1. Cuando hemos detectado que entre dos o más variables hay una relación significativa una opción es intentar matematizar esa relación, crear una fórmula matemática que materialice, formalmente, esa relación y que permita calcular pronósticos de una o de varias variables a partir del conocimiento de valores de una o de varias variables evaluadas en un individuo concreto.
2. Esta matematización, esta creación de una fórmula, de una ecuación, que relacione varias variables, es la Regresión.
3. La Regresión ha tenido y tiene una importancia extraordinaria en el ámbito de las aplicaciones de la Estadística. A lo largo de este curso deberemos dedicar diferentes momentos a hablar del mundo de la Regresión.
4. Empezaremos los temas dedicados a este mundo con esta Introducción a la Regresión, aunque en mucho momentos focalizaremos especialmente en el caso más básico de Regresión: el de la Regresión lineal simple, para introducirnos así, con mayor facilidad, en algunas nociones generales.
5. La Regresión consiste en la creación de una fórmula matemática que relacione variables, en la creación de lo que llamamos una función matemática.
6. Por lo tanto, lo primero que tenemos que recordar es el concepto de función matemática.
7. Una función matemática de dos variables, y=f(x), es la representación (la modelización) matemática de una relación entre las dos variables: “x” e “y”. A la variable en la posición de la “y” se la denomina dependiente. A la variable en la posición de la “x” se la denomina independiente.
8. Las funciones matemáticas, evidentemente, pueden ser entre más de dos variables. La función y=f(x1, x2, …, xd) relaciona a la variable “y” con las “d” variables x1, x2, …, xd. Estas funciones son las llamadas funciones de varias variables, también llamadas funciones de variable vectorial, porque la “x” es, en realidad, un vector de variables (cuando tenemos dos o más variables analizadas conjuntamente en matemáticas decimos que tenemos un “vector de variables”).
9. También existen las funciones donde la posición de la “y” está ocupada por más de una variable: (y1, y2, …, ym)= f(x1, x2, …, xd), que son las llamadas funciones vectoriales (“m” variables en la posición de la “y”) de variable vectorial (“d” variables en la posición de la “x”) .
10. Obsérvese que suele usarse el mismo signo «y» para las diferentes posibles variables dependientes y el mismo signo «x» para las variables independientes. Los subíndices concretan el número de variables que hay en cada una de las dos posiciones. Así es como habitualmente se representan los diferentes modelos de Regresión en Estadística.
11. Pero para empezar a ver algunas nociones generales de la Regresión utilizaremos el caso de las funciones más sencillas: las funciones y=f(x):
12. Si digo: «Si el domingo llueve me quedaré en casa, si no llueve iré a Girona», estoy construyendo una función.
13. La x tiene dos valores: llueve y no llueve. La y tiene también dos valores posibles: me quedo en casa y voy a Girona. Y con la frase construyo una relación, construyo la función.
14. Porque una función es una relación establecida entre un conjunto de valores y otro conjunto de valores. Una relación que tiene la siguiente condición: Todo elemento del conjunto llamado Dominio (el conjunto de la variable x) tiene que tener asignado, mediante la regla de la función concreta establecida, un y sólo un elemento del conjunto llamado Codominio o Recorrido (el conjunto de la variable “y”).
15. Es fácil comprobar que el ejemplo: «Si el domingo llueve me quedaré en casa, si no llueve iré a Girona», cumple las condiciones de función. También lo cumpliría, por ejemplo: “Llueva o no llueva, el domingo iré a Girona”.
16. En nuestro día a día continuamente estamos estableciendo relaciones de tipo funcional, que cumplen la condición de ser función.
17. En ciencia son muy importantes las funciones. Porque la ciencia intenta continuamente establecer relaciones entre las cosas.
18. La Regresión es una parte de la Estadística que se cuida de la creación de funciones entre variables cuya relación no es exacta, como veremos ahora:
19. Otro ejemplo de función: cuando expreso una distancia en Km y la quiero pasar a metros creo una relación matemática (una función): y=1000x.
20. Si quiero relacionar Altura y Peso la cosa no funciona tan bien porque no hay una fórmula que lo haga de forma exacta.
