Se trata de un artículo muy interesante desde el punto de vista estadístico por la enorme masa de datos que maneja y la gran capacidad que tiene de ir articulando diferentes agrupaciones buscando su relación con la mortalidad.
El abstract es el siguiente:

Durante seis años de seguimiento de 231048 personas se ha podido establecer cuáles son los riesgos de mortalidad en función de una serie de estilos de vida que se analizaron en todos estas personas. Los comportamientos analizados han sido: Fumar, beber alcohol, tipo de alimentación, actividad física, comportamiento sedentario y horas de dormir.
Los resultados de riesgos se establecen mediante la Hazard ratio (HR). La significación la obtenemos del intervalo de confianza.
La HR es una relación entre las funciones de riesgo de mortalidad de dos grupos que se quieren relacionar. Estas funciones son el reverso de las llamadas curvas de supervivencia. Una HR de 1 ó, aunque no sea 1 exactamente, si su intervalo de confianza contiene al 1, indica que los miembros de los dos grupos tienen el mismo riesgo de morir. Si la HR es mayor que 1 significativamente (el intervalo de confianza no contiene al 1) será que el grupo estudiado, respecto al grupo referencia, tiene más riesgo de morir. Tanto mayor, claro, cuanto más grande sea esa HR. Si fuera menor que 1, significativamente (sin contener al 1 su intervalo de confianza) entonces indicaría un grupo protector de la mortalidad.
Los distintos comportamientos y su relación de riesgo respecto al grupo de referencia lo muestra la siguiente ilustrativa tabla:
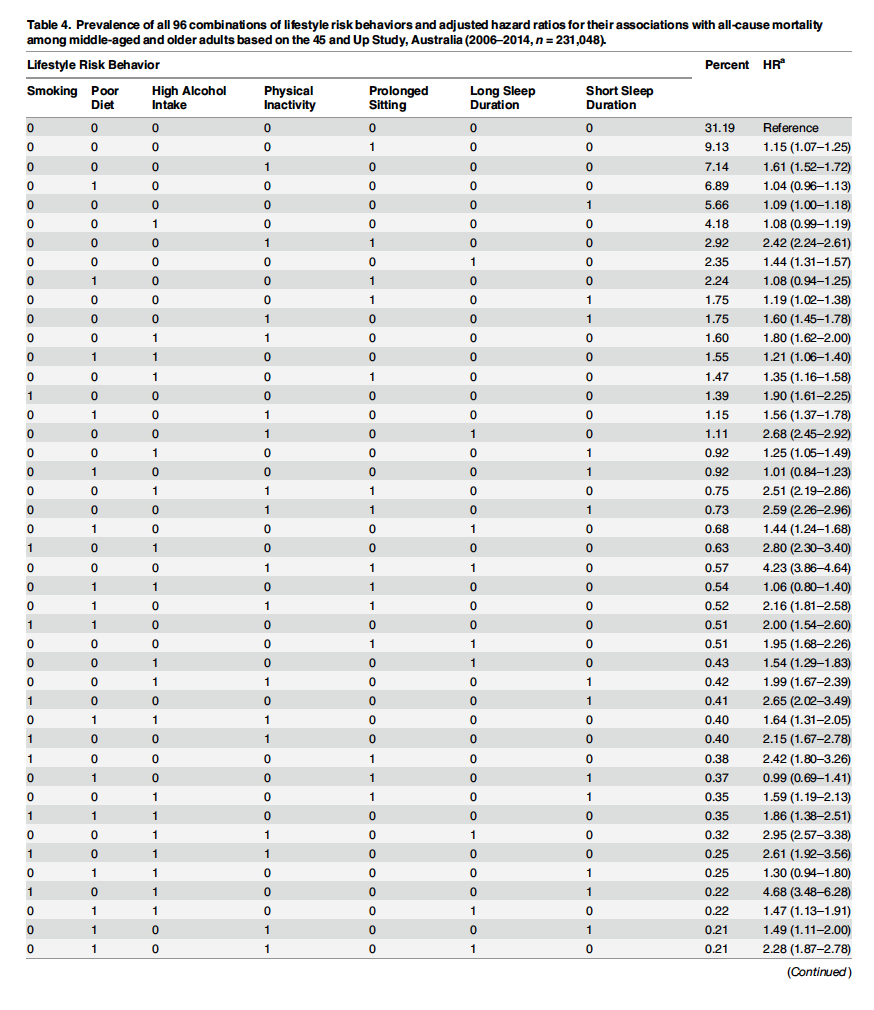


Evidentemente esta fragmentación de la muestra en tantos grupos distintos únicamente es posible en muestras enormes como esta. Observemos que en esta fantástica tabla se pueden visualizar situaciones muy diferentes. A la derecha tenemos el porcentaje de personas que representa cada grupo respecto al total de la muestra. Y más a la derecha tenemos la HR con su intervalo de confianza que si no contiene al 1 se entiende como estadísticamente significativa.
