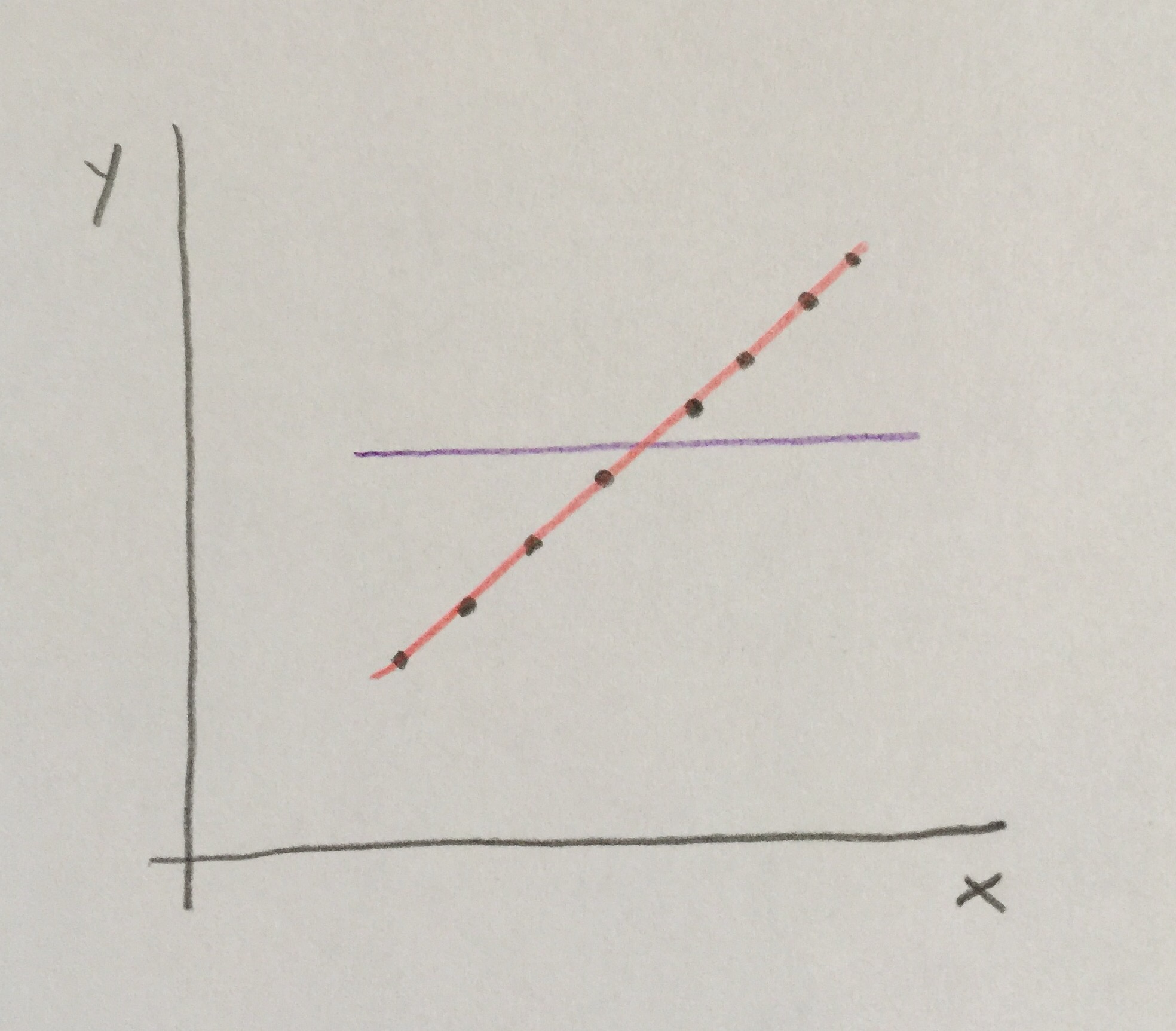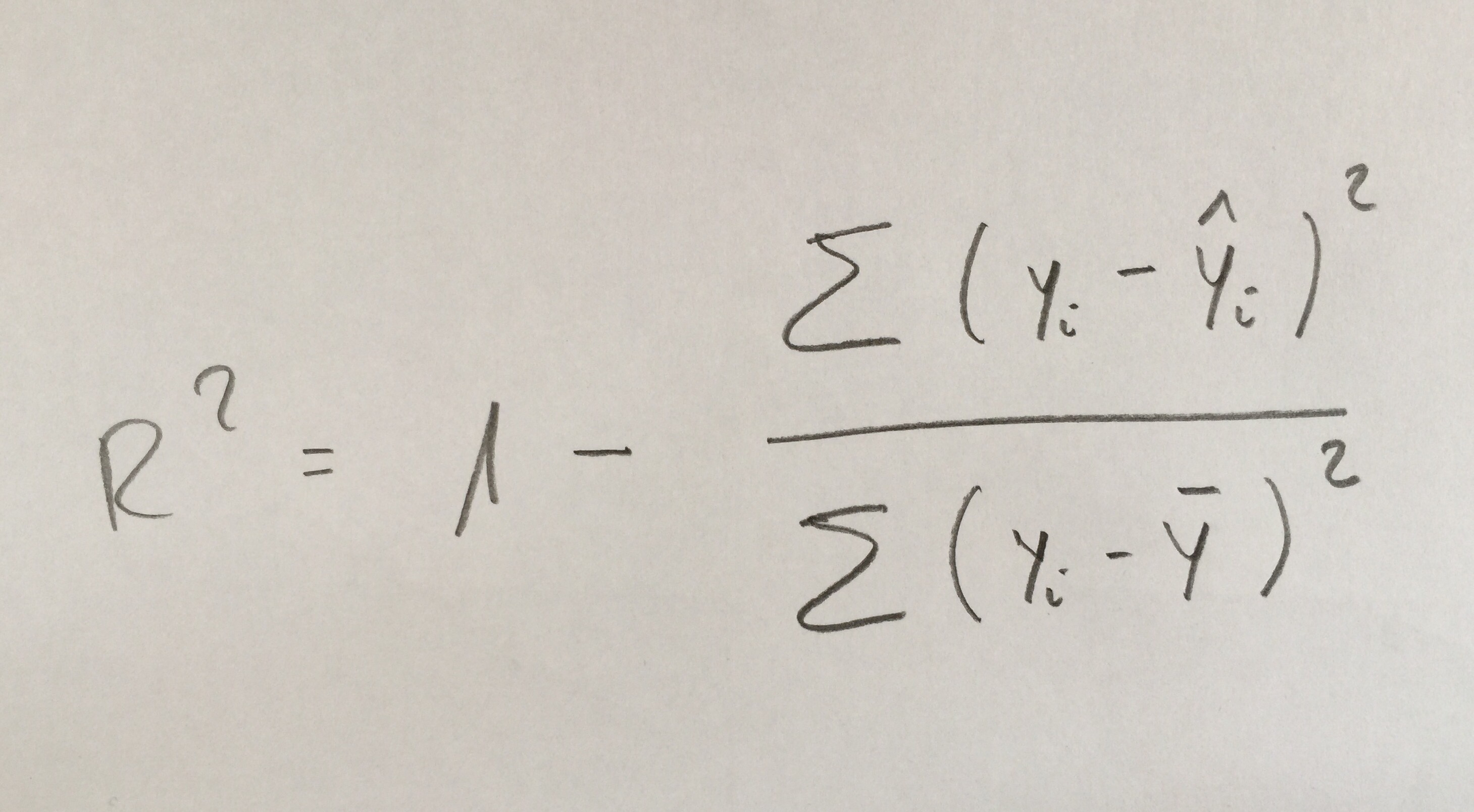El Test de la t de Student para una muestra permite comprobar si es posible aceptar que la media de la población es un valor determinado. Se toma una muestra y el Test permite evaluar si es razonable mantener la Hipótesis nula de que la media es tal valor.
