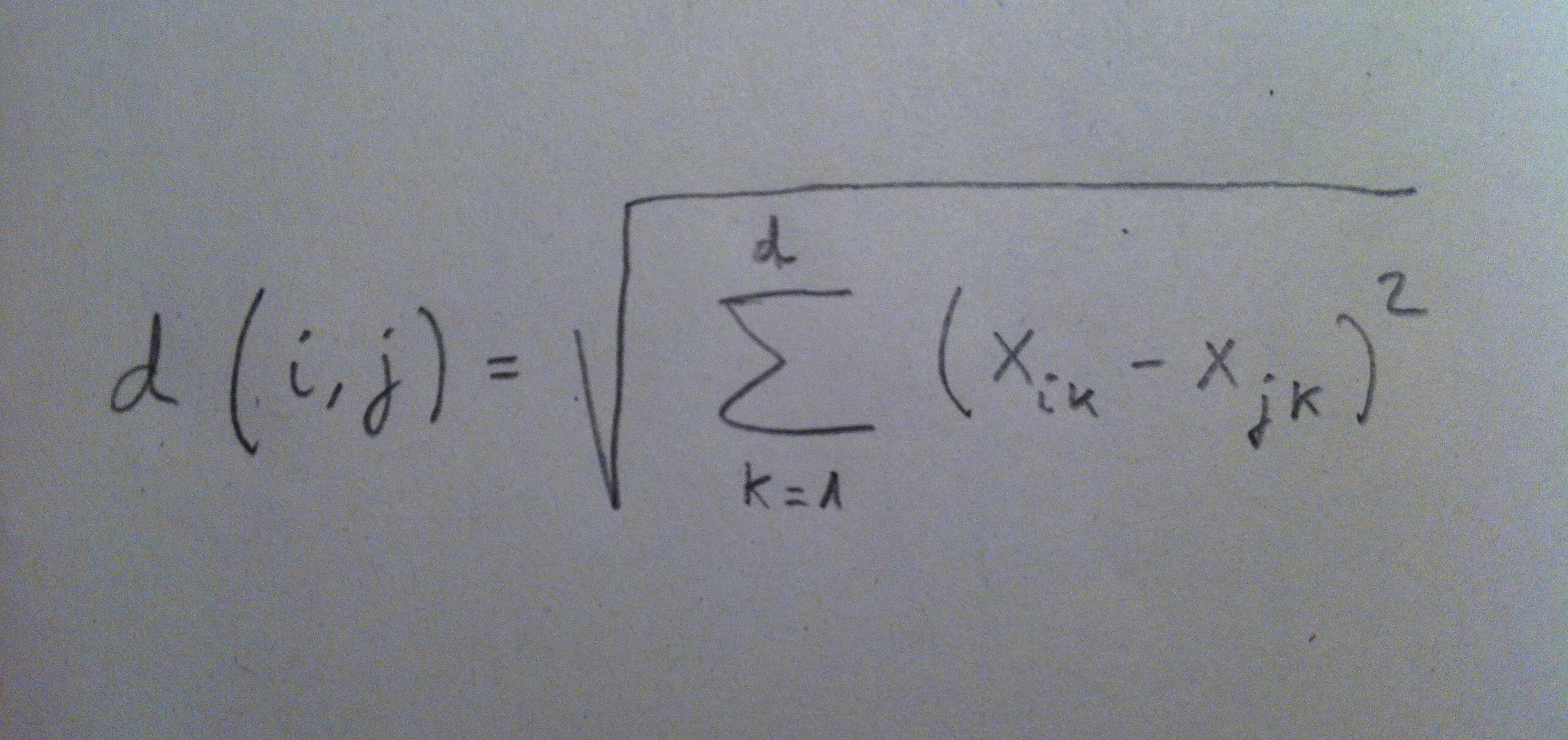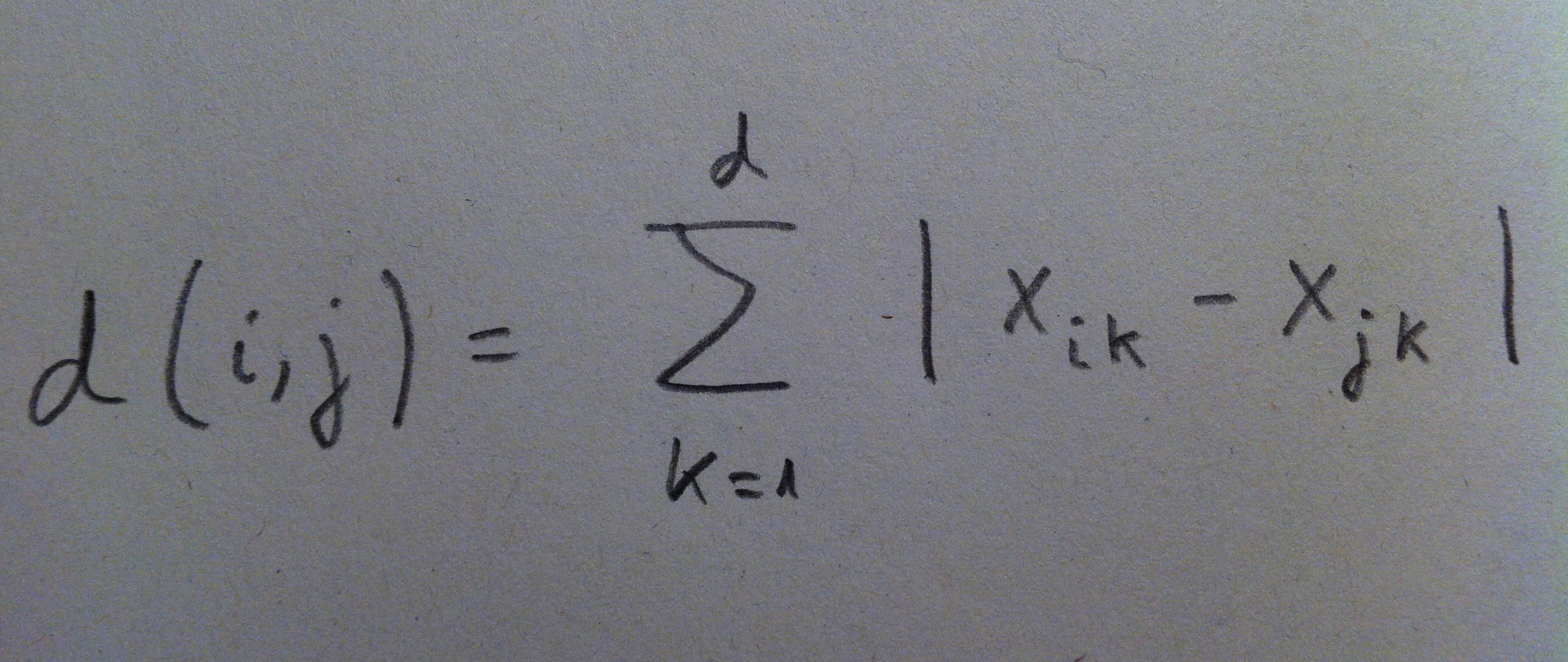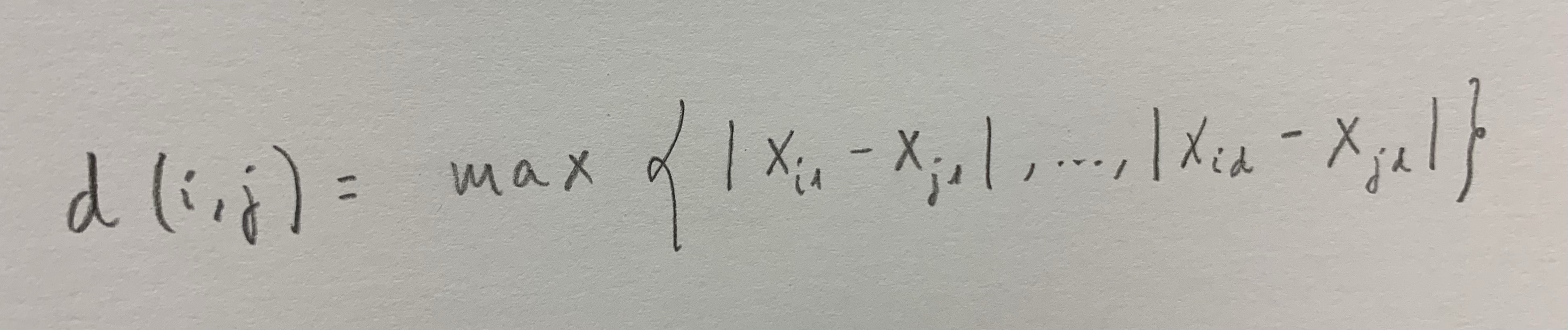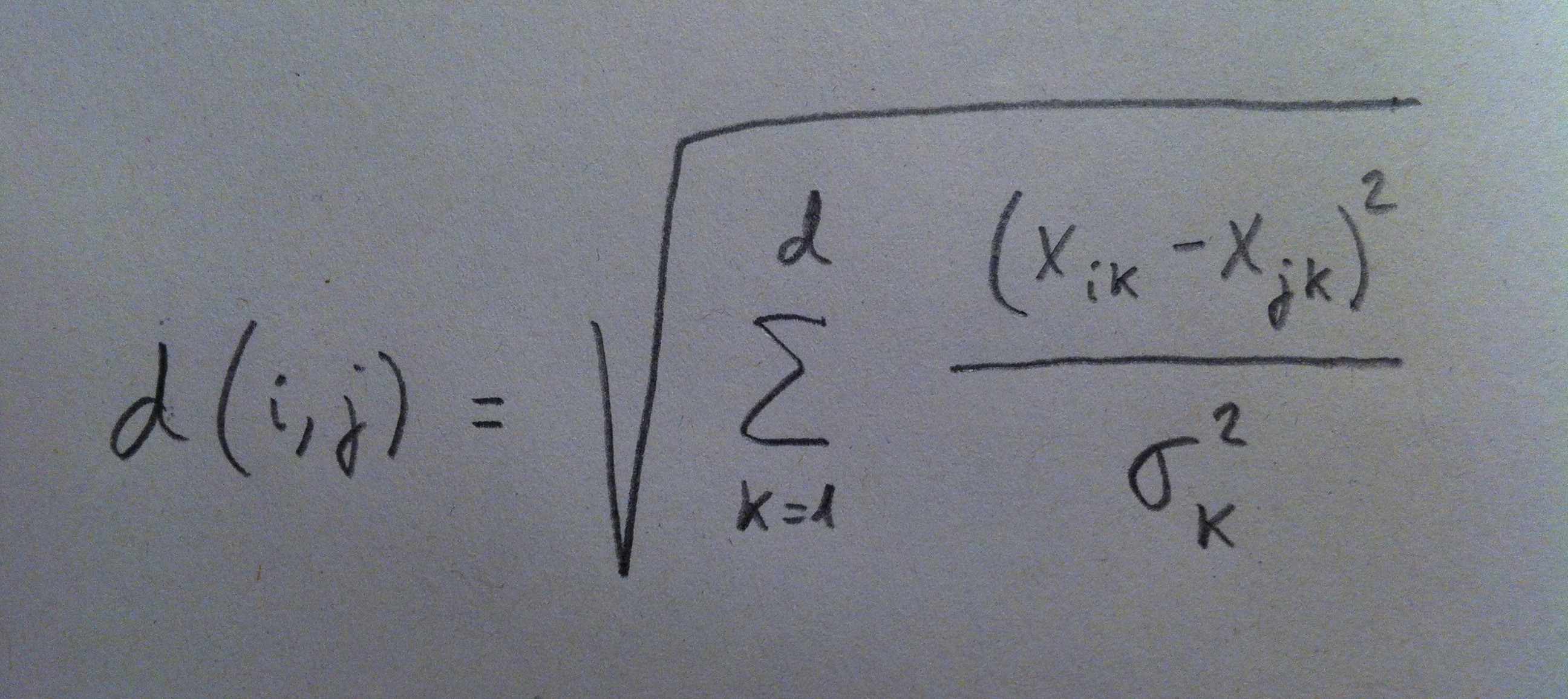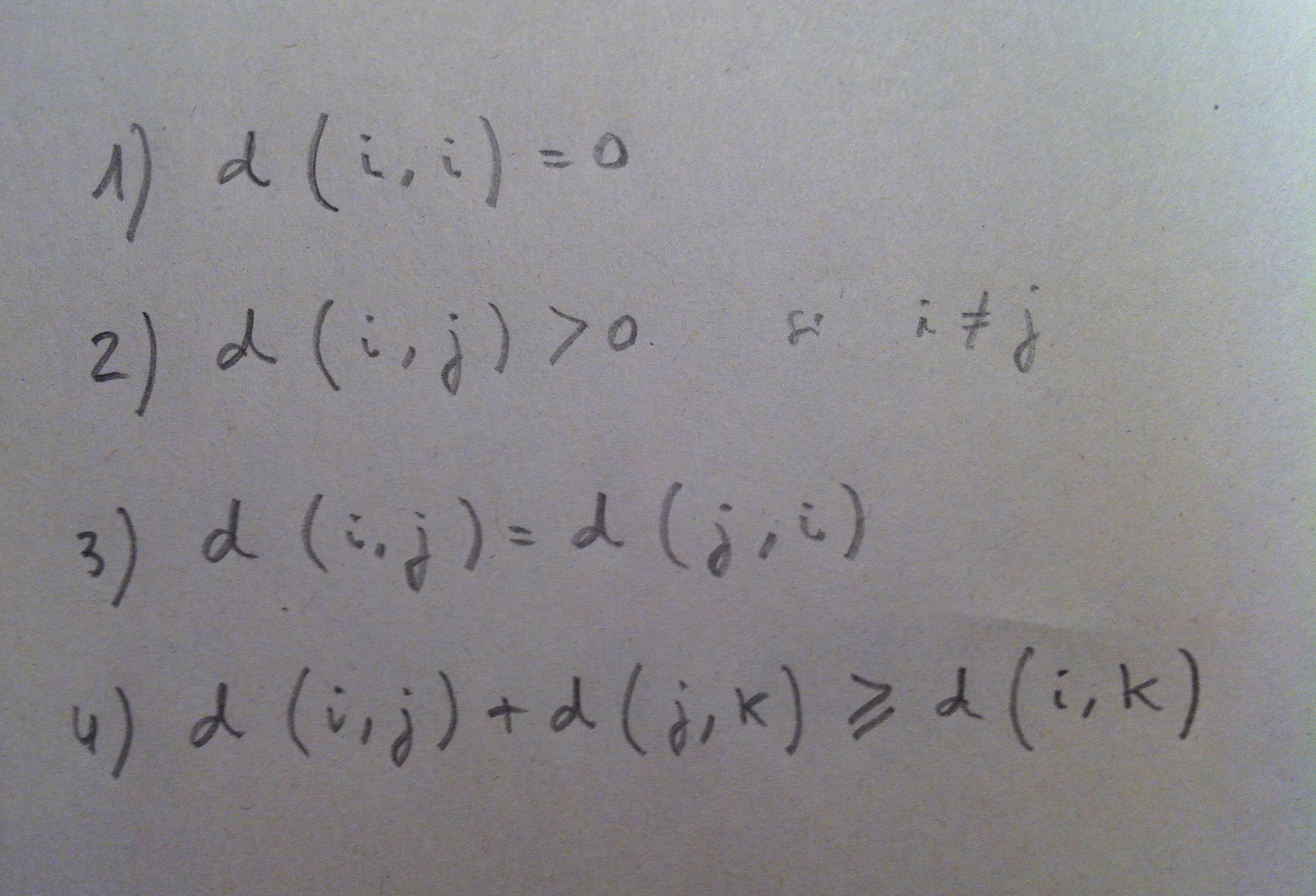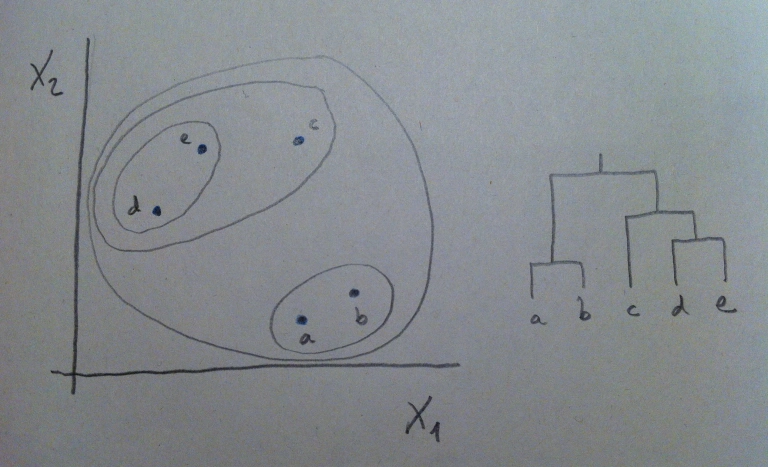En muchas ocasiones nos interesa comparar dos o más desviaciones estándar:
Nos puede interesar esta comparación como finalidad o, también, en muchas ocasiones, porque en las comparaciones de medias necesitamos saber si estamos comparando medias de poblaciones con igual dispersión o no.
Podemos tener dos medianas o más de dos medianas. El objetivo es comparar esas medianas; o sea, ver cuál es la diferencia entre ellas. Se suele evaluar si se puede aceptar que la diferencia de esas medianas es, poblacionalmente, cero, que es sinónimo de decir que las medianas son iguales.
Para evaluar si esas medianas son iguales o no realizamos un contraste de hipótesis o un intervalo de confianza.
Podemos tener dos medias o más de dos medias. El objetivo es comparar esas medias; o sea, ver cuál es la diferencia entre ellas. Se suele evaluar si se puede aceptar que la diferencia de esas medias es, poblacionalmente, cero, que es sinónimo de decir que las medias son iguales.
Para evaluar si esas medias son iguales o no realizamos un contraste de hipótesis o un intervalo de confianza.
Podemos comparar una población respecto a un valor de referencia, dos poblaciones o más de dos poblaciones.