21. No hay ninguna fórmula mediante la cual sabiendo el peso de una persona podamos saber, de forma exacta, su altura. No obstante, como hay una cierta relación entre la altura y el peso podemos establecer una fórmula funcional pero añadiendo un elemento a esa fórmula, un elemento que será clave en el ámbito de la Regresión, como ahora veremos.
22. No nos olvidemos que hemos dicho antes que la Regresión es una parte de la Estadística que se cuida de la creación de funciones entre variables cuya relación no es exacta.
23. La relación entre la Altura y el Peso no es exacta, pero puedo crear el modelo: Altura=f(Peso)+ɛ. Antes podía escribir Metros=f(Km), sin tener que añadir esa “ɛ”. Porque la relación es exacta.
24. Por lo tanto, esta “ɛ”, de momento, la hemos de ver simplemente como lo que le falta o lo que le sobra a la fórmula que relaciona altura con peso para que la relación sea exacta.
25. En la Regresión siempre se crean funciones matemáticas donde es imprescindible añadir esta “ɛ”. Veremos más tarde el papel de esta “ɛ”.
26. Si relacionamos ahora la Altura con la Longitud de pie podemos decir que la función sería Altura=f(Pie)+ɛ . De nuevo la “ɛ”. Porque tampoco se trata de una relación exacta.
27. Como hemos dicho la Altura tiene una correlación r más grande con la Longitud del pie que con el peso.
28. Por lo tanto, la “ɛ” en Altura=f(Pie)+ ɛ es una variable con menos dispersión que la «ɛ» en Altura=f(Peso)+ ɛ. Esto es básico entenderlo para ir introduciéndose en el peculiar mundo de la Regresión.
29. De momento estamos hablando de relaciones entre unas variables que pueden quedar dibujadas por rectas, que los puntos que dibujan quedan articulados en torno a una recta. Pero evidentemente la relación entre dos variables puede no ser una relación lineal, como sucedería, por ejemplo, con la relación entre el Euribor y el Tiempo, que no quedarían, los puntos, ni mucho menos, organizados en torno a una recta, sino, por el contrario, quedarían articulados en torno a complicadas curvas con subidas y bajadas.
30. Por lo tanto, de momento estamos escribiendo expresiones generales de relación, como Altura=f(Pie)+ ɛ, o bien como Altura=f(Peso)+ ɛ, pero, como iremos concretando, en realidad ahora nos limitaremos a relaciones lineales, relaciones que se estructuran alrededor de una recta.
31. Una regla fundamental: Cuanta mayor correlación haya entre dos variables, en la representación bidimensional, estructurada en forma de recta, los valores estarán reunidos más próximos a la recta.
32. Y la dispersión de los valores de la «ɛ”, de esos valores, por exceso o por defecto, necesarios para que la función creada sea una relación exacta, tiene que ver con la dispersión de esa representación bidimensional alrededor de la recta.
33. Y Alturas con Pies tienen una representación bidimensional menos dispersa alrededor de la recta que la representación de Alturas con Pesos.
34. Veamos, gráficamente, de lo que estamos hablando. Puede verse perfectamente en el gráfico adjunto que los valores de Altura y Longitud de pie están menos dispersos en torno a la recta que los valores de Altura y Peso. Y que, por el contrario, los valores de Km y metros no tienen ninguna dispersión:
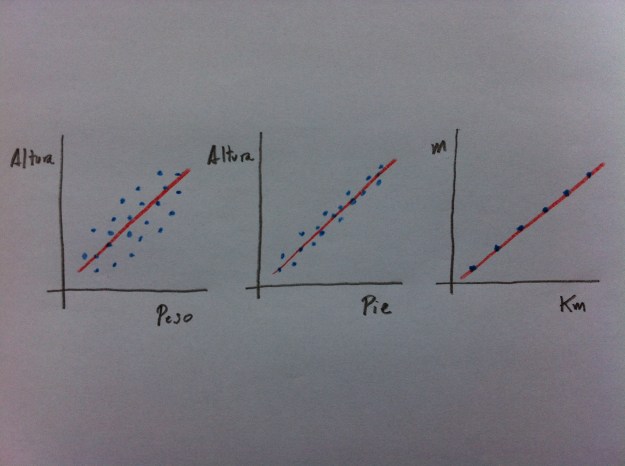
35. A la “ɛ” de la ecuación de una Regresión se le denomina Residuo. En ocasiones también se le llama Error.
36. Y en condiciones normales las distancias desde los valores de la representación bidimensional a la recta que pasa entre los puntos (distancias positivas y negativas) sigue una distribución normal N(0, DE).