En el artículo hay otra interesante forma de agrupar los datos. De los factores estudiados calculan un score según acumulen desde 0, 1, … , 6 factores de riesgo, según el siguiente criterio:

Por lo tanto, pueden crear 7 grupos según el valor del score: 0, 1, 2, 3, 4, 5 y 6.
Entonces analizan los datos según diferentes grupos y según el valor del score:
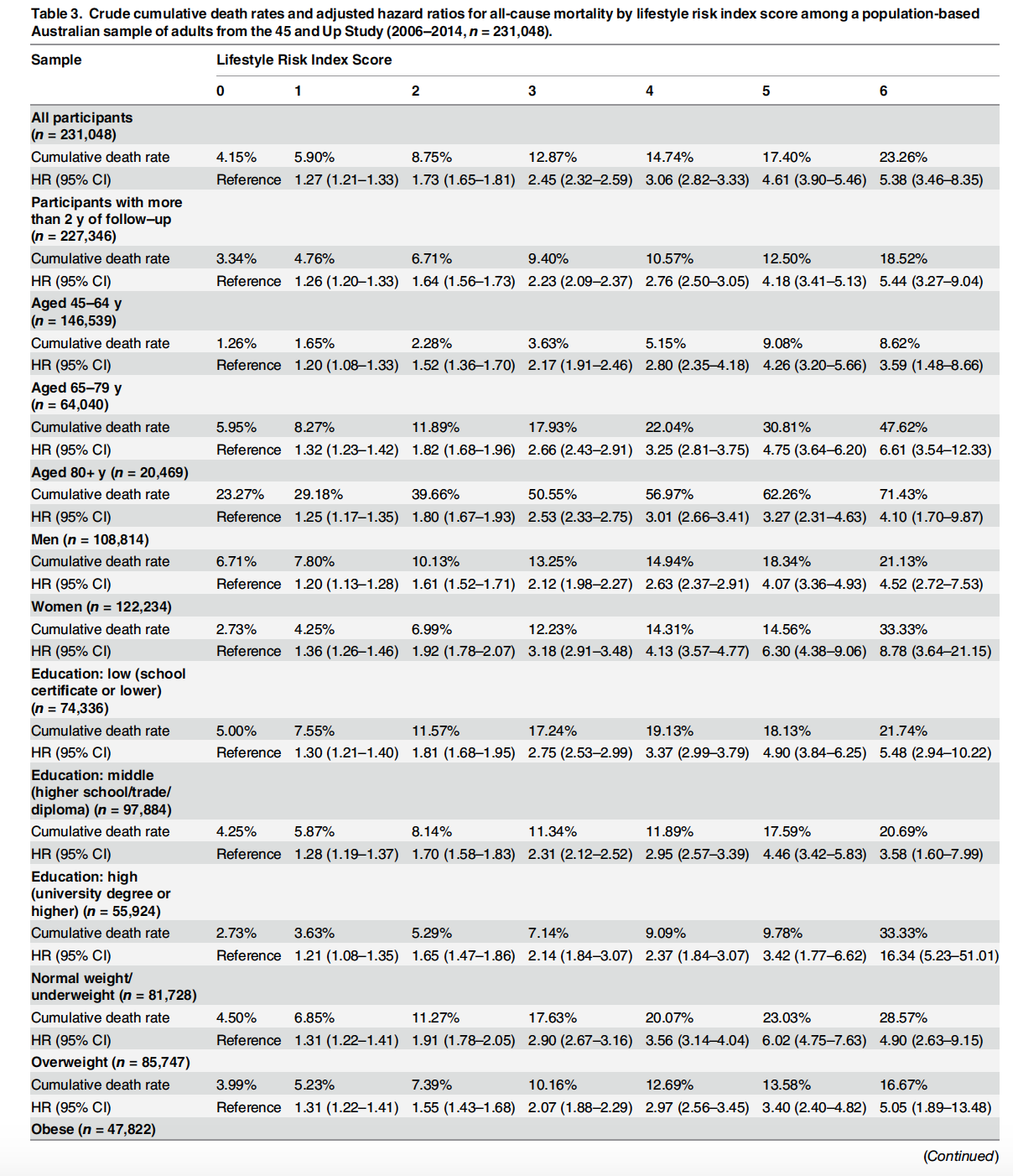
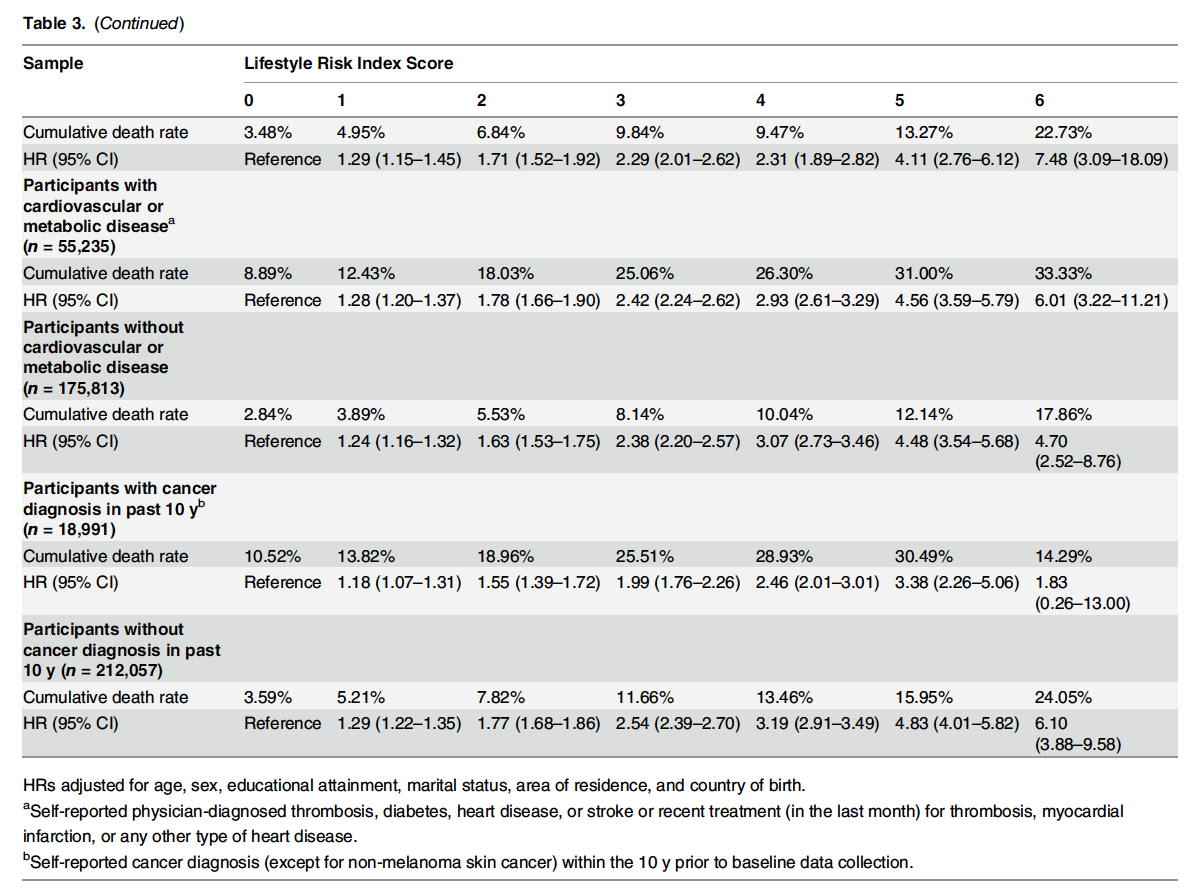
Realmente se trata de un artículo extraordinario desde el punto de vista estadístico.