Veamos ejemplos de diferencia de medias de más de dos poblaciones:
En la siguiente tabla comparamos, en tres localidades, por ejemplo, la longitud de ejemplares de una especie de insecto:
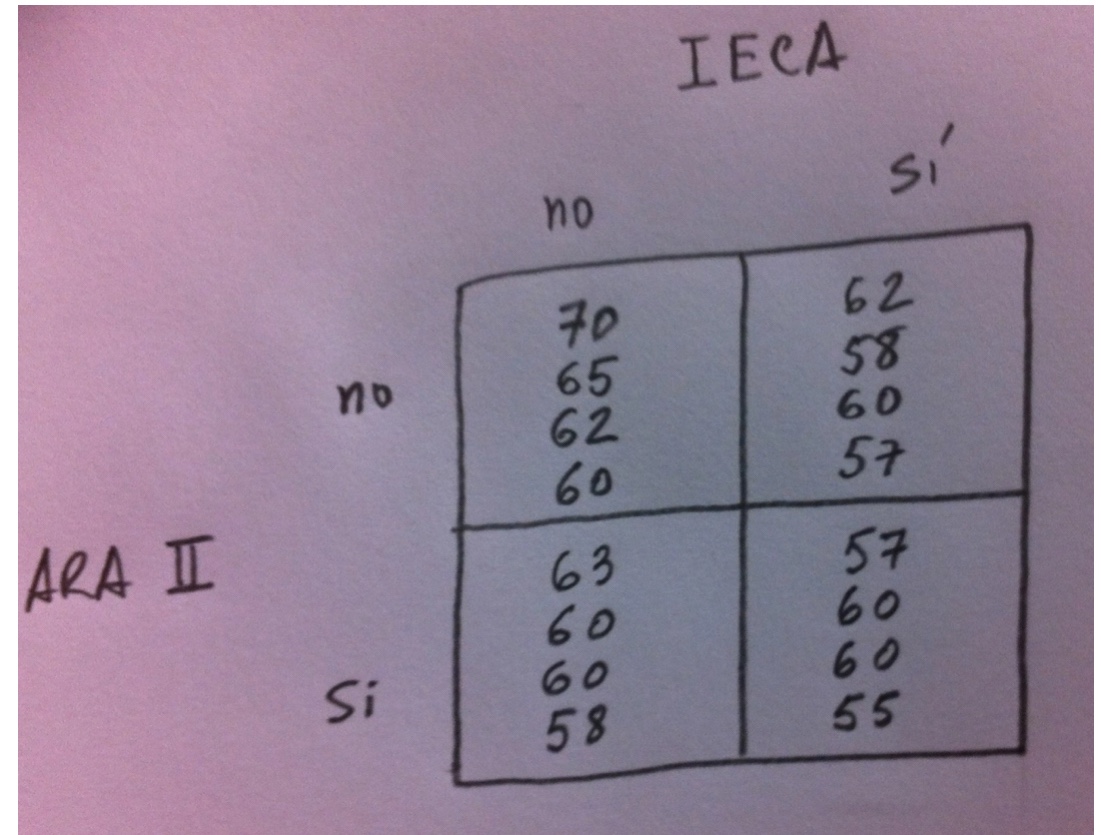
En la siguiente tabla comparamos cuatro poblaciones: pacientes que no toman ni ARA II ni IECA, pacientes que toman IECA pero no ARA II, pacientes que toman ARA II y no toman IECA y pacientes que toman los dos fármacos. Tenemos cuatro pacientes de cada grupo. La variable estudiada es la presión diastólica:
Otro ejemplo de cuatro poblaciones:
Otro ejemplo de cuatro poblaciones, con dos factores no cruzados sino anidados:
Podemos tener dos proporciones o más de dos proporciones. El objetivo es comparar esas proprociones; o sea, ver cuál es la diferencia entre ellas. Se suele evaluar si se puede aceptar que la diferencia es cero, que es sinónimo de decir que las proporciones son iguales:
Para evaluar si esas proporciones son iguales o no realizamos un contraste de hipótesis o un intervalo de confianza, que son los dos métodos, equivalentes en realidad, para tomar decisiones en Estadística.
Toda la explicación que a continuación tenéis del Análisis de componentes principales la podéis seguir, también, paralalamente, con la explicación de los siguientes vídeos:
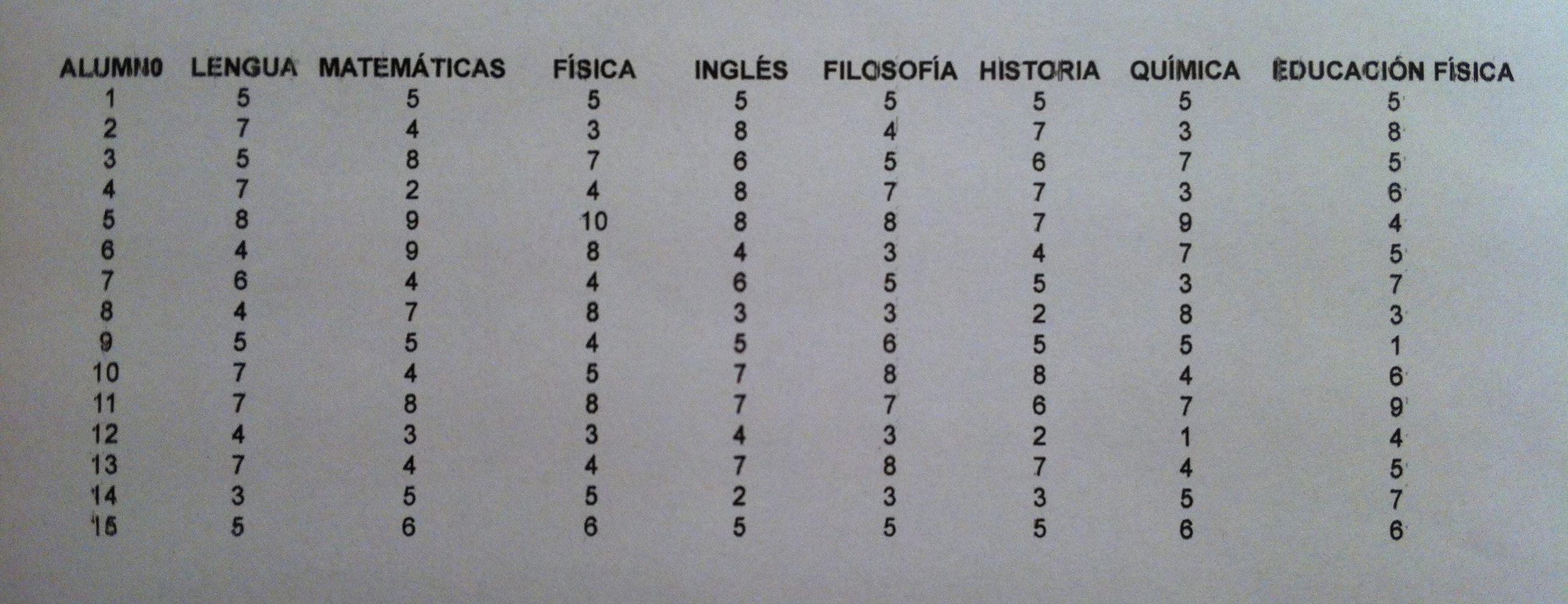
1. El Análisis de componentes principales (ACP) es una técnica estadística descriptiva que tiene como punto de partida una matriz de datos con una serie de individuos a los que se les ha medido varias variables. Por eso suele clasificarse como una técnica multivariante. Para guiarnos en esta técnica vamos a manejar unos datos como los que a continuación muestro:
2. Se trata de unos datos que todos comprendemos perfectamente porque todos hemos sido estudiantes. Se trata de las notas de diferentes materias que obtienen 15 alumnos de bachillerato. Tenemos, pues, 15 individuos en el estudio; o sea, una muestra de tamaño 15 pero con ocho variables, tantas como asignaturas tenemos.
3. Si quisiéramos representar los 15 alumnos de esta muestra en un gráfico lo podríamos hacer tomando dos notas y representando los 15 puntos según sus valores en el eje de abscisas y de ordenadas. Podríamos también, eso sí, hacer una representación de tres de esas ocho variables en un gráfico tridimensional. Pero aquí se acaba. Ya no podríamos visualizar una representación en más dimensiones. Por lo tanto, es imposible ver en un gráfico una representación de los 15 individuos respecto a todas las variables al mismo tiempo.
4. El ACP tiene como objetivo básico inicial suplir este déficit. Pretende, cuando vale la pena hacerlo (ya veremos cuándo vale la pena y cuándo no), realizar una representación de una nube de puntos multidimensional (de más de tres dimensiones), en dos o tres dimensiones. En definitiva, se trata de visualizar lo que no vemos. En nuestro ejemplo de los estudiantes de bachillerato el ACP trataría de hacer una representación de los 15 alumnos en dos o tres dimensiones pero contemplando todas las variables, sin prescindir de ninguna de ellas en el análisis.
5. Hay que hacer notar que, aunque el objetivo inicial es éste: la representación en dos o tres dimensiones de unos puntos que originariamente están en muchas dimensiones; o sea, visualizar lo que no vemos, la propia técnica, como consecuencia de su propio procedimiento, consigue crear unos objetos matemáticos (las componentes) muy interesantes que, en realidad, también podrían considerarse objetivos de la técnica porque, en muchas ocasiones, nos permiten establecer relaciones entre las variables, ver cómo se asocian, cómo se distancian, etc. De esto, no obstante, hablaré más tarde.
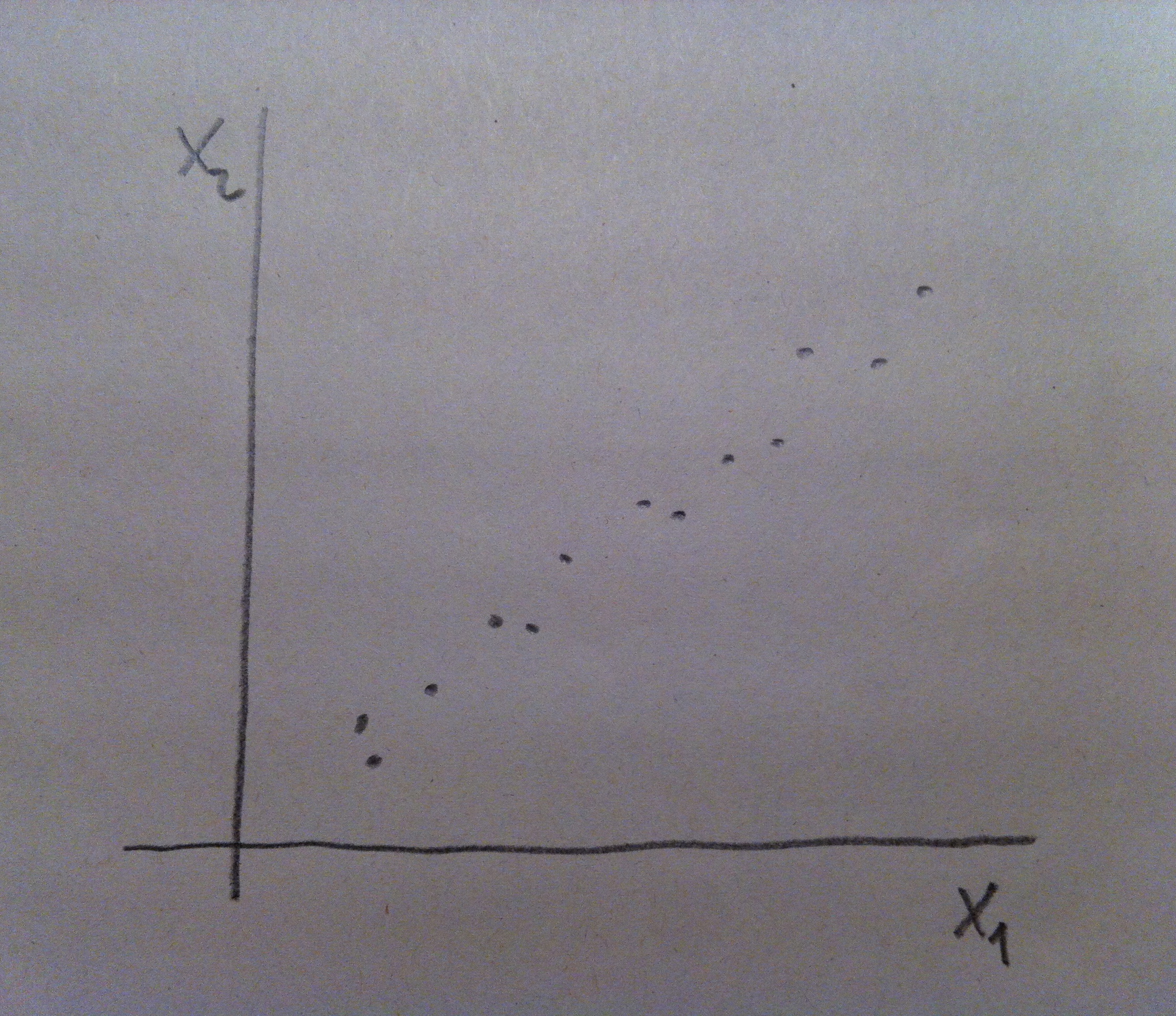
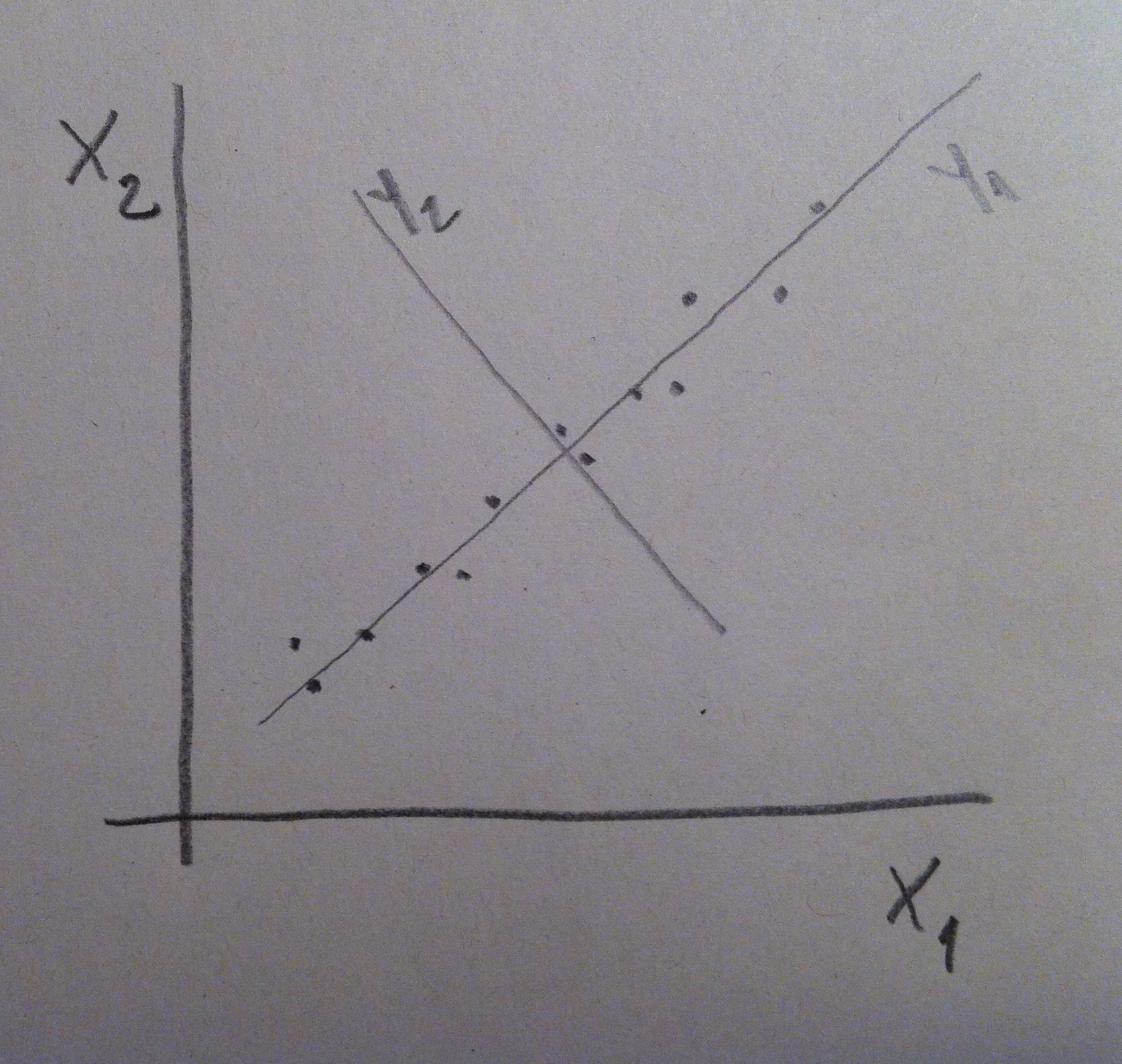
6. Vamos a ver el problema que estoy planteando pero miniaturizado. Así se entenderá mejor la esencia de la técnica. Supongamos que tenemos la siguiente representación bidimensional con dos variables X1 y X2:
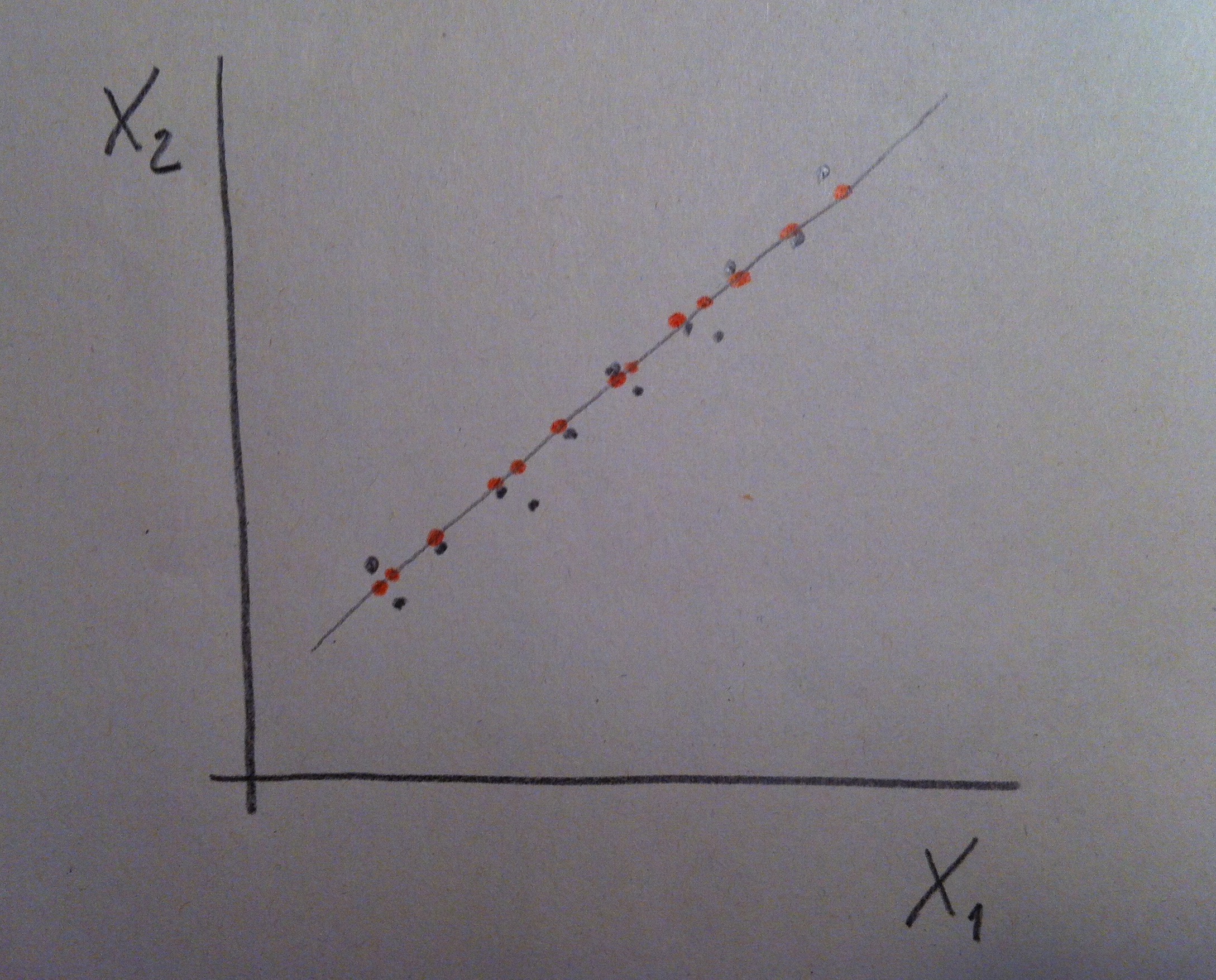
7. Y supongamos que unos seres unidimensionales, que únicamente ven las cosas si están en una dimensión, quieren representar, en una única dimensión, esta nube de puntos que ellos, evidentemente, no pueden ver. Observemos que si lo que quieren es no prescindir de ninguna de las dos variables lo que pueden hacer es representar las proyecciones de los puntos sobre un eje como el dibujado en la siguiente figura:
8. Observemos que la nube de puntos roja, que está integrada por las proyecciones de los puntos originales sobre el nuevo eje, se parece bastante a la nube de puntos original. Las posiciones relativas de los puntos se respetan bastante. Y ahora los seres que sólo ven en una dimensión lo ven. Están viendo una representación unidimensional de una realidad bidimensional y lo hacen con bastante fidelidad. La nube de puntos roja se parece bastante a la negra. Ellos sólo ven la roja pero realmente es una buena aproximación de la original, que es la negra.