Se trata de un Test paramétrico; o sea, parte de la suposición de que la variable analizada en el conjunto de la población sigue una variabilidad, una distribución como la de la campana de Gauss. Por lo tanto, podemos pensar que la distribución normal es un buen modelo de esa población.
Puede observarse que se construye un estadístico que sigue la distribución t de Student si es cierta la Hipótesis nula. Por lo tanto, como siempre, el cálculo del estadístico a la muestra que tenemos es un número. Un número que pondremos en relación con la distribución del estadístico en caso de ser cierta la Hipótesis nula. Si cae en una zona central de esa distribución de probabilidad 0.95 (el 95%, porcentualmente) mantendremos la Hipótesis nula. Si cae fuera de esa zona, la rechazaremos y nos decantaremos por la alternativa. Este es el proceder de siempre en Estadística. Veamos el esquema del Test:
(Cuando en Estadística se escriben tres líneas paralelas horizontales a la derecha de un cálculo, de un estadístico, y a continuación se escribe una determinada distribución nos referimos a que tal estadístico sigue esa distribución)
1. En la Regresión lineal múltiple modelizamos la relación entre una variable dependiente y dos o más variables independientes mediante una función lineal, una función que será, ahora, no una recta, como sucedía con la Regresión lineal simple, sino un plano (si tenemos dos variables independientes) o un hiperplano (si tenemos más de dos variables independientes).
2. En la Regresión lineal múltiple el punto de partida es el mismo que en la Regresión lineal simple. Se pretende modelizar la relación entre unas variables con la finalidad última de poder pronosticar una de ellas: la variable dependiente, a partir del conocimientos de las otras: las variables independientes. En la Regresión lineal múltiple se introducen nuevas variables independientes con la finalidad de reducir la dispersión de la predicción, con la finalidad de disminuir el residuo.
3. El modelo matemático es, ahora:
y=a1x1+a2x2+…+adxd+b+e
donde a1, a2,…, ad y b son los coeficientes del modelo y donde e es el residuo, que, como en la Regresión lineal simple, supondremos que sigue una distribución normal N(0, DE).
4. Aunque la Regresión lineal múltiple es, en buena parte, una generalización de la Regresión lineal simple, tiene unas particularidades que conviene precisar.
5. Una de sus peculiaridades es la tendencia a llenar excesivamente el modelo. Hay la tendencia a ir introduciendo variables, hinchando el modelo y esto es muy perjudicial. Para que las cosas funcionen lo mejor posible conviene trabajar con variables que sean independientes entre ellas.
6. Observemos que en el punto anterior he usado la noción de independencia entre variables para referirme a las variables que se denominan independientes en el modelo de regresión. Recordemos que de esas variables tendremos, en el futuro, valores concretos para un individuo y a partir de ellos trataremos de pronosticar el valor de una variable dependiente que desconoceremos su valor para ese individuo.
7. Pueden observarse dos nociones de independencia distintas, pues, en lo que estamos diciendo ahora. Una cosa es la posición de las variables en el modelo de Regresión y otra es el que las variables sean independientes entre ellas, que significa que la correlación entre ellas sea cero.
8. Cuando no se cumple esta relación de independencia entre las variables independientes se produce un fenómeno de colinealidad. Esto es perjudicial para el modelo. El perjuicio representa que las estimaciones de los parámetros del modelo (los coeficientes), que son los elementos básicos para la construcción de los pronósticos de la variable dependiente, tienen más Error estándar. Y el Error estándar, como Desviación estándar de una predicción, es uno de los principales criterios de calidad de una estimación.
9. Hay distintos mecanismos para comprobar si tenemos un exceso de colinealidad. El Test de Belsey, Kuh y Welsch (Ver Herbario de técnicas) es uno de los más usados para comprobar si tenemos ese exceso de colinealidad. Ante un exceso de colinealidad conviene hacer una revisión y una nueva consideración de las variables independientes a usar en el modelo de Regresión, eliminando alguna de ellas o haciendo una Análisis de componentes principales (Técnica multivariante que veremos más adelante).
10. De hecho, parece lógico, en una Regresión lineal múltiple, pedirle a las variables independientes que sean independientes entre ellas. Pensemos que si no lo son, si tienen un cierto grado de dependencia, es porque de alguna forma comparten aspectos entre ellas, en cierta forma dicen cosas similares esas variables. Por lo tanto, a la hora de ser usadas para predecir una variable dependiente se produce un fenómeno de redundancia: estamos usando varias veces lo mismo para pronosticar algo. Y esto se paga con más imprecisión en las estimaciones.
11. Otra peculiaridad de la Regresión lineal múltiple es la posibilidad de construir el modelo paso a paso. Es el procedimiento denominado, en inglés, Stepwise.
12. Al realizar una Regresión lineal múltiple hay, pues, tres modalidades de estimación del modelo:
a. Forzando la entrada en el modelo de todas las variables elegidas.
b. Mediante un Stepwise hacia delante. La Regresión entonces se denomina Fordward Stepwise Regression.
c. Mediante un Stepwise hacia atrás. La Regresión entonces se denomina Backward Stepwise Regression.
13. Expliquemos las dos variantes últimas, puesto que la primera no precisa ninguna explicación.
14. El Stepwise hacia delante lo que hace es, paso a paso, ir introduciendo, en el modelo de Regresión lineal, como dice su nombre: paso a paso, variables independientes, hasta completar el mejor modelo posible.
15. En primer lugar crea un modelo con una única variable independiente. En realidad, pues, el primer paso es crear una Regresión lineal simple. Pero lo hace eligiendo entre todas las variables independientes la que consigue un mejor modelo, si es que lo consigue. En este primer paso debe existir entre las variables independientes una variable que tenga una relación significativa con la variable dependiente. De lo contrario el procedimiento acabaría aquí y no tendríamos modelo matemático para relacionar esas variables.
16. En el segundo paso se prueba de introducir, entre las variables independientes que quedan, cuál es la que consigue un modelo mejor, si es que alguna lo consigue. Se trata de establecer unos criterios de calidad mínimos. Lo que se denomina un Criterio de entrada. Si no se alcanzan nos quedamos con una Regresión lineal simple y se rechazan las otras variables.
17. Si hemos conseguido introducir en el modelo una segunda variable independiente se valora, probando con todas las variables independientes que quedan, la posibilidad de introducir una tercera. De nuevo se aplican unos criterios de entrada que si no se alcanzan no se introduce ninguna variable más.
18. Y así se va haciendo hasta alcanzar el mejor modelo. Es importante tener en cuenta que en cualquiera de estos pasos hay la posibilidad de extraer una variable que anteriormente se había introducido. Y cambiar así la disposición inicial. Por ejemplo, supongamos que en los pasos anteriores se habían introducido las variables x3 y x5 y, al probar una nueva introducción, al ensayar con, por ejemplo, x7, el procedimiento observa que consigue mejores resultados sacando del modelo la variable x3 que había sido la primera que había introducido, quedando, entonces, el modelo con x5 y x7.
19. El Stepwise hacia atrás es lo mismo pero ahora partiendo que hemos empezado forzando la entrada de todas las variables dentro del modelo y, a continuación, en el siguiente paso, mirar de sacar una de las variables independientes: una variable que al sacarla alteremos la calidad del modelo menos que un valor umbral establecido, lo que se denomina, ahora, un Criterio de salida. Si es así, si podemos extraer sin perjudicar por encima de ese valor preestablecido, reducimos el modelo.
20. Y así, paso a paso, pero en sentido contrario, vamos creando el mejor modelo posible, la mejor ecuación posible que relacione una variable dependiente con varias variables independientes.
21. Los criterios de entrada y de salida, que en muchas ocasiones son el mismo valor, generalmente vienen dados por el valor de un estadístico, por el valor de la F de Fisher. Puede verse en el Herbario de técnicas, en concreto, la técnica “Contraste de hipótesis de la pendiente de Regresión” que valores de F pequeños implican buena relación entre la variable dependiente y la independiente. Y valores grandes implican mala relación. Pues el criterio de entrada será que el valor de la F esté por debajo de cierto valor y el de salida que esté por encima de también de cierto valor, que suele ser el mismo. En otras ocasiones el criterio de entrada o de salida es un determinado p-valor prefijado asociado al parámetro de la variable que se decide si entra o no en el modelo.
22. Dados unos datos muestrales de una serie de individuos donde tengamos de ellos los valores tanto de la variable dependiente como de todas las variables independientes, cualquiera de los tres procedimientos estima los coeficientes del modelo y el valor de la Desviación estándar del residuo; o sea, de ese elemento que sumamos a cualquier procedimiento de Regresión.
23. Todos estos coeficientes debe decidirse si son coeficientes significativos, valores fiables que nos proporcionan una modelo asentado, estable, que refleja una realidad no sólo muestral, sino una realidad poblacional.
24. Para que todas estas estimaciones y estas significaciones proporcionadas, mediante p-valores, por técnicas estadística, sean fiables es necesario que se cumplan algunas condiciones que ahora comentaré.
25. No olvidemos que toda la llamada Estadística paramétrica se construye con procedimientos cuyas decisiones y cuyas construcciones se basan en unas suposiciones, bastante exigentes, que deben cumplirse.
26. Por otro lado las suposiciones que ahora comentaré son condiciones compartidas con la Regresión lineal simple. Habitualmente la mayor parte de software estadísticos que realizan Regresión lineal, tanto la simple como la múltiple, y, en ésta última, tanto los dos tipos de Stepwise como la que fuerza la entrada de todas las variables independientes, sus inferencias se basan en estas suposiciones.
27. Una de las comprobaciones necesarias a hacer en estos modelos es que realmente los residuos sigan la distribución normal N(0, DE). Suposición nuclear en la Estadística paramétrica. Y fundamental para el buen funcionamiento de la mayor parte módulos de Regresión lineal en los distintos software comerciales.
28. Una de las técnicas para comprobar esta normalidad es el Test de la ji-cuadrado de bondad de ajuste a una distribución. Otra muy utilizada es el Test de Kolmogorov.
29. Otra comprobación importante es la Homogeneidad de varianzas. Esto significa que el residuo tienen una dispersión homogénea, igual, sean cuales sean los valores de las variables independientes. Hay diversas pruebas que se han desarrollado para comprobar si se cumple o no esta condición. Una es el Test de Glesjer.
30. Otra comprobación importante es que no haya autocorrelación entre los valores en su orden de obtención. Que sean valores independientes uno respecto a otro. El Test de Durbin-Watson es el apropiado en estos casos. La independencia de los datos entre sí es una suposición también del modelo de Regresión lineal.
31. Otra consideración importante a investigación en una Regresión es la influencia de cada punto. No todo punto tiene la misma influencia. Es importante que no haya puntos excesivamente influyentes. Que las estimaciones de los parámetros del modelo queden demasiado en manos de esos puntos. Entre muchos criterios existentes uno de los más usados es el criterio de Cook (Ver Herbario de técnicas) para la detección de influencia.
32. Cuando alguna o varias de las condiciones necesarias no se cumplen una de las opciones más usuales es la Regresión no paramétrica. En este ámbito los métodos más usados se basan en la utilización de estimaciones de funciones de densidad no paramétricas.
33. De hecho, los diferentes procedimientos de Regresión no paramétrica, tanto simple como múltiple, se basan en procedimientos de construcción, sobre el terreno, partiendo de la muestra, donde habrá una enorme flexibilidad que vendrá dada porque la función irá siempre a remolque de la posición de los valores muestrales que tengamos.
34. Posiblemente el modelo de Regresión no paramétrica más utilizado es el Estimador de Nadaraya-Watson que se puede consultar en la sección Herbario de técnicas.
35. Finalmente un criterio de calidad de una Regresión lineal múltiple, como sucede también en la Regresión lineal simple, es el Coeficiente de determinación, la R2 (Ver Herbario de técnicas). Aunque el valor de este coeficiente es un número que va del 0 al 1 es frecuente expresarlo en tanto por ciento. Es una forma de expresar el grado de determinación de la variable dependiente por parte de las independientes.
En la Historia de la Estadística ha habido tres grandes revoluciones:
Estadística paramétrica
Estadística no paramétrica
Remuestreo
Veamos con un poco de detalle lo que supone cada una de ellas:
La primera gran revolución es la creación de la llamada Estadística paramétrica. Pearson, Fisher, Student y otros estadísticos emprendieron la labor de crear procedimientos de decisión estadística: estimación puntual, estimación por intervalos y contrastes de hipótesis, basados en unas suposiciones prefijadas sobre la distribución de las variables analizadas, especialmente la suposición de normalidad. A partir de esta suposición construían una serie de procedimientos que permitían tomar decisiones.
La segunda gran revolución la introducen unos estadísticos que perciben que las suposiciones de la Estadística paramétrica son muy exigentes y que, en muchas ocasiones, no se cumplen. En este caso usar un método paramétrico es arriesgado porque estás tomando decisiones en base a unos criterios que no son ciertos. Percibieron que habían de construir mecanismos de decisión estadísticos que no dependieran de suposiciones tan exigentes. Y construyeron una estadística cuyos estadísticos, cuyos cálculos a una muestra para tomar decisiones, su distribución dependiera de ellos mismos, de su estructura, no de la distribución de la población.
La tercera gran revolución viene de la mano de la simulación, del remuestreo, de las posibilidades ofrecidas por la informática y la programación. Estos procedimientos han permitido encontrar la distribución de un estadístico de test cualquiera puesto que la simulan. Además lo pueden hacer bajo el supuesto de ser cierta la Hipótesis nula. Y lo hacen a través de una genialidad: catapultando la muestra a población. Haciendo de la muestra la población. Y generando, así, desde esta población artificial muchas muestras posibles bajo las condiciones que se quiera. Así podemos encontrar cuál es la distribución simulada de un estadístico y construir intervalos de confianza, realizar contrastes de hipótesis, etc.
Es un importante estadístico en la Regresión. Es una medida del grado de relación existente entre la variable dependiente y las variables independientes (si es una regresión simple, entonces «la variable independiente»). Mide cuánto está determinada la variable dependiente respecto a la variable o variables independientes.
Aunque es un valor que va del 0 al 1, suele darse en porcentaje.
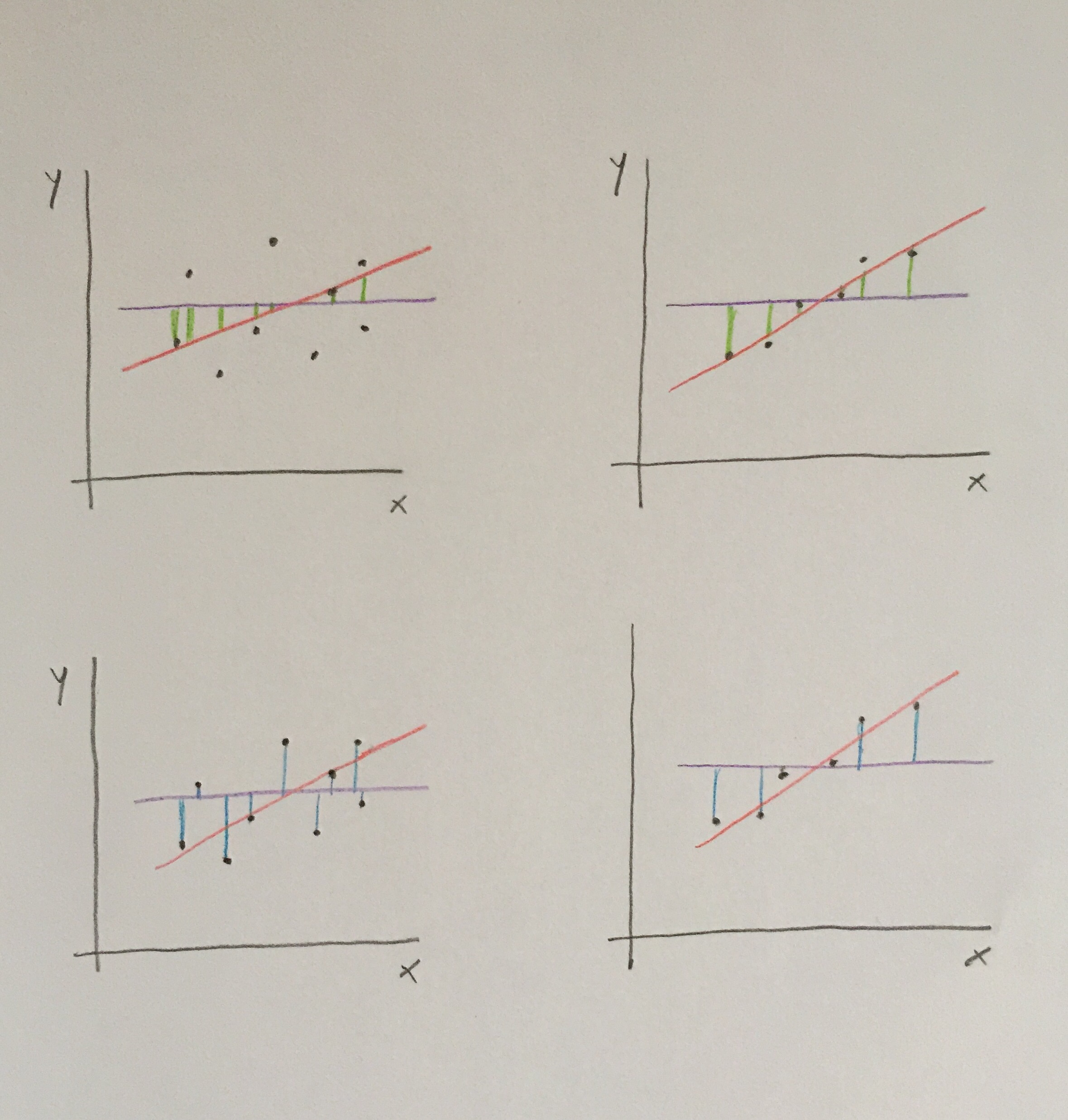
Puede observarse el cálculo y, también, un caso de valor alto y otro de valor bajo de este coeficiente:
Observemos el siguiente gráfico que tal vez aclare mejor los dos ejemplos:
A la izquierda tenemos el caso con coeficiente bajo y a la derecha el caso con coeficiente de determinación alto.
En cada uno de los casos tenemos arriba el numerador del cálculo del coeficiente y abajo el denominador del cálculo. Líneas verdes para el numerador y azules para el denominador.
Observemos que en el caso de la izquierda las líneas azules son mucho más largas que las verdes. Esto indica que nuestra recta de regresión no explica mucho la posición de los valores en la relación dibujada entre las dos variables.
En cambio, en el caso de la derecha hay una gran aproximación de las líneas verdes a las azules. Esto indica que realmente nuestra recta de regresión consigue situarse muy próxima a la realidad posicional de los puntos en el diagrama de dispersión.
Observemos qué pasaría si los puntos se adaptaran totalmente a la línea recta:
En este casos las distancias verdes y azules son exactamente las mismas. No las dibujo porque se superpondrían, evidentemente. En este caso el coeficiente de determinación valdría 1.
En una regresión lineal simple el coeficiente de determinación coincide con la correlación de Pearson elevada al cuadrado.
Sin embargo, este coeficiente es utilizado en cualquier modelo de regresión.
A veces, este coeficiente de determinación se plantea de otra forma, aunque equivalente, de esta forma:
En forma más explícita:
Puede comprobarse en los dos ejemplos extremos expuestos cómo se trata de una formulación equivalente a la anterior.