1. Cuando hablábamos de la correlación entre variables cuantitativas decíamos que en una correlación hay siempre tres elementos a considerar: el signo, la magnitud y la significación.
2. Al hablar de la relación entre variables cuantitativas poníamos inmediatamente sobre la mesa una medida del grado de esta relación entre esas variables: la correlación. Desde esa medida del grado de relación construíamos toda la visión de esa relación.
3. Sin embargo, al abordar la relación entre variables cualitativas, únicamente hemos hablado de significación. En ningún momento hemos hablado de una medida, de una cuantificación del grado de esa relación.
4. Con las variables cualitativas hemos planteado la técnica de la ji-cuadrado, que es una técnica para valorar la significación de la relación, pero no para medirla, no para cuantificarla. La ji-cuadrado nos dice si hay relación o no, no nos mide la cantidad de relación.
5. En realidad, la ji-cuadrado sí que mide la cantidad de relación entre variables cualitativas, lo que sucede es que lo hace de forma no estandarizada. De una forma que no nos es útil.
6. El cálculo de la ji-cuadrado es un número que es tanto mayor cuanta más relación haya entre las variables y tanto menor, más próximo a cero, cuanto más cerca estemos de la no relación (de la independencia) entre esas variables. Por lo tanto, en este sentido, sí es una medida.
7. Lo que sucede, y esto es importante entenderlo, es que esta medición de la relación no la hace de forma estandarizada. Cada tabla de contingencias tiene, en definitiva, su escala. Cada tabla tiene un ámbito distinto de valores posibles del cálculo de la ji-cuadrado. Y, por lo tanto, nos faltan unas referencias globales que nos valgan para todas las situaciones.
8. El valor del cálculo de la ji-cuadrado en una tabla de contingencias puede oscilar entre 0 y nm, donde “n” es el número total de observaciones en la tabla de contingencias y m = mín (f-1, c-1), siendo “f” el número de filas y “c” el número de columnas y la expresión mín (f-1, c-1) significa que se toma el valor mínimo de los dos incluidos en el intervalo.
9. Por lo tanto, el 0 siempre es el valor mínimo pero el máximo depende tanto del número de observaciones que tengamos como del tipo de tabla de contingencias que tengamos. En una tabla de contingencias de dos filas y dos columnas (2×2) el máximo será, pues, n, porque aquí m vale 1.
10. Usar el valor de la ji-cuadrado, pues, como medidor del grado de relación es como si atendiéramos a la calificación que un profesor pudiera hacer de los puntos que computa a la hora de valorar a un alumno. Un profesor podría valorar en un examen del 0 al 20, otro del 0 al 120, otro del 0 al 78. Según las preguntas que pudiera hacer en un examen.
11. La posible situación planteada nos va bien para entender lo que vamos a explicar a partir de ahora. Porque a pesar de que diferentes profesores puedan puntuar interiormente entre los dos valores que quieran, al final, todos lo transforman a un número del 0 al 10, que es como nos entendemos todos a la hora de valorar las notas.
12. Pues por esto se han introducido diferentes índice que midan de forma estandarizada el grado de relación. Y esto es lo que vamos a explicar a partir de ahora: algunos de los índices propuestos y los criterios seguidos, por cada uno de ellos, para esta estandarización.
13. Observemos, en primer lugar, cómo en las siguientes tablas de contingencias podemos ver cómo de izquierda a derecha va aumentando el grado de relación entre ambas variables cualitativas. Pasamos de una no relación, a la izquierda, a una relación cada vez mayor, hacia la derecha:
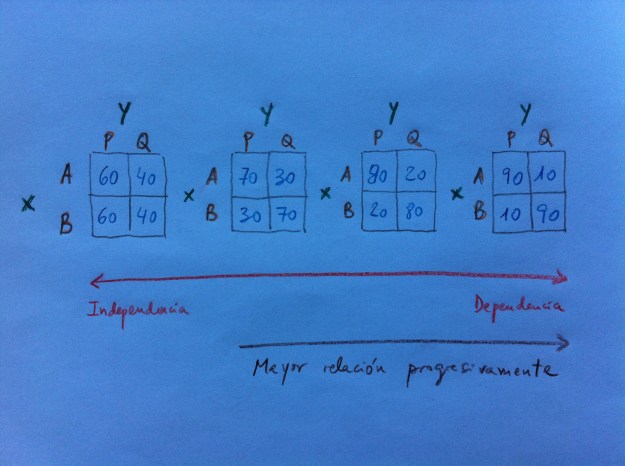
14. Para cuantificar el distinto grado de relación entre variables cualitativas se manejan distintos índices. Pero ninguno ha conseguido alcanzar el nivel de universalidad que ha obtenido el coeficiente de correlación de las variables cuantitativas.