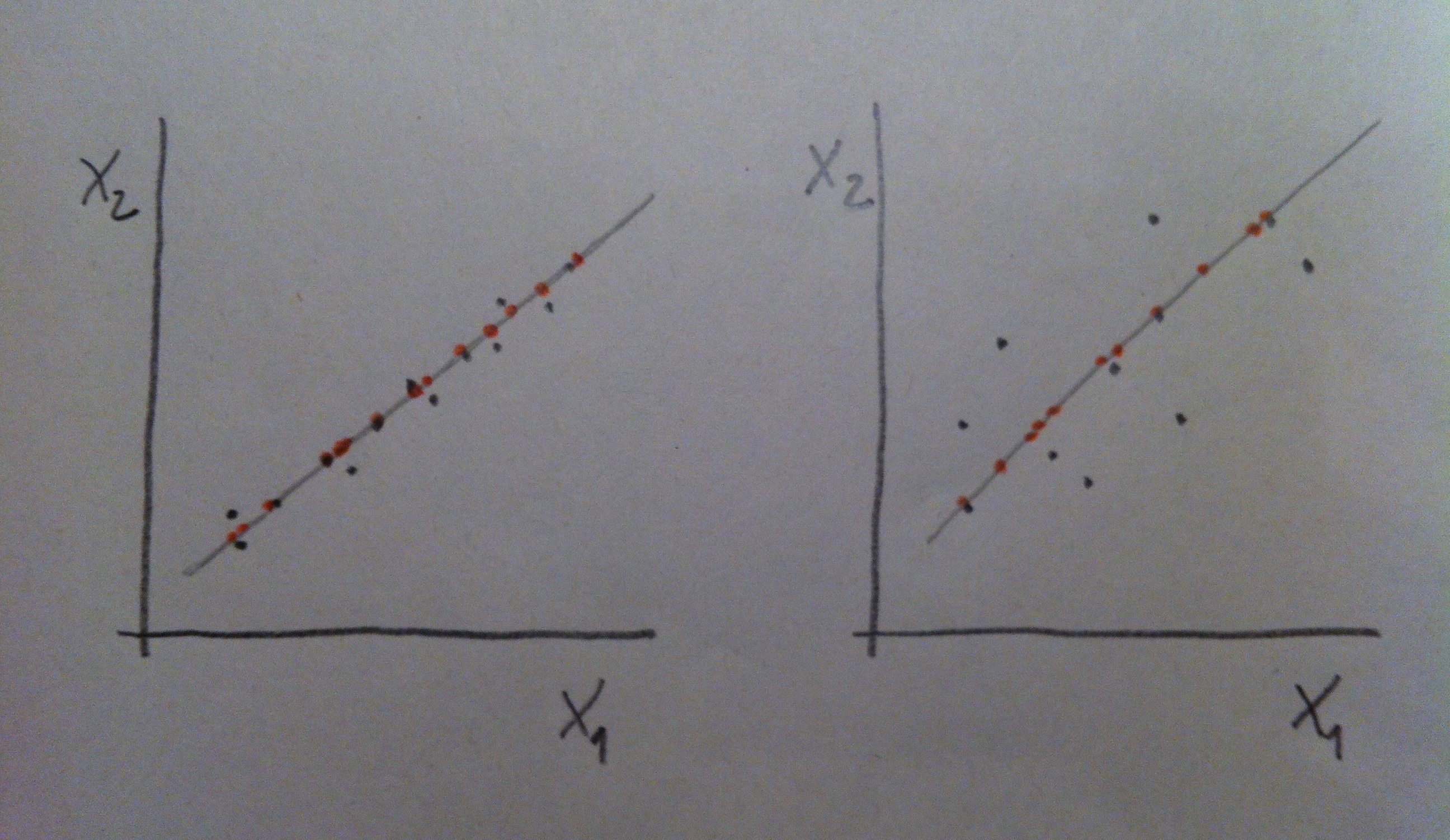
9. La representación en menos dimensiones no siempre tiene la misma calidad. En el gráfico siguiente vemos que a la izquierda la nube de puntos proyectada sobre el nuevo eje (la nube de puntos roja) se parece más a la original de lo que se parecen la roja y la negra en la situación mostrada en el gráfico de la derecha. Por lo tanto, en los datos de la derecha tiene menos valor realizar un ACP:
10. Y observemos que cuando he dibujado el eje para proyectar los valores sobre él lo he hecho situándolo de una forma, pero lo hubiera podido situar de otra. Observemos en el gráfico siguiente que el eje dispuesto en el ejemplo de la derecha no consigue, mediante la proyección de los puntos sobre ella, una nube de puntos representativa de la nube de puntos original:
11. Lo que hemos hecho es, en definitiva, un giro de los ejes de coordenadas sin tocar los puntos. Observemos lo que hemos hecho:
12. Lo importante es que ahora vemos la nube de puntos desde unos ejes donde uno es mucho más importante que el otro. Ahora los ejes son Y1 y Y2. Si X1 y X2 eran dos variables que tenían la misma cantidad de información, ahora Y1 y Y2 no tienen la misma cantidad de información. Y1 tiene mucha más información que Y2. En Estadística información es equivalente a dispersión, a varianza. Una variable que no varía no tiene información. Una variable que varía mucho tener el valor de un individuo es muy informativo.
13. El objetivo de la técnica ACP es, pues, éste: conseguir girar los ejes de tal forma que exista la mayor desigualdad posible entre la varianza de la nube de puntos original en las proyecciones en cada uno de los respectivos nuevos ejes y que, además, estos ejes, estas nuevas variables, sean independientes entre sí; o sea, que tengan correlación cero.
14. La búsqueda de estos nuevos ejes se hace mediante el cálculo de los llamados valores propios y vectores propios de la matriz de correlaciones entre todas las variables del estudio. Puede hacerse también a partir de otra matriz, la de varianzas-covarianzas, pero ésta tiene el problema de que cuando las variables tienen unidades de escala muy diferentes introduce un exceso de influencia por parte de las variables con mayor varianza. Por esto suele trabajarse con la matriz de correlaciones. De esta forma se unifica el peso de las variables iniciales del estudio. Suele hablarse de variables estandarizadas cuando se trabaja con la matriz de correlaciones. Una variable es estandarizada cuando la muestra se transforma a media cero y Desviación estándar uno. Esto se hace restando a cada valor muestral la media muestral y dividiendo por la Desviación estándar. De esta forma todas las variables del estudio tienen la misma media y la misma Desviación estándar y ninguna pesa más que otra. De esta forma la vocalización del estudio se pone en cómo es la forma de la nube de puntos, de cuáles son las relaciones entre las variables que permiten reducir dimensiones perdiendo el mínimo de información.
15. Algo muy importante: ¿Cuál es la relación existente entre las variables originales y las nuevas variables, los nuevos ejes; o sea, cuál es la relación, en el caso que hemos dibujado entre las variables X1 y X2 y las variables Y1 y Y2?
16. En primer lugar decir que a las variables Y1 y Y2, que son, eso, variables, también, como las originales, las llamamos en esta técnica “Componentes”. Y son cada una de ellas una combinación de las variables originales. Observemos la fórmula de esa combinación:
17. En realidad estos coeficientes que multiplican a las variables originales son los vectores propios de la matriz de correlaciones, es la fórmula de la transformación lineal realizada. Hemos cambiado de ejes y para llegar de los ejes originales a los nuevos ejes hace falta esta transformación. En definitiva, si tenemos un punto representado por las coordenadas originales, éstas son las fórmulas necesarias para conseguir las coordenadas de la nueva representación: la representación mediante los ejes constituidos por las componentes.
18. Si en el lugar de estar trabajando con dos variables originales estuviéramos trabajando con d variables originales la fórmula de las d componentes sería:
19. Se llama a la técnica Análisis de componentes principales porque transforma a las variables originales en nuevas variables, las componentes, las cuales tiene desigualdad en cuanto a la información explicada, lo que significa que tenemos unas componentes muy informativas y otras que no. Por eso tenemos unas componentes principales, que son las que usaremos para hacer la representación. Esta desigualdad generada al crear las componentes nos permite elegir, entre ellas, las principales y eliminar las poco importantes, cosa que no sucedía con las originales porque ellas eran todas principales, todas eran importantes, no podíamos prescindir de ninguna de ellas.
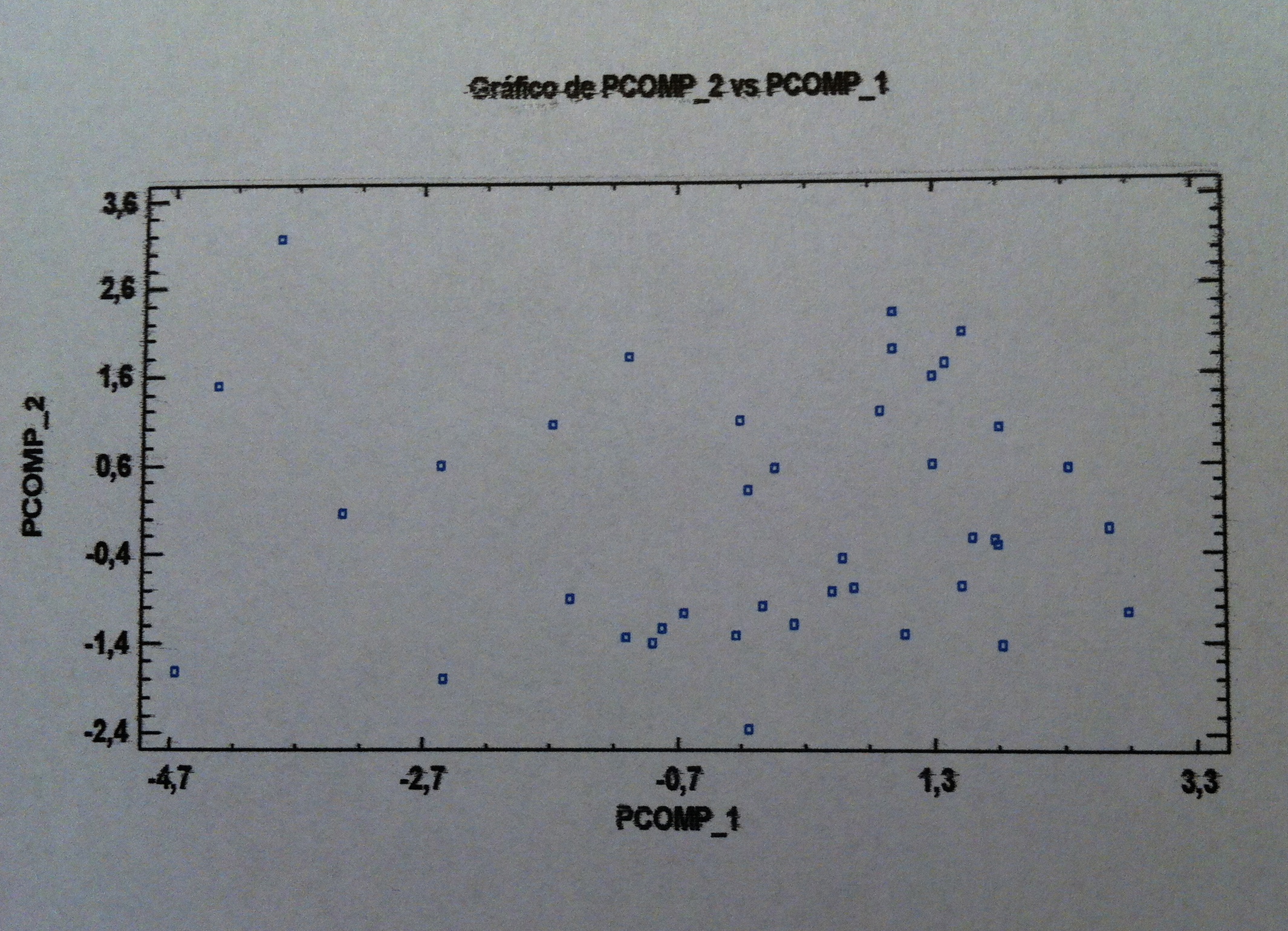
20. A los datos de los 15 estudiantes que se les ha evaluado en las ocho materias citadas en la matriz de datos mostrada al principio de este tema si se les hace un ACP tenemos la siguiente representación usando las dos primeras componentes principales: PCOMP_1 y PCOMP_2:
21. Observemos ahora que esta representación se asemeja mucho a la original en ocho dimensiones. Si observamos en el gráfico de dos dimensiones el alumno 1 y el 9 están muy próximos, prácticamente solapados. Miremos qué sucede en la matriz de datos. Observaremos que las notas, excepto Educación física, son prácticamente las mismas. Lo de Educación física tiene una explicación que ahora veremos.
22. Si, por el contrario, elegimos los individuos 5 y 12 vemos que en nuestro gráfico de dos dimensiones están completamente en los extremos, están en dos vértices de la representación. Si ahora miramos la matriz de datos veremos que el alumno 5 lo aprueba todo con buenas notas excepto la Educación física. En cambio el alumno 12 lo suspende todo, incluso la Educación física. Sorprendentemente en este caso son en todo distintos excepto en la Educación física que tienen justo la misma nota.
23. Por lo tanto, con el gráfico de dos dimensiones estamos viendo una muy buena fotografía de las posiciones relativas de los puntos en la representación de ocho dimensiones original que no vemos. Digo fotografía porque la metáfora es apropiada. Pensemos que cuando estamos viendo una fotografía en realidad estamos viendo una representación bidimensional de una realidad tridimensional. En el ACP estamos haciendo algo similar. Miramos de hacer una fotografía bidimensional o tridimensional, para que la podamos visualizar, de una realidad constituida por muchas dimensiones y que no visualizamos. Por lo tanto, en nuestro caso estamos viendo una fotografía bidimensional de una realidad ochodimensional.
24. Pero, algo muy importante: ¿Qué cantidad de información perdemos? Y, ¿qué representan los nuevos ejes?
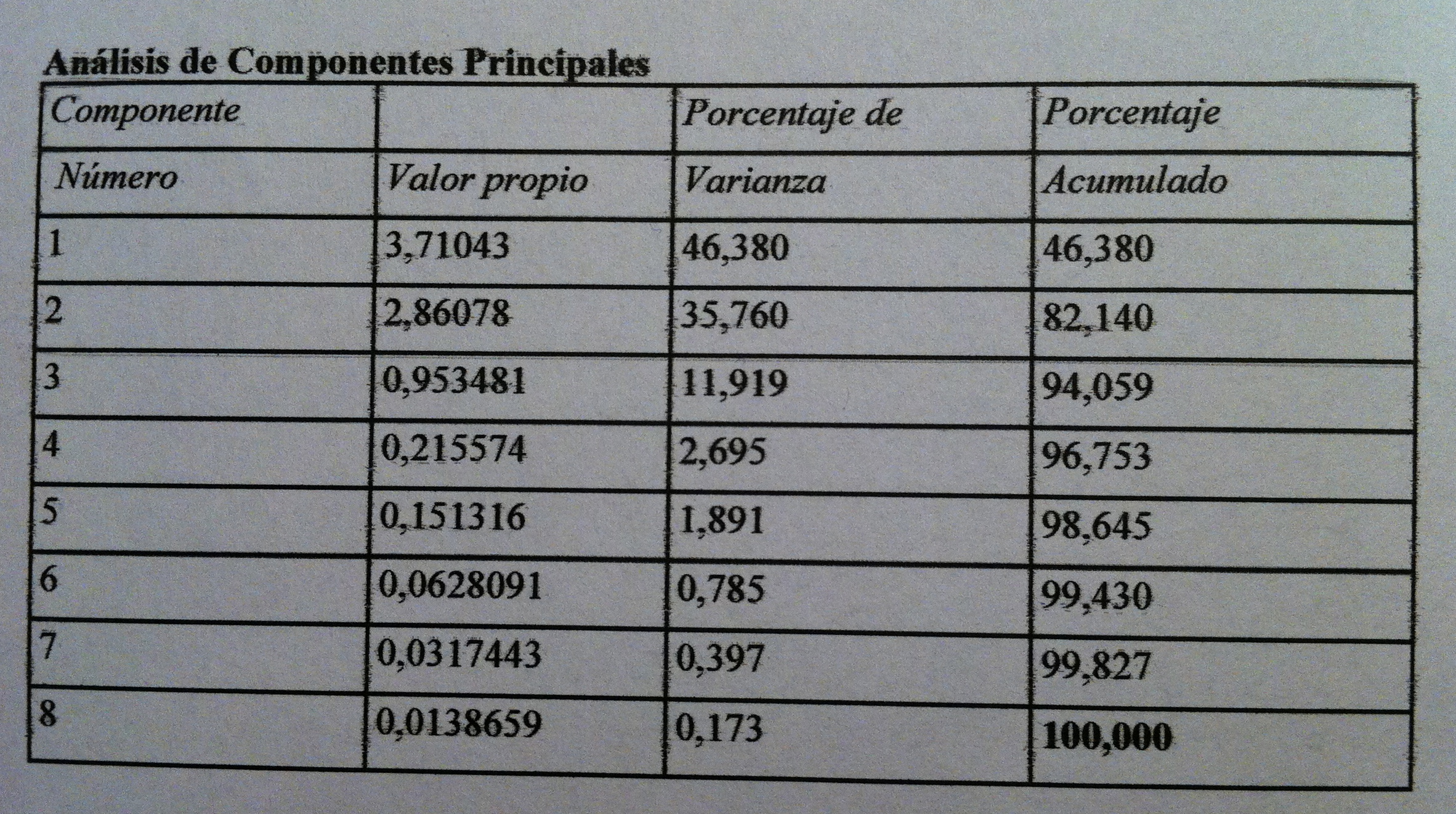
25. Respecto a la cantidad de información observemos la siguiente tabla:
26. Los valores propios de cada componentes nos indican la cantidad de varianza, la cantidad de información que tiene cada componente. Como podemos ver en esta tabla la primera componente tiene un 46.38% de información y la segunda un 35.76%. Las dos juntas tienen un 82.14. Por lo tanto, haciendo una representación en dos dimensiones con esas dos primeras componentes perdemos un 17.86% de información únicamente.