37. Esto se interpreta de la siguiente forma: Si tomáramos todos los puntos de la representación bidimensional y fuéramos calculando las distancias que hay entre cada uno de esos puntos y la recta, que unas serían positivas (los puntos por encima de la recta) y otros serían negativos (los puntos por debajo de la recta), entonces la reunión de todas esos valores quedaría bien modelizado por un N(0, DE).
38. Esta Desviación estándar (DE) será tanto mayor cuanto menor sea la correlación entre las variables “x” e “y”.
39. En el dibujo de las tres relaciones: Altura versus Peso, Altura versus Pie y Metros versus Km, puede comprobarse perfectamente esta relación entre DE del residuo, de la ɛ, y la correlación entre las variables.
40. Ya hemos visto que esta “ɛ” de la regresión, el residuo, son valores de distancias positivas y negativas.
41. Este residuo tiene generalmente una distribución normal centrada en el cero, por ser valores por exceso y por defecto respecto a la recta, y por tener, generalmente, muchos más valores próximos a la recta y con cierta simetría.
42. Y tiene, por lo tanto, este residuo, una dispersión, una Desviación estándar (DE). Por esto podemos decir que esta ɛ, muchas veces, sigue una distribución N(0, DE), donde esta DE dependerá de la correlación r.
43. Observemos que si planteáramos la relación entre Km y Metros como una Regresión: m=1000•Km+ɛ, la DE de esta ɛ sería obviamente cero.
44. En el gráfico adjunto se ve un caso de relación entre dos variables, se ve la recta de Regresión que modeliza esta relación y se ve, también, que si se proyectaran los valores, los puntos, sobre una recta donde el 0 fuera el punto de intersección de esa recta con la vertical dibujada por la propia recta de Regresión, entonces los puntos proyectados quedarían bien modelizados por una distribución N(0, DE).

45. Una vez comentadas unas nociones básicas del mundo de la Regresión, vamos a intentar trazar ahora un mapa de los diferentes tipos de Regresión que se manejan en Estadística. Esto nos permitirá, después, cuando veamos tipos concretos de Regresión, en diferentes temas de este curso, saber situar cada uno dentro del plano que ahora vamos a dibujar.
46. Recordemos, antes de empezar con el mapa que la estructura general de la Regresión es la ecuación y=f(x), que a la variable o al vector de variables (si es más de una variable) “y” se la denomina variable o vector dependiente y a la variable o vector “x” se de denomina variable o vector independiente.
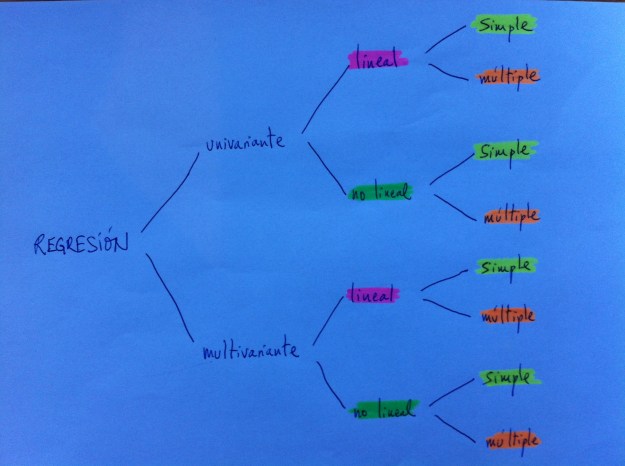
47. Una primera distinción es la que se establece entre Regresión univariante y Regresión multivariante. Esta bifurcación viene determinada por el hecho de tener una o más de una variable dependiente.
48. La dicotomía está en estas dos formulaciones: tener una única variable “y” o tener más de una. Los dos tipos de Regresión quedarían ejemplificados en las dos siguientes fórmulas generales:
y=f(x)
(y1, y2, …, ym)= f(x)
si tenemos una única variable independiente, o de esta forma:
y=f(x1, x2, …, xd)
(y1, y2, …, ym)= f(x1, x2, …, xd)
si tenemos varias variables independientes.
49. Obsérvese que aquí lo que diferencia entre Regresión univariante y multivariante es el número de variables dependientes no el número de variables independientes.
50. Si atendemos al tipo de función diferenciaremos entre la Regresión lineal y la Regresión no lineal.
51. En la Regresión lineal la f(x) es la ecuación de una función lineal, una función que será una recta, un plano o un hiperplano, según el número de variables independientes.
52. La Regresión lineal es la representada por el modelo matemático: y=ax+b+e en el caso de tener una única variable independiente, o por el modelo matemático: y=a1x1+a2x2+…+adxd+b+ɛ en el caso de estar trabajando con dos o más variables independientes.
53. Estoy escribiendo la fórmula de la Regresión lineal para el caso de Regresión univariante, pero podríamos hacer lo mismo con la Regresión multivariante. Después haremos una representación general de todas las posibilidades combinatorias y veremos los diferentes esquemas que tendríamos en cada caso.
54. Recordemos que la “ɛ” es siempre el símbolo del residuo, de lo que falta para la exactitud del modelo.
55. La Regresión no lineal es la que sigue cualquier otra función que no sea lineal. Estas funciones, como veremos en su momento, pueden ser exponenciales, pueden ser polinómicas, etc.
56. Si atendemos al números de variables independientes, distinguiremos dos tipos de Regresión: la Regresión simple y la Regresión múltiple.
57. En la Regresión simple tenemos únicamente una variable independiente. En la Regresión múltiple, por el contrario, tenemos dos o más variables independientes. Ahora focalizamos no en el número de variables dependientes sino en el número de variables independientes. Si tenemos una o más de una variable independiente.
58. En la Regresión simple la fórmula general es, pues, y=f(x)+ ɛ si se trata de una Regresión univariante o (y1, y2, …, ym)= f(x)+ ɛ si se trata de una Regresión multivariante.
59. En la múltiple la función es: y= f(x1, x2, …, xd)+ ɛ si se trata de una Regresión univariante o (y1, y2, …, ym)= f(x1, x2, …, xd)+ɛ si se trata de una Regresión multivariante.
60. Por lo tanto, las dicomomías vistas: Univariante versus Multivariante, Lineal versus No lineal y Simple versus Múltiple, se pueden mezclar mediante todas las combinaciones posibles.
61. Vemos en el gráfico siguiente cómo estas tres dicotomías combinadas dan lugar a los diferentes tipos de Regresión posibles:
62. Dentro de estos ocho tipos de Regresión se pueden dar casos especiales. Por ejemplo, es el caso de trabajar con una variable dependiente cualitativa hablamos entonces de Regresión logística. Ésta puede ser, también, simple o múltiple, dependiendo de si tenemos una o más de una variables independientes.
63. La Regresión logística es siempre, en realidad, una Regresión no lineal, como veremos en el tema 11. Y siempre es, también, además, univariante. Por lo tanto, podemos decir que los dos tipos de Regresión logística, la simple y la múltiple son casos especiales de Regresión no lineal simple y múltiple, respectivamente.
64. En realidad la Regresión no lineal es un amplio mundo donde se pueden diferenciar diferentes familias dependiendo del tipo de función no lineal que consideremos. Lo veremos en su momento.
65. En la medida que vayamos viendo, pues, estos diferentes tipos de Regresión iremos perfilando y completando este interesante mapa de este apasionante mundo de la Regresión.
66. A modo de resumen y después de visto el esquema que nos proporciona, por combinación de las tres dicotomías vista, los ocho tipos básicos de Regresión, vamos a ver el tipo general de modelo de Regresión de cada una de estas ocho familias; o sea, la forma de cada una de las ocho ecuaciones de los ocho tipos de Regresión.
67. En el caso no lineal he optado por poner una ecuación exponencial pero se trata de la elección de un tipo entre los muchos tipos de funciones que pueden ser usados como modelos de Regresión no lineal.
68. También es importante recordar que la “ɛ” añadida al final de la ecuación es el Residuo. En el esquema adjunto está escrito, ahora, con la letra griega épsilon y se suma siempre a todas las ecuaciones porque es aquel elemento que es necesario introducir siempre en la Regresión por el mismo hecho esencial de estar trabajando con relaciones entre variables que no son relaciones exactas.
69. Obsérvese, también, que el Residuo en la Regresión multivariante es un residuo con subíndice porque cada variable del vector dependiente tiene un valor residual.
70. En cambio en las Regresiones no lineales aparece una “e” que no es el Residuo, es el número e. Obsérvese que este número e siempre está elevado a algo. Es un número básico en las funciones exponenciales.
71. Las otras letras, “a” y “b”, con sus subíndices, cuando los tienen, son los parámetros del modelo, son números que se habrán de estimar, en cada caso concreto, para adaptar el modelo, la ecuación, a un caso concreto.
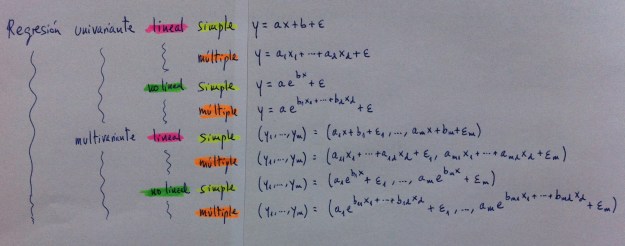

¿Esta correcto…
49. Obsérvese que aquí lo que diferencia entre Regresión univariante y multivariante es el número de variables dependientes no el número de variables independientes.
Sí, porque el número de variables dependientes determina esa dualida. El número de variables independientes separa la Regresión simple de la múltiple. Es verdad que a veces a la múltiple se le denomina multivariante, pero lo históricamente correcto es eso que escribo.
Hola, soy Santiago, estoy concluyendo mi tesis doctoral, en la que estoy intentando «forzar una relación» entre el PIB y varias variables, como son la valoración de empresas, las fusiones, reestructuraciones, consolidación, incluso la escisión, la liquidación de empresas. Es decir, en realidad, un país que quiere aumentar su PIB, debe procurar que la ingeniería financiera sea aplicada en dicha economía productiva (conjunto de empresas). Y sabiendo el PIB es, en una forma, la sumatoria de los valores añadidos de todas las empresas de una economía.
Mi pregunta es, CÓMO YO, SIN MUCHAS HERRAMIENTAS MATEMATICAS COMO VD, PUEDO ASOCIAR, demostrando esta eventual regresión lineal múltiple? cómo relacionar dichas variables empresariales con el PIB que es la variable dependiente en mis hipótesis.
NECESITO AYUDA Y SU NOMBRE FIGURARÁ EN MIS AGRADECIMIENTOS DE LA TESIS DOCTORAL que presento este noviembre. Muchas gracias.
Debes acceder a un software estadístico y aplicar una regresión múltiple. Te recomiendo el uso de un stepwise para hacer la búsqueda de las variables independientes más adecuadas. Valora la R2 para ver si tienes una buena determinación.
Estoy siguiendo su curso paso a paso, pero en este tema me perdí un poco. Asumiendo que con la estadística descriptiva determino que mi variable no sigue una función normal. Sin embargo al correlacionar mi variable con otra variable, ¿la proyección de los puntos como explica, debería ser una distribución normal?
Para fiarse de los contrastes de hipótesis sobre la pendiente es necesario que esas proyecciones se ajusten a la normal. Esas proyecciones son los llamados residuos: la diferencia entre cada valor y su pronóstico siguiendo la recta construida. Si tienes una anormalidad grande puedes hacer transformaciones de la variable hasta conseguir la normalidad.