1. En diferentes temas de este curso hemos tratado de la relación entre variables. La Estadística ha creado diferentes mecanismos para detectar (ver si la hay o no, significativamente) y cuantificar la relación entre variables. También hemos visto diferentes técnicas de comparación entre poblaciones. Técnicas que tratan de valorar si las diferencias de medias, de porcentajes o de otro valor, que vemos entre muestras son estadísticamente significativas; o sea generalizables a las poblaciones que estamos comparando.
2. Cuando se valora la relación entre dos variables, sean las dos cuantitativas, cualitativas las dos o cualitativa una y cuantitativa la otra, nos podemos encontrar que la relación que estemos detectando sea confundida por una tercera variable. O por varias terceras variables. Lo mismo sucede en una comparación entre poblaciones: puede ser que las diferencias que veamos o que no veamos sean atribuibles al efecto producido por terceras variables.
3. El ejemplo típico que se plantea para ejemplificar esta situación es el siguiente: si se relaciona o compara la mortalidad anual en Florida y Boston, hay más mortalidad, significativa, en Florida. ¿Significa esto que en Florida la gente se muere más? Pues, no, significa que tenemos una variable confusora. Una variable que nos confunde, que hace que veamos una relación que, en realidad, no existe. Sucede que en Florida la edad media es mucho mayor porque mucha gente en EEUU al jubilarse se va a vivir allí y, por lo tanto, es lógico que esa zona acabará teniendo más mortalidad anual superior a otras zonas, como sucede con Boston.
4. En este tema vamos a abordar mecanismos de detección de esas variables confusoras y mecanismos de evitación la influencia de esas variables. Veremos, también, mecanismos que controlan esa confusión al mismo tiempo que la detectan.
5. Una evidencia es que en la naturaleza las variables van juntas. Las variables se relacionan, interfieren unas a otras, se influyen mutuamente. Lo cierto es que el análisis de la relación entre variables es mucho más complejo de lo que parecería a primera vista. A veces detectamos una relación entre dos variables que debería ser atribuible, en realidad, a una tercera variable y a veces, también, no vemos una relación por culpa de una tercera variable que nos está interfiriendo y confundiendo.
6. El Test estadístico más usado para comprobar la posible confusión que puede generar una tercera variable en la relación entre dos variables cualitativas es el Test de Cochran-Mantel-Haenszel.
7. El Test de Cochran-Mantel-Haenszel es un contraste de hipótesis para evaluar la igualdad de Odds ratio entre k tablas de contingencia 2×2. Es una forma de evaluar la posible influencia que pueda tener, sobre la relación entre esas variables cualitativas dicotómicas, una tercera variable también cualitativa con k valores posibles. El Test consiste en ir calculando las Odds ratio de las dos variables originales en tantas tablas de contingencias como valores diferentes tengamos de la tercera variable que pretendemos evaludar si es o no confusora.
8. En este Test si se mantiene la Hipótesis nula que afirma que las Odds ratio son iguales en todas las tablas de contingencias desplegadas, la tercera variable no será contemplada como confusora; si, por el contrario, se rechaza la Hipótesis nula y se acepta la Hipótesis alternativa, significa que esa tercera variable, a través de la cual hemos construido las diferentes tablas de contingencias, está influyendo en la relación entre las dos primeras variables. Es, pues, una variable confusora. Es un Test, por lo tanto, importante, que conviene aplicar cuando se quiere detectar variables confusoras a ese nivel de estudios.
9. El Análisis de propensiones (Propensity score analysis) es una importante técnica estadística para evitar la confusión de variables. En el tema dedicado a esa técnica podemos ver cómo se trata de una técnica que trata de evitar la confusión a través de igualar los individuos a comparar.
10. El Análisis de propensiones es especialmente usado cuando lo que se pretende es comparar grupos en estudios observacionales, estudios donde, por sus peculiaridades en el procedimiento de toma de muestras, es muy frecuente encontrarse con perfiles muy distintos entre los individuos de los grupos a comparar.
11. En estas situaciones muchas de las diferencias estadísticamente significativas que veamos entre los grupos son atribuibles a variables confusoras más que a los elementos característicos que delimitan los grupos a comparar. Por ejemplo, supongamos que queremos comparar la respuesta a dos tipos de cirugía y se ha hecho mediante un estudio observacional, no mediante un estudio randomizado. Muy posiblemente las edades medias, la proporción de sexos, la asociación con ciertas comorbilidades serán muy distintas entre los dos grupos. Y no sabemos si las diferencias que vemos son atribuibles a las dos cirugías o a la presencia en ambos grupos de individuos bien distintos en cuanto a diferentes variables.
12. El Análisis de propensiones, el Propensity score analysis, trata de evitar esto mediante un original mecanismo de reestructuración de los grupos, que se puede ver explicado con detalle en el Tema dedicado a ello: Tema 24: Análisis de propensiones (Propensity score analysis).
13. Es obligatorio hablar del la Regresión logística al abordar el tema de las variables confusoras. La Regresión logística es una técnica para detectar relaciones entre una variable dependiente dicotómica y una o variables variables independientes, pero la Regresión logística en sí, también, como veremos ahora, un mecanismo de control de la confusión. El hecho de introducir diferentes variables en el modelo supone, como veremos a continuación, un control de la confusión. Veámoslo con un ejemplo con valores ficticios.
14. Planteemos la situación del ejemplo clásico de confusión que planteábamos al comienzo de este tema. Supongamos que hemos aplicado una Regresión logística comparando la mortalidad (variable dependiente) con vivir en Florida y en Boston (variable independiente) y tenemos una Odds ratio, por ejemplo, de 3, significativa, indicando que existe una relación significativa entre la mortalidad y la zona donde se vive; o sea, que hay más posibilidades de morir en Florida que en Boston. Diríamos, entonces, que vivir en Florida es un factor de riesgo.
15. Pero supongamos ahora que analizamos las edades de la gente que vive en Florida y en Boston y, supongamos, que tenemos la siguiente distribución de edades:

16. Observemos que en Florida hay más gente mayor que en Boston, relativamente. La distribución de edades es distinta.
17. Si hacemos ahora una Regresión logística entre mueren o no mueren durante, por ejemplo, un año, en esta muestra elegida, los datos que podríamos tener serían los siguientes:
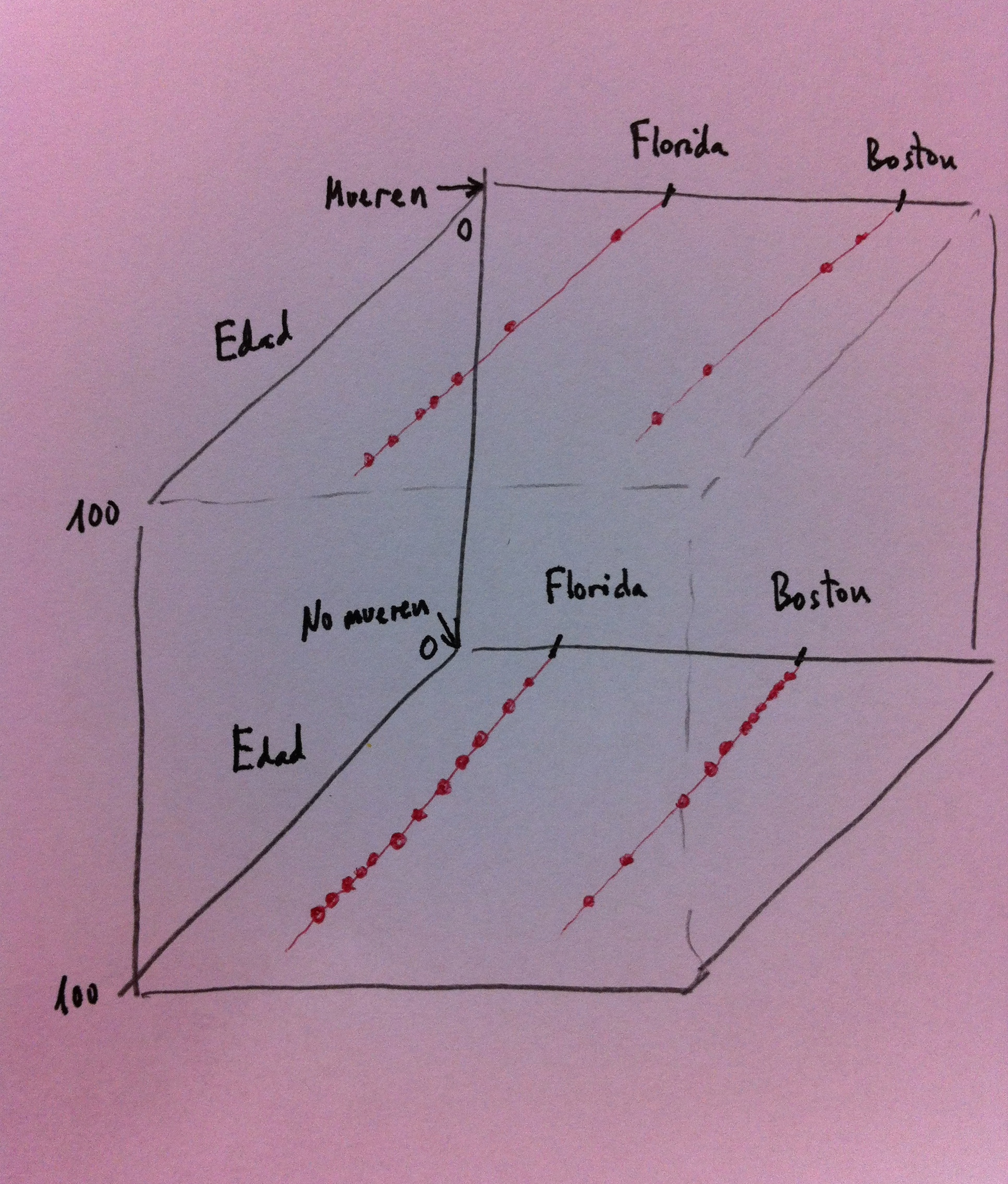
18. Observemos que ahora no sólo compararemos los que mueren o no respecto a ser de Florida o de Boston, cosa que nos daba antes una relación significativa a favor de morir en Florida. Ahora esta relación la hacemos introduciendo en el modelo de Regresión logística una tercera variable, la variable edad. Las cosas ahora cambian. Ahora la Regresión calculará dos curvas de probabilidad de morir, y lo interesante es que ahora esas curvas de de probabilidad de morir serán similares. Veámoslo:

19. Observemos que son curvas muy similares. Porque ahora lo que se valora no es cuántos mueren o no en Florida y Boston, sino cuántos mueren en esas dos zonas pero en función de la edad. La probabilidad de morir ahora se estima relativizando respecto a la edad, y respecto a la edad las probabilidades de morir son las mismas, vivas en Florida o vivas en Boston. Tenemos en ambos casos la misma curva:
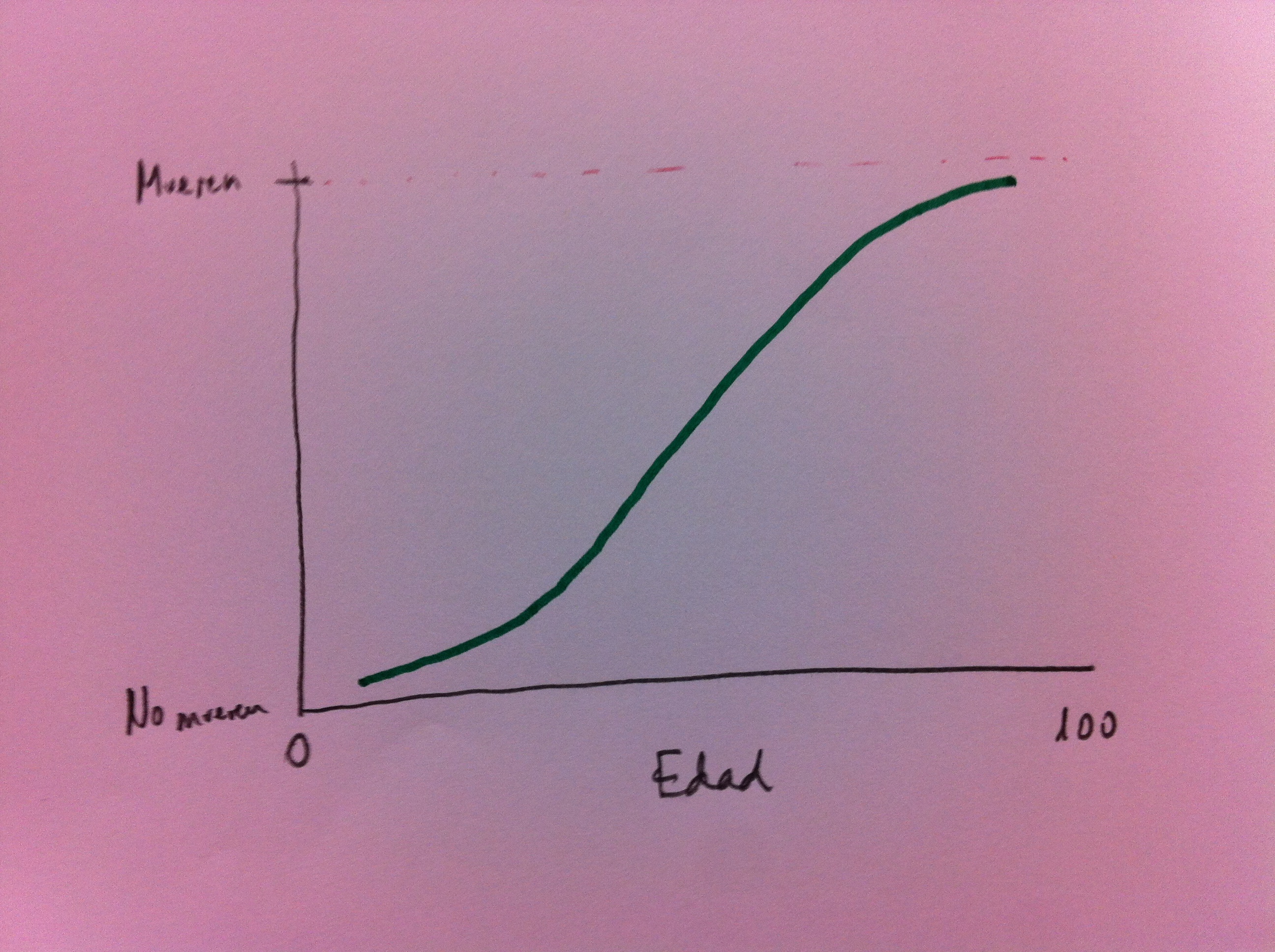
20. Esta es la curva que nos construiría tanto para Florida como para Boston el modelo de Regresión logística. He preparado un ejemplo numérico donde se refleja esta realidad y vamos a ver a continuación la salida de ordenador que da un software estadístico, con la opción de Regresión logística, para las curvas de probabilidad de morir Boston y de Florida, según la edad. Son las siguientes:
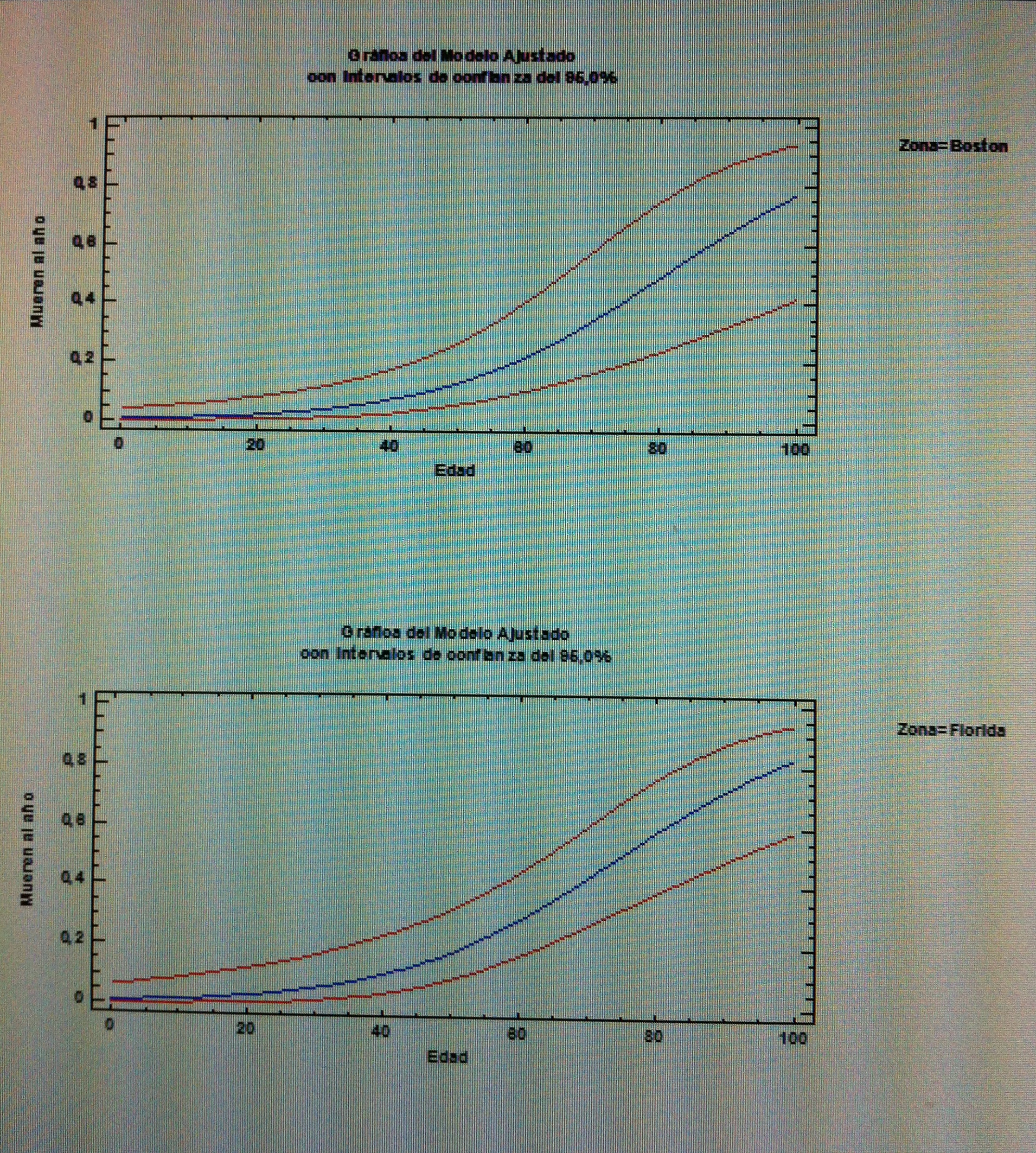
21. Como puede apreciarse se trata de dos curvas muy similares. No son distintas significativamente. Ahora la Odds ratio entre la variable dicotómica muere o no muere y zona (Florida o Boston) no es distinta significativamente de 1, lo que significa que no hay relación. Y es 1 y no 3, como lo era antes, por la entrada de la edad en el modelo, en la Regresión logística. Antes el 3 era consecuencia de la variable confusora edad; ahora, al entrar la edad en el modelo de Regresión logística hemos controlado esa confusión.
22. Es muy importante entender bien esto. Observemos que, ahora, al entrar la edad se evita que ella actúe como confusora. Por lo tanto, la Regresión logística múltiple, con variables independientes, consigue que las variables que entran en el modelo sean eliminadas como variables confusoras. Tenemos, pues, así, que la Regresión logística nos permite establecer relaciones entre una variable dependiente dicotómica y diversas variables independientes controlando la confusión entre ellas.