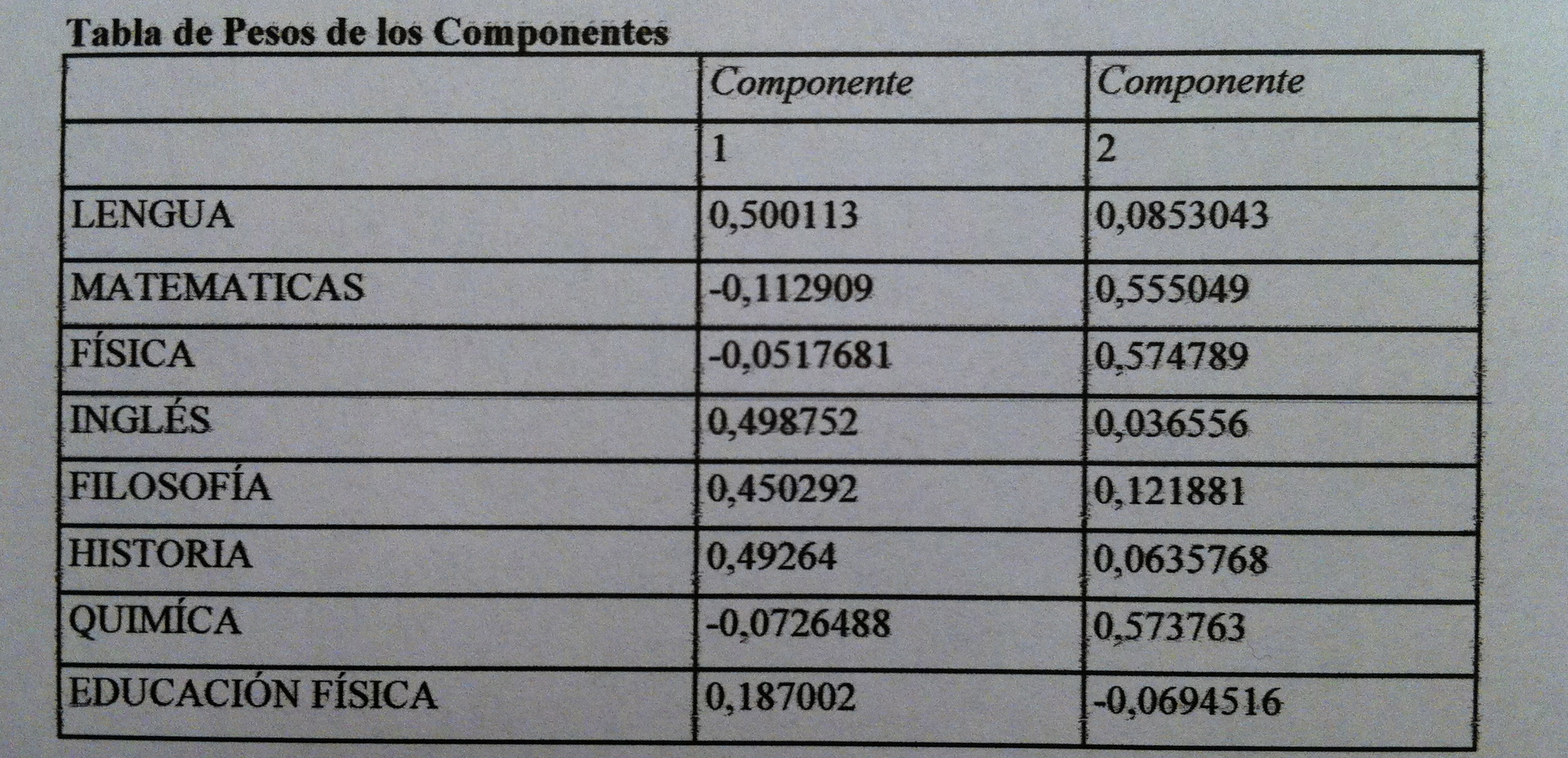
27. Respecto a lo que representan los nuevos ejes observemos la fórmula de las dos primeras componentes principales:
28. Esto indica que la primera componente principal tiene los coeficientes de la primera columna y la segunda componente tiene los coeficientes de la segunda. O sea, que para conocer las coordenadas que tendrá cada alumno de esas dos componentes hay que multiplicar sus ocho notas por sus coeficientes respectivos. Y así es como obtenemos la representación gráfica bidimensional mostrada antes.
29. Para interpretar una componente hay que seguir el siguiente procedimiento: 1) Mirar el valor absoluto de los coeficientes distinguiendo los que tienen un valor grande y un valor pequeño. En nuestro caso en la primera componente observemos que Lengua, Inglés, Filosofía e Historia tienen coeficientes con valor absoluto grande, cercano en todos los casos a 0.5. Los demás ya son bastante más pequeños, pesan mucho menos en esta componente. En la segunda componente el peso principal se lo llevan Matemáticas, Física y Química, con coeficientes cercanos a 0.57. Las demás asignaturas pesan poco. 2) Mirar entre los coeficientes con valor absoluto grande el juego de signos que hay. En nuestro caso el signo es el mismo, por lo tanto, las variables que pesan en una componente y en la otra todas van en la misma dirección. Pero en otro caso nos podríamos encontrar con valores de signo contrario. Entonces hay que interpretar el juego de fuerzas de los signos.
30. En el ejemplo que venimos usando la interpretación es muy clara. En la primera componente tenemos reunidas las materias de letras. En la segunda componente tenemos reunidas, por el contrario, las materias de ciencias. La educación física no pesa ni en una ni en otra. Porque no tiene ninguna relación ni con las materias de letras ni con las de ciencias.
31. Viendo el gráfico bidimensional donde en el eje de las abscisas tenemos la primera componente y en el eje de las ordenadas tenemos la segunda componente podemos ver que los alumnos buenos en ciencias y letras estarán situados a la derecha y arriba, los alumnos buenos en letras y malos en ciencias se situarán a la derecha y abajo, los buenos en ciencias y malos en letras a la izquierda y arriba y, finalmente, los malos en ciencias y letras se situarán a la izquierda y abajo.
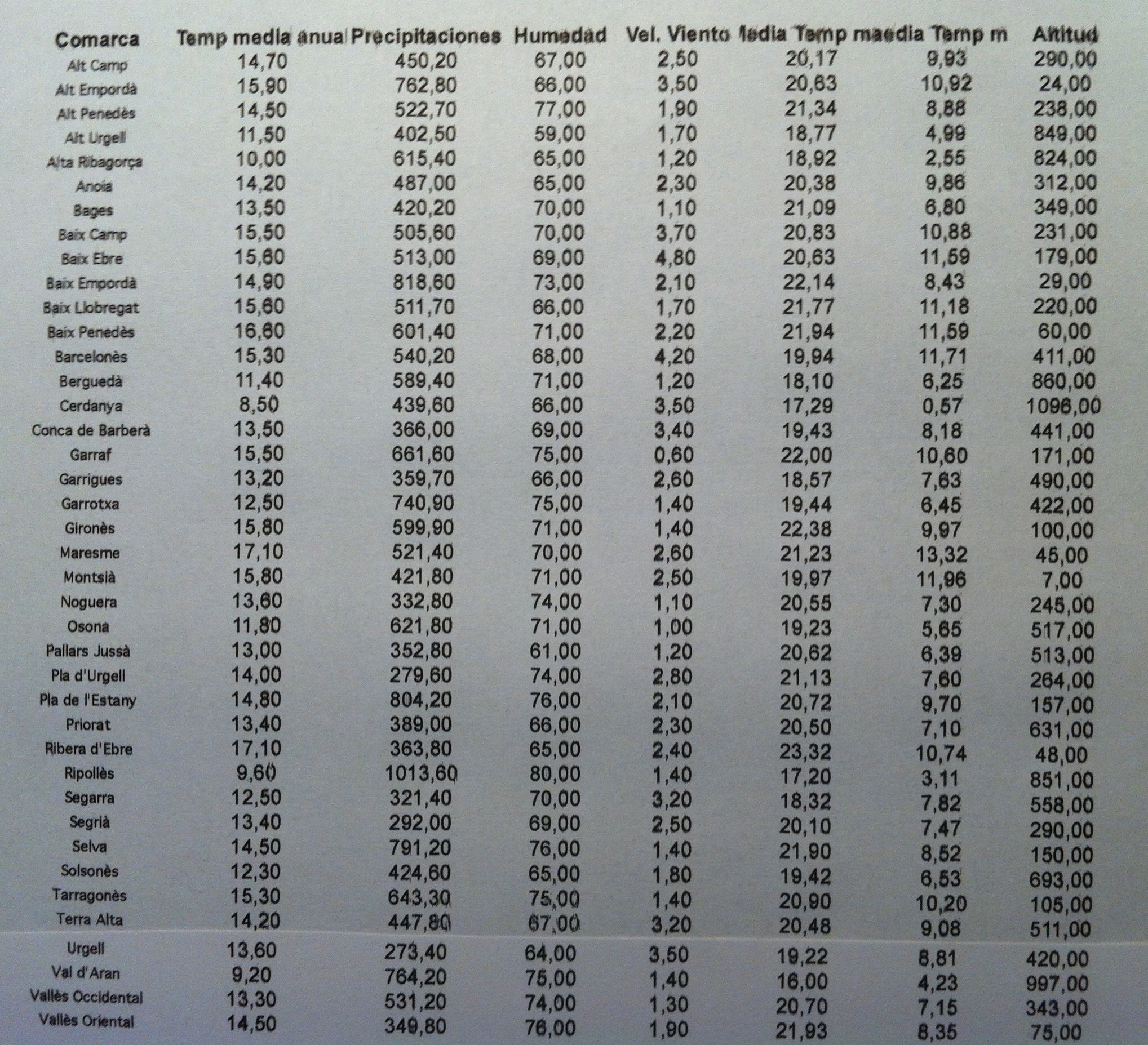
32. Veamos otro ejemplo de ACP. La matriz de datos son variables meteorológicas según comarcas catalanas el año 2005. Los datos son los siguientes:
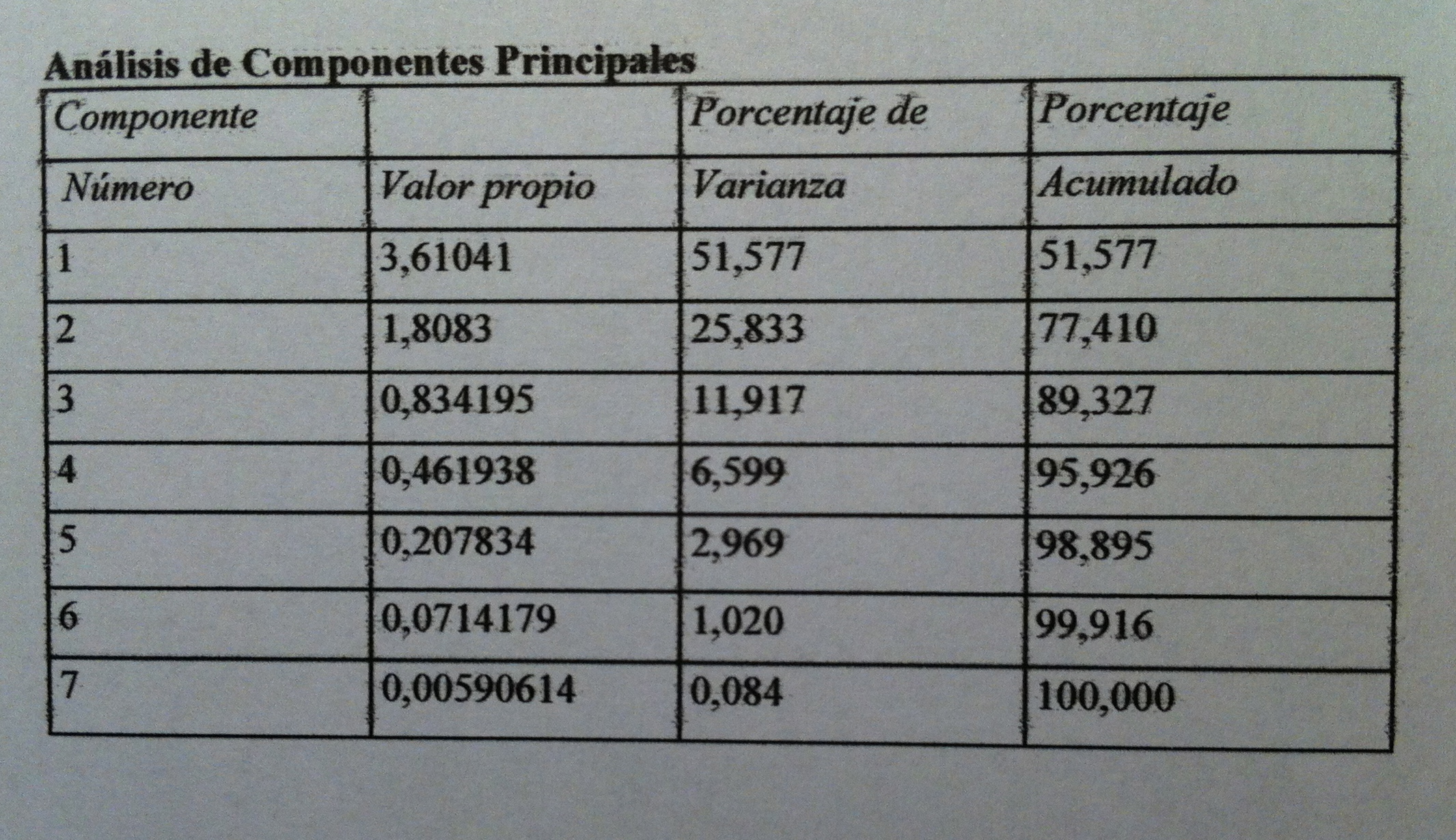
33. Al hacer un ACP, los valores propios de las componentes principales son los siguientes:
34. Como puede verse con las dos primeras componentes explicamos el 77.41% de la varianza, de la información contenida en la nube de puntos original.
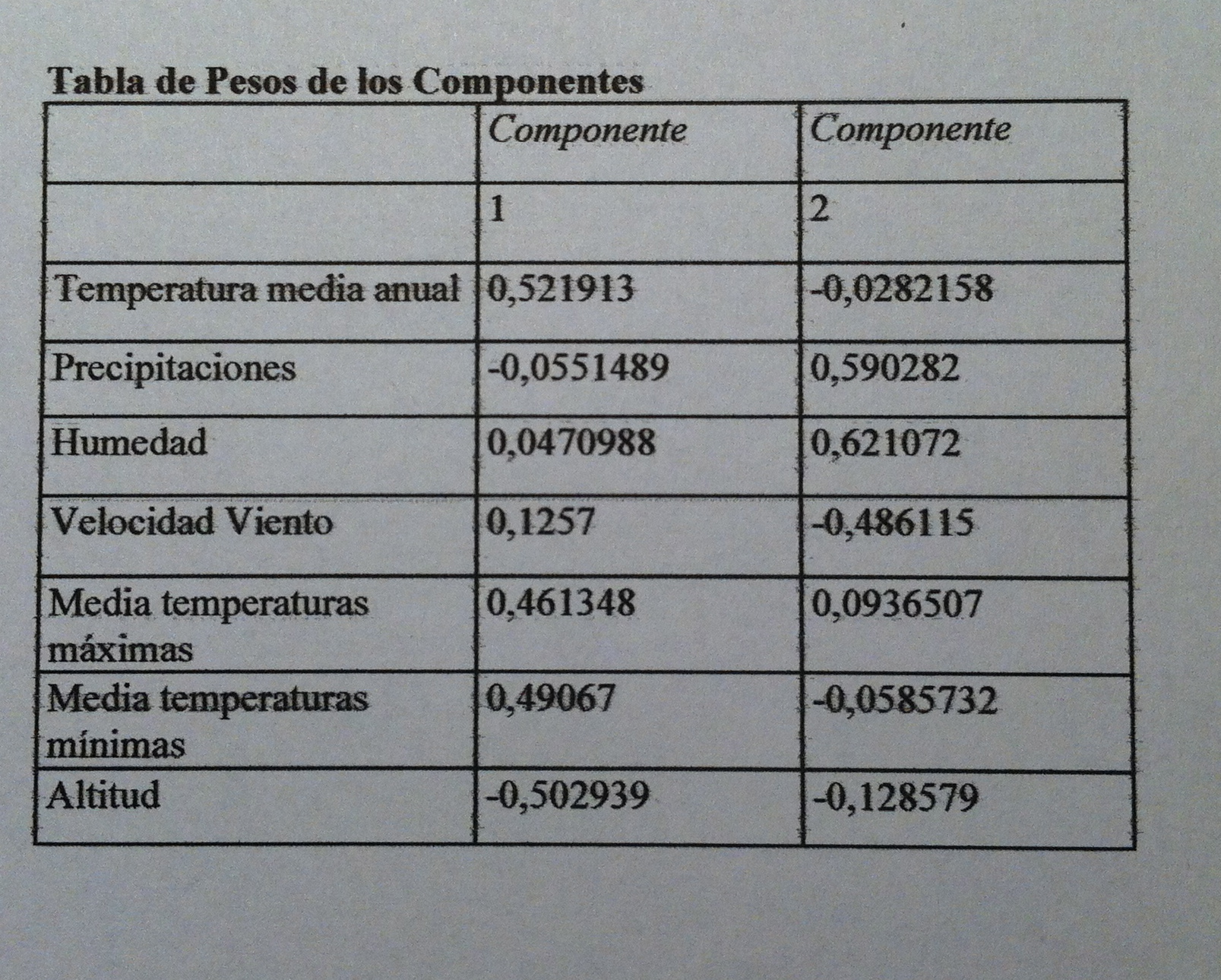
35. Y los vectores propios; o sea, los coeficientes de las dos primeras componentes, son los siguientes valores:
36. En la primera componente pesan; o sea, tiene valor absoluto grande, las tres variables de temperatura y la altitud media de la comarca. Además lo hacen las temperaturas con signo positivo y la altitud con signo negativo. Lo que indica que valores grandes de la primera componente corresponden a comarcas con temperaturas altas y altitud baja. Altitud baja porque como el coeficiente es negativo para que la componente tenga un valor alto hace falta que la altitud reste poco, sea un valor pequeño. Contrariamente, valores pequeños de esta primera componente indica temperaturas bajas y altitud alta.