15. Vamos a ver tres de esos índices: la V de Crámer, el Kappa y la Odds ratio. Podríamos ver otros pero estos son los más usados.
16. La V de Crámer:

17. La V de Crámer cuantifica entre 0 y 1 el grado de relación. Desde la posición de la total independencia entre las variables y la total dependencia, nos movemos entre estos dos números. Observemos, en el gráfico siguiente, cómo es su cálculo, en dos tablas distintas:

18. Sin embargo, observemos que la V de Crámer no proporciona valores distintos en dos tablas diferentes como las siguientes:
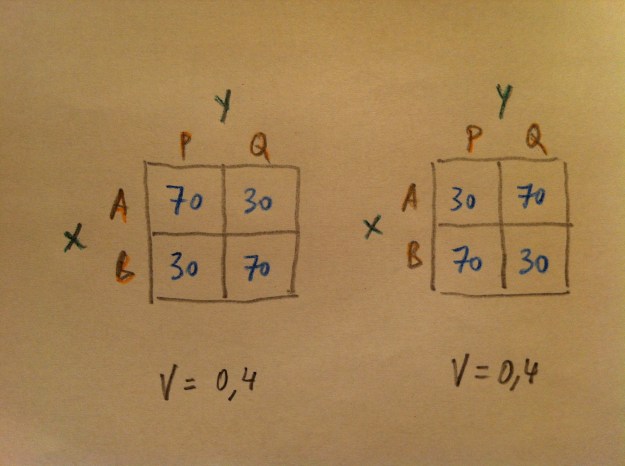
19. La V de Crámer no distingue estas situaciones. No distingue algo así como un signo en la relación (usando como elemento comparativo el signo de la correlación: el positivo y el negativo, que marca relación directa o inversa entre variables cuantitativas). Cosa que sí hace la Odds ratio, como veremos después extensamente.
20. El índice Kappa es otra medida del grado de relación entre variables cualitativas. Es utilizado para cuantificar el grado de concordancia que hay entre dos observadores. Puede también evaluarse la concordancia de un observador consigo mismo en pruebas denominada Test-retest.
21. Las tablas de contingencias que se dan en estos casos son tablas cuadradas; o sea, con el mismo número de filas y columnas, donde las categorías fila y las categorías columna son las mismas y donde lo que interesa es evaluar que los valores estén lo más articulados en la diagonal donde coinciden las valoraciones de un y otro observador.
22. Veamos en el siguiente gráfico las peculiaridades de este índice. Pensemos que aquí tenemos una única variable con tres categorías, en este caso (A, B y C), y dos observadores. Los valores de las celdas son las frecuencias de las combinaciones de las categorías de uno y otro observador a la hora de asignar valores a la variable cualitativa estudiada a ejemplares distintos:
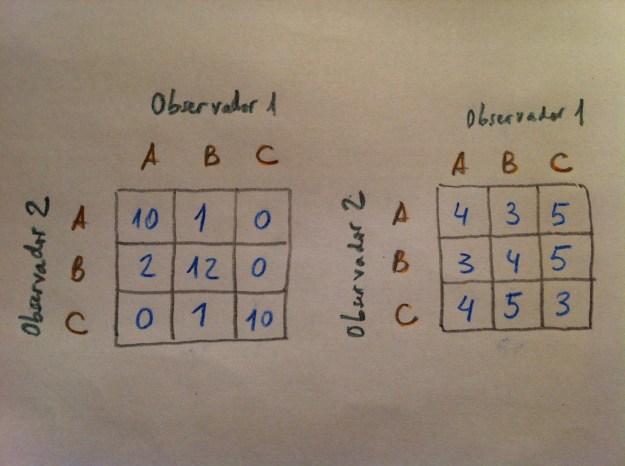
23. El índice Kappa calcula el grado de concordancia. Cuanto mayor concordancia más próximo a 1 y cuanta menor concordancia mayor cercanía a 0. En el cálculo usado si la discordancia es muy grande puede dar un índice incluso negativo. En el gráfico anterior es evidente que la tabla de la izquierda muestra dos observadores muy concordados y la de la derecha, por el contrario, muestra dos observadores muy mal concordados. La tabla de la derecha muestra independencia entre los dos observadores. La de la izquierda además de mostrar dependencia marca una buena concordancia. Lo ideal es que todos los valores estén en la diagonal que va de arriba a abajo.
24. Vamos ahora a centrarnos en otro índice para cuantificar la relación entre variables cualitativas. Se trata de un índice muy usado especialmente en Medicina: la Odds ratio (OR). A pesar de ser un índice muy usado en Medicina, en realidad, se trata de un concepto matemático exportable a cualquier ámbito.
25. Vamos a verlo aplicándolo a un tipo de estudios llamados Caso-Control, los cuales analizan individuos que tienen una determinada patología (Casos) y otros que no la tienen (Controles).
26. Supongamos que queremos ver la relación de esa patología con un factor concreto o con la exposición a un determinado riesgo. Para ello se separan cuántos de los casos y de los controles han estado expuestos y cuántos no. Por ejemplo: cáncer de pulmón y exposición al tabaco (fumador).
27. Utilizaré el siguiente código: casos (CA), controles (CO), expuestos (E) y no expuestos (NE).
28. Veamos la siguiente tabla de contingencias:
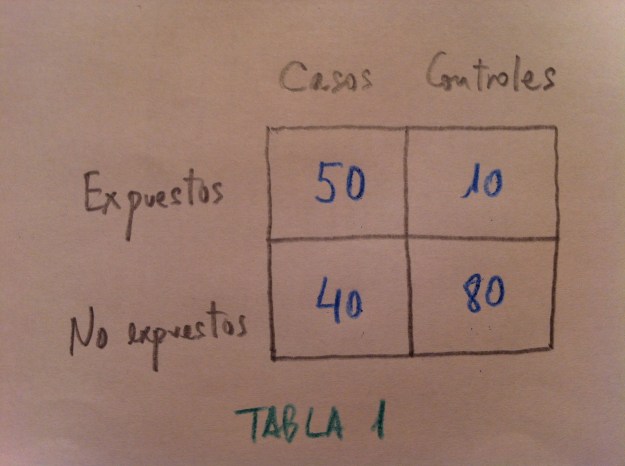
29. Observemos primero que si aplicáramos una ji-cuadrado tendríamos un caso de relación significativa: hay relación entre la exposición o no y el ser caso o control.
30. Entre los expuestos tenemos un cociente CA/CO de 50/10; o sea, un cociente de 5. Entre los no expuestos este cociente es (40/80) = 0,5.
31. Esto significa que entre los expuestos hay cinco veces más CA que CO y entre los no expuestos hay la mitad de CA que de CO ó 0,5 veces.
32. Vamos a hacer, ahora, el cociente CA/CO de los expuestos respecto al CA/CO de los no expuestos; o sea: ((CA/CO) de E) / ((CA/CO) de NE). Es posible que nos ayude a ver mejor el cociente de la OR el siguiente gráfico:
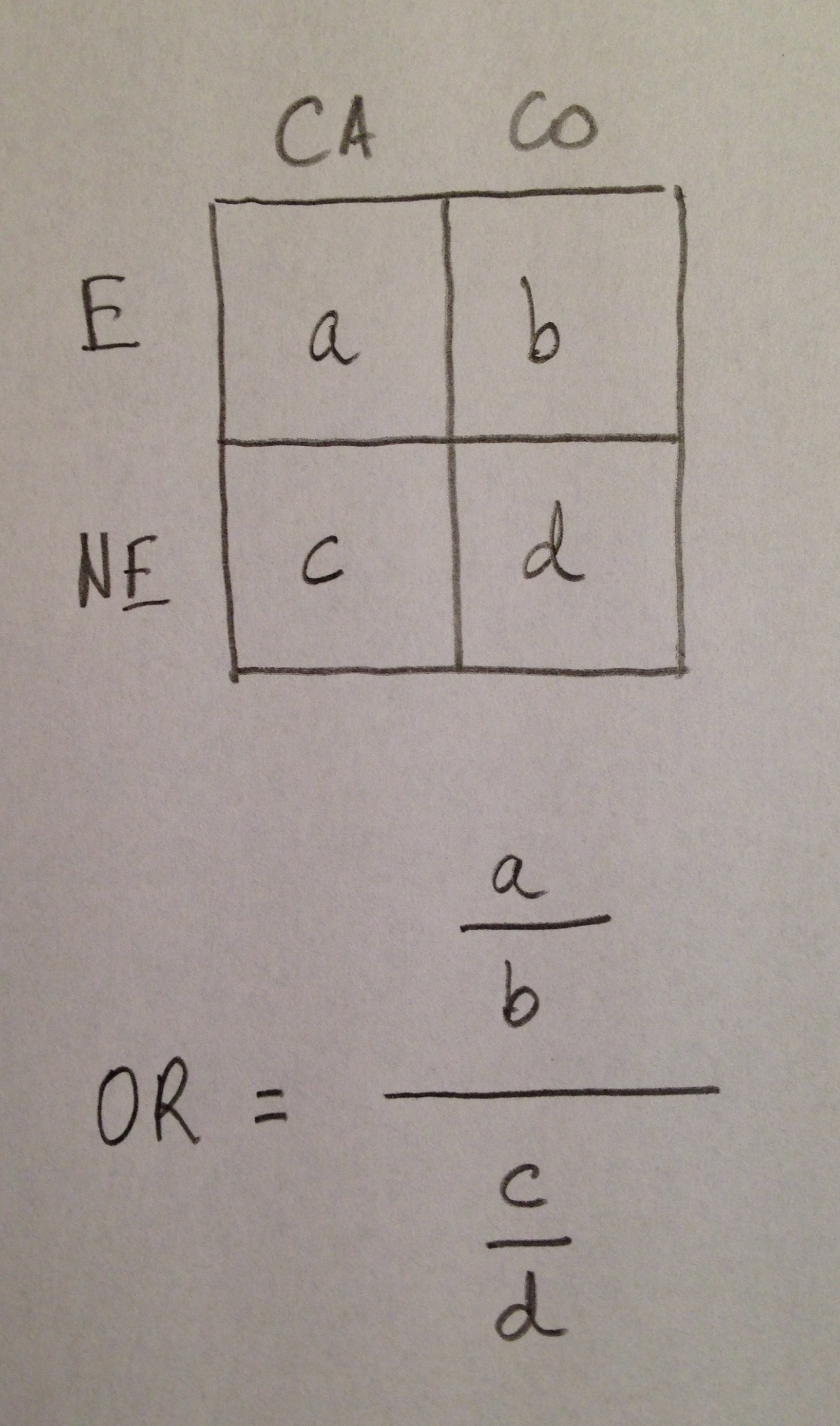
33. Estaremos estimando, así, cuántas veces la relación CA/CO entre los expuestos (a/b, en este esquema) está contenida en la relación CA/CO entre los no expuestos (c/d, en este esquema.
34. La OR es justo este cociente. Si OR = 1 significa que numerador y denominador son iguales y, por lo tanto, el cociente CA/CO es igual entre los expuestos y los no expuestos.
35. Cuanto más distinto de 1 sea la OR querrá decir que hay más relación; o sea, que el cociente CA/CO es distinto entre expuestos y no expuestos al factor estudiado.
36. Si es mayor que 1 querrá decir que la exposición al riesgo acarrea más proporción de enfermos.
37. Por el contrario, si la OR es menor que 1 tendremos que pensar que esta exposición más bien protege de la adquisición de tal patología. Por lo tanto, como vemos perfectamente, la OR distingue situaciones donde hay inclinación hacia un lado u otro de la tabla de contingencias, cosa que, como hemos visto antes, no distinguía la V de Crámer.
38. Pero observemos esta otra situación:

39. Observemos que es como la tabla de contingencias anterior pero eliminando un cero en las cuatro situaciones posibles. O sea, tenemos la misma relación entre numerador y denominador del índice OR, pero con una muestra mucho más pequeña.
40. Por lo tanto, la OR será la misma. Calculémosla en ambos casos: En la tabla 1 es (5/0,5)=10. Y ahora, en la tabla 2, es la misma: 10.
41. Pero, ¿cuál es la diferencia? La significación, por supuesto. En la tabla 1 la OR es significativa, en la tabla 2 no es significativa.
42. Si hacemos un contraste de hipótesis lo comprobamos. El contraste es ahora: H0: OR=1, H1: OR<>1. En la muestra de la tabla 1 el p-valor es 0,0005. Por lo tanto, rechazamos la H0 y aceptamos H1, por lo tanto podemos decir que esta OR de 10 es significativa, es fiable, es estable.
43. En la muestra de la tabla 2 el p-valor es 0,067. Ahora la OR a pesar de ser la misma que antes; o sea, 10, no es una OR significativa, con la información de que disponemos se trata de una OR no es fiable, no es un valor estable, está demasiado abierto todavía.
44. El tamaño de muestra es decisivo, como siempre. El tamaño de muestra en Estadística es clave. Es muy importante, es clave a la hora de tomar decisiones en Ciencia.
45. Vamos a recuperar ahora la noción de intervalo de confianza. Una noción muy usada a la hora de hacer predicciones.
46. Recordemos que al hacer una estimación de un valor poblacional a través de un cálculo muestral podemos construir un intervalo de confianza de la estimación.
47. En general, esta estimación, dependerá de dos cosas: de la dispersión y del tamaño de muestra.
48. La dispersión alta crea intervalos amplios y el mayor tamaño muestral crea intervalos más estrechos.
49. La dispersión de una estimación depende siempre de un cociente donde en el numerador tenemos la dispersión de la variable con la que estamos trabajando y en el denominador tenemos, en alguna forma, el tamaño de muestra. Es, recordemos, la noción de Error estándar, siempre presente en la estimación de algún valor poblacional.
50. Recordemos que en el Tema 3 vimos que la Desviación estándar (DE) de la media muestral de una variable normal con una Desviación estándar DE, era DE/raíz(n).
51. En el numerador tenemos la DE de la variable de trabajo y en el denominador una forma del tamaño muestral: su raíz cuadrada.
52. Pues bien, la OR que calculamos a través de una muestra expresada en una tabla de contingencias también tiene su intervalo de confianza.
53. Intervalo que será más estrecho cuanto mayor sea el tamaño muestral. Vamos a calcular un intervalo de confianza de la OR en las dos tablas que estamos manejando.
54. Retomemos la tabla 1. Decíamos que OR=10 y que el p-valor era 0,0005, por lo tanto significativa.
55. En esta tabla un intervalo de confianza del 95% de la OR es el siguiente: (4.59, 21.76).
56. Tenemos una confianza del 95% de acertar. El verdadero valor poblacional de OR está entre 4.59 y 21.76. En cualquier caso, por encima de 1.
57. Por eso es significativa esa OR porque la probabilidad de que el verdadero valor sea 1 o menor que 1 es muy pequeña.
58. Hay, por lo tanto, una sintonía entre el p-valor del contraste de hipótesis y mirar si intervalo de confianza del 95% contiene al 1.
59. Es lógico: si el intervalo contiene al 1 es que este valor es posible que sea el real, luego no es significativa la OR calculada.
60. Tomemos ahora, de nuevo, la tabla 2. La OR era también 10, el p-valor era, recordémoslo, 0,067.
61. O sea, este p-valor nos dice que este valor de 10 de OR no es significativo. Recordemos que la frontera de la significación está en el 0,05 y 0,069>0,05.
62. El intervalo de confianza del 95% de la OR es, ahora, (0.85, 117.02). Muy amplio, claro, porque el tamaño de muestra es muy pequeño.
63. Pero, además, observemos que el intervalo contiene al 1. El valor de OR=1 es posible perfectamente.
64. Por esto, ante una tabla así, aunque la OR sea grande (10 en este caso), se trata de un valor no fiable, que puede ser atribuible al azar del muestreo.
65. De nuevo hay coherencia entre lo que nos dice el p-valor del contraste de hipótesis y lo que nos dice mirar si el 1 está en el intervalo.
66. Obsérvese que la OR funciona un poco como la correlación.
67. Decíamos que de una correlación interesaban tres cosas de ella: signo, magnitud y significación.
68. Pues en la OR, de forma paralela, interesa si es mayor o menor que 1 (porque ya hemos visto que una cosa y la otra tienen significados completamente opuestos), interesa también la magnitud y la significación.
69. Un apunte final: A veces, ante situaciones de este tipo, en lugar de la OR se calcula el Riesgo relativo (RR). Es un cálculo bastante similar, especialmente es muy similar si hablamos de patología con baja prevalencia, con bajo porcentaje de afectados. En todo caso, a continuación incluyo el cálculo de ese RR para poderlo comparar con la OR:

70. Observemos que ahora lo que se hace es comparar los Casos no respecto a los Controles sino respecto a la suma de los Casos+Controles.

Pingback: Herramientas estadísticas en Medicina (Una hoja de ruta) | LA ESTADÍSTICA: UNA ORQUESTA HECHA INSTRUMENTO
Pingback: ¿Qué es Informática Médica? – informatica médica y bioestadistica