37. En la segunda componente pesan especialmente las variables Precipitaciones, Humedad y Velocidad del viento. Las dos primeras con signo positivo y la tercera con signo negativo. Valores grandes de esta componente indicarán zonas con mucha lluvia, mucha humedad y poco viento. Por el contrario, valores bajos de esta segunda componente corresponderán a comarcas de bajas precipitaciones, baja humedad y alta velocidad del viento.
38. La representación de las comarcas según las dos primeras componentes es la siguiente:
39. Viendo el gráfico y la anterior interpretación de las componentes podemos dividir el gráfico en cuatro cuadrantes y afirmar: 1) Arriba a la derecha: Comarcas calurosas y húmedas. 2) Abajo a la derecha: Comarcas calurosas y secas. 3) Arriba a la izquierda: Comarcas frías y húmedas. 4) Abajo a la izquierda: Comarcas frías y secas.
40. Observemos, pues, que conseguimos con esta técnica representar en pocas dimensiones una realidad multidimensional y, también, crear estas componentes, estas variables de variables, variables que son combinación de las variables originales. Y estas combinaciones son interesantes en sí mismas, porque nos ayudan a crear una especie de conglomerados de variables combinadas de una forma que, en realidad, reflejan la vida interna que tienen ellas entre sí en cuanto a la covariación conjunta.
41. En el primer ejemplo, el caso de las notas, las componentes nos han creado la noción de Letras y la noción de Ciencias, reflejando una idea que todos tenemos en mente: que las capacidades hacia un ámbito u otro son como dos dimensiones independientes que se pueden tener ambas, que se puede tener una y no otra o que se puede, también, no tener ninguna.
42. En el segundo ejemplo, las componentes nos separan dos elementos independientes: aspectos de frío o calor, ligados a la altitud de la zona, por un lado, y aspectos referentes a la humedad climática, por otro. Aspectos que pueden ir asociados entre sí de forma independiente creando cuatro tipos de comarcas o de zonas distintas según la combinación de los valores extremos de estas dos componentes.
44. Otro ejemplo interesante es el planteado en la Situación 66, donde aparecen unos datos de diferentes países y las proporciones que tienen que hay en ellos en cuanto a las distintas formaciones universitarias. El análisis de los datos los podéis ver en la Solución Situación 66.
45. Otro ejemplo, ahora con Pokémons, está planteado en la Situación 47. La solución se puede ver en el fichero Solución Situación 47.
47. Como puede verse, en este tema hemos hablado de una técnica esencialmente descriptiva. No hemos hablado, aquí, de otra cosa que de muestras. No hay voluntad inferencial en esta técnica. Es cierto que se ha estudiado y creado técnicas inferenciales relacionadas con el ACP pero no es muy utilizada en la práctica. Es por ello que debemos considerarla una técnica descriptiva, una técnica que intenta buscar la representación de una muestra de individuos de los que tenemos muchas variables de interés. Una técnica donde la muestra es la finalidad.
48. Podéis practicar los conceptos de este tema con ejercicios comentados en el siguiente:
1. El Análsis clúster (AC), también llamado en ocasiones Análisis de conglomerados, se dice habitualmente que es una técnica estadística clasificadora, pero, en realidad, es una técnica que, como el Análisis de componentes principales (ACP) o como el Análisis factorial (AF), pretende representar una realidad que no conseguimos visualizar, una realidad cuya representación original es multidimensional y es imposible que la podamos ver en su estado puro.
2. En el fondo tanto ACP, como AF, como AC son técnicas que tratan de representan una nube de puntos original situada en un espacio de tantas dimensiones que es imposible visualizar. Y cada una de ellas, también, en el fondo, puede ser usada como método clasificatorio, como método para crear subpoblaciones, subgrupos.
3. La diferencia fundamental entre ellas es la forma de presentación que utilizan, la forma de resolver el problema de no visualización de la nube de puntos originales. El ACP y el AF lo hacen construyendo una nube de puntos de la misma naturaleza pero de menor número de dimensiones perdiendo una parte de la información original. Sin embargo, el AC lo que hace es crear una representación distinta a la de la nube de puntos. Crea otro tipo de representación. Cambia la forma: no lo hace mediante una nube de puntos, lo hace mediante un dendrograma.
4. Cada una de las opciones tiene sus ventajas y sus desventajas, como iremos viendo a continuación.
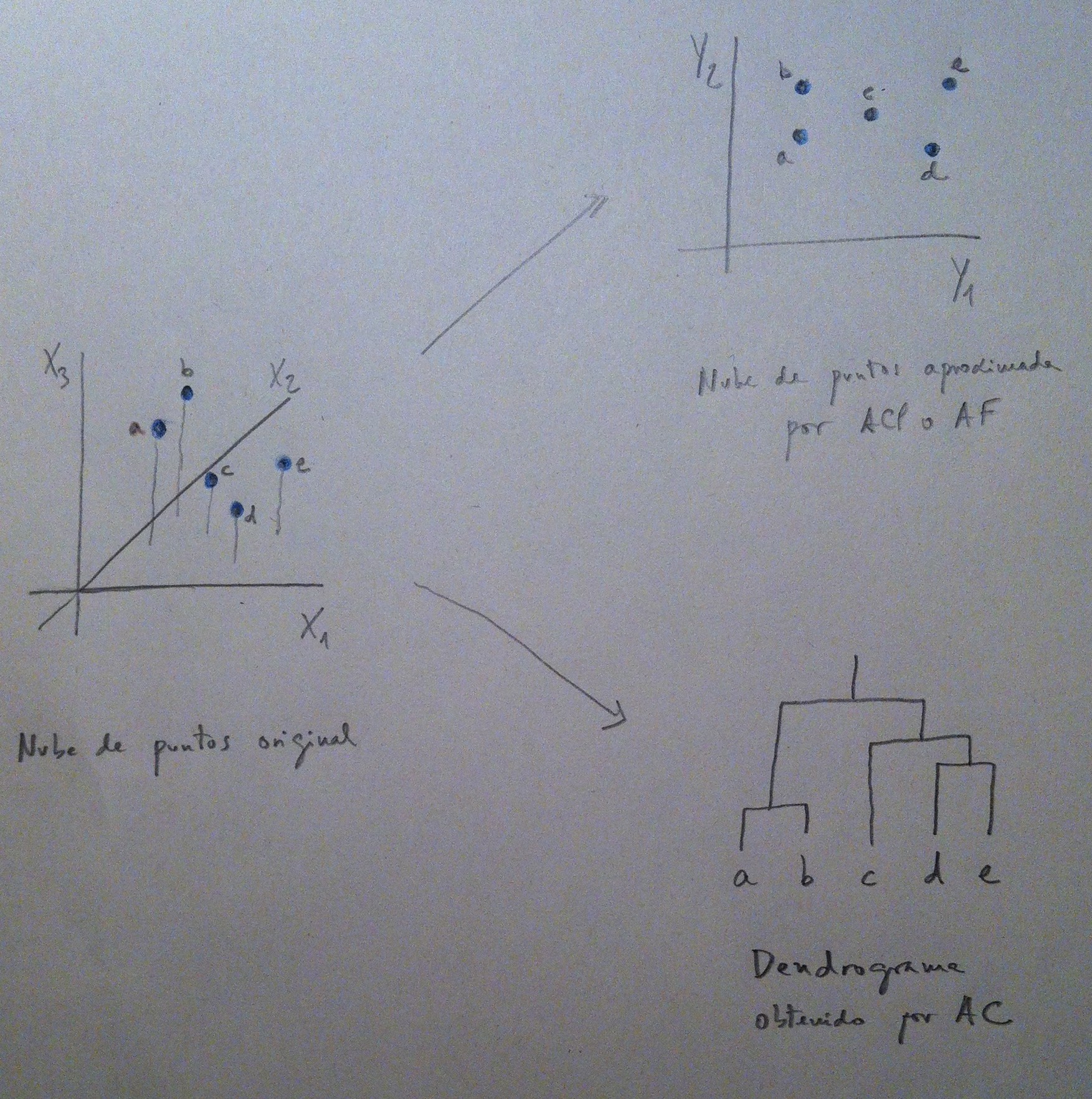
5. El ACP y el AF respetan el tipo de representación: una nube de puntos, pero al reducir dimensiones se pierde información y esto es un problema, especialmente si la pérdida es importante. El AC respeta la nube de puntos original, no reduce dimensiones y, por lo tanto, no se pierde información, pero, eso sí, se cambia el mecanismo de representación, se cambia el estilo de representación. Representamos la nube de puntos mediante un dendrograma. Digamos que en el ACP y el AF se hace una representación figurativa y en el AC se hace una representación abstracta. Veamos un gráfico que nos ilustra la comparación:
6. A la izquierda de este gráfico tenemos una supuesta nube de puntos original. En este caso con tres dimensiones para que lo visualicemos, pero normalmente esta nube de puntos no la veremos, será una nube de puntos de muchas más dimensiones. A la derecha vemos las dos estrategias gráficas: Arriba una representación mediante una nube de puntos también, aunque en dos dimensiones que pueden ser las diseñadas por dos componentes principales o por dos factores, según la técnica utilizada. Abajo una representación bien distinta: un dendrograma, que, como a continuación veremos, se construye a partir de la nube de puntos original mediante unos procedimientos que conviene explicar con detalle.
7. Visto así parecería que el AC tiene ventajas: cambiamos la forma de representación pero no perdemos información. Parece mejor opción, pero sólo lo parece. Porque ahora veremos que en el AC hay dos momentos de decisión en la técnica que nos lleva a procedimientos que nos pueden generar realmente representaciones muy diferentes.
8. Veamos el procedo seguido por el AC para construir un dendrograma a partir de una nube de puntos original constituida por una serie de individuos de los que tienes los valores de varias variables.
9. El primer momento en el AC es definir una noción de distancia entre puntos. Necesitamos elegir una distancia, una medida que nos cuantifique distancias entre los individuos dentro de la nube de puntos original. Y aquí aparece de repente el primer problema del AC: que hay muchas distancias propuestas.
10. Ejemplos de distancias: La distancia euclídea es la más intuitiva y la más utilizada, de largo. Es la que calcula la distancia en línea recta entre los puntos en el espacio o en el hiperespacio de la nube de puntos original. Esta distancia en realidad es una aplicación del Teorema de Pitágoras:
Otra distancia muy utilizada es la denominada distancia Ciudad, que también se la llama distancia Taxi:
Otra distancia utilizada frecuentemente es la denominada distancia del máximo:
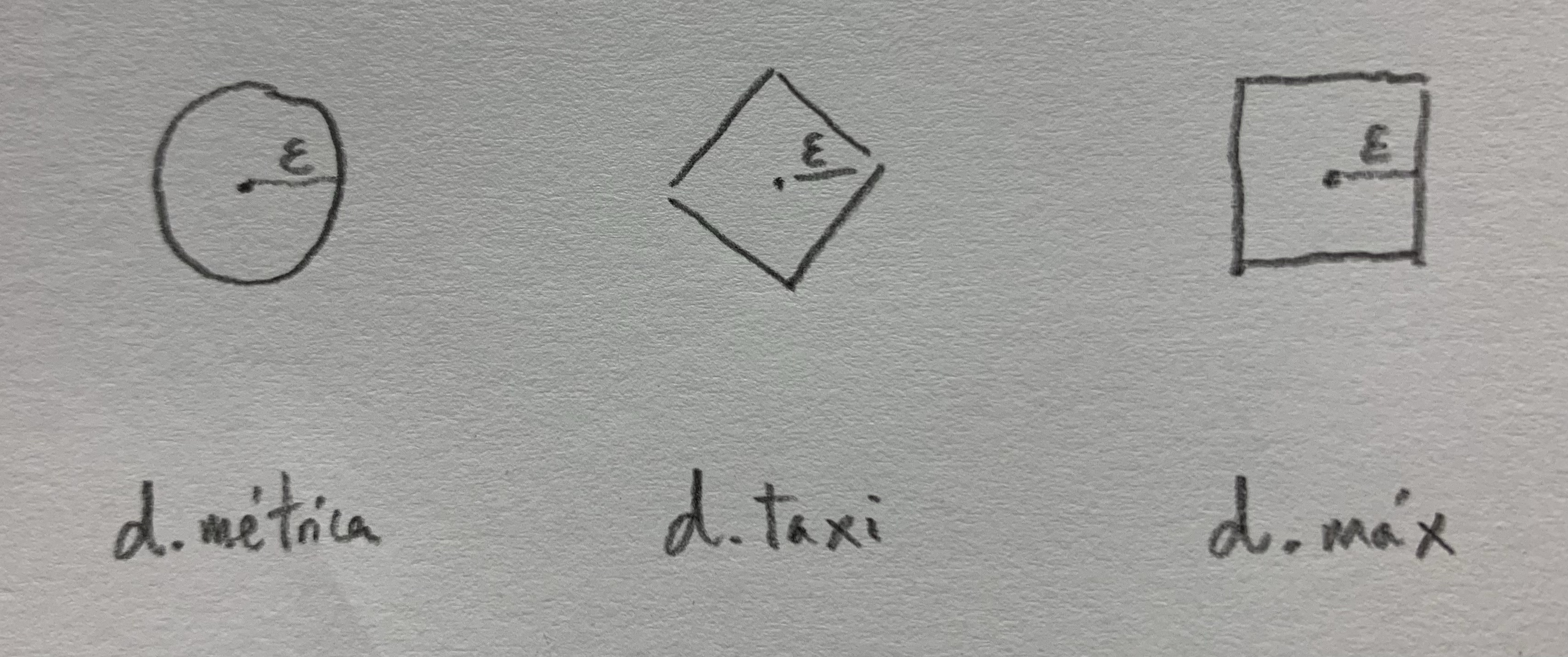
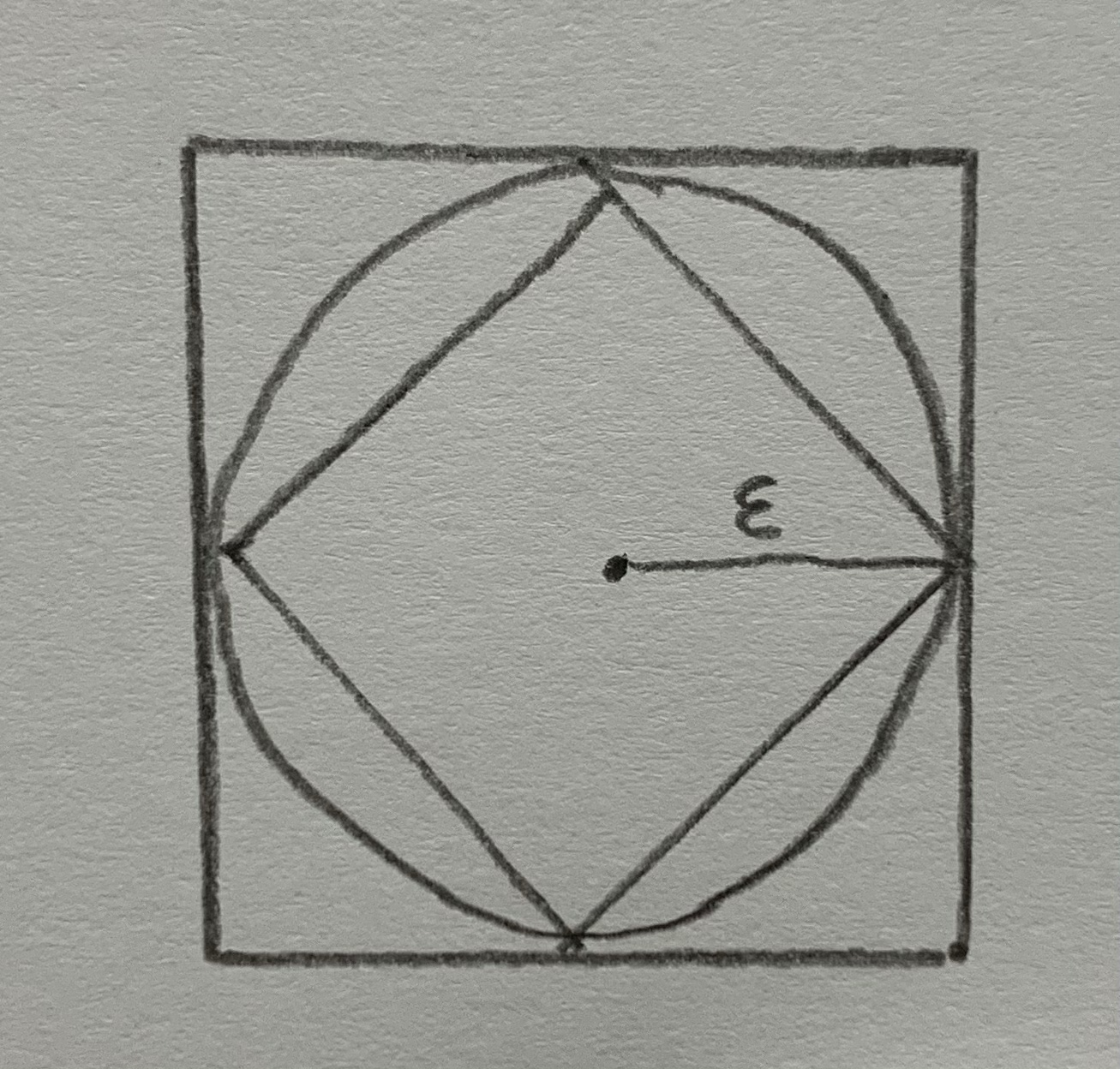
11. Veamos una comparación entre estas tres distancias:
El círculo en la métrica, el rombo en la distancia taxi y el cuadrado en la distancia del máximo delimitan puntos que están a una distanacia Épsilon del centro.
Se pueden superponer y ver cómo asignan valores diferentes de distancia a un mismo punto, o, por el contrario, asignan la misma distancia a puntos que no ocupan la misma posición; o sea, que no tienen las mismas coordenadas:
12. La distancia Mahalanobis es una distancia de mucho prestigio en Estadística Se trata de una distancia que tiene en cuenta no sólo las distancias que hay en cada una de las variables sino que cada una de estas distancias la relativiza respecto a la dispersión que tiene cada una de esas variables originales:
13. Hay muchas más distancias definidas y utilizadas. De hecho, para ser distancia una función debe cumplir las siguientes propiedades:
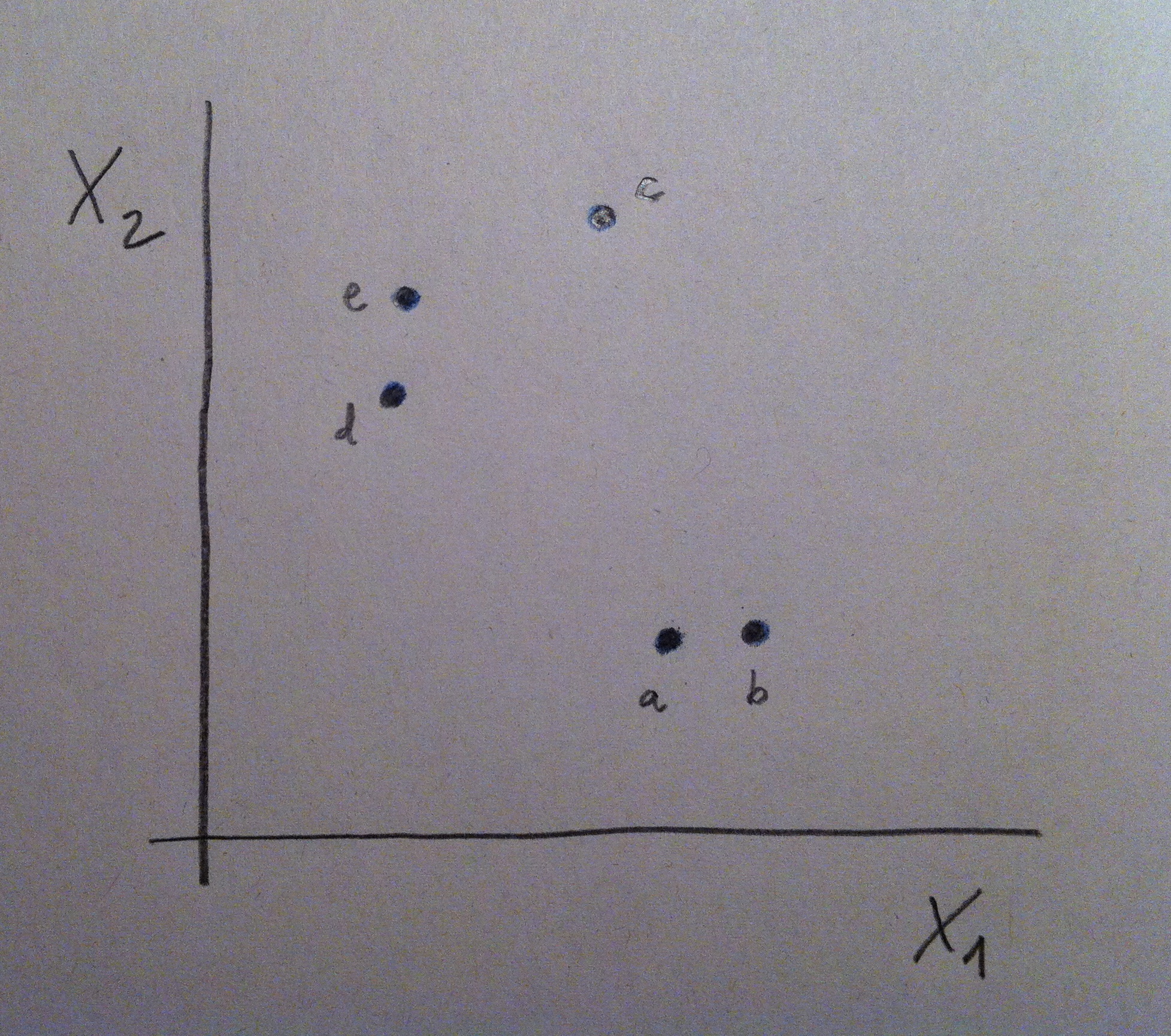
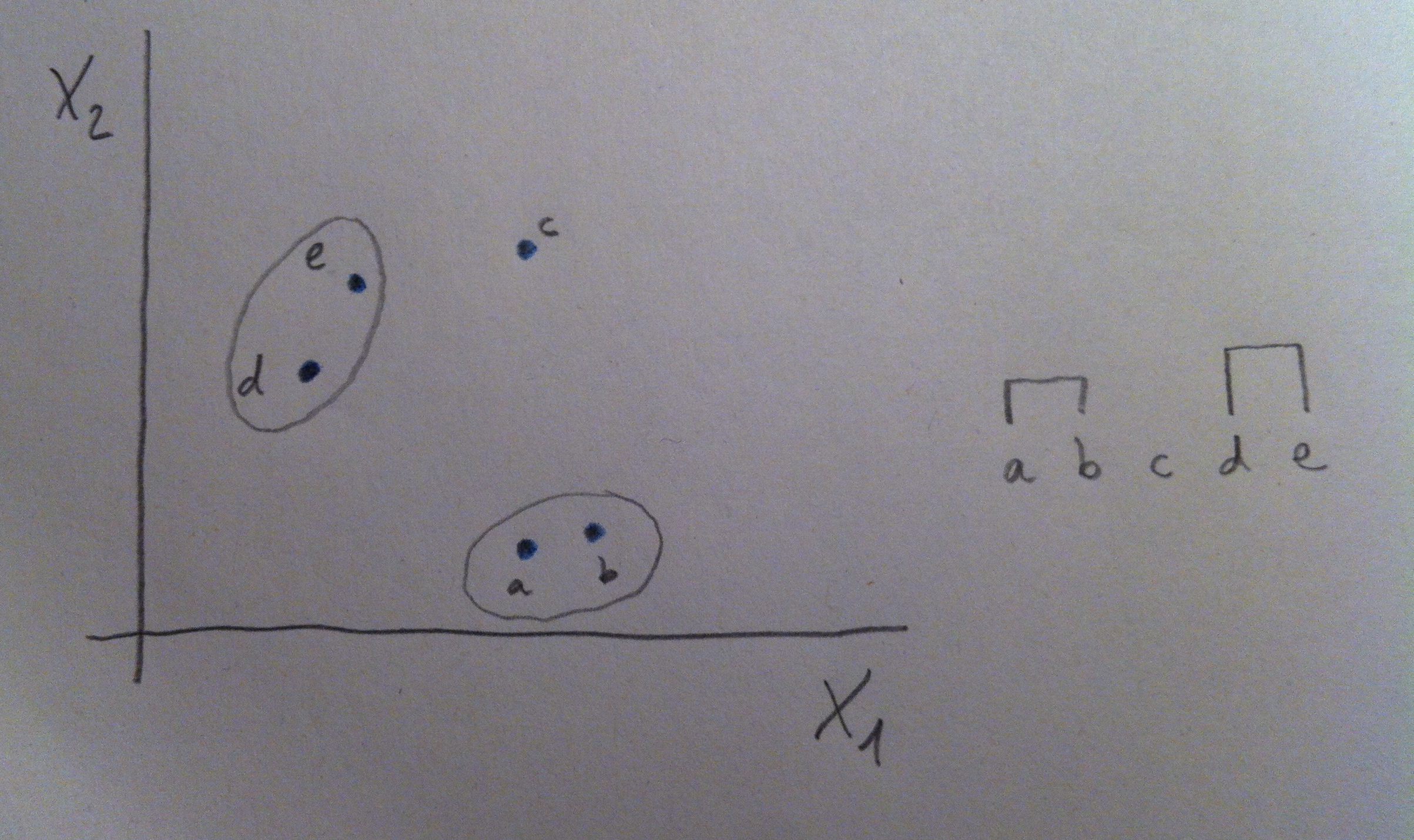
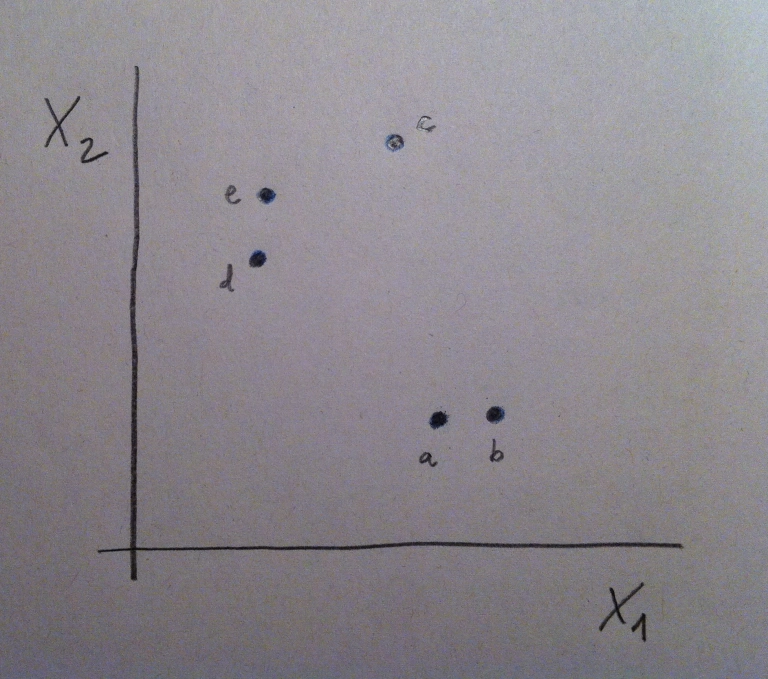
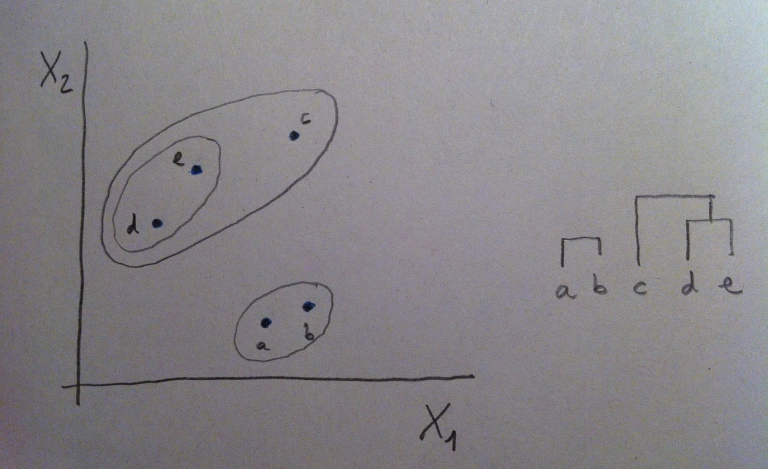
14. Veamos un ejemplo, en miniatura, para ver así qué pasos se siguen a la hora de hacer un AC. Vamos a ver un caso con sólo dos variables para visualizar con detalle microscópicamente todo lo que se hace, pero pensemos que lo que diga es perfectamente extrapolable al número de variables que sean. Supongamos los siguientes cinco individuos: a, b, c, d y e:
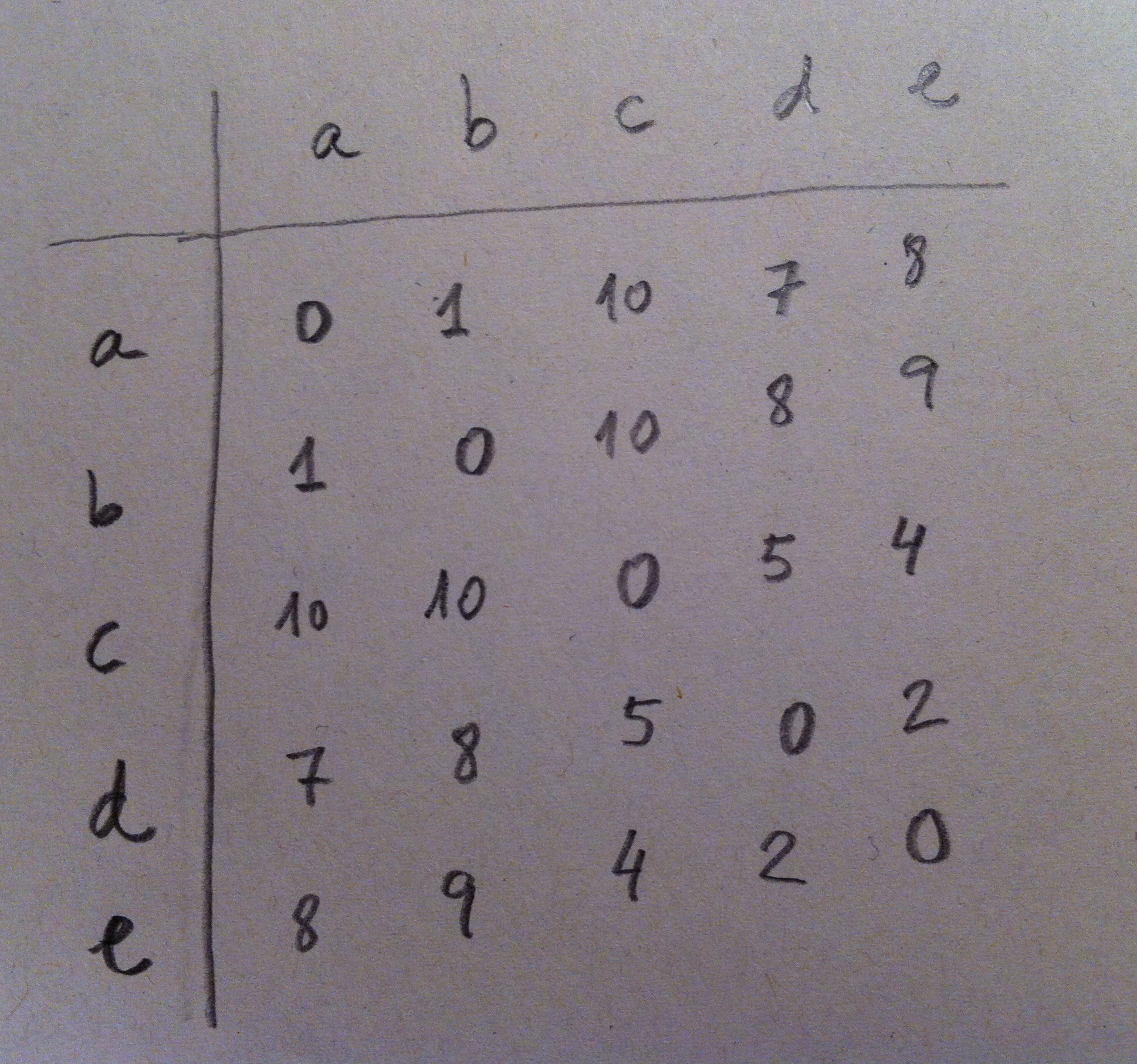
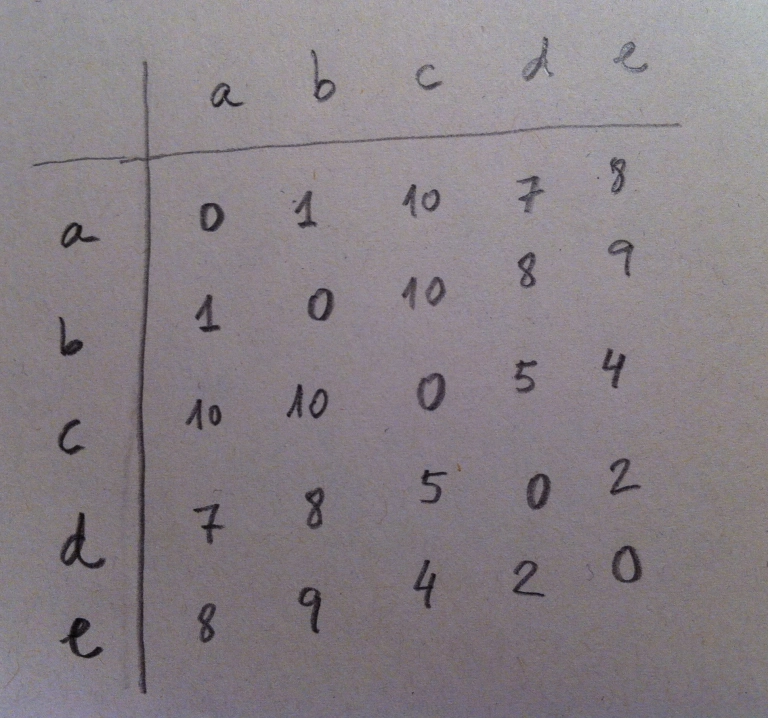
15. Vamos a construir, paso a paso, el dendrograma. Lo primero es elegir una distancia, como ya hemos dicho. Una vez elegida calcularíamos todas las distancias entre los puntos mediante esa distancia elegida. Obtendríamos, así, una matriz de distancias. Una matriz de distancias es una matriz cuadrada, simétrica y con la diagonal principal con ceros. Un ejemplo, en nuestro caso, sería la siguiente matriz:
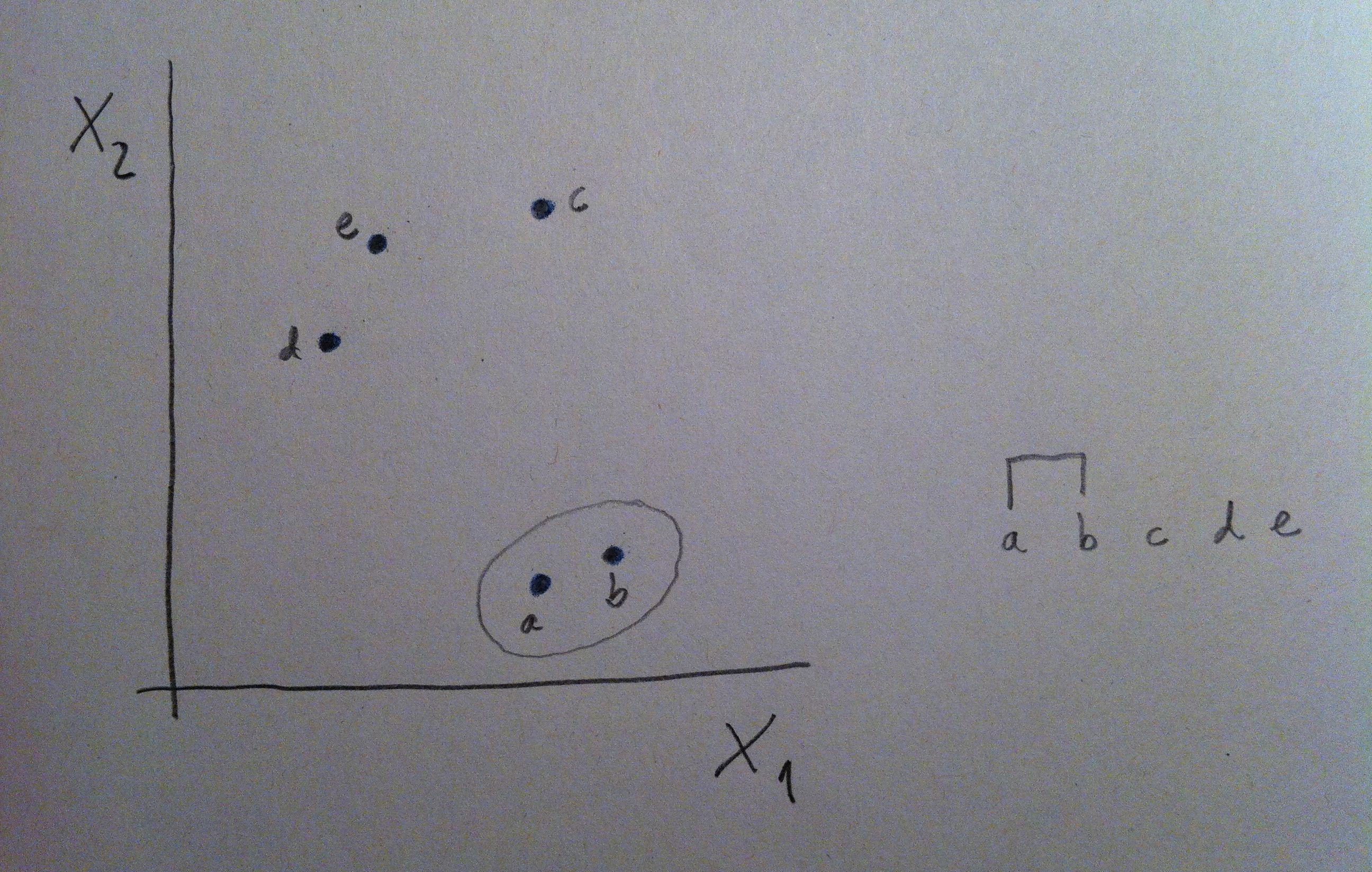
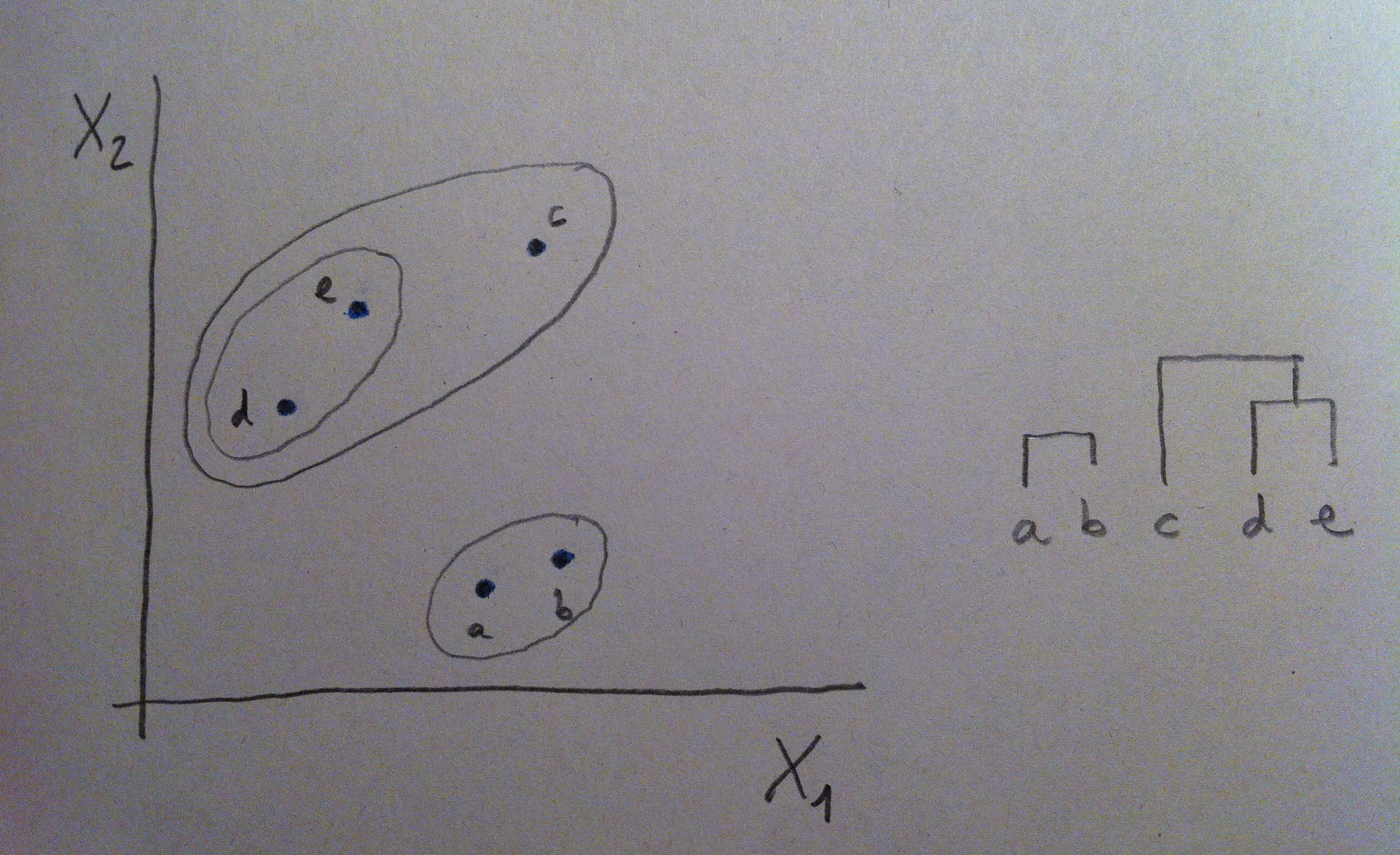
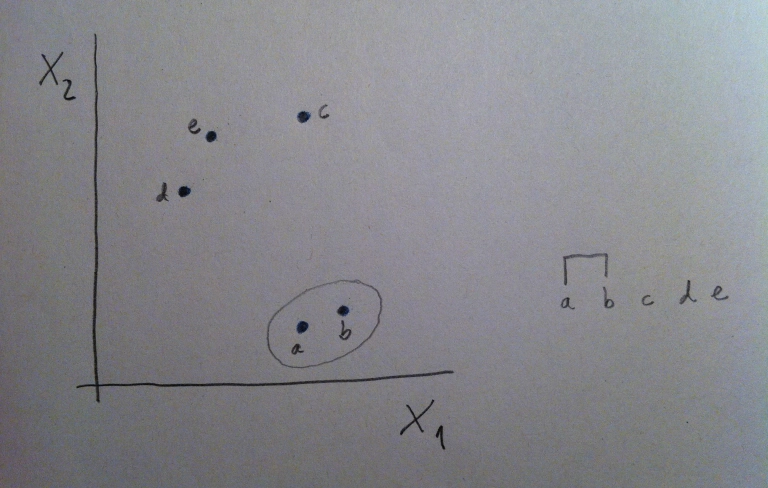
15. La primera agrupación de puntos se hace en base a la matriz de distancias. Se agrupan los dos puntos diferentes de distancia menor. En nuestro caso serían los puntos a y b:
17. Y, por lo tanto, realizamos la primera unión en el dendrograma, la unión entre a y b.
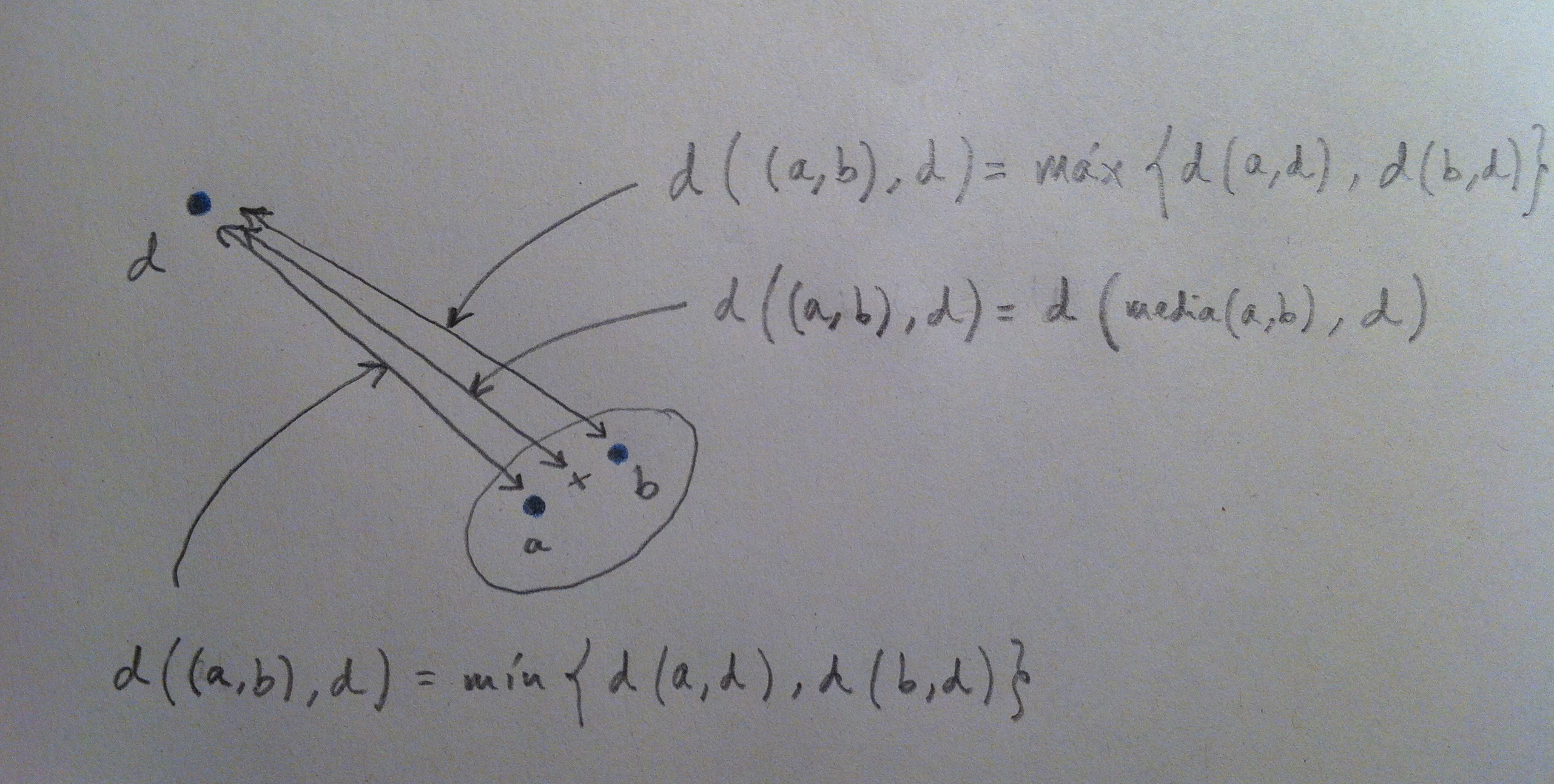
18. A continuación nos encontramos con un problema. Ahora tenemos, en realidad, cuatro entidades para medir distancias y continuar, pero el problema es que ahora tenemos que una de esas entidades, y así será ya continuamente, son un grupo de individuos. Por lo tanto, debemos definir cómo calcularemos la distancia entre un punto y un grupo de puntos que sea, también, un criterio que nos sirva para establecer la distancia entre dos grupos de puntos, porque esto también nos aparecerá a la que tengamos en un análisis un mínimo de dos grupos.
19. Se han establecido diferentes criterios para definir la distancia entre un punto y un grupo o la distancia entre dos grupos. Veamos tres ejemplos de esos criterios: 1) El criterio del mínimo. 2) El criterio del máximo. 3) El criterio de la media. Veamos un gráfico que ejemplifica en nuestro caso cómo calcularíamos estos tres criterios:
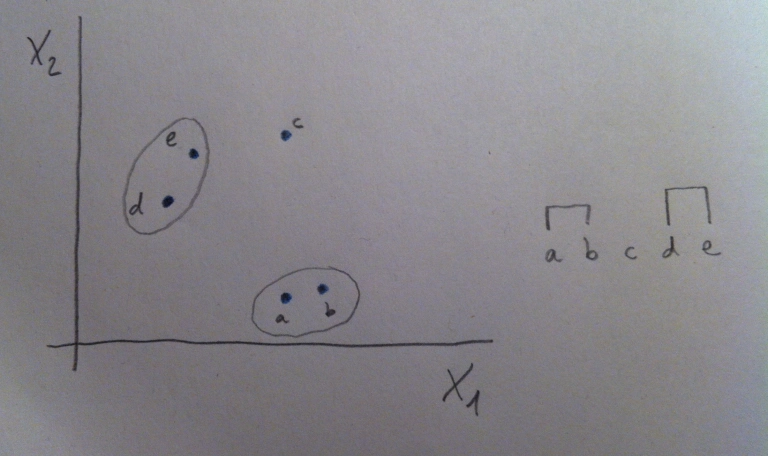
20. Según apliquemos un criterio u otro nos podemos a encontrar con agrupaciones diferentes. Si aplicamos uno de estos criterios, por ejemplo el de la media, nos encontraríamos que, en nuestro ejemplo, la distancia menor es la que hay entre los puntos d y e:
21. Y, si continuamos con el mismo procedimiento, ahora la distancia menor entre las tres entidades que nos quedan (el grupo (a, b), el grupo (d, e) y el punto c) será la que hay entre el grupo (d, e) y el punto c:
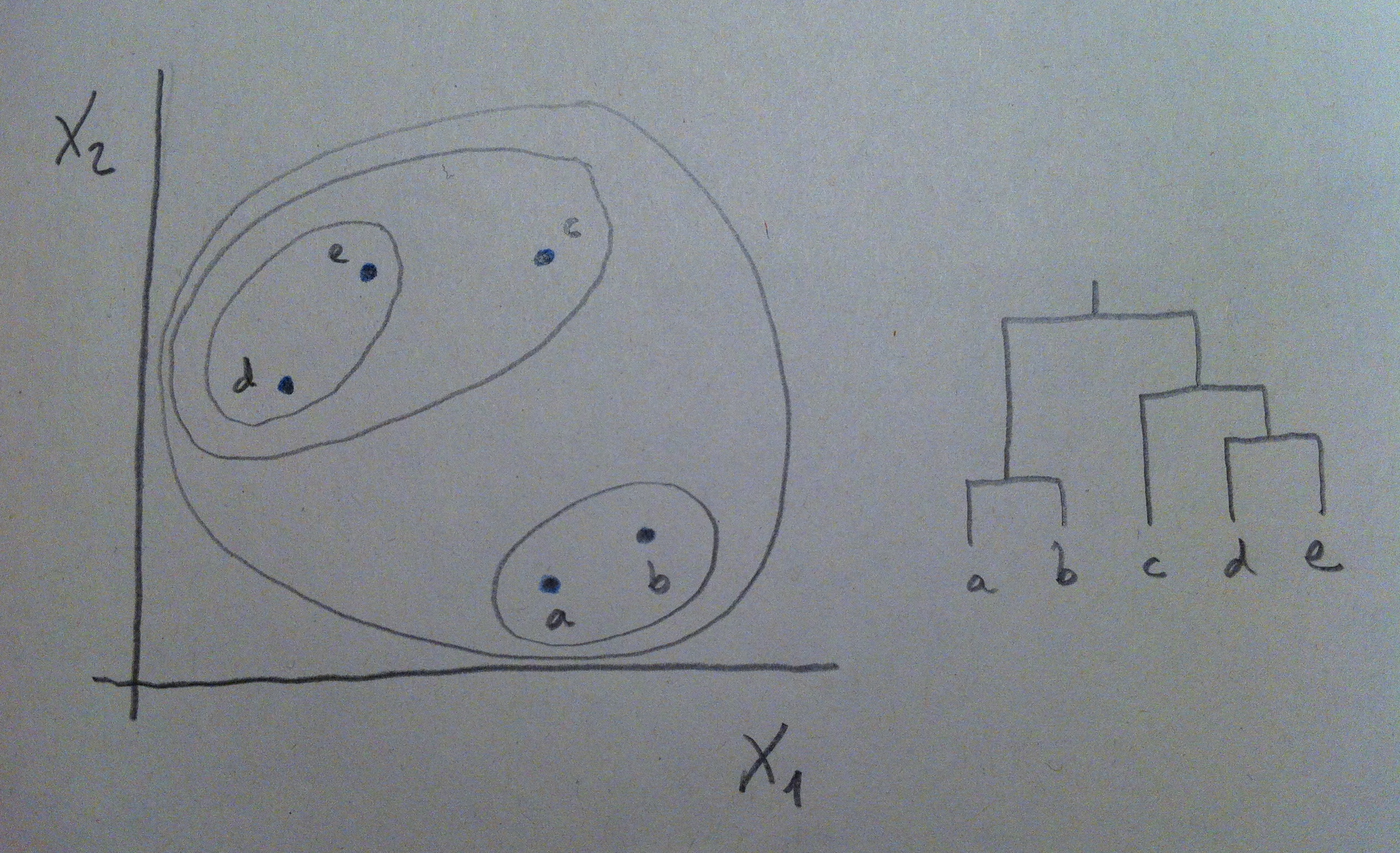
22. Y, finalmente ya, lo último es agrupar lo que queda:
23. Y tenemos, así, el dendrograma completo. Este es el procedimiento que sigue un software estadístico para construir el dendrograma, que es la forma de representación que persigue el Análisis clúster.
24. Pero observemos cómo hemos tenido que establecer dos decisiones claves que cambian el transcurso del proceso: La distancia con la que trabajar y el criterio de cálculo de distancia entre punto y grupo o entre grupo y grupo. Y según sea la elección el resultado puede cambiar, las agrupaciones pueden ser distintas. Es cierto que si las cosas son muy claras los resultados son prácticamente los mismos, sigamos el procedimiento que sigamos, pero no siempre sucede así.
25. Una opción que suele ser también interesante es hacer el Análisis clúster girando la matriz de datos; o sea, viendo las variables como individuos y los individuos como variables. Entonces agrupamos no individuos sino variables. Vemos la proximidad de unas respecto a otras, qué agrupaciones tendría sentido hacer, etc.
26. De hecho, si hacemos un AC, de una matriz de datos, primero con los individuos y luego con las variables, estamos cubriendo aquellas dos finalidades que persiguen tanto el ACP como el AF, que son: 1) Representar los puntos, visualizarlos. 2) Ver relaciones entre las variables, agrupaciones, conexiones entre ellas.
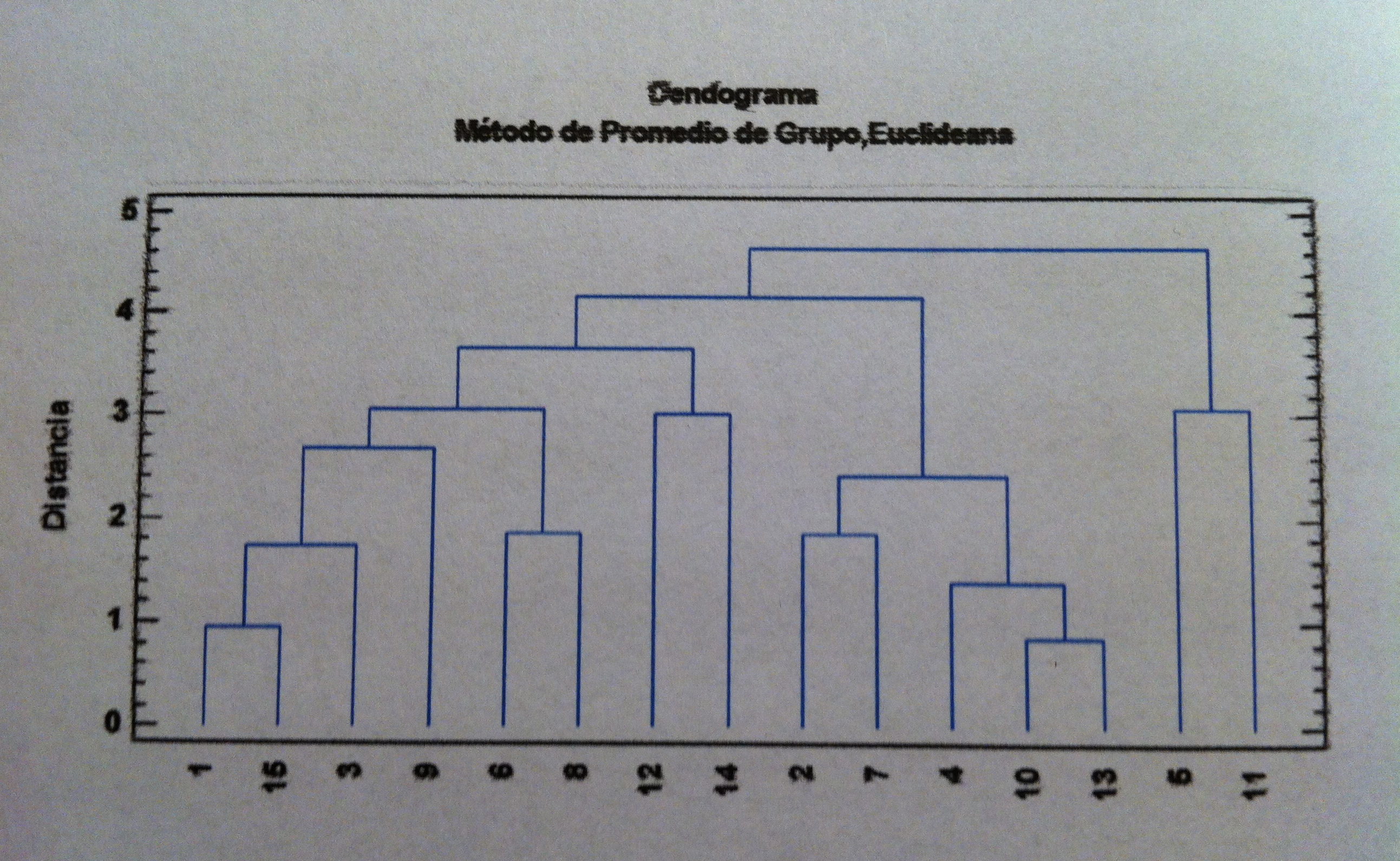
27. Veamos la aplicación del AC a los datos de los estudiantes que hemos visto en los temas dedicados al ACP y al AF. Al aplicar a los 15 alumnos para todas las variables; o sea, a la nube de puntos original, el AC con la distancia euclídea y el criterio de distancia entre punto y grupo o entre grupo y grupo el de la media del grupo, el dendrograma que se construye es el siguiente:
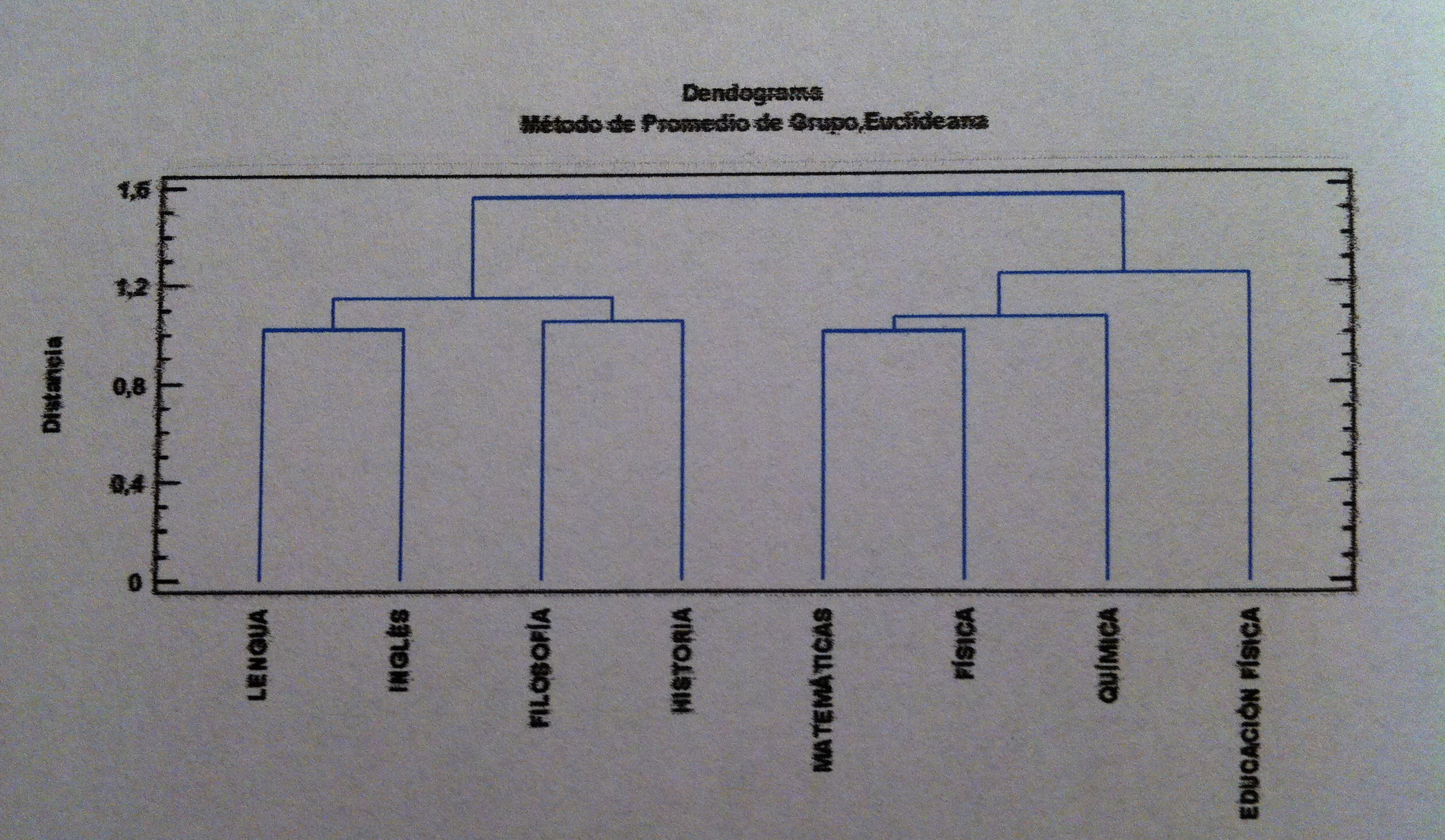
28. Si hacemos lo mismo pero ahora con las variables obtenemos el siguiente dendrograma:
29. Lo que muestra realmente lo que decíamos de la agrupación que se produce entre variables: Letras por un lado y Ciencias por otro. Aquí Educación acaba agrupándose primero con las ciencias que con las letras, pero es la última agrupación, si quisiéramos crear tres grupos de variables y cortáramos el dendrograma a nivel de obtención de tres grupos de variables tendríamos: Letras, Ciencias y Educación física.
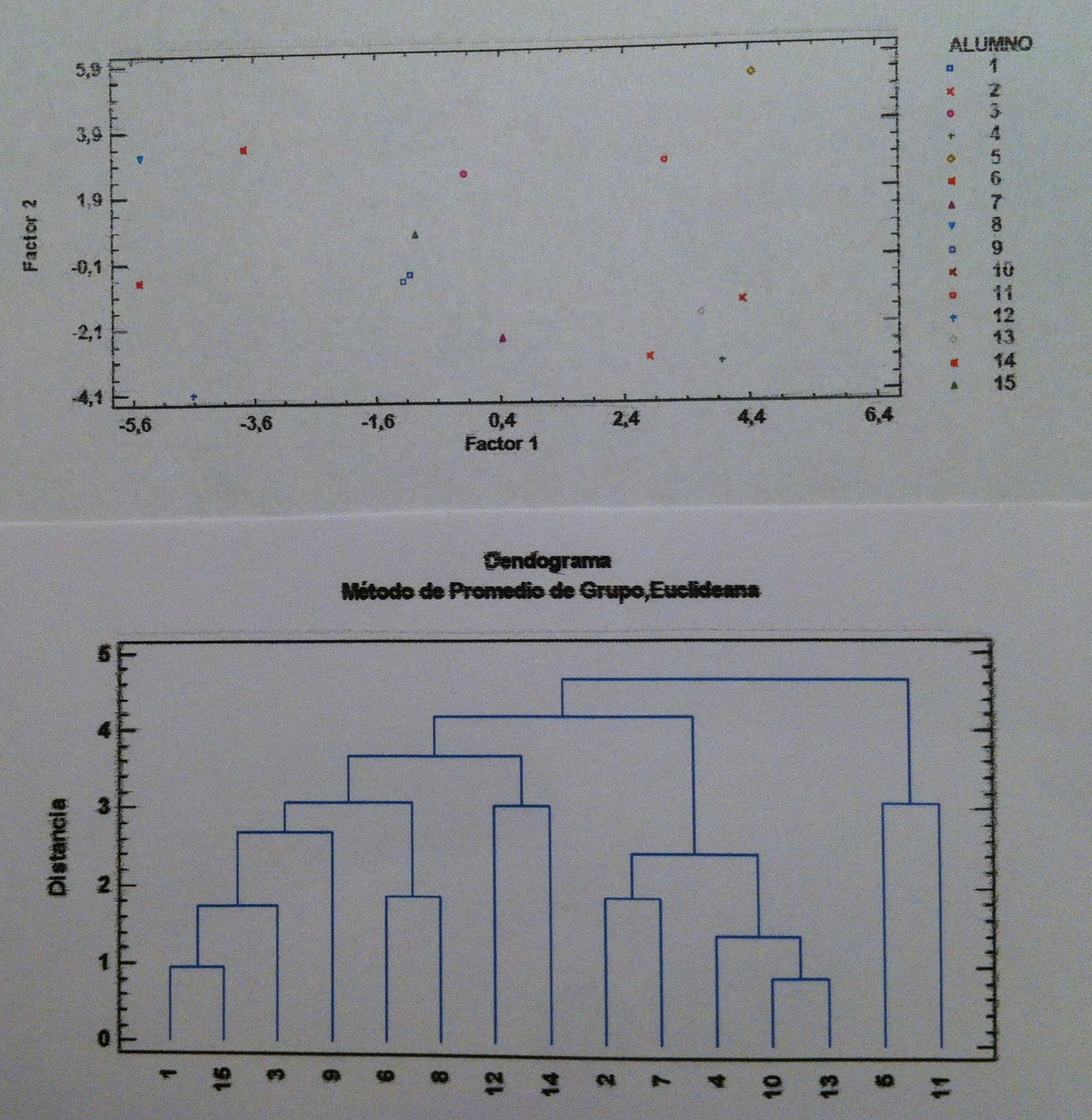
30. Es interesante comparar los resultados obtenidos, las representaciones dibujadas, con las tres técnicas: ACP, AF y AC a los mismos datos. Al final tenemos, como ya hemos dicho, dos formas muy distintas de hacer lo misma: la del ACP y AF, por un lado, y la del AC, por otro. Dos formas de representación muy distinta. Pero la finalidad fundamental de ambas es descriptiva: representar lo que no podemos visualizar en su estado original, hacer una representación aproximada, crear un modelo de aquella realidad que no tenemos. Y junto ahora las dos formas tan distintas de hacer lo mismo en un mismo gráfico. Pongo sólo el AF en representación de la opción generada por AF o por ACP:
31. Lo primero que vemos si comparamos ambos gráficos es que son dos representaciones muy distintas: como cuando vemos un cuadro de Picasso o de Velazquez. A lo mejor los dos intentan pintar lo mismo: las meninas, por ejemplo, pero lo hacen mediante técnicas pictóricas bien distintas. Una figurativa, la otra más abstracta. Pero con un poco de paciencia pueden irse estableciendo paralelismos entre ambos gráficos igual que con las merinas de Velazaquez y de Picasso.
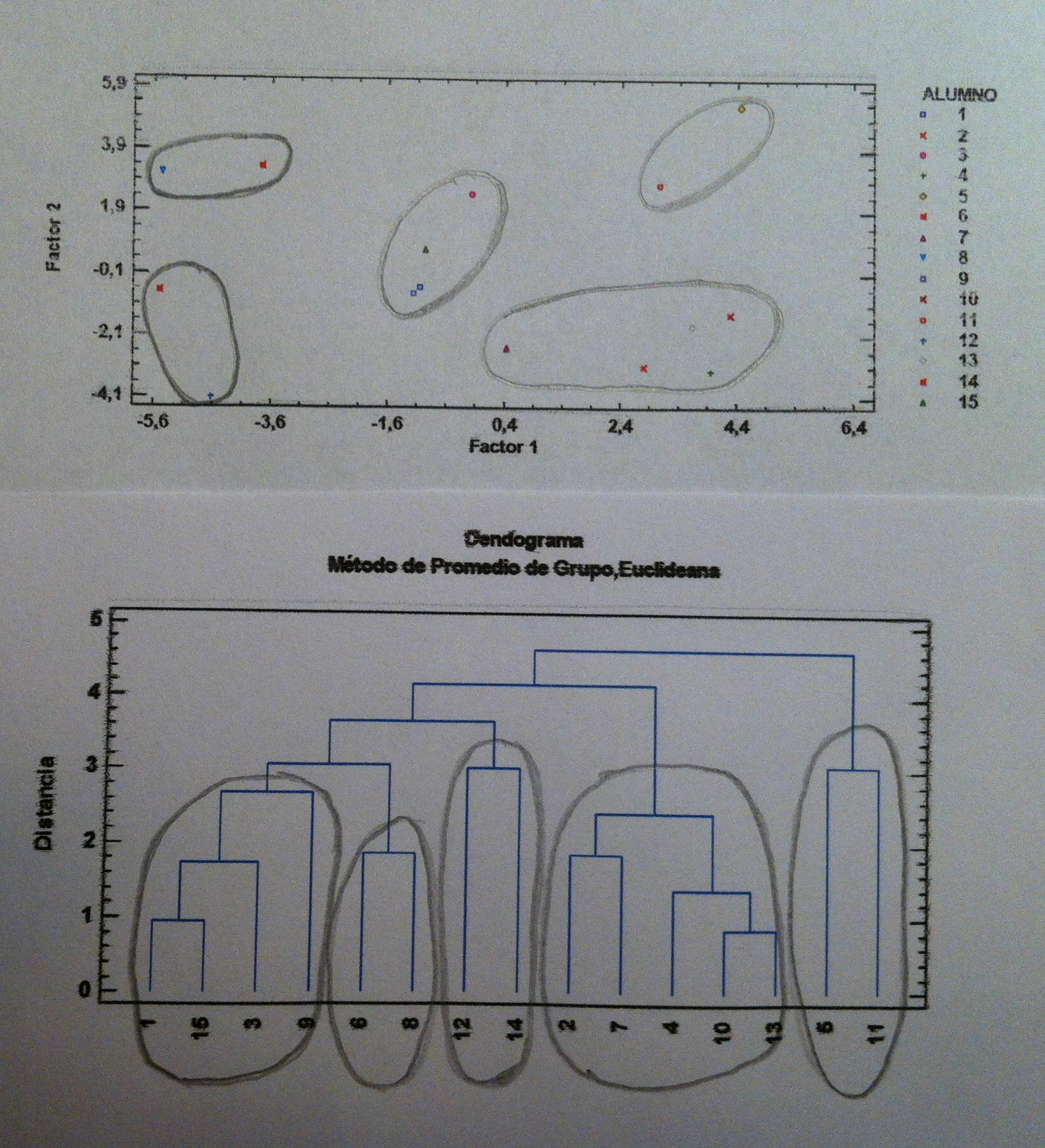
32. El 5 y el 11 forman un grupo: son los alumnos que son buenos tanto en ciencias como en letras. El 2, 7, 4, 10 y 13 forman otro grupo: son los alumnos buenos en letras pero malos en ciencias. El 6 y 8 otro grupo: son los alumnos buenos en ciencias pero malos en letras. El 12 y 14: el grupo de los malos en ciencias y en letras. Finalmente, hay un grupo formado por el 1, 15, 3 y 9 que están en medio, que les va todo justo, están en la frontera entre el aprobado y el suspenso tanto en ciencias como en letras. Veámoslo en el siguiente gráfico que es el mismo de antes pero con estos grupos marcados tanto en una como en la otra representación:
32. Como puede verse estamos haciendo cosas similares aunque a través de procedimentos bien distintos